
txt
stringlengths 93
37.3k
|
|---|
## parse-base.md
parse-base
Combined from primary sources listed below.
# [In Str](#___top "go to top of document")[§](#(Str)_routine_parse-base "direct link")
See primary documentation
[in context](/type/Str#routine_parse-base)
for **routine parse-base**.
```raku
multi parse-base(Str:D $num, Int:D $radix --> Numeric)
multi method parse-base(Str:D $num: Int:D $radix --> Numeric)
```
Performs the reverse of [`base`](/routine/base) by converting a string with a base-`$radix` number to its [`Numeric`](/type/Numeric) equivalent. Will [`fail`](/routine/fail) if radix is not in range `2..36` or if the string being parsed contains characters that are not valid for the specified base.
```raku
1337.base(32).parse-base(32).say; # OUTPUT: «1337»
'Raku'.parse-base(36).say; # OUTPUT: «1273422»
'FF.DD'.parse-base(16).say; # OUTPUT: «255.863281»
```
See also: [syntax for number literals](/syntax/Number%20literals)
|
## baggy.md
role Baggy
Collection of distinct weighted objects
```raku
role Baggy does QuantHash { }
```
A role for collections of weighted objects. See [`Bag`](/type/Bag), [`BagHash`](/type/BagHash), and [`Mixy`](/type/Mixy).
# [Methods](#role_Baggy "go to top of document")[§](#Methods "direct link")
## [method new-from-pairs](#role_Baggy "go to top of document")[§](#method_new-from-pairs "direct link")
```raku
method new-from-pairs(Baggy: *@pairs --> Baggy:D)
```
Constructs a Baggy objects from a list of [`Pair`](/type/Pair) objects given as positional arguments:
```raku
say Mix.new-from-pairs: 'butter' => 0.22, 'sugar' => 0.1, 'sugar' => 0.02;
# OUTPUT: «Mix(butter(0.22) sugar(0.12))»
```
**Note:** be sure you aren't accidentally passing the Pairs as positional arguments; the quotes around the keys in the above example are significant.
## [method grab](#role_Baggy "go to top of document")[§](#method_grab "direct link")
```raku
multi method grab(Baggy:D: --> Any)
multi method grab(Baggy:D: $count --> Seq:D)
```
Like [pick](#method_pick), a `grab` returns a random selection of elements, weighted by the values corresponding to each key. Unlike `pick`, it works only on mutable structures, e.g. [`BagHash`](/type/BagHash). Use of `grab` on an immutable structure results in an [`X::Immutable`](/type/X/Immutable) exception. If `*` is passed as `$count`, or `$count` is greater than or equal to the [total](#method_total) of the invocant, then `total` elements from the invocant are returned in a random sequence; i.e. they are returned shuffled.
Grabbing decrements the grabbed key's weight by one (deleting the key when it reaches 0). By definition, the `total` of the invocant also decreases by one, so the probabilities stay consistent through subsequent `grab` operations.
```raku
my $cars = ('Ford' => 2, 'Rover' => 3).BagHash;
say $cars.grab; # OUTPUT: «Ford»
say $cars.grab(2); # OUTPUT: «(Rover Rover)»
say $cars.grab(*); # OUTPUT: «(Rover Ford)»
my $breakfast = ('eggs' => 2, 'bacon' => 3).Bag;
say $breakfast.grab;
CATCH { default { put .^name, ': ', .Str } };
# OUTPUT: «X::Immutable: Cannot call 'grab' on an immutable 'Bag'»
```
## [method grabpairs](#role_Baggy "go to top of document")[§](#method_grabpairs "direct link")
```raku
multi method grabpairs(Baggy:D: --> Any)
multi method grabpairs(Baggy:D: $count --> Seq:D)
```
Returns a [`Pair`](/type/Pair) or a [`Seq`](/type/Seq) of [`Pair`](/type/Pair)s depending on the version of the method being invoked. Each [`Pair`](/type/Pair) returned has an element of the invocant as its key and the element's weight as its value. Unlike [pickpairs](/routine/pickpairs), it works only on mutable structures, e.g. [`BagHash`](/type/BagHash). Use of `grabpairs` on an immutable structure results in an `X::Immutable` exception. If `*` is passed as `$count`, or `$count` is greater than or equal to the number of [elements](#method_elems) of the invocant, then all element/weight [`Pair`](/type/Pair)s from the invocant are returned in a random sequence.
What makes `grabpairs` different from [pickpairs](#method_pickpairs) is that the 'grabbed' elements are in fact removed from the invocant.
```raku
my $breakfast = (eggs => 2, bacon => 3).BagHash;
say $breakfast.grabpairs; # OUTPUT: «bacon => 3»
say $breakfast; # OUTPUT: «BagHash.new(eggs(2))»
say $breakfast.grabpairs(1); # OUTPUT: «(eggs => 2)»
say $breakfast.grabpairs(*); # OUTPUT: «()»
my $diet = ('eggs' => 2, 'bacon' => 3).Bag;
say $diet.grabpairs;
CATCH { default { put .^name, ': ', .Str } };
# OUTPUT: «X::Immutable: Cannot call 'grabpairs' on an immutable 'Bag'»
```
## [method pick](#role_Baggy "go to top of document")[§](#method_pick "direct link")
```raku
multi method pick(Baggy:D: --> Any)
multi method pick(Baggy:D: $count --> Seq:D)
```
Like an ordinary list [pick](/type/List#routine_pick), but returns keys of the invocant weighted by their values, as if the keys were replicated the number of times indicated by the corresponding value and then list pick used. The underlying metaphor for picking is that you're pulling colored marbles out a bag. (For "picking with replacement" see [roll](#method_roll) instead). If `*` is passed as `$count`, or `$count` is greater than or equal to the [total](#method_total) of the invocant, then `total` elements from the invocant are returned in a random sequence.
Note that each `pick` invocation maintains its own private state and has no effect on subsequent `pick` invocations.
```raku
my $breakfast = bag <eggs bacon bacon bacon>;
say $breakfast.pick; # OUTPUT: «eggs»
say $breakfast.pick(2); # OUTPUT: «(eggs bacon)»
say $breakfast.total; # OUTPUT: «4»
say $breakfast.pick(*); # OUTPUT: «(bacon bacon bacon eggs)»
```
## [method pickpairs](#role_Baggy "go to top of document")[§](#method_pickpairs "direct link")
```raku
multi method pickpairs(Baggy:D: --> Pair:D)
multi method pickpairs(Baggy:D: $count --> Seq:D)
```
Returns a [`Pair`](/type/Pair) or a [`Seq`](/type/Seq) of [`Pair`](/type/Pair)s depending on the version of the method being invoked. Each [`Pair`](/type/Pair) returned has an element of the invocant as its key and the element's weight as its value. The elements are 'picked' without replacement. If `*` is passed as `$count`, or `$count` is greater than or equal to the number of [elements](#method_elems) of the invocant, then all element/weight [`Pair`](/type/Pair)s from the invocant are returned in a random sequence.
Note that each `pickpairs` invocation maintains its own private state and has no effect on subsequent `pickpairs` invocations.
```raku
my $breakfast = bag <eggs bacon bacon bacon>;
say $breakfast.pickpairs; # OUTPUT: «eggs => 1»
say $breakfast.pickpairs(1); # OUTPUT: «(bacon => 3)»
say $breakfast.pickpairs(*); # OUTPUT: «(eggs => 1 bacon => 3)»
```
## [method roll](#role_Baggy "go to top of document")[§](#method_roll "direct link")
```raku
multi method roll(Baggy:D: --> Any:D)
multi method roll(Baggy:D: $count --> Seq:D)
```
Like an ordinary list [roll](/type/List#routine_roll), but returns keys of the invocant weighted by their values, as if the keys were replicated the number of times indicated by the corresponding value and then list roll used. The underlying metaphor for rolling is that you're throwing `$count` dice that are independent of each other, which (in bag terms) is equivalent to picking a colored marble out your bag and then putting it back, and doing this `$count` times. In dice terms, the number of marbles corresponds to the number of sides, and the number of marbles of the same color corresponds to the number of sides with the same color. (For "picking without replacement" see [pick](#method_pick) instead).
If `*` is passed to `$count`, returns a lazy, infinite sequence of randomly chosen elements from the invocant.
```raku
my $breakfast = bag <eggs bacon bacon bacon>;
say $breakfast.roll; # OUTPUT: «bacon»
say $breakfast.roll(3); # OUTPUT: «(bacon eggs bacon)»
my $random_dishes := $breakfast.roll(*);
say $random_dishes[^5]; # OUTPUT: «(bacon eggs bacon bacon bacon)»
```
## [method pairs](#role_Baggy "go to top of document")[§](#method_pairs "direct link")
```raku
method pairs(Baggy:D: --> Seq:D)
```
Returns all elements and their respective weights as a [`Seq`](/type/Seq) of [`Pair`](/type/Pair)s where the key is the element itself and the value is the weight of that element.
```raku
my $breakfast = bag <bacon eggs bacon>;
my $seq = $breakfast.pairs;
say $seq.sort; # OUTPUT: «(bacon => 2 eggs => 1)»
```
## [method antipairs](#role_Baggy "go to top of document")[§](#method_antipairs "direct link")
```raku
method antipairs(Baggy:D: --> Seq:D)
```
Returns all elements and their respective weights as a [`Seq`](/type/Seq) of [`Pair`](/type/Pair)s, where the element itself is the value and the weight of that element is the key, i.e. the opposite of method [pairs](#method_pairs).
```raku
my $breakfast = bag <bacon eggs bacon>;
my $seq = $breakfast.antipairs;
say $seq.sort; # OUTPUT: «(1 => eggs 2 => bacon)»
```
## [method invert](#role_Baggy "go to top of document")[§](#method_invert "direct link")
```raku
method invert(Baggy:D: --> Seq:D)
```
Returns all elements and their respective weights as a [`Seq`](/type/Seq) of [`Pair`](/type/Pair)s, where the element itself is the value and the weight of that element is the key, i.e. the opposite of method [pairs](#method_pairs). Except for some esoteric cases, `invert` on a Baggy type returns the same result as [antipairs](#method_antipairs).
```raku
my $breakfast = bag <bacon eggs bacon>;
my $seq = $breakfast.invert;
say $seq.sort; # OUTPUT: «(1 => eggs 2 => bacon)»
```
## [method classify-list](#role_Baggy "go to top of document")[§](#method_classify-list "direct link")
```raku
multi method classify-list(&mapper, *@list --> Baggy:D)
multi method classify-list(%mapper, *@list --> Baggy:D)
multi method classify-list(@mapper, *@list --> Baggy:D)
```
Populates a *mutable* `Baggy` by classifying the possibly-empty `@list` of values using the given `mapper`. The `@list` cannot be lazy.
```raku
say BagHash.new.classify-list: { $_ %% 2 ?? 'even' !! 'odd' }, ^10;
# OUTPUT: BagHash(even(5) odd(5))
my @mapper = <zero one two three four five>;
say MixHash.new.classify-list: @mapper, 1, 2, 3, 4, 4, 6;
# OUTPUT: MixHash((Any) two three four(2) one)
```
The mapper can be a [`Callable`](/type/Callable) that takes a single argument, an [`Associative`](/type/Associative), or an [`Iterable`](/type/Iterable). With [`Associative`](/type/Associative) and an [`Iterable`](/type/Iterable) mappers, the values in the `@list` represent the key and index of the mapper's value respectively. A [`Callable`](/type/Callable) mapper will be executed once per each item in the `@list`, with that item as the argument and its return value will be used as the mapper's value.
The mapper's value is used as the key of the `Baggy` that will be incremented by `1`. See [`.categorize-list`](/routine/categorize-list) if you wish to classify an item into multiple categories at once.
**Note:** unlike the [`Hash`](/type/Hash)'s `.classify-list`, returning an [`Iterable`](/type/Iterable) mapper's value will throw, as `Baggy` types do not support nested classification. For the same reason, `Baggy`'s `.classify-list` does not accept `:&as` parameter.
## [method categorize-list](#role_Baggy "go to top of document")[§](#method_categorize-list "direct link")
```raku
multi method categorize-list(&mapper, *@list --> Baggy:D)
multi method categorize-list(%mapper, *@list --> Baggy:D)
multi method categorize-list(@mapper, *@list --> Baggy:D)
```
Populates a *mutable* `Baggy` by categorizing the possibly-empty `@list` of values using the given `mapper`. The `@list` cannot be lazy.
```raku
say BagHash.new.categorize-list: {
gather {
take 'largish' if $_ > 5;
take .is-prime ?? 'prime' !! 'non-prime';
take $_ %% 2 ?? 'even' !! 'odd';
}
}, ^10;
# OUTPUT: BagHash(largish(4) even(5) non-prime(6) prime(4) odd(5))
my %mapper = :sugar<sweet white>, :lemon<sour>, :cake('sweet', 'is-a-lie');
say MixHash.new.categorize-list: %mapper, <sugar lemon cake>;
# OUTPUT: MixHash(is-a-lie sour white sweet(2))
```
The mapper can be a [`Callable`](/type/Callable) that takes a single argument, an [`Associative`](/type/Associative), or an [`Iterable`](/type/Iterable). With [`Associative`](/type/Associative) and an [`Iterable`](/type/Iterable) mappers, the values in the `@list` represent the key and index of the mapper's value respectively. A [`Callable`](/type/Callable) mapper will be executed once per each item in the `@list`, with that item as the argument and its return value will be used as the mapper's value.
The mapper's value is used as a possibly-empty list of keys of the `Baggy` that will be incremented by `1`.
**Note:** unlike the [`Hash`](/type/Hash)'s `.categorize-list`, returning a list of [`Iterables`](/type/Iterable) as mapper's value will throw, as `Baggy` types do not support nested categorization. For the same reason, `Baggy`'s `.categorize-list` does not accept `:&as` parameter.
## [method keys](#role_Baggy "go to top of document")[§](#method_keys "direct link")
```raku
method keys(Baggy:D: --> Seq:D)
```
Returns a [`Seq`](/type/Seq) of all keys in the `Baggy` object without taking their individual weights into account as opposed to [kxxv](#method_kxxv).
```raku
my $breakfast = bag <eggs spam spam spam>;
say $breakfast.keys.sort; # OUTPUT: «(eggs spam)»
my $n = ("a" => 5, "b" => 2).BagHash;
say $n.keys.sort; # OUTPUT: «(a b)»
```
## [method values](#role_Baggy "go to top of document")[§](#method_values "direct link")
```raku
method values(Baggy:D: --> Seq:D)
```
Returns a [`Seq`](/type/Seq) of all values, i.e. weights, in the `Baggy` object.
```raku
my $breakfast = bag <eggs spam spam spam>;
say $breakfast.values.sort; # OUTPUT: «(1 3)»
my $n = ("a" => 5, "b" => 2, "a" => 1).BagHash;
say $n.values.sort; # OUTPUT: «(2 6)»
```
## [method kv](#role_Baggy "go to top of document")[§](#method_kv "direct link")
```raku
method kv(Baggy:D: --> Seq:D)
```
Returns a [`Seq`](/type/Seq) of keys and values interleaved.
```raku
my $breakfast = bag <eggs spam spam spam>;
say $breakfast.kv; # OUTPUT: «(spam 3 eggs 1)»
my $n = ("a" => 5, "b" => 2, "a" => 1).BagHash;
say $n.kv; # OUTPUT: «(a 6 b 2)»
```
## [method kxxv](#role_Baggy "go to top of document")[§](#method_kxxv "direct link")
```raku
method kxxv(Baggy:D: --> Seq:D)
```
Returns a [`Seq`](/type/Seq) of the keys of the invocant, with each key multiplied by its weight. Note that `kxxv` only works for `Baggy` types which have integer weights, i.e. [`Bag`](/type/Bag) and [`BagHash`](/type/BagHash).
```raku
my $breakfast = bag <spam eggs spam spam bacon>;
say $breakfast.kxxv.sort; # OUTPUT: «(bacon eggs spam spam spam)»
my $n = ("a" => 0, "b" => 1, "b" => 2).BagHash;
say $n.kxxv; # OUTPUT: «(b b b)»
```
## [method elems](#role_Baggy "go to top of document")[§](#method_elems "direct link")
```raku
method elems(Baggy:D: --> Int:D)
```
Returns the number of elements in the `Baggy` object without taking the individual elements' weight into account.
```raku
my $breakfast = bag <eggs spam spam spam>;
say $breakfast.elems; # OUTPUT: «2»
my $n = ("b" => 9.4, "b" => 2).MixHash;
say $n.elems; # OUTPUT: «1»
```
## [method total](#role_Baggy "go to top of document")[§](#method_total "direct link")
```raku
method total(Baggy:D:)
```
Returns the sum of weights for all elements in the `Baggy` object.
```raku
my $breakfast = bag <eggs spam spam bacon>;
say $breakfast.total; # OUTPUT: «4»
my $n = ("a" => 5, "b" => 1, "b" => 2).BagHash;
say $n.total; # OUTPUT: «8»
```
## [method default](#role_Baggy "go to top of document")[§](#method_default "direct link")
```raku
method default(Baggy:D: --> 0)
```
Returns zero.
```raku
my $breakfast = bag <eggs bacon>;
say $breakfast.default; # OUTPUT: «0»
```
## [method hash](#role_Baggy "go to top of document")[§](#method_hash "direct link")
```raku
method hash(Baggy:D: --> Hash:D)
```
Returns a [`Hash`](/type/Hash) where the elements of the invocant are the keys and their respective weights the values.
```raku
my $breakfast = bag <eggs bacon bacon>;
my $h = $breakfast.hash;
say $h.^name; # OUTPUT: «Hash[Any,Any]»
say $h; # OUTPUT: «{bacon => 2, eggs => 1}»
```
## [method Bool](#role_Baggy "go to top of document")[§](#method_Bool "direct link")
```raku
method Bool(Baggy:D: --> Bool:D)
```
Returns `True` if the invocant contains at least one element.
```raku
my $breakfast = ('eggs' => 1).BagHash;
say $breakfast.Bool; # OUTPUT: «True»
# (since we have one element)
$breakfast<eggs> = 0; # weight == 0 will lead to element removal
say $breakfast.Bool; # OUTPUT: «False»
```
## [method Set](#role_Baggy "go to top of document")[§](#method_Set "direct link")
```raku
method Set(--> Set:D)
```
Returns a [`Set`](/type/Set) whose elements are the [keys](#method_keys) of the invocant.
```raku
my $breakfast = (eggs => 2, bacon => 3).BagHash;
say $breakfast.Set; # OUTPUT: «Set(bacon eggs)»
```
## [method SetHash](#role_Baggy "go to top of document")[§](#method_SetHash "direct link")
```raku
method SetHash(--> SetHash:D)
```
Returns a [`SetHash`](/type/SetHash) whose elements are the [keys](#method_keys) of the invocant.
```raku
my $breakfast = (eggs => 2, bacon => 3).BagHash;
my $sh = $breakfast.SetHash;
say $sh.^name; # OUTPUT: «SetHash»
say $sh.elems; # OUTPUT: «2»
```
## [method ACCEPTS](#role_Baggy "go to top of document")[§](#method_ACCEPTS "direct link")
```raku
method ACCEPTS($other --> Bool:D)
```
Used in smartmatching if the right-hand side is a `Baggy`.
If the right-hand side is the type object, i.e. `Baggy`, the method returns `True` if `$other` [does](/type/Mu#routine_does) `Baggy` otherwise `False` is returned.
If the right-hand side is a `Baggy` object, `True` is returned only if `$other` has the same elements, with the same weights, as the invocant.
```raku
my $breakfast = bag <eggs bacon>;
say $breakfast ~~ Baggy; # OUTPUT: «True»
say $breakfast.does(Baggy); # OUTPUT: «True»
my $second-breakfast = (eggs => 1, bacon => 1).Mix;
say $breakfast ~~ $second-breakfast; # OUTPUT: «True»
my $third-breakfast = (eggs => 1, bacon => 2).Bag;
say $second-breakfast ~~ $third-breakfast; # OUTPUT: «False»
```
# [See Also](#role_Baggy "go to top of document")[§](#See_Also "direct link")
[Sets, Bags, and Mixes](/language/setbagmix)
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Baggy`
raku-type-graph
Baggy
Baggy
QuantHash
QuantHash
Baggy->QuantHash
Associative
Associative
QuantHash->Associative
Mu
Mu
Any
Any
Any->Mu
Bag
Bag
Bag->Baggy
Bag->Any
BagHash
BagHash
BagHash->Baggy
BagHash->Any
Mixy
Mixy
Mixy->Baggy
Mix
Mix
Mix->Any
Mix->Mixy
MixHash
MixHash
MixHash->Any
MixHash->Mixy
[Expand chart above](/assets/typegraphs/Baggy.svg)
|
## dist_zef-masukomi-UUID-V4.md
# NAME
UUID::V4 - generates a random v4 UUID (Universally Unique IDentifier)
## SYNOPSIS
```
use UUID::V4;
# generate a uuid
my $uuid = uuid-v4(); # 62353163-3235-4165-b337-316436626539
# validate a string against uuid-v4 regexp
my $confirmation = is-uuid-v4($uuid); # True
```
## DESCRIPTION
UUID::V4 generates a random v4 UUID (Universally Unique IDentifier). See [the RFC 4122 specification](https://www.ietf.org/rfc/rfc4122.txt) for details.
## AUTHOR
masukomi (a.k.a Kay Rhodes) based on Nobuyoshi Nakada's work in Ruby.
## COPYRIGHT AND LICENSE
Copyright 2022
This library is free software; you can redistribute it and/or modify it under the MIT license.
## WHY
Unfortunately [LibUUID](https://github.com/CurtTilmes/perl6-libuuid) requires the `uuid` dynamic library which didn't exist on my mac. This library uses [Crypt::Random](https://github.com/skinkade/crypt-random) which doesn't suffer from that problem and should work on all Unix / Linux systems and Windows.
### sub uuid-v4
```
sub uuid-v4() returns Str
```
Generate a UUID in V4 format.
### sub is-uuid-v4
```
sub is-uuid-v4(
Str $maybe_uuid
) returns Bool
```
Test if a string matches the UUID v4 format.
|
## dist_github-MadcapJake-App-P6Dx.md
> Bring your Perl 6 workflow to the next level!
[](http://github.com/madcapjake/p6dx)
[](https://coveralls.io/r/MadcapJake/p6dx)[](https://travis-ci.org/MadcapJake/p6dx)[](https://github.com/MadcapJake/p6dx/issues)[](https://github.com/MadcapJake/p6dx/blob/master/LICENSE)[](http://perl6.bestforever.com)
**[About](#about)**
|
**[Usage](#usage)**
|
**[Documentation](/docs/README.md)**
|
**[Rules](https://github.com/MadcapJake/p6dx/wiki#rules)**
|
**[Contributing](#contributing)**
## About
*P6Dx* provides a platform for leveraging language workflow tools in any text editor. The included `p6dx` bin script provides several flags with easy access to:
* Code completions (per file, per package, even required packages)
* Syntax checking (cascading rule declarations)
* And more? (Code coverage? ctags? let me know!)
## Usage
### Install
```
panda install p6dx
```
```
zef install p6dx
```
### Config
Mostly TBD. You will be able to specify syntax rules in either a user's home folder, the project's base path, a manually supplied file, or via a special comment syntax.
### Command Line
```
p6dx # displays help
p6dx --complete="$part_of_string" --file=$file_or_dir # completions
p6dx --tags --json # prints json format of all tags
p6dx --tags --ctag # prints ctag representation
p6dx --examine=$file_or_dir # syntax check [NOT YET IMPLEMENTED]
```
### Editors
Currently no editors are using P6Dx, however after I've finalized some of the data design, I plan to integrate this into `linter-perl6` for Atom Editor and then I'll try my hand at writing a Gedit plugin.
# Contributing
I'm gonna try and keep some high-level issues for each feature. Right now, I mostly need help hashing out conventions and solving bugs in my really early code. Feel free to submit PRs too though!
# Ideas
* code coverage
* ctags generation
* code formatter
# Acknowledgements
* [Camelia](https://github.com/perl6/mu/blob/master/misc/camelia.txt)
* [Kettlebell by TMD from the Noun Project](https://thenounproject.com/term/kettlebell/253682)
|
## dist_zef-lizmat-Hash-LRU.md
[](https://github.com/lizmat/Hash-LRU/actions) [](https://github.com/lizmat/Hash-LRU/actions) [](https://github.com/lizmat/Hash-LRU/actions)
# NAME
Hash::LRU - trait for limiting number of keys in hashes by usage
# SYNOPSIS
```
use Hash::LRU; # Least Recently Used
my %h is LRU; # defaults to elements => 100
my %h is LRU(elements => 42); # note: value must be known at compile time!
my %h{Any} is LRU; # object hashes also supported
```
# DESCRIPTION
Hash::LRU provides a `is LRU` trait on `Hash`es as an easy way to limit the number of keys kept in the `Hash`. Keys will be added as long as the number of keys is under the limit. As soon as a new key is added that would exceed the limit, the least recently used key is removed from the `Hash`.
Both "normal" as well as object hashes are supported.
# EXAMPLE
```
use Hash::LRU;
my %h is LRU(elements => 3);
%h<name> = "Alex";
%h<language> = "Raku";
%h<occupation> = "devops";
%h<location> = "Russia";
say %h.raku;
# {:location("Russia"), :occupation("devops"), :language("Raku")}
```
# COMPATIBILITY
## Cache::LRU
```
#my $cache = Cache::LRU.new(size => 3);
my $cache = my % is LRU(elements => 3);
```
If your code depended on the now obsolete `Cache::LRU` module, you can use this module instead provided the cache size is known at compile time.
In that case, the above statement change is enough to keep your code working using a maintained module.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Hash-LRU> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2018, 2020, 2021, 2024 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-FRITH-Math-Libgsl-Function.md
## Chunk 1 of 3
[](https://github.com/frithnanth/raku-Math-Libgsl-Function/actions)
# NAME
Math::Libgsl::Function - An interface to libgsl, the Gnu Scientific Library - Special functions.
# SYNOPSIS
```
use Math::Libgsl::Raw::Function :ALL;
use Math::Libgsl::Function :ALL;
```
# DESCRIPTION
Math::Libgsl::Function provides an interface to special function evaluation in libgsl, the GNU Scientific Library.
Math::Libgsl::Function makes these tags available:
* :airy
* :bessel
* :coulomb
* :coupling
* :dawson
* :debye
* :dilog
* :mult
* :ellint
* :ellfun
* :err
* :exp
* :fermidirac
* :gammabeta
* :gegen
* :hermite
* :hyperg
* :laguerre
* :lambert
* :legendre
* :log
* :mathieu
* :pow
* :psi
* :sync
* :transport
* :trig
* :zeta
Throughout this module the subs whose name ends with "-e" return a List of two values: the result and its associated error.
### sub Ai(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Ai-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the Airy function Ai(x) with an accuracy specified by mode.
### sub Bi(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Bi-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the Airy function Bi(x) with an accuracy specified by mode.
### sub Ai-scaled(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Ai-scaled-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the scaled value of the Airy function Ai(x) with an accuracy specified by mode.
### sub Bi-scaled(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Bi-scaled-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the scaled value of the Airy function Bi(x) with an accuracy specified by mode.
### sub Ai-deriv(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Ai-deriv-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the scaled value of the Airy function derivative A'i(x) with an accuracy specified by mode.
### sub Bi-deriv(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Bi-deriv-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the scaled value of the Airy function derivative B'i(x) with an accuracy specified by mode.
### sub Ai-deriv-scaled(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Ai-deriv-scaled-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the scaled value of the Airy function derivative A'i(x) with an accuracy specified by mode.
### sub Bi-deriv-scaled(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Bi-deriv-scaled-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the scaled value of the Airy function derivative B'i(x) with an accuracy specified by mode.
### sub Ai-zero(UInt $s --> Num) is export(:airy)
### sub Ai-zero-e(UInt $s --> List) is export(:airy)
These routines compute the location of the s-th zero of the Airy function Ai(x).
### sub Bi-zero(UInt $s --> Num) is export(:airy)
### sub Bi-zero-e(UInt $s --> List) is export(:airy)
These routines compute the location of the s-th zero of the Airy function Bi(x).
### sub Ai-deriv-zero(UInt $s --> Num) is export(:airy)
### sub Ai-deriv-zero-e(UInt $s --> List) is export(:airy)
These routines compute the location of the s-th zero of the Airy function derivative A'i(x).
### sub Bi-deriv-zero(UInt $s --> Num) is export(:airy)
### sub Bi-deriv-zero-e(UInt $s --> List) is export(:airy)
These routines compute the location of the s-th zero of the Airy function derivative B'i(x).
### sub J0(Num(Cool) $x --> Num) is export(:bessel)
### sub J0-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular cylindrical Bessel function of zeroth order, J₀(x).
### sub J1(Num(Cool) $x --> Num) is export(:bessel)
### sub J1-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular cylindrical Bessel function of first order, J₁(x).
### sub Jn(Int $n, Num(Cool) $x --> Num) is export(:bessel)
### sub Jn-e(Int $n, Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular cylindrical Bessel function of order n, Jₙ(x).
### sub Jn-array(Int $nmin, Int $nmax where $nmin < $nmax, Num(Cool) $x --> List) is export(:bessel)
This routine computes the values of the regular cylindrical Bessel functions Jₙ(x) for n from nmin to nmax inclusive.
### sub Y0(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Y0-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the irregular cylindrical Bessel function of zeroth order, Y₀(x).
### sub Y1(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Y1-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the irregular cylindrical Bessel function of first order, Y₁(x).
### sub Yn(Int $n, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Yn-e(Int $n, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the irregular cylindrical Bessel function of order n, Yₙ(x).
### sub Yn-array(Int $nmin, Int $nmax where $nmin < $nmax, Num(Cool) $x --> List) is export(:bessel)
This routine computes the values of the irregular cylindrical Bessel functions Yₙ(x) for n from nmin to nmax inclusive.
### sub I0(Num(Cool) $x --> Num) is export(:bessel)
### sub I0-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular modified cylindrical Bessel function of zeroth order, I₀(x).
### sub I1(Num(Cool) $x --> Num) is export(:bessel)
### sub I1-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular modified cylindrical Bessel function of first order, I₁(x).
### sub In(Int $n, Num(Cool) $x --> Num) is export(:bessel)
### sub In-e(Int $n, Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular modified cylindrical Bessel function of order n, Iₙ(x).
### sub In-array(UInt $nmin, UInt $nmax where $nmin < $nmax, Num(Cool) $x --> List) is export(:bessel)
This routine computes the values of the regular modified cylindrical Bessel functions Iₙ(x) for n from nmin to nmax inclusive.
### sub I0-scaled(Num(Cool) $x --> Num) is export(:bessel)
### sub I0-scaled-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the scaled regular modified cylindrical Bessel function of zeroth order exp(−|x|)I₀(x).
### sub I1-scaled(Num(Cool) $x --> Num) is export(:bessel)
### sub I1-scaled-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the scaled regular modified cylindrical Bessel function of first order exp(−|x|)I₁(x).
### sub In-scaled(Int $n, Num(Cool) $x --> Num) is export(:bessel)
### sub In-scaled-e(Int $n, Num(Cool) $x --> List) is export(:bessel)
These routines compute the scaled regular modified cylindrical Bessel function of order n exp(−|x|)Iₙ(x).
### sub In-scaled-array(UInt $nmin, UInt $nmax where $nmin < $nmax, Num(Cool) $x --> List) is export(:bessel)
This routine computes the values of the scaled regular cylindrical Bessel functions exp(−|x|)Iₙ(x) for n from nmin to nmax inclusive.
### sub K0(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub K0-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the irregular modified cylindrical Bessel function of zeroth order, K₀(x).
### sub K1(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub K1-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the irregular modified cylindrical Bessel function of first order, K₁(x).
### sub Kn(Int $n, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Kn-e(Int $n, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the irregular modified cylindrical Bessel function of order n, Kₙ(x).
### sub Kn-array(UInt $nmin, UInt $nmax where $nmin < $nmax, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
This routine computes the values of the irregular modified cylindrical Bessel functions K n (x) for n from nmin to nmax inclusive.
### sub K0-scaled(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub K0-scaled-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified cylindrical Bessel function of zeroth order exp(x)K₀(x).
### sub K1-scaled(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub K1-scaled-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified cylindrical Bessel function of first order exp(x)K₁(x).
### sub Kn-scaled(Int $n, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Kn-scaled-e(Int $n, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified cylindrical Bessel function of order n exp(x)Kₙ(x).
### sub Kn-scaled-array(UInt $nmin, UInt $nmax where $nmin < $nmax, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
This routine computes the values of the scaled irregular cylindrical Bessel functions exp(x)Kₙ(x) for n from nmin to nmax inclusive.
### sub j0(Num(Cool) $x --> Num) is export(:bessel)
### sub j0-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular spherical Bessel function of zeroth order, j₀(x).
### sub j1(Num(Cool) $x --> Num) is export(:bessel)
### sub j1-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular spherical Bessel function of first order, j₁(x).
### sub j2(Num(Cool) $x --> Num) is export(:bessel)
### sub j2-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular spherical Bessel function of second order, j₂(x).
### sub jl(UInt $l, Num(Cool) $x where \* ≥ 0 --> Num) is export(:bessel)
### sub jl-e(UInt $l, Num(Cool) $x where \* ≥ 0 --> List) is export(:bessel)
These routines compute the regular spherical Bessel function of order l, jₗ(x).
### sub jl-array(UInt $lmax, Num(Cool) $x where \* ≥ 0 --> List) is export(:bessel)
This routine computes the values of the regular spherical Bessel functions jₗ(x) for l from 0 to lmax inclusive.
### sub jl-steed-array(UInt $lmax, Num(Cool) $x where \* ≥ 0 --> List) is export(:bessel)
This routine uses Steed’s method to compute the values of the regular spherical Bessel functions jₗ(x) for l from 0 to lmax inclusive.
### sub y0(Num(Cool) $x --> Num) is export(:bessel)
### sub y0-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the irregular spherical Bessel function of zeroth order, y₀(x).
### sub y1(Num(Cool) $x --> Num) is export(:bessel)
### sub y1-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the irregular spherical Bessel function of first order, y₁(x).
### sub y2(Num(Cool) $x --> Num) is export(:bessel)
### sub y2-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the irregular spherical Bessel function of second order, y₂(x).
### sub yl(UInt $l, Num(Cool) $x --> Num) is export(:bessel)
### sub yl-e(UInt $l, Num(Cool) $x --> List) is export(:bessel)
These routines compute the irregular spherical Bessel function of order l, yₗ(x).
### sub yl-array(UInt $lmax, Num(Cool) $x --> List) is export(:bessel)
This routine computes the values of the irregular spherical Bessel functions yₗ(x) for l from 0 to lmax inclusive.
### sub i0-scaled(Num(Cool) $x --> Num) is export(:bessel)
### sub i0-scaled-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the scaled regular modified spherical Bessel function of zeroth order.
### sub i1-scaled(Num(Cool) $x --> Num) is export(:bessel)
### sub i1-scaled-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the scaled regular modified spherical Bessel function of first order.
### sub i2-scaled(Num(Cool) $x --> Num) is export(:bessel)
### sub i2-scaled-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the scaled regular modified spherical Bessel function of second order.
### sub il-scaled(UInt $l, Num(Cool) $x --> Num) is export(:bessel)
### sub il-scaled-e(UInt $l, Num(Cool) $x --> List) is export(:bessel)
These routines compute the scaled regular modified spherical Bessel function of order l.
### sub il-scaled-array(UInt $lmax, Num(Cool) $x --> List) is export(:bessel)
This routine computes the values of the scaled regular modified spherical Bessel functions for l from 0 to lmax inclusive.
### sub k0-scaled(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub k0-scaled-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified spherical Bessel function of zeroth order.
### sub k1-scaled(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub k1-scaled-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified spherical Bessel function of first order.
### sub k2-scaled(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub k2-scaled-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified spherical Bessel function of second order.
### sub kl-scaled(UInt $l, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub kl-scaled-e(UInt $l, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified spherical Bessel function of order l.
### sub kl-scaled-array(UInt $lmax, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
This routine computes the values of the scaled irregular modified spherical Bessel functions for l from 0 to lmax inclusive.
### sub Jnu(Num(Cool) $ν, Num(Cool) $x --> Num) is export(:bessel)
### sub Jnu-e(Num(Cool) $ν, Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular cylindrical Bessel function of fractional order ν, Jν(x).
### sub Jnu-sequence(Num(Cool) $ν, UInt $mode, Positional $x --> List) is export(:bessel)
This function computes the regular cylindrical Bessel function of fractional order ν, Jν(x), with an accuracy specified by $mode, evaluated at a series of x values.
### sub Ynu(Num(Cool) $ν, Num(Cool) $x --> Num) is export(:bessel)
### sub Ynu-e(Num(Cool) $ν, Num(Cool) $x --> List) is export(:bessel)
These routines compute the irregular cylindrical Bessel function of fractional order ν, Yν(x).
### sub Inu(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0--> Num) is export(:bessel)
### sub Inu-e(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the regular modified Bessel function of fractional order ν, Iν(x).
### sub Inu-scaled(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Inu-scaled-e(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled regular modified Bessel function of fractional order ν.
### sub Knu(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Knu-e(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the irregular modified Bessel function of fractional order ν, Kν(x).
### sub lnKnu(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub lnKnu-e(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the logarithm of the irregular modified Bessel function of fractional order ν, ln(Kν(x)).
### sub Knu-scaled(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Knu-scaled-e(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified Bessel function of fractional order ν.
### sub J0-zero(UInt $s --> Num) is export(:bessel)
### sub J0-zero-e(UInt $s --> List) is export(:bessel)
These routines compute the location of the s-th positive zero of the Bessel function J₀(x).
### sub J1-zero(UInt $s --> Num) is export(:bessel)
### sub J1-zero-e(UInt $s --> List) is export(:bessel)
These routines compute the location of the s-th positive zero of the Bessel function J₁(x).
### sub Jnu-zero(Num(Cool) $ν where \* ≥ 0, UInt $s --> Num) is export(:bessel)
### sub Jnu-zero-e(Num(Cool) $ν where \* ≥ 0, UInt $s --> List) is export(:bessel)
These routines compute the location of the s-th positive zero of the Bessel function Jν(x).
### sub clausen(Num(Cool) $x --> Num) is export(:clausen)
### sub clausen-e(Num(Cool) $x --> List) is export(:clausen)
These routines compute the Clausen integral Cl₂(x).
### sub hydrogenic-R1(Num(Cool) $Z, Num(Cool) $r --> Num) is export(:coulomb)
### sub hydrogenic-R1-e(Num(Cool) $Z, Num(Cool) $r --> List) is export(:coulomb)
These √ routines compute the lowest-order normalized hydrogenic bound state radial wavefunction R₁.
### sub hydrogenic-R(Int $n, Int $l, Num(Cool) $Z, Num(Cool) $r --> Num) is export(:coulomb)
### sub hydrogenic-R-e(Int $n, Int $l, Num(Cool) $Z, Num(Cool) $r --> List) is export(:coulomb)
These routines compute the n-th normalized hydrogenic bound state radial wavefunction Rₙ.
### sub coulomb-wave-FG-e(Num(Cool) $eta, Num(Cool) $x where \* > 0, Num(Cool) $LF where \* > -½, Int $k --> List) is export(:coulomb)
This function computes the Coulomb wave functions Fₗ(η, x), Gₗ₋ₖ(η, x) and their derivatives Fₗ’(η, x), Gₗ₋ₖ’(η, x) with respect to x. It returns a List of Pairs (that can be read as a Hash):
* :Fval the Fₗ(η, x) value
* :Ferr the Fₗ(η, x) error
* :Fpval the Fₗ’(η, x) value
* :Fperr the Fₗ’(η, x) error
* :Gval the Gₗ₋ₖ(η, x) value
* :Gerr the Gₗ₋ₖ(η, x) error
* :Gpval the Gₗ₋ₖ’(η, x) value
* :Gperr the Gₗ₋ₖ’(η, x) error
* :overflow Bool: if an overflow occurred, this is True, otherwise False
* :expF if an overflow occurred, this is the scaling exponent for Fₗ(η, x)
* :expG if an overflow occurred, this is the scaling exponent for Gₗ₋ₖ(η, x)
```
my %res = coulomb-wave-FG-e(1, 5, 0, 0);
say %res<Fval>;
say %res<Fpval>;
say %res<Gval>;
say %res<Gpval>;
```
### sub coulomb-wave-F-array(Num(Cool) $lmin, UInt $kmax, Num(Cool) $eta, Num(Cool) $x where \* > 0 --> List) is export(:coulomb)
This function computes the Coulomb wave function Fₗ(η, x) for l = lmin … lmin + kmax. It returns a List of Pairs (that can be read as a Hash):
* :outF array of Fₗ(η, x) values
* :overflow Bool: if an overflow occurred, this is True, otherwise False
* :expF if an overflow occurred, this is the scaling exponent for Fₗ(η, x)
### sub coulomb-wave-FG-array(Num(Cool) $lmin, UInt $kmax, Num(Cool) $eta, Num(Cool) $x where \* > 0 --> List) is export(:coulomb)
This function computes the functions Fₗ(η, x), Gₗ(η, x) for l = lmin … lmin + kmax. It returns a List of Pairs (that can be read as a Hash):
* :outF array of Fₗ(η, x) values
* :outG array of Gₗ(η, x) values
* :overflow Bool: if an overflow occurred, this is True, otherwise False
* :expF if an overflow occurred, this is the scaling exponent for Fₗ(η, x)
* :expG if an overflow occurred, this is the scaling exponent for Gₗ₋ₖ(η, x)
### sub coulomb-wave-FGp-array(Num(Cool) $lmin, UInt $kmax, Num(Cool) $eta, Num(Cool) $x where \* > 0 --> List) is export(:coulomb)
This function computes the functions Fₗ(η, x), Gₗ(η, x) and their derivatives F’ₗ(η, x), G’ₗ(η, x) for l = lmin … lmin + kmax It returns a List of Pairs (that can be read as a Hash):
* :outF array of Fₗ(η, x) values
* :outG array of Gₗ(η, x) values
* :outFp array of Fₗ’(η, x) values
* :outGp array of Gₗ’(η, x) values
* :overflow Bool: if an overflow occurred, this is True, otherwise False
* :expF if an overflow occurred, this is the scaling exponent for Fₗ(η, x)
* :expG if an overflow occurred, this is the scaling exponent for Gₗ₋ₖ(η, x)
### sub coulomb-wave-sphF-array(Num(Cool) $lmin, UInt $kmax, Num(Cool) $eta, Num(Cool) $x where \* > 0 --> List) is export(:coulomb)
This function computes the Coulomb wave function divided by the argument Fₗ(η, x)/x for l = lmin… lmin + kmax It returns a List of Pairs (that can be read as a Hash):
* :outF array of Fₗ(η, x) values
* :overflow Bool: if an overflow occurred, this is True, otherwise False
* :expF if an overflow occurred, this is the scaling exponent for Fₗ(η, x)
### sub coulomb-CL-e(Num(Cool) $L where \* > -1, Num(Cool) $eta --> List) is export(:coulomb)
This function computes the Coulomb wave function normalization constant Cₗ(η).
### sub coulomb-CL-array(Num(Cool) $lmin where \* > -1, UInt $kmax, Num(Cool) $eta --> List) is export(:coulomb)
This function computes the Coulomb wave function normalization constant C L (η) for l = lmin … lmin + kmax.
### sub coupling3j(Int $two-ja, Int $two-jb, Int $two-jc, Int $two-ma, Int $two-mb, Int $two-mc --> Num) is export(:coupling)
### sub coupling3j-e(Int $two-ja, Int $two-jb, Int $two-jc, Int $two-ma, Int $two-mb, Int $two-mc --> List) is export(:coupling)
These routines compute the Wigner 3-j coefficient. The arguments are given in half-integer units: two\_ja/2, two\_ma/2, etc.
### sub coupling6j(Int $two-ja, Int $two-jb, Int $two-jc, Int $two-jd, Int $two-je, Int $two-jf --> Num) is export(:coupling)
### sub coupling6j-e(Int $two-ja, Int $two-jb, Int $two-jc, Int $two-jd, Int $two-je, Int $two-jf --> List) is export(:coupling)
These routines compute the Wigner 6-j coefficient. The arguments are given in half-integer units: two\_ja/2, two\_ma/2, etc.
### sub coupling9j(Int $two-ja, Int $two-jb, Int $two-jc, Int $two-jd, Int $two-je, Int $two-jf, Int $two-jg, Int $two-jh, Int $two-ji --> Num) is export(:coupling)
### sub coupling9j-e(Int $two-ja, Int $two-jb, Int $two-jc, Int $two-jd, Int $two-je, Int $two-jf, Int $two-jg, Int $two-jh, Int $two-ji --> List) is export(:coupling)
These routines compute the Wigner 9-j coefficient. The arguments are given in half-integer units: two\_ja/2, two\_ma/2, etc.
### sub dawson(Num(Cool) $x --> Num) is export(:dawson)
### sub dawson-e(Num(Cool) $x --> List) is export(:dawson)
These routines compute the value of Dawson’s integral for x.
### sub debye1(Num(Cool) $x --> Num) is export(:debye)
### sub debye1-e(Num(Cool) $x --> List) is export(:debye)
These routines compute the first-order Debye function D₁(x).
### sub debye2(Num(Cool) $x --> Num) is export(:debye)
### sub debye2-e(Num(Cool) $x --> List) is export(:debye)
These routines compute the first-order Debye function D₂(x).
### sub debye3(Num(Cool) $x --> Num) is export(:debye)
### sub debye3-e(Num(Cool) $x --> List) is export(:debye)
These routines compute the first-order Debye function D₃(x).
### sub debye4(Num(Cool) $x --> Num) is export(:debye)
### sub debye4-e(Num(Cool) $x --> List) is export(:debye)
These routines compute the first-order Debye function D₄(x).
### sub debye5(Num(Cool) $x --> Num) is export(:debye)
### sub debye5-e(Num(Cool) $x --> List) is export(:debye)
These routines compute the first-order Debye function D₅(x).
### sub debye6(Num(Cool) $x --> Num) is export(:debye)
### sub debye6-e(Num(Cool) $x --> List) is export(:debye)
These routines compute the first-order Debye function D₆(x).
### sub dilog(Num(Cool) $x --> Num) is export(:dilog)
### sub dilog-e(Num(Cool) $x --> List) is export(:dilog)
These routines compute the dilogarithm for a real argument.
### sub complex-dilog-xy-e(Num(Cool) $x, Num(Cool) $y --> List) is export(:dilog)
### sub complex-dilog-e(Num(Cool) $r, Num(Cool) $θ --> List) is export(:dilog)
This function computes the full complex-valued dilogarithm for the complex argument z = r exp(iθ).
### sub complex-spence-xy-e(Num(Cool) $x, Num(Cool) $y --> List) is export(:dilog)
This function computes the full complex-valued Spence integral. It returns a List: the first element is the value as a Raku’s Complex datatype, the following are the errors on the real and imaginary part.
### sub multiply(Num(Cool) $x, Num(Cool) $y --> Num) is export(:mult)
### sub multiply-e(Num(Cool) $x, Num(Cool) $y --> List) is export(:mult)
These functions multiply x and y, allowing for the propagation of errors.
### sub multiply-err-e(Num(Cool) $x, Num(Cool) $dx, Num(Cool) $y, Num(Cool) $dy --> List) is export(:mult)
This function multiplies x and y with associated absolute errors dx and dy.
### sub Kcomp(Num(Cool) $k, UInt $mode --> Num) is export(:ellint)
### sub Kcomp-e(Num(Cool) $k, UInt $mode --> List) is export(:ellint)
These routines compute the complete elliptic integral K(k) to the accuracy specified by the mode variable mode.
### sub Ecomp(Num(Cool) $k, UInt $mode --> Num) is export(:ellint)
### sub Ecomp-e(Num(Cool) $k, UInt $mode --> List) is export(:ellint)
These routines compute the complete elliptic integral E(k) to the accuracy specified by the mode variable mode.
### sub Pcomp(Num(Cool) $k, Num(Cool) $n, UInt $mode --> Num) is export(:ellint)
### sub Pcomp-e(Num(Cool) $k, Num(Cool) $n, UInt $mode --> List) is export(:ellint)
These routines compute the complete elliptic integral Π(k,n) to the accuracy specified by the mode variable mode.
### sub Dcomp(Num(Cool) $k, UInt $mode --> Num) is export(:ellint)
### sub Dcomp-e(Num(Cool) $k, UInt $mode --> List) is export(:ellint)
These routines compute the complete elliptic integral D(k) to the accuracy specified by the mode variable mode.
### sub F(Num(Cool) $Φ, Num(Cool) $k, UInt $mode --> Num) is export(:ellint)
### sub F-e(Num(Cool) $Φ, Num(Cool) $k, UInt $mode --> List) is export(:ellint)
These routines compute the incomplete elliptic integral F(φ, k) to the accuracy specified by the mode variable mode.
### sub E(Num(Cool) $Φ, Num(Cool) $k, UInt $mode --> Num) is export(:ellint)
### sub E-e(Num(Cool) $Φ, Num(Cool) $k, UInt $mode --> List) is export(:ellint)
These routines compute the incomplete elliptic integral E(φ, k) to the accuracy specified by the mode variable mode.
### sub P(Num(Cool) $Φ, Num(Cool) $k, Num(Cool) $n, UInt $mode --> Num) is export(:ellint)
### sub P-e(Num(Cool) $Φ, Num(Cool) $k, Num(Cool) $n, UInt $mode --> List |
## dist_zef-FRITH-Math-Libgsl-Function.md
## Chunk 2 of 3
) is export(:ellint)
These routines compute the incomplete elliptic integral P(φ, k) to the accuracy specified by the mode variable mode.
### sub D(Num(Cool) $Φ, Num(Cool) $k, UInt $mode --> Num) is export(:ellint)
### sub D-e(Num(Cool) $Φ, Num(Cool) $k, UInt $mode --> List) is export(:ellint)
These routines compute the incomplete elliptic integral D(φ, k) to the accuracy specified by the mode variable mode.
### sub RC(Num(Cool) $x, Num(Cool) $y, UInt $mode --> Num) is export(:ellint)
### sub RC-e(Num(Cool) $x, Num(Cool) $y, UInt $mode --> List) is export(:ellint)
These routines compute the incomplete elliptic integral RC(x, y) to the accuracy specified by the mode variable mode.
### sub RD(Num(Cool) $x, Num(Cool) $y, Num(Cool) $z, UInt $mode --> Num) is export(:ellint)
### sub RD-e(Num(Cool) $x, Num(Cool) $y, Num(Cool) $z, UInt $mode --> List) is export(:ellint)
These routines compute the incomplete elliptic integral RD(x, y, z) to the accuracy specified by the mode variable mode.
### sub RF(Num(Cool) $x, Num(Cool) $y, Num(Cool) $z, UInt $mode --> Num) is export(:ellint)
### sub RF-e(Num(Cool) $x, Num(Cool) $y, Num(Cool) $z, UInt $mode --> List) is export(:ellint)
These routines compute the incomplete elliptic integral RF(x, y, z) to the accuracy specified by the mode variable mode.
### sub RJ(Num(Cool) $x, Num(Cool) $y, Num(Cool) $z, Num(Cool) $p, UInt $mode --> Num) is export(:ellint)
### sub RJ-e(Num(Cool) $x, Num(Cool) $y, Num(Cool) $z, Num(Cool) $p, UInt $mode --> List) is export(:ellint)
These routines compute the incomplete elliptic integral RJ(x, y, z, p) to the accuracy specified by the mode variable mode.
### sub elljac-e(Num(Cool) $u, Num(Cool) $m --> List) is export(:ellfun)
This function computes the Jacobian elliptic functions sn(u|m), cn(u|m), dn(u|m) by descending Landen transformations.
### sub erf(Num(Cool) $x --> Num) is export(:err)
### sub erf-e(Num(Cool) $x --> List) is export(:err)
These routines compute the error function erf(x).
### sub erfc(Num(Cool) $x --> Num) is export(:err)
### sub erfc-e(Num(Cool) $x --> List) is export(:err)
These routines compute the complementary error function erfc(x) = 1 − erf(x).
### sub log-erfc(Num(Cool) $x --> Num) is export(:err)
### sub log-erfc-e(Num(Cool) $x --> List) is export(:err)
These routines compute the logarithm of the complementary error function log(erfc(x)).
### sub erf-Z(Num(Cool) $x --> Num) is export(:err)
### sub erf-Z-e(Num(Cool) $x --> List) is export(:err)
These routines compute the Gaussian probability density function Z(x).
### sub erf-Q(Num(Cool) $x --> Num) is export(:err)
### sub erf-Q-e(Num(Cool) $x --> List) is export(:err)
These routines compute the upper tail of the Gaussian probability function Q(x).
### sub hazard(Num(Cool) $x --> Num) is export(:err)
### sub hazard-e(Num(Cool) $x --> List) is export(:err)
These routines compute the hazard function for the normal distribution.
### sub gexp(Num(Cool) $x --> Num) is export(:exp)
### sub gexp-e(Num(Cool) $x --> List) is export(:exp)
These routines provide an exponential function exp(x) using GSL semantics and error checking.
### sub gexp-e10(Num(Cool) $x --> List) is export(:exp)
This function computes the exponential exp(x) and returns a result with extended range. This function may be useful if the value of exp(x) would overflow the numeric range of double. It returns a list of three numbers: the value, the error, and the scaling exponent.
### sub gexp-mult(Num(Cool) $x, Num(Cool) $y --> Num) is export(:exp)
### sub gexp-mult-e(Num(Cool) $x, Num(Cool) $y --> List) is export(:exp)
These routines exponentiate x and multiply by the factor y to return the product y exp(x).
### sub gexp-mult-e10(Num(Cool) $x, Num(Cool) $y --> List) is export(:exp)
This function computes the product y exp(x) and returns a result with extended range. This function may be useful if the value of exp(x) would overflow the numeric range of double. It returns a list of three numbers: the value, the error, and the scaling exponent.
### sub gexpm1(Num(Cool) $x --> Num) is export(:exp)
### sub gexpm1-e(Num(Cool) $x --> List) is export(:exp)
These routines compute the quantity exp(x) − 1 using an algorithm that is accurate for small x.
### sub gexprel(Num(Cool) $x --> Num) is export(:exp)
### sub gexprel-e(Num(Cool) $x --> List) is export(:exp)
These routines compute the quantity (exp(x) − 1)/x using an algorithm that is accurate for small x.
### sub gexprel2(Num(Cool) $x --> Num) is export(:exp)
### sub gexprel2-e(Num(Cool) $x --> List) is export(:exp)
These routines compute the quantity 2(exp(x) − 1 − x)/x 2 using an algorithm that is accurate for small x.
### sub gexprel-n(Int $n, Num(Cool) $x --> Num) is export(:exp)
### sub gexprel-n-e(Int $n, Num(Cool) $x --> List) is export(:exp)
These routines compute the N -relative exponential, which is the n-th generalization of the functions gexprel, gexprel2, gexprel-e, and gexprel2-e.
### sub gexp-err-e(Num(Cool) $x, Num(Cool) $dx --> List) is export(:exp)
This function exponentiates x with an associated absolute error dx.
### sub gexp-err-e10(Num(Cool) $x, Num(Cool) $dx --> List) is export(:exp)
This function exponentiates a quantity x with an associated absolute error dx and returns a result with extended range. This function may be useful if the value of exp(x) would overflow the numeric range of double. It returns a list of three numbers: the value, the error, and the scaling exponent.
### sub gexp-mult-err-e(Num(Cool) $x, Num(Cool) $dx, Num(Cool) $y, Num(Cool) $dy --> List) is export(:exp)
This routine computes the product y exp(x) for the quantities x, y with associated absolute errors dx, dy.
### sub gexp-mult-err-e10(Num(Cool) $x, Num(Cool) $dx, Num(Cool) $y, Num(Cool) $dy --> List) is export(:exp)
This routine computes the product y exp(x) for the quantities x, y with associated absolute errors dx, dy and returns a result with extended range. This function may be useful if the value of exp(x) would overflow the numeric range of double. It returns a list of three numbers: the value, the error, and the scaling exponent.
### sub E1(Num(Cool) $x --> Num) is export(:expint)
### sub E1-e(Num(Cool) $x --> List) is export(:expint)
These routines compute the exponential integral E₁(x).
### sub E2(Num(Cool) $x --> Num) is export(:expint)
### sub E2-e(Num(Cool) $x --> List) is export(:expint)
These routines compute the exponential integral E₂(x).
### sub En(Int $n, Num(Cool) $x --> Num) is export(:expint)
### sub En-e(Int $n, Num(Cool) $x --> List) is export(:expint)
These routines compute the exponential integral Eₙ(x) of order n.
### sub Ei(Num(Cool) $x --> Num) is export(:expint)
### sub Ei-e(Num(Cool) $x --> List) is export(:expint)
These routines compute the exponential integral Ei(x).
### sub Shi(Num(Cool) $x --> Num) is export(:expint)
### sub Shi-e(Num(Cool) $x --> List) is export(:expint)
These routines compute the hyperbolic integral Shi(x).
### sub Chi(Num(Cool) $x --> Num) is export(:expint)
### sub Chi-e(Num(Cool) $x --> List) is export(:expint)
These routines compute the hyperbolic integral Chi(x).
### sub expint3(Num(Cool) $x where \* ≥ 0 --> Num) is export(:expint)
### sub expint3-e(Num(Cool) $x where \* ≥ 0 --> List) is export(:expint)
These routines compute the third-order exponential integral Ei₃(x).
### sub Si(Num(Cool) $x --> Num) is export(:expint)
### sub Si-e(Num(Cool) $x --> List) is export(:expint)
These routines compute the Sine integral Si(x).
### sub Ci(Num(Cool) $x where \* > 0 --> Num) is export(:expint)
### sub Ci-e(Num(Cool) $x where \* > 0 --> List) is export(:expint)
These routines compute the Cosine integral Ci(x).
### sub atanint(Num(Cool) $x --> Num) is export(:expint)
### sub atanint-e(Num(Cool) $x --> List) is export(:expint)
These routines compute the Arctangent integral.
### sub fd-m1(Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd-m1-e(Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral with an index of −1.
### sub fd0(Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd0-e(Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral with an index of 0.
### sub fd1(Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd1-e(Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral with an index of 1.
### sub fd2(Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd2-e(Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral with an index of 2.
### sub fd-int(Int $j, Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd-int-e(Int $j, Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral with an integer index j.
### sub fd-mhalf(Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd-mhalf-e(Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral F₋₁/₂(x).
### sub fd-half(Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd-half-e(Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral F₁/₂(x).
### sub fd-half3(Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd-half3-e(Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral F₃/₂(x).
### sub fd-inc0(Num(Cool) $x, Num(Cool) $b --> Num) is export(:fermidirac)
### sub fd-inc0-e(Num(Cool) $x, Num(Cool) $b --> List) is export(:fermidirac)
These routines compute the incomplete Fermi-Dirac integral with an index of zero, F₀(x, b).
### sub gamma(Num(Cool) $x where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> Num) is export(:gammabeta)
### sub gamma-e(Num(Cool) $x where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> List) is export(:gammabeta)
These routines compute the Gamma function Γ(x).
### sub lngamma(Num(Cool) $x where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> Num) is export(:gammabeta)
### sub lngamma-e(Num(Cool) $x where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> List) is export(:gammabeta)
These routines compute the logarithm of the Gamma function, log(Γ(x)).
### sub lngamma-sgn-e(Num(Cool) $x where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> List) is export(:gammabeta)
This routine computes the sign of the gamma function and the logarithm of its magnitude. It returns three numbers: the value, its associated error, and the sign.
### sub gammastar(Num(Cool) $x where \* > 0 --> Num) is export(:gammabeta)
### sub gammastar-e(Num(Cool) $x where \* > 0 --> List) is export(:gammabeta)
These routines compute the regulated Gamma Function Γ\*(x).
### sub gammainv(Num(Cool) $x where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> Num) is export(:gammabeta)
### sub gammainv-e(Num(Cool) $x where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> List) is export(:gammabeta)
These routines compute the reciprocal of the gamma function, 1/Γ(x) using the real Lanczos method.
### sub lngamma-complex-e(Num(Cool) $zr where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) }, Num(Cool) $zi where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> List) is export(:gammabeta)
This routine computes log(Γ(z)) for complex z = zᵣ + izᵢ. The returned parameters are lnr = log |Γ(z)|, its error, arg = arg(Γ(z)) in (−π, π], and its error.
### sub fact(UInt $n where \* ≤ GSL\_SF\_FACT\_NMAX --> Num) is export(:gammabeta)
### sub fact-e(UInt $n where \* ≤ GSL\_SF\_FACT\_NMAX --> List) is export(:gammabeta)
These routines compute the factorial n!.
### sub doublefact(UInt $n where \* ≤ GSL\_SF\_DOUBLEFACT\_NMAX --> Num) is export(:gammabeta)
### sub doublefact-e(UInt $n where \* ≤ GSL\_SF\_DOUBLEFACT\_NMAX --> List) is export(:gammabeta)
These routines compute the double factorial n!! = n(n − 2)(n − 4)…
### sub lnfact(UInt $n --> Num) is export(:gammabeta)
### sub lnfact-e(UInt $n --> List) is export(:gammabeta)
These routines compute the logarithm of the factorial of n, log(n!).
### sub lndoublefact(UInt $n --> Num) is export(:gammabeta)
### sub lndoublefact-e(UInt $n --> List) is export(:gammabeta)
These routines compute the logarithm of the double factorial of n, log(n!!).
### sub choose(UInt $n, UInt $m --> Num) is export(:gammabeta)
### sub choose-e(UInt $n, UInt $m --> List) is export(:gammabeta)o
These routines compute the combinatorial factor n choose m = n!/(m!(n − m)!).
### sub lnchoose(UInt $n, UInt $m --> Num) is export(:gammabeta)
### sub lnchoose-e(UInt $n, UInt $m --> List) is export(:gammabeta)
These routines compute the logarithm of n choose m.
### sub taylorcoeff(UInt $n, Num(Cool) $x where \* ≥ 0 --> Num) is export(:gammabeta)
### sub taylorcoeff-e(UInt $n, Num(Cool) $x where \* ≥ 0 --> List) is export(:gammabeta)
These routines compute the Taylor coefficient xⁿ/n!.
### sub poch(Num(Cool) $a, Num(Cool) $x --> Num) is export(:gammabeta)
### sub poch-e(Num(Cool) $a, Num(Cool) $x --> List) is export(:gammabeta)
These routines compute the Pochhammer symbol (a)ₓ = Γ(a + x)/Γ(a).
### sub lnpoch(Num(Cool) $a, Num(Cool) $x --> Num) is export(:gammabeta)
### sub lnpoch-e(Num(Cool) $a, Num(Cool) $x --> List) is export(:gammabeta)
These routines compute the Pochhammer symbol log((a)ₓ) = log(Γ(a + x)/Γ(a)).
### sub lnpoch-sgn-e(Num(Cool) $a, Num(Cool) $x --> List) is export(:gammabeta)
These routines compute the sign of the Pochhammer symbol and the logarithm of its magnitude. It returns three numbers: the value, its associated error, and the sign.
### sub pochrel(Num(Cool) $a, Num(Cool) $x --> Num) is export(:gammabeta)
### sub pochrel-e(Num(Cool) $a, Num(Cool) $x --> List) is export(:gammabeta)
These routines compute the relative Pochhammer symbol ((a)ₓ − 1)/x
### sub gamma-inc(Num(Cool) $a where \* > 0, Num(Cool) $x where \* ≥ 0 --> Num) is export(:gammabeta)
### sub gamma-inc-e(Num(Cool) $a, Num(Cool) $x where \* ≥ 0 --> List) is export(:gammabeta)
These functions compute the unnormalized incomplete Gamma Function Γ(a, x).
### sub gamma-inc-Q(Num(Cool) $a where \* > 0, Num(Cool) $x where \* ≥ 0 --> Num) is export(:gammabeta)
### sub gamma-inc-Q-e(Num(Cool) $a where \* > 0, Num(Cool) $x where \* ≥ 0 --> List) is export(:gammabeta)
These routines compute the normalized incomplete Gamma Function Q(a, x) = 1/Γ(a).
### sub gamma-inc-P(Num(Cool) $a where \* > 0, Num(Cool) $x where \* ≥ 0 --> Num) is export(:gammabeta)
### sub gamma-inc-P-e(Num(Cool) $a where \* > 0, Num(Cool) $x where \* ≥ 0 --> List) is export(:gammabeta)
These routines compute the complementary normalized incomplete Gamma Function P (a, x).
### sub beta(Num(Cool) $a where \* > 0, Num(Cool) $b where \* > 0 --> Num) is export(:gammabeta)
### sub beta-e(Num(Cool) $a where \* > 0, Num(Cool) $b where \* > 0 --> List) is export(:gammabeta)
These routines compute the Beta Function, B(a, b).
### sub lnbeta(Num(Cool) $a where \* > 0, Num(Cool) $b where \* > 0 --> Num) is export(:gammabeta)
### sub lnbeta-e(Num(Cool) $a where \* > 0, Num(Cool) $b where \* > 0 --> List) is export(:gammabeta)
These routines compute the logarithm of the Beta Function, log(B(a, b)).
### sub beta-inc(Num(Cool) $a where \* > 0, Num(Cool) $b where \* > 0, Num(Cool) $x where 0 ≤ \* ≤ 1 --> Num) is export(:gammabeta)
### sub beta-inc-e(Num(Cool) $a where \* > 0, Num(Cool) $b where \* > 0, Num(Cool) $x where 0 ≤ \* ≤ 1 --> List) is export(:gammabeta)
These routines compute the normalized incomplete Beta function I x (a, b).
### sub gegenpoly1(Num(Cool) $lambda, Num(Cool) $x --> Num) is export(:gegen)
### sub gegenpoly1-e(Num(Cool) $lambda, Num(Cool) $x --> List) is export(:gegen)
### sub gegenpoly2(Num(Cool) $lambda, Num(Cool) $x --> Num) is export(:gegen)
### sub gegenpoly2-e(Num(Cool) $lambda, Num(Cool) $x --> List) is export(:gegen)
### sub gegenpoly3(Num(Cool) $lambda, Num(Cool) $x --> Num) is export(:gegen)
### sub gegenpoly3-e(Num(Cool) $lambda, Num(Cool) $x --> List) is export(:gegen)
These functions evaluate the Gegenbauer polynomials Cₙλ(x) using explicit representations for n = 1, 2, 3.
### sub gegenpolyn(UInt $n, Num(Cool) $lambda where \* > -½, Num(Cool) $x --> Num) is export(:gegen)
### sub gegenpolyn-e(UInt $n, Num(Cool) $lambda where \* > -½, Num(Cool) $x --> List) is export(:gegen)
These functions evaluate the Gegenbauer polynomials Cₙλ(x) for a specific value of n, λ, x.
### sub gegenpoly-array(UInt $nmax, Num(Cool) $lambda where \* > -½, Num(Cool) $x --> List) is export(:gegen)
This function computes an array of Gegenbauer polynomials Cₙλ(x) for n = 0, 1, 2 … $nmax.
### sub hermite(Int $n, Num(Cool) $x --> Num) is export(:hermite)
### sub hermite-e(Int $n, Num(Cool) $x --> List) is export(:hermite)
These routines evaluate the physicist Hermite polynomial H n (x) of order n at position x.
### sub hermite-array(Int $nmax, Num(Cool) $x --> List) is export(:hermite)
This routine evaluates all physicist Hermite polynomials H n up to order nmax at position x.
### sub hermite-series(Int $n, Num(Cool) $x, \*@a --> Num) is export(:hermite)
### sub hermite-series-e(Int $n, Num(Cool) $x, \*@a --> List) is export(:hermite)
These routines evaluate the series Σ aⱼHⱼ(x) for j = 0 … n.
### sub hermite-prob(Int $n, Num(Cool) $x --> Num) is export(:hermite)
### sub hermite-prob-e(Int $n, Num(Cool) $x --> List) is export(:hermite)
These routines evaluate the probabilist Hermite polynomial He n (x) of order n at position x.
### sub hermite-prob-array(Int $nmax, Num(Cool) $x --> List) is export(:hermite)
This routine evaluates all probabilist Hermite polynomials Heₙ(x) up to order nmax at position x.
### sub hermite-prob-series(Int $n, Num(Cool) $x, \*@a --> Num) is export(:hermite)
### sub hermite-prob-series-e(Int $n, Num(Cool) $x, \*@a --> List) is export(:hermite)
These routines evaluate the series Σ aⱼHeⱼ(x) for j = 0 … n.
### sub hermite-der(Int $n, Int $m, Num(Cool) $x --> Num) is export(:hermite)
### sub hermite-der-e(Int $n, Int $m, Num(Cool) $x --> List) is export(:hermite)
These routines evaluate the m-th derivative of the physicist Hermite polynomial Hₙ(x) of order n at position x.
### sub hermite-array-der(Int $m, Int $nmax, Num(Cool) $x --> List) is export(:hermite)
This routine evaluates the m-th derivative of all physicist Hermite polynomials Hₙ(x) from orders 0 … nmax at position x.
### sub hermite-der-array(Int $mmax, Int $n, Num(Cool) $x --> List) is export(:hermite)
This routine evaluates all derivative orders from 0 … mmax of the physicist Hermite polynomial of order n, Hₙ, at position x.
### sub hermite-prob-der(Int $m, Int $n, Num(Cool) $x --> Num) is export(:hermite)
### sub hermite-prob-der-e(Int $m, Int $n, Num(Cool) $x --> List) is export(:hermite)
These routines evaluate the m-th derivative of the probabilist Hermite polynomial Heₙ(x) of order n at position x.
### sub hermite-prob-array-der(Int $m, Int $nmax, Num(Cool) $x --> List) is export(:hermite)
This routine evaluates the m-th derivative of all probabilist Hermite polynomials Heₙ(x) from orders 0 … nmax at position x.
### sub hermite-prob-der-array(Int $mmax, Int $n, Num(Cool) $x --> List) is export(:hermite)
This routine evaluates all derivative orders from 0 … mmax of the probabilist Hermite polynomial of order n, Heₙ, at position x.
### sub hermite-func(Int $n, Num(Cool) $x --> Num) is export(:hermite)
### sub hermite-func-e(Int $n, Num(Cool) $x --> List) is export(:hermite)
These routines evaluate the Hermite function ψₙ(x) of order n at position x.
### sub hermite-func-array(Int $nmax, Num(Cool) $x --> List) is export(:hermite)
This routine evaluates all Hermite functions ψₙ(x) for orders n = 0 … nmax at position x.
### sub hermite-func-series(Int $n, Num(Cool) $x, \*@a --> Num) is export(:hermite)
### sub hermite-func-series-e(Int $n, Num(Cool) $x, \*@a --> List) is export(:hermite)
These routines evaluate the series Σ aⱼψⱼ(x) for j = 0 … n.
### sub hermite-func-der(Int $m, Int $n, Num(Cool) $x --> Num) is export(:hermite)
### sub hermite-func-der-e(Int $m, Int $n, Num(Cool) $x --> List) is export(:hermite)
These routines evaluate the m-th derivative of the Hermite function ψₙ(x) of order n at position x.
### sub hermite-zero(Int $n, Int $s --> Num) is export(:hermite)
### sub hermite-zero-e(Int $n, Int $s --> List) is export(:hermite)
These routines evaluate the s-th zero of the physicist Hermite polynomial Hₙ(x) of order n.
### sub hermite-prob-zero(Int $n, Int $s --> Num) is export(:hermite)
### sub hermite-prob-zero-e(Int $n, Int $s --> List) is export(:hermite)
These routines evaluate the s-th zero of the probabilist Hermite polynomial Heₙ(x) of order n.
### sub hermite-func-zero(Int $n, Int $s --> Num) is export(:hermite)
### sub hermite-func-zero-e(Int $n, Int $s --> List) is export(:hermite)
These routines evaluate the s-th zero of the Hermite function ψₙ(x) of order n.
### sub F01(Num(Cool) $c, Num(Cool) $x --> Num) is export(:hyperg)
### sub F01-e(Num(Cool) $c, Num(Cool) $x --> List) is export(:hyperg)
These routines compute the hypergeometric function ₀F₁(c, x).
### sub F11(Num(Cool) $a, Num(Cool) $b, Num(Cool) $x --> Num) is export(:hyperg)
### sub F11-e(Num(Cool) $a, Num(Cool) $b, Num(Cool) $x --> List) is export(:hyperg)
These routines compute the confluent hypergeometric function ₁F₁(a, b, x).
### sub F11-int(Int $m, Int $n, Num(Cool) $x --> Num) is export(:hyperg)
### sub F11-int-e(Int $m, Int $n, Num(Cool) $x --> List) is export(:hyperg)
These routines compute the confluent hypergeometric function ₁F₁(m, n, x) for integer parameters m, n.
### sub U(Num(Cool) $a, Num(Cool) $b, Num(Cool) $x --> Num) is export(:hyperg)
### sub U-e(Num(Cool) $a, Num(Cool) $b, Num(Cool) $x --> List) is export(:hyperg)
These routines compute the confluent hypergeometric function U(a, b, x).
### sub U-e10(Num(Cool) $a, Num(Cool) $b, Num(Cool) $x --> List) is export(:hyperg)
This routine computes the confluent hypergeometric function U(a, b, x) and returns a result with extended range. It returns a list of three numbers: the value, the error, and the scaling exponent.
### sub U-int(Int $m, Int $n, Num(Cool) $x --> Num) is export(:hyperg)
### sub U-int-e(Int $m, Int $n, Num(Cool) $x --> List) is export(:hyperg)
These routines compute the confluent hypergeometric function U(m, n, x) for integer parameters m, n.
### sub U-int-e10(Int $m, Int $n, Num(Cool) $x --> List) is export(:hyperg)
This routine computes the confluent hypergeometric function U(m, n, x) for integer parameters m, n and returns a result with extended range. It returns a list of three numbers: the value, the error, and the scaling exponent.
### sub F21(Num(Cool) $a, Num(Cool) $b, Num(Cool) $c, Num(Cool) $x --> Num) is export(:hyperg)
### sub F21-e(Num(Cool) $a, Num(Cool) $b, Num(Cool) $c, Num(Cool) $x --> List) is export(:hyperg)
These routines compute the Gauss hypergeometric function ₂F₁(a, b, c, x).
### sub F21-conj(Num(Cool) $aR, Num(Cool) $aI, Num(Cool) $c, Num(Cool) $x where -1 < \* < 1 --> Num) is export(:hyperg)
### sub F21-conj-e(Num(Cool) $aR, Num(Cool) $aI, Num(Cool) $c, Num(Cool) $x where -1 < \* < 1 --> List) is export(:hyperg)
These routines compute the Gauss hypergeometric function ₂F₁(aᵣ + iaᵢ, aᵣ − iaᵢ, c, x).
### sub F21-renorm(Num(Cool) $a, Num(Cool) $b, Num(Cool) $c, Num(Cool) $x where -1 < \* < 1 --> Num) is export(:hyperg)
### sub F21-renorm-e(Num(Cool) $a, Num(Cool) $b, Num(Cool) $c, Num(Cool) $x where -1 < \* < 1 --> List) is export(:hyperg)
These routines compute the renormalized Gauss hypergeometric function ₂F₁(a, b, c, x)/Γ(c).
### sub F21-conj-renorm(Num(Cool) $aR, Num(Cool) $aI, Num(Cool) $c, Num(Cool) $x where -1 < \* < 1 --> Num) is export(:hyperg)
### sub F21-conj-renorm-e(Num(Cool) $aR, Num(Cool) $aI, Num(Cool) $c, Num(Cool) $x where -1 < \* < 1 --> List) is export(:hyperg)
These routines compute the renormalized Gauss hypergeometric function ₂F₁(aᵣ + iaᵢ, aᵣ − iaᵢ, c, x)/Γ(c).
### sub F20(Num(Cool) $a, Num(Cool) $b, Num(Cool) $x --> Num) is export(:hyperg)
### sub F20-e(Num(Cool) $a, Num(Cool) $b, Num(Cool) $x --> List) is export(:hyperg)
These routines compute the hypergeometric function ₂F₀(a, b, x).
### sub laguerre1(Num(Cool) $a, Num(Cool) $x --> Num) is export(:laguerre)
### sub laguerre1-e(Num(Cool) $a, Num(Cool) $x --> List) is export(:laguerre)
### sub laguerre2(Num(Cool) $a, Num(Cool) $x --> Num) is export(:laguerre)
### sub laguerre2-e(Num(Cool) $a, Num(Cool) $x --> List) is export(:laguerre)
### sub laguerre3(Num(Cool) $a, Num(Cool) $x --> Num) is export(:laguerre)
### sub laguerre3-e(Num(Cool) $a, Num(Cool) $x --> List) is export(:laguerre)
These routines evaluate the generalized Laguerre polynomials L₁a(x), L₂a(x), L₃a(x) using explicit representations.
### sub laguerre-n(UInt $n, Num(Cool) $a where \* > -1, Num(Cool) $x --> Num) is export(:laguerre)
### sub laguerre-n-e(UInt $n, Num(Cool) $a where \* > -1, Num(Cool) $x --> List) is export(:laguerre)
These routines evaluate the generalized Laguerre polynomials Lₙa(x).
### sub lambert-W0(Num(Cool) $x --> Num) is export(:lambert)
### sub lambert-W0-e(Num(Cool) $x --> List |
## dist_zef-FRITH-Math-Libgsl-Function.md
## Chunk 3 of 3
) is export(:lambert)
These compute the principal branch of the Lambert W function, W₀(x).
### sub lambert-Wm1(Num(Cool) $x --> Num) is export(:lambert)
### sub lambert-Wm1-e(Num(Cool) $x --> List) is export(:lambert)
These compute the principal branch of the Lambert W function, W₋₁(x).
### sub legendre-P1(Num(Cool) $x --> Num) is export(:legendre)
### sub legendre-P1-e(Num(Cool) $x --> List) is export(:legendre)
### sub legendre-P2(Num(Cool) $x --> Num) is export(:legendre)
### sub legendre-P2-e(Num(Cool) $x --> List) is export(:legendre)
### sub legendre-P3(Num(Cool) $x --> Num) is export(:legendre)
### sub legendre-P3-e(Num(Cool) $x --> List) is export(:legendre)
These functions evaluate the Legendre polynomials Pₗ(x) using explicit representations for l = 1, 2, 3.
### sub legendre-Pl(UInt $l, Num(Cool) $x where -1 ≤ \* ≤ 1 --> Num) is export(:legendre)
### sub legendre-Pl-e(UInt $l, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
These functions evaluate the Legendre polynomial Pₗ(x) for a specific value of l, x.
### sub legendre-Pl-array(UInt $lmax, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
### sub legendre-Pl-deriv-array(UInt $lmax, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
These functions compute arrays of Legendre polynomials Pₗ(x) and derivatives dPₗ(x)/dx for l = 0 … lmax.
### sub legendre-Q0(Num(Cool) $x where
### sub legendre-Q0-e(Num(Cool) $x where
These routines compute the Legendre function Q₀(x).
### sub legendre-Q1(Num(Cool) $x where
### sub legendre-Q1-e(Num(Cool) $x where
These routines compute the Legendre function Q₁(x).
### sub legendre-Ql(UInt $l, Num(Cool) $x where { $\_ > -1 && $\_ ≠ 1 } --> Num) is export(:legendre)
### sub legendre-Ql-e(UInt $l, Num(Cool) $x where { $\_ > -1 && $\_ ≠ 1 } --> List) is export(:legendre)
These routines compute the Legendre function Qₗ(x).
### sub legendre-array-index(UInt $l, UInt $n --> UInt) is export(:legendre)
This function returns the index into the result array, corresponding to Pⁿₗ(x), P’ⁿₗ, or P”ⁿₗ(x).
### sub legendre-array(Int $norm, size\_t $lmax where \* ≤ 150, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
### sub legendre-array-e(Int $norm, UInt $lmax, Num(Cool) $x where -1 ≤ \* ≤ 1, Num(Cool) $csphase where \* == 1|-1 --> List) is export(:legendre)
These functions calculate all normalized associated Legendre polynomials. The parameter norm specifies the normalization to be used.
### sub legendre-deriv-array(Int $norm, size\_t $lmax where \* ≤ 150, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
### sub legendre-deriv-array-e(Int $norm, UInt $lmax, Num(Cool) $x where -1 ≤ \* ≤ 1, Num(Cool) $csphase where \* == 1|-1 --> List) is export(:legendre)
These functions calculate all normalized associated Legendre functions and their first derivatives up to degree lmax. The parameter norm specifies the normalization to be used. They return a List of Pairs (that can be read as a Hash):
* :out array of Pⁿₗ(x) values
* :derout array of dPⁿₗ(x)/dx values
### sub legendre-deriv-alt-array(Int $norm, size\_t $lmax where \* ≤ 150, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
### sub legendre-deriv-alt-array-e(Int $norm, UInt $lmax, Num(Cool) $x where -1 ≤ \* ≤ 1, Num(Cool) $csphase where \* == 1|-1 --> List) is export(:legendre)
These functions calculate all normalized associated Legendre functions and their (alternate) first derivatives up to degree lmax. The parameter norm specifies the normalization to be used. To include or exclude the Condon-Shortley phase factor of (−1)ⁿ, set the parameter csphase to either −1 or 1 respectively. They return a List of Pairs (that can be read as a Hash):
* :out array of Pⁿₗ(x) values
* :derout array of dPⁿₗ(x)/dx values
### sub legendre-deriv2-array(Int $norm, size\_t $lmax where \* ≤ 150, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
### sub legendre-deriv2-array-e(Int $norm, UInt $lmax, Num(Cool) $x where -1 ≤ \* ≤ 1, Num(Cool) $csphase where \* == 1|-1 --> List) is export(:legendre)
These functions calculate all normalized associated Legendre functions and their first and second derivatives up to degree lmax. The parameter norm specifies the normalization to be used. They return a List of Pairs (that can be read as a Hash):
* :out array of Pⁿₗ(x) values
* :derout array of dPⁿₗ(x)/dx values
* :derout2 array of d²Pⁿₗ(x)/d²x values
### sub legendre-deriv2-alt-array(Int $norm, size\_t $lmax where \* ≤ 150, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
### sub legendre-deriv2-alt-array-e(Int $norm, UInt $lmax, Num(Cool) $x where -1 ≤ \* ≤ 1, Num(Cool) $csphase where \* == 1|-1 --> List) is export(:legendre)
These functions calculate all normalized associated Legendre functions and their (alternate) first and second derivatives up to degree lmax. The parameter norm specifies the normalization to be used. To include or exclude the Condon-Shortley phase factor of (−1)ⁿ, set the parameter csphase to either −1 or 1 respectively. They return a List of Pairs (that can be read as a Hash):
* :out array of normalized Pⁿₗ(x) values
* :derout array of dPⁿₗ(cos(θ))/dθ values
* :derout2 array of d²Pⁿₗ(cos(θ))/d²θ values
### sub legendre-Plm(UInt $l, UInt $n, Num(Cool) $x where -1 ≤ \* ≤ 1 --> Num) is export(:legendre)
### sub legendre-Plm-e(UInt $l, UInt $n, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
These routines compute the associated Legendre polynomial Pⁿₗ(x).
### sub legendre-sphPlm(UInt $l, UInt $m, Num(Cool) $x where -1 ≤ \* ≤ 1 --> Num) is export(:legendre)
### sub legendre-sphPlm-e(UInt $l, UInt $m, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
These routines compute the normalized associated Legendre polynomial.
### sub conicalP-half(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> Num) is export(:legendre)
### sub conicalP-half-e(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> List) is export(:legendre)
These routines compute the irregular Spherical Conical Function.
### sub conicalP-mhalf(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> Num) is export(:legendre)
### sub conicalP-mhalf-e(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> List) is export(:legendre)
These routines compute the regular Spherical Conical Function.
### sub conicalP0(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> Num) is export(:legendre)
### sub conicalP0-e(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> List) is export(:legendre)
These routines compute the conical function P⁰.
### sub conicalP1(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> Num) is export(:legendre)
### sub conicalP1-e(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> List) is export(:legendre)
These routines compute the conical function P¹.
### sub conicalP-sph-reg(Int $l where \* ≥ -1, Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> Num) is export(:legendre)
### sub conicalP-sph-reg-e(Int $l where \* ≥ -1, Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> List) is export(:legendre)
These routines compute the Regular Spherical Conical Function.
### sub conicalP-cyl-reg(Int $m where \* ≥ -1, Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> Num) is export(:legendre)
### sub conicalP-cyl-reg-e(Int $m where \* ≥ -1, Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> List) is export(:legendre)
These routines compute the Regular Cylindrical Conical Function.
### sub legendre-H3d0(Num(Cool) $lambda, Num(Cool) $eta where \* ≥ 0 --> Num) is export(:legendre)
### sub legendre-H3d0-e(Num(Cool) $lambda, Num(Cool) $eta where \* ≥ 0 --> List) is export(:legendre)
These routines compute the zeroth radial eigenfunction of the Laplacian on the 3-dimensional hyperbolic space.
### sub legendre-H3d1(Num(Cool) $lambda, Num(Cool) $eta where \* ≥ 0 --> Num) is export(:legendre)
### sub legendre-H3d1-e(Num(Cool) $lambda, Num(Cool) $eta where \* ≥ 0 --> List) is export(:legendre)
These routines compute the first radial eigenfunction of the Laplacian on the 3-dimensional hyperbolic space.
### sub legendre-H3d(UInt $l, Num(Cool) $lambda, Num(Cool) $eta where \* ≥ 0 --> Num) is export(:legendre)
### sub legendre-H3d-e(UInt $l, Num(Cool) $lambda, Num(Cool) $eta where \* ≥ 0 --> List) is export(:legendre)
These routines compute the l-th radial eigenfunction of the Laplacian on the 3-dimensional hyperbolic space.
### sub legendre-H3d-array(UInt $lmax, Num(Cool) $lambda, Num(Cool) $eta where \* ≥ 0 --> List) is export(:legendre)
This function computes an array of radial eigenfunctions.
### sub gsl-log(Num(Cool) $x where \* > 0 --> Num) is export(:log)
### sub gsl-log-e(Num(Cool) $x where \* > 0 --> List) is export(:log)
These routines compute the logarithm of x.
### sub gsl-log-abs(Num(Cool) $x where \* ≠ 0 --> Num) is export(:log)
### sub gsl-log-abs-e(Num(Cool) $x where \* ≠ 0 --> List) is export(:log)
These routines compute the logarithm of the magnitude of x.
### sub gsl-log-complex-e(Num(Cool) $zr, Num(Cool) $zi --> List) is export(:log)
This routine computes the complex logarithm of z = zᵣ + izᵢ. The returned parameters are the radial part, its error, θ in the range [−π, π], and its error.
### sub gsl-log1plusx(Num(Cool) $x where \* > -1 --> Num) is export(:log)
### sub gsl-log1plusx-e(Num(Cool) $x where \* > -1 --> List) is export(:log)
These routines compute log(1 + x).
### sub gsl-log1plusx-mx(Num(Cool) $x where \* > -1 --> Num) is export(:log)
### sub gsl-log1plusx-mx-e(Num(Cool) $x where \* > -1 --> List) is export(:log)
These routines compute log(1 + x) − x.
### sub mathieu-a(Int $n, Num(Cool) $q --> Num) is export(:mathieu)
### sub mathieu-a-e(Int $n, Num(Cool) $q --> List) is export(:mathieu)
### sub mathieu-b(Int $n, Num(Cool) $q --> Num) is export(:mathieu)
### sub mathieu-b-e(Int $n, Num(Cool) $q --> List) is export(:mathieu)
These routines compute the characteristic values aₙ(q), bₙ(q) of the Mathieu functions ceₙ(q, x) and seₙ(q, x), respectively.
### sub mathieu-a-array(Int $order-min, Int $order-max, Num(Cool) $q --> List) is export(:mathieu)
### sub mathieu-b-array(Int $order-min, Int $order-max, Num(Cool) $q --> List) is export(:mathieu)
These routines compute a series of Mathieu characteristic values aₙ(q), bₙ(q) for n from order\_min to order\_max inclusive.
### sub mathieu-ce(Int $n, Num(Cool) $q, Num(Cool) $x --> Num) is export(:mathieu)
### sub mathieu-ce-e(Int $n, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
### sub mathieu-se(Int $n, Num(Cool) $q, Num(Cool) $x --> Num) is export(:mathieu)
### sub mathieu-se-e(Int $n, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
These routines compute the angular Mathieu functions ceₙ(q, x) and seₙ(q, x), respectively.
### sub mathieu-ce-array(Int $order-min, Int $order-max, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
### sub mathieu-se-array(Int $order-min, Int $order-max, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
These routines compute a series of the angular Mathieu functions ceₙ(q, x) and seₙ(q, x) of order n from nmin to nmax inclusive.
### sub mathieu-Mc(Int $j where \* == 1|2, Int $n, Num(Cool) $q, Num(Cool) $x --> Num) is export(:mathieu)
### sub mathieu-Mc-e(Int $j where \* == 1|2, Int $n, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
### sub mathieu-Ms(Int $j where \* == 1|2, Int $n, Num(Cool) $q, Num(Cool) $x --> Num) is export(:mathieu)
### sub mathieu-Ms-e(Int $j where \* == 1|2, Int $n, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
These routines compute the radial j-th kind Mathieu functions Mcₙ(q, x) and Msₙ(q, x) of order n.
### sub mathieu-Mc-array(Int $j where \* == 1|2, Int $nmin, Int $nmax, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
### sub mathieu-Ms-array(Int $j where \* == 1|2, Int $nmin, Int $nmax, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
These routines compute a series of the radial Mathieu functions of kind j, with order from nmin to nmax inclusive.
### sub pow-int(Num(Cool) $x, Int $n --> Num) is export(:pow)
### sub pow-int-e(Num(Cool) $x, Int $n --> List) is export(:pow)
These routines compute the power xⁿ for integer n.
### sub psi-int(UInt $n where \* > 0 --> Num) is export(:psi)
### sub psi-int-e(UInt $n where \* > 0 --> List) is export(:psi)
These routines compute the Digamma function ψ(n) for positive integer n.
### sub psi(Num(Cool) $x where \* ≠ 0 --> Num) is export(:psi)
### sub psi-e(Num(Cool) $x where \* ≠ 0 --> List) is export(:psi)
These routines compute the Digamma function ψ(x) for general x.
### sub psi1piy(Num(Cool) $y --> Num) is export(:psi)
### sub psi1piy-e(Num(Cool) $y --> List) is export(:psi)
These routines compute the real part of the Digamma function on the line 1 + iy.
### sub psi1-int(UInt $n where \* > 0 --> Num) is export(:psi)
### sub psi1-int-e(UInt $n where \* > 0 --> List) is export(:psi)
These routines compute the Trigamma function ψ’(n) for positive integer n.
### sub psi1(Num(Cool) $x --> Num) is export(:psi)
### sub psi1-e(Num(Cool) $x --> List) is export(:psi)
These routines compute the Trigamma function ψ’(x) for general x.
### sub psin(UInt $n, Num(Cool) $x where \* > 0 --> Num) is export(:psi)
### sub psin-e(UInt $n, Num(Cool) $x where \* > 0 --> List) is export(:psi)
These routines compute the polygamma function ψ⁽ⁿ⁾(x).
### sub synchrotron1(Num(Cool) $x where \* ≥ 0 --> Num) is export(:sync)
### sub synchrotron1-e(Num(Cool) $x where \* ≥ 0 --> List) is export(:sync)
These routines compute the first synchrotron function.
### sub synchrotron2(Num(Cool) $x where \* ≥ 0 --> Num) is export(:sync)
### sub synchrotron2-e(Num(Cool) $x where \* ≥ 0 --> List) is export(:sync)
These routines compute the second synchrotron function.
### sub transport2(Num(Cool) $x where \* ≥ 0 --> Num) is export(:transport)
### sub transport2-e(Num(Cool) $x where \* ≥ 0 --> List) is export(:transport)
These routines compute the transport function J(2, x).
### sub transport3(Num(Cool) $x where \* ≥ 0 --> Num) is export(:transport)
### sub transport3-e(Num(Cool) $x where \* ≥ 0 --> List) is export(:transport)
These routines compute the transport function J(3, x).
### sub transport4(Num(Cool) $x where \* ≥ 0 --> Num) is export(:transport)
### sub transport4-e(Num(Cool) $x where \* ≥ 0 --> List) is export(:transport)
These routines compute the transport function J(4, x).
### sub transport5(Num(Cool) $x where \* ≥ 0 --> Num) is export(:transport)
### sub transport5-e(Num(Cool) $x where \* ≥ 0 --> List) is export(:transport)
These routines compute the transport function J(5, x).
### sub gsl-sin(Num(Cool) $x --> Num) is export(:trig)
### sub gsl-sin-e(Num(Cool) $x --> List) is export(:trig)
These routines compute the sine function sin(x).
### sub gsl-cos(Num(Cool) $x --> Num) is export(:trig)
### sub gsl-cos-e(Num(Cool) $x --> List) is export(:trig)
These routines compute the cosine function cos(x).
### sub gsl-hypot(Num(Cool) $x, Num(Cool) $y --> Num) is export(:trig)
### sub gsl-hypot-e(Num(Cool) $x, Num(Cool) $y --> List) is export(:trig)
These routines compute the hypotenuse function.
### sub gsl-sinc(Num(Cool) $x --> Num) is export(:trig)
### sub gsl-sinc-e(Num(Cool) $x --> List) is export(:trig)
These routines compute sinc(x) = sin(πx)/(πx).
### sub gsl-complex-sin-e(Num(Cool) $zr, Num(Cool) $zi --> List) is export(:trig)
This function computes the complex sine.
### sub gsl-complex-cos-e(Num(Cool) $zr, Num(Cool) $zi --> List) is export(:trig)
This function computes the complex cosine.
### sub gsl-complex-logsin-e(Num(Cool) $zr, Num(Cool) $zi --> List) is export(:trig)
This function computes the logarithm of the complex sine.
### sub gsl-lnsinh(Num(Cool) $x where \* > 0 --> Num) is export(:trig)
### sub gsl-lnsinh-e(Num(Cool) $x where \* > 0 --> List) is export(:trig)
These routines compute log(sinh(x)).
### sub gsl-lncosh(Num(Cool) $x --> Num) is export(:trig)
### sub gsl-lncosh-e(Num(Cool) $x --> List) is export(:trig)
These routines compute log(cosinh(x)).
### sub polar-to-rect(Num(Cool) $r, Num(Cool) $θ where -π ≤ \* ≤ π --> List) is export(:trig)
This function converts the polar coordinates (r, θ) to rectilinear coordinates (x, y).
### sub rect-to-polar(Num(Cool) $x, Num(Cool) $y --> List) is export(:trig)
This function converts the rectilinear coordinates (x, y) to polar coordinates (r, θ).
### sub angle-restrict-symm(Num(Cool) $θ --> Num) is export(:trig)
### sub angle-restrict-symm-e(Num(Cool) $θ --> Num) is export(:trig)
These routines force the angle θ to lie in the range (−π, π].
### sub angle-restrict-pos(Num(Cool) $θ --> Num) is export(:trig)
### sub angle-restrict-pos-e(Num(Cool) $θ --> Num) is export(:trig)
These routines force the angle θ to lie in the range [0, 2π).
### sub gsl-sin-err-e(Num(Cool) $x, Num(Cool) $dx --> List) is export(:trig)
This routine computes the sine of an angle x with an associated absolute error dx, sin(x ± dx).
### sub gsl-cos-err-e(Num(Cool) $x, Num(Cool) $dx --> List) is export(:trig)
This routine computes the cosine of an angle x with an associated absolute error dx, cosin(x ± dx).
### sub zeta-int(Int $n where \* ≠ 1 --> Num) is export(:zeta)
### sub zeta-int-e(Int $n where \* ≠ 1 --> List) is export(:zeta)
These routines compute the Riemann zeta function ζ(n).
### sub zeta(Num(Cool) $s where \* ≠ 1 --> Num) is export(:zeta)
### sub zeta-e(Num(Cool) $s where \* ≠ 1 --> List) is export(:zeta)
These routines compute the Riemann zeta function ζ(s) for arbitrary s.
### sub zetam1-int(Int $n where \* ≠ 1 --> Num) is export(:zeta)
### sub zetam1-int-e(Int $n where \* ≠ 1 --> List) is export(:zeta)
These routines compute ζ(n) − 1 for integer n.
### sub zetam1(Num(Cool) $s where \* ≠ 1 --> Num) is export(:zeta)
### sub zetam1-e(Num(Cool) $s where \* ≠ 1 --> List) is export(:zeta)
These routines compute ζ(s) − 1 for arbitrary s.
### sub hzeta(Num(Cool) $t where \* > 1, Num(Cool) $q where \* > 0 --> Num) is export(:zeta)
### sub hzeta-e(Num(Cool) $t where \* > 1, Num(Cool) $q where \* > 0 --> List) is export(:zeta)
These routines compute the Hurwitz zeta function ζ(t, q).
### sub eta-int(Int $n --> Num) is export(:zeta)
### sub eta-int-e(Int $n --> List) is export(:zeta)
These routines compute the eta function η(n) for integer n.
### sub eta(Num(Cool) $s --> Num) is export(:zeta)
### sub eta-e(Num(Cool) $s --> List) is export(:zeta)
These routines compute the eta function η(s) for arbitrary s.
# C Library Documentation
For more details on libgsl see <https://www.gnu.org/software/gsl/>. The excellent C Library manual is available here <https://www.gnu.org/software/gsl/doc/html/index.html>, or here <https://www.gnu.org/software/gsl/doc/latex/gsl-ref.pdf> in PDF format.
# Prerequisites
This module requires the libgsl library to be installed. Please follow the instructions below based on your platform:
## Debian Linux and Ubuntu 20.04
```
sudo apt install libgsl23 libgsl-dev libgslcblas0
```
That command will install libgslcblas0 as well, since it's used by the GSL.
## Ubuntu 18.04
libgsl23 and libgslcblas0 have a missing symbol on Ubuntu 18.04. I solved the issue installing the Debian Buster version of those three libraries:
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgslcblas0_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl23_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl-dev_2.5+dfsg-6_amd64.deb>
# Installation
To install it using zef (a module management tool):
```
$ zef install Math::Libgsl::Function
```
# AUTHOR
Fernando Santagata [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2020 Fernando Santagata
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-jonathanstowe-FastCGI-NativeCall-Async.md
# FastCGI::NativeCall::Async
An asynchronous wrapper for [FastCGI::NativeCall](https://github.com/jonathanstowe/raku-fcgi-nativecall)

## Synopsis
```
use FastCGI::NativeCall::Async;
my $fna = FastCGI::NativeCall::Async.new(path => "/tmp/fastcgi.sock", backlog => 32 );
my $count = 0;
react {
whenever $fna -> $fcgi {
say $fcgi.env;
$fcgi.Print("Content-Type: text/html\r\n\r\n{++$count}");
}
}
```
## Description
The rationale behind this module is to help
[FastCGI::NativeCall](https://github.com/jonathanstowe/raku-fcgi-nativecall)
play nicely in a larger program by managing the blocking accept loop as
a Supply that can for instance be used in a `react` block as above.
It doesn't actually allow more than one FastCGI request to be processed at
once for the same URI as the protocol itself precludes that. However it
does allow more than one FastCGI handler to be present in the same Raku
program, potentially sharing data and other resources.
## Installation
You will need a working HTTP server that can handle FastCGI to be able to
use this properly.
Assuming you have a working Rakudo installation you should be able to install this with *zef* :
```
zef install FastCGI::NativeCall::Async
# Or from a local clone
zef install .
```
## Support
This module itself is fairly simple, but does depend on both other modules and the configuration of
of your HTTP Server.
Please send any suggestions/patches etc to [github](https://github.com/jonathanstowe/FastCGI-NativeCall-Async/issues)
I'd be interested in working configurations for various HTTP servers.
## Licence & Copyright
This is free software see the <LICENCE> file in the distribution.
© 2017 - 2021 Jonathan Stowe
|
## dist_cpan-DONPDONP-BlkMeV.md
the bitcoin protocol in perl6, because why not.
##
run from source
```
$ git clone https://github.com/donpdonp/blkmev
Cloning into 'blkmev'...
remote: Counting objects: 451, done.
remote: Compressing objects: 100% (268/268), done.
remote: Total 451 (delta 240), reused 363 (delta 152), pack-reused 0
Receiving objects: 100% (451/451), 88.04 KiB | 117.00 KiB/s, done.
Resolving deltas: 100% (240/240), done.
Checking connectivity... done.
$ cd blkmev
$ zef install .
===> Testing: BlkMev
===> Testing [OK] for BlkMev
===> Installing: BlkMev
1 bin/ script [blkmev] installed to:
~/.rakudobrew/moar-2018.04.1/install/share/perl6/site/bin
```
##
`blkmev <bitcoin|bitcoincash|litecoin|dogecoin> [seed peer]`
```
$ ./bin/blkmev dogecoin
* pool new client dogecoin {:host("seed.multidoge.org")}. pool size 1
* connecting dogecoin seed.multidoge.org:22556
176.31.106.41 [dogecoin] -> VERSION 1100004 BlkMev:dogecoin block height 2150000 payload len 100
176.31.106.41 [dogecoin] command: VERSION (105 bytes)
176.31.106.41 [dogecoin] /Shibetoshi:1.10.0/ version #70004 height #2220526
176.31.106.41 [dogecoin] -> VERACK
176.31.106.41 [dogecoin] command: VERACK (0 bytes)
176.31.106.41 [dogecoin] command: PING (8 bytes)
176.31.106.41 [dogecoin] -> pong d012d0c672c01404
176.31.106.41 [dogecoin] command: GETHEADERS (1093 bytes)
176.31.106.41 [dogecoin] command: INV (37 bytes)
176.31.106.41 [dogecoin] TX 4b5f4c7b23d52ff2c7ca6a7aec7ee66923f3887d2a306b249921926ad00a3a9d mempool#1
176.31.106.41 [dogecoin] command: ADDR (30003 bytes)
176.31.106.41 [dogecoin] peers: [20:01:00:00:9d:38:6a:bd:08:5f:17:ed:23:12:a0:19] 22556 ... 1000 peer addresses
```
## roadmap
* build hashlock/timelock transactions and watch the mempool as the atomic swap process progresses.
|
## dist_zef-Scimon-Range-SetOps.md
[](https://travis-ci.org/Scimon/p6-Range-SetOps)
# NAME
Range::SetOps - Provides set operators geared to work on ranges.
# SYNOPSIS
```
use Range::SetOps;
say 10 (elem) (1.5 .. 15.2);
```
# DESCRIPTION
The standard Set operators work on Ranges by first converting them to lists and then applying the set operations to these lists. But Ranges can also represent a Range of possible values for which this type of comparison does not work well. The Range::SetOps module aims to provide operators based on the Set operators but geared to work on Ranges without list conversion.
# IMPLEMENTED OPERATORS
The following operators have been implemented for continous numerical ranges and also tested on string and date range. They also work on Sets of Ranges like those returned by the (|) or ∪ operators.
* (elem)
* ∈
* ∉
* (cont)
* ∋
* ∌
The following operators already work for continuous Ranges as expected.
* (<=)
* ⊆
* (>=)
* ⊇
* (<)
* ⊂
* (>)
* ⊃
* ⊅
* ⊄
* ⊉
* ⊈
The following Operations will return Sets comprising one or more Ranges. When the Ranges within the Set overlap they will be combined into one larger Range.
* (|)
* ∪
* (&)
* ∩
# AUTHOR
Simon Proctor [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2018 Simon Proctor
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-FRITH-Math-Libgsl-DigitalFiltering.md
[](https://github.com/frithnanth/raku-Math-Libgsl-DigitalFiltering/actions)

# NAME
Math::Libgsl::DigitalFiltering - An interface to libgsl, the Gnu Scientific Library - Digital Filtering
# SYNOPSIS
```
use Math::Libgsl::Vector;
use Math::Libgsl::DigitalFiltering;
my constant $N = 1000;
my constant $K = 21;
my Math::Libgsl::Vector $x .= new: :size($N);
$x.scanf('data.dat');
my Math::Libgsl::DigitalFiltering::Gaussian $gauss .= new: :size($K);
my $y = $gauss.filter(2.5, $x);
```
# DESCRIPTION
Math::Libgsl::DigitalFiltering is an interface to the Digital Filtering functions of libgsl, the Gnu Scientific Library.
This module exports four classes:
* Math::Libgsl::DigitalFiltering::Gaussian
* Math::Libgsl::DigitalFiltering::Median
* Math::Libgsl::DigitalFiltering::RMedian
* Math::Libgsl::DigitalFiltering::Impulse
each encapsulates the methods and the buffers needed to create and use the filter on the data stored in a Math::Libgsl::Vector object.
## Math::Libgsl::DigitalFiltering::Gaussian
This class encapsulate a Gaussian filter.
### multi method new(Int $size!)
### multi method new(Int :$size!)
The constructor accepts one simple or named argument: the kernel size.
### filter(Num() $alpha!, Math::Libgsl::Vector $x!, Int :$order = 0, Int :$endtype = GSL\_MOVSTAT\_END\_PADZERO, Bool :$inplace? --> Math::Libgsl::Vector)
This method applies a Gaussian filter parameterized by **$alpha** to the input vector **$x**. The optional named argument **:$order** specifies the derivative order, with `0` corresponding to a Gaussian, `1` corresponding to a first derivative Gaussian, and so on. The optional named argument **:$endtype** specifies how the signal end points are handled. The symbolic names for this argument are listed in the Math::Libgsl::Constants module as follows:
* **GSL\_MOVSTAT\_END\_PADZERO**: inserts zeros into the window near the signal end points
* **GSL\_MOVSTAT\_END\_PADVALUE**: pads the window with the first and last sample in the input signal
* **GSL\_MOVSTAT\_END\_TRUNCATE**: no padding is performed: the windows are truncated as the end points are approached
The boolean named argument **:$inplace** directs the method to apply the filter in-place. This method returns the filter output as a **Math::Libgsl::Vector** object.
### kernel(Num() $alpha!, Int $size, Int :$order = 0, Int :$normalize = 0 --> Math::Libgsl::Vector)
This method constructs a Gaussian kernel parameterized by **$alpha**, of size **$size**. The optional named argument **:$order** specifies the derivative order. The optional named argument **:$normalize** specifies if the kernel is to be normalized to sum to one on output. This method returns the filter output as a **Math::Libgsl::Vector** object.
## Math::Libgsl::DigitalFiltering::Median
This class encapsulate a Median filter.
### multi method new(Int $size!)
### multi method new(Int :$size!)
The constructor accepts one simple or named argument: the kernel size.
### filter(Math::Libgsl::Vector $x!, Int :$endtype = GSL\_MOVSTAT\_END\_PADZERO, Bool :$inplace? --> Math::Libgsl::Vector)
This method applies a Median filter to the input vector **$x**. The optional named argument **:$endtype** specifies how the signal end points are handled. The optional boolean named argument **:$inplace** directs the method to apply the filter in-place. This method returns the filter output as a **Math::Libgsl::Vector** object.
## Math::Libgsl::DigitalFiltering::RMedian
This class encapsulate a recursive Median filter.
### multi method new(Int $size!)
### multi method new(Int :$size!)
The constructor accepts one simple or named argument: the kernel size.
### filter(Math::Libgsl::Vector $x!, Int :$endtype = GSL\_MOVSTAT\_END\_PADZERO, Bool :$inplace? --> Math::Libgsl::Vector)
This method applies a Median filter to the input vector **$x**. The optional named argument **:$endtype** specifies how the signal end points are handled. The optional boolean named argument **:$inplace** directs the method to apply the filter in-place. This method returns the filter output as a **Math::Libgsl::Vector** object.
## Math::Libgsl::DigitalFiltering::Impulse
This class encapsulate an Impulse detection filter.
### multi method new(Int $size!)
### multi method new(Int :$size!)
The constructor accepts one simple or named argument: the kernel size.
### filter(Math::Libgsl::Vector $x!, Num() $tuning, Int :$endtype = GSL\_MOVSTAT\_END\_PADZERO, Int :$scaletype = GSL\_FILTER\_SCALE\_MAD, Bool :$inplace? --> List)
This method applies an Impulse filter to the input vector **$x**, using the tuning parameter **$tuning**. The optional named argument **:$endtype** specifies how the signal end points are handled. The optional named argument **:$scaletype** specifies how the scale estimate Sₙ of the window is calculated. The symbolic names for this argument are listed in the Math::Libgsl::Constants module as follows:
* **GSL\_FILTER\_SCALE\_MAD**: specifies the median absolute deviation (MAD) scale estimate
* **GSL\_FILTER\_SCALE\_IQR**: specifies the interquartile range (IQR) scale estimate
* **GSL\_FILTER\_SCALE\_SN**: specifies the so-called Sₙ statistic
* **GSL\_FILTER\_SCALE\_QN**: specifies the so-called Qₙ statistic
The optional boolean named argument **:$inplace** directs the method to apply the filter in-place. This method returns a List of values:
* the window medians, as a **Math::Libgsl::Vector** object
* the window Sₙ, as a **Math::Libgsl::Vector** object
* the number of outliers as an Int
* the location of the outliers as a **Math::Libgsl::Vector::Int32** object
# C Library Documentation
For more details on libgsl see <https://www.gnu.org/software/gsl/>. The excellent C Library manual is available here <https://www.gnu.org/software/gsl/doc/html/index.html>, or here <https://www.gnu.org/software/gsl/doc/latex/gsl-ref.pdf> in PDF format.
# Prerequisites
This module requires the libgsl library to be installed. Please follow the instructions below based on your platform:
## Debian Linux and Ubuntu 20.04+
```
sudo apt install libgsl23 libgsl-dev libgslcblas0
```
That command will install libgslcblas0 as well, since it's used by the GSL.
## Ubuntu 18.04
libgsl23 and libgslcblas0 have a missing symbol on Ubuntu 18.04. I solved the issue installing the Debian Buster version of those three libraries:
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgslcblas0_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl23_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl-dev_2.5+dfsg-6_amd64.deb>
# Installation
To install it using zef (a module management tool):
```
$ zef install Math::Libgsl::DigitalFiltering
```
# AUTHOR
Fernando Santagata [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2020 Fernando Santagata
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-gfldex-Rakudo-Slippy-Semilist.md
# Rakudo::Slippy::Semilist
[](https://travis-ci.org/gfldex/perl6-rakudo-slippy-semilists)
Implements `postcircumfix:<{|| }>` to allow coercion of Array to semilist.
Implements `postcircumfix:<{; }>:exists` and `postcircumfix:<{|| }>`.
see: <http://design.perl6.org/S09.html#line_419>
# Usage:
```
use Rakudo::Slippy::Semilist;
my @a = 1,2,3;
my %h;
%h{||@a} = 42;
dd %h;
# OUTPUT«Hash %h = {"1" => ${"2" => ${"3" => 1}}}»
dd %h{1;2;3}:exists;
# OUTPUT«Bool::True»
```
|
## dist_cpan-DMAESTRO-Module-Pod.md
# NAME
Module::Pod
# SYNOPSIS
```
use Module::Loader;
use Module::Pod;
my $l = Module::Loader.new(module => <Seq::Bounded>);
say describe-compunit($l.compunit);
say Module::Pod.new(:loader($l)).pod
use Module::Pod;
my $pod1 = pod-from-module(Module::Loader);
```
# ATTRIBUTES
* `loader` - An object of type Module::Loader, specifying the external module
# METHODS
### method pod
```
method pod() returns Mu
```
Return the $=pod from the module, precompiling if necessary
# EXPORTS
### sub pod-from-module
```
sub pod-from-module(
$module where { ... }
) returns Mu
```
Get the $=pod from the named module
# LICENSE
This file is licensed under the same terms as perl itself.
# AUTHOR
Doug Schrag [[email protected]](mailto:[email protected])
|
## dist_zef-antononcube-DSL-English-RecommenderWorkflows.md
# Recommenders Workflows
## In brief
This Raku (Perl 6) package has grammar classes and action classes for the parsing and
interpretation of natural Domain Specific Language (DSL) commands that specify recommendations workflows.
The interpreters (actions) target different programming languages: R, Mathematica, Python, Raku.
Also, different natural languages.
The generated pipelines are for the software monads
["SMRMon-R"](https://github.com/antononcube/R-packages/tree/master/SMRMon-R) and
["SMRMon-WL"](https://github.com/antononcube/MathematicaForPrediction/blob/master/MonadicProgramming/MonadicLatentSemanticAnalysis.m)
implemented in R and WL respectively, [AAp2, AAp3], and the object oriented Python and Raku implementations [AAp4, AAp5].
**Remark:** "SMR" stands for "Sparse Matrix Recommender". "SBR" stands for "Streams Blending Recommender".
**Remark:** "WL" stands for "Wolfram Language". "Mathematica" and "WL" are used as synonyms.
---
## Installation
Zef ecosystem:
```
zef install DSL::English::RecommenderWorkflows
```
GitHub:
```
zef install https://github.com/antononcube/Raku-DSL-English-RecommenderWorkflows.git
```
---
## Examples
### Programming languages
Here is a simple invocation:
```
use DSL::English::RecommenderWorkflows;
ToRecommenderWorkflowCode('recommend by profile action->10, drama->7', 'R::SMRMon');
```
```
# SMRMonRecommendByProfile( profile = c("action"=10, "drama"=7))
```
Here is a more complicated pipeline specification used to generate the code
for recommender systems implemented in different languages:
```
my $command = q:to/END/;
create from dfTitanic;
apply the LSI functions inverse document frequency, term frequency, and cosine;
recommend by profile female->3, 30->0.1;
extend recommendations with dfTitanic;
show pipeline value
END
say $_.key, "\n", $_.value, "\n" for ($_ => ToRecommenderWorkflowCode($command, $_ ) for <R::SMRMon WL::SMRMon Python::SMRMon Raku>);
```
```
# R::SMRMon
# SMRMonCreate(data = dfTitanic) %>%
# SMRMonApplyTermWeightFunctions(globalWeightFunction = "IDF", localWeightFunction = "TermFrequency", normalizerFunction = "Cosine") %>%
# SMRMonRecommendByProfile( profile = c("female"=3, "30"=0.1)) %>%
# SMRMonJoinAcross( data = dfTitanic ) %>%
# SMRMonEchoValue()
#
# WL::SMRMon
# SMRMonUnit[] \[DoubleLongRightArrow] SMRMonCreate[dfTitanic] \[DoubleLongRightArrow]
# SMRMonApplyTermWeightFunctions["GlobalWeightFunction" -> "IDF", "LocalWeightFunction" -> "TermFrequency", "NormalizerFunction" -> "Cosine"] \[DoubleLongRightArrow]
# SMRMonRecommendByProfile[<|"female"->3, "30"->0.1|>] \[DoubleLongRightArrow]
# SMRMonJoinAcross[dfTitanic] \[DoubleLongRightArrow]
# SMRMonEchoValue[]
#
# Python::SMRMon
# obj = SparseMatrixRecommender().create_from_wide_form(data = dfTitanic).apply_term_weight_functions(global_weight_func = "IDF", local_weight_func = "TermFrequency", normalizer_func = "Cosine").recommend_by_profile( profile = {"female":3, "30":0.1}).join_across( data = dfTitanic ).echo_value()
#
# Raku
# my $sbrObj = ML::StreamsBlendingRecommender::CoreSBR.new;
# $sbrObj.makeTagInverseIndexesFromWideForm( dfTitanic);
# $sbrObj.applyTermWeightFunctions(globalWeightFunction => "IDF", localWeightFunction = "TermFrequency", normalizerFunction => "Cosine");
# $sbrObj.recommendByProfile( profile => %("female"=>3, "30"=>0.1));
# $sbrObj.joinAcross( dfTitanic );
# say $sbrObj.takeValue
```
### Natural languages
```
say $_.key, "\n", $_.value, "\n" for ($_ => ToRecommenderWorkflowCode($command, $_ ) for <Bulgarian English Russian>);
```
```
# Bulgarian
# създай с таблицата: dfTitanic
# приложи тегловите функции: глобално-теглова функция: "IDF", локално-теглова функция: "TermFrequency", нормализираща функция: "Cosine"
# препоръчай с профила: {"female":3, "30":0.1}
# напречно съединение с таблицата: dfTitanic
# покажи лентовата стойност
#
# English
# create with data table: dfTitanic
# apply the term weight functions: global weight function: "IDF", local weight function: "TermFrequency", normalizing function: "Cosine"
# recommend with the profile: {"female":3, "30":0.1}
# join across with the data table: dfTitanic
# show the pipeline value
#
# Russian
# создать с таблицу: dfTitanic
# применять весовые функции: глобальная весовая функция: "IDF", локальная весовая функция: "TermFrequency", нормализующая функция: "Cosine"
# рекомендуй с профилю: {"female":3, "30":0.1}
# перекрестное соединение с таблицу: dfTitanic
# показать текущее значение конвейера
```
---
## CLI
The package provides a Command Line Interface (CLI) script. Here is its usage message:
```
ToRecommenderWorkflowCode --help
```
```
# Translates natural language commands into recommender workflow programming code.
# Usage:
# ToRecommenderWorkflowCode <command> [--target=<Str>] [--language=<Str>] [--format=<Str>] [-c|--clipboard-command=<Str>] -- Translates natural language commands into (machine learning) recommender workflow programming code.
# ToRecommenderWorkflowCode <target> <command> [--language=<Str>] [--format=<Str>] [-c|--clipboard-command=<Str>] -- Both target and command as arguments.
# ToRecommenderWorkflowCode [<words> ...] [-t|--target=<Str>] [-l|--language=<Str>] [-f|--format=<Str>] [-c|--clipboard-command=<Str>] -- Command given as a sequence of words.
#
# <command> A string with one or many commands (separated by ';').
# --target=<Str> Target (programming language with optional library spec.) [default: 'WL::SMRMon']
# --language=<Str> The natural language to translate from. [default: 'English']
# --format=<Str> The format of the output, one of 'automatic', 'code', 'hash', or 'raku'. [default: 'automatic']
# -c|--clipboard-command=<Str> Clipboard command to use. [default: 'Whatever']
# <target> Programming language.
# [<words> ...] Words of a data query.
# -t|--target=<Str> Target (programming language with optional library spec.) [default: 'WL::SMRMon']
# -l|--language=<Str> The natural language to translate from. [default: 'English']
# -f|--format=<Str> The format of the output, one of 'automatic', 'code', 'hash', or 'raku'. [default: 'automatic']
# Details:
# If --clipboard-command is the empty string then no copying to the clipboard is done.
# If --clipboard-command is 'Whatever' then:
# 1. It is attempted to use the environment variable CLIPBOARD_COPY_COMMAND.
# If CLIPBOARD_COPY_COMMAND is defined and it is the empty string then no copying to the clipboard is done.
# 2. If the variable CLIPBOARD_COPY_COMMAND is not defined then:
# - 'pbcopy' is used on macOS
# - 'clip.exe' on Windows
# - 'xclip -sel clip' on Linux.
```
---
## Versions
The original version of this Raku package was developed/hosted at
[ [AAp3](https://github.com/antononcube/ConversationalAgents/tree/master/Packages/Perl6/RecommenderWorkflows) ].
A dedicated GitHub repository was made in order to make the installation with Raku's `zef` more direct.
(As shown above.)
---
## References
[AAp1] Anton Antonov,
[Recommender Workflows Raku Package](https://github.com/antononcube/ConversationalAgents/tree/master/Packages/Perl6/RecommenderWorkflows),
(2019),
[ConversationalAgents at GitHub](https://github.com/antononcube/ConversationalAgents).
[AAp2] Anton Antonov,
[Sparse Matrix Recommender Monad in R](https://github.com/antononcube/R-packages/tree/master/SMRMon-R),
(2019),
[R-packages at GitHub](https://github.com/antononcube/R-packages).
[AAp3] Anton Antonov,
[Monadic Sparse Matrix Recommender Mathematica package](https://github.com/antononcube/MathematicaForPrediction/blob/master/MonadicProgramming/MonadicSparseMatrixRecommender.m),
(2018),
[MathematicaForPrediction at GitHub](https://github.com/antononcube/MathematicaForPrediction).
[AAp4] Anton Antonov,
[SparseMatrixRecommender Python package](https://github.com/antononcube/Python-packages/tree/main/SparseMatrixRecommender),
(2021),
[Python-packages at GitHub](https://github.com/antononcube/Python-packages).
[AAp5] Anton Antonov,
[ML::StreamsBlendingRecommender Raku package](https://github.com/antononcube/Raku-ML-StreamsBlendingRecommender)
(2021),
[GitHub/antononcube](https://github.com/antononcube).
|
## dist_zef-titsuki-Algorithm-Treap.md
[](https://github.com/titsuki/raku-Algorithm-Treap/actions)
# NAME
Algorithm::Treap - randomized search tree
# SYNOPSIS
```
use Algorithm::Treap;
# store Int key
my $treap = Algorithm::Treap[Int].new;
$treap.insert(0, 0);
$treap.insert(1, 10);
$treap.insert(2, 20);
$treap.insert(3, 30);
$treap.insert(4, 40);
my $value = $treap.find-value(3); # 30
my $first-key = $treap.find-first-key(); # 0
my $last-key = $treap.find-last-key(); # 4
# delete
$treap.delete(4);
# store Str key
my $treap = Algorithm::Treap[Str].new;
$treap.insert('a', 0);
$treap.insert('b', 10);
$treap.insert('c', 20);
$treap.insert('d', 30);
$treap.insert('e', 40);
my $value = $treap.find-value('a'); # 0
my $first-key = $treap.find-first-key(); # 'a'
my $last-key = $treap.find-last-key(); # 'e'
# delete
$treap.delete('c');
```
# DESCRIPTION
Algorithm::Treap is a implementation of the Treap algorithm. Treap is the one of the self-balancing binary search tree. It employs a randomized strategy for maintaining balance.
## CONSTRUCTOR
### new
```
my $treap = Algorithm::Treap[::KeyT].new(%options);
```
Sets either one of the type objects(Int or Str) for `::KeyT` and some `%options`, where `::KeyT` is a type of insertion items to the treap.
#### OPTIONS
* `order-by => TOrder::ASC|TOrder::DESC`
Sets key order `TOrder::ASC` or `TOrder::DESC` in the treap. Default is `TOrder::ASC`.
## METHODS
### insert
```
$treap.insert($key, $value);
```
Inserts the key-value pair to the treap. If the treap already has the same key, it overwrites existing one.
### delete
```
$treap.delete($key);
```
Deletes the node associated with the key from the treap.
### find-value
```
my $value = $treap.find-value($key);
```
Returns the value associated with the key in the treap. When it doesn't hit any keys, it returns type object Any.
### find
```
my $node = $treap.find($key);
```
Returns the instance of the Algorithm::Treap::Node associated with the key in the treap. When it doesn't hit any keys, it returns type object Any.
### find-first-key
```
my $first-key = $treap.find-first-key();
```
Returns the first key in the treap.
### find-last-key
```
my $last-key = $treap.find-last-key();
```
Returns the last key in the treap.
# METHODS NOT YET IMPLEMENTED
join, split, finger-search, sort
# AUTHOR
titsuki [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2016 titsuki
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
The algorithm is from Seidel, Raimund, and Cecilia R. Aragon. "Randomized search trees." Algorithmica 16.4-5 (1996): 464-497.
|
## dist_cpan-JFORGET-Date-Calendar-CopticEthiopic.md
# NAME
Date::Calendar::CopticEthiopic - conversions from / to the Coptic calendar and from / to the Ethiopic calendar
# SYNOPSIS
Converting a Gregorian date to both Coptic and Ethiopic
```
use Date::Calendar::Coptic;
use Date::Calendar::Ethiopic;
my Date $Perlcon-Riga-grg;
my Date::Calendar::Coptic $Perlcon-Riga-cop;
my Date::Calendar::Ethiopic $Perlcon-Riga-eth;
$Perlcon-Riga-grg .= new(2019, 8, 7);
$Perlcon-Riga-cop .= new-from-date($Perlcon-Riga-grg);
$Perlcon-Riga-eth .= new-from-date($Perlcon-Riga-grg);
say $Perlcon-Riga-cop.strftime("%A %e %B %Y");
#--> Peftoou 1 Mesori 1735
say $Perlcon-Riga-eth.strftime("%A %e %B %Y");
#--> Rob 1 Nahas 2011
```
Converting a Coptic date and an Ethiopic date to Gregorian
```
use Date::Calendar::Coptic;
use Date::Calendar::Ethiopic;
my Date::Calendar::Coptic $TPC-Pittsburgh-cop;
my Date::Calendar::Ethiopic $TPC-Pittsburgh-eth;
my Date $TPC-Pittsburgh-grg1;
my Date $TPC-Pittsburgh-grg2;
$TPC-Pittsburgh-cop .= new(year => 1735, month => 10, day => 9);
$TPC-Pittsburgh-grg1 = $TPC-Pittsburgh-cop.to-date;
#--> 9 Paoni 1735 = 16 June 2019
$TPC-Pittsburgh-eth .= new(year => 2011, month => 10, day => 14);
$TPC-Pittsburgh-grg2 = $TPC-Pittsburgh-eth.to-date;
#--> 14 Sane 2011 = 21 June 2019
```
# INSTALLATION
```
zef install Date::Calendar::CopticEthiopic
```
or
```
git clone https://github.com/jforget/raku-Date-Calendar-CopticEthiopic.git
cd Date-Calendar-CopticEthiopic
zef install .
```
# DESCRIPTION
Date::Calendar::CopticEthiopic is a module distribution providing two
classes, Date::Calendar::Coptic and Date::Calendar::Ethiopic. The
corresponding calendars both derive from the ancient Egyptian
calendar. In each, a year consists of 12 months with 30 days each,
plus 5 or 6 additional days (epagomene) at the end of the year. Leap
years occurs every fourth year, with no adjustment for century years.
The calendars also define weeks which last for 7 days, beginning on
sunday and ending on saturday.
# AUTHOR
Jean Forget [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright © 2019, 2020 Jean Forget
This library is free software; you can redistribute it and/or modify
it under the Artistic License 2.0.
|
## dist_cpan-TYIL-Matrix-Bot-Plugin-AutoAcceptInvites.md
# NAME
Matrix::Bot::Plugin::AutoAcceptInvites
# AUTHOR
Patrick Spek [[email protected]](mailto:[email protected])
# VERSION
0.0.0
# Description
A plugin for Matrix::Bot to automatically accept all room invites
# Installation
Install this module through [zef](https://github.com/ugexe/zef):
```
zef install Matrix::Bot::Plugin::AutoAcceptInvites
```
# Usage
To use this plugin in your Matrix bot, include it in the `plugins` list.
```
use Matrix::Bot;
use Matrix::Bot::Plugin::AutoAcceptInvites;
Matrix::Bot.new(
home-server => $*ENV<MATRIX_HOMESERVER> // "https://matrix.org",
username => %*ENV<USER>,
password => %*ENV<MATRIX_PASSWORD>,
plugins => [
Matrix::Bot::Plugin::AutoAcceptInvites.new,
],
);
```
# License
This module is distributed under the terms of the AGPL-3.0.
|
## iterator.md
iterator
Combined from primary sources listed below.
# [In role Iterable](#___top "go to top of document")[§](#(role_Iterable)_method_iterator "direct link")
See primary documentation
[in context](/type/Iterable#method_iterator)
for **method iterator**.
```raku
method iterator(--> Iterator:D)
```
Method stub that ensures all classes doing the `Iterable` role have a method `iterator`.
It is supposed to return an [`Iterator`](/type/Iterator).
```raku
say (1..10).iterator;
```
# [In Seq](#___top "go to top of document")[§](#(Seq)_method_iterator "direct link")
See primary documentation
[in context](/type/Seq#method_iterator)
for **method iterator**.
```raku
method iterator(Seq:D:)
```
If the `Seq` is not cached, returns the underlying iterator and marks the invocant as consumed. If called on an already consumed sequence, throws an error of type [`X::Seq::Consumed`](/type/X/Seq/Consumed).
Otherwise returns an iterator over the cached list.
# [In Any](#___top "go to top of document")[§](#(Any)_method_iterator "direct link")
See primary documentation
[in context](/type/Any#method_iterator)
for **method iterator**.
```raku
multi method iterator(Any:)
```
Returns the object as an iterator after converting it to a list. This is the function called from the `for` statement.
```raku
.say for 3; # OUTPUT: «3»
```
Most subclasses redefine this method for optimization, so it's mostly types that do not actually iterate the ones that actually use this implementation.
# [In Mu](#___top "go to top of document")[§](#(Mu)_method_iterator "direct link")
See primary documentation
[in context](/type/Mu#method_iterator)
for **method iterator**.
```raku
method iterator(--> Iterator)
```
Coerces the invocant to a `list` by applying its [`.list`](/routine/list) method and uses [`iterator`](/type/Iterable#method_iterator) on it.
```raku
my $it = Mu.iterator;
say $it.pull-one; # OUTPUT: «(Mu)»
say $it.pull-one; # OUTPUT: «IterationEnd»
```
# [In role PositionalBindFailover](#___top "go to top of document")[§](#(role_PositionalBindFailover)_method_iterator "direct link")
See primary documentation
[in context](/type/PositionalBindFailover#method_iterator)
for **method iterator**.
```raku
method iterator(PositionalBindFailover:D:) { ... }
```
This method stub ensure that a class implementing role `PositionalBindFailover` provides an `iterator` method.
# [In HyperSeq](#___top "go to top of document")[§](#(HyperSeq)_method_iterator "direct link")
See primary documentation
[in context](/type/HyperSeq#method_iterator)
for **method iterator**.
```raku
method iterator(HyperSeq:D: --> Iterator:D)
```
Returns the underlying iterator.
# [In Junction](#___top "go to top of document")[§](#(Junction)_method_iterator "direct link")
See primary documentation
[in context](/type/Junction#method_iterator)
for **method iterator**.
```raku
multi method iterator(Junction:D:)
```
Returns an iterator over the `Junction` converted to a [`List`](/type/List).
# [In RaceSeq](#___top "go to top of document")[§](#(RaceSeq)_method_iterator "direct link")
See primary documentation
[in context](/type/RaceSeq#method_iterator)
for **method iterator**.
```raku
method iterator(RaceSeq:D: --> Iterator:D)
```
Returns the underlying iterator.
|
## dist_zef-CIAvash-Sway-Config.md
# NAME
Sway::Config - A [Raku](https://www.raku-lang.ir/en) library and script for parsing [Sway](https://swaywm.org/) window manager's config.
# DESCRIPTION
Sway::Config is a module and program for parsing [Sway](https://swaywm.org/) window manager's config, and getting the raw `Match`, configs, variables, modes and key bindings, either as Raku data structures or as JSON.
# INSTALLATION
You need to have [Raku](https://www.raku-lang.ir/en) and [zef](https://github.com/ugexe/zef), then run:
```
zef install --/test "Sway::Config:auth<zef:CIAvash>"
```
or if you have cloned the repo:
```
zef install .
```
# TESTING
```
prove -ve 'raku -I.' --ext rakutest
```
# CLI
## SYNOPSIS
```
sway-config - Parses Sway config and prints the specified section
By default gets the config from sway, unless config or config path is provided via stdin or command option.
Then parses the config and prints the requested output as JSON.
Usage:
bin/sway-config -v|--version -- Prints version
bin/sway-config all [-i|--stdin] [-c|--config-path=<Str>] -- Prints configs, variables, modes and key_bindings as JSON
bin/sway-config configs [-i|--stdin] [-c|--config-path=<Str>] -- Prints configs as JSON
bin/sway-config match [-i|--stdin] [-c|--config-path=<Str>] -- Prints raw match as JSON
bin/sway-config variable [-i|--stdin] [-c|--config-path=<Str>] -- Prints variables as JSON
bin/sway-config mode [-i|--stdin] [-c|--config-path=<Str>] -- Prints modes as JSON
bin/sway-config key_binding [-i|--stdin] [-c|--config-path=<Str>] -- Prints key bindings as JSON (Object/Hash)
bin/sway-config key_bindings [-i|--stdin] [-c|--config-path=<Str>] -- Prints key bindings as JSON (Array)
```
## COPYRIGHT
Copyright © 2021 Siavash Askari Nasr
## LICENSE
sway-config is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
sway-config is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with sway-config. If not, see <http://www.gnu.org/licenses/>.
# LIBRARY
## SYNOPSIS
```
use Sway::Config:auth<zef:CIAvash>;
# By default Sway::Config gets the config from Sway
my $config = Sway::Config.new;
# Giving the config content to Sway::Config
my $config2 = Sway::Config.new: :config('Your Config Here');
# Giving path of a config file to Sway::Config
my $config3 = Sway::Config.new: :config_path<Path to config file>;
put $config.match;
put $config.mode<resize>;
put $config.configs: :json;
```
## ATTRIBUTES
### has Str $.config
Content of the config to parse
### has IO() $.config\_path
Path to the config file
## METHODS
### multi method match
```
multi method match() returns Match
```
Returns the raw match object
### multi method match
```
multi method match(
Bool:D :json($)
) returns Str
```
Returns the raw `Match` object as JSON
### multi method configs
```
multi method configs() returns Array
```
Returns the parsed confis as an `Array`
### multi method configs
```
multi method configs(
Bool:D :json($)
) returns Str
```
Returns the parsed confis as JSON
### multi method variable
```
multi method variable() returns Hash
```
Returns the parsed variables as a `Hash`
### multi method variable
```
multi method variable(
Bool:D :json($)
) returns Str
```
Returns the parsed variables as JSON
### multi method mode
```
multi method mode() returns Hash
```
Returns the parsed modes as a `Hash`
### multi method mode
```
multi method mode(
Bool:D :json($)
) returns Str
```
Returns the parsed modes as JSON
### multi method key\_binding
```
multi method key_binding() returns Hash
```
Returns the parsed key bindings as a `Hash`
### multi method key\_binding
```
multi method key_binding(
Bool:D :json($)
) returns Str
```
Returns the parsed key bindings as JSON (Object/Hash)
### multi method key\_bindings
```
multi method key_bindings() returns List
```
Returns the parsed key bindings as a `List`
### multi method key\_bindings
```
multi method key_bindings(
Bool:D :json($)
) returns Str
```
Returns the parsed key bindings as JSON (Array)
### multi method all
```
multi method all() returns Hash
```
Returns the parsed configs, variables, modes and key bindings as a `Hash`
### multi method all
```
multi method all(
Bool:D :json($)
) returns Str
```
Returns the parsed configs, variables, modes and key bindings as JSON
## COPYRIGHT
Copyright © 2021 Siavash Askari Nasr
## LICENSE
Sway::Config is free software: you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
Sway::Config is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public License along with Sway::Config. If not, see <http://www.gnu.org/licenses/>.
# REPOSITORY
<https://codeberg.org/CIAvash/Sway-Config/>
# BUG
<https://codeberg.org/CIAvash/Sway-Config/issues>
# AUTHOR
Siavash Askari Nasr - <https://siavash.askari-nasr.com>
|
## nativecast.md
nativecast
Combined from primary sources listed below.
# [In Native calling interface](#___top "go to top of document")[§](#(Native_calling_interface)_sub_nativecast "direct link")
See primary documentation
[in context](/language/nativecall#sub_nativecast)
for **sub nativecast**.
```raku
sub nativecast($target-type, $source) is export(:DEFAULT)
```
This will *cast* the `Pointer` `$source` to an object of `$target-type`. The source pointer will typically have been obtained from a call to a native subroutine that returns a pointer or as a member of a `struct`, this may be specified as `void *` in the `C` library definition for instance, but you may also cast from a pointer to a less specific type to a more specific one.
As a special case, if a [`Signature`](/type/Signature) is supplied as `$target-type` then a `subroutine` will be returned which will call the native function pointed to by `$source` in the same way as a subroutine declared with the `native` trait. This is described in [Function Pointers](/language/nativecall#Function_pointers).
|
## dist_zef-raku-community-modules-Locale-US.md
[](https://github.com/raku-community-modules/Locale-US/actions)
# NAME
Locale::US - Two letter codes for identifying United States territories and vice versa
# SYNOPSIS
```
use Locale::US;
say state-to-code("California"); # CA
say code-to-state("CA"); # CALIFORNIA
.say for all-state-names; # ALABAMA, ALASKA...
.say for all-state-codes; # AK, AL, ...
```
# DESCRIPTION
A Raku module for mapping two character state abbreviations for United States territories to their state name and vice versa. This module was very much inspired by the Perl module of the same name.
# EXPORTED SUBROUTINES
## state-to-code
Map a state name to a two-letter code.
## code-to-state
Map a two-letter code to a state name (all uppercase).
## all-state-names
Returns a `List` of all state names in alphabetical order.
## all-state-codes
Returns a `List` of all state codes in alphabetical order.
# AUTHOR
Jonathan Scott Duff
# COPYRIGHT AND LICENSE
Copyright 2012 - 2017 Jonathan Scott Duff
Copyright 2018 - 2022 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## statement-prefixes.md
Statement prefixes
Prefixes that alter the behavior of a statement or a set of them
Statement prefixes are written in front of a statement, and change their meaning, their output, or the moment they are going to be run. Since they have a specific behavior, they are also sometimes specific to some statement or group of statements.
## [`lazy`](#Statement_prefixes "go to top of document")[§](#lazy "direct link")
As a statement prefix, `lazy` acts in front of any statement, including `for` loops, saving the execution for when the variable they are assigned to is actually needed.
```raku
my $incremented = 0;
my $var = lazy for <1 2 3 4> -> $d {
$incremented++
};
say $incremented; # OUTPUT: «0»
say eager $var; # OUTPUT: «(0 1 2 3)»
say $incremented; # OUTPUT: «4»
```
The `$incremented` variable is only incremented, that is, the internal part of the loop is only run when we eagerly evaluate the variable `$var` that contains the lazy loop. Eagerness can be applied on a variable in other ways, such as calling the `.eager` method on it.
```raku
my @array = lazy { (^3).map( *² ) };
say @array; # OUTPUT: «[...]»
say @array.eager; # OUTPUT: «[0 1 4]»
```
This prefix can also be used [in front of `gather`](/language/control#gather/take) to make the inner statements behave lazily; in general, any set of statements that returns a value will be made lazy using this.
## [`eager`](#Statement_prefixes "go to top of document")[§](#eager "direct link")
The `eager` statement prefix will eagerly return the result of the statements behind, throwing away laziness and returning the result.
```raku
my $result := eager gather { for 1..3 { say "Hey"; take $_² } };
say $result[0]; # OUTPUT: «HeyHeyHey1»
```
`gather` is [implicitly lazy when bound to a scalar](/syntax/gather%20take). However, with `eager` as a statement prefix it will run all three iterations in the loop, as shown by the printed "Hey", even if we are just requesting the first one in a row.
## [`hyper`](#Statement_prefixes "go to top of document")[§](#hyper,_race "direct link")
A `for` loop will automatically serialize any [`HyperSeq`](/type/HyperSeq) or [`RaceSeq`](/type/RaceSeq) used in it; on the other hand `hyper` and `race` use (maybe simultaneous) threads to run different iterations in a loop:
```raku
my @a = hyper for ^100_000 { .is-prime }
```
This code is around 3x faster than the bare `for`. But there are a couple of caveats here:
* The operation inside the loop should take enough time for threading to make sense.
* There should be no read or write access to the same data structure inside the loop. Let the loop produce a result, and assign it.
* If there's an I/O operation inside the loop, there might be some contention so please avoid it.
Main difference between `hyper` and `race` is the ordering of results. Use `hyper` if you need the loop results to be produced in order, `race` if you don't care.
## [`quietly`](#Statement_prefixes "go to top of document")[§](#quietly "direct link")
As a prefix, `quietly` suppresses all runtime warnings produced by the block or statement it precedes.
```raku
sub marine() {};
quietly say ~&marine; # OUTPUT: «marine»
sub told-you { warn 'hey...' };
quietly { told-you; warn 'kaput!' };
warn 'Telling you now!'; # OUTPUT: «Telling you now! [...] »
```
Calling [`.Str` on `code` produces a warning](/type/Code#method_Str). Preceding the code with `quietly` will just produce the output without warning.
## [`try`](#Statement_prefixes "go to top of document")[§](#try "direct link")
If you use `try` in front of a statement, it will contain the exception produced in it and store it in the `$!` variable, just like when [it's used in front of a block](/language/exceptions#try_blocks).
```raku
try [].pop;
say $!; # OUTPUT: «Cannot pop from an empty Array..»
```
## [`do`](#Statement_prefixes "go to top of document")[§](#do "direct link")
`do` can be used as a statement prefix to disambiguate the statement they precede; this is needed, for instance, if you want to assign the result of a `for` statement. A bare `for` will fail, but this will work:
```raku
my $counter = 0;
my $result = do for ^5 { $counter++ };
say $counter; # OUTPUT: «5»
say $result; # OUTPUT: «(0 1 2 3 4)»
```
`do` is equivalent, as in other cases, to surrounding a statement with a parenthesis. It can be used as an alternative with a (possibly more) straightforward syntax.
## [`sink`](#Statement_prefixes "go to top of document")[§](#sink "direct link")
As in the [case of the routine](/routine/sink), `sink` will run the statement, throwing away the result. Use it in case you want to run some statement for the side effects it produces.
```raku
my $counter = 0;
my $result = sink for ^5 { $counter++ };
say $counter; # OUTPUT: «5»
say $result; # OUTPUT: «(Any)»
```
The `sink` statement prefix will also convert [`Failure`](/type/Failure)s into exceptions:
```raku
sub find-the-number ( Int $n where $n < 10 ) {
if $n == 7 {
return True;
} else {
fail "Not that number" ;
}
}
for 1..^10 {
try {
sink find-the-number($_);
};
say "Found $_" unless $!;
}
```
In this case, we will know that the number has been found only when the `try` block is not catching an exception.
## [`react`](#Statement_prefixes "go to top of document")[§](#react "direct link")
`react` can be used in concurrent programs to create blocks of code that run whenever some event occurs. It [works with blocks](/syntax/react), and also as a statement prefix.
```raku
my Channel $KXGA .= new;
for ^100 {
$KXGA.send( (100000..200000).pick );
}
my @sums = ( start react whenever $KXGA -> $number {
say "In thread ", $*THREAD.id;
say "→ ", (^$number).sum;
} ) for ^10;
start { sleep 10; $KXGA.close(); }
await @sums;
```
In this case `react` prefixes `whenever`, which makes a long sum with every number read from a channel.
|
## dist_zef-neula-IO-Maildir.md
# NAME
`IO::Maildir` provides functions for safely dealing with maildir directories.
# SYNOPSIS
```
use IO::Maildir;
my $inbox = maildir "~/mail/INBOX";
$inbox.create;
my $msg = $inbox.receive($somemail);
```
# DESCRIPTION
`IO::Maildir` tries to implement the [maildir](https://cr.yp.to/proto/maildir.html) spec. It can serve as a basis for mail delivery agents or mail user agents (or a mixture of both). The named `agent` parameter can be used to set the behaviour for some methods. Default behaviour can be changed by setting `$maildir-agent`.
### sub maildir
```
sub maildir($path --> IO::Maildir)
```
Returns a maildir object from `$path`. `$path` will be coerced to IO.
### maildir-agent
```
our Agent $maildir-agent = IO::Maildir::DELIVERY
```
Set this to either `IO::Maildir::DELIVERY` or `IO::Maildir::USER`. Affects behaviour of following methods:
* `IO::Maildir::File`: `flag`, `move`
* `IO::Maildir`: `walk`
## class IO::Maildir
Class for maildir directories.
```
my $maildir = IO::Maildir.new "~/Mail/INBOX";
my $maildir = maildir "~/Mail/INBOX" # Same
```
### method create
```
method create( --> IO::Maildir) { ... }
```
Creates a new maildir directory including its cur, new and tmp subdirectories.
### method receive
```
multi method receive($mail --> IO::Maildir::File) { ... }
```
Adds a new file to the maildir. `receive` will always deliver to new and write the file to tmp first if neccessary. `$mail` may be of any type which is accepted by `IO::Path.spurt`, which are any `Cool` or `Blob` types.
Up to version 0.0.2 receiving an IO object would delete the original file. This behaviour was fixed and the original file now remains after receiving.
### method walk
```
method walk(:$all, :$agent = $maildir-agent --> Seq) { ... }
```
Returns the new mails in the maildir (or all if you set it). Newest mails will be returned first.
If called with `$agent = IO::Maildir::USER` it will also do the following actions:
* 1. Look inside tmp and delete files older than 36 hours.
* 1. Move files from new to cur **after** the returned Seq is consumed.
## class IO::Maildir::Files
Handle for files inside a maildir.
```
#Create from IO::Path
my $file = IO::Maildir::File.new( path => "~/Mail/INBOX/cur/uniquefilename:2,".IO );
#Create from maildir
my $file = IO::Maildir::File.new( dir => $maildir, name => "uniquefilename:2," );
```
Usually you don't need to do anything of the above, since you will receive your `IO::Maildir::File` objects from `IO::Maildir`s methods.
### attribute dir
```
has IO::Maildir $.dir
```
Points to the maildir containing this file.
### attribute name
```
has $.name
```
Complete file name including flags and stuff.
### method IO
```
method IO( --> IO ) { ... }
```
Returns the `IO::Path` object pointing to the file.
### method flags
```
method flags( --> Set ) { ... }
```
Returns the `Set` of flags set for this file.
### method flag
```
multi method flag(:$agent = $maildir-agent, *%flags)
multi method flag(
%flags where *.keys.Set ⊆ <P R S T D>.Set,
:$agent = $maildir-agent)
```
Use this to set flags. Fails if `$agent` is set to `IO::Maildir::DELIVERY`. This will also move the file to cur, because it has been seen by the MUA.
### method move
```
multi method move(IO::Maildir $maildir, Agent :$agent = $maildir-agent --> IO::Maildir::File) { ... }
multi method move (IO $iodir, Agent :$agent = $maildir-agent --> IO::Maildir::File) { ... }
```
Moves the file to a different maildir and returns the updated file-handle. If called in `IO::Maildir::DELIVERY` mode, the file will be moved to new and old flags will be removed. If called in `IO::Maildir::USER` mode, it will be moved to cur and flags will be preserved.
# AUTHOR
neula [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/neula/IO-Maildir> . Comments and Pull Requests are welcome.
# LICENSE
This library is free software; you may redistribute or modify it under the Artistic License 2.0.
|
## dist_zef-masukomi-Terminal-Graphing-BarChart.md
# Terminal::Graphing::BarChart
Terminal::Graphing::BarChart is a simple library to let you produce bar graphs on the command line.
It takes special care to give you good looking output.

Currently limited to vertical bar charts. See the end of this document for future plans & contribution guidelines.
# SYNOPSIS
## Common Usage Example
```
# VERTICAL BAR CHART
use Terminal::Graphing::BarChart::Vertical;
my $x_and_y_axis_graph = Terminal::Graphing::BarChart::Vertical.new(
data => [0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100],
bar_length => 10,
x_axis_labels => <a b c d e f g h i j k>,
y_axis_labels => <0 1 2 3 4 5 6 7 8 9>
);
# to get the string version of the graph
$x_and_y_axis_graph.generate();
# to print the graph to Standard Out
$x_and_y_axis_graph.print();
```
Note that for a *vertical* graph the 0 x 0 point of this graph is the bottom left corner.
Data and labels start from there and move outwards. BUT for a *horizontal* graph the 0 x 0 point is the top left corner.
```
my $horizontal_graph = Terminal::Graphing::BarChart::Horizontal.new(
data => [0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100],
bar_length => 20,
x_axis_labels => <a b c d e f g h i j>,
y_axis_labels => <alpha bravo charlie delta echo foxtrot golf hotel india juliet kilo>
);
# to get the string version of the graph
$horizontal_graph.generate();
# to print the graph to Standard Out
$horizontal_graph.print();
```
There are 3 notable restrictions in the horizontal graph
1. x axis labels can't be longer than 1 character
2. `bar_length` must be evenly divisible by the number of x axis labels.
3. the x axis labels will be spread evenly across `bar_length` characters of width.
Folks using Arabic & other Right-to-Left are encouraged to make a PR
to support reversed graphs.
## Required Attributes
When creating a graph there are two required keys. `bar_length` and `data`.
`bar_length` is how tall or wide you wish the core graph's bars to be (in characters).
This does not include the additional lines for labels or the lines separating them
from the graph.
`data` is an array of numbers. Each is expected to be a percentage from 0 to 100.
100 create a vertical bar `bar_length` lines tall. 0 will create an empty bar.
Note, there *will* be rounding issues if your `bar_length` is anything other than
an even multiple of 100. This is ok.
Just to set expectations, if for example, you specify a `bar_length`
of 10 that means there are only 10 vertical/horizontal elements to each bar. If
one of your data points is 7 you'll end up with an empty bar because that's
less than the number needed to activate the 1st element (10).
## Optional Attributes
`x_axis_labels` This is an array of labels for the x axis.
In the vertical bar chart it must be equal in length
to the number of data points. If you want some of your bars to be unlabeled
then specify a space for that "label". In the horizontal bar chart it must be
a number that's `bar_length` can be evenly divided by. In the horizontal bar
chart they must also be no longer than 1 character.
For the horizontal graph I recommend just making it the same number of elements
as the `bar_length`. That way you can precisely specify where each label appears.
`y_axis_labels` This is an array of labels for the y axis.
In the vertical bar graph it must be equal in length
to the `bar_length` (one label per row). Again, if you want some of
the points to be unlabeled, you should use a space character. In the horizontal graph it can be less.
Note that the 0 x 0 point of the vertical graph is the bottom left. So its list
of `y_axis_labels` will go from bottom up. This corresponds to how the
`data` and `x_axis_labels` go from left to right. In the horizontal bar graph it's top left
so data moves from that column out.
In the Vertical bar graph you can specify `space_between_columns` This is a
`Bool` which defaults to `True`. If you set it to `False` the system will *not*
introduce a space between each column. This works fine, and may be a good
choice if you have a large number of data points, but for short graphs it's
almost always worse looking.
### Advice
From a purely visual perspective it is not recommended that you use
full words for your `x_axis_labels`. In order to not introduce a false sense
of time compression or similar meaning, every bar gets spread out by the
length of the longest label.
`y_axis_labels` should be fine regardless of length. They are right-aligned, and
just shove the graph farther to the right.
I would not recommend generating a vertical graph that's more than 10 characters high.
I would recommend making a horizontal graph that's >=20 characters wide. Otherwise they
look too squished.
See `vertical-graph-tester.raku` and `horizontal-graph-tester.raku` for examples.
## Legend
This library does not support generating a legend for your graph.
My advice is to use single letter `x_axis_labels` and then use
[Prettier::Table](https://github.com/masukomi/Prettier-Table/)
to generate a legend that explains your x axis.
# Future + Contributing
## Contributing
Please do. All I ask is that you include unit tests that cover whatever changes or additions you make, and that you're fine with your contributions being distributed under the AGPL.
What kind of contributions? New Features, refactored code, more tests, etc.
For best results, please ping me on mastodon (see below) to make sure I see your PR right away.
# AUTHOR
web: [masukomi](https://masukomi.org)
mastodon: [@[email protected]](https://connectified.com/@masukomi)
# COPYRIGHT AND LICENSE
Copyright 2023 Kay Rhodes (a.k.a. masukomi)
This library is free software; you can redistribute it and/or modify it under the AGPL 3.0 or later. See LICENSE.md for details.
|
## dist_zef-raku-community-modules-Text-T9.md
[](https://github.com/raku-community-modules/Text-T9/actions) [](https://github.com/raku-community-modules/Text-T9/actions) [](https://github.com/raku-community-modules/Text-T9/actions)
# NAME
Text::T9 - Guess words based on a T9 key sequence
# SYNOPSIS
```
use Text::T9;
my @words = <this is a simple kiss test lips here how>;
.say for t9(5477, @words); # kiss lips
my %additional-keys = ź => 9, ń => 6;
@words.push: 'jaźń';
.say for t9(5296, @words, %additional-keys); # jaźń
```
# DESCRIPTION
The `Text::T9` distribution exports a single subroutine `t9` that looks up matching words from a given list of words using the [T9 predictive text](https://en.wikipedia.org/wiki/T9_(predictive_text)) algorithm known from older mobile phones (pre-smart phone).
# AUTHOR
Tadeusz Sośnierz
Source can be located at: <https://github.com/raku-community-modules/Text::T9> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2012 - 2017 Tadeusz Sośnierz
Copyright 2025 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-MELEZHIK-Sparky-Plugin-Hello.md
# SYNOPSIS
Sparky Hello Plugin
# INSTALL
```
$ zef install Sparky::Plugin::Hello
```
# USAGE
```
$ cat sparky.yaml
plugins:
- Sparky::Plugin::Hello:
parameters:
name: "Sparrow"
```
# Author
Alexey Melezhik
|
## later.md
later
Combined from primary sources listed below.
# [In role Dateish](#___top "go to top of document")[§](#(role_Dateish)_method_later "direct link")
See primary documentation
[in context](/type/Dateish#method_later)
for **method later**.
```raku
multi method later(DateTime:D: *%unit)
```
Returns an object based on the current one (belonging to any class that mixes this role in), but with a time delta applied. The time delta can be passed as a named argument where the argument name is the unit.
Unless the given unit is `second` or `seconds`, the given value will be converted to an [`Int`](/type/Int).
Allowed units are `second`, `seconds`, `minute`, `minutes`, `hour`, `hours`, `day`, `days`, `week`, `weeks`, `month`, `months`, `year`, `years`. Please note that the plural forms can only be used with the `later` and `earlier` methods.
The `:2nd` form of colonpairs can be used as a compact and self-documenting way of specifying the delta:
```raku
say DateTime.new('2015-12-24T12:23:00Z').later(:2years);
# OUTPUT: «2017-12-24T12:23:00Z»
```
Since addition of several different time units is not commutative, only one unit may be passed (and the first multi will be used).
```raku
my $d = DateTime.new(date => Date.new('2015-02-27'));
say $d.later(month => 1).later(:2days); # OUTPUT: «2015-03-29T00:00:00Z»
say $d.later(days => 2).later(:1month); # OUTPUT: «2015-04-01T00:00:00Z»
say $d.later(days => 2).later(:month); # same, as +True === 1
```
You can also (since release 2021.02 of the Rakudo compiler) pass several units at the same time, but you will have to join them in a [`List`](/type/List) to activate the second form:
```raku
say DateTime.new(date => Date.new('2015-02-27')).later( (:1month, :2days) )
# OUTPUT: «2015-03-29T00:00:00Z»
```
If the resultant time has value `60` for seconds, yet no leap second actually exists for that time, seconds will be set to `59`:
```raku
say DateTime.new('2008-12-31T23:59:60Z').later: :1day;
# OUTPUT: «2009-01-01T23:59:59Z»
```
Negative offsets are allowed, though [earlier](/routine/earlier) is more idiomatic for that.
Objects of type [`Date`](/type/Date) will behave in the same way:
```raku
my $d = Date.new('2015-02-27');
say $d.later(month => 1).later(:2days); # OUTPUT: «2015-03-29»
say $d.later(days => 2).later(:1month); # OUTPUT: «2015-04-01»
say $d.later(days => 2).later(:month); # same, as +True === 1
```
|
## dist_zef-Kaiepi-Acme-BaseCJK.md

# NAME
Acme::BaseCJK - More digits for more better
# SYNOPSIS
```
use Acme::BaseCJK;
put my $x = CJK:of(0x1541DBAD); # OUTPUT: 崁㼄
put CJK:to($x).base(16); # OUTPUT: 1541DBAD
```
# DESCRIPTION
While clear about each bit's value, binary makes for a rather sparse encoding of integers compared to decimal. Hexadecimal is more compact, making it a little easier to read at a glance. `Acme::BaseCJK` takes this a step further by encoding integers with Unicode 13.0.0's CJK Unified Ideographs block, along with extensions A-G, making for a base 92 844 encoding.
# AUTHOR
Ben Davies (Kaiepi)
# COPYRIGHT AND LICENSE
Copyright 2022 Ben Davies
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-wbiker-IO-Prompt.md
IO::Prompt -- Interactive validating terminal prompt
# HTML
[](https://travis-ci.org/wbiker/io-prompt)
# SYNOPSIS
```
use v6;
use IO::Prompt;
my $a = ask( "Defaults to 42, type Num?", 42, :type(Num) );
say $a.perl;
say '------------------------------';
$a = ask( "Defaults to false?", Bool::False );
say $a.perl;
say '------------------------------';
$a = ask( "No default but type Bool?", :type(Bool) );
say $a.perl;
say '------------------------------';
## OO style ##
my $prompt = IO::Prompt.new();
$a = $prompt.ask( "Dot notation?", Bool::False );
say $a.perl;
say '------------------------------';
## You can override the IO methods for testing purposes
class IO::Prompt::Testable is IO::Prompt {
method !do_say( Str $question ) returns Bool {
say "Testable saying '$question'";
say 'Please do not continue questioning';
return Bool::False; # do not continue
}
method !do_prompt( Str $question ) returns Str {
say "Testable saying '$question'";
say "Testable answering 'daa'";
return 'daa';
}
}
my $prompt_test = IO::Prompt::Testable.new();
$a = $prompt_test.ask_yn( "Testable, defaults to false?", Bool::False );
say $a.perl;
say '------------------------------';
## You can override the language class attributes
class IO::Prompt::Finnish is IO::Prompt {
our $.lang_prompt_Yn = 'K/e';
our $.lang_prompt_yN = 'k/E';
our $.lang_prompt_yn = 'k/e';
our $.lang_prompt_yn_retry = 'Sano kyllä tai ei';
our $.lang_prompt_match_y = m/ ^^ <[kK]> /;
our $.lang_prompt_match_n = m/ ^^ <[eE]> /;
our $.lang_prompt_int = 'Int';
our $.lang_prompt_int_retry = 'Anna kokonaisluku';
our $.lang_prompt_num = 'Num';
our $.lang_prompt_num_retry = 'Anna luku';
our $.lang_prompt_str = 'Str';
our $.lang_prompt_str_retry = 'Anna merkkijono';
}
my $prompt_fi = IO::Prompt::Finnish.new();
$a = $prompt_fi.ask( "Suomeksi Bool?", :type(Bool) );
say $a.perl;
say '------------------------------';
$a = $prompt_fi.ask( "Suomeksi Num?", :type(Num) );
say $a.perl;
say '------------------------------';
$a = $prompt_fi.ask( "Suomeksi Str?", :type(Str) );
say $a.perl;
say '------------------------------';
```
# DESCRIPTION
This is a generic module for interactive prompting from the console.
The build-in function prompt is great, but sometimes it is convenient to have default values and/or the control over the return type.
IO::Prompt provides both.
Original written bei pnu.
## FUNCTIONAL METHODS
IO::Prompt provides method ask to set the question string, a default answer and/or a return type.
Examples:
```
use IO::Prompt;
my $answer = ask("What do you want for Christmas?", "Perl6");
$answer = Whatever the user entered or if just Enter was pressed the string Perl6
```
## OO
IO::Prompt provides also a OO interface.
Example:
```
use IO::Prompt;
my $asker = IO::Prompt.new;
my $answer = $asker.ask("Wanna some money?", 2e9, :type(Num));
```
# COPYRIGHT
Written by pnu, maintained by wbiker
|
## dist_zef-coke-App-Unicode-Mangle.md
# Overview
Silly script to let you take unicode input and transform it.
Some samples:
```
$ uni-mangler --circle '#rakulang'
#ⓡⓐⓚⓤⓛⓐⓝⓖ
$ uni-mangler --invert 'Hello, github!'
¡quɥʇıƃ ,oʃʃǝH
$ uni-mangler --bold 'A bird, a plane.'
𝐀 𝐛𝐢𝐫𝐝, 𝐚 𝐩𝐥𝐚𝐧𝐞.
$ uni-mangler --paren 'lisplike'
⒧⒤⒮⒫⒧⒤⒦⒠
$ uni-mangler --combo 'combo breaker'
c̩͘o̍ͧmͮ͠b̄͋o̸̫ ̣͚b͠ͅř̗ẻ͔aͪ͢k̥̀e̒͋r͎̦
$ uni-mangler --italic 'The Telltale Heart'
𝘛𝘩𝘦 𝘛𝘦𝘭𝘭𝘵𝘢𝘭𝘦 𝘏𝘦𝘢𝘳𝘵
$ uni-mangler --square 'Presenting'
🄿 🅁 🄴 🅂 🄴 🄽 🅃 🄸 🄽 🄶
$ uni-mangler --nsquare 'A little boxy'
🅰 🅻 🅸 🆃 🆃 🅻 🅴 🅱 🅾 ❎ 🆈
$ uni-mangler --random 'Happy Birthday!'
Ⓗ⒜ⓟ𝐩𝐲 𐐒⒤𝐫⒯⒣pɐ⒴¡
```
## Combining Characters
Where possible, preserve input combining marks:
```
$ uni-mangler --outline rákü
𝕣𝕒́𝕜𝕦̈
```
## Related Modules
For a more focused approach on the Mathematical Alphanumeric Symbols unicode block, try:
<https://modules.raku.org/dist/Text::MathematicalCase:cpan:ELIZABETH/>
|
## dist_zef-japhb-MUGS-UI-WebSimple.md
[](https://github.com/Raku-MUGS/MUGS-UI-WebSimple/actions)
# NAME
MUGS-UI-WebSimple - WebSimple UI for MUGS, including HTTP gateway and game UIs
# SYNOPSIS
```
# Set up a full-stack MUGS-UI-WebSimple development environment
mkdir MUGS
cd MUGS
git clone [email protected]:Raku-MUGS/MUGS-Core.git
git clone [email protected]:Raku-MUGS/MUGS-Games.git
git clone [email protected]:Raku-MUGS/MUGS-UI-WebSimple.git
cd MUGS-Core
zef install --exclude="pq:ver<5>:from<native>" .
mugs-admin create-universe
cd ../MUGS-Games
zef install .
cd ../MUGS-UI-WebSimple
zef install --deps-only . # Or skip --deps-only if you prefer
### GAME SERVER (handles actual gameplay; used by the web UI gateway)
# Start a TLS WebSocket game server on localhost:10000 using fake certs
mugs-ws-server
# Specify a different MUGS identity universe (defaults to "default")
mugs-ws-server --universe=other-universe
# Start a TLS WebSocket game server on different host:port
mugs-ws-server --host=<hostname> --port=<portnumber>
# Start a TLS WebSocket game server using custom certs
mugs-ws-server --private-key-file=<path> --certificate-file=<path>
# Write a Log::Timeline JSON log for the WebSocket server
LOG_TIMELINE_JSON_LINES=log/mugs-ws-server mugs-ws-server
### WEB UI GATEWAY (frontend for a MUGS backend game server)
# Start a web UI gateway on localhost:20000 to play games in a web browser
mugs-web-simple --server-host=<websocket-host> --server-port=<websocket-port>
mugs-web-simple --server=<websocket-host>:<websocket-port>
# Start a web UI gateway on a different host:port
mugs-web-simple --host=<hostname> --port=<portnumber>
# Use a different CA to authenticate the WebSocket server's certificates
mugs-web-simple --server-ca-file=<path>
# Use custom certs for the web UI gateway itself
mugs-web-simple --private-key-file=<path> --certificate-file=<path>
# Turn off TLS to the web browser (serving only unencrypted HTTP)
mugs-web-simple --/secure
```
# DESCRIPTION
**NOTE: See the [top-level MUGS repo](https://github.com/Raku-MUGS/MUGS) for more info.**
MUGS::UI::WebSimple is a Cro-based web gateway for MUGS, including templates and UI plugins to play games from [MUGS-Core](https://github.com/Raku-MUGS/MUGS-Core) and [MUGS-Games](https://github.com/Raku-MUGS/MUGS-Games) via a web browser. The WebSimple UI focuses on low-bandwidth, resource-friendly HTML.
This Proof-of-Concept release only contains very simple turn-based games, plus a simple front door for creating identities and choosing games to play. Future releases will include many more games and genres, plus better handling of asynchronous events such as inter-player messaging.
# GOTCHAS
In this early release, there are a couple rough edges (aside from the very simple UI and trivial game selection):
* Templates only work in checkout dir; must run mugs-web-simple from checkout root
* Each mugs-web-simple instance can only serve *either* HTTP or HTTPS (not both at once)
* Session cookies do not have a SameSite setting; some browsers will complain if not using HTTPS
# ROADMAP
MUGS is still in its infancy, at the beginning of a long and hopefully very enjoyable journey. There is a [draft roadmap for the first few major releases](https://github.com/Raku-MUGS/MUGS/tree/main/docs/todo/release-roadmap.md) but I don't plan to do it all myself -- I'm looking for contributions of all sorts to help make it a reality.
# CONTRIBUTING
Please do! :-)
In all seriousness, check out [the CONTRIBUTING doc](docs/CONTRIBUTING.md) (identical in each repo) for details on how to contribute, as well as [the Coding Standards doc](https://github.com/Raku-MUGS/MUGS/tree/main/docs/design/coding-standards.md) for guidelines/standards/rules that apply to code contributions in particular.
The MUGS project has a matching GitHub org, [Raku-MUGS](https://github.com/Raku-MUGS), where you will find all related repositories and issue trackers, as well as formal meta-discussion.
More informal discussion can be found on IRC in Libera.Chat #mugs.
# AUTHOR
Geoffrey Broadwell [[email protected]](mailto:[email protected]) (japhb on GitHub and Libera.Chat)
# COPYRIGHT AND LICENSE
Copyright 2021-2024 Geoffrey Broadwell
MUGS is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-cygx-Image-RGBA.md
# Image::RGBA [Build Status](https://travis-ci.org/cygx/p6-image-rgba)
Create and manipulate 32-bit RGBA images
# Synopsis
```
use Image::RGBA;
my $img = Image::RGBA.create(10, 20);
my $pixel = $img.pixel(2, 5);
$pixel.g = 0xA0;
say $pixel;
```
```
use Image::RGBA::Text;
use Image::PGN::Inflated;
my $img = Image::RGBA::Text.load('examples/camelia.txt'.IO);
spurt 'camelia.png', to-png($img);
for Image::RGBA::Text.slurp('examples/feep.txt'.IO) {
spurt "{.meta<name>}.png", .&to-png;
}
```
```
use Image::RGBA::Fun;
use Image::PGN::Inflated;
my $img = load-rgba-from-textfile('examples/camelia.txt');
spurt 'camelia.png', to-png($img);
my %palette = x => 'fbf', o => 'a33';
say create-rgba-from-text(q:to/THE_END/, 2, 2, :%palette).pixel(0, 1);
x o
o x
THE_END
```
# Description
This module allows the manipulation of raw RGBA images on a per-pixel basis
and the creation of such images from a simple text format.
The pixel data is held in a flat byte buffer, with each 4-byte sequence
describing the red, green, blue and alpha channel.
The text representation of a pixel is given by a sequence of non-whitespace
characters (a 'word'), separated by whitespace to form the image data.
Before decoding, each word gets filtered through a 'palette', a hash mapping
arbitrary words to hexadecimal color values in one of the 6 supported formats.
Images may be embedded in structured text files, with each line potentially
holding a parsing directive starting in `=`, or pixel data.
## The Base Module Image::RGBA
Wraps binary pixel data.
```
class Image::RGBA {
has buf8 $.bytes;
has uint $.width is required;
has uint $.height is required;
has %.meta;
method create($width, $height, $bytes?) { ... }
method pixel($x, $y) { ... }
}
my class Pixel {
# numerical manipulation
method r is rw { ... }
method g is rw { ... }
method b is rw { ... }
method a is rw { ... }
method value($order = BigEndian) is rw { ... }
# stringification
method Str { ... } # rgba(?,?,?,?)
method hex { ... } # hexadecimal, excluding alpha channel
method hexa { ... } # hexadecimal, including alpha channel
}
```
## Parsing Text with Image::RGBA::Text
Methods `load` and `slurp` for text parsing are exposed via the type object.
```
class Image::RGBA::Text {
# loads a single image
method load($src, :%palettes = {}) { ... }
# returns a sequence of all images
method slurp($src, :%palettes = {}) { ... }
}
```
The `$src` argument must provide a `lines` method. Examples of valid sources
are strings, file handles and path objects. A hash of named palette hashes may
be passed in, allowing communication betweeen sources.
The module contains two decoder classes that implement parsing of color values
and colorization of the image.
```
class Image::RGBA::Text::Decoder {
has Image::RGBA $.image is required;
has Associative $.palette = {};
method create($width, $height, %palette?) { ... }
# colorize a single pixel, moving the cursor forward
method paint($color) { ... }
# use each word of the text to colorize a subsequent pixel
method decode($text) { ... }
# check if the image has been fully colorized
method done { ... }
}
class Image::RGBA::Text::ScalingDecoder is Image::RGBA::Text::Decoder {
has uint $.scale is required;
method create($width, $height, $scale, %palette?) { ... }
}
```
The latter class allows automatic scaling of the image by an integer factor.
## Functional API provided by Image::RGBA::Fun
```
# Create individual images from raw data
sub create-rgba($width, $height, $bytes?) { ... }
sub create-rgba-from-text($text, $width, $height, $scale = 1, :%palette) { ... }
# Load individual image, parsing directives
sub load-rgba-from-text($text, :%palettes) { ... }
sub load-rgba-from-textfile($file, :%palettes) { ... }
# Load all images, parsing directives
sub slurp-rgba-from-text($text, :%palettes) { ... }
sub slurp-rgba-from-textfile($file, :%palettes) is export { ... }
```
If a file argument is not of type `IO::Handle`, it is assumed to be a file
path and converted via a call to `.IO`.
# The Textual Format
Yet to be properly documented. When in doubt, check the [`examples`](https://github.com/cygx/p6-image-rgba/tree/master/examples)
directory for working code.
## Supported Directives
```
=img <width> <height> <scale>?
=palette <name>
=map <alias> <color>
=use <palette>
=meta <key> <value>
```
Following an `=img` directive, until the image has been fully colorized,
each line that does not start in `=` is assumed to hold pixel data.
A `=palette` directive may occur between `=img` directives, but must not
occur until any given image is complete.
## Supported Color Formats
There are six different ways to specify colors. They are distinguished by the
number of characters in the given string.
### A single hexadecimal digit
Numbers 0 through 7 are black and dark colors, all opaque. Number 8 is a
transparent black pixel. Numbers 9 through F are bright colors followed
by white.
| Digit | RGB value | Alpha value | Name |
| --- | --- | --- | --- |
| 0 | #000000 | 100% | black |
| 1 | #800000 | 100% | dark red (maroon) |
| 2 | #008000 | 100% | dark green |
| 3 | #808000 | 100% | dark yellow (olive) |
| 4 | #000080 | 100% | dark blue (navy) |
| 5 | #800080 | 100% | dark magenta (purple) |
| 6 | #008080 | 100% | dark cyan (teal) |
| 7 | #808080 | 100% | dark gray |
| 8 | #000000 | 0% | transparent black |
| 9 | #FF0000 | 100% | red |
| A | #00FF00 | 100% | green (lime) |
| B | #FFFF00 | 100% | yellow |
| C | #0000FF | 100% | blue |
| D | #FF00FF | 100% | magenta (fuchsia) |
| E | #00FFFF | 100% | cyan (aqua) |
| F | #FFFFFF | 100% | white |
### Double hexadecimal digits
Double hexadecimal digits, i.e. 00 through FF, will result in a greyscale of
opaque pixels. 00 is black, FF is white, the values in between just have the
given hexadecimal number for the R, G, B channels and FF for the alpha channel.
### Three hexadecimal digits
Three hexadecimal digits will result in opaque pixels where the individual
hexadecimal digits are doubled and stored as the R, G, and B value
respectively. For example, the value `47e` would result in the RGB color
value `#4477ee` at fixed alpha value FF.
### Four hexadecimal digits
This works the same way as three hexadecimal digits, but the alpha channel
takes its value from the fourth digit rather than being fixed at FF.
### Six hexadecimal digits
Six hexadecimal digits work exactly like you would expect from HTML, CSS,
or graphics software in general: The first two digits are for the red
channel, the next two for the green channel, and the last two for the blue
channel. The alpha channel is always FF.
### Eight hexadecimal digits
This works the same way as six hexadecimal digits, but the last two digits
are used for the alpha channel.
# Bugs and Development
Development happens at [GitHub](https://github.com/cygx/p6-image-rgba). If you found a bug or have a feature
request, use the [issue tracker](https://github.com/cygx/p6-image-rgba/issues) over there.
# Copyright and License
Copyright (C) 2019 by cygx <[[email protected]](mailto:[email protected])>
Distributed under the [Boost Software License, Version 1.0](https://www.boost.org/LICENSE_1_0.txt)
|
## dist_zef-raku-community-modules-File-Find.md
[](https://github.com/raku-community-modules/File-Find/actions) [](https://github.com/raku-community-modules/File-Find/actions) [](https://github.com/raku-community-modules/File-Find/actions)
# NAME
File::Find - Get a lazy sequence of a directory tree
# SYNOPSIS
```
use File::Find;
my @list = lazy find(dir => 'foo'); # Keep laziness
say @list[0..3];
my $list = find(dir => 'foo'); # Keep laziness
say $list[0..3];
my @list = find(dir => 'foo'); # Drop laziness
say @list[0..3];
```
# DESCRIPTION
`File::Find` allows you to get the contents of the given directory, recursively, depth first. The only exported function, `find()`, generates a `Seq` of files in given directory. Every element of the `Seq` is an `IO::Path` object, described below. `find()` takes one (or more) named arguments. The `dir` argument is mandatory, and sets the directory `find()` will traverse. There are also few optional arguments. If more than one is passed, all of them must match for a file to be returned.
## name
Specify a name of the file `File::Find` is ought to look for. If you pass a string here, `find()` will return only the files with the given name. When passing a regex, only the files with path matching the pattern will be returned. Any other type of argument passed here will just be smartmatched against the path (which is exactly what happens to regexes passed, by the way).
## type
Given a type, `find()` will only return files being the given type. The available types are `file`, `dir` or `symlink`.
## exclude
Exclude is meant to be used for skipping certain big and uninteresting directories, like '.git'. Neither them nor any of their contents will be returned, saving a significant amount of time.
The value of `exclude` will be smartmatched against each IO object found by File::Find. It's recommended that it's passed as an IO object (or a Junction of those) so we avoid silly things like slashes vs backslashes on different platforms.
## keep-going
Parameter `keep-going` tells `find()` to not stop finding files on errors such as 'Access is denied', but rather ignore the errors and keep going.
## recursive
By default, `find` will recursively traverse a directory tree, descending into any subdirectories it finds. This behaviour can be changed by setting `recursive` to a false value. In this case, only the first level entries will be processed.
# Perl's File::Find
Please note, that this module is not trying to be the verbatim port of Perl's File::Find module. Its interface is closer to Perl's File::Find::Rule, and its features are planned to be similar one day.
# CAVEATS
List assignment is eager by default in Raku, so if you assign a `find()` result to an array, the laziness will be dropped by default. To keep the laziness either insert `lazy` or assign to a scalar value (see SYNOPSIS).
|
## dist_cpan-HOLLI-Test-Color.md
[](https://travis-ci.org/holli-holzer/perl6-Test-Color)
# NAME
Test::Color - Colored Test - output
# SYNOPSIS
```
use Test;
use Test::Color;
use Test::Color sub { :ok("blue on_green"), :nok("255,0,0 on_255,255,255") };
```
# DESCRIPTION
Test::Color uses [Terminal::ANSIColor](https://github.com/tadzik/Terminal-ANSIColor) to color your test output. Simply add the `use Color` statement to your test script.
## Setup
If you don't like the default colors, you can configure them by passing an anonymous sub to the use statement.
The sub must return a hash; keys representing the output category (one of ), and the values being color commands as in [Terminal::ANSIColor](https://github.com/tadzik/Terminal-ANSIColor).
You can tweak the behaviour even further by setting output handles of the `Test` module directly.
```
Test::output() = Test::Color.new( :handle($SOME-HANDLE) );
Test::failure_output() = Test::Color.new( :handle($SOME-HANDLE) );
Test::todo_output() = Test::Color.new( :handle($SOME-HANDLE) );
```
## Caveat
This module works using escape sequences. This means that test suite runners will most likely trip over it. The module is mainly meant for the development phase, by helping to spot problematic tests in longish test outputs.
# AUTHOR
```
Markus 'Holli' Holzer
```
# COPYRIGHT AND LICENSE
Copyright © [[email protected]](mailto:[email protected])
License GPLv3: The GNU General Public License, Version 3, 29 June 2007 <https://www.gnu.org/licenses/gpl-3.0.txt>
This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law.
|
## dist_zef-bradclawsie-Hash-Consistent.md
[](https://opensource.org/licenses/BSD-2-Clause)
[](https://github.com/bradclawsie/Hash-Consistent/actions)
# Hash::Consistent
A Raku implementation of a Consistent Hash.
## DESCRIPTION
A "consistent" hash allows the user to create a data structure in which a set of string
flags are entered in the hash at intervals specified by the CRC32 hash of the flag.
Optionally, each flag can have suffixes appended to it in order to create multiple
entries in the hash.
Once flags are entered into the hash, we can find which flag would be associated with
a candidate string of our choice. A typical use-case for this is to enter host
names into the hash the represent destination hosts where values are stored
for particular keys, as determined by the result of searching for the corresponding
flag in the hash.
This technique is best explained in these links:
<http://en.wikipedia.org/wiki/Consistent_hashing>
<http://www.tomkleinpeter.com/2008/03/17/programmers-toolbox-part-3-consistent-hashing/>
## SYNOPSIS
```
use v6;
use Hash::Consistent;
use String::CRC32;
use Test;
my $ch = Hash::Consistent.new(mult=>2);
$ch.insert('example.org');
$ch.insert('example.com');
is $ch.sum_list.elems(), 4, 'correct hash cardinality';
# > $ch.print();
# 0: 2725249910 [crc32 of example.org.0 derived from example.org]
# 1: 3210990709 [crc32 of example.com.1 derived from example.com]
# 2: 3362055395 [crc32 of example.com.0 derived from example.com]
# 3: 3581359072 [crc32 of example.org.1 derived from example.org]
# > String::CRC32::crc32('blah');
# 3458818396
# (should find next at 3581359072 -> example.org)
is $ch.find('blah'), 'example.org', 'found blah -> example.org';
# > String::CRC32::crc32('whee');
# 3023755156
# (should find next at 3210990709 -> example.com)
is $ch.find('whee'), 'example.com', 'found whee -> example.com';
```
## AUTHOR
Brad Clawsie (zef:bradclawsie, email:[email protected])
## Notice
This repository was uploaded via `fez` under the username `b7j0c`,
and later `bradclawsie`. This change was made so the username would match
Github. Sorry for any confusion.
## Installation
```
zef install Hash::Consistent
```
|
## dist_github-niner-Grammar-Highlighter.md
# TITLE
Grammar::Highlighter
# SYNOPSIS
```
use Grammar::Highlighter;
use Whatever::Grammar::You::Like;
my $highlighter = Grammar::Highlighter.new;
my $parser = Whatever::Grammar::You::Like.new;
say $parser.parse($string, :actions($highlighter)).ast.Str;
```
# DESCRIPTION
Get automatic syntax highlighting for any grammar you provide.
Grammar::Highlighter is a generic syntax highlighter. You use it as an actions
object for a grammar's parse method. It will assign a different color to all
the grammar's tokens, rules and regexes. The generated parse tree stringifies
to the original string with colors applied.
# AUTHOR
Stefan Seifert [[email protected]](mailto:[email protected])
|
## dist_github-antifessional-Net-ZMQ.md
# Net::ZMQ
## SYNOPSIS
Net::ZMQ is a Perl6 binding library for ZeroMQ
## Introduction
#### Version 0.1.2
#### Status
This is in development. The only certainty is that the tests pass on my machine.
#### Alternatives
There is an an earlier project on github: <https://github.com/arnsholt/Net-ZMQ>
I started this one primarily to learn both Perl6 and ZMQ. The older project
may be more stable and suitable to your needs. If you do boldly go and use this
one, please share bugs and fixes!
#### ZMQ Versions
Current development is with ZeroMQ 4.2.
#### Portability
Development is on linux/x64. Due to some pointer voodoo, it is possible the code
will break on other architectures/OSes. This should not be too hard to fix, but
it depends on other people trying it on other platforms.
## Example Code
```
use v6;
use Net::ZMQ::V4::Constants;
use Net::ZMQ::Context;
use Net::ZMQ::Socket;
use Net::ZMQ::Message;
my Context $ctx .= new :throw-everything;
my Socket $s1 .= new($ctx, :pair, :throw-everything);
my Socket $s2 .= new($ctx, :pair, :throw-everything);
my $endpoint = 'inproc://con';
$s1.bind($endpoint);
$s2.connect($endpoint);
my $counter = 0;
my $callme = sub ($d, $h) { say 'sending ++$counter'};
MsgBuilder.new\
.add('a short envelope' )\
.add( :newline )\
.add( :empty )\
.add('a very long story', :max-part-size(255), :newline )\
.add('another long chunk à la française', :divide-into(3), :newline )\
.add( :empty )\
.finalize\
.send($s1, :callback( $callme ));
my $message = $s2.receive( :slurp );
say $message;
$s1.unbind.close;
$s2.disconnect.close;
```
## Documentation
#### Net::ZMQ::V4::Constants
holds all the constants from zmq.h v4. They are grouped with tags.
The tags not loaded by default are
* :EVENT
* :DEPRECATED
* :DRAFT Experimental, not in stable version
* :RADIO
* :IOPLEX multiplexing
* :SECURITY
#### Net::ZMQ::V4::LowLevel
holds NativeCall bindings for all the functions in zmq.h
most calls are machine generated and the only check is that they compile.
constant ZMQ\_LOW\_LEVEL\_FUNCTIONS\_TESTED holds a list of the calls used and tested
in the module so far. loading Net::ZMQ::V4::Version prints it
#### Net::ZMQ::V4::Version
use in order to chack version compatibility. It exports
* verion()
* version-major()
#### Net::ZMQ::Context, ::Socket, ::Message, ::Poll
These are the main classes providing a higher-level Perl6 OO interface to ZMQ
##### Context
```
.new( :throw-everything(True)) # set to True to throw non fatal errors
.terminate() # manually release all resources (gc would do that)
.shutdown() # close all sockets
.get-option(name) # get Context option
.set-option(name, value) # set Context option
options can also be accessed through methods with the name of the option
with/without get- and set- prefixes.
e.g get: .get-io-threads() .io-threads()
set: .set-io-threads(2) .io-threads(2)
Net::ZMQ::ContextOptions holds the dispatch table
```
##### Socket
```
Attributes
context - the zmq-context; must be supplied to new()
type - the ZMQ Socket Type constant: One of
:pair :publisher :subscriber :client :server :dealer :router :pull :push :xpub :xsub :stream
must be supplied to new()
last-error - the last zmq error reported
throw-everything - when true, all non-fatal errors except EAGAIN (async) throw
async-fail-throw - when true, EAGAIN (async) throws; when false EAGAIN returns Any
max-send-bytes - largest single part send in bytes
max-recv-number - longest charcter string representing an integer number
in a single, integer message part
max-recv-bytes - bytes threshhold for truncating receive methods
Methods
Methods that do not return a useful value return self on success and Any on failure.
Send methods return the number of bytes sent or Any.
Socket Wrapper Methods
close()
bind( endpoint --> self ) ;endpoint must be a string with a valid zmq endpoint
unbind( endpoint = last-endpoint --> self )
connect( endpoint --> self )
disconnect( endpoint = last-endpoint --> self )
Send Methods
-part sends with SNDMORE flag (incomplete)
-split causes input to be split and sent in message parts
-async duh!
all methods return the number of bytes sent or Any
send( Str , :async, :part, :enc --> Int)
send( Int, :async, :part -->Int )
send( buf8, :async, :part, :max-send-bytes -->Int )
send(Str, Int split-at :split! :async, :part. :enc -->Int )
send(buf8, Int split-at :split! :async, :part -->Int )
send(buf8, Array splits, :part, :async, :callback, :max-send-bytes -->Int )
send(:empty!, :async, :part -->Int )
Receive Methods
-bin causes return type to be a byte buffer (buf8) instead of a string
-int retrieves a single integer message
-slurp causes all waiting parts of a message to be aseembled and returned as single object
-truncate truncates at a maximum byte length
-async duh!
receive(:truncate!, :async, :bin, :enc )
receive(:int!, :async, :max-recv-number --> Int)
receive(:slurp!, :async, :bin, :enc)
receive(:async, :bin, :enc)
Options Methods
there are option getters and setter for every socket option
the list of options is in SocketOptions.pm
every option name creates four legal invocations
-setters
option-name(new-value)
set-option:$name(new-value)
-getters
option-name()
get-option-name()
e.g.
* .get-identity() .identity()
* .set-identity(id) .identity(id)
options can also be accessed explicitly with the ZMQ option Constant.
valid Type Objects are Str, buf8 and Int
get-option(Int opt-contant, Type-Object return-type, Int size )
Misc Methods
doc(-->Str) ;this
```
The Message classes is an OO interface to the zero-copy mechanism.
It uses a builder to build an immutable message that can be sent (and re-sent)
zero-copied. See example above for useage.
##### MsgBuilder
builds a Message object that can be used to send complex messages.
uses zero-copy internally.
```
USAGE example
my MsgBuilder $builder .= new;
my Message $msg =
$builder.add($envelope)\
.add(:empty)\
.add($content-1, :max-part-size(1024) :newline)\
.add($content-2, :max-part-size(1024) :newline)\
.finalize;
$msg.send($socket);
Methods
new()
add( Str, :max-part-size :divide-into, :newline, :enc --> self)
add( :empty --> self)
add( :newline --> self)
finalize( --> Message)
```
##### Message
Immutable message
```
Methods
send(Socket, :part, :async, Callable:($,$ --> Int:D) :callback --> Int)
send-all(@sockets, :part, :async, Callable:($,$ --> Int:D) :callback --> Int)
bytes( --> Int)
segments( --> Int)
copy(:enc --> Str)
```
##### MsgRecv
MsgRecv accumulates message parts received on one or more sockets with minimal copying.
parts can be examined, slectevely sent over sockets. and transforming functions can be
queued on each part.
```
methods:
slurp(Socket, :async)
accumulate waiting message parts from a socket
push-transform(UInt, &func)
queue a transfrm function ( for example, encoding). The function should
conform to :(Str:D --> Str:D|Any ) or (Blob:D --> Str:D|Any
. Any effectively delete the part.
push-transform(&func)
queue a global transfrm function
set-encoding( 'ENCODING' )
a wrapper of push-transform
send(Socket, $from = 0, $n = elems, :async ) sends all or ome of the parts
[ UInt ] returns message part, transformed by all the transformers
at-raw( UInt ) returns message part as raw bunary data
```
##### PollBuilder
PollBuilder builds a polled set of receiving sockets
```
(Silly) Usage
my $poll = PollBuilder.new\
.add( StrPollHandler.new( $socket-1, sub ($m) { say "got --$m-- on socket 1";} ))\
.add( StrPollHandler.new( $socket-2, sub ($m) { say "got --$m-- on socket 2";} ))\
.add( $socket-3, { False })\
.delay( 500 )\
.finalize;
1 while $poll.poll(:serial);
say "Done!";
Methods
add( PollHandler --> self)
add( Socket, Callable:(Socket) --> self)
delay( Int msecs --> self) # -1 => blocks, 0 => no delay
finalize( --> Poll)
```
##### PollHandler
PollHandler is an an abstract class that represents an action to do on a socket when
it polls positive. It has four readymade subclasses that feed the action a different
```
argument:
* StrPollHandler
* MessagePollHandler
* SocketPollHandler
* MsgRecvPollHandler
Methods
new( Socket, Callable:(T) )
do( Socket ) -- this method is called by the Poll object and can be subclassed
to create new types of responses
```
##### Poll
Poll holds and polls an immutable collection of receiving sockets
```
Methods
poll()
poll returns a sequence of the results of the callback functions associated with the succesfully
polled sockets or an empty sequence. It throws on error.
poll(:serial)
primarily fo testing: returns a single result, from the callback of the first succesfully polled
socket, or Any. The order is defined by the building invocation.
```
##### Proxy
runs a steerable proxy
```
new( :frontend!($socket.as-ptr), :backend!($socket.as-ptr)
:capture($socket.as-ptr) , :control($socket.as-ptr))
run()
```
##### EchoServer
runs an echo server (connect with :client )
```
methods
new( :uri )
run blocks on the invoking thread
detach( --> Promise) runs in a promise
shutdown stops the server (no restart possible)
```
## LICENSE
All files (unless noted otherwise) can be used, modified and redistributed
under the terms of the Artistic License Version 2. Examples (in the
documentation, in tests or distributed as separate files) can be considered
public domain.
ⓒ 2017 Gabriel Ash
|
## dist_github-scmorrison-Web-Cache.md
# Web::Cache [Build Status](https://travis-ci.org/scmorrison/perl6-Web-Cache)
Web::Cache is a Perl 6 web framework independant LRU caching module.
The goal of this module is to provide a variety of cache backend wrappers and utilities that simplify caching tasks within the context of a web application.
**note:** this is very much a work in progress. Ideas, issues, and pull-requests welcome.
# Usage
```
# Bailador example
use v6;
use Bailador;
use Web::Cache;
Bailador::import; # for the template to work
# Create a new cache store
my &memory-cache = cache-create-store( size => 2048,
backend => 'memory' );
# TODO: Create multiple cache stores using different
# backends. This will enable caching certain
# content to different stores.
# Cached templates!
get / ^ '/template/' (.+) $ / => sub ($x) {
my $template = 'tmpl.tt';
my %params = %{ name => $x };
my $fancy_cache_key = [$template, $x].join('-');
# Any callback passed will be run on initial
# cache insert only. Once cache expiration is
# supported, this code will re-run again when
# the key expires.
memory-cache(key => $fancy_cache_key, {
template($template, %params)
});
}
#
# Remove a key
# memory-cache( key => $fancy_cache_key, :remove );
#
# Empty / clear cache
# memory-cache( :clear );
#
baile;
```
# Config
Currently only memory caching is supported.
```
# Create cache store
my &memory-cache = create-cache-store( size => 2048,
backend => 'memory' );
```
## Todo:
```
my &memory-cache = create-cache-store( size => 2048,
expires => 3600, # add expires parameter
backend => 'memory' );
my &disk-cache = create-cache-store( path => '/tmp/webcache/',
expires => 3600,
backend => 'disk' );
my &memcached = create-cache-store( servers => ["127.0.0.1:11211"],
expires => 3600,
backend => 'memcached' );
my &redis = create-cache-store( host => "127.0.0.1",
port => 6379,
expires => 3600,
backend => 'redis' );
```
# Installation
## zef
```
zef install Web::Cache
```
## Manual
```
git clone https://github.com/scmorrison/perl6-Web-Cache.git
cd perl6-Web-Cache/
zef install .
```
# Todo
* Support additional backends (disk, Memcached, Redis)
* Cache key generator
* Partial / fragment support
* Tests
# Requirements
* [Perl 6](http://perl6.org/)
# AUTHORS
* Sam Morrison
# Copyright and license
Copyright 2017 Sam Morrison
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-BDUGGAN-Jupyter-Kernel.md
## Jupyter::Kernel for Raku
[](https://mybinder.org/v2/gh/bduggan/p6-jupyter-kernel/master?filepath=hello-world.ipynb)
This is a pure Raku implementation of a Raku kernel for Jupyter clients¹.
Jupyter notebooks provide a web-based (or console-based)
Read Eval Print Loop (REPL) for running code and serializing input and output.
## REALLY QUICK START
[Binder](https://mybinder.org/) provides a way to instantly launch a Docker
image and open a notebook². Click `launch | binder` above
to start this kernel with a sample notebook. (See below
for similar alternatives.)
## QUICK START
* [Installation](#Installation)
* [Configuration](#Configuration)
* [Running](#Running)
### Installation
You'll need to install zmq. Note that currently, version 4.1 is
recommended by Net::ZMQ (though 4.2 is installed by, e.g. homebrew).
If you run into stability issues, you may need to downgrade.
```
brew install zmq # on OS/X
apt-get install libzmq-dev # on Ubuntu
```
You'll also want jupyter, for the front end:
```
pip install jupyter
```
Finally, install `Jupyter::Kernel`:
```
zef install Jupyter::Kernel
```
At the end of the above installation, you'll see the location
of the `bin/` directory which has `jupyter-kernel.raku`. Make
sure that is in your `PATH`.
### Configuration
#### Server Configuration
To generate a configuration directory, and to install a kernel
config file and icons into the default location:
```
jupyter-kernel.raku --generate-config
```
* Use `--location=XXX` to specify another location.
* Use `--force` to override an existing configuration.
#### Logging
By default a log file `jupyter.log` will be written in the
current directory. An option `--logfile=XXX` argument can be
added to the argv argument of the server configuration file
(located at `$(jupyter --data)/kernels/raku/kernel.json`)
to change this.
#### Client configuration
The jupyter documentation describes the client configuration.
To start, you can generate files for the notebook or
console clients like this:
```
jupyter notebook --generate-config
jupyter console --generate-config
```
Some suggested configuration changes for the console client:
* set `kernel_is_complete_timeout` to a high number. Otherwise,
if the kernel takes more than 1 second to respond, then from
then on, the console client uses internal (non-Raku) heuristics
to guess when a block of code is complete.
* set `highlighting_style` to `vim`. This avoids having dark blue
on a black background in the console client.
### Running
Start the web UI with:
```
jupyter-notebook
Then select New -> Raku.
```
You can also use it in the console like this:
```
jupyter-console --kernel=raku
```
Or make a handy shell alias:
```
alias iraku='jupyter-console --kernel=raku'
```
## FEATURES
* **Autocompletion:** Typing `[tab]` in the client will send an autocomplete request. Possible autocompletions are:
* methods: after a `.` the invocant will be evaluated to find methods
* set operators: after a `(`, set operators (unicode and texas) will be shown (note the whitespace before the `(`)).
* equality/inequality operators: after `=`, `<`, or `>`, related operators will be shown.
* autocompleting `*` or `/` will give `×` or `÷` respectively.
* autocompleting `**` or a superscript will give you superscripts (for typing exponents).
* the word 'atomic' autocompletes to the [atomic operators](https://docs.raku.org/type/atomicint#Operators). (Use `atomic-` or `atom` to get the subroutines with their ASCII names).
* a colon followed by a sequence of word characters will autocomplete
to characters whose unicode name contains that string. Dashes are
treated as spaces.
e.g. :straw will find 🍓 ("STRAWBERRY") or 🥤 ("CUP WITH STRAW") and :smiling-face-with-smiling-eye will find 😊 ("SMILING FACE WITH SMILING EYES")
* **Keep output:** All cells are evaluated in item context. Outputs are then saved to an array
named `$Out`. You can read from this directly or:
* via the subroutine `Out` (e.g. `Out[3]`)
* via an underscore and the output number (e.g. `_3`)
* for the most recent output: via a plain underscore (`_`).
* **Magics:** There is some support for jupyter "magics". If the first line
of a code cell starts with `#%` or `%%`, it may be interpreted as a directive
by the kernel. See EXAMPLES. The following magics are supported:
* `#% javascript`: interpret the cell as javascript; i.e. run it in the browser
* `#% js`: return the output as javascript
* `#% > js`: return stdout as javascript
* `#% html`: return the output as html
* `#% latex`: return the output as LaTeX. Use `latex(equation)` to wrap
the output in `\begin{equation}` and `\end{equation}`. (Or replace
"`equation`" with another string to use something else.)
* `#% markdown` (or `md`): the output will be interpreted as markdown.
Note that this is for generating markdown as the output of a cell, not for
writing markdown, which can be done without magics. Also, this simply
sends the data with the markdown mime-type, and the notebook does the rendering.
* `#% > markdown` (or `md`): interpret stdout as markdown
* `#% html > latex`: The above can be combined to render, for instance,
the output cell as HTML, but stdout as LaTeX. The word before the `>`
indicates the type of the output cell. The word after the `>` indictes
the type of stdout.
* `%% bash`: Interpret the cell as bash. stdout becomes the contents of
the next cell. Behaves like Raku's built-in `shell`.
* `%% run FILENAME`: Prepend the contents of FILENAME to the
contents of the current cell (if any) before execution.
Note this is different from the built-in `EVALFILE` in that
if any lexical variables, subroutines, etc. are declared in FILENAME,
they will become available in the notebook execution context.
* `%% always [SUBCOMMAND] CODE`: SUBCOMMAND defaults to `prepend` but can be:
* `prepend`: Prepend each cell by `CODE;\n`
* `append`: Append `;\nCODE` after each command
* `clear`: Clear all `always` registered actions
* `show`: Show `always` registered actions
You can combine it with another magic. For example:
`%% always prepend %% run file.raku`
* **Comms:** Comms allow for asynchronous communication between a notebook
and the kernel. For an example of using comms, see [this notebook](eg/comms.ipynb)
### Usage notes
* In the console, pressing return will execute the code in a cell. If you want
a cell to span several lines, put a `\` at the end of the line, like so:
```
In [1]: 42
Out[1]: 42
In [2]: 42 +
Out[2]: Missing required term after infix
In [3]: 42 + \
: 10 + \
: 3 + \
: 12
Out[3]: 67
```
Note that this is not the same as the raku 'unspace' -- a backslash followed
by a newline will be replaced with a newline before the code is executed. To
create an unspace at the end of the line, you can use two backslashes.
## DOCKER
[This blog post](https://sumankhanal.netlify.com/post/raku_notebook/) provides
a tutorial for running this kernel with Docker. [This one](https://sumdoc.wordpress.com/2018/01/04/using-perl-6-notebooks-in-binder/) describes using [Binder](https://mybinder.org/).
## EXAMPLES
The <eg/> directory of this repository has some
example notebooks:
* [Hello, world](eg/hello-world.ipynb).
* [Generating an SVG](eg/svg.ipynb).
* [Some unicodey math examples](http://nbviewer.jupyter.org/github/bduggan/p6-jupyter-kernel/blob/master/eg/math.ipynb)
* [magics](http://nbviewer.jupyter.org/github/bduggan/p6-jupyter-kernel/blob/master/eg/magics.ipynb)
## SEE ALSO
* [Docker image for Raku](https://hub.docker.com/r/sumankhanal/raku-notebook/)
* [iperl6kernel](https://github.com/timo/iperl6kernel)
## KNOWN ISSUES
* Newly declared methods might not be available in autocompletion unless SPESH is disabled (see tests in [this PR](https://github.com/bduggan/p6-jupyter-kernel/pull/11)).
## THANKS
Matt Oates
Suman Khanal
Timo Paulssen
Tinmarino
Anton Antonov
## FOOTNOTES
¹ Jupyter clients are user interfaces to interact with an interpreter kernel like `Jupyter::Kernel`.
Jupyter [Lab | Notebook | Console | QtConsole ] are the jupyter maintained clients.
More info in the [jupyter documentations site](https://jupyter.org/documentation).
² mybinder.org provides a way to instantly launch a Docker image and open a notebook.
|
## dist_github-peelle-Finance-CompoundInterest.md
# Finance::CompoundInterest
Subroutines for calculating compound interest.
2018 Update: While I still find the below documentation more fun to read that strictly facts documentation, I wanted to disclose I did make money, but no where near my my predictions.
# SYNOPSIS
I started a Lending Club account. While waiting on it to open I thought, What if I put in $5000, and assume I will make the minimum 6%? I can leave it alone and just come back after those three year notes done. What will that look like?
```
use Finance::CompoundInterest;
say compound_interest
5000, # My initial payment, or principal
.005, # Since it compounds monthly and that 6% really means yearly, it should be .06 / 12
36, # Number of months we expect it to compound.
3; # At year 3 how will this look.
```
> 5075.56003652364
Well that's kinda cruddy. I can't retire to the Bahamas on that. I can't own a luxury yacht with a butler. Oh wait, for that matter I don't actually have $5K lying around. I live paycheck to paycheck like most everyone else I know.
What if I throw $150 a month into it, every month, for the next three years. How is it gonna look then?
```
say compound_interest_with_payments
150, # $150 every month.
.005, # I wish that was .06 monthly
36; # Number of months we expect it to compound.
```
> 5900.41574470244
Woohoo! I already out performed the first one! Using some multiplication and subtraction, I can see that I put in a little more money $5400, but I got way more interest out. $500 in interest. ChaChing!
What is this gonna look like if I can keep it up until I am 75? Lets see I'm 32 now, so I got another 43 years.
```
say compound_interest_with_payments
150, # $150 every month.
.005, # .06 / 12
43 * 12; # Number of months we expect it to compound.
```
> 363377.142315735
Now that is a chunk of change, and I only put in $1,800 a year.
But wait, I am a programmer. I am totally smarter than all those other guys that use their gut to choose stocks, loans, ponies, etc. I can use ~~spread sheets~~ databases, to comb through the data and make better choices.
Lending Club says their returns are between 6% and 10%. Lets assume I can hit that 10% mark. How many payment periods will it take me to get to the same dollar amount?
```
say ciwp_payment_period
363377, # Final amount.
.0083, # We gotz skillz. 10% anually.
150; # Monthly payments.
```
> 368.944160846191
Sweet, so I went from 516(43x12) contributions to 369(30.75x12). Sweet, almost 13 years saved! I knew learning ~~spread sheets~~ databases would pay off someday.
Hold on, not only am I a programmer, but I am a proper lazy Perl programmer. I don't wanna be working until I am 75, or 63! I wanna go live on that island, programming Perl, and sipping Mojitos sooner rather than later.
How much $$ do I need to put in to get this done in 20 years at age 52? Just over the hill, and out the door.
```
say ciwp_payment_size
363377, # Final amount.
.0083, # Interest.
20 * 12; # Number of months we want it to compound.
```
> 481.012899065815
About $481 a month? That's a bit rough, but doable. Island life is the life for me!
# DESCRIPTION
* **I am not a certified financial anything. Use at your own ruination.**
These modules were created to scratch my own itch. They do some simple financial calculations related to compound interest, so I can count my imaginary money.
# CAVEATS
* I am **not** a certified financial anything. Use at your own financial risk.
* My example calculations do not take into account any of that real world stuff, like taxes, fees, risk, giant spiders, or economic collapse.
# BUGS
* Did I mention that I am not a certified financial person? Double check me and submit patches. :).
* This uses the built in Rat data type. The Perl 6 tutorial said limited precision.
# TODO/HELP PLEASE
* To return the interest rate, given a final amount, payments, and periods.
* Add a formula where starting amount and periodic payments differ.
* Add a formula where payments more or less frequently added than the interest compounds.
* Add in other types of compound interest formulas.
* Make it more Perl6-ey
# AUTHOR
James (Jeremy) Carman [[email protected]](mailto:[email protected])
# ACKNOWLEDGEMENTS
This README is shamelessly based on other Perl6 modules. So is my module layout, tests, and other not code files. Thank you for figuring this out first so I didn't have to.
|
## contains.md
contains
Combined from primary sources listed below.
# [In Str](#___top "go to top of document")[§](#(Str)_method_contains "direct link")
See primary documentation
[in context](/type/Str#method_contains)
for **method contains**.
```raku
multi method contains(Str:D: Cool:D $needle, :i(:$ignorecase), :m(:$ignoremark) --> Bool:D)
multi method contains(Str:D: Str:D $needle, :i(:$ignorecase), :m(:$ignoremark) --> Bool:D)
multi method contains(Str:D: Regex:D $needle --> Bool:D)
multi method contains(Str:D: Cool:D $needle, Int(Cool:D) $pos, :i(:$ignorecase), :m(:$ignoremark) --> Bool:D)
multi method contains(Str:D: Str:D $needle, Int:D $pos, :i(:$ignorecase), :m(:$ignoremark) --> Bool:D)
multi method contains(Str:D: Regex:D $needle, Int:D $pos --> Bool:D)
multi method contains(Str:D: Regex:D $needle, Cool:D $pos --> Bool:D)
```
Given a `Str` invocant (known as the *haystack*) and a first argument (known as the `$needle`), it searches for the `$needle` in the *haystack* from the beginning of the string and returns `True` if `$needle` is found. If the optional parameter `$pos` is provided, then `contains` will search the *haystack* starting from `$pos` characters into the string.
```raku
say "Hello, World".contains('Hello'); # OUTPUT: «True»
say "Hello, World".contains('hello'); # OUTPUT: «False»
say "Hello, World".contains('Hello', 1); # OUTPUT: «False»
say "Hello, World".contains(','); # OUTPUT: «True»
say "Hello, World".contains(',', 3); # OUTPUT: «True»
say "Hello, World".contains(',', 10); # OUTPUT: «False»
```
In the first case, `contains` searches for the `'Hello'` string on the invocant right from the start of the invocant string and returns `True`. In the third case, the `'Hello'` string is not found since we have started looking from the second position (index 1) in `'Hello, World'`.
Since Rakudo version 2020.02, the `$needle` can also be a [`Regex`](/type/Regex) in which case the `contains` method quickly returns whether the regex matches the string at least once. No [`Match`](/type/Match) objects are created, so this is relatively fast.
```raku
say 'Hello, World'.contains(/\w <?before ','>/); # OUTPUT: «True»
say 'Hello, World'.contains(/\w <?before ','>/, 5); # OUTPUT: «False»
```
Since Rakudo version 2020.02, if the optional named parameter `:ignorecase`, or `:i`, is specified, the search for `$needle` ignores the distinction between uppercase, lowercase, and titlecase letters.
```raku
say "Hello, World".contains("world"); # OUTPUT: «False»
say "Hello, World".contains("world", :ignorecase); # OUTPUT: «True»
```
Since Rakudo version 2020.02, if the optional named parameter `:ignoremark`, or `:m`, is specified, the search for `$needle` only considers base characters, and ignores additional marks such as combining accents.
```raku
say "abc".contains("ä"); # OUTPUT: «False»
say "abc".contains("ä", :ignoremark); # OUTPUT: «True»
```
Note that because of how a [`List`](/type/List) or [`Array`](/type/Array) is [coerced](/type/List#method_Str) into a `Str`, the results may sometimes be surprising.
```raku
say <Hello, World>.contains('Hello'); # OUTPUT: «True»
say <Hello, World>.contains('Hello', 0); # OUTPUT: «True»
say <Hello, World>.contains('Hello', 1); # OUTPUT: «False»
```
See [traps](/language/traps#Lists_become_strings,_so_beware_.contains()).
# [In Cool](#___top "go to top of document")[§](#(Cool)_method_contains "direct link")
See primary documentation
[in context](/type/Cool#method_contains)
for **method contains**.
```raku
method contains(Cool:D: |c)
```
Coerces the invocant to a [`Str`](/type/Str), and calls [`Str.contains`](/type/Str#method_contains) on it. Please refer to that version of the method for arguments and general syntax.
```raku
say 123.contains("2")# OUTPUT: «True»
```
Since [`Int`](/type/Int) is a subclass of `Cool`, `123` is coerced to a [`Str`](/type/Str) and then `contains` is called on it.
```raku
say (1,1, * + * … * > 250).contains(233)# OUTPUT: «True»
```
[`Seq`](/type/Seq)s are also subclasses of `Cool`, and they are stringified to a comma-separated form. In this case we are also using an [`Int`](/type/Int), which is going to be stringified also; `"233"` is included in that sequence, so it returns `True`. Please note that this sequence is not lazy; the stringification of lazy sequences does not include each and every one of their components for obvious reasons.
|
## redeclaration.md
class X::Redeclaration
Compilation error due to declaring an already declared symbol
```raku
class X::Redeclaration does X::Comp { }
```
Thrown when a symbol (variable, routine, type, parameter, ...) is redeclared. Note that redeclarations are generally fine in an inner scope, but if the redeclaration appears in the same scope as the original declaration, it usually indicates an error and is treated as one.
Examples
```raku
my $x; my $x;
```
dies with
「text」 without highlighting
```
```
===SORRY!===
Redeclaration of symbol $x
```
```
It works with routines too:
```raku
sub f() { }
sub f() { }
```
dies with
「text」 without highlighting
```
```
===SORRY!===
Redeclaration of routine f
```
```
But those are fine
```raku
my $x;
sub f() {
my $x; # not a redeclaration,
# because it's in an inner scope
sub f() { }; # same
}
```
# [Methods](#class_X::Redeclaration "go to top of document")[§](#Methods "direct link")
## [method symbol](#class_X::Redeclaration "go to top of document")[§](#method_symbol "direct link")
Returns the name of the symbol that was redeclared.
## [method what](#class_X::Redeclaration "go to top of document")[§](#method_what "direct link")
Returns the kind of symbol that was redeclared. Usually `symbol`, but can also be `routine`, `type` etc.
## [method postfix](#class_X::Redeclaration "go to top of document")[§](#method_postfix "direct link")
Returns a string that is attached to the end of the error message. It usually explains the particular problem in more detail, or suggests way to fix the problem.
|
## dist_zef-raku-community-modules-DBIish.md
# NAME
DBIish - a simple database interface for Raku
# SYNOPSIS
```
use v6;
use DBIish;
my $dbh = DBIish.connect("SQLite", :database<example-db.sqlite3>);
$dbh.execute(q:to/STATEMENT/);
DROP TABLE IF EXISTS nom
STATEMENT
$dbh.execute(q:to/STATEMENT/);
CREATE TABLE nom (
name varchar(4),
description varchar(30),
quantity int,
price numeric(5,2)
)
STATEMENT
$dbh.execute(q:to/STATEMENT/);
INSERT INTO nom (name, description, quantity, price)
VALUES ( 'BUBH', 'Hot beef burrito', 1, 4.95 )
STATEMENT
my $sth = $dbh.prepare(q:to/STATEMENT/);
INSERT INTO nom (name, description, quantity, price)
VALUES ( ?, ?, ?, ? )
STATEMENT
$sth.execute('TAFM', 'Mild fish taco', 1, 4.85);
$sth.execute('BEOM', 'Medium size orange juice', 2, 1.20);
# For one-off execution
$sth = $dbh.execute(q:to/STATEMENT/);
SELECT name, description, quantity, price, quantity*price AS amount
FROM nom
STATEMENT
say $sth.rows; # 3
for $sth.allrows() -> $row {
say $row[0]; # BUBHTAFMBEOM
}
$sth.dispose;
# For efficient multiple execution
$sth = $dbh.prepare('SELECT description FROM nom WHERE name = ?');
for <TAFM BEOM> -> $name {
for $sth.execute($name).allrows(:array-of-hash) -> $row {
say $row<description>;
}
}
$dbh.dispose;
```
# DESCRIPTION
The DBIish project provides a simple database interface for Raku.
It's not a port of the Perl 5 DBI and does not intend to become one.
It is, however, a simple and useful database interface for Raku that works
now. It looks like a DBI, and it talks like a DBI (although it only offers
a subset of the functionality).
## Connecting to, and disconnecting from, a database
You obtain a `DataBaseHandler` by calling the static `DBIish.connect` method, passing
as the only positional argument the driver name followed by any required named arguments.
Those named arguments are driver specific, but commonly required ones are:
`database`, `user` and `password`.
For the different syntactic forms of
[named arguments](https://doc.perl6.org/language/functions#Arguments) see
the language documentation.
For example, for connect to a database 'hierarchy' on PostgreSQL, with the user in `$user`
and using the function `get-secret` to obtain you password, you can:
```
my $dbh = DBIish.connect('Pg', :database<hierarchy>, :$user, password => get-secret());
```
See ahead more examples.
To disconnect from a database and free the allocated resources you should call the
`dispose` method:
```
$dbh.dispose;
```
## Executing queries
### `execute`
For a single execution of a query you may use execute directly. This starts the query within the database and returns
a `StatementHandle` which will be used for [Retrieving Data](#retrieving-data).
```
$dbh.execute(q:to/SQL/);
CREATE TABLE tab (
id serial PRIMARY KEY
col text
);
SQL
```
Errors occurring within the database for an SQL statement will typically throw an exception within Raku. The level of
detail within the exception object depends on the database driver.
```
$dbh.execute('CREATE TABLE failtab ( id );');
CATCH {
when X::DBDish::DBError {
say .message;
}
}
```
In order to build a query dynamically without risk of SQL injection you need to use parameter binding. The `?`
will be replaced by an escaped copy of the parameter provided after the query.
```
my $value-id = 19;
$dbh.execute('INSERT INTO tab (id) VALUES (?)', $value-id);
my $value-text = q{Complex text ' value " with quotes};
$dbh.execute('INSERT INTO tab (id, col) VALUES (?, ?)', $value-id, $value-text);
# Undefined or Nil values will be converted to NULL by parameter binding.
my $value-nil;
$dbh.execute('INSERT INTO tab (id, col) VALUES (?, ?), $value-id, $value-nil);
```
Parameter binding should be used where-ever possible, even if the number of parameters is dynamic. In this case the
number of elements for IN is dynamic. The number of `?`'s is scaled to fit the list of items, and the list
is provided to execute as individual items.
```
my @value-list = 1 .. 6;
my $parameter-bind-marks = @value-list.map({'?'}).join(',') # ?,?,?,?,?,?
my $query = 'SELECT id FROM tab WHERE id IN (%s)'.sprintf($parameter-bind-marks);
$dbh.execute($query, |@value-list);
```
All database drivers support basic Raku types like Int, Rat, Str, and Buf; some databases may support additional
complex types such as an Array of Str or Array of Int which may simplify the above example significantly. Please see
database specific documentation for additional type support.
### `prepare`
Execute performs a couple of steps on the client side, and often the database side as well, which may be cached
if a query is going to be executed several times. For simple queries, prepare() may increase performance by up to 50%
This is an inefficient example of running a query multiple times:
```
for 1 .. 100 -> $id {
$dbh.execute('INSERT INTO tab (id) VALUES (?)', $id);
}
```
This example is more efficient as it uses prepare to decrease overhead on the client side; often on the
server-side too as the database may only need to parse the SQL once.
```
my $sth = $dbh.prepare('INSERT INTO tab (id) VALUES (?)');
for 1 .. 100 -> $id {
$sth.execute($id);
}
```
## Retrieving data
DBIish provides the `row` and `allrows` methods to fetch values from a `StatementHandle` object returned by execute.
These functions provide you typed values; for example an int4 field in the database will be provided as an Int
scalar in Raku.
### `row`
`row` take the `hash` adverb if you want to have the values in a Hash form instead of a plain Array
Example:
```
my $sth = $dbh.execute('SELECT id, col FROM tab WHERE id = ?', $value-id);
my @values = $sth.row();
my %values = $sth.row(:hash);
```
### `allrows`
`allrows` lazily returns all the rows as a list of arrays.
If you want to fetch the values in a hash form, use one of the two adverbs `array-of-hash`
or `hash-of-array`
Example:
```
my $sth = $dbh.execute('SELECT id, col FROM tab');
my @data = $sth.allrows(); # [[1, 'val1'], [3, 'val2']]
my @data = $sth.allrows(:array-of-hash); # [ ( id => 1, col => 'val1'), ( id => 3, col => 'val2') ]
my %data = $sth.allrows(:hash-of-array); # id => [1, 3], col => ['val1', 'val2']
for $sth.allrows(:array-of-hash) -> $row {
say $row<id>; # 13
}
# Or as a shorter example:
for $dbh.execute('SELECT id, col FROM tab').allrows(:array-of-hash) -> $row {
say $row<id> # 13
}
```
### `dispose`
After you have fetched all data using the statement handle, you can free its memory immediately using `dispose`.
```
$sth.dispose;
```
### `server-version`
`server-version` returns a `Version` object for the version of the server you are connected to. Not all drivers support
this function (some may not connect to a server at all) so it's best to wrap in a `can`.
```
my Version $version = $dbh.server-version() if $dbh.can('server-version');
```
## Statement Exceptions
All exceptions for a query result are thrown as or inherit `X::DBDish::DBError`. Additional functionality may
be provided by the database driver.
* `driver-name`
Database Driver name for the connection
* `native-message`
Unmodified message received from the database server.
* `code`
Int return code from the local client library for the call; typically -1. This is not an SQL state.
* `why`
A Str indicating why the exception was thrown. Typically 'Error'.
* `message`
Human friendly and more informative version of the database message.
* `is-temporary`
A Boolean flag which when true indicates that the transaction may succeed if retried. Connectivity issues,
serialization issues and other temporary items may set this as True.
## Advanced Query Building
In general you should use the `?` parameter for substitution whenever possible. The database driver
will ensure values are properly escaped prior to insertion into the database. However, if you need to create
a query string by hand then you can use `quote` to help prevent an SQL injection attack from being successful.
### `quote($literal)` and `quote($identifier, :as-id)`
Using parameter substitution is preferred:
```
my $val = 'literal';
$dbh.execute('INSERT INTO tab VALUES (?)', $val);
```
However, if you must build the query directly you can:
```
my $val = 'literal';
my $query = 'INSERT INTO tab VALUES (%s)'.sprintf( $dbh.quote($val) );
$dbh.execute($query);
```
To build a query with a dynamic identifier:
```
# Notice that C<?> is still used for the value being inserted; it is still recommended where possible.
my $id = 'table';
my $val = 'literal';
my $query = 'INSERT INTO %s VALUES (?)'.sprintf( $dbh.quote($id, :as-id) );
$dbh.execute($query, $val);
```
# INSTALLATION
```
$ zef install DBIish
```
# DBDish CLASSES
Some DBDish drivers install together with DBIish.pm6 and are maintained as a single project.
Search the Raku ecosystem for additional [DBDish](https://modules.raku.org/search/?q=dbdish) drivers such
as [ODBC](https://github.com/salortiz/DBDish-ODBC).
Currently the following backends are included:
## Pg (PostgreSQL)
Supports basic CRUD operations and prepared statements with placeholders
```
my $dbh = DBIish.connect('Pg', :host<db01.yourdomain.com>, :port(5432),
:database<blerg>, :user<myuser>, password => get-secret());
```
Pg supports the following named arguments:
`host`, `hostaddr`, `port`, `database` (or its alias `dbname`), `user`, `password`,
`connect-timeout`, `client-encoding`, `options`, `application-name`, `keepalives`,
`keepalives-idle`, `keepalives-interval`, `sslmode`, `requiressl`, `sslcert`, `sslkey`,
`sslrootcert`, `sslcrl`, `requirepeer`, `krbsrvname`, `gsslib`, and `service`.
See your [PostgreSQL documentation](https://www.postgresql.org/docs/current/libpq-envars.html) for details.
### Parameter Substitution
In addition to the `?` style of parameter substitution supported by all drivers, PostgreSQL also supports numbered
parameter. The advantage is that a numbered parameter may be reused
```
$dbh.execute('INSERT INTO tab VALUES ($1, $2, $2 - $1)', $var1, $var2);
```
This is equivalent to the below statement except the subtraction operation is performed by PostgreSQL:
```
$dbh.execute('INSERT INTO tab VALUES (?, ?, ?)', $var1, $var2, $var2 - $var1);
```
### pg arrays
Pg arrays are supported for both writing via execute and retrieval via `row/allrows`.
You will get the properly typed array according to the field type.
Passing an array to `execute` is now implemented. But you can also use the
`pg-array-str` method on your Pg StatementHandle to convert an Array to a
string Pg can understand:
```
# Insert an array via an execute statement
my $sth = $dbh.execute('INSERT INTO tab (array_column) VALUES ($1);', @data);
# Prepare an insertion of an array field
my $sth = $dbh.prepare('INSERT INTO tab (array_column) VALUES ($1);');
$sth.execute(@data1); # or $sth.execute($sth.pg-array-str(@data1));
$sth.execute(@data2);
# Retrieve the array values back again.
for $dbh.execute('SELECT array_column FROM tab').allrows() -> $row {
my @array-column = $row[0];
}
# Check if "value" is in the dataset. This is similar to an IN statement.
my $sth = $dbh.prepare('SELECT * FROM tab WHERE value = ANY($1)');
$sth.execute(@data);
# If a datatype is needed you can cast the placeholder with the PostgreSQL datatype.
my $sth = $dbh.prepare('SELECT * FROM tab WHERE value = ANY($1::_cidr)');
$sth.execute(['127.0.0.1', '10.0.0.1']);
```
### `pg-consume-input`
Consume available input from the server, buffering the read data if there is any.
This is only necessary if you are planning on calling `pg-notifies` without having
requested input by other means (such as an `execute`.)
### `pg-notifies`
```
$ret = $dbh.pg-notifies;
```
Looks for any asynchronous notifications received and returns a pg-notify object that looks like this
```
class pg-notify {
has Str $.relname; # Channel Name
has int32 $.be_pid; # Backend pid
has Str $.extra; # Payload
}
```
or nothing if there are no pending notifications.
In order to receive the notifications you should execute the PostgreSQL command "LISTEN"
prior to calling `pg-notifies` the first time; if you have not executed any other
commands in the meantime you will also need to execute `pg-consume-input` first.
For example:
```
$dbh.execute("LISTEN foo");
loop {
$dbh.pg-consume-input
if $dbh.pg-notifies -> $not {
say $not;
}
}
```
The payload is optional and will always be an empty string for PostgreSQL servers less than version 9.0.
### `ping`
Test to see if the connection is still considered live.
```
$dbh.ping
```
### Statement Exceptions
Exceptions for a query result are thrown as `X::DBDish::DBError::Pg` objects (inherits `X::DBDish::DBError`)
and have the following additional attributes (described with a `PG_DIAG_*` source name) as provided by the
[PostgreSQL client library libpq](https://www.postgresql.org/docs/current/libpq-exec.html):
* `message`
`PG_DIAG_MESSAGE_PRIMARY` -
The primary human-readable error message (typically one line). Always present.
* `message-detail`
`PG_DIAG_MESSAGE_DETAIL` -
Detail: an optional secondary error message carrying more detail about the problem. Might run to multiple lines.
* `message-hint`
`PG_DIAG_MESSAGE_HINT` -
Hint: an optional suggestion what to do about the problem. This is intended to differ from detail in that it offers advice (potentially inappropriate) rather than hard facts. Might run to multiple lines.
* `context`
`PG_DIAG_CONTEXT` -
An indication of the context in which the error occurred. Presently this includes a call stack traceback of active procedural language functions and internally-generated queries. The trace is one entry per line, most recent first.
* `type`
`PG_DIAG_SEVERITY_NONLOCALIZED` -
The severity; the field contents are ERROR, FATAL, or PANIC (in an error message), or WARNING, NOTICE, DEBUG, INFO, or LOG (in a notice message). This is identical to the PG\_DIAG\_SEVERITY field except that the contents are never localized. This is present only in reports generated by PostgreSQL versions 9.6 and later.
* `type-localized`
`PG_DIAG_SEVERITY` -
The severity; the field contents are ERROR, FATAL, or PANIC (in an error message), or WARNING, NOTICE, DEBUG, INFO, or LOG (in a notice message), or a localized translation of one of these. Always present.
* `sqlstate`
`PG_DIAG_SQLSTATE` -
The SQLSTATE code for the error. The SQLSTATE code identifies the type of error that has occurred; it can be used by front-end applications to perform specific operations (such as error handling) in response to a particular database error. For a list of the possible SQLSTATE codes, see Appendix A. This field is not localizable, and is always present.
* `statement`
Statement provided to prepare() or execute()
* `statement-name`
Statement Name provided to prepare() or created internally
* `statement-position`
`PG_DIAG_STATEMENT_POSITION` -
A string containing a decimal integer indicating an error cursor position as an index into the original statement string. The first character has index 1, and positions are measured in characters not bytes.
* `internal-position`
`PG_DIAG_INTERNAL_POSITION` -
This is defined the same as the `PG_DIAG_STATEMENT_POSITION` field, but it is used when the cursor position refers to an internally generated command rather than the one submitted by the client. The `PG_DIAG_INTERNAL_QUERY` field will always appear when this field appears.
* `internal-query`
`PG_DIAG_INTERNAL_QUERY` -
The text of a failed internally-generated command. This could be, for example, a SQL query issued by a PL/pgSQL function.
* `dbname`
Database Name from libpq `pg-db()`
* `host`
Host from libpq `pg-host()`
* `user`
User from libpq `pg-user()`
* `port`
Port from libpq `pg-port()`
* `schema`
`PG_DIAG_SCHEMA_NAME` -
If the error was associated with a specific database object, the name of the schema containing that object, if any.
* `table`
`PG_DIAG_TABLE_NAME` -
If the error was associated with a specific table, the name of the table. (Refer to the schema name field for the name of the table's schema.)
* `column`
`PG_DIAG_COLUMN_NAME` -
If the error was associated with a specific table column, the name of the column. (Refer to the schema and table name fields to identify the table.)
* `datatype`
`PG_DIAG_DATATYPE_NAME` -
If the error was associated with a specific data type, the name of the data type. (Refer to the schema name field for the name of the data type's schema.)
* `constraint`
`PG_DIAG_CONSTRAINT_NAME` -
If the error was associated with a specific constraint, the name of the constraint. Refer to fields listed above for the associated table or domain. (For this purpose, indexes are treated as constraints, even if they weren't created with constraint syntax.)
* `source-file`
`PG_DIAG_SOURCE_FILE` -
The file name of the source-code location where the error was reported.
* `source-line`
`PG_DIAG_SOURCE_LINE` -
The line number of the source-code location where the error was reported.
* `source-function`
`PG_DIAG_SOURCE_FUNCTION` -
The name of the source-code function reporting the error.
Please see the [PostgreSQL documentation](https://www.postgresql.org/docs/current/static/libpq-exec.html#LIBPQ-PQRESULTERRORFIELD)
for additional information.
A special `is-temporary()` method returns True if an immediate retry of the full transaction should be attempted:
It is set to true when the [SQLState](https://www.postgresql.org/docs/current/static/errcodes-appendix.html)
is any of the following codes:
* SQLState Class 08XXX
All connection exceptions (possible temporary network issues)
* SQLState 40001
serialization\_failure - Two or more transactions conflicted in a manner which may succeed if executed later.
* SQLState 40P01
deadlock\_detected - Two or more transactions had locking conflicts resulting in a deadlock and this transaction being rolled back.
* SQLState Class 57XXX
Operator Intervention (early/forced connection termination).
* SQLState 72000
snapshot\_too\_old - The transaction took too long to execute. It may succeed during a quieter period.
### `pg-socket`
```
my Int $socket = $dbh.pg-socket;
```
Returns the file description number of the connection socket to the server.
## SQLite
Supports basic CRUD operations and prepared statements with placeholders
```
my $dbh = DBIish.connect('SQLite', :database<thefile>);
```
The `:database` parameter can be an absolute file path as well (or even an
`IO::Path` object):
```
my $dbh = DBIish.connect('SQLite', database => '/path/to/sqlite.db' );
```
If the SQLite library was compiled to be threadsafe (which is usually the
case), then it is possible to use SQLite from multiple threads. This can be
introspected:
```
say DBIish.install-driver('SQLite').threadsafe;
```
SQLite does support using one connection object concurrently, however other
databases may not; if portability is a concern, then only use a particular
connection object from one thread at a time (and so have multiple connection
objects).
When using a SQLite database concurrently (from multiple threads, or even
multiple processes), operations may not be able to happen immediately due to
the database being locked. DBIish sets a default timeout of 10000 milliseconds;
this can be changed by passing the `busy-timeout` option to `connect`.
```
my $dbh = DBIish.connect('SQLite', :database<thefile>, :60000busy-timeout);
```
Passing a value less than or equal to zero will disable the timeout, resulting
in any operation that cannot take place immediately producing a database
locked error.
### Function rows()
Since SQLite may retrieve records in the background, the `rows()` method will not be accurate
until all records have been retrieved from the database. A warning is thrown when this may be the case.
This warning message may be suppressed using a `CONTROL` phaser:
```
CONTROL {
when CX::Warn {
when .message.starts-with('SQLite rows()') { .resume }
default { .rethrow }
}
}
```
Making `rows()` accurate for all calls would require the driver pre-retrieving and caching
all records with a large performance and memory penalty, then providing the records as requested.
For best performance you are recommended to use:
```
while my $row = $sth.row {
# Do something with all records as retrieved
}
if my $row = $sth.row {
# Do something with a single record
}
```
## MySQL
Supports basic CRUD operations and prepared statements with placeholders
```
my $dbh = DBIish.connect('mysql', :host<db02.yourdomain.com>, :port(3306),
:database<blerg>, :user<myuser>, :$password);
# Or via socket:
my $dbh = DBIish.connect('mysql', :socket<mysql.sock>,
:database<blerg>, :user<myuser>, :$password);
```
MySQL driver supports the following named arguments:
`connection-timeout`, `read-timeout`, `write-timeout`
See your [MySQL documentation](https://dev.mysql.com/doc/c-api/5.6/en/mysql-options.html) for details.
Since MariaDB uses the same wire protocol as MySQL, the `mysql` backend
also works for MariaDB.
### Statement Exceptions
Exceptions for a query result are thrown as `X::DBDish::DBError::mysql` objects (inherits `X::DBDish::DBError`)
and have the following additional attributes as provided by the MySQL client libraries.
* `message`
`mysql_error` -
The primary human-readable error message (typically one line). Always present.
* `code`
`mysql_errno` -
Integer code. Always present.
* `sqlstate`
`mysql_sqlstate` -
The SQLSTATE code for the error. The SQLSTATE code identifies the type of error that has occurred; it can be used by front-end applications to perform specific operations (such as error handling) in response to a particular database error. For a list of the possible SQLSTATE codes, see Appendix A. This field is not localizable, and is always present.
### Required Client-C libraries
DBDish::mysql by default searches for 'mysql' (libmysql.ddl) on Windows, and
'mariadb' (libmariadb.so.xx where xx in 0 .. 4) then
'mysqlclient' (libmysqlclient.so.xx where xx in 16..21) on POSIX systems.
Remember that Windows uses `PATH` to locate the library. On POSIX,
unversionized `*.so` files installed by "dev" packages aren't needed nor used,
you need the run-time versionized library.
On POSIX you can use the `$DBIISH_MYSQL_LIB` environment variable to request another
client library to be searched and loaded.
Example using the unadorned name:
```
DBIISH_MYSQL_LIB=mariadb rakudo t/25-mysql-common.t
```
Using the absolute path in uninstalled DBIish:
```
DBIISH_MYSQL_LIB=/lib64/libmariadb.so.3 rakudo -t lib t/25-mysql-common.t
```
With MariaBD-Embedded:
```
DBIISH_MYSQL_LIB=mariadbd rakudo -I lib t/01-basic.t
```
### `insert-id`
Returns the AUTO\_INCREMENT value of the most recently inserted record.
```
my $sth = $dbh.execute( 'INSERT INTO tab (description) VALUES (?)', $description );
my $id = $sth.insert-id;
# or
my $id = $dbh.insert-id;
```
## Oracle
Supports basic CRUD operations and prepared statements with placeholders
```
my $dbh = DBIish.connect('Oracle', database => 'XE', :user<sysadm>, :password('secret'));
```
By default connections to Oracle will apply this session alteration in an attempt to
ensure the formatted "TIMESTAMP WITH TIME ZONE" field string will be compatible with DateTime
and returned to the user as DateTime.new($ts\_str).
```
ALTER SESSION SET nls_timestamp_tz_format = 'YYYY-MM-DD"T"HH24:MI:SS.FFTZR'
```
WARNING: This alteration does not include support for these field types. Also until now these
types would have thrown an exception as an unknown TYPE.
```
TIMESTAMP
TIMESTAMP WITH LOCAL TIME ZONE
```
WARNING: Any form of TIMESTAMP(0) will produce a string not compatible with DateTime
due to the ".FF" and the lack of fractional seconds to fulfill it.
You can choose to use this session alteration in an attempt to simplify the use of
ISO-8601 timestamps; strictly speaking, formatted as "YYYY-MM-DDTHH:MI:SSZ"; no offsets
etc shown but Oracle outo converts to GMT(00:00).
This session management forces all client sessions to UTC and sets formats for all DATE
and TIMESTAMP types; it does however sacrifice any fraction seconds TIMESTAMPS may be
storing. It also insures TIMSTAMP(0) works without causing DateTime.new($ts) to fault.
```
DBIish.connect( 'Oracle', :alter-session-iso8601, ... );
ALTER SESSION SET time_zone = '-00:00'
ALTER SESSION SET nls_date_format = 'YYYY-MM-DD"T"HH24:MI:SS"Z"'
ALTER SESSION SET nls_timestamp_format = 'YYYY-MM-DD"T"HH24:MI:SS"Z"'
ALTER SESSION SET nls_timestamp_tz_format = 'YYYY-MM-DD"T"HH24:MI:SS"Z"'
```
WARNING: Preexisting databases that used time zones other than UTC/GMT/-00:00 may need
to convert current timestamps to -00:00 to ensure timestamp correctness. It will depend
on the type of TIMESTAMP used and how Oracle was configured.
NOTICE: By default DBIish lower-cases FIELD names. This is noticed when data is returned
as a hash.
For consumer purists that desire DBIish to leave session management alone, the above
behaviors can be disabled using these options in the connect method. These options will
allow DBIish to most closely behave like Perl5's DBI defaults. These are my personal
favorite settings.
```
:no-alter-session # don't alter session
:no-datetime-container # return the date/timestamps as stings
:no-lc-field-names # return field names unaltered
```
## Threads
I have a long history of using Threads, Oracle and Perl5. I have yet to read any
useful online notes regarding successful usage of Raku, threads & DBIish; I thought
I'd share recent experience.
Since early 2021 I've successfully implemented my Raku solution for using as
many as Eight(8) threads all connected to Oracle performing simultaneous Reads and
writes. As with Perl-5 the number one requirement is to ensure each thread
creates is own connection handle with Oracle. In case you're interested; its
implemented as a layer on top of DBIish that when .enable(N) is used determines
the number of worker threads; each capable to handling reads or writes. The
primary application delegates writes to the workers and reads are asynchronously
delivered where requested. This solution allows the application to stay focused on
it's primary purpose while dedicated writers handle the DB updates.
Regards,
ancient-wizard
# TESTING
The `DBIish::CommonTesting` module, now with over 100 tests, provides a common unit
testing that allows a driver developer to test its driver capabilities and the
minimum expected compatibility.
Set environment variable `DBIISH_WRITE_TEST=YES` to run tests which may leave permanent state changes in the database.
# SEE ALSO
The Raku Pod in the doc:DBIish module and examples in the [examples](https://github.com/raku-community-modules/DBIish/tree/master/examples) directory.
This README and the documentation of the DBIish and the DBDish modules
are in the Pod6 format. It can be extracted by running
```
rakudo --doc <filename>
```
Or, if [Pod::To::HTML](https://metacpan.org/pod/Pod%3A%3ATo%3A%3AHTML) is installed,
```
rakudo --doc=html <filename>
```
Additional modules of interest may include:
* [DBIish::Transaction](https://modules.raku.org/dist/DBIish::Transaction:cpan:RBT)
A wrapper for managing transactions, including automatic retry for temporary failures.
* [DBIish::Pool](https://modules.raku.org/dist/DBIish::Pool:cpan:RBT)
Connection reuse for DBIish to reduce loads on high-volume or heavily encrypted database sessions.
## HISTORY
DBIish is based on Martin Berends' [MiniDBI](https://github.com/mberends/MiniDBI) project, but unlike MiniDBI, DBDish
aims to provide an interface that takes advantage of Raku idioms.
There is/was an intention to integrate with the [DBDI project](http://github.com/timbunce/DBDI)
once it has sufficient functionality.
So, while it is indirectly inspired by [Perl 5 DBI](https://metacpan.org/pod/DBI), there are also many differences.
# COPYRIGHT
Written by Moritz Lenz, based on the MiniDBI code by Martin Berends.
See the [CREDITS](https://github.com/raku-community-modules/DBIish/blob/master/CREDITS) file for a list of all contributors.
# LICENSE
Copyright © 2009-2020, the DBIish contributors
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright notice,
this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS
OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY
WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
POSSIBILITY OF SUCH DAMAGE.
|
## dist_zef-raku-community-modules-Geo-Region.md
[](https://github.com/raku-community-modules/Geo-Region/actions) [](https://github.com/raku-community-modules/Geo-Region/actions) [](https://github.com/raku-community-modules/Geo-Region/actions)
# NAME
Geo::Region - Geographical regions and groupings using UN M.49 and CLDR data
# VERSION
This document describes Geo::Region for Raku, built with Unicode CLDR v26.
# SYNOPSIS
```
use Geo::Region;
use Geo::Region::Enum;
$amer = Geo::Region.new(include => Region::Americas);
$emea = Geo::Region.new(
include => (Region::Europe, Region::WesternAsia, Region::Africa)
);
$apac = Geo::Region.new(
include => (Region::Asia, Region::Oceania),
exclude => Region::WesternAsia,
);
if $amer.contains($country) {
# country is in the Americas (US, MX, BR, etc.)
}
elsif $emea.contains($country) {
# country is in Europe, the Middle East, and Africa (FR, SA, ZW, etc.)
}
elsif $apac.contains($country) {
# country is in Asia-Pacific (JP, TH, AU, etc.)
}
```
# DESCRIPTION
The `Geo::Region` class is used to create geographical regions and groupings of subregions and countries. Default regional groupings are provided using the [Unicode CLDR v26 Territory Containment](https://unicode.org/cldr/charts/26/supplemental/territory_containment_un_m_49.html) data, which is an extension of the United Nations [UN M.49 (Rev.3)](https://unstats.un.org/unsd/methods/m49/m49regin.htm) standard.
## Regions
Regions and subregions are represented with UN M.49 region codes, such as **419** for Latin America and **035** for Southeast Asia. Either the official format using a three-digit `0`-padded string like `'035'` or an integer like `35` may be used with this class. Note when using the `0`-padded format that it must be quoted as a string so as not to be treated as on octal literal.
The CLDR also adds two additional two-letter region codes which are supported: **EU** for the European Union and **QO** for Outlying Oceania. These region codes are all available as enumerations in Geo::Region::Enum.
## Countries
Countries and territories are represented with ISO 3166-1 alpha-2 country codes, such as **JP** for Japan and **AQ** for Antarctica, and are case insensitive. Unlike with region codes, the three-digit forms of country codes are not currently supported, nor are three-letter codes. The deprecated code **UK** for the United Kingdom is supported as an alias of the official code **GB**.
## Constructor
The `new` class method is used to construct a Geo::Region object along with the `include` argument and optional `exclude` argument.
### include
Accepts either a single region code or an array reference of region or country codes to be included in the resulting custom region.
```
# countries in the European Union (EU)
Geo::Region.new(include => Region::EuropeanUnion);
# countries in Asia (142) plus Russia (RU)
Geo::Region.new(include => (Region::Asia, Country::Russia));
```
### exclude
Accepts values in the same format as `include`. This can be used to exclude countries or subregions from a region.
```
# countries in Europe (150) which are not in the European Union (EU)
Geo::Region.new(
include => Region::Europe,
exclude => Region::EuropeanUnion,
);
```
## Methods
### contains
Given a country or region code, determines if the region represented by the Geo::Region instance contains it.
```
if $region.contains($country) {
```
### is-within
Given a region code, determines if all the countries and regions represented by the Geo::Region instance are within it.
```
if $subregion.is-within($region) {
```
### countries
Returns a list of country codes of the countries within the region represented by the Geo::Region instance.
```
for $region.countries -> $country {
```
# SEE ALSO
* [Unicode CLDR: UN M.49 Territory Containment](http://unicode.org/cldr/charts/26/supplemental/territory_containment_un_m_49.html)
* [United Nations: UN M.49 Standard Country, Area, & Region Codes](http://unstats.un.org/unsd/methods/m49/m49regin.htm)
# AUTHOR
Nova Patch
# COPYRIGHT AND LICENSE
Copyright 2014 - 2018 Nova Patch
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the same terms as Raku itself.
|
## dist_zef-tbrowder-Mi6-Helper.md
[](https://github.com/tbrowder/Mi6-Helper/actions) [](https://github.com/tbrowder/Mi6-Helper/actions) [](https://github.com/tbrowder/Mi6-Helper/actions)
# NAME
**Mi6::Helper** - Creates a base repository for a new Raku module managed by **App::Mi6**
# SYNOPSIS
This module installs a Raku executable named `mi6-helper` which is designed for the following operation:
```
$ mi6-helper new=Foo::Bar
```
That creates a new module named `Foo::Bar` in the current directory (or a specified directory if the option `dir=/path` is used). The new module is then ready to be enhanced and managed by app `mi6` to easily build build documentation, run tests, and release new versions.
Run `mi6-helper` without arguments to see its help screen showing its options:
```
Usage: mi6-helper <mode> [options...]
Modes:
new=X - Creates a new module (named 'X') in the current directory
by executing 'mi6', then modifying files and adding new
files in the new repository to add the benefits produced
by this module. NOTE: The program will abort if directory
'X' exists.
Options:
dir=P - Selects directory 'P' as the parent directory for the
operations (default is '.', the current directory, i.e.,
'$*CWD').
force - Allows the program to continue without a hidden file
and bypass the prompt/response dialog.
```
# DESCRIPTION
The installed program, `mi6-helper`, enables easy creation of a template for a new Raku module repository for management by `App::Mi6`. It does that by first executing `mi6` to create the base module and then modifying the result to add new capabilities. (Note the directory for module 'X::Y-Z' will be 'P/X-Y-Z'. See details in the README.)
Note when `mi6` creates its files, it shows text in the `README.md` file as 'Foo::Bar - blah blah blah'. That can be changed to a brief summary statement by creating a hidden file in the parent directory with the same name as the new diretory. For example, new module `Foo::Bar` will be created in a new directory `Foo-Bar`. You can create hidden file `.Foo-Bar` and put any text desired in it. The author typically puts in text something like this:
```
Provides routines to check existing module base repositories for errors.
```
If the hidden file does not exist, the user will be asked if he or she wishes to continue without it. If the answer is `yes`, then the program will continue and the "blah blah blah" will remain. If the answer is `no`, the program will terminate. (Note the program will wait indefinitely for a response, so you should use option "force" if you are testing or otherwise executing the program apart from a terminal inteface.)
## Post repository creation
The changes and additions in your new repository include:
1. Modifying the `dist.ini` file for the enhancements
2. User choice of the brief descriptive text (recommended, but not required)
3. `README.md` file source placed in a new `docs/README.rakudoc` file so you can update your docs using Rakupod instead of Markdown (convert to updated Markdown by running `mi6 build`).
4. Using three separate OS tests in `.github/workflows`: shows results of each in the now auto-generated `README.md` file
5. Publishing in the **Zef** Raku module ecosystem (now standard with the current `mi6`)
**NOTE**: If one of the non-Linux OS tests fail during remote testing on Github, you can eliminate that test by doing the following two steps (for example, remove the `windows` test which is the most likely to fail):
* Move the `windows.yml` file out of the `.github/workflows/` directory (the author uses a subdir named `dev` to hold such things).
* Put a semicolon in the `dist.ini` file to comment out the line naming the `windows.yml` file.
## Modified files for the repository
In addition to those changes, the README is converted to a Rakudoc file in a new `./docs/` directory. Then the `dist.ini` file is modified to create the `README.md` file in the base directory. Both files are placed under `git` control.
See [RepoChanges](RepoChanges.md) for full details of each changed line from the original created by `App::Mi6`.
See published module `Foo::Bar` for an example of a module created by `mi6-helper`.
## Special installation requirements
The user must install and have an account with `fez` to use this module to create a new module repository. To do that:
```
zef install fez
fez register
```
## Define the branch `git origin`
The author uses and recommends **GitHub** for the `git origin` for your new module's repository.
A short list of steps to define such for our example 'Foo::Bar':
1. Define a new repo on GitHub named 'Foo-Bar' (note no '::' separator)
2. On your computer, use the shell terminal to run these commands (for Linux or MacOS):
$ cd /path/to/some-parent-dir
$ mi6-helper new=Foo::Bar
The new repository should be created with a branch name per your personal settings for the Git default branch name (I use 'main' here). This is the output:
```
Getting description text from hidden file '.Foo-Bar'
[main (root-commit) 30a8b25] 'initial'
12 files changed, 431 insertions(+)
create mode 100644 .github/workflows/linux.yml
create mode 100644 .github/workflows/macos.yml
create mode 100644 .github/workflows/windows.yml
create mode 100644 .gitignore
create mode 100644 Changes
create mode 100644 LICENSE
create mode 100644 META6.json
create mode 100644 README.md
create mode 100644 dist.ini
create mode 100644 docs/README.rakudoc
create mode 100644 lib/Foo/Bar.rakumod
create mode 100644 t/0-load-test.rakutest
Using directory '/path/to/some-parent-dir'
as the working directory.
Exit after 'new' mode run. See new module repo 'Foo-Bar'
in parent dir '/path/to/some-parent-dir'.
```
At this point, execute the following commands to define the origin and push the new branch to the repo awaiting it on GitHub:
```
# GitHub shows this choice: ...or push an existing repository from the command line...
# We follow those instructions with our fresh 'Foo::Bar' repo:
$ git remote add origin [email protected]:user/Foo-Bar.git
$ git branch -M main
$ git push -u origin main
```
## See also
A new, in-work [App::DistroLint](https://github.com/tbrowder/App-DistroLint) by the author.
# AUTHOR
Tom Browder [[email protected]](mailto:[email protected])
# CREDITS
The very useful Raku modules used herein:
* [`App::Mi6`](https://github.com/skaji/mi6) by **zef:skaji**
* [`File::Directory::Tree`](https://github.com/labster/p6-file-directory-tree) by **github:labster**
* [`File::Temp`](https://github.com/raku-community-modules/File-Temp) by **zef:rbt**
* [`Proc::Easier`](https://github.com/sdondley/Proc-Easier) by **zef:sdondley**
* [`File::Find`](https://github.com/raku-community-modules/File-Find) by **zef:raku-community-modules**
* [`MacOS::NativeLib`](https://github.com/lizmat/MacOS-NativeLib) by **zef:lizmat**
# COPYRIGHT AND LICENSE
© 2020-2025 Tom Browder
This library is free software; you may redistribute it or modify it under the Artistic License 2.0.
|
## dist_github-ALANVF-LLVM.md
# Raku-LLVM
Raku bindings for the LLVM that go beyond the C API (like it uses raku stuff).
Make sure that you have LLVM 7 installed (for now at least).
Todo:
* Add more examples.
* Add helper constructs/functions (such as an if/else function for `Builder`s).
* Add documentation (might use POD6 or pages idk).
* Add (at least a few) tests.
|
## tap.md
tap
Combined from primary sources listed below.
# [In Supply](#___top "go to top of document")[§](#(Supply)_method_tap "direct link")
See primary documentation
[in context](/type/Supply#method_tap)
for **method tap**.
```raku
method tap(Supply:D: &emit = -> $ { },
:&done = -> {},
:&quit = -> $ex { $ex.throw },
:&tap = -> $ {} )
```
Creates a new tap (a kind of subscription if you will), in addition to all existing taps. The first positional argument is a piece of code that will be called when a new value becomes available through the `emit` call.
The `&done` callback can be called in a number of cases: if a supply block is being tapped, when a `done` routine is reached; if a supply block is being tapped, it will be automatically triggered if the supply block reaches the end; if the `done` method is called on the parent [`Supplier`](/type/Supplier) (in the case of a supply block, if there are multiple Suppliers referenced by `whenever`, they must all have their `done` method invoked for this to trigger the `&done` callback of the tap as the block will then reach its end).
The `&quit` callback is called if the tap is on a supply block which exits with an error. It is also called if the `quit` method is invoked on the parent [`Supplier`](/type/Supplier) (in the case of a supply block any one [`Supplier`](/type/Supplier) quitting with an uncaught exception will call the `&quit` callback as the block will exit with an error). The error is passed as a parameter to the callback.
The `&tap` callback is called once the [`Tap`](/type/Tap) object is created, which is passed as a parameter to the callback. The callback is called ahead of `emit`/`done`/`quit`, providing a reliable way to get the [`Tap`](/type/Tap) object. One case where this is useful is when the `Supply` begins emitting values synchronously, since the call to `.tap` won't return the [`Tap`](/type/Tap) object until it is done emitting, preventing it from being stopped if needed.
Method `tap` returns an object of type [`Tap`](/type/Tap), on which you can call the `close` method to cancel the subscription.
```raku
my $s = Supply.from-list(0 .. 5);
my $t = $s.tap(-> $v { say $v }, done => { say "no more ticks" });
```
Produces:
「text」 without highlighting
```
```
0
1
2
3
4
5
no more ticks
```
```
|
## dist_cpan-TITSUKI-Algorithm-ZhangShasha.md
[](https://travis-ci.org/titsuki/raku-Algorithm-ZhangShasha)
# NAME
Algorithm::ZhangShasha - Tree edit distance between trees
# SYNOPSIS
```
use Algorithm::ZhangShasha;
my class SimpleHelper does Algorithm::ZhangShasha::Helpable[Algorithm::ZhangShasha::Node] {
method delete-cost(Algorithm::ZhangShasha::Node $this --> Int) {
1;
}
method insert-cost(Algorithm::ZhangShasha::Node $another --> Int) {
1;
}
method replace-cost(Algorithm::ZhangShasha::Node $this, Algorithm::ZhangShasha::Node $another --> Int) {
$another.content eq $this.content ?? 0 !! 1;
}
method children(Algorithm::ZhangShasha::Node $node) {
$node.children
}
}
my constant $ZN = 'Algorithm::ZhangShasha::Node';
my $root1 = ::($ZN).new(:content("f"))\
.add-child(::($ZN).new(:content("d"))\
.add-child(::($ZN).new(:content("a")))\
.add-child(::($ZN).new(:content("c"))\
.add-child(::($ZN).new(:content("b")))\
)\
)\
.add-child(::($ZN).new(:content("e")));
my $root2 = ::($ZN).new(:content("f"))\
.add-child(::($ZN).new(:content("c"))\
.add-child(::($ZN).new(:content("d"))\
.add-child(::($ZN).new(:content("a")))\
.add-child(::($ZN).new(:content("b")))\
)\
)\
.add-child(::($ZN).new(:content("e")));
my Algorithm::ZhangShasha::Tree[Algorithm::ZhangShasha::Node] $tree1 .= new(:root($root1), :helper(SimpleHelper.new));
my Algorithm::ZhangShasha::Tree[Algorithm::ZhangShasha::Node] $tree2 .= new(:root($root2), :helper(SimpleHelper.new));
say $tree1.tree-distance($tree2).key; # 2
say $tree1.tree-distance($tree2).value; # ({op => KEEP, pair => 1 => 1} {op => KEEP, pair => 2 => 2} {op => DELETE, pair => 3 => 2} {op => KEEP, pair => 4 => 3} {op => INSERT, pair => 4 => 4} {op => KEEP, pair => 5 => 5} {op => KEEP, pair => 6 => 6})
```
# DESCRIPTION
Algorithm::ZhangShasha is an implementation for efficiently computing tree edit distance between trees.
## METHODS of Algorithm::ZhangShasha::Tree
### BUILD
Defined as:
```
submethod BUILD(NodeT :$!root!, Algorithm::ZhangShasha::Helpable :$!helper!)
```
Creates an `Algorithm::ZhangShasha::Tree` instance.
* `$!root` is the root node of the tree
* `$!helper` is the helper class that implements four methods: `delete-cost`, `insert-cost`, `replace-cost`, `children`. If you want to combine 3rd-party node representation (e.g., `DOM::Tiny`), you should define a custom helper. (See `t/01-basic.t`. It implements an exmple for `DOM::Tiny`.)
### size
Defined as:
```
method size(--> Int)
```
Returns the size of the tree.
### tree-distance
Defined as:
```
method tree-distance(Algorithm::ZhangShasha::Tree $another --> Pair)
```
Returns a `Pair` instance that has the optimal edit distance and the corresponding operations (e.g., DELETE(3,2)) between the two trees. Where `.key` has the distance and `.value` has the operations.
# AUTHOR
Itsuki Toyota [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2020 Itsuki Toyota
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
This algorithm is from
* [0] Zhang, Kaizhong, and Dennis Shasha. "Simple fast algorithms for the editing distance between trees and related problems." SIAM journal on computing 18.6 (1989): 1245-1262.
|
## dist_zef-jforget-Date-Calendar-Persian.md
# NAME
Date::Calendar::Persian - Conversions from / to the Persian calendar
# SYNOPSIS
Converting a Gregorian date (e.g. 16th February 2021) into Persian
```
use Date::Calendar::Persian;
my Date $dt-greg;
my Date::Calendar::Persian $dt-persian;
$dt-greg .= new(2021, 2, 16);
$dt-persian .= new-from-date($dt-greg);
say $dt-persian;
# --> 1399-11-28
say $dt-persian.strftime("%A %d %B %Y");
# --> Se shanbe 28 Bahman 1399
```
Converting a Persian date (e.g. 1 Farvardin 1400) into Gregorian
```
use Date::Calendar::Persian;
my Date::Calendar::Persian $dt-persian;
my Date $dt-greg;
$dt-persian .= new(year => 1400, month => 1, day => 1);
$dt-greg = $dt-persian.to-date;
say $dt-greg;
# --> 2021-03-21
```
# DESCRIPTION
Date::Calendar::Persian is a class representing dates in the Persian
calendar. It allows you to convert a Persian date into Gregorian or
into other implemented calendars, and it allows you to convert dates
from Gregorian or from other calendars into Persian.
The Date::Calendar::Persian class gives the arithmetic version of the
Persian calendar. The astronomic Persian calendar is partially
implemented in Date::Calendar::Persian::Astronomical, included in this
distribution.
# INSTALLATION
```
zef install Date::Calendar::Persian
```
or
```
git clone https://github.com/jforget/raku-Date-Calendar-Persian.git
cd raku-Date-Calendar-Persian
zef install .
```
# AUTHOR
Jean Forget
# COPYRIGHT AND LICENSE
Copyright (c) 2021, 2024 Jean Forget, all rights reserved.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-japhb-CBOR-Simple.md
[](https://github.com/japhb/CBOR-Simple/actions)
# NAME
CBOR::Simple - Simple codec for the CBOR serialization format
# SYNOPSIS
```
use CBOR::Simple;
# Encode a Raku value to CBOR, or vice-versa
my $cbor = cbor-encode($value);
my $val1 = cbor-decode($cbor); # Fails if more data past first decoded value
my $val2 = cbor-decode($cbor, my $pos = 0); # Updates $pos after decoding first value
# By default, cbor-decode() marks partially corrupt parsed structures with
# Failure nodes at the point of corruption
my $bad = cbor-decode(buf8.new(0x81 xx 3)); # [[[Failure]]]
# Callers can instead force throwing exceptions on any error
my $*CBOR_SIMPLE_FATAL_ERRORS = True;
my $bad = cbor-decode(buf8.new(0x81 xx 3)); # BOOM!
# Decode CBOR into diagnostic text, used for checking encodings and complex structures
my $diag = cbor-diagnostic($cbor);
# Force the encoder to tag a value with a particular tag number
my $tagged = CBOR::Simple::Tagged.new(:$tag-number, :$value);
my $cbor = cbor-encode($tagged);
```
# DESCRIPTION
`CBOR::Simple` is an easy-to-use implementation of the core functionality of the [CBOR serialization format](https://cbor.io/), implementing the standard as of [RFC 8949](https://tools.ietf.org/html/rfc8949), plus a collection of common tag extensions as described below in [TAG IMPLEMENTATION STATUS](#tag-implementation-status).
## PERFORMANCE
`CBOR::Simple` is one of the fastest data structure serialization codecs available for Raku. It is comparable in round-trip speed to `JSON::Fast` for data structures that are the most JSON-friendly. For all other cases tested, `CBOR::Simple` produces smaller, higher fidelity encodings, faster. For more detail, and comparison with other Raku serialization codecs, see [serializer-perf](https://github.com/japhb/serializer-perf).
## NYI
Currently known NOT to work:
* Any tag marked '✘' (valid but not yet supported) or 'D' (deprecated spec) in the ENCODE or DECODE column of the Tag Status Details table below, or any tag not explicitly listed therein, will be treated as an opaque tagged value rather than treated as a native type.
* Packed arrays of 128-bit floats (num128); these are not supported in Rakudo yet.
* Encoding *finite* 16-bit floats (num16); encoding 16-bit NaN and ±Inf, as well as decoding any num16 all work. This is a performance tradeoff rather than a technical limitation; detecting whether a finite num32 can be shrunk to 16 bits without losing information is costly and rarely results in space savings except in trivial cases (e.g. Nums containing only small integers).
## TAG CONTENT STRICTNESS
When encoding, `CBOR::Simple` makes every attempt to encode tagged content strictly within the tag standards as written, always producing spec-compliant encoded values.
When decoding, `CBOR::Simple` will often slightly relax the allowed content types in tagged content, especially when later tag proposals made no change other than to extend the allowed content types and allocate a new tag number for that. In the extension case `CBOR::Simple` is likely to allow both the old and new tag to accept the same content domain when decoding.
For example, when encoding `CBOR::Simple` will always encode `Instant` or `DateTime` as a CBOR epoch-based date/time (tag 1), using standard integer or floating point content data. But when *decoding*, `CBOR::Simple` will accept any content that decodes properly as a Raku `Real` value -- and in particular will handle a CBOR Rational (tag 30) as another valid content type.
## DATE, DATETIME, INSTANT
Raku's builtin time handling is richer than the default CBOR data model (though certain tag extensions improve this), so the following mappings apply:
* Encoding
* `Instant` and `DateTime` are both written as tag 1 (epoch-based date/time) with integer (if lossless) or floating point content.
* Other `Dateish` are written as tag 100 (RFC 8943 days since 1970-01-01).
* Decoding
* Tag 0 (date/time string) is parsed as a `DateTime`.
* Tag 1 (epoch-based date/time) is parsed via `Instant.from-posix()`, and handles any Real type in the tag content.
* Tag 100 (days since 1970-01-01) is parsed via `Date.new-from-daycount()`.
* Tag 1004 (date string) is parsed as a `Date`.
## UNDEFINED VALUES
* CBOR's `null` is translated as `Any` in Raku.
* CBOR's `undefined` is translated as `Mu` in Raku.
* A real `Nil` in an array (which must be *bound*, not assigned) is encoded as a CBOR Absent tag (31). Absent values will be recognized on decode as well, but since array contents are *assigned* into their parent array during decoding, a `Nil` in an array will be translated to `Any` by Raku's array assignment semantics.
## OTHER SPECIAL CASES
* To mark a substructure for lazy decoding (treating it as an opaque `Blob` until explicitly decoded), use the tagged value idiom in the SYNOPSIS with `:tag-number(24)` (encoded CBOR value) or `:tag-number(63)` (encoded CBOR Sequence).
* CBOR strings claiming to be longer than `2⁶³-1` are treated as malformed.
* Bigfloats and decimal fractions (tags 4, 5, 264, 265) with very large exponents may result in numeric overflow when decoded.
* Keys for Associative types are sorted using Raku's internal `sort` method rather than the RFC 8949 default sort, because the latter is much slower.
* `cbor-diagnostic()` always adds encoding indicators for float values.
## TAG IMPLEMENTATION STATUS
Note that unrecognized tags will decode to their contents wrapped with a `CBOR::Simple::Tagged` object that records its `tag-number`; check marks in the details table indicate conversion to/from an appropriate native Raku type rather than this default behavior.
Tag Status Overview: Native Raku Types
| GROUP | SUPPORT | NOTES |
| --- | --- | --- |
| Core | Good | Core RFC 8949 CBOR data model and syntax |
| Collections | Good | Sets, maps with only object or only string keys |
| Graph | NONE | Cyclic, indirected, and self-referential structures |
| Numbers | Good | Rational/BigInt/BigFloat support except non-finite triplets |
| Packed Arrays | Partial | Packed num32/64, [u]int\* arrays full; num16 is read-only |
| Special Arrays | NONE | Explicit multi-dim/homogenous arrays |
| Tag Fallbacks | Good | Round tripping of unknown tagged content |
| Date/Time | Partial | All but tagged time (tags 1001-1003) supported |
Tag Status Overview: Specialty Types
| GROUP | SUPPORT | NOTES |
| --- | --- | --- |
| Encodings | NONE | baseN, MIME, YANG, BER, non-UTF-8 strings |
| Geo | NONE | Geographic coordinates and shapes |
| Identifiers | NONE | URI, IRI, UUID, IPLD CID, general identifiers |
| Networking | NONE | IPv4/IPv6 addresses, subnets, and masks |
| Security | NONE | COSE and CWT |
| Specialty | NONE | IoT data, Openswan, PlatformV, DOTS, ERIS, RAINS |
| String Hints | NONE | JSON conversions, language tags, regex |
Tag Status Details
| SPEC | TAGS | ENCODE | DECODE | NOTES |
| --- | --- | --- | --- | --- |
| RFC 8949 | 0 | → | ✓ | DateTime strings → Encoded as tag 1 |
| RFC 8949 | 1 | ✓ | ✓ | DateTime/Instant |
| RFC 8949 | 2,3 | ✓ | ✓ | (Big) Int |
| RFC 8949 | 4,5 | → | ✓ | Big fractions → Encoded as tag 30 |
| unassigned | 6-15 | | | |
| COSE | 16-18 | ✘ | ✘ | MAC/Signatures |
| unassigned | 19-20 | | | |
| RFC 8949 | 21-23 | ✘ | ✘ | Expected JSON conversion to baseN |
| RFC 8949 | 24 | T | ✓ | Encoded CBOR data item |
| [Lehmann] | 25 | ✘ | ✘ | String backrefs |
| [Lehmann] | 26,27 | ✘ | ✘ | General serialized objects |
| [Lehmann] | 28,29 | ✘ | ✘ | Shareable referenced values |
| [Occil] | 30 | ✓ | ✓ | Rational numbers |
| [Vaarala] | 31 | ✓ | \* | Absent values |
| RFC 8949 | 32-34 | ✘ | ✘ | URIs and base64 encoding |
| RFC 7094 | 35 | D | D | PCRE/ECMA 262 regex (DEPRECATED) |
| RFC 8949 | 36 | ✘ | ✘ | Text-based MIME message |
| [Clemente] | 37 | ✘ | ✘ | Binary UUID |
| [Occil] | 38 | ✘ | ✘ | Language-tagged string |
| [Clemente] | 39 | ✘ | ✘ | Identifier semantics |
| RFC 8746 | 40 | ✘ | ✘ | Row-major multidim array |
| RFC 8746 | 41 | ✘ | ✘ | Homogenous array |
| [Mische] | 42 | ✘ | ✘ | IPLD content identifier |
| [YANG] | 43-47 | ✘ | ✘ | YANG datatypes |
| unassigned | 48-51 | | | |
| draft | 52 | D | D | IPv4 address/network (DEPRECATED) |
| unassigned | 53 | | | |
| draft | 54 | D | D | IPv6 address/network (DEPRECATED) |
| unassigned | 55-60 | | | |
| RFC 8392 | 61 | ✘ | ✘ | CBOR Web Token (CWT) |
| unassigned | 62 | | | |
| [Bormann] | 63 | T | ✓ | Encoded CBOR Sequence |
| RFC 8746 | 64-79 | ✓ | ✓ | Packed int arrays |
| RFC 8746 | 80-87 | \* | ✓ | Packed num arrays (except 128-bit) |
| unassigned | 88-95 | | | |
| COSE | 96-98 | ✘ | ✘ | Encryption/MAC/Signatures |
| unassigned | 99 | | | |
| RFC 8943 | 100 | ✓ | ✓ | Date |
| unassigned | 101-102 | | | |
| [Vidovic] | 103 | ✘ | ✘ | Geo coords |
| [Clarke] | 104 | ✘ | ✘ | Geo coords ref system WKT/EPSG |
| unassigned | 105-109 | | | |
| RFC 9090 | 110-112 | ✘ | ✘ | BER-encoded object ID |
| unassigned | 113-119 | | | |
| [Vidovic] | 120 | ✘ | ✘ | IoT data point |
| unassigned | 121-255 | | | |
| [Lehmann] | 256 | ✘ | ✘ | String backrefs (see tag 25) |
| [Occil] | 257 | ✘ | ✘ | Binary MIME message |
| [Napoli] | 258 | ✓ | ✓ | Set |
| [Holloway] | 259 | T | ✓ | Map with object keys |
| [Raju] | 260-261 | ✘ | ✘ | IPv4/IPv6/MAC address/network |
| [Raju] | 262-263 | ✘ | ✘ | Embedded JSON/hex strings |
| [Occil] | 264-265 | → | \* | Extended fractions -> Encoded as tag 30 |
| [Occil] | 266-267 | ✘ | ✘ | IRI/IRI reference |
| [Occil] | 268-270 | ✘✘ | ✘✘ | Triplet non-finite numerics |
| RFC 9132 | 271 | ✘✘ | ✘✘ | DDoS Open Threat Signaling (DOTS) |
| [Vaarala] | 272-274 | ✘ | ✘ | Non-UTF-8 strings |
| [Cormier] | 275 | T | ✓ | Map with only string keys |
| [ERIS] | 276 | ✘ | ✘ | ERIS binary read capability |
| [Meins] | 277-278 | ✘ | ✘ | Geo area shape/velocity |
| unassigned | 279-1000 | | | |
| [Bormann] | 1001-1003 | ✘ | ✘ | Extended time representations |
| RFC 8943 | 1004 | → | ✓ | → Encoded as tag 100 |
| unassigned | 1005-1039 | | | |
| RFC 8746 | 1040 | ✘ | ✘ | Column-major multidim array |
| unassigned | 1041-22097 | | | |
| [Lehmann] | 22098 | ✘ | ✘ | Hint for additional indirection |
| unassigned | 22099-25440 | | | |
| [Broadwell] | 25441 | ✓ | ✓ | Capture: reference implementation |
| unassigned | 25442-49999 | | | |
| [Tongzhou] | 50000-50011 | ✘✘ | ✘✘ | PlatformV |
| unassigned | 50012-55798 | | | |
| RFC 8949 | 55799 | ✓ | ✓ | Self-described CBOR |
| [Richardson] | 55800 | ✓ | ✓ | Self-described CBOR Sequence |
| unassigned | 55801-65534 | | | |
| invalid | 65535 | | ✓ | Invalid tag detected |
| unassigned | 65536-15309735 | | | |
| [Trammell] | 15309736 | ✘✘ | ✘✘ | RAINS message |
| unassigned | 15309737-1330664269 | | | |
| [Hussain] | 1330664270 | ✘✘ | ✘✘ | CBOR-encoded Openswan config file |
| unassigned | 1330664271-4294967294 | | | |
| invalid | 4294967295 | | ✓ | Invalid tag detected |
| unassigned | ... | | | |
| invalid | 18446744073709551615 | | ✓ | Invalid tag detected |
Tag Table Symbol Key
| SYMBOL | MEANING |
| --- | --- |
| ✓ | Fully supported |
| \* | Supported, but see notes above |
| T | Encoding supported by explicitly tagging contents |
| → | Raku values will be encoded using a different tag |
| D | Deprecated and unsupported tag spec; may eventually be decodable |
| ✘ | Not yet implemented |
| ✘! | Not yet implemented, but already requested |
| ✘? | Not yet implemented, but may be easy to add |
| ✘✘ | Probably won't be implemented in CBOR::Simple |
# AUTHOR
Geoffrey Broadwell [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2021,2025 Geoffrey Broadwell
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-masukomi-XDG-GuaranteedResources.md
# NAME
XDG::GuaranteedResources - Guarantees that a resource is present in the expected XDG Base Directory directory
# SYNOPSIS
First, you need to implement a class that can get resources from within your package. I suggest you copy this, and change the class name. Alas, this is not something that another package like this one can provide.
```
use XDG::GuaranteedResources::AbstractResourcer;
unit class My::Resourcer does XDG::GuaranteedResources::AbstractResourcer;
# for XDG::GuaranteedResources::AbstractResourcer
method fetch-resource(::?CLASS:U:){%?RESOURCES;}
```
Once you've got that, you can just pass it in as the 2nd param to either of the provided methods, or assign it to a variable and pass that in.
```
use XDG::GuaranteedResources;
# pass it the relative path to a file under your resources directory
# path must be listed in the resources array of your META6.json
guarantee-resource("config/my_app/app_config.toml", My::Resourcer);
# assigning your resourcer to a variable is fine.
my $resourcer = My::Resourcer;
# if you have multiple to guarantee you pass a list to the plural form.
guarantee-resources(<config/my_app/app_config.toml data/my_app/cool_database.db>, $resourcer);
```
# DESCRIPTION
Many tools expect a config file, sqlite database, or similar to be present. We store these in the resources listed in `META6.json`, and need to test if they exist and copy them over from `resources` if not.
`XDG::GuaranteedResources` handles this common operation.
For example:
Let's assume your script uses a pre-prepared sqlite db that you store under resources. Store it under `resources/data/my_app/my_database.db`, then when your script boots up you can call `guarantee-resource("data/my_app/my_database.db");`. If that file already exists under `%*ENV<XDG_CONFIG_HOME>/my_app/my_database.db` nothing will happen. If it isn't found there, a fresh copy will be placed there from the one you referenced in `resources`.
Note that `my_app` should be the directory name your apps files should be stored under. For example, a config file for [clu](https://github.com/masukomi/clu) would be stored under `~/.config/clu/` after install. So, you would store it under `resources/config/clu/` in your package.
Resources that should be copied to `XDG_CONFIG_HOME` should be stored under `resources/config/my_app`
Resources that should be copied to `XDG_DATA_HOME` should be stored under `resources/data/my_app`
Subdirectories are fine. E.g. `resources/data/my_app/subdir/my_db.db`
⚠ Currently only works on Unix (Linux, BSD, macOS, etc.) systems.
# AUTHOR
Kay Rhodes a.k.a masukomi ([[email protected]](mailto:[email protected]))
# COPYRIGHT AND LICENSE
Copyright 2022
This library is free software; you can redistribute it and/or modify it under the MIT License.
### multi sub guarantee-resource
```
multi sub guarantee-resource(
Str $resource_path,
$resourcer
) returns Str
```
Guarantees a resource is present & provides the path it can be found at.
### sub guarantee-resources
```
sub guarantee-resources(
@resource_paths,
$resourcer
) returns Array
```
Guarantees a list of resources are present. Returns the paths they can be found at.
|
## community.md
Community
Information about the people working on and using Raku
# [Overview](#Community "go to top of document")[§](#Overview "direct link")
"Perl 5 was my rewrite of Perl. I want Perl 6 to be the community's rewrite of Perl and of the community." - Larry Wall (circa 2000)
"I am in favor of this change [a community driven renaming from Perl 6 to Raku], because it reflects an ancient wisdom: 'No one sews a patch of unshrunk cloth on an old garment, for the patch will pull away from the garment, making the tear worse. Neither do people pour new wine into old wineskins. If they do, the skins will burst; the wine will run out and the wineskins will be ruined. No, they pour new wine into new wineskins, and both are preserved.'" - Larry Wall ([2019](https://github.com/Raku/problem-solving/pull/89#pullrequestreview-300789072))
# [The Raku community](#Community "go to top of document")[§](#The_Raku_community "direct link")
## [Online communities](#Community "go to top of document")[§](#Online_communities "direct link")
[IRC](/language/glossary#IRC) communication has played an integral role in the Raku community for more than a decade. There are various channels for Raku-related activities on `libera.chat`. There are several [bots](/language/glossary#Bot) to make IRC activity more convenient and fun. You can read about IRC content [here](https://raku.org/community/irc/) in greater details.
[The Raku Discord server](https://discord.gg/VzYpdQ6) serves a similar purpose. Thanks to the bridges written by fellow Raku members, it integrates well with the main IRC channels.
[StackOverflow](https://stackoverflow.com/questions/tagged/raku) is also a great resource for asking questions and helping others with their Raku problems and challenges.
More resources can be found in the [raku.org community page](https://raku.org/community/).
## [Offline communities](#Community "go to top of document")[§](#Offline_communities "direct link")
Raku is also a common topic at [Perl conferences](https://www.perl.org/events.html) and [Perl Monger meetings](https://www.pm.org/). If you prefer in-person meetings, these are warmly recommended!
## [Other resources](#Community "go to top of document")[§](#Other_resources "direct link")
[Camelia](https://raku.org/), the multi-color butterfly with P 6 in her wings, is the symbol of this diverse and welcoming community.
# [Rakudo Weekly](#Community "go to top of document")[§](#Rakudo_Weekly "direct link")
Elizabeth Mattijsen usually posts in [the "Rakudo Weekly" blog](https://rakudoweekly.blog/), a summary of Raku posts, tweets, comments and other interesting tidbits. If you want a single resource to know what is going on in the Raku community now, this is your best resource.
Historical articles (pre name change) can be found archived on [the "Perl 6 Weekly" blog](https://p6weekly.wordpress.com/).
# [Raku Advent calendar](#Community "go to top of document")[§](#Raku_Advent_calendar "direct link")
The Raku community publishes every December an [Advent Calendar](https://raku-advent.blog/), with Raku tutorials every day until Christmas. Previous calendars (pre name change) are [still available](https://perl6advent.wordpress.com/) and relevant.
Organization and assignment of days is done through the different Raku channels and the [Raku/advent](https://github.com/Raku/advent) repository. If you want to participate, its organization starts by the end of October, so check out the channels above to keep up to date.
|
## dist_cpan-ASHER-Operator-Listcat.md
# Operator-Listcat
A module that adds operators and methods for merging lists
in a clean way. See:
## [Perl 6 Needs a List Concatenation Op](http://ajs.github.io/tools/perl-6-list-concat-op/)
From that article:
There are three things here:
* The infix operator `listcat` that works as `<a b c> listcat <x y z>` and
returns `<a b c x y z>` but without flattening any further than one level.
* The Unicode alias `⊕` for listcat that evokes the Python (among a small
number of other languages') convention of using
`+` for this purpose without actually muddying the type waters.
* A modification to `List` that adds the `sling` method that performs
a `listcat` between the `List` object that it's called on and its
arguments, returning the unified list.
## Licence
This is free software.
Please see the [LICENCE](LICENSE.md) for the details.
|
## dist_zef-tbrowder-SantaClaus-Utils.md
[](https://github.com/tbrowder/SantaClaus-Utils/actions)
# NAME
**SantaClaus::Utils** - Provides Raku software tools for Santa Claus and his Elves
# SYNOPSIS
```
use SantaClaus::Utils;
add-entry; # adds a journal entry template to the
# user's '$HOME/journal' text file
check-journal; # checks the journal file for correct syntax
```
# DESCRIPTION
The Raku module **SantaClaus::Utils** is used by Santa's staff to create and manage individual task journal entries. It also provide tools to manage as the entire collection of task journals for all Santa's helpers to provide status reports and other reports for Santa and his staff.
# AUTHOR
Tom Browder [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2021 Tom Browder
This library is free software; you may redistribute it or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-Text-LDIF.md
[](https://github.com/raku-community-modules/Text-LDIF/actions) [](https://github.com/raku-community-modules/Text-LDIF/actions) [](https://github.com/raku-community-modules/Text-LDIF/actions)
# NAME
Text::LDIF - Pure Raku LDIF file parser
# SYNOPSIS
```
use Text::LDIF;
my $ldif-content = slurp @*ARGS[0];
my $ldif = Text::LDIF.new;
my $result = $ldif.parse($ldif-content);
if $result {
for $result<entries><> -> $entry {
say "dn -> ", $entry<dn>;
my %attrs = $entry<attrs>;
for %attrs.kv -> $attr, $value {
say "\t$attr ->\t$_" for @$value;
# some further processing for cases of attributes with options,
# base64, file urls, etc
}
say "-" x 40;
}
}
else {
say "Parsing error";
}
```
# DESCRIPTION
`Text::LDIF` is a Raku module for parsing LDIF files according to RFC 2849.
For the end-user, the `Text::LDIF` class is available to use. It has a `parse` method that accepts a `Str` that contains text of LDIF file and returns a structure that describes the file.
# OUTPUT STRUCTURE
LDIF can contain either a description of a number of LDAP entries or a set of changes made to directory entries. In case of LDAP entries description, the parsing result looks this way:
```
{
version => 1, # exact number is parsed from file
entries => [
{
dn => $dn-string,
attrs => {
# For a simple value, just string
attr1 => 'foo',
# For an attribute with many values, a list
attr2 => ['foo', 'baz', 'bar'],
# For base64 string a Pair
attr3 => base64 => 'V2hhdCBh...',
attr-with-opts => { # OPTIONS
'' => 'value-of-just-attr-with-opts',
lang-ja => 'value of attr-with-opts:lang-ja',
lang-ja,phonetic => 'value of attr-with-opts:lang-ja:phonetic',
},
fileattr => file => 'file://foo.jpg', # eternal file url
...
}
},
...
]
}
```
A parsing result of modifications looks this way:
```
{
version => 1,
changes => [
{ # ADD
dn => $dn-string,
change => add => {
attr1 => ...
},
controls => []
},
{ # DELETE
dn => $dn-string,
change => 'delete',
controls => []
},
{ # MODDN
dn => $dn-string,
change => moddn => {
delete-on-rdn => True, # Bool value
newrdn => 'foo=baz',
superior => Any # if not specified
},
controls => []
},
{ # MODIFY
dn => $dn-string,
change => modify => [
add => attr1 => 'attr1-value',
delete => attr2,
replace => attr3 => ['old-value', 'new-value'],
...
],
controls => [ # CONTROLS
{
ldap-oid => '1.2.840...',
criticality => True, # Bool value
value => 'new-foo-value'
},
...
]
},
...
]
}
```
# AUTHOR
* Sylwester Lunski
* Alexander Kiryuhin
# COPYRIGHT AND LICENSE
Copyright 2016 - 2021 Alexander Kiryuhin
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## shift.md
shift
Combined from primary sources listed below.
# [In Independent routines](#___top "go to top of document")[§](#(Independent_routines)_sub_shift "direct link")
See primary documentation
[in context](/type/independent-routines#sub_shift)
for **sub shift**.
```raku
multi shift(@a) is raw
```
Calls method `shift` on the [`Positional`](/type/Positional) argument. That method, on a mutable collection that actually implements it (such as an [`Array`](/routine/shift#(Array)_method_shift) or a [`Buf`](/type/Buf#method_shift)), is supposed to remove and return the first element, or return a [`Failure`](/type/Failure) if the collection is empty.
Example:
```raku
say shift [1,2]; # OUTPUT: «1»
```
```raku
my @a of Int = [1];
say shift @a; # OUTPUT: «1»
say shift @a; # ERROR: «Cannot shift from an empty Array[Int]»
```
# [In Array](#___top "go to top of document")[§](#(Array)_method_shift "direct link")
See primary documentation
[in context](/type/Array#method_shift)
for **method shift**.
```raku
method shift(Array:D:) is nodal
```
Removes and returns the first item from the array. Fails if the array is empty.
Example:
```raku
my @foo = <a b>;
say @foo.shift; # OUTPUT: «a»
say @foo.shift; # OUTPUT: «b»
say @foo.shift;
CATCH { default { put .^name, ': ', .Str } };
# OUTPUT: «X::Cannot::Empty: Cannot shift from an empty Array»
```
# [In role Buf](#___top "go to top of document")[§](#(role_Buf)_method_shift "direct link")
See primary documentation
[in context](/type/Buf#method_shift)
for **method shift**.
```raku
method shift()
```
Removes and returns the first element of the buffer.
```raku
my $bú = Buf.new( 1, 1, 2, 3, 5 );
say $bú.shift(); # OUTPUT: «1»
say $bú.raku; # OUTPUT: «Buf.new(1,2,3,5)»
```
|
## dist_cpan-UZLUISF-Colorizable.md
# Colorizable
A Raku module for colorizing text using ANSI escape codes.
## Synopsis
```
use Colorizable;
my $string = "Hello" but Colorizable;
given $string {
say .colorize: red; # red text
say .colorize: :fg(red); # same as previous
say .red; # same as previous
say .colorize: red, blue; # red text on blue background
say .colorize: :fg(red), :bg(blue); # same as previous
say .red.on-blue; # same as previous
say .colorize: red, blue, bold; # bold red text on blue background
say .colorize: :fg(red), :bg(blue), :mo(bold); # same as previous
say .red.on-blue.bold; # same as previous
}
```
## Installation
From [Raku module ecosystem](https://modules.raku.org/) using `zef`:
```
$ zef install Colorizable
```
From source code:
```
$ git clone https://gitlab.com/uzluisf/raku-colorizable.git
$ cd raku-colorizable/
$ zef install .
```
## Description
The module allows to colorize text using ANSI escape code by composing the `Colorizable` role into a string. After doing this, the method `colorize` can be used to set the text color, background color and text effects (e.g., bold, italic, etc.):
```
use Colorizable;
my $planet = "Arrakis" but Colorizable;
say $planet.colorize(:fg(blue), :bg(red), :mo(bold));
```
If composed into a class, `Colorizable` assumes the class implements the appropriate `Str` method:
```
use Colorizable;
class A does Colorizable {
}
say A.new.colorize(blue); #=> A<94065101711120>, in blue
class B does Colorizable {
method Str { 'Class B' }
}
say B.new.colorize(blue); #=> class B, in blue
```
Invocations to the `colorize` method are chainable:
```
use Colorizable;
my $text = "Bold red text on yellow background" but Colorizable;
say $text
.colorize(:fg(red))
.colorize(:bg(yellow))
.colorize(:mo(bold));
```
Colors and modes can be invoked as methods: `.color` for foreground, `.on-color` for background, and `.mode` for mode given `color` and `mode` respectively:
```
use Colorizable;
my $text = "Bold red text on yellow background" but Colorizable;
say $text.red.on-yellow.bold;
```
To get a list of available colors and modes, use the `colors` and `modes` methods respectively
Although this might not be advisable, you can make regular strings colorizable by augmenting the `Str` class:
```
use Colorizable;
use MONKEY-TYPING;
# making strings colorizable
augment class Str {
also does Colorizable;
}
say "Bold red text on yellow background"
.colorize(:fg(red))
.colorize(:bg(yellow))
.colorize(:mo(bold));
```
Note the use of the pragma [`MONKEY-TYPING`](https://docs.raku.org/language/pragmas#index-entry-MONKEY-TYPING__pragma).
## Methods
# colorize
`method colorize($fg, $bg, $mo)`
Change color of string.
**Examples:**
```
my $str = "Hello" does Colorizable;
say $str.colorize(yellow); # yellow text
say $str.colorize('yellow'); # yellow text
say $str.colorize(blue, red, bold); # bold blue text in red background
```
**Parameters:**
* `$fg` the string's foreground color
* `$bg` the string's background color
* `$mo` the string's mode
# colorize
`method colorize(:fg(:$foreground), :bg(:$background), :mo(:$mode))`
Change color of string.
**Examples:**
```
my $str = "Hello" does Colorizable;
say $str.colorize(:fg(yellow)); # yellow text
say $str.colorize(:foreground('yellow')); # yellow text
say $str.colorize(:fg(blue), :bg(red)); # blue text in red background
```
**Parameters:**
* `$fg` the string's foreground color
* `$bg` the string's background color
* `$mo` the string's mode
# colors
`method colors(--> List)`
Return list of available colors as allomorphs. By default, the `IntSt` values for the foreground are returned. To return the values for the background, pass the Boolean named argument `bg` (or `background`).
**Examples:**
```
my $str = "Hello" does Colorizable;
say $str.colors.head(3).join(' '); #=> «black red green»
say $str.colors.head(3)».Int.join(' '); #=> «30 31 32»
say $str.colors(:bg).head(3).join(' '); #=> «black red green»
say $str.colors(:bg).head(3)».Int.join(' '); #=> «40 41 42»
```
# modes
`method modes( --> List )`
Return list of available modes as allomorphs.
**Examples:**
```
my $str = "Hello" does Colorizable;
say $str.modes.head(3).join(' '); #=> «default-mode bold italic»
say $str.modes.head(3)».Int.join(' '); #=> «0 1 3»
```
# is-colorized
`method is-colorized( --> Bool )`
Return true if the string is colorized. Otherwise, false. A string is considered colorized if it has at least one element (foreground, background, or mode) set.
**Examples:**
```
my $str = "Hello" does Colorizable;
say $str.is-colorized;
```
# uncolorize
`method uncolorize( --> Str )`
Return uncolorized string.
**Examples:**
```
my $str = "Hello" does Colorizable;
say $str.uncolorize;
```
# color-samples
`method color-samples()`
Display color samples.
**Examples:**
```
my $str = "Hello" does Colorizable;
$str.color-samples; # display color samples
```
## More examples
### How to make rainbow-y strings?
An option is to create a subroutine that colorizes a string character by character:
```
sub rainbow( $str, :@only ) {
sub rainbowize( @colors ) {
$str.comb
.batch(@colors.elems)
.map({($_ Z @colors).map(-> ($ch, $fg) { ($ch does Colorizable).colorize($fg) }).join })
.join
}
return rainbowize(@only) if @only;
return rainbowize Color.enums.keys.list;
}
say rainbow "Hello, World!";
say rainbow "Hello, World!", :only[blue, red, yellow];
```
Another "I know what I'm doing" alternative is to implement a somewhat similar routine right into the `Str` class after composing `Colorizable` into it:
```
use MONKEY-TYPING;
augment class Str {
also does Colorizable;
method rainbow( $str : :@only ) {
sub rainbowize( @colors ) {
$str.comb
.batch(@colors.elems)
.map({($_ Z @colors).map(-> ($ch, $fg) { $ch.colorize($fg) }).join })
.join
}
return rainbowize(@only) if @only;
return rainbowize Color.enums.keys.list;
}
}
say "Hello, World!".rainbow;
say "Hello, World!".rainbow: :only[blue, red, yellow];
```
## Acknowledgement
This module is inspired by [Michał Kalbarczyk](https://github.com/fazibear)'s Ruby gem [colorize](https://github.com/fazibear/colorize).
## Authors
Luis F. Uceta
## License
You can use and distribute this module under the terms of the The Artistic License 2.0. See the LICENSE file included in this distribution for complete details.
The META6.json file of this distribution may be distributed and modified without restrictions or attribution.
|
## dist_zef-librasteve-Physics-Constants.md
[](https://opensource.org/licenses/Artistic-2.0)
[](https://github.com/librasteve/raku-Physics-Constants/actions/workflows/constants-weekly.yaml)
Bridging physical constants into [Physics::Measure](https://github.com/librasteve/raku-Physics-Measure) objects
# SYNOPSIS
```
#!/usr/bin/env raku
use Physics::Constants; #<== must use before Physics::Measure
use Physics::Measure :ALL;
say ~kg-amu; #6.02214076e+26 mol^-1 (avogadro number = Na)
say ~plancks-h; #6.626070015e-34 J.s
say ~faraday-constant; #96485.33212 C/mol
say ~fine-structure-constant; #0.0072973525693 (dimensionless)
say ~μ0; #1.25663706212e-06 H/m
say ~ℏ; #1.054571817e-34 J.s
my \λ = 2.5nm;
say "Wavelength of photon (λ) is " ~λ;
my \ν = c / λ;
say "Frequency of photon (ν) is " ~ν.in('petahertz');
my \Ep = ℎ * ν;
say "Energy of photon (Ep) is " ~Ep.in('attojoules');
#Wavelength of photon (λ) is 2.5 nm
#Frequency of photon (ν) is 119.9169832 petahertz
#Energy of photon (Ep) is 79.45783266707788 attojoules
This module is a wrapper on JJ Merelo Math::Constants
https://github.com/JJ/p6-math-constants
#say '----------------';
#say @physics-constants;
#say '----------------';
#say @physics-constants-names.sort;
#say '----------------';
#say @physics-constants-symbols.sort;
```
Copyright (c) Henley Cloud Consulting Ltd. 2021-2023
|
## tapbeforespawn.md
class X::Proc::Async::TapBeforeSpawn
Error due to tapping a Proc::Async stream after spawning its process
```raku
class X::Proc::Async::TapBeforeSpawn is Exception {}
```
If the `stdout` or `stderr` methods of [`Proc::Async`](/type/Proc/Async) are called after the program has been `start`ed, an exception of type `X::Proc::Async::TapBeforeSpawn` is thrown.
```raku
my $proc = Proc::Async.new("echo", "foo");
$proc.start;
$proc.stdout.tap(&print);
CATCH { default { put .^name, ': ', .Str } };
# OUTPUT: «X::Proc::Async::TapBeforeSpawn: To avoid data races, you must tap stdout before running the process»
```
The right way is the reverse order
```raku
my $proc = Proc::Async.new("echo", "foo");
$proc.stdout.tap(&print);
await $proc.start;
```
# [Methods](#class_X::Proc::Async::TapBeforeSpawn "go to top of document")[§](#Methods "direct link")
## [method handle](#class_X::Proc::Async::TapBeforeSpawn "go to top of document")[§](#method_handle "direct link")
```raku
method handle(X::Proc::Async::TapBeforeSpawn:D: --> Str:D)
```
Returns the name of the handle (`stdout` or `stderr`) that was accessed after the program started.
|
## dist_zef-deoac-App-APOTD.md
[](https://github.com/deoac/App-APOTD/actions)
### multi sub MAIN
```
multi sub MAIN(
Bool :$pod!
) returns Mu
```
Run with '--pod' to see all of the POD6 objects
### multi sub MAIN
```
multi sub MAIN(
Str :$doc!
) returns Mu
```
Run with '--doc' to generate a document from the POD6 It will be rendered in Text format unless specified with the --format option. e.g. --format=HTML
# TITLE
Astronomy Picture of the Day
# SUBTITLE
Download Today's Astronomy Picture of the Day
# VERSION
This documentation refers to `apotd` version 1.0.9
# USAGE
```
apotd [-v|-V|--version] [--verbose]
apotd [-d|--dir=<Str>] [-f|--filename=<Str>] [-a|--prepend-count]
-d|--dir=<Str> What directory should the image be saved to? [default: '$*HOME/Pictures/apotd']
-f|--filename=<Str> What filename should it be saved under? [default: the caption of the image]
-a|--prepend-count Add a count to the start of the filename. [default: False]
```
To downloand the image and save it using the default behavior, simply:
```
$ apotd
```
# DESCRIPTION
[Astronomy Picture of the Day](https://apod.nasa.gov/apod/astropix.html) is a website provided by NASA and Michigan Technological University which provides a different astronomy picture every day.
**Each day a different image or photograph of our fascinating universe is**
featured, along with a brief explanation written by a professional astronomer.
Set `apotd` as a cronjob (\*nux), launch agent (MacOS), or Task Scheduler (Windows) and you'll accumulate a beautiful collection of images for wallpaper, screen savers, etc.
# SYNOPSIS
By default, `apotd` will save to
```
~/Pictures/apotd/
```
with the filename taken from the caption of the photo e.g.
```
Dark Nebulae and Star Formation in Taurus.jpg
```
and will optionally prepend a number which increments with each new image, e.g.
```
2483-Dark Nebulae and Star Formation in Taurus.jpg
```
Macintosh allows a comment to be associated with each file. So on Macs, `apodt` will copy the `alt` text and the permalink for the image into the file's comment, e.g.
**A star field strewn with bunches of brown dust is pictured. In the center is a bright area of light brown dust, and in the center of that is a bright region of star formation.**
<https://apod.nasa.gov/apod/ap230321.html>
# OPTIONS
```
# Save to directory "foo"
$ apotd --dir=foo
$ apotd -d=foo
# Save with the filename "bar"
# The image's extension, e.g. ".jpg", will be automatically added.
$ apotd --file=bar
$ apotd -f=bar
# Prepend a count to the filename
$ apotd --prepend-count
$ apotd -p
```
# DIAGNOSTICS
## General problems
Failed to get the directory contents of <*directory*>: Failed to open dir: No such file or directory
Failed to create directory <*directory*>: Failed to mkdir: No such file or directory
Failed to resolve host name 'apod.nasa.gov'
## Problems specific to `apotd`
Couldn't find an image on the site. It's probably a video today.
The image has already been saved as <*filename*>.
Couldn't write the alt-text to <*path*>.
## Success
Successfully wrote Pictures/apotd/ 2483-Dark Nebulae and Star Formation in Taurus.jpg
Successfully wrote the alt-text and permanent link as a comment to the file.
# DEPENDENCIES
```
LWP::Simple;
Filetype::Magic;
Digest::SHA1::Native;
```
# ASSUMPTIONS
`apotd` assumes that the caption of the photo is the first `<b> ... </b>` line in the HTML code.
And that the image is the first `<IMG SRC=` html tag.
And that tag has an `alt=` attribute.
# BUGS AND LIMITATIONS
There are no known bugs in this module.
# AUTHOR
Shimon Bollinger [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/deoac/apotd.git>
Comments, suggestions, and pull requests are welcome.
# LICENSE AND COPYRIGHT
© 2023 Shimon Bollinger
This module is free software; you can redistribute it and/or modify it under the same terms as Perl itself. See [perlartistic](http://perldoc.perl.org/perlartistic.html).
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
|
## dist_zef-lizmat-CLI-Version.md
[](https://github.com/lizmat/CLI-Version/actions) [](https://github.com/lizmat/CLI-Version/actions) [](https://github.com/lizmat/CLI-Version/actions)
# NAME
CLI::Version - add -V / --version parameters to your script
# SYNOPSIS
```
proto sub MAIN(|) {*}
use CLI::Version $?DISTRIBUTION, &MAIN;
# alternately:
use CLI::Version $?DISTRIBUTION, proto sub MAIN(|) {*}
# only allow --version
use CLI::Version $?DISTRIBUTION, proto sub MAIN(|) {*}, "long-only";
```
# DESCRIPTION
CLI::Version adds a `multi sub` candidate to the `&MAIN` function in your script, that will trigger if the script is called with `-V` or `--version` arguments **only**.
For instance, in the [App::Rak](https://raku.land/zef:lizmat/App::Rak) distribution, which provides a `rak` CLI, calling `rak -V` will result in something like:
```
$ rak --version
rak - provided by App::Rak 0.3.2, running Raku 6.d with Rakudo 2024.07.
```
If the candidate is triggered, it will exit with the default value for `exit` (which is usually **0**).
If you would also like to see the description of the module, you can add `--verbose` as an argument: then you get something like:
```
$ rak --version --verbose
rak - 21st century grep / find / ack / ag / rg on steroids.
Provided by App::Rak 0.3.2, running Raku 6.d with Rakudo 2024.07.
```
By specifying a true value as the 3rd argument in the `use` statement, will cause only `--version` to trigger the candidate.
# IMPLEMENTATION NOTES
Due to the fact that the `$?DISTRIBUTION` and `&MAIN` of the code that uses this module, can **not** be obtained by a public API, it is necessary to provide them in the `use` statement. This need may disappear in future versions of the Raku Programming Language.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/CLI-Version> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2022, 2024 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-rawleyfowler-Humming-Bird.md
# Humming-Bird


[](https://ci.sparrowhub.io)
Humming-Bird is a simple, composable, and performant web-framework for Raku on MoarVM.
Humming-Bird was inspired mainly by [Sinatra](https://sinatrarb.com), and [Express](https://expressjs.com), and tries to keep
things minimal, allowing the user to pull in things like templating engines, and ORM's on their own terms.
## Features
Humming-Bird has 2 simple layers, at the lowest levels we have `Humming-Bird::Glue` which is a simple "glue-like" layer for interfacing with
`Humming-Bird::Backend`'s.
Then you have the actual application logic in `Humming-Bird::Core` that handles: routing, middleware, error handling, cookies, etc.
* Powerful function composition based routing and application logic
* Routers
* Groups
* Middleware
* Advice (end of stack middleware)
* Simple global error handling
* Plugin system
* Simple and helpful API
* get, post, put, patch, delete, etc
* Request content will be converted to the appropriate Raku data-type if possible
* Static files served have their content type infered
* Request/Response stash's for inter-layer route talking
* Swappable backends
**Note**: Humming-Bird is not meant to face the internet directly. Please use a reverse proxy such as Apache, Caddy or NGiNX.
## How to install
Make sure you have [zef](https://github.com/ugexe/zef) installed.
#### Install latest
```
zef -v install https://github.com/rawleyfowler/Humming-Bird.git
```
#### Install stable
```
zef install Humming-Bird
```
## Performance
See [this](https://github.com/rawleyfowler/Humming-Bird/issues/43#issuecomment-1454252501) for a more detailed performance preview
vs. Ruby's Sinatra using `Humming-Bird::Backend::HTTPServer`.
## Examples
#### Simple example:
```
use v6.d;
use Humming-Bird::Core;
get('/', -> $request, $response {
$response.html('<h1>Hello World</h1>');
});
listen(8080);
# Navigate to localhost:8080!
```
#### Simple JSON CRUD example:
```
use v6.d;
use Humming-Bird::Core;
use JSON::Fast; # A dependency of Humming-Bird
my %users = Map.new('bob', %('name', 'bob'), 'joe', %('name', 'joe'));
get('/users/:user', -> $request, $response {
my $user = $request.param('user');
if %users{$user}:exists {
$response.json(to-json %users{$user});
} else {
$response.status(404).html("Sorry, $user does not exist.");
}
});
post('/users', -> $request, $response {
my %user = $request.content; # Different from $request.body, $request.content will do its best to decode the data to a Map.
if my-user-validation-logic(%user) { # Validate somehow, i'll leave that up to you.
%users{%user<name>} = %user;
$response.status(201); # 201 created
} else {
$response.status(400).html('Bad request');
}
});
listen(8080);
```
#### Using plugins
```
use v6.d;
use Humming-Bird::Core;
plugin 'Logger'; # Corresponds to the pre-built Humming-Bird::Plugin::Logger plugin.
plugin 'Config'; # Corresponds to the pre-built Humming-Bird::Plugin::Config plugin.
get('/', sub ($request, $response) {
my $database_url = $request.config<database_url>;
$response.html("Here's my database url :D " ~ $database_url);
});
listen(8080);
```
#### Routers
```
use v6.d;
use Humming-Bird::Core;
use Humming-Bird::Middleware;
# NOTE: Declared routes persist through multiple 'use Humming-Bird::Core' statements
# allowing you to declare routing logic in multiple places if you want. This is true
# regardless of whether you're using the sub or Router process for defining routes.
my $router = Router.new(root => '/');
plugin 'Logger';
$router.get(-> $request, $response { # Register a GET route on the root of the router
$response.html('<h1>Hello World</h1>');
});
$router.get('/foo', -> $request, $response { # Register a GET route on /foo
$response.html('<span style="color: blue;">Bar</span>');
});
my $other-router = Router.new(root => '/bar');
$other-router.get('/baz', -> $request, $response { # Register a GET route on /bar/baz
$response.file('hello-world.html'); # Will render hello-world.html and infer its content type
});
# No need to register routers, it's underlying routes are registered with Humming-Bird on creation.
listen(8080);
```
#### Middleware
```
use v6.d;
use Humming-Bird::Core;
use Humming-Bird::Middleware;
get('/logged', -> $request, $response {
$response.html('This request has been logged!');
}, [ &middleware-logger ]); # &middleware-logger is provided by Humming-Bird::Middleware
# Custom middleware
sub block-firefox($request, $response, &next) {
return $response.status(400) if $request.header('User-Agent').starts-with('Mozilla');
$response.status(200);
}
get('/no-firefox', -> $request, $response {
$response.html('You are not using Firefox!');
}, [ &middleware-logger, &block-firefox ]);
listen(8080);
```
Since Humming-Bird `3.0.4` it may be more favorable to use plugins to register global middlewares.
#### Swappable Backends
```
use v6.d;
use Humming-Bird::Core;
get('/', -> $request, $response {
$response.html('This request has been logged!');
});
# Run on a different backend, assuming:
listen(:backend(Humming-Bird::Backend::MyBackend));
```
More examples can be found in the [examples](https://github.com/rawleyfowler/Humming-Bird/tree/main/examples) directory.
## Swappable backends
In Humming-Bird `3.0.0` and up you are able to write your own backend, please follow the API outlined by the `Humming-Bird::Backend` role,
and view `Humming-Bird::Backend::HTTPServer` for an example of how to implement a Humming-Bird backend.
## Plugin system
Humming-Bird `3.0.4` (`4.0.0` created a breaking change for plugins) and up features the Humming-Bird Plugin system, this is a straight forward way to extend Humming-Bird with desired functionality before the server
starts up. All you need to do is create a class that inherits from `Humming-Bird::Plugin`, for instance `Humming-Bird::Plugin::Config`, expose a single method `register` which
takes arguments that align with the arguments specified in `Humming-Bird::Plugin.register`, for more arguments, take a slurpy at the end of your register method.
If the return value of a `Humming-Bird::Plugin.register` is a `Hash`, Humming-Bird will assume that you
are returning helpers from your plugin, meaning the keys and values will be bound to `Humming-Bird::HTTPAction`.
This allows you to use functionality easily in your request/response life-cycles.
Here is an example of a plugin:
```
use JSON::Fast;
use Humming-Bird::Plugin;
use Humming-Bird::Core;
unit class Humming-Bird::Plugin::Config does Humming-Bird::Plugin;
method register($server, %routes, @middleware, @advice, **@args) {
my $filename = @args[0] // '.humming-bird.json';
my %config = from-json($filename.IO.slurp // '{}');
# The key will become the name, and the value will become a method on Humming-Bird::Glue::HTTPAction,
# allowing you to have helper methods available in your request/response life-cycle.
return %(
config => sub (Humming-Bird::Glue::HTTPAction $action) {
%config;
}
);
CATCH {
default {
warn 'Failed to find or parse your ".humming-bird.json" configuration. Ensure your file is well formed, and does exist.';
}
}
}
```
This plugin embeds a `.config` method on the base class for Humming-Bird's Request and Response classes, allowing your config to be accessed during the request/response lifecycle.
Then to register it in a Humming-Bird application:
```
use Humming-Bird::Core;
plugin 'Config', 'config/humming-bird.json'; # Second arg will be pushed to he **@args array in the register method.
get('/', sub ($request, $response) {
$response.write($request.config<foo>); # Echo back the <foo> field in our JSON config.
});
listen(8080);
```
## Design
* Humming-Bird should be easy to pickup, and simple for developers new to Raku and/or web development.
* Humming-Bird is not designed to be exposed to the internet directly. You should hide Humming-Bird behind a reverse-proxy like NGiNX, Apache, or Caddy.
* Simple and composable via middlewares.
## Things to keep in mind
* This project is in active development, things will break.
* You may run into bugs.
* This project is largely maintained by one person.
## Contributing
All contributions are encouraged! I know the Raku community is amazing, so I hope to see
some people get involved :D
Please make sure you squash your branch, and name it accordingly before it gets merged!
#### Testing
Install App::Prove6
```
zef install --force-install App::Prove6
```
Ensure that the following passes:
```
cd Humming-Bird
zef install . --force-install --/test
prove6 -v -I. t/ it/
```
## License
Humming-Bird is available under the MIT, you can view the license in the `LICENSE` file
at the root of the project. For more information about the MIT, please click
[here](https://mit-license.org/).
|
## quoting.md
Quoting constructs
Writing strings and word lists, in Raku
# [The Q lang](#Quoting_constructs "go to top of document")[§](#The_Q_lang "direct link")
Strings are usually represented in Raku code using some form of quoting construct. The most minimalistic of these is `Q`, usable via the shortcut `「…」`, or via `Q` followed by any pair of delimiters surrounding your text, including many [Unicode pairs](https://github.com/Raku/roast/blob/aa4994a7f6b3f6b450a9d231bebd5fba172439b0/S02-literals/quoting-unicode.t#L49-L65). Most of the time, though, the most you'll need is `'…'` or `"…"`, described in more detail in the following sections.
For information about quoting as applied in regexes, see the [regular expression documentation](/language/regexes).
## [Literal strings: Q](#Quoting_constructs "go to top of document")[§](#Literal_strings:_Q "direct link")
```raku
Q[A literal string]
「More plainly.」
Q^Almost any non-word character can be a delimiter!^
Q「「Delimiters can be repeated/nested if they are adjacent.」」
Q⦅Quoting with fancy unicode pairs⦆
```
Delimiters can be nested, but in the plain `Q` form, backslash escapes aren't allowed. In other words, basic `Q` strings are as literal as possible.
Some delimiters are not allowed immediately after `Q`, `q`, or `qq`. Any characters that are allowed in [identifiers](/language/syntax#Identifiers) are not allowed to be used, since in such a case, the quoting construct together with such characters are interpreted as an identifier. In addition, `( )` is not allowed because that is interpreted as a function call. If you still wish to use those characters as delimiters, separate them from `Q`, `q`, or `qq` with a space. Please note that some natural languages use a left delimiting quote on the right side of a string. `Q` will not support those as it relies on unicode properties to tell left and right delimiters apart.
```raku
Q'this will not work!'
Q(this won't work either!)
```
The examples above will produce an error. However, this will work
```raku
Q (this is fine, because of space after Q)
Q 'and so is this'
Q<Make sure you <match> opening and closing delimiters>
Q{This is still a closing curly brace → \}
```
These examples produce:
```raku
this is fine, because of space after Q
and so is this
Make sure you <match> opening and closing delimiters
This is still a closing curly brace → \
```
The behavior of quoting constructs can be modified with adverbs, as explained in detail in later sections.
| | | |
| --- | --- | --- |
| Short | Long | Meaning |
| :x | :exec | Execute as command and return results |
| :w | :words | Split result on words (no quote protection) |
| :ww | :quotewords | Split result on words (with quote protection) |
| :q | :single | Interpolate \\, \qq[...] and escaping the delimiter with \ |
| :qq | :double | Interpolate with :s, :a, :h, :f, :c, :b |
| :s | :scalar | Interpolate $ vars |
| :a | :array | Interpolate @ vars (when followed by postcircumfix) |
| :h | :hash | Interpolate % vars (when followed by postcircumfix) |
| :f | :function | Interpolate & calls |
| :c | :closure | Interpolate {...} expressions |
| :b | :backslash | Enable backslash escapes (\n, \qq, \$foo, etc) |
| :to | :heredoc | Parse result as heredoc terminator |
| :v | :val | Convert to allomorph if possible |
These adverbs can be used together with `Q`, so that it will interpolate even if the quoting operator does not:
```raku
my %þ = :is-mighty;
say Q "Þor %þ<>"; # OUTPUT: «Þor %þ<>»
say Q:h"Þor %þ<>"; # OUTPUT: «Þor is-mighty True»
%þ = :42foo, :33bar;
say Q:h:c "Þor %þ<> → { [+] %þ.values}"; # OUTPUT: «Þor bar 33foo 42 → 75»
my @þ= <33 44>; say Q:a "Array contains @þ[]"; # OUTPUT: «Array contains 33 44»
say Q:v<33> + 3; # OUTPUT: «36»
```
By default, and as shown, `Q` quotes directly without any kind of transformation of the quoted string. The adverbs will modify its behavior, converting, for instance, the string into an allomorph (with the `:v` adverb) or allowing interpolation of hashes (via `:h`) or `{}` code sections (via `:c`). Arrays and hashes must be *followed by a postcircumfix*; that is, the sigiled identifier will not interpolate, but followed by an indexing, decont operator or a method call with parentheses, it will:
```raku
my @þ= <33 44>;
say Q:a "Array contains @þ.elems()"; # OUTPUT: «Array contains 2»
```
The same code without the parentheses will simply not interpolate, absent the post-circumfix operator.
## [Escaping: q](#Quoting_constructs "go to top of document")[§](#Escaping:_q "direct link")
```raku
'Very plain';
q[This back\slash stays];
q[This back\\slash stays]; # Identical output
q{This is not a closing curly brace → \}, but this is → };
Q :q $There are no backslashes here, only lots of \$\$\$!$;
'(Just kidding. There\'s no money in that string)';
'No $interpolation {here}!';
Q:q!Just a literal "\n" here!;
```
The `q` form allows for escaping characters that would otherwise end the string using a backslash. The backslash itself can be escaped, too, as in the third example above. The usual form is `'…'` or `q` followed by a delimiter, but it's also available as an adverb on `Q`, as in the fifth and last example above.
These examples produce:
「text」 without highlighting
```
```
Very plain
This back\slash stays
This back\slash stays
This is not a closing curly brace → } but this is →
There are no backslashes here, only lots of $$$!
(Just kidding. There's no money in that string)
No $interpolation {here}!
Just a literal "\n" here
```
```
The `\qq[...]` escape sequence enables [`qq` interpolation](/language/quoting#Interpolation:_qq) for a portion of the string. Using this escape sequence is handy when you have HTML markup in your strings, to avoid interpretation of angle brackets as hash keys:
```raku
my $var = 'foo';
say '<code>$var</code> is <var>\qq[$var.uc()]</var>';
# OUTPUT: «<code>$var</code> is <var>FOO</var>»
```
## [Interpolation: qq](#Quoting_constructs "go to top of document")[§](#Interpolation:_qq "direct link")
```raku
my $color = 'blue';
say "My favorite color is $color!"; # OUTPUT: «My favorite color is blue!»
```
The `qq` form – usually written using double quotes – allows for interpolation of backslash escape sequences (like `q:backslash`), all sigiled variables (like `q:scalar:array:hash:function`), and any code inside `{...}` (like `q:closure`).
### [Interpolating variables](#Quoting_constructs "go to top of document")[§](#Interpolating_variables "direct link")
Inside a `qq`-quoted string, you can use variables with a sigil to trigger interpolation of the variable's value. Variables with the `$` sigil are interpolated whenever the occur (unless escaped); that's why, in the example above, `"$color"` became `blue`.
Variables with other sigils, however, only trigger interpolation when you follow the variable with the appropriate postfix (`[]` for Arrays, `<>`, for Hashes, `&` for Subs). This allows you to write expressions like `"[email protected]"` without interpolating the `@raku` variable.
To interpolate an Array (or other [`Positional`](/type/Positional) variable), append a `[]` to the variable name:
```raku
my @neighbors = "Felix", "Danielle", "Lucinda";
say "@neighbors[] and I try our best to coexist peacefully."
# OUTPUT: «Felix Danielle Lucinda and I try our best to coexist peacefully.»
```
Alternatively, rather than using `[]`, you can interpolate the Array by following it with a method call with parentheses after the method name. Thus the following code will work:
```raku
say "@neighbors.join(', ') and I try our best to coexist peacefully."
# OUTPUT: «Felix, Danielle, Lucinda and I try our best to coexist peacefully.»
```
However, `"@example.com"` produces `@example.com`.
To call a subroutine, use the `&`-sigil and follow the subroutine name with parentheses.
```raku
say "uc 'word'"; # OUTPUT: «uc 'word'»
say "&uc 'word'"; # OUTPUT: «&uc 'word'»
say "&uc('word')"; # OUTPUT: «WORD»
# OUTPUT: «abcDEFghi»
```
To interpolate a Hash (or other [`Associative`](/type/Associative) variable), use the `<>` postcircumfix operator.
```raku
my %h = :1st; say "abc%h<st>ghi";
# OUTPUT: «abc1ghi»
```
The way `qq` interpolates variables is the same as `q:scalar:array:hash:function`. You can use these adverbs (or their short forms, `q:s:a:h:f`) to interpolate variables without enabling other `qq` interpolations.
### [Interpolating closures](#Quoting_constructs "go to top of document")[§](#Interpolating_closures "direct link")
Another feature of `qq` is the ability to interpolate Raku code from within the string, using curly braces:
```raku
my ($x, $y, $z) = 4, 3.5, 3;
say "This room is {$x}m by {$y}m by {$z}m."; # OUTPUT: «This room is 4m by 3.5m by 3m.»
say "Therefore its volume should be { $x * $y * $z }m³!"; # OUTPUT: «Therefore its volume should be 42m³!»
```
This provides the same functionality as the `q:closure`/`q:c` quoting form.
### [Interpolating escape codes](#Quoting_constructs "go to top of document")[§](#Interpolating_escape_codes "direct link")
The `qq` quoting form also interpolates backslash escape sequences. Several of these print invisible/whitespace ASCII control codes or whitespace characters:
| | | | |
| --- | --- | --- | --- |
| Sequence | Hex Value | Character | Reference URL |
| \0 | \x0000 | Nul | https://util.unicode.org/UnicodeJsps/character.jsp?a=0000 |
| \a | \x0007 | Bel | https://util.unicode.org/UnicodeJsps/character.jsp?a=0007 |
| \b | \x0008 | Backspace | https://util.unicode.org/UnicodeJsps/character.jsp?a=0008 |
| \e | \x001B | Esc | https://util.unicode.org/UnicodeJsps/character.jsp?a=001B |
| \f | \x000C | Form Feed | https://util.unicode.org/UnicodeJsps/character.jsp?a=000C |
| \n | \x000A | Newline | https://util.unicode.org/UnicodeJsps/character.jsp?a=000A |
| \r | \x000D | Carriage Return | https://util.unicode.org/UnicodeJsps/character.jsp?a=000D |
| \t | \x0009 | Tab | https://util.unicode.org/UnicodeJsps/character.jsp?a=0009 |
`qq` also supports two multi-character escape sequences: `\x` and `\c`. You can use `\x` or `\x[]` with the hex-code of a Unicode character or a list of characters:
```raku
my $s = "I \x2665 Raku!";
say $s;
# OUTPUT: «I ♥ Raku!»
$s = "I really \x[2661,2665,2764,1f495] Raku!";
say $s;
# OUTPUT: «I really ♡♥❤💕 Raku!»
```
You can also create a Unicode character with `\c` and that character's [unicode name](/language/unicode#Entering_unicode_codepoints_and_codepoint_sequences) , [named sequences](/language/unicode#Named_sequences) or [name alias](/language/unicode#Name_aliases):
```raku
my $s = "Camelia \c[BROKEN HEART] my \c[HEAVY BLACK HEART]!";
say $s;
# OUTPUT: «Camelia 💔 my ❤!»
```
See the description of [\c[]](/language/unicode#Entering_unicode_codepoints_and_codepoint_sequences) on the [Unicode](/language/unicode) documentation page for more details.
`qq` provides the same interpolation of escape sequences as that provided by `q:backslash`/`q:b`.
### [preventing interpolation and handling missing values](#Quoting_constructs "go to top of document")[§](#preventing_interpolation_and_handling_missing_values "direct link")
You can prevent any undesired interpolation in a `qq`-quoted string by escaping the sigil or other initial character:
```raku
say "The \$color variable contains the value '$color'"; # OUTPUT: «The $color variable contains the value 'blue'»
```
Interpolation of undefined values will raise a control exception that can be caught in the current block with [CONTROL](/language/phasers#CONTROL).
```raku
sub niler {Nil};
my Str $a = niler;
say("$a.html", "sometext");
say "alive"; # this line is dead code
CONTROL { .die };
```
## [Word quoting: qw](#Quoting_constructs "go to top of document")[§](#Word_quoting:_qw "direct link")
```raku
qw|! @ # $ % ^ & * \| < > | eqv '! @ # $ % ^ & * | < >'.words.list;
q:w { [ ] \{ \} } eqv ('[', ']', '{', '}');
Q:w | [ ] { } | eqv ('[', ']', '{', '}');
```
The `:w` form, usually written as `qw`, splits the string into "words". In this context, words are defined as sequences of non-whitespace characters separated by whitespace. The `q:w` and `qw` forms inherit the interpolation and escape semantics of the `q` and single quote string delimiters, whereas `Qw` and `Q:w` inherit the non-escaping semantics of the `Q` quoter.
This form is used in preference to using many quotation marks and commas for lists of strings. For example, where you could write:
```raku
my @directions = 'left', 'right,', 'up', 'down';
```
It's easier to write and to read this:
```raku
my @directions = qw|left right up down|;
```
## [Word quoting: `< >`](#Quoting_constructs "go to top of document") [§](#Word_quoting:_<_> "direct link")
```raku
say <a b c> eqv ('a', 'b', 'c'); # OUTPUT: «True»
say <a b 42> eqv ('a', 'b', '42'); # OUTPUT: «False», the 42 became an IntStr allomorph
say < 42 > ~~ Int; # OUTPUT: «True»
say < 42 > ~~ Str; # OUTPUT: «True»
```
The angle brackets quoting is like `qw`, but with extra feature that lets you construct [allomorphs](/language/glossary#Allomorph) or literals of certain numbers:
```raku
say <42 4/2 1e6 1+1i abc>.raku;
# OUTPUT: «(IntStr.new(42, "42"), RatStr.new(2.0, "4/2"), NumStr.new(1000000e0, "1e6"), ComplexStr.new(<1+1i>, "1+1i"), "abc")»
```
To construct a [`Rat`](/type/Rat) or [`Complex`](/type/Complex) literal, use angle brackets around the number, without any extra spaces:
```raku
say <42/10>.^name; # OUTPUT: «Rat»
say <1+42i>.^name; # OUTPUT: «Complex»
say < 42/10 >.^name; # OUTPUT: «RatStr»
say < 1+42i >.^name; # OUTPUT: «ComplexStr»
```
Compared to `42/10` and `1+42i`, there's no division (or addition) operation involved. This is useful for literals in routine signatures, for example:
```raku
sub close-enough-π (<355/113>) {
say "Your π is close enough!"
}
close-enough-π 710/226; # OUTPUT: «Your π is close enough!»
```
```raku
# WRONG: can't do this, since it's a division operation
sub compilation-failure (355/113) {}
```
## [Word quoting with quote protection: qww](#Quoting_constructs "go to top of document")[§](#Word_quoting_with_quote_protection:_qww "direct link")
The `qw` form of word quoting will treat quote characters literally, leaving them in the resulting words:
```raku
say qw{"a b" c}.raku; # OUTPUT: «("\"a", "b\"", "c")»
```
Using the `qww` variant allows you to use quote characters for embedding strings in the word quoting structure:
```raku
say qww{"a b" c}.raku; # OUTPUT: «("a b", "c")»
```
Other kinds of quotes are also supported with their usual semantics:
```raku
my $one = 'here';
my $other = 'there';
say qww{ ’this and that’ “$one or $other” 「infinity and beyond」 }.raku;
# OUTPUT: «("this and that", "here or there", "infinity and beyond")»
```
The delimiters of embedded strings are always considered word splitters:
```raku
say qww{'alpha'beta'gamma' 'delta'"epsilon"}.raku; # OUTPUT: «("alpha", "beta", "gamma", "delta", "epsilon")»
```
## [Word quoting with interpolation: qqw](#Quoting_constructs "go to top of document")[§](#Word_quoting_with_interpolation:_qqw "direct link")
The `qw` form of word quoting doesn't interpolate variables:
```raku
my $a = 42; say qw{$a b c}; # OUTPUT: «$a b c»
```
Thus, if you wish for variables to be interpolated within the quoted string, you need to use the `qqw` variant:
```raku
my $a = 42;
my @list = qqw{$a b c};
say @list; # OUTPUT: «[42 b c]»
```
Note that variable interpolation happens before word splitting:
```raku
my $a = "a b";
my @list = qqw{$a c};
.say for @list; # OUTPUT: «abc»
```
## [Word quoting with interpolation and quote protection: qqww](#Quoting_constructs "go to top of document")[§](#Word_quoting_with_interpolation_and_quote_protection:_qqww "direct link")
The `qqw` form of word quoting will treat quote characters literally, leaving them in the resulting words:
```raku
my $a = 42; say qqw{"$a b" c}.raku; # OUTPUT: «("\"42", "b\"", "c")»
```
Using the `qqww` variant allows you to use quote characters for embedding strings in the word quoting structure:
```raku
my $a = 42; say qqww{"$a b" c}.raku; # OUTPUT: «("42 b", "c")»
```
The delimiters of embedded strings are always considered word splitters:
```raku
say qqww{'alpha'beta'gamma' 'delta'"epsilon"}.raku; # OUTPUT: «("alpha", "beta", "gamma", "delta", "epsilon")»
```
Unlike the `qqw` form, interpolation also always splits (except for interpolation that takes place in an embedded string):
```raku
my $time = "now";
$_ = 'ni';
my @list = qqww<$time$time {6*7}{7*6} "$_$_">;
.say for @list; # OUTPUT: «nownow4242nini»
```
Quote protection happens before interpolation, and interpolation happens before word splitting, so quotes coming from inside interpolated variables are just literal quote characters:
```raku
my $a = "1 2";
say qqww{"$a" $a}.raku; # OUTPUT: «("1 2", "1", "2")»
my $b = "1 \"2 3\"";
say qqww{"$b" $b}.raku; # OUTPUT: «("1 \"2 3\"", "1", "\"2", "3\"")»
```
## [Word quoting with interpolation and quote protection: « »](#Quoting_constructs "go to top of document")[§](#Word_quoting_with_interpolation_and_quote_protection:_«_» "direct link")
This style of quoting is like `qqww`, but with the added benefit of constructing [allomorphs](/language/glossary#Allomorph) (making it functionally equivalent to [qq:ww:v](#index-entry-:val_(quoting_adverb))). The ASCII equivalent to `« »` are double angle brackets `<< >>`.
```raku
# Allomorph Construction
my $a = 42; say « $a b c ».raku; # OUTPUT: «(IntStr.new(42, "42"), "b", "c")»
my $a = 42; say << $a b c >>.raku; # OUTPUT: «(IntStr.new(42, "42"), "b", "c")»
# Quote Protection
my $a = 42; say « "$a b" c ».raku; # OUTPUT: «("42 b", "c")»
my $a = 42; say << "$a b" c >>.raku; # OUTPUT: «("42 b", "c")»
```
## [Shell quoting: qx](#Quoting_constructs "go to top of document")[§](#Shell_quoting:_qx "direct link")
To run a string as an external program, not only is it possible to pass the string to the `shell` or `run` functions but one can also perform shell quoting. There are some subtleties to consider, however. `qx` quotes *don't* interpolate variables. Thus
```raku
my $world = "there";
say qx{echo "hello $world"}
```
prints simply `hello`. Nevertheless, if you have declared an environment variable before calling `raku`, this will be available within `qx`, for instance
```raku
WORLD="there" raku
> say qx{echo "hello $WORLD"}
```
will now print `hello there`.
The result of calling `qx` is returned, so this information can be assigned to a variable for later use:
```raku
my $output = qx{echo "hello!"};
say $output; # OUTPUT: «hello!»
```
See also [shell](/routine/shell), [run](/routine/run) and [`Proc::Async`](/type/Proc/Async) for other ways to execute external commands.
## [Shell quoting with interpolation: qqx](#Quoting_constructs "go to top of document")[§](#Shell_quoting_with_interpolation:_qqx "direct link")
If one wishes to use the content of a Raku variable within an external command, then the `qqx` shell quoting construct should be used:
```raku
my $world = "there";
say qqx{echo "hello $world"}; # OUTPUT: «hello there»
```
Again, the output of the external command can be kept in a variable:
```raku
my $word = "cool";
my $option = "-i";
my $file = "/usr/share/dict/words";
my $output = qqx{grep $option $word $file};
# runs the command: grep -i cool /usr/share/dict/words
say $output; # OUTPUT: «CooleyCooley'sCoolidgeCoolidge'scool...»
```
Be aware of the content of the Raku variable used within an external command; malicious content can be used to execute arbitrary code. See [`qqx` traps](/language/traps#Beware_of_variables_used_within_qqx)
See also [run](/routine/run) and [`Proc::Async`](/type/Proc/Async) for better ways to execute external commands.
## [Heredocs: :to](#Quoting_constructs "go to top of document")[§](#Heredocs:_:to "direct link")
A convenient way to write a multi-line string literal is by using a *heredoc*, which lets you choose the delimiter yourself:
```raku
say q:to/END/;
Here is
some multi-line
string
END
```
The contents of the *heredoc* always begin on the next line, so you can (and should) finish the line.
```raku
my $escaped = my-escaping-function(q:to/TERMINATOR/, language => 'html');
Here are the contents of the heredoc.
Potentially multiple lines.
TERMINATOR
```
If the terminator is indented, that amount of indention is removed from the string literals. Therefore this *heredoc*
```raku
say q:to/END/;
Here is
some multi line
string
END
```
produces this output:
「text」 without highlighting
```
```
Here is
some multi line
string
```
```
*Heredocs* include the newline from before the terminator.
To allow interpolation of variables use the `qq` form, but you will then have to escape metacharacters `\{` as well as `$` if it is not the sigil for a defined variable. For example:
```raku
my $f = 'db.7.3.8';
my $s = qq:to/END/;
option \{
file "$f";
};
END
say $s;
```
would produce:
「text」 without highlighting
```
```
option {
file "db.7.3.8";
};
```
```
Some other situations to pay attention to are innocent-looking ones where the text looks like a Raku expression. For example, the following generates an error:
「text」 without highlighting
```
```
my $title = 'USAFA Class of 1965';
say qq:to/HERE/;
<a href='https://usafa-1965.org'>$title</a>
HERE
# Output:
Type Str does not support associative indexing.
in block <unit> at here.raku line 2
```
```
The angle bracket to the right of '$title' makes it look like a hash index to Raku when it is actually a [`Str`](/type/Str) variable, hence the error message. One solution is to enclose the scalar with curly braces which is one way to enter an expression in any interpolating quoting construct:
「text」 without highlighting
```
```
say qq:to/HERE/;
<a href='https://usafa-1965.org'>{$title}</a>
HERE
```
```
Another option is to escape the `<` character to avoid it being parsed as the beginning of an indexing operator:
「text」 without highlighting
```
```
say qq:to/HERE/;
<a href='https://usafa-1965.org'>$title\</a>
HERE
```
```
Because a *heredoc* can be very long but is still interpreted by Raku as a single line, finding the source of an error can sometimes be difficult. One crude way to debug the error is by starting with the first visible line in the code and treating is as a *heredoc* with that line only. Then, until you get an error, add each line in turn. (Creating a Raku program to do that is left as an exercise for the reader.)
You can begin multiple Heredocs in the same line. If you do so, the second heredoc will not start until after the first heredoc has ended.
```raku
my ($first, $second) = qq:to/END1/, qq:to/END2/;
FIRST
MULTILINE
STRING
END1
SECOND
MULTILINE
STRING
END2
say $first; # OUTPUT: «FIRSTMULTILINESTRING»
say $second; # OUTPUT: «SECONDMULTILINESTRING»
```
## [Unquoting](#Quoting_constructs "go to top of document")[§](#Unquoting "direct link")
Literal strings permit interpolation of embedded quoting constructs by using the escape sequences such as these:
```raku
my $animal="quaggas";
say 'These animals look like \qq[$animal]'; # OUTPUT: «These animals look like quaggas»
say 'These animals are \qqw[$animal or zebras]'; # OUTPUT: «These animals are quaggas or zebras»
```
In this example, `\qq` will do double-quoting interpolation, and `\qqw` word quoting with interpolation. Escaping any other quoting construct as above will act in the same way, allowing interpolation in literal strings.
|
## whatever.md
class Whatever
Placeholder for the value of an unspecified argument
```raku
class Whatever { }
```
`Whatever` is a class whose objects don't have any explicit meaning; it gets its semantics from other routines that accept `Whatever`-objects as markers to do something special. Using the `*` literal as an operand creates a `Whatever` object.
Much of `*`'s charm comes from *Whatever-priming*. When `*` is used in term position, that is, as an operand, in combination with most operators, the compiler will transform the expression into a closure of type [`WhateverCode`](/type/WhateverCode), which is actually a [`Block`](/type/Block) that can be used wherever [`Callable`](/type/Callable)s are accepted.
```raku
my $c = * + 2; # same as -> $x { $x + 2 };
say $c(4); # OUTPUT: «6»
```
Multiple `*` in one expression generate closures with as many arguments:
```raku
my $c = * + *; # same as -> $x, $y { $x + $y }
```
Using `*` in complex expressions will also generate closures:
```raku
my $c = 4 * * + 5; # same as -> $x { 4 * $x + 5 }
```
Calling a method on `*` also creates a closure:
```raku
<a b c>.map: *.uc; # same as <a b c>.map: -> $char { $char.uc }
```
As mentioned before, not all operators and syntactic constructs prime `*` (or `Whatever`-stars) to [`WhateverCode`](/type/WhateverCode). In the following cases, `*` will remain a `Whatever` object.
| Exception | Example | What it does |
| --- | --- | --- |
| comma | 1, \*, 2 | generates a List with a \* element |
| range operators | 1 .. \* | Range from 1 to Inf |
| series operator | 1 ... \* | infinite lazy Seq |
| assignment | $x = \* | assign \* to $x |
| binding | $x := \* | bind \* to $x |
| list repetition | 1 xx \* | generates an infinite list |
The range operators are handled specially. They do not prime with `Whatever`-stars, but they do prime with [`WhateverCode`](/type/WhateverCode)
```raku
say (1..*).^name; # OUTPUT: «Range»
say ((1..*-1)).^name; # OUTPUT: «WhateverCode»
```
This allows all these constructs to work:
```raku
.say for 1..*; # infinite loop
```
and
```raku
my @a = 1..4;
say @a[0..*]; # OUTPUT: «(1 2 3 4)»
say @a[0..*-2]; # OUTPUT: «(1 2 3)»
```
Because *Whatever-priming* is a purely syntactic compiler transform, you will get no runtime priming of stored `Whatever`-stars into [`WhateverCode`](/type/WhateverCode)s.
```raku
my $x = *;
$x + 2; # Not a closure, dies because it can't coerce $x to Numeric
CATCH { default { put .^name, ': ', .Str } };
# OUTPUT: «X::Multi::NoMatch: Cannot resolve caller Numeric(Whatever: );
# none of these signatures match:
# (Mu:U \v: *%_)»
```
The use cases for stored `Whatever`-stars involve those prime-exception cases mentioned above. For example, if you want an infinite series by default.
```raku
my $max = potential-upper-limit() // *;
my $series = known-lower-limit() ... $max;
```
A stored `*` will also result in the generation of a [`WhateverCode`](/type/WhateverCode) in the specific case of smartmatch. Note that this is not actually the stored `*` which is being primed, but rather the `*` on the left-hand side.
```raku
my $constraint = find-constraint() // *;
my $maybe-always-matcher = * ~~ $constraint;
```
If this hypothetical `find-constraint` were to have found no constraint, `$maybe-always-matcher` would evaluate to `True` for anything.
```raku
$maybe-always-matcher(555); # True
$maybe-always-matcher(Any); # True
```
[`HyperWhatever`](/type/HyperWhatever)'s functionality is similar to `Whatever`, except it refers to multiple values, instead of a single one.
# [Methods](#class_Whatever "go to top of document")[§](#Methods "direct link")
## [method ACCEPTS](#class_Whatever "go to top of document")[§](#method_ACCEPTS "direct link")
```raku
multi method ACCEPTS(Whatever:D: Mu $other)
multi method ACCEPTS(Whatever:U: Mu $other)
```
If the invocant is [an instance](/language/classtut#A_word_on_types), always returns `True`. If the invocant is a type object, performs a typecheck.
```raku
say 42 ~~ (*); # OUTPUT: «True»
say 42 ~~ Whatever; # OUTPUT: «False»
```
## [method Capture](#class_Whatever "go to top of document")[§](#method_Capture "direct link")
```raku
method Capture()
```
Throws `X::Cannot::Capture`.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Whatever`
raku-type-graph
Whatever
Whatever
Any
Any
Whatever->Any
Mu
Mu
Any->Mu
[Expand chart above](/assets/typegraphs/Whatever.svg)
|
## round.md
round
Combined from primary sources listed below.
# [In Complex](#___top "go to top of document")[§](#(Complex)_method_round "direct link")
See primary documentation
[in context](/type/Complex#method_round)
for **method round**.
```raku
multi method round(Complex:D: --> Complex:D)
multi method round(Complex:D: Real() $scale --> Complex:D)
```
With no arguments, rounds both the real and imaginary parts to the nearest integer and returns a new `Complex` number. If `$scale` is given, rounds both parts of the invocant to the nearest multiple of `$scale`. Uses the same algorithm as [Real.round](/type/Real#method_round) on each part of the number.
```raku
say (1.2-3.8i).round; # OUTPUT: «1-4i»
say (1.256-3.875i).round(0.1); # OUTPUT: «1.3-3.9i»
```
# [In Cool](#___top "go to top of document")[§](#(Cool)_routine_round "direct link")
See primary documentation
[in context](/type/Cool#routine_round)
for **routine round**.
```raku
multi round(Numeric(Cool), $scale = 1)
multi method round(Cool:D: $scale = 1)
```
Coerces the invocant (or in sub form, its argument) to [`Numeric`](/type/Numeric), and rounds it to the unit of `$scale`. If `$scale` is 1, rounds to the nearest integer; an arbitrary scale will result in the closest multiple of that number.
```raku
say 1.7.round; # OUTPUT: «2»
say 1.07.round(0.1); # OUTPUT: «1.1»
say 21.round(10); # OUTPUT: «20»
say round(1000, 23.01) # OUTPUT: «989.43»
```
Always rounds **up** if the number is at mid-point:
```raku
say (−.5 ).round; # OUTPUT: «0»
say ( .5 ).round; # OUTPUT: «1»
say (−.55).round(.1); # OUTPUT: «-0.5»
say ( .55).round(.1); # OUTPUT: «0.6»
```
**Pay attention** to types when using this method, as ending up with the wrong type may affect the precision you seek to achieve. For [`Real`](/type/Real) types, the type of the result is the type of the argument ([`Complex`](/type/Complex) argument gets coerced to [`Real`](/type/Real), ending up a [`Num`](/type/Num)). If rounding a [`Complex`](/type/Complex), the result is [`Complex`](/type/Complex) as well, regardless of the type of the argument.
```raku
9930972392403501.round(1) .raku.say; # OUTPUT: «9930972392403501»
9930972392403501.round(1e0) .raku.say; # OUTPUT: «9.9309723924035e+15»
9930972392403501.round(1e0).Int.raku.say; # OUTPUT: «9930972392403500»
```
# [In role Real](#___top "go to top of document")[§](#(role_Real)_method_round "direct link")
See primary documentation
[in context](/type/Real#method_round)
for **method round**.
```raku
method round(Real:D: $scale = 1)
```
Rounds the number to scale `$scale`. If `$scale` is 1, rounds to an integer. If scale is `0.1`, rounds to one digit after the radix point (period or comma), etc.
|
## dist_zef-lizmat-Acme-Cow.md
[](https://github.com/lizmat/Acme-Cow/actions)
# NAME
Acme::Cow - Talking barnyard animals (or ASCII art in general)
# SYNOPSIS
```
use Acme::Cow;
my Acme::Cow $cow .= new;
$cow.say("Moo!");
$cow.print;
my $sheep = Acme::Cow::Sheep.new; # Derived from Acme::Cow
$sheep.wrap(20);
$sheep.think;
$sheep.text("Yeah, but you're taking the universe out of context.");
$sheep.print($*ERR);
my $duck = Acme::Cow.new(File => "duck.cow");
$duck.fill(0);
$duck.say(`figlet quack`);
$duck.print($socket);
```
# DESCRIPTION
Acme::Cow is the logical evolution of the old cowsay program. Cows are derived from a base class (Acme::Cow) or from external files.
Cows can be made to say or think many things, optionally filling and justifying their text out to a given margin.
Cows are nothing without the ability to print them, or sling them as strings, or what not.
# METHODS
## new
```
my $cow = Acme::Cow.new(
over => 0, # optional
wrap => 40, # optional
fill => True, # optional
text => "hello world", # specify the text of the cow
File => "/foo/bar", # specify when loading cow from a file
);
```
Create a new `Acme::Cow` object. Optionally takes the following named parameters:
has Str $.el is rw = 'o'; has Str $.er is rw = 'o'; has Str $.U is rw = ' ';
## over
Specify (or retrieve) how far to the right (in spaces) the text balloon should be shoved.
## wrap
Specify (or retrieve) the column at which text inside the balloon should be wrapped. This number is relative to the balloon, not absolute screen position.
The number set here has no effect if you decline filling/adjusting of the balloon text.
## think
Tell the cow to think its text instead of saying it. Optionally takes the text to be thought.
## say
Tell the cow to say its text instead of thinking it. Optionally takes the text to the said.
## text
Set (or retrieve) the text that the cow will say or think.
Expects a list of lines of text (optionally terminated with newlines) to be displayed inside the balloon.
## print
Print a representation of the cow to the specified filehandle ($\*OUT by default).
## fill
Inform the cow to fill and adjust (or not) the text inside its balloon. By default, text inside the balloon is filled and adjusted.
## as\_string
Render the cow as a string.
# WRITING YOUR OWN COW FILES
{$balloon} is the text balloon; it should be on a line by itself, flush-left. {$tl} and {$tr} are what goes to the text balloon from the thinking/speaking part of the picture; {$tl} is a backslash ("") for speech, while {$tr} is a slash ("/"); both are a lowercase letter O ("o") for thought. {$el} is a left eye, and {$er} is a right eye; both are "o" by default. Finally {$U} is a tongue, because a capital U looks like a tongue. (Its default value is "U ".)
There are two methods to make your own cow file: the standalone file and the Perl module.
For the standalone file, take your piece of ASCII art and modify it according to the rules above. Note that the balloon must be flush-left in the template if you choose this method. If the balloon isn't meant to be flush-left in the final output, use its `over()` method.
For a Perl module, declare that your module is a subclass of `Acme::Cow`. You may do other modifications to the variables in the template, if you wish: many examples are provided with the `Acme::Cow` distribution.
# HISTORY
They're called "cows" because the original piece of ASCII art was a cow. Since then, many have been contributed (i.e. the author has stolen some) but they're still all cows.
# SEE ALSO
<perl>, <cowsay>, <figlet>, <fortune>, <cowpm>
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Original Perl version: Copyright 2002 Tony McEnroe, Raku adaptation: Copyright 2019, 2021 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-tokuhirom-HTTP-Server-Tiny.md
[](https://travis-ci.org/tokuhirom/p6-HTTP-Server-Tiny)
# NAME
HTTP::Server::Tiny - a simple HTTP server for Perl6
# SYNOPSIS
```
use HTTP::Server::Tiny;
my $port = 8080;
# Only listen for connections from the local host
# if you want this to be accessible from another
# host then change this to '0.0.0.0'
my $host = '127.0.0.1';
HTTP::Server::Tiny.new(:$host , :$port).run(sub ($env) {
my $channel = Channel.new;
start {
for 1..100 {
$channel.send(($_ ~ "\n").Str.encode('utf-8'));
}
$channel.close;
};
return 200, ['Content-Type' => 'text/plain'], $channel
});
```
# DESCRIPTION
HTTP::Server::Tiny is a standalone HTTP/1.1 web server for perl6.
# METHODS
* `HTTP::Server::Tiny.new($host, $port)`
Create new instance.
* `$server.run(Callable $app, Promise :$control-promise)`
Run http server with P6W app. The named parameter `control-promise` if provided, can be *kept* to quit the server loop, which may be useful if the server is run asynchronously to the main thread of execution in an application.
If the optional named parameter `control-promise` is provided with a `Promise` then the server loop will be quit when the promise is kept.
# VERSIONING RULE
This module respects [Semantic versioning](http://semver.org/)
# TODO
* Support timeout
# COPYRIGHT AND LICENSE
Copyright 2015, 2016 Tokuhiro Matsuno [[email protected]](mailto:[email protected])
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-azawawi-Terminal-Caca.md
# Terminal::Caca
[](https://github.com/azawawi/raku-terminal-caca/actions)
Terminal::Caca - Use libcaca (Colour AsCii Art library) API in Raku
**NOTE:** The library is currently **experimental**. You have been warned :)
Normally you would use the safer object-oriented API via `Terminal::Caca`. If
you need to access raw API for any reason, please use `Terminal::Caca::Raw`.
## Example
```
use v6;
use Terminal::Caca;
# Initialize library
given my $o = Terminal::Caca.new {
# Set window title
.title("Raku rocks");
# Say hello world
my $text = ' Hello world, from Raku! ';
.color(white, blue);
.text(10, 10, $text);
# Draw an ASCII-art box around it
.thin-box(9, 9, $text.chars + 2, 3);
# Refresh display
.refresh;
# Wait for a key press event
.wait-for-keypress;
# Cleanup on scope exit
LEAVE {
.cleanup;
}
}
```
For more examples, please see the <examples> folder.
## Installation
* On Debian-based linux distributions, please use the following command:
```
$ sudo apt-get install libcaca-dev
```
* On Mac OS X, please use the following command:
```
$ brew update
$ brew install libcaca
```
* Using zef (a module management tool bundled with Rakudo Star):
```
$ zef install Terminal::Caca
```
## Testing
* To run tests:
```
$ prove --ext .rakutest -ve "raku -I."
```
* To run all tests including author tests (Please make sure
[Test::Meta](https://github.com/jonathanstowe/Test-META) is installed):
```
$ zef install Test::META
$ AUTHOR_TESTING=1 prove --ext .rakutest -ve "raku -I."
```
## Author
Ahmad M. Zawawi, azawawi on #raku, <https://github.com/azawawi/>
## License
MIT
|
## dist_cpan-SACOMO-Magento.md
# Magento [build status](https://travis-ci.org/scmorrison/perl6-Magento)
Perl 6 Magento 2 API client module.
* [Features](#features)
* [Getting started](#getting-started)
* [Module usage](#module-usage)
* [Response format](#response-format)
* [Error messages](#error-messages)
* [Search critera](#search-criteria)
* [Custom API endpoints](#custom-api-endpoints)
* [Custom API endpoints](#custom-api-endpoints)
* [CLI usage](#cli-usage)
* [Config](#config)
* [Config variables](#config-variables)
* [Installation](#installation)
* [Todo](#todo)
* [Requirements](#requirements)
* [Troubleshooting](#troubleshooting)
* [Authors](#authors)
* [License](#license)
* [See also](#see-also)
# Features
* **Magento 2 compatable**: Works with the latest Magento 2 API
* **Integration token support**: Can utilize Integration tokens for authentication
* **Admin & Customer token support**: Supports username / password authentication for access token generation
* **Use Perl 6 hash for search critera**: Write complex search criteria queries as Perl 6 Hash
# Getting started
For long-use Integration Access Token usage use the `6mag init` command:
```
6mag init
```
Enter your Magento installation base URL (e.g. <https://my.magento>), store identifier (e.g. default), and Integration Access Token (generated in Magento > System > Integrations).
By default this will generate the file `~/.6mag/config.yml`:
```
---
host: "https://my.magento"
store: default
access_token: ********************************
```
# Module Usage
All subroutines are documented in <docs/Subroutines.md>.
Using long-use Integration Access Token from `~/.6mag/config.yml`:
```
use Magento::Config;
use Magento::Customer;
my %config = Magento::Config::from-file;
#GET /V1/customers/:customerId
say customers %config, id => 1;
```
Using pre-generated Access Token without `~/.6mag/config.yml`:
```
use Magento::Customer;
my $host = 'https://my.magento';
my %config = %{
host => $host,
access_token => '********************************',
store => 'default'
}
#GET /V1/customers/:customerId
say customers %config, id => 1;
```
Using password authentication as Admin:
```
use Magento::Auth;
use Magento::Customer;
my $host = 'https://my.magento';
my %config = %{
host => $host,
access_token => request-access-token(username => 'admin', password => '****', :$host),
store => 'default'
}
#GET /V1/customers/:customerId
say customers %config, id => 1;
```
Using password authentication as Customer:
```
use Magento::Auth;
use Magento::Customer;
my $host = 'https://my.magento';
my $access_token =
request-access-token(
:$host,
username => '[email protected]',
password => '****',
user_type => 'customer');
my %config = %{:$host, :$access_key, store => 'default'};
#GET /V1/customers/me
say customers-me %config;
```
### Response format
By default, all responses are returned as `Perl 6` variables. To return the raw `json` or `xml` body add the following to your config Hash:
```
my %config = %{
host => $host,
access_token => '********************************',
store => 'default',
format => 'json',
# or
format => 'xml'
}
```
### Error messages
For a successful request only the relevant data will be returned from the server response. For example, only the `cart_id` value will be returned when a new cart is successfully created on the server.
When an error occurs, the response will return a `Perl 6` Hash with a `message` and `status` pair, like this:
```
%{
message => 'Cannot assign customer to the given cart. Customer already has active cart.',
status => 400
}
```
### Search criteria
Use a `Perl 6` Hash to define search criteria:
```
use Magento::Config;
use Magento::Customer;
my %config = Magento::Config::from-file;
my %customer_search_criteria = %{
searchCriteria => %{
filterGroups => [
{
filters => [
{
field => 'email',
value => '[email protected]',
condition_type => 'eq'
},
]
},
],
current_page => 1,
page_size => 10
}
}
# Do a customer search using the search criteria hash
say customers-search %config, search_criteria => %customer_search_criteria;
```
#### search-criteria Helper routine
In addition to the `Hash` approach above, you can also use the `search-critera` helper routine from `Magento::Utils`. This creates a search criteria `Hash` using more condensed notation.
Only the initial `Array` is required. The `conditions` named argument is optional.
```
use Magento::Utils;
# Single filter
my %critera = search-critera
# field value condition_type
['email', '[email protected]', 'eq'],
conditions => %{
current_page => 1,
page_size => 10
}
# Logical AND filter
my %criteria = search-critera
[
['email', '[email protected]', 'eq'],
['email', '[email protected]', 'eq'],
],
conditions => %{
current_page => 1,
page_size => 10
}
# Logical OR
my %criteria = search-critera
[
[
['email', '[email protected]', 'eq'],
['email', '[email protected]', 'eq'],
],
[
['email', '[email protected]', 'eq'],
['email', '[email protected]', 'eq'],
],
],
conditions => %{
current_page => 1,
page_size => 10
}
```
### Custom API endpoints
You can use the `request` subroutine directly to make requests against custom API endpoints:
```
use Magento::HTTP;
use JSON::Fast;
# GET
Magento::HTTP::request
method => 'GET',
config => %config,
uri => "myCustom/endpoint/123";
# POST/PUT/DELETE
Magento::HTTP::request
method => 'POST', # or PUT / DELETE
config => %config,
uri => "myCustom/endpoint",
content => to-json %content-hash;
```
# CLI Usage
```
Usage:
6mag init - Generate Integration token based config
6mag print-config - Print Integration token config
6mag version - Print 6mag version and exit
Optional arguments:
--config= - Specify a custom config file location
Default is `~/.6mag/config.yml`
e.g. 6mag --config=path/to/config.yml init
```
# Config
Each project has its own `config.yml` which uses the following format:
```
---
host: "https://my.magento"
store: default
access_token: ********************************
format: json
version: V1
```
### Config variables
Config variables are defined in `config.yml`:
#### Required
* `host`: Magento base URL
* `access_token`: Magento access token. For long-use configurations, integrations, use an Integration Access Token.
#### Optional
* `format`: By default all results are returned as `Perl 6` variables. You can specify `json` or `xml` with this variable to return the raw response body in either format.
* `store`: Store identifier, defaults to `default`.
* `version`: Magento API version, defaults to `V1`.
# Installation
```
git clone https://github.com/scmorrison/perl6-Magento.git
cd perl6-Magento/
zef install .
```
Installation issue? See [Troubleshooting](#troubleshooting).
# Todo
* More tests
* More API endpoints
# Requirements
* [Perl 6](http://perl6.org/)
# Troubleshooting
* **Errors installing from previous version:**
Remove the zef tmp / store perl6-Magento.git directories:
```
# Delete these folders from your zef install
# directory.
rm -rf ~/.zef/store/perl6-Magento.git ~/.zef/tmp/perl6-Magento.git
```
In some instances it might help to delete your local `~/.perl6/precomp` directory.
# Authors
* [Sam Morrison](@samcns)
# License
This Perl 6 Magento module is free software; you can redistribute it and/or modify it under the terms of the Artistic License 2.0. (Note that, unlike the Artistic License 1.0, version 2.0 is GPL compatible by itself, hence there is no benefit to having an Artistic 2.0 / GPL disjunction.) See the file LICENSE for details.
# See also
* [Magento](https://magento.com/)
|
## dist_zef-raku-community-modules-Email-Simple.md
[](https://github.com/raku-community-modules/Email-Simple/actions) [](https://github.com/raku-community-modules/Email-Simple/actions) [](https://github.com/raku-community-modules/Email-Simple/actions)
# NAME
Email::Simple - Simple email parsing module
# SYNOPSIS
```
use Email::Simple;
my $eml = Email::Simple.new($raw-mail-text);
say $eml.body;
my $new = Email::Simple.create(
header => [
['To', '[email protected]'],
['From', '[email protected]'],
['Subject', 'test']
],
body => 'This is a test.',
);
say ~$new;
```
# DESCRIPTION
This is my attempt at porting Email::Simple from Perl to Raku (mostly just because I can)
# METHODS
## new(Str $text, :$header-class = Email::Simple::Header)
## new(Array $header, Str $body, :$header-class = Email::Simple::Header)
Alias of `.create` with positional arguments.
## create(Array :$header, Str :$body, :$header-class = Email::Simple::Header)
## header($name, :$multi)
Returns the email header with the name `$name`. If `:$multi` is not passed, then this will return the first header found. If `:$multi` is set, then this will return a list of all headers with the name `$name` (note the change from v1.0!)
## header-set($name, \*@lines)
Sets the header `$name`. Adds one `$name` header for each additional argument passed.
## header-names
Returns a list of header names in the email.
## headers
Alias of `header-names`
## header-pairs
Returns the full header data for an email.
```
$eml.header-pairs(); # --> [['Subject', 'test'], ['From', '[email protected]']]
```
## body
Returns the mail body. Note that this module does not try to do any decoding, it just returns the body as-is.
## body-set($text)
Sets the mail body to `$text`. Note that this module does not try to properly encode the body.
## as-string, Str>
Returns the full raw email, suitable for piping into sendmail.
## crlf
## header-obj
## header-obj-set($obj)
# AUTHOR
Andrew Egeler
# COPYRIGHT AND LICENSE
Copyright 2012 - 2018 Andrew Egeler
Copyright 2019 - 2022 Raku Community
All files in this repository are licensed under the terms of Create Commons License; for details please see the LICENSE file
|
## dist_zef-CIAvash-Curry.md
# NAME
Curry - a [Raku](https://www.raku-lang.ir/en) module for currying functions.
# DESCRIPTION
Curry is a [Raku](https://www.raku-lang.ir/en) module for currying functions plus partially applying them.
# SYNOPSIS
```
use Curry:auth<zef:CIAvash> :all;
# Curried subs
sub f ($a, $b) is curry {
$a × $b;
}
my &pf = f 2;
say pf 3;
=output 6
sub f2 ($a, $b, :$c = 1) is curry {
[×] $a, $b, $c;
}
my &pf2 = f 2, :c(4);
say pf 3;
=output 24
sub f3 (*@a) is curry {
[×] @a;
}
my &pf3 = f 2, 3;
say pf;
=output 6
say pf(4)();
=output 24
# Curried method and attribute
my class C {
has &.f is curry is rw;
method m (Int $a, Int $b) is curry {
$a × $b;
}
}
my C $c .= new;
# Method
say $c.m(2, 3)()
=output 6
my &pm = $c.m(2, 3);
say pm;
=output 6
say pm(4)();
=output 24
# Attribute
$c.f = * + *;
say $c.f.(1, 2);
=output 3
my &pa = $c.f.(1);
say pa 2;
=output 3
# Making Curry
my &f3 = Curry[* + *];
# Or
my &f4 = make_curry * + *;
my &cgrep = Curry[&grep];
# Or better
my &cgrep2 = new_curry &grep;
# Be careful with this
make_curry &grep;
# Or
make_curryable &grep; # This changes function's signature
# Original function (before being curried)
my &lost_grep = &grep.original_function;
```
# INSTALLATION
You need to have [Raku](https://www.raku-lang.ir/en) and [zef](https://github.com/ugexe/zef), then run:
```
zef install --/test "Curry:auth<zef:CIAvash>"
```
or if you have cloned the repo:
```
zef install .
```
# TESTING
```
prove -ve 'raku -I.' --ext rakutest
```
# ROLES
## role Curry [Code:D $function]
Curry role takes a function as parameter and does the `Callable` role
### method CALL-ME
```
method CALL-ME(
|c
) returns Mu
```
Calls the function if all parameters are provided or returns a partially applied function
### method curry
```
method curry(
|c
) returns Curry:D
```
Like `assuming` but returns a Curry. And tries to preserve the parameters of the partial function.
### method original\_function
```
method original_function() returns Code:D
```
Returns the original function, the function that was curried
## role Curry::CaptureAll
A role with a signature that captures all arguments
# SUBS
## multi sub make\_curry
```
multi sub make_curry(
Code:D $f
) returns Curry:D is export(:all, :subs)
```
Takes a function, gives a cloned version of it to `Curry`, then adds the role to the function
## multi sub make\_curry
```
multi sub make_curry(
*@f where { ... }
) returns Array[Curry:D] is export(:all, :subs)
```
Takes functions, gives a cloned version of each to `Curry`, then adds the role to each function
## multi sub new\_curry
```
multi sub new_curry(
Code:D $f
) returns Curry:D is export(:all, :subs)
```
Takes a function, creates a copy of it with role `Curry` mixed in
## multi sub new\_curry
```
multi sub new_curry(
*@f where { ... }
) returns Array[Curry:D] is export(:all, :subs)
```
Takes functions, creates a copy of each with role `Curry` mixed in
## multi sub make\_curryable
```
multi sub make_curryable(
Code:D $f
) returns Curry:D is export(:all, :subs)
```
Takes a function and returns a curried function that does `Curry::CaptureAll`
## multi sub make\_curryable
```
multi sub make_curryable(
*@f where { ... }
) returns Array[Curry:D] is export(:all, :subs)
```
Takes functions and returns an array of curried functions that does `Curry::CaptureAll`
## multi sub trait\_mod:
```
multi sub trait_mod:<is>(
Sub:D $sub,
:$curry!
) returns Mu is export(:all, :traits)
```
`is curry` trait for `Sub`; Makes the function a curried function that does `Curry::CaptureAll`
## multi sub trait\_mod:
```
multi sub trait_mod:<is>(
Method:D $method,
:$curry!
) returns Mu is export(:all, :traits)
```
`is curry` trait for `Method`; Makes the function a curried function that does `Curry::CaptureAll`
## multi sub trait\_mod:
```
multi sub trait_mod:<is>(
Attribute:D $attribute,
:$curry!
) returns Mu is export(:all, :traits)
```
`is curry` trait for `Attribute`; Makes the function a curried function that does `Curry::CaptureAll`.
If you want to be able to set the function from outside of the class, you need to make the attribute writable
with `is rw`. Setting the attribute with `new` doesn't work, only assignment works.
# REPOSITORY
<https://codeberg.org/CIAvash/Curry/>
# BUG
<https://codeberg.org/CIAvash/Curry/issues>
# AUTHOR
Siavash Askari Nasr - <https://siavash.askari-nasr.com>
# COPYRIGHT
Copyright © 2021 Siavash Askari Nasr
# LICENSE
Curry is free software: you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
Curry is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public License along with Curry. If not, see <http://www.gnu.org/licenses/>.
|
## dist_zef-leont-YAMLish.md
[](https://github.com/Leont/yamlish/actions) [](https://github.com/Leont/yamlish/actions) [](https://github.com/Leont/yamlish/actions)
# NAME
YAMLish - a YAML parser/emitter written in pure raku
# DESCRIPTION
This is a YAML parser written in pure-raku. It aims at being feature complete (though there still a few features left to implement). Patches are welcome.
# INSTALLATION
```
$ zef install YAMLish
```
# EXPORTED SUBS
* `load-yaml(Str $input, ::Grammar:U :$schema = ::Schema::Core, :%tags)`
* `load-yamls(Str $input, ::Grammar:U :$schema = ::Schema::Core, :%tags)`
* `save-yaml($document, :$sorted = True)`
* `save-yamls(**@documents, :$sorted = True)`
# Example use for a configuration file
This configuration file begins with a comment followed by three lines of key/value:
```
# key: value
lang: en
lat: 46.12345
lon: -82.6231
```
Access the file in your code like this:
```
use YAMLish;
my $str = "config.yml".IO.slurp:
my %conf = load-yaml $str;
say %conf<lang>; # OUTPUT: «en»
say %conf<lat>; # OUTPUT: «46.12345»
say %conf<lon>; # OUTPUT: «-82.6231»
```
# TODO
Please have a look at <./TODO.md>
# AUTHOR
Leon Timmermans
# LICENSE
Artistic License 2.0
|
## dist_zef-jonathanstowe-Linux-Cpuinfo.md
# Linux::Cpuinfo
Obtain Linux CPU information.

## Synopsis
```
use Linux::Cpuinfo;
my $cpuinfo = Linux::Cpuinfo.new();
my $cnt = $cpuinfo.num-cpus(); # > 1 for an SMP system
for $cpuinfo.cpus -> $cpu {
say $cpu.bogomips;
}
```
## Description
On Linux systems various information about the CPU ( or CPUs ) in the
computer can be gleaned from `/proc/cpuinfo`. This module provides an
object oriented interface to that information for relatively simple use
in Raku programs.
## Installation
Assuming you have a working Rakudo installation you should be able to
install this with *zef* :
```
# From the source directory
zef install .
# Remote installation
zef install Linux::Cpuinfo
```
## Support
Suggestions/patches are welcomed via github at <https://github.com/jonathanstowe/Raku-Linux-Cpuinfo/issues>
I'd be particularly interested in the /proc/cpuinfo from a variety of
architectures to test against, the ones that I already have can be seen
in t/proc
I'm not able to test on a wide variety of platforms so any help there
would be appreciated.
## Licence
Please see the <LICENCE> file in the distribution.
© Jonathan Stowe 2015, 2016, 2017, 2019
|
## dist_zef-FRITH-Math-Libgsl-Random.md
[](https://github.com/frithnanth/raku-Math-Libgsl-Random/actions)
# NAME
Math::Libgsl::Random - An interface to libgsl, the Gnu Scientific Library - Random Number Generation.
# SYNOPSIS
```
use Math::Libgsl::Random;
my Math::Libgsl::Random $r .= new;
$r.get-uniform.say for ^10;
```
# DESCRIPTION
Math::Libgsl::Random is an interface to the Random Number Generation routines of libgsl, the Gnu Scientific Library.
### new(Int :$type?)
The constructor allows one optional parameter, the random number generator type. One can find an enum listing all the generator types in the Math::Libgsl::Constants module.
All the following methods *throw* on error if they return **self**, otherwise they *fail* on error.
### get(--> Int)
Returns the next random number as an Int.
### get-uniform(--> Num)
Returns the next random number as a Num in the interval [0, 1).
### get-uniform-pos(--> Num)
Returns the next random number as a Num in the interval (0, 1).
### get-uniform-int(Int $n --> Int)
This method returns an Int in the range [0, n - 1].
### seed(Int $seed)
This method initializes the random number generator. This method returns **self**, so it can be concatenated to the **.new()** method:
```
my $r = Math::Libgsl::Random.new.seed(42);
$r.get.say;
# or even
Math::Libgsl::Random.new.seed(42).get.say;
```
### name(--> Str)
This method returns the name of the current random number generator.
### min(--> Int)
This method returns the minimum value the current random number generator can generate.
### max(--> Int)
This method returns the maximum value the current random number generator can generate.
### copy(Math::Libgsl::Random $src)
This method copies the source generator **$src** into the current one and returns the current object, so it can be concatenated. The generator state is also copied, so the source and destination generators deliver the same values.
### clone(--> Math::Libgsl::Random)
This method clones the current object and returns a new object. The generator state is also cloned, so the source and destination generators deliver the same values.
```
my $r = Math::Libgsl::Random.new;
my $clone = $r.clone;
```
### write(Str $filename!)
Writes the generator to a file in binary form. This method can be chained.
### read(Str $filename!)
Reads the generator from a file in binary form. This method can be chained.
# C Library Documentation
For more details on libgsl see <https://www.gnu.org/software/gsl/>. The excellent C Library manual is available here <https://www.gnu.org/software/gsl/doc/html/index.html>, or here <https://www.gnu.org/software/gsl/doc/latex/gsl-ref.pdf> in PDF format.
# Prerequisites
This module requires the libgsl library to be installed. Please follow the instructions below based on your platform:
## Debian Linux and Ubuntu 20.04+
```
sudo apt install libgsl23 libgsl-dev libgslcblas0
```
That command will install libgslcblas0 as well, since it's used by the GSL.
## Ubuntu 18.04
libgsl23 and libgslcblas0 have a missing symbol on Ubuntu 18.04. I solved the issue installing the Debian Buster version of those three libraries:
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgslcblas0_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl23_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl-dev_2.5+dfsg-6_amd64.deb>
# Installation
To install it using zef (a module management tool):
```
$ zef install Math::Libgsl::Random
```
# AUTHOR
Fernando Santagata [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2020 Fernando Santagata
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## minpairs.md
minpairs
Combined from primary sources listed below.
# [In Any](#___top "go to top of document")[§](#(Any)_method_minpairs "direct link")
See primary documentation
[in context](/type/Any#method_minpairs)
for **method minpairs**.
```raku
multi method minpairs(Any:D:)
```
Calls [`.pairs`](/routine/pairs) and returns a [`Seq`](/type/Seq) with all of the Pairs with minimum values, as judged by the [`cmp` operator](/routine/cmp):
```raku
<a b c a b c>.minpairs.raku.put; # OUTPUT: «(0 => "a", 3 => "a").Seq»
%(:42a, :75b).minpairs.raku.put; # OUTPUT: «(:a(42),).Seq»
```
# [In role Setty](#___top "go to top of document")[§](#(role_Setty)_method_minpairs "direct link")
See primary documentation
[in context](/type/Setty#method_minpairs)
for **method minpairs**.
```raku
multi method minpairs(Setty:D: --> Seq:D)
```
Returns the value of [`self.pairs`](/routine/pairs) (as all Pairs have minimum values). See also [`Any.minpairs`](/routine/minpairs)
|
## dist_cpan-AZAWAWI-Inline-Go.md
# Inline::Go
[](https://travis-ci.org/azawawi/perl6-inline-go) [](https://ci.appveyor.com/project/azawawi/perl6-inline-go/branch/master)
Use inline [Go](https://golang.org/) code within your Perl 6 source code. The
project has the following ambitious goals to achieve:
* Parse Go code using Perl 6 grammars with test suite taking directly from Go
language specification.
* Transform Go functions and classes to be usable within Perl 6.
* Provide a simple and robust way to take advantage of Go groutines in Perl 6.
**Note:** This currently a totally **experimental** module. Please do not use on
a production system.
The module is currently using simple regular expression to find exported go
functions signatures with a simple Go-to-Perl-6 type mapping. The Perl 6
NativeCall Go function wrapper is added via an evil `EVAL` into the current
object via a role (to support multiple objects).
## Example
```
use v6.c;
my $code = '
package main
import ("C"; "fmt")
//export Add_Int32
func Add_Int32(a int, b int) int { return a + b }
//export Hello
func Hello() { fmt.Println("Hello from Go!") }
func main() { }
';
my $go = Inline::Go.new( :code( $code ) );
$go.import-all;
$go.Hello;
say $go.Add_Int32(1, 2);
```
For more examples, please see the <examples> folder.
## Installation
* Please install the Go language toolchain from [here](https://golang.org/dl/). You
need at least Go 1.5 or later.
* **On windows**, you need the gcc toolchain. Luckily you can have that easily
by installing [Strawberry Perl](http://strawberryperl.com/).
* Install it using zef (a module management tool bundled with Rakudo Star):
```
$ zef install Inline::Go
```
## Testing
* To run tests:
```
$ prove -ve "perl6 -Ilib"
```
* To run all tests including author tests (Please make sure
[Test::Meta](https://github.com/jonathanstowe/Test-META) is installed):
```
$ zef install Test::META
$ AUTHOR_TESTING=1 prove -e "perl6 -Ilib"
```
## See Also
* [Calling Go Functions from Other Languages](https://medium.com/learning-the-go-programming-language/calling-go-functions-from-other-languages-4c7d8bcc69bf).
* [The Go Programming Language Specification](https://golang.org/ref/spec) .
* [cgo Wiki](https://github.com/golang/go/wiki/cgo)
## Author
Ahmad M. Zawawi, [azawawi](https://github.com/azawawi/) on #perl6
## License
MIT License
|
## dist_cpan-RBT-Test-Differences.md
# Test::Differences
Test complex data structures and output the differences between them in
diagnostics. This is helpful for spotting minor changes over a large dataset.
## SYNOPSIS
```
use Test;
use Test::Differences;
eq_or_diff $got, "a\nb\nc\n", "testing strings";
eq_or_diff @got, [{foo => <a b c>}, 1, Nil], "testing compex structure";
```
## DESCRIPTION
When the code you're testing returns multiple lines, records or data
structures and they're just plain wrong, an equivalent to the Unix
C utility may be just what's needed. Here's output from an
example test script that checks two text documents and then two
(trivial) data structures:
```
# Failed test 'Differences in text'
# +---+----------------+----------------+
# | Ln|Got |Expected |
# +---+----------------+----------------+
# | 0|this is line 1 |this is line 1 |
# * 1|this is line 2 |this is line b *
# | 2|this is line 3 |this is line 3 |
# +---+----------------+----------------+
not ok 1 - Differences in text
#
# Failed test 'Differences in whitespace'
# +---+--------------+--------------+
# | Ln|Got |Expected |
# +---+--------------+--------------+
# | 0| indented | indented |
# * 1|indented |indented *
# | 2| indented | indented |
# +---+--------------+--------------+
not ok 2 - Differences in whitespace
#
# Failed test 'Differences in structure'
# +---+-----------------------------------+---+---------------------------+
# | Ln|Got | Ln|Expected |
# +---+-----------------------------------+---+---------------------------+
# * 0|{ * 0|[ *
# * 1|ITEM => "Dry humourless message", * 1|"ITEM", *
# * 2|} * 2|"Dry humourless message", *
# | | * 3|] *
# +---+-----------------------------------+---+---------------------------+
not ok 3 - Differences in structure
#
# You failed 3 tests of 3
```
eq\_or\_diff() compares two strings or (limited) data structures and
either emits an ok indication or a side-by-side diff. Test::Differences
is designed to be used with Test.
### eq-or-diff
```
eq_or_diff $got, $want, $test-title, OutputStyle :output-style = Table, :context-lines = 5, :dump-overrides => {};
```
* `output-style` may be any OutputStyle supported by [Text::Diff](https://github.com/rbt/raku-Text-Diff).
* `context-lines` is the number of lines above/below within the formatted output around
the change to present.
* `dump-overrides` is a set of overrides to default [Data::Dump](https://github.com/tony-o/perl6-data-dump)
styling.
## COPYRIGHT
Copyright Barrie Slaymaker, Curtis "Ovid" Poe, and David Cantrell.
Ported, with non-trivial restructuring, to Raku by Rod Taylor.
## LICENSE
You can use and distribute this module under the terms of the The Artistic License 2.0. See the LICENSE file included in this distribution for complete details.
|
## dist_zef-tbrowder-Modf.md
[](https://github.com/tbrowder/Modf/actions)
# Modf
This module Provides a Raku version of routine 'modf' as used in other languages.
Note the `modf` routine is **not** currently available in the Raku core, but there is an open Rakudo Pull Request (#4434) to add it. Thus it is likely to be in the core by the 2021.07 release of Rakudo.
# SYNOPSIS
```
use Modf;
say modf(3.2); # OUTPUT: «3 0.2»
say modf(-3.2); # OUTPUT: «-3 -0.2»
```
# DESCRIPTION
## modf
```
sub modf($x is copy, $places? --> List) is export(:modf) {...}
```
The c routine (currently not available in the *Raku* core) is similar to those in other languages including *C*, *C++*, *Python*, and *Haskell*. It coerces its input into a base 10 number and returns the integral and fractional parts in a list as shown below. (Note the `modf` routine has been submitted as a PR for the Raku core and may be part of the language soon.)
```
say modf(3.24); # OUTPUT: «3 0.24»
say modf(-2.7); # OUTPUT: «-2 -0.7»
say modf(10); # OUTPUT: «10 0»
say modf(0x10); # OUTPUT: «16 0»
say modf(-0o10); # OUTPUT: «-8 0»
```
Note the sign of the input value is applied to both parts, unless the part is zero. As expected, the fractional part of an integer will be zero. If desired, the user may use the optional parameter `$places` (a positive integer) to specify the precision to be shown in the fractional part.
```
say modf(1.23456); # OUTPUT: «1 0.23456»
say modf(1.23456, 3); # OUTPUT: «1 0.235»
```
# AUTHOR
Tom Browder [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
© 2021 Tom Browder
This library is free software; you can redistribute it or modify it under the Artistic License 2.0.
|
## prepost.md
class X::Phaser::PrePost
Error due to a false return value of a PRE/POST phaser
```raku
class X::Phaser::PrePost is Exception { }
```
Thrown when the condition inside a `PRE` or `POST` phaser evaluate to a false value.
For example
```raku
sub f($x) { PRE { $x ~~ Int } };
f "foo";
CATCH { default { put .^name, ': ', .Str } };
# OUTPUT: X::Phaser::PrePost: Precondition '{ $x ~~ Int }' failed«»
```
# [Methods](#class_X::Phaser::PrePost "go to top of document")[§](#Methods "direct link")
## [method phaser](#class_X::Phaser::PrePost "go to top of document")[§](#method_phaser "direct link")
```raku
method phaser(--> Str:D)
```
Returns the name of the failed phaser, `"PRE"` or `"POST"`.
## [method condition](#class_X::Phaser::PrePost "go to top of document")[§](#method_condition "direct link")
```raku
method condition(--> Str:D)
```
Returns the part of the source code that describes the phaser condition.
|
## binarymode.md
class X::IO::BinaryMode
Error while invoking methods on a handle in binary mode.
```raku
class X::IO::BinaryMode does X::IO is Exception { }
```
Thrown from certain [`IO::Handle`](/type/IO/Handle) methods if the handle is [in binary mode](/type/IO/Handle#method_encoding).
A typical error message is
「text」 without highlighting
```
```
Cannot do 'comb' on a handle in binary mode.
```
```
# [Methods](#class_X::IO::BinaryMode "go to top of document")[§](#Methods "direct link")
## [method trying](#class_X::IO::BinaryMode "go to top of document")[§](#method_trying "direct link")
Returns a string describing the failed operation; in this example, `comb`.
|
## dist_cpan-CCWORLD-CCLog.md
## [CCLog](https://github.com/ccworld1000/CCLog)
```
Simple and lightweight cross-platform logs,
easy-to-use simple learning,
and support for multiple languages,
such as C, C++, Perl 6, shell, Objective-C
support ios, osx, watchos, tvos
support pod, cocoapods https://cocoapods.org/pods/CCLog
```
## Perl 6
```
There are 2 (CCLog & CCLogFull) ways of binding.
```
Call CCLog.pm6
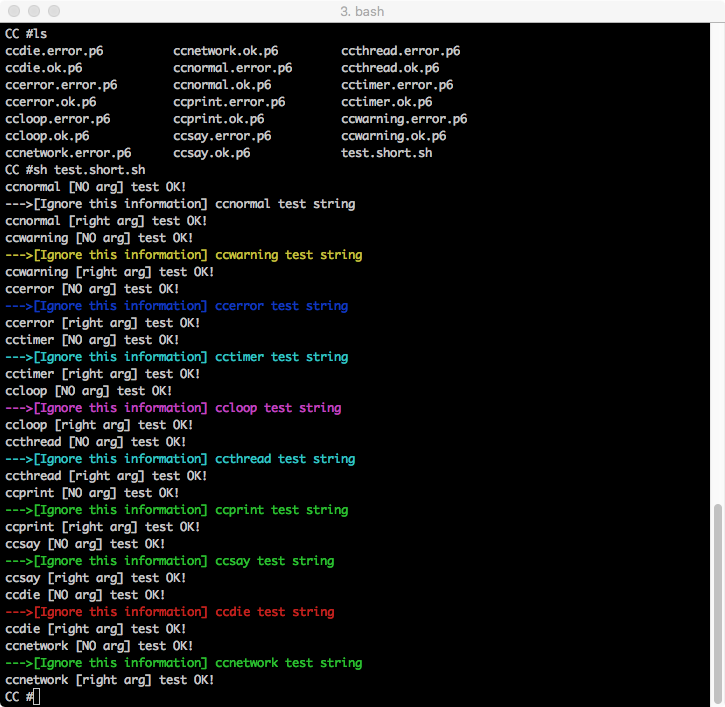
Call CCLogFull.pm6
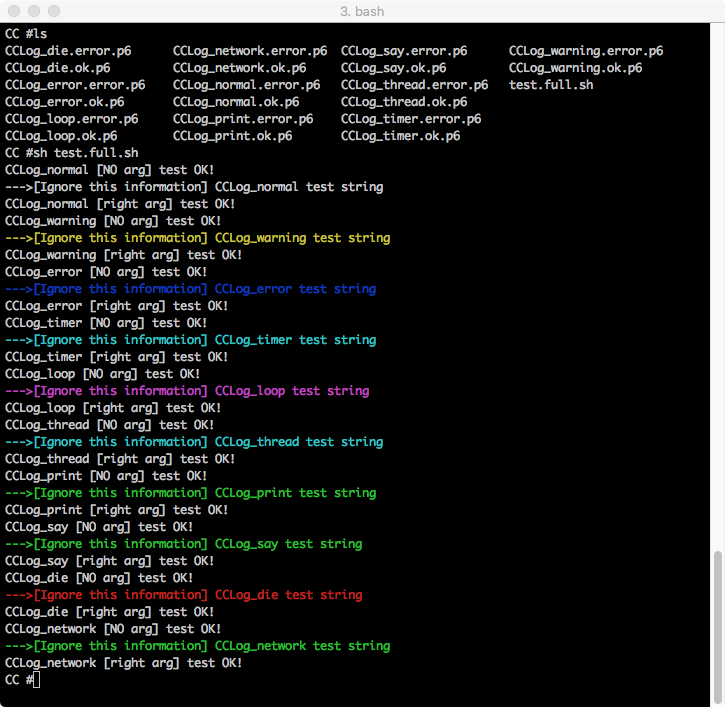
## Shell
```
Provide simple commands. fg:
ccnormal
ccwarning
ccerror
cctimer
ccloop
ccthread
ccprint
ccsay
ccdie
ccnetwork
These commands are automatically installed locally and can be called directly.
```
Call shell
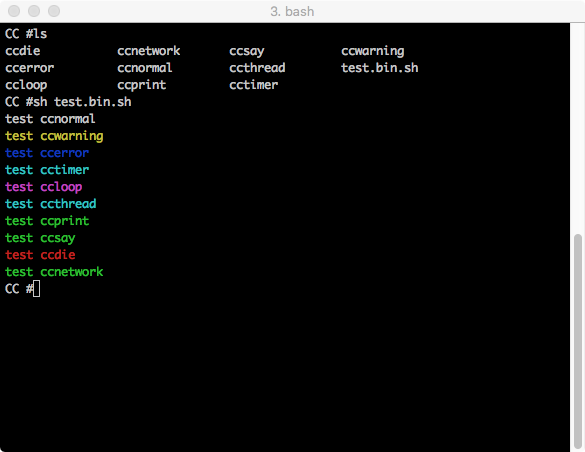
## C && C++ && Objective-C
```
You can use C library or C source (CCLog.h CCLog.c) code directly.
```
Call C && C++ && Objective-C
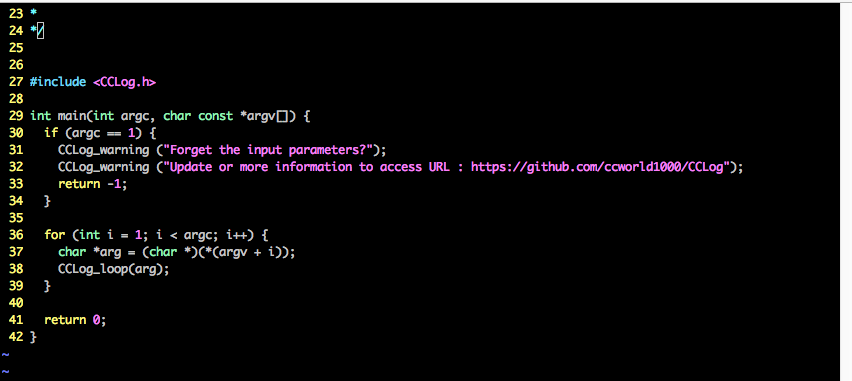
## Objective-C
```
Objective-C can call C directly, Or follow other ways to import.
or use pod https://github.com/ccworld1000/CCLog
pod 'CCLog'
```
## Local installation and unloading
```
zef install .
zef uninstall CCLog
```
## Network install
```
zef update
zef install CCLog
```
## Check if the installation is successful
The installation may be as follows
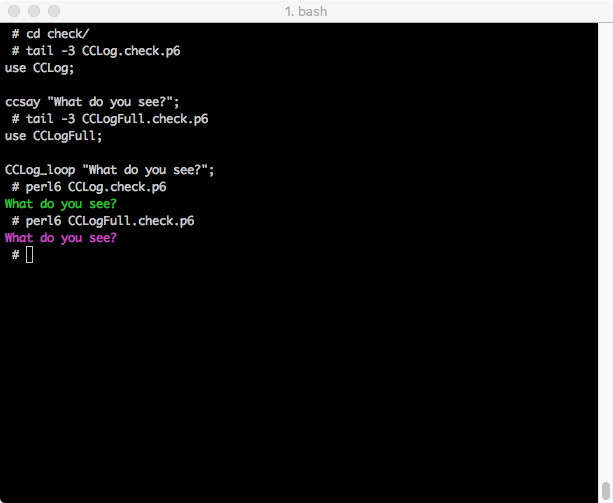
Installation failure may be as follows, you can try again
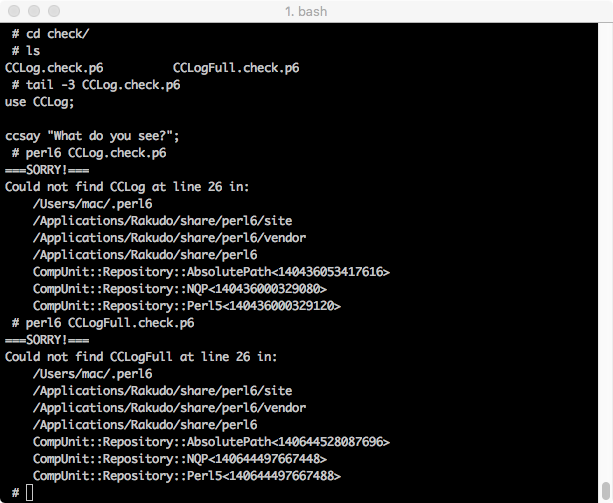
## Color display control
Perl6 CCLog.pm6 call ccshowColor
Perl6 CCLogFull.pm6 call CCLog\_showColor
C && C++ && Objective-C call CCLog\_showColor
fg:
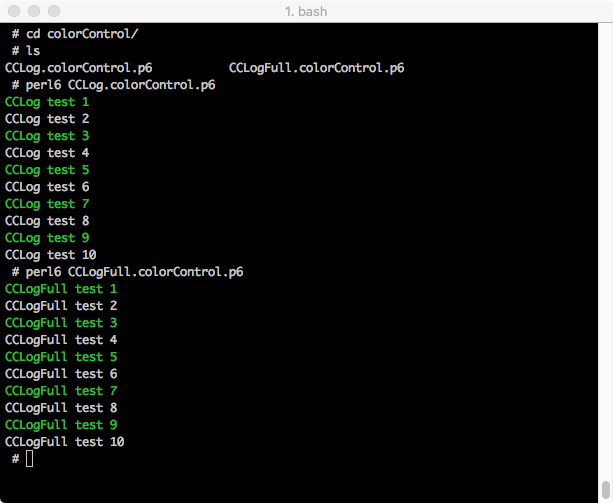
## Tips display control
fg:
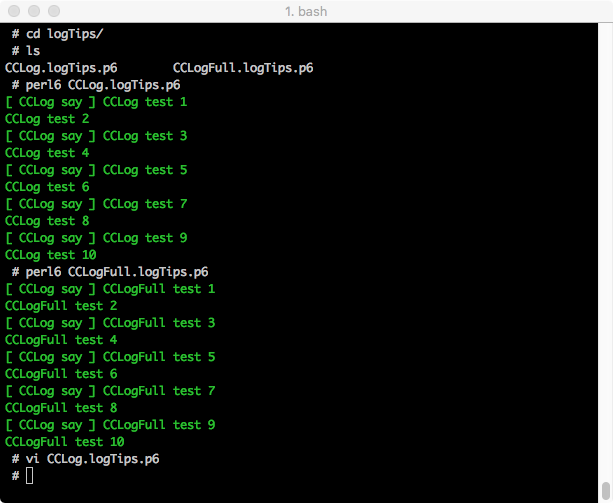
## Display log control
fg:
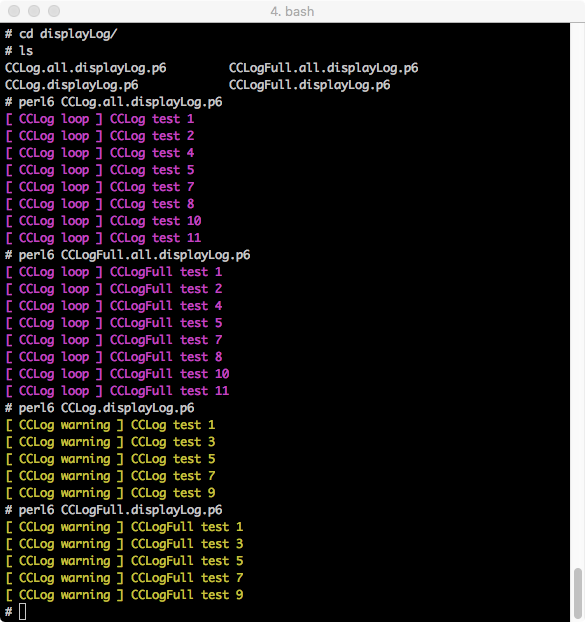
|
## dist_cpan-DARRENF-Test-Declare.md
[](https://travis-ci.org/darrenf/p6-test-declare)
# NAME
Test::Declare - Declare common test scenarios as data.
## CAVEAT
The author is a novice at Perl 6. Please be nice if you've stumbled across this and have opinions to express. Furthermore I somehow failed to notice the pre-existence of a Perl 5 `Test::Declare`, to which this code is **no relation**. Apologies for any confusion; I renamed late in the day, being fed up with the length of my first choice of `Test::Declarative`.
# SYNOPSIS
```
use Test::Declare;
use Module::Under::Test;
declare(
${
name => 'multiply',
call => {
class => Module::Under::Test,
construct => \(2),
method => 'multiply',
},
args => \(multiplicand => 4),
expected => {
return-value => 8,
},
},
${
name => 'multiply fails',
call => {
class => Module::Under::Test,
construct => \(2),
method => 'multiply',
},
args => \(multiplicand => 'four'),
expected => {
dies => True,
},
},
${
name => 'multiply fails',
call => {
class => Module::Under::Test,
construct => \(2),
method => 'multiply',
},
args => \(multiplicand => 8),
expected => {
# requires Test::Declare::Comparisons
return-value => roughly(&[>], 10),
},
},
);
```
# DESCRIPTION
Test::Declare is an opinionated framework for writing tests without writing (much) code. The author hates bugs and strongly believes in the value of tests. Since most tests are code, they themselves are susceptible to bugs; this module provides a way to express a wide variety of common testing scenarios purely in a declarative way.
# USAGE
Direct usage of this module is via the exported subroutine `declare`. The tests within the distribution in [t/](https://github.com/darrenf/p6-test-declare/tree/master/t) can also be considered to be a suite of examples which exercise all the options available.
## declare(${ … }, ${ … })
`declare` takes an array of hashes describing the test scenarios and expectations. Each hash should look like this:
* name
The name of the test, for developer understanding in the TAP output.
* call
A hash describing the code to be called.
```
* class
```
The actual concrete class - not a string representation, and not an instance either.
```
* method
```
String name of the method to call.
```
* construct
```
If required, a [Capture](https://docs.perl6.org/type/Capture.html) of the arguments to the class's `new` method.
* args
If required, a [Capture](https://docs.perl6.org/type/Capture.html) of the arguments to the instance's method.
* expected
A hash describing the expected behaviour when the method gets called.
```
* return-value
```
The return value of the method, which will be compared to the actual return value via `eqv`.
```
* lives/dies/throws
```
`lives` and `dies` are booleans, expressing simply whether the code should work or not. `throws` should be an Exception type.
```
* stdout/stderr
```
Strings against which the method's output/error streams are compared, using `eqv` (i.e. not a regex).
# SEE ALSO
Elsewhere in this distribution:
* `Test::Declare::Comparisons` - for fuzzy matching including some naive/rudimentary attempts at copying the [Test::Deep](https://metacpan.org/pod/Test::Deep) interface where Perl 6 does not have it builtin.
* [Test::Declare::Suite](https://github.com/darrenf/p6-test-declare/tree/master/lib/Test/Declare/Suite.pm6) - for a role which bundles tests together against a common class/method, to reduce repetition.
Used by the code here:
* [Test](https://github.com/rakudo/rakudo/blob/master/lib/Test.pm6)
* [IO::Capture::Simple](https://github.com/sergot/IO-Capture-Simple)
Conceptually or philosophically similar projects:
* Perl 5's `Test::Declare|https://metacpan.org/pod/Test::Declare` (oops, didn't see the name clash when I started)
* Perl 5's `Test::Spec|https://metacpan.org/pod/Test::Spec`
* [TestML](http://testml.org/)
And of course:
* [Perl 6](https://perl6.org/)
# AUTHOR
Darren Foreman [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2018 Darren Foreman
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-dwarring-PDF-Font-Loader-CSS.md
## Name
PDF::Font::Loader::CSS
## Synopsis
```
use CSS::Stylesheet;
use PDF::Font::Loader::FontObj;
use PDF::Font::Loader::CSS;
my CSS::Stylesheet $css .= parse: q:to<END>;
@font-face {
font-family: "DejaVu Sans";
src: url("fonts/DejaVuSans.ttf");
}
@font-face {
font-family: "DejaVu Sans";
src: url("fonts/DejaVuSans-Bold.ttf");
font-weight: bold;
}
@font-face {
font-family: "DejaVu Sans";
src: url("fonts/DejaVuSans-Oblique.ttf");
font-style: oblique;
}
@font-face {
font-family: "DejaVu Sans";
src: url("fonts/DejaVuSans-BoldOblique.ttf");
font-weight: bold;
font-style: oblique;
}
END
my CSS::Font::Descriptor @font-face = $css.font-face;
my PDF::Font::Loader::CSS $font-loader .= new: :@font-face, :base-url<t/>;
my CSS::Font() $font = "bold italic 12pt DejaVu Sans";
say $font-loader.find-font(:$font); # t/fonts/DejaVuSans-BoldOblique.ttf';
my PDF::Loader::FontObj $font-obj = $font-loader.load-font: :$font;
say $font-obj.font-name; # DejaVuSans-BoldOblique;
```
## Description
This module extends PDF::Font::Loader, adding `@font-face` attributes and rules to enable CSS
compatible font selection.
In particular, it extends the `find-font()` and `load-font()` methods; adding multi candidates to
handle CSS font properties and select from a list of `@font-face` font descriptors.
## Methods
### find-font
```
multi method find-font( CSS::Font:D() :$font) returns Str
```
Returns a matching font file name. This will either been a local file, or
a temporary file, fetched from a remote URI.
### load-font
```
multi method load-font( CSS::Font:D() :$font) returns Font::Loader::FontObj
```
Returns a matching font file name. This will either been a local file, or
a temporary file, fetched from a remote URI.
### source
```
method source CSS::Font:D() :$font() returns CSS::Font::Resources::Source
```
Returns a matching source for the font. This is the first matching font of an acceptable
PDF format (`opentype`, `truetype`, `postscript`, or `cff`).
|
## dist_cpan-JEFFOBER-Algorithm-SkewHeap.md
# NAME
Algorithm::SkewHeap - a mergable min heap
# VERSION
0.0.1
# SYNOPSIS
```
use Algorithm::SkewHeap;
my $heap = Algorithm::SkewHeap.new;
for (1 .. 1000).pick(1000) -> $n {
$heap.put($n);
}
until $heap.is-empty {
my $n = $heap.take;
}
$heap.merge($other-heap);
```
# DESCRIPTION
A skew heap is a type of heap based on a binary tree in which all operations are based on merging subtrees, making it possible to quickly combine multiple heaps, while still retaining speed and efficiency. Ammortized performance is O(log n) or better (see <https://en.wikipedia.org/wiki/Skew_heap>).
# SORTING
Items in the heap are returned with the lowest first. Comparisons are done with the greater than operator, which may be overloaded as needed for types intended to be used in the heap.
## class Algorithm::SkewHeap
SkewHeap class
### method size
```
method size() returns Int
```
Returns the number of items in the heap
### method is-empty
```
method is-empty() returns Bool
```
Returns true when the heap is empty
### method top
```
method top() returns Any
```
Returns the top item in the heap without removing it.
### method take
```
method take() returns Any
```
Removes and returns the top item in the heap.
### method put
```
method put(
$value
) returns Int
```
Adds a new item to the heap. Returns the new size of the heap.
### method merge
```
method merge(
Algorithm::SkewHeap $other
) returns Int
```
Destructively merges with another heap. The other heap should be considered unusable afterward. Returns the new size of the heap.
### method explain
```
method explain() returns Nil
```
Prints the structure of the heap for debugging purposes.
|
## dist_github-skids-Proc-Screen.md
# perl6-Proc-Screen
Perl6 programmatic interface for manipulating GNU screen sesssions
## Status
This is in "release early" status. Basic use of Proc::Screen may
work and Test::Screen may also work, but has very few available tests.
The version of GNU screen must be 4.02 (a.k.a. 4.2) or greater since
there is no way I know of to get the session ID back from a detached launch
on prior versions.
## Proc::Screen
Proc::Screen currently allows you to silently create screen sessions
and send commands to them. Eventually managing previously created
screen sessions and support for programmatic generation of screenrc
and screen commandlines is planned, but for now the main objective
is to provide only what Test::Screen needs.
## Test::Screen
Test::Screen will allow development environments that contain or
interface to interactive terminal applications to run non-interactive
tests on an emulated terminal. This is not as thorough as interactive
tests on actual terminals, but it is better than no testing at all.
## External Requirements
GNU screen wil not be available everywhere that a Perl6 application may
be installed, so both packages gracefully "pass" tests unless it
is detected. To actually run tests, screen should be installed
and from the perspective of the test environment, should be findable
as an executable named "screen" -- this does not need to be the
case for general use, as the package can work with custom installations,
it just needs to be that way for automated testing.
|
## dist_zef-lizmat-Tuple.md
[](https://github.com/lizmat/Tuple/actions) [](https://github.com/lizmat/Tuple/actions) [](https://github.com/lizmat/Tuple/actions)
# NAME
Tuple - provide an immutable List value type
# SYNOPSIS
```
use Tuple;
my @a is Tuple = ^10; # initialization follows single-argument semantics
my @b is Tuple = ^10;
set( @a, @b ); # elems == 1
my $t = tuple(^10); # also exports a "tuple" sub
```
# DESCRIPTION
Raku provides a semi-immutable `Positional` datatype: List. A `List` can not have any elements added or removed from it. However, since a list **can** contain containers of which the value can be changed, it is not a value type. So you cannot use Lists in data structures such as `Set`s, because each List is considered to be different from any other List, because they are not value types.
Since Lists are used very heavily internally with the current semantics, it is a daunting task to make them truly immutable value types. Hence the introduction of the `Tuple` data type.
# IMPLEMENTATION NOTES
In newer versions of Raku and the `Tuple` class, this class is now simply a child of the `ValueList` class (either supplied by the core or by the `ValueList` module).
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Tuple> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2018, 2020, 2021, 2022, 2024, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-melezhik-Cromtit.md
# Cromtit
Run [Tomtit](https://github.com/melezhik/Tomtit) scenarios as cron jobs and more.
# Build status
[](https://ci.sparrowhub.io)
# "What's in a name?"
Cromtit = Crontab + Tomtit
# Features
* Run Tomtit jobs as cron jobs
* Job dependencies
* Asynchronous jobs queue
* Distributed jobs
* Shared jobs artifacts
* Throttling to protect a system from overload (TBD)
* View job logs and reports via cro app web interface
# Install
Cromtit uses Sparky as job runner engine, so please install
and configure Sparky first:
1. Install [Sparky](https://github.com/melezhik/sparky#installation)
2. Install Cromtit
```
zef install Cromtit
```
# Quick start
This example would restart Apache server every Sunday 08:00 local server time.
Create Bash task:
```
mkdir -p tasks/apache/restart
cat << HERE > tasks/apache/restart/task.bash
sudo apachectl graceful
HERE
```
Create Tomtit scenario:
```
tom --init
tom --edit apache-restart
#!raku
task-run "tasks/apache/restart";
```
Create Cromtit configuration file `jobs.yaml`:
```
projects:
apache:
# should be a git repository with tomtit scenarios
path: [email protected]:melezhik/cromtit-cookbook.git
action: restart
crontab: "0 8 * * 0"
```
Commit changes to git repo:
```
git init
echo ".cache" > .gitignore
git add .tom/ .gitignore jobs.yaml
git commit -a -m "apache restart"
git remote add origin [email protected]:melezhik/cromtit-cookbook.git
git branch -M main
git push -u origin main
```
# Configuration DSL
Cromtit comes with configuration language allows use to define
jobs logic.
Create `jobs.yaml` file and edit it. Then apply changes:
```
cromt --conf jobs.yaml
```
# Configuration file specification
Cromtit configuration contains a list of Tomtit projects:
```
# list of Tomtit projects
projects:
rakudo:
path: ~/projects/rakudo
r3:
path: ~/projects/r3tool
crontab: "30 * * * *"
action: pull html-report
options: --no_index_update --dump_task
before:
-
name: rakudo
action: pull install
```
## Project specific configuration
Every project item has a specific configuration:
```
app:
# run `tom install`
# every one hour
crontab: "30 * * * *"
action: install
# with tomtit options:
options: --no_index_update
# setting env variables:
vars:
foo: 1
bar: 2
```
### Key
Key should define a unique project name.
### action
Should define name of tomtit scenario that will be run. Optional.
```
action: install
```
Multiple actions could be set as a space separated string:
```
# will trigger `tom pull` && `tom build` && `tom install`
action: pull build install
```
### path
Tomtit project path. Optional.
Either:
* file path
Sets local directory path with Tomtit project:
```
path: ~/projects/r3
```
Or:
* git repo
Sets git repository with Tomtit project
```
path: [email protected]:melezhik/r3tool.git
```
One can use either `git@` or `https://` schemes for git urls:
```
path: https://github.com/melezhik/r3tool.git
```
Triggering overs SCM changes. Use `trigger` flag to automatically trigger job
over SCM changes:
```
# trigger a new job in case of
# any new changes (commits)
# arrive to a default branch
# if r3tool.git repo
path: https://github.com/melezhik/r3tool.git
trigger: true
```
To set a specific branch for triggering, use `branch` option:
```
branch: dev
```
### crontab
Should represents crontab entry (how often and when to run a project), should
follow [Sparky crontab format](https://github.com/melezhik/sparky#run-by-cron).
Optional. If not set, implies manual run.
```
# run every 10 minutes
crontab: "*/10 * * * *"
```
### options
Tomtit cli options. Optional
```
options: --dump_task --verbose
```
### vars
Additional environment variables get passed to a job. Optional
```
vars:
# don't pass creds
# as clear text
user: admin
password: SecRet123
```
### url
Set Sparky API url. Optional. See "hosts.url" description.
### queue-id
Sparky project name. Optional. See "hosts.queue-id" description
### title
Job title. Optional. See "Job description" section.
### sparrowdo
Override job sparrowdo configuration. Optional. For example:
```
sparrowdo:
# run job in docker container
# named raku-apline-repo
docker: raku-apline-repo
```
### hosts
By default jobs get run on localhost.
To run jobs on specific hosts in parallel, use `hosts` list:
```
projects:
system-update:
path: ~/project/system-update
options: update
# runs `tom update` on every host
# in parallel
hosts:
-
url: https://192.168.0.1
-
url: https://192.168.0.2
-
url: https://192.168.0.3
```
Hosts list contains a list of Sparky API URLs (see also comment on optional url)
and hosts need to be a part of the same [Sparky cluster](https://github.com/melezhik/sparky#cluster-jobs).
Optionally every host could override vars:
```
hosts:
-
url: https://192.168.0.1
vars:
WORKER: 1
-
url: https://192.168.0.2
vars:
WORKER: 2
-
url: https://192.168.0.3
vars:
WORKER: 3
```
And sparrowdo configurations:
```
hosts:
-
url: https://192.168.0.1
vars:
WORKER: 1
sparrowdo:
docker: old_boy
bootstrap: true
```
`url` is optional, if omitted - a job gets on the same host, so this code will
run 3 jobs in parallel on the same host:
```
hosts:
-
vars:
WORKER: 1
-
vars:
WORKER: 2
-
vars:
WORKER: 3
```
`title` and `queue-id` parameters are also applicable for `hosts`
## Job Dependencies
Projects might have dependencies, so that some jobs might be run before or after
a project's job:
```
projects:
database:
path: ~/projects/database
app:
path: ~/projects/app
action: test
before:
-
name: database
action: create
vars:
db_name: test
db_user: test
db_password: pass
after:
-
name: database
action: remove
vars:
db_name: test
```
So, `before` and `after` are list of objects that accept following parameters:
### name
Project name. Required
### action
Override project job action. Optional. See project action specification.
### vars
Override project job vars. Optional. See project vars specification.
### sparrowdo
Override project job sparrowdo configuration. Optional. See project sparrowdo configuration specification.
### hosts
Override project job hosts. Optional. See project hosts specification.
## Nested Dependencies
Nested dependencies are allowed, so a dependency might have another dependency, so on.
Just be cautious about cycles. This should be directed acycling graph of dependencies.
# Job timeouts
One can set job timeout by using `timeout` parameter:
```
# wait 1200 sec till all 4 jobs have finished
timeout: 1200
hosts:
-
vars:
WORKER: 1
-
vars:
WORKER: 2
-
vars:
WORKER: 3
```
So `timeout` set in a job with hosts parallelization will cause wait till all
hosts jobs have finished for `timeout` seconds or raise "job timeout" exception
`timeout` for a single job (without hosts parallelization) will affect only this job,
will wait for `timeout` second till a job finished
`timeout` set in dependent job (that have other job dependencies) will cause wait
for `timeout` seconds till all dependencies jobs have finished or raise "job timeout" exception
# Job queues
Jobs from `hosts` list executed in parallel, to enable sequential execution use `queue-id` option,
jobs, with the *same* `queue-id` are executed in the same queue and thus executed one by one:
```
hosts:
-
url: https://192.168.0.1
queue-id: Q1
-
url: https://192.168.0.2
queue-id: Q1
-
url: https://192.168.0.3
queue-id: Q1
-
url: https://192.168.0.4
queue-id: Q2
-
url: https://192.168.0.5
queue-id: Q2
```
In this example jobs are executed in 2 parallel queues:
* hosts 192.168.0.1 - 192.168.0.3 are executed one by one in queue Q1
* hosts 192.168.0.4 - 192.168.0.5 are executed one by one in queue Q2
# Job description
One can override standard job title appears in reports
by inserting `title` option into arbitrary level:
```
jobs:
hosts:
-
title: jobA
-
title: jobB
-
title: jobC
```
This example runs the same job 3 times in parallel, with job titles appears in report list as:
```
jobA
jobB
jobC
```
# Artifacts
Jobs can share artifacts with each other:
```
projects:
fastspec-build:
path: [email protected]:melezhik/fastspec.git
action: build-rakudo
artifacts:
out:
-
file: rakudo.tar.gz
path: .build/rakudo.tar.gz
fastspec-test:
path: [email protected]:melezhik/fastspec.git
action: spectest
after:
-
name: fastspec-build
artifacts:
in:
- rakudo.tar.gz
hosts:
-
url: https://sparrowhub.io:4000
vars:
WORKER: 1
-
url: https://192.168.0.3:4001
vars:
WORKER: 2
-
url: http://127.0.0.1:4000
vars:
WORKER: 3
```
In this example dependency job `fastspec-build` copies file `.build/rakudo.tar.gz` into *internal storage*
so that dependent job `fastspec-test` would access it. The file will be located within tomtit scenario at
`.artifacts/rakudo.tar.gz` path.
## Dedicated storage server
Sometimes when hosts do not see each other directly (for example when some jobs get run on localhost )
a dedicated storage server could be an option, ensuring artifacts get copied and read from publicly accessed
Sparky API instance:
```
storage: https://sparrowhub.io:4000
```
# cromt cli
`cromt` is a Cromtit cli.
Options:
## --conf
Path to cromtit configuration file to apply. Optional. Default value is `~/cromtit.yaml`
# Web console
Sparky exposes a web UI to track projects, cron jobs and reports:
http://127.0.0.1:4000
# More
## Configuration file examples
You can find a configuration file examples at `examples/` directory
## Cookbook
[Cookbook.md](cookbook.md) file contains useful users scenarios
## Existing Cromit based projects
* [Fastspec](https://github.com/melezhik/fastspec)
* [Rakusta](https://github.com/melezhik/rakusta)
* [RAR](https://github.com/melezhik/raku-alpine-repo)
# Thanks to
God and Christ as "For the LORD gives wisdom; from his mouth come knowledge and understanding."
|
## hyperseq.md
class HyperSeq
An object for performing batches of work in parallel with ordered output
```raku
class HyperSeq does Iterable does Sequence { }
```
A `HyperSeq` is the intermediate object used when [`hyper`](/routine/hyper) is invoked on a [`Seq`](/type/Seq). In general, it's not intended for direct consumption by the developer.
# [Methods](#class_HyperSeq "go to top of document")[§](#Methods "direct link")
## [method iterator](#class_HyperSeq "go to top of document")[§](#method_iterator "direct link")
```raku
method iterator(HyperSeq:D: --> Iterator:D)
```
Returns the underlying iterator.
## [method grep](#class_HyperSeq "go to top of document")[§](#method_grep "direct link")
```raku
method grep(HyperSeq:D: $matcher, *%options)
```
Applies `grep` to the `HyperSeq` similarly to how it would do it on a [`Seq`](/type/Seq).
```raku
my @hyped = (^10000).map(*²).hyper;
@hyped.grep( * %% 3 ).say;
# OUTPUT: «(0 9 36 81 144 ...)»
```
When you use `hyper` on a [`Seq`](/type/Seq), this is the method that is actually called.
## [method map](#class_HyperSeq "go to top of document")[§](#method_map "direct link")
```raku
method map(HyperSeq:D: $matcher, *%options)
```
Uses maps on the `HyperSeq`, generally created by application of `hyper` to a preexisting [`Seq`](/type/Seq).
## [method invert](#class_HyperSeq "go to top of document")[§](#method_invert "direct link")
```raku
method invert(HyperSeq:D:)
```
Inverts the `HyperSeq` created from a [`Seq`](/type/Seq) by `.hyper`.
## [method hyper](#class_HyperSeq "go to top of document")[§](#method_hyper "direct link")
```raku
method hyper(HyperSeq:D:)
```
Returns the object.
## [method race](#class_HyperSeq "go to top of document")[§](#method_race "direct link")
```raku
method race(HyperSeq:D:)
```
Creates a [`RaceSeq`](/type/RaceSeq) object out of the current one.
## [method serial](#class_HyperSeq "go to top of document")[§](#method_serial "direct link")
```raku
multi method serial(HyperSeq:D:)
```
Converts the object to a [`Seq`](/type/Seq) and returns it.
## [method is-lazy](#class_HyperSeq "go to top of document")[§](#method_is-lazy "direct link")
```raku
method is-lazy(--> False )
```
Returns `False`.
## [method sink](#class_HyperSeq "go to top of document")[§](#method_sink "direct link")
```raku
method sink(--> Nil)
```
Sinks the underlying data structure, producing any side effects.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `HyperSeq`
raku-type-graph
HyperSeq
HyperSeq
Any
Any
HyperSeq->Any
Iterable
Iterable
HyperSeq->Iterable
Sequence
Sequence
HyperSeq->Sequence
Mu
Mu
Any->Mu
PositionalBindFailover
PositionalBindFailover
Sequence->PositionalBindFailover
[Expand chart above](/assets/typegraphs/HyperSeq.svg)
|
## capture.md
Capture
Combined from primary sources listed below.
# [In Signature](#___top "go to top of document")[§](#(Signature)_method_Capture "direct link")
See primary documentation
[in context](/type/Signature#method_Capture)
for **method Capture**.
```raku
method Capture()
```
Throws [`X::Cannot::Capture`](/type/X/Cannot/Capture).
# [In List](#___top "go to top of document")[§](#(List)_method_Capture "direct link")
See primary documentation
[in context](/type/List#method_Capture)
for **method Capture**.
```raku
method Capture(List:D: --> Capture:D)
```
Returns a [`Capture`](/type/Capture) where each [`Pair`](/type/Pair), if any, in the <`List` has been converted to a named argument (with the [key](/type/Pair#method_key) of the [`Pair`](/type/Pair) stringified). All other elements in the `List` are converted to positional arguments in the order they are found, i.e. the first non pair item in the list becomes the first positional argument, which gets index `0`, the second non pair item becomes the second positional argument, getting index `1` etc.
```raku
my $list = (7, 5, a => 2, b => 17);
my $capture = $list.Capture;
say $capture.keys; # OUTPUT: «(0 1 a b)»
my-sub(|$capture); # OUTPUT: «7, 5, 2, 17»
sub my-sub($first, $second, :$a, :$b) {
say "$first, $second, $a, $b"
}
```
A more advanced example demonstrating the returned [`Capture`](/type/Capture) being matched against a [`Signature`](/type/Signature).
```raku
my $list = (7, 5, a => 2, b => 17);
say so $list.Capture ~~ :($ where * == 7,$,:$a,:$b); # OUTPUT: «True»
$list = (8, 5, a => 2, b => 17);
say so $list.Capture ~~ :($ where * == 7,$,:$a,:$b); # OUTPUT: «False»
```
# [In Num](#___top "go to top of document")[§](#(Num)_method_Capture "direct link")
See primary documentation
[in context](/type/Num#method_Capture)
for **method Capture**.
```raku
method Capture()
```
Throws `X::Cannot::Capture`.
# [In Capture](#___top "go to top of document")[§](#(Capture)_method_Capture "direct link")
See primary documentation
[in context](/type/Capture#method_Capture)
for **method Capture**.
```raku
method Capture(Capture:D: --> Capture:D)
```
Returns itself, i.e. the invocant.
```raku
say \(1,2,3, apples => 2).Capture; # OUTPUT: «\(1, 2, 3, :apples(2))»
```
# [In Version](#___top "go to top of document")[§](#(Version)_method_Capture "direct link")
See primary documentation
[in context](/type/Version#method_Capture)
for **method Capture**.
```raku
method Capture()
```
Throws [`X::Cannot::Capture`](/type/X/Cannot/Capture).
# [In Str](#___top "go to top of document")[§](#(Str)_method_Capture "direct link")
See primary documentation
[in context](/type/Str#method_Capture)
for **method Capture**.
```raku
method Capture()
```
Throws `X::Cannot::Capture`.
# [In Seq](#___top "go to top of document")[§](#(Seq)_method_Capture "direct link")
See primary documentation
[in context](/type/Seq#method_Capture)
for **method Capture**.
```raku
method Capture()
```
Coerces the object to a [`List`](/type/List), which is in turn coerced into a [`Capture`](/type/Capture).
# [In Range](#___top "go to top of document")[§](#(Range)_method_Capture "direct link")
See primary documentation
[in context](/type/Range#method_Capture)
for **method Capture**.
```raku
method Capture(Range:D: --> Capture:D)
```
Returns a [`Capture`](/type/Capture) with values of [`.min`](/type/Range#method_min) [`.max`](/type/Range#method_max), [`.excludes-min`](/type/Range#method_excludes-min), [`.excludes-max`](/type/Range#method_excludes-max), [`.infinite`](/type/Range#method_infinite), and [`.is-int`](/type/Range#method_is-int) as named arguments.
# [In Map](#___top "go to top of document")[§](#(Map)_method_Capture "direct link")
See primary documentation
[in context](/type/Map#method_Capture)
for **method Capture**.
```raku
method Capture(Map:D:)
```
Returns a [`Capture`](/type/Capture) where each key, if any, has been converted to a named argument with the same value as it had in the original `Map`. The returned [`Capture`](/type/Capture) will not contain any positional arguments.
```raku
my $map = Map.new('a' => 2, 'b' => 17);
my $capture = $map.Capture;
my-sub(|$capture); # OUTPUT: «2, 17»
sub my-sub(:$a, :$b) {
say "$a, $b"
}
```
# [In Whatever](#___top "go to top of document")[§](#(Whatever)_method_Capture "direct link")
See primary documentation
[in context](/type/Whatever#method_Capture)
for **method Capture**.
```raku
method Capture()
```
Throws `X::Cannot::Capture`.
# [In Mu](#___top "go to top of document")[§](#(Mu)_method_Capture "direct link")
See primary documentation
[in context](/type/Mu#method_Capture)
for **method Capture**.
```raku
method Capture(Mu:D: --> Capture:D)
```
Returns a [`Capture`](/type/Capture) with named arguments corresponding to invocant's public attributes:
```raku
class Foo {
has $.foo = 42;
has $.bar = 70;
method bar { 'something else' }
}.new.Capture.say; # OUTPUT: «\(:bar("something else"), :foo(42))»
```
# [In Failure](#___top "go to top of document")[§](#(Failure)_method_Capture "direct link")
See primary documentation
[in context](/type/Failure#method_Capture)
for **method Capture**.
```raku
method Capture()
```
Throws `X::Cannot::Capture` if the invocant is a type object or a [handled](/routine/handled) `Failure`. Otherwise, throws the invocant's [exception](/routine/exception).
# [In role Blob](#___top "go to top of document")[§](#(role_Blob)_method_Capture "direct link")
See primary documentation
[in context](/type/Blob#method_Capture)
for **method Capture**.
```raku
method Capture(Blob:D:)
```
Converts the object to a [`List`](/type/List) which is, in turn, coerced to a [`Capture`](/type/Capture).
# [In role QuantHash](#___top "go to top of document")[§](#(role_QuantHash)_method_Capture "direct link")
See primary documentation
[in context](/type/QuantHash#method_Capture)
for **method Capture**.
```raku
method Capture()
```
Returns the object as a [`Capture`](/type/Capture) by previously coercing it to a [`Hash`](/type/Hash).
# [In Channel](#___top "go to top of document")[§](#(Channel)_method_Capture "direct link")
See primary documentation
[in context](/type/Channel#method_Capture)
for **method Capture**.
```raku
method Capture(Channel:D: --> Capture:D)
```
Equivalent to calling [`.List.Capture`](/type/List#method_Capture) on the invocant.
# [In Int](#___top "go to top of document")[§](#(Int)_method_Capture "direct link")
See primary documentation
[in context](/type/Int#method_Capture)
for **method Capture**.
```raku
method Capture()
```
Throws `X::Cannot::Capture`.
# [In role Callable](#___top "go to top of document")[§](#(role_Callable)_method_Capture "direct link")
See primary documentation
[in context](/type/Callable#method_Capture)
for **method Capture**.
```raku
method Capture()
```
Throws [`X::Cannot::Capture`](/type/X/Cannot/Capture).
# [In ComplexStr](#___top "go to top of document")[§](#(ComplexStr)_method_Capture "direct link")
See primary documentation
[in context](/type/ComplexStr#method_Capture)
for **method Capture**.
```raku
method Capture(ComplexStr:D: --> Capture:D)
```
Equivalent to [`Mu.Capture`](/type/Mu#method_Capture).
# [In RatStr](#___top "go to top of document")[§](#(RatStr)_method_Capture "direct link")
See primary documentation
[in context](/type/RatStr#method_Capture)
for **method Capture**.
```raku
method Capture(RatStr:D: --> Capture:D)
```
Equivalent to [`Mu.Capture`](/type/Mu#method_Capture).
# [In Supply](#___top "go to top of document")[§](#(Supply)_method_Capture "direct link")
See primary documentation
[in context](/type/Supply#method_Capture)
for **method Capture**.
```raku
method Capture(Supply:D: --> Capture:D)
```
Equivalent to calling [`.List.Capture`](/type/List#method_Capture) on the invocant.
|
## dist_zef-jonathanstowe-Cro-HTTP-BodyParser-JSONClass.md
# Cro::HTTP::BodyParser::JSONClass
Parse and deserialise application/json HTTP body to a specified JSON::Class
[](https://github.com/jonathanstowe/Cro-HTTP-BodyParser-JSONClass/actions/workflows/main.yml)
## Synopsis
```
use Cro::HTTP::Router;
use Cro::HTTP::Server;
use JSON::Class;
use Cro::HTTP::BodyParser::JSONClass;
class HelloClass does JSON::Class {
has Str $.firstname;
has Str $.lastname;
method hello(--> Str ) {
"Hello, $.firstname() $.lastname()";
}
}
# This intermediate class is only necessary in older rakudo, as of
# 2021.09 the parameterised role can be use directly
class SomeBodyParser does Cro::HTTP::BodyParser::JSONClass[HelloClass] {
}
my $app = route {
body-parser SomeBodyParser;
post -> 'hello' {
request-body -> $hello {
content 'text/plain', $hello.hello;
}
}
};
my Cro::Service $service = Cro::HTTP::Server.new(:host<127.0.0.1>, :port<7798>, application => $app);
$service.start;
react { whenever signal(SIGINT) { $service.stop; exit; } }
```
```
use Cro::HTTP::Client;
use JSON::Class;
use Cro::HTTP::BodyParser::JSONClass;
my $client1 = Cro::HTTP::Client.new: body-parsers => [Cro::HTTP::BodyParser::JSONClass[HelloClass]];
my $obj1 = await $client1.get-body: 'https://jsonclass.free.beeceptor.com/hello';
say $obj1.raku;
=output HelloClass.new(firstname => "fname", lastname => "lname")
# Setting the JSON class after creating an instance of Cro::HTTP::Client
my $body-parser = Cro::HTTP::BodyParser::JSONClass.new;
my $client2 = Cro::HTTP::Client.new: body-parsers => [$body-parser];
$body-parser.set-json-class: HelloClass;
my $obj2 = await $client2.get-body: 'https://jsonclass.free.beeceptor.com/hello';
say $obj2.raku;
=output HelloClass.new(firstname => "fname", lastname => "lname")
```
## Description
This provides a specialised [Cro::BodyParser](https://cro.services/docs/reference/cro-http-router#Adding_custom_request_body_parsers) that will parse a JSON ('application/json') request body to the specified
[JSON::Class](https://github.com/jonathanstowe/JSON-Class) type. This is useful if you have `JSON::Class` classes that you want to create from HTTP data, and will lead to less code and perhaps better
abstraction.
The BodyParser is implemented as a Parameterised Role with the target class as the parameter. Because this will basically over-ride the Cro's builtin JSON parsing it probably doesn't want to be installed at the
top level in the Cro::HTTP instance, but rather in a specific `route` block with the `body-parser` helper, also because it is specialised to a single class it may want to be isolated to its own `route`
block so other routes keep the default behaviour or have parsers parameterised to different classes, so you may want to do something like:
```
my $app = route {
delegate 'hello' => route {
body-parser SomeBodyParser;
post -> {
request-body -> $hello {
content 'text/plain', $hello.hello;
}
}
}
};
```
The test as to whether this body parser should be used (defined in the method `is-applicable` ) is generalised to the `application/json` content type, (hence the caveat above regarding reducing the scope.)
If you want to make a more specific test (or even if the Content-Type supplied *isn't* `application/json`,) then you can compose this to a new class the over-rides the `is-applicable`:
```
class SomeBodyParser does Cro::HTTP::BodyParser::JSONClass[HelloClass] {
method is-applicable(Cro::HTTP::Message $message --> Bool) {
$message.header('X-API-Message-Type').defined && $message.header('X-API-Message-Type') eq 'Hello';
}
}
```
And then use `SomeBodyParser` in place of `Cro::HTTP::BodyParser::JSONClass`.
The BodyParser has a `set-json-class` method which can be used to set the `JSON::Class` class to another class whenever needed.
## Installation
Assuming you have a working installation of rakudo you should be able to install this with *zef* :
zef install Cro::HTTP::BodyParser::JSONClass
Or from a local clone of the repository:
zef install .
## Support
Please direct any patches, suggestions or feedback to [Github](https://github.com/jonathanstowe/Cro-HTTP-BodyParser-JSONClass/issues).
# Licence and copyright
This is free software, please see the <LICENCE> file in the distribution.
© Jonathan Stowe 2021
|
## dist_zef-raku-community-modules-Web-Template.md
[](https://github.com/raku-community-modules/Web-Template/actions)
# Web::Template
## Introduction
A simple abstraction layer, providing a consistent API for different
template engines. This is designed for use in higher level web frameworks
such as [Web::App::Ballet](https://github.com/raku-community-modules/Web-App-Ballet/)
and [Web::App::MVC](https://github.com/raku-community-modules/Web-App-MVC/).
## Supported Template Engines
* [Template6](https://github.com/raku-community-modules/Template6/)
An engine inspired by Template Toolkit. Has many features.
Wrapper is Web::Template::Template6
* [Template::Mojo](https://github.com/raku-community-modules/Template-Mojo/)
A template engine inspired by Perl's Mojo::Template.
Wrapper is Web::Template::Mojo
* [HTML::Template](https://github.com/masak/html-template/)
A template engine inspired by Perl's HTML::Template.
Wrapper is Web::Template::HTML
## Broken Template Engines
* [Flower::TAL](https://github.com/supernovus/flower/)
An implementation of the TAL/METAL XML-based template languages from Zope.
Wrapper is Web::Template::TAL
I will get this fixed up when I can and re-add it to the list of supported
template engines.
## Methods
All of the wrapper classes provide common API methods, so as long as your
web framework or application supports the following API, it doesn't have to
worry about the APIs of the individual template engines themselves.
### set-path ($path, ...)
Set the directory or directories to find the template files in.
For engines without native support of multiple search paths, or even
file-based templates to begin with, the wrapper classes add such support.
### render ($template, ...)
Takes the template name to render, and passes any additional parameters
through to the template engine. Most template engines use named parameters,
but some like Mojo, use positional parameters. This handles both.
## Usage
```
use Web::Template::Template6;
my $engine = Web::Template::Template6.new;
$engine.set-path('./views');
$engine.render('example.xml', :name<Bob>);
```
See one of the web application frameworks using this for better examples.
## TODO
* Add a test suite with all supported template engines covered.
* Add support for the Plosurin template engine.
## AUTHOR
Timothy Totten
Source can be located at: <https://github.com/raku-community-modules/Web-Template> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2013 - 2019 Timothy Totten
Copyright 2020 - 2023 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-Slang-NumberBase.md
[](https://github.com/lizmat/Slang-NumberBase/actions) [](https://github.com/lizmat/Slang-NumberBase/actions) [](https://github.com/lizmat/Slang-NumberBase/actions)
# NAME
Slang::NumberBase - provide number base literals
# SYNOPSIS
```
use Slang::NumberBase;
say ₈123.45; # 173.346315
say ₃₆123.45; # 3F.G77777
```
# DESCRIPTION
The `Slang::NumberBase` distribution provides a slang that will interprete literal numeric values that start with subscripted digits ("₀₁₂₃₄₅₆₇₈₉") as the number base in which the numeric value should be expressed.
So in effect "₈123.45" is short for "123.45.base(8)".
Note that only number bases 2..36 are currently supported, as these are the values that are supported by the [`base`](https://docs.raku.org/routine/base) method.
# ACKNOWLEDGEMENTS
Tom Browder for the idea.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Slang-NumberBase> . Comments and Pull Requests are welcome.
If you like this module, or what I'm doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-PSGI.md
[](https://github.com/raku-community-modules/PSGI/actions)
# NAME
PSGI - Helper library for creating P6SGI/PSGI compliant frameworks
# SYNOPSIS
```
use PSGI;
# Using a traditional PSGI response array.
# Headers are an Array of Pairs.
# Body is an Array of Str or Buf.
my $status = 200;
my $headers = ['Content-Type'=>'text/plain'];
my $body = ["Hello world"];
my @response = [ $status, $headers, $body ];
my $string = encode-psgi-response(@response);
#
# Status: 200 OK
# Content-Type: text/plain
#
# Hello world
#
# Passing the elements individually.
# Also, this time, we want to use NPH output.
$string = encode-psgi-response($status, $headers, $body, :nph);
#
# HTTP/1.0 200 OK
# Content-Type: text/plain
#
# Hello world
#
# Now an example using a Hash for headers, and a singleton
# for the body.
my %headers =
Content-Type => 'text/plain',
;
my $body-text = "Hello world";
$string = encode-psgi-response($code, %headers, $body-text);
#
# Same output as first example
#
# Populate an %env with P6SGI/PSGI variables.
#
my %env;
populate-psgi-env %env, :input($in), :errors($err), :p6sgi<latest>;
```
See the tests for further examples.
# DESCRIPTION
Provides functions for encoding P6SGI/PSGI responses, and populating P6SGI/PSGI environments.
It supports (in order of preference), P6SGI 0.7Draft, P6SGI 0.4Draft, and a minimal subset of PSGI Classic (from Perl).
If the `populate-psgi-env` subroutine is called without specifying a specific version, both P6SGI 0.7Draft and P6SGI 0.4Draft headers will be included. PSGI Classic headers must be explicitly requested.
# AUTHOR
Timothy Totten
# COPYRIGHT AND LICENSE
Copyright 2013 - 2016 Timothy Totten
Copyright 2017 - 2022 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-App-MoarVM-HeapAnalyzer-Model.md
[](https://github.com/raku-community-modules/App-MoarVM-HeapAnalyzer/actions) [](https://github.com/raku-community-modules/App-MoarVM-HeapAnalyzer/actions) [](https://github.com/raku-community-modules/App-MoarVM-HeapAnalyzer/actions)
# NAME
App::MoarVM::HeapAnalyzer - MoarVM heap snapshot analysis tool
# SYNOPSIS
```
$ moar-ha file.snapshot
```
# DESCRIPTION
This is a command line application for analyzing MoarVM heap snapshots. First, obtain a heap snapshot file from something running on MoarVM. For example:
```
$ raku --profile=heap something.raku
```
Then run this application on the heap snapshot file it produces (the filename will be at the end of the program output).
```
$ moar-ha heap-snapshot-1473849090.9
```
Type `help` inside the shell to learn about the set of supported commands. You may also find [these](https://6guts.wordpress.com/2016/03/27/happy-heapster/) [two](https://6guts.wordpress.com/2016/04/15/heap-heap-hooray/) posts on the 6guts blog about using the heap analyzer to hunt leaks interesting also.
# AUTHOR
Jonathan Worthington
# COPYRIGHT AND LICENSE
Copyright 2016 - 2024 Jonathan Worthington
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## predictiveiterator.md
role PredictiveIterator
Iterators that can predict number of values
A `PredictiveIterator` is a special kind of [`Iterator`](/type/Iterator) that can know how many values it will (still) generate **without** actually needing to generate those values.
The main addition to the API of the [`Iterator`](/type/Iterator) role, is the `count-only` method, which should return the number of values the Iterator is still able to generate.
The other addition is the `bool-only` method, that should return a [`Bool`](/type/Bool) indicating whether the Iterator is still capable of producing values (aka, is not exhausted yet). By default, this is the Booleanification of the result of the call to the `count-only` method.
# [Methods](#role_PredictiveIterator "go to top of document")[§](#Methods "direct link")
## [method count-only](#role_PredictiveIterator "go to top of document")[§](#method_count-only "direct link")
```raku
method count-only(--> Int:D) { ... }
```
It is expected to return the number of values the iterator can still produce **without** actually producing them. The returned number **must adjust itself** for items already pulled, so that the method can be called on a partially consumed [`Iterator`](/type/Iterator).
It will be used in situations where only the **number** of values of an iterator is needed, e.g. when the `.elems` method is called.
**Important:** it's expected the [`Iterator`](/type/Iterator)s that implement this method can return that number **without** producing any values. In other words, it's expected the user of the class will be able to still [pull-one](/routine/pull-one) after calling this method, and eventually receive as many values as the return value of this method indicated.
## [method bool-only](#role_PredictiveIterator "go to top of document")[§](#method_bool-only "direct link")
Defaults to the Booleanification of the result of calling the `count-only` method. If it is possible to have a faster way of finding out whether the iterator is capable of producing any value, it should be implemented.
```raku
method bool-only(--> Bool:D) { self.count-only.Bool }
```
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `PredictiveIterator`
raku-type-graph
PredictiveIterator
PredictiveIterator
Iterator
Iterator
PredictiveIterator->Iterator
[Expand chart above](/assets/typegraphs/PredictiveIterator.svg)
|
## dist_github-zostay-P6W.md
## Chunk 1 of 2
# NAME
Web API for Raku (RakuWAPI)
# STATUS
This is a Proposed Draft.
Version 0.9.Draft
# 0 INTRODUCTION
This document standardizes an API for web application and server framework developers in Raku. It provides a standard protocol by which web applications and application servers may communicate with each other.
This standard has the following goals:
* Standardize the interface between server and application so that web developers may focus on application development rather than the nuances of supporting different server platforms.
* Keep the interface simple so that a web application or middleware requires no additional tools or libraries other than what exists in a standard Raku environment, and no module installations are required.
* Keep the interface simple so that servers and middleware are simple to implement.
* Allow the interface to be flexible enough to accommodate a variety of common use-cases and simple optimzations as well as supporting unanticipated use-cases and future extensions.
Aside from that is the underlying assumption that this is a simple interface and ought to at least somewhat resemble work in the standards it is derived from, including [Rack](http://www.rubydoc.info/github/rack/rack/master/file/SPEC), [WSGI](https://www.python.org/dev/peps/pep-0333/), [PSGI](https://metacpan.com/pod/PSGI), [CGI](http://www.w3.org/CGI/), and others.
# 1 TERMINOLOGY
## 1.0 Glossary
A RakuWAPI application is a Raku routine that expects to receive an environment from an *application server* and returns a response each time it is called by the server.
A Web Server is an application that processes requests and responses according to a web-related protocol, such as HTTP or WebSockets or similar protocol.
The origin is the external entity that makes a given request and/or expects a response from the application server. This can be thought of generically as a web browser, bot, or other user agent.
An application server is a program that is able to provide an environment to a *RakuWAPI application* and process the value returned from such an application.
The *application server* might be associated with a *web server*, might itself be a *web server*, might process a protocol used to communicate with a *web server* (such as CGI or FastCGI), or may be something else entirely not related to a *web server* (such as a tool for testing *RakuWAPI applications*).
Middleware is a *RakuWAPI application* that wraps another *RakuWAPI application* for the purpose of performing some auxiliary task such as preprocessing request environments, logging, postprocessing responses, etc.
A framework developer is a developer who writes an *application server*.
An application developer is a developer who writes a *RakuWAPI application*.
A sane Supply is a Supply object that follows the emit\*-done/quit protocol, i.e., it will emit 0 or more objects followed by a call to the done or quit handler. See [Supply](http://doc.perl6.org/type/Supply) for details.
## 1.1 Type Constraints
The following type constraints are defined for use with this document.
```
subset NonEmptyStr of Str where { !.defined || .chars > 0 };
subset PathStr of Str where { !.defined || $_ ~~ any('', m{ ^ "/" }) };
subset PositiveInt of Int where { !.defined || $_ > 0 };
subset Supplierish of Any where { !.defined || ?.can('emit').grep(*.arity == 2) };
```
Any place a type is used in this document, the implementation is free to use any subtype (either subset or sub-class) of that type in place of the named type so long as the type constraint is guaranteed to hold for the subtype. For example, if an `Int` is required, it would be permissible to use an `IntStr` instead.
# 2 SPECIFICATION
This specification is divided into three layers:
* Layer 0: Server
* Layer 1: Middleware
* Layer 2: Application
Each layer has a specific role related to the other layers. The server layer is responsible for managing the application lifecycle and performing communication with the origin. The application layer is responsible for receiving metadata and content from the server and delivering metadata and content back to the server. The middleware layer is responsible for enhancing the application or server by providing additional services and utilities.
This specification goes through each layer in order. In the process, each section only specifies the requirements and recommendations for the layer that section describes. When other layers a mentioned outside of its section, the specification is deliberately vague to keep all specifics in the appropriate section.
To aid in reading this specification, the numbering subsections of 2.0, 2.1, and 2.2 are matched so that you can navigate between them to compare the requirements of each layer. For example, 2.0.1 describes the environment the server provides, 2.1.1 describes how the application interacts with that environment, and 2.1.1 describes how middleware may manipulate that environment.
## 2.0 Layer 0: Server
A RakuWAPI application server is a program capable of running RakuWAPI applications as defined by this specification.
A RakuWAPI application server implements some kind of web service. For example, this may mean implementing an HTTP or WebSocket service or a related protocol such as CGI, FastCGI, SCGI, etc. An application server also manages the application lifecycle and executes the application, providing it with a complete environment, and processing the response from the application to determine how to respond to the origin.
One important aspect of this specification that is not defined is the meaning of a server error. At times it is suggested that certain states be treated as a server error, but what that actually means to a given implementation is deliberatly undefined. That is a complex topic which varies by implementation and by the state the server is in when such a state is discovered. The server SHOULD log such events and SHOULD use the appropriate means of communication provided to notify the application that a server error has occurred while responding.
### 2.0.0 Application Definition
A RakuWAPI application is defined as a class or object, which must be implemented according to a particular interface. The application server MUST provide a means by which an application is loaded. The application server SHOULD be able to load them by executing a RakuWAPI script file.
For example, here is a simple application:
```
use v6;
sub app(%env) {
start {
200, [ Content-Type => 'text/plain' ], [ 'Hello World!' ]
}
}
```
For full details on how an application is defined, see Section 2.2.0. For details on how a server interacts with the application, see Section 2.0.4.
### 2.0.1 The Environment
The environment is delivered to the application via hashes, they MUST be [Associative](http://doc.perl6.org/type/Associative). The application server makes the environment available to the application at runtime. The environment is used to:
* Communicate server capabilities to the application,
* Allow the application to communicate with the server, and
* Allow the application to respond to calls to the application.
Each variable or key in the environment is described as belonging to one of two roles:
* A configuration environment variable describes global capabilities and configuration information to application.
* A runtime environment variable describes per-call information related to the particular request.
Calls to the runtime routine MUST be provided with all required environment variables belonging to either of these roles in the passed environment hash. However, calls to the configuration routine (see 2.0.4) MUST include the configuration envrionment and SHOULD NOT include runtime environment in the passed environment hash.
The server MAY provide variables in the environment in either role in addition to the ones defined here, but they MUST contain a period and SHOULD be given a unique prefix to avoid name clashes.
The following prefixes are reserved and SHOULD NOT be used unless defined by this specification and only according to the definition given here.
* `wapi.` is for RakuWAPI core standard environment.
* `wapix.` is for RakuWAPI standard extensions to the environment.
In the tables below, a type constraint is given for each variable. The application server MUST provide each key as the named type. All variables given in the tables with 2.0.1.0 and 2.0.1.1 MUST be provided.
#### 2.0.1.0 Configuration Environment
The configuration environment MUST be made available to the application during every call made to the application, both to the configuration routine and the runtime routine.
| Variable | Constraint | Description |
| --- | --- | --- |
| `wapi.version` | `Version:D` | This is the version of this specification, `v0.9.Draft`. |
| `wapi.errors` | `Supplierish:D` | The error stream for logging. |
| `wapi.multithread` | `Bool:D` | True if the app may be simultaneously invoked in another thread in the same process. |
| `wapi.multiprocess` | `Bool:D` | True if the app may be simultaneously invoked in another process. |
| `wapi.run-once` | `Bool:D` | True if the server expects the app to be invoked only once during the life of the process. This is not a guarantee. |
| `wapi.protocol.support` | `Set:D` | This is a [Set](http://doc.perl6.org/type/Set) of strings naming the protocols supported by the application server. |
| `wapi.protocol.enabled` | `SetHash:D` | This is the set of enabled protocols. The application may modify this set with those found in `wapi.protocol.support` to enable/disable protocols the server is permitted to use. |
#### 2.0.1.1 Runtime Environment
Many of the runtime environment variables are derived from the old Common Gateway Interface (CGI). This environment MUST be given when the application is being called, i.e., whenever the runtime routine is called.
| Variable | Constraint | Description |
| --- | --- | --- |
| `REQUEST_METHOD` | `NonEmptyStr:D` | The HTTP request method, such as "GET" or "POST". |
| `SCRIPT_NAME` | `PathStr:D` | This is the initial portion of the URI path that refers to the application. |
| `PATH_INFO` | `PathStr:D` | This is the remainder of the request URI path within the application. This value SHOULD be URI decoded by the application server according to [RFC 3875](http://www.ietf.org/rfc/rfc3875) |
| `REQUEST_URI` | `Str:D` | This is the exact URI sent by the client in the request line of the HTTP request. The application server SHOULD NOT perform any decoding on it. |
| `QUERY_STRING` | `Str:D` | This is the portion of the requested URL following the `?`, if any. |
| `SERVER_NAME` | `NonEmptyStr:D` | This is the name of the web server. |
| `SERVER_PORT` | `PositiveInt:D` | This is the port number of the web server. |
| `SERVER_PROTOCOL` | `NonEmptyStr:D` | This is the server protocol sent by the client, e.g. "HTTP/1.0" or "HTTP/1.1". |
| `CONTENT_LENGTH` | `Int:_` | This corresponds to the Content-Length header sent by the client. If no such header was sent the application server MUST set this key to the [Int](http://doc.perl6.org/type/Int) type value. |
| `CONTENT_TYPE` | `Str:_` | This corresponds to the Content-Type header sent by the client. If no such header was sent the application server MUST set this key to the [Str](http://doc.perl6.org/type/Str) type value. |
| `HTTP_*` | `Str:_` | The remaining request headers are placed here. The names are prefixed with `HTTP_`, in ALL CAPS with the hyphens ("-") turned to underscores ("\_"). Multiple incoming headers with the same name MUST have their values joined with a comma (", ") as described in [RFC 2616](http://www.ietf.org/rfc/rfc2616). The `HTTP_CONTENT_LENGTH` and `HTTP_CONTENT_TYPE` headers MUST NOT be set. |
| Other CGI Keys | `Str:_` | The server MUST attempt to provide as many other CGI variables as possible, but no others are required or formally specified. |
| `wapi.url-scheme` | `Str:D` | Either "http" or "https". |
| `wapi.input` | `Supply:D` | The input stream for reading the body of the request, if any. |
| `wapi.ready` | `Promise:D` | This is a vowed Promise that MUST be kept by the server as soon as the server has tapped the application's output Supply and is ready to receive emitted messages. The value of the kept Promise is irrelevent. The server SHOULD NOT break this Promise. |
| `wapi.body.encoding` | `Str:D` | Name of the encoding the server will use for any strings it is sent. |
| `wapi.protocol` | `Str:D` | This is a string naming the response protocols the server is expecting from the application for call. |
In the environment, either `SCRIPT_NAME` or `PATH_INFO` must be set to a non-empty string. When `REQUEST_URI` is "/", the `PATH_INFO` SHOULD be "/" and `SCRIPT_NAME` SHOULD be the empty string. `SCRIPT_NAME` MUST NOT be set to "/".
### 2.0.2 The Input Stream
The input stream is set in the `wapi.input` key of the runtime environment. This represents the request payload sent from the origin. Unless otherwise indicated as part of the protocol definition, the server MUST provide a *sane* [Supply](http://doc.perl6.org/type/Supply) that emits [Blob](http://doc.perl6.org/type/Blob) objects containing the content of the request payload. It MAY emit nothing and just signal `done` if the request payload is empty.
### 2.0.3 The Error Stream
The error stream MUST be given in the configuration environment via `wapi.errors`. This MUST be a [Supplierish](http://doc.perl6.org/type/Supplierish) (see Section 1.1) object the server provides for emitting errors. This is a defined object that has an `emit` method that has the same signature as `Supplier.emit`.
The application MAY call `emit` on this object zero or more times, passing any object that may be stringified. The server SHOULD write these log entries to a suitable log file or to `$*ERR` or wherever appropriate. If written to a typical file handle, it should automatically append a newline to each emitted message.
### 2.0.4 Application Lifecycle
After the application has been defined, it will be called each time the application server needs to respond to the origin. What that means will vary depending on which protocol is needed to appropriately respond to the origin.
These requirements, however, are in held in common regardless of protocol, the application server requirements are as follows:
* The application server MUST check the type of the return value of the application routine. If the application return value is [Callable](http://doc.perl6.org/type/Callable), the application has returned a configuration routine. Otherwise, the application has returned a runtime routine.
* If the application returned a configuration routine, as detected by the previous requirement, the application server MUST call this routine and pass the configuration environment in a hash as the first argument to the routine. The return value of this routine is the runtime routine for the application.
* Prior to each call to runtime routine, the application server MUST set the `wapi.protocol` variable to the name of the protocol the server will use to communicate with the application.
* The server MUST receive the return value of runtime routine and process it according to the application protocol in use for this call, the protocol matching the one set in the previous requirement.
* The server MUST pass a [Hash](http://doc.perl6.org/type/Hash) containing all variables of both the configuration environment and runtime environments as the first argument to the runtime routine.
The server MUST NOT call the application with `wapi.protocol` set to a protocol that has been previously disabled by the application via the `wapi.protocol.enabled` setting.
For details on how each protocol handles the application call, see section 4.
## 2.1 Layer 1: Middleware
RakuWAPI middleware is simply an application that wraps another application. Middleware is used to perform any kind of pre-processing, post-processing, or side-effects that might be added onto an application. Possible uses include logging, encoding, validation, security, debugging, routing, interface adaptation, and header manipulation.
For example, in the following snippet, `mw` is a middleware application that adds a custom header:
```
sub app(%env) { start { 200, [ Content-Type => 'text/plain' ], [ 'Hello World' ] } }
sub mw(&wrappee is copy, %config) returns Callable {
&wrappee = wrappee(%config) if &wrappee.returns ~~ Callable;
sub (%env) {
wrappee(%env).then(
-> $p {
my @r = $p.result;
@r[1].push: 'WAPI-Used' => 'True';
@r
}
);
}
}
my &mw-app = &mw.assuming(&app);
```
### 2.1.0 Middleware Definition
The way in which middleware is defined and applied is left up to the middleware author. The example in the previous section uses a combination of priming and defining a closure. This is, by no means, the only way to define RakuWAPI middleware in Raku.
What is important in middleware definition is the following:
* A middleware application MUST be a RakuWAPI application, viz., it MUST be a configuration routine or runtime routine as defined in section 2.2.0.
* Middleware SHOULD check to see if the application being wrapped returns a configuration routine or a runtime routine by testing whether the return value of the routine is [Callable](http://doc.perl6.org/type/Callable).
* A middleware configuration routine SHOULD run the wrapped configuration application at configuration time with the configuration environment.
* A middleware runtime routine SHOULD fail if the wrapped configuration application is a configuration routine.
Any general purpose middleware should be defined as a configuration routine.
Otherwise, There Is More Than One Way To Do It.
### 2.1.1 The Environment
Middleware applications MAY set or modify the environment (both configuration and runtime environment) as needed. Middleware applications MUST maintain the typing required for the server in Sections 2.0.1.0 and 2.0.1.1 above, as modified by extensions and the application protocol in use.
Whenever setting new variables in the environment, the variables MUST contain a period and SHOULD use a unique prefix to avoid name clashes with servers, other middleware, and applications.
### 2.1.2 The Input Stream
An application server is required to provide the input stream as a [Supply](http://doc.perl6.org/type/Supply) emitting [Blob](http://doc.perl6.org/type/Blob)s. Middleware MUST provide the same.
However, it is possible that the middleware will consume the data in `wapi.input` for the purpose of parsing or providing the data contained in another form. In such a case, the middleware SHOULD provide an empty, already closed, [Supply](http://doc.perl6.org/type/Supply). The middleware should provide the data in another environment variable.
### 2.1.3 The Error Stream
See sections 2.0.3 and 2.2.3.
### 2.1.4 Application Lifecycle
Middleware MUST return a valid response to the server according to the value set in `wapi.protocol` by the server (or whatever middleware came before it).
See sections 2.0.4 and 2.2.4. Middleware MUST adhere to all requirements of the application as respects the server (2.2.4) and all requirements of the server as respects the application (2.0.4).
See section 4 for details on protocol handling.
## 2.2 Layer 2: Application
A RakuWAPI application is a Raku routine. The application MUST be [Callable](http://doc.perl6.org/type/Callable). An application may be defined as either a runtime routine or a configuration routine. A configuration routine receives a RakuWAPI configuration environment and returns a runtime routine. A runtime routine receives a RakuWAPI runtime environment and responds to it by returning a response.
As an example, a simple Hello World RakuWAPI application defined with a runtime routine could be implemented as follows:
```
sub app(%env) {
start {
200, [ Content-Type => 'text/plain' ], [ 'Hello World' ]
}
}
```
Or, a slightly more complex Hello World application could be implemented using a configuration routine instead like so:
```
sub app-config(%config) returns Callable {
%config<wapi.protocol.enabled> ∩= set('request-response');
sub app(%env) {
start {
200, [ Content-Type => 'text/plain' ], [ 'Hello World' ]
}
}
}
```
This second application makes sure that only the request-response protocol is enabled before returning an application only capable of responding that way (see Section 4).
### 2.2.0 Defining an Application
An application is defined in one of two mechanisms, as mentioned in the previous section:
* A runtime routine defines just the part of the application that reacts to incoming calls from the application server. (See Section 2.2.0.0.)
* A configuration routine defines a special routine that is called prior to handling any incoming calls from the application server to give the application a chance to communicate with the server. (See Section 2.2.0.1.)
During application defintion, the application MAY also instantiate and apply middleware to be used by the application.
### 2.2.0.0 Runtime Routine
To define an application as a runtime routine, the application is defined as a [Callable](http://doc.perl6.org/type/Callable) (typically a [Routine](http://doc.perl6.org/type/Routine)). This application MUST accept a single parameter as its argument. When the application server handles a request, the server will set this parameter to the runtime environment for the request. The application MUST NOT have a return type set to a [Callable](http://doc.perl6.org/type/Callable).
The application SHOULD respond to the caller, i.e., the application server or outer middleware, according to the `wapi.protocol` string set in the passed environment.
Here, for example, is a RakuWAPI application that calculates and prints the Nth Lucas number depending on the value passed in the query string. This assumes a `request-response` protocol (see Section 4.0).
```
sub lucas-runtime(%env) {
start {
my $n = %env<QUERY_STRING>.Int;
my $lucas-number := 2, 1, * + * ... *;
200, [ Content-Type => 'text/plain' ], [ $lucas-number[$n] ];
}
}
```
This application is vulnerable, however, to problems if the server might call the application with a different protocol.
### 2.2.0.1 Configuration Routine
An application SHOULD return a configuration routine, which is defined just like the runtime routine, but it must constrain its return type to something [Callable](http://doc.perl6.org/type/Callable). This application MUST accept a single parameter as its argument, just like the runtime routine. This single parameter will be set to the configuration environment when called by the application server. This routine will also be called prior to any request or other contact from an origin has occurred, which gives the application the opportunity to communicate with the server early.
The application SHOULD modify the configuration environment to suit the needs of the application. The application SHOULD end the routine by returning a runtime routine (see the previous section).
Here is the example from the previous section, but using a configuration routine to guarantee that the only protocol the application can use to contact it is the request-response protocol (see Section 4.0). It ends by returning the `&lucas-app` subroutine defined in the previous section:
```
sub lucas-config(%config) returns Callable {
# Only permit the request-response protocol
%config<wapi.protocol.enabled> ∩= set('request-response');
&lucas-runtime;
}
```
### 2.2.1 The Environment
Calls to the configuration routine of the application (if defined) will receive the configuration environment as defined in Section 2.0.1.0. Calls to the runtime routine of the application will receive the combination of the runtime environment and configuration environment as defined in Sections 2.0.1.0 and 2.0.1.1. Additional variables may be provided by your application server and middleware in either environment hash.
The application itself MAY store additional values in the environment as it sees fit. This allows the application to communicate with a server or middleware or even with itself. When the application modifies the environment, the variables set MUST contain a period and SHOULD start with a unique name that is not `wapi.` or `wapix.` as these are reserved.
### 2.2.2 The Input Stream
Some calls to your application may be accompanied by a request payload. For example, a POST or PUT request sent by an origin using HTTP will typically include such a payload. The application MAY choose to read the payload using the sane [Supply](http://doc.perl6.org/type/Supply) provided in the `wapi.input` variable of the runtime environment. This will provide a stream lf [Blob](http://doc.perl6.org/type/Blob)s.
### 2.2.3 The Error Stream
The application server is required to provide a `wapi.errors` variable in the environment with a [Supplierish](http://doc.perl6.org/type/Supplierish) object (see Section 1.1). The application MAY emit any errors or messages here using any object that stringifies. The application SHOULD NOT terminate such messages with a newline as the server will do so if necessary.
### 2.2.4 Application Call
To handle requests from the origin, the application server will make calls to the application routine. The application SHOULD return a valid response to the server. The response required will depend on what string is set in `wapi.protocol` within the runtime environment, so the application SHOULD check that on every call if it may vary.
The application SHOULD attempt to return a value as quickly as possible via the runtime routine. For protocols that require the application to return a [Promise](http://doc.perl6.org/type/Promise), the application SHOULD wrap the entire body of the call in a `start` block to minimize the time the server will be waiting on the application.
See section 4 on how different application protocols are handled.
# 3 Extensions
In addition to the standard specification, there are a number of extensions that servers or middleware MAY choose to implement. They are completely optional and applications and middleware SHOULD check for their presence before using them. Such checks SHOULD be performed as early as possible.
Unless stated otherwise, all environment variables described here are set in the runtime environment, which is passed as the single argument with each call to the runtime routine.
## 3.0 Header Done
The `wapix.header.done` environment variable, if provided, MUST be a vowed [Promise](http://doc.perl6.org/type/Promise). This Promise MUST be kept when the server is done sending or processing the response header. The Promise MUST be broken if the server is unable or unwilling to send the application provided headers.
This is not an exhaustive list, but here are a few possible reasons why this Promise MAY be broken:
* The headers are invalid and the application server will not send them.
* An internal error occurred in the application server.
* The client hungup the connection before the headers could be sent.
When broken, this Promise SHOULD be broken with a helpful diagnostic exception.
## 3.1 Body Done
The `wapix.body.done` environment variable, if provided, MUST be a vowed [Promise](http://doc.perl6.org/type/Promise). This Promise MUST be kept when the server is done sending or processing the response body. The Promise MUST be broken if the server is unable or unwilling to send the complete application body.
This is not an exhaustive list, but here are a few possible reasons why this Promise MAY be broken:
* The application server has already transmitted `Content-Length`, but the application continued to send bytes after that point.
* The client hungup the connection before it finished sending the response.
* An application initiated an HTTP/2 push-promise, which the server had begun to fulfill when it received a cancel message from the client.
In particular, `wapix.body.done` MUST be broken if `wapix.header.done` is broken (assuming both extensions are implemented).
When broken, the Promise SHOULD be broken with a helpful diagnostic exception.
## 3.2 Raw Socket
The `wapix.io` environment variable, if provided, SHOULD be the socket object used to communicate to the client. This is the interface of last resort as it sidesteps the entire RakuWAPI interface. It may be useful in cases where an application wishes to control details of the socket itself.
If your application requires the use of this socket, please file an issue describing the nature of your application in detail. You may have a use-case that a future revision to RakuWAPI can improve.
This variable MAY be made available as part of the configuration environment.
## 3.3 Logger
The `wapix.logger` environment variable, if provided, MUST be a [Routine](http://doc.perl6.org/type/Routine) defined with a signature as follows:
```
sub (Str:D $message, Str:D :$level = 'info');
```
When called application MUST provide a `$level` that is one of: `"debug"`, `"info"`, `"warn"`, `"error"`, `"fatal"`.
Te `wapix.logger` environment variable SHOULD be provided in the configuration environment.
## 3.4 Sessions
This extension implements basic session handling that allows certain data to persist across requests. Session data SHOULD be associated with a particular origin.
The `wapix.session` environment variable, if provided, MUST be an [Associative](http://doc.perl6.org/type/Associative). This hash maps arbitrary keys and values that may be read and written to by an application. The application SHOULD only use [Str](http://doc.perl6.org/type/Str) keys and values. The details of persisting this data is up to the application server or middleware implementing the session extension.
The `wapix.session.options` environment variable, if provided, MUST be an [Associative](http://doc.perl6.org/type/Associative). This variable uses implementation-specific keys and values to communicate between the application and the extension implementation. This allows the application a channel by which to instruct the session handler how to operate.
## 3.5 Harakiri Mode
The `wapix.harakiri` environment variable, if provided, MUST be a [Bool](http://doc.perl6.org/type/Bool). If set to `True` it signals to the application that the server supports harakiri mode, which allows the application to ask the server to terminate the current work when the request is complete. This variable SHOULD be set in the configuration environment.
The `wapix.harakiri.commit` environment variable MAY be set to a `True` value by the application to signal to the server that the current worker should be killed after the current request has been processed.
## 3.6 Cleanup Handlers
The `wapix.cleanup` environment variable, if provided, MUST be a [Bool](http://doc.perl6.org/type/Bool). If set to `True` it tells the application that the server supports running cleanup handlers after the request is complete. This variable SHOULD be set in the configuration environment.
The `wapix.cleanup.handlers` environment variable MUST be provided if the `wapix.cleanup` flag is set. This MUST an [Array](http://doc.perl6.org/type/Array). The application adds cleanup handlers to the array by putting [Callable](http://doc.perl6.org/type/Callable)s into the Array (usually by `push`ing). Each handler will be given a copy of the `%env` as the first argument. The server MUST run these handlers, but only after the application has completely finished returning the response and any response payload.
If the server supports the harakiri extension, it SHOULD allow the cleanup handlers to invoke harakiri mode by setting `wapix.harakiri.commit` (see 3.5).
## 3.7 Output Block Detection
The `wapix.body.backpressure` environment variable, if provided, MUST be a [Bool](http://doc.perl6.org/type/Bool) flag. It is set to `True` to indicate that the RakuWAPI server provide response backpressure detection by polling for non-blocking I/O problems. In this case, the server MUST provide the other two environment variables. If `False` or not defined, the server does not provide these two environment variables. This variable SHOULD be defined in the configuration environment.
The `wapix.body.backpressure.supply` environment variable MUST be provided if `wapix.body.backpressure` is `True`. When provided, it MUST be a live [Supply](http://doc.perl6.org/type/Supply) that periodically emits `True` and `False` values. `True` is emitted when the server polls for backpressure and detects a blocked output socket. `False` is emitted when the server polls for backpressure and detects the previously blocked socket is no longer blocked.
The `wapix.body.backpressure.test` environment variable MUST be provided if `wapix.body.backpressure` is `True`. When provided, it MUST be a [Bool](http://doc.perl6.org/type/Bool) that is `True` while output has last been detected as blocked and `False` otherwise. This can be useful for detecting the initial state before the backpressure supply has emitted any value or just as a way to poll the last known status of the socket.
## 3.8 Protocol Upgrade
The `wapix.net-protocol.upgrade` environment variable MUST be provided in the configuration environment, if the server implements the protocol upgrade extension. It MUST be the [Set](http://doc.perl6.org/type/Set) of names of protocols the server supports for upgrade.
When the client makes a protocol upgrade request using an `Upgrade` header, the application MAY request that the server negotiate the upgrade to one of these supported protocols by sending a `WAPIx-Upgrade` header back to the server with the named protocol. The application MAY send any other headers related to the Upgrade and MAY send a message payload if the upgrade allows it. These SHOULD override any server supplied values or headers.
The server MUST negotiate the new protocol and enable any environment variables required for interacting through that protocol. After the handshake or upgrade negoatiation is complete, the server MUST make a new call to the application with a new environment to process the remainder of the network request with the origin.
### 3.8.0 HTTP/2 Protocol Upgrade
The workings of HTTP/2 are similar enough to HTTP/1.0 and HTTP/1.1 that use of a protocol upgrade may not be necessary in most or all use-cases. However, servers MAY choose to delegate this to the application using the protocol upgrade extension.
Servers that support this protocol upgrade MUST place the name "h2c" and/or "h2" into the `wapix.net-protocol.upgrade` set, for support of HTTP/2 over cleartext connections and HTTP/2 over TLS, respectively.
The application MUST NOT request an upgrade using the `WAPIx-Upgrade` header for "h2c" unless the `wapi.url-scheme` is "http". Similarly, the application MUST NOT request an upgrade for "h2" unless the `wapi.url-scheme` is "https". The application server SHOULD enforce this requirement for security reasons.
The application MUST NOT tap the `wapi.input` stream when performing this upgrade. The application SHOULD NOT return a message payload aside from an empty [Supply](http://doc.perl6.org/type/Supply).
### 3.8.1 WebSocket Protocol Upgrade
Servers that support the WebSocket protocol upgrade MUST place the name "ws" into the `wapix.net-protocol.upgrade` set.
The application MUST NOT tap the `wapi.input` stream when performing this upgrade. The application SHOULD NOT return a message payload aside from an empty [Supply](http://doc.perl6.org/type/Supply).
## 3.9 Transfer Encoding
This extension is only for HTTP/1.1 protocol connections. When the server supports this extension, it MUST provide a `wapix.http11.transfer-encoding` variable containing a `Set` naming the transfer encodings the server supports as strings. This SHOULD be set in the configuration environment.
When the application returns a header named `WAPIx-Transfer-Encoding` with the name of one of the supported transfer encoding strings, the server MUST apply that transfer encoding to the message payload. If the connection is not HTTP/1.1, the server SHOULD ignore this header.
### 3.9.0 Chunked Encoding
When the server supports and the application requests "chunked" encoding. The application server SHOULD treat each emitted [Str](http://doc.perl6.org/type/Str) or [Blob](http://doc.perl6.org/type/Blob) as a chunk to be encoded according to [RFC7230](https://tools.ietf.org/html/draft-ietf-httpbis-p1-messaging). It MUST adhere to requirements of RFC7230 when sending the response payload to the origin.
### 3.9.1 Other Encodings
All other encodings should be handled as required by the relevant rules for HTTP/1.1.
### 3.10 HTTP/2 Push Promises
When the `SERVER_PROTOCOL` is "HTTP/2", servers SHOULD support the HTTP/2 push promises extension |
## dist_github-zostay-P6W.md
## Chunk 2 of 2
. However, applications SHOULD check to make sure that the `wapix.h2.push-promise` variable is set to a defined value before using this extension.
This extension is implemented by providing a variable named `wapix.h2.push-promise`. When provided, this MUST be a [Supplier](http://doc.perl6.org/type/Supplier).
When the application wishes to invoke a server push, it MUST emit a message describing the request the server is pushing. The application server will receive this request and make a new, separate call to the application to fulfill that request.
Push-promise messages are sent as an [Array](http://doc.perl6.org/type/Array) of [Pair](http://doc.perl6.org/type/Pair)s. This is a set of headers to send with the PUSH\_PROMISE frame, including HTTP/2 pseudo-headers like ":path" and ":authority".
Upon receiving a message to `wapix.h2.push-promise`, the server SHOULD schedule a followup call to the application to fulfill the push-promise as if the push-promise were an incoming request from the client. (The push-promise could be canceled by the client, so the call to the application might not actually happen.)
# 4 Application Protocol Implementation
One goal of RakuWAPI application servers is to allow the application to focus on building web applications without having to implement the mundane details of web protocols. In times past, this was simply a matter of implementing HTTP/1.x or some kind of front-end to HTTP/1.x (such as CGI or FastCGI). While HTTP/1.x is still relevant to the web today, new protocols have also become important to modern web applications, such as HTTP/2 and WebSocket.
These protocols may have different interfaces that do not lend themselves to the request-response pattern specifed by PSGI. Therefore, we provide a means by which servers and applications may implement these alternate protocols, which each may have different requirements. These protocols are called application protocols to differentiate them from network protocols. For example, rather than providing a protocol for HTTP, we provide the "request-response" protocol. The underlying network protocol may be HTTP/1.0, HTTP/1.1, HTTP/2 or it may be something else that operates according to a similar pattern.
The application and application server MUST communicate according to the application protocol used for the current application call. For many applications, just implementing the basic request-response protocol is enough. However, to allow for more complete applications, RakuWAPI provides additional tools to help application and application server to communicate through a variety of situations. This is handled primarily via the `wapi.protocol`, `wapi.protocol.support`, and `wapi.protocol.enabled` values in the environment.
The application SHOULD check the value in `wapi.protocol`. If the application needs to make a decision based upon the network protocol, the application SHOULD check the `SERVER_PROTOCOL`.
The application SHOULD check `wapi.protocol.support` to discover which protocols are supported by the application server. An application that is not able to support all supported protocols SHOULD modify `wapi.protocol.enabled` to only include protocols supported by the application as early as possible.
The application server MUST provide the `wapi.protocol.support` and `wapi.protocol.enabled` values as part of the configuration environment. The application server MUST NOT use any protocol that is not a member of the `wapi.protocol.enabled` set.
This specification defines the following protocols:
* **request-response** for request-response protocols, including HTTP
* **framed-socket** for framed-socket protocols, such as WebSocket
* **psgi** for legacy PSGI applications
* **socket** for raw, plain socket protocols, which send and receive data with no expectation of special server handling
It is recommended that an application server that implements all of these protocols only enable the request-response protocol within `wapi.protocol.enabled` by default. This allows simple RakuWAPI applications to safely operate without having to perform any special configuration.
## 4.0 Request-Response Protocol
The "request-response" protocol SHOULD be used for any HTTP-style client-server web protocol, this include HTTP/1.x and HTTP/2 connections over plain text and TLS or SSL.
### 4.0.0 Response
Here is an example application that implements the "request-response" protocol:
```
sub app(%env) {
start {
200,
[ Content-Type => 'text/plain' ],
supply {
emit "Hello World"
},
}
}
```
The runtime routine for the application MUST return a [Promise](http://doc.perl6.org/type/Promise). This Promise MUST be kept with a [Capture](http://doc.perl6.org/type/Capture) (or something that becomes one on return) and MAY be broken. The Capture MUST contain 3 positional elements, which are the status code, the list of headers, and the response payload.
* The status code MUST be an [Int](http://doc.perl6.org/type/Int) or an object that coerces to an Int. It MUST be a valid status code for the [SERVER\_PROTOCOL](http://doc.perl6.org/type/SERVER_PROTOCOL).
* The headers MUST be a [List](http://doc.perl6.org/type/List) of [Pair](http://doc.perl6.org/type/Pair)s or an object that when coerced into a List becomes a List of Pairs. These pairs name the headers to return with the response. Header names MAY be repeated.
* The message payload MUST be a *sane* [Supply](http://doc.perl6.org/type/Supply) or an object that coerces into a *sane* Supply, such as a [List](http://doc.perl6.org/type/List).
Here is a more interesting example application of this interface:
```
sub app(%env) {
start {
my $n = %env<QUERY_STRING>.Int;
200,
[ Content-Type => 'text/plain' ],
supply {
my $acc = 1.FatRat;
for 1..$n -> $v {
emit $acc *= $v;
emit "\n";
}
},
}
}
```
The example application above will print out all the values of factorial from 1 to N where N is given in the query string. The header may be returned immediately and the lines of the body may be returned as the values of factorial are calculated by the application server.
And here is an example demonstrating a couple ways in which coercion can be used by an application to simplify the result:
```
sub app(%env) {
my enum HttpStatus (OK => 200, NotFound => 404, ServerError => 500);
start {
OK, [ Content-Type => 'text/plain' ], [ 'Hello World' ]
}
}
```
In this example, the status is returned using an enumeration which coerces to an appropriate integer value. The payload is returned as a list, which is automatically coerced into a Supply.
Applications SHOULD return a Promise as soon as possible. It is recommended that applications wrap all operations within a `start` block to make this automatic.
Application servers SHOULD NOT assume that the returned [Promise](http://doc.perl6.org/type/Promise) will be kept. It SHOULD assume that the Promise has been vowed and MUST NOT try to keep or break the Promise from the application.
### 4.0.1 Response Payload
The response payload, in the result of the application's promise, must be a *sane* [Supply](http://doc.perl6.org/type/Supply). This supply MUST emit nothing for requests whose response must be empty.
For any other request, the application MAY emit zero or more messages in the returned payload Supply. The messages SHOULD be handled as follows:
* [Blob](http://doc.perl6.org/type/Blob). Any Blob emitted by the application SHOULD be treated as binary data to be passed through to the origin as-is.
* [List](http://doc.perl6.org/type/List) of [Pair](http://doc.perl6.org/type/Pair)s. Some response payloads may contain trailing headers. Any List of Pairs emitted should be treated as trailing headers.
* [Associative](http://doc.perl6.org/type/Associative). Any Associative object emitted should be treated as a message to communicate between layers of the application, middleware, and server. These should be ignored and passed on by middleware to the next layer unless consumed by the current middleware. Any message that reaches the application server but is not consumed by the application server MAY result in a warning being reported, but SHOULD otherwise be ignored. These objects MUST NOT be transmitted to the origin.
* [Mu](http://doc.perl6.org/type/Mu). Any other Mu SHOULD be stringified with the `Str` method and encoded by the application server. If an object given cannot be stringified, the server SHOULD report a warning.
### 4.0.2 Encoding
The application server SHOULD handle encoding of strings or stringified objects emitted to it. When performing encoding, the application server SHOULD honor the `charset` set within the `Content-Type` header, if given. If it does not honor the `charset` or no `charset` is set by the application, it MUST encode any strings in the response payload according to the encoding named in `wapi.body.encoding`.
### 4.0.3 Request-Response Lifecycle
The application server performs the following during a single request-response interaction:
* Receive a request from an origin and begin parsing the request according to the network protocol.
* Construct a runtime environment and combine it with the configuration environment. The `wapi.input` part of the environment should continue reading data from the origin as it arrives until the request has been completely read.
* Call the application runtime routine with the constructed environment and await a value from the returned [Promise](http://doc.perl6.org/type/Promise).
* Return the start of the response using the HTTP status code and headers provided, formatted according to the protocol requirements.
* Tap the supply part of the response and return data to the origin, formatted in ways appropriate for the environment settings and the network protocol in place.
The server processes requests from an origin, passes the processed request information to the application by calling the application, waits for the application's response, and then returns the response to the origin. In the simplest example this means handling an HTTP roundtrip. Yet, it may also mean implementing a related protocol like CGI or FastCGI or SCGI or something else entirely.
In the modern web, an application may want to implement a variety of complex HTTP interactions. These use-cases are not described by the typical HTTP request-response roundtrip with which most web developers are familiar. For example, an interactive Accept-Continue response or a data stream to or from the origin or an upgrade request to switch protocols. As such, application servers SHOULD make a best effort to be implemented in such a way as to make this variety applications possible.
The application server SHOULD pass control to the application as soon as the headers have been received and the environment can be constructed. The application server MAY continue processing the request payload while the application server begins its work. The server SHOULD NOT emit the request payload to `wapi.input` yet.
Once the application has returned the its [Promise](http://doc.perl6.org/type/Promise) to respond, the server SHOULD wait until the promise is kept. Once kept, the server SHOULD tap the response payload as soon as possible. After tapping the Supply, the application server SHOULD keep the [Promise](http://doc.perl6.org/type/Promise) in `wapi.ready` (the application server SHOULD NOT break this Promise). Once that promise has been kept, only then SHOULD the server start emitting the contents of the request payload, if any, to `wapi.input`.
The server SHOULD return the application response headers back to the origin as soon as they are received. After which, the server SHOULD return each chunk emitted by the response body from the application as soon as possible.
This particular order of operations during the application call will ensure that the application has the greatest opportunity to perform well and be able to execute a variety of novel HTTP interactions.
### 4.0.4 HTTP/1.1 Keep Alive
When an application server supports HTTP/1.1 with keep-alive, each request sent on the connection MUST be handled as a separate call to the application.
### 4.0.4 HTTP/2 Handling
When a server supports HTTP/2 it SHOULD implement the HTTP/2 Push Promise Extension defined in section 3.10. An application server MAY want to consider implementing HTTP/2 protocol upgrades using the extension described in section 3.8 or MAY perform such upgrades automatically instead.
The application MUST be called once for each request or push-promise made on an HTTP/2 stream.
## 4.1 Framed-Socket Protocol
The "framed-socket" protocol is appropriate for WebSocket-style peer-to-peer TCP connections. The following sections assume a WebSocket connection, but might be adaptable for use with other framed message exchanges, such as message queues or chat servers.
### 4.1.0 Response
Any application server implementing WebSocket MUST adhere to all the requirements described above with the following modifications when calling the application for a WebSocket:
* The `REQUEST_METHOD` MUST be set to the HTTP method used when the WebSocket connection was negotiated, i.e., usually "GET". Similarly, `SCRIPT_NAME`, `PATH_INFO`, `REQUEST_URI`, `QUERY_STRING`, `SERVER_NAME`, `SERVER_PORT`, `CONTENT_TYPE`, and `HTTP_*` variables in the environment MUST be set to the values from the original upgrade request sent from the origin.
* The `SERVER_PROTOCOL` MUST be set to "WebSocket/13" or a similar string representing the revision of the WebSocket network protocol which in use.
* The `CONTENT_LENGTH` SHOULD be set to an undefined [Int](http://doc.perl6.org/type/Int).
* The `wapi.url-scheme` MUST be set to "ws" for plain text WebSocket connections or "wss" for encrypted WebSocket connections.
* The `wapi.protocol` MUST be set to "framed-socket".
* The server MUST decode frames received from the client and emit each of them to `wapi.input`. The frames MUST NOT be buffered or concatenated.
* The server's supplied `wapi.input` [Supply](http://doc.perl6.org/type/Supply) must be *sane*. The server SHOULD signal `done` through the Supply when either the client or server closes the WebSocket connection normally and `quit` on abnormal termination of the connection.
* The server MUST encode frames emitted by the application in the message payload as data frames sent to the client. The frames MUST be separated out as emitted by the application without any buffering or concatenation.
The application MUST return a [Promise](http://doc.perl6.org/type/Promise) that is kept with just a [Supply](http://doc.perl6.org/type/Supply) (i.e., not a 3-element Capture as is used with the request-response protocol). The application MAY break this Promise. The application will emit frames to send back to the origin using the promised Supply.
### 4.1.1 Response Payload
Applications MUST return a *sane* [Supply](http://doc.perl6.org/type/Supply) that emits an object for every frame it wishes to return to the origin. The application MAY emit zero or more messages to this supply. The application MAY emit `done` to signal that the connection is to be terminated with the client.
The messages MUST be framed and returned to the origin by the application server as follows, based on message type:
* [Blob](http://doc.perl6.org/type/Blob). Any Blob emitted by the application SHOULD be treated as binary data, framed exactly as is, and returned to the client.
* [Associative](http://doc.perl6.org/type/Associative). Any Associative object emitted should be treated as a message to communicate between layers of the application, middleware, and server. These should be ignored and passed on by middleware to the next layer unless consumed by the current middleware. Any message that reaches the application server but is not consumed by the application server MAY result in a warning being reported, but SHOULD otherwise be ignored. These objects MUST NOT be transmitted to the origin.
* [Mu](http://doc.perl6.org/type/Mu). Any other Mu SHOULD be stringified, if possible, and encoded by the application server. If an object given cannot be stringified, the server SHOULD report a warning.
### 4.1.2 Encoding
The application server SHOULD handle encoding of strings or stringified objects emitted to it. The server MUST encode any strings in the message payload according to the encoding named in `wapi.body.encoding`.
## 4.2 PSGI Protocol
To handle legacy applications, this specification defines the "psgi" protocol. If `wapi.protocol.enabled` has both "psgi" and "request-response" enabled, the "request-response" protocol SHOULD be preferred.
### 4.2.0 Response
The application SHOULD return a 3-element [Capture](http://doc.perl6.org/type/Capture) directly. The first element being the numeric status code, the second being an array of pairs naming the headers to return in the response, and finally an array of values representing the response payload.
### 4.2.1 Payload
The payload SHOULD be delivered as an array of strings, never as a supply.
### 4.2.2 Encoding
String encoding is not defined by this document.
## 4.3 Socket Protocol
The "socket" protocol can be provided by an application server wishing to allow the application to basically take over the socket connection with the origin. This allows the application to implement an arbitrary protocol. It does so, however, in a way that is aimed toward providing better portability than using the socket extension.
The socket provided sends and receives data directly to and from the application without any framing, buffering, or modification.
The "socket" protocol SHOULD only be used when it is enabled in `wapi.protocol.enabled` and no other protocol enabled there can fulfill the current application call.
## 4.3.0 Response
Here's an example application that implements the "socket" protocol to create a naïve HTTP server:
```
sub app(%env) {
start {
supply {
whenever %env<wapi.input> -> $msg {
my $req = parse-http-request($msg);
if $req.method eq 'GET' {
emit "200 OK HTTP/1.0\r\n";
emit "\r\n";
emit "Custom HTTP Server";
}
}
}
}
}
```
The socket protocol behaves very much like "framed-socket", but with fewer specified details in the environment. Some of the mandatory environment are not mandatory for the socket protocol.
The following parts of the environment SHOULD be provided as undefined values:
* REQUEST\_METHOD
* SCRIPT\_NAME
* PATH\_INFO
* REQUEST\_URI
* QUERY\_STRING
* SERVER\_NAME
* SERVER\_PORT
* CONTENT\_TYPE
* HTTP\_\*
* wapi.url-scheme
* wapi.ready
* wapi.body.encoding
* SERVER\_PROTOCOL
The `wapi.protocol` must be set to "socket".
The application server SHOULD provide data sent by the origin to the application through the `wapi.input` supply as it arrives. It MUST still be a *sane* supply.
The application server MAY tunnel the connection through another socket, stream, file handle, or what-not. That is, the application MAY NOT assume the communication is being performed over any particular medium. The application server SHOULD transmit the data to the origin as faithfully as possible, keeping the intent of the application as much as possible.
The application server SHOULD forward on data emitted by the application in the returned payload supply as it arrives. The application server SHOULD send no other data to the origin over that socket once the application is handed control, unless related to how the data is being tunneled or handled by the server. The application server SHOULD close the connection with the origin when the application server sends the "done" message to the supply. Similarly, the application server SHOULD send "done" the `wapi.input` supply when the connection is closed by the client or server.
### 4.3.1 Response Payload
Applications MUST return a *sane* [Supply](http://doc.perl6.org/type/Supply) which emits a string of bytes for every message to be sent. The messages returned on this stream MUST be [Blob](http://doc.perl6.org/type/Blob) objects.
### 4.3.2 Encoding
The application server SHOULD reject any object other than a [Blob](http://doc.perl6.org/type/Blob) sent as part of the message payload. The application server is not expected to perform any encoding or stringification of messages.
# Changes
## 0.9.Draft
* The error stream is now defined to be a `Supplierish` object, defined in Section 1.1.
* Section 2.2.0.0 has been changed to forbid runtime routines from having a `Callable` return type.
* Section 2.1.2 was rewritten to disallow what was previously allowed: the modification of the input stream.
* Eliminated ambiguity regarding typing of environment in the middleware section.
* Added a section for type constraints and made better use of subset types to streamline and simplify some of the documentation.
* Cleaned up some old language left over from previous versions of the specification.
* Eliminated some ambiguities in the type required for undefined environment values. The undefined environment values MUST match the given type constraint and be set to type objects of that type if they are not defined.
* Changed the abbreviation from P6WAPI to RakuWAPI.
* Changed all `p6w.*` environment prefixes to `wapi.*`
* Changed all `p6wx.*` environment prefixes to `wapix.*`
* Changed all `P6Wx-*` header names to `WAPIx-*` header names
* Renamed all example `*.p6w` files to `*.wapi`
## 0.8.Draft
* Changed the abbreviation from P6W to P6WAPI.
## 0.7.Draft
* Renamed the standard from Perl 6 Standard Gateway Interface (P6SGI) to the Web API for Perl 6 (P6W).
* Some grammar fixes, typo fixes, and general verbiage cleanup and simplification.
* Renaming `p6sgi.*` to `p6w.*` and `p6sgix.*` to `p6wx.*`.
* The errors stream is now a `Supplier` rather than a `Supply` because of recent changes to the Supply interface in Perl 6. Made other supply-related syntax changes because of design changes to S17.
* Eliminating the requirement that things emitted in the response payload be [Cool](http://doc.perl6.org/type/Cool) if they are to be stringified and encoded. Any stringifiable [Mu](http://doc.perl6.org/type/Mu) is permitted.
* Adding `p6w.protocol`, `p6w.protocol.support`, and `p6w.protocol.enabled` to handle server-to-application notification of the required response protocol.
* Breaking sections 2.0.4, 2.1.4, and 2.2.4 up to discuss the difference between the HTTP and WebSocket protocol response requirements.
* Moving 2.0.5, 2.1.5, and 2.2.5 under 2.*.4 because of the protocol changes made in 2.*.4.
* Changed `p6wx.protocol.upgrade` from an [Array](http://doc.perl6.org/type/Array) to a [Set](http://doc.perl6.org/type/Set) of supported protocol names.
* Split the environment and the application into two parts: configuration and runtime.
* Added Section 4 to describe protocol-specific features of the specification. Section 4.0 is for HTTP, 4.1 is for WebSocket, 4.2 is for PSGI, and 4.3 is for Socket.
## 0.6.Draft
* Added Protocol-specific details and modifications to the standard HTTP/1.x environment.
* Adding the Protocol Upgrade extension and started details for HTTP/2 and WebSocket upgrade handling.
* Adding the Transfer Encoding extension because leaving this to the application or unspecified can lead to tricky scenarios.
## 0.5.Draft
* Adding `p6sgi.ready` and added the Application Lifecycle section to describe the ideal lifecycle of an application.
* Changed `p6sgi.input` and `p6sgi.errors` to Supply objects.
* Porting extensions from PSGI and moving the existing extensions into the extension section.
* Adding some notes about middleware encoding.
* Renamed `p6sgi.encoding` to `p6sgi.body.encoding`.
* Renamed `p6sgix.response.sent` to `p6sgix.body.done`.
* Added `p6sgix.header.done` as a new P6SGI extension.
## 0.4.Draft
* Cutting back on some more verbose or unnecessary statements in the standard, trying to stick with just what is important and nothing more.
* The application response has been completely restructured in a form that is both easy on applications and easy on middleware, mainly taking advantage of the fact that a List easily coerces into a Supply.
* Eliminating the P6SGI compilation unit again as it is no longer necessary.
* Change the Supply to emit Cool and Blob rather than just Str and Blob.
## 0.3.Draft
* Splitting the standard formally into layers: Application, Server, and Middleware.
* Bringing back the legacy standards and bringing back the variety of standard response forms.
* Middleware is given a higher priority in this revision and more explanation.
* Adding the P6SGI compilation unit to provide basic tools that allow middleware and possibly servers to easily process all standard response forms.
* Section numbering has been added.
* Added the Changes section.
* Use `p6sgi.` prefixes in the environment rather than `psgi.`
## 0.2.Draft
This second revision eliminates the legacy standard and requires that all P6SGI responses be returned as a [Promise](http://doc.perl6.org/type/Promise). The goal is to try and gain some uniformity in the responses the server must deal with.
## 0.1.Draft
This is the first published version. It was heavily influenced by PSGI and included interfaces based on the standard, deferred, and streaming responses of PSGI. Instead of callbacks, however, it used [Promise](http://doc.perl6.org/type/Promise) to handle deferred responses and [Channel](http://doc.perl6.org/type/Channel) to handle streaming. It mentioned middleware in passing.
|
## dist_zef-wayland-TOP.md
# Raku TOP: Table-Oriented Programming (TOP) in the Raku programming language
This package implements TOP in Raku.
For more information on TOP (Table Oriented Programming): [What is Table-Oriented Programming?](https://wayland.github.io/table-oriented-programming/TOP/Introduction/What.xml)
## Raku TOP Introductory Documents
[Raku Introductory Docs](https://wayland.github.io/table-oriented-programming/Raku-TOP/Introduction.xml)
## The Object Model Overview
Any classes below in () are not implemented yet
Conceptually, what we're moddeling is:
* Relation
* Table
* (DataDictionary)
* (View)
* (TupleSet)
* Tuple
* (Section)
* Field
* (Lot)
* Database
* Join
Most of the above concepts are directly from Relational Set Theory. The exceptions are:
* DataDictionary: Just a set of tables that explain what the rest of the database is doing; may be implemented differently
* Lot: A group of columns
* TupleSet: A set of tuples, usually that are the result of a query
In addition to the above, we have:
* Storage: This is data we can read/write; used for modelling SQL databases, but could also be in-memory tables, spreadsheets, CSV files, etc
* Formatters: This is for outputting data. Could be tables drawn with CLI box characters, CSV files, etc
* Parsers: This is for reading from tables. This includes reading in space-separated data, CSV files, etc
# Formats and their Parameters
Some formats are only really used as storage (eg. Memory, Postgres). Some things are only ever used as input/output (eg. WithBorders is generally not very useful except as output).
| Format | Storage | Parser | Formatter | Tree Format |
| --- | --- | --- | --- | --- |
| Memory | Yes | No | No | |
| Postgres | Yes | No | No | |
| HalfHuman | No | Yes | Yes | |
| WithBorders | No | No | Yes | |
| CSV | Yes | Yes | Make | |
| HTML | Make | Make | Make | XML |
| Spreadsheet | Make | No | No | XML |
| JSON | Make | Make | Make | JSON |
| Pod6 | ? | ? | Make | AST |
| SQLite | Accept | No | No | |
| MySQL | Accept | No | No | |
| Postgres option with not using cursors (has to support both cursor and non-cursor) | Accept | No | No | |
| Dan | Accept | ? | ? | | |
| DataQueryWorkflows | Accept | ? | ? | |
## Key to Formats
* **Yes**: This item exists
* **No**: No plans for this
* **Make**: Plans for this, but nothing yet
* **Accept**: No plans to make this, but would gladly accept it if someone made it
* **Tree**: These ones will be made, but not until Tree-Oriented Programming has been inaugurated
## Raku TOP Class References
Note that the following links don't yet work on raku.land -- you'll need to go to github to read them.
Also, Database::Storage::CSV doesn't work yet (TODO), but the others should; probably start with TOP, then go to Memory, then as you please.
* [class TOP::Parser::CSV](docs/Markdown/Reference/TOP/Parser/CSV.md)
* [class TOP::Parser::HalfHuman](docs/Markdown/Reference/TOP/Parser/HalfHuman.md)
* [class TOP::FieldMode::Error](docs/Markdown/Reference/TOP/FieldMode/Error.md)
* [class TOP::FieldMode::Automatic](docs/Markdown/Reference/TOP/FieldMode/Automatic.md)
* [class TOP::FieldMode::Overflow](docs/Markdown/Reference/TOP/FieldMode/Overflow.md)
* [class TOP::Formatter::WithBorders](docs/Markdown/Reference/TOP/Formatter/WithBorders.md)
* [class TOP::Formatter::HalfHuman](docs/Markdown/Reference/TOP/Formatter/HalfHuman.md)
* [class TOP::FieldMode](docs/Markdown/Reference/TOP/FieldMode.md)
* [class Database::Storage](docs/Markdown/Reference/Database/Storage.md)
* [class Database::Storage::CSV](docs/Markdown/Reference/Database/Storage/CSV.md)
* [class Database::Storage::Memory](docs/Markdown/Reference/Database/Storage/Memory.md)
* [class Database::Storage::Postgres](docs/Markdown/Reference/Database/Storage/Postgres.md)
* [class TOP](docs/Markdown/Reference//TOP.md)
## Plans for Raku TOP
For more information on the plans for Raku TOP, see [Raku TOP TODO](https://wayland.github.io/table-oriented-programming/Raku-TOP/TODO.xml)
|
## dist_cpan-CONO-Algorithm-Heap-Binary.md
[](https://travis-ci.org/cono/p6-algorithm-heap-binary)
# NAME
Algorithm::Heap::Binary - Implementation of a BinaryHeap
# SYNOPSIS
```
use Algorithm::Heap::Binary;
my Algorithm::Heap::Binary $heap .= new(
comparator => * <=> *,
3 => 'c',
2 => 'b',
1 => 'a'
);
$heap.size.say; # 3
# heap-sort example
$heap.delete-min.value.say; # a
$heap.delete-min.value.say; # b
$heap.delete-min.value.say; # c
```
# DESCRIPTION
Algorithm::Heap::Binary provides to you BinaryHeap data structure with basic heap operations defined in Algorithm::Heap role:
## peek
find a maximum item of a max-heap, or a minimum item of a min-heap, respectively
## push
returns the node of maximum value from a max heap [or minimum value from a min heap] after removing it from the heap
## pop
removing the root node of a max heap [or min heap]
## replace
pop root and push a new key. More efficient than pop followed by push, since only need to balance once, not twice, and appropriate for fixed-size heaps
## is-empty
return true if the heap is empty, false otherwise
## size
return the number of items in the heap
## merge
joining two heaps to form a valid new heap containing all the elements of both, preserving the original heaps
# METHODS
## Constructor
BinaryHeap contains `Pair` objects and define order between `Pair.key` by the comparator. Comparator - is a `Code` which defines how to order elements internally. With help of the comparator you can create Min-heap or Max-heap.
* empty constructor
```
my $heap = Algorithm::Heap::Binary.new;
```
Default comparator is: `* <=> *`
* named constructor
```
my $heap = Algorithm::Heap::Binary.new(comparator => -> $a, $b {$b cmp $a});
```
* constructor with heapify
```
my @numbers = 1 .. *;
my @letters = 'a' .. *;
my @data = @numbers Z=> @letters;
my $heap = Algorithm::Heap::Binary.new(comparator => * <=> *, |@data[^5]);
```
This will automatically heapify data for you.
## clone
Clones heap object for you with all internal data.
## is-empty
Returns `Bool` result as to empty Heap or not.
## size
Returns `Int` which corresponds to amount elements in the Heap data structure.
## push(Pair)
Adds new Pair to the heap and resort it.
## insert(Pair)
Alias for push method.
## peek
Returns `Pair` from the top of the Heap.
## find-max
Just an syntatic alias for peek method.
## find-min
Just an syntatic alias for peek method.
## pop
Returns `Piar` from the top of the Heap and also removes it from the Heap.
## delete-max
Just an syntatic alias for pop method.
## delete-min
Just an syntatic alias for pop method.
## replace(Pair)
Replace top element with another Pair. Returns replaced element as a result.
## merge(Algorithm::Heap)
Construct a new Heap merging current one and passed to as an argument.
## Seq
Returns `Seq` of Heap elements. This will clone the data for you, so initial data structure going to be untouched.
## Str
Prints internal representation of the Heap (as an `Array`).
## iterator
Method wich provides iterator (`role Iterable`). Will clone current Heap for you.
## sift-up
Internal method to make sift-up operation.
## sift-down
Internal method to make sift-down operation.
# AUTHOR
[cono](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2018 cono
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
# LINKS
* <https://en.wikipedia.org/wiki/Heap_(data_structure)>
* <https://en.wikipedia.org/wiki/Binary_heap>
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.