

tags:
- biology license: other
AIDO.RAGProtein-3B
AIDO.RAGProtein-3B (AIDO.RAGPLM) is a pretrained model for Retrieval-AuGmented protein language model in an AI-driven Digital Organism. AIDO.RAGProtein-3B (and AIDO.RAGFold) integrates pre-trained protein language models with retrieved MSA, allowing for the incorporation of co-evolutionary information in structure prediction while compensating for insufficient MSA information through large-scale pretraining.
AIDO.RAGProtein-3B surpasses single-sequence protein language models in perplexity, contact prediction, and fitness prediction. We utilized AIDO.RAGProtein-3B as the feature extractor for protein structure prediction, resulting in the development of AIDO.RAGFold. When sufficient MSA is available, AIDO.RAGFold achieves TM-scores comparable to AlphaFold2 and operates up to eight times faster. In scenarios where MSA is insufficient, our method significantly outperforms AlphaFold2 (∆TM-score=0.379, 0.116 and 0.059 for 0, 5 and 10 MSA sequences as input).
Model Architecture Details
AIDO.RAGProtein-3B is a transformer encoder-only architecture with the dense MLP layer in each transformer block (Panel c below). It uses single amino acid tokenization and is optimized using a masked languange modeling (MLM) training objective.
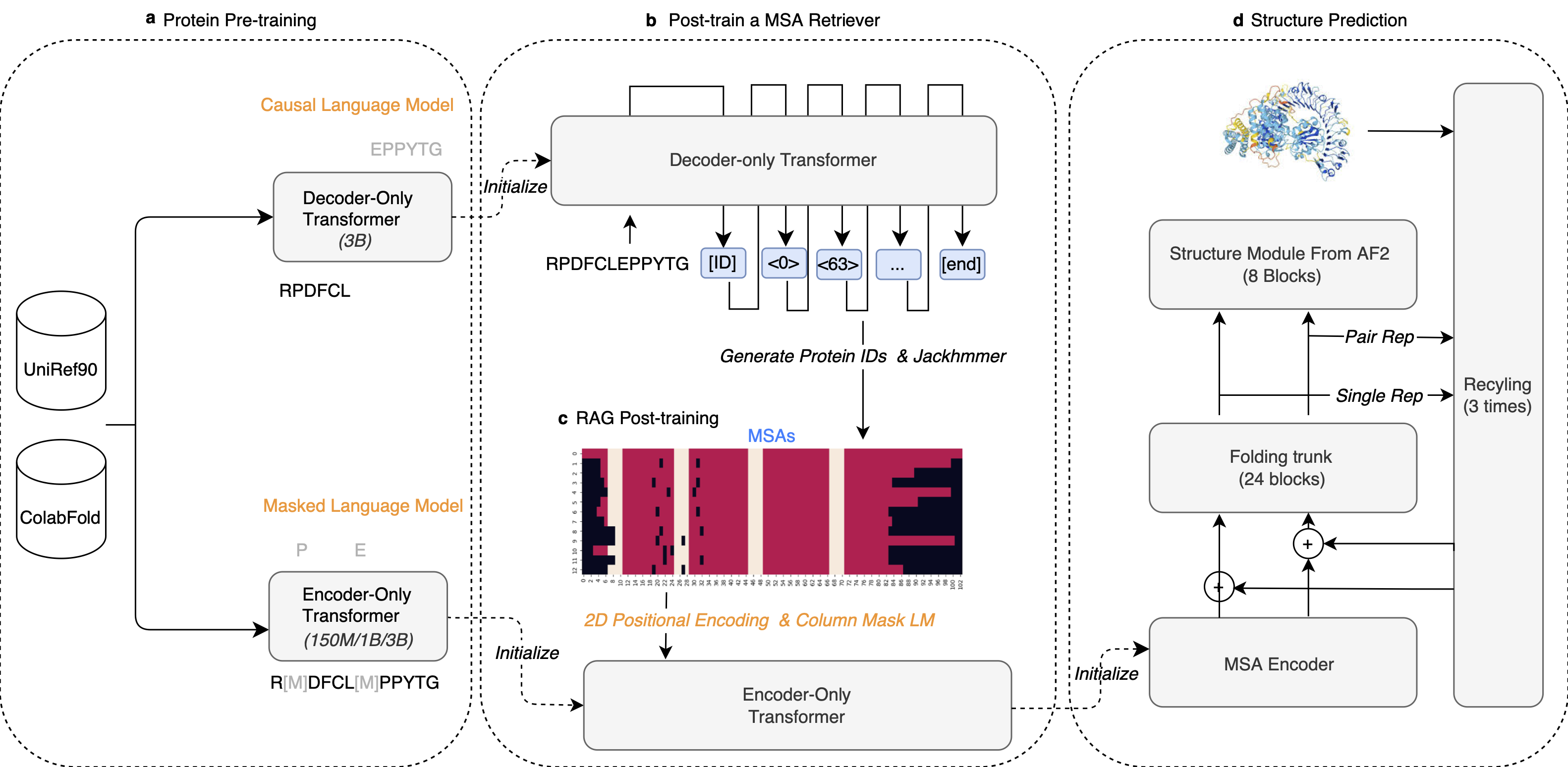
More architecture details are shown below:
| Model Arch | Value |
|---|---|
| Num Attention Head | 40 |
| Num Hidden Layer | 36 |
| Hidden Size | 2560 |
| FFN Hidden Size | 6832 |
| Context Length | 12.8K |
Pre-training of AIDO.RAGProtein-3B
Data
UniRef50/Uniclust30 MSA dataset: We utilized sequences from UniRef50 as queries to search for homologous sequences in UniClust30, subsequently constructing multiple sequence alignments (MSAs). UniRef50 comprises a total of 53.6 million sequences. Using HHblits, we searched all sequences, identifying over 25 homologous sequences for 23.7 million of them. This dataset was directly used as the training set, referred to as HHblits_MSA. The remaining 29.9 million sequences were input into MSA Retriever, resulting in 7.7 million sequences with more than 25 homologous sequences. This dataset was designated as Retriever_MSA. During training, RAGPLM randomly sampled from the two datasets with probabilities of 0.75 and 0.25
Training Details
We fine-tuned a pretrained masked language model with 3-billion parameters (MLM-3B) using MSA data by concatenating the query sequence with homologous sequences. We introduced several modifications to the standard BERT masking strategy: (1) We randomly sampled 0.05×L span positions from a query sequence of length L, with span lengths following a geometric distribution (p=0.2), and capped the maximum length at 10. Our experiments revealed that this settings lead to an average of 15% of the query tokens were masked. (2) To prevent information leakage, when a residue was selected, all residues at the same index across all sequences (the column of the MSA matrix) were also masked. (3) When a column of MSA was selected for masking, the entire column was replaced with the <MASK> token in 80% of cases, with random amino acids in 10% of cases, and remained unchanged in the remaining 10% of cases. To help the model distinguish which tokens are from the same chain and which tokens have the same residue index, we use 2D rotary position embedding to encode the tokens.
| MLM-3B | AIDO.RAGProtein-3B | |
|---|---|---|
| Training data | UniRef+ColabFoldDB | HHblits_MSA, Retriever_MSA |
| Initial params | Random | MLM-3B |
| Learning rate | 2.5e-4 | 1e-4 |
| Training tokens | 1000B | 100B |
| Batch size | 2560 | 256 |
| Micro batch size | 4 | 1 |
| Sample length | 1024 | 12,800 |
| Attention | Bi-directional | Bi-directional |
Tokenization
We encode protein sequence with single amino acid resolution with 44 vocabularies, where 24 tokens represent amino acid types and 20 are special tokens. Sequences were also suffixed with a [SEP] token as hooks for downstream tasks.
Evaluation of AIDO.RAGProtein-3B
AIDO.RAGProtein-3B surpasses single-sequence protein language models in perplexity, contact prediction, and fitness prediction. Subsequently, we utilized AIDO.RAGProtein-3B as a feature extractor, integrating it with the folding trunks and Structure Modules to achieve end-to-end structural prediction (AIDO.RAGFold). Our findings indicate that when sufficient MSA is available, our method achieves results comparable to AlphaFold2 and is eight times faster; when MSA is insufficient, our method significantly outperforms AlphaFold2.
Results
Unsupervised Contact Prediction
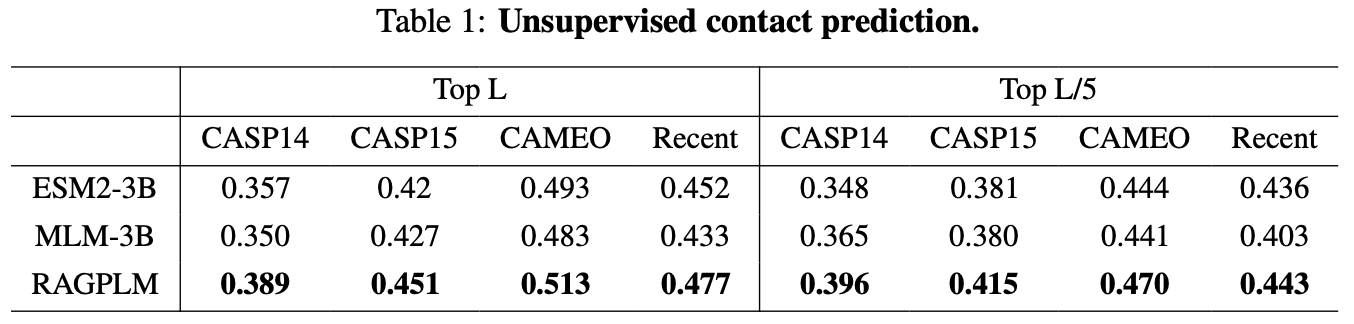
Supervised Contact Prediction & ProteinGym zero-shot prediction

AIDO.RAGFold

How to Use
Build any downstream models from this backbone with ModelGenerator
For more information, visit: Model Generator
mgen fit --model SequenceClassification --model.backbone aido_ragprotein_3b --data SequenceClassificationDataModule --data.path <hf_or_local_path_to_your_dataset>
mgen test --model SequenceClassification --model.backbone aido_ragprotein_3b --data SequenceClassificationDataModule --data.path <hf_or_local_path_to_your_dataset>
Or use directly in Python
Embedding
import torch
from modelgenerator.tasks import Embed
model = Embed.from_config({"model.backbone": "aido_ragprotein_3b"}).eval()
model.backbone.max_length = 12800
data = torch.load("ModelGenerator/experiments/AIDO.RAGPLM/examples.pt", 'cpu')[0]
transformed_batch = model.transform(data)
with torch.no_grad():
embedding = model(transformed_batch)
print(embedding.shape)
Sequence Level Classification
import torch
from modelgenerator.tasks import SequenceClassification
model = SequenceClassification.from_config({"model.backbone": "aido_ragprotein_3b", "model.n_classes": 2}).eval()
model.backbone.max_length = 12800
data = torch.load("ModelGenerator/experiments/AIDO.RAGPLM/examples.pt", 'cpu')[0]
transformed_batch = model.transform(data)
with torch.no_grad():
logits = model(transformed_batch)
print(logits)
print(torch.argmax(logits, dim=-1))
Token Level Classification
import torch
from modelgenerator.tasks import TokenClassification
model = TokenClassification.from_config({"model.backbone": "aido_ragprotein_3b", "model.n_classes": 3}).eval()
model.backbone.max_length = 12800
data = torch.load("ModelGenerator/experiments/AIDO.RAGPLM/examples.pt", 'cpu')[0]
transformed_batch = model.transform(data)
with torch.no_grad():
logits = model(transformed_batch)
print(logits)
print(torch.argmax(logits, dim=-1))
Regression
from modelgenerator.tasks import SequenceRegression
model = SequenceRegression.from_config({"model.backbone": "aido_protein_16b_ragplm"}).eval()
model.backbone.max_length = 12800
data = torch.load("experiments/AIDO.RAGPLM/examples.pt", 'cpu')[0]
transformed_batch = model.transform(data)
with torch.no_grad():
logits = model(transformed_batch)
print(logits.shape)
Citation
Please cite AIDO.RAGProtein-3B using the following BibTex code:
@article {Li2024.12.02.626519,
author = {Li, Pan and Cheng, Xingyi and Song, Le and Xing, Eric},
title = {Retrieval Augmented Protein Language Models for Protein Structure Prediction},
url = {https://www.biorxiv.org/content/10.1101/2024.12.02.626519v1},
year = {2024},
doi = {10.1101/2024.12.02.626519},
publisher = {bioRxiv},
booktitle={NeurIPS 2024 Workshop on Machine Learning in Structural Biology},
}