
txt
stringlengths 93
37.3k
|
|---|
## rand.md
rand
Combined from primary sources listed below.
# [In Num](#___top "go to top of document")[§](#(Num)_method_rand "direct link")
See primary documentation
[in context](/type/Num#method_rand)
for **method rand**.
```raku
method rand(Num:D: --> Num)
```
Returns a pseudo random number between 0 and the invocant.
# [In Terms](#___top "go to top of document")[§](#(Terms)_term_rand "direct link")
See primary documentation
[in context](/language/terms#term_rand)
for **term rand**.
Returns a pseudo-random [`Num`](/type/Num) in the range `0..^1`.
# [In Range](#___top "go to top of document")[§](#(Range)_method_rand "direct link")
See primary documentation
[in context](/type/Range#method_rand)
for **method rand**.
```raku
method rand(Range:D --> Num:D)
```
Returns a pseudo-random value belonging to the range.
```raku
say (1^..5).rand; # OUTPUT: «1.02405550417031»
say (0.1..0.3).rand; # OUTPUT: «0.2130353370062»
```
# [In role Real](#___top "go to top of document")[§](#(role_Real)_routine_rand "direct link")
See primary documentation
[in context](/type/Real#routine_rand)
for **routine rand**.
```raku
sub term:<rand> (--> Num:D)
method rand(Real:D: --> Real:D)
```
Returns a pseudo-random number between zero (inclusive) and the number (non-inclusive). The [`Bridge` method](/routine/Bridge) is used to coerce the `Real` to a numeric that supports [rand](/routine/rand) method.
The term form returns a pseudo-random [`Num`](/type/Num) between 0e0 (inclusive) and 1e0 (non-inclusive.)
# [In Cool](#___top "go to top of document")[§](#(Cool)_method_rand "direct link")
See primary documentation
[in context](/type/Cool#method_rand)
for **method rand**.
```raku
method rand()
```
Coerces the invocant to [`Num`](/type/Num) and returns a pseudo-random value between zero and the number.
```raku
say 1e5.rand; # OUTPUT: «33128.495184283»
```
|
## dist_zef-raku-community-modules-IO-CatHandle-AutoLines.md
[](https://github.com/raku-community-modules/IO-CatHandle-AutoLines/actions)
# NAME
IO::CatHandle::AutoLines - Get IO::CatHandle's current handle's line number
# SYNOPSIS
```
use IO::CatHandle::AutoLines;
'some' .IO.spurt: "a\nb\nc";
'files' .IO.spurt: "d\ne\nf";
'to-read'.IO.spurt: "g\nh";
my $kitty = IO::CatHandle.new(<some files to-read>, :on-switch{
say "Meow!"
}) does IO::CatHandle::AutoLines;
say "$kitty.ln(): $_" for $kitty.lines;
# OUTPUT:
# Meow!
# 1: a
# 2: b
# 3: c
# Meow!
# 1: d
# 2: e
# 3: f
# Meow!
# 1: g
# 2: h
# Meow!
```
# DESCRIPTION
A role that adds an <C.ln> method to the [`IO::CatHandle`](https://docs.raku.org/type/IO::CatHandle) type that will contain the current line number. Optionally, the lines counter can be reset when next source handle get switched into.
**Note:** only the [`.lines`](https://docs.raku.org/type/IO::CatHandle#method_lines) and [`.get`](https://docs.raku.org/type/IO::CatHandle#method_get) methods are overriden to increment the line counter. Using any other methods to read data will **not** increment the line counter.
# EXPORTED TYPES
## role IO::CatHandle::AutoLines
Defined as:
```
role IO::CatHandle::AutoLines[Bool:D :$reset = True]
```
Provides an `.ln` method containing `Int:D` of the current line number. If `:$reset` parameter is set to `True` (default), then on source handle switch, the line number will be reset back to zero.
```
# Reset on-switch enabled
my $cat1 = IO::CatHandle.new(…) does role IO::CatHandle::AutoLines;
# Reset on-switch disabled
my $cat2 = IO::CatHandle.new(…) does role IO::CatHandle::AutoLines[:!reset];
```
# AUTHOR
Zoffix Znet
# COPYRIGHT AND LICENSE
Copyright 2017 - 2018 Zoffix Znet
Copyright 2019 - 2022 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-Altai-man-App-Whiff.md
# perl6-app-whiff [Build Status](https://travis-ci.org/Altai-man/perl6-app-whiff)
Old plain whiff is here, now in Perl 6;
```
use App::Whiff;
whiff(["cat", "dog"]);
```
or just `perl6 bin/whiff cat dog`.
|
## dist_zef-rir-IUP.md
# Raku IUP IUP Logo
Raku interface to the IUP toolkit for building GUI's.
| Operating System | Build Status |
| --- | --- |
| Linux | None |
## Description
[IUP](http://www.tecgraf.puc-rio.br/iup/ "IUP - Portable User Interface") is a multi-platform toolkit for building graphical user interfaces.
IUP's purpose is to allow a program source code to be compiled in different
systems without any modification. Its main advantages are:
* It offers a simple API.
* High performance, due to the fact that it uses native interface elements.
* Fast learning by the user, due to the simplicity of its API.
## Installation
Get the below IUP library, or later, and install it:
```
mkdir libiup
cd libiup
curl -L https://sourceforge.net/projects/iup/files/3.25/Linux%20Libraries/iup-3.25_Linux44_64_lib.tar.gz > libiup.tar.gz
tar xvzf libiup.tar.gz
sudo bash install
sudo bash install_dev
cd ..
```
Install the Raku module with Zef:
```
zef update
zef install IUP
```
## Synopsis
WARNING:
This module is in its early stages and should be considered a Work in Progress.
The interface is not final and may change in the future.
Some of these methods also have longer names or names with underscores
instead of hyphens.
| Method | Description |
| --- | --- |
| destroy | Destroy self |
| detach | NYI |
| append | Append control to child-list |
| insert | Insert control after child |
| get-child | Get child by position in list |
| get-child-pos | NYI |
| get-child-count | NYI |
| get-next-child | Get next child from list |
| get-brother | NYI |
| get-parent | Get parent of self |
| get-dialog | Get the dialog (top-level) of self |
| get-dialog-child | I don't remember this one |
| reparent | NYI |
| popup | Popup self at x,y |
| show | Show widget, optionally at x,y |
| hide | Hide self |
| map | Map self into the display layout |
| unmap | NYI Unmap self out of the display layout |
| set-attr | Workhorse to set attribute(s) by ref or by :copy and etc |
| get-attr | Get attribute by name |
| get-attrs | Get attributes of self |
| get-int | Get integer attribute by name |
| set-global | Set global by key (name) and value |
| set-str-global | Deprecated, use set-global( :copy, $name) |
| get-global | Get named global's value |
| set-focus | Set focus on self |
| get-focus | Get widget that has focus |
| set-callback | Set a callback for a widget |
| set-callbacks | Set callbacks with key value pairs |
| get-handle | Get named widget by name |
| set-handle | Set a name for self |
| set-attr-handle | Name a referenced widget |
| fill | Fill space in layout |
| radio | Create a radio button widget |
| vbox | Create a vertical box with 1..N child widgets |
| zbox | Create a zbox with 1..N child widgets. |
| hbox | Create a horizontal box with 1..N child widgets. |
| sbox | Create a sbox (split box) |
| gridbox | Create a grid box |
| multibox | Create a multibox |
| expander | Create an expander |
| backgroundbox | Create a backgroundbox |
| frame | Create a frame |
| image | Create an image by dimensions and pixel list |
| item | Create an item |
| submenu | Create a titled submenu |
| separator | Create a separator in a menu |
| menu | Create a menu with 0..N members |
| button | Create a button with label and action |
| canvas | Create a canvas NOT WORKING |
| dialog | Create a dialog Perhaps the top-level or a nodal |
| user | Create a user widget |
| label | Create a label |
| list | Create a list with a string |
| text | Create a text widget |
| multiline | Create a multiline widget Text & multiline are same |
| toggle | Create a toggle switch |
| val | Create a Val (aka slider or scale) for choosing a value |
| dial | Create a dial widget |
| file-dlg | File choice dialog |
| message-dlg | Message displaying dialog |
| color-dlg | Color choice dialog |
| font-dlg | Font choice dialog |
| progress-dlg | Progress displaying dialog |
| get-file | Get file by name |
| message | Display message with title |
| alarm | Display message and title with three user choices |
| list-dialog | List choices for one or more selection, opt w/ defaults |
| open | Create the IUP system |
| close | Shutdown the IUP system |
| image-lib-open | Open the widget library |
| main-loop | Start an event loop on user inputs |
| set-language | Set the language to English, Portuguese or Spanish |
| get-language | Get the language |
| version | Get the IUP library version |
| get-version | Get the IUP library version |
| get-version-date | Return version's date |
| get-version-number | Get version number |
For convenience a IUP::Colors module exists with 140 common colors
named by their standard English names. Which standard is *the* standard
is a standard problem.
Sample GUI:
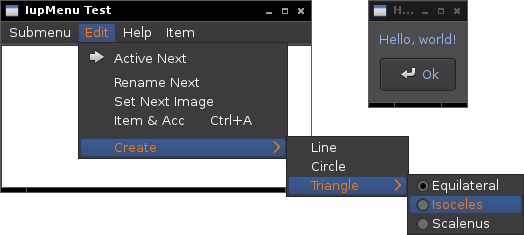
Sample code:
```
use IUP;
# initialize iup
my $iup = IUP.new;
$iup.image-lib-open;
$iup.open;
# create widgets and set their attributes
my $btn = $iup.button("&Ok", "");
$btn.set-callback("ACTION", &exit-callback);
$btn.set-attr("IMAGE", "IUP_ActionOk");
$btn.set-attr("EXPAND", "YES");
$btn.set-attr("TIP", "Exit button");
my $lbl = $iup.label("Hello, world!");
my $vb = $iup.vbox($lbl, $btn);
$vb.set-attr("MARGIN", "10x10");
$vb.set-attr("GAP", "10");
$vb.set-attribute("ALIGNMENT", "ACENTER");
my $dlg = $iup.dialog($vb);
$dlg.set-attribute("TITLE", "Hello");
# Map widgets and show dialog
$dlg.show;
# Wait for user interaction
$iup.main-loop;
# Clean up
$dlg.destroy;
$iup.close;
exit;
sub exit-callback( --> Int) {
return IUP_CLOSE;
}
```
## Authors and Contributors
* Henrique Dias [[email protected]](mailto:[email protected])
* Naoum Hankache [[email protected]](mailto:[email protected])
* Tobias Leich [[email protected]](mailto:[email protected])
* Zoffix Znet [[email protected]](mailto:[email protected])
* David Warring [[email protected]](mailto:[email protected])
* Robert Ransbottom [[email protected]](mailto:[email protected])
* Günter Milder
## Blame
Robert Ransbottom, as I have messed with most of the code.
## See Also
* [Raku IUP Module Documentation](lib/IUP.rakudoc "Raku IUP Module Documentation")
* [IUP Site](http://www.tecgraf.puc-rio.br/iup/ "IUP - Portable User Interface")
* [IUP on SourceForge](https://sourceforge.net/projects/iup/ "IUP Source Repository")
## License
This library is free software; you can redistribute it and/or modify it under
the same terms as Raku itself.
|
## dist_github-khalidelboray-Zap.md
## Chunk 1 of 3
# [OWASP ZAP API](https://www.zaproxy.org/docs/api/) Raku module
# SYNOPSIS
## `Zap`
```
use lib 'lib';
use Zap;
# Config Zap Client
ZapConfig(:apikey<apikey12345>,:port<8081>,:addr<127.0.0.1>);
# send a url to the spider
my $scanId = Zap::Spider.scan(:url<https://perl.org>);
# get the spider status
my $status = Zap::Spider.status(:$scanId);
# wait for the spider to finish then get the result
$*OUT = $*OUT.open(:!buffer);
while Zap::Spider.status(:$scanId) < 100 {
print "Spider progress {Zap::Spider.status(:$scanId)} \r";
}
$*OUT = $*OUT.open(:buffer);
put "URL : $_" for Zap::Spider.results(:$scanId);
my @scans = Zap::Spider.scans; # this needs some work
put "ID , Progress , State";
for @scans -> %scan {
put %scan<id progress state>.fmt("%s",', ')
}
```
# Installation
`zef install Zap`
# TODO
* Make the code and API Response more easy to handle
* Write a Script to provide a CLI `raku-zap` maybe ?
* Write an Interface for the zap CLI
* Automate Spider and Scanners
* Since we are using Cro::HTTP::Client , we can handel the other response formats with `body-parsers` (a `Cro::HTTP::BodyParser` class)
# Bad Generated Docs (needs more work)
## class Zap::Ruleconfig
class `Zap::Ruleconfig` Methods
### method resetAllRuleConfigValues
```
method resetAllRuleConfigValues() returns Mu
```
Reset all of the rule configurations
### method resetRuleConfigValue
```
method resetRuleConfigValue(
:$key!
) returns Mu
```
Reset the specified rule configuration, which must already exist
### method setRuleConfigValue
```
method setRuleConfigValue(
:$key!,
:$value
) returns Mu
```
Set the specified rule configuration, which must already exist
## class Zap::Break
class `Zap::Break` Methods
### method isBreakRequest
```
method isBreakRequest() returns Mu
```
Returns True if ZAP will break on requests
### method isBreakResponse
```
method isBreakResponse() returns Mu
```
Returns True if ZAP will break on responses
### method waitForHttpBreak
```
method waitForHttpBreak(
:$poll,
:$keepalive
) returns Mu
```
Waits until an HTTP breakpoint has been hit, at which point it returns the message. Poll is the number of milliseconds ZAP will pause between checking for breakpoints being hit (default 500). If keepalive is zero or less then the response will be returned as a Server Sent Event, otherwise it is used as the frequency in seconds at which 'keepalive' events should be returned and the response is sent as a standard response.
### method addHttpBreakpoint
```
method addHttpBreakpoint(
:$string!,
:$location!,
:$match!,
:$inverse!,
:$ignorecase!
) returns Mu
```
Adds a custom HTTP breakpoint. The string is the string to match. Location may be one of: url, request\_header, request\_body, response\_header or response\_body. Match may be: contains or regex. Inverse (match) may be true or false. Lastly, ignorecase (when matching the string) may be true or false.
### method break
```
method break(
:$type!,
:$state!,
:$scope
) returns Mu
```
Controls the global break functionality. The type may be one of: http-all, http-request or http-response. The state may be true (for turning break on for the specified type) or false (for turning break off). Scope is not currently used.
### method continue
```
method continue() returns Mu
```
Submits the currently intercepted message and unsets the global request/response breakpoints
### method drop
```
method drop() returns Mu
```
Drops the currently intercepted message
### method removeHttpBreakpoint
```
method removeHttpBreakpoint(
:$string!,
:$location!,
:$match!,
:$inverse!,
:$ignorecase!
) returns Mu
```
Removes the specified breakpoint
### method setHttpMessage
```
method setHttpMessage(
:$httpHeader!,
:$httpBody
) returns Mu
```
Overwrites the currently intercepted message with the data provided
### method step
```
method step() returns Mu
```
Submits the currently intercepted message, the next request or response will automatically be intercepted
## class Zap::Hud
class `Zap::Hud` Methods
### method hudAlertData
```
method hudAlertData(
:$url!
) returns Mu
```
Returns the alert summary needed by the HUD for the specified URL
### method optionAllowUnsafeEval
```
method optionAllowUnsafeEval() returns Mu
```
Returns true if the 'Allow unsafe-eval' option is set
### method optionBaseDirectory
```
method optionBaseDirectory() returns Mu
```
Returns the base directory from which the HUD files are loaded
### method optionDevelopmentMode
```
method optionDevelopmentMode() returns Mu
```
Returns true if the 'Development mode' option is set
### method optionEnableOnDomainMsgs
```
method optionEnableOnDomainMsgs() returns Mu
```
No Doc
### method optionEnabledForDaemon
```
method optionEnabledForDaemon() returns Mu
```
No Doc
### method optionEnabledForDesktop
```
method optionEnabledForDesktop() returns Mu
```
No Doc
### method optionInScopeOnly
```
method optionInScopeOnly() returns Mu
```
Returns true if the 'In scope only' option is set
### method optionRemoveCSP
```
method optionRemoveCSP() returns Mu
```
Returns true if the 'Remove CSP' option is set
### method optionShowWelcomeScreen
```
method optionShowWelcomeScreen() returns Mu
```
No Doc
### method optionSkipTutorialTasks
```
method optionSkipTutorialTasks() returns Mu
```
No Doc
### method optionTutorialHost
```
method optionTutorialHost() returns Mu
```
No Doc
### method optionTutorialPort
```
method optionTutorialPort() returns Mu
```
No Doc
### method optionTutorialTasksDone
```
method optionTutorialTasksDone() returns Mu
```
No Doc
### method optionTutorialTestMode
```
method optionTutorialTestMode() returns Mu
```
No Doc
### method optionTutorialUpdates
```
method optionTutorialUpdates() returns Mu
```
No Doc
### method tutorialUpdates
```
method tutorialUpdates() returns Mu
```
No Doc
### method upgradedDomains
```
method upgradedDomains() returns Mu
```
No Doc
### method changesInHtml
```
method changesInHtml() returns Mu
```
Returns the changelog in HTML format
### method log
```
method log(
:$record!
) returns Mu
```
Used by the HUD to log messages from the browser
### method recordRequest
```
method recordRequest(
:$header!,
:$body!
) returns Mu
```
Used by the HUD to cache a request the user wants to send in the browser
### method resetTutorialTasks
```
method resetTutorialTasks() returns Mu
```
Reset the tutorial tasks so that they must be completed again
### method setOptionBaseDirectory
```
method setOptionBaseDirectory(
:$String!
) returns Mu
```
Set the base directory from which the HUD files are loaded
### method setOptionDevelopmentMode
```
method setOptionDevelopmentMode(
:$Boolean!
) returns Mu
```
Sets the boolean option 'Development mode'
### method setOptionEnableOnDomainMsgs
```
method setOptionEnableOnDomainMsgs(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionEnabledForDaemon
```
method setOptionEnabledForDaemon(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionEnabledForDesktop
```
method setOptionEnabledForDesktop(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionInScopeOnly
```
method setOptionInScopeOnly(
:$Boolean!
) returns Mu
```
Sets the boolean option 'In scope only'
### method setOptionRemoveCSP
```
method setOptionRemoveCSP(
:$Boolean!
) returns Mu
```
Sets the boolean option 'Remove CSP'
### method setOptionShowWelcomeScreen
```
method setOptionShowWelcomeScreen(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionSkipTutorialTasks
```
method setOptionSkipTutorialTasks(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionTutorialTaskDone
```
method setOptionTutorialTaskDone(
:$String!
) returns Mu
```
No Doc
### method setOptionTutorialTestMode
```
method setOptionTutorialTestMode(
:$Boolean!
) returns Mu
```
No Doc
### method setUiOption
```
method setUiOption(
:$key!,
:$value
) returns Mu
```
Sets a UI option with the given key and value. The key must be 50 or fewer alphanumeric characters
## class Zap::Forceduser
class `Zap::Forceduser` Methods
### method setForcedUser
```
method setForcedUser(
:$contextId!,
:$userId!
) returns Mu
```
Sets the user (ID) that should be used in 'forced user' mode for the given context (ID)
### method setForcedUserModeEnabled
```
method setForcedUserModeEnabled(
:$boolean!
) returns Mu
```
Sets if 'forced user' mode should be enabled or not
## class Zap::Stats
class `Zap::Stats` Methods
### method clearStats
```
method clearStats(
:$keyPrefix
) returns Mu
```
Clears all of the statistics
### method setOptionInMemoryEnabled
```
method setOptionInMemoryEnabled(
:$Boolean!
) returns Mu
```
Sets whether in memory statistics are enabled
### method setOptionStatsdHost
```
method setOptionStatsdHost(
:$String!
) returns Mu
```
Sets the Statsd service hostname, supply an empty string to stop using a Statsd service
### method setOptionStatsdPort
```
method setOptionStatsdPort(
:$Integer!
) returns Mu
```
Sets the Statsd service port
### method setOptionStatsdPrefix
```
method setOptionStatsdPrefix(
:$String!
) returns Mu
```
Sets the prefix to be applied to all stats sent to the configured Statsd service
### method optionStatsdEnabled
```
method optionStatsdEnabled() returns Mu
```
Returns 'true' if a Statsd server has been correctly configured, otherwise returns 'false'
### method optionStatsdHost
```
method optionStatsdHost() returns Mu
```
Gets the Statsd service hostname
### method optionStatsdPort
```
method optionStatsdPort() returns Mu
```
Gets the Statsd service port
### method optionStatsdPrefix
```
method optionStatsdPrefix() returns Mu
```
Gets the prefix to be applied to all stats sent to the configured Statsd service
### method siteStats
```
method siteStats(
:$site!,
:$keyPrefix
) returns Mu
```
Gets all of the global statistics, optionally filtered by a key prefix
### method stats
```
method stats(
:$keyPrefix
) returns Mu
```
Statistics
## class Zap::Alertfilter
class `Zap::Alertfilter` Methods
### method addAlertFilter
```
method addAlertFilter(
:$contextId!,
:$ruleId!,
:$newLevel!,
:$url,
:$urlIsRegex,
:$parameter,
:$enabled,
:$parameterIsRegex,
:$attack,
:$attackIsRegex,
:$evidence,
:$evidenceIsRegex
) returns Mu
```
Adds a new alert filter for the context with the given ID.
### method addGlobalAlertFilter
```
method addGlobalAlertFilter(
:$ruleId!,
:$newLevel!,
:$url,
:$urlIsRegex,
:$parameter,
:$enabled,
:$parameterIsRegex,
:$attack,
:$attackIsRegex,
:$evidence,
:$evidenceIsRegex
) returns Mu
```
Adds a new global alert filter.
### method removeAlertFilter
```
method removeAlertFilter(
:$contextId!,
:$ruleId!,
:$newLevel!,
:$url,
:$urlIsRegex,
:$parameter,
:$enabled,
:$parameterIsRegex,
:$attack,
:$attackIsRegex,
:$evidence,
:$evidenceIsRegex
) returns Mu
```
Removes an alert filter from the context with the given ID.
### method removeGlobalAlertFilter
```
method removeGlobalAlertFilter(
:$ruleId!,
:$newLevel!,
:$url,
:$urlIsRegex,
:$parameter,
:$enabled,
:$parameterIsRegex,
:$attack,
:$attackIsRegex,
:$evidence,
:$evidenceIsRegex
) returns Mu
```
Removes a global alert filter.
## class Zap::Ascan
class `Zap::Ascan` Methods
### method addExcludedParam
```
method addExcludedParam(
:$name!,
:$type,
:$url
) returns Mu
```
Adds a new parameter excluded from the scan, using the specified name. Optionally sets if the new entry applies to a specific URL (default, all URLs) and sets the ID of the type of the parameter (default, ID of any type). The type IDs can be obtained with the view excludedParamTypes.
### method addScanPolicy
```
method addScanPolicy(
:$scanPolicyName!,
:$alertThreshold,
:$attackStrength
) returns Mu
```
No Doc
### method clearExcludedFromScan
```
method clearExcludedFromScan() returns Mu
```
Clears the regexes of URLs excluded from the active scans.
### method disableAllScanners
```
method disableAllScanners(
:$scanPolicyName
) returns Mu
```
Disables all scanners of the scan policy with the given name, or the default if none given.
### method disableScanners
```
method disableScanners(
:$ids!,
:$scanPolicyName
) returns Mu
```
Disables the scanners with the given IDs (comma separated list of IDs) of the scan policy with the given name, or the default if none given.
### method enableAllScanners
```
method enableAllScanners(
:$scanPolicyName
) returns Mu
```
Enables all scanners of the scan policy with the given name, or the default if none given.
### method enableScanners
```
method enableScanners(
:$ids!,
:$scanPolicyName
) returns Mu
```
Enables the scanners with the given IDs (comma separated list of IDs) of the scan policy with the given name, or the default if none given.
### method excludeFromScan
```
method excludeFromScan(
:$regex!
) returns Mu
```
Adds a regex of URLs that should be excluded from the active scans.
### method importScanPolicy
```
method importScanPolicy(
:$path!
) returns Mu
```
Imports a Scan Policy using the given file system path.
### method modifyExcludedParam
```
method modifyExcludedParam(
:$idx!,
:$name,
:$type,
:$url
) returns Mu
```
Modifies a parameter excluded from the scan. Allows to modify the name, the URL and the type of parameter. The parameter is selected with its index, which can be obtained with the view excludedParams.
### method pause
```
method pause(
:$scanId!
) returns Mu
```
No Doc
### method pauseAllScans
```
method pauseAllScans() returns Mu
```
No Doc
### method removeAllScans
```
method removeAllScans() returns Mu
```
No Doc
### method removeExcludedParam
```
method removeExcludedParam(
:$idx!
) returns Mu
```
Removes a parameter excluded from the scan, with the given index. The index can be obtained with the view excludedParams.
### method removeScan
```
method removeScan(
:$scanId!
) returns Mu
```
No Doc
### method removeScanPolicy
```
method removeScanPolicy(
:$scanPolicyName!
) returns Mu
```
No Doc
### method resume
```
method resume(
:$scanId!
) returns Mu
```
No Doc
### method resumeAllScans
```
method resumeAllScans() returns Mu
```
No Doc
### method scan
```
method scan(
:$url,
:$recurse,
:$inScopeOnly,
:$scanPolicyName,
:$method,
:$postData,
:$contextId
) returns Mu
```
Runs the active scanner against the given URL and/or Context. Optionally, the 'recurse' parameter can be used to scan URLs under the given URL, the parameter 'inScopeOnly' can be used to constrain the scan to URLs that are in scope (ignored if a Context is specified), the parameter 'scanPolicyName' allows to specify the scan policy (if none is given it uses the default scan policy), the parameters 'method' and 'postData' allow to select a given request in conjunction with the given URL.
### method scanAsUser
```
method scanAsUser(
:$url,
:$contextId,
:$userId,
:$recurse,
:$scanPolicyName,
:$method,
:$postData
) returns Mu
```
Active Scans from the perspective of a User, obtained using the given Context ID and User ID. See 'scan' action for more details.
### method setEnabledPolicies
```
method setEnabledPolicies(
:$ids!,
:$scanPolicyName
) returns Mu
```
No Doc
### method setOptionAddQueryParam
```
method setOptionAddQueryParam(
:$Boolean!
) returns Mu
```
Sets whether or not the active scanner should add a query param to GET requests which do not have parameters to start with.
### method setOptionAllowAttackOnStart
```
method setOptionAllowAttackOnStart(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionAttackPolicy
```
method setOptionAttackPolicy(
:$String!
) returns Mu
```
No Doc
### method setOptionDefaultPolicy
```
method setOptionDefaultPolicy(
:$String!
) returns Mu
```
No Doc
### method setOptionDelayInMs
```
method setOptionDelayInMs(
:$Integer!
) returns Mu
```
No Doc
### method setOptionHandleAntiCSRFTokens
```
method setOptionHandleAntiCSRFTokens(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionHostPerScan
```
method setOptionHostPerScan(
:$Integer!
) returns Mu
```
No Doc
### method setOptionInjectPluginIdInHeader
```
method setOptionInjectPluginIdInHeader(
:$Boolean!
) returns Mu
```
Sets whether or not the active scanner should inject the HTTP request header X-ZAP-Scan-ID, with the ID of the scanner that's sending the requests.
### method setOptionMaxChartTimeInMins
```
method setOptionMaxChartTimeInMins(
:$Integer!
) returns Mu
```
No Doc
### method setOptionMaxResultsToList
```
method setOptionMaxResultsToList(
:$Integer!
) returns Mu
```
No Doc
### method setOptionMaxRuleDurationInMins
```
method setOptionMaxRuleDurationInMins(
:$Integer!
) returns Mu
```
No Doc
### method setOptionMaxScanDurationInMins
```
method setOptionMaxScanDurationInMins(
:$Integer!
) returns Mu
```
No Doc
### method setOptionMaxScansInUI
```
method setOptionMaxScansInUI(
:$Integer!
) returns Mu
```
No Doc
### method setOptionPromptInAttackMode
```
method setOptionPromptInAttackMode(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionPromptToClearFinishedScans
```
method setOptionPromptToClearFinishedScans(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionRescanInAttackMode
```
method setOptionRescanInAttackMode(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionScanHeadersAllRequests
```
method setOptionScanHeadersAllRequests(
:$Boolean!
) returns Mu
```
Sets whether or not the HTTP Headers of all requests should be scanned. Not just requests that send parameters, through the query or request body.
### method setOptionShowAdvancedDialog
```
method setOptionShowAdvancedDialog(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionTargetParamsEnabledRPC
```
method setOptionTargetParamsEnabledRPC(
:$Integer!
) returns Mu
```
No Doc
### method setOptionTargetParamsInjectable
```
method setOptionTargetParamsInjectable(
:$Integer!
) returns Mu
```
No Doc
### method setOptionThreadPerHost
```
method setOptionThreadPerHost(
:$Integer!
) returns Mu
```
No Doc
### method setPolicyAlertThreshold
```
method setPolicyAlertThreshold(
:$id!,
:$alertThreshold!,
:$scanPolicyName
) returns Mu
```
No Doc
### method setPolicyAttackStrength
```
method setPolicyAttackStrength(
:$id!,
:$attackStrength!,
:$scanPolicyName
) returns Mu
```
No Doc
### method setScannerAlertThreshold
```
method setScannerAlertThreshold(
:$id!,
:$alertThreshold!,
:$scanPolicyName
) returns Mu
```
No Doc
### method setScannerAttackStrength
```
method setScannerAttackStrength(
:$id!,
:$attackStrength!,
:$scanPolicyName
) returns Mu
```
No Doc
### method skipScanner
```
method skipScanner(
:$scanId!,
:$scannerId!
) returns Mu
```
Skips the scanner using the given IDs of the scan and the scanner.
### method stop
```
method stop(
:$scanId!
) returns Mu
```
No Doc
### method stopAllScans
```
method stopAllScans() returns Mu
```
No Doc
### method updateScanPolicy
```
method updateScanPolicy(
:$scanPolicyName!,
:$alertThreshold,
:$attackStrength
) returns Mu
```
No Doc
### method excludedFromScan
```
method excludedFromScan() returns Mu
```
Gets the regexes of URLs excluded from the active scans.
### method excludedParamTypes
```
method excludedParamTypes() returns Mu
```
Gets all the types of excluded parameters. For each type the following are shown: the ID and the name.
### method excludedParams
```
method excludedParams() returns Mu
```
Gets all the parameters that are excluded. For each parameter the following are shown: the name, the URL, and the parameter type.
### method messagesIds
```
method messagesIds(
:$scanId!
) returns Mu
```
Gets the IDs of the messages sent during the scan with the given ID. A message can be obtained with 'message' core view.
### method optionAddQueryParam
```
method optionAddQueryParam() returns Mu
```
Tells whether or not the active scanner should add a query parameter to GET request that don't have parameters to start with.
### method optionAllowAttackOnStart
```
method optionAllowAttackOnStart() returns Mu
```
No Doc
### method optionAttackPolicy
```
method optionAttackPolicy() returns Mu
```
No Doc
### method optionDefaultPolicy
```
method optionDefaultPolicy() returns Mu
```
No Doc
### method optionDelayInMs
```
method optionDelayInMs() returns Mu
```
No Doc
### method optionExcludedParamList
```
method optionExcludedParamList() returns Mu
```
Use view excludedParams instead.
### method optionHandleAntiCSRFTokens
```
method optionHandleAntiCSRFTokens() returns Mu
```
No Doc
### method optionHostPerScan
```
method optionHostPerScan() returns Mu
```
No Doc
### method optionInjectPluginIdInHeader
```
method optionInjectPluginIdInHeader() returns Mu
```
Tells whether or not the active scanner should inject the HTTP request header X-ZAP-Scan-ID, with the ID of the scanner that's sending the requests.
### method optionMaxChartTimeInMins
```
method optionMaxChartTimeInMins() returns Mu
```
No Doc
### method optionMaxResultsToList
```
method optionMaxResultsToList() returns Mu
```
No Doc
### method optionMaxRuleDurationInMins
```
method optionMaxRuleDurationInMins() returns Mu
```
No Doc
### method optionMaxScanDurationInMins
```
method optionMaxScanDurationInMins() returns Mu
```
No Doc
### method optionMaxScansInUI
```
method optionMaxScansInUI() returns Mu
```
No Doc
### method optionPromptInAttackMode
```
method optionPromptInAttackMode() returns Mu
```
No Doc
### method optionPromptToClearFinishedScans
```
method optionPromptToClearFinishedScans() returns Mu
```
No Doc
### method optionRescanInAttackMode
```
method optionRescanInAttackMode() returns Mu
```
No Doc
### method optionScanHeadersAllRequests
```
method optionScanHeadersAllRequests() returns Mu
```
Tells whether or not the HTTP Headers of all requests should be scanned. Not just requests that send parameters, through the query or request body.
### method optionShowAdvancedDialog
```
method optionShowAdvancedDialog() returns Mu
```
No Doc
### method optionTargetParamsEnabledRPC
```
method optionTargetParamsEnabledRPC() returns Mu
```
No Doc
### method optionTargetParamsInjectable
```
method optionTargetParamsInjectable() returns Mu
```
No Doc
### method optionThreadPerHost
```
method optionThreadPerHost() returns Mu
```
No Doc
### method policies
```
method policies(
:$scanPolicyName,
:$policyId
) returns Mu
```
No Doc
### method scanPolicyNames
```
method scanPolicyNames() returns Mu
```
No Doc
### method scanProgress
```
method scanProgress(
:$scanId
) returns Mu
```
No Doc
### method scanners
```
method scanners(
:$scanPolicyName,
:$policyId
) returns Mu
```
Gets the scanners, optionally, of the given scan policy and/or scanner policy/category ID.
### method scans
```
method scans() returns Mu
```
No Doc
### method status
```
method status(
:$scanId
) returns Mu
```
No Doc
## class Zap::Spider
class `Zap::Spider` Methods
### method domainsAlwaysInScope
```
method domainsAlwaysInScope() returns Mu
```
Gets all the domains that are always in scope. For each domain the following are shown: the index, the value (domain), if enabled, and if specified as a regex.
### method excludedFromScan
```
method excludedFromScan() returns Mu
```
Gets the regexes of URLs excluded from the spider scans.
### method fullResults
```
method fullResults(
:$scanId!
) returns Mu
```
No Doc
### method optionAcceptCookies
```
method optionAcceptCookies() returns Mu
```
Gets whether or not a spider process should accept cookies while spidering.
### method optionDomainsAlwaysInScope
```
method optionDomainsAlwaysInScope() returns Mu
```
Use view domainsAlwaysInScope instead.
### method optionDomainsAlwaysInScopeEnabled
```
method optionDomainsAlwaysInScopeEnabled() returns Mu
```
Use view domainsAlwaysInScope instead.
### method optionHandleODataParametersVisited
```
method optionHandleODataParametersVisited() returns Mu
```
No Doc
### method optionHandleParameters
```
method optionHandleParameters() returns Mu
```
No Doc
### method optionMaxChildren
```
method optionMaxChildren() returns Mu
```
Gets the maximum number of child nodes (per node) that can be crawled, 0 means no limit.
### method optionMaxDepth
```
method optionMaxDepth() returns Mu
```
Gets the maximum depth the spider can crawl, 0 if unlimited.
### method optionMaxDuration
```
method optionMaxDuration() returns Mu
```
No Doc
### method optionMaxParseSizeBytes
```
method optionMaxParseSizeBytes() returns Mu
```
Gets the maximum size, in bytes, that a response might have to be parsed.
### method optionMaxScansInUI
```
method optionMaxScansInUI() returns Mu
```
No Doc
### method optionParseComments
```
method optionParseComments() returns Mu
```
No Doc
### method optionParseGit
```
method optionParseGit() returns Mu
```
No Doc
### method optionParseRobotsTxt
```
method optionParseRobotsTxt() returns Mu
```
No Doc
### method optionParseSVNEntries
```
method optionParseSVNEntries() returns Mu
```
No Doc
### method optionParseSitemapXml
```
method optionParseSitemapXml() returns Mu
```
No Doc
### method optionPostForm
```
method optionPostForm() returns Mu
```
No Doc
### method optionProcessForm
```
method optionProcessForm() returns Mu
```
No Doc
### method optionRequestWaitTime
```
method optionRequestWaitTime() returns Mu
```
No Doc
### method optionScope
```
method optionScope() returns Mu
```
No Doc
### method optionScopeText
```
method optionScopeText() returns Mu
```
No Doc
### method optionSendRefererHeader
```
method optionSendRefererHeader() returns Mu
```
Gets whether or not the 'Referer' header should be sent while spidering.
### method optionShowAdvancedDialog
```
method optionShowAdvancedDialog() returns Mu
```
No Doc
### method optionSkipURLString
```
method optionSkipURLString() returns Mu
```
No Doc
### method optionThreadCount
```
method optionThreadCount() returns Mu
```
No Doc
### method optionUserAgent
```
method optionUserAgent() returns Mu
```
No Doc
### method results
```
method results(
:$scanId
) returns Mu
```
No Doc
### method scans
```
method scans() returns Mu
```
No Doc
### method status
```
method status(
:$scanId
) returns Mu
```
No Doc
### method addDomainAlwaysInScope
```
method addDomainAlwaysInScope(
:$value!,
:$isRegex,
:$isEnabled
) returns Mu
```
Adds a new domain that's always in scope, using the specified value. Optionally sets if the new entry is enabled (default, true) and whether or not the new value is specified as a regex (default, false).
### method clearExcludedFromScan
```
method clearExcludedFromScan() returns Mu
```
Clears the regexes of URLs excluded from the spider scans.
### method disableAllDomainsAlwaysInScope
```
method disableAllDomainsAlwaysInScope() returns Mu
```
Disables all domains that are always in scope.
### method enableAllDomainsAlwaysInScope
```
method enableAllDomainsAlwaysInScope() returns Mu
```
Enables all domains that are always in scope.
### method excludeFromScan
```
method excludeFromScan(
:$regex!
) returns Mu
```
Adds a regex of URLs that should be excluded from the spider scans.
### method modifyDomainAlwaysInScope
```
method modifyDomainAlwaysInScope(
:$idx!,
:$value,
:$isRegex,
:$isEnabled
) returns Mu
```
Modifies a domain that's always in scope. Allows to modify the value, if enabled or if a regex. The domain is selected with its index, which can be obtained with the view domainsAlwaysInScope.
### method pause
```
method pause(
:$scanId!
) returns Mu
```
No Doc
### method pauseAllScans
```
method pauseAllScans() returns Mu
```
No Doc
### method removeAllScans
```
method removeAllScans() returns Mu
```
No Doc
### method removeDomainAlwaysInScope
```
method removeDomainAlwaysInScope(
:$idx!
) returns Mu
```
Removes a domain that's always in scope, with the given index. The index can be obtained with the view domainsAlwaysInScope.
### method removeScan
```
method removeScan(
:$scanId!
) returns Mu
```
No Doc
### method resume
```
method resume(
:$scanId!
) returns Mu
```
No Doc
### method resumeAllScans
```
method resumeAllScans() returns Mu
```
No Doc
### method scan
```
method scan(
:$url,
:$maxChildren,
:$recurse,
:$contextName,
:$subtreeOnly
) returns Mu
```
Runs the spider against the given URL (or context). Optionally, the 'maxChildren' parameter can be set to limit the number of children scanned, the 'recurse' parameter can be used to prevent the spider from seeding recursively, the parameter 'contextName' can be used to constrain the scan to a Context and the parameter 'subtreeOnly' allows to restrict the spider under a site's subtree (using the specified 'url').
### method scanAsUser
```
method scanAsUser(
:$contextId!,
:$userId!,
:$url,
:$maxChildren,
:$recurse,
:$subtreeOnly
) returns Mu
```
Runs the spider from the perspective of a User, obtained using the given Context ID and User ID. See 'scan' action for more details.
### method setOptionAcceptCookies
```
method setOptionAcceptCookies(
:$Boolean!
) returns Mu
```
Sets whether or not a spider process should accept cookies while spidering.
### method setOptionHandleODataParametersVisited
```
method setOptionHandleODataParametersVisited(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionHandleParameters
```
method setOptionHandleParameters(
:$String!
) returns Mu
```
No Doc
### method setOptionMaxChildren
```
method setOptionMaxChildren(
:$Integer!
) returns Mu
```
Sets the maximum number of child nodes (per node) that can be crawled, 0 means no limit.
### method setOptionMaxDepth
```
method setOptionMaxDepth(
:$Integer!
) returns Mu
```
Sets the maximum depth the spider can crawl, 0 for unlimited depth.
### method setOptionMaxDuration
```
method setOptionMaxDuration(
:$Integer!
) returns Mu
```
No Doc
### method setOptionMaxParseSizeBytes
```
method setOptionMaxParseSizeBytes(
:$Integer!
) returns Mu
```
Sets the maximum size, in bytes, that a response might have to be parsed. This allows the spider to skip big responses/files.
### method setOptionMaxScansInUI
```
method setOptionMaxScansInUI(
:$Integer!
) returns Mu
```
No Doc
### method setOptionParseComments
```
method setOptionParseComments(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionParseGit
```
method setOptionParseGit(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionParseRobotsTxt
```
method setOptionParseRobotsTxt(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionParseSVNEntries
```
method setOptionParseSVNEntries(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionParseSitemapXml
```
method setOptionParseSitemapXml(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionPostForm |
## dist_github-khalidelboray-Zap.md
## Chunk 2 of 3
```
method setOptionPostForm(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionProcessForm
```
method setOptionProcessForm(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionRequestWaitTime
```
method setOptionRequestWaitTime(
:$Integer!
) returns Mu
```
No Doc
### method setOptionScopeString
```
method setOptionScopeString(
:$String!
) returns Mu
```
Use actions [add|modify|remove]DomainAlwaysInScope instead.
### method setOptionSendRefererHeader
```
method setOptionSendRefererHeader(
:$Boolean!
) returns Mu
```
Sets whether or not the 'Referer' header should be sent while spidering.
### method setOptionShowAdvancedDialog
```
method setOptionShowAdvancedDialog(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionSkipURLString
```
method setOptionSkipURLString(
:$String!
) returns Mu
```
No Doc
### method setOptionThreadCount
```
method setOptionThreadCount(
:$Integer!
) returns Mu
```
No Doc
### method setOptionUserAgent
```
method setOptionUserAgent(
:$String!
) returns Mu
```
No Doc
### method stop
```
method stop(
:$scanId
) returns Mu
```
No Doc
### method stopAllScans
```
method stopAllScans() returns Mu
```
No Doc
## class Zap::Selenium
class `Zap::Selenium` Methods
### method setOptionChromeDriverPath
```
method setOptionChromeDriverPath(
:$String!
) returns Mu
```
Sets the current path to ChromeDriver
### method setOptionFirefoxBinaryPath
```
method setOptionFirefoxBinaryPath(
:$String!
) returns Mu
```
Sets the current path to Firefox binary
### method setOptionFirefoxDriverPath
```
method setOptionFirefoxDriverPath(
:$String!
) returns Mu
```
Sets the current path to Firefox driver (geckodriver)
### method setOptionIeDriverPath
```
method setOptionIeDriverPath(
:$String!
) returns Mu
```
No Doc
### method setOptionPhantomJsBinaryPath
```
method setOptionPhantomJsBinaryPath(
:$String!
) returns Mu
```
Sets the current path to PhantomJS binary
### method optionFirefoxDriverPath
```
method optionFirefoxDriverPath() returns Mu
```
Returns the current path to Firefox driver (geckodriver)
### method optionIeDriverPath
```
method optionIeDriverPath() returns Mu
```
No Doc
### method optionPhantomJsBinaryPath
```
method optionPhantomJsBinaryPath() returns Mu
```
Returns the current path to PhantomJS binary
## class Zap::Httpsessions
class `Zap::Httpsessions` Methods
### method addDefaultSessionToken
```
method addDefaultSessionToken(
:$sessionToken!,
:$tokenEnabled
) returns Mu
```
Adds a default session token with the given name and enabled state.
### method addSessionToken
```
method addSessionToken(
:$site!,
:$sessionToken!
) returns Mu
```
Adds the session token to the given site.
### method createEmptySession
```
method createEmptySession(
:$site!,
:$session
) returns Mu
```
Creates an empty session for the given site. Optionally with the given name.
### method removeDefaultSessionToken
```
method removeDefaultSessionToken(
:$sessionToken!
) returns Mu
```
Removes the default session token with the given name.
### method removeSession
```
method removeSession(
:$site!,
:$session!
) returns Mu
```
Removes the session from the given site.
### method removeSessionToken
```
method removeSessionToken(
:$site!,
:$sessionToken!
) returns Mu
```
Removes the session token from the given site.
### method renameSession
```
method renameSession(
:$site!,
:$oldSessionName!,
:$newSessionName!
) returns Mu
```
Renames the session of the given site.
### method setActiveSession
```
method setActiveSession(
:$site!,
:$session!
) returns Mu
```
Sets the given session as active for the given site.
### method setDefaultSessionTokenEnabled
```
method setDefaultSessionTokenEnabled(
:$sessionToken!,
:$tokenEnabled!
) returns Mu
```
Sets whether or not the default session token with the given name is enabled.
### method setSessionTokenValue
```
method setSessionTokenValue(
:$site!,
:$session!,
:$sessionToken!,
:$tokenValue!
) returns Mu
```
Sets the value of the session token of the given session for the given site.
### method unsetActiveSession
```
method unsetActiveSession(
:$site!
) returns Mu
```
Unsets the active session of the given site.
### method sessionTokens
```
method sessionTokens(
:$site!
) returns Mu
```
Gets the names of the session tokens for the given site.
### method sessions
```
method sessions(
:$site!,
:$session
) returns Mu
```
Gets the sessions for the given site. Optionally returning just the session with the given name.
### method sites
```
method sites() returns Mu
```
Gets all of the sites that have sessions.
## class Zap::Localproxies
class `Zap::Localproxies` Methods
### method removeAdditionalProxy
```
method removeAdditionalProxy(
:$address!,
:$port!
) returns Mu
```
Removes the additional proxy with the specified address and port.
## class Zap::Websocket
class `Zap::Websocket` Methods
### method message
```
method message(
:$channelId!,
:$messageId!
) returns Mu
```
Returns full details of the message specified by the channelId and messageId
### method messages
```
method messages(
:$channelId,
:$start,
:$count,
:$payloadPreviewLength
) returns Mu
```
Returns a list of all of the messages that meet the given criteria (all optional), where channelId is a channel identifier, start is the offset to start returning messages from (starting from 0), count is the number of messages to return (default no limit) and payloadPreviewLength is the maximum number bytes to return for the payload contents
### method sendTextMessage
```
method sendTextMessage(
:$channelId!,
:$outgoing!,
:$message!
) returns Mu
```
Sends the specified message on the channel specified by channelId, if outgoing is 'True' then the message will be sent to the server and if it is 'False' then it will be sent to the client
### method setBreakTextMessage
```
method setBreakTextMessage(
:$message!,
:$outgoing!
) returns Mu
```
Sets the text message for an intercepted websockets message
## class Zap::Authentication
class `Zap::Authentication` Methods
### method setAuthenticationMethod
```
method setAuthenticationMethod(
:$contextId!,
:$authMethodName!,
:$authMethodConfigParams
) returns Mu
```
Sets the authentication method for the context with the given ID.
### method setLoggedInIndicator
```
method setLoggedInIndicator(
:$contextId!,
:$loggedInIndicatorRegex!
) returns Mu
```
Sets the logged in indicator for the context with the given ID.
### method setLoggedOutIndicator
```
method setLoggedOutIndicator(
:$contextId!,
:$loggedOutIndicatorRegex!
) returns Mu
```
Sets the logged out indicator for the context with the given ID.
### method getLoggedInIndicator
```
method getLoggedInIndicator(
:$contextId!
) returns Mu
```
Gets the logged in indicator for the context with the given ID.
### method getLoggedOutIndicator
```
method getLoggedOutIndicator(
:$contextId!
) returns Mu
```
Gets the logged out indicator for the context with the given ID.
### method getSupportedAuthenticationMethods
```
method getSupportedAuthenticationMethods() returns Mu
```
Gets the name of the authentication methods.
## class Zap::Pscan
class `Zap::Pscan` Methods
### method disableAllScanners
```
method disableAllScanners() returns Mu
```
Disables all passive scanners
### method disableAllTags
```
method disableAllTags() returns Mu
```
Disables all passive scan tags.
### method disableScanners
```
method disableScanners(
:$ids!
) returns Mu
```
Disables all passive scanners with the given IDs (comma separated list of IDs)
### method enableAllScanners
```
method enableAllScanners() returns Mu
```
Enables all passive scanners
### method enableAllTags
```
method enableAllTags() returns Mu
```
Enables all passive scan tags.
### method enableScanners
```
method enableScanners(
:$ids!
) returns Mu
```
Enables all passive scanners with the given IDs (comma separated list of IDs)
### method setEnabled
```
method setEnabled(
:$enabled!
) returns Mu
```
Sets whether or not the passive scanning is enabled (Note: the enabled state is not persisted).
### method setMaxAlertsPerRule
```
method setMaxAlertsPerRule(
:$maxAlerts!
) returns Mu
```
Sets the maximum number of alerts a passive scan rule should raise.
### method setScanOnlyInScope
```
method setScanOnlyInScope(
:$onlyInScope!
) returns Mu
```
Sets whether or not the passive scan should be performed only on messages that are in scope.
### method setScannerAlertThreshold
```
method setScannerAlertThreshold(
:$id!,
:$alertThreshold!
) returns Mu
```
Sets the alert threshold of the passive scanner with the given ID, accepted values for alert threshold: OFF, DEFAULT, LOW, MEDIUM and HIGH
### method recordsToScan
```
method recordsToScan() returns Mu
```
The number of records the passive scanner still has to scan
### method scanOnlyInScope
```
method scanOnlyInScope() returns Mu
```
Tells whether or not the passive scan should be performed only on messages that are in scope.
### method scanners
```
method scanners() returns Mu
```
Lists all passive scanners with its ID, name, enabled state and alert threshold.
## class Zap::Sessionmanagement
class `Zap::Sessionmanagement` Methods
### method getSupportedSessionManagementMethods
```
method getSupportedSessionManagementMethods() returns Mu
```
Gets the name of the session management methods.
### method setSessionManagementMethod
```
method setSessionManagementMethod(
:$contextId!,
:$methodName!,
:$methodConfigParams
) returns Mu
```
Sets the session management method for the context with the given ID.
## class Zap::Script
class `Zap::Script` Methods
### method globalVar
```
method globalVar(
:$varKey!
) returns Mu
```
Gets the value of the global variable with the given key. Returns an API error (DOES\_NOT\_EXIST) if no value was previously set.
### method globalVars
```
method globalVars() returns Mu
```
Gets all the global variables (key/value pairs).
### method listEngines
```
method listEngines() returns Mu
```
Lists the script engines available
### method listScripts
```
method listScripts() returns Mu
```
Lists the scripts available, with its engine, name, description, type and error state.
### method listTypes
```
method listTypes() returns Mu
```
Lists the script types available.
### method scriptCustomVar
```
method scriptCustomVar(
:$scriptName!,
:$varKey!
) returns Mu
```
Gets the value (string representation) of a custom variable. Returns an API error (DOES\_NOT\_EXIST) if no script with the given name exists or if no value was previously set.
### method scriptCustomVars
```
method scriptCustomVars(
:$scriptName!
) returns Mu
```
Gets all the custom variables (key/value pairs, the value is the string representation) of a script. Returns an API error (DOES\_NOT\_EXIST) if no script with the given name exists.
### method scriptVar
```
method scriptVar(
:$scriptName!,
:$varKey!
) returns Mu
```
Gets the value of the variable with the given key for the given script. Returns an API error (DOES\_NOT\_EXIST) if no script with the given name exists or if no value was previously set.
### method scriptVars
```
method scriptVars(
:$scriptName!
) returns Mu
```
Gets all the variables (key/value pairs) of the given script. Returns an API error (DOES\_NOT\_EXIST) if no script with the given name exists.
### method clearGlobalCustomVar
```
method clearGlobalCustomVar(
:$varKey!
) returns Mu
```
Clears a global custom variable.
### method clearGlobalVar
```
method clearGlobalVar(
:$varKey!
) returns Mu
```
Clears the global variable with the given key.
### method clearGlobalVars
```
method clearGlobalVars() returns Mu
```
Clears the global variables.
### method clearScriptCustomVar
```
method clearScriptCustomVar(
:$scriptName!,
:$varKey!
) returns Mu
```
Clears a script custom variable.
### method clearScriptVar
```
method clearScriptVar(
:$scriptName!,
:$varKey!
) returns Mu
```
Clears the variable with the given key of the given script. Returns an API error (DOES\_NOT\_EXIST) if no script with the given name exists.
### method clearScriptVars
```
method clearScriptVars(
:$scriptName!
) returns Mu
```
Clears the variables of the given script. Returns an API error (DOES\_NOT\_EXIST) if no script with the given name exists.
### method disable
```
method disable(
:$scriptName!
) returns Mu
```
Disables the script with the given name
### method enable
```
method enable(
:$scriptName!
) returns Mu
```
Enables the script with the given name
### method load
```
method load(
:$scriptName!,
:$scriptType!,
:$scriptEngine!,
:$fileName!,
:$scriptDescription,
:$charset
) returns Mu
```
Loads a script into ZAP from the given local file, with the given name, type and engine, optionally with a description, and a charset name to read the script (the charset name is required if the script is not in UTF-8, for example, in ISO-8859-1).
### method remove
```
method remove(
:$scriptName!
) returns Mu
```
Removes the script with the given name
### method runStandAloneScript
```
method runStandAloneScript(
:$scriptName!
) returns Mu
```
Runs the stand alone script with the given name
### method setGlobalVar
```
method setGlobalVar(
:$varKey!,
:$varValue
) returns Mu
```
Sets the value of the global variable with the given key.
### method setScriptVar
```
method setScriptVar(
:$scriptName!,
:$varKey!,
:$varValue
) returns Mu
```
Sets the value of the variable with the given key of the given script. Returns an API error (DOES\_NOT\_EXIST) if no script with the given name exists.
## class Zap::Ajaxspider
class `Zap::Ajaxspider` Methods
### method optionBrowserId
```
method optionBrowserId() returns Mu
```
No Doc
### method optionClickDefaultElems
```
method optionClickDefaultElems() returns Mu
```
No Doc
### method optionClickElemsOnce
```
method optionClickElemsOnce() returns Mu
```
No Doc
### method optionEventWait
```
method optionEventWait() returns Mu
```
No Doc
### method optionMaxCrawlDepth
```
method optionMaxCrawlDepth() returns Mu
```
No Doc
### method optionMaxCrawlStates
```
method optionMaxCrawlStates() returns Mu
```
No Doc
### method optionMaxDuration
```
method optionMaxDuration() returns Mu
```
No Doc
### method optionNumberOfBrowsers
```
method optionNumberOfBrowsers() returns Mu
```
No Doc
### method optionRandomInputs
```
method optionRandomInputs() returns Mu
```
No Doc
### method optionReloadWait
```
method optionReloadWait() returns Mu
```
No Doc
### method results
```
method results(
:$start,
:$count
) returns Mu
```
No Doc
### method status
```
method status() returns Mu
```
No Doc
### method scan
```
method scan(
:$url,
:$inScope,
:$contextName,
:$subtreeOnly
) returns Mu
```
Runs the spider against the given URL and/or context, optionally, spidering everything in scope. The parameter 'contextName' can be used to constrain the scan to a Context, the option 'in scope' is ignored if a context was also specified. The parameter 'subtreeOnly' allows to restrict the spider under a site's subtree (using the specified 'url').
### method scanAsUser
```
method scanAsUser(
:$contextName!,
:$userName!,
:$url,
:$subtreeOnly
) returns Mu
```
Runs the spider from the perspective of a User, obtained using the given context name and user name. The parameter 'url' allows to specify the starting point for the spider, otherwise it's used an existing URL from the context (if any). The parameter 'subtreeOnly' allows to restrict the spider under a site's subtree (using the specified 'url').
### method setOptionBrowserId
```
method setOptionBrowserId(
:$String!
) returns Mu
```
No Doc
### method setOptionClickDefaultElems
```
method setOptionClickDefaultElems(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionClickElemsOnce
```
method setOptionClickElemsOnce(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionEventWait
```
method setOptionEventWait(
:$Integer!
) returns Mu
```
No Doc
### method setOptionMaxCrawlDepth
```
method setOptionMaxCrawlDepth(
:$Integer!
) returns Mu
```
No Doc
### method setOptionMaxCrawlStates
```
method setOptionMaxCrawlStates(
:$Integer!
) returns Mu
```
No Doc
### method setOptionMaxDuration
```
method setOptionMaxDuration(
:$Integer!
) returns Mu
```
No Doc
### method setOptionNumberOfBrowsers
```
method setOptionNumberOfBrowsers(
:$Integer!
) returns Mu
```
No Doc
### method setOptionRandomInputs
```
method setOptionRandomInputs(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionReloadWait
```
method setOptionReloadWait(
:$Integer!
) returns Mu
```
No Doc
### method stop
```
method stop() returns Mu
```
No Doc
## class Zap::Core
class `Zap::Core` Methods
### method alertsSummary
```
method alertsSummary(
:$baseurl
) returns Mu
```
Gets number of alerts grouped by each risk level, optionally filtering by URL
### method childNodes
```
method childNodes(
:$url
) returns Mu
```
Gets the child nodes underneath the specified URL in the Sites tree
### method excludedFromProxy
```
method excludedFromProxy() returns Mu
```
Gets the regular expressions, applied to URLs, to exclude from the local proxies.
### method homeDirectory
```
method homeDirectory() returns Mu
```
No Doc
### method hosts
```
method hosts() returns Mu
```
Gets the name of the hosts accessed through/by ZAP
### method message
```
method message(
:$id!
) returns Mu
```
Gets the HTTP message with the given ID. Returns the ID, request/response headers and bodies, cookies, note, type, RTT, and timestamp.
### method messages
```
method messages(
:$baseurl,
:$start,
:$count
) returns Mu
```
Gets the HTTP messages sent by ZAP, request and response, optionally filtered by URL and paginated with 'start' position and 'count' of messages
### method messagesById
```
method messagesById(
:$ids!
) returns Mu
```
Gets the HTTP messages with the given IDs.
### method mode
```
method mode() returns Mu
```
Gets the mode
### method numberOfAlerts
```
method numberOfAlerts(
:$baseurl,
:$riskId
) returns Mu
```
Gets the number of alerts, optionally filtering by URL or riskId
### method numberOfMessages
```
method numberOfMessages(
:$baseurl
) returns Mu
```
Gets the number of messages, optionally filtering by URL
### method optionAlertOverridesFilePath
```
method optionAlertOverridesFilePath() returns Mu
```
Gets the path to the file with alert overrides.
### method optionDefaultUserAgent
```
method optionDefaultUserAgent() returns Mu
```
Gets the user agent that ZAP should use when creating HTTP messages (for example, spider messages or CONNECT requests to outgoing proxy).
### method optionDnsTtlSuccessfulQueries
```
method optionDnsTtlSuccessfulQueries() returns Mu
```
Gets the TTL (in seconds) of successful DNS queries.
### method optionHttpState
```
method optionHttpState() returns Mu
```
No Doc
### method optionHttpStateEnabled
```
method optionHttpStateEnabled() returns Mu
```
No Doc
### method optionMaximumAlertInstances
```
method optionMaximumAlertInstances() returns Mu
```
Gets the maximum number of alert instances to include in a report.
### method optionMergeRelatedAlerts
```
method optionMergeRelatedAlerts() returns Mu
```
Gets whether or not related alerts will be merged in any reports generated.
### method optionProxyChainName
```
method optionProxyChainName() returns Mu
```
No Doc
### method optionProxyChainPassword
```
method optionProxyChainPassword() returns Mu
```
No Doc
### method optionProxyChainPort
```
method optionProxyChainPort() returns Mu
```
No Doc
### method optionProxyChainPrompt
```
method optionProxyChainPrompt() returns Mu
```
No Doc
### method optionProxyChainRealm
```
method optionProxyChainRealm() returns Mu
```
No Doc
### method optionProxyChainSkipName
```
method optionProxyChainSkipName() returns Mu
```
Use view proxyChainExcludedDomains instead.
### method optionProxyChainUserName
```
method optionProxyChainUserName() returns Mu
```
No Doc
### method optionProxyExcludedDomains
```
method optionProxyExcludedDomains() returns Mu
```
Use view proxyChainExcludedDomains instead.
### method optionProxyExcludedDomainsEnabled
```
method optionProxyExcludedDomainsEnabled() returns Mu
```
Use view proxyChainExcludedDomains instead.
### method optionSingleCookieRequestHeader
```
method optionSingleCookieRequestHeader() returns Mu
```
No Doc
### method optionTimeoutInSecs
```
method optionTimeoutInSecs() returns Mu
```
Gets the connection time out, in seconds.
### method optionUseProxyChain
```
method optionUseProxyChain() returns Mu
```
No Doc
### method optionUseProxyChainAuth
```
method optionUseProxyChainAuth() returns Mu
```
No Doc
### method proxyChainExcludedDomains
```
method proxyChainExcludedDomains() returns Mu
```
Gets all the domains that are excluded from the outgoing proxy. For each domain the following are shown: the index, the value (domain), if enabled, and if specified as a regex.
### method sessionLocation
```
method sessionLocation() returns Mu
```
Gets the location of the current session file
### method sites
```
method sites() returns Mu
```
Gets the sites accessed through/by ZAP (scheme and domain)
### method urls
```
method urls(
:$baseurl
) returns Mu
```
Gets the URLs accessed through/by ZAP, optionally filtering by (base) URL.
### method version
```
method version() returns Mu
```
Gets ZAP version
### method zapHomePath
```
method zapHomePath() returns Mu
```
Gets the path to ZAP's home directory.
### method htmlreport
```
method htmlreport() returns Mu
```
Generates a report in HTML format
### method jsonreport
```
method jsonreport() returns Mu
```
Generates a report in JSON format
### method mdreport
```
method mdreport() returns Mu
```
Generates a report in Markdown format
### method messageHar
```
method messageHar(
:$id!
) returns Mu
```
Gets the message with the given ID in HAR format
### method messagesHar
```
method messagesHar(
:$baseurl,
:$start,
:$count
) returns Mu
```
Gets the HTTP messages sent through/by ZAP, in HAR format, optionally filtered by URL and paginated with 'start' position and 'count' of messages
### method messagesHarById
```
method messagesHarById(
:$ids!
) returns Mu
```
Gets the HTTP messages with the given IDs, in HAR format.
### method proxypac
```
method proxypac() returns Mu
```
No Doc
### method rootcert
```
method rootcert() returns Mu
```
Gets the Root CA certificate used by the local proxies.
### method sendHarRequest
```
method sendHarRequest(
:$request!,
:$followRedirects
) returns Mu
```
Sends the first HAR request entry, optionally following redirections. Returns, in HAR format, the request sent and response received and followed redirections, if any. The Mode is enforced when sending the request (and following redirections), custom manual requests are not allowed in 'Safe' mode nor in 'Protected' mode if out of scope.
### method setproxy
```
method setproxy(
:$proxy!
) returns Mu
```
No Doc
### method xmlreport
```
method xmlreport() returns Mu
```
Generates a report in XML format
### method accessUrl
```
method accessUrl(
:$url!,
:$followRedirects
) returns Mu
```
Convenient and simple action to access a URL, optionally following redirections. Returns the request sent and response received and followed redirections, if any. Other actions are available which offer more control on what is sent, like, 'sendRequest' or 'sendHarRequest'.
### method addProxyChainExcludedDomain
```
method addProxyChainExcludedDomain(
:$value!,
:$isRegex,
:$isEnabled
) returns Mu
```
Adds a domain to be excluded from the outgoing proxy, using the specified value. Optionally sets if the new entry is enabled (default, true) and whether or not the new value is specified as a regex (default, false).
### method clearExcludedFromProxy
```
method clearExcludedFromProxy() returns Mu
```
Clears the regexes of URLs excluded from the local proxies.
### method deleteAlert
```
method deleteAlert(
:$id!
) returns Mu
```
Deletes the alert with the given ID.
### method deleteAllAlerts
```
method deleteAllAlerts() returns Mu
```
Deletes all alerts of the current session.
### method deleteSiteNode
```
method deleteSiteNode(
:$url!,
:$method,
:$postData
) returns Mu
```
Deletes the site node found in the Sites Tree on the basis of the URL, HTTP method, and post data (if applicable and specified).
### method disableAllProxyChainExcludedDomains
```
method disableAllProxyChainExcludedDomains() returns Mu
```
Disables all domains excluded from the outgoing proxy.
### method disableClientCertificate
```
method disableClientCertificate() returns Mu
```
Disables the option for use of client certificates.
### method enableAllProxyChainExcludedDomains
```
method enableAllProxyChainExcludedDomains() returns Mu
```
Enables all domains excluded from the outgoing proxy.
### method enablePKCS12ClientCertificate
```
method enablePKCS12ClientCertificate(
:$filePath!,
:$password!,
:$index
) returns Mu
```
Enables use of a PKCS12 client certificate for the certificate with the given file system path, password, and optional index.
### method excludeFromProxy
```
method excludeFromProxy(
:$regex!
) returns Mu
```
Adds a regex of URLs that should be excluded from the local proxies.
### method generateRootCA
```
method generateRootCA() returns Mu
```
Generates a new Root CA certificate for the local proxies.
### method loadSession
```
method loadSession(
:$name!
) returns Mu
```
Loads the session with the given name. If a relative path is specified it will be resolved against the "session" directory in ZAP "home" dir.
### method modifyProxyChainExcludedDomain
```
method modifyProxyChainExcludedDomain(
:$idx!,
:$value,
:$isRegex,
:$isEnabled
) returns Mu
```
Modifies a domain excluded from the outgoing proxy. Allows to modify the value, if enabled or if a regex. The domain is selected with its index, which can be obtained with the view proxyChainExcludedDomains.
### method newSession
```
method newSession(
:$name,
:$overwrite
) returns Mu
```
Creates a new session, optionally overwriting existing files. If a relative path is specified it will be resolved against the "session" directory in ZAP "home" dir.
### method removeProxyChainExcludedDomain
```
method removeProxyChainExcludedDomain(
:$idx!
) returns Mu
```
Removes a domain excluded from the outgoing proxy, with the given index. The index can be obtained with the view proxyChainExcludedDomains.
### method runGarbageCollection
```
method runGarbageCollection() returns Mu
```
No Doc
### method saveSession
```
method saveSession(
:$name!,
:$overwrite
) returns Mu
```
Saves the session.
### method sendRequest
```
method sendRequest(
:$request!,
:$followRedirects
) returns Mu
```
Sends the HTTP request, optionally following redirections. Returns the request sent and response received and followed redirections, if any. The Mode is enforced when sending the request (and following redirections), custom manual requests are not allowed in 'Safe' mode nor in 'Protected' mode if out of scope.
### method setHomeDirectory
```
method setHomeDirectory(
:$dir!
) returns Mu
```
No Doc
### method setMode
```
method setMode(
:$mode!
) returns Mu
```
Sets the mode, which may be one of [safe, protect, standard, attack]
### method setOptionAlertOverridesFilePath
```
method setOptionAlertOverridesFilePath(
:$filePath
) returns Mu
```
Sets (or clears, if empty) the path to the file with alert overrides.
### method setOptionDefaultUserAgent
```
method setOptionDefaultUserAgent(
:$String!
) returns Mu
```
Sets the user agent that ZAP should use when creating HTTP messages (for example, spider messages or CONNECT requests to outgoing proxy).
### method setOptionDnsTtlSuccessfulQueries
```
method setOptionDnsTtlSuccessfulQueries(
:$Integer!
) returns Mu
```
Sets the TTL (in seconds) of successful DNS queries (applies after ZAP restart).
### method setOptionHttpStateEnabled
```
method setOptionHttpStateEnabled(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionMaximumAlertInstances
```
method setOptionMaximumAlertInstances(
:$numberOfInstances!
) returns Mu
```
Sets the maximum number of alert instances to include in a report. A value of zero is treated as unlimited.
### method setOptionMergeRelatedAlerts
```
method setOptionMergeRelatedAlerts(
:$enabled!
) returns Mu
```
Sets whether or not related alerts will be merged in any reports generated.
### method setOptionProxyChainName
```
method setOptionProxyChainName(
:$String!
) returns Mu
```
No Doc
### method setOptionProxyChainPassword
```
method setOptionProxyChainPassword(
:$String!
) returns Mu
```
No Doc
### method setOptionProxyChainPort
```
method setOptionProxyChainPort(
:$Integer!
) returns Mu
```
No Doc
### method setOptionProxyChainPrompt
```
method setOptionProxyChainPrompt(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionProxyChainRealm
```
method setOptionProxyChainRealm(
:$String!
) returns Mu
```
No Doc
### method setOptionProxyChainSkipName
```
method setOptionProxyChainSkipName(
:$String!
) returns Mu
```
Use actions [add|modify|remove]ProxyChainExcludedDomain instead.
### method setOptionProxyChainUserName
```
method setOptionProxyChainUserName(
:$String!
) returns Mu
```
No Doc
### method setOptionSingleCookieRequestHeader
```
method setOptionSingleCookieRequestHeader(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionTimeoutInSecs
```
method setOptionTimeoutInSecs(
:$Integer!
) returns Mu
```
Sets the connection time out, in seconds.
### method setOptionUseProxyChain
```
method setOptionUseProxyChain(
:$Boolean!
) returns Mu
```
Sets whether or not the outgoing proxy should be used. The address/hostname of the outgoing proxy must be set to enable this option.
### method setOptionUseProxyChainAuth
```
method setOptionUseProxyChainAuth(
:$Boolean!
) returns Mu
```
No Doc
### method shutdown
```
method shutdown() returns Mu
```
Shuts down ZAP
### method snapshotSession
```
method snapshotSession(
:$name,
:$overwrite
) returns Mu
```
Snapshots the session, optionally with the given name, and overwriting existing files. If no name is specified the name of the current session with a timestamp appended is used. If a relative path is specified it will be resolved against the "session" directory in ZAP "home" dir.
## class Zap::Users
class `Zap::Users` Methods
### method newUser
```
method newUser(
:$contextId!,
:$name!
) returns Mu
```
Creates a new user with the given name for the context with the given ID.
### method removeUser
```
method removeUser(
:$contextId!,
:$userId!
) returns Mu
```
Removes the user with the given ID that belongs to the context with the given ID.
### method setAuthenticationCredentials
```
method setAuthenticationCredentials(
:$contextId!,
:$userId!,
:$authCredentialsConfigParams
) returns Mu
```
Sets the authentication credentials for the user with the given ID that belongs to the context with the given ID.
### method setUserEnabled
```
method setUserEnabled(
:$contextId!,
:$userId!,
:$enabled!
) returns Mu
```
Sets whether or not the user, with the given ID that belongs to the context with the given ID, should be enabled.
### method setUserName
```
method setUserName(
:$contextId!,
:$userId!,
:$name!
) returns Mu
```
Renames the user with the given ID that belongs to the context with the given ID.
### method getUserById
```
method getUserById(
:$contextId!,
:$userId!
) returns Mu
```
Gets the data of the user with the given ID that belongs to the context with the given ID.
### method usersList
```
method usersList(
:$contextId
) returns Mu
```
Gets a list of users that belong to the context with the given ID, or all users if none provided.
## class Zap::Acsrf
class `Zap::Acsrf` Methods
### method removeOptionToken
```
method removeOptionToken(
:$String!
) returns Mu
```
Removes the anti-CSRF token with the given name
### method genForm
```
method genForm(
:$hrefId!
) returns Mu
```
Generate a form for testing lack of anti-CSRF tokens |
## dist_github-khalidelboray-Zap.md
## Chunk 3 of 3
- typically invoked via ZAP
## class Zap::Search
class `Zap::Search` Methods
### method harByHeaderRegex
```
method harByHeaderRegex(
:$regex!,
:$baseurl,
:$start,
:$count
) returns Mu
```
Returns the HTTP messages, in HAR format, that match the given regular expression in the header(s) optionally filtered by URL and paginated with 'start' position and 'count' of messages.
### method harByRequestRegex
```
method harByRequestRegex(
:$regex!,
:$baseurl,
:$start,
:$count
) returns Mu
```
Returns the HTTP messages, in HAR format, that match the given regular expression in the request optionally filtered by URL and paginated with 'start' position and 'count' of messages.
### method harByResponseRegex
```
method harByResponseRegex(
:$regex!,
:$baseurl,
:$start,
:$count
) returns Mu
```
Returns the HTTP messages, in HAR format, that match the given regular expression in the response optionally filtered by URL and paginated with 'start' position and 'count' of messages.
### method harByUrlRegex
```
method harByUrlRegex(
:$regex!,
:$baseurl,
:$start,
:$count
) returns Mu
```
Returns the HTTP messages, in HAR format, that match the given regular expression in the URL optionally filtered by URL and paginated with 'start' position and 'count' of messages.
### method messagesByResponseRegex
```
method messagesByResponseRegex(
:$regex!,
:$baseurl,
:$start,
:$count
) returns Mu
```
Returns the HTTP messages that match the given regular expression in the response optionally filtered by URL and paginated with 'start' position and 'count' of messages.
### method messagesByUrlRegex
```
method messagesByUrlRegex(
:$regex!,
:$baseurl,
:$start,
:$count
) returns Mu
```
Returns the HTTP messages that match the given regular expression in the URL optionally filtered by URL and paginated with 'start' position and 'count' of messages.
### method urlsByHeaderRegex
```
method urlsByHeaderRegex(
:$regex!,
:$baseurl,
:$start,
:$count
) returns Mu
```
Returns the URLs of the HTTP messages that match the given regular expression in the header(s) optionally filtered by URL and paginated with 'start' position and 'count' of messages.
### method urlsByRequestRegex
```
method urlsByRequestRegex(
:$regex!,
:$baseurl,
:$start,
:$count
) returns Mu
```
Returns the URLs of the HTTP messages that match the given regular expression in the request optionally filtered by URL and paginated with 'start' position and 'count' of messages.
### method urlsByResponseRegex
```
method urlsByResponseRegex(
:$regex!,
:$baseurl,
:$start,
:$count
) returns Mu
```
Returns the URLs of the HTTP messages that match the given regular expression in the response optionally filtered by URL and paginated with 'start' position and 'count' of messages.
### method urlsByUrlRegex
```
method urlsByUrlRegex(
:$regex!,
:$baseurl,
:$start,
:$count
) returns Mu
```
Returns the URLs of the HTTP messages that match the given regular expression in the URL optionally filtered by URL and paginated with 'start' position and 'count' of messages.
## class Zap::Replacer
class `Zap::Replacer` Methods
### method removeRule
```
method removeRule(
:$description!
) returns Mu
```
Removes the rule with the given description
### method setEnabled
```
method setEnabled(
:$description!,
:$bool!
) returns Mu
```
Enables or disables the rule with the given description based on the bool parameter
## class Zap::Context
class `Zap::Context` Methods
### method excludeAllContextTechnologies
```
method excludeAllContextTechnologies(
:$contextName!
) returns Mu
```
Excludes all built in technologies from a context
### method excludeContextTechnologies
```
method excludeContextTechnologies(
:$contextName!,
:$technologyNames!
) returns Mu
```
Excludes technologies with the given names, separated by a comma, from a context
### method excludeFromContext
```
method excludeFromContext(
:$contextName!,
:$regex!
) returns Mu
```
Add exclude regex to context
### method exportContext
```
method exportContext(
:$contextName!,
:$contextFile!
) returns Mu
```
Exports the context with the given name to a file. If a relative file path is specified it will be resolved against the "contexts" directory in ZAP "home" dir.
### method importContext
```
method importContext(
:$contextFile!
) returns Mu
```
Imports a context from a file. If a relative file path is specified it will be resolved against the "contexts" directory in ZAP "home" dir.
### method includeAllContextTechnologies
```
method includeAllContextTechnologies(
:$contextName!
) returns Mu
```
Includes all built in technologies in to a context
### method includeContextTechnologies
```
method includeContextTechnologies(
:$contextName!,
:$technologyNames!
) returns Mu
```
Includes technologies with the given names, separated by a comma, to a context
### method includeInContext
```
method includeInContext(
:$contextName!,
:$regex!
) returns Mu
```
Add include regex to context
### method newContext
```
method newContext(
:$contextName!
) returns Mu
```
Creates a new context with the given name in the current session
### method removeContext
```
method removeContext(
:$contextName!
) returns Mu
```
Removes a context in the current session
### method setContextInScope
```
method setContextInScope(
:$contextName!,
:$booleanInScope!
) returns Mu
```
Sets a context to in scope (contexts are in scope by default)
### method setContextRegexs
```
method setContextRegexs(
:$contextName!,
:$incRegexs!,
:$excRegexs!
) returns Mu
```
Set the regexs to include and exclude for a context, both supplied as JSON string arrays
### method excludeRegexs
```
method excludeRegexs(
:$contextName!
) returns Mu
```
List excluded regexs for context
### method excludedTechnologyList
```
method excludedTechnologyList(
:$contextName!
) returns Mu
```
Lists the names of all technologies excluded from a context
### method includeRegexs
```
method includeRegexs(
:$contextName!
) returns Mu
```
List included regexs for context
### method includedTechnologyList
```
method includedTechnologyList(
:$contextName!
) returns Mu
```
Lists the names of all technologies included in a context
### method technologyList
```
method technologyList() returns Mu
```
Lists the names of all built in technologies
### method urls
```
method urls(
:$contextName!
) returns Mu
```
Lists the URLs accessed through/by ZAP, that belong to the context with the given name.
## class Zap::Autoupdate
class `Zap::Autoupdate` Methods
### method downloadLatestRelease
```
method downloadLatestRelease() returns Mu
```
Downloads the latest release, if any
### method installAddon
```
method installAddon(
:$id!
) returns Mu
```
Installs or updates the specified add-on, returning when complete (i.e. not asynchronously)
### method setOptionCheckAddonUpdates
```
method setOptionCheckAddonUpdates(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionCheckOnStart
```
method setOptionCheckOnStart(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionDownloadNewRelease
```
method setOptionDownloadNewRelease(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionInstallAddonUpdates
```
method setOptionInstallAddonUpdates(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionInstallScannerRules
```
method setOptionInstallScannerRules(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionReportAlphaAddons
```
method setOptionReportAlphaAddons(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionReportBetaAddons
```
method setOptionReportBetaAddons(
:$Boolean!
) returns Mu
```
No Doc
### method setOptionReportReleaseAddons
```
method setOptionReportReleaseAddons(
:$Boolean!
) returns Mu
```
No Doc
### method uninstallAddon
```
method uninstallAddon(
:$id!
) returns Mu
```
Uninstalls the specified add-on
### method latestVersionNumber
```
method latestVersionNumber() returns Mu
```
Returns the latest version number
### method localAddons
```
method localAddons() returns Mu
```
Returns a list with all local add-ons, installed or not.
### method marketplaceAddons
```
method marketplaceAddons() returns Mu
```
Return a list of all of the add-ons on the ZAP Marketplace (this information is read once and then cached)
### method newAddons
```
method newAddons() returns Mu
```
Return a list of any add-ons that have been added to the Marketplace since the last check for updates
### method optionAddonDirectories
```
method optionAddonDirectories() returns Mu
```
No Doc
### method optionCheckAddonUpdates
```
method optionCheckAddonUpdates() returns Mu
```
No Doc
### method optionCheckOnStart
```
method optionCheckOnStart() returns Mu
```
No Doc
### method optionDayLastChecked
```
method optionDayLastChecked() returns Mu
```
No Doc
### method optionDayLastInstallWarned
```
method optionDayLastInstallWarned() returns Mu
```
No Doc
### method optionDayLastUpdateWarned
```
method optionDayLastUpdateWarned() returns Mu
```
No Doc
### method optionDownloadDirectory
```
method optionDownloadDirectory() returns Mu
```
No Doc
### method optionDownloadNewRelease
```
method optionDownloadNewRelease() returns Mu
```
No Doc
### method optionInstallAddonUpdates
```
method optionInstallAddonUpdates() returns Mu
```
No Doc
### method optionInstallScannerRules
```
method optionInstallScannerRules() returns Mu
```
No Doc
### method optionReportAlphaAddons
```
method optionReportAlphaAddons() returns Mu
```
No Doc
### method optionReportBetaAddons
```
method optionReportBetaAddons() returns Mu
```
No Doc
### method optionReportReleaseAddons
```
method optionReportReleaseAddons() returns Mu
```
No Doc
### method updatedAddons
```
method updatedAddons() returns Mu
```
Return a list of any add-ons that have been changed in the Marketplace since the last check for updates
## class Zap::Alert
class `Zap::Alert` Methods
### method addAlert
```
method addAlert(
:$messageId!,
:$name!,
:$riskId!,
:$confidenceId!,
:$description!,
:$param,
:$attack,
:$otherInfo,
:$solution,
:$references,
:$evidence,
:$cweId,
:$wascId
) returns Mu
```
Add an alert associated with the given message ID, with the provided details. (The ID of the created alert is returned.)
### method deleteAlert
```
method deleteAlert(
:$id!
) returns Mu
```
Deletes the alert with the given ID.
### method deleteAllAlerts
```
method deleteAllAlerts() returns Mu
```
Deletes all alerts of the current session.
### method updateAlert
```
method updateAlert(
:$id!,
:$name!,
:$riskId!,
:$confidenceId!,
:$description!,
:$param,
:$attack,
:$otherInfo,
:$solution,
:$references,
:$evidence,
:$cweId,
:$wascId
) returns Mu
```
Update the alert with the given ID, with the provided details.
### method alerts
```
method alerts(
:$baseurl,
:$start,
:$count,
:$riskId
) returns Mu
```
Gets the alerts raised by ZAP, optionally filtering by URL or riskId, and paginating with 'start' position and 'count' of alerts
### method alertsByRisk
```
method alertsByRisk(
:$url,
:$recurse
) returns Mu
```
Gets a summary of the alerts, optionally filtered by a 'url'. If 'recurse' is true then all alerts that apply to urls that start with the specified 'url' will be returned, otherwise only those on exactly the same 'url' (ignoring url parameters)
### method alertsSummary
```
method alertsSummary(
:$baseurl
) returns Mu
```
Gets number of alerts grouped by each risk level, optionally filtering by URL
### method numberOfAlerts
```
method numberOfAlerts(
:$baseurl,
:$riskId
) returns Mu
```
Gets the number of alerts, optionally filtering by URL or riskId
|
## dist_zef-raku-community-modules-Color.md
[](https://github.com/raku-community-modules/Color/actions)
# NAME
Color - Format conversion, manipulation, and math operations on colors
# SYNOPSIS
```
use Color;
my $white = Color.new(255, 255, 255);
my $almost_black = Color.new('#111');
say Color.new(:hsv<152 80 50>).hex; # convert HSV to HEX
say "$white is way lighter than $almost_black";
my $lighter_pink = Color.new('#ED60A2').lighten(20);
my $lighter_pink = Color.new('#ED60A2') ◐ 20; # same as above
my $saturated_pink = Color.new('#ED60A2').saturate(20);
my $saturated_pink = Color.new('#ED60A2') 🞉 20; # same as above
# Create an inverted colour scheme:
$_ = .invert for @colours_in_my_colourscheme;
# Some ops to use on Color objects
my $gray = $white / 2;
say $gray.hex; # prints "#808080"
say $almost_black + 25; # prints "42, 42, 42"
```
# DESCRIPTION
This module allows you to perform mathematical operations on RGB color tuples, as well as convert them into other color formats, like hex, and manipulate them by, for example, making them lighter, darker, or more or less saturated.
# CONSTRUCTOR
## `new`
```
my $rgb = Color.new('abc');
Color.new('#abc');
Color.new('face');
Color.new('#face');
Color.new('abcdef');
Color.new('#abcdef');
Color.new('abcdefaa');
Color.new('#abcdefaa');
Color.new(:hex<abc>); # same applies to all other hex variants
Color.new( 255, 100, 25 ); # RGB
Color.new( .5, .1, .3, .4 ); # CMYK
Color.new( rgb => [ 255, 100, 25 ] );
Color.new(:rgb<255 100 25>); # same works on other formats
Color.new( rgbd => [.086, .165, .282] ); # decimal RGB
Color.new( rgba => [ 22, 42, 72, 88 ] );
Color.new( rgbad => [ .086, .165, .282, .345 ] );
Color.new( cmyk => [.55, .25, .85, .12] );
Color.new( hsl => [ 72, 78, 65] );
Color.new( hsla => [ 72, 78, 65, 42] );
Color.new( hsv => [ 90, 60, 70] );
Color.new( hsva => [ 90, 60, 70, 88] );
```
Creates new `Color` object. All of the above formats are supported. **Note:** internally, the color will be converted to RGBA, which might incur slight precision loss when converting from other formats.
# ATTRIBUTES
## `alpha-math`
```
my $c = Color.new('abc');
$c.alpha-math = True;
my $c = Color.new('abca');
$c.alpha-math = False;
```
Boolean. Specifies whether operator math from `Color::Operators` should affect the alpha channel. Colors constructed from RGBA automatically get this attribute set to `True`, rest of formats have it set as `False`.
# MANIPULATION METHODS
# `alpha`
```
my Color $c .= new('#ff0088');
say $c.alpha; # OUTPUT: 255
$c.alpha(128);
say $c.alpha-math; # OUTPUT: True
```
Get or set the alpha channel value.
## `darken`
```
say $c.darken(10).cmyk; # darken by 10%
```
Creates a new `Color` object that is darkened by the percentage given as the argument.
## `desaturate`
```
say $c.desaturate(20).cmyk;
```
Creates a new `Color` object that is desaturated by the percentage given as the argument.
## `invert`
```
say $c.invert.cmyk;
```
Creates a new `Color` object that is inverted (black becomes white, etc).
## `lighten`
```
say $c.lighten(10).cmyk; # lighten by 10%
```
Creates a new `Color` object that is lightened by the percentage given as the argument.
## `saturate`
```
say $c.saturate(20).cmyk;
```
Creates a new `Color` object that is saturated by the percentage given as the argument.
## `rotate`
```
$inverse = $c.rotate( 180 );
```
Creates a new `Color` object, rotated around the HSL color wheel by the angle $α (in degrees).
For all methods `darken`, `desaturate`, `invert`, `lighten`, `saturate` and `rotate` the colors will have their alpha channel copied from the input color. The attribute alpha-math is copied as well.
# CONVERSION METHODS
## `to-string`
```
$c.to-string('cmyk'); # cmyk(0.954955, 0.153153, 0, 0.129412)
$c.to-string('hsl'); # hsl(189.622642, 91.379310, 45.490196)
$c.to-string('hsla'); # hsl(189.622642, 91.379310, 45.490196, 255)
$c.to-string('hsv'); # hsv(189.622642, 95.495495, 87.058824)
$c.to-string('hsva'); # hsva(189.622642, 95.495495, 87.058824, 255)
$c.to-string('rgb'); # rgb(10, 188, 222)
$c.to-string('rgba'); # rgba(10, 188, 222, 255)
$c.to-string('rgbd'); # rgb(0.039216, 0.737255, 0.870588)
$c.to-string('rgbad');# rgba(0.039216, 0.737255, 0.870588, 1)
$c.to-string('hex'); # #0ABCDE
$c.to-string('hex3'); # #1CE
$c.to-string('hex8'); # #0ABCDEFF
```
Converts the color to the format given by the argument and returns a string representation of it. See above for the format of the string for each color format.
**Note:** the `.gist` and `.Str` methods of the `Color` object are equivalent to `.to-string('hex')`.
## `cmyk`
```
say $c.cmyk; # (<106/111>, <17/111>, 0.0, <11/85>)
```
Converts the color to CMYK format and returns a list containing each color (ranging `0`..`1`).
## `hex`
```
say $c.hex; # (0A BC DE);
```
Returns a list of 3 2-digit hex numbers representing the color.
## `hex3`
```
say $c.hex3; # (1 C E);
```
Returns a list of 3 1-digit hex numbers representing the color. They will be rounded and they need to be doubled (i.e. the above would be `11CCEE`) to get the actual value.
## `hex4`
```
say $c.hex4; # (1 C E F);
```
Returns a list of 4 1-digit hex numbers representing the color. They will be rounded and they need to be doubled (i.e. the above would be `11CCEEFF`) to get the actual value.
## `hex8`
```
say $c.hex8; # (0A BC DE FF);
```
Returns a list of 4 2-digit hex numbers representing the color, including the Alpha space.
## `hsl`
```
say $c.hsl; # (<10050/53>, <10600/111>, <1480/17>),
```
Converts the colour to HSL format and returns the three values (hue, saturation, lightness). The S/L are returned as percentages, not decimals, so 50% saturation is returned as `50`, not `.5`.
## `hsla`
```
say $c.hsla; # (<10050/53>, <10600/111>, <1480/17>, 255),
```
Converts the color to HSL format and returns the three values, and alpha channel.
## `hsv`
```
say $c.hsv; # (<10050/53>, <10600/111>, <1480/17>),
```
Converts the colour to HSV format and returns the three values (hue, saturation, value). The S/V are returned as percentages, not decimals, so 50% saturation is returned as `50`, not `.5`.
## `hsva`
```
say $c.hsva; # (<10050/53>, <10600/111>, <1480/17>, 255),
```
Converts the color to HSV format and returns the three values, and alpha channel.
## `rgb`
```
say $c.rgb; # (10, 188, 222)
```
Converts the color to RGB format and returns a list of the three colors.
## `rgba`
```
say $c.rgba; # (10, 188, 222, 255);
```
Converts the color to RGBA format and returns a list of the three colors, and alpha channel.
## `rgbd`
```
say $c.rgbd; # (<2/51>, <188/255>, <74/85>)
```
Converts the color to RGB format ranging `0`..`1` and returns a list of the three colours.
## `rgbad`
```
say $c.rgbad; # (<2/51>, <188/255>, <74/85>, 1.0)
```
Converts the color to RGBA format ranging `0`..`1` and returns a list of the three colours, and alpha channel.
# OPERATORS
## `+`
```
Color.new('424') + 10;
10 + Color.new('424');
Color.new('424') + Color.new('424');
```
Add individual RGB values of each color. Plain numbers are added to each value. If </alpha-math> is turned on, alpha channel is affected as well. The operation returns a new `Color` object.
## `-`
```
Color.new('424') - 10;
10 - Color.new('424');
Color.new('424') - Color.new('666');
```
Subtract individual RGB values of each color. Plain numbers are subtracted from each value. If </alpha-math> is turned on, alpha channel is affected as well. The operation returns a new `Color` object.
## `*`
```
Color.new('424') * 10;
10 * Color.new('424');
Color.new('424') * Color.new('424');
```
Multiply individual RGB values of each color. Plain numbers are multiplied with each value. If </alpha-math> is turned on, alpha channel is affected as well. The operation returns a new `Color` object.
## `/`
```
Color.new('424') / 10;
Color.new('424') / 0; # doesn't die; sets values to 0
10 / Color.new('424');
Color.new('424') / Color.new('424');
```
Divide individual RGB values of each color. Plain numbers are divided with each value. If </alpha-math> is turned on, alpha channel is affected as well. The operation returns a new `Color` object. Illegal operation of division by zero, doesn't die and simply sets the value to `0`.
## `◐`
```
say $c ◐ 20; # lighten by 20%
```
`U+25D0 (e2 97 90): CIRCLE WITH LEFT HALF BLACK [◐]`. Same as `/lighten`
## `◑`
```
say $c ◑ 20; # darken by 20%
```
`U+25D1 (e2 97 91): CIRCLE WITH RIGHT HALF BLACK [◑]`. Same as `/darken`
## `🞉`
```
say $c 🞉 20; # saturate by 20%
```
`U+1F789 (f0 9f 9e 89): EXTREMELY HEAVY WHITE CIRCLE [🞉]`. Same as `/desaturate`
## `¡`
```
say $c¡; # invert colour
```
`U+00A1 (c2 a1): INVERTED EXCLAMATION MARK [¡]`. Same as `/invert`
# STRINGIFICATION
```
say $c;
say "$c";
```
The `Color` object overrides `.Str` and `.gist` methods to be equivalent to `.to-string('hex')`.
# Functional interface
The color conversion, manipulation and utility functions are defined within the modules `Color::Conversion`, `Color::Manipulation` and `Color::Utilities` and can be used without the OO interface. The names of functions are the same as those of methods.
# AUTHOR
Zoffix Znet
Source can be located at: <https://github.com/raku-community-modules/Color> . Comments and Pull Requests are welcome.
# CONTRIBUTORS
Thanks to timotimo++, jnthn++, psch++, RabidGravy++, ab5tract++, moritz++, holli++, and anyone else who I forgot who helped me with questions on IRC.
# COPYRIGHT AND LICENSE
Copyright 2015 - 2018 Zoffix Znet
Copyright 2019 - 2022 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-tony-o-flow.md
# flow
## a pp6 implementation of prove with the ability to adapt to *newer* methods of testing
`flow` is intended to be an extensible `prove` replacement written entirely in `perl6`. it's written in a way that it can be configured to use any new testing methods (think: a harness designed for parallel testing, like `mocha`). can't prove do this? kind of, you can run your tests through whatever you'd like as long as they end up in a TAP output and it will work with `prove`.
with `flow`, there isn't any need to translate your test files into TAP as long as there is a `::Plugin` available for how you write your tests.
# current state
`flow` ships with only parsing `TAP` output, there are other testing harnesses out there but they're not widely used if at all.
`flow` is being released in the environment to try and help test the TAP output parsing and provide a speedier alternative to plain `prove` (`prove -j9` is faster on my system for modules with very few tests/scripts but `prove` isn't commonly run this way by package installers)
# `flow` vs `prove`
Here is the benchmark for `Bailador` module - chosen since it has a medium level of testing -
### Script
```
# !/usr/bin/env perl6
use Bench;
my $b = Bench.new;
$b.cmpthese(500, {
prove => sub {
qx<prove -j9 -e 'perl6 -Ilib' t/>;
},
flow => sub {
qx<perl6 -I../../p6-flow/lib ../../p6-flow/bin/flow test>;
}
});
```
### Benchmark
```
tonyo@mbp:~/projects/benchmark/Bailador$ ./prove-vs-flow.pl6
Benchmark:
Timing 500 iterations of flow, prove...
flow: 1728.3408 wallclock secs @ 0.2893/s (n=500)
prove: 3006.5033 wallclock secs @ 0.1663/s (n=500)
O-------O--------O-------O------O
| | s/iter | prove | flow |
O=======O========O=======O======O
| prove | 6.01 | -- | -43% |
| flow | 3.46 | 74% | -- |
---------------------------------
```
# what is being worked on now
* interface changes
* having the tests stream live results instead of just the end result
* more configuration options
# usage
Current directory:
`flow test`
Some other directory or directories:
`flow test [<dir>]`
# installation
`zef install flow`
or
`panda install flow`
# license
[WTFPL](http://www.wtfpl.net/about/)
|
## dist_zef-librasteve-CLI-Wordpress-Migrator.md
# NAME
CLI::Wordpress::Migrator
# GETTING STARTED
```
zef install CLI::Wordpress::Migrator
```
# SYNOPSIS
```
> rawm
Usage:
./rawm [--ts=<Str>] [--backup-only] [--download-only] [--upload-only] [--restore-only] [--cleanup-only] [--dry-run] <cmd>
<cmd> One of <connect export install import search-replace migrate>
--ts=<Str> Enter timestamp of files [Str] eg. --ts='20241025-17-02-42'
--backup-only Only perform remote backup
--download-only Only perform download (requires timestamp [--ts])
--upload-only Only perform upload (requires timestamp [--ts])
--restore-only Only perform restore (requires timestamp [--ts])
--cleanup-only Only perform remote cleanup
--dry-run Do not perform replace
```
# DESCRIPTION
CLI::Wordpress::Migrator is a script to migrate a Wordpress site from one server to another. This performs export (backup), install, import (restore) and search-replace steps according to the configuration in `~/.rawm-config/rawm-config.yaml`
The process involves three systems:
* `from` server which is running the source site
* `to` server which is ready for the migrated site
* local client which connects to the export / import servers in turn
This module installs the raku `rawm` command for use from the local client command line. (RAku Wordpress Migrator).
Here is a sample config file:
```
from:
user: myusername
subdom: sdname
domain: mydomain.com
key-pub: kpname
port: 22
to:
user: myusername
subdom: sdname
domain: mydomain.com
key-pub: kpname
port: 22
wp-config:
locale: en_GB
db:
name: dbname
user: dbuser
pass: dbpass
prefix: wp_
title: My New WP Installation
url: mysite.com
admin:
user: aduser
pass: adpass
email: ademail
```
Notes:
1. The install Build process creates a new default config file at `~/.rawm-config/rawm-config.yaml`. To persist your (private) settings, copy and populate this file and save as `~/.rawm-config/rawm-configBAK.yaml`, then subsequent install Build process will restore your settings over the default.
2. If there is no subdomain use `subdom: _` (ie an underscore) to indicate none.
Prerequisites for connection:
* Uses `ssh -i` access. Please generate an ssh key pair, authorize and save private key in e.g. `~.ssh/id_rsa`, `chmod 400 id_rsa`
### Export
| Action | Pseudo Command |
| --- | --- |
| Connect to the `from` Server: | `ssh user@host` |
| Go to to temp dir: | `cd /path/to/temp` |
| Export the Database: | `wp db export mysite.sql` |
| Export the WordPress Files: | `tar -czf backup-fs...tar.gz /../wp-content` |
| Transfer Files to local drive: | `scp user@host:/path/to/temp .` |
### Install
Prerequisites for install (example):
* Create new (sub)domain and (sub)dir via cPanel
* Create new empty database via cPanel
* Add db user & set their permissions via cPanel
* Adjust the PHP upload max size to 512M via cPanel > PHP > Options
* Register url and adjust DNS A record to server IP
* Use TLS status refresh to get certificates via cPanel
Edit your `~/.rawm-config/rawm-config.yaml` to populate these `wp-config` private settings (and copy it to `~/.rawm-config/rawm-configBAK.yaml` if you want them to persist through a re-install).
viz. <https://make.wordpress.org/cli/handbook/how-to/how-to-install/>
| Action | Pseudo Command |
| --- | --- |
| Connect to the `to` Server: | `ssh user@host` |
| Go to to destination dir | `cd /path/to/wpserver` |
| Download WP core | `wp core download` |
| Create WP config | `wp config create` |
| Install WP core | `wp core install` |
| Adjust file/dir permissions | `chmod -R a=r,a+X,u+w .` |
### Import
| Action | Pseudo Command |
| --- | --- |
| Transfer Files to the Import Server: | `scp . user@host:/path/to/temp` |
| Connect to the Import Server: | `ssh user@host` |
| Import the Database: | `wp db import mysite.sql` |
| Extract the WordPress Files: | `tar -xzf wordpress_files.tar.gz /..` |
| Update WordPress Configuration: | `wp-config.php s/xxx/yyy/` |
| Set File Permissions[1]: | `chmod -R a=r,a+X,u+w .` |
Notes:
* a failed import (eg. "to" site has WP web admin configurator asking for info like a new install) is often caused by incorrect wp-config>db>prefix in `rawm-config.yaml`
### Search & Replace
| Action | Pseudo Command |
| --- | --- |
| Search and Replace URLs (option): | `wp search-replace 'old' 'new'` |
| Update Permalinks (option): | `wp rewrite flush` |
Postrequisites for restore (example):
* use Elementor>Tools search replace x4
* edit all SS3 sliders
# AUTHOR
librasteve [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2024 librasteve
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-ddlws-Radamsa.md
# radamsa
Raku bindings for radamsa, a general purpose fuzzer <https://gitlab.com/akihe/radamsa>
When you have to start fuzzing RIGHT NOW, radamsa is hard to beat. However, hidden under a mountain of parentheses in the radamsa git repo is real black magic, libradamsa, which is what these bindings are actually for. This is multithreaded fuzzing on easy mode.
### Installation
> `zef install Radamsa`
The build fetches radamsa source from <https://gitlab.com/akihe/radamsa> and builds libradamsa.so. It'll take a minute.
### Using it
`use Radamsa;`
There is one class, `radamsa`. You'll need to initialize it with good input(s).
There are three convenience constructors:
**`new(Str $s)`**
seeds radamsa with a single string
> `my $r = radamsa.new("fuzz me");`
**`new(IO::Path $p)`**
If `$p` is a file, then `$p`'s contents are the seed. If `$p` is a directory, radamsa adds every file and recurses through subdirectories. Use this to fuzz file formats.
**`new(buf8 @inputs)`**
Inputs are stored as an array of `buf8`s, so this sets it directly.
> `my $r = radamsa.new(@arrayofbuf8s);`
#### Optional parameters
**`:maxoutsz`**
This sets a byte limit for the length of radamsa's output. If you don't specify it, radamsa will set it to the length of the longest input provided to the constructor.
**`:minqsz`**
Radamsa tries to avoid idle workers by keeping a minimum number of ouputs in the queue. More detail is provided below. You can ignore this.
### Changing inputs
You can modify the inputs at runtime if you'd like to guide the fuzzer. The array of inputs is directly accessible through `$r.inputs` (an array of buf8s) or through **`addinput(Blob)`**, **`addinput(Str)`**, or **`addinput(IO::Path)`**.
Radamsa will randomly choose one input for each ouput it generates, so choose your inputs wisely.
### Getting output
All results are `buf8` because there's no telling what you'll get.
**`gen1()`**
Returns a single item of output.
```
> for ^10 { say $r.gen1.decode }
fuzzfzzfuzzfuzz mefuzz me mefuzme
fuzz me mefuzz me
fuzz me mefuzz me mefuzz me
mefuzz me
fuzz mefuzz me
fuz me
Malformed UTF-8 at line 1 col 1
in block <unit> at <unknown file> line 1
```
### Getting a lot of ouput
The radamsa class is a Raku `Channel`, so you can call `.receive` on it. The queue will be empty until you initialize it with `.startchannel`. This starts a worker thread that tries to keep at least `$.minqsz` items available on the channel. Radamsa will naively increase its minqsz whenever the queue gets too short. It's not PID control, but it works for most usecases. You can outrun libradamsa with very quick tests. If that happens, ignore it or use fewer threads; libradamsa isn't thread safe.
Here is an example that writes to some temp files.
```
use Radamsa;
my $r = radamsa.new("go fuzz your software", :maxoutsz(100), :minqsz(100));
$r.startchannel();
my $keepgoing = True;
my @workers;
for ^10 { # starting 10 threads
my $fh = ('/tmp/libradtest'~$_).IO.open(:w);
@workers.push(
start {
while ?$keepgoing {
my $b = $r.receive;
$b.append(0x0a); # newline to make it somewhat readable
$fh.write($b);
}
$fh.close;
}
);
}
sleep 5;
$keepgoing = False;
await @workers;
```
and some of it's output
```
> head -n 5 /tmp/libradtest*
==> /tmp/libradtest0 <==
go fuzó z your software
go fuzzˑ ʵyour software
â€ó ƒ‡go óʶ §fuzz your sr sofï¿¿twaâ §ró še
go fuzz your softwó ³are
go fuzz your softwarego fuzz your só ›oftware
==> /tmp/libradtest1 <==
go fuzz your ÷dLsoftware
g„1•259ó €o fó €»uzzó Žó «ó ´ your só ó „ žoâ ¥ftware
go fuzz yoâ€ó €²‡ur sof twaró €¢ó € e
go fuzz y só ›o fuzz your software
go fuzz your softward
==> /tmp/libradtest2 <==
go fuzó »z your software
go fuzz softwarego fuzz your software
ó go fuzz your software
go fuzz your softwarego fuzz your softwarego fuzz your softwarego fuzz your softwaregoï¼ fuzz your
go fuzz xour softw`re
==> /tmp/libradtest3 <==
go fuzz your ‬software
go fuzz your softwarego fuzz your só ›oftwarer software
go fuzzó … your software
go fu fuzz youzz your softwarego fuzz your só ›oftwarego fuzz your só ›oftware
go ftware
==> /tmp/libradtest4 <==
à¿go fuó «zz yougo fuzz fuô ¿¾zz your s·ó ›oftware
go fuzz your software
go fuzz yoó ”ur software
go fuzz your sofó €¼tware
go fuzz your softwarego fuz
==> /tmp/libradtest5 <==
go fuzz your softwarego fuzz your softwarego fuzz your softwarego fuzz your softwarego fuzz your sof
go fuzz  your só ¿oftwaró· ˜e
go fuzz your sof tware
âó »€ó •á Žóó ” €½„óשּׁ ó ó ’ Ÿgo fuzz yo fuzz your só ›oftwarer software
go ftó ›ware
==> /tmp/libradtest6 <==
go fuzó ó ©•z your software
go fuzz yoó €¹ur software
go fuzz your softwarego fuzz your só ›oftware
goó ur software
go your softwaretó šsoftó ‘ó šsoftó šsoftó šsoftó šsoftware
==> /tmp/libradtest7 <==
go fuz z your so fuzz your software
go Ê°fþÿuzz your so‮ftâ §warego fuó ³zz yó €¯our só ›ó ‰oftware
go fuzz your software
go fuzz your software
ó šsoftó ftware
==> /tmp/libradtest8 <==
go fuzz yo ur ó ™software
go fuzz your softwarego fuzz your software
go fó €¤uzz yó †our software
go fuzz your softwarez your software
go fuzz your softó ›ware
==> /tmp/libradtest9 <==
go fuzz you
go fuzz your softwarego fuzzgo fuzz your softwarego fuzz your só ›oftware
go fuzz your softwaregoe
go fuzz your softwarego fuzz your só ›oftware
go fuï· zz your ó šsofuzz ougo ‪fuzz your softwarego fuzz your softwarego fuzz your só ó €± ›oftw
```
|
## dist_cpan-FISCHER-Lingua-Pangram.md
# Lingua::Pangram
Module and script for checking whether a string is a pangram.
[](https://github.com/sfischer13/perl6-Lingua-Pangram/releases) [](https://github.com/sfischer13/perl6-Lingua-Pangram/blob/master/LICENSE) [](https://travis-ci.org/sfischer13/perl6-Lingua-Pangram)
---
## Introduction
`Lingua::Pangram` is a Perl 6 module for checking whether a string is a pangram.
## Installation
```
# latest release
zef install Lingua::Pangram
# specific version
zef -v install https://github.com/sfischer13/[email protected]
# developer version
zef -v install https://github.com/sfischer13/perl6-Lingua-Pangram.git
```
## Development
```
git archive --prefix=Lingua-Pangram-0.1.0/ -o ../Lingua-Pangram-0.1.0.tar.gz HEAD
```
## Credits
This project is authored and maintained by Stefan Fischer.
The source code is available under the **MIT License**.
See [LICENSE](https://github.com/sfischer13/perl6-Lingua-Pangram/blob/master/LICENSE) for further details.
|
## dist_zef-lizmat-Code-Coverage.md
[](https://github.com/lizmat/Code-Coverage/actions) [](https://github.com/lizmat/Code-Coverage/actions) [](https://github.com/lizmat/Code-Coverage/actions)
# NAME
Code::Coverage - produce code coverage reports
# SYNOPSIS
```
use Code::Coverage;
my $coverage := Code::Coverage.new(
targets => @modules,
runners => @test-scripts
);
$coverage.run;
say .key ~ ": " ~ .value for $coverage.missed;
```
# DESCRIPTION
Code::Coverage is a class that contains the logic to run one or more Raku programs and produce code coverage of one or more targets (usually modules).
# METHODS
## new
```
my $cc := Code::Coverage.new(
targets => @modules,
runners => @test-scripts,
extra => "-I.", # default: none
repo => $repo, # default: $*REPO
tmpdir => ".", # default: %*ENV<TMPDIR> // $*HOME
slug => "foobar", # default: "code-coverage-"
keep => True, # default: False
);
$cc.run;
say "$cc.coverage() of code was covered";
```
The `new` method accepts the following named arguments:
### :targets
The `targets` named argument indicates one or more targets for which coverage information should be created. Each of these can be specified as a path (either as string, or as an `IO::Path` object), or as a `use` target (identity) such as "`String::Utils`".
Whatever was specified, will be returned by the `targets` method.
### :runners
The `runners` named argument indicates the paths of one or more scripts that should be executed to determine coverage information. It should specify at least one script.
Whatever was specified, will be returned by the `runners` method.
### :extra
The `extra` named argument indicates any extra command line arguments that should be set when calling the `:runners` scripts. By default, no extra arguments are added. A typical usage would be "-I." to ensure that the current source of a module is used.
Whatever was specified, will be returned by the `extra` method.
### :repo
The `repo` named argument indicates the `CompUnit::Repository` object to be used when coverable lines are being deduced from bytecode. It defaults to `$*REPO`, aka the default repository chain.
Whatever was specified, will be returned by the `repo` method.
### :tmpdir
The `tmpdir` named argument specifies the path of the directory that should be used to store the temporary coverage files. It defaults to the `TMPDIR` environment variable, or the home directory as known by `$*HOME`.
Whatever was (implicitely) specified, will be returned by the `tmpdir` method.
### :slug
The `slug` named argument specifies the prefix of the coverage files to be created. It defaults to "code-coverage-".
Whatever was (implicitely) specified, will be returned by the `slug` method.
### :keep
The `keep` named argument specifies whether the temporary coverage files should be kept or not. Defaults to `False`, which means that any coverage files will be removed after each call to `.run`.
Whatever was (implicitely) specified, will be returned by the `keep` method.
## run
```
$cc.run("foo"); # test the "foo" code path
$cc.run("bar"); # test the "bar" code path
```
The `run` method will execute all of the `:runners` scripts, gather the coverage information, and update all internal information as applicable.
Any positional arguments specified will be added as command line arguments to the `:runners` scripts. Note that it is fully ok to call this method more than once with a different set of parameters, to test different code paths in the runners.
## out
```
print $cc.out;
```
The `out` method returns the collected STDOUT output of all of the `:runners` scripts since the last time the `run` method was executed.
## err
```
print $cc.err;
```
The `err` method returns the collected STDERR output of all of the `:runners` scripts since the last time the `run` method was executed.
## coverables
```
for $cc.coverables.values {
say .source.relative;
say .line-numbers;
}
```
The `coverables` method returns a `Map` with [`Code::Coverable`](https://raku.land/zef:lizmat/Code::Coverable) objects created for the `:targets` specified, keyed by coverage key that will appear in coverage logs.
## keys
```
say "Coverage keys:";
.say for $cc.keys;
```
The `keys` method returns the coverage keys that were found for the given targets.
## covered
```
say "Lines covered";
for $cc.covered {
say .key ~ ":\n$_.value.join(',')\n";
}
```
The `covered` method returns a `Map`, keyed by coverage key, with all of the lines that appear to have been covered by executing the runner scripts (possibly multiple times).
## missed
```
say "Lines NOT covered";
for $cc.missed {
say .key ~ ":\n$_.value.join(',')\n";
}
```
The `missed` method returns a `Map`, keyed by coverage key, with all of the lines that appear to have **NOT** been covered by executing the runners (possibly multiple times).
## coverage
```
say "Coverage:"
for $cc.coverage {
say .key ~ ": " ~ .value;
}
```
The `coverage` method returns a `Map`, keyed by coverage key, with as value a string containing the percentage of lines that were covered so far by executing the runners (possibly multiple times).
## sources
```
say "Source files:"
for $cc.sources {
say .key ~ ": " ~ .value.absolute;
}
```
The `sources` method returns a `Map`, keyed by coverage key, with an `IO::Path` object for the associated source file as the value.
## source
```
say "$key: $cc.source($key).relative";
```
The `source` method returns an `IO::Path` object for the source file associated with the given coverage key.
## annotated
```
print $cc.annotated($key);
```
The `annotated` method produces the contents of the source-file indicated by the coverage key, with each line annotated with the coverage result. The following annotations are given:
* `*` - line was coverable, and covered
* `✱` - line was **not** coverable, but covered anyway
* `x` - line was coverable and **not** covered
* `` - line was not coverable
## num-coverable-lines
```
say $cc.num-coverable-lines;
```
The `num-coverable-lines` method returns the total number of lines that are marked coverable in all coverage keys.
## num-covered-lines
```
say $cc.num-covered-lines;
```
The `num-covered-lines` method returns the total number of lines that are marked covered in all coverage keys.
## num-missed-lines
```
say $cc.num-missed-lines;
```
The `num-missed-lines` method returns the total number of lines that are marked coverable, but have not been covered in all coverage keys (yet).
## max-lines
```
say $cc.max-lines; # max number of lines that can be covered
```
The `max-lines` method returns the maximum number of lines that can be covered. In some edge cases, this may actually be greater than the number of lines that are marked coverable because some lines may appear in the coverage log that were **not** marked as coverable.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Code-Coverage> . Comments and Pull Requests are welcome.
If you like this module, or what I'm doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2024, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-labster-File-Directory-Tree.md
# p6-file-directory-tree
| last push to main | [Linux Status](https://github.com/labster/p6-file-directory-tree/actions) | [MacOS Status](https://github.com/labster/p6-file-directory-tree/actions) | [Windows Status](https://github.com/labster/p6-file-directory-tree/actions) |
| --- | --- | --- | --- |
| scheduled health check | [Linux Status](https://github.com/labster/p6-file-directory-tree/actions) | [MacOS Status](https://github.com/labster/p6-file-directory-tree/actions) | [Windows Status](https://github.com/labster/p6-file-directory-tree/actions) |
Raku module to create and delete directory trees.
## SYNOPSIS
```
use File::Directory::Tree;
# make a new directory tree
mktree "foo/bar/baz/quux";
# delete what you just made
rmtree "foo";
# clean up your /tmp -- but don't delete /tmp itself
empty-directory "/tmp";
```
## DESCRIPTION
This module provides recursive versions of mkdir and rmdir. This might be useful for things like setting up a repo all at once.
## FUNCTIONS
#### mktree
Makes a directory tree with the given path. If any elements of the tree do not already exist, this will make new directories.
```
sub mktree ($path, $mask = 0o777)
```
Accepts an optional second argument, the permissions mask. This is supplied to mkdir, and used for all of the directories it makes; the default is `777` (`a+rwx`). It takes an integer, but you really should supply something in octal like 0o755 or :8('500').
Returns True if successful.
#### rmtree
This deletes all files under a directory tree with the given path before deleting the directory itself. It will recursively call unlink and rmdir until everything under the path is deleted.
Returns True if successful, and False if it cannot delete a file.
#### empty-directory
Also deletes all items in a given directory, but leaves the directory itself intact. After running this, the only thing in the path should be '.' and '..'.
Returns True if successful, and False if it cannot delete a file.
## TODO
* Probably handle errors in the test file better
## SEE ALSO
* [IO::Path](https://docs.raku.org/type/IO::Path)
* [File::Spec](https://github.com/FROGGS/p6-File-Spec) (now part of [IO::Spec](https://docs.raku.org/type/IO::Spec))
## AUTHOR
Brent "Labster" Laabs, 2013.
Contact the author at [[email protected]](mailto:[email protected]) or as labster on #perl6. File [bug reports](https://github.com/labster/p6-IO-Path-More/issues) on github.
Based loosely on code by written Daniel Muey in Perl 5's [File::Path::Tiny](http://search.cpan.org/~dmuey/File-Path-Tiny-0.5/lib/File/Path/Tiny.pod).
## COPYRIGHT
This code is free software, licensed under the same terms as Perl 6; see the LICENSE file for details.
|
## bind.md
class X::Bind
Error due to binding to something that is not a variable or container
```raku
class X::Bind is Exception {}
```
If you write code like this:
```raku
floor(1.1) := 42;
```
it dies with an `X::Bind` exception:
「text」 without highlighting
```
```
Cannot use bind operator with this left-hand side
```
```
|
## dist_zef-lizmat-Time-gmtime.md
[](https://github.com/lizmat/Time-gmtime/actions)
# NAME
Raku port of Perl's Time::gmtime module
# SYNOPSIS
```
use Time::gmtime;
$gm = gmtime;
printf "The day in Greenwich is %s\n",
<Sun Mon Tue Wed Thu Fri Sat Sun>[ $gm.wday ];
use Time::gmtime :FIELDS;
gmtime;
printf "The day in Greenwich is %s\n",
<Sun Mon Tue Wed Thu Fri Sat Sun>[ $tm_wday ];
$now = gmctime();
use Time::gmtime;
$date_string = gmctime($file.IO.modified);
```
# DESCRIPTION
This module tries to mimic the behaviour of Perl's `Time::gmtime` module as closely as possible in the Raku Programming Language.
This module's default exports a `gmtime` and `gmctime` functions. The `gmtime` function returns a "Time::gmtime" object. This object has methods that return the similarly named structure field name from the C's tm structure from time.h; namely sec, min, hour, mday, mon, year, wday, yday, and isdst.
You may also import all the structure fields directly into your namespace as regular variables using the :FIELDS import tag. (Note that this still exports the functions.) Access these fields as variables named with a preceding tm\_. Thus, `$group_obj.year` corresponds to `$tm_year` if you import the fields.
The `gmctime` function provides a way of getting at the scalar sense of the `gmtime` function in Perl.
# PORTING CAVEATS
This module depends on the availability of POSIX semantics. This is generally not available on Windows, so this module will probably not work on Windows.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Time-gmtime> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2018, 2019, 2020, 2021 Elizabeth Mattijsen
Re-imagined from Perl as part of the CPAN Butterfly Plan.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-MELEZHIK-Sparrowdo.md
# Sparrowdo
Sparrow Based Configuration Management Tool.
# Build status
[](https://travis-ci.org/melezhik/sparrowdo)
# Install
```
zef install Sparrowdo
```
# Usage
```
sparrowdo --host=remote-host [options]
```
For example:
```
# ssh host, bootstrap first, use of local repository
sparrowdo --host=13.84.166.232 --repo=file:///home/gimy/repo --verbose --bootstrap
# docker host, don't add sudo
sparrowdo --docker=SparrowBird --no_sudo
# localhost, with sudo
sparrowdo --localhost
# read hosts from file
sparrowdo --host=hosts.raku
```
# DSL
Sparrow6 DSL is high level functions to manage configurations.
Just create a file named `sparrowdo` in current working directory and add few functions:
```
$ cat sparrowfile
user 'zookeeper';
group 'birds';
directory '/var/data/avifauna/greetings/', %( owner => 'zookeeper' );
file-create '/var/data/avifauna/greetings/sparrow.txt', %(
owner => 'zookeeper',
group => 'birds',
mode => '0644',
content => 'I am little but I am smart'
);
service-start 'nginx';
package-install ('nano', 'ncdu', 'mc' );
```
The full list of function is available at [Sparrow6 DSL](https://github.com/melezhik/Sparrow6/blob/master/documentation/dsl.md)
documentation.
If DSL is not enough you can call any Sparrow6 plugin using `task-run` function:
```
task-run "show me your secrets", "azure-kv-show", %(
kv => "Stash" # key vault name
secret => ( "password", "login" ) # secret names
)
```
## DSL vs `task-run` function
DSL is high level adapter with addition of some "syntax sugar" to make a code concise and readable.
DSL functions are Perl6 functions, you take advantage of input parameters validation.
However DSL is limited. Not every Sparrow6 plugin has related DSL function.
Once we've found some Sparrow6 plugin common enough we add a proper DSL wrapper for it.
In case you need more DSL wrappers let us know!
# Sparrowdo workflow
```
==================== ====================
| | --- [ Bootstrap ] | | LocalHost
| MasterHost | --- [ Sparrowdo Scenario ] ---> | TargetHost | Docker
| | * | | Ssh
==================== | ====================
{Sparrow6 Module} | {Sparrow6 Module}
\ parameters
\-----------------> [ tasks ]
^ ^ ^
/ / /
------------ / / /
{ Repository } ---------------------
------------ [ plugins ]
------------
/ | \
/ | \
/ | \
/ | \
[CPAN] [RubyGems] [PyPi]
```
## Master host
Master host is where Sparrow6 tasks "pushed" to target hosts.
Sparrowdo should be installed on master host:
```
$ zef install Sparrowdo
```
## Sparrowdo scenario
Sparrowdo scenario is collection of Sparrow6 tasks executed on target host.
## Target hosts
Target hosts are configured by Sparrow6 which should be installed there as well:
```
$ zef install Sparrow6
```
## Bootstrap
Bootstrap is process of automation of Sparrow6 installation on target host:
```
$ sparrowdo --host=192.168.0.1 --bootstrap
```
Bootstrap runs under `sudo` and requires sudo privileges on target host.
## Sudo
Execution of Sparrow6 tasks on target host is made under `sudo` by default, to disable this use `no_sudo` flag:
```
$ sparrowdo --docker=brave_cat --no_sudo # We don't need sudo on docker
```
## Various types of target hosts
Once sparrowfile is created it could be run on target host.
Ssh host:
```
$ sparrowdo --host=192.168.0.1
```
Docker container:
```
$ sparrowdo --docker=old_dog
```
Localhost:
```
$ sparrowdo --localhost
```
## Repositories
Sparrowdo use Sparrow6 repository to download tasks that are executed on target hosts.
During scenario execution Sparrowdo pulls plugins from repository and runs it *with parameters*.
Plugin that gets run with parameters is a Sparrow6 task.
* Detailed explanation of Sparrow6 tasks is available at [Sparrow6 development](https://github.com/melezhik/Sparrow6/blob/master/documentation/development.md) documentation.
* Detailed explanation of Sparrow6 plugins [Sparrow6 plugins](https://github.com/melezhik/Sparrow6/blob/master/documentation/plugins.md) documentation
* Detailed explanation of Sparrow6 repositories is available at [Sparrow6 repositories](https://github.com/melezhik/Sparrow6/blob/master/documentation/repository.md) documentation.
By default local repository located at `~/repo` is used:
```
$ sparrowdo --host=192.168.0.1 # using repo ~/repo
```
Use `--repo` flag to set repository URI. For example:
```
$ sparrowdo --repo=file:///tmp/repo --localhost # use /tmp/repo repository for local mode
$ docker run --name --name=fox -d sh -v /tmp/repo:/var/data
$ sparrowdo --repo=/var/data --docker=fox --repo=file://var/data # mount /tmp/repo to /var/data within docker instance
$ sparrowdo --repo=http://sparrow.repo # use http repository
```
Ssh mode supports synchronizing local file repositories with master and target host using scp.
It extremely useful if for some reason you can't use http based repositories:
```
# scp local repository /tmp/repo to target host
# and use it within target host
$ sparrowdo --sync=/tmp/repo --host=192.168.0.1
```
Read [Sparrow6 documentation](https://github.com/melezhik/Sparrow6/blob/master/documentation/repository.md)
to know more about Sparrow6 repositories.
# Sparrowdo files anatomy
When Sparrowdo scenario executed there are might be *related* that get *copied* to a target host,
for convenience, so that one can reliably refer to those files inside Sparrowdo scenario.
Thus Sparrowdo *project* might consists of various files and folders:
```
.
├── conf
│ └── alternative.pl6
├── config.pl6
├── data
│ └── list.dat
├── files
│ └── baz.txt
├── sparrowfile
└── templates
└── animals.tmpl
```
* `sparrowfile`
The minimal setup is just `sparrowfile` placed in the current working directory.
That file contains Sparrowdo scenario to be executed.
One may optionally define other data that make up the whole set up:
* `conf`
Directory to hold configuration files
* `config.pl6`
Default configuration file, if placed in current working directory will define Sparrowdo configuration, see
also [scenarios configuration](#scenario-configuration) section, alternatively one may place configuration file to `conf` directory and
choose to run with that file:
```
$ sparrowdo --conf=conf/alternative.pl6
```
* `files`
Directory containing files, so one could write such a scenario:
```
file "/foo/bar/baz.txt", %( source => "files/baz.txt" )
```
* `templates`
The same as `files` directory, but for templates, technically `templates` and `files` as equivalent, but
named separately for logical reasons. Obviously one can populate templates using that directory:
```
template-create '/var/data/animals.txt', %(
source => ( slurp 'templates/animals.tmpl' ),
owner => 'zookeeper',
group => 'animals' ,
mode => '644',
variables => %(
name => 'red fox',
language => 'English'
),
);
```
* `data`
The same as `files` and `templates` folder but to keep "data" files, just another folder
to separate logically different pieces of data:
```
file "/data/list.txt", %( source => "data/list.dat" )
```
# Scenario configuration
If `config.pl6` file exists at the current working directory it *will be
loaded* via Perl6 [EVALFILE](https://docs.perl6.org/routine/EVALFILE) at the *beginning* of scenario.
For example:
```
$ cat config.pl6
{
user => 'foo',
install-base => '/opt/foo/bar'
}
```
Later on in the scenario you may access config data via `config` function, that returns
configuration as Perl6 Hash object:
```
$ cat sparrowfile
my $user = config<user>;
my $install-base = config<install-base>;
```
To refer configuration files at arbitrary location use `--conf` parameter:
```
$ sparrowdo --conf=conf/alternative.conf
```
See also [Sparrowdo files anatomy](#sparrowdo-files-anatomy) section.
# Including other Sparrowdo scenarios
Because Sparrowdo scenarios are Perl6 code files, you're free to include other scenarios into
"main" one using via Perl6 [EVALFILE](https://docs.perl6.org/routine/EVALFILE) mechanism:
```
$ cat sparrowfile
EVALFILE "another-sparrowfile";
```
Including another scenario does not include related files (`data`, `files`, `templates`) into main one,
so you can only reuse Sparrowdo scenario itself, but not it's *related* files.
# Bootstrap and manual install
To ensure that target hosts has all required Sparrow6 dependencies one may choose bootstrap mechanism that
installs those dependencies on target host. This operation is carried out under `sudo`.
Bootstrap is disabled by default and should be enabled by `--bootstrap` option:
```
$ sparrowdo --host=192.168.0.1 --bootstrap
```
Be aware that all dependencies will be installed *system wide* rather then user account, because `sudo` is used.
if you don't want bootstrap target host, you can always choose to install Sparrow6 zef module
on target host, which is enough to start using Sparrowdo to manage target host:
```
$ zef install Sparrow6
```
# Run Sparrowdo on docker
Sparrowdo supports docker as target host, just refer to running docker container by name to
run Sparrowdo scenario on it:
```
$ sparrowdo --docker=running-horse
```
# Run Sparrowdo on ssh hosts
This is probably one the most common use case for Sparrowdo - configuring servers by ssh:
```
$ sparrowdo --host=192.168.0.1
```
# Run Sparrowdo in local mode
In case you need to run sparrowdo on localhost use `--localhost` flag:
```
$ sparrowdo --localhost
```
# Sparrowdo cli
`sparrowdo` is Sparrowdo cli to run Sparrowdo scenarios, it accepts following arguments:
* `--host`
One of two things:
Ssh host to run Sparrowdo scenario on. Default value is `127.0.0.1`. For example:
```
--host=192.168.0.1
```
Path to raku file with dynamic hosts configuration. For example:
```
--host=hosts.raku
```
This will effectively runs Sparrowdo in asynchronous mode through a Sparky backend.
See [Dynamic hosts](https://github.com/melezhik/sparrowdo/wiki/Dynamic-hosts) wiki.
* `--docker`
Docker container name to run Sparrowdo scenario on, none required.
* `--localhost`
If set, runs Sparrowdo in localhost, in that case Sparrow6 tasks get run directly without launching ssh
* `--ssh_user`
If set defines ssh user when run Sparrowdo scenario over ssh, none required.
* `--ssh_port`
If set defines ssh port to use when run Sparrowdo scenario over ssh. Default value is 22.
If set, run Sparrowdo scenario on localhost, don't confuse with `--host=127.0.0.1` which
runs scenario on the machine but using ssh.
* `--repo`
Defines Sparrow6 repository `URI`, for example:
```
--repo=https://192.168.0.1 # Remote http repository
--repo=file:///var/data/repo # Local file system repository
```
If `--repo` is not set, Sparrowdo uses default local repository located at `~/repo` path.
Sparrowdo uses repository to pull plugins from, see also [Sparrowdo workflow](#sparrowdo-workflow) section.
See also [Sparrow6 Repositories](https://github.com/melezhik/Sparrow6/blob/master/documentation/repository.md)
documentation.
* `--sync`
If set synchronize local file system repository with target hosts using `scp`, it's useful if for some reasons
remote http repositories are not available or disable, so one can *automatically copy* repository from master host
to target. `--sync` parameter value should file path pointing repository directory at master host:
```
--sync=/var/data/repository
```
* `--no_index_update`
If set, don't request Sparrow6 repository update. Useful when in limited internet and using http based remote repositories.
* `--dry_run`
Runs in dry run mode. Only applies when run in asynchronous mode through a Sparky backend.
See [Dynamic hosts](https://github.com/melezhik/sparrowdo/wiki/Dynamic-hosts) wiki.
* `--tags`
Set host(s) tags, see [Dynamic hosts](https://github.com/melezhik/sparrowdo/wiki/Dynamic-hosts#tags) wiki.
* `--verbose`
If set print additional information during Sparrowdo scenario execution.
* `--debug`
If set, runs Sparrow6 tasks in `debug` mode, giving even more information, during scenario execution.
* `--prefix`
If set, define path to be appending to local cache directory on target host, used predominantly
when running concurrent Sparrowdo scenario on one target host, for example in Sparky CI server.
None required, no default value.
# Advanced topics
[Run Sparrowdo scenarios in asynchronous mode, using Sparky backend](https://github.com/melezhik/sparrowdo/blob/master/doc/sparky-integration.md)
# Author
Alexey Melezhik
# See also
* [Sparrow6](https://github.com/melezhik/Sparrow6)
# Thanks
To God as the One Who inspires me to do my job!
|
## dist_github-MattOates-BioInfo.md
# BioInfo [Build Status](https://travis-ci.org/MattOates/BioInfo)
BioInfo is a reimagining of bioinformatics libraries for Perl6 based on all the new goodies available such as parallel processing through Promises and Channels and well defined and extensible parsing with the use of Grammars. Not to be confused with the [bioperl6](https://github.com/cjfields/bioperl6/) project lead by [Chris Fields](http://www.bioperl.org/wiki/User:Cjfields) which aims to be a reimplementation of the BioPerl API for Perl6. Checkout Chris' project for any serious business.
### The Good
* Being built to work in parallel use cases so you don't have to worry too much about this yourself.
* Using sped up parse as you go forms of Perl6 Grammars so that a whole file isn't read into RAM and you can just play with getting higher level objects quickly.
* I'll attempt to work on reasonable requests for anything, pull requests are welcome just maybe contact me first if you have to make some big architectural decisions to get what you want.
* A fresh project for anyone who has an opinon to get involved pushing that opinion on others.
### The Bad
* I'm mostly ignoring BioPerl.
* Like the [bioperl6](https://github.com/cjfields/bioperl6/) project I am trying things out so the API is in flux. If you want something production ready, you're going to have to help to get there.
### The Ugly
* The author of these modules ([Matt Oates](http://bioinformatics.bris.ac.uk/people/matt_oates.php)) mostly concerns himself with amino acid sequences so other considerations are secondary. Sorry about that.
* [bioperl6](https://github.com/cjfields/bioperl6/) does exist. So this is a bit of a split effort, really [bioperl6](https://github.com/cjfields/bioperl6/) should get any attention.
---
## An Example
Dealing with sequences from a file:
```
use BioInfo::Parser::FASTA;
use BioInfo::IO::FileParser;
#Spawn an IO thread that parses the file and creates BioInfo::Seq objects on .get
my $seq_file = BioInfo::IO::FileParser.new(file => 'myseqs.fa', parser => BioInfo::Parser::FASTA);
#Print all the IDs from the sequence file
while (my $seq = $seq_file.get()) {
say $seq.id;
}
```
Using the BioInfo slang to seamlessly manipulate sequences in your code. Anything within backticks or grave accents `` will be treated as FASTA sequence data and create an array of sequence objects:
```
use BioInfo;
my @seqs = `
>ENST00000505673 cds:NOVEL_protein_coding
NGGTGTGGAGCCATAGGCTGTGAAATGTTGAAAAATTTTGCTTTACTTGGTGTTGGCACA
AGCAAAGAGAAAGGAATGATTACAGTTACAGATCCTGACTTGATAGAGAAATCCAACTTA
AATAGACAGTTCCTATTTCGTCCTCATCACATACAGAAACCTAAAAGCTACACTGCTGCT
GATGCTACTCTGAAAATAAATTCTCAAATAAAGATAGATGCACACCTGAACAAAGTATGT
CCAACCACTGAGACCATTTACAATGATGAGTTCTATACTAAACAAGATGTAATTATTACA
GCATTAGATAATGTGGAAGCCAGGAGATACGTAGACAGTCGTTGCTTAGCAAATCTAAGG
CCTCTTTTAGATTCTGGAACAATGGGCACTAAGGGACACACTGAAGTTATTGTACCGCAT
TTGACTGAGTCTTACAATAGTCATCGGGATCCCCCAGAAGAGGAAATACCATTTTGTACT
CTAAAATCCTTTCCAGCTGCTATTGAACATACCATACAGTGGGCAAGAGATAAGTTTGAA
AGTTCCTTTTCCCACAAACCTTCATTGTTTAACAAATTTTGGCAAACCTATTCATCTGCA
GAAGAAGTCTTACAGGCTCTTCAGCTTCTTCACTGTTTCCCTCTGGACATACGATTAAAA
GATGGCAGTTTATTTTGGCAGTCACCAAAGAGGCCACCCTCTCCAATAAAATTTGATTTA
AATGAGCCTTTGCACCTCAGTTTCCTTCAGAATGCTGCAAAACTATATGCTACAGTATAT
TGTATTCCATTTGCAGAAGAGGTAAGATATTCT
>ENST00000505673 peptide: ENSP00000421984 pep:NOVEL_protein_coding
XCGAIGCEMLKNFALLGVGTSKEKGMITVTDPDLIEKSNLNRQFLFRPHHIQKPKSYTAA
DATLKINSQIKIDAHLNKVCPTTETIYNDEFYTKQDVIITALDNVEARRYVDSRCLANLR
PLLDSGTMGTKGHTEVIVPHLTESYNSHRDPPEEEIPFCTLKSFPAAIEHTIQWARDKFE
SSFSHKPSLFNKFWQTYSSAEEVLQALQLLHCFPLDIRLKDGSLFWQSPKRPPSPIKFDL
NEPLHLSFLQNAAKLYATVYCIPFAEEVRYS
`;
#Print out all of the sequences, if the sequence was DNA translate to Amino Acids
for @seqs -> $seq {
say $seq ~~ BioInfo::Seq::DNA ?? $seq.translate !! $seq;
}
```
The previous example will output the protein sequence twice since the DNA was the coding sequence for the protein. Notice that what type of sequence was automatically detected, for very short sequences this could get confused. However, it does allow for convenient and quick manipualtion of sequences.
---
## Installation
Installation is quite simple at the moment, but might become more involved once third party software is involved.
### With zef (part of the Rakudo\* distribution)
```
zef install BioInfo
perl6 -M BioInfo -e 'say BioInfo::Seq.new(id => "seq1", sequence => "MDADAFA");'
```
### By hand
```
#Get the code into your library path
cd ~/wherever_you_keep_perl6_libs
git clone 'https://github.com/MattOates/BioInfo'
#Run some tests
cd BioInfo
prove -e 'perl6 -I ./lib' -lrv t/
```
---
## License
Artistic, for now just so that I don't have to worry about hardcore Perl users being fearful of anything else.
|
## dist_github-azawawi-Farabi6.md
# Farabi6 [Build Status](https://travis-ci.org/azawawi/farabi6)
This is a fun Perl 6 port of the Farabi Modern Perl Editor <http://metacpan.org/module/Farabi>.
The idea here is to experiment with a Perl 6 in-browser editor running over Rakudo Perl 6.
Please use rakudo Perl 6 MoarVM backend because it is the most compatible at the
time of this writing.
Have fun!
## Installation
To run it from the local directory:
```
$ bin/farabi6
# farabi6 will try to open http://localhost:3030 in your browser
```
To install it using zef (a module management tool bundled with Rakudo Star):
```
$ zef install Farabi6
$ farabi6
# farabi6 will try to open http://localhost:3030 in your browser
```
You can also change the host name and port using the following command:
```
$ farabi6 --host=localhost --port=4040
```
## Testing
To run tests:
```
$ prove -e "perl6 -Ilib"
```
## Author
Ahmad M. Zawawi, azawawi on #perl6, <https://github.com/azawawi/>
## License
Artistic License 2.0
|
## dist_zef-leont-SQL-Abstract.md
[](https://github.com/Leont/sql-abstract/actions)
# Name
SQL::Abstract - Generate SQL from Raku data structures
# Synopsis
```
use SQL::Abstract;
my $abstract = SQL::Abstract.new(:renderer<sqlite>);
my $query = $abstract.select('table', <foo bar>, { :id(3) });
my $result = $dbh.query($result.sql, $result.arguments);
my $join = { :left<books>, :right<authors>, :using<author_id> };
my $result = $abstract.select($join, ['books.name', 'authors.name'], { :cost('<' => 10) });
```
# Description
SQL::Abstract abstracts the generation of SQL queries. Fundamentally its functionality has three components
* An AST to represent SQL queries
* A set of helpers to convert standard raku datatypes into such an AST
* A renderer to turn that AST into an SQL query
It should be able to represent any `SELECT`, `UPDATE`, `INSERT`, or `DELETE` query that is valid in both Postgresql and SQLite. This subset should be generally portable to other databases as well.
# Class SQL::Abstract
This is the main class of the module.
### new(:$renderer!, Bool :$quoting, \*%renderer-args)
This creates a new `SQL::Abstract` object.
It supports at least two named arguments:
* `Bool :$quote`
* `:$renderer`
This can either be a `Renderer` type-object, or the name of such an object. Valid values include:
```
* `'postgres'`/`SQL::Abstract::Renderer::Postgres`
* `'sqlite'`/`SQL::Abstract::Renderer::SQLite`
* `'mysql'`/`SQL::Abstract::Renderer::MySQL`
```
The postgres renderer takes an additional argument `:$placeholders`, which takes one of the following values:
```
* `'dbi'`/`SQL::Abstract::Placeholders::DBI`
This will use DBI style `(?, ?)` placeholders
* `'postgres'`/`SQL::Abstract::Placeholders::Postgres`
This will use Postgres style `($1, $2)` placeholders.
```
It also takes an optional argument `:$quoting`, if enabled table and column names will always be quoted.
## select
```
method select(Source(Any) $from, Column::List(Any) $columns = *, Conditions(Any) $where?, Common(Any) :$common,
Distinction(Any) :$distinct, GroupBy(Any) :$group-by, Conditions(Any) :$having, Window::Clauses(Any) :$windows,
Compound(Pair) :$compound, OrderBy(Any) :$order-by, Limit :$limit, Offset :$offset, Locking(Any) :$locking)
```
This will generate a `SELECT` query. It will select `$columns` from `$from`, filtering by $conditions.
```
my $join = { :left<books>, :right<authors>, :using<author_id> };
my $result = $abstract.select($join, ['books.name', 'authors.name'], { :cost{ '<' => 10 } });
# SELECT books.name, authors.name FROM books INNER JOIN authors USING (author_id) WHERE cost < 10
my @columns = [ 'name', :sum{ :function<count>, :arguments(*) } ];
my $counts = $$abstract.select('artists', @columns, { :name(like => 'A%') }, :group-by<name>, :order-by(:sum<desc>));
# SELECT name, COUNT(*) as sum FROM artists WHERE name LIKE 'A%' GROUP BY name ORDER BY sum DESC
```
## update
```
method update(Table(Any) $target, Assigns(Any) $assigns, Conditions(Any) $where?,
Common(Any) :$common, Source(Any) :$from, Column::List(Any) :$returning)
```
This will update `$target` by assigning the columns and values from `$set` if they match `$where`, returning `$returning`.
```
$abtract.update('artists', { :name('The Artist (Formerly Known as Prince)') }, { :name<Prince> });
# UPDATE artists SET name = 'The Artist (Formerly Known as Prince)' WHERE name = 'Prince'
```
## insert
### Map insertion
```
method insert(Table(Any) $target, Assigns(Any) $values, Common(Any) :$common,
Overriding(Str) :$overriding, Conflicts(Any) :$conflicts, Column::List(Any) :$returning)
```
Inserts the values in `$values` into the table `$target`, returning the columns in `$returning`
```
$abstract.insert('artists', { :name<Metallica> }, :returning(*));
# INSERT INTO artists (name) VALUES ('Metallica') RETURNING *
```
### List insertions
```
method insert(Table(Any) $target, Identifiers(Any) $columns, Rows(List) $rows, Common(Any) :$common,
Overriding(Str) :$overriding, Conflicts(Any) :$conflicts, Column::List(Any) :$returning)
```
Insert into `$target`, assigning each of the values in Rows to a new row in the table. This way one can insert a multitude of rows into a table.
```
$abstract.insert('artists', ['name'], [ ['Metallica'], ['Motörhead'] ], :returning(*));
# INSERT INTO artists (name) VALUES ('Metallica'), ('Motörhead') RETURNING *
$abstract.insert('artists', List, [ [ 'Metallica'], ], :returning<id>);
# INSERT INTO artists VALUES ('Metallica') RETURNING id
```
### Select insertion
```
method insert(Table(Any) $target, Identifiers(Any) $columns, Select(Map) $select, Common(Any) :$common,
Overriding(Str) :$overriding, Conflicts(Any) :$conflicts, Column::List(Any) :$returning)
```
This selects from a (usually different) table, and inserts the values into the table.
```
$abstract.insert('artists', 'name', { :from<new_artists>, :columns<name> }, :returning(*));
# INSERT INTO artists (name) SELECT name FROM new_artists RETURNING *
```
## upsert
```
method upsert(Table(Any) $target, Assigns(Any) $values, Conflict::Targets $targets, Common(Any) :$common,
Overriding(Str) :$overriding, Column::List(Any) :$returning)
```
This upserts data into the table: it tries to insert data but if it fails because of a unique index constraint on one of `$targets` it will update the other columns instead.
```
$abstract.upsert('phone_numbers', { :$name, :$number}, ['name']);
# INSERT INTO phone_numbers (name, number) VALUES (?, ?) ON CONFLICT (name) UPDATE number = ?
=end
=head2 delete
=begin code :lang<raku>
method delete(Table(Any) $target, Conditions(Any) $where, Common(Any) :$common,
Source(Any) :$using, Column::List(Any) :$returning)
```
This deletes rows from the database, optionally returning their values.
```
$abstract.delete('artists', { :name<Madonna> });
# DELETE FROM artists WHERE name = 'Madonna'
```
# Builder Types
Builder objects generate SQL statements using the builder pattern
```
my $builder = SQL::Abstract::Builder(:renderer<sqlite>);
my $query = $builder.on('table').where({ :1a, :b<bar> }).update({ :$b }).build;
# "UPDATE table SET b = ? WHERE a = 1 AND b = 'bar'", [ $b ]
```
## Builder
### on
```
method on(Source(Any) $name --> Builder::Source)
```
This will return a source builder for the indicated table or join
### with
```
method with(Common(Any) $cte --> Builder)
```
This returns a new `Builder` object with common table expressions injected into it.
## Builder::Source
### select
```
multi method select(Column::List(Any) $columns --> Builder::Select)
multi method select(*@columns --> Builder::Select)
```
This returns a select builder with the given columns.
### insert
```
multi method insert(Assigns(Any) $values)
multi method insert(Identifiers(Any) $main-columns, Rows(List) $main-rows)
multi method insert(Identifiers(Any) $columns, Value::Default $)
```
This returns a select builder with the given values.
```
$builder.insert({ :1a, :b<foo>, :c(Nil) }).build
```
### update
```
method update(Assigns(Any) $assigns --> Builder::Update)
```
This returns a select builder with the given assignments.
```
$builder.on('table').where({ :1a }).update({ :2a })
$builder.on('table').update({ :2a }).where({ :1a })
```
### delete
```
method delete(--> Builder::Delete)
```
This return a new delete builder for the given table
### upsert
```
method upsert(Assigns $assigns, Conflict::Targets $targets --> Builder::Insert)
```
This returns a new insert builder with an upsert clause.
### join
```
method join(Source(Any) $source, Join::Conditions() :$on)
method join(Source(Any) $source, Identifiers() :$using)
method join(Source(Any) $source, Bool :$natural)
method join(Source(Any) $source, Bool :$cross)
```
Join the target to another table.
```
$on.join('Bar', :using<id>);
$on.join('Bar', :on{ 'Foo.id' => 'Bar.foo_id' });
```
### where
```
method where(Conditions(Any) $where --> Builder::On)
```
This adds a condition to the subsequent operation, or if it's an insert operation adds those values if possible.
## Builder::Select
* method distinct(Distinction(Any) $distinct --> Builder::Select)
* method where(Conditions(Any) $where --> Builder::Select)
* method group-by(GroupBy(Any) $group-by --> Builder::Select)
* method having(Conditions(Any) $having --> Builder::Select)
* method windows(Window::Clauses(Any) $windows --> Builder::Select)
* method compound(Compound(Pair) $compound --> Builder::Select)
* method order-by(OrderBy(Any) $order-by --> Builder::Select)
* method limit(Limit(Any) $limit --> Builder::Select)
* method offset(Offset(Any) $offset --> Builder::Select)
* method locking(Locking(Any) $locking --> Builder::Select)
* method insert(Table(Any) $target, Identifiers(Any) $columns? --> Builder::Insert)
## Builder::Insert
* method overriding(Overriding(Str) $overriding --> Builder::Insert)
* method conflicts(Conflicts(Any) $conflicts --> Builder::Insert)
* method returning(Column::List(Any) $returning --> Builder::Insert)
## Builder::Update
* method from(Update::From(Any) $from --> Builder::Update)
* method where(Conditions(Any) $where --> Builder::Update)
* method returning(Column::List(Any) $returning --> Builder::Update)
## Builder::Delete
* method using(Update::From(Any) $using --> Builder::Delete)
* method where(Column::List(Any) $where --> Builder::Delete)
* method returning(Column::List(Any) $returning --> Builder::Delete)
# Helper types
SQL::Abstract uses various helper types that will generally coerce from basic datastructures:
## SQL::Abstract::Identifier
This represents an identifier (typically a table name or column name, or an alias for such). It can be coerced from a string (e.g. `"foo"` or `"foo.bar"`).
## SQL::Abstract::Identifiers
This takes either a list of `Identifier()`, or a single `Identifier()`.
```
my SQL::Abstract::Identifiers() $identifiers = <name email website>;
```
## SQL::Abstract::Source
A source is source of data, usually a table or a join. If not passed as a `Source` object it will upconvert from the following types:
* Str
This represents the named table, e.g. `"my_table"`.
* List
This represents the named table, with the elements of the list representing the components of the table name. E.g. `<bar baz>` is equivalent to `"bar.baz"` .
* Pair (Str => Identifier(Cool))
This will rename the table in the value to the name in the key.
* Pair (Str => Select(Map))
This will use the result of a subquery as if it's a table.
* Pair (Str => Function(Map))
This will use the function as a subquery.
* Map
This will join two `Source`s, named `left` and `right`, it requires one of the following entries to join them on:
```
* Join::Conditions() :$on
* Identifiers() :$using
* Bool :$natural
* Bool :$cross
```
e.g. `{ :left<artist>, :right<album>, :using<album_id> }` or `{ :left<artist>, :right<album>, :on{'artist.id' => 'album.artist_id'} }`
The first three joiners take an optional `:$type` argument that can be any of `"inner"`/`Join::Type::Inner`, `"left"`/`Join::Type::Left`, `"right"`/`Join::Type::Right` or `"full"`/`Join::Type::Full`.
## SQL::Abstract::Table does SQL::Abstract::Source
This role takes the same conversions as `Source`, but only the ones that represent a table. Unlike other sources, this can be used for mutating operations (update/insert/delete).
## SQL::Abstract::Column::List
```
my Column::List() $columns = ('name', :number(:count(*)));
# name, COUNT(*) AS number;
```
This is a list of items representing a column. Each item can either be a: much like `Identifiers`, however it will accept not just identifiers but any expression (e.g. comparisons, function calls, etc…). If given a pair it will rename the value to the key (`value AS key`). A whatever-star will represent all columns.
## SQL::Abstract::Conditions
```
my Conditions() $conditions = { :name(:like<%leon%>), :age(25..45), :country('nl'|'be'|lu') };
# name LIKE '%leon%' AND AGE BETWEEN 25 AND 45 AND country IN('nl', 'be', 'lu')
```
This is a pair, a list of pairs, a hash or an `Expression`. In the former three cases, the key (called left in the rest of this section) shall be an `Identifier()` designating a column name, or an `Expression`. The right hand side can be one of several types:
### Expression
This will be used as-is
### Any:U
This will check if the left expression is `NULL`; `:left(Any)` equals `left IS NULL`.
### Pair
This will use the key as operator to compare left against another value or expression. E.g. `:left('<' => 42)` renders like `left < 42` . The following keys are known:
* `=`
* `!=`
* `<>`
* `<`
* `<=`
* `>`
* `>=`
* `like`
* `not-like`
* `distinct`
* `not-distinct`
* `||`
* `->`
* `->>`
* `#>`
* `#>>`
* `*`
* `/`
* `%`
* `+`
* `-`
* `&`
* `|`
* `<<`
* `>>`
A few operators are not binary operators as such.
* `null`
will do `IS NULL`, or `IS NOT NULL` if its argument is false(`:!null`).
* `in`/`not-in`
This takes a list of values that the column will be compared to. E.g. `:in(1, 2, 3)`.
* `and`/`or`
The logical operators take a list or arguments, that are all expanded like pair values. So `:foo(:and('>' => 3, '<' => 42))` renders as `foo > 3 AND foo < 42`
### Range
This will check if a value is in a certain range. E.g. `:left(1..42)` will render like `left BETWEEN 1 AND 42`.
### Junction
This will check against the values in the function. E.g. `:left(1|2|4)` will render like `left IN (1, 2, 4)`.
### Capture
This will be expanded as a capture expression (. E.g. `:left(\'NOW()')` will render like `left = NOW()`. If it's an `:op` expression, the column will be inserted as first/left operand: `:left(\(:op('<' => 42)))` renders like `left < 42` .
### Any
If none of the above options match, the value will be compared to as is (as a placeholder). `:left(2)` will render equivalent to `left = 2`.
## SQL::Abstract::Assigns
This takes a list of pairs, or a hash. The keys shall be a value or an expression. E.g. `:name<author>, :id(SQL::Abstract::Values::Default), :timestamp(\'NOW()')`
## SQL::Abstract::OrderBy
This takes a list of things to sort by. Much like `Column::List` this accepts identifiers and expressions, but `*` isn't allowed and pair values are interpreted as order modifier (e.g. `:column<desc>`). A hash element will be expanded as well (e.g. `{ :column<column_name>, :order<desc>, :nulls<last> }` )
## SQL::Abstract::Common
This represents a common table expression. It converts from a pair or a list of pairs, with the keys being the name and the values being either a table name, a select hash or an `SQL::Abstract::Query` object.
```
my Common() $cte = recent => { :from<users>, :columns('name', :count(:count(*)), :group-by(name) };
# WITH recent AS (SELECT name, COUNT(*) AS count FROM users GROUP BY name);
)
```
## SQL::Abstract::Locking
This takes one or more locking clauses. A locking clause is usually taken ... strings: `'update'`, C'<no key update'>, `'share'`, `'key share'`, but it can also take a pair of stregth
## SQL::Abstract::GroupBy
This takes a list of grouping elements. Usually these are just columns, but they may also be arbitrary expressions (inclusing lists of columns). A pair is taken as a function call with the key as function name and the value as arguments.
## SQL::Abstract::Conflicts
This represents one or more upsert clause. It can either be the string `'nothing'`, or a pair with the columns as keys and an `Assigns(Map)`.
```
my SQL::Abstract::Conflicts = <name organization> => { :$email };
# ON CONFLICT (name, organization) DO UPDATE email = ?
```
## SQL::Abstract::Distinction
This takes `True`for a distinct row, or a `Column::List` for specific rows that have to be distinct.
## Window::Definition
Window definiton converts from a map taking the following keys, all optional:
* Identifier(Cool) :$existing
This takes the name of an existing window
* Column::List(Any) :$partition-by
This lists expressions to partition the rows by, somewhat similar to a `GROUP BY`.
* OrderBy(Any) :$order-by
The order within a frame.
* Boundary(Any) :$from
This argument defines the starting boundary of the frame. This can be any of:
```
* 'preceding'
* :preceding($amount)
* 'current'
* :following($amount)
```
It defaults to 'preceding'.
* Boundary(Any) :$to
This optional argument defines the ending boundary of the frame, This can be any of:
```
* :preceding($amount)
* 'current'
* :following($amount)
* 'following'
```
* Mode:D(Str) :$mode = Mode::Range
The mode of the frame takes one of `'rows'`, `'range'` or `'groups'`, defaulting to `'range'`.
* Exclusion(Str) :$exclude
The exclusion of the frame, it takes one of `'current row'`, `'group'`, `'ties'` or `'no others'` (the default).
```
my Window::Definition $d = { :partition-by<foo bar>, :from<current> :to(:following(5)), :exclude<ties> }
# PARTITION BY foo, bar RANGE BETWEEN CURRENT ROW AND 5 FOLLOWING EXCLUDE TIES
```
## Window::Clauses
This takes one or more pairs, with the names being windows names and the values taking window definition maps.
```
my Windows::Clauses $clauses =
over5 => { :frame{ :preceding(5) } },
foo => { :partition-by<foo bar>, :mode<range>, :from<current> :to(:following(5)), :exclude<ties> };
# WINDOW
# over5 AS (ROWS 5 PRECEDING),
# foo as (PARTITION BY foo, bar RANGE BETWEEN CURRENT ROW AND 5 FOLLOWING EXCLUDE TIES)
```
## SQL::Abstract::Limit / SQL::Abstract::Offset
These both take either an `Int` or an `Expression`.
# Capture expressions
Captures can be used in most places where Expressions can be used. They allow for SQL expressions that can't be encoded using simpler values.
There are two kinds of capture expressions. The first kind has one or more named arguments; the first will be used as literal SQL, the rest will be arguments for the literal. E.g. `\'NOW()'`.
The second kind takes a single named argument that may or may not contain a value. Currently supported are:
* Any :$bind
This represents a placeholder variable with the given value
* Bool :$default
This represents the `DEFAULT` keyword
* Bool :$true
This represents the `TRUE` keyword
* Bool :$false
This represents the `FALSE` keyword
* Bool :$null
This represents the `NULL` keyword
* Str :$ident
This represents an identifier (typically a column or table name)
* Bool :$star
This represents a `*`.
* Any :$idents
This represents a list of identifiers
* Any :$columns
This represents a list of column expressions
* :op(@) ('not'|'+'|'-'|'~', Any $expr)
This represents a unary operator (`NOT`, `+`, `-`, `~`).
* :op(@) ('like'|'not-like', Any $left-expr, Any $right-expr, Any $escape-expr)
This represents a `LIKE` operator, e.h. `column LIKE '%foo?' ESCAPE '\\'`
* :op(@) ('between'|'not-between', Any $column-expr, Any $left-expr, Any $right-expr)
This represents a `BETWEEN` expression.
* :@and
This represents an AND expresssion. Typically the contents of this will be further capture expressions.
* :@or
This represents an OR expresssion. Typically the contents of this will be further capture expressions.
* :@op ('in'|'not-in', Any $left-expr, Capture $ (SQL::Abstract::Select(Map) :$select!))
This represents an expression with subquery. E.g. `foo in (SELECT bar from baz where baz.id = table.id)`.
* :@op ('in'|'not-in', Any $left-expr, \*@args)
This represents an expression with list. E.g. `foo in (1, 2, 3)`.
* Select(Map) :$exists
This represents an `EXISTS` expression. E.g. `\(:exists{ :from<table>, columns<1>, :where{ :id(\(:ident<outer.id>)) }` for `EXISTS(SELECT 1 FROM table WHERE id = outer.id`.
* Select(Map) :$not-exists
This is like :exists, but negated.
* :@op ("cast", Any $expression, Str $typename)
This is a expression. E.g. `CAST(columns AS INTEGER)`.
* :op(@) (Str $key, Any $left-expr, Any $right-expr)
Any binary operator applied to two expressions.
* Identifier(Any) :$current
This represents a `CURRENT FOR cursor_name` clause, typically used in an `UPDATE` or `DELETE` statement.
* List :$row
This represents a row expression, e.g. `(a, b, c)`.
* Function(Map) :$function
This represents a function call.
* Select(Map) :$select
This represents a subquery expression.
# Author
Leon Timmermans [[email protected]](mailto:[email protected])
# Copyright and License
Copyright 2022 Leon Timmermans
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-bduggan-Map-Leaflet.md
[](https://github.com/bduggan/raku-map-leaflet/actions/workflows/linux.yml)
[](https://github.com/bduggan/raku-map-leaflet/actions/workflows/macos.yml)
# NAME
Map::Leaflet - Generate maps using leaflet.js
# SYNOPSIS
```
use Map::Leaflet;
my $map = Map::Leaflet.new;
$map.add-marker({ :lat(40.7128), :lon(-74.0060) }, "New York City");
$map.add-marker({ :lat(40.7589), :lon(-73.9851) }, "Empire State Building");
$map.add-marker( 40.7267, -73.9815, "Tompkins Square Park");
$map.add-geojson(q:to/GEOJSON/);
{
"type": "Feature",
"geometry": {
"type": "LineString",
"coordinates": [
[-74.0060, 40.7128],
[-73.9851, 40.7589],
[-73.9815, 40.7267],
[-74.0060, 40.7128]
]
}
}
GEOJSON
my $icon = $map.create-div-icon: html => "You are here";
$map.create-marker: latlng => [40.7128, -74.0060], options => %( icon => $icon );
$map.show;
```

# DESCRIPTION
Generate HTML that renders a map, using the excellent leaflet.js library.
The `Map::Leaflet` class represents a map which can be rendered as HTML. Use a map object to create objects which are analogous to their javascript counterparts, and then render the entire page to generate the javascript.
There are default values for many of the leaflet objects, in an attempt to make common cases work more easily out of the box.
When creating layers, markers, icons, etc., methods named `add-*` are provided with convenient interfaces. For more control, use the `create-*` methods, which pass the options to the constructor for the corresponding object.
In other words, `create-geojson-layer(...)` is equivalent to `add-layer(Map::Leaflet::GeoJSON.new(...))`.
See the `eg/` directory for more examples.
## EXPORTS
If an argument is given when using the module, it is treated as the name of a new object to create. e.g.
```
use Map::Leaflet 'map';
map.add-marker(40.7128, -74.0060, "New York City");
```
is the same as
```
use Map::Leaflet 'map';
my \map = Map::Leaflet.new;
map.add-marker(40.7128, -74.0060, "New York City");
```
## ATTRIBUTES
All of the attributes listed here <https://leafletjs.com/reference.html#map-factory> are available as attributes in the `Map::Leaflet` object. They will be passed to the javascript constructor. For callbacks, use a `Pair` object -- the key and value will be the left and right hand side of a javascript pointy block.
## title
The title of the HTML page. Defaults to 'Map'.
## center
A hash with `lat` and `lon` keys.
## zoom
The zoom level (integer).
## width, height
The height and width of the map. Defaults to 95vw and 95vh, respectively.
## extra-css
Extra CSS to include in the HTML. The default adds a border, centers the map, and provides a class for div-icons.
## tile-provider
The tile provider to use. Defaults to 'CartoDB.Positron'. For a complete list of providers, see <https://leaflet-extras.github.io/leaflet-providers/preview/>.
Here are a few of the providers listed: `CartoDB.Positron`, `OpenStreetMap.Mapnik`, `Esri.WorldstreetMap`
## leaflet-version, leaflet-providers-version
The version of leaflet.js and leaflet-providers.js to use. Defaults to 1.9.4 and 1.13.0, respectively.
## output-path
The filename to write the HTML to. Defaults to 'map-leaflet-tmp.html'.
## other attributes
Other attributes that are passed on to the javascript constructor include: `preferCanvas`, `attributionControl`, `zoomControl`, `closePopupOnClick`, `boxZoom`, `doubleClickZoom`, `dragging`, `zoomSnap`, `zoomDelta`, `trackResize`, `inertia`, `inertiaDeceleration`, `inertiaMaxSpeed`, `easeLinearity`, `worldCopyJump`, `maxBoundsViscosity`, `keyboard`, `keyboardPanDelta`, `scrollWheelZoom`, `wheelDebounceTime`, `wheelPxPerZoomLevel`, `tapHold`, `tapTolerance`, `touchZoom`, `bounceAtZoomLimits`, `crs`, `minZoom`, `maxZoom`, `maxBounds`, `renderer`, `zoomAnimation`, `zoomAnimationThreshold`, `fadeAnimation`, `markerZoomAnimation`, `transform3DLimit`.
# METHODS
## new
```
my $map = Map::Leaflet.new;
my $map = Map::Leaflet.new(
center => { :lat(40.7128), :lon(-74.0060) },
zoom => 13
);
```
Constructor. If no center is specified, then bounds are computed, and the starting view will have a zoom level and extents that fit all of the layers that have been added. See `ATTRIBUTES` for more options.
## add-marker
```
$map.add-marker: { :lat(40.7128), :lon(-74.0060) }, "New York City";
$map.add-marker: 40.7128, -74.0060, "New York City";
$map.add-marker: [40.7128, -74.0060], div => "You are here";
```
Add a marker. The first argument is a hash with `lat` and `lon` keys, and the second argument is an optional popup text. Or the first two arguments can be numeric for the lat + lon. Or they can be an array of two numbers. If a `div` option is provided, it will be used as the `html` option for a `create-div-icon` call, and an `icon` option will be added to the marker.
See `create-marker` below for a more complete way to create markers. Returns a `Map::Leaflet::Marker` object.
## create-div-icon
```
my $div-icon = $map.create-div-icon(html => '<b>New York City</b>');
my $div-icon = $map.create-div-icon: html => '<b>Paris</b>', iconSize => 'auto', className => 'mlraku-div-icon';
```
Create a divIcon. Accepts all of the leaflet.js options. See <https://leafletjs.com/reference.html#divicon>. Defaults to auto-sizing, a yellow background, and a black border, and a class of 'mlraku-div-icon'.
Also accepts a `name` option, which is used to name the icon in the javascript (defaults to an auto-generated name).
Returns a `Map::Leaflet::DivIcon` object.
## create-icon
```
my $icon = $map.create-icon(iconUrl => 'https://leafletjs.com/examples/custom-icons/leaf-green.png');
my $icon = $map.create-icon: iconUrl => 'https://leafletjs.com/examples/custom-icons/leaf-green.png', iconSize => '[38, 95]';
```
Create an icon. Accepts all of the leaflet.js options. See <https://leafletjs.com/reference.html#icon>. Note that the iconSize, iconAnchor, popupAnchor, and tooltipAnchor are all `PointStr` objects, which can be either a string of the form "[x, y]" or the string "auto".
## create-marker
```
$map.create-marker(latlng => [ $lat, $lon ], options => %( icon => $icon ));
$map.create-marker: latlng => [ $lat, $lon ], options => %( title => 'New York City', popup-text => 'The Big Apple' );
```
Create a marker. Accepts all of the leaflet.js options. See <https://leafletjs.com/reference.html#marker>. Also accepts popup-text as an option to generate a popup that is bound to the marker.
Defaults to False values for autoPan and autoPanFocus.
Returns a new `Map::Leaflet::Marker`.
## add-geojson
```
$map.add-geojson($geojson, $style);
$map.add-geojson(q:to/GEOJSON/);
{
"type": "Feature",
"geometry": {
"type": "LineString",
"coordinates": [
[-74.0060, 40.7128],
[-73.9851, 40.7589],
[-73.9815, 40.7267],
[-74.0060, 40.7128]
]
}
}
GEOJSON
$map.add-geojson(
%( :type<Feature>, :geometry(
%( :type<LineString>, :coordinates(
[
[-74.0060, 40.7128],
[-73.9851, 40.7589],
[-73.9815, 40.7267],
[-74.0060, 40.7128]
]
))
)),
style => { :color<red> }
);
```
Add a GeoJSON layer. `$geojson` can be a string or a hash. `$style` is optional and can also be a string or a hash.
## add-circle, create-circle
```
my $circle = $map.create-circle(
center => [40.7128, -74.0060],
radius => 500, # meters
color => 'red',
fillColor => 'red',
fillOpacity => 0.5,
);
$map.add-circle( 40.7128, -74.0060, 500, { color => 'red' } );
```
Create a circle. Accepts all of the leaflet.js options. See <https://leafletjs.com/reference.html#circle>. Returns a new `Map::Leaflet::Circle`.
## add-rectangle, create-rectangle
```
$map.add-rectangle(40.7128, -74.0060, 40.7589, -73.9851, color => 'red');
$map.add-rectangle([40.7128, -74.0060, 40.7589, -73.9851], color => 'red');
$map.add-rectangle([ [40.7128, -74.0060], [40.7589, -73.9851]], color => 'red');
my $rectangle = $map.create-rectangle(
bounds => [[40.7128, -74.0060], [40.7589, -73.9851]],
color => 'red',
fillColor => 'red',
fillOpacity => 0.5,
);
```
Create a rectangle. The bounds can be specified either as four separate coordinates (lat1, lon1, lat2, lon2) or as an array of four numbers. Accepts all of the leaflet.js options. See <https://leafletjs.com/reference.html#rectangle>. Returns a new `Map::Leaflet::Rectangle`.
## add-polygon, create-polygon
```
my $polygon = $map.create-polygon(
latlngs => [
[40.7128, -74.0060],
[40.7589, -73.9851],
[40.7267, -73.9815]
],
color => 'blue',
fillColor => 'blue',
fillOpacity => 0.3,
);
$map.add-polygon(latlngs => [[40.7128, -74.0060], [40.7589, -73.9851], [40.7267, -73.9815]]);
```
Create a polygon. The `latlngs` parameter is required and should be an array of coordinate pairs. Accepts all of the leaflet.js options. See <https://leafletjs.com/reference.html#polygon>. Returns a new `Map::Leaflet::Polygon`.
## add-polyline, create-polyline
```
my $polyline = $map.create-polyline(
latlngs => [
[40.7128, -74.0060],
[40.7589, -73.9851]
],
color => 'red',
weight => 3,
);
$map.add-polyline(latlngs => [[40.7128, -74.0060], [40.7589, -73.9851]]);
```
Create a polyline. The `latlngs` parameter is required and should be an array of coordinate pairs. Accepts all of the leaflet.js options. See <https://leafletjs.com/reference.html#polyline>. Returns a new `Map::Leaflet::Polyline`.
## add-icons, add-markers
These exist if you create icons or markers without using the `create-*` methods. They will add the objects to the map. For examples, see `Map::Leaflet::Icon`
## render
```
spurt "map.html", $map.render;
```
Generate a complete HTML page for the map (including html, head, body, etc.). Returns a string.
## show
```
$map.show;
```
Generate the HTML, write it to <$.output-path>, and open a browser to view it.
## write
```
$map.write;
```
Generate the HTML and write it to <$.output-path>. Returns true if a new file was created, false if the file already existed and was overwritten.
# SEE ALSO
<https://leafletjs.com/>
# AUTHOR
Brian Duggan
|
## dist_github-erickjordan-Parse-STDF.md
# Parse::STDF - Module for parsing files in Standard Test Data Format
Standard Test Data Format (STDF) is a widely used standard file format for semiconductor test information.
It is a commonly used format produced by automatic test equipment (ATE) platforms from companies such as
LTX-Credence, Roos Instruments, Teradyne, Advantest, and others.
A STDF file is compacted into a binary format according to a well defined specification originally designed by
Teradyne. The record layouts, field definitions, and sizes are all described within the specification. Over the
years, parser tools have been developed to decode this binary format in several scripting languages, but as
of yet nothing has been released for Perl6.
Parse::STDF is a first attempt. It is an object oriented module containing methods which invoke APIs of
an underlying C library called **libstdf** (see <http://freestdf.sourceforge.net/>). **libstdf** performs
the grunt work of reading and parsing binary data into STDF records represented as C-structs. These
structs are in turn referenced as Perl6 class objects.
## SYNOPSIS
```
use Parse::STDF;
try
{
my $s = Parse::STDF.new( stdf => $stdf );
while $s.get_record
{
given ( $s.recname )
{
when "MIR"
{
my $mir = $s.mir;
printf("Started At: %s\n", $mir.START_T.ctime);
printf("Station Number: %d\n", $mir.STAT_NUM);
printf("Station Mode: %s\n", $mir.MODE_COD.chr);
printf("Retst_Code: %s\n", $mir.RTST_COD.chr);
printf("Lot: %s\n", $mir.LOT_ID.cnstr);
printf("Part Type: %s\n", $mir.PART_TYP.cnstr);
printf("Node Name: %s\n", $mir.NODE_NAM.cnstr);
printf("Tester Type: %s\n", $mir.TSTR_TYP.cnstr);
printf("Program: %s\n", $mir.JOB_NAM.cnstr);
printf("Version: %s\n", $mir.JOB_REV.cnstr);
printf("Sublot: %s\n", $mir.SBLOT_ID.cnstr);
printf("Operator: %s\n", $mir.OPER_NAM.cnstr);
printf("Executive: %s\n", $mir.EXEC_TYP.cnstr);
printf("Test Code: %s\n", $mir.TEST_COD.cnstr);
printf("Test Temperature: %s\n", $mir.TST_TEMP.cnstr);
printf("Package Type: %s\n", $mir.PKG_TYP.cnstr);
printf("Facility ID: %s\n", $mir.FACIL_ID.cnstr);
printf("Design Revision: %s\n", $mir.DSGN_REV.cnstr);
printf("Flow ID: %s\n", $mir.FLOW_ID.cnstr);
last;
}
default {}
}
}
CATCH
{
when X::Parse::STDF { say $_.message; }
default { say $_; }
}
}
```
## INSTALLATION
Since Parse::STDF uses **libstdf**, 'libstdf.so' must be in your library path (e.g. /usr/local/lib).
To install **libstdf** on Ubuntu for example, use the following commands:
```
$ wget https://sourceforge.net/projects/freestdf/files/libstdf/libstdf-0.4.tar.bz2
$ bunzip2 libstdf-0.4.tar.bz2
$ tar -xvf libstdf-0.4.tar
$ cd libstdf-0.4
$ ./configure --disable-warn-untested
$ make
$ sudo make install
$ sudo ldconfig
```
Using zef (Rakudo module management tool) install:
```
$ zef install Parse::STDF
```
## TESTED PLATFORMS
The following platforms have been tested:
* RHEL Linux 6.x (x84\_64)
* Ubuntu 16.04 LTS (x86\_64)
[](https://travis-ci.org/erickjordan/perl6-Parse-STDF)
## EXAMPLES
Have a look at the examples. There are several scripts that demonstrate how to access the underlying objects and their attributes.
In particular, **dump\_records\_to\_ascii.p6** does a fair job of visiting each Parse::STDF object class.
## NativeCall
Parse::STDF uses NativeCall to interface with **libstdf**. Its easy to use, a natural fit and the next best
thing since sliced cheese. No need for ::XS, SWIG (or other bridging software) to interface a C library with Perl.
NativeCall makes installation of Parse::STDF simple and straightforward. There are only two things required
to get Parse::STDF up and running. Thing one; install **libstdf**. Thing two; install Parse::STDF.
The appeal for using **libstdf** is in its representation of STDF records using C-structs. These structs
are highly reusable and provide a solid foundation to quickly and easily build an application specific parser.
For example, a parser to extract token/value pairs from DTR records to insert rows into a data base table.
NativeCall represents C-structs nicely as Perl6 class objects. This is accomplished by declaring a Perl6 class
using the **repr** trait. See detail documenation here <https://doc.perl6.org/language/nativecall>. In addition
to C-structs NativeCall also represents pointer types which is critical for navigating the various APIs and
structs employed by **libstdf**. These powerful features (and others) make it possible to extend Perl seamlessly
without having to write customized C code.
### NativeCast
Navigating objects of **libstdf** requires a fair amount of C type casting. Following example was taken from
**libstdf/examples/dump\_records\_to\_ascii.c**:
```
case REC_DTR: {
rec_dtr *dtr = (rec_dtr*)rec;
print_str("TEXT_DAT", dtr->TEXT_DAT);
break;
}
```
Here, `rec` is a pointer to C-struct called `rec_unknown`. It is later type casted as a `rec_dtr` type. To mimic
this behavior in Perl6 NativeCall provides an API called `nativecast` which effectively performs the same task as a C
type cast. The above can be written as the following in perl6:
```
nativecast(Pointer[rec_dtr], Pointer[rec]);
```
`nativecast` along with some other perl6 tricks made available by NaticeCall makes it possible to navigate **libstdf**
objects just as if it were written in C.
## SEE ALSO
For an intro to the Standard Test Data Format (along with references to detailed documentation)
see <http://en.wikipedia.org/wiki/Standard_Test_Data_Format>.
## AUTHOR
Erick F. Jordan [[email protected]](mailto:[email protected])
|
## dist_cpan-JDV-Data-Selector.md
```
NAME
Data::Selector - data selection dsl parser and applicator
INSTALLATION
To install this module type the following:
panda install Data::Selector
SEE ALSO
See the individual module documentation for more information.
```
|
## mode.md
mode
Combined from primary sources listed below.
# [In IO::Special](#___top "go to top of document")[§](#(IO::Special)_method_mode "direct link")
See primary documentation
[in context](/type/IO/Special#method_mode)
for **method mode**.
```raku
method mode(IO::Special:D: --> Nil)
```
The mode for the filehandle, it always returns [`Nil`](/type/Nil)
# [In IO::Path](#___top "go to top of document")[§](#(IO::Path)_method_mode "direct link")
See primary documentation
[in context](/type/IO/Path#method_mode)
for **method mode**.
Return an [`IntStr`](/type/IntStr) object representing the POSIX permissions of a file. The [`Str`](/type/Str) part of the result is the octal representation of the file permission, like the form accepted by the `chmod(1)` utility.
```raku
say ~"path/to/file".IO.mode; # e.g. '0644'
say +"path/to/file".IO.mode; # e.g. 420, where sprintf('%04o', 420) eq '0644'
```
The result of this can be used in the other methods that take a mode as an argument.
```raku
"path/to/file1".IO.chmod("path/to/file2".IO.mode); # will change the
# permissions of file1
# to be the same as file2
```
# [In X::IO::Mkdir](#___top "go to top of document")[§](#(X::IO::Mkdir)_method_mode "direct link")
See primary documentation
[in context](/type/X/IO/Mkdir#method_mode)
for **method mode**.
Returns the permissions mask of the failed [mkdir](/routine/mkdir) operation as an [`Int`](/type/Int).
|
## supply.md
## Chunk 1 of 2
class Supply
Asynchronous data stream with multiple subscribers
```raku
class Supply does Awaitable {}
```
A supply is a thread-safe, asynchronous data stream like a [`Channel`](/type/Channel), but it can have multiple subscribers (*taps*) that all get the same values flowing through the supply.
It is a thread-safe implementation of the [Observer Pattern](https://en.wikipedia.org/wiki/Observer_pattern), and central to supporting reactive programming in Raku.
There are two types of Supplies: `live` and `on demand`. When tapping into a `live` supply, the tap will only see values that are flowing through the supply **after** the tap has been created. Such supplies are normally infinite in nature, such as mouse movements. Closing such a tap does not stop mouse events from occurring, it just means that the values will go by unseen. All tappers see the same flow of values.
A tap on an `on demand` supply will initiate the production of values, and tapping the supply again may result in a new set of values. For example, `Supply.interval` produces a fresh timer with the appropriate interval each time it is tapped. If the tap is closed, the timer simply stops emitting values to that tap.
A `live` `Supply` is obtained from the [`Supplier`](/type/Supplier) factory method `Supply`. New values are emitted by calling `emit` on the [`Supplier`](/type/Supplier) object.
```raku
my $supplier = Supplier.new;
my $supply = $supplier.Supply;
$supply.tap(-> $v { say "$v" });
$supplier.emit(42); # Will cause the tap to output "42"
```
The [live method](#method_live) returns `True` on live supplies. Factory methods such as [interval](#method_interval), [from-list](#method_from-list) will return *on demand* supplies.
A live `Supply` that keeps values until tapped the first time can be created with [`Supplier::Preserving`](/type/Supplier/Preserving).
Further examples can be found in the [concurrency page](/language/concurrency#Supplies).
# [Methods that return Taps](#class_Supply "go to top of document")[§](#Methods_that_return_Taps "direct link")
## [method tap](#class_Supply "go to top of document")[§](#method_tap "direct link")
```raku
method tap(Supply:D: &emit = -> $ { },
:&done = -> {},
:&quit = -> $ex { $ex.throw },
:&tap = -> $ {} )
```
Creates a new tap (a kind of subscription if you will), in addition to all existing taps. The first positional argument is a piece of code that will be called when a new value becomes available through the `emit` call.
The `&done` callback can be called in a number of cases: if a supply block is being tapped, when a `done` routine is reached; if a supply block is being tapped, it will be automatically triggered if the supply block reaches the end; if the `done` method is called on the parent [`Supplier`](/type/Supplier) (in the case of a supply block, if there are multiple Suppliers referenced by `whenever`, they must all have their `done` method invoked for this to trigger the `&done` callback of the tap as the block will then reach its end).
The `&quit` callback is called if the tap is on a supply block which exits with an error. It is also called if the `quit` method is invoked on the parent [`Supplier`](/type/Supplier) (in the case of a supply block any one [`Supplier`](/type/Supplier) quitting with an uncaught exception will call the `&quit` callback as the block will exit with an error). The error is passed as a parameter to the callback.
The `&tap` callback is called once the [`Tap`](/type/Tap) object is created, which is passed as a parameter to the callback. The callback is called ahead of `emit`/`done`/`quit`, providing a reliable way to get the [`Tap`](/type/Tap) object. One case where this is useful is when the `Supply` begins emitting values synchronously, since the call to `.tap` won't return the [`Tap`](/type/Tap) object until it is done emitting, preventing it from being stopped if needed.
Method `tap` returns an object of type [`Tap`](/type/Tap), on which you can call the `close` method to cancel the subscription.
```raku
my $s = Supply.from-list(0 .. 5);
my $t = $s.tap(-> $v { say $v }, done => { say "no more ticks" });
```
Produces:
「text」 without highlighting
```
```
0
1
2
3
4
5
no more ticks
```
```
## [method act](#class_Supply "go to top of document")[§](#method_act "direct link")
```raku
method act(Supply:D: &actor, *%others)
```
Creates a tap on the given supply with the given code. Differently from `tap`, the given code is guaranteed to be executed by only one thread at a time.
# [Utility methods](#class_Supply "go to top of document")[§](#Utility_methods "direct link")
## [method Capture](#class_Supply "go to top of document")[§](#method_Capture "direct link")
```raku
method Capture(Supply:D: --> Capture:D)
```
Equivalent to calling [`.List.Capture`](/type/List#method_Capture) on the invocant.
## [method Channel](#class_Supply "go to top of document")[§](#method_Channel "direct link")
```raku
method Channel(Supply:D: --> Channel:D)
```
Returns a [`Channel`](/type/Channel) object that will receive all future values from the supply, and will be `close`d when the Supply is done, and quit (shut down with error) when the supply is quit.
## [method Promise](#class_Supply "go to top of document")[§](#method_Promise "direct link")
```raku
method Promise(Supply:D: --> Promise:D)
```
Returns a [`Promise`](/type/Promise) that will be kept when the `Supply` is `done`. If the `Supply` also emits any values, then the [`Promise`](/type/Promise) will be kept with the final value. Otherwise, it will be kept with [`Nil`](/type/Nil). If the `Supply` ends with a `quit` instead of a `done`, then the [`Promise`](/type/Promise) will be broken with that exception.
```raku
my $supplier = Supplier.new;
my $s = $supplier.Supply;
my $p = $s.Promise;
$p.then(-> $v { say "got $v.result()" });
$supplier.emit('cha'); # not output yet
$supplier.done(); # got cha
```
The [`Promise`](/type/Promise) method is most useful when dealing with supplies that will tend to produce just one value, when only the final value is of interest, or when only completion (successful or not) is relevant.
## [method live](#class_Supply "go to top of document")[§](#method_live "direct link")
```raku
method live(Supply:D: --> Bool:D)
```
Returns `True` if the supply is "live", that is, values are emitted to taps as soon as they arrive. Always returns `True` in the default `Supply` (but for example on the supply returned from `Supply.from-list` it's `False`).
```raku
say Supplier.new.Supply.live; # OUTPUT: «True»
```
## [method schedule-on](#class_Supply "go to top of document")[§](#method_schedule-on "direct link")
```raku
method schedule-on(Supply:D: Scheduler $scheduler)
```
Runs the emit, done and quit callbacks on the specified scheduler.
This is useful for GUI toolkits that require certain actions to be run from the GUI thread.
# [Methods that wait until the supply is done](#class_Supply "go to top of document")[§](#Methods_that_wait_until_the_supply_is_done "direct link")
## [method wait](#class_Supply "go to top of document")[§](#method_wait "direct link")
```raku
method wait(Supply:D:)
```
Taps the `Supply` it is called on, and blocks execution until the either the supply is `done` (in which case it evaluates to the final value that was emitted on the `Supply`, or [`Nil`](/type/Nil) if not value was emitted) or `quit` (in which case it will throw the exception that was passed to `quit`).
```raku
my $s = Supplier.new;
start {
sleep 1;
say "One second: running.";
sleep 1;
$s.emit(42);
$s.done;
}
$s.Supply.wait;
say "Two seconds: done";
```
## [method list](#class_Supply "go to top of document")[§](#method_list "direct link")
```raku
multi method list(Supply:D:)
```
Taps the `Supply` it is called on, and returns a lazy list that will be reified as the `Supply` emits values. The list will be terminated once the `Supply` is `done`. If the `Supply` `quit`s, then an exception will be thrown once that point in the lazy list is reached.
## [method Seq](#class_Supply "go to top of document")[§](#method_Seq "direct link")
```raku
method Seq(Supply:D:)
```
Returns a [`Seq`](/type/Seq) with an iterator containing the values that the `Supply` contains.
## [method grab](#class_Supply "go to top of document")[§](#method_grab "direct link")
```raku
method grab(Supply:D: &when-done --> Supply:D)
```
Taps the `Supply` it is called on. When it is `done`, calls `&when-done` and then emits the list of values that it returns on the result `Supply`. If the original `Supply` `quit`s, then the exception is immediately conveyed on the return `Supply`.
```raku
my $s = Supply.from-list(4, 10, 3, 2);
my $t = $s.grab(&sum);
$t.tap(&say); # OUTPUT: «19»
```
## [method reverse](#class_Supply "go to top of document")[§](#method_reverse "direct link")
```raku
method reverse(Supply:D: --> Supply:D)
```
Taps the `Supply` it is called on. Once that `Supply` emits `done`, all of the values it emitted will be emitted on the returned `Supply` in reverse order. If the original `Supply` `quit`s, then the exception is immediately conveyed on the return `Supply`.
```raku
my $s = Supply.from-list(1, 2, 3);
my $t = $s.reverse;
$t.tap(&say); # OUTPUT: «321»
```
## [method sort](#class_Supply "go to top of document")[§](#method_sort "direct link")
```raku
method sort(Supply:D: &custom-routine-to-use? --> Supply:D)
```
Taps the `Supply` it is called on. Once that `Supply` emits `done`, all of the values that it emitted will be sorted, and the results emitted on the returned `Supply` in the sorted order. Optionally accepts a comparator [`Block`](/type/Block). If the original `Supply` `quit`s, then the exception is immediately conveyed on the return `Supply`.
```raku
my $s = Supply.from-list(4, 10, 3, 2);
my $t = $s.sort();
$t.tap(&say); # OUTPUT: «23410»
```
## [method collate](#class_Supply "go to top of document")[§](#method_collate "direct link")
```raku
method collate(Supply:D:)
```
Taps the `Supply` it is called on. Once that `Supply` emits `done`, all of the values that it emitted will be sorted taking into account Unicode grapheme characteristics. A new `Supply` is returned with the sorted values emitted. See [Any.collate](/type/Any#method_collate) for more details on the collated sort.
```raku
my $s = Supply.from-list(<ä a o ö>);
my $t = $s.collate();
$t.tap(&say); # OUTPUT: «aäoö»
```
## [method reduce](#class_Supply "go to top of document")[§](#method_reduce "direct link")
```raku
method reduce(Supply:D: &with --> Supply:D)
```
Creates a "reducing" supply, which will emit a single value with the same semantics as [List.reduce](/type/List#routine_reduce).
```raku
my $supply = Supply.from-list(1..5).reduce({$^a + $^b});
$supply.tap(-> $v { say "$v" }); # OUTPUT: «15»
```
# [Methods that return another Supply](#class_Supply "go to top of document")[§](#Methods_that_return_another_Supply "direct link")
## [method from-list](#class_Supply "go to top of document")[§](#method_from-list "direct link")
```raku
method from-list(Supply:U: +@values --> Supply:D)
```
Creates an on-demand supply from the values passed to this method.
```raku
my $s = Supply.from-list(1, 2, 3);
$s.tap(&say); # OUTPUT: «123»
```
## [method share](#class_Supply "go to top of document")[§](#method_share "direct link")
```raku
method share(Supply:D: --> Supply:D)
```
Creates a live supply from an on-demand supply, thus making it possible to share the values of the on-demand supply on multiple taps, instead of each tap seeing its own copy of all values from the on-demand supply.
```raku
# this says in turn: "first 1" "first 2" "second 2" "first 3" "second 3"
my $s = Supply.interval(1).share;
$s.tap: { "first $_".say };
sleep 1.1;
$s.tap: { "second $_".say };
sleep 2
```
## [method flat](#class_Supply "go to top of document")[§](#method_flat "direct link")
```raku
method flat(Supply:D: --> Supply:D)
```
Creates a supply on which all of the values seen in the given supply are flattened before being emitted again.
## [method do](#class_Supply "go to top of document")[§](#method_do "direct link")
```raku
method do(Supply:D: &do --> Supply:D)
```
Creates a supply to which all values seen in the given supply, are emitted again. The given code, executed for its side-effects only, is guaranteed to be only executed by one thread at a time.
## [method on-close](#class_Supply "go to top of document")[§](#method_on-close "direct link")
```raku
method on-close(Supply:D: &on-close --> Supply:D)
```
Returns a new `Supply` which will run `&on-close` whenever a [`Tap`](/type/Tap) of that `Supply` is closed. This includes if further operations are chained on to the `Supply`. (for example, `$supply.on-close(&on-close).map(*.uc)`). When using a `react` or `supply` block, using the [CLOSE](/language/phasers#CLOSE) phaser is usually a better choice.
```raku
my $s = Supplier.new;
my $tap = $s.Supply.on-close({ say "Tap closed" }).tap(
-> $v { say "the value is $v" },
done => { say "Supply is done" },
quit => -> $ex { say "Supply finished with error $ex" },
);
$s.emit('Raku');
$tap.close; # OUTPUT: «Tap closed»
```
## [method interval](#class_Supply "go to top of document")[§](#method_interval "direct link")
```raku
method interval(Supply:U: $interval, $delay = 0, :$scheduler = $*SCHEDULER --> Supply:D)
```
Creates a supply that emits a value every `$interval` seconds, starting `$delay` seconds from the call. The emitted value is an integer, starting from 0, and is incremented by one for each value emitted.
Implementations may treat too-small and negative values as lowest resolution they support, possibly warning in such situations; e.g. treating `0.0001` as `0.001`. For 6.d language version, the minimal value specified is `0.001`.
## [method grep](#class_Supply "go to top of document")[§](#method_grep "direct link")
```raku
method grep(Supply:D: Mu $test --> Supply:D)
```
Creates a new supply that only emits those values from the original supply that smartmatch against `$test`.
```raku
my $supplier = Supplier.new;
my $all = $supplier.Supply;
my $ints = $all.grep(Int);
$ints.tap(&say);
$supplier.emit($_) for 1, 'a string', 3.14159; # prints only 1
```
## [method map](#class_Supply "go to top of document")[§](#method_map "direct link")
```raku
method map(Supply:D: &mapper --> Supply:D)
```
Returns a new supply that maps each value of the given supply through `&mapper` and emits it to the new supply.
```raku
my $supplier = Supplier.new;
my $all = $supplier.Supply;
my $double = $all.map(-> $value { $value * 2 });
$double.tap(&say);
$supplier.emit(4); # OUTPUT: «8»
```
## [method batch](#class_Supply "go to top of document")[§](#method_batch "direct link")
```raku
method batch(Supply:D: :$elems, :$seconds --> Supply:D)
```
Creates a new supply that batches the values of the given supply by either the number of elements in the batch (using `:elems`) or a duration (using `:seconds`) or both. Any remaining values are emitted in a final batch when the supply is done.
**Note**: Since Rakudo version 2020.12, the `:seconds` parameter has a millisecond granularity: for example a 1 millisecond duration could be specified as `:seconds(0.001)`. Before Rakudo version 2020.12, the `:seconds` parameter had a second granularity.
## [method elems](#class_Supply "go to top of document")[§](#method_elems "direct link")
```raku
method elems(Supply:D: $seconds? --> Supply:D)
```
Creates a new supply in which changes to the number of values seen are emitted. It optionally also takes an interval (in seconds) if you only want to be updated every so many seconds.
## [method head](#class_Supply "go to top of document")[§](#method_head "direct link")
```raku
multi method head(Supply:D:)
multi method head(Supply:D: Callable:D $limit)
multi method head(Supply:D: \limit)
```
Creates a "head" supply with the same semantics as [List.head](/type/List#method_head).
```raku
my $s = Supply.from-list(4, 10, 3, 2);
my $hs = $s.head(2);
$hs.tap(&say); # OUTPUT: «410»
```
Since release 2020.07, A [`WhateverCode`](/type/WhateverCode) can be used also, again with the same semantics as `List.head`
```raku
my $s = Supply.from-list(4, 10, 3, 2, 1);
my $hs = $s.head( * - 2);
$hs.tap(&say); # OUTPUT: «4103»
```
## [method tail](#class_Supply "go to top of document")[§](#method_tail "direct link")
```raku
multi method tail(Supply:D:)
multi method tail(Supply:D: Callable:D $limit)
multi method tail(Supply:D: \limit)
```
Creates a "tail" supply with the same semantics as [List.tail](/type/List#method_tail).
```raku
my $s = Supply.from-list(4, 10, 3, 2);
my $ts = $s.tail(2);
$ts.tap(&say); # OUTPUT: «32»
```
You can call `.tail` with [`Whatever`](/type/Whatever) or `Inf`; which will return a new supply equivalent to the initial one. Calling it with a [`WhateverCode`](/type/WhateverCode) will be equivalent to skipping until that number.
```raku
my $s = Supply.from-list(4, 10, 3, 2);
my $ts = $s.tail( * - 2 );
$ts.tap(&say); # OUTPUT: «32»
```
This feature is only available from the 2020.07 release of Raku.
## [method first](#class_Supply "go to top of document")[§](#method_first "direct link")
```raku
method first(Supply:D: :$end, |c)
```
This method creates a supply of the first element, or the last element if the optional named parameter `:end` is truthy, from a supply created by calling the `grep` method on the invocant, with any remaining arguments as parameters. If there is no remaining argument, this method is equivalent to calling on the invocant, without parameter, the `head` or the `tail` method, according to named parameter `:end`.
```raku
my $rand = supply { emit (rand × 100).floor for ^∞ };
my $first-prime = $rand.first: &is-prime;
# output the first prime from the endless random number supply $rand,
# then the $first-prime supply reaches its end
$first-prime.tap: &say;
```
## [method split](#class_Supply "go to top of document")[§](#method_split "direct link")
```raku
multi method split(Supply:D: \delimiter)
multi method split(Supply:D: \delimiter, \limit)
```
This method creates a supply of the values returned by the `Str.split` method called on the string collected from the invocant. See [`Str.split`](/type/Str#routine_split) for details on the `\delimiter` argument as well as available extra named parameters. The created supply can be limited with the `\limit` argument, see [`.head`](#method_head).
```raku
my $words = Supply.from-list(<Hello World From Raku!>);
my $s = $words.split(/ <?upper> /, 2, :skip-empty);
$s.tap(&say); # OUTPUT: «HelloWorld»
```
## [method rotate](#class_Supply "go to top of document")[§](#method_rotate "direct link")
```raku
method rotate(Supply:D: $rotate = 1)
```
Creates a supply with elements rotated to the left when `$rotate` is positive or to the right otherwise, in which case the invocant is tapped on before a new supply is returned.
```raku
my $supply = Supply.from-list(<a b c d e>).rotate(2);
$supply.tap(&say); # OUTPUT: «cdeab»
```
**Note**: Available since Rakudo 2020.06.
## [method rotor](#class_Supply "go to top of document")[§](#method_rotor "direct link")
```raku
method rotor(Supply:D: @cycle --> Supply:D)
```
Creates a "rotoring" supply with the same semantics as [List.rotor](/type/List#routine_rotor).
## [method delayed](#class_Supply "go to top of document")[§](#method_delayed "direct link")
```raku
method delayed(Supply:D: $seconds, :$scheduler = $*SCHEDULER --> Supply:D)
```
Creates a new supply in which all values flowing through the given supply are emitted, but with the given delay in seconds.
## [method throttle](#class_Supply "go to top of document")[§](#method_throttle "direct link")
```raku
multi method throttle(Supply:D:
Int() $elems,
Real() $seconds,
Real() $delay = 0,
:$scheduler = $*SCHEDULER,
:$control,
:$status,
:$bleed,
:$vent-at,
)
```
```raku
multi method throttle(Supply:D:
Int() $elems,
Callable:D $process,
Real() $delay = 0,
:$scheduler = $*SCHEDULER,
:$control,
:$status,
:$bleed,
:$vent-at,
)
```
Arguments to `.throttle` are defined as follows:
| Argument | Meaning |
| --- | --- |
| $limit, | values / time or simultaneous processing |
| $seconds or $process | time-unit / code to process simultaneously |
| $delay = 0, | initial delay before starting, in seconds |
| :$control, | supply to emit control messages on (optional) |
| :$status, | supply to tap status messages from (optional) |
| :$bleed, | supply to bleed messages to (optional) |
| :$vent-at, | bleed when so many buffered (optional) |
| :$scheduler, | scheduler to use, default $\*SCHEDULER |
This method produces a `Supply` from a given one, but makes sure the number of messages passed through is limited.
It has two modes of operation: per time-unit or by maximum number of executions of a block of code: this is determined by the type of the second positional parameter.
The first positional parameter specifies the limit that should be applied.
If the second positional parameter is a [`Callable`](/type/Callable), then the limit indicates the maximum number of parallel processes executing the Callable, which is given the value that was received. The emitted values in this case will be the [`Promise`](/type/Promise)s that were obtained from `start`ing the [`Callable`](/type/Callable).
If the second positional parameter is a real number, it is interpreted as the time-unit (in seconds). If you specify **.1** as the value, then it makes sure you don't exceed the limit for every tenth of a second.
If the limit is exceeded, then incoming messages are buffered until there is room to pass on / execute the Callable again.
The third positional parameter is optional: it indicates the number of seconds the throttle will wait before passing on any values.
The `:control` named parameter optionally specifies a Supply that you can use to control the throttle while it is in operation. Messages that can be sent, are strings in the form of "key:value". Please see below for the types of messages that you can send to control the throttle.
The `:status` named parameter optionally specifies a Supply that will receive any status messages. If specified, it will at least send one status message after the original Supply is exhausted. See [status message](#status_message) below.
The `:bleed` named parameter optionally specifies a Supply that will receive any values that were either explicitly bled (with the **bleed** control message), or automatically bled (if there's a **vent-at** active).
The `:vent-at` named parameter indicates the number of values that may be buffered before any additional value will be routed to the `:bleed` Supply. Defaults to 0 if not specified (causing no automatic bleeding to happen). Only makes sense if a `:bleed` Supply has also been specified.
The `:scheduler` named parameter indicates the scheduler to be used. Defaults to `$*SCHEDULER`.
### [control messages](#class_Supply "go to top of document")[§](#control_messages "direct link")
These messages can be sent to the `:control` Supply. A control message consists of a string of the form "key: value", e.g. "limit: 4".
* limit
Change the number of messages (as initially given in the first positional) to the value given.
* bleed
Route the given number of buffered messages to the `:bleed` Supply.
* vent-at
Change the maximum number of buffered values before automatic bleeding takes place. If the value is lower than before, will cause immediate rerouting of buffered values to match the new maximum.
* status
Send a status message to the `:status` Supply with the given id.
### [status message](#class_Supply "go to top of document")[§](#status_message "direct link")
The status return message is a hash with the following keys:
* allowed
The current number of messages / callables that is still allowed to be passed / executed.
* bled
The number of messages routed to the `:bleed` Supply.
* buffered
The number of messages currently buffered because of overflow.
* emitted
The number of messages emitted (passed through).
* id
The id of this status message (a monotonically increasing number). Handy if you want to log status messages.
* limit
The current limit that is being applied.
* vent-at
The maximum number of messages that may be buffered before they're automatically re-routed to the `:bleed` Supply.
### [Examples](#class_Supply "go to top of document")[§](#Examples "direct link")
Have a simple piece of code announce when it starts running asynchronously, wait a random amount of time, then announce when it is done. Do this 6 times, but don't let more than 3 of them run simultaneously.
```raku
my $s = Supply.from-list(^6); # set up supply
my $t = $s.throttle: 3, # only allow 3 at a time
{ # code block to run
say "running $_"; # announce we've started
sleep rand; # wait some random time
say "done $_" # announce we're done
} # don't need ; because } at end of line
$t.wait; # wait for the supply to be done
```
and the result of one run will be:
「text」 without highlighting
```
```
running 0
running 1
running 2
done 2
running 3
done 1
running 4
done 4
running 5
done 0
done 3
done 5
```
```
## [method stable](#class_Supply "go to top of document")[§](#method_stable "direct link")
```raku
method stable(Supply:D: $time, :$scheduler = $*SCHEDULER --> Supply:D)
```
Creates a new supply that only passes on a value flowing through the given supply if it wasn't superseded by another value in the given `$time` (in seconds). Optionally uses another scheduler than the default scheduler, using the `:scheduler` parameter.
To clarify the above, if, during the timeout `$time`, additional values are emitted to the [`Supplier`](/type/Supplier) all but the last one will be thrown away. Each time an additional value is emitted to the [`Supplier`](/type/Supplier), during the timeout, `$time` is reset.
This method can be quite useful when handling UI input, where it is not desired to perform an operation until the user has stopped typing for a while rather than on every keystroke.
```raku
my $supplier = Supplier.new;
my $supply1 = $supplier.Supply;
$supply1.tap(-> $v { say "Supply1 got: $v" });
$supplier.emit(42);
my Supply $supply2 = $supply1.stable(5);
$supply2.tap(-> $v { say "Supply2 got: $v" });
sleep(3);
$supplier.emit(43); # will not be seen by $supply2 but will reset $time
$supplier.emit(44);
sleep(10);
# OUTPUT: «Supply1 got: 42Supply1 got: 43Supply1 got: 44Supply2 got: 44»
```
As can be seen above, `$supply1` received all values emitted to the [`Supplier`](/type/Supplier) while `$supply2` only received one value. The 43 was thrown away because it was followed by another 'last' value 44 which was retained and sent to `$supply2` after approximately eight seconds, this due to the fact that the timeout `$time` was reset after three seconds.
## [method produce](#class_Supply "go to top of document")[§](#method_produce "direct link")
```raku
method produce(Supply:D: &with --> Supply:D)
```
Creates a "producing" supply with the same semantics as [List.produce](/type/List#routine_produce).
```raku
my $supply = Supply.from-list(1..5).produce({$^a + $^b});
$supply.tap(-> $v { say "$v" }); # OUTPUT: «1361015»
```
## [method lines](#class_Supply "go to top of document")[§](#method_lines "direct link")
```raku
method lines(Supply:D: :$chomp = True --> Supply:D)
```
Creates a supply that will emit the characters coming in line by line from a supply that's usually created by some asynchronous I/O operation. The optional `:chomp` parameter indicates whether to remove line separators: the default is `True`.
## [method words](#class_Supply "go to top of document")[§](#method_words "direct link")
```raku
method words(Supply:D: --> Supply:D)
```
Creates a supply that will emit the characters coming in word for word from a supply that's usually created by some asynchronous I/O operation.
```raku
my $s = Supply.from-list("Hello Word!".comb);
my $ws = $s.words;
$ws.tap(&say); # OUTPUT: «HelloWord!»
```
## [method unique](#class_Supply "go to top of document")[§](#method_unique "direct link")
```raku
method unique(Supply:D: :$as, :$with, :$expires --> Supply:D)
```
Creates a supply that only provides unique values, as defined by the optional `:as` and `:with` parameters (same as with [`unique`](/type/independent-routines#routine_unique)). The optional `:expires` parameter how long to wait (in seconds) before "resetting" and not considering a value to have been seen, even if it's the same as an old value.
## [method repeated](#class_Supply "go to top of document")[§](#method_repeated "direct link")
```raku
method repeated(Supply:D: :&as, :&with)
```
Creates a supply that only provides repeated values, as defined by the optional `:as` and `:with` parameters (same as with [`unique`](/type/independent-routines#routine_unique)).
```raku
my $supply = Supply.from-list(<a A B b c b C>).repeated(:as(&lc));
$supply.tap(&say); # OUTPUT: «AbbC»
```
See [`repeated`](/type/independent-routines#routine_repeated) for more examples that use its sub form.
**Note**: Available since version 6.e ([Rakudo](/language/glossary#Rakudo) 2020.01 and later).
## [method squish](#class_Supply "go to top of document")[§](#method_squish "direct link")
```raku
method squish(Supply:D: :$as, :$with --> Supply:D)
```
Creates a supply that only provides unique values, as defined by the optional `:as` and `:with` parameters (same as with [`squish`](/type/independent-routines#routine_squish)).
## [method max](#class_Supply "go to top of document")[§](#method_max "direct link")
```raku
method max(Supply:D: &custom-routine-to-use = &infix:<cmp> --> Supply:D)
```
Creates a supply that only emits values from the given supply if they are larger |
## supply.md
## Chunk 2 of 2
than any value seen before. In other words, from a continuously ascending supply it will emit all the values. From a continuously descending supply it will only emit the first value. The optional parameter specifies the comparator, just as with [Any.max](/type/Any#routine_max).
## [method min](#class_Supply "go to top of document")[§](#method_min "direct link")
```raku
method min(Supply:D: &custom-routine-to-use = &infix:<cmp> --> Supply:D)
```
Creates a supply that only emits values from the given supply if they are smaller than any value seen before. In other words, from a continuously descending supply it will emit all the values. From a continuously ascending supply it will only emit the first value. The optional parameter specifies the comparator, just as with [Any.min](/type/Any#routine_min).
## [method minmax](#class_Supply "go to top of document")[§](#method_minmax "direct link")
```raku
method minmax(Supply:D: &custom-routine-to-use = &infix:<cmp> --> Supply:D)
```
Creates a supply that emits a Range every time a new minimum or maximum values is seen from the given supply. The optional parameter specifies the comparator, just as with [Any.minmax](/type/Any#routine_minmax).
## [method skip](#class_Supply "go to top of document")[§](#method_skip "direct link")
```raku
method skip(Supply:D: Int(Cool) $number = 1 --> Supply:D)
```
Returns a new `Supply` which will emit all values from the given `Supply` except for the first `$number` values, which will be thrown away.
```raku
my $supplier = Supplier.new;
my $supply = $supplier.Supply;
$supply = $supply.skip(3);
$supply.tap({ say $_ });
$supplier.emit($_) for 1..10; # OUTPUT: «45678910»
```
## [method start](#class_Supply "go to top of document")[§](#method_start "direct link")
```raku
method start(Supply:D: &startee --> Supply:D)
```
Creates a supply of supplies. For each value in the original supply, the code object is scheduled on another thread, and returns a supply either of a single value (if the code succeeds), or one that quits without a value (if the code fails).
This is useful for asynchronously starting work that you don't block on.
Use `migrate` to join the values into a single supply again.
## [method migrate](#class_Supply "go to top of document")[§](#method_migrate "direct link")
```raku
method migrate(Supply:D: --> Supply:D)
```
Takes a `Supply` which itself has values that are of type `Supply` as input. Each time the outer `Supply` emits a new `Supply`, this will be tapped and its values emitted. Any previously tapped `Supply` will be closed. This is useful for migrating between different data sources, and only paying attention to the latest one.
For example, imagine an application where the user can switch between different stocks. When they switch to a new one, a connection is established to a web socket to get the latest values, and any previous connection should be closed. Each stream of values coming over the web socket would be represented as a Supply, which themselves are emitted into a Supply of latest data sources to watch. The `migrate` method could be used to flatten this supply of supplies into a single Supply of the current values that the user cares about.
Here is a simple simulation of such a program:
```raku
my Supplier $stock-sources .= new;
sub watch-stock($symbol) {
$stock-sources.emit: supply {
say "Starting to watch $symbol";
whenever Supply.interval(1) {
emit "$symbol: 111." ~ 99.rand.Int;
}
CLOSE say "Lost interest in $symbol";
}
}
$stock-sources.Supply.migrate.tap: *.say;
watch-stock('GOOG');
sleep 3;
watch-stock('AAPL');
sleep 3;
```
Which produces output like:
「text」 without highlighting
```
```
Starting to watch GOOG
GOOG: 111.67
GOOG: 111.20
GOOG: 111.37
Lost interest in GOOG
Starting to watch AAPL
AAPL: 111.55
AAPL: 111.6
AAPL: 111.6
```
```
# [Methods that combine supplies](#class_Supply "go to top of document")[§](#Methods_that_combine_supplies "direct link")
## [method merge](#class_Supply "go to top of document")[§](#method_merge "direct link")
```raku
method merge(Supply @*supplies --> Supply:D)
```
Creates a supply to which any value seen from the given supplies, is emitted. The resulting supply is done only when all given supplies are done. Can also be called as a class method.
## [method zip](#class_Supply "go to top of document")[§](#method_zip "direct link")
```raku
method zip(**@s, :&with)
```
Creates a supply that emits combined values as soon as there is a new value seen on **all** of the supplies. By default, [`List`](/type/List)s are created, but this can be changed by specifying your own combiner with the `:with` parameter. The resulting supply is done as soon as **any** of the given supplies are done. Can also be called as a class method.
This can also be used as a class method; in case it's used as an object method the corresponding supply will be one of the supplies combined (with no special treatment).
## [method zip-latest](#class_Supply "go to top of document")[§](#method_zip-latest "direct link")
```raku
method zip-latest(**@s, :&with, :$initial )
```
Creates a supply that emits combined values as soon as there is a new value seen on **any** of the supplies. By default, [`List`](/type/List)s are created, but this can be changed by specifying your own combiner with the `:with` parameter. The optional :initial parameter can be used to indicate the initial state of the combined values. By default, all supplies have to have at least one value emitted on them before the first combined values is emitted on the resulting supply. The resulting supply is done as soon as **any** of the given supplies are done. Can also be called as a class method.
# [I/O features exposed as supplies](#class_Supply "go to top of document")[§](#I/O_features_exposed_as_supplies "direct link")
## [sub signal](#class_Supply "go to top of document")[§](#sub_signal "direct link")
```raku
sub signal(*@signals, :$scheduler = $*SCHEDULER)
```
Creates a supply for the Signal enums (such as SIGINT) specified, and an optional `:scheduler` parameter. Any signals received, will be emitted on the supply. For example:
```raku
signal(SIGINT).tap( { say "Thank you for your attention"; exit 0 } );
```
would catch Control-C, thank you, and then exit.
To go from a signal number to a Signal, you can do something like this:
```raku
signal(Signal(2)).tap( -> $sig { say "Received signal: $sig" } );
```
The list of supported signals can be found by checking `Signal::.keys` (as you would any enum). For more details on how enums work see [enum](/language/typesystem#enum).
**Note:** [Rakudo](/language/glossary#Rakudo) versions up to 2018.05 had a bug due to which numeric values of signals were incorrect on some systems. For example, `Signal(10)` was returning `SIGBUS` even if it was actually `SIGUSR1` on a particular system. That being said, using `signal(SIGUSR1)` was working as expected on all Rakudo versions except 2018.04, 2018.04.1 and 2018.05, where the intended behavior can be achieved by using `signal(SIGBUS)` instead. These issues are resolved in Rakudo releases after 2018.05.
## [method IO::Notification.watch-path](#class_Supply "go to top of document")[§](#method_IO::Notification.watch-path "direct link")
```raku
method watch-path($path --> Supply:D)
```
Creates a supply to which the OS will emit values to indicate changes on the filesystem for the given path. Also has a shortcut with the `watch` method on an IO object, like this:
```raku
IO::Notification.watch-path(".").act( { say "$^file changed" } );
".".IO.watch.act( { say "$^file changed" } ); # same
```
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Supply`
raku-type-graph
Supply
Supply
Any
Any
Supply->Any
Mu
Mu
Any->Mu
[Expand chart above](/assets/typegraphs/Supply.svg)
|
## volume.md
volume
Combined from primary sources listed below.
# [In IO::Path](#___top "go to top of document")[§](#(IO::Path)_method_volume "direct link")
See primary documentation
[in context](/type/IO/Path#method_volume)
for **method volume**.
```raku
method volume(IO::Path:D:)
```
Returns the volume portion of the path object. On Unix system, this is always the empty string.
```raku
say IO::Path::Win32.new("C:\\Windows\\registry.ini").volume; # OUTPUT: «C:»
```
|
## dist_zef-melezhik-bird.md
# Bird 🐦
Bird - Raku DSL for Linux Servers Verification.
It's written in Raku and exposes pure Raku API.
# WARNING ⚠️
Bird is under active development now, things might change.
# Build Status
[](https://ci.sparrowhub.io)
# INSTALL
```
zef install Bird
```
Bird uses Sparrow6 plugin `ssh-bulk-check` to do it's work, so one needs
to setup Sparrow6 repository:
```
export SP6_REPO=http://sparrowhub.io/repo
```
To run check remotely install ssh-pass:
```
sudo yum install sshpass
```
# USAGE
Create rules:
`cat rules.raku`
```
directory-exists "{%*ENV<HOME>}";
file-exists "{%*ENV<HOME>}/.bashrc";
bash "echo hello > /tmp/bird.tmp";
bash "echo bird >> /tmp/bird.tmp";
file-has-line "/tmp/bird.tmp", "hello", "bird";
file-has-permission "documentation/dsl.md", %( read-all => True );
file-has-permission "bin/bird", %( execute-all => True, read-all => True );
bash "chmod a+r /tmp/bird.tmp";
bash "chmod a+w /tmp/bird.tmp";
file-has-permission "/tmp/bird.tmp", %( write-all => True, read-all => True );
command-has-stdout "echo hello; echo bird", "hello", "bird";
command-exit-code "raku --version", 0;
package-installed "nano";
pip3-package-installed "PyYAML";
file-has-permission "rules.raku", %( read-all => True );
package-installed "nano";
bash "echo username=admin > /tmp/creds.txt; echo password=123 >> /tmp/creds.txt;";
file-data-not-empty "/tmp/creds.txt",
"username=", "password=";
```
Run checks against hosts:
`bird`
```
bird:: [read hosts from file] [hosts.raku]
bird:: [cmd file] [/root/.bird/274302/cmd.sh]
bird:: [check file] [/root/.bird/274302/state.check]
bird:: [init cmd file]
[bash: echo hello > /tmp/bird.tmp] :: <empty stdout>
[bash: echo bird >> /tmp/bird.tmp] :: <empty stdout>
[bash: chmod a+r /tmp/bird.tmp] :: <empty stdout>
[bash: chmod a+w /tmp/bird.tmp] :: <empty stdout>
[bash: echo username=admin > /tmp/creds.txt; echo passwor ...] :: <empty stdout>
[repository] :: index updated from file:///root/repo/api/v1/index
[check my hosts] :: check host [localhost]
[check my hosts] :: ==========================================================
[check my hosts] :: <<< test_01: directory /root exists
[check my hosts] :: directory /root exists
[check my hosts] :: >>>
[check my hosts] :: <<< test_02: file /root/.bashrc exists
[check my hosts] :: file /root/.bashrc exists
[check my hosts] :: >>>
[check my hosts] :: <<< test_03: file /tmp/bird.tmp has lines
[check my hosts] :: hello
[check my hosts] :: bird
[check my hosts] :: >>>
[check my hosts] :: <<< test_04: file documentation/dsl.md is readable by all
[check my hosts] :: -rw-r--r--
[check my hosts] :: >>>
[check my hosts] :: <<< test_05: file bin/bird is readable by all
[check my hosts] :: -rwxr-xr-x
[check my hosts] :: >>>
[check my hosts] :: <<< test_06: file bin/bird is executable by all
[check my hosts] :: -rwxr-xr-x
[check my hosts] :: >>>
[check my hosts] :: <<< test_07: file /tmp/bird.tmp is readable by all
[check my hosts] :: -rw-rw-rw-
[check my hosts] :: >>>
[check my hosts] :: <<< test_08: file /tmp/bird.tmp is writable by all
[check my hosts] :: -rw-rw-rw-
[check my hosts] :: >>>
[check my hosts] :: <<< test_09: command [echo hello; echo bird] has stdout
[check my hosts] :: hello
[check my hosts] :: bird
[check my hosts] :: >>>
[check my hosts] :: <<< test_10: command [raku --version] has exit code
[check my hosts] :: command [raku --version] exit code [0]
[check my hosts] :: >>>
[check my hosts] :: <<< test_11: package(s) installed
[check my hosts] :: Installed Packages
[check my hosts] :: nano.x86_64 2.9.8-1.el8 @baseos
[check my hosts] :: package nano is installed
[check my hosts] :: >>>
[check my hosts] :: <<< test_12: pip3 package(s) installed
[check my hosts] :: PyYAML 3.12
[check my hosts] :: >>>
[check my hosts] :: <<< test_13: file rules.raku is readable by all
[check my hosts] :: -rw-r--r--
[check my hosts] :: >>>
[check my hosts] :: <<< test_14: package(s) installed
[check my hosts] :: Installed Packages
[check my hosts] :: nano.x86_64 2.9.8-1.el8 @baseos
[check my hosts] :: package nano is installed
[check my hosts] :: >>>
[check my hosts] :: <<< test_15: file /tmp/creds.txt data not empty
[check my hosts] :: >>> username=[censored]
[check my hosts] :: >>> password=[censored]
[check my hosts] :: >>>
[check my hosts] :: end check host [localhost]
[check my hosts] :: ==========================================================
[task check] verify host [localhost] start
[task check] test_01: directory /root exists
[task check] stdout match (r) <directory /root exists> True
[task check] test_02: file /root/.bashrc exists
[task check] stdout match (r) <file /root/.bashrc exists> True
[task check] test_03: file /tmp/bird.tmp has lines ["hello", "bird"]
[task check] stdout match (r) <hello> True
[task check] stdout match (r) <bird> True
[task check] test_04: file documentation/dsl.md is readable by all
[task check] stdout match (r) <^^^ \S "r"\S\S "r"\S\S "r"\S\S $$> True
[task check] test_05: file bin/bird is readable by all
[task check] stdout match (r) <^^^ \S "r"\S\S "r"\S\S "r"\S\S $$> True
[task check] test_06: file bin/bird is executable by all
[task check] stdout match (r) <^^^ \S \S\S"x" \S\S"x" \S\S"x" $$> True
[task check] test_07: file /tmp/bird.tmp is readable by all
[task check] stdout match (r) <^^^ \S "r"\S\S "r"\S\S "r"\S\S $$> True
[task check] test_08: file /tmp/bird.tmp is writable by all
[task check] stdout match (r) <^^^ \S \S"w"\S \S"w"\S \S"w"\S $$> True
[task check] test_09: command [echo hello; echo bird] has stdout
[task check] ["hello", "bird"]
[task check] stdout match (r) <hello> True
[task check] stdout match (r) <bird> True
[task check] test_10: command [raku --version] has exit code [0]
[task check] stdout match (r) <command [raku --version] exit code [0]> True
[task check] test_11: package(s) installed "nano"
[task check] stdout match (r) <package nano is installed> True
[task check] test_12: pip3 package(s) installed "PyYAML"
[task check] stdout match (r) <^^ 'PyYAML' \s+> True
[task check] test_13: file rules.raku is readable by all
[task check] stdout match (r) <^^^ \S "r"\S\S "r"\S\S "r"\S\S $$> True
[task check] test_14: package(s) installed "nano"
[task check] stdout match (r) <package nano is installed> True
[task check] test_15: file /tmp/creds.txt data not empty ["username=", "password="]
[task check] stdout match (r) <^^ '>>>'> True
[task check] <>>> username=[censored] is not empty> True
[task check] <>>> password=[censored] is not empty> True
[task check] verify host [localhost] end
```
# Rules DSL
Rules DSL is special language to validate states of Linux host.
This is just plain Raku functions:
```
file-exists "{%*ENV<HOME>}/.bashrc";
```
The full list of DSL functions available [here](https://github.com/melezhik/bird/blob/master/documentation/dsl.md).
# Ssh hosts
There are two ways to set ssh hosts:
## Command line
By using `--host`, `--user`, `--password` options:
```
bird --host=192.168.0.1 --user=alex --password=PasSword
```
## Hosts.raku
To define dynamic hosts configuration, use `hosts.raku`, this should
be Raku script that returns `@Array` of hosts:
```
[
'192.168.0.1',
'foo.bar.baz',
# so on
]
```
For example:
```
use Sparrow6::DSL;
my %state = task-run "worker nodes", "ambari-hosts", %(
ambari_host => 'cluster.fqdn.host',
admin => 'super-jack',
password => 'PaSsWord123',
cluster => "cluster01",
node_type => "worker",
);
%state<hosts><>.map: { %i<ip> }
```
# cli options
* `--rules`
Path to rules file. If not set `rules.pl` in cwd is taken
* `--password`
Ssh password. Optional
* `--user`
Ssh user. Optional
* `--host`
Ssh host. Optional, see also `hosts.raku`
* `--nocolor`
Disable color output. Optional
* `--debug`
Debug mode (produce a lot of useful, but low level info). Optional
# Examples
See:
* `rules.raku` file
* `rules/` folder
# Author
Alexey Melezhik
# See Also
* [Chef Inspec](https://www.inspec.io/)
* [Goss](https://github.com/aelsabbahy/goss)
# Thanks to
God Who inspires me in my life!
|
## dist_zef-FRITH-Linux-NFTables.md
[](https://github.com/frithnanth/raku-Linux-NFTables/actions)
# NAME
Linux::NFTables - An interface to libnftables, a library to interact with Linux NFTables
# SYNOPSIS
```
use Linux::NFTables;
my Linux::NFTables $nft .= new;
$nft.exec('list ruleset');
```
# DESCRIPTION
Linux::NFTables is an interface to libnftables, a library to interact with Linux NFTables
## Return values
Many methods return a Bool value to indicate whether the action has been successfully performed.
### new()
The constructor takes no arguments.
### multi method dry-run(Bool $active!)
### multi method dry-run(--> Bool)
The first method sets the operations for a dry run, the second returns the state of the dry-run flag.
List commands produce output, but no real action will be performed on the firewall rules.
### flags(UInt $flags!)
### flags(--> UInt)
The first method allows to add bit-mapped flags to modify the library's behavior, the second returns the value of the flags.
The available flags are:
* **NFT\_CTX\_OUTPUT\_NONE**
* **NFT\_CTX\_OUTPUT\_REVERSEDNS**
* **NFT\_CTX\_OUTPUT\_SERVICE**
* **NFT\_CTX\_OUTPUT\_STATELESS**
* **NFT\_CTX\_OUTPUT\_HANDLE**
* **NFT\_CTX\_OUTPUT\_JSON**
* **NFT\_CTX\_OUTPUT\_ECHO**
* **NFT\_CTX\_OUTPUT\_GUID**
* **NFT\_CTX\_OUTPUT\_NUMERIC\_PROTO**
* **NFT\_CTX\_OUTPUT\_NUMERIC\_PRIO**
* **NFT\_CTX\_OUTPUT\_NUMERIC\_SYMBOL**
* **NFT\_CTX\_OUTPUT\_NUMERIC\_TIME**
* **NFT\_CTX\_OUTPUT\_NUMERIC\_ALL**
* **NFT\_CTX\_OUTPUT\_TERSE**
### debug(UInt $flags!)
### debug(--> UInt)
The first method sets, the second reads the debug level.
The available levels are:
* **NFT\_DEBUG\_NONE**
* **NFT\_DEBUG\_SCANNER**
* **NFT\_DEBUG\_PARSER**
* **NFT\_DEBUG\_EVALUATION**
* **NFT\_DEBUG\_NETLINK**
* **NFT\_DEBUG\_MNL**
* **NFT\_DEBUG\_PROTO\_CTX**
* **NFT\_DEBUG\_SEGTREE**
### set-output(Str $filename! --> Bool)
### set-output(--> Bool)
These methods redirect the command output to a file or to stdout.
### set-error(Str $filename! --> Bool)
### set-error(--> Bool)
These methods redirect the command errors to a file or to stderr.
### buffer-output(Bool $active --> Bool)
### buffer-output(--> Bool)
### buffer-error(Bool $active --> Bool)
### buffer-error(--> Bool)
These methods ask to send the command outout or error to a buffer. They take one Bool parameter; when invoked without parameter they default to False.
### get-output-buffer(--> Str)
### get-error-buffer(--> Str)
These methods return the output or error buffer content (if the the system was asked to buffer its output)
### add-path(Str $path! --> Bool)
### clear-path(--> Bool)
The first method adds a search path for the **include** command in nftables, the second one removes all the include paths.
### add-var(Str $var! --> Bool)
### clear-vars()
The first method defines a variable, the second removes all variables.
### exec(Str $command! --> Bool)
This method executes a nftables command.
### exec-from-file(Str $filename! --> Bool)
This method reads and executes nftables comands from a file.
# C Library Documentation
For more details on libnftables see `man 3 libnftables`.
For more details on nftables see <https://wiki.nftables.org/wiki-nftables/index.php/Main_Page>.
# Prerequisites
This module requires the libnftables library to be installed.
On Debian-like systems install both libnftables1 and libnftables-dev.
# Installation
To install it using zef (a module management tool):
```
$ zef install Linux::NFTables
```
# AUTHOR
Fernando Santagata [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2023 Fernando Santagata
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-antononcube-Math-SparseMatrix.md
# Math::SparseMatrix
[](https://github.com/antononcube/Raku-Math-SparseMatrix/actions)
[](https://github.com/antononcube/Raku-Math-SparseMatrix/actions)
[](https://github.com/antononcube/Raku-Math-SparseMatrix/actions)
[](https://raku.land/zef:antononcube/Math::SparseMatrix)
[](https://opensource.org/licenses/Artistic-2.0)
Raku package for sparse matrix algorithms:
* Implements (some of) the algorithms described (and spelled-out in FORTRAN) in the book
"Sparse Matrix Technology" by S. Pissanetzky, [SP1].
* Provides convenient interface to accessing sparse matrix elements, rows, column, and sub-matrices.
---
## Motivation
Sparse Matrix Algebra (SMA) is a "must have" for many computational workflows.
Here is a (non-exhaustive) list given in the order of *my* preferences:
* Recommendation Systems (RS)
* I make recommenders often during Exploratory Data Analysis (EDA).
* For me, RS are "first order regression."
* I also specialize in the making of RS.
* I implemented a Raku recommender without SMA,
["ML::StreamsBlendingRecommender"](https://github.com/antononcube/Raku-ML-StreamsBlendingRecommender), [AAp1],
but it is too slow for "serious" datasets.
* Still useful; see [AAv1].
* Latent Semantic Analysis (LSA)
* LSA is one my favorite Unsupervised Machine Learning (ML) workflows.
* That means that this SMA package should have algorithms facilitating the programming of:
* Singular Value Decomposition (SVD)
* Non-Negative Matrix Factorization (NNMF)
* Graphs
* There is a natural (representation) connection between sparse matrices and graphs.
* Many graph algorithms can leverage (fast) SMA.
* So far (2024-09-25) the algorithms in "Graph", [AAp2], do not use SMA and that is feature- and speed limiting.
* Optimization
* For large scale optimization problems using SMA is a must.
* Since their constraints are given with sparse matrices.
* Partial Differential Equations (PDE) solving
---
## Usage examples
Here is a *simple* sparse matrix in Compressed Sparse Row (CSR) format:
```
use Math::SparseMatrix;
use Math::SparseMatrix::Utilities;
my $nrow = 5;
my $ncol = 8;
my $density = 0.2;
my $tol = 0.01;
my $type = 'CSR';
my $matrix1 = generate-random-sparse-matrix($nrow, $ncol, :$density, :$tol, :$type):!decorated;
say $matrix1;
```
```
# Math::SparseMatrix::CSR(:specified-elements(6), :dimensions((5, 8)), :density(0.15))
```
Here it is "pretty printed":
```
$matrix1.print;
```
```
# . . . . . . . .
# . . . . . . . .
# . . 0.35 0.85 . . 0.52 .
# . . . . . 0.92 . .
# . . 0.43 . . 0.07 . .
```
Here `10` is multiplied with all elements:
```
my $matrix2 = $matrix1.multiply(10);
$matrix2.print;
```
```
# . . . . . . . .
# . . . . . . . .
# . . 3.5 8.5 . . 5.2 .
# . . . . . 9.2 . .
# . . 4.3 . . 0.7 . .
```
Here is the dot-product of the original matrix with its transpose:
```
my $matrix3 = $matrix1.dot($matrix1.transpose);
$matrix3.print;
```
```
# . . . . .
# . . . . .
# . . 1.1154 . 0.1505
# . . . 0.8464 0.06440000000000001
# . . 0.1505 0.06440000000000001 0.18979999999999997
```
---
## Special features
Here are few features that other SMA packages typically do not provide.
### Named rows and columns
It is very convenient to have named rows and columns that are respected (or preserved)
in the typical SMA operations.
Here is an example:
```
my $smat = Math::SparseMatrix.new($matrix1, row-names => 'a' .. 'e', column-names => 'A' .. 'H');
$smat.print;
```
```
# –––––––––––––––––––––––––––––––––––––––––––
# A B C D E F G H
# ––┼––––––––––––––––––––––––––––––––––––––––
# a │ . . . . . . . .
# b │ . . . . . . . .
# c │ . . 0.35 0.85 . . 0.52 .
# d │ . . . . . 0.92 . .
# e │ . . 0.43 . . 0.07 . .
```
Here is the dot-product of that matrix with its transpose:
```
my $smat2 = $smat.dot($smat.transpose);
$smat2.round(0.02).print;
```
```
# ––––––––––––––––––––––––––––
# a b c d e
# ––┼–––––––––––––––––––––––––
# a │ . . . . .
# b │ . . . . .
# c │ . . 1.12 . 0.16
# d │ . . . 0.84 0.06
# e │ . . 0.16 0.06 0.18
```
### Implicit value
The sparse matrices can have an *implicit value* that is different from 0.
For example, adding a number to a sparse matrix produces another sparse matrix
with different implicit value:
```
my $matrix3 = $matrix1.add(10);
```
```
# Math::SparseMatrix::CSR(:specified-elements(6), :dimensions((5, 8)), :density(0.15))
```
```
$matrix3.implicit-value
```
```
# 10
```
Here is the pretty print:
```
$matrix3.print(:iv)
```
```
# 10 10 10 10 10 10 10 10
# 10 10 10 10 10 10 10 10
# 10 10 10.35 10.85 10 10 10.52 10
# 10 10 10 10 10 10.92 10 10
# 10 10 10.43 10 10 10.07 10 10
```
**Remark:** Currently, the implicit values are ignored in `dot`.
---
## Design
### General
* There should be a "main" class, `Math::SpareMatrix` that:
* Provides the SMA functionalities
* Delegates to concrete sparse matrix classes that are based on different representation formats
* Can have named rows, columns, and dimensions
* Gives access to sparse matrix elements, rows, columns, and sub-matrices
* The default or "main" core sparse matrix class should use Compressed Sparse Row (CSR) format.
* Also, a class using Dictionary Of Keys (DOK) format should be provided.
* The core sparse matrix classes do not have named rows, columns, and dimensions.
* Ideally, a class using `NativeCall` should be implemented at some point.
* It looks like this is "a must", since the CSR and DOK classes are fairly slow.
* Both "plain C" and macOS [Accelerate](https://developer.apple.com/accelerate/) implementations should be made.
* The *most important operation* is Matrix-Vector Dot Product.
* The current design is to use one-row or one-column matrices for the vectors.
* Dense vectors are (of course) also supported
### Object-Oriented Programming (OOP) architecture
* The OOP [Decorator Design Pattern](https://en.wikipedia.org/wiki/Decorator_pattern) is used to organize the SMA functionalities.
* In that pattern:
* The *Component* is played by the class [`Math::SparseMatrix::Abstract`](./lib/Math/SparseMatrix/Abstract.rakumod).
* The *ConcreteComponent* is played by the classes:
* [`Math::SparseMatrix::CSR`](./lib/Math/SparseMatrix/CSR.rakumod)
* [`Math::SparseMatrix::DOK`](./lib/Math/SparseMatrix/DOK.rakumod)
* The concrete component classes provide the core SMA operations.
* The *Decorator* is played by [`Math::SparseMatrix`](./lib/Math/SparseMatrix.rakumod).
* That is a "top level", interface class.
* Allows access using named rows and columns.
* "Hides" the actual component class used.
Here is a corresponding diagram:
```
classDiagram
class Abstract["Math::SparseMatrix::Abstract"] {
<<abstract>>
+value-at()
+row-at()
+column-at()
+row-slice()
+AT-POS()
+print()
+transpose()
+add()
+multiply()
+dot()
}
class CSRStruct {
<<C struct>>
}
class NativeCSR["Math::SparseMatrix::CSR::Native"] {
$row_ptr
$col_index
@values
nrow
ncol
implicit_value
}
class NativeAdapater["Math::SparseMatrix::NativeAdapter"] {
+row-ptr
+col-index
+values
+nrow
+ncol
+implicit-value
}
class CSR["Math::SparseMatrix::CSR"] {
@row-ptr
@col-index
@values
nrow
ncol
implicit-value
}
class DOK["Math::SparseMatrix::DOK"] {
%adjacency-map
nrow
ncol
implicit-value
}
class SparseMatrix["Math::SparseMatrix"] {
Abstract core-matrix
+AT-POS()
+print()
+transpose()
+add()
+multiply()
+dot()
}
CSR --> Abstract : implements
DOK --> Abstract : implements
NativeAdapater --> Abstract : implements
SparseMatrix --> Abstract : Hides actual component class
SparseMatrix *--> Abstract
NativeAdapater *--> NativeCSR
NativeCSR -- CSRStruct : reprents
```
### Implementation details
* Again, the most important operation is Matrix-Vector Dot Product.
* It has to be as fast as possible.
* There are two Dot Product implementations for CSR:
* Direct
* Symbolic-&-numeric
* (Currently) the direct one is 20-50% faster.
* It seems it is a good idea to provide for some operations *symbolic* (or sparse matrix elements pattern) methods.
* For example:
* `add-pattern` / `add`
* `dot-pattern` / `dot-numeric`
* It is important to have access methods / operators.
* All three are used in the accessor implementation: `AT-POS`, `postcircumfix:<[ ]>`, `postcircumfix:<[; ]>` .
---
## Performance
* Performance of CSR and DOK sparse matrices is not good: between 40 to 150 times slower than Wolfram Language.
* (Using the same matrices, of course.)
* It is somewhat surprising that DOK is faster than CSR.
* (Using pure-Raku.)
* `NativeCall` based implementations are ≈ 100 times faster.
* See ["Math::SparseMatrix::Native"](https://github.com/antononcube/Raku-Math-SparseMatrix-Native), [AAp3].
---
## Acknowledgements
Thanks to [@lizmat](https://github.com/lizmat) and [@tony-o](https://github.com/tony-o) for helping figuring out the proper use of `postcircumfix:<[]>` and `postcircumfix:<[; ]>`
in order to have the named rows and columns functionalities.
---
## References
### Books
[SP1] Sergio Pissanetzky, Sparse Matrix Technology, Academic Pr (January 1, 1984), ISBN-10: 0125575807, ISBN-13: 978-0125575805.
### Packages
[AAp1] Anton Antonov,
[ML::StreamsBlendingRecommender Raku package](https://github.com/antononcube/Raku-ML-StreamsBlendingRecommender),
(2021-2024),
[GitHub/antononcube](https://github.com/antononcube).
[AAp2] Anton Antonov,
[Graph Raku package](https://github.com/antononcube/Raku-Graph),
(2024),
[GitHub/antononcube](https://github.com/antononcube).
[AAp3] Anton Antonov,
[Math::SparseMatrix::Native Raku package](https://github.com/antononcube/Raku-Math-SparseMatrix-Native),
(2024),
[GitHub/antononcube](https://github.com/antononcube).
### Videos
[AAv1] Anton Antonov,
["TRC 2022 Implementation of ML algorithms in Raku"](https://youtu.be/efRHfjYebs4?si=J5P8pK1TgGSxdlmD&t=193),
(2022),
[YouTube/antononcube](https://www.youtube.com/@AAA4prediction).
|
## dist_zef-lizmat-Git-Status.md
[](https://github.com/lizmat/Git-Status/actions) [](https://github.com/lizmat/Git-Status/actions) [](https://github.com/lizmat/Git-Status/actions)
# NAME
Git::Status - obtain status of a git repository
# SYNOPSIS
```
use Git::Status;
my $status := Git::Status.new(:$directory);
if $status.is-clean {
say "Is clean";
}
if $status.modified -> @modified {
say "Modified:";
.say for @modified;
}
if $status.added -> @added {
say "Added:";
.say for @added;
}
if $status.deleted -> @deleted {
say "Deleted:";
.say for @deleted;
}
if $status.renamed -> @renamed {
say "Renamed:";
.say for @renamed;
}
if $status.copied -> @copied {
say "Copied:";
.say for @copied;
}
if $status.updated -> @updated {
say "Updated:";
.say for @updateded;
}
if $status.untracked -> @untracked {
say "Untracked:";
.say for @untracked;
}
```
# DESCRIPTION
Git::Status provides a simple way to obtain the status of a git repository using the `git status --porcelain` command (version 1) and simplifying the results to indicate whether the repository is 'clean' or 'dirty'. This module's primary purpose is to determine whether any action is required to satisfy further use by `App::Mi6` or to indicate user intervention is necessary.
Note the full output of `git status --porcelain` is quite complex and completely identifies the situation with regards to both the index and the working tree (a complex task with many possible combinations). See the `git-status` man page for details.
# PARAMETERS
## directory
The directory of the git repository. Can be specified as either an `IO::Path` object, or as a string. Defaults to `$*CWD`. It should be readable.
# METHODS
## is-clean
Returns the value of the $!clean variable which is True for a "clean" Git directory.
## gist
A text representation of the object, empty string if there were no modified, added, deleted, renamed, copied, updated, or untracked files.
## added
The paths of files that have been added.
## deleted
The paths of files that have been deleted.
## directory
The directory of the repository, as an `IO::Path` object.
## modified
The paths of files that have been modified.
## untracked
The paths of files that are not tracked yet.
## newfile
The paths of files that are new.
## renamed
The paths of files that are renamed.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Git-Status> . Comments and Pull Requests are welcome.
If you like this module, or what I'm doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2021, 2024, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-Chemistry-Elements.md
[](https://github.com/raku-community-modules/Chemistry-Elements/actions) [](https://github.com/raku-community-modules/Chemistry-Elements/actions)
# NAME
Chemistry::Elements - do things with the Periodic Table
# SYNOPSIS
```
use Chemistry::Elements;
put "Name for 37 is ", get_name_by_Z( 37 );
put "Name for Rb is ", get_name_by_symbol( 'Rb' );
put "Symbol for 37 is ", get_symbol_by_Z( 37 );
put "Symbol for Rubidium is ", get_symbol_by_name( 'Rubidium' );
put "Symbol for Rubidium is ", get_symbol_by_name( 'Rubidium', );
put "Atomic number for Rb is ", get_Z_by_symbol( 'Rb' );
put "Atomic number for Rubidium", get_Z_by_name( 'Rubidium' );
# use a German name
put "Atomic number for Rubidium is ", get_symbol_by_name( 'Schwefel', 'de' );
# Use some types
my ZInt $Z = 37; # works
my ZInt $BigZ = 138; # nope, because that's not on the chart (yet)
my $minimum = min_Z(); # Always 1, unless something big changes
my $maximum = max_Z(); # More
my ChemicalSymbol $symbol = 'Rb'; # okay
my ChemicalSymbol $other_symbol = 'X9'; # not okay, not a known symbol
```
# DESCRIPTION
The Perl version of `Chemistry::Elements` was my first module, so I'm making it my first Raku module too. It's not complicated.
The module maps between element names (*e.g.* Rubidium), symbol (*e.g.* Ru ), and number (*e.g.* 37). It's multi-language aware although the language switching isn't sophisticated yet.
## class Chemistry::Elements
Do various things with chemical elements. Convert between symbols, names, and atomic numbers.
A Str that is one of the known chemical symbols
### method max\_Z
```
method max_Z() returns Chemistry::Elements::ZInt
```
Return the maximum recognized atomic number (as a ZInt type).
### method min\_Z
```
method min_Z() returns Chemistry::Elements::ZInt
```
Return the minimum recognized atomic number. This is always be 1 (as a ZInt type).
A Str that is one of the known chemical symbols
### method get\_name\_by\_Z
```
method get_name_by_Z(
Chemistry::Elements::ZInt(Cool) $Z,
Str:D $lang = "default"
) returns Str:D
```
Return the element name by the atomic number. You can pass an untyped number or a ZInt
### method get\_name\_by\_symbol
```
method get_name_by_symbol(
Str $symbol where { ... },
Str:D $lang = "default"
) returns Str:D
```
provide a second argument to choose the language.
### method get\_symbol\_by\_Z
```
method get_symbol_by_Z(
Chemistry::Elements::ZInt(Cool) $Z
) returns Chemistry::Elements::ChemicalSymbol
```
Return the chemical symbol (as a ChemicalSymbol type) by the atomic number.
### method get\_symbol\_by\_name
```
method get_symbol_by_name(
Str:D $name
) returns Chemistry::Elements::ChemicalSymbol
```
Return the chemical symbol (as a ChemicalSymbol object) by the element name.
### method get\_Z\_by\_symbol
```
method get_Z_by_symbol(
Str $symbol where { ... }
) returns Chemistry::Elements::ZInt
```
Return the atomic number (as a ZInt type) by the ChemicalSymbol.
### method get\_Z\_by\_name
```
method get_Z_by_name(
Str:D $name,
Str:D $lang = "default"
) returns Chemistry::Elements::ZInt
```
Return the atomic number (as a ZInt type) by the element name.
# TO DO
* Integrate the other languages in the Lib/Languages directory.
* Guess the langauge based on a name or symbol
* Allow historical symbols that aren't
# SEE ALSO
# SOURCE AVAILABILITY
This module is in Github:
```
https://github.com/raku-community-modules/Chemistry-Elements
```
# AUTHORS
* brian d foy
* Raku Community
# COPYRIGHT AND LICENSE
Copyright © 2016-2022, brian d foy [[email protected]](mailto:[email protected]). All rights reserved.
Copyright © 2024 Raku Community
This program is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-Hash2Class.md
[](https://github.com/lizmat/Hash2Class/actions) [](https://github.com/lizmat/Hash2Class/actions) [](https://github.com/lizmat/Hash2Class/actions)
# NAME
Hash2Class - A role to create class instances out of a Hash
# SYNOPSIS
```
use Hash2Class;
class UpdateInfo does Hash2Class[
added => Date(Str),
changed => Date(Str),
] { }
class FBB does Hash2Class[
"foo",
bar => Int,
baz => UpdateInfo,
'@bazlist' => UpdateInfo,
'%bazmap' => UpdateInfo,
zap => {
type => Str,
name => "zippo",
why => "Because we can",
},
] { }
my %hash =
foo => "foo",
bar => 42,
baz => {
added => "2020-07-18",
changed => "2020-07-19",
},
bazlist => [
{ added => "2020-07-14", changed => "2020-07-15" },
{ added => "2020-07-16", changed => "2020-07-17" },
],
bazmap => {
first => { added => "2020-07-01", changed => "2020-07-02" },
second => { added => "2020-07-03", changed => "2020-07-04" },
third => { added => "2020-07-05", changed => "2020-07-06" },
},
zap => "Groucho",
;
my $fbb = FBB.new(%hash);
dd $fbb.foo; # "foo"
dd $fbb.bar; # 42
dd $fbb.zippo; # "Groucho"
dd $fbb.bazlist[1].added; # Date.new("2020-07-01")
dd $fbb.bazmap<third>.changed; # Date.new("2020-07-06")
```
# DESCRIPTION
The `Hash2Class` role allows one to create a class from a parameterization of the role. The parameterization consists of a list of `Pair`s in which the key indicates the name of key in the hash, and the value indicates the type the value in the hash is supposed to have, or be coerced to. The key becomes the name of a method accessing that key in the hash, unless it is overriden in more extensive parameterization.
A key can be prefixed with `@` to indicate an Array of values in the hash, or be prefixed with `%` to indicate a hash, or `$` to indicate a scalar value (which is the default).
The types specified can **also** be classes created by the `Hash2Class` role, so recursive structures are possible, as long as they are defined in the correct order.
Classes made with the `Hash2Class` role are instantiated by calling `.new` with a hash as its only parameter. Such a hash is typically the result of rakufication of a `JSON` blob (e.g. with `from-json` of the JSON::Fast module). But the hash can be created in any manner.
Values are checked lazily, so no work is done on parts of the hash that are not accessed.
# WHY
Hashes can be filled in many ways: JSON just being one of them. And data is not always as clean as you would hope they would be. This role allows you to add lazy typechecking to such a hash of data. It also prevents problems caused by spelling errors in keys in your code: instead of silently returning `Nil`, you will get a "Method not found" error on misspelled method names.
Since the type checking occurs lazily, no CPU is spent on typechecking values you do not actually need. Should you do want to have complete typechecking on all keys / values in the hash, then you can call the `.invalid` method on the object: this will visit **all** values in the hash recursively and produce a corresponding hash of any errors found, or `Nil` if all is ok.
# PARAMETERIZATION
There are three modes of parameterization:
* identifier
```
"foo",
```
Just specifying an identifier (a string of a single word), will create a method with the same name, and assume the value is a `Str`.
* identifier => type
```
bar => Int,
```
A pair consisting of an identifier and a type, will create a method with the same name as the identifier, and assume the value is constraint by the given type.
The type can also be specified as a string if necessary:
```
bar => "Int",
```
Coercing types are also supported:
```
bar => Int(Str),
```
* identifier => { ... }
```
zap => {
type => Str,
name => "zippo",
default => "(none)",
why => "Because we can",
},
```
A pair consisting of an identifier and a `Hash` with further parameterization values.
Four keys are recognized in such as Hash: `type` (the type to constrain to), `name` (the name to create the method with, useful in case the key conflicts with other methods, such as `new`), `default` to indicate a default value (defaults to `Nil`) and `why` (to set the contents of the `.WHY` function on the method object.
# CREATING A CLASS DEFINITION FROM A JSON BLOB
If you have a file with a JSON blob for which you need to create a class definition, you can call the `h2c-skeleton` script. You call this script with the JSON blob on standard input, and it will print a class definition on standard output.
Class names will be selected randomly, but will be consistent within the definition of the classes. The order in which classes are defined, is also correct for compilation: generally one only needs to globally modify the class names to something that makes more sense for the given data. And possibly tweak some standard types into subsets with a more limited range of values, e.g. `Int` to `UInt`, or `Str` to `DateTime(Str)`.
# METHODS
## new
```
my $foo = Foo.new(%hash);
```
An object of a class that does the `Hash2Class` role, is created by calling the `new` method with a hash of keys and values. Each of these values can be another hash or array: these will be handled automatically if they were so parameterized.
## invalid
```
with $foo.invalid {
note "Errors found:";
dd $_;
}
```
The `invalid` method either returns `Nil` if all values in the hash where valid. Otherwise it returns a hash of error messages of which the keys are the names of the `methods`, and the values are the error messages. Please note that this check will access *all* values in the hash, so it may take some time for big hashes.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Hash2Class> . Comments and Pull Requests are welcome.
If you like this module, or what I'm doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2020, 2021, 2024, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-guifa-Intl-Format-Number.md
# Intl::Format::Number
A module for formatting numbers in a localized manner
To use, simply say
```
use Intl::Format::Number;
# Assuming user-language is 'en' (English)
say format-number 4834853; # 4,834,853
say format-number 12.394; # 12.394
say format-number 1/3; # 0.333333333333333
# A separate call can get a number formatter which allows you to specify more options
my $formatter = local-number-formatter('en', :minimum-significant-digits<2>);
```
It's that easy :-)
Currently supports percent, permille and scientific formatting in addition to the basic number format for languages with decimal number systems (sorry ancient Romans or Mayans!).
Other formatting styles (like compact) styles and options specified in TR 35 / CLDR, are NYI but will be available soon (current will be available via a separate module).
Performance is about an order of magnitude slower than `.Str` for most formatting, and I continue to try to optimize it farther.
Balancing performance with the ability to, e.g., format a `FatRat` of several thousand digits, isn't easy :-)
### Options
The Raku-defined variable `$*TOLERANCE` is used in the case of extremely long decimals (e.g. any repeating decimal like `1/3`).
Raku defaults it to `1e-15` (thus providing 15 digits of decimals) but you can set it to any number.
You are highly advised *not* to set it to 0 as this may cause an infinite loop unless.
(In the future, setting the maximum fractional digits to `Inf` and `$*TOLERANCE` to `0` will generate an error).
Basic options
* **`:language<…>`**
Sets the language to use for formatting. If the Unicode U Extension tag `nu` (for numbering system) is present, it will be respected.
* **`:type<…>`** (*standard, percent, permille, scientific, compact*)
Sets the type of number desired. If percent or permille is selected, the number is multiplied by 100 or 1000 prior to display (such that .123 becomes 12.3% or 123‰). Compact numbers are not yet supported.
* **`:length<…>`**
Sets the length to use for formatting. Defaults to `standard`, which is the only option available outside of compact numbers.
Number formatter options (for use with `get-number-formatter`)
| option | description | example |
| --- | --- | --- |
| `maximum-integer-digits` | No more whole digits than this | when **2** `1234` yields `34` |
| `minimum-integer-digits` | Pad with zeros to have at least this many | when **4** `12` yields `0012` |
| `maximum-fractional-digits` | No more decimal digits than this | when **2** `1.2345` yields `1.23` |
| `minimum-fractional-digits` | Add trailing zeros to have at least this many | when **3** `1.2` yields `1.200` |
| `maximum-significant-digits` | Limits the amount of significant digits used | when **2** `1234` yields `1200` |
| `minimum-significant-digits` | Add trailing zeros if necessary | when **3** `1` yields `1.00` |
| `show-decimal` | Forces the decimal to be shown | when **True** `1` yields `1.` |
| `show-sign` | Shows the sign regardless polarity | when **True** `1` yields `+1` |
| `symbols` | Adjusts the symbols used in formatting. | |
| `number-system` | Set the digits used. Must be a CLDR code. | when **arab**, `1234` yields `١٢٣٤` |
| `rast` | Returns a `RakuAST` node instead | |
If significant digits are specified, then the integral/fractional digits are currently ignored.
Presently, the `RakuAST` node generated is a `RakuAST::Sub`. Additional documentation on it will
be included in future updates to improve its integration with other modules.
### Todo
* Better documentation
* More tests
* Cleanup code
## Version history
* **v0.4.0**
* Formally add support for `local-number-formatter` and `number-formatter`
* **v0.3.0**
* Added support for exponential formats (`:type<exponential>`)
* Adjust some code for the newest version of RakuAST
* **v0.2.1**
* Added support for percent and permille formats (`:type<percent>` and `:type<permille>`)
* Respects language tag's numering system (`:language<en-u-nu-limb>` will use Limbu numerals)
* Fixed (mostly) a caching bug
* **v0.2.0**
* First version to use RakuAST (requires Rakudo 2022.12 or higher)
* Initial support for negative numbers (should work for most all languages)
* Initial support for formatting options
* New and improved number format parser (faster, more accurate, and more maintainable!)
* Added test file for grammar parsing
* **v0.1.1**
* Fix bug for ***n* = 0**, ***n*** **=** **10*ˣ***, and ***n* < 0**
* **v0.1.0**
* Initial version
## License and Copyright
© 2020-2023 Matthew Stephen Stuckwisch.
Licensed under the Artistic License 2.0.
|
## dist_zef-lizmat-highlighter.md
[](https://github.com/lizmat/highlighter/actions) [](https://github.com/lizmat/highlighter/actions) [](https://github.com/lizmat/highlighter/actions)
# NAME
highlighter - highlight something inside a string
# SYNOPSIS
```
use highlighter;
say highlighter "foo bar", "bar", "<b>", "</b>", :type<words>; # foo <b>bar</b>
say highlighter "foo bar", "bar" but Type<words>, "*"; # foo *bar*
say columns "foo bar", "bar", :type<words>; # (5)
say matches "foo bar", "O", :type<contains>, :ignorecase; # o o
```
# DESCRIPTION
The highlighter distribution exports three subroutines by default that are related to highlighting / indicating subsections of strings depending on the result of some type of search.
It also exports a role `Type` by default, which allows one to associate the type of search wanted for a given string needle.
The `highlighter` subroutine can be called to highlight a word, a string or the match of a regular expression inside a string.
The `columns` subroutine returns the columns (1-based) at which highlighting should occur using the same search semantics as with `highlighter`.
The `matches` returns the actual matches inside the string as a `Slip`, using the same search semantics as with `highlighter`.
# NAMED ARGUMENTS
The following named arguments may be specified with all of the subroutines in this distribution.
## :type
Optional named argument. If the needle is a regular expression, it is ignored. Otherwise `"contains"` is assumed.
It indicates the type of search that should be performed. Possible options are `words` (look for the needle at word boundaries only), `contains` (look for the needle at any position), `starts-with` (only look for the needle at the start of the string), `ends-with` (only look for the needle at the end of the string) and `equal` (if needle is the same size as the string and starts at the beginning of the string).
## :ignorecase or :i
Optional named argument. If the second positional argument is a string, then this indicates whether any searches should be done in a case insensitive manner.
## :smartcase
Optional named argument. If the second positional argument is a string, and it does **not** contain any uppercase characters, then this indicates that any searches should be done in a case insensitive manner.
## :ignoremark or :m
Optional named argument. If the second positional argument is a string, then this indicates whether any searches should be done on the base characters only.
## :smartmark
Optional named argument. If the second positional argument is a string, and it does **not** contain any accented characters, then this indicates then this indicates that any searches should be done on the base characters only.
# EXPORTED SUBROUTINES
## highlighter
The `highlighter` subroutine for a given string (the haystack), returns a string with highlighting codes for a word, a string or the match of a regular expression (the needle) with a given highlight string. Returns the haystack If the needle could not be found.
```
use highlighter 'highlighter';
say highlighter "foo bar", "bar", "<b>", "</b>", :type<words>; # foo <b>bar</b>
say highlighter "foo bar", "O", "*", :type<contains>, :ignorecase; # f*o**o* bar
say highlighter "foo bar", "fo", "*", :type<starts-with>; # *fo*o bar
say highlighter "foo bar", "ar", "*", :type<ends-with>; # foo b*ar*
say highlighter "foo", "foo", "*", :type<equal>; # *foo*
say highlighter "foo bar", / b.r /, "*"; # foo *bar*
```
The following positional parameters can be passed:
* haystack
This is the string in which things should be highlighted.
* needle
This is either a string, or a regular expression indicating what should be highlighted, or a list of strings / regular expressions.
If a list was specified, then the `highlighter` subroutine will be called for all elements in the list, and the first actually producing a highlighted string, will be returned.
* before
This is the string that should be put **before** the thing that should be highlighted.
* after
Optional. This is the string that should be put **after** the thing that should be highlighted. Defaults to the `before` string>.
The following additional named arguments may also be specified:
* :only
Optional named argument. Indicates that only the strings that were found should be returned (and not have anything inbetween, except for any `before` and `after` strings). Defaults to `False`.
* :summary-if-larger-than
Optional named argument. Indicates the number of characters a string must exceed to have the non-highlighted parts shortened to try to fit the indicated number of characters. Defaults to `Any`, indicate no summarizing should take place.
## columns
The `columns` subroutine returns the columns (1-based) at which highlighting should occur, given a haystack, needle and optional named arguments.
```
use highlighter 'columns';
say columns "foo bar", "bar", :type<words>; # (5)
say columns "foo bar", "O", :type<contains>, :ignorecase; # (2,3)
say columns "foo bar", "fo", :type<starts-with>; # (1)
say columns "foo bar", "ar", :type<ends-with>; # (6)
say columns "foo", "foo", :type<equal>; # (1)
say columns "foo bar", / b.r /; # (5)
```
The following positional parameters can be passed:
* haystack
This is the string in which should be searched to determine the column positions.
* needle
This is either a string, or a regular expression indicating what should be searched for to determine the column positions, or a list of strings and regular exprssions.
If a list was specified, then the `columns` subroutine will be called for all elements in the list, and the first actually producing a result, will be returned.
## matches
The `matches` subroutine returns the actual matches inside the string as a `Slip` for the given haystack and needle and optional named arguments.
```
use highlighter 'matches';
say matches "foo bar", "bar", :type<words>; # bar
say matches "foo bar", "O", :type<contains>, :ignorecase; # o o
say matches "foo bar", "fo", :type<starts-with>; # fo
say matches "foo bar", "ar", :type<ends-with>; # ar
say matches "foo", "foo", :type<equal>; # foo
say matches "foo bar", / b.r /; # bar
```
* haystack
This is the string from which any matches should be returned.
* needle
This is either a string, or a regular expression indicating what should be used to determine what a match is, or a list consisting of strings and regular expressions.
If a list was specified, then the `matches` subroutine will be called for all elements in the list, and the first actually producing a result, will be returned.
# SELECTIVE IMPORTING
```
use highlighter <columns>; # only export sub columns
```
By default all three subroutines and the `Type` role are exported. But you can limit this to the functions you actually need by specifying the name(s) in the `use` statement.
To prevent name collisions and/or import any subroutine (or role) with a more memorable name, one can use the "original-name:known-as" syntax. A semi-colon in a specified string indicates the name by which the subroutine is known in this distribution, followed by the name with which it will be known in the lexical context in which the `use` command is executed.
```
use highlighter <columns:the-columns>; # export "columns" as "the-columns"
say the-columns "foo bar", "bar", :type<words>; # (5)
```
```
use highlighter <Type:Needle>; # export "Type" as "Needle"
say columns "foo bar", "bar" but Needle<words>; # (5)
```
# NOTES
## Callable as a needle
If a simple `Callable` (rather than a `Regex`) is passed as a needle, then the haystack will **always** be returned, as there is no way to determine what will need to be highlighted. Any other arguments, apart from the `:summary-if-larger-than` named argument, will be ignored.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2021, 2022, 2024 Elizabeth Mattijsen
Source can be located at: <https://github.com/lizmat/highlighter> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## self.md
self
Combined from primary sources listed below.
# [In Terms](#___top "go to top of document")[§](#(Terms)_term_self "direct link")
See primary documentation
[in context](/language/terms#term_self)
for **term self**.
Inside a method, `self` refers to the invocant (i.e. the object the method was called on). If used in a context where it doesn't make sense, a compile-time exception of type [`X::Syntax::NoSelf`](/type/X/Syntax/NoSelf) is thrown.
# [In Mu](#___top "go to top of document")[§](#(Mu)_method_self "direct link")
See primary documentation
[in context](/type/Mu#method_self)
for **method self**.
```raku
method self(--> Mu)
```
Returns the object it is called on.
# [In Failure](#___top "go to top of document")[§](#(Failure)_method_self "direct link")
See primary documentation
[in context](/type/Failure#method_self)
for **method self**.
```raku
method self(Failure:D: --> Failure:D)
```
If the invocant is a [handled](/routine/handled) `Failure`, returns it as is. If not handled, throws its [`Exception`](/type/Exception). Since [`Mu`](/type/Mu) type [provides `.self`](/type/Mu#method_self) for every class, calling this method is a handy way to explosively filter out Failures:
```raku
my $num1 = '♥'.Int;
# $num1 now contains a Failure object, which may not be desirable
my $num2 = '♥'.Int.self;
# .self method call on Failure causes an exception to be thrown
my $num3 = '42'.Int.self;
# Int type has a .self method, so here $num3 has `42` in it
(my $stuff = '♥'.Int).so;
say $stuff.self; # OUTPUT: «(HANDLED) Cannot convert string to number…»
# Here, Failure is handled, so .self just returns it as is
```
|
## dist_github-mattn-Path-Canonical.md
[](https://travis-ci.org/mattn/p6-Path-Canonical)
# NAME
Path::Canonical - blah blah blah
# SYNOPSIS
```
use Path::Canonical;
```
# DESCRIPTION
Path::Canonical is ...
# COPYRIGHT AND LICENSE
Copyright 2015 Yasuhiro Matsumoto [[email protected]](mailto:[email protected])
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-tony-o-raku-mailgun.md
# Mailgun
*raku-mailgun*
A very incomplete mailgun module. All it does is send messages.
Usage:
```
use Mailgun;
my $msg = Message.new(
:from<[email protected]>,
:to<[email protected]>,
:subject("you suck"),
:text("haha you read this"),
);
my $client = Client.new(
:domain<zef.pm>,
:api-key<rofl>
);
dd $client.send($msg);
# {:id("<some-numbers\@zef.pm>"),
# :message("Queued. Thank you.")
# }
```
Messages are defaultable so you don't need to provide the same info over and over:
```
my &email-generator = Message.new(
:from<[email protected]>,
:subject<Welcome!>,
).defaults;
# some time in the future:
my $msg = email-generator(:to('some@one.'), :body('Hello, world!'));
```
|
## dist_zef-lizmat-P5sleep.md
[](https://github.com/lizmat/P5sleep/actions)
# NAME
Raku port of Perl's sleep() built-in
# SYNOPSIS
```
use P5sleep; # exports sleep()
```
# DESCRIPTION
This module tries to mimic the behaviour of Perl's `sleep` built-in as closely as possible in the Raku Programming Language.
# ORIGINAL PERL DOCUMENTATION
```
sleep EXPR
sleep Causes the script to sleep for (integer) EXPR seconds, or forever
if no argument is given. Returns the integer number of seconds
actually slept.
May be interrupted if the process receives a signal such as
"SIGALRM".
eval {
local $SIG{ALARM} = sub { die "Alarm!\n" };
sleep;
};
die $@ unless $@ eq "Alarm!\n";
You probably cannot mix "alarm" and "sleep" calls, because "sleep"
is often implemented using "alarm".
On some older systems, it may sleep up to a full second less than
what you requested, depending on how it counts seconds. Most
modern systems always sleep the full amount. They may appear to
sleep longer than that, however, because your process might not be
scheduled right away in a busy multitasking system.
For delays of finer granularity than one second, the Time::HiRes
module (from CPAN, and starting from Perl 5.8 part of the standard
distribution) provides usleep(). You may also use Perl's
four-argument version of select() leaving the first three
arguments undefined, or you might be able to use the "syscall"
interface to access setitimer(2) if your system supports it. See
perlfaq8 for details.
See also the POSIX module's "pause" function.
```
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/P5sleep> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2018, 2019, 2020, 2021 Elizabeth Mattijsen
Re-imagined from Perl as part of the CPAN Butterfly Plan.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-rbt-LogP6-Writer-StackDriver.md
# NAME
**LogP6::Writer::StackDriver** - writer implementation for local `stackdriver` logging
# SYNOPSIS
Useful for logging within the Google Cloud environment where fluentd will pickup logs
and feed them into StackDriver.
Use of this module ensures your messages are treated as single entries (no multi-line issues)
and enables use of triggers/calculations on special fields via MDC.
# CONFIGURATION
You can configure the writer from code by instantiating object of
`LogP6::WriterConf::StackDriver` class. It takes the following parameters:
* `name` - name of the writer configuration
* `handle` - location to write the json formatted log lines; STDOUT by default.
* `use-mdc` - boolean property. Enabled by default. All content of LogP6 `MDC`
will be passed to `stackdriver` as json fields.
* `use-mdc-cro` - boolean property. Enabled by default. Will look for and use the
CRO request/response objects in the MDC information to fill out various HTTP related
fields including `requestMethod`, `requestURL`, `userAgent`, `referer`, `remoteIp`,
and `status`.
* `mdc-key-cro-request` - string property. `cro-request` by default. Tells the logger
which field may provide the CRO request object.
* `mdc-key-cro-response` - string property. `cro-response` by default. Tells the logger which
field may provde the CRO response object.
* `use-source-location` - boolean property, True by default. Will include the source
location in the log entry. Use of this functionalty may slow down your porgram as it requires a `callframe` call
for each log entry.
# EXAMPLE
```
use LogP6 :configure; # use library in configure mode
use LogP6::WriterConf::StackDriver;
use Cro::HTTP::Router;
my $sd = LogP6::WriterConf::StackDriver.new(
:handle($*ERR), # Change to use STDERR
:name<audit>
use-source-location => False, # Disable source location
mdc-key-cro-request => 'webapp-request',
);
cliche(
:name<cl>,
:matcher<audit>,
grooves => ( writer($sd), filter(:level($debug)) ) # Debug level to $sd
);
my $app = route {
get -> 'healthz' {
# Note, any instance of 'audit' log will have the MDC information only in
# the current Thread. Consider creating a context object for the request
# and passing it along the work pipeline.
my $log = get-logger('audit');
$log.mdc-put('webapp-request', request());
$log.debug('Request for healthz');
content 'text/plain', 'READY';
}
}
$!cro-service = Cro::HTTP::Server.new(:host<0.0.0.0>, :port<10000>, :$app);
$!cro-service.start;
```
# AUTHOR
Rod Taylor [[email protected]](mailto:[email protected])
Source can be located at:
[github](https://github.com/rbt/raku-LogP6-Writer-StackDriver). Comments and
Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2020 Rod Taylor
This library is free software; you can redistribute it and/or modify it under
the Artistic License 2.0.
|
## dist_github-ufobat-XML-Rabbit.md
# XML::Rabbit
[](https://travis-ci.org/ufobat/p6-XML-Rabbit)
A Perl 6 Library for building Attribues from XML files with xpath Expressions.
# XPath Specification
Specification on XPath Expressions can be found at <https://www.w3.org/TR/xpath/>.
# Synopsis
```
use XML::Rabbit;
class MyClass does XML::Rabbit::Node {
has $.x is xpath-object('MyOtherClass, '/xml/b/@key' => '/xml/b');
}
class MyOtherClass does XML::Rabbit::Node {
has $.value is xpath('.');
has $.key is xpath('./@key');
}
my $object = MyClass.new(file => '/path/to/file.xml');
```
# Example
If you want to see more examples please have a look at the [testcases](t).
# Documentation
This is my attempt to bring the ideas of [perl5 XML::Rabbit](https://metacpan.org/pod/XML::Rabbit) into perl6. Thanks to [AttrX::Lazy](https://github.com/pierre-vigier/Perl6-AttrX-Lazy) where I got the blueprint how to do the Meta programming.
# License
Artistic License 2.0.
|
## isa.md
isa
Combined from primary sources listed below.
# [In Mu](#___top "go to top of document")[§](#(Mu)_routine_isa "direct link")
See primary documentation
[in context](/type/Mu#routine_isa)
for **routine isa**.
```raku
multi method isa(Mu $type --> Bool:D)
multi method isa(Str:D $type --> Bool:D)
```
Returns `True` if the invocant is an instance of class `$type`, a subset type or a derived class (through inheritance) of `$type`. [`does`](/routine/does#(Mu)_routine_does) is similar, but includes roles.
```raku
my $i = 17;
say $i.isa("Int"); # OUTPUT: «True»
say $i.isa(Any); # OUTPUT: «True»
role Truish {};
my $but-true = 0 but Truish;
say $but-true.^name; # OUTPUT: «Int+{Truish}»
say $but-true.does(Truish); # OUTPUT: «True»
say $but-true.isa(Truish); # OUTPUT: «False»
```
|
## dist_zef-lizmat-from.md
[](https://github.com/lizmat/from/actions) [](https://github.com/lizmat/from/actions) [](https://github.com/lizmat/from/actions)
# NAME
from - load a module and import selected items from it
# SYNOPSIS
```
use from <Test &plan &ok>; # only import "plan" and "ok"
plan 1;
ok "foo", "bar"; # ok 1 - bar
use from "Foo"; # use Foo, but don't import anything
use from <Test ! &skip>; # import everything *except* skip
```
# DESCRIPTION
The `from` distribution is a helper module that allows you to load any given module and only import selected items from whatever that module imports by default. This can be helpful when there is a conflict between different modules exporting something with the same name (such as `skip` in the Raku core, and the `skip` subroutine provided by `Test`.
The first argument indicates the name of the module to be loaded. If it is the only argument, then the module will be loaded without doing **any** of its imports (which is basically the same as `need`).
If the second argument is a sole exclamation mark, it indicates that the rest of the arguments are items that should **not** be imported.
The rest of the arguments indicate the items that should (not) be imported.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/from> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2022, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-Data-TextOrBinary.md
[](https://github.com/raku-community-modules/Data-TextOrBinary/actions) [](https://github.com/raku-community-modules/Data-TextOrBinary/actions) [](https://github.com/raku-community-modules/Data-TextOrBinary/actions)
# NAME
Data::TextOrBinary - Heuristic detection of text vs. binary data
# SYNOPSIS
```
use Data::TextOrBinary;
# Test a Buf/Blob
say is-text('Vánoční stromek'.encode('utf-8')); # True
say is-text(Buf.new(0x02, 0xFF, 0x00, 0x38)); # False
# Test a file
say is-text('/bin/bash'.IO); # False
say is-text('/usr/share/dict/words'.IO); # True
```
# DESCRIPTION
Implements a heuristic algorithm, very much like the one used by Git, to decide if some data is most likely to be text or binary.
# SUBROUTINES
The module exports a single subroutine `is-text`, which has candidates for `Blob` and `IO::Path`, enabling it to be used on data that has already been read into memory as well as data in a file.
* On a Blob
```
my $text = is-text($the-blob, test-bytes => 8192);
```
When called on a `Blob`, `is-text` will test the first `test-bytes` bytes of it to decide if it contains text or binary data. The `test-bytes` named argument is optional, and its default value is 4096.
* On an IO::Path
```
my $text = is-text($filename.IO, test-bytes => 8192);
```
When called on an `IO::Path`, `is-text` will read the first `test-bytes` bytes from the file it points to. It will then test these to decide if the file is text or binary. The `test-bytes` named argument is optional, and its default value is 4096.
# Algorithm
The algorithm will flag a file as binary if it encounters a NULL byte or a lone carriage return (`\r`). Otherwise, it considers the ratio of printable to ASCII-range control characters, with newline sequences excluded. If there is less than one byte representing an unprintable ASCII character per 128 bytes representing printable ASCII characters, then the data is considered to be text.
# Thread safety
The function exported by this module is safe to call from multiple threads at the same time.
# AUTHOR
Jonathan Worthington
# COPYRIGHT AND LICENSE
Copyright 2017 - 2022 Jonathan Worthington
Copyright 2024, 2025 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-HANENKAMP-Path-Router.md
# NAME
Path::Router - A tool for routing paths
# SYNOPSIS
```
my $router = Path::Router.new;
$router.add-route('blog' => %(
conditions => %( :method<GET> ),
defaults => {
controller => 'blog',
action => 'index',
},
# you can provide a fixed "target"
# for a match as well, this can be
# anything you want it to be ...
target => My::App.get_controller('blog').get_action('index')
));
$router.add-route('blog/:year/:month/:day' => %(
conditions => %( :method<GET> ),
defaults => {
controller => 'blog',
action => 'show_date',
},
# validate with ...
validations => {
# ... raw-Regexp refs
year => rx/\d ** 4/,
# ... custom types you created
month => NumericMonth,
# ... anon-subsets created inline
day => (anon subset NumericDay of Int where * <= 31),
}
));
$router.add-route('blog/:action/?:id' => %(
defaults => {
controller => 'blog',
},
validations => {
action => rx/\D+/,
id => Int, # also use Perl6 types too
}
));
# even include other routers
$router.include-router( 'polls/' => $another_router );
# ... in your dispatcher
# returns a Path::Router::Route::Match object
my $match = $router.match('/blog/edit/15', context => %( method => 'GET' ));
# ... in your code
my $uri = $router.path-for(
controller => 'blog',
action => 'show_date',
year => 2006,
month => 10,
day => 5,
);
```
# DESCRIPTION
This module provides a way of deconstructing paths into parameters suitable for dispatching on. It also provides the inverse in that it will take a list of parameters, and construct an appropriate uri for it.
## Reversable
This module places a high degree of importance on reversability. The value produced by a path match can be passed back in and you will get the same path you originally put in. The result of this is that it removes ambiguity and therefore reduces the number of possible mis-routings.
## Verifiable
This module also provides additional tools you can use to test and verify the integrity of your router. These include:
* An interactive shell in which you can test various paths and see the match it will return, and also test the reversability of that match.
* A Test::Path::Router module which can be used in your applications test suite to easily verify the integrity of your paths.
## Validated and Automatically Coerced
Each path may use one or more variables, each given a validation. If a numeric type is used, the value passed on to the action will also be coerced into the correct value.
## Flexible
This module has no opinions about what it might be useful for. It simply produces a hash of values that can be used for dispatch, logging, or whatever your application is.
# ATTRIBUTES
## routes
```
has Path::Router::Route @.routes
```
Stores all the route objects that have been added to the router.
# METHODS
## method add-route
```
method add-route(Str $path, *%options --> Int)
```
Adds a new route to the *end* of the routes list.
Returns the number of routes stored.
## method insert-route
```
method insert-route(Str $path, *%options --> Int)
```
Adds a new route to the routes list. You may specify an `at` parameter, which would indicate the position where you want to insert your newly created route. The `at` parameter is the `index` position in the list, so it starts at 0.
Returns the number of routes stored.
Examples:
```
# You have more than three paths, insert a new route at
# the 4th item
$router.insert-route($path => %(
at => 3, |%options
));
# If you have less items than the index, then it's the same as
# as add_route -- it's just appended to the end of the list
$router.insert-route($path => %(
at => 1_000_000, |%options
));
# If you want to prepend, omit "at", or specify 0
$router.insert-route($path => %(
at => 0, |%options
));
```
## method include-router
```
method include-router (Str $path, Path::Router $other-router --> Int)
```
This extracts all the route from `$other-router` and includes them into the invocant router and prepends `$path` to all their paths.
It should be noted that this does **not** do any kind of redispatch to the `$other-router`, it actually extracts all the paths from `$other-router` and inserts them into the invocant router. This means any changes to `$other-router` after inclusion will not be reflected in the invocant.
Returns the number of routes stored.
## method match
```
method match(Str $path, :%context --> Path::Router::Route::Match)
```
Return a Path::Router::Route::Match object for the best route that matches the given the `$path` and `%context` (if given), or an undefined type-object if no routes match.
The `%context` is an optional value that is only used if routes with conditions are present. The context is used as an additional match in the process and can be used to apply extra conditions, such as matching the HTTP method when used in a web application.
The "best route" is chosen by first matching the `$path` against every route and then applying the following rules:
# over
* If no route matches, an undefined type object will be returned. If exactly one route matches, a match for that route will be returned.
* If multiple routes match, the one with the most required variables will be considered the best match and be returned.
* In the case that exactly two routes match and have the same number of variables, but one has conditions and the other does not, the one that has conditions will be considered best and returned.
* Otherwise, if there is more than one matching route with the same number of required variables, an [X::Path::Router::AmbiguousMatch::PathMatch](#X::Path::Router::AmbiguousMatch::PathMatch) exception is thrown. This exception contains all the best matches, so your code can disambiguate them in any way you want or treat this as an error condition as suits your application.
## method path-for
```
method path-for(:%context, *%path_descriptor --> Str)
```
Find the path that, when passed to `method match` , would produce the given arguments. Returns the path without any leading `/`. Returns an undefined type-object if no routes match.
The `%context` is optional, but if present, this will also apply any route conditions to the given `%context`.
This will throw an [X::Path::Router::AmbiguousMatch::ReverseMatch](#X::Path::Router::AmbiguousMatch::ReverseMatch) exception if multiple URLs match. This exception includes the possible routes so your code can disambiguate them in whatever fashion makes sense to you.
# DEBUGGING
You can turn on the verbose debug logging with the `PATH_ROUTER_DEBUG` environment variable. Set that environment variable to a truthy value to enable debugging.
# DIAGNOSTIC
## X::Path::Router
All path router exceptions inherit from this exception class.
## X::Path::Router::AmbiguousMatch::PathMatch
This exception is thrown when a path is found to match two different routes equally well.
Provides:
* `method path(--> Str)` returns the ambiguous path.
* `method matches(--> Array)` returns the best matches found.
## X::Path::Router::AmbiguousMatch::ReverseMatch
This exception is thrown when two paths are found to match a given criteria when looking up the `path-for` a path
Provides:
* `method match-keys(--> Array[Str])` returns the mapping that was ambiguous
* `method routes(--> Array[Str])` returns the best matches found
## X::Path::Router::BadInclusion
This exception is thrown whenever an attempt is made to include one router in another incorrectly.
## X::Path::Router::BadRoute
This exception is thrown when a route has some serious flaw.
Provides:
* `method path(--> Str)` returns the bad route
## X::Path::Router::BadValidation
This is an [X::Path::Router::BadRoute](#X::Path::Router::BadRoute) exception that is thrown when a validation for a variable that is not found in the path.
Provides:
* `method validation(--> Str)` returns the validation variable that was named in the route, but was not found in the path
## X::Path::Router::BadSlurpy
This is an [X::Path::Router::BadRoute](#X::Path::Router::BadRoute) exception that is thrown when a validation attempts to add a slurpy parameter that is not at the end of the path.
# AUTHOR
Andrew Sterling Hanenkamp [[email protected]](mailto:[email protected])
Based very closely on the original Perl 5 version by Stevan Little [[email protected]](mailto:[email protected])
# COPYRIGHT
Copyright 2015 Andrew Sterling Hanenkamp.
# LICENSE
This library is free software; you can redistribute it and/or modify it under the same terms as Perl itself.
|
## dist_zef-raku-community-modules-Trait-IO.md
[](https://github.com/raku-community-modules/Trait-IO/actions)
# NAME
Trait::IO - Helper IO traits
# SYNOPSIS
```
use Trait::IO;
for <a b c> {
my $fh does auto-close = .IO.open: :w;
# ... do things with the file handle
# $fh is auto-closed on block leave
}
# Top-level is OK too; will close on scope leave
my $fh does auto-close = "foo".IO.open: :w;
# ...
```
# DESCRIPTION
Useful traits for working with Raku IO.
# EXPORTS
-head2 does auto-close
```
my $fh does auto-close = "foo".IO.open: :w;
```
Installs a `LEAVE` phaser to automatically close the file handle when scope is left.
Exports the constant and the `trait_mod:<does>` multi that accepts it as a value.
Currently works only with variables and not with attributes or parameters. Patches welcome.
# AUTHOR
Zoffix Znet
# COPYRIGHT AND LICENSE
Copyright 2017 - 2018 Zoffix Znet
Copyright 2019 - 2022 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## denominator.md
denominator
Combined from primary sources listed below.
# [In role Rational](#___top "go to top of document")[§](#(role_Rational)_method_denominator "direct link")
See primary documentation
[in context](/type/Rational#method_denominator)
for **method denominator**.
```raku
method denominator(Rational:D: --> DeT:D)
```
Returns the denominator.
|
## dist_zef-antononcube-Math-Polynomial-Chebyshev.md
# Math::Polynomial::Chebyshev
Raku package for functionalities based on Chebyshev polynomials.
---
## Installation
From Zef ecosystem:
```
zef install Math::Polynomial::Chebyshev
```
From GitHub:
```
zef install https://github.com/antononcube/Raku-Math-Polynomial-Chebyshev.git
```
---
## Usage examples
Evaluate the numerical value of the Chebyshev polynomial of first kind $T\_2(3)$:
```
use Math::Polynomial::Chebyshev;
chebyshev-t(2, 0.3)
```
```
# -0.82
```
The default method is "recursive":
```
chebyshev-t(2, 6, method => 'recursive')
```
```
# 71
```
Here is an invocation of the "trigonometric" method:
```
chebyshev-t(2, 3, method => 'trigonometric')
```
```
# 17
```
**Remark:** Currently, the trigonometric method is implemented only for the Chebyshev polynomials of first kind
(Chebyshev-T.)
Plot the 7th Chebyshev-T polynomial:
```
use Text::Plot;
my @x = (-1, -0.99 ... 1);
text-list-plot(@x, chebyshev-t(6, @x), width => 60)
```
```
# +---+------------+-----------+------------+------------+---+
# | |
# + * ****** ***** * + 1.00
# | * * ** ** * * |
# + * ** ** ** + 0.50
# | * ** * ** ** * |
# | * * * * * * |
# + * ** * * + 0.00
# | * * ** ** * * |
# | * * ** ** * * |
# + * ** ** ** ** ** + -0.50
# | * ** ** ** * * |
# + *** ****** *** + -1.00
# | |
# +---+------------+-----------+------------+------------+---+
# -1.00 -0.50 0.00 0.50 1.00
```
Here we make a Chebyshev-T function:
```
chebyshev-u(4)
```
```
# -> ;; $_? is raw = OUTER::<$_> { #`(Block|2377734473048) ... }
```
A list of Chebyshev polynomials can be used as a basis for the models in
"Math::Fitting", [AAp2].
Here is an example:
```
use Math::Fitting;
my @basis = (^4).map({ chebyshev-t($_) });
my @data = [2.rand - 1, 10.rand] xx 20;
my &lm = linear-model-fit(@data, :@basis);
```
```
# Math::Fitting::FittedModel(type => linear, data => (20, 2), response-index => 1, basis => 4)
```
Here are plots:
```
my @fit = (-1, -0.98 ... 1).map({ [$_, &lm($_)] });
say <fit data> Z=> <* □>;
say text-list-plot([@fit, @data])
```
```
# (fit => * data => □)
# +---+------------+-----------+------------+------------+---+
# + + 10.00
# | □ |
# | □ □ |
# + □ + 8.00
# | □ ****□□**** □□ |
# + ******** **** + 6.00
# | ******* □ |
# + □ ****** □ □ + 4.00
# | □***□ ********** |
# + ****** □ □ + 2.00
# | □ |
# | □ |
# + + 0.00
# +---+------------+-----------+------------+------------+---+
# -1.00 -0.50 0.00 0.50 1.00
```
---
## References
### Articles
[WK1] Wolfram Koepf,
["Efficient Computation of Chebyshev Polynomials in Computer Algebra"](https://www.researchgate.net/publication/2321141_Efficient_Computation_of_Chebyshev_Polynomials_in_Computer_Algebra).
(1999),
Computer Algebra Systems: A Practical Guide. 79-99.
[Wk1] Wikipedia entry, [Chebyshev polynomials](https://en.wikipedia.org/wiki/Chebyshev_polynomials).
### Packages
[AAp1] Anton Antonov,
[Text::Plot Raku package](https://github.com/antononcube/Raku-Text-Plot),
(2022-2023),
[GitHub/antononcube](https://github.com/antononcube).
[AAp2] Anton Antonov,
[Math::Fitting Raku package](https://github.com/antononcube/Raku-Math-Fitting),
(2024),
[GitHub/antononcube](https://github.com/antononcube).
[SFp1] Solomon Foster,
[Math::ChebyshevPolynomial Raku package](https://github.com/colomon/Math-ChebyshevPolynomial),
(2013-2015),
[GitHub/colomon](https://github.com/colomon).
|
## dist_zef-raku-community-modules-File-Temp.md
[](https://github.com/raku-community-modules/File-Temp/actions) [](https://github.com/raku-community-modules/File-Temp/actions) [](https://github.com/raku-community-modules/File-Temp/actions)
# NAME
File::Temp - Create temporary files & directories
# SYNOPSIS
```
# Generate a temp dir
my $tmpdir = tempdir;
# Generate a temp file in a temp dir
my ($filename, $filehandle) = tempfile;
# specify a template for the filename
# * are replaced with random characters
my ($filename, $filehandle) = tempfile("******");
# Automatically unlink files at end of program (this is the default)
my ($filename, $filehandle) = tempfile("******", :unlink);
# Specify the directory where the tempfile will be created
my ($filename, $filehandle) = tempfile(:tempdir("/path/to/my/dir"));
# don't unlink this one
my ($filename, $filehandle) = tempfile(:tempdir('.'), :!unlink);
# specify a prefix and suffix for the filename
my ($filename, $filehandle) = tempfile(:prefix('foo'), :suffix(".txt"));
```
# DESCRIPTION
This module exports two routines:
* tempfile Creates a temporary file and returns a filehandle to that file opened for writing and the filename of that temporary file
* tempdir Creates a temporary directory and returns the directory name
# AUTHORS
* Jonathan Scott Duff
* Rod Taylor
* Polgár Márton
* Tom Browder
# COPYRIGHT AND LICENSE
Copyright 2012 - 2017 Jonathan Scott Duff
Copyright 2018 - 2021 Rod Taylor
Copyright 2022 - 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-BDUGGAN-Curlie.md
## NAME
Curlie -- A simple HTTP client built on top of libcurl
## DESCRIPTION
An HTTP Client built on libcurl, that provides an OO interface, logging and error handling.
## SYNOPSIS
Create a new object manually:
```
use Curlie;
my \c = Curlie.new;
```
Any options sent in the constructor will be sent to libcurl's setopt.
```
my $username = 'alice';
my $password = 's3cret';
my \c = Curlie.new(:$username, :$password);
```
or create a new object automatically:
```
use Curlie :c;
```
Send a request, and print the full response headers and body:
```
say c.get('https://httpbin.org/get').res;
say c.get('https://httpbin.org/get?name=bob').res;
say c.get('https://httpbin.org/get', query => %( name => 'bob' )).res;
say c.get('https://httpbin.org/get', query => rocket => '🚀').res;
```
or
```
c.get: 'https://httpbin.org/get';
say c.res;
say c.res.content;
```
The response object is a `Curlie::Response`, and has the following
methods: `status`, `statusline`, `success`, `content`, `raw-headers`, `headers`,
and `json`.
Non-success responses return soft failures:
```
say c.get('https://httpbin.org/status/500').res;
# Fails with:
# HTTP/2 500
# and a stack trace
```
Which means to see the entire response, use it in a boolean context:
```
c.get('https://httpbin.org/status/500') or say c.res;
# Does not fail, prints:
# HTTP/2 500
# [ headers, response...]
```
If you also want to see the request, start a logger using Log::Async, and call `c.debug` beforehand:
```
use Log::Async;
logger.send-to($*ERR);
c.debug;
c.get('https://httpbin.org/status/500');
```
Add `curl` or `ssl` options to see extra libcurl or ssl messages:
```
c.debug(:curl, :ssl);
```
Getting json, posting json, posting forms work like this:
```
c.get: 'https://httpbin.org/status/200', :json;
c.post: 'https://httpbin.org/post', :json(:hello<world>);
c.post: 'https://httpbin.org/post', :form(:hello<world>);
```
The response object also has a `json` method which will decode
the body:
```
say c.get('https://httpbin.org/get').res.json<url>
# https://httpbin.org/get
```
Also other headers can be sent in a `headers` argument
```
say c.get('https://httpbin.org/get', :headers(:X-Hello<world>)).res.json<headers><X-Hello>
# world
```
That's it! (so far!)
## INSTALLATION
The last version of Curlie can be found at <https://git.sr.ht/~bduggan/raku-curlie>
Specific versions of Curlie can be install using zef, for instance:
```
zef install https://git.sr.ht/~bduggan/raku-curlie/archive/0.0.2.tar.gz
```
## SEE ALSO
[raku-libcurl](https://github.com/CurtTilmes/raku-libcurl)
## BUGS
Probably! Send me patches!
## AUTHOR
Brian Duggan (bduggan @ matatu.org)
|
## dist_zef-dwarring-HarfBuzz-Font-FreeType.md
[[Raku HarfBuzz Project]](https://harfbuzz-raku.github.io)
/ [[HarfBuzz-Font-FreeType Module]](https://harfbuzz-raku.github.io/HarfBuzz-Font-FreeType-raku)
## class HarfBuzz::Font::FreeType
A HarfBuzz FreeType face integrated font
### has Font::FreeType::Face:D $.ft-face
HarfBuzz FreeType bound font data-type
## Synopsis
```
use HarfBuzz::Font::FreeType;
use HarfBuzz::Shaper;
use Font::FreeType::Face;
my Font::FreeType::Face $ft-face .= new: ...;
my HarfBuzz::Font::FreeType() .= %( :$ft-face, :@features, :$size, :@scale );
my HarfBuzz::Shaper $shaper .= new: :$font, :buf{ :text<Hello> };
```
## Description
This modules supports [FreeType integration](https://harfbuzz.github.io/integration-freetype.html) for the HarfBuzz library.
It may be used to do [HarfBuzz](https://harfbuzz-raku.github.io/HarfBuzz-raku/HarfBuzz) shaping from a [Font::FreeType](https://pdf-raku.github.io/Font-FreeType-raku/Font/FreeType) object.
Note that HarfBuzz can load OpenType and TrueType format fonts directly. The FreeType integration most likely to be useful for other font formats, that can be loaded by [Font::FreeType](https://harfbuzz-raku.github.io/Font-FreeType-raku/).
## Methods
This class inherits from [HarfBuzz::Font](https://harfbuzz-raku.github.io/HarfBuzz-raku/HarfBuzz/Font) and has all its methods available.
### new
```
use Font::FreeType::Face;
use HarfBuzz::Font::FreeType;
method new(
Font::FreeType::Face:D :$ft-face!, # FreeeType face
Bool :$funcs = True, # use FreeType functions
Num() :$size = 12e0, # font size (points)
:@scale, # font scale [x, y?]
) returns HarfBuzz::Font::FreeType:D
```
Creates a new FreeType integrated font.
```
multi method COERCE(
% (Font::FreeType::Face:D :$ft-face!, |etc)
) returns HarfBuzz::Font::FreeType:D
```
Coerces a FreeType integrated font, from an options hash.
### method ft-load-flags
```
method ft-load-flags() returns Int
```
Get or set the FreeType load flags
|
## lines.md
lines
Combined from primary sources listed below.
# [In IO::Socket::INET](#___top "go to top of document")[§](#(IO::Socket::INET)_method_lines "direct link")
See primary documentation
[in context](/type/IO/Socket/INET#method_lines)
for **method lines**.
```raku
method lines()
```
Returns a lazy list of lines read from the socket.
# [In IO::Handle](#___top "go to top of document")[§](#(IO::Handle)_routine_lines "direct link")
See primary documentation
[in context](/type/IO/Handle#routine_lines)
for **routine lines**.
```raku
sub lines( $what = $*ARGFILES, |c)
multi method lines( IO::Handle:D: $limit, :$close )
multi method lines( IO::Handle:D: :$close )
```
The sub form, which takes `$*ARGFILES` by default, will apply the `lines` method to the object that's the first argument, and pass it the rest of the arguments.
The method will return a [`Seq`](/type/Seq) each element of which is a line from the handle (that is chunks delineated by [`.nl-in`](/type/IO/Handle#method_nl-in)). If the handle's [`.chomp`](/type/IO/Handle#method_chomp) attribute is set to `True`, then characters specified by [`.nl-in`](/type/IO/Handle#method_nl-in) will be stripped from each line.
Reads up to `$limit` lines, where `$limit` can be a non-negative [`Int`](/type/Int), `Inf`, or [`Whatever`](/type/Whatever) (which is interpreted to mean `Inf`). If `:$close` is set to `True`, will close the handle when the file ends or `$limit` is reached. Subroutine form defaults to [`$*ARGFILES`](/language/variables#index-entry-%24%2AARGFILES), if no handle is provided.
Attempting to call this method when the handle is [in binary mode](/type/IO/Handle#method_encoding) will result in [`X::IO::BinaryMode`](/type/X/IO/BinaryMode) exception being thrown.
**NOTE:** the lines are read lazily, so ensure the returned [`Seq`](/type/Seq) is either [fully reified](/language/glossary#Reify) or is no longer needed when you close the handle or attempt to use any other method that changes the file position.
```raku
say "The file contains ",
'50GB-file'.IO.open.lines.grep(*.contains: 'Raku').elems,
" lines that mention Raku";
# OUTPUT: «The file contains 72 lines that mention Raku»
```
You can use `lines` in `/proc/*` files (from the 6.d version):
```raku
say lines( "/proc/$*PID/statm".IO ); # OUTPUT: «(58455 31863 8304 2 0 29705 0)»
```
# [In Supply](#___top "go to top of document")[§](#(Supply)_method_lines "direct link")
See primary documentation
[in context](/type/Supply#method_lines)
for **method lines**.
```raku
method lines(Supply:D: :$chomp = True --> Supply:D)
```
Creates a supply that will emit the characters coming in line by line from a supply that's usually created by some asynchronous I/O operation. The optional `:chomp` parameter indicates whether to remove line separators: the default is `True`.
# [In IO::Path](#___top "go to top of document")[§](#(IO::Path)_method_lines "direct link")
See primary documentation
[in context](/type/IO/Path#method_lines)
for **method lines**.
```raku
method lines(IO::Path:D: :$chomp = True, :$enc = 'utf8', :$nl-in = ["\x0A", "\r\n"], |c --> Seq:D)
```
Opens the invocant and returns its [lines](/type/IO/Handle#routine_lines).
The behavior is equivalent to [opening](/routine/open) the file specified by the invocant, forwarding the `:$chomp`, `:$enc`, and `:$nl-in` arguments to [`IO::Handle.open`](/type/IO/Handle#method_open), then calling [`IO::Handle.lines`](/type/IO/Handle#routine_lines) on that handle, forwarding any of the remaining arguments to that method, and returning the resultant [`Seq`](/type/Seq).
**NOTE:** the lines are ready lazily and the handle used under the hood won't get closed until the returned [`Seq`](/type/Seq) is [fully reified](/language/glossary#Reify), so ensure it is, or you'll be leaking open filehandles. (TIP: use the [`$limit` argument](/type/IO/Handle#routine_lines))
```raku
say "The file contains ",
'50GB-file'.IO.lines.grep(*.contains: 'Raku').elems,
" lines that mention Raku";
# OUTPUT: «The file contains 72 lines that mention Raku»
```
# [In IO::CatHandle](#___top "go to top of document")[§](#(IO::CatHandle)_method_lines "direct link")
See primary documentation
[in context](/type/IO/CatHandle#method_lines)
for **method lines**.
```raku
method lines(IO::CatHandle:D: $limit = Inf, :$close --> Seq:D)
```
Same as [`IO::Handle.lines`](/type/IO/Handle#routine_lines). Note that a boundary between source handles is considered to be a newline break.
```raku
(my $f1 = 'foo'.IO).spurt: "foo\nbar";
(my $f2 = 'bar'.IO).spurt: 'meow';
IO::CatHandle.new($f1, $f2).lines.raku.say;
# OUTPUT: «("foo", "bar", "meow").Seq»
```
Note: if `:$close` is `False`, fully-consumed handles are **still** going to be closed.
# [In Str](#___top "go to top of document")[§](#(Str)_routine_lines "direct link")
See primary documentation
[in context](/type/Str#routine_lines)
for **routine lines**.
```raku
multi method lines(Str:D: $limit, :$chomp = True)
multi method lines(Str:D: :$chomp = True)
```
Returns a list of lines. By default, it chomps line endings the same as a call to `$input.comb( / ^^ \N* /, $limit )` would. To keep line endings, set the optional named parameter `$chomp` to `False`.
Examples:
```raku
say lines("a\nb").raku; # OUTPUT: «("a", "b").Seq»
say lines("a\nb").elems; # OUTPUT: «2»
say "a\nb".lines.elems; # OUTPUT: «2»
say "a\n".lines.elems; # OUTPUT: «1»
# Keep line endings
say lines(:!chomp, "a\nb").raku; # OUTPUT: «("a\n", "b").Seq»
say "a\n".lines(:!chomp).elems; # OUTPUT: «1»
```
You can limit the number of lines returned by setting the `$limit` variable to a non-zero, non-`Infinity` value:
```raku
say <not there yet>.join("\n").lines( 2 ); # OUTPUT: «(not there)»
```
**DEPRECATED as of `6.d` language**, the `:count` argument was used to return the total number of lines:
```raku
say <not there yet>.join("\n").lines( :count ); # OUTPUT: «3»
```
Use [elems](/routine/elems) call on the returned [`Seq`](/type/Seq) instead:
```raku
say <not there yet>.join("\n").lines.elems; # OUTPUT: «3»
```
# [In Cool](#___top "go to top of document")[§](#(Cool)_routine_lines "direct link")
See primary documentation
[in context](/type/Cool#routine_lines)
for **routine lines**.
```raku
sub lines(Str(Cool))
method lines()
```
Coerces the invocant (and in sub form, the argument) to [`Str`](/type/Str), decomposes it into lines (with the newline characters stripped), and returns the list of lines.
```raku
say lines("a\nb\n").join('|'); # OUTPUT: «a|b»
say "some\nmore\nlines".lines.elems; # OUTPUT: «3»
```
This method can be used as part of an [`IO::Path`](/type/IO/Path) to process a file line-by-line, since [`IO::Path`](/type/IO/Path) objects inherit from `Cool`, e.g.:
```raku
for 'huge-csv'.IO.lines -> $line {
# Do something with $line
}
# or if you'll be processing later
my @lines = 'huge-csv'.IO.lines;
```
Without any arguments, sub `lines` operates on [`$*ARGFILES`](/language/variables#$*ARGFILES).
To modify values in place use [`is copy`](/language/signatures#Parameter_traits_and_modifiers) to force a writable container.
```raku
for $*IN.lines -> $_ is copy { s/(\w+)/{$0 ~ $0}/; .say }
```
|
## dist_zef-hythm-Pakku.md
[](https://github.com/hythm7/Pakku/actions/workflows/linux.yml)
[](https://github.com/hythm7/Pakku/actions/workflows/mac.yml)
[](https://github.com/hythm7/Pakku/actions/workflows/windows.yml)
[](https://ci.sparrowhub.io)
# Pakku
Package Manager for the Raku Programming Language.
# Installation
```
# Install
git clone https://github.com/hythm7/Pakku.git
cd Pakku
raku -I. bin/pakku add .
# Install using Zef
zef install Pakku
```
# Usage
Pakku manages Raku distributions with commands like `add`, `remove`, `update` etc.
Full command consists of:
`pakku [general-options] <command> [command-options] <dists>`
There are two types of options:
**General options:**
These are the options that control the general behavior of Pakku, eg. specify the configuration file, run asynchronously or disable colors. The general options are valid for all commands, and must be placed before the command.
**Command options:**
These are the options that control the specified command, for example when installing a distributions one can add `notest` option to disable testing. these options must be placed after the command.
## Pakku Commands
### add
Install distributions
**options:**
```
deps → all dependencies
deps < build > → build dependencies only
deps < test > → test dependencies only
deps < runtime > → runtime dependencies only
deps < only > → install dependencies but not the dist
exclude < Spec > → exclude Spec
test → test distribution
xtest → xTest distribution
build → build distribution
serial → add distributions in serial order
contained → add distributions and all transitive deps (regardless if they are installed)
precomp → precompile distribution
to < repo > → add distribution to repo < home site vendor core /path/to/MyApp >
nodeps → no dependencies
nobuild → bypass build
notest → bypass test
noxtest → bypass xtest
noserial → no serial
noprecomp → no precompile
```
**Examples:**
```
pakku add dist # add dist
pakku add notest dist # add dist without testing
pakku add nodeps dist # add dist but dont add dependencies
pakku add serial dist # add dists in serial order
pakku add deps only dist # add dist dependencies but dont add dist
pakku add exclude Dep1 dist # add dist and exclude Dep1 from dependenncies
pakku add noprecomp notest dist # add dist without testing and no precompilation
pakku add contained to /opt/MyApp dist # add dist and all transitive deps to custom repo
pakku add to vendor dist1 dist2 # add dist1 and dist2 to vendor repo even if they are installed
```
### remove
Remove distributions
**options:**
```
from < repo > → remove distribution from provided repo only
```
**Examples:**
```
pakku remove dist # remove dist from all repos
pakku remove from site dist # remove dist from site repo only
```
### list
List installed distributions
**options:**
```
details → details
repo < name-or-path > → list specific repo
```
**Examples:**
```
pakku list # list all installed dists
pakku list dist # list installed dist
pakku list details dist # list installed dist details
pakku list repo home # list all dists installed to home repo
pakku list repo /opt/MyApp dist # list installed dist in custom repo
```
### search
Search available distributions
**options:**
```
latest → latest version
relaxed → relaxed search
details → details of dist
count < number > → number of dists to be returned
norelaxed → no relaxed search
```
**Examples:**
```
pakku search dist # search distributions matching dist (ignored case) on online recman
pakku search latest dist # show latest version
pakku search norelaxed dist # no relaxed search
pakku search count 4 dist # search dist and return the lates 4 versions only
pakku search details dist # search dist and list all details
```
### build
Build distributions
**Examples:**
```
pakku build dist
pakku build .
```
### test
Test distributions
**options:**
```
xtest → XTest distribution
build → Build distribution
noxtest → Bypass xtest
nobuild → Bypass build
```
**Examples:**
```
pakku test dist
pakku test ./dist
pakku test xtest ./dist
pakku test nobuild ./dist
```
### update
Update distributions to latest version
**options:**
```
clean → clean not needed dists after update
deps → update dependencies
nodeps → no dependencies
exclude Dep1 → exclude Dep1
deps only → dependencies only
build → build distribution
nobuild → bypass build
test → test distribution
notest → bypass test
xtest → xTest distribution
noxtest → bypass xtest
precomp → precompile distribution
noprecomp → no precompile
noclean → dont clean unneeded dists
in < repo > → update distribution and install in repo < home site vendor core /path/to/MyApp >
```
**Examples:**
```
pakku update # update all installed distribution
pakku update dist
pakku update nodeps dist
pakku update notest dist1 dist2
```
### state
Check the state of installed distributions
**options:**
```
updates → check updates for dists
clean → clean older versions of dists
noupdates → dont check updates for dists
noclean → dont clean older versions
```
**Examples:**
```
pakku state
pakku state dist
pakku state clean dist
pakku state noupdates dist
```
### download
Download distribution source
**Examples:**
```
pakku download dist # download dist and extract to temp directory
```
### nuke
Nuke directories
**Examples:**
```
pakku nuke cache # nuke cache
pakku nuke pakku # nuke pakku home directory
pakku nuke home # nuke home repo
pakku nuke site # nuke site repo
pakku nuke vendor # nuke vendor repo
```
### config
Each Pakku command like `add`, `remove`, `search` etc. corresponds to a config module with the same name in the config file.
one can use config command to `enable`, `disable`, `set`, `unset` an option in the config file.
**options:**
```
enable → enable option
disable → disable option
set < value > → set option to value
unset → unset option
```
**Examples:**
```
pakku config # view all config modules
pakku config new # create a new config file
pakku config add # view add config module
pakku config add precompile # view precompile option in add config module
pakku config add enable xtest # enable option xtest in add module
pakku config add set to home # set option to to home (change default repo to home) in add module
pakku config pakku enable async # enable option async in pakku module (general options)
pakku config pakku unset verbose # unset option verbose in pakku module
pakku config recman MyRec disable # disable recman named MyRec in recman module
pakku config recman MyRec set priority 1 # set recman MyRec's priority to 1 in recman module
pakku config add reset # reset add config module to default
pakku config reset # reset all config modules to default
```
### help
Get help on a specific command
**Examples:**
```
pakku
pakku help add
pakku help list
pakku help remove
pakku add
pakku help
pakku help help
```
## Pakku General Options
**Options:**
```
pretty → use colors
force → use force
async → run asynchronously (disabled by default because some dists tests are not async safe)
dont → do everything but dont do it (dry run)
bar → use progress bar
spinner → use spinner
verbose < level > → verbosity < nothing error warn info now debug all >
cores < number > → number of cores used when run in async mode
config < path > → specify config file
recman → enable all remote recommendation manager
recman < MyRec > → use MyRec recommendation manager only
norecman → disable all remote recommendation manager
norecman < MyRec > → use all recommendation managers excepts MyRec
nopretty → no colors
noforce → no force
nobar → no progress bar
nospinner → no spinner
noasync → dont run asynchronously
nocache → disable cache
yolo → proceed if error occured (eg. test failure)
please → be nice to butterflies
```
**Examples:**
```
pakku async add dist # run in async mode while adding dist
pakku nocache add dist # dont use cache
pakku dont add dist # dont add dist (dry run)
pakku pretty please remove dist
```
### Feeling Rakuish Today?
Most of `Pakku` commands and options can be written in shorter form, for example:
```
add → a update → u yolo → y nopretty → np nothing → «N 0»
remove → r download → d exclude → x nodeps → nd all → «A 6»
list → l help → h deps → d noforce → nf debug → «D 5»
search → s verbose → v force → f notest → nt now → «N 4»
build → b pretty → p details → d nobuild → nb info → «I 3»
test → t only → o norecman → nr nocache → nc warn → «W 2»
```
The below are `Pakku` commands as well!
```
pakku 👓 🧚 ↓ dist
pakku ↪
pakku ❓
```
## ENV Options
Options can be set via environment variables as well:
**General**
```
PAKKU_VERBOSE PAKKU_CACHE PAKKU_RECMAN PAKKU_NORECMAN PAKKU_CONFIG PAKKU_DONT
PAKKU_FORCE PAKKU_PRETTY PAKKU_BAR PAKKU_SPINNER PAKKU_ASYNC PAKKU_CORES PAKKU_YOLO
```
**Add**
```
PAKKU_ADD_TO PAKKU_ADD_DEPS PAKKU_ADD_TEST PAKKU_ADD_BUILD PAKKU_ADD_XTEST
PAKKU_ADD_SERIAL PAKKU_ADD_PRECOMPILE PAKKU_ADD_EXCLUDE
```
**Test**
```
PAKKU_TEST_BUILD PAKKU_TEST_XTEST
```
**Remove**
```
PAKKU_REMOVE_FROM
```
**List**
```
PAKKU_LIST_REPO PAKKU_LIST_DETAILS
```
**Search**
```
PAKKU_SEARCH_LATEST PAKKU_SEARCH_DETAILS PAKKU_SEARCH_RELAXED PAKKU_SEARCH_COUNT
```
**Update**
```
PAKKU_UPDATE_IN PAKKU_UPDATE_DEPS PAKKU_UPDATE_TEST PAKKU_UPDATE_XTEST PAKKU_UPDATE_BUILD
PAKKU_UPDATE_CLEAN PAKKU_UPDATE_PRECOMPILE PAKKU_UPDATE_EXCLUDE
```
**State**
```
PAKKU_STATE_CLEAN> PAKKU_STATE_UPDATES
```
# Pakku Output
Pakku output aims to be tidy and concise, uses emojis, colors and three letters key words to convey messages.
For example, the `🦋` emoji indicates that Pakku is starting a task, while `🧚` means Pakku successfully completed a task.
An output line like:
`🦋 BLD: 「Inline::Perl5:ver<0.60>:auth<cpan:NINE>:api<>」`
means Pakku is starting to build `Inline::Perl5:ver<0.60>:auth<cpan:NINE>:api<>`, and based on the result another output line could be:
`🧚 BLD: 「Inline::Perl5:ver<0.60>:auth<cpan:NINE>:api<>」` # build success
`🦗 BLD: 「Inline::Perl5:ver<0.60>:auth<cpan:NINE>:api<>」` # build failure
Below is a list of output lines that one can see and their meaning:
```
🧚 ADD → start add command
🦋 SPC → processing Spec
🦋 MTA → processing Meta
🦋 FTC → fetching
🦋 BLD → building
🦋 STG → staging
🦋 TST → testing
🧚 BLD → build success
🧚 TST → test success
🧚 BIN → binary added
🐞 WAI → waiting
🐞 TOT → timed out
🦗 SPC → error processing Spec
🦗 MTA → error processing Meta
🦗 BLD → build failure
🦗 TST → test failure
🦗 CNF → config error
🦗 CMD → command error
```
**Pakku verbosity levels:**
```
- 1 `「 all 」` 🐝 → All avaialble output
- 2 `「debug」` 🐛 → Debug output
- 3 `「 now 」` 🦋 → What is happenning now
- 4 `「info 」` 🧚 → Important things only
- 5 `「warn 」` 🐞 → Warnings only
- 6 `「error」` 🦗 → Errors only
- 0 `「nothing」` → Nothing
```
> [!WARNING]
> Pakku uses emoji and ANSI escape codes, If your terminal doesn't support them, you can disable colors, bars and spinners, (eg. `pakku nopretty nobar nospinner add Foo`), or disable permanently in config file. also for emojis, eg. to change the `debug` emoji for example, in config file replace `"debug": {"prefix": "🐛"}` with `"debug": {"prefix": "D"}`.
**Command result**:
* `-Ofun` - Success
* `Nofun` - Failure
# Gotchas
**Caching downloaded distributions**
When one installs a distribution via `pakku add dist`, Pakku first looks in the local cache to see if there is a downloaded distribution matches `dist` specification, if nothing found in the cache, Pakku then searches the configured `RecMan` and obtain the latest version of `dist` (e.g. `dist:ver<0.4.1>`), download, cache, and install it.
After sometime when a new version `dist:ver<0.4.2>` is released and available in `RecMan`, if one try to install `dist` via `pakku add dist`, what happens is Pakku will find `dist:ver<0.4.1>` available in local cache and will install that version because it matches `dist` specification. so one will not get the latest version `dist:ver<0.4.2>`.
There are two ways to avoid this and get the latest version, either specify the version e.g. `pakku add dist:ver<0.4.2>` or disable cache lookup e.g. `pakku nocache add dist` (also, one can permenantly disable cache in config file).
**Pakku installs to *site* repo by default**
If the user doesn't have `rw` permision to `site` repo, one can change the default repo to `home` in config file using:
`pakku config add set to home`
or specify the repo in the command e.g. `pakku add to home dist`
# Credits
Thanks to `Panda` and `Zef` for `Pakku` inspiration.
also Thanks to the nice `#raku` community.
# Motto
Light like a 🧚, Colorful like a 🧚
# Author
Haytham Elganiny `elganiny.haytham at gmail.com`
# Copyright and License
Copyright 2023 Haytham Elganiny
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-App-Nopaste.md
[](https://github.com/raku-community-modules/App-Nopaste/actions)
# NAME
App::Nopaste - command line interface to pastebins
# SYNOPSIS
```
nopaste http://fpaste.scsys.co.uk/500226
nopaste https://gist.github.com/zoffixznet/83adc0789cdb0cf57d43
nopaste file1 dir/foo/file2 file3
```
# DESCRIPTION
This module allows to paste to create GitHub Gists as retrieve them.
# PASTEBINS
Currently, the module supports fetching/pasting from <https://gist.github.com/> and <http://fpaste.scsys.co.uk/>. To use <https://gist.github.com/> you need to [create a GitHub token](https://github.com/settings/tokens). Only the `gist` permission is needed. Set `PASTEBIN_GIST_TOKEN` environmental variable to the value of that token.
If `PASTEBIN_GIST_TOKEN` is set, pastes will be created on <https://gist.github.com/>; otherwise on <http://fpaste.scsys.co.uk/>.
# AUTHOR
Zoffix Znet
# COPYRIGHT AND LICENSE
Copyright 2015 - 2016 Zoffix Znet
Copyright 2017 - 2022 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-tony-o-JSON-Path.md
# JSON::Path
A pure perl JSON path implementation for perl6.
## Implementation
This module implements most of the spec outlined [here](https://goessner.net/articles/JsonPath/)
```
use JSON::Path;
my $jpath = '$.options';
my $json = from-json( '{ "options": { "is-rad": true } }' );
# Get results from the json:
my $results = filter-json($jpath, $json);
#`[
[ { "is-rad" => True } ]
]
# Get paths from the json:
my $results = filter-json($jpath, $json, :want-path);
#`[
[ "options" ]
]
# Alter the json:
my $modifier = sub ($val is rw) {
$val = !$val;
};
filter-json($jpath, $json, :assign($modifier));
#`[
$json before: {"options":{"is-rad":true}}
$json after: {"options":{"is-rad":false}}
]
```
|
## dist_cpan-MARTIMM-Gnome-Cairo.md

# Cairo - Binding of Cairo to the Gnome modules

# Description
Cairo is a 2D graphics library with support for multiple output devices. Currently supported output targets include the X Window System (via both Xlib and XCB), Quartz, Win32, image buffers, PostScript, PDF, and SVG file output. Experimental backends include OpenGL, BeOS, OS/2, and DirectFB.
This package can be used on its own but it is meant to be used by the other Gnome packages to draw in widgets. However, if you want to use it standalone to make drawings saved in a file on disk, I would advice you to use the **Cairo** package of Timo.
Note that all modules are now in `:api<1>`. This is done to prevent clashes with future distributions having the same class names only differing in this api string. So, add this string to your import statements and dependency modules of these classes in META6.json. Furthermore add this api string also when installing with zef.
I found out while developing the api<2> version, that it is possible to use the Cairo version of Timo. An example of this will be given later. So in some time, this package **Gnome::Cairo** will be deprecated.
# Documentation
* [🔗 License document](http://www.perlfoundation.org/artistic_license_2_0)
* [🔗 Release notes](https://github.com/MARTIMM/perl6-gnome-gobject/blob/master/CHANGES.md)
* [🔗 Issues](https://github.com/MARTIMM/gnome-gtk3/issues)
# Installation
As mentioned above, this package can be used on its own. But better install **Gnome::Gtk3:api<1>** instead.
`zef install 'Gnome::Cairo:api<1>'`
# Author
Name: **Marcel Timmerman**
Github account name: **MARTIMM**
# Issues
There are always some problems! If you find one please help by filing an issue at [my Gnome::Gtk3 github project](https://github.com/MARTIMM/perl6-gnome-gtk3/issues).
# Attribution
* The developers of Raku of course and the writers of the documentation which help me out every time again and again.
* The builders of the GTK+ library and the documentation.
* The builders of the Cairo library and the documentation.
* Other helpful modules for their insight and use.
|
## dist_zef-raku-community-modules-XML-Entity-HTML.md
[](https://github.com/raku-community-modules/XML-Entity-HTML/actions)
# NAME
XML::Entity::HTML - Extension of XML::Entity for (X)HTML 5 entities.
# SYNOPSIS
```
use XML::Entity::HTML;
my $xeh = XML::Entity::HTML.new;
say $xeh.decode: 'Text with <entities> & «more»';
# Text with <entities> & «more»
say $xeh.encode: 'Text with <entities> & «more»';
# Text with <entities> & «more»
say decode-html-entities 'Text with <entities> & «more»';
# Text with <entities> & «more»
say encode-html-entities 'Text with <entities> & «more»';
# Text with <entities> & «more»
```
# DESCRIPTION
It's simply an extension class of XML::Entity, but with a lot more entities taken from the [official JSON list](https://www.w3.org/TR/html5/entities.json).
Any entities that wouldn't compile properly have been blacklisted and aren't supported. See the `build.raku` script in the `build` directory on how this module is built.
# METHODS
## decode
Overrides the `XML::Entity.decode` method. Expects a string and an optional named argument `:numeric`.
## encode
Overrides the `XML::Entity.encode` method. Expects a string and an optional named argument `:hex`.
# EXPORTED SUBROUTINES
## decode-html-entities
Provides procedural access to the `decode` method on a singleton `XML::Entity::HTML` object. Takes the same parameters.
## encode-html-entities
Provides procedural access to the `encode` method on a singleton `XML::Entity::HTML` object. Takes the same parameters.
# AUTHOR
Timothy Totten
# COPYRIGHT AND LICENSE
Copyright 2019 Timothy Totten
Copyright 2020 - 2022 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## flush.md
flush
Combined from primary sources listed below.
# [In IO::Handle](#___top "go to top of document")[§](#(IO::Handle)_method_flush "direct link")
See primary documentation
[in context](/type/IO/Handle#method_flush)
for **method flush**.
```raku
method flush(IO::Handle:D: --> True)
```
Will flush the handle, writing any of the buffered data. Returns `True` on success; otherwise, [fails](/routine/fail) with [`X::IO::Flush`](/type/X/IO/Flush).
```raku
given "foo".IO.open: :w {
LEAVE .close;
.print: 'something';
'foo'.IO.slurp.say; # (if the data got buffered) OUTPUT: «»
.flush; # flush the handle
'foo'.IO.slurp.say; # OUTPUT: «something»
}
```
|
## dist_cpan-JULIODCS-BigRoot.md
[](https://github.com/juliodcs/BigRoot/actions)
# NAME
BigRoot - Class for supporting roots with arbitrary precision.
# SYNOPSIS
```
use BigRoot;
# Can change precision level (Default precision is 30)
BigRoot.precision = 50;
my $root2 = BigRoot.newton's-sqrt: 2;
# 1.41421356237309504880168872420969807856967187537695
say $root2.WHAT;
# (FatRat)
# Can use other root numbers
say BigRoot.newton's-root: root => 3, number => 30;
# 3.10723250595385886687766242752238636285490682906742
# Numbers can be Int, Rational and Num:
say BigRoot.newton's-sqrt: 2.123;
# 1.45705181788431944566113502812562734420538186940001
# Can use other rational roots
say BigRoot.newton's-root: root => FatRat.new(2, 3), number => 30;
# 164.31676725154983403709093484024064018582340849939498
# Results are rounded:
BigRoot.precision = 8;
say BigRoot.newton's-sqrt: 2;
# 1.41421356
BigRoot.precision = 7;
say BigRoot.newton's-sqrt: 2;
# 1.4142136
# By default, results are cached for given precision.
BigRoot.precision = 150_000;
BigRoot.newton's-sqrt: 2;
my $start = now;
BigRoot.newton's-sqrt: 2;
say (now - $start) < 0.1;
# (True)
# Cache can be disabled with:
BigRoot.use-cache = False;
```
# DESCRIPTION
This module provides a way of having arbitrary precision for roots. In order to do that it calculates the roots using [Newton's method](https://en.wikipedia.org/wiki/Newton%27s_method) and uses raku's `FatRat` primitives.
The module supports rooting `Int`, `Num`, and `Rational` numbers and allows using a Rational number as the root. Also, the level of precision can be changed.
# METHODS
## method precision
```
method precision is rw
```
Allows for getting/setting the level of precision. Defaults to 30.
To put precision into scale:
* [NASA uses 15 decimals for Pi](https://www.jpl.nasa.gov/edu/news/2016/3/16/how-many-decimals-of-pi-do-we-really-need/)
* 1/10^30: a millimeter compared to the diameter of the universe
* 1/10^35: diameter of a human hair compared to the diameter of the universe
* 1/10^42: size of a proton compared to the diameter of the universe
* 1/10^62: Planck length compared to the diameter of the universe
* 1/10^86: one atom out of all atoms of the universe
## method newton's-root
```
method newton's-root(RootNumber:D :$root, PositiveNumber:D :$number) returns FatRat
```
Calculates the nth-root for the given number
## method newton's-sqrt
```
method newton's-sqrt(PositiveNumber:D $number)
```
Calculates square root for the given number.
Same as `newton's-root(root => 2, :$number)`
## method use-cache
```
method use-cache is rw
```
Allows enabling/disabling result cache (cache is enabled by default)
|
## dist_zef-bduggan-Slang-Comments.md
[](https://github.com/bduggan/raku-slang-comments/actions/workflows/linux.yml)
[](https://github.com/bduggan/raku-slang-comments/actions/workflows/macos.yml)
# NAME
Slang::Comments - Use comments to provide diagnostics for a Raku program
# SYNOPSIS
First,
```
export RAKUDO_RAKUAST=1
```
Then, in your program:
```
#!/usr/bin/env raku
use Slang::Comments;
say "starting!";
for 100 .. 110 { #= ### running
sleep 1;
}
say "we are done!";
```
Output:
```
starting!
--> for 100 .. 110 { #= ### running [#### ] 3/11 (27%). about 5 seconds remaining
we are done!
```
# DESCRIPTION
Slang::Comments is inspired by the excellent [Smart::Comments](https://metacpan.org/pod/Smart::Comments), and provides a way to use comments to get diagnostics about your program while it is running.
To use it, attach a comment to a for-loop using Raku's pod-declarator syntax (#=), and start the comment with three #s, as shown above. This line will be printed, along with a progress bar.
```
use Slang::Comments;
for 1..10 { #= ### calculating ...
do-something-complicated;
}
```
If the comment ends with three of the same character, those will be used instead of a '#'. So the above will show a progress bar like this:
```
--> for 100 .. 110 { #= ### calculating ... [.... ] 3/11 (27%)
```
A percentage, count and estimated time remaining will be shown if the number of elements can be easily computed.
To turn off the diagnostics, just don't "use" the module, For instance, comment it out, like so:
```
# use Slang::Comments;
for 1..10 { #= ### calculating ...
do-something-complicated;
}
```
This module only works with RakuAST, so you need to set the RAKUDO\_RAKUAST environment variable to a true value.
```
export RAKUDO_RAKUAST=1
```
# AUTHOR
Brian Duggan
|
## dist_cpan-CTILMES-epoll.md
# NAME
epoll - I/O event notification facility
# SYNOPSIS
```
use epoll;
my $epoll = epoll.new(maxevents => 1); # 1 is default
$epoll.add($file-descriptor, :in, :out, :priority, :edge-triggered);
# timeout in milliseconds, default -1 = block forever
for $epoll.wait(:2000timeout)
{
say "{.fd} is ready for reading" if .in;
say "{.fd} is ready for writing" if .out;
}
# Or use chained calls:
for epoll.new.add(0, :in).wait
{
say "ready to read on {.fd}" if .in;
}
```
# DESCRIPTION
Simple low level interface around the Linux `epoll(7)` I/O event notification facility. It can monitor multiple file descriptors to see if I/O is possible on any of them. Mainly useful for interfacing with other NativeCall modules, since Perl itself has a rich I/O system. If you really want to use this with Perl `IO::Handle`s, you can use `native-descriptor()` to get a suitable descriptor.
## class **epoll**
* method **new**(:$maxevents = 1)
Create a new epoll object. Maxevents is the maximum number of events that can be returned from a single call to wait.
* method **add**(int32 $file-descriptor, ...event flags...)
Flags:
| | | |
| --- | --- | --- |
| :in | EPOLLIN | ready for read |
| :out | EPOLLOUT | ready for write |
| :priority | EPOLLPRI | urgent data available for read |
| :edge-triggered | EPOLLET | Edge Triggered |
| :one-shot | EPOLLONESHOT | Disables after 1 event |
| :mod | EPOLL\_CTL\_MOD | Modify an existing file descriptor |
:mod is equivalent to EPOLL\_CTL\_MOD to change the events for a file descriptor already added. It will also re-enable a file descriptor disabled by :one-shot mode.
For convenience, always returns the object itself, so you can chain calls.
* method **remove**(int32 $file-descriptor)
Remove a file descriptor previously added.
* method **wait**(int32 :$timeout = -1)
Wait for 1 or more events to occur on the add()ed file descriptors. You can specify an optional timeout in milliseconds.
Returns a List of up up to $maxevents **epoll-event**s.
## class **epoll-event**
* method int32 **fd**()
The file descriptor for the event.
* method uint32 **events**()
A bitmask of the events that occurred. You can check them like this:
if $event.events +& EPOLLIN {...}
or use the much easier:
* method Bool **in**()
Ready to read
* method Bool **out**()
Ready to write
## EXCEPTIONS
Throws Ad-hoc exceptions for any errors.
(Should save errno, and make real Exceptions -- patches welcome!)
## NOTE
epoll is a Linux specific mechanism, and is typically not available on other architectures.
# LICENSE
Copyright © 2017 United States Government as represented by the Administrator of the National Aeronautics and Space Administration. No copyright is claimed in the United States under Title 17, U.S.Code. All Other Rights Reserved.
|
## dist_zef-tbrowder-AVL-Tree.md
[](https://github.com/tbrowder/AVL-Tree/actions)
# AVL-Tree
This implementation of an AVL Tree has been uploaded to [rosettacode.org](https://rosettacode.org).
It was initially a translation of the Java version on Rosetta Code. In addition to the translated code, other public methods have been added as shown by the leading asterisk in the following list of all public methods:
* insert node
* delete node
* show all node keys
* show all node balances
* \*delete nodes by a list of node keys
* \*find and return node objects by key
* \*attach data per node
* \*return list of all node keys
* \*return list of all node objects
## Synopsis
See the example in the Github repository and on Rosetta Code.
```
#!/usr/bin/env perl6
use AVL-Tree;
# ...create a tree and some nodes...
my $tree = AVL-Tree.new;
$tree.insert: 1;
$tree.insert: 2, :data<some important tidbit of knowledge>;
$my $n = $tree.find: 2;
say $n.data;
some important tidbit of knowledge
```
# CREDITS
Thanks for help from IRC `#raku` friends:
* `thundergnat` (for the idea and check of the initial version)
# AUTHOR
Tom Browder, ([[email protected]](mailto:[email protected]))
# COPYRIGHT
& LICENSE
Copyright (c) 2019-2022 Tom Browder, all rights reserved.
This program is free software; you can redistribute it or modify it under the same terms as Raku itself with the following exception:
The code for the methods **without a leading asterisk** in the list above are covered by the GNU Free Document License 1.2.
|
## dist_github-melezhik-Sparrowdo-Chef-Manager.md
# SYNOPSIS
Sparrowdo module to manage chef users.
WARNING! --- This soft is far from being ideal, but at least some functions work for me.
# Install
```
$ panda install Sparrowdo::Chef::Manager
```
# Usage
NOTE! An assumption is made that *chef server* runs at the same host where sparrow client runs,
as under the hood this module uses `chef-server-ctl` command.
Chef::Manager module exposes two commands to create/remove chef users.
## Delete user
```
module_run 'Chef::Manager', %(
action => 'delete-user',
user-id => 'alexey',
);
```
## Create user
```
module_run 'Chef::Manager', %(
action => 'create-user',
user-id => 'alexey',
email => '[email protected]',
name => 'Alexey',
last-name => 'Melezhik',
password => '123456',
org => 'devops'
);
```
## Add user to organization
```
module_run 'Chef::Manager', %(
action => 'add-to-org',
user-id => 'alexey',
org => 'IT'
);
```
# Parameters
## action
One of two - `create-user|delete-user|add-to-org`.
## user-id
A chef user ID.
## password
A chef user password.
## org
Chef server organization. This one is optional, no default value.
If `org` parameter is set, then `create-user` action will add a new user to chef organization.
## name
A user name, this one is obligatory.
## last-name
A user last-name, this one is obligatory.
## email
A user email, this one is obligatory.
# Author
[Alexey Melezhik](mailto:[email protected])
# See also
* [SparrowDo](https://github.com/melezhik/sparrowdo)
* [chef-server-ctl (executable)](https://docs.chef.io/ctl_chef_server.html)
|
## dist_zef-raku-community-modules-Benchy.md
[](https://github.com/raku-community-modules/Benchy/actions)
# NAME
Benchy - Benchmark some code
# SYNOPSIS
```
use Benchy;
b 20_000, # number of times to loop
{ some-setup; my-old-code }, # your old version
{ some-setup; my-new-code }, # your new version
{ some-setup } # optional "bare" loop to eliminate setup code's time
# SAMPLE OUTPUT:
# Bare: 0.0606532677866851s
# Old: 2.170558s
# New: 0.185170s
# NEW version is 11.72x faster
```
# DESCRIPTION
Takes 2 `Callable`s and measures which one is faster. Optionally takes a 3rd `Callable` that will be run the same number of times as other two callables, and the time it took to run will be subtracted from the other results.
# EXPORTED PRAGMAS
## MONKEY
The `use` of this module enables `MONKEY` pragma, so you can augment, use NQP, EVAL, etc, without needing to specify those pragmas.
# EXPORTED SUBROUTINES
## b(int $n, &old, &new, &bare = { $ = $ }, :$silent)
Benches the codes and prints the results. Will print in colour, if [`Terminal::ANSIColor`](https://modules.raku.org/repo/Terminal::ANSIColor) is installed.
### $n
How many times to loop.
Note that the exact number to loop will always be evened out, as the bench splits the work into two chunks that are measured at different times, so the total time is `2 × floor ½ × $n`.
### &old
Your "old" code; assumption is you have "old" code and you're trying to write some "new" code to replace it.
### &new
Your "new" code.
### &bare
Optional (defaults to `{ $ = $ }`). When specified, this `Callable` will be run same number of times as other code and the time it took to run will be subtracted from the `&new` and `&old` times. Use this to run some "setup" code. That is code that's used in `&new` and `&old` but should not be part of the benched times.
### :$silent
If set to a truthy value, the routine will not print anything.
### returns
Returns a hash with three keys - `bare`, `new`, and `old` — whose values are `Duration` objects representing the time it took the corresponding `Callable`s to run. **NOTE:** the `new` and `old` already have the duration of `bare` subtracted from them.
```
{
:bare(Duration.new(<32741983139/488599474770>)),
:new(Duration.new(<167/956>)),
:old(Duration.new(<1280561957330937733/590077351150947660>))
}
```
# AUTHOR
Zoffix Znet
# COPYRIGHT AND LICENSE
Copyright 2017 Zoffix Znet
Copyright 2018 - 2022 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-cro-cro.md
# Cro Build Status
This is part of the Cro libraries for implementing services and distributed
systems in Raku. See the [Cro website](https://cro.services/) for further
information and documentation.
This repository contains the [`cro` command line tool](/docs/cro-tool.md), as well as the sources for the Cro documentation included in the [Cro website](http://cro.services/) for further
information and documentation in the [`docs`](/docs/index.md) directory.
## Install
Install this using zef
```
zef install --/test cro
```
|
## dist_cpan-FISCHER-Lingua-Lipogram.md
# Lingua::Lipogram
Module and script for checking whether a string is a Lipogram.
[](https://github.com/sfischer13/perl6-Lingua-Lipogram/releases) [](https://github.com/sfischer13/perl6-Lingua-Lipogram/blob/master/LICENSE) [](https://travis-ci.org/sfischer13/perl6-Lingua-Lipogram)
---
## Introduction
`Lingua::Lipogram` is a Perl 6 module for checking whether a string is a Lipogram.
## Installation
```
# latest release
zef install Lingua::Lipogram
# specific version
zef -v install https://github.com/sfischer13/[email protected]
# developer version
zef -v install https://github.com/sfischer13/perl6-Lingua-Lipogram.git
```
## Development
```
git archive --prefix=Lingua-Lipogram-0.1.0/ -o ../Lingua-Lipogram-0.1.0.tar.gz HEAD
```
## Credits
This project is authored and maintained by Stefan Fischer.
The source code is available under the **MIT License**.
See [LICENSE](https://github.com/sfischer13/perl6-Lingua-Lipogram/blob/master/LICENSE) for further details.
|
## pseudostash.md
class PseudoStash
Stash type for pseudo-packages
```raku
class PseudoStash is Map { }
```
`PseudoStash` is the stash type (hanging off `.WHO`) that backs various pseudo-packages. So, when you do `MY::` or `CALLER::`, that gives back a `PseudoStash`. In most cases, `Package::` gives back a [`Stash`](/type/Stash). Neither of these are objects the user is expected to create by themselves, but in case you have one, you can just use it like a hash.
```raku
my $a = 42;
my $b = q/$a/;
say MY::{$b};
# OUTPUT: «42»
```
This shows how you can use a `PseudoStash` to look up variables, by name, at runtime.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `PseudoStash`
raku-type-graph
PseudoStash
PseudoStash
Map
Map
PseudoStash->Map
Mu
Mu
Any
Any
Any->Mu
Cool
Cool
Cool->Any
Iterable
Iterable
Associative
Associative
Map->Cool
Map->Iterable
Map->Associative
[Expand chart above](/assets/typegraphs/PseudoStash.svg)
|
## dist_zef-lizmat-Array-Rounded.md
[](https://github.com/lizmat/Array-Rounded/actions) [](https://github.com/lizmat/Array-Rounded/actions) [](https://github.com/lizmat/Array-Rounded/actions)
# NAME
Array::Rounded - arrays that round indices while accessing elements
# SYNOPSIS
```
use Array::Rounded;
my @a is Rounded = ^10;
say @a[1.5]; # 2
```
# DESCRIPTION
Array::Rounded provides a subclass of `Array` called `Rounded` that will **round** non-integer indices on the array, rather than truncating them. Other than that, any arrays created with the `Rounded` class will act as a normal `Array`.
# IMPLEMENTATION DETAILS
Because `postcircumfix:<[ ]>` already intifies any non-integer value in current and possibly future versions of the Raku Programming Language, this module also exports some `postcircumfix:<[ ]>` candidates to circumvent the premature intifications.
Also, due to some issues with native arrays, it has as yet been impossible to provide similar functionality for native arrays.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Array-Rounded> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2022, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-japhb-Terminal-Widgets.md
[](https://github.com/japhb/Terminal-Widgets/actions)
# NAME
Terminal::Widgets - Basic TUI Widgets
# SYNOPSIS
```
# See examples/ directory!
```
# DESCRIPTION
Terminal::Widgets is in a *very* early state, pretty much the minimum for which I could write not-completely-embarassing proof-of-concept working scripts in examples/ and on which I could start to port some of my old bespoke TUI scripts.
It is **CERTAIN** that many things will be changing in the near future, although finally a few things seem like they aren't terrible and might stick around for a while.
**This is not version `0.1.x` because I'm modest, it's because it really is that early!**
Not completely scared off yet? Come visit `#mugs` on `libera.chat` IRC and feel free to ask questions or offer ideas.
# AUTHOR
Geoffrey Broadwell [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2019, 2022-2024 Geoffrey Broadwell
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-JNTHN-Email-SendGrid.md
# Email::SendGrid
A basic Raku module for sending email using the [SendGrid Web API (v3)](https://sendgrid.com/docs/API_Reference/api_v3.html).
At the time of writing, SendGrid allows sending up to 100 emails a day free
of charge. This module most certainly does not provide full coverage of the
SendGrid API; if you need more, pull requests are welcome.
## Usage
Construct an `Eamil::SendGrid` object using your SendGrid API key:
```
my $sendgrid = Email::SendGrid.new(api-key => 'your_key_here');
```
Then call `send-mail` to send email:
```
$sendgrid.send-mail:
from => address('[email protected]', 'Sender name'),
to => address('[email protected]', 'Recipient name'),
subject => 'Yay, SendGrid works!',
content => {
'text/plain' => 'This is the plain text message',
'text/html' => '<strong>HTML mail!</strong>'
};
```
It is not required to including a HTML version of the body. Optionally, pass
`cc`, `bcc`, and `reply-to` to send these addresses. It is also possible to
pass a list of up to 1000 addresses to `to`, `cc`, and `bcc`.
If sending the mail fails, an exception will be thrown. Since `Cro::HTTP::Client`
is used internally, it will be an exception from that. Study the body for more
details.
```
CATCH {
default {
note await .response.body;
}
}
```
Pass `:async` to `send-mail` to get a `Promise` back instead. Otherwise, it will
be `await`ed for you by `send-mail`.
|
## dist_zef-ab5tract-Resource-Wrangler.md
# Resource::Wrangler
This module provides a very simple wrapper to handle the
scenario where you need to have a path that points to a
resource bundled in your Raku distribution.
The answer is really quite simple and easy enough to
hand-roll on one's own.
However, the plan is to cook up some good heuristics for
safely generating files that won't clash in terms of names.
That's the primary edge case I can think of so far, but
nevertheless it's nice not to have to write this transfer code
over and over again.
Release under the Artistic License 2.0
|
## dist_zef-raku-community-modules-SQL-NamedPlaceholder.md
[](https://github.com/raku-community-modules/SQL-NamedPlaceholder/actions) [](https://github.com/raku-community-modules/SQL-NamedPlaceholder/actions) [](https://github.com/raku-community-modules/SQL-NamedPlaceholder/actions)
# NAME
SQL::NamedPlaceholder - extension of placeholder
# SYNOPSIS
```
use SQL::NamedPlaceholder;
my ($sql, $bind) = bind-named(q[
SELECT *
FROM entry
WHERE
user_id = :user_id
], {
user_id => $user_id
});
$dbh.prepare($sql).execute(|$bind);
```
# DESCRIPTION
SQL::NamedPlaceholder is extension of placeholder. This enable more readable and robust code.
# SUBROUTINES
## bind-named($sql, $hash)
```
[$sql, $bind] = bind-named($sql, $hash);
```
The $sql parameter is SQL string which contains named placeholders. The $hash parameter is map of bind parameters.
The returned $sql is new SQL string which contains normal placeholders ('?'), and $bind is List of bind parameters.
# SYNTAX
## :foobar
Replace as placeholder which uses value from $hash{foobar}.
```
foobar = ?, foobar > ?, foobar < ?, foobar <> ?, etc.
```
This is same as 'foobar (op.) :foobar'.
# AUTHOR
Asato Wakisaka
# ORIGINAL AUTHOR
This module is a port of [SQL::NamedPlaceholder in Perl](https://metacpan.org/pod/SQL::NamedPlaceholder).
Author of original SQL::NamedPlaceholder in Perl is cho45.
# COPYRIGHT AND LICENSE
Copyright 2016 - 2018 Asato Wakisaka
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
Original Perl's SQL::NamedPlaceholder is licensed under following terms:
This library is free software; you can redistribute it and/or modify it under the same terms as Perl itself.
|
## split.md
split
Combined from primary sources listed below.
# [In IO::Handle](#___top "go to top of document")[§](#(IO::Handle)_method_split "direct link")
See primary documentation
[in context](/type/IO/Handle#method_split)
for **method split**.
```raku
method split(IO::Handle:D: :$close, |c)
```
[Slurps](/routine/slurp) the handle's content and calls [`Str.split`](/type/Str#routine_split) on it, forwarding any of the given arguments. If `:$close` named parameter is set to `True`, will [close](/routine/close) the invocant after slurping.
Attempting to call this method when the handle is [in binary mode](/type/IO/Handle#method_encoding) will result in [`X::IO::BinaryMode`](/type/X/IO/BinaryMode) exception being thrown.
```raku
my $fh = 'path/to/file'.IO.open;
$fh.split: '♥', :close; # Returns file content split on ♥
```
# [In IO::Spec::Cygwin](#___top "go to top of document")[§](#(IO::Spec::Cygwin)_method_split "direct link")
See primary documentation
[in context](/type/IO/Spec/Cygwin#method_split)
for **method split**.
```raku
method split(IO::Spec::Cygwin: Cool:D $path)
```
Same as [`IO::Spec::Win32.split`](/type/IO/Spec/Win32#method_split), except it replaces backslashes with slashes in all the values of the final result.
# [In IO::Spec::Unix](#___top "go to top of document")[§](#(IO::Spec::Unix)_method_split "direct link")
See primary documentation
[in context](/type/IO/Spec/Unix#method_split)
for **method split**.
```raku
method split(IO::Spec::Unix: Cool:D $path)
```
Creates an [`IO::Path::Parts`](/type/IO/Path/Parts) for `$path`, with an empty string as its `volume` attribute's value.
```raku
IO::Spec::Unix.split('C:/foo/bar.txt').raku.say;
# OUTPUT: «IO::Path::Parts.new("","C:/foo","bar.txt")»
IO::Spec::Unix.split('/foo/').raku.say;
# OUTPUT: «IO::Path::Parts.new("","/","foo")»
IO::Spec::Unix.split('///').raku.say;
# OUTPUT: «IO::Path::Parts.new("","/","/")»
IO::Spec::Unix.split('./').raku.say;
# OUTPUT: «IO::Path::Parts.new("",".",".")»
IO::Spec::Unix.split('.').raku.say;
# OUTPUT: «IO::Path::Parts.new("",".",".")»
IO::Spec::Unix.split('').raku.say;
# OUTPUT: «IO::Path::Parts.new("","","")»
```
**Note**: Before Rakudo version 2020.06 this method split the given `$path` into "volume", "dirname", and "basename" and returned the result as a [`List`](/type/List) of three [`Pair`](/type/Pair)s, in that order.
# [In Supply](#___top "go to top of document")[§](#(Supply)_method_split "direct link")
See primary documentation
[in context](/type/Supply#method_split)
for **method split**.
```raku
multi method split(Supply:D: \delimiter)
multi method split(Supply:D: \delimiter, \limit)
```
This method creates a supply of the values returned by the `Str.split` method called on the string collected from the invocant. See [`Str.split`](/type/Str#routine_split) for details on the `\delimiter` argument as well as available extra named parameters. The created supply can be limited with the `\limit` argument, see [`.head`](#method_head).
```raku
my $words = Supply.from-list(<Hello World From Raku!>);
my $s = $words.split(/ <?upper> /, 2, :skip-empty);
$s.tap(&say); # OUTPUT: «HelloWorld»
```
# [In IO::Path](#___top "go to top of document")[§](#(IO::Path)_method_split "direct link")
See primary documentation
[in context](/type/IO/Path#method_split)
for **method split**.
```raku
method split(IO::Path:D: |args --> Seq:D)
```
Opens the file and processes its contents the same way [`Str.split`](/type/Str#routine_split) does, taking the same arguments. Implementations may slurp the file in its entirety when this method is called.
# [In IO::CatHandle](#___top "go to top of document")[§](#(IO::CatHandle)_method_split "direct link")
See primary documentation
[in context](/type/IO/CatHandle#method_split)
for **method split**.
```raku
method split(IO::CatHandle:D: |args --> Seq:D)
```
Read the handle and processes its contents the same way [`Str.split`](/type/Str#routine_split) does, taking the same arguments. **Implementations may slurp the contents of all the source handles** in their entirety when this method is called.
```raku
(my $f1 = 'foo'.IO).spurt: 'foo';
(my $f2 = 'bar'.IO).spurt: 'bar';
IO::CatHandle.new($f1, $f2).split(/o+/).raku.say;
# OUTPUT: «("f", "bar").Seq»
```
# [In Allomorph](#___top "go to top of document")[§](#(Allomorph)_method_split "direct link")
See primary documentation
[in context](/type/Allomorph#method_split)
for **method split**.
```raku
method split(Allomorph:D: |c)
```
Calls [`Str.split`](/type/Str#routine_split) on the invocant's [`Str`](/type/Str) value.
# [In Str](#___top "go to top of document")[§](#(Str)_routine_split "direct link")
See primary documentation
[in context](/type/Str#routine_split)
for **routine split**.
```raku
multi split( Str:D $delimiter, Str:D $input, $limit = Inf,
:$skip-empty, :$v, :$k, :$kv, :$p)
```
```raku
multi split(Regex:D $delimiter, Str:D $input, $limit = Inf,
:$skip-empty, :$v, :$k, :$kv, :$p)
```
```raku
multi split(List:D $delimiters, Str:D $input, $limit = Inf,
:$skip-empty, :$v, :$k, :$kv, :$p)
```
```raku
multi method split(Str:D: Str:D $delimiter, $limit = Inf,
:$skip-empty, :$v, :$k, :$kv, :$p)
```
```raku
multi method split(Str:D: Regex:D $delimiter, $limit = Inf,
:$skip-empty, :$v, :$k, :$kv, :$p)
```
```raku
multi method split(Str:D: List:D $delimiters, $limit = Inf,
:$skip-empty, :$v, :$k, :$kv, :$p)
```
Splits a string up into pieces based on delimiters found in the string.
If `DELIMITER` is a string, it is searched for literally and not treated as a regex. If `DELIMITER` is the empty string, it effectively returns all characters of the string separately (plus an empty string at the begin and at the end). If `PATTERN` is a regular expression, then that will be used to split up the string. If `DELIMITERS` is a list, then all of its elements will be considered a delimiter (either a string or a regular expression) to split the string on.
The optional `LIMIT` indicates in how many segments the string should be split, if possible. It defaults to **Inf** (or **\***, whichever way you look at it), which means "as many as possible". Note that specifying negative limits will not produce any meaningful results.
A number of optional named parameters can be specified, which alter the result being returned. The `:v`, `:k`, `:kv` and `:p` named parameters all perform a special action with regards to the delimiter found.
* :skip-empty
If specified, do not return empty strings before or after a delimiter.
* :v
Also return the delimiter. If the delimiter was a regular expression, then this will be the associated [`Match`](/type/Match) object. Since this stringifies as the delimiter string found, you can always assume it is the delimiter string if you're not interested in further information about that particular match.
* :k
Also return the **index** of the delimiter. Only makes sense if a list of delimiters was specified: in all other cases, this will be **0**.
* :kv
Also return both the **index** of the delimiter, as well as the delimiter.
* :p
Also return the **index** of the delimiter and the delimiter as a [`Pair`](/type/Pair).
Examples:
```raku
say split(";", "a;b;c").raku; # OUTPUT: «("a", "b", "c").Seq»
say split(";", "a;b;c", :v).raku; # OUTPUT: «("a", ";", "b", ";", "c").Seq»
say split(";", "a;b;c", 2).raku; # OUTPUT: «("a", "b;c").Seq»
say split(";", "a;b;c", 2, :v).raku; # OUTPUT: «("a", ";", "b;c").Seq»
say split(";", "a;b;c,d").raku; # OUTPUT: «("a", "b", "c,d").Seq»
say split(/\;/, "a;b;c,d").raku; # OUTPUT: «("a", "b", "c,d").Seq»
say split(<; ,>, "a;b;c,d").raku; # OUTPUT: «("a", "b", "c", "d").Seq»
say split(/<[;,]>/, "a;b;c,d").raku; # OUTPUT: «("a", "b", "c", "d").Seq»
say split(<; ,>, "a;b;c,d", :k).raku; # OUTPUT: «("a", 0, "b", 0, "c", 1, "d").Seq»
say split(<; ,>, "a;b;c,d", :kv).raku; # OUTPUT: «("a", 0, ";", "b", 0, ";", "c", 1, ",", "d").Seq»
say "".split("x").raku; # OUTPUT: «("",).Seq»
say "".split("x", :skip-empty).raku; # OUTPUT: «().Seq»
say "abcde".split("").raku; # OUTPUT: «("", "a", "b", "c", "d", "e", "").Seq»
say "abcde".split("",:skip-empty).raku; # OUTPUT: «("a", "b", "c", "d", "e").Seq»
```
# [In Cool](#___top "go to top of document")[§](#(Cool)_routine_split "direct link")
See primary documentation
[in context](/type/Cool#routine_split)
for **routine split**.
```raku
multi split( Str:D $delimiter, Str(Cool) $input, $limit = Inf, :$k, :$v, :$kv, :$p, :$skip-empty)
multi split(Regex:D $delimiter, Str(Cool) $input, $limit = Inf, :$k, :$v, :$kv, :$p, :$skip-empty)
multi split(@delimiters, Str(Cool) $input, $limit = Inf, :$k, :$v, :$kv, :$p, :$skip-empty)
multi method split( Str:D $delimiter, $limit = Inf, :$k, :$v, :$kv, :$p, :$skip-empty)
multi method split(Regex:D $delimiter, $limit = Inf, :$k, :$v, :$kv, :$p, :$skip-empty)
multi method split(@delimiters, $limit = Inf, :$k, :$v, :$kv, :$p, :$skip-empty)
```
[[1]](#fn1)
Coerces the invocant (or in the sub form, the second argument) to [`Str`](/type/Str), splits it into pieces based on delimiters found in the string and returns the result as a [`Seq`](/type/Seq).
If `$delimiter` is a string, it is searched for literally and not treated as a regex. You can also provide multiple delimiters by specifying them as a list, which can mix `Cool` and [`Regex`](/type/Regex) objects.
```raku
say split(';', "a;b;c").raku; # OUTPUT: «("a", "b", "c").Seq»
say split(';', "a;b;c", 2).raku; # OUTPUT: «("a", "b;c").Seq»
say split(';', "a;b;c,d").raku; # OUTPUT: «("a", "b", "c,d").Seq»
say split(/\;/, "a;b;c,d").raku; # OUTPUT: «("a", "b", "c,d").Seq»
say split(/<[;,]>/, "a;b;c,d").raku; # OUTPUT: «("a", "b", "c", "d").Seq»
say split(['a', /b+/, 4], '1a2bb345').raku; # OUTPUT: «("1", "2", "3", "5").Seq»
```
By default, `split` omits the matches, and returns a list of only those parts of the string that did not match. Specifying one of the `:k, :v, :kv, :p` adverbs changes that. Think of the matches as a list that is interleaved with the non-matching parts.
The `:v` interleaves the values of that list, which will be either [`Match`](/type/Match) objects, if a [`Regex`](/type/Regex) was used as a matcher in the split, or [`Str`](/type/Str) objects, if a `Cool` was used as matcher. If multiple delimiters are specified, [`Match`](/type/Match) objects will be generated for all of them, unless **all** of the delimiters are `Cool`.
```raku
say 'abc'.split(/b/, :v); # OUTPUT: «(a 「b」 c)»
say 'abc'.split('b', :v); # OUTPUT: «(a b c)»
```
`:k` interleaves the keys, that is, the indexes:
```raku
say 'abc'.split(/b/, :k); # OUTPUT: «(a 0 c)»
```
`:kv` adds both indexes and matches:
```raku
say 'abc'.split(/b/, :kv); # OUTPUT: «(a 0 「b」 c)»
```
and `:p` adds them as [`Pair`](/type/Pair)s, using the same types for values as `:v` does:
```raku
say 'abc'.split(/b/, :p); # OUTPUT: «(a 0 => 「b」 c)»
say 'abc'.split('b', :p); # OUTPUT: «(a 0 => b c)»
```
You can only use one of the `:k, :v, :kv, :p` adverbs in a single call to `split`.
Note that empty chunks are not removed from the result list. For that behavior, use the `:skip-empty` named argument:
```raku
say ("f,,b,c,d".split: /","/ ).raku; # OUTPUT: «("f", "", "b", "c", "d").Seq»
say ("f,,b,c,d".split: /","/, :skip-empty).raku; # OUTPUT: «("f", "b", "c", "d").Seq»
```
# [In IO::Spec::Win32](#___top "go to top of document")[§](#(IO::Spec::Win32)_method_split "direct link")
See primary documentation
[in context](/type/IO/Spec/Win32#method_split)
for **method split**.
```raku
method split(IO::Spec::Win32: Cool:D $path)
```
Creates an [`IO::Path::Parts`](/type/IO/Path/Parts) for `$path`.
```raku
IO::Spec::Win32.split('C:/foo/bar.txt').raku.say;
# OUTPUT: «IO::Path::Parts.new("C:","/foo","bar.txt")»
IO::Spec::Win32.split('/foo/').raku.say;
# OUTPUT: «IO::Path::Parts.new("","/","foo")»
IO::Spec::Win32.split('///').raku.say;
# OUTPUT: «IO::Path::Parts.new("","/","\\")»
IO::Spec::Win32.split('./').raku.say;
# OUTPUT: «IO::Path::Parts.new("",".",".")»
IO::Spec::Win32.split('.').raku.say;
# OUTPUT: «IO::Path::Parts.new("",".",".")»
IO::Spec::Win32.split('').raku.say;
# OUTPUT: «IO::Path::Parts.new("","","")»
```
**Note**: Before Rakudo version 2020.06 this method split the given `$path` into "volume", "dirname", and "basename" and returned the result as a [`List`](/type/List) of three [`Pair`](/type/Pair)s, in that order.
|
## dist_zef-FRITH-Math-Libgsl-QuasiRandom.md
[](https://github.com/frithnanth/raku-Math-Libgsl-QuasiRandom/actions)
# NAME
Math::Libgsl::QuasiRandom - An interface to libgsl, the Gnu Scientific Library - Quasi-Random Sequences.
# SYNOPSIS
```
use Math::Libgsl::QuasiRandom;
use Math::Libgsl::Constants;
my Math::Libgsl::QuasiRandom $q .= new: :type(SOBOL), :2dimensions;
$q.get».say for ^10;
```
# DESCRIPTION
Math::Libgsl::QuasiRandom is an interface to the Quasi-Random Sequences of libgsl, the Gnu Scientific Library.
### new(Int :$type, Int :$dimensions)
The constructor allows two parameters, the quasi-random sequence generator type and the dimensions. One can find an enum listing all the generator types in the Math::Libgsl::Constants module.
### init()
This method re-inits the sequence.
### get(--> List)
Returns the next item in the sequence as a List of Nums.
### name(--> Str)
This method returns the name of the current quasi-random sequence.
### copy(Math::Libgsl::QuasiRandom $src)
This method copies the source generator **$src** into the current one and returns the current object, so it can be concatenated. The generator state is also copied, so the source and destination generators deliver the same values.
### clone(--> Math::Libgsl::QuasiRandom)
This method clones the current object and returns a new object. The generator state is also cloned, so the source and destination generators deliver the same values.
```
my $q = Math::Libgsl::QuasiRandom.new;
my $clone = $q.clone;
```
# C Library Documentation
For more details on libgsl see <https://www.gnu.org/software/gsl/>. The excellent C Library manual is available here <https://www.gnu.org/software/gsl/doc/html/index.html>, or here <https://www.gnu.org/software/gsl/doc/latex/gsl-ref.pdf> in PDF format.
# Prerequisites
This module requires the libgsl library to be installed. Please follow the instructions below based on your platform:
## Debian Linux and Ubuntu 20.04+
```
sudo apt install libgsl23 libgsl-dev libgslcblas0
```
That command will install libgslcblas0 as well, since it's used by the GSL.
## Ubuntu 18.04
libgsl23 and libgslcblas0 have a missing symbol on Ubuntu 18.04. I solved the issue installing the Debian Buster version of those three libraries:
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgslcblas0_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl23_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl-dev_2.5+dfsg-6_amd64.deb>
# Installation
To install it using zef (a module management tool):
```
$ zef install Math::Libgsl::QuasiRandom
```
# AUTHOR
Fernando Santagata [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2020 Fernando Santagata
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-p6steve-Dan-Pandas.md
# raku Dan::Pandas
Dan::Pandas is the first specializer for the raku [Dan](https://github.com/p6steve/raku-Dan) **D**ata **AN**alysis Module.
Dan::Pandas uses the raku [Inline::Python](https://raku.land/cpan:NINE/Inline::Python) module to construct shadow Python objects and to wrap them to maintain the Dan API.
* Dan::Pandas::Series is a specialized Dan::Series
* Dan::Pandas::DataFrame is a specialized Dan::DataFrame
It adapts Dan maintaining **the base set of raku-style** datatype roles, accessors & methods - with a few exceptions as noted below, a Dan::Pandas object can be a drop in replacement for it's Dan equivalent.
A Dockerfile is provided based on the Python [jupyter/scipy-notebook](https://jupyter-docker-stacks.readthedocs.io/en/latest/using/selecting.html#jupyter-scipy-notebook) - ideal for example Dan Jupyter notebooks!
*Contributions via PR are very welcome - please see the backlog Issue, or just email [[email protected]](mailto:[email protected]) to share ideas!*
# Installation
* docker run -it p6steve/raku-dan:pandas-2022.02-amd64 -or- :pandas-2022.02.arm64 (see Dockerfile)
* zef install <https://github.com/p6steve/raku-Dan-Pandas.git>
* cd /usr/share/perl6/site/bin && ./synopsis-dan-pandas.raku
# SYNOPOSIS
The raku Dan [README.md](https://github.com/p6steve/raku-Dan/blob/main/README.md) is a good outline of the Dan API. This synopsis emphasizes the differences, more examples in [bin/synopsis-dan-pandas.raku](https://github.com/p6steve/raku-Dan/blob/main/bin/synopsis-dan-pandas.raku).
```
#!/usr/bin/env raku
use lib '../lib';
use Dan; #<== unlike a standalone Dan script, do NOT use the :ALL selector here
use Dan::Pandas;
### Series ###
## Dan Similarities...
my \s = Series.new( [rand xx 5], index => <a b c d e>);
say ~s;
#`[
a 0.297975
b 0.881274
c 0.868242
d 0.593949
e 0.141334
Name: anon, dtype: float64 #<== Dan::Pandas::Series has a Python numpy dtype
#]
# Methods
s.dtype;
s.ix;
s.index;
s.elems;
s.map(*+2);
s.splice(1,2,(j=>3));
my \t = Series.new( [f=>1, e=>0, d=>2] );
s.concat: t;
# Operators & Accessors
[+] s;
s >>+>> 2;
s >>+<< s;
s[2];
s<c>;
say "---------------------------------------------";
## Dan Differences...
say ~s.reindex(['d','e','f','g','h','i']); #<== reindex Pandas style, padding NaN
#`[
d 0.593949
e 0.141334
f NaN
g NaN
h NaN
i NaN
#]
Name: anon, dtype: float64
s.pull; #explicit pull operation synchronizes raku object attributes to shadow Python values (@.data, %.index, %.columns)
#The Dan::Pandas .pd method takes a Python method call string and handles it from raku:
s.pd: '.shape';
s.pd: '.flags';
s.pd: '.T';
s.pd: '.to_json("test.json")';
s.pd: '.to_csv("test.csv")';
s.pd: '.iloc[2] = 23';
s.pd: '.iloc[2]';
# 2-arity .pd methods are done like this:
say ~my \quants = Series.new([100, 15, 50, 15, 25]);
say ~my \prices = Series.new([1.1, 4.3, 2.2, 7.41, 2.89]);
my \costs = quants;
costs.pd: '.mul', prices;
# round-trip to/from Dan::Series:
my \u = s.Dan-Series; #Dan::Series [coerce from Dan::Pandas::Series]
my \v = Series.new( u ); #Dan::Pandas::Series [construct from Dan::Series]
say "---------------------------------------------";
### DataFrames ###
## Dan Similarities...
my \dates = (Date.new("2022-01-01"), *+1 ... *)[^6];
my \df = DataFrame.new( [[rand xx 4] xx 6], index => dates, columns => <A B C D> );
say ~df;
# Accessors
df[0;0]; # Data Accessors [row;col]
df[0;0] = 3; # NOPE! <== unlike Dan, must use .pd method to set values, then optionally .pull
df[0]<A>; # Cascading Accessors (mix Positional and Associative)
df[0]; # 1d Row 0 (DataSlice)
df[*]<A>; # 1d Col A (Series)
# Operations
[+] df[*;1]; # 2d Map/Reduce
df >>+>> 2; # Hyper
df.T; # Transpose
df.shape; # Shape
df.describe; # Describe
df.sort: {.[1]}; # Sort by 2nd col (ascending)
df.grep( {.[1] < 0.5} ); # Grep (binary filter) by 2nd column
# Splice
df2.splice( 1, 2, [j => $ds] ); # row-wise splice:
df2.splice( :ax, 1, 2, [K => $se] ); # column-wise splice: axis => 1
# Concat
my \dfa = DataFrame.new( [['a', 1], ['b', 2]], columns => <letter number> );
my \dfc = DataFrame.new( [['c', 3, 'cat'], ['d', 4, 'dog']], columns => <animal letter number> );
dfa.concat(dfc);
say ~dfa;
#`[
letter number animal
0 a 1 NaN
1 b 2 NaN
0⋅1 cat c 3.0
1⋅1 dog d 4.0
#]
say "---------------------------------------------";
## Dan Differences...
df.pull; #explicit pull operation synchronizes raku object attributes to shadow Python values (@.data, %.index, %.columns)
### .pd Methods ###
#The Dan::Pandas .pd method takes a Python method call string and handles it from raku:
df.pd: '.flags';
df.pd: '.to_json("test.json")';
df.pd: '.to_csv("test.csv")';
df.pd: '.iloc[2] = 23';
df.pd: '.iloc[2]';
say ~df;
#`[
A B C D
2022-01-01 0.744346 0.963167 0.548315 0.667035
2022-01-02 0.109722 0.007992 0.999305 0.613870
2022-01-03 23.000000 23.000000 23.000000 23.000000
2022-01-04 0.403802 0.762486 0.220328 0.152730
2022-01-05 0.245156 0.864305 0.577664 0.365762
2022-01-06 0.414237 0.981379 0.571082 0.926982
#]
# 2-arity .pd methods and round trip follow the Series model
```
|
## dist_github-khalidelboray-Pastebin-Pasteee.md
# Pastebin::Pasteee
### DESCRIPTION
```
use paste.ee API via Raku
```
# Example
```
use Pastebin::Pasteee::Paste;
use Pastebin::Pasteee::Paste::Section;
use Pastebin::Pasteee;
my $p = Pastebin::Pasteee.new: :token<your_api_token>;
my $paste-url = $p.paste:
Pastebin::Pasteee::Paste.new: :description("Test"),
:sections(
Pastebin::Pasteee::Paste::Section.new:
:name<Section1>,
:syntax<perl>,
:contents('print "Hellow World!"')
);
say $paste-url; # https://paste.ee/p/<paste_id>
```
## class Pastebin::Pasteee
use paste.ee API via Raku
### method pastes
```
method pastes(
Int :$page = 1,
Int :$perpage = 25
) returns Mu
```
Get user pastes.
### multi method paste
```
multi method paste(
Pastebin::Pasteee::Paste :$paste!
) returns Mu
```
Create a paste
### multi method paste
```
multi method paste(
Str $id
) returns Mu
```
Fetch Paste info
### multi method paste
```
multi method paste(
Str $id,
Bool :$delete!
) returns Mu
```
Delete a paste
### method delete
```
method delete(
Str $id
) returns Mu
```
Delete a paste
### method fetch
```
method fetch(
Str $id
) returns Mu
```
Fetch Paste info
### method info
```
method info() returns Mu
```
User/key information
|
## dist_cpan-JFORGET-Date-Calendar-FrenchRevolutionary.md
# NAME
Date::Calendar::FrenchRevolutionary - Conversions from / to the French Revolutionary calendar
# SYNOPSIS
Converting a Gregorian date (e.g. 9th November 1799) into French
Revolutionary (18 Brumaire VIII).
```
use Date::Calendar::FrenchRevolutionary;
my Date $Bonaparte's-coup-gr;
my Date::Calendar::FrenchRevolutionary $Bonaparte's-coup-fr;
$Bonaparte's-coup-gr .= new(1799, 11, 9);
$Bonaparte's-coup-fr .= new-from-date($Bonaparte's-coup-gr);
say $Bonaparte's-coup-fr.strftime("%A %e %B %Y");
```
Converting a French Revolutionary date (e.g. 9th Thermidor II) to
Gregorian (which gives 27th July 1794).
```
use Date::Calendar::FrenchRevolutionary;
my Date::Calendar::FrenchRevolutionary $Robespierre's-downfall-fr;
my Date $Robespierre's-downfall-gr;
$Robespierre's-downfall-fr .= new(year => 2
, month => 11
, day => 9);
$Robespierre's-downfall-gr = $Robespierre's-downfall-fr.to-date;
say $Robespierre's-downfall-gr;
```
# INSTALLATION
```
zef install Date::Calendar::FrenchRevolutionary
```
or
```
git clone https://github.com/jforget/raku-Date-Calendar-FrenchRevolutionary.git
cd raku-Date-Calendar-FrenchRevolutionary
zef install .
```
# DESCRIPTION
Date::Calendar::FrenchRevolutionary is a class representing dates in
the French Revolutionary calendar. It allows you to convert a
Gregorian date into a French Revolutionary date or the other way.
The Revolutionary calendar was in use in France from 24 November 1793
(4 Frimaire II) to 31 December 1805 (10 Nivôse XIV). The modules in
this distribution extend the calendar to the present and to a few
centuries in the future, not limiting to Gregorian year 1805.
This new calendar was an attempt to apply the decimal rule (the basis
of the metric system) to the calendar. Therefore, the week
disappeared, replaced by the décade, a 10-day period. In addition, all
months have exactly 3 décades, no more, no less.
Since 12 months of 30 days each do not make a full year (365.24 days),
there are 5 or 6 additional days at the end of a year. These days are
called "Sans-culottides", named after a political faction, but we
often find the phrase "jours complémentaires" (additional days). These
days do not belong to any month, but for programming purposes, it is
convenient to consider they form a 13th month.
At first, the year was beginning on the equinox of autumn, for two
reasons. First, the republic had been established on 22 September
1792, which happened to be the equinox, and second, the equinox was
the symbol of equality, the day and the night lasting exactly 12 hours
each. It was therefore in tune with the republic's motto "Liberty,
Equality, Fraternity". But it was not practical, so Romme proposed a
leap year rule similar to the Gregorian calendar rule.
The distribution contains two other classes, one where there was no
reform and the automn equinox rule stayed in effect, another where the
arithmetic rule was established since the beginning of the calendar.
# AUTHOR
Jean Forget [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright © 2019, 2020 Jean Forget, all rights reserved
This library is free software; you can redistribute it and/or modify
it under the Artistic License 2.0.
|
## dist_github-retupmoca-UUID.md
# UUID
```
my $uuid = UUID.new;
say ~$uuid;
my $uuid = UUID.new(:version(4));
```
Currently supports version 4 (random) UUID generation.
|
## dist_github-lestrrat-p6-Crust-Middleware-Session.md
[](https://travis-ci.org/lestrrat/p6-Crust-Middleware-Session)
# NAME
Crust::Middleware::Session - Session Middleware for Crust Framework
# SYNOPSIS
```
use Crust::Builder;
use Crust::Middleware::Session;
# $store can be anything that implements Crust::Middleware:Session::StoreRole.
# This here is a dummy that stores everything in memory
my $store = Crust::Middleware::Session::Store::Memory.new();
builder {
enable 'Session', :store($store);
&app;
};
```
# DESCRIPTION
Crust::Middleware::Session manages sessions for your Crust app. This
module uses cookies to keep session state and does not support URI
based session state.
A session object will be available under the kye `p6sgix.session` in
the P6SGI environment hash. You can use this to access session data
```
my &app = ->%env {
%env<p6sgix.session>.get("username").say;
...
};
```
# AUTHOR
Daisuke Maki [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2015 Daisuke Maki
This library is free software; you can redistribute it and/or modify
it under the Artistic License 2.0.
|
## dist_zef-tbrowder-Date-Easter.md
[](https://github.com/tbrowder/Date-Easter/actions) [](https://github.com/tbrowder/Date-Easter/actions) [](https://github.com/tbrowder/Date-Easter/actions)
# NAME
Date::Easter - Provides routines to calculate the dates of Easter and related events in the Christian calendar
# SYNOPSIS
```
use Date::Easter;
say Easter 2022; # OUTPUT: «2022-04-17»
```
# DESCRIPTION
**Date::Easter** is a module which provides a subroutine to calculate the dates of Easter in the Christian calendar. The sub returns a Raku **Date** object.
The routine's code is the Raku version of the algorithm shown at [Isn’t there a simpler way to calculate Easter?](https://www.tondering.dk/claus/cal/easter.php#simplecalc). The website is a treasure trove of calendar information, courtesy of the very generous and talented **Claus Tøndering**, to whom I am greatly indebted.
Another routine returns a hash of `Date::Event`s for use with the `Calendar` module. The hash is keyed by a `Date` with each key's value an array of `Date::Event` objects whose attributes describe the Lenten and post-Lenten Christian celebratory events of:
* Ash Wednesday
The beginning of Lent [46 days before Easter]
* Palm Sunday
Jesus Christ's entry into Jerusalem [the Sunday before Easter]
* Good Friday
Jesus Christ's crucifixion [the Friday before Easter]
* Easter Sunday
The resurrection of Jesus Christ
* Ascension
The ascension into Heaven of Jesus Christ [40 days after Easter]
* Pentecost
The descent of the Holy Sprit upon the Virgin Mary and the Disciples of Jesus Christ [50 days after Easter]
## The subroutine exporting all the events
```
sub get-easter-events-hashlist(:$year --> Hash) is export {...}
```
# AUTHOR
Tom Browder [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
© 2021-2024 Tom Browder
This library is free software; you may redistribute it or modify it under the Artistic License 2.0.
|
## dist_cpan-JMERELO-App-Game-Concentration.md
[](https://travis-ci.org/JJ/p6-app-concentration)
# NAME
App::Game::Concentration - Implementation of the game of Concentration
# SYNOPSIS
```
use App::Game::Concentration;
```
# DESCRIPTION
App::Game::Concentration is a fast and dirty implementation of Concentration: <https://en.wikipedia.org/wiki/Concentration_(card_game)>
# Methods and subs
## new()
Generates a random deck.
## `select( Pair $first, Pair $second --` Array )> and `select( @positions --` Array )>
Takes an array of Pairs, and selects the cards in that position. If the cards are paired (same number), they are substituted by `✖✖✖`, "eliminating" them from the deck. If the cards are paired, the array returned will have the "Pair" trait mixed in. You can check for it using `$returned-array.?Str eq "Pair"`.
## sub paired( $first-card, $second-card)
Checks if the cards are paired by extracting the figure from the suit.
# AUTHOR
JJ Merelo [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2019 JJ Merelo
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-retupmoca-Web-RF.md
# Web::RF
See <https://github.com/retupmoca/egeler.us> for a more comprehensive example.
Web::RF is a simple routing web framework designed to work with Crust. It attempts
to decouple your controller code from the URL's used to access them.
Note that this framework doesn't handle data storage or templating - it simply
gets program flow into one of your controllers and lets you do whatever is needed.
```
# Site/Root.pm6
use Web::RF;
use Page::Home;
# etc
unit class Site::Root is Web::RF::Router;
# the route strings here are passed to Path::Router, so any of the variable
# features in that package can be used here
method routes {
$.route('', Page::Home); # Web::RF::Controller class
$.route('login', Page::Login);
$.route('blog/', Site::Blog); # can include other Web::RF::Routers to create trees
$.route('redirect', Web::RF::Redirect.new(301, '/blog/'));
}
# gets called before every request is routed
method before(:$request) {
return Web::RF::Redirect.go(301, 'https://my-site.com'~$request.request-uri) unless $request.secure; # force https
}
method error(:$request, :$exception) {
given $exception {
when X::NotFound { # will return an empty 404 response if not handled
return Page::NotFound.handle(:$request);
}
when X::BadRequest { # will return an empty 400 response if not handled
return Page::BadRequest.handle(:$request);
}
default { # will rethrow the exception if not handled
return Page::ShowError.handle(:$request, :$exception);
}
}
}
```
```
# Page/Home.pm6
use Web::RF;
unit class Page::Home is Web::RF::Controller;
# %mapping is the mapping created by Path::Router (for variables in the URL)
method handle(:$request, :%mapping) {
return [200, [ Content-Type => 'text/html' ], [ $content-here ]];
}
```
```
# bin/app.p6sgi
use Web::RF;
use Site::Root;
my $webrf = Web::RF.new(:root(Site::Root.new));
my $app = sub (%env) { $webrf.handle(%env) };
```
|
## failure.md
class Failure
Delayed exception
```raku
class Failure is Nil { }
```
A `Failure` is a *soft* or *unthrown* [`Exception`](/type/Exception), usually generated by calling `&fail`. It acts as a wrapper around an [`Exception`](/type/Exception) object.
Sink (void) context causes a `Failure` to throw, i.e. turn into a regular exception. The [`use fatal` pragma](/language/pragmas#fatal) causes this to happen in all contexts within the pragma's scope. Inside [`try` blocks](/language/exceptions#try_blocks), `use fatal` is automatically set, and you can *disable* it with `no fatal`.
That means that Failures are generally only useful in cases of code that normally would produce an rvalue; Failures are more or less equivalent to Exceptions in code that will frequently be called in sink context (i.e., for its side-effects, such as with `say`).
Similarly, you should generally use `&fail` only inside code that is normally expected to return something.
Checking a Failure for truth (with the `Bool` method) or definedness (with the `defined` method) marks the failure as handled, and causes it not to throw in sink context anymore.
You can call the `handled` method to check if a failure has been handled.
Calling methods on unhandled failures propagates the failure. The specification says the result is another `Failure`; in Rakudo it causes the failure to throw.
Because a Failure is [`Nil`](/type/Nil), which is undefined, a common idiom for safely executing code that may fail uses a [`with/else`](/language/control#with_orwith_without) statement:
```raku
sub may_fail( --> Numeric:D ) {
my $value = (^10).pick || fail "Zero is unacceptable";
fail "Odd is also not okay" if $value % 2;
return $value;
}
with may_fail() -> $value { # defined, so didn't fail
say "I know $value isn't zero or odd."
} else { # undefined, so failed, and the Failure is the topic
say "Uh-oh: {.exception.message}."
}
```
# [Methods](#class_Failure "go to top of document")[§](#Methods "direct link")
## [method new](#class_Failure "go to top of document")[§](#method_new "direct link")
```raku
multi method new(Failure:D:)
multi method new(Failure:U:)
multi method new(Failure:U: Exception:D \exception)
multi method new(Failure:U: $payload)
multi method new(Failure:U: |cap (*@msg))
```
Returns a new `Failure` instance with payload given as argument. If called without arguments on a `Failure` object, it will throw; on a type value, it will create an empty `Failure` with no payload. The latter can be either an [`Exception`](/type/Exception) or a payload for an [`Exception`](/type/Exception). A typical payload would be a [`Str`](/type/Str) with an error message. A list of payloads is also accepted.
```raku
my $e = Failure.new(now.DateTime, 'WELP‼');
say $e;
CATCH{ default { say .^name, ': ', .Str } }
# OUTPUT: «X::AdHoc: 2017-09-10T11:56:05.477237ZWELP‼»
```
## [method handled](#class_Failure "go to top of document")[§](#method_handled "direct link")
```raku
method handled(Failure:D: --> Bool:D) is rw
```
Returns `True` for handled failures, `False` otherwise.
```raku
sub f() { fail }; my $v = f; say $v.handled; # OUTPUT: «False»
```
The `handled` method is an [lvalue](/language/glossary#lvalue), see [routine trait `is rw`](/type/Routine#trait_is_rw), which means you can also use it to set the handled state:
```raku
sub f() { fail }
my $v = f;
$v.handled = True;
say $v.handled; # OUTPUT: «True»
```
## [method exception](#class_Failure "go to top of document")[§](#method_exception "direct link")
```raku
method exception(Failure:D: --> Exception)
```
Returns the [`Exception`](/type/Exception) object that the failure wraps.
```raku
sub failer() { fail };
my $failure = failer;
my $ex = $failure.exception;
put "$ex.^name(): $ex";
# OUTPUT: «X::AdHoc: Failed»
```
## [method self](#class_Failure "go to top of document")[§](#method_self "direct link")
```raku
method self(Failure:D: --> Failure:D)
```
If the invocant is a [handled](/routine/handled) `Failure`, returns it as is. If not handled, throws its [`Exception`](/type/Exception). Since [`Mu`](/type/Mu) type [provides `.self`](/type/Mu#method_self) for every class, calling this method is a handy way to explosively filter out Failures:
```raku
my $num1 = '♥'.Int;
# $num1 now contains a Failure object, which may not be desirable
my $num2 = '♥'.Int.self;
# .self method call on Failure causes an exception to be thrown
my $num3 = '42'.Int.self;
# Int type has a .self method, so here $num3 has `42` in it
(my $stuff = '♥'.Int).so;
say $stuff.self; # OUTPUT: «(HANDLED) Cannot convert string to number…»
# Here, Failure is handled, so .self just returns it as is
```
## [method Bool](#class_Failure "go to top of document")[§](#method_Bool "direct link")
```raku
multi method Bool(Failure:D: --> Bool:D)
```
Returns `False`, and marks the failure as handled.
```raku
sub f() { fail };
my $v = f;
say $v.handled; # OUTPUT: «False»
say $v.Bool; # OUTPUT: «False»
say $v.handled; # OUTPUT: «True»
```
## [method Capture](#class_Failure "go to top of document")[§](#method_Capture "direct link")
```raku
method Capture()
```
Throws `X::Cannot::Capture` if the invocant is a type object or a [handled](/routine/handled) `Failure`. Otherwise, throws the invocant's [exception](/routine/exception).
## [method defined](#class_Failure "go to top of document")[§](#method_defined "direct link")
```raku
multi method defined(Failure:D: --> Bool:D)
```
Returns `False` (failures are officially undefined), and marks the failure as handled.
```raku
sub f() { fail };
my $v = f;
say $v.handled; # OUTPUT: «False»
say $v.defined; # OUTPUT: «False»
say $v.handled; # OUTPUT: «True»
```
## [method list](#class_Failure "go to top of document")[§](#method_list "direct link")
```raku
multi method list(Failure:D:)
```
Marks the failure as handled and throws the invocant's [exception](/type/Failure#method_exception).
## [sub fail](#class_Failure "go to top of document")[§](#sub_fail "direct link")
```raku
multi fail(--> Nil)
multi fail(*@text)
multi fail(Exception:U $e --> Nil )
multi fail($payload --> Nil)
multi fail(|cap (*@msg) --> Nil)
multi fail(Failure:U $f --> Nil)
multi fail(Failure:D $fail --> Nil)
```
Exits the calling [`Routine`](/type/Routine) and returns a `Failure` object wrapping the exception `$e` - or, for the `cap` or `$payload` form, an [`X::AdHoc`](/type/X/AdHoc) exception constructed from the concatenation of `@text`. If the caller activated fatal exceptions via the pragma `use fatal;`, the exception is thrown instead of being returned as a `Failure`.
```raku
# A custom exception defined
class ForbiddenDirectory is Exception {
has Str $.name;
method message { "This directory is forbidden: '$!name'" }
}
sub copy-directory-tree ($dir) {
# We don't allow for non-directories to be copied
fail "$dir is not a directory" if !$dir.IO.d;
# We don't allow 'foo' directory to be copied too
fail ForbiddenDirectory.new(:name($dir)) if $dir eq 'foo';
# or above can be written in method form as:
# ForbiddenDirectory.new(:name($dir)).fail if $dir eq 'foo';
# Do some actual copying here
...
}
# A Failure with X::AdHoc exception object is returned and
# assigned, so no throwing Would be thrown without an assignment
my $result = copy-directory-tree("cat.jpg");
say $result.exception; # OUTPUT: «cat.jpg is not a directory»
# A Failure with a custom Exception object is returned
$result = copy-directory-tree('foo');
say $result.exception; # OUTPUT: «This directory is forbidden: 'foo'»
```
If it's called with a generic `Failure`, an ad-hoc undefined failure is thrown; if it's a defined `Failure`, it will be marked as unhandled.
```raku
sub re-fail {
my $x = +"a";
unless $x.defined {
$x.handled = True;
say "Something has failed in \$x ", $x.^name;
# OUTPUT: «Something has failed in $x Failure»
fail($x);
return $x;
}
}
my $x = re-fail;
say $x.handled; # OUTPUT: «False»
```
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Failure`
raku-type-graph
Failure
Failure
Nil
Nil
Failure->Nil
Mu
Mu
Any
Any
Any->Mu
Cool
Cool
Cool->Any
Nil->Cool
[Expand chart above](/assets/typegraphs/Failure.svg)
|
## dist_zef-dwarring-Pod-To-PDF.md
# TITLE
Pod::To::PDF
# SUBTITLE
Render Pod to PDF via Cairo
# Usage
From command line:
```
$ raku --doc=PDF lib/To/Class.rakumod --save-as=To-Class.pdf
```
From Raku:
```
use Pod::To::PDF;
use Cairo;
=NAME
foobar.pl
=head2 SYNOPSIS
=code foobar.pl <options> files ...
my Cairo::Surface::PDF $pdf = pod2pdf($=pod, :save-as<foobar.pdf>);
$pdf.finish();
```
### Command Line Options:
**--save-as=pdf-filename**
File-name for the PDF output file. If not given, the output will be saved to a temporary file. The file-name is echoed to `stdout`.
**--width=n**
Page width in points (default: 592)
**--height=n**
Page height in points (default: 792)
**--margin=n --margin-left=n --margin-right=n --margin-top=n --margin-bottom=n**
Page margin in points (default: 20)
**--/toc**
Disable table of contents
**--/index**
Disable index of terms
**--page-numbers**
Add page numbers (bottom right)
**--compress**
Compress the rendered PDF. The optional [Compress::PDF](https://raku.land/zef:tbrowder/Compress::PDF) module needs to be installed to use this option.
**--page-style**
```
-raku --doc=PDF lib/to/class.rakumod --page-style='margin:10px 20px; width:200pt; height:500pt" --save-as=class.pdf
```
Perform CSS `@page` like styling of pages. At the moment, only margins (`margin`, `margin-left`, `margin-top`, `margin-bottom`, `margin-right`) and the page `width` and `height` can be set. The optional [CSS::Properties](https://css-raku.github.io/CSS-Properties-raku/) module needs to be installed to use this option.
# Exports
* `class Pod::To::PDF;`
* `sub pod2pdf; # See below`
From Raku code, the `pod2pdf` function returns a Cairo::Surface::PDF object which can be further manipulated, or finished to complete rendering.
# Description
This module does simple rendering of Pod to PDF documents via Cairo.
The generated PDF has a table of contents and is tagged for accessibility and testing purposes.
It uses HarfBuzz for font shaping and glyph selection and FontConfig for system font loading.
# Subroutines
### sub pod2pdf()
```
sub pod2pdf(
Pod::Block $pod
) returns Cairo::Surface::PDF;
```
#### pod2pdf() Options
**`Str() :$save-as`**
A filename for the output PDF file.
**`Cairo::Surface::PDF :$surface`**
A surface to render to
**`UInt:D :$width, UInt:D :$height`**
The page size in points (there are 72 points per inch).
**`UInt:D :$margin`**
The page margin in points (default 20).
**`Hash :@fonts`**
By default, Pod::To::PDF loads system fonts via FontConfig. This option can be used to preload selected fonts.
```
use Pod::To::PDF;
use Cairo;
my @fonts = (
%(:file<fonts/Raku.ttf>),
%(:file<fonts/Raku-Bold.ttf>, :bold),
%(:file<fonts/Raku-Italic.ttf>, :italic),
%(:file<fonts/Raku-BoldItalic.ttf>, :bold, :italic),
%(:file<fonts/Raku-Mono.ttf>, :mono),
);
my Cairo::Surface::PDF $pdf = pod2pdf($=pod, :@fonts, :save-as<out.pdf>);
$pdf.finish();
```
Each font entry should have a `file` entry and various combinations of `bold`, `italic` and `mono` flags. Note that `mono` is used to render code blocks and inline code.
**`Str :%metadata`**
This can be used to preset values for `title`, `subtitle`, `name`, `author` or `version`.
This is an alternative to, and will override `=TITLE`, `=SUBTITLE`, `=NAME`, `=AUTHOR` or `=VERSION` directives.
Note: All of these are options are provided for compatibility, however only `=TITLE` and `=AUTHOR` are directly supported in PDF metadata.
**`:!contents`**
Disables Table of Contents generation.
**`:!index`**
Disable writing of a `Index` section to the table of contents.
**`:$linker`**
Provides a class or object to intercept and sanitise or rebase links. The class/object should provide a method `resolve-link` that accepts the target component of C<L<>> formatting codes and returns the actual link to be embedded in the PDF. The link is omitted, if the method returns an undefined value.
**`:%replace`**
Specify replacements for `R<>` placeholders in the POD. Replacement values should be simple strings (`Str`), Pod blocks (type `Pod::Block`), or a `List`. For example:
```
use Pod::To::PDF;
my $title = 'Sample Title';
my Str() $date = now.Date;
my $author = 'David Warring';
my $description = "sample Pod with replaced content";
my %replace = :$date, :$title, :$author, :$description;
my $renderer = pod2pdf($=pod, :%replace, :save-as<replace-example.pdf>);
$renderer.finish();
=begin pod
=TITLE R<title>
=AUTHOR R<author>
=DATE R<date>
=head2 Description
=para R<description>;
=end pod
```
# Installation
This module's dependencies include [HarfBuzz](https://harfbuzz-raku.github.io/HarfBuzz-raku/), [Font::FreeType](https://pdf-raku.github.io/Font-FreeType-raku/), [FontConfig](https://raku.land/zef:dwarring/FontConfig) and [Cairo](https://raku.land/github:timo/Cairo), which further depend on native `harfbuzz`, `freetype6`, `fontconfig` and `cairo` libraries.
Please check these module's installation instructions.
# Testing
Note that installation of the PDF::Tags::Reader module enables structural testing.
For example, to test this module from source.
```
$ git clone https://github.com/pod-to-pdf/Pod-To-PDF-raku
$ cd Pod-To-PDF-raku
$ zef install PDF::Tags::Reader # enable structural tests
$ zef APP::Prove6
$ zef --deps-only install .
$ prove6 -I .
```
|
## dist_zef-raku-community-modules-Algorithm-LCS.md
[](https://github.com/raku-community-modules/Algorithm-LCS/actions) [](https://github.com/raku-community-modules/Algorithm-LCS/actions) [](https://github.com/raku-community-modules/Algorithm-LCS/actions)
# NAME
Algorithm::LCS - Implementation of the longest common subsequence algorithm
# SYNOPSIS
```
use Algorithm::LCS;
# regular usage
say lcs(<A B C D E F G>, <A C F H J>); # prints T<A C F>
# custom comparator via :compare
say lcs(<A B C>, <D C F>, :compare(&infix:<eq>));
# extra special custom comparison via :compare-i
my @a = slurp('one.txt');
my @b = slurp('two.txt');
my @a-hashed = @a.map({ hash-algorithm($_) });
my @b-hashed = @b.map({ hash-algorithm($_) });
say lcs(@a, @b, :compare-i({ @a-hashed[$^i] eqv @b-hashed[$^j] }));
```
# DESCRIPTION
This module contains a single subroutine, `lcs`, that calculates the longest common subsequence between two sequences of data. `lcs` takes two lists as required parameters; you may also specify the comparison function (which defaults to `eqv`) via the `&compare` named parameter).
Sometimes you may want to maintain a parallel array of information to consult during calculation (for example, if you're comparing long lines of a file, and you'd like a speedup by comparing their hashes rather than their contents); for that, you may use the `&compare-i` named argumeny
# SUBROUTINES
### sub lcs
```
sub lcs(
@a,
@b,
:&compare = Code.new,
:&compare-i is copy
) returns Mu
```
Returns the longest common subsequence of two sequences of data.
## class Mu $
The first sequence
## class Mu $
The second sequence
## class Mu $
The comparison function (defaults to C)
## class Mu $
The compare-by-index function (defaults to using &compare)
# SEE ALSO
[Wikipedia article](http://en.wikipedia.org/wiki/Longest_common_subsequence_problem)
# AUTHORS
* Rob Hoelz
* Raku Community
# COPYRIGHT AND LICENSE
Copyright (c) 2014 - 2017 Rob Hoelz
Copyright (c) 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the MIT license.
|
## dist_zef-librasteve-Rat-Power.md
[](https://opensource.org/licenses/Artistic-2.0)
# Rat::Power
# SYNOPSIS
```
use Rat::Power;
say 64 ** ⅓; #Int
say 64 ** ⅔; #Int
say 60 ** ⅓; #Num
```
### Caveats
* exponent must be Rat where \* == (½,⅓,⅔,¼,¾).any
* base and result must be Int
# AUTHOR
librasteve [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2024 librasteve
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-TYIL-Config-Parser-yaml.md
# Config::Parser::yaml
A YAML parser for [Config](https://github.com/scriptkitties/p6-Config).
[](https://travis-ci.org/scriptkitties/p6-Config-Parser-yaml)
## Installation
```
zef install Config::Parser::yaml
```
## License
This program is free software: you can redistribute it and/or modify it under
the terms of the GNU General Public License as published by the Free Software
Foundation, either version 3 of the License, or (at your option) any later
version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY
WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with
this program. If not, see <http://www.gnu.org/licenses/>.
|
## dist_github-shantanubhadoria-Printer-ESCPOS.md
# NAME
Printer::ESCPOS - Interface to ESCPOS printers
# SYNOPSIS
## Network printer in asynchronous mode
```
use Printer::ESCPOS::Network::Async;
// Asynchronous control over your network ESCPOS printer
await Printer::ESCPOS::Network::Async.connect('10.0.13.108', 9100).then( -> $p {
if $p.status {
given $p.result {
.init;
.barcode("TEST", system => 'CODE93');
.lf;
.tab-positions(3,1,2);
$printer.tab;
.send('hmargin 1');
.lf;
.send('margin 2');
.lf;
.cut-paper;
.lf;
.close;
}
}
});
```
## Network printer in synchronous mode
```
use Printer::ESCPOS::Network;
my $printer = Printer::ESCPOS::Network.new(:host<10.0.13.108>, :port(9100));
$printer.init;
$printer.barcode("TEST", system => 'CODE93');
$printer.lf;
$printer.tab-positions(3,1,2);
$printer.tab;
$printer.send('hmargin 1');
$printer.lf;
$printer.send('margin 2');
$printer.lf;
$printer.cut-paper;
$printer.lf;
$printer.close;
```
# DESCRIPTION
ESC/P, short for Epson Standard Code for Printers and sometimes styled Escape/P, is a printer control language developed by Epson to control computer printers. It was mainly used in dot matrix printers and some inkjet printers, and is still widely used in many receipt printers. During the era of dot matrix printers, it was also used by other manufacturers (e.g. NEC), sometimes in modified form. At the time, it was a popular mechanism to add formatting to printed text, and was widely supported in software. These days its almost a standard communication mode for talking to thermal and dot-matrix receipt printers used for printing bills, receipts etc. in retail outlets, restaurants etc. There are several variants of ESC/P, as not all printers implement all commands. Epson refers to a more recent variant of ESC/P as ESC/P2. ESC/P2 is backward compatible with ESC/P, but adds commands for new printer features such as scalable fonts and enhanced graphics printing.
# ADDING A CONNECTION CLASS
Perl 6 classes allow easy extendability of the Printer::ESCPOS to support newer communication ports/protocols. See below examples for examples of how I have added TCP IP support(for Async and Synchronous modes):
## Extending IO::Socket::INET in just 4 lines of code:
IO::Socket::INET allows synchronous communication with a TCP device. Watch how we can use this module to talk to ESCPOS printers in just 4 lines of code.
```
use v6;
use Printer::ESCPOS;
class Printer::ESCPOS::Network is IO::Socket::INET is Printer::ESCPOS {
method send(Str $string) { # Send is the subroutine called by Printer::ESCPOS to send data to the Printer
# Since IO::Socket::INET uses print() method to send data to the peer. We route data
# Sent on send() to IO::Socket::INET's print() method.
self.print($string);
}
}
```
Now you can use Printer::ESCPOS::Network class to talk to any network printer:
```
use Printer::ESCPOS::Network;
my $printer = Printer::ESCPOS::Network.new(:host<10.0.13.108>, :port(9100));
$printer.init;
$printer.barcode("TEST", system => 'CODE93');
$printer.lf;
$printer.tab-positions(3,1,2);
$printer.tab;
$printer.send('hmargin 1');
$printer.lf;
$printer.send('margin 2');
$printer.lf;
$printer.cut-paper;
$printer.lf;
$printer.close;
```
## Extending IO::Socket::Async in just 4 lines of code:
IO::Socket::Async allows asynchronous communication with a TCP device. Watch how we can use this module to talk to ESCPOS printers in just 4 lines of code.
```
use v6;
use Printer::ESCPOS;
class Printer::ESCPOS::Network::Async is IO::Socket::Async is Printer::ESCPOS {
method send(Str $string) {
self.print($string);
}
}
```
Now you can use Printer::ESCPOS::Network::Async class to talk to any network printer:
```
use Printer::ESCPOS::Network::Async;
await Printer::ESCPOS::Network::Async.connect('10.0.13.108', 9100).then( -> $p {
if $p.status {
given $p.result {
.init;
.text-size(height => 3, width => 2);
.barcode("TEST", system => 'CODE93');
.lf;
.tab-positions(3,1,2);
.send('hmargin 1');
.lf;
.send('margin 2');
.lf;
.cut-paper;
.lf;
.close;
}
}
});
```
# ATTRIBUTES
At the moment the attributes used are dependent on the communication protocol/port that you use. If your Printer is connected over a network you will need to provide a IP Address and port number. At the moment only network driver is supported. USB, Serial and Bluetooth support will be added as Modules for the same become available in Perl 6
```
use Printer::ESCPOS;
class Printer::ESCPOS::Network::Async is IO::Socket::Async is Printer::ESCPOS {
method send(Str $string) {
self.print($string);
}
}
use Printer::ESCPOS::Network::Async;
await Printer::ESCPOS::Network::Async.connect('10.0.13.108', 9100).then( -> $p {
if $p.status {
given $p.result {
.init;
.barcode("TEST", system => 'CODE93');
.lf;
.send('hmargin 1');
.lf;
.cut-paper;
.close;
}
}
});
```
# METHODS
## init
Initializes the Printer. Clears the data in print buffer and resets the printer to the mode that was in effect when the power was turned on. This function is automatically called on creation of printer object.
# SUPPORT
## Bugs / Feature Requests
Please report any bugs or feature requests through github at <https://github.com/shantanubhadoria/p6-printer-escpos/issues>. You will be notified automatically of any progress on your issue.
## Source Code
This is open source software. The code repository is available for public review and contribution under the terms of the license.
<https://github.com/shantanubhadoria/p6-printer-escpos>
```
git clone git://github.com/shantanubhadoria/p6-printer-escpos.git
```
# AUTHOR
Shantanu Bhadoria [[email protected]](mailto:[email protected]) <https://www.shantanubhadoria.com>
# COPYRIGHT AND LICENSE
This software is copyright (c) 2016 by Shantanu Bhadoria.
This is free software; you can redistribute it and/or modify it under the same terms as the Perl 6 programming language system itself.
|
## dist_zef-lizmat-Unix-errno.md
[](https://github.com/lizmat/Unix-errno/actions) [](https://github.com/lizmat/Unix-errno/actions)
# NAME
Unix::errno - Provide transparent access to errno
# SYNOPSIS
```
use Unix::errno; # exports errno, set_errno
set_errno(2);
say errno; # No such file or directory (errno = 2)
say "failed: {errno}"; # failed: No such file or directory
say +errno; # 2
```
# DESCRIPTION
This module provides access to the `errno` variable that is available on all Unix-like systems. Please note that in a threaded environment such as Raku is, the value of `errno` is even more volatile than it has been already. For now, this issue is ignored.
# CAVEATS
Since setting of any "extern" variables is not supported yet by `NativeCall`, the setting of `errno` is faked. If `set_errno` is called, it will set the value only in a shadow copy. That value will be returned as long as the underlying "real" errno doesn't change (at which point that value will be returned.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Unix-errno> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2018, 2021, 2024, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-jaffa4-Rakudo-Perl6-Format.md
# Rakudo::Perl6::Format
Format Perl6 code.
Known limitations: if there is a `BEGIN`, there will not be any formatting.
Also, if classes are imported from nqp.
## Usage
```
use Rakudo::Perl6::Format;
my $f = Rakudo::Perl6::Format.new(); # create a new object
say $f.format({indentsize=>4},$content); # format using indentsize 4.
```
Only identation size can be set now.
## Command line access:
```
$ perl6 format.p6 -h
$ perl6 format.p6 -is 4 \<Dagrammar.p6 \>formatted.p6
```
|
## dist_zef-bbkr-UpRooted.md
# Extract subtrees of data from relational databases in [Raku](https://www.raku.org) language.
[](https://github.com/bbkr/UpRooted/actions/workflows/test.yml)
## DESCRIPTION
This module allows to extract tree of data from relational database and process it.
Tree of data may be for example some user account and all records in related tables that belong to him.
Useful for cases like:
* Transferring users between database shards for better load balancing.
* Cloning user data from production environment to devel to debug some issues in isolated manner.
* Saving user state for backup or legal purposes.
This module is NOT continuous replication tool (like for example Debezium).
## SYNOPSIS
Let's say you have MySQL database and want to save user of `id = 1` from `users` table with all his data from other tables to `.sql` file.
```
my $connection = DBIish.connect( 'mysql', host => ..., port => ..., ... );
use UpRooted::Schema::MySQL;
my $schema = UpRooted::Schema::MySQL.new( :$connection );
use UpRooted::Tree;
my $tree = UpRooted::Tree.new( root-table => $schema.table( 'users' ) );
use UpRooted::Reader::MySQL;
my $reader = UpRooted::Reader::MySQL.new( :$connection, :$tree );
use UpRooted::Writer::MySQLFile;
my $writer = UpRooted::Writer::MySQLFile.new;
$writer.write( $reader, id => 1 );
```
Your user will be saved as `out.sql` file.
## DOCKER
If you do not have Raku installed UpRooted is also available as [Docker image](https://hub.docker.com/repository/docker/bbkr2/uprooted).
## MODULES
This section explains role of every module in `UpRooted` stack and tells which variants of each module are available.
### UpRooted::Schema
`UpRooted::Schema` describes relation between `UpRooted::Tables`.
It can be discovered automatically by plugins like:
* `UpRooted::Schema::MySQL`
* `UpRooted::Schema::PostgreSQL`
In rare cases you may need to construct or fine tune `UpRooted::Schema` manually. For example if you use MySQL MyISAM engine or MySQL partitioning. Or you use PostgreSQL foreign keys relying on unique keys instead of unique constraints. Without proper foreign keys relations between `UpRooted::Table`s cannot be auto discovered and must be defined by hand. There is [separate manual](docs/Schema.md) describing this process.
Creating `UpRooted::Schema` must be done only once per schema.
### UpRooted::Tree
`UpRooted::Tree` knows how to reach each leaf `UpRooted::Table` from chosen root `UpRooted::Table`.
It also resolves `UpRooted::Table`s order correctly to satisfy foreign key constraints, which is important for example when writing data tree to online database.
You can derive many `UpRooted::Tree`s from single `UpRooted::Schema`, depending on which root `UpRooted::Table` is used.
Creating `UpRooted::Tree` must be done only once per root `UpRooted::Table`.
### UpRooted::Reader
`UpRooted::Reader` transforms `UpRooted::Tree` to series of queries allowing to extract data that belong to given row in root `UpRooted::Table`. This is always database engine specific.
Available variants:
* `UpRooted::Reader::MySQL`
* `UpRooted::Reader::PostgreSQL`
Creating `UpRooted::Reader` must be done only once per `UpRooted::Tree`.
### UpRooted::Writer
`UpRooted::Writer` writes data provided by `UpRooted::Reader`.
Available variants:
* `UpRooted::Writer::MySQL` - Write directly to another MySQL database.
* `UpRooted::Writer::MySQLFile` - Write to `.sql` file compatible with MySQL.
* `UpRooted::Writer::PostgreSQL` - Write directly to another PostgreSQL database.
* `UpRooted::Writer::PostgreSQLFile` - Write to `.sql` file compatible with PostgreSQL.
Note that `UpRooted::Reader` and `UpRooted::Writer` are independent. You can read from MySQL database and write directly to PostgreSQL database if needed.
Disabling `UpRooted::Schema` name in Fully Qualified Names in queries may be useful for example when you need to write data to whatever schema is / will be used in connection.
To do so provide flag to constructor like this: `UpRooted::Writer::MySQL.new( :!use-schema-name )`.
To find other options accepted by each `UpRooted::Writer` call `p6doc` on chosen module.
Note that not every `UpRooted::Writer` can save every data type provided by `UpRooted::Reader`. For example MySQL does not support PostgreSQL array types and will save them as joined strings.
## CACHING
Creating instances of modules mentioned above are heavy operations, especially on large schemas. You can reuse all of them for great speed improvement.
For example if you need to save multiple users you need to create `UpRooted::Schema`, `UpRooted::Tree`, `UpRooted::Reader` and `UpRooted::Writer` only once.
```
my $schema = ...;
my $tree = ...;
my $reader = ...;
my $writer = UpRooted::Writer::MySQLFile.new(
# name generator to avoid file name conflicts
file-naming => sub ( $tree, %conditions ) {
%conditions{ 'id' } ~ '.sql'
}
);
$writer.write( $reader, id => 1 );
$writer.write( $reader, id => 2 );
$writer.write( $reader, id => 3 );
```
It will create `1.sql`, `2.sql`, `3.sql` files without rediscovering everything every time.
## EXTENSIONS
`UpRooted` is written with extensibility in mind.
Base version will focus on MySQL and PostgreSQL databases, as those are the two most common open source ones.
However if you need for example to create `UpRooted::Schema` from Red ORM, make `UpRooted::Writer` to save set of CSV files or even implement whole `UpRooted` stack to work with MS SQL - do not be afraid to implement it. Interfaces are simple, well documented and checking existing MySQL / PostgreSQL code will give you the idea how little is actually needed to extend `UpRooted` capabilities.
## SCHEMA DESIGN ISSUES
Relational databases are extremly flexible in terms of schema design.
However there are few rules you must follow if you want to work with data trees.
If you use `UpRooted` but do not get expected results please go through this list carefully before creating issue on GitHub.
### Data is transformed (extra rows, counters are too high) when written to another database
**Cause:** There are `ON INSERT` triggers changing data.
This one is very easy to overlook.
Triggers are convenient, relaible and cheap way of managing entangled data state.
For example when row is inserted into `orders` table increase counter in `order_stats` table by `1`.
But those triggers will get in a way of copying / moving data trees literally between databases, because they will "replay" their logic when data tree is written to another database.
**Fix:** When designing schema with data tree reading / writing in mind triggers can be only used to verify constraints.
### Data tree is not writable to another database without disabling foreign key constraints
**Cause 1:** There are self-looped tables. Usually implementing tree logic.
By default `UpRooted` resolves dependencies and whole purpose of `UpRooted::Tree` is to provide data in correct order. However it may be not possible if table is directly referencing itself.
```
+----------+
| users |
+----------+
| id |----------------------+
| login | |
| password | |
+----------+ |
|
+--------------------+ |
| albums | |
+--------------------+ |
+---| id | |
| | user_id |>-+
+--<| parent_album_id |
| name |
+--------------------+
```
For example user has album with `id = 2` as subcategory of album with `id = 1`. Then he rearranges his collection, so that the album with `id = 2` is on top. In such scenario if database returned data tree rows in primary key order then it will not be possible to insert album with `id = 1` because it requires presence of album with `id = 2`.
**Hint 1:**
You can check if `UpRooted::Tree` has loops by running:
```
my $tree = ...;
say $tree.paths.grep: *.is-looped;
```
**Fix 1:** Have separate table that establishes tree hierarchy between rows:
```
+----------+
| users |
+----------+
| id |----------------------+
| login | |
| password | |
+----------+ |
|
+--------------------+ |
| albums | |
+--------------------+ |
+-+=====| id | |
| | | user_id |>-+
| | | name |
| | +--------------------+
| |
| | +------------------+
| | | album_hierarchy |
| | +------------------+
| +---<| parent_album_id |
+-----<| child_album_id |
+------------------+
```
**Cause 2:** Jailbreak. Data from one tree links to data from another tree. Usually implementing relations or activities between users.
```
+----------+ +------------+
| users | | blog_posts |
+----------+ +------------+
+-| id |---+ | id |---+
| | login | +---<| user_id | |
| | password | | text | |
| +----------+ +------------+ |
| |
| +--------------+ |
| | comments | |
| +--------------+ |
| | blog_post_id |>-----------------+
+---<| user_id |
| text |
+--------------+
```
For example user with `id = 1` created a blog post that was commented by user with `id = 2`. Now record from `comments` table has two owners, one direct (belongs to user with `id = 2`) and one indirect (belongs to post written by user with `id =` 1`).
**Fix 2:** Unfortunately the only way to detach two data trees in such case is to remove one of foreign key constraints.
### Some rows from table are missing
**Cause:** Ambiguity in correct way of reaching rows in table. Only multiple nullable relation paths to this table exist.
```
+----------+
| users |
+----------+
+-------------| id |-------------+
| | login | |
| | password | |
| +----------+ |
| |
| +-----------+ +-----------+ |
| | time | | distance | |
| +-----------+ +-----------+ |
| | id |--+ +--| id | |
+-<| user_id | | | | user_id |>-+
| amount | | | | amount |
+-----------+ | | +-----------+
| |
(nullable)
| |
| |
+--------+ +---------+
| |
| +-------------+ |
| | parts | |
| +-------------+ |
+--<| time_id | |
| distance_id |>--+
| name |
+-------------+
```
This time our product is application that helps you with car maintenance schedule. Our users car has 4 tires that must be replaced after 10 years or 100000km and 4 spark plugs that must be replaced after 100000km. So 4 indistinguishable rows for tires are added to parts table (they reference both time and distance) and 4 indistinguishable rows are added for spark plugs (they reference only distance).
Now to extract to shard we have to find which rows from parts table does he own. By following relations through time table we will get 4 tires. But because this path is nullable at some point we are not sure if we found all records. And indeed, by following relations through distance table we found 4 tires and 4 spark plugs. Since this path is also nullable at some point we are not sure if we found all records. So we must combine result from time and distance paths, which gives us... 8 tires and 4 spark plugs? Well, that looks wrong. Maybe let's group it by time and distance pair, which gives us... 1 tire and 1 spark plug? So depending how you combine indistinguishable rows from many nullable paths to get final row set, you may suffer either data duplication or data loss.
To understand this issue better consider two answers to question `How many legs does the horse have?`:
* `Eight. Two front, two rear, two left and two right.` This answer is incorrect because each leg is counted multiple times from different nullable relations.
* `Four. Those attached to it.` This answer is correct because each leg is counted exactly once through not nullable relation.
**Hint:**
You can check if `UpRooted::Tree` has ambiguities by running:
```
my $tree = ...;
say $tree.paths.grep: *.is-ambiguous;
```
**Fix:** Redesign schema so that at least one not nullable relations path leads to every table.
|
## dist_github-azawawi-GTK-Simpler.md
# GTK::Simpler [Build Status](https://travis-ci.org/azawawi/perl6-gtk-simpler) [Build status](https://ci.appveyor.com/project/azawawi/perl6-gtk-simpler/branch/master)
This module provides a simpler API for
[GTK::Simple](https://github.com/perl6/gtk-simple). The idea here is to load
GTK::Simple widgets lazily at runtime and type less characters. For example
instead of writing the following:
```
# This is slow since it will load a lot of GTK::Simple widgets by default
use GTK::Simple;
my $app = GTK::Simple::App.new(title => "Hello");
```
you write the more concise shorter form:
```
# Exports a bunch of subroutines by default
use GTK::Simpler;
# GTK::Simple::App is loaded and created only here
my $app = app(title => "Hello");
```
## Example
```
use v6;
use GTK::Simpler;
my $app = app(title => "Hello GTK!");
$app.set-content(
vbox(
my $first-button = button(label => "Hello World!"),
my $second-button = button(label => "Goodbye!")
)
);
$app.border-width = 20;
$second-button.sensitive = False;
$first-button.clicked.tap({
.sensitive = False;
$second-button.sensitive = True
});
$second-button.clicked.tap({
$app.exit;
});
$app.run;
```
For more examples, please see the <examples> folder.
## Documentation
Please see the [GTK::Simpler](doc/GTK-Simpler.md) generated documentation.
## Installation
Please check [GTK::Simple prerequisites](https://github.com/perl6/gtk-simple/blob/master/README.md#prerequisites) section
for more information.
To install it using zef (a module management tool bundled with Rakudo Star):
```
$ zef install GTK::Simpler
```
## Testing
* To run tests:
```
$ prove -e "perl6 -Ilib"
```
* To run all tests including author tests (Please make sure
[Test::Meta](https://github.com/jonathanstowe/Test-META) is installed):
```
$ zef install Test::META
$ AUTHOR_TESTING=1 prove -ve "perl6 -Ilib"
```
## Author
Ahmad M. Zawawi, [azawawi](https://github.com/azawawi/) on #perl6
## License
MIT License
|
## dist_github-alabamenhu-Regex-FuzzyToken.md

A Raku module enabling the use of fuzzy tokens in regexen and grammars:
```
use Regex::FuzzyToken;
my @fruits = <apple banana mango orange kiwi>;
"My favorite fruit is a bnana" ~~ /My favorite fruit is a <fuzzy: @fruits>/;
say $<fuzzy>.fuzz; # bnana
say $<fuzzy>.Str; # banana
```
Support for more flexible capturing options is forthcoming. The signature for
the fuzzy token are the following:
```
fuzzy(*@words,
:$i = False,
:$m = False,
:$ws = True,
:$q = 33,
:$capture = (@words.tail ~~ Regex
?? @words.tail
!! /\w+/ )
)
```
Basically, you should provide a list of strings to be the “goal” words you want to find,
but will accept if they're slightly misspelled. The `i`, `m`, and `ws` options mimic
the regex matching behavior, and will make comparisons ignore differences in case (**i**),
marks (**m**) or white space (**ws**). The `q` option is the minimum Q-gram score desired to
allow for a match. The default of 33 is fine for most cases, but through testing you
may find it necessary to increase or decrease the sensitivity (100 = only match exact,
0 = match everything).
The final option of :$capture allows you to specify the capture regex to use. By
default it will only capture a sequence of word characters, but that will cause
problems if you need it to match spaces/apostrophes. While you *can* make things
explicit with `:capture(/foo/)`, the signature was designed to allow you to
specify the final item as the capture regex, and so the following are equivalent:
```
<fuzzy: @foo, /bar/>
<fuzzy: @foo, :capture(/bar/)>
```
# To do
It could be interesting to allow for a more complex capture, for example, that
matches only as many characters as it needs using `.match($capture, :exhaustive)` on a
substring from the current `.pos`. That would require some tuning of the Q gram algorithm
and in many cases could take exponentially more time, but would be more accurate / usable.
# Licenses
All code is and documentation is licensed under the Artistic License 2.0, included with
the module. The image used on Github is based on
[this butterfly](https://www.piqsels.com/en/public-domain-photo-frbsj)
which is licensed under CC-0 and modified in accordance with that license and released
under [CC-BY 4.0](https://creativecommons.org/licenses/by/4.0/)
|
## dist_zef-FCO-Heap.md
[](https://travis-ci.org/FCO/Heap)
Impleementation of Heap data structure
### has Callable &.cmp
The comparator function
### has Positional[Any] @.data
The array with the heap data
### method new
```
method new(
+@arr is copy
) returns Mu
```
Receives a array and transforms that array in a Heap (O(n))
### method push
```
method push(
$new
) returns Mu
```
Add a ney value on the Heap
### method pop
```
method pop() returns Mu
```
Removes and returns the first element of the heap
### method peek
```
method peek() returns Mu
```
Returns the first element of the heap
### method all
```
method all() returns Mu
```
Pops the Heap until its empty
# Heap
A simple perl6 module implementing the heap data structure.
```
my Heap $heap .= new: 9, 7, 5, 3, 1;
$heap.push: 8;
say $heap.pop; # 1
say $heap.pop; # 3
say $heap.pop; # 5
say $heap.all # (7, 8, 9)
```
```
my Heap[-*] $heap .= new: <9 7 5 3 1>;
$heap.push: 8;
say $heap.pop; # 9
say $heap.pop; # 8
say $heap.pop; # 7
```
```
my Heap[{$^b <=> $^a}] $heap .= new: <9 7 5 3 1>;
$heap.push: 8;
say $heap.pop; # 9
say $heap.pop; # 8
say $heap.pop; # 7
```
```
my Heap[*<order>] $heap .= new:
{:something<ble>, :order<2>},
{:something<bla>, :order<1>},
{:something<bli>, :order<3>},
{:something<blu>, :order<5>},
;
$heap.push: {:something<blo>, :order<4>},
say $heap.pop; # {:something<bla>, :order<1>}
say $heap.pop; # {:something<ble>, :order<2>}
say $heap.pop; # {:something<bli>, :order<3>}
```
|
## dist_zef-antononcube-Lingua-Stem-Portuguese.md
# Lingua::Stem::Portuguese Raku package
## Introduction
This Raku package is for stemming Portuguese words.
It implements the Snowball algorithm presented in
[[SNa1](http://snowball.tartarus.org/algorithms/portuguese/stemmer.html)].
---
## Usage examples
The `PortugueseStem` function is used to find stems:
```
use Lingua::Stem::Portuguese;
say PortugueseStem('brotação')
```
```
# brot
```
`PortugueseStem` also works with lists of words:
```
say PortugueseStem('Os brotos são aguardados com paciência, bebida e bacon.'.words)
```
```
# (Os brot sao aguard com paciencia, beb e bacon.)
```
The function `portuguese-word-stem` can be used as a synonym of `PortugueseStem`.
---
## Command Line Interface (CLI)
The package provides the CLI function `PortugueseStem`. Here is its usage message:
```
PortugueseStem --help
```
```
# Usage:
# PortugueseStem <text> [--splitter=<Str>] [--format=<Str>] -- Finds stems of Portuguese words in text.
# PortugueseStem [<words> ...] [--format=<Str>] -- Finds stems of Portuguese words.
# PortugueseStem [--format=<Str>] -- Finds stems of Portuguese words in (pipeline) input.
#
# <text> Text to spilt and its words stemmed.
# --splitter=<Str> String to make a split regex with. [default: '\W+']
# --format=<Str> Output format one of 'text', 'lines', or 'raku'. [default: 'text']
# [<words> ...] Words to be stemmed.
```
Here are example shell commands of using the CLI function `PortugueseStem`:
```
PortugueseStem Boataria
```
```
# Boat
```
```
PortugueseStem --format=raku "Módulo Raku que fornece um procedimento para a língua portuguesa."
```
```
# ["Modul", "Raku", "que", "fornec", "um", "proced", "par", "a", "lingu", "portugu", ""]
```
```
PortugueseStem Verificar a exatidão da seleção usando dicionários e regras
```
```
# Verific a exatid da selec us dicion e regr
```
Here is a pipeline example using the CLI function `get-tokens` of the package
["Grammar::TokenProcessing"](https://github.com/antononcube/Raku-Grammar-TokenProcessing),
[AAp1]:
```
get-tokens ./DataQueryPhrases-template | PortugueseStem --format=raku
```
**Remark:** These kind of tokens (literals) transformations are used in the packages
["DSL::Bulgarian"](https://github.com/antononcube/Raku-DSL-Bulgarian), [AAp2],
["DSL::Portuguese"](https://github.com/antononcube/Raku-DSL-Portuguese), [AAp3],
and
["DSL::Russian"](https://github.com/antononcube/Raku-DSL-Russian), [AAp4],
---
## Implementation notes
* Reprogrammed to Raku from : <https://github.com/neilb/Lingua-PT-Stemmer/blob/master/lib/Lingua/PT/Stemmer.pm> .
---
## TODO
* TODO Respect the word case in the returned result.
* `PortugueseStem('TABLADO')` should return `'TABL'`.
* (Not `'tabl'` as it currently does.)
* DONE CLI that can be inserted in UNIX pipelines.
* TODO Gallician stemmer.
* TODO Performance statistics.
* TODO More detailed documentation.
---
## References
### Articles
[SNa1] Snowball Team,
[Portuguese stemming algorithm](http://snowball.tartarus.org/algorithms/portuguese/stemmer.html),
(2002),
[snowball.tartarus.org](http://snowball.tartarus.org).
### Packages
[AAp1] Anton Antonov,
[Grammar::TokenProcessing Raku package](https://github.com/antononcube/Raku-Grammar-TokenProcessing),
(2022),
[GitHub/antononcube](https://github.com/antononcube).
[AAp2] Anton Antonov,
[DSL::Bulgarian Raku package](https://github.com/antononcube/Raku-DSL-Bulgarian),
(2022),
[GitHub/antononcube](https://github.com/antononcube).
[AAp3] Anton Antonov,
[DSL::Portuguese Raku package](https://github.com/antononcube/Raku-DSL-Portuguese),
(2023),
[GitHub/antononcube](https://github.com/antononcube).
[AAp3] Anton Antonov,
[DSL::Russian Raku package](https://github.com/antononcube/Raku-DSL-Russian),
(2022),
[GitHub/antononcube](https://github.com/antononcube).
|
## dist_cpan-SCIMON-Game-Sudoku.md
[](https://travis-ci.org/Scimon/p6-Game-Sudoku)
# NAME
Game::Sudoku - Store, validate and solve sudoku puzzles
# SYNOPSIS
```
use Game::Sudoku;
# Create an empty game
my $game = Game::Sudoku.new();
# Set some cells
$game.cell(0,0,1).cell(0,1,2);
# Test the results
$game.valid();
$game.full();
$game.complete();
# Get possible values for a cell
$game.possible(0,2);
```
# DESCRIPTION
Game::Sudoku is a simple library to store, test and attempt to solve sudoku puzzles.
Currently the libray can be used as a basis for doing puzzles and can solve a number of them. I hope to add additional functionality to it in the future.
The Game::Sudoku::Solver module includes documenation for using the solver.
# METHODS
## new( Str :code -> Game::Sudoku )
The default constructor will accept and 81 character long string comprising of combinations of 0-9. This code can be got from an existing Game::Sudoku object by calling it's .Str method.
## valid( -> Bool )
Returns True if the sudoku game is potentially valid, IE noe row, colum or square has 2 of any number. A valid puzzle may not be complete.
## full( -> Bool )
Returns True if the sudoku game has all it's cells set to a non zero value. Note that the game may not be valid.
## complete( -> Bool )
Returns True is the sudoku game is both valid and full.
## possible( Int, Int, Bool :$set -> List )
Returns the sorted Sequence of numbers that can be put in the current cell. Note this performs a simple check of the row, column and square the cell is in it does not perform more complex logical checks.
Returns an empty List if the cell already has a value set or if there are no possible values.
If the optional :set parameter is passed then returns a Set of the values instead.
## cell( Int, Int -> Int )
## cell( Int, Int, Int -> Game::Sudoku )
Getter / Setter for individual cells. The setter returns the updated game allowing for method chaining. Note that attempting to set a value defined in the constructor will not work, returning the unchanged game object.
## row( Int -> List(List) )
Returns the list of (x,y) co-ordinates in the given row.
## col( Int -> List(List) )
Returns the list of (x,y) co-ordinates in the given column.
## square( Int -> List(List) )
## square( Int, Int -> List(List) )
Returns the list of (x,y) co-ordinates in the given square of the grid. A square can either be references by a cell within it or by it's index.
```
0|1|2
-----
3|4|5
-----
6|7|8
```
## reset( Str :$code )
Resets the puzzle to the state given in the $code argument. If the previous states initial values are all contained in the new puzzle then they will not be updated. Otherwise the puzzle will be treated as a fresh one with the given state.
# AUTHOR
Simon Proctor [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2017 Simon Proctor
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-P5print.md
[](https://github.com/lizmat/P5print/actions)
# NAME
Raku port of Perl's print() and associated built-ins
# SYNOPSIS
```
use P5print; # exports print, printf, say, STDIN, STDOUT, STDERR
print STDOUT, "foo";
printf STDERR, "%s", $bar;
say STDERR, "foobar"; # same as "note"
```
# DESCRIPTION
This module tries to mimic the behaviour of Perl's `print`, `printf` and `say` built-ins as closely as possible in the Raku Programming Language.
# ORIGINAL PERL 5 DOCUMENTATION
```
print FILEHANDLE LIST
print FILEHANDLE
print LIST
print Prints a string or a list of strings. Returns true if successful.
FILEHANDLE may be a scalar variable containing the name of or a
reference to the filehandle, thus introducing one level of
indirection. (NOTE: If FILEHANDLE is a variable and the next token
is a term, it may be misinterpreted as an operator unless you
interpose a "+" or put parentheses around the arguments.) If
FILEHANDLE is omitted, prints to the last selected (see "select")
output handle. If LIST is omitted, prints $_ to the currently
selected output handle. To use FILEHANDLE alone to print the
content of $_ to it, you must use a real filehandle like "FH", not
an indirect one like $fh. To set the default output handle to
something other than STDOUT, use the select operation.
The current value of $, (if any) is printed between each LIST
item. The current value of $\ (if any) is printed after the entire
LIST has been printed. Because print takes a LIST, anything in the
LIST is evaluated in list context, including any subroutines whose
return lists you pass to "print". Be careful not to follow the
print keyword with a left parenthesis unless you want the
corresponding right parenthesis to terminate the arguments to the
print; put parentheses around all arguments (or interpose a "+",
but that doesn't look as good).
If you're storing handles in an array or hash, or in general
whenever you're using any expression more complex than a bareword
handle or a plain, unsubscripted scalar variable to retrieve it,
you will have to use a block returning the filehandle value
instead, in which case the LIST may not be omitted:
print { $files[$i] } "stuff\n";
print { $OK ? STDOUT : STDERR } "stuff\n";
Printing to a closed pipe or socket will generate a SIGPIPE
signal. See perlipc for more on signal handling.
printf FILEHANDLE FORMAT, LIST
printf FILEHANDLE
printf FORMAT, LIST
printf Equivalent to "print FILEHANDLE sprintf(FORMAT, LIST)", except
that $\ (the output record separator) is not appended. The FORMAT
and the LIST are actually parsed as a single list. The first
argument of the list will be interpreted as the "printf" format.
This means that "printf(@_)" will use $_[0] as the format. See
sprintf for an explanation of the format argument. If "use locale"
(including "use locale ':not_characters'") is in effect and
POSIX::setlocale() has been called, the character used for the
decimal separator in formatted floating-point numbers is affected
by the LC_NUMERIC locale setting. See perllocale and POSIX.
For historical reasons, if you omit the list, $_ is used as the
format; to use FILEHANDLE without a list, you must use a real
filehandle like "FH", not an indirect one like $fh. However, this
will rarely do what you want; if $_ contains formatting codes,
they will be replaced with the empty string and a warning will be
emitted if warnings are enabled. Just use "print" if you want to
print the contents of $_.
Don't fall into the trap of using a "printf" when a simple "print"
would do. The "print" is more efficient and less error prone.
say FILEHANDLE LIST
say FILEHANDLE
say LIST
say Just like "print", but implicitly appends a newline. "say LIST" is
simply an abbreviation for "{ local $\ = "\n"; print LIST }". To
use FILEHANDLE without a LIST to print the contents of $_ to it,
you must use a real filehandle like "FH", not an indirect one like
$fh.
This keyword is available only when the "say" feature is enabled,
or when prefixed with "CORE::"; see feature. Alternately, include
a "use v5.10" or later to the current scope.
```
# PORTING CAVEATS
## Syntax differences
In Raku, there **must** be a comma after the handle, as opposed to Perl where the whitespace after the handle indicates indirect object syntax.
```
print STDERR "whee!"; # Perl way
print STDERR, "whee!"; # Raku mimicing Perl
```
## Parentheses
Because of some overzealous checks for Perl 5isms, it is necessary to put parentheses when using `print` and `say` as a function. Since the 2018.09 Rakudo compiler release, it is possible to use the `isms` pragma to avoid having to do that:
```
use isms <Perl5>;
$_ = "foo";
say; # foo
```
## $\_ no longer accessible from caller's scope
In future language versions of Raku, it will become impossible to access the `$_` variable of the caller's scope, because it will not have been marked as a dynamic variable. So please consider changing:
```
print;
```
to either:
```
print($_);
```
or, using the subroutine as a method syntax, with the prefix `.` shortcut to use that scope's `$_` as the invocant:
```
.&print;
```
# IDIOMATIC PERL 6 WAYS
When needing to write to specific handle, it's probably easier to use the method form.
```
$handle.print("foo");
$handle.printf("foo");
$handle.say("foo");
```
If you want to do a `say` on `STDERR`, this is easier done with the `note` builtin function:
```
$*ERR.say("foo"); # "foo\n" on standard error
note "foo"; # same
```
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
Source can be located at: <https://github.com/lizmat/P5print> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2018, 2019, 2020, 2021, 2023 Elizabeth Mattijsen
Re-imagined from Perl as part of the CPAN Butterfly Plan.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## first.md
first
Combined from primary sources listed below.
# [In List](#___top "go to top of document")[§](#(List)_routine_first "direct link")
See primary documentation
[in context](/type/List#routine_first)
for **routine first**.
```raku
sub first(Mu $matcher, *@elems, :$k, :$kv, :$p, :$end)
method first(List:D: Mu $matcher?, :$k, :$kv, :$p, :$end)
```
Returns the first item of the list which smartmatches against `$matcher`, returns [`Nil`](/type/Nil) when no values match. The optional named parameter `:end` indicates that the search should be from the **end** of the list, rather than from the start.
Examples:
```raku
say (1, 22/7, 42, 300).first: * > 5; # OUTPUT: «42»
say (1, 22/7, 42, 300).first: * > 5, :end; # OUTPUT: «300»
say ('hello', 1, 22/7, 42, 'world').first: Complex; # OUTPUT: «Nil»
```
The optional named parameters `:k`, `:kv`, `:p` provide the same functionality as on slices:
* k
Return the index value of the matching element. Index is always counted from the beginning of the list, regardless of whether the `:end` named parameter is specified or not.
* kv
Return both the index and matched element.
* p
Return the index and the matched element as a [`Pair`](/type/Pair).
Examples:
```raku
say (1, 22/7, 42, 300).first: * > 5, :k; # OUTPUT: «2»
say (1, 22/7, 42, 300).first: * > 5, :p; # OUTPUT: «2 => 42»
say (1, 22/7, 42, 300).first: * > 5, :kv, :end; # OUTPUT: «(3 300)»
```
In method form, the `$matcher` can be omitted, in which case the first available item (or last if `:end` is set) will be returned. See also [`head`](/routine/head) and [`tail`](/routine/tail) methods.
# [In Any](#___top "go to top of document")[§](#(Any)_routine_first "direct link")
See primary documentation
[in context](/type/Any#routine_first)
for **routine first**.
```raku
multi method first(Bool:D $t)
multi method first(Regex:D $test, :$end, *%a)
multi method first(Callable:D $test, :$end, *%a is copy)
multi method first(Mu $test, :$end, *%a)
multi method first(:$end, *%a)
multi first(Bool:D $t, |)
multi first(Mu $test, +values, *%a)
```
In general, coerces the invocant to a `list` by applying its [`.list`](/routine/list) method and uses [`List.first`](/type/List#routine_first) on it.
However, this is a multi with different signatures, which are implemented with (slightly) different behavior, although using it as a subroutine is equivalent to using it as a method with the second argument as the object.
For starters, using a [`Bool`](/type/Bool) as the argument will always return a [`Failure`](/type/Failure). The form that uses a `$test` will return the first element that smartmatches it, starting from the end if `:end` is used.
```raku
say (3..33).first; # OUTPUT: «3»
say (3..33).first(:end); # OUTPUT: «33»
say (⅓,⅔…30).first( 0xF ); # OUTPUT: «15»
say first 0xF, (⅓,⅔…30); # OUTPUT: «15»
say (3..33).first( /\d\d/ ); # OUTPUT: «10»
```
The third and fourth examples use the `Mu $test` forms which smartmatches and returns the first element that does. The last example uses as a test a regex for numbers with two figures, and thus the first that meets that criterion is number 10. This last form uses the [`Callable`](/type/Callable) multi:
```raku
say (⅓,⅔…30).first( * %% 11, :end, :kv ); # OUTPUT: «(65 22)»
```
Besides, the search for first will start from the `:end` and returns the set of key/values in a list; the *key* in this case is simply the position it occupies in the [`Seq`](/type/Seq). The `:kv` argument, which is part of the `%a` argument in the definitions above, modifies what `first` returns, providing it as a flattened list of keys and values; for a listy object, the key will always be the index.
From version 6.d, the test can also be a [`Junction`](/type/Junction):
```raku
say (⅓,⅔…30).first( 3 | 33, :kv ); # OUTPUT: «(8 3)»
```
# [In Supply](#___top "go to top of document")[§](#(Supply)_method_first "direct link")
See primary documentation
[in context](/type/Supply#method_first)
for **method first**.
```raku
method first(Supply:D: :$end, |c)
```
This method creates a supply of the first element, or the last element if the optional named parameter `:end` is truthy, from a supply created by calling the `grep` method on the invocant, with any remaining arguments as parameters. If there is no remaining argument, this method is equivalent to calling on the invocant, without parameter, the `head` or the `tail` method, according to named parameter `:end`.
```raku
my $rand = supply { emit (rand × 100).floor for ^∞ };
my $first-prime = $rand.first: &is-prime;
# output the first prime from the endless random number supply $rand,
# then the $first-prime supply reaches its end
$first-prime.tap: &say;
```
|
## dist_zef-Altai-man-ASN-META.md
### ASN::META
Experimental Raku module that is able to compile [ASN.1](https://en.wikipedia.org/wiki/Abstract_Syntax_Notation_One) specification into set of Raku types.
#### What ASN::META does not?
* It does not generate Raku code (at least, textual form).
* The module knows nothing about ASN.1 encoding means, it purely generates Raku types.
For this purpose a separate module may be used. Currently, goal is to have full compatibility
with [ASN::BER](https://github.com/Altai-man/ASN-BER) module.
#### What ASN::META does?
Main workflow is as follows:
* A specification is passed to ASN::META on module `use`
* (internally, `ASN::Grammar` is used to parse the specification)
* ASN::META uses parsed specification to generate appropriate types with [MOP](https://docs.perl6.org/language/mop)
* Generated types for particular ASN.1 specification are precompiled and exported
#### What it does?
#### Synopsis
```
# In file `schema.asn`:
WorldSchema
DEFINITIONS IMPLICIT TAGS ::= BEGIN
Rocket ::= SEQUENCE
{
name UTF8String,
message UTF8String DEFAULT "Hello World",
fuel ENUMERATED {
solid(0),
liquid(1),
gas(2)
},
speed CHOICE {
mph [0] INTEGER,
kmph [1] INTEGER
} OPTIONAL,
payload SEQUENCE OF UTF8String
}
END
# In file `User.pm6`:
# Note usage of BEGIN block to gather file's content at compile time
use ASN::META BEGIN [ 'file', slurp 'schema.asn' };
# In case of re-compilation on dependency change, package User may be
# re-built from the place where local paths are useless, in this case use %?RESOURCES:
# `use ASN::META BEGIN { 'file', slurp %?RESOURCES<schema.asn> }`
# `Rocket` type is exported by ASN::META
my Rocket $rocket = Rocket.new(name => 'Rocker', :fuel(solid),
speed => Speed.new((mph => 9001)),
payload => Array[Str].new('A', 'B', 'C'));
# As well as inner types being promoted to top level:
say Fuel; # generated enum
say solid; # value of this enum, (solid ~~ Fuel) == true
say Speed; # Generated type based on ASNChoice from ASN::BER
```
|
## chars.md
chars
Combined from primary sources listed below.
# [In Match](#___top "go to top of document")[§](#(Match)_method_chars "direct link")
See primary documentation
[in context](/type/Match#method_chars)
for **method chars**.
```raku
method chars()
```
Returns the numbers of characters in the matched string or 0 if there's been no match.
Returns the same as `.Str.chars`.
# [In role Blob](#___top "go to top of document")[§](#(role_Blob)_method_chars "direct link")
See primary documentation
[in context](/type/Blob#method_chars)
for **method chars**.
```raku
method chars(Blob:D:)
```
Throws [`X::Buf::AsStr`](/type/X/Buf/AsStr) with `chars` as payload.
# [In Str](#___top "go to top of document")[§](#(Str)_routine_chars "direct link")
See primary documentation
[in context](/type/Str#routine_chars)
for **routine chars**.
```raku
multi chars(Cool $x --> Int:D)
multi chars(Str:D $x --> Int:D)
multi chars(str $x --> int)
multi method chars(Str:D: --> Int:D)
```
Returns the number of characters in the string in graphemes. On the JVM, this currently erroneously returns the number of codepoints instead.
# [In Cool](#___top "go to top of document")[§](#(Cool)_routine_chars "direct link")
See primary documentation
[in context](/type/Cool#routine_chars)
for **routine chars**.
```raku
multi chars(Cool $x)
multi chars(Str:D $x)
multi chars(str $x --> int)
method chars(--> Int:D)
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns the number of characters in the string. Please note that on the JVM, you currently get codepoints instead of graphemes.
```raku
say 'møp'.chars; # OUTPUT: «3»
say 'ã̷̠̬̊'.chars; # OUTPUT: «1»
say '👨👩👧👦🏿'.chars; # OUTPUT: «1»
```
If the string is native, the number of chars will be also returned as a native `int`.
Graphemes are user visible characters. That is, this is what the user thinks of as a “character”.
Graphemes can contain more than one codepoint. Typically the number of graphemes and codepoints differs when `Prepend` or `Extend` characters are involved (also known as [Combining characters](https://en.wikipedia.org/wiki/Combining_character)), but there are many other cases when this may happen. Another example is `\c[ZWJ]` ([Zero-width joiner](https://en.wikipedia.org/wiki/Zero-width_joiner)).
You can check `Grapheme_Cluster_Break` property of a character in order to see how it is going to behave:
```raku
say ‘ã̷̠̬̊’.uniprops(‘Grapheme_Cluster_Break’); # OUTPUT: «(Other Extend Extend Extend Extend)»
say ‘👨👩👧👦🏿’.uniprops(‘Grapheme_Cluster_Break’); # OUTPUT: «(E_Base_GAZ ZWJ E_Base_GAZ ZWJ E_Base_GAZ ZWJ E_Base_GAZ E_Modifier)»
```
You can read more about graphemes in the [Unicode Standard](https://unicode.org/reports/tr29/#Grapheme_Cluster_Boundaries), which Raku tightly follows, using a method called [NFG, normal form graphemes](/language/glossary#NFG) for efficiently representing them.
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.