
license: apache-2.0
pipeline_tag: image-text-to-text
library_name: transformers
MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm
![]()
![]()


MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm
Zhang Li, Yuliang Liu, Qiang Liu, Zhiyin Ma, Ziyang Zhang, Shuo Zhang, Zidun Guo, Jiarui Zhang, Xinyu Wang, Xiang Bai




Introduction
MonkeyOCR adopts a Structure-Recognition-Relation (SRR) triplet paradigm, which simplifies the multi-tool pipeline of modular approaches while avoiding the inefficiency of using large multimodal models for full-page document processing.
- Compared with the pipeline-based method MinerU, our approach achieves an average improvement of 5.1% across nine types of Chinese and English documents, including a 15.0% gain on formulas and an 8.6% gain on tables.
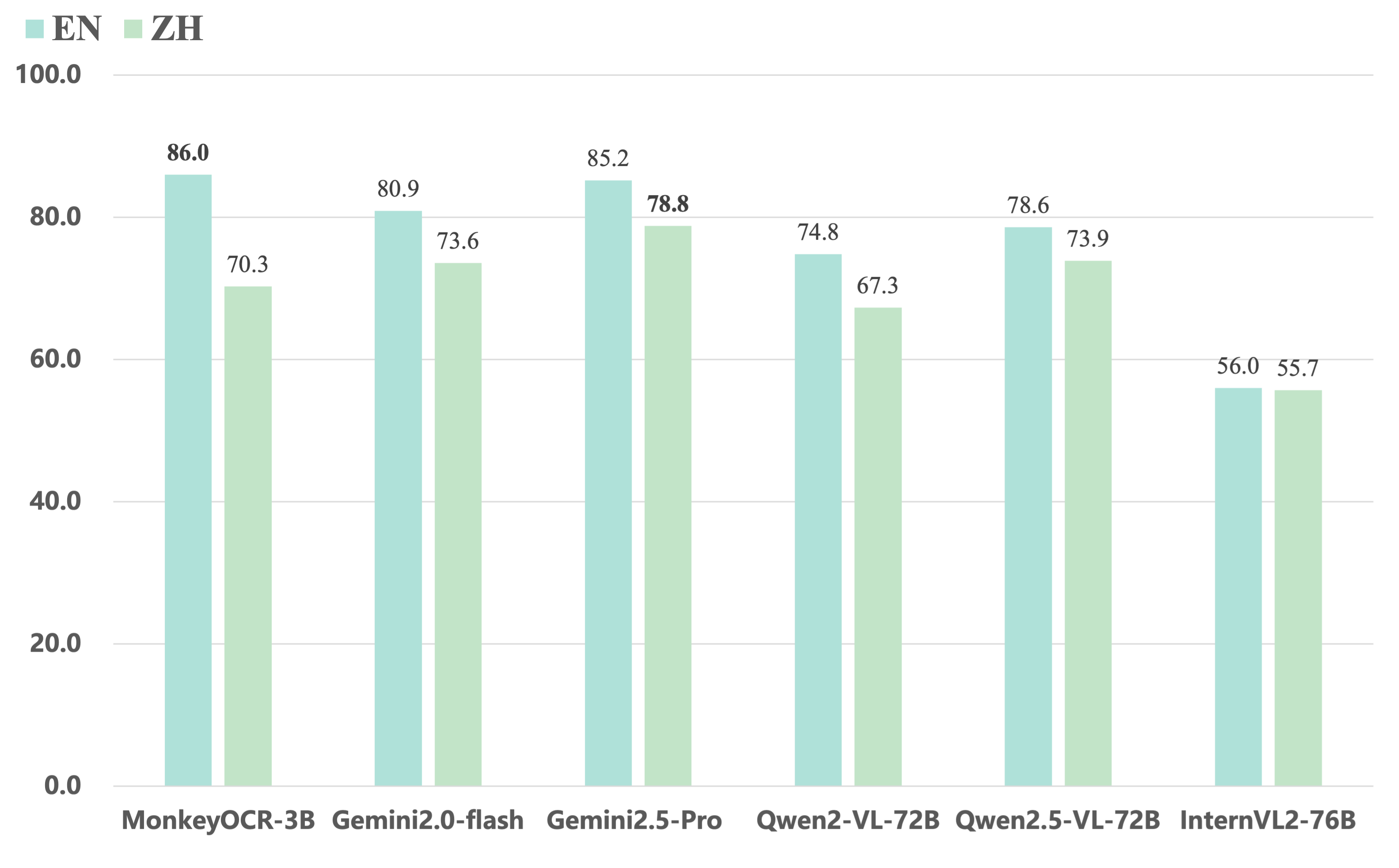
- Compared to end-to-end models, our 3B-parameter model achieves the best average performance on English documents, outperforming models such as Gemini 2.5 Pro and Qwen2.5 VL-72B.
- For multi-page document parsing, our method reaches a processing speed of 0.84 pages per second, surpassing MinerU (0.65) and Qwen2.5 VL-7B (0.12).
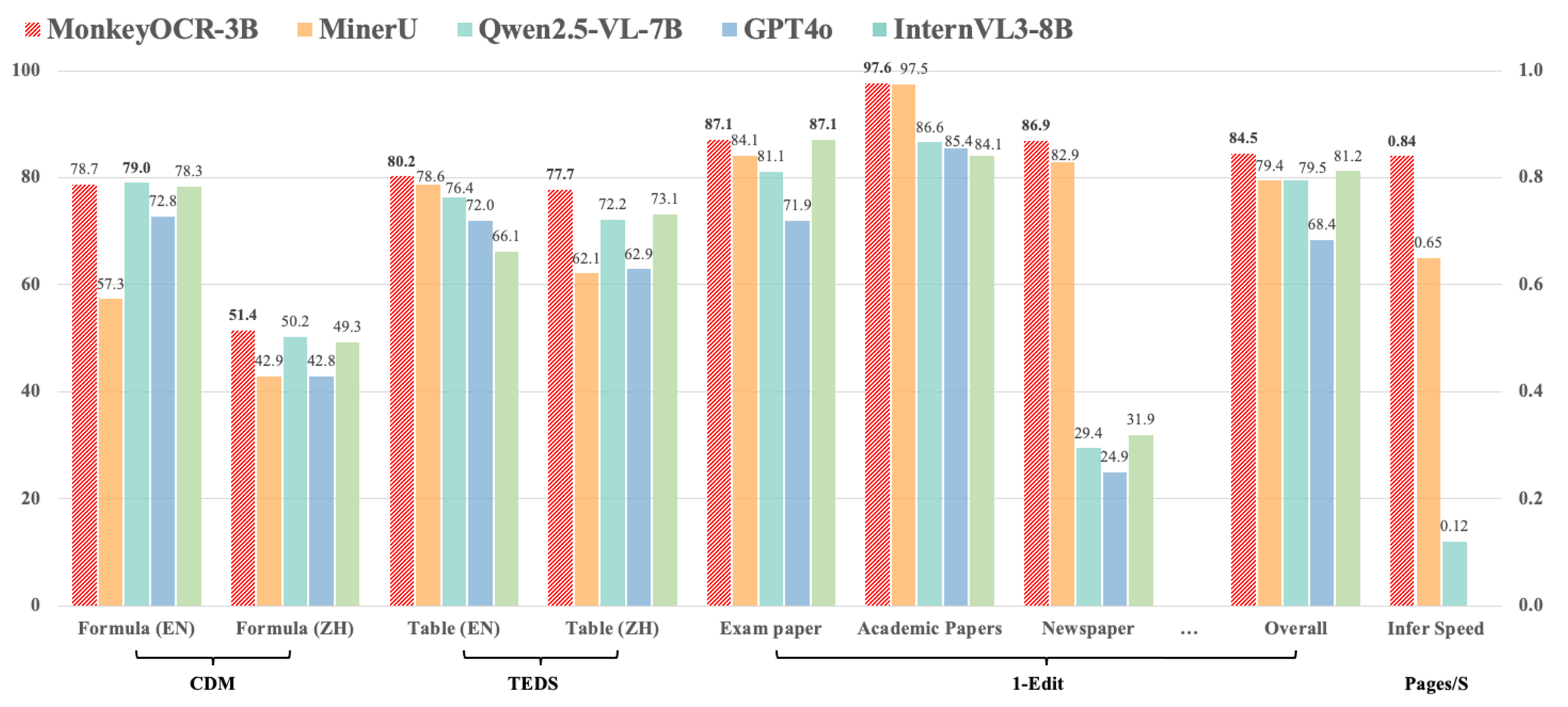
MonkeyOCR currently does not support photographed documents, but we will continue to improve it in future updates. Stay tuned! Currently, our model is deployed on a single GPU, so if too many users upload files at the same time, issues like “This application is currently busy” may occur. We're actively working on supporting Ollama and other deployment solutions to ensure a smoother experience for more users. Additionally, please note that the processing time shown on the demo page does not reflect computation time alone—it also includes result uploading and other overhead. During periods of high traffic, this time may be longer. The inference speeds of MonkeyOCR, MinerU, and Qwen2.5 VL-7B were measured on an H800 GPU.
News
2025.06.05🚀 We release MonkeyOCR, which supports the parsing of various types of Chinese and English documents.
Quick Start
1. Install MonkeyOCR
conda create -n MonkeyOCR python=3.10
conda activate MonkeyOCR
git clone https://github.com/Yuliang-Liu/MonkeyOCR.git
cd MonkeyOCR
# Install pytorch, see https://pytorch.org/get-started/previous-versions/ for your cuda version
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124
pip install -e .
2. Download Model Weights
Download our model from Huggingface.
pip install huggingface_hub
python tools/download_model.py
You can also download our model from ModelScope.
pip install modelscope
python tools/download_model.py -t modelscope
3. Inference
# Make sure in MonkeyOCR directory
python parse.py path/to/your.pdf
# or with image as input
pyhton parse.py path/to/your/image
# Specify output path and model configs path
python parse.py path/to/your.pdf -o ./output -c config.yaml
Output Results
MonkeyOCR generates three types of output files:
- Processed Markdown File (
your.md): The final parsed document content in markdown format, containing text, formulas, tables, and other structured elements. - Layout Results (
your_layout.pdf): The layout results drawed on origin PDF. - Intermediate Block Results (
your_middle.json): A JSON file containing detailed information about all detected blocks, including:- Block coordinates and positions
- Block content and type information
- Relationship information between blocks
These files provide both the final formatted output and detailed intermediate results for further analysis or processing.
4. Gradio Demo
# Prepare your env for gradio
pip install gradio==5.23.3
pip install pdf2image==1.17.0
# Start demo
python demo/demo_gradio.py
Fix shared memory error on RTX 3090 / 4090 / ... GPUs (Optional)
Our 3B model runs efficiently on NVIDIA RTX 3090. However, when using LMDeploy as the inference backend, you may encounter compatibility issues on RTX 3090 / 4090 GPUs — particularly the following error:
triton.runtime.errors.OutOfResources: out of resource: shared memory
To work around this issue, you can apply the patch below:
python tools/lmdeploy_patcher.py patch
⚠️ Note: This command will modify LMDeploy's source code in your environment. To revert the changes, simply run:
python tools/lmdeploy_patcher.py restore
Special thanks to @pineking for the solution!
Switch inference backend (Optional)
You can switch inference backend to transformers following the steps below:
- Install required dependency (if not already installed):
# install flash attention 2, you can download the corresponding version from https://github.com/Dao-AILab/flash-attention/releases/ pip install flash-attn==2.7.4.post1 --no-build-isolation - Open the
model_configs.yamlfile - Set
chat_config.backendtotransformers - Adjust the
batch_sizeaccording to your GPU's memory capacity to ensure stable performance
Example configuration:
chat_config:
backend: transformers
batch_size: 10 # Adjust based on your available GPU memory
Benchmark Results
Here are the evaluation results of our model on OmniDocBench. MonkeyOCR-3B uses DocLayoutYOLO as the structure detection model, while MonkeyOCR-3B* uses our trained structure detection model with improved Chinese performance.
1. The end-to-end evaluation results of different tasks.
| Model Type | Methods | Overall Edit↓ | Text Edit↓ | Formula Edit↓ | Formula CDM↑ | Table TEDS↑ | Table Edit↓ | Read Order Edit↓ | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | ||
| Pipeline Tools | MinerU | 0.150 | 0.357 | 0.061 | 0.215 | 0.278 | 0.577 | 57.3 | 42.9 | 78.6 | 62.1 | 0.180 | 0.344 | 0.079 | 0.292 |
| Marker | 0.336 | 0.556 | 0.080 | 0.315 | 0.530 | 0.883 | 17.6 | 11.7 | 67.6 | 49.2 | 0.619 | 0.685 | 0.114 | 0.340 | |
| Mathpix | 0.191 | 0.365 | 0.105 | 0.384 | 0.306 | 0.454 | 62.7 | 62.1 | 77.0 | 67.1 | 0.243 | 0.320 | 0.108 | 0.304 | |
| Docling | 0.589 | 0.909 | 0.416 | 0.987 | 0.999 | 1 | - | - | 61.3 | 25.0 | 0.627 | 0.810 | 0.313 | 0.837 | |
| Pix2Text | 0.320 | 0.528 | 0.138 | 0.356 | 0.276 | 0.611 | 78.4 | 39.6 | 73.6 | 66.2 | 0.584 | 0.645 | 0.281 | 0.499 | |
| Unstructured | 0.586 | 0.716 | 0.198 | 0.481 | 0.999 | 1 | - | - | 0 | 0.06 | 1 | 0.998 | 0.145 | 0.387 | |
| OpenParse | 0.646 | 0.814 | 0.681 | 0.974 | 0.996 | 1 | 0.11 | 0 | 64.8 | 27.5 | 0.284 | 0.639 | 0.595 | 0.641 | |
| Expert VLMs | GOT-OCR | 0.287 | 0.411 | 0.189 | 0.315 | 0.360 | 0.528 | 74.3 | 45.3 | 53.2 | 47.2 | 0.459 | 0.520 | 0.141 | 0.280 |
| Nougat | 0.452 | 0.973 | 0.365 | 0.998 | 0.488 | 0.941 | 15.1 | 16.8 | 39.9 | 0 | 0.572 | 1.000 | 0.382 | 0.954 | |
| Mistral OCR | 0.268 | 0.439 | 0.072 | 0.325 | 0.318 | 0.495 | 64.6 | 45.9 | 75.8 | 63.6 | 0.600 | 0.650 | 0.083 | 0.284 | |
| OLMOCR-sglang | 0.326 | 0.469 | 0.097 | 0.293 | 0.455 | 0.655 | 74.3 | 43.2 | 68.1 | 61.3 | 0.608 | 0.652 | 0.145 | 0.277 | |
| SmolDocling-256M | 0.493 | 0.816 | 0.262 | 0.838 | 0.753 | 0.997 | 32.1 | 0.55 | 44.9 | 16.5 | 0.729 | 0.907 | 0.227 | 0.522 | |
| General VLMs | GPT4o | 0.233 | 0.399 | 0.144 | 0.409 | 0.425 | 0.606 | 72.8 | 42.8 | 72.0 | 62.9 | 0.234 | 0.329 | 0.128 | 0.251 |
| Qwen2.5-VL-7B | 0.312 | 0.406 | 0.157 | 0.228 | 0.351 | 0.574 | 79.0 | 50.2 | 76.4 | 72.2 | 0.588 | 0.619 | 0.149 | 0.203 | |
| InternVL3-8B | 0.314 | 0.383 | 0.134 | 0.218 | 0.417 | 0.563 | 78.3 | 49.3 | 66.1 | 73.1 | 0.586 | 0.564 | 0.118 | 0.186 | |
| Mix | MonkeyOCR-3B [Weight] | 0.140 | 0.297 | 0.058 | 0.185 | 0.238 | 0.506 | 78.7 | 51.4 | 80.2 | 77.7 | 0.170 | 0.253 | 0.093 | 0.244 |
| MonkeyOCR-3B* [Weight] | 0.154 | 0.277 | 0.073 | 0.134 | 0.255 | 0.529 | 78.5 | 50.8 | 78.2 | 76.2 | 0.182 | 0.262 | 0.105 | 0.183 | |
2. The end-to-end text recognition performance across 9 PDF page types.
| Model Type | Models | Book | Slides | Financial Report | Textbook | Exam Paper | Magazine | Academic Papers | Notes | Newspaper | Overall |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pipeline Tools | MinerU | 0.055 | 0.124 | 0.033 | 0.102 | 0.159 | 0.072 | 0.025 | 0.984 | 0.171 | 0.206 |
| Marker | 0.074 | 0.340 | 0.089 | 0.319 | 0.452 | 0.153 | 0.059 | 0.651 | 0.192 | 0.274 | |
| Mathpix | 0.131 | 0.220 | 0.202 | 0.216 | 0.278 | 0.147 | 0.091 | 0.634 | 0.690 | 0.300 | |
| Expert VLMs | GOT-OCR | 0.111 | 0.222 | 0.067 | 0.132 | 0.204 | 0.198 | 0.179 | 0.388 | 0.771 | 0.267 |
| Nougat | 0.734 | 0.958 | 1.000 | 0.820 | 0.930 | 0.830 | 0.214 | 0.991 | 0.871 | 0.806 | |
| General VLMs | GPT4o | 0.157 | 0.163 | 0.348 | 0.187 | 0.281 | 0.173 | 0.146 | 0.607 | 0.751 | 0.316 |
| Qwen2.5-VL-7B | 0.148 | 0.053 | 0.111 | 0.137 | 0.189 | 0.117 | 0.134 | 0.204 | 0.706 | 0.205 | |
| InternVL3-8B | 0.163 | 0.056 | 0.107 | 0.109 | 0.129 | 0.100 | 0.159 | 0.150 | 0.681 | 0.188 | |
| Mix | MonkeyOCR-3B [Weight] | 0.046 | 0.120 | 0.024 | 0.100 | 0.129 | 0.086 | 0.024 | 0.643 | 0.131 | 0.155 |
| MonkeyOCR-3B* [Weight] | 0.054 | 0.203 | 0.038 | 0.112 | 0.138 | 0.111 | 0.032 | 0.194 | 0.136 | 0.120 |
3. Comparing MonkeyOCR with closed-source and extra large open-source VLMs.
Visualization Demo
Get a Quick Hands-On Experience with Our Demo: http://vlrlabmonkey.xyz:7685
Our demo is simple and easy to use:
- Upload a PDF or image.
- Click “Parse (解析)” to let the model perform structure detection, content recognition, and relationship prediction on the input document. The final output will be a markdown-formatted version of the document.
- Select a prompt and click “Test by prompt” to let the model perform content recognition on the image based on the selected prompt.
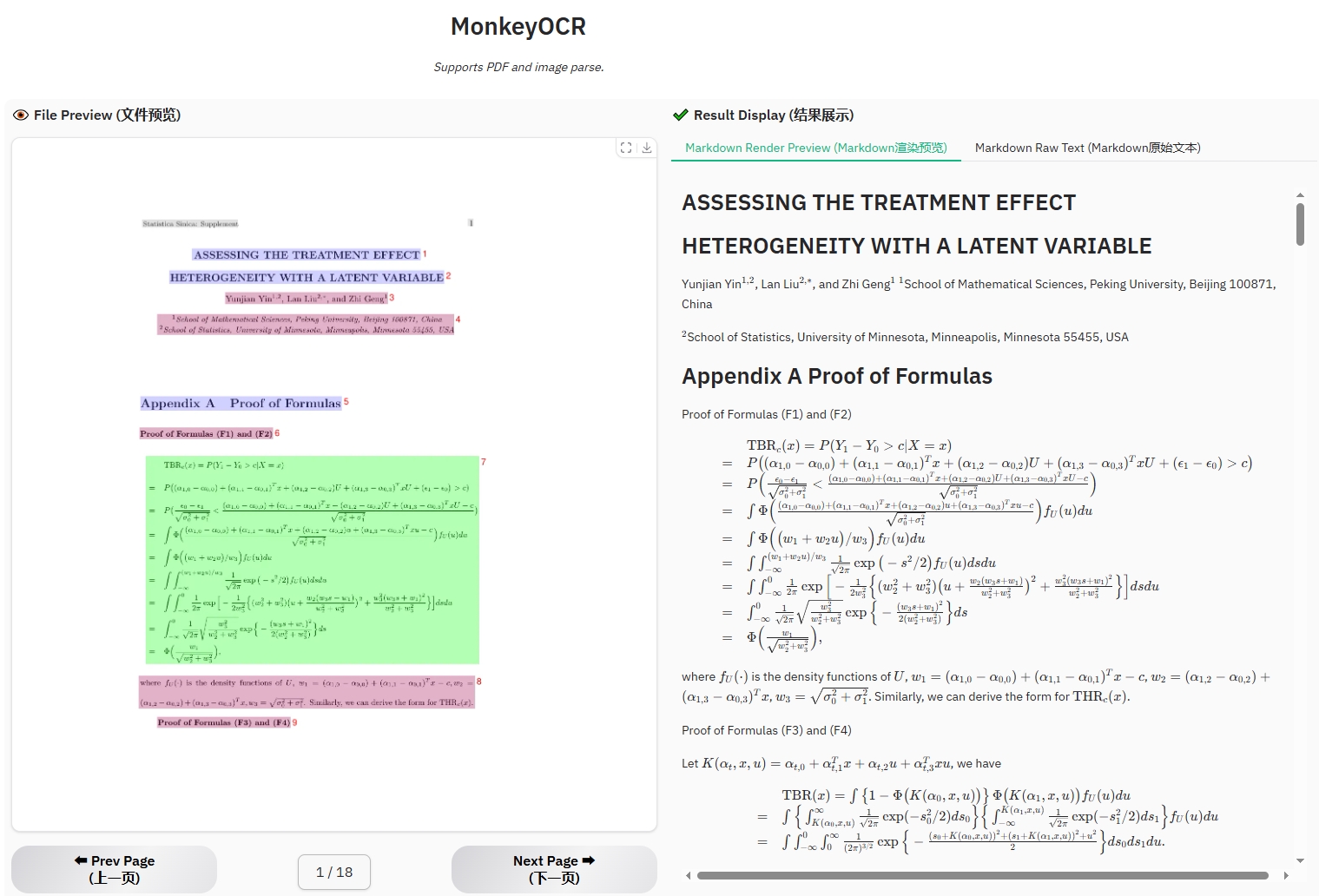
Example for formula document
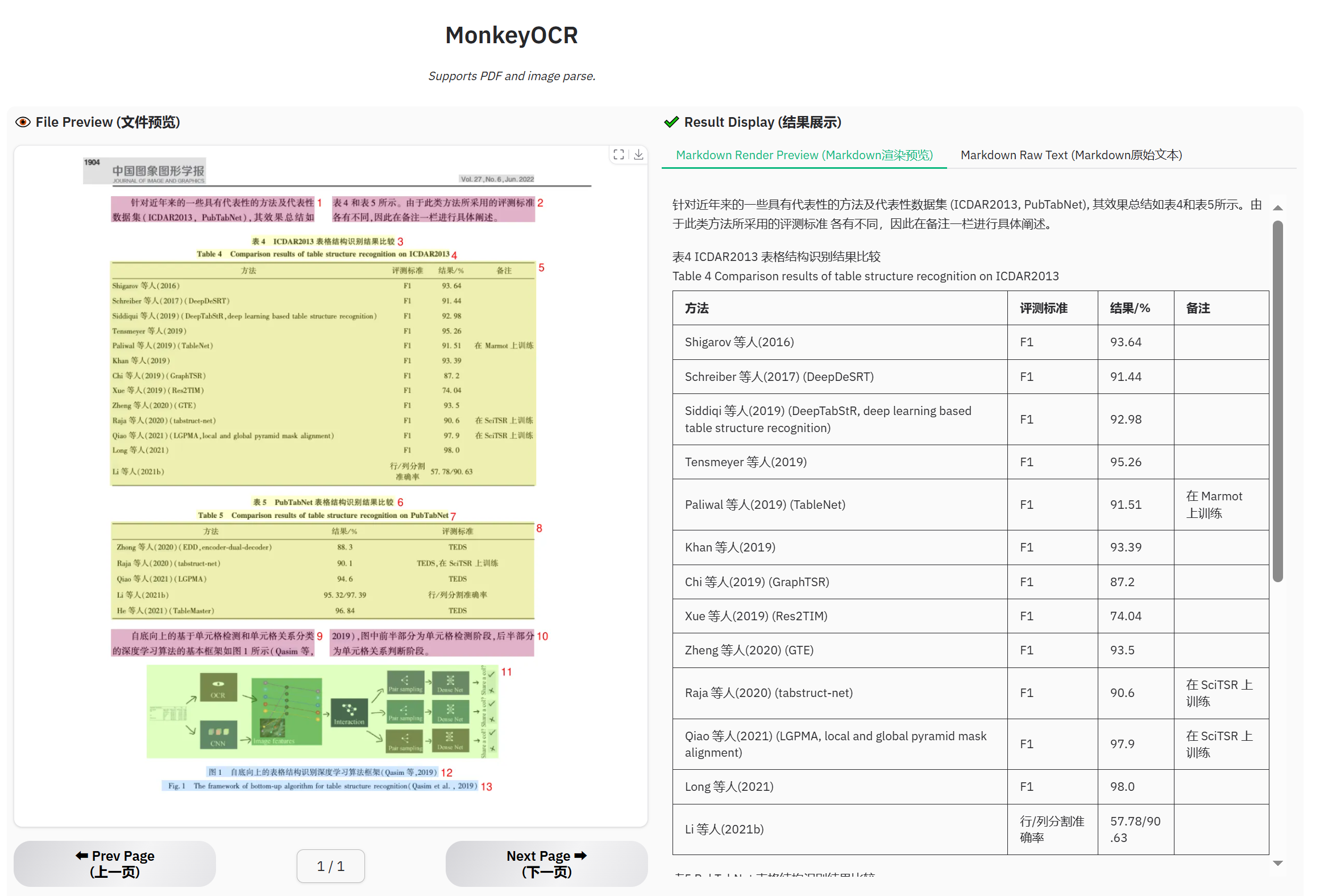
Example for table document
Example for newspaper

Example for financial report

Citing MonkeyOCR
If you wish to refer to the baseline results published here, please use the following BibTeX entries:
@misc{li2025monkeyocrdocumentparsingstructurerecognitionrelation,
title={MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm},
author={Zhang Li and Yuliang Liu and Qiang Liu and Zhiyin Ma and Ziyang Zhang and Shuo Zhang and Zidun Guo and Jiarui Zhang and Xinyu Wang and Xiang Bai},
year={2025},
eprint={2506.05218},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.05218},
}
Acknowledgments
We would like to thank MinerU, DocLayout-YOLO, PyMuPDF, layoutreader, Qwen2.5-VL, LMDeploy, and InternVL3 for providing base code and models, as well as their contributions to this field. We also thank M6Doc, DocLayNet, CDLA, D4LA, DocGenome, PubTabNet, and UniMER-1M for providing valuable datasets.
Copyright
Please don’t hesitate to share your valuable feedback — it’s a key motivation that drives us to continuously improve our framework. The current technical report only presents the results of the 3B model. Our model is intended for non-commercial use. If you are interested in larger one, please contact us at [email protected] or [email protected].