

Upload folder using huggingface_hub
Browse files- .gitattributes +1 -0
- LICENSE +49 -0
- README.md +161 -3
- architecture.png +3 -0
- config.json +37 -0
- generation_config.json +5 -0
- pytorch_model-00001-of-00003.bin +3 -0
- pytorch_model-00002-of-00003.bin +3 -0
- pytorch_model-00003-of-00003.bin +3 -0
- pytorch_model.bin.index.json +587 -0
- structure_prediction.png +0 -0
- supervised_contact_prediction_fitness.png +0 -0
- unsupervised_contact_prediction.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
architecture.png filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
GENBIO AI COMMUNITY LICENSE AGREEMENT
|
| 2 |
+
|
| 3 |
+
This GenBio AI Community License Agreement (the “License”) constitutes an agreement between you or the legal entity you represent (“you” or “your”) and GENBIO.AI, INC. (“GenBio”), governing your use of the GenBio Materials. If you are using the GenBio Materials on behalf of a legal entity, you represent and warrant to GenBio that you have full legal authority to act on behalf of that legal entity as applicable under the License. If you do not have the authority to accept this License or if you disagree with any or all of the License, you shall not use the GenBio Materials in any manner. By using or distributing any portion or element of the GenBio Materials, you imply your agreement to be bound by the License.
|
| 4 |
+
|
| 5 |
+
“GenBio Materials” means any datasets, code, model weights or any other materials provided by GenBio at the following GitHub Page https://github.com/genbio-ai or Hugging Face Page https://huggingface.co/genbio-ai, including any updates or modifications made from time to time, whether in Source or Object form, and is made available to you under this License.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
1. License Grant.
|
| 9 |
+
1.1 License Scope. Subject to the terms of this License, GenBio grants you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable and royalty-free limited license under GenBio’s intellectual property or other rights owned by GenBio embodied in the GenBio Materials to use, reproduce, distribute, and create Derivative Works of, and make modifications to, the GenBio Materials for any Non-Commercial Purposes.
|
| 10 |
+
1.2 Use Restrictions. Restricted activities in relation to the License or use of GenBio Materials include:
|
| 11 |
+
1.2.1 You shall use the GenBio Materials, Contributions, Derivative Works, Outputs and Output Derivatives (as defined below) solely for Non-Commercial Purposes;
|
| 12 |
+
1.2.2 You shall not, directly or indirectly: (a) use or provide access to any Outputs or Output Derivatives to train, optimize, improve, or otherwise enhance the functionality or performance of any machine learning models or related technologies that are similar to the GenBio Materials; (b) engage in any form of model distillation or other methods that would achieve the purposes described in subsection (a) above. Notwithstanding the foregoing, you may use Outputs and Output Derivatives to train, optimize, improve, or enhance the functionality or performance of: (i) The GenBio Materials itself; and (ii) downstream Derivative Works of the GenBio Materials;
|
| 13 |
+
1.2.3 Your use of the GenBio Materials shall be subject to any additional terms and conditions that: (a) GenBio provides to you separately; or (b) GenBio otherwise makes available to you.
|
| 14 |
+
|
| 15 |
+
2. Sharing and Distribution.
|
| 16 |
+
2.1 Subject to Section 1, if you distribute or make available the GenBio Materials or a Derivative Work to a third party for your Non-Commercial Purposes, in Source or Object form, you shall:
|
| 17 |
+
2.1.1 provide a copy of this License to that third party;
|
| 18 |
+
2.1.2 retain the following attribution notice within a “Notice” text file distributed as a part of such copies: “This is licensed under the GenBio AI Community License Agreement, Copyright © GENBIO.AI, INC. All Rights Reserved”; and
|
| 19 |
+
2.1.3 prominently display “Powered by GenBio AI” on a related website, user interface, blogpost, about page, or product documentation.
|
| 20 |
+
2.2 If You create a Derivative Work, you may add your own attribution notice(s) to the “Notice” text file included with that Derivative Work, provided that you clearly indicate which attributions apply to the GenBio Materials and state in the “Notice” text file that you changed the GenBio Materials and how it was modified.
|
| 21 |
+
|
| 22 |
+
3. Submission of Contribution.
|
| 23 |
+
Unless you explicitly state otherwise, any Contribution intentionally submitted for inclusion in the GenBio Materials by you to GenBio shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with GenBio regarding such Contributions.
|
| 24 |
+
|
| 25 |
+
4. Export Control.
|
| 26 |
+
You shall comply with the applicable U.S. Foreign Corrupt Practices Act and all applicable export laws, restrictions and regulations of the U.S. Department of Commerce, and any other applicable U.S. and foreign authority.
|
| 27 |
+
|
| 28 |
+
5. Disclaimer of Warranty.
|
| 29 |
+
GENBIO MATERIALS PROVIDED BY GENBIO OR ANY OUTPUT YOU RECEIVED ARE PROVIDED “AS IS.” EXCEPT TO THE EXTENT PROHIBITED BY LAW. GENBIO MAKES NO REPRESENTATIONS OR WARRANTIES OF ANY KIND, WHETHER EXPRESS, IMPLIED OR OTHERWISE, REGARDING THE ACCURACY, COMPLETENESS OR PERFORMANCE OF THE SERVICES AND YOUR OUTPUT, OR WITH RESPECT TO SATISFACTORY QUALITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT.
|
| 30 |
+
|
| 31 |
+
6. Limitation of Liability.
|
| 32 |
+
In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the GenBio Materials (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
|
| 33 |
+
|
| 34 |
+
7. General Terms.
|
| 35 |
+
7.1 Relationship of Parties. You and GenBio are independent contractors, and nothing herein shall be deemed to constitute either party as the agent or representative of the other or both parties as joint venturers or partners for any purpose.
|
| 36 |
+
7.2 Assignment. This License and the rights and obligations herein may not be assigned or transferred, in whole or in part, by You without the prior written consent of GenBio. Any assignment in violation of this provision is void. GenBio may freely assign or transfer this License, in whole or in part. This License shall be binding upon, and inure to the benefit of, the successors and permitted assigns of the parties.
|
| 37 |
+
7.3 Governing Law. This License shall be governed, construed and interpreted in accordance with the laws of the State of California, without giving effect to principles of conflicts of law. Each of the parties to this License consents to the exclusive jurisdiction and venue of the courts of the state and federal courts of California.
|
| 38 |
+
7.4 Severability. If any provision of this License is held to be invalid, illegal or unenforceable in any respect, that provision shall be limited or eliminated to the minimum extent necessary so that this License otherwise remains in full force and effect and enforceable.
|
| 39 |
+
|
| 40 |
+
8. Definitions.
|
| 41 |
+
8.1 “Commercial Entity” means any entity engaged in any activity intended for or directed toward commercial advantage or monetary compensation, including, without limitation, the development of any product or service intended to be sold or made available for a fee. For the purpose of this License, references to a Commercial Entity expressly exclude any universities, non-profit organizations, not-for-profit entities, research institutes and educational and government bodies.
|
| 42 |
+
8.2 “Contribution” means any work of authorship, including the original version of the GenBio Materials and any modifications or additions to that GenBio Materials or Derivative Works thereof, that is intentionally submitted to GenBio for inclusion in the GenBio Materials by the copyright owner or by an individual or legal entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, “submitted” means any form of electronic, verbal, or written communication sent to GenBio or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, GenBio for the purpose of discussing and improving the GenBio Materials, but excluding Outputs and all communications that are conspicuously marked or otherwise designated in writing by the copyright owner as “Not a Contribution”.
|
| 43 |
+
8.3 “Contributor” means GenBio and any individual or legal entity on behalf of whom a Contribution has been received by GenBio and subsequently incorporated within the GenBio Materials.
|
| 44 |
+
8.4 “Derivative Work” means any work, whether in Source or Object form, that is based on (or derived from) the GenBio Materials and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the GenBio Materials and Derivative Works thereof.
|
| 45 |
+
8.5 “Non-Commercial Purposes” means uses not intended for or directed toward commercial advantage or monetary compensation, or the facilitation of development of any product or service to be sold or made available for a fee. For the avoidance of doubt, the provision of Outputs as a service is not a Non-Commercial Purpose.
|
| 46 |
+
8.6 “Object” means any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
|
| 47 |
+
8.7 “Output” means any output, including any protein sequence, structure prediction, functional annotation, molecule, descriptions of a molecule, model, sequence, text, and/or image that is elicited directly or indirectly by, or otherwise made available to, you in connection with your use of the GenBio Materials, including, but not limited to, the use of AI-Powered Technology. For the avoidance of doubt, it includes any intermediate results, such as activations across model layers, intermediate outputs from model layers (e.g., attention maps), as well as gradients and embeddings produced by the GenBio Materials.
|
| 48 |
+
8.8 “Output Derivatives” means any enhancements, modifications and derivative works of Outputs (including, but not limited to, any derivative sequences or molecules).
|
| 49 |
+
8.9 “Source” means the preferred form for making modifications, including but not limited to GenBio Materials source code, documentation source, and configuration files.
|
README.md
CHANGED
|
@@ -1,3 +1,161 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
tags:
|
| 2 |
+
|
| 3 |
+
- biology
|
| 4 |
+
license: other
|
| 5 |
+
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
# AIDO.RAGProtein-3B
|
| 9 |
+
|
| 10 |
+
AIDO.RAGProtein-3B (AIDO.RAGPLM) is a pretrained model for Retrieval-AuGmented protein language model in an [AI-driven Digital Organism](https://arxiv.org/abs/2412.06993). AIDO.RAGProtein-3B (and [AIDO.RAGFold](https://www.biorxiv.org/content/10.1101/2024.12.02.626519v1)) integrates pre-trained protein language models with retrieved MSA, allowing for the incorporation of co-evolutionary information in structure prediction while compensating for insufficient MSA information through large-scale pretraining.
|
| 11 |
+
|
| 12 |
+
AIDO.RAGProtein-3B surpasses single-sequence protein language models in perplexity, contact prediction, and fitness prediction. We utilized AIDO.RAGProtein-3B as the feature extractor for protein structure prediction, resulting in the development of [AIDO.RAGFold](https://www.biorxiv.org/content/10.1101/2024.12.02.626519v1). When sufficient MSA is available, AIDO.RAGFold achieves TM-scores comparable to AlphaFold2 and operates up to eight times faster. In scenarios where MSA is insufficient, our method significantly outperforms AlphaFold2 (∆TM-score=0.379, 0.116 and 0.059 for 0, 5 and 10 MSA sequences as input).
|
| 13 |
+
|
| 14 |
+
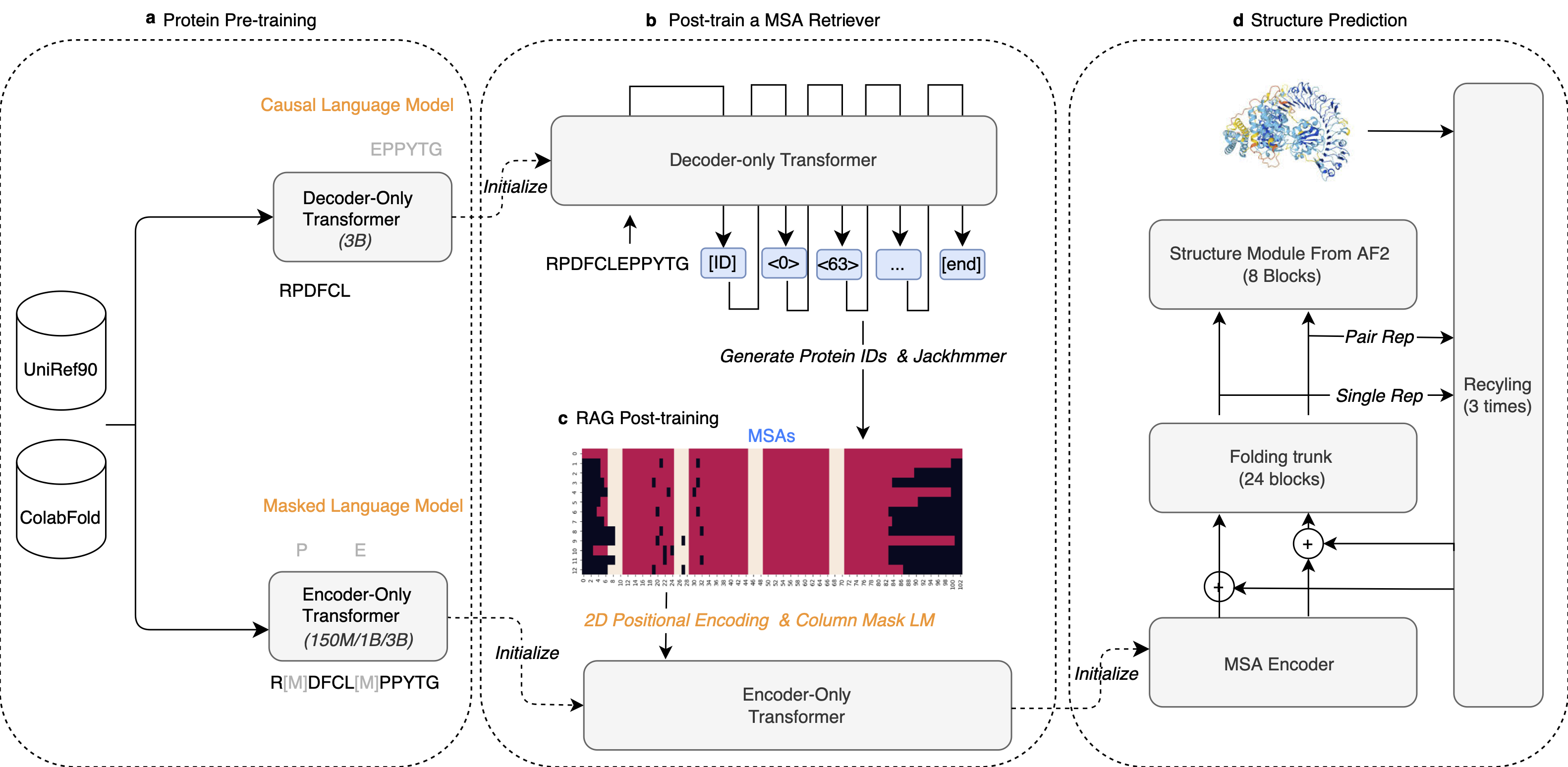
## Model Architecture Details
|
| 15 |
+
|
| 16 |
+
AIDO.RAGProtein-3B is a transformer encoder-only architecture with the dense MLP layer in each transformer block (Panel **c** below). It uses single amino acid tokenization and is optimized using a masked languange modeling (MLM) training objective.
|
| 17 |
+
|
| 18 |
+
<center><img src="architecture.png" alt="An Overview of AIDO.Protein" style="width:70%; height:auto;" /></center>
|
| 19 |
+
|
| 20 |
+
More architecture details are shown below:
|
| 21 |
+
|
| 22 |
+
| Model Arch | Value |
|
| 23 |
+
| ------------------ | :---: |
|
| 24 |
+
| Num Attention Head | 40 |
|
| 25 |
+
| Num Hidden Layer | 36 |
|
| 26 |
+
| Hidden Size | 2560 |
|
| 27 |
+
| FFN Hidden Size | 6832 |
|
| 28 |
+
| Context Length | 12.8K |
|
| 29 |
+
|
| 30 |
+
## Pre-training of AIDO.RAGProtein-3B
|
| 31 |
+
|
| 32 |
+
### Data
|
| 33 |
+
|
| 34 |
+
**UniRef50/Uniclust30 MSA dataset**: We utilized sequences from UniRef50 as queries to search for homologous sequences in UniClust30, subsequently constructing multiple sequence alignments (MSAs). UniRef50 comprises a total of 53.6 million sequences. Using HHblits, we searched all sequences, identifying over 25 homologous sequences for 23.7 million of them. This dataset was directly used as the training set, referred to as `HHblits_MSA`. The remaining 29.9 million sequences were input into MSA Retriever, resulting in 7.7 million sequences with more than 25 homologous sequences. This dataset was designated as `Retriever_MSA`. During training, RAGPLM randomly sampled from the two datasets with probabilities of 0.75 and 0.25
|
| 35 |
+
|
| 36 |
+
### Training Details
|
| 37 |
+
|
| 38 |
+
We fine-tuned a pretrained masked language model with 3-billion parameters ([MLM-3B](https://www.biorxiv.org/content/10.1101/2024.06.06.597716v1)) using MSA data by concatenating the query sequence with homologous sequences. We introduced several modifications to the standard BERT masking strategy: (1) We randomly sampled `0.05×L` span positions from a query sequence of length `L`, with span lengths following a geometric distribution (`p=0.2`), and capped the maximum length at 10. Our experiments revealed that this settings lead to an average of 15% of the query tokens were masked. (2) To prevent information leakage, when a residue was selected, all residues at the same index across all sequences (the column of the MSA matrix) were also masked. (3) When a column of MSA was selected for masking, the entire column was replaced with the `<MASK>` token in 80% of cases, with random amino acids in 10% of cases, and remained unchanged in the remaining 10% of cases. To help the model distinguish which tokens are from the same chain and which tokens have the same residue index, we use [2D rotary position embedding](https://arxiv.org/abs/2406.05347) to encode the tokens.
|
| 39 |
+
|
| 40 |
+
| | MLM-3B | AIDO.RAGProtein-3B |
|
| 41 |
+
| ---------------- | ------------------ | -------------------------- |
|
| 42 |
+
| Training data | UniRef+ColabFoldDB | HHblits_MSA, Retriever_MSA |
|
| 43 |
+
| Initial params | Random | MLM-3B |
|
| 44 |
+
| Learning rate | 2.5e-4 | 1e-4 |
|
| 45 |
+
| Training tokens | 1000B | 100B |
|
| 46 |
+
| Batch size | 2560 | 256 |
|
| 47 |
+
| Micro batch size | 4 | 1 |
|
| 48 |
+
| Sample length | 1024 | 12,800 |
|
| 49 |
+
| Attention | Bi-directional | Bi-directional |
|
| 50 |
+
|
| 51 |
+
### Tokenization
|
| 52 |
+
|
| 53 |
+
We encode protein sequence with single amino acid resolution with 44 vocabularies, where 24 tokens represent amino acid types and 20 are special tokens. Sequences were also suffixed with a `[SEP]` token as hooks for downstream tasks.
|
| 54 |
+
|
| 55 |
+
## Evaluation of AIDO.RAGProtein-3B
|
| 56 |
+
|
| 57 |
+
AIDO.RAGProtein-3B surpasses single-sequence protein language models in perplexity, contact prediction, and fitness prediction. Subsequently, we utilized AIDO.RAGProtein-3B as a feature extractor, integrating it with the folding trunks and Structure Modules to achieve end-to-end structural prediction ([AIDO.RAGFold](https://www.biorxiv.org/content/10.1101/2024.12.02.626519v1)). Our findings indicate that when sufficient MSA is available, our method achieves results comparable to AlphaFold2 and is eight times faster; when MSA is insufficient, our method significantly outperforms AlphaFold2.
|
| 58 |
+
|
| 59 |
+
## Results
|
| 60 |
+
|
| 61 |
+
### Unsupervised Contact Prediction
|
| 62 |
+
|
| 63 |
+
<center><img src="unsupervised_contact_prediction.png" alt="xxx" style="width:70%; height:auto;" /></center>
|
| 64 |
+
|
| 65 |
+
### Supervised Contact Prediction & ProteinGym zero-shot prediction
|
| 66 |
+
|
| 67 |
+
<center><img src="supervised_contact_prediction_fitness.png" alt="xxx" style="width:70%; height:auto;" /></center>
|
| 68 |
+
|
| 69 |
+
### AIDO.RAGFold
|
| 70 |
+
|
| 71 |
+
<center><img src="structure_prediction.png" alt="xxx" style="width:70%; height:auto;" /></center>
|
| 72 |
+
|
| 73 |
+
## How to Use
|
| 74 |
+
|
| 75 |
+
### Build any downstream models from this backbone with ModelGenerator
|
| 76 |
+
|
| 77 |
+
For more information, visit: [Model Generator](https://github.com/genbio-ai/modelgenerator)
|
| 78 |
+
|
| 79 |
+
```bash
|
| 80 |
+
mgen fit --model SequenceClassification --model.backbone aido_ragprotein_3b --data SequenceClassificationDataModule --data.path <hf_or_local_path_to_your_dataset>
|
| 81 |
+
mgen test --model SequenceClassification --model.backbone aido_ragprotein_3b --data SequenceClassificationDataModule --data.path <hf_or_local_path_to_your_dataset>
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
### Or use directly in Python
|
| 85 |
+
|
| 86 |
+
#### Embedding
|
| 87 |
+
|
| 88 |
+
```python
|
| 89 |
+
import torch
|
| 90 |
+
from modelgenerator.tasks import Embed
|
| 91 |
+
model = Embed.from_config({"model.backbone": "aido_ragprotein_3b"}).eval()
|
| 92 |
+
model.backbone.max_length = 12800
|
| 93 |
+
data = torch.load("ModelGenerator/experiments/AIDO.RAGPLM/examples.pt", 'cpu')[0]
|
| 94 |
+
transformed_batch = model.transform(data)
|
| 95 |
+
with torch.no_grad():
|
| 96 |
+
embedding = model(transformed_batch)
|
| 97 |
+
|
| 98 |
+
print(embedding.shape)
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
#### Sequence Level Classification
|
| 102 |
+
|
| 103 |
+
```python
|
| 104 |
+
import torch
|
| 105 |
+
from modelgenerator.tasks import SequenceClassification
|
| 106 |
+
model = SequenceClassification.from_config({"model.backbone": "aido_ragprotein_3b", "model.n_classes": 2}).eval()
|
| 107 |
+
model.backbone.max_length = 12800
|
| 108 |
+
data = torch.load("ModelGenerator/experiments/AIDO.RAGPLM/examples.pt", 'cpu')[0]
|
| 109 |
+
transformed_batch = model.transform(data)
|
| 110 |
+
with torch.no_grad():
|
| 111 |
+
logits = model(transformed_batch)
|
| 112 |
+
|
| 113 |
+
print(logits)
|
| 114 |
+
print(torch.argmax(logits, dim=-1))
|
| 115 |
+
```
|
| 116 |
+
|
| 117 |
+
#### Token Level Classification
|
| 118 |
+
|
| 119 |
+
```python
|
| 120 |
+
import torch
|
| 121 |
+
from modelgenerator.tasks import TokenClassification
|
| 122 |
+
model = TokenClassification.from_config({"model.backbone": "aido_ragprotein_3b", "model.n_classes": 3}).eval()
|
| 123 |
+
model.backbone.max_length = 12800
|
| 124 |
+
data = torch.load("ModelGenerator/experiments/AIDO.RAGPLM/examples.pt", 'cpu')[0]
|
| 125 |
+
transformed_batch = model.transform(data)
|
| 126 |
+
with torch.no_grad():
|
| 127 |
+
logits = model(transformed_batch)
|
| 128 |
+
|
| 129 |
+
print(logits)
|
| 130 |
+
print(torch.argmax(logits, dim=-1))
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
#### Regression
|
| 134 |
+
|
| 135 |
+
```python
|
| 136 |
+
from modelgenerator.tasks import SequenceRegression
|
| 137 |
+
model = SequenceRegression.from_config({"model.backbone": "aido_protein_16b_ragplm"}).eval()
|
| 138 |
+
model.backbone.max_length = 12800
|
| 139 |
+
data = torch.load("experiments/AIDO.RAGPLM/examples.pt", 'cpu')[0]
|
| 140 |
+
transformed_batch = model.transform(data)
|
| 141 |
+
with torch.no_grad():
|
| 142 |
+
logits = model(transformed_batch)
|
| 143 |
+
|
| 144 |
+
print(logits.shape)
|
| 145 |
+
```
|
| 146 |
+
|
| 147 |
+
# Citation
|
| 148 |
+
|
| 149 |
+
Please cite AIDO.RAGProtein-3B using the following BibTex code:
|
| 150 |
+
|
| 151 |
+
```
|
| 152 |
+
@article {Li2024.12.02.626519,
|
| 153 |
+
author = {Li, Pan and Cheng, Xingyi and Song, Le and Xing, Eric},
|
| 154 |
+
title = {Retrieval Augmented Protein Language Models for Protein Structure Prediction},
|
| 155 |
+
url = {https://www.biorxiv.org/content/10.1101/2024.12.02.626519v1},
|
| 156 |
+
year = {2024},
|
| 157 |
+
doi = {10.1101/2024.12.02.626519},
|
| 158 |
+
publisher = {bioRxiv},
|
| 159 |
+
booktitle={NeurIPS 2024 Workshop on Machine Learning in Structural Biology},
|
| 160 |
+
}
|
| 161 |
+
```
|
architecture.png
ADDED
|
Git LFS Details
|
config.json
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_linear_bias": true,
|
| 3 |
+
"apply_residual_connection_post_layernorm": true,
|
| 4 |
+
"architectures": [
|
| 5 |
+
"FM4BioForMaskedLM"
|
| 6 |
+
],
|
| 7 |
+
"attention_probs_dropout_prob": 0,
|
| 8 |
+
"experts_per_token": 2,
|
| 9 |
+
"gradient_checkpointing": false,
|
| 10 |
+
"hidden_act": "geglu",
|
| 11 |
+
"hidden_dropout_prob": 0,
|
| 12 |
+
"hidden_size": 2560,
|
| 13 |
+
"initializer_range": 0.02,
|
| 14 |
+
"intermediate_size": 6832,
|
| 15 |
+
"layer_norm_eps": 1e-05,
|
| 16 |
+
"max_position_embeddings": 2048,
|
| 17 |
+
"model_type": "fm4bio",
|
| 18 |
+
"moe": false,
|
| 19 |
+
"normalization_type": "LayerNorm",
|
| 20 |
+
"num_attention_heads": 40,
|
| 21 |
+
"num_experts": 8,
|
| 22 |
+
"num_hidden_layers": 36,
|
| 23 |
+
"output_vocab_size": null,
|
| 24 |
+
"pad_token_id": 0,
|
| 25 |
+
"position_embedding_type": "rope_2d",
|
| 26 |
+
"rotary_percent": 1.0,
|
| 27 |
+
"seq_len_interpolation_factor": null,
|
| 28 |
+
"str_embedding_in": null,
|
| 29 |
+
"tie_word_embeddings": false,
|
| 30 |
+
"tokenizer_insert_str_tokens": false,
|
| 31 |
+
"torch_dtype": "float32",
|
| 32 |
+
"transformers_version": "4.48.3",
|
| 33 |
+
"type_vocab_size": 2,
|
| 34 |
+
"use_cache": true,
|
| 35 |
+
"use_lm_head": false,
|
| 36 |
+
"vocab_size": 128
|
| 37 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"pad_token_id": 0,
|
| 4 |
+
"transformers_version": "4.48.3"
|
| 5 |
+
}
|
pytorch_model-00001-of-00003.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d50efa37938af31911a03e8e7fef8bed5f0c269a007020a13c5e699b8bd8628a
|
| 3 |
+
size 4969563679
|
pytorch_model-00002-of-00003.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:809189cd3742ca97ce207a6ca924782001ce8dcf2db6d771bdf1036495f176af
|
| 3 |
+
size 4898248668
|
pytorch_model-00003-of-00003.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:433f42e6287f0644e514038cd02454a36a223093ef5fd0cb15bd335eb456cf66
|
| 3 |
+
size 1470833384
|
pytorch_model.bin.index.json
ADDED
|
@@ -0,0 +1,587 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 11338446336
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"bert.embeddings.word_embeddings.weight": "pytorch_model-00001-of-00003.bin",
|
| 7 |
+
"bert.encoder.layer.0.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 8 |
+
"bert.encoder.layer.0.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 9 |
+
"bert.encoder.layer.0.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 10 |
+
"bert.encoder.layer.0.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 11 |
+
"bert.encoder.layer.0.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 12 |
+
"bert.encoder.layer.0.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 13 |
+
"bert.encoder.layer.0.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 14 |
+
"bert.encoder.layer.0.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 15 |
+
"bert.encoder.layer.0.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 16 |
+
"bert.encoder.layer.0.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 17 |
+
"bert.encoder.layer.0.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 18 |
+
"bert.encoder.layer.0.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 19 |
+
"bert.encoder.layer.0.mlp.dense_4h_to_h.bias": "pytorch_model-00001-of-00003.bin",
|
| 20 |
+
"bert.encoder.layer.0.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 21 |
+
"bert.encoder.layer.0.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 22 |
+
"bert.encoder.layer.0.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 23 |
+
"bert.encoder.layer.1.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 24 |
+
"bert.encoder.layer.1.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 25 |
+
"bert.encoder.layer.1.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 26 |
+
"bert.encoder.layer.1.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 27 |
+
"bert.encoder.layer.1.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 28 |
+
"bert.encoder.layer.1.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 29 |
+
"bert.encoder.layer.1.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 30 |
+
"bert.encoder.layer.1.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 31 |
+
"bert.encoder.layer.1.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 32 |
+
"bert.encoder.layer.1.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 33 |
+
"bert.encoder.layer.1.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 34 |
+
"bert.encoder.layer.1.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 35 |
+
"bert.encoder.layer.1.mlp.dense_4h_to_h.bias": "pytorch_model-00001-of-00003.bin",
|
| 36 |
+
"bert.encoder.layer.1.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 37 |
+
"bert.encoder.layer.1.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 38 |
+
"bert.encoder.layer.1.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 39 |
+
"bert.encoder.layer.10.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 40 |
+
"bert.encoder.layer.10.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 41 |
+
"bert.encoder.layer.10.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 42 |
+
"bert.encoder.layer.10.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 43 |
+
"bert.encoder.layer.10.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 44 |
+
"bert.encoder.layer.10.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 45 |
+
"bert.encoder.layer.10.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 46 |
+
"bert.encoder.layer.10.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 47 |
+
"bert.encoder.layer.10.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 48 |
+
"bert.encoder.layer.10.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 49 |
+
"bert.encoder.layer.10.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 50 |
+
"bert.encoder.layer.10.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 51 |
+
"bert.encoder.layer.10.mlp.dense_4h_to_h.bias": "pytorch_model-00001-of-00003.bin",
|
| 52 |
+
"bert.encoder.layer.10.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 53 |
+
"bert.encoder.layer.10.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 54 |
+
"bert.encoder.layer.10.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 55 |
+
"bert.encoder.layer.11.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 56 |
+
"bert.encoder.layer.11.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 57 |
+
"bert.encoder.layer.11.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 58 |
+
"bert.encoder.layer.11.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 59 |
+
"bert.encoder.layer.11.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 60 |
+
"bert.encoder.layer.11.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 61 |
+
"bert.encoder.layer.11.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 62 |
+
"bert.encoder.layer.11.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 63 |
+
"bert.encoder.layer.11.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 64 |
+
"bert.encoder.layer.11.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 65 |
+
"bert.encoder.layer.11.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 66 |
+
"bert.encoder.layer.11.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 67 |
+
"bert.encoder.layer.11.mlp.dense_4h_to_h.bias": "pytorch_model-00001-of-00003.bin",
|
| 68 |
+
"bert.encoder.layer.11.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 69 |
+
"bert.encoder.layer.11.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 70 |
+
"bert.encoder.layer.11.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 71 |
+
"bert.encoder.layer.12.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 72 |
+
"bert.encoder.layer.12.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 73 |
+
"bert.encoder.layer.12.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 74 |
+
"bert.encoder.layer.12.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 75 |
+
"bert.encoder.layer.12.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 76 |
+
"bert.encoder.layer.12.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 77 |
+
"bert.encoder.layer.12.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 78 |
+
"bert.encoder.layer.12.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 79 |
+
"bert.encoder.layer.12.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 80 |
+
"bert.encoder.layer.12.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 81 |
+
"bert.encoder.layer.12.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 82 |
+
"bert.encoder.layer.12.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 83 |
+
"bert.encoder.layer.12.mlp.dense_4h_to_h.bias": "pytorch_model-00001-of-00003.bin",
|
| 84 |
+
"bert.encoder.layer.12.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 85 |
+
"bert.encoder.layer.12.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 86 |
+
"bert.encoder.layer.12.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 87 |
+
"bert.encoder.layer.13.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 88 |
+
"bert.encoder.layer.13.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 89 |
+
"bert.encoder.layer.13.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 90 |
+
"bert.encoder.layer.13.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 91 |
+
"bert.encoder.layer.13.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 92 |
+
"bert.encoder.layer.13.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 93 |
+
"bert.encoder.layer.13.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 94 |
+
"bert.encoder.layer.13.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 95 |
+
"bert.encoder.layer.13.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 96 |
+
"bert.encoder.layer.13.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 97 |
+
"bert.encoder.layer.13.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 98 |
+
"bert.encoder.layer.13.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 99 |
+
"bert.encoder.layer.13.mlp.dense_4h_to_h.bias": "pytorch_model-00001-of-00003.bin",
|
| 100 |
+
"bert.encoder.layer.13.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 101 |
+
"bert.encoder.layer.13.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 102 |
+
"bert.encoder.layer.13.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 103 |
+
"bert.encoder.layer.14.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 104 |
+
"bert.encoder.layer.14.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 105 |
+
"bert.encoder.layer.14.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 106 |
+
"bert.encoder.layer.14.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 107 |
+
"bert.encoder.layer.14.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 108 |
+
"bert.encoder.layer.14.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 109 |
+
"bert.encoder.layer.14.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 110 |
+
"bert.encoder.layer.14.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 111 |
+
"bert.encoder.layer.14.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 112 |
+
"bert.encoder.layer.14.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 113 |
+
"bert.encoder.layer.14.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 114 |
+
"bert.encoder.layer.14.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 115 |
+
"bert.encoder.layer.14.mlp.dense_4h_to_h.bias": "pytorch_model-00001-of-00003.bin",
|
| 116 |
+
"bert.encoder.layer.14.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 117 |
+
"bert.encoder.layer.14.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 118 |
+
"bert.encoder.layer.14.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 119 |
+
"bert.encoder.layer.15.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 120 |
+
"bert.encoder.layer.15.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 121 |
+
"bert.encoder.layer.15.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 122 |
+
"bert.encoder.layer.15.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 123 |
+
"bert.encoder.layer.15.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 124 |
+
"bert.encoder.layer.15.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 125 |
+
"bert.encoder.layer.15.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 126 |
+
"bert.encoder.layer.15.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 127 |
+
"bert.encoder.layer.15.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 128 |
+
"bert.encoder.layer.15.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 129 |
+
"bert.encoder.layer.15.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 130 |
+
"bert.encoder.layer.15.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 131 |
+
"bert.encoder.layer.15.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 132 |
+
"bert.encoder.layer.15.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 133 |
+
"bert.encoder.layer.15.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 134 |
+
"bert.encoder.layer.15.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 135 |
+
"bert.encoder.layer.16.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 136 |
+
"bert.encoder.layer.16.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 137 |
+
"bert.encoder.layer.16.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 138 |
+
"bert.encoder.layer.16.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 139 |
+
"bert.encoder.layer.16.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 140 |
+
"bert.encoder.layer.16.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 141 |
+
"bert.encoder.layer.16.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 142 |
+
"bert.encoder.layer.16.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 143 |
+
"bert.encoder.layer.16.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 144 |
+
"bert.encoder.layer.16.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 145 |
+
"bert.encoder.layer.16.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 146 |
+
"bert.encoder.layer.16.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 147 |
+
"bert.encoder.layer.16.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 148 |
+
"bert.encoder.layer.16.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 149 |
+
"bert.encoder.layer.16.mlp.dense_h_to_4h.bias": "pytorch_model-00002-of-00003.bin",
|
| 150 |
+
"bert.encoder.layer.16.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 151 |
+
"bert.encoder.layer.17.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 152 |
+
"bert.encoder.layer.17.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 153 |
+
"bert.encoder.layer.17.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 154 |
+
"bert.encoder.layer.17.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 155 |
+
"bert.encoder.layer.17.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 156 |
+
"bert.encoder.layer.17.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 157 |
+
"bert.encoder.layer.17.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 158 |
+
"bert.encoder.layer.17.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 159 |
+
"bert.encoder.layer.17.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 160 |
+
"bert.encoder.layer.17.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 161 |
+
"bert.encoder.layer.17.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 162 |
+
"bert.encoder.layer.17.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 163 |
+
"bert.encoder.layer.17.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 164 |
+
"bert.encoder.layer.17.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 165 |
+
"bert.encoder.layer.17.mlp.dense_h_to_4h.bias": "pytorch_model-00002-of-00003.bin",
|
| 166 |
+
"bert.encoder.layer.17.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 167 |
+
"bert.encoder.layer.18.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 168 |
+
"bert.encoder.layer.18.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 169 |
+
"bert.encoder.layer.18.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 170 |
+
"bert.encoder.layer.18.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 171 |
+
"bert.encoder.layer.18.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 172 |
+
"bert.encoder.layer.18.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 173 |
+
"bert.encoder.layer.18.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 174 |
+
"bert.encoder.layer.18.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 175 |
+
"bert.encoder.layer.18.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 176 |
+
"bert.encoder.layer.18.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 177 |
+
"bert.encoder.layer.18.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 178 |
+
"bert.encoder.layer.18.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 179 |
+
"bert.encoder.layer.18.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 180 |
+
"bert.encoder.layer.18.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 181 |
+
"bert.encoder.layer.18.mlp.dense_h_to_4h.bias": "pytorch_model-00002-of-00003.bin",
|
| 182 |
+
"bert.encoder.layer.18.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 183 |
+
"bert.encoder.layer.19.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 184 |
+
"bert.encoder.layer.19.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 185 |
+
"bert.encoder.layer.19.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 186 |
+
"bert.encoder.layer.19.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 187 |
+
"bert.encoder.layer.19.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 188 |
+
"bert.encoder.layer.19.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 189 |
+
"bert.encoder.layer.19.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 190 |
+
"bert.encoder.layer.19.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 191 |
+
"bert.encoder.layer.19.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 192 |
+
"bert.encoder.layer.19.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 193 |
+
"bert.encoder.layer.19.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 194 |
+
"bert.encoder.layer.19.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 195 |
+
"bert.encoder.layer.19.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 196 |
+
"bert.encoder.layer.19.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 197 |
+
"bert.encoder.layer.19.mlp.dense_h_to_4h.bias": "pytorch_model-00002-of-00003.bin",
|
| 198 |
+
"bert.encoder.layer.19.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 199 |
+
"bert.encoder.layer.2.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 200 |
+
"bert.encoder.layer.2.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 201 |
+
"bert.encoder.layer.2.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 202 |
+
"bert.encoder.layer.2.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 203 |
+
"bert.encoder.layer.2.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 204 |
+
"bert.encoder.layer.2.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 205 |
+
"bert.encoder.layer.2.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 206 |
+
"bert.encoder.layer.2.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 207 |
+
"bert.encoder.layer.2.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 208 |
+
"bert.encoder.layer.2.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 209 |
+
"bert.encoder.layer.2.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 210 |
+
"bert.encoder.layer.2.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 211 |
+
"bert.encoder.layer.2.mlp.dense_4h_to_h.bias": "pytorch_model-00001-of-00003.bin",
|
| 212 |
+
"bert.encoder.layer.2.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 213 |
+
"bert.encoder.layer.2.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 214 |
+
"bert.encoder.layer.2.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 215 |
+
"bert.encoder.layer.20.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 216 |
+
"bert.encoder.layer.20.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 217 |
+
"bert.encoder.layer.20.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 218 |
+
"bert.encoder.layer.20.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 219 |
+
"bert.encoder.layer.20.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 220 |
+
"bert.encoder.layer.20.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 221 |
+
"bert.encoder.layer.20.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 222 |
+
"bert.encoder.layer.20.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 223 |
+
"bert.encoder.layer.20.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 224 |
+
"bert.encoder.layer.20.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 225 |
+
"bert.encoder.layer.20.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 226 |
+
"bert.encoder.layer.20.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 227 |
+
"bert.encoder.layer.20.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 228 |
+
"bert.encoder.layer.20.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 229 |
+
"bert.encoder.layer.20.mlp.dense_h_to_4h.bias": "pytorch_model-00002-of-00003.bin",
|
| 230 |
+
"bert.encoder.layer.20.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 231 |
+
"bert.encoder.layer.21.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 232 |
+
"bert.encoder.layer.21.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 233 |
+
"bert.encoder.layer.21.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 234 |
+
"bert.encoder.layer.21.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 235 |
+
"bert.encoder.layer.21.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 236 |
+
"bert.encoder.layer.21.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 237 |
+
"bert.encoder.layer.21.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 238 |
+
"bert.encoder.layer.21.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 239 |
+
"bert.encoder.layer.21.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 240 |
+
"bert.encoder.layer.21.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 241 |
+
"bert.encoder.layer.21.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 242 |
+
"bert.encoder.layer.21.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 243 |
+
"bert.encoder.layer.21.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 244 |
+
"bert.encoder.layer.21.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 245 |
+
"bert.encoder.layer.21.mlp.dense_h_to_4h.bias": "pytorch_model-00002-of-00003.bin",
|
| 246 |
+
"bert.encoder.layer.21.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 247 |
+
"bert.encoder.layer.22.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 248 |
+
"bert.encoder.layer.22.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 249 |
+
"bert.encoder.layer.22.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 250 |
+
"bert.encoder.layer.22.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 251 |
+
"bert.encoder.layer.22.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 252 |
+
"bert.encoder.layer.22.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 253 |
+
"bert.encoder.layer.22.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 254 |
+
"bert.encoder.layer.22.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 255 |
+
"bert.encoder.layer.22.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 256 |
+
"bert.encoder.layer.22.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 257 |
+
"bert.encoder.layer.22.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 258 |
+
"bert.encoder.layer.22.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 259 |
+
"bert.encoder.layer.22.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 260 |
+
"bert.encoder.layer.22.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 261 |
+
"bert.encoder.layer.22.mlp.dense_h_to_4h.bias": "pytorch_model-00002-of-00003.bin",
|
| 262 |
+
"bert.encoder.layer.22.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 263 |
+
"bert.encoder.layer.23.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 264 |
+
"bert.encoder.layer.23.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 265 |
+
"bert.encoder.layer.23.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 266 |
+
"bert.encoder.layer.23.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 267 |
+
"bert.encoder.layer.23.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 268 |
+
"bert.encoder.layer.23.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 269 |
+
"bert.encoder.layer.23.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 270 |
+
"bert.encoder.layer.23.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 271 |
+
"bert.encoder.layer.23.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 272 |
+
"bert.encoder.layer.23.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 273 |
+
"bert.encoder.layer.23.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 274 |
+
"bert.encoder.layer.23.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 275 |
+
"bert.encoder.layer.23.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 276 |
+
"bert.encoder.layer.23.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 277 |
+
"bert.encoder.layer.23.mlp.dense_h_to_4h.bias": "pytorch_model-00002-of-00003.bin",
|
| 278 |
+
"bert.encoder.layer.23.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 279 |
+
"bert.encoder.layer.24.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 280 |
+
"bert.encoder.layer.24.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 281 |
+
"bert.encoder.layer.24.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 282 |
+
"bert.encoder.layer.24.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 283 |
+
"bert.encoder.layer.24.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 284 |
+
"bert.encoder.layer.24.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 285 |
+
"bert.encoder.layer.24.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 286 |
+
"bert.encoder.layer.24.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 287 |
+
"bert.encoder.layer.24.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 288 |
+
"bert.encoder.layer.24.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 289 |
+
"bert.encoder.layer.24.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 290 |
+
"bert.encoder.layer.24.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 291 |
+
"bert.encoder.layer.24.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 292 |
+
"bert.encoder.layer.24.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 293 |
+
"bert.encoder.layer.24.mlp.dense_h_to_4h.bias": "pytorch_model-00002-of-00003.bin",
|
| 294 |
+
"bert.encoder.layer.24.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 295 |
+
"bert.encoder.layer.25.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 296 |
+
"bert.encoder.layer.25.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 297 |
+
"bert.encoder.layer.25.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 298 |
+
"bert.encoder.layer.25.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 299 |
+
"bert.encoder.layer.25.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 300 |
+
"bert.encoder.layer.25.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 301 |
+
"bert.encoder.layer.25.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 302 |
+
"bert.encoder.layer.25.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 303 |
+
"bert.encoder.layer.25.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 304 |
+
"bert.encoder.layer.25.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 305 |
+
"bert.encoder.layer.25.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 306 |
+
"bert.encoder.layer.25.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 307 |
+
"bert.encoder.layer.25.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 308 |
+
"bert.encoder.layer.25.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 309 |
+
"bert.encoder.layer.25.mlp.dense_h_to_4h.bias": "pytorch_model-00002-of-00003.bin",
|
| 310 |
+
"bert.encoder.layer.25.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 311 |
+
"bert.encoder.layer.26.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 312 |
+
"bert.encoder.layer.26.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 313 |
+
"bert.encoder.layer.26.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 314 |
+
"bert.encoder.layer.26.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 315 |
+
"bert.encoder.layer.26.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 316 |
+
"bert.encoder.layer.26.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 317 |
+
"bert.encoder.layer.26.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 318 |
+
"bert.encoder.layer.26.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 319 |
+
"bert.encoder.layer.26.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 320 |
+
"bert.encoder.layer.26.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 321 |
+
"bert.encoder.layer.26.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 322 |
+
"bert.encoder.layer.26.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 323 |
+
"bert.encoder.layer.26.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 324 |
+
"bert.encoder.layer.26.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 325 |
+
"bert.encoder.layer.26.mlp.dense_h_to_4h.bias": "pytorch_model-00002-of-00003.bin",
|
| 326 |
+
"bert.encoder.layer.26.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 327 |
+
"bert.encoder.layer.27.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 328 |
+
"bert.encoder.layer.27.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 329 |
+
"bert.encoder.layer.27.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 330 |
+
"bert.encoder.layer.27.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 331 |
+
"bert.encoder.layer.27.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 332 |
+
"bert.encoder.layer.27.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 333 |
+
"bert.encoder.layer.27.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 334 |
+
"bert.encoder.layer.27.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 335 |
+
"bert.encoder.layer.27.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 336 |
+
"bert.encoder.layer.27.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 337 |
+
"bert.encoder.layer.27.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 338 |
+
"bert.encoder.layer.27.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 339 |
+
"bert.encoder.layer.27.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 340 |
+
"bert.encoder.layer.27.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 341 |
+
"bert.encoder.layer.27.mlp.dense_h_to_4h.bias": "pytorch_model-00002-of-00003.bin",
|
| 342 |
+
"bert.encoder.layer.27.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 343 |
+
"bert.encoder.layer.28.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 344 |
+
"bert.encoder.layer.28.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 345 |
+
"bert.encoder.layer.28.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 346 |
+
"bert.encoder.layer.28.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 347 |
+
"bert.encoder.layer.28.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 348 |
+
"bert.encoder.layer.28.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 349 |
+
"bert.encoder.layer.28.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 350 |
+
"bert.encoder.layer.28.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 351 |
+
"bert.encoder.layer.28.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 352 |
+
"bert.encoder.layer.28.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 353 |
+
"bert.encoder.layer.28.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 354 |
+
"bert.encoder.layer.28.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 355 |
+
"bert.encoder.layer.28.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 356 |
+
"bert.encoder.layer.28.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 357 |
+
"bert.encoder.layer.28.mlp.dense_h_to_4h.bias": "pytorch_model-00002-of-00003.bin",
|
| 358 |
+
"bert.encoder.layer.28.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 359 |
+
"bert.encoder.layer.29.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 360 |
+
"bert.encoder.layer.29.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 361 |
+
"bert.encoder.layer.29.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 362 |
+
"bert.encoder.layer.29.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 363 |
+
"bert.encoder.layer.29.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 364 |
+
"bert.encoder.layer.29.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 365 |
+
"bert.encoder.layer.29.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 366 |
+
"bert.encoder.layer.29.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 367 |
+
"bert.encoder.layer.29.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 368 |
+
"bert.encoder.layer.29.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 369 |
+
"bert.encoder.layer.29.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 370 |
+
"bert.encoder.layer.29.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 371 |
+
"bert.encoder.layer.29.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 372 |
+
"bert.encoder.layer.29.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 373 |
+
"bert.encoder.layer.29.mlp.dense_h_to_4h.bias": "pytorch_model-00002-of-00003.bin",
|
| 374 |
+
"bert.encoder.layer.29.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 375 |
+
"bert.encoder.layer.3.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 376 |
+
"bert.encoder.layer.3.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 377 |
+
"bert.encoder.layer.3.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 378 |
+
"bert.encoder.layer.3.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 379 |
+
"bert.encoder.layer.3.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 380 |
+
"bert.encoder.layer.3.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 381 |
+
"bert.encoder.layer.3.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 382 |
+
"bert.encoder.layer.3.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 383 |
+
"bert.encoder.layer.3.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 384 |
+
"bert.encoder.layer.3.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 385 |
+
"bert.encoder.layer.3.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 386 |
+
"bert.encoder.layer.3.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 387 |
+
"bert.encoder.layer.3.mlp.dense_4h_to_h.bias": "pytorch_model-00001-of-00003.bin",
|
| 388 |
+
"bert.encoder.layer.3.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 389 |
+
"bert.encoder.layer.3.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 390 |
+
"bert.encoder.layer.3.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 391 |
+
"bert.encoder.layer.30.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 392 |
+
"bert.encoder.layer.30.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 393 |
+
"bert.encoder.layer.30.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 394 |
+
"bert.encoder.layer.30.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 395 |
+
"bert.encoder.layer.30.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 396 |
+
"bert.encoder.layer.30.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 397 |
+
"bert.encoder.layer.30.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 398 |
+
"bert.encoder.layer.30.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 399 |
+
"bert.encoder.layer.30.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 400 |
+
"bert.encoder.layer.30.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 401 |
+
"bert.encoder.layer.30.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 402 |
+
"bert.encoder.layer.30.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 403 |
+
"bert.encoder.layer.30.mlp.dense_4h_to_h.bias": "pytorch_model-00002-of-00003.bin",
|
| 404 |
+
"bert.encoder.layer.30.mlp.dense_4h_to_h.weight": "pytorch_model-00002-of-00003.bin",
|
| 405 |
+
"bert.encoder.layer.30.mlp.dense_h_to_4h.bias": "pytorch_model-00002-of-00003.bin",
|
| 406 |
+
"bert.encoder.layer.30.mlp.dense_h_to_4h.weight": "pytorch_model-00002-of-00003.bin",
|
| 407 |
+
"bert.encoder.layer.31.attention.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 408 |
+
"bert.encoder.layer.31.attention.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 409 |
+
"bert.encoder.layer.31.attention.output.dense.bias": "pytorch_model-00002-of-00003.bin",
|
| 410 |
+
"bert.encoder.layer.31.attention.output.dense.weight": "pytorch_model-00002-of-00003.bin",
|
| 411 |
+
"bert.encoder.layer.31.attention.self.key.bias": "pytorch_model-00002-of-00003.bin",
|
| 412 |
+
"bert.encoder.layer.31.attention.self.key.weight": "pytorch_model-00002-of-00003.bin",
|
| 413 |
+
"bert.encoder.layer.31.attention.self.query.bias": "pytorch_model-00002-of-00003.bin",
|
| 414 |
+
"bert.encoder.layer.31.attention.self.query.weight": "pytorch_model-00002-of-00003.bin",
|
| 415 |
+
"bert.encoder.layer.31.attention.self.value.bias": "pytorch_model-00002-of-00003.bin",
|
| 416 |
+
"bert.encoder.layer.31.attention.self.value.weight": "pytorch_model-00002-of-00003.bin",
|
| 417 |
+
"bert.encoder.layer.31.ln.bias": "pytorch_model-00002-of-00003.bin",
|
| 418 |
+
"bert.encoder.layer.31.ln.weight": "pytorch_model-00002-of-00003.bin",
|
| 419 |
+
"bert.encoder.layer.31.mlp.dense_4h_to_h.bias": "pytorch_model-00003-of-00003.bin",
|
| 420 |
+
"bert.encoder.layer.31.mlp.dense_4h_to_h.weight": "pytorch_model-00003-of-00003.bin",
|
| 421 |
+
"bert.encoder.layer.31.mlp.dense_h_to_4h.bias": "pytorch_model-00003-of-00003.bin",
|
| 422 |
+
"bert.encoder.layer.31.mlp.dense_h_to_4h.weight": "pytorch_model-00003-of-00003.bin",
|
| 423 |
+
"bert.encoder.layer.32.attention.ln.bias": "pytorch_model-00003-of-00003.bin",
|
| 424 |
+
"bert.encoder.layer.32.attention.ln.weight": "pytorch_model-00003-of-00003.bin",
|
| 425 |
+
"bert.encoder.layer.32.attention.output.dense.bias": "pytorch_model-00003-of-00003.bin",
|
| 426 |
+
"bert.encoder.layer.32.attention.output.dense.weight": "pytorch_model-00003-of-00003.bin",
|
| 427 |
+
"bert.encoder.layer.32.attention.self.key.bias": "pytorch_model-00003-of-00003.bin",
|
| 428 |
+
"bert.encoder.layer.32.attention.self.key.weight": "pytorch_model-00003-of-00003.bin",
|
| 429 |
+
"bert.encoder.layer.32.attention.self.query.bias": "pytorch_model-00003-of-00003.bin",
|
| 430 |
+
"bert.encoder.layer.32.attention.self.query.weight": "pytorch_model-00003-of-00003.bin",
|
| 431 |
+
"bert.encoder.layer.32.attention.self.value.bias": "pytorch_model-00003-of-00003.bin",
|
| 432 |
+
"bert.encoder.layer.32.attention.self.value.weight": "pytorch_model-00003-of-00003.bin",
|
| 433 |
+
"bert.encoder.layer.32.ln.bias": "pytorch_model-00003-of-00003.bin",
|
| 434 |
+
"bert.encoder.layer.32.ln.weight": "pytorch_model-00003-of-00003.bin",
|
| 435 |
+
"bert.encoder.layer.32.mlp.dense_4h_to_h.bias": "pytorch_model-00003-of-00003.bin",
|
| 436 |
+
"bert.encoder.layer.32.mlp.dense_4h_to_h.weight": "pytorch_model-00003-of-00003.bin",
|
| 437 |
+
"bert.encoder.layer.32.mlp.dense_h_to_4h.bias": "pytorch_model-00003-of-00003.bin",
|
| 438 |
+
"bert.encoder.layer.32.mlp.dense_h_to_4h.weight": "pytorch_model-00003-of-00003.bin",
|
| 439 |
+
"bert.encoder.layer.33.attention.ln.bias": "pytorch_model-00003-of-00003.bin",
|
| 440 |
+
"bert.encoder.layer.33.attention.ln.weight": "pytorch_model-00003-of-00003.bin",
|
| 441 |
+
"bert.encoder.layer.33.attention.output.dense.bias": "pytorch_model-00003-of-00003.bin",
|
| 442 |
+
"bert.encoder.layer.33.attention.output.dense.weight": "pytorch_model-00003-of-00003.bin",
|
| 443 |
+
"bert.encoder.layer.33.attention.self.key.bias": "pytorch_model-00003-of-00003.bin",
|
| 444 |
+
"bert.encoder.layer.33.attention.self.key.weight": "pytorch_model-00003-of-00003.bin",
|
| 445 |
+
"bert.encoder.layer.33.attention.self.query.bias": "pytorch_model-00003-of-00003.bin",
|
| 446 |
+
"bert.encoder.layer.33.attention.self.query.weight": "pytorch_model-00003-of-00003.bin",
|
| 447 |
+
"bert.encoder.layer.33.attention.self.value.bias": "pytorch_model-00003-of-00003.bin",
|
| 448 |
+
"bert.encoder.layer.33.attention.self.value.weight": "pytorch_model-00003-of-00003.bin",
|
| 449 |
+
"bert.encoder.layer.33.ln.bias": "pytorch_model-00003-of-00003.bin",
|
| 450 |
+
"bert.encoder.layer.33.ln.weight": "pytorch_model-00003-of-00003.bin",
|
| 451 |
+
"bert.encoder.layer.33.mlp.dense_4h_to_h.bias": "pytorch_model-00003-of-00003.bin",
|
| 452 |
+
"bert.encoder.layer.33.mlp.dense_4h_to_h.weight": "pytorch_model-00003-of-00003.bin",
|
| 453 |
+
"bert.encoder.layer.33.mlp.dense_h_to_4h.bias": "pytorch_model-00003-of-00003.bin",
|
| 454 |
+
"bert.encoder.layer.33.mlp.dense_h_to_4h.weight": "pytorch_model-00003-of-00003.bin",
|
| 455 |
+
"bert.encoder.layer.34.attention.ln.bias": "pytorch_model-00003-of-00003.bin",
|
| 456 |
+
"bert.encoder.layer.34.attention.ln.weight": "pytorch_model-00003-of-00003.bin",
|
| 457 |
+
"bert.encoder.layer.34.attention.output.dense.bias": "pytorch_model-00003-of-00003.bin",
|
| 458 |
+
"bert.encoder.layer.34.attention.output.dense.weight": "pytorch_model-00003-of-00003.bin",
|
| 459 |
+
"bert.encoder.layer.34.attention.self.key.bias": "pytorch_model-00003-of-00003.bin",
|
| 460 |
+
"bert.encoder.layer.34.attention.self.key.weight": "pytorch_model-00003-of-00003.bin",
|
| 461 |
+
"bert.encoder.layer.34.attention.self.query.bias": "pytorch_model-00003-of-00003.bin",
|
| 462 |
+
"bert.encoder.layer.34.attention.self.query.weight": "pytorch_model-00003-of-00003.bin",
|
| 463 |
+
"bert.encoder.layer.34.attention.self.value.bias": "pytorch_model-00003-of-00003.bin",
|
| 464 |
+
"bert.encoder.layer.34.attention.self.value.weight": "pytorch_model-00003-of-00003.bin",
|
| 465 |
+
"bert.encoder.layer.34.ln.bias": "pytorch_model-00003-of-00003.bin",
|
| 466 |
+
"bert.encoder.layer.34.ln.weight": "pytorch_model-00003-of-00003.bin",
|
| 467 |
+
"bert.encoder.layer.34.mlp.dense_4h_to_h.bias": "pytorch_model-00003-of-00003.bin",
|
| 468 |
+
"bert.encoder.layer.34.mlp.dense_4h_to_h.weight": "pytorch_model-00003-of-00003.bin",
|
| 469 |
+
"bert.encoder.layer.34.mlp.dense_h_to_4h.bias": "pytorch_model-00003-of-00003.bin",
|
| 470 |
+
"bert.encoder.layer.34.mlp.dense_h_to_4h.weight": "pytorch_model-00003-of-00003.bin",
|
| 471 |
+
"bert.encoder.layer.35.attention.ln.bias": "pytorch_model-00003-of-00003.bin",
|
| 472 |
+
"bert.encoder.layer.35.attention.ln.weight": "pytorch_model-00003-of-00003.bin",
|
| 473 |
+
"bert.encoder.layer.35.attention.output.dense.bias": "pytorch_model-00003-of-00003.bin",
|
| 474 |
+
"bert.encoder.layer.35.attention.output.dense.weight": "pytorch_model-00003-of-00003.bin",
|
| 475 |
+
"bert.encoder.layer.35.attention.self.key.bias": "pytorch_model-00003-of-00003.bin",
|
| 476 |
+
"bert.encoder.layer.35.attention.self.key.weight": "pytorch_model-00003-of-00003.bin",
|
| 477 |
+
"bert.encoder.layer.35.attention.self.query.bias": "pytorch_model-00003-of-00003.bin",
|
| 478 |
+
"bert.encoder.layer.35.attention.self.query.weight": "pytorch_model-00003-of-00003.bin",
|
| 479 |
+
"bert.encoder.layer.35.attention.self.value.bias": "pytorch_model-00003-of-00003.bin",
|
| 480 |
+
"bert.encoder.layer.35.attention.self.value.weight": "pytorch_model-00003-of-00003.bin",
|
| 481 |
+
"bert.encoder.layer.35.ln.bias": "pytorch_model-00003-of-00003.bin",
|
| 482 |
+
"bert.encoder.layer.35.ln.weight": "pytorch_model-00003-of-00003.bin",
|
| 483 |
+
"bert.encoder.layer.35.mlp.dense_4h_to_h.bias": "pytorch_model-00003-of-00003.bin",
|
| 484 |
+
"bert.encoder.layer.35.mlp.dense_4h_to_h.weight": "pytorch_model-00003-of-00003.bin",
|
| 485 |
+
"bert.encoder.layer.35.mlp.dense_h_to_4h.bias": "pytorch_model-00003-of-00003.bin",
|
| 486 |
+
"bert.encoder.layer.35.mlp.dense_h_to_4h.weight": "pytorch_model-00003-of-00003.bin",
|
| 487 |
+
"bert.encoder.layer.4.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 488 |
+
"bert.encoder.layer.4.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 489 |
+
"bert.encoder.layer.4.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 490 |
+
"bert.encoder.layer.4.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 491 |
+
"bert.encoder.layer.4.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 492 |
+
"bert.encoder.layer.4.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 493 |
+
"bert.encoder.layer.4.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 494 |
+
"bert.encoder.layer.4.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 495 |
+
"bert.encoder.layer.4.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 496 |
+
"bert.encoder.layer.4.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 497 |
+
"bert.encoder.layer.4.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 498 |
+
"bert.encoder.layer.4.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 499 |
+
"bert.encoder.layer.4.mlp.dense_4h_to_h.bias": "pytorch_model-00001-of-00003.bin",
|
| 500 |
+
"bert.encoder.layer.4.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 501 |
+
"bert.encoder.layer.4.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 502 |
+
"bert.encoder.layer.4.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 503 |
+
"bert.encoder.layer.5.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 504 |
+
"bert.encoder.layer.5.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 505 |
+
"bert.encoder.layer.5.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 506 |
+
"bert.encoder.layer.5.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 507 |
+
"bert.encoder.layer.5.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 508 |
+
"bert.encoder.layer.5.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 509 |
+
"bert.encoder.layer.5.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 510 |
+
"bert.encoder.layer.5.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 511 |
+
"bert.encoder.layer.5.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 512 |
+
"bert.encoder.layer.5.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 513 |
+
"bert.encoder.layer.5.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 514 |
+
"bert.encoder.layer.5.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 515 |
+
"bert.encoder.layer.5.mlp.dense_4h_to_h.bias": "pytorch_model-00001-of-00003.bin",
|
| 516 |
+
"bert.encoder.layer.5.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 517 |
+
"bert.encoder.layer.5.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 518 |
+
"bert.encoder.layer.5.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 519 |
+
"bert.encoder.layer.6.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 520 |
+
"bert.encoder.layer.6.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 521 |
+
"bert.encoder.layer.6.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 522 |
+
"bert.encoder.layer.6.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 523 |
+
"bert.encoder.layer.6.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 524 |
+
"bert.encoder.layer.6.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 525 |
+
"bert.encoder.layer.6.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 526 |
+
"bert.encoder.layer.6.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 527 |
+
"bert.encoder.layer.6.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 528 |
+
"bert.encoder.layer.6.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 529 |
+
"bert.encoder.layer.6.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 530 |
+
"bert.encoder.layer.6.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 531 |
+
"bert.encoder.layer.6.mlp.dense_4h_to_h.bias": "pytorch_model-00001-of-00003.bin",
|
| 532 |
+
"bert.encoder.layer.6.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 533 |
+
"bert.encoder.layer.6.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 534 |
+
"bert.encoder.layer.6.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 535 |
+
"bert.encoder.layer.7.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 536 |
+
"bert.encoder.layer.7.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 537 |
+
"bert.encoder.layer.7.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 538 |
+
"bert.encoder.layer.7.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 539 |
+
"bert.encoder.layer.7.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 540 |
+
"bert.encoder.layer.7.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 541 |
+
"bert.encoder.layer.7.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 542 |
+
"bert.encoder.layer.7.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 543 |
+
"bert.encoder.layer.7.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 544 |
+
"bert.encoder.layer.7.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 545 |
+
"bert.encoder.layer.7.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 546 |
+
"bert.encoder.layer.7.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 547 |
+
"bert.encoder.layer.7.mlp.dense_4h_to_h.bias": "pytorch_model-00001-of-00003.bin",
|
| 548 |
+
"bert.encoder.layer.7.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 549 |
+
"bert.encoder.layer.7.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 550 |
+
"bert.encoder.layer.7.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 551 |
+
"bert.encoder.layer.8.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 552 |
+
"bert.encoder.layer.8.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 553 |
+
"bert.encoder.layer.8.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 554 |
+
"bert.encoder.layer.8.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 555 |
+
"bert.encoder.layer.8.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 556 |
+
"bert.encoder.layer.8.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 557 |
+
"bert.encoder.layer.8.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 558 |
+
"bert.encoder.layer.8.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 559 |
+
"bert.encoder.layer.8.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 560 |
+
"bert.encoder.layer.8.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 561 |
+
"bert.encoder.layer.8.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 562 |
+
"bert.encoder.layer.8.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 563 |
+
"bert.encoder.layer.8.mlp.dense_4h_to_h.bias": "pytorch_model-00001-of-00003.bin",
|
| 564 |
+
"bert.encoder.layer.8.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 565 |
+
"bert.encoder.layer.8.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 566 |
+
"bert.encoder.layer.8.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 567 |
+
"bert.encoder.layer.9.attention.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 568 |
+
"bert.encoder.layer.9.attention.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 569 |
+
"bert.encoder.layer.9.attention.output.dense.bias": "pytorch_model-00001-of-00003.bin",
|
| 570 |
+
"bert.encoder.layer.9.attention.output.dense.weight": "pytorch_model-00001-of-00003.bin",
|
| 571 |
+
"bert.encoder.layer.9.attention.self.key.bias": "pytorch_model-00001-of-00003.bin",
|
| 572 |
+
"bert.encoder.layer.9.attention.self.key.weight": "pytorch_model-00001-of-00003.bin",
|
| 573 |
+
"bert.encoder.layer.9.attention.self.query.bias": "pytorch_model-00001-of-00003.bin",
|
| 574 |
+
"bert.encoder.layer.9.attention.self.query.weight": "pytorch_model-00001-of-00003.bin",
|
| 575 |
+
"bert.encoder.layer.9.attention.self.value.bias": "pytorch_model-00001-of-00003.bin",
|
| 576 |
+
"bert.encoder.layer.9.attention.self.value.weight": "pytorch_model-00001-of-00003.bin",
|
| 577 |
+
"bert.encoder.layer.9.ln.bias": "pytorch_model-00001-of-00003.bin",
|
| 578 |
+
"bert.encoder.layer.9.ln.weight": "pytorch_model-00001-of-00003.bin",
|
| 579 |
+
"bert.encoder.layer.9.mlp.dense_4h_to_h.bias": "pytorch_model-00001-of-00003.bin",
|
| 580 |
+
"bert.encoder.layer.9.mlp.dense_4h_to_h.weight": "pytorch_model-00001-of-00003.bin",
|
| 581 |
+
"bert.encoder.layer.9.mlp.dense_h_to_4h.bias": "pytorch_model-00001-of-00003.bin",
|
| 582 |
+
"bert.encoder.layer.9.mlp.dense_h_to_4h.weight": "pytorch_model-00001-of-00003.bin",
|
| 583 |
+
"bert.encoder.ln.bias": "pytorch_model-00003-of-00003.bin",
|
| 584 |
+
"bert.encoder.ln.weight": "pytorch_model-00003-of-00003.bin",
|
| 585 |
+
"output_embed.weight": "pytorch_model-00003-of-00003.bin"
|
| 586 |
+
}
|
| 587 |
+
}
|
structure_prediction.png
ADDED

|
supervised_contact_prediction_fitness.png
ADDED

|
unsupervised_contact_prediction.png
ADDED
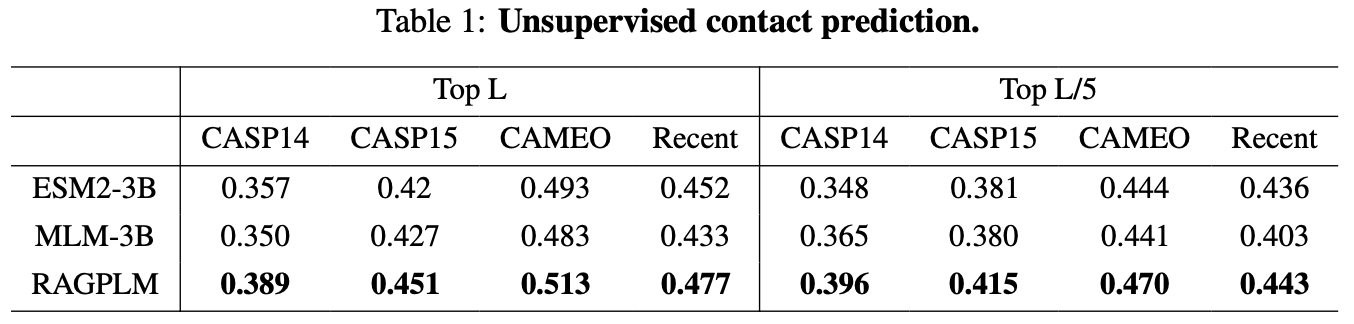
|