
txt
stringlengths 93
37.3k
|
|---|
## dist_github-shuppet-Net-RCON.md

`Net::RCON` is a Perl 6 module for interacting with the Source RCON (remote console) protocol. Built on top of [`IO::Socket::INET`](https://docs.perl6.org/type/IO::Socket::INET), it allows server administrators to issue and recieve the results of commands executed against RCON-compatiable servers.
## Installation
### ... from zef
```
zef install Net::RCON
```
### ... from source
```
git clone https://github.com/shuppet/p6-net-rcon
cd p6-net-rcon/ && zef install ${PWD}
```
|
## dist_zef-sthiriet-Env-File.md
[](https://github.com/sthiriet/Env-File/actions)
# NAME
Env::File - allow for "$PASSWORD\_FILE" to fill in the value of "$PASSWORD" from a file, especially for Docker's secrets feature
# SYNOPSIS
```
use Env::File;
my $password = %ENVFILE<PASSWORD> ||
die("Missing PASSWORD or PASSWORD_FILE in environment");
```
# DESCRIPTION
Env::File export the "%ENVFILE" variable that contains:
* a copy of all "%\*ENV" key value pairs
* for each environment variables of type "$XYZ\_FILE", an XYZ key which contains the content of this file
# AUTHOR
sthiriet [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2022 sthiriet
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-librasteve-Moonphase.md
# Moonphase
# Synopsis
```
use Moonphase;
my @tests = (
{ :desc("New Moon (approx.)"), :ts(1704067200) }, # Jan 1, 2024
{ :desc("First Quarter (approx.)"), :ts(1704585600) }, # Jan 7, 2024
{ :desc("Full Moon (approx.)"), :ts(1705017600) }, # Jan 12, 2024
{ :desc("Last Quarter (approx.)"), :ts(1705449600) }, # Jan 17, 2024
{ :desc("Random date"), :ts(1711920000) }, # April 1, 2024
{ :desc("Unix Epoch"), :ts(0) } # Jan 1, 1970
);
for @tests -> %test {
my $radians = moonphase(%test<ts>);
say "%test<desc>:";
say " Timestamp: %test<ts>";
say " Moon phase (radians): $radians";
say " Degrees: { $radians * 180 / pi }";
say "";
}
```
# Description
Adapted from "moontool.c" by John Walker: See <http://www.fourmilab.ch/moontool/>
Inspired by <https://github.com/oliverkwebb/moonphase/tree/main>
Copyright 2024 Henley Cloud Consulting Ltd.
|
## dist_zef-antononcube-Graphviz-DOT-Chessboard.md
# Graphviz::DOT::Chessboard
Raku package for making chessboard plots via the
[DOT language](https://graphviz.org/doc/info/lang.html)
of
[Graphviz](https://graphviz.org).
---
## Installation
From Zef ecosystem:
```
zef install Graphviz::DOT::Chessboard
```
From GitHub:
```
zef install https://github.com/antononcube/Raku-Graphviz-DOT-Chessboard.git
```
---
## Basic usage
Load the package:
```
use Graphviz::DOT::Chessboard;
```
Generate DOT spec:
```
say dot-chessboard(4, 4, title => 'Example small chessboard'):!svg;
```
Generate an SVG plot:
```
my %opts = black-square-color => 'SandyBrown', white-square-color => 'Moccasin', :4size;
dot-chessboard(8, 8, |%opts):svg;
```

Using a FEN string (on a smaller board):
```
my $fen = '8/8/8/3K4/5r2/8/1k6/8';
dot-chessboard($fen, :5r, :6c):svg
```

---
## TODO
* DONE White pieces should have contours
* DONE Chess positions by Forsyth-Edwards Notation (FEN) strings
* TODO Fuller set of unit tests
* TODO CLI script
---
## References
[AAp1] Anton Antonov,
[Graph Raku package](https://github.com/antononcube/Raku-Graph),
(2024),
[GitHub/antononcube](https://github.com/antononcube).
[AAp2] Anton Antonov,
[Graphviz::DOT::Grammar Raku package](https://github.com/antononcube/Raku-Graphviz-DOT-Grammar),
(2024),
[GitHub/antononcube](https://github.com/antononcube).
|
## dist_cpan-FRITH-Math-Libgsl-Polynomial.md
[](https://github.com/frithnanth/raku-Math-Libgsl-Polynomial/actions)
# NAME
Math::Libgsl::Polynomial - An interface to libgsl, the Gnu Scientific Library - Polynomials.
# SYNOPSIS
```
use Math::Libgsl::Raw::Polynomial :ALL;
use Math::Libgsl::Polynomial :ALL;
```
# DESCRIPTION
Math::Libgsl provides an interface to polynomial evaluation in libgsl, the GNU Scientific Library.
Math::Libgsl::Polynomial makes these tags available:
* :eval
* :divdiff
* :quad
* :cubic
* :complexsolve
### sub poly-eval(Positional $c, Num(Cool) $x --> Num) is export(:eval)
Evaluates a polynomial with real coefficients for the real variable x.
```
my @c = 1, 2, 3;
say poly-eval(@c, 10); # prints 321
```
### sub poly-eval-derivs(Num(Cool) $x, Int $maxn, Positional $c --> List) is export(:eval)
This function evaluates a polynomial and its derivatives. The output array contains the values of dⁿP(x)/dxⁿ for the specified value of x starting with n = 0.
### sub poly-dd(Positional $xa, Positional $ya, Positional $x --> List) is export(:divdiff)
This function computes a divided-difference representation of the interpolating polynomial for the points (xa, ya) and evaluates the polynomial for each point x.
### sub poly-dd-taylor(Positional $xa, Positional $ya, Num(Cool) $x --> List) is export(:divdiff)
This function converts the divided-difference representation of a polynomial to a Taylor expansion and evaluates the Taylor coefficients about the point x.
### sub poly-dd-hermite(Positional $xa, Positional $ya, Positional $dya, Positional $x --> List) is export(:divdiff)
This function computes a divided-difference representation of the interpolating Hermite polynomial for the points (xa, ya) and evaluates the polynomial for each point x.
### sub poly-solve-quadratic(Num(Cool) $a, Num(Cool) $b, Num(Cool) $c --> List) is export(:quad)
This function finds the real roots of the quadratic equation ax² + bx + c = 0. It returns a list of values: the number of the real roots found and zero, one or two roots; if present the roots are sorted in ascending order.
### sub poly-complex-solve-quadratic(Num(Cool) $a, Num(Cool) $b, Num(Cool) $c --> List) is export(:quad)
This function finds the complex roots of the quadratic equation ax² + bx + c = 0. It returns a list of values: the number of the real roots found and zero, one or two roots. The root are returned as Raku Complex values.
### sub poly-solve-cubic(Num(Cool) $a, Num(Cool) $b, Num(Cool) $c --> List) is export(:cubic)
This function finds the real roots of the cubic equation x³ + ax² + bx + c = 0. It returns a list of values: the number of the real roots found and one or three roots; the roots are sorted in ascending order.
### sub poly-complex-solve-cubic(Num(Cool) $a, Num(Cool) $b, Num(Cool) $c --> List) is export(:cubic)
This function finds the complex roots of the cubic equation x³ + ax² + bx + c = 0. The number of complex roots is returned (always three); the roots are returned in ascending order, sorted first by their real components and then by their imaginary components. The root are returned as Raku Complex values.
### sub poly-complex-solve(\*@a --> List) is export(:complexsolve)
This function computes the roots of the general polynomial a₀ + a₁x + a₂x² + … + aₙ₋₁xⁿ⁻¹ The root are returned as Raku Complex values.
# C Library Documentation
For more details on libgsl see <https://www.gnu.org/software/gsl/>. The excellent C Library manual is available here <https://www.gnu.org/software/gsl/doc/html/index.html>, or here <https://www.gnu.org/software/gsl/doc/latex/gsl-ref.pdf> in PDF format.
# Prerequisites
This module requires the libgsl library to be installed. Please follow the instructions below based on your platform:
## Debian Linux and Ubuntu 20.04
```
sudo apt install libgsl23 libgsl-dev libgslcblas0
```
That command will install libgslcblas0 as well, since it's used by the GSL.
## Ubuntu 18.04
libgsl23 and libgslcblas0 have a missing symbol on Ubuntu 18.04. I solved the issue installing the Debian Buster version of those three libraries:
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgslcblas0_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl23_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl-dev_2.5+dfsg-6_amd64.deb>
# Installation
To install it using zef (a module management tool):
```
$ zef install Math::Libgsl::Polynomial
```
# AUTHOR
Fernando Santagata [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2020 Fernando Santagata
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-PowellDean-WebService-HashiCorp-Vault.md
[](https://github.com/PowellDean/WebService-HashiCorp-Vault/actions)
# NAME
WebService::HashiCorp::Vault - An API for managing secrets with Vault
# SYNOPSIS
```
use WebService::HashiCorp::Vault;
```
# DESCRIPTION
WebService::HashiCorp::Vault is a module written in pure Raku for managing secrets with Vault by [HashiCorp](https://hashicorp.com). For more information on what Vault is and how to use it, visit the official [Vault](https://vaultproject.io) website.
**Note**: This is a work in progress, and the supported endpoints are subject to change.
# PRE-REQUISITES
* HashiCorp's executable for Vault, available from their website
* JSON::Tiny
* Cro HTTP Client tools
* The latest Raku compiler (this project was created with v6.d)
# INSTALLATION
Installation is by the standard Raku package manager, [Zef](https://raku.land/github:ugexe/zef)
`zef install WebService::HashiCorp::Vault`
To successfully run the test suite, you will need to have your Vault instance running and unsealed. Please set the environment variable $VAULT\_TOKEN with the value of your token prior to running the tests.
Also ensure you set $VAULT\_ADDR with the address/port of your running Vault instance.
# USAGE
## Connecting to a Running Vault Instance
### Using an authentication token
```
use WebService::HashiCorp::Vault;
my $connection = Client.new(baseURL => 'http://127.0.0.1:8200',
token => '<token generated by your Vault server>');
```
You don't have to pass in $baseURL if you've set the environment variable $VAULT\_ADDR:
```
use WebService::HashiCorp::Vault;
my $connection = Client.new(token => '<token generated by your Vault server>');
```
You don't have to pass in $token if you've set the environment variable $VAULT\_TOKEN:
```
export VAULT_TOKEN=<token generated by your vault server>
use WebService::HashiCorp::Vault;
my $connection = Client.new();
```
Note that if you do not pass the Vault URL explicitly, and the environment variable $VAULT\_ADDR is not set, the Client will use the default value <http://127.0.0.1:8200>
## Working With Secrets
### Saving Secrets
```
# Save SecretV1 'foo' into vault 'cubbyhole'
my $status = $connection.putSecretV1(vault => 'cubbyhole', key => 'foo',
keyValues => %('bar', 'baz'));
say $status.status; # Will return standard HTTP return code 204 on success
# Save SecretV2 'foo' into vault 'secret'
my $status = $connection.putSecretV2(vault => 'secret', key => 'foo',
keyValues => %('bar', 'baz'));
say $status.status; # Will return standard HTTP return code 204 on success
```
```
```
### Listing Secrets
To list all the secret keys in the vault 'cubbyhole'
```
say $connection.listV1Secrets(vault => 'cubbyhole');
```
If successful, the output will be a list of secret keys: ['foo', 'foo1', 'snafu'].
To list all the key/pair values found in a specific vault and key:
```
# get a SecretV1 from vault 'cubbyhole'
say $connection.getSecretV1(vault => 'cubbyhole', key => 'foo').data;
# get a SecretV2 from vault 'secret'
say $connection.getSecretV2(vault => 'secret', key => 'foo').data;
```
### Deleting Secrets
```
# Delete SecretV1 'foo' from vault 'cubbyhole'
say $connection.deleteV1Secret(vault => 'cubbyhole', key => 'foo');
# Will return 204 upon successful completion (standard HTTP return code)
# Delete SecretV2 from vault 'secret'
say $connection.deleteV2Secret(vault => 'secret', key => 'foo');
# Will return 204 upon successful completion (standard HTTP return code)
```
# AUTHOR
Dean Powell [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2023 Dean Powell
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
```
http://www.apache.org/licenses/LICENSE-2.0
```
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
## class WebService::HashiCorp::Vault::Client
A client for communicating with the Vault API
### multi method baseURL
```
multi method baseURL() returns Mu
```
Return the baseURL
### multi method baseURL
```
multi method baseURL(
$url
) returns Mu
```
Set the baseURL
### multi method token
```
multi method token() returns Mu
```
Return the current session token
### multi method token
```
multi method token(
$aToken
) returns Mu
```
Set the current session token
### method deleteV1Secret
```
method deleteV1Secret(
Str :$vault!,
Str :$key!
) returns Mu
```
Delete the secret with the key $key from vault $vault Will catch any generic error
### method generateRandomBytes
```
method generateRandomBytes(
Str :$format!,
Int :$length!
) returns Mu
```
Return high-quality random bytes of the given length, in the requested format. Supported formats are: =item base64 =item hex
### method getEncryptionKeyStatus
```
method getEncryptionKeyStatus() returns Mu
```
Query for encryption key status $status is a KeyStatus object with the following attributes: Int encryptions Str installTime Int leaseDuration Bool renewable Str requestId
### method getSecretV1
```
method getSecretV1(
Str :$vault!,
Str :$key!
) returns Mu
```
Return the V1 secret found in the given vault, at the given key The returned value is a SecretV1 object with the following attributes: ResponseHeader header (Hash of key/value pairs) data
|
## dist_cpan-SAMGWISE-ScaleVec.md
[](https://travis-ci.org/samgwise/p6-ScaleVec)
# NAME
ScaleVec - A flexible yet accurate music representation system.
# SYNOPSIS
```
use ScaleVec;
my ScaleVec $major-scale .= new( :vector(0, 2, 4, 5, 7, 9, 11, 12) );
# Midi notes 0 - 127 with our origin on middle C (for most midi specs)
use ScaleVec::Scale::Fence;
my ScaleVec::Scale::Fence $midi .= new(
:vector(60, 61)
:repeat-interval(12)
:lower-limit(0)
:upper-limit(127)
);
# A two octave C major scale in midi note values
say do for -7..7 {
$midi.step: $major-scale.step($_)
}
```
# DESCRIPTION
Encapsulating the power of linear algebra in an easy to use music library, ScaleVec provides a way to represent musical structures such as chords, rhythms, scales and tempos with a common format.
# CONTRIBUTIONS
To contribute, head to the github page: <https://github.com/samgwise/p6-ScaleVec>
# AUTHOR
```
Sam Gillespie
```
# COPYRIGHT AND LICENSE
Copyright 2016 Sam Gillespie
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-P5push.md
[](https://github.com/lizmat/P5push/actions)
# NAME
Raku port of Perl's push() / pop() built-ins
# SYNOPSIS
```
use P5push;
my @a = 1,2,3;
say push @a, 42; # 4
say pop; # pop from @*ARGS, if any
sub a { dd @_; dd pop; dd @_ }; a 1,2,3;
[1, 2, 3]
3
[1, 2]
```
# DESCRIPTION
This module tries to mimic the behaviour of Perl's `push` and `pop` built-ins as closely as possible in the Raku Programming Language.
# ORIGINAL PERL 5 DOCUMENTATION
```
push ARRAY,LIST
push EXPR,LIST
Treats ARRAY as a stack by appending the values of LIST to the end
of ARRAY. The length of ARRAY increases by the length of LIST. Has
the same effect as
for $value (LIST) {
$ARRAY[++$#ARRAY] = $value;
}
but is more efficient. Returns the number of elements in the array
following the completed "push".
Starting with Perl 5.14, "push" can take a scalar EXPR, which must
hold a reference to an unblessed array. The argument will be
dereferenced automatically. This aspect of "push" is considered
highly experimental. The exact behaviour may change in a future
version of Perl.
To avoid confusing would-be users of your code who are running
earlier versions of Perl with mysterious syntax errors, put this
sort of thing at the top of your file to signal that your code
will work onlyon Perls of a recent vintage:
use 5.014; # so push/pop/etc work on scalars (experimental)
pop ARRAY
pop EXPR
pop Pops and returns the last value of the array, shortening the array
by one element.
Returns the undefined value if the array is empty, although this
may also happen at other times. If ARRAY is omitted, pops the
@ARGV array in the main program, but the @_ array in subroutines,
just like "shift".
Starting with Perl 5.14, "pop" can take a scalar EXPR, which must
hold a reference to an unblessed array. The argument will be
dereferenced automatically. This aspect of "pop" is considered
highly experimental. The exact behaviour may change in a future
version of Perl.
To avoid confusing would-be users of your code who are running
earlier versions of Perl with mysterious syntax errors, put this
sort of thing at the top of your file to signal that your code
will work [4monly[m on Perls of a recent vintage:
use 5.014; # so push/pop/etc work on scalars (experimental)
```
# PORTING CAVEATS
In future language versions of Raku, it will become impossible to access the `@_` variable of the caller's scope, because it will not have been marked as a dynamic variable. So please consider changing:
```
pop;
```
to:
```
pop(@_);
```
or, using the subroutine as a method syntax:
```
@_.&pop;
```
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
Source can be located at: <https://github.com/lizmat/P5push> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2018, 2019, 2020, 2021, 2023 Elizabeth Mattijsen
Re-imagined from Perl as part of the CPAN Butterfly Plan.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-vars.md
[](https://github.com/lizmat/vars/actions)
# NAME
Raku port of Perl's 'vars' pragma
# SYNOPSIS
```
use vars <$frob @mung %seen>;
```
# DESCRIPTION
This module tries to mimic the behaviour of Perl's `vars` pragma as closely as possible in the Raku Programming Language.
This will predeclare all the subroutine whose names are in the list, allowing you to use them without parentheses even before they're declared.
Unlike pragmas that affect the $^H hints variable, the "use vars" declarations are not BLOCK-scoped. They are thus effective for the entire package in which they appear. You may not rescind such declarations with "no vars".
See "Pragmatic Modules" in perlmodlib and "strict vars" in strict.
# PORTING CAVEATS
Due to the nature of the export mechanism in raku, it is impossible (at the moment of this writing: 2018.05) to export to the OUR:: stash from a module. Therefore the raku version of this module exports to the **lexical** scope in which the `use` command occurs. For most standard uses, this is equivalent to the Perl behaviour.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/vars> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2018, 2019, 2020, 2021 Elizabeth Mattijsen
Re-imagined from Perl as part of the CPAN Butterfly Plan.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## sequence.md
role Sequence
Common methods of sequences
```raku
role Sequence does PositionalBindFailover { }
```
This role implements a series of methods for converting sequences and accessing their elements. These methods should work on all sequences: serial [`Seq`](/type/Seq), ordered parallel [`HyperSeq`](/type/HyperSeq), and unordered parallel [`RaceSeq`](/type/RaceSeq).
These methods have in common that they all access the underlying iterator if the sequence has not been [cached](/type/PositionalBindFailover#method_cache) yet. Therefore they will throw an error of type [`X::Seq::Consumed`](/type/X/Seq/Consumed) if called on a [`Seq`](/type/Seq) that was already consumed.
# [Methods](#role_Sequence "go to top of document")[§](#Methods "direct link")
## [method Str](#role_Sequence "go to top of document")[§](#method_Str "direct link")
```raku
multi method Str(::?CLASS:D:)
```
[Stringifies](/type/List#method_Str) the [cached](/type/PositionalBindFailover#method_cache) sequence.
## [method Stringy](#role_Sequence "go to top of document")[§](#method_Stringy "direct link")
```raku
multi method Stringy(::?CLASS:D:)
```
Calls `.Stringy` on the [cached](/type/PositionalBindFailover#method_cache) sequence.
## [method Numeric](#role_Sequence "go to top of document")[§](#method_Numeric "direct link")
```raku
method Numeric(::?CLASS:D:)
```
Returns the number of elements in the [cached](/type/PositionalBindFailover#method_cache) sequence.
## [method AT-POS](#role_Sequence "go to top of document")[§](#method_AT-POS "direct link")
```raku
multi method AT-POS(::?CLASS:D: Int:D $idx)
multi method AT-POS(::?CLASS:D: int $idx)
```
Returns the element at position `$idx` in the [cached](/type/PositionalBindFailover#method_cache) sequence.
## [method EXISTS-POS](#role_Sequence "go to top of document")[§](#method_EXISTS-POS "direct link")
```raku
multi method EXISTS-POS(::?CLASS:D: Int:D $idx)
multi method EXISTS-POS(::?CLASS:D: int $idx)
```
Returns a [`Bool`](/type/Bool) indicating whether there is an element at position `$idx` in the [cached](/type/PositionalBindFailover#method_cache) sequence.
## [method eager](#role_Sequence "go to top of document")[§](#method_eager "direct link")
```raku
method eager(::?CLASS:D: --> List:D)
```
Returns an eagerly evaluated [`List`](/type/List) based on the invocant sequence, and marks it as consumed. If called on an already consumed [`Seq`](/type/Seq), throws an error of type [`X::Seq::Consumed`](/type/X/Seq/Consumed).
```raku
my $s = lazy 1..5;
say $s.is-lazy; # OUTPUT: «True»
say $s.eager; # OUTPUT: «(1 2 3 4 5)»
say $s.eager;
CATCH {
when X::Seq::Consumed {
say 'Throws exception if already consumed';
}
}
# OUTPUT: «Throws exception if already consumed»
```
## [method fmt](#role_Sequence "go to top of document")[§](#method_fmt "direct link")
```raku
method fmt($format = '%s', $separator = ' ' --> Str:D)
```
[Formats](/type/List#method_fmt) the [cached](/type/PositionalBindFailover#method_cache) sequence.
## [method gist](#role_Sequence "go to top of document")[§](#method_gist "direct link")
```raku
multi method gist(::?CLASS:D:)
```
Returns the [gist](/type/List#method_gist) of the [cached](/type/PositionalBindFailover#method_cache) sequence.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Sequence`
raku-type-graph
Sequence
Sequence
PositionalBindFailover
PositionalBindFailover
Sequence->PositionalBindFailover
Mu
Mu
Any
Any
Any->Mu
Iterable
Iterable
RaceSeq
RaceSeq
RaceSeq->Sequence
RaceSeq->Any
RaceSeq->Iterable
Cool
Cool
Cool->Any
Seq
Seq
Seq->Sequence
Seq->Iterable
Seq->Cool
HyperSeq
HyperSeq
HyperSeq->Sequence
HyperSeq->Any
HyperSeq->Iterable
[Expand chart above](/assets/typegraphs/Sequence.svg)
|
## bind-key.md
BIND-KEY
Combined from primary sources listed below.
# [In Subscripts](#___top "go to top of document")[§](#(Subscripts)_method_BIND-KEY "direct link")
See primary documentation
[in context](/language/subscripts#method_BIND-KEY)
for **method BIND-KEY**.
```raku
multi method BIND-KEY (::?CLASS:D: $key, \new)
```
Expected to bind the value or container `new` to the slot associated with `$key`, replacing any container that would be naturally found there. This is what is called when you write:
```raku
my $x = 10;
%age<Claire> := $x;
```
The generic [`Hash`](/type/Hash) class supports this in order to allow building complex linked data structures, but for more domain-specific types it may not make sense, so don't feel compelled to implement it. If you don't, users will get an appropriate error message when they try to bind to an associative slot of an object of this type.
|
## dist_zef-raku-community-modules-Number-Denominate.md
# NAME [Tests on source](https://github.com/raku-community-modules/Number-Denominate/actions/workflows/test.yaml)
Number::Denominate - Break up numbers into preset or arbitrary denominations
# SYNOPSIS
```
use Number::Denominate;
# 2 weeks, 6 hours, 56 minutes, and 7 seconds
say denominate 1234567;
# 1 day
say denominate 23*3600 + 54*60 + 50, :1precision;
# 21 tonnes, 212 kilograms, and 121 grams
say denominate 21212121, :set<weight>;
# This script's size is 284 bytes
say "This script's size is " ~ denominate $*PROGRAM-NAME.IO.s, :set<info>;
# 4 foos, 2 boors, and 1 ber
say denominate 449, :units( foo => 3, <bar boors> => 32, 'ber' );
# {:hours(6), :minutes(56), :seconds(7), :weeks(2)}
say (denominate 1234567, :hash).perl;
# [
# {:denomination(7), :plural("weeks"), :singular("week"), :value(2) },
# {:denomination(24), :plural("days"), :singular("day"), :value(0) },
# {:denomination(60), :plural("hours"), :singular("hour"), :value(6) },
# {:denomination(60), :plural("minutes"), :singular("minute"), :value(56)},
# {:denomination(1), :plural("seconds"), :singular("second"), :value(7) }
#]
say (denominate 1234567, :array).perl;
```
# TABLE OF CONTENTS
* [NAME](#name)
* [SYNOPSIS](#synopsis)
* [DESCRIPTION](#description)
* [EXPORTED SUBROUTINES](#exported-subroutines)
* [`denominate`](#denominate)
* [`array`](#array)
* [`denomination`](#denomination)
* [`plural`](#plural)
* [`singular`](#singular)
* [`value`](#value)
* [`hash`](#hash)
* [`precision`](#precision)
* [`set`](#set)
* [`info`](#info)
* [`info-1024`](#info-1024)
* [`length`](#length)
* [`length-imperial`](#length-imperial)
* [`length-mm`](#length-mm)
* [`time`](#time)
* [`volume`](#volume)
* [`volume-imperial`](#volume-imperial)
* [`weight`](#weight)
* [`weight-imperial`](#weight-imperial)
* [`string`](#string)
* [`units`](#units)
* [REPOSITORY](#repository)
* [BUGS](#bugs)
* [AUTHOR](#author)
* [LICENSE](#license)
# DESCRIPTION
Define arbitrary set of units and split up a number into those units. The
module includes preset sets of units for some measures.
Negative values will cause all units to obtain a negative sign.
# EXPORTED SUBROUTINES
## `denominate`
```
say denominate 1234567;
say denominate 23*3600 + 54*60 + 50, :1precision;
denominate 449, :units( foo => 3, <bar boors> => 32, 'ber' );
denominate 1234567, :hash;
denominate 1234567, :array;
# Valid unit sets: info info-1024 length length-imperial length-mm time
# volume volume-imperial weight weight-imperial
denominate 21212121, :set<weight>;
```
**Takes** one mandatory positional argument—the number to denominate—and
several optional named arguments that affect how the number is denominated
and what format the denomination is returned in. See [`hash`](#hash)
and [`array`](#array) arguments to modify the default [`string`](#string)
return value. The named arguments are as follows:
### `array`
```
# [
# {:denomination(7), :plural("weeks"), :singular("week"), :value(2) },
# {:denomination(24), :plural("days"), :singular("day"), :value(0) },
# {:denomination(60), :plural("hours"), :singular("hour"), :value(6) },
# {:denomination(60), :plural("minutes"), :singular("minute"), :value(56)},
# {:denomination(1), :plural("seconds"), :singular("second"), :value(7) }
#]
say (denominate 1234567, :array).perl;
```
Boolean. **Defaults to** `False`. When `True`, [`denominate`](#denominate)
will return denominations as an array of hashes. Each hash represents a single
unit and has the following keys. The array will always contain each
[`unit`](#units), ordered from largest to smallest.
#### `denomination`
How many of the next smaller unit fits into this unit. This value is `1` for
the smallest unit in the set.
#### `plural`
The plural name of the unit.
#### `singular`
The singular name of the unit.
#### `value`
The actual value of this unit.
### `hash`
```
# {:hours(6), :minutes(56), :seconds(7), :weeks(2)}
say (denominate 1234567, :hash).perl;
```
Boolen. **Defaults to** `False`. When `True`, [`denominate`](#denominate)
will return denominations as a hash. The keys will be the **singular** names of
units and values will be the values of those units. **Note:** units whose values
are zero will not be included.
### `precision`
```
# 23 hours, 54 minutes, and 50 seconds
say denominate 23*3600 + 54*60 + 50;
# 1 day
say denominate 23*3600 + 54*60 + 50, :1precision;
# 23 hours and 55 minutes
say denominate 23*3600 + 54*60 + 50, :2precision;
```
**Takes** positive integers as the value. **Defaults to** the number of
[`units`](#units) given (or the number of units in the [`set`](#set)).
Specifies how many, at most, units to include in the output. Rounding will
be performed if needed. When output mode is set to [`array`](#array), all units
will be present, but at most [`precision`](#precision) units will have non-zero
values.
### `set`
```
# 2 weeks, 6 hours, 56 minutes, and 7 seconds
say denominate 1234567;
# 21 tonnes, 212 kilograms, and 121 grams
say denominate 21212121, :set<weight>;
# This script's size is 284 bytes
say "This script's size is " ~ denominate $*PROGRAM-NAME.IO.s, :set<info>;
```
Loads a pre-defined set of [`units`](#units) to use for denominations.
Has effect only when[`units`](#units) argument is not specified.
**Defaults to** [`time`](#time). **Takes** the name of one of the predefined
unit sets, which are as follows (see description of [`units`](#units) argument,
if the meaning of values is not clear):
#### `info`
```
yottabyte => 1000, zettabyte => 1000, exabyte => 1000, petabyte => 1000,
terabyte => 1000, gigabyte => 1000, megabyte => 1000, kilobyte => 1000,
'byte'
```
Units of information.
#### `info-1024`
```
yobibyte => 1024, zebibyte => 1024, exbibyte => 1024, pebibyte => 1024,
tebibyte => 1024, gibibyte => 1024, mebibyte => 1024, kibibyte => 1024,
'byte'
```
Units of information (multiples of 1024).
#### `length`
```
'light year' => 9_460_730_472.5808,
kilometer => 1000,
'meter'
```
Units of length (large only).
#### `length-imperial`
```
mile => 1760,
yard => 3,
<foot feet> => 12,
<inch inches>
```
Units of length (Imperial).
#### `length-mm`
```
'light year' => 9_460_730_472.5808,
kilometer => 1000,
meter => 100,
centimeter => 10,
'millimeter'
```
Units of length (includes smaller units).
#### `time`
```
week => 7,
day => 24,
hour => 60,
minute => 60,
'second'
```
Units of time.
#### `volume`
```
Liter => 1000,
'milliliter'
```
Units of volume.
#### `volume-imperial`
```
gallon => 4,
quart => 2,
pint => 2,
cup => 8,
'fluid ounce'
```
Units of volume (Imperial).
#### `weight`
```
tonne => 1000,
kilogram => 1000,
'gram'
```
Units of weight.
#### `weight-imperial`
```
ton => 2_000,
pound => 16,
'ounce'
```
Units of weight (Imperial).
### `string`
```
# 2 weeks, 6 hours, 56 minutes, and 7 seconds
say denominate 1234567;
```
Boolean. Has effect only when [`hash`](#hash) and [`array`](#array) arguments
are `False` (that's the default). **Defaults to** `True`. When `True`,
[`denominate`](#denominate) will return its output as a string. Units
whose values are zero won't be included, unless the number to denominate is
`0`, in which case the smallest available unit will be present in the
string (set to `0`).
### `units`
```
# 4 foos, 2 boors, and 1 ber
say denominate 449, :units( foo => 3, <bar boors> => 32, 'ber' );
# These two are the same:
denominate 42, :units( day => 24, hour => 60, minute => 60, 'second' );
denominate 42, :units(
<day days> => 24,
<hour hours> => 60,
<minute minutes> => 60,
<second seconds>
);
```
Specifies units to use for denominations. These can be set to one of the
presets using the [`set`](#set) argument. Takes a list of pairs where the
key is the name of the unit and the value is the number of the next smaller
unit that fits into this unit. The name is a list of singular and plural name
of the unit. If the name is set to a string, the plural name will be derived
by appending `s` to the singular unit name. The smallest unit is specified
simply as a string indicating its name (or as a list of singular/plural
strings).
# REPOSITORY
Fork this module on GitHub:
<https://github.com/raku-community-modules/Number-Denominate>
# BUGS
To report bugs or request features, please use
<https://github.com/raku-community-modules/Number-Denominate/issues>
# AUTHOR
Zoffix Znet (<http://zoffix.com/>)
# LICENSE
You can use and distribute this module under the terms of the
The Artistic License 2.0. See the `LICENSE` file included in this
distribution for complete details.
|
## dist_zef-jonathanstowe-Log-Syslog-Native.md
# Log::Syslog::Native
Provide access to the Native syslog facility on Unix-like systems for Raku

## Synopsis
```
use Log::Syslog::Native;
my $logger = Log::Syslog::Native.new(facility => Log::Syslog::Native::Mail);
$logger.warning("Couldn't activate wormhole interface");
```
## Description
This provides a simple, perhaps naive,interface to the POSIX syslog facility
found on most Unix-like systems.
It should be enough to get you started with simple logging to your system's
log files, though exactly what files those might be and how they are logged
is a function of the system configuration and the exact logging software
that is being used.
This does not provide logging to a remote syslog server, nor does it provide
syslog style logging to platforms that do not provide a ''syslog()'' function
in their standard runtime library.
## Installation
Currently there is no dedicated test to determine whether your platform is
supported, the unit tests will simply fail horribly.
Assuming you have a working Rakudo installation you should be able to install this with *zef* :
```
# From the source directory
zef install .
# Remove installation
zef install Log::Syslog::Native
```
Other install mechanisms may be become available in the future.
## Support
Suggestions/patches are welcomed via github at:
<https://github.com/jonathanstowe/Log-Syslog-Native/issues>
I'm not able to test on a wide variety of platforms so any help there would be
appreciated.
Things that I know don't work as of the current release are:
```
* The built in sprintf is emulated because no varargs in NativeCall yet
```
Help with these is explicitly invited.
## Licence
This is free software.
Please see the <LICENCE> file in the distribution.
© Jonathan Stowe 2015, 2016, 2017, 2019, 2021
|
## dist_zef-jonathanstowe-Igo.md
# Igo
An expedient CPAN uploader for Raku

## Synopsis
```
igo create-layout [--directory=.]
igo create-archive [--directory=.]
igo upload --user=<user> --password=<password> [--directory=.]
```
## Description
This provides a simple way to upload Raku modules to CPAN.
I made it because I found that other things either took over the whole
workflow, or didn't do enough.
So all this does is create a tarball of the files in the distribution,
using the name and version specified in the META6 file and then uploads
it to PAUSE with the credentials specified.
The way this works is that the first time it runs it creates an
[Oyatul](https://github.com/jonathanstowe/Oyatul) layout specification
in your distribution's directory as `.layout` this will contain all
of the files found in the directory which don't begin with a '.', now
if you're anything like me you may have your working directory littered
with test files and backups and so forth so you may want to edit this file
before creating the archive, this can be achieved by running
```
igo create-layout
```
When you have all the files that you want to release and then edit
the `.layout` as required (it's JSON and quite obvious,) to remove
extraneous files (or, if you want to distribute dot files that didn't get
added for instance add them.)
If you want to check that you really have all the files you need in the
archive that would be uploaded then you can run
```
igo create-archive
```
and inspect and test as you see fit.
When you are all happy with what you are going to upload then you just
do
```
igo upload --username=<PAUSE username> --password=<PAUSE password>
```
Which will create the archive and upload it with the credentials supplied.
If you don't want to continuously type the credentials at the command line
you can create the file `$HOME/.config/igo/pause.ini` with :
```
user <username>
password <password>
```
If you are unhappy with having your password in plaintext then
[CPAN::Uploader::Tiny](https://github.com/Leont/cpan-upload-tiny) does
support encrypted files, but you can work that our for yourself.
Please feel free to use the `Igo` module in your own code, but
it isn't well documented for the time being.
## Installation
This uses [Archive::LibArchive](https://modules.raku.org/dist/Archive::Libarchive:cpan:FRITH) to make the tarball to upload, so you will need to have `libarchive` installed, either via your platform's package manager or by some other means. I don't know if it is available for Windows.
Assuming you have a working Rakudo installation you should be able to install this with *zef* :
```
# From the source directory
zef install .
# Remote installation
zef install Igo
```
## Support
Suggestions and patches that may make this more useful in your software are welcomed via github at
<https://github.com/jonathanstowe/Igo/issues>
## Licence
This is free software.
Please see the <LICENCE> file in the distribution.
© Jonathan Stowe 2019 - 2021
|
## dist_github-ccworld1000-CCChart.md
## Simple draw chart for Perl 6 , easy-to-use simple learning.
## Local installation and unloading
```
zef install .
zef uninstall CCChart
```
##
## Network install
```
zef update
zef install CCChart
```
##
## CCChart pie
## CCChart lines
##
## CCChart rect
##
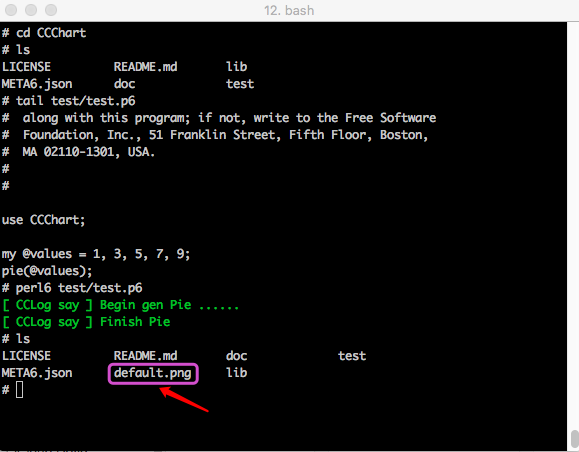
## CCChart test
The call will generate a default "default.png" in the command line execution directory.
|
## cancellation.md
class Cancellation
Removal of a task from a Scheduler before normal completion
```raku
my class Cancellation {}
```
A low level part of the Raku [concurrency](/language/concurrency#Schedulers) system. Some [`Scheduler`](/type/Scheduler) objects return a `Cancellation` with the [.cue](/type/Scheduler#method_cue) method which can be used to cancel the scheduled execution before normal completion. `Cancellation.cancelled` is a Boolean that is true after `cancel` is called.
# [Methods](#class_Cancellation "go to top of document")[§](#Methods "direct link")
## [method cancel](#class_Cancellation "go to top of document")[§](#method_cancel "direct link")
```raku
method cancel()
```
Usage:
```raku
Cancellation.cancel
```
Cancels the scheduled execution of a task before normal completion.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Cancellation`
raku-type-graph
Cancellation
Cancellation
Any
Any
Cancellation->Any
Mu
Mu
Any->Mu
[Expand chart above](/assets/typegraphs/Cancellation.svg)
|
## dist_cpan-VRURG-Concurrent-PChannel.md
[](https://travis-ci.org/vrurg/raku-Concurrent-PChannel)
# NAME
Concurrent::PChannel - prioritized channel
# SYNOPSIS
```
use Concurrent::PChannel;
my Concurrent::PChannel:D $pchannel .= new( :priorities(10) );
$pchannel.send("low prio", 0);
$pchannel.send("high prio", 1);
say $pchannel.receive; ‘high prio’
say $pchannel.receive; ‘low prio’
```
# DESCRIPTION
`Concurrent::PChannel` implements concurrent channel where each item sent over the channel has a priority attached allowing items with higher priority to be pulled first from the channel even if they were sent later in time.
For example, imagine there is a factory of devices supplying our input with different kind of events. Some event types are considered critical and must be processed ASAP. And some are, say, informative and can be taken care of when we're idling. In code this could be implemented the following way:
```
my $pchannel = Concurrent::PChannel.new( :priorities(3) );
for $dev-factory.devices -> $dev {
start {
react {
whenever $dev.event-supply -> $event {
given $event.type {
when EvCritical {
$pchannel.send: $event, 2;
}
when EvInformative {
$pchannel.send: $event, 0;
}
default {
$pchannel.send: $event, 1;
}
}
}
}
}
}
for ^WORKER-COUNT {
start {
while $pchannel.receive -> $event {
...
}
}
}
```
## Performance
The performance was the primary target of this module development. It is implemented using highly-concurrent almost lock-less approach. Benchmarking of different numbers of sending/receiving threads (measured over `receive()` method) results in send operations been 1.3-8 times slower than sending over the core `Channel`; receiving is 1.1-6 times slower. The difference in numbers is only determined by the ratio of sending/receving threads.
What's more important, the speed is almost independent of the number of priorities used! I.e. it doesn't matter if code is using 10 or 1000 priorities – the time needed to process the two channels would only be dependent on the number of items sent over them.
## Terms
### Closed And Drained
A channel could be in three different states: normal, closed, and drained. The difference between the last two is that when the channel is closed it might still have some data available for receiving. Only when all items were consumed by the user code then the channel transitions into the *closed* and the *drained* state.
### Priority
Priority is a positive integer value with 0 being the lowest possible priority. The higher the value the sooner an item with this priority will reach the consumer.
# ATTRIBUTES
## `closed`
`True` if channel has been closed.
## `closed-promise`
A `Promise` which is kept with `True` when the channel is closed and broken with a cause object if channel is marked as failed.
## `drained`
`True` if channel is closed and no items left to fetch.
## `drained-promise`
A `Promise` which is kept with `True` when the channel is drained.
## `elems`
Likely number of elements ready for fetch. It is *"likely"* because in a concurrent environment this value might be changing too often.
## `prio-count`
Number of priority queues pre-allocated.
# METHODS
## `new`
`new` can be used with any parameters. But usually it is recommended to specifiy `:priorities(n)` named parameter to specify the expected number of priorities to be used. This allows the class to pre-allocate all required priority queues beforehand. Without this parameter a class instance starts with only one queue. If method `send` is used with a priority which doesn't have a queue assigned yet then the class starts allocating new ones by multiplying the number of existing ones by 2 until get enough of them to cover the requested priority. For example:
```
my $pchannel.new;
$pchannel.send(42, 5);
```
In this case before sending `42` the class allocates 2 -> 4 -> 8 queues.
Queue allocation code is the only place where locking is used.
Use of `priorities` parameter is recommended if some really big number of priorities is expected. This might help in reducing the memory footprint of the code by preventing over-allocation of queues.
## `send(Mu \item, Int:D $priority = 0)`
Send a `item` using `$priority`. If `$priority` is omitted then default 0 is used.
## `receive`
Receive an item from channel. If no data available and the channel is not *drained* then the method `await` for the next item. In other words, it soft-blocks allowing the scheduler to reassing the thread onto another task if necessary until some data is ready for pick up.
If the method is called on a *drained* channel then it returns a `Failure` wrapped around `X::PChannel::OpOnClosed` exception with its `op` attribute set to string *"receive"*.
## `poll`
Non-blocking fetch of an item. Contrary to `receive` doesn't wait for a missing item. Instead the method returns `Nil but NoData` typeobject. `Concurrent::PChannel::NoData` is a dummy role which sole purpose is to indicate that there is no item ready in a queue.
## `close`
Close a channel.
## `fail($cause)`
Marks a channel as *failed* and sets failure cause to `$cause`.
## `failed`
Returns `True` if channel is marked as failed.
## `Supply`
Wraps `receive` into a supplier.
# EXCEPTIONS
Names is the documentation are given as the exception classes are exported.
## `X::PChannel::Priorities`
Thrown if wrong `priorities` parameter passed to the method `new`. Attribute `priorities` contains the value passed.
## `X::PChannel::NegativePriority`
Thrown if a negative priority value has passed in from user code. Attribute `prio` contains the value passed.
## `X::PChannel::OpOnClosed`
Thrown or passed in a `Failure` when an operation is performed on a closed channel. Attribute `op` contains the operation name.
*Note* that semantics of this exception is a bit different depending on the kind of operation attempted. For `receive` this exception is used when channel is *drained*. For `send`, `close`, and `fail` it is thrown right away if channel is in *closed* state.
# AUTHOR
Vadim Belman [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2020 Vadim Belman
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-jmaslak-App-Heater.md
[](https://travis-ci.org/jmaslak/Raku-App-Heater)
# POD
# NAME
`heater.raku` - Raku-based Foot Warmer
# SYNOPSIS
```
heater.raku
```
# DESCRIPTION
This program was written during a period of brutally cold weather, when the author was trying to figure out how to keep her feet warm. Since her computer is on the floor by her feet, and because she knows that the busier the CPU, the more heat generated, she wrote this module to load up the CPU.
# CAVEATS
Obviously your electrical usage footprint (no pun intended) will increase if you run this program. That said, I believe this program is only slightly less efficient to turn your computer into a space heater than an actual space heater of the same wattage would be (I.E. energy used for "useful work" on the computer like sending signals to your monitor or lighting the power LED would not be turned into heat, while an electric space heater has even less of these "housekeeping" functions). In practice, I believe the energy difference to be negligable.
Only use this if your feet are cold!
# USAGE
## ARGUMENTS
### `processes`
```
heater.raku --processes=3
```
Sets the number of "heater" threads to start. This defaults to the number of CPU cores in the machine, determined by `$*KERNEL.cpu-cores`.
# AUTHOR
Joelle Maslak `[email protected]`
# LEGAL
Licensed under the same terms as Raku.
Copyright © 2021-2022 by Joelle Maslak
|
## dist_zef-raku-community-modules-Slang-Roman.md
[](https://github.com/raku-community-modules/Slang-Roman/actions)
# NAME
Slang::Roman - lets you use Roman numerals in your code
# SYNOPSIS
```
use Slang::Roman;
say 0rI + 0rIX; # 10
my $i = 0rMMXVI; # $i = 2016
```
# DESCRIPTION
This bit of admittedly twisted code let you use Roman numerals in your Raku code. It patches the running grammar so you can use a Roman numeral anywhere you would use a regular integer.
Future enhancements will include expansions to printf/sprintf with a custom formatting type, and the equivalents of `hex()` to handle string conversion.
While it handles both additive and subtractive Roman numerals, it doesn't check that they're properly formatted. For instance 'IC' should be a compile-time error but instead it'll generate 101 as if nothing of consequence happened.
# REFERENCE
According to [Wikipedia](https://en.wikipedia.org/wiki/Roman_numerals), the standard form is:
| # | Thousands | Hundreds | Tens | Units |
| --- | --- | --- | --- | --- |
| 1 | M | C | X | I |
| 2 | MM | CC | XX | II |
| 3 | MMM | CCC | XXX | III |
| 4 | | CD | XL | IV |
| 5 | | D | L | V |
| 6 | | DC | LX | VI |
| 7 | | DCC | LXX | VII |
| 8 | | DCCC | LXXX | VIII |
| 9 | | CM | XC | IX |
The numerals for 4 (IV) and 9 (IX) are written using subtractive notation,where the smaller symbol (I) is subtracted from the larger one (V, or X), thus avoiding the clumsier IIII and VIIII. Subtractive notation is also used for 40 (XL), 90 (XC), 400 (CD) and 900 (CM). These are the only subtractive forms in standard use.
# AUTHOR
Jeff Goff (DrForr)
Source can be located at: <https://github.com/raku-community-modules/Slang-Roman> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2016, 2018 Jeff Goff, 2020-2023 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-tony-o-DB-Xoos-MySQL.md
# DB::Xoos::MySQL
DB::Xoos::MySQL is an ORM designed for convenience and ease of use. It is based upon [DB::Xoos](https://github.com/tony-o/p6-xoo), provides roles and enhancements and allows you to connect to postgres for ultimate magic.
[](https://circleci.com/gh/tony-o/db-xoos-mysql/tree/master)
# Usage
Below is a minimum viable model setup for your app. Xoos does *not* create the table for you, that is up to you.
## autoloading model
### lib/app.pm6
```
use DB::Xoos::MySQL;
my DB::Xoos::MySQL $d .=new;
$d.connect('mysql://xyyz/example', options => { :dynamic-loading });
my $customer-model = $d.model('Customer');
my $new-customer = $customer-model.new-row;
$new-customer.name('xyz co');
$new-customer.rate(150);
$new-customer.update; # runs an insert because this is a new row
my $xyz = $customer-model.search({ name => { 'like' => '%xyz%' } }).first;
$xyz.rate( $xyz.rate * 2 ); #twice the rate!
$xyz.update; # UPDATEs the database
my $xyz-orders = $xyz.orders.count;
```
## same example with model modules
### lib/app.pm6
```
use DB::Xoos::MySQL;
my DB::Xoos::MySQL $d .=new;
$d.connect('sqlite://xyz.sqlite3');
my $customer-model = $d.model('Customer');
my $new-customer = $customer-model.new-row;
$new-customer.name('xyz co');
$new-customer.rate(150);
$new-customer.update; # runs an insert because this is a new row
my $xyz = $customer-model.search({ name => { 'like' => '%xyz%' } }).first;
$xyz.rate( $xyz.rate * 2 ); #twice the rate!
$xyz.update; # UPDATEs the database
my $xyz-orders = $xyz.orders.count;
```
### lib/Model/Customer.pm6
```
use DB::Xoos::Model;
unit class Model::Customer does DB::Xoos::Model['customer'];
has @.columns = [
id => {
type => 'integer',
nullable => False,
is-primary-key => True,
auto-increment => 1,
},
name => {
type => 'text',
},
rate => {
type => 'integer',
},
];
has @.relations = [
orders => { :has-many, :model<Order>, :relate(id => 'customer_id') },
];
```
# role DB::Xoos::Model
What is a model? A model is essentially a table in your database. Your ::Model::X is pretty barebones, in this module you'll defined `@.columns` and `@.relations` (if there are any relations).
## Example
```
use DB::Xoos::Model;
# the second argument below is optional and also accepts a type.
# if the arg is omitted then it attempts to auto load ::Row::Customer
# if it fails to auto load then it uses an anonymous Row and adds convenience methods to that
unit class X::Model::Customer does DB::Xoos::Model['customer', 'X::Row::Customer'];
has @.columns = [
id => {
type => 'integer',
nullable => False,
is-primary-key => True,
auto-increment => 1,
},
name => {
type => 'text',
},
contact => {
type => 'text',
},
country => {
type => 'text',
},
];
has @.relations = [
orders => { :has-many, :model<Order>, :relate(id => 'customer_id') },
open_orders => { :has-many, :model<Order>, :relate(id => 'customer_id', '+status' => 'open') },
completed_orders => { :has-many, :model<Order>, :relate(id => 'customer_id', '+status' => 'closed') },
];
# down here you can have convenience methods
method delete-all { #never do this in real life
die '.delete-all disabled in prod or if %*ENV{in-prod} not defined'
if !defined %*ENV{in-prod} || so %*ENV{in-prod};
my $s = self.search({ id => { '>' => -1 } });
$s.delete;
!so $s.count;
}
```
In this example we're creating a customer model with columns `id, name, contact, country` and relations with specific filter criteria. You may notice the `+status => 'open'` on the open\_orders relationship, the `+` here indicates it's a filter on the original table.
### Breakdown
`class :: does DB::Xoos::Model['table-name', 'Optional String or Type'];`
Here you can see the role accepts one or two parameters, the first is the DB table name, the latter is a String or Type of the row you'd like to use for this model. If no row is found then Xoos will create a generic row and add helper methods for you using the model's column data.
`@.columns`
A list of columns in the table. It is highly recommended you have *one* `is-primary-key` or `.update` will have unexpected results.
`@.relations`
This accepts a list of key values, the key defining the accessor name, the later a hash describing the relationship. `:has-one` and `:has-many` are both used to dictate whether a Xoos model returns an inflated object (:has-one) or a filterable object (:has-many).
## Methods
### `search(%filter?, %options?)`
Creates a new filterable model and returns that. Every subsequent call to `.search` will *add* to the existing filters and options the best it can.
Example:
```
my $customer = $dbo.model('Customer').search({
name => { like => '%bozo%' },
}, {
order-by => [ created_date => 'DESC', 'customer_name' ],
});
# later on ...
my $geo-filtered-customers = $customer.search({ country => 'usa' });
# $geo-filtered-customers effective filter is:
# {
# name => { like => '%bozo%' },
# country => 'usa',
# }
```
### `.all(%filter?)`
Returns all rows from query (an array of inflated `::Row::XYZ`). Providing `%filter` is the same as doing `.search(%filter).all` and is provided only for convenience.
### `.first(%filter?, :$next = False)`
Returns the first row (again, inflated `::Row::XYZ`) and caches the prepared statement (this is destroyed and ignored if $next is falsey)
### `.next(%filter?)`
Same as calling `.first(%filter, :next)`
### `.count(%filter?)`
Returns the result of a `select count` for the current filter selection. Providing `%filter` results in `.search(%filter).count`
### `.delete(%filter?)`
Deletes all rows matching criteria. Providing `%filter` results in `.search(%filter).delete`
### `.insert(%field-data?)`
Creates a new row with %field-data.
## Convenience methods
DB::Xoos::Model inheritance allows you to have convenience methods, these methods can act on whatever the current set of filters is.
Consider the following:
Convenience model definition:
```
class X::Model::Customer does DB::Xoos::Model['customer'];
# columns and relations
method remove-closed-orders {
self.closed_orders.delete;
}
```
Later in your code:
```
my $customers = $dbo.model('Customer');
my $all-customers = $customers.search({ id => { '>' => -1 } });
my $single-customers = $customers.search({ id => 5 });
$all-customers.remove-closed-orders;
# this removes all orders for customers with an id > -1
$single-customer.remove-closed-orders;
# this removes all orders for customers with id = 5
```
# role DB::Xoos::Row
A role to apply to your `::Row::Customer`. If there is no `::Row::Customer` a generic row is created using the column and relationship data specified in the corresponding `Model` and this file is only really necessary if you want to add convenience methods.
When a `class :: does DB::Xoos::Row`, it receives the info from the model and adds the methods for setting/getting field data.
With the model definition above:
```
my $invoice-model = $dbo.model('invoice');
my $invoice = $invoice-model.new-row({
customer_id => $customer.id,
amount => 400,
}); # this $invoice is NOT in the database until .update
my $old-amount = $invoice.amount; # = 400
$invoice.amount($invoice.amount * 2);
my $new-amount = $invoice.amount; # = 800
$invoice.update;
```
If there is a collision in the naming conventions between your model and the row then you'll need to use `[set|get]-column`
## Methods
### `.duplicate`
Duplicates the row omitting the `is-primary-key` field so the subsequent `.save` results in a new row rather than updating
### `.as-hash`
Returns the current field data for the row as a hash. If there has been unsaved updates to fields then it returns *those* values instead of what is in the database. You can determine whether the row has field-changes with `is-dirty`
### `.set-column(Str $key, $value)`
Updates the field data for the column (not stored in database until `.update` is called). If you want to `.wrap` a field setter for a certain key, wrap this and filter for the key
### `.get-column(Str $key)`
Retrieves the value for `$key` with any field changes having priority over data in database, use `.is-dirty`
### `.get-relation(Str $column, :%spec?)`
It is recommended any Model with a relationship name that conflicts and causes no convenience method to be generated be renamed, but use this if you must. `$customer.orders` is calling essentially `$customer.get-relation('orders')`. Do not provide `%spec` unless you know what you're doing.
### `.update`
Saves the row in the database. If the field with a positive `is-primary-key` is *set* then it runs and `UPDATE ...` statement, otherwise it `INSERT ...`s and updates the Row's `is-primary-key` field. Ensure you set one field with `is-primary-key`
## Field validation
It's just this easy:
```
has @.columns = [
qw<...>,
phone => {
type => 'text',
validate => sub ($new-value) {
# return Falsey value here for validation to fail
# Truthy value will cause validation to succeed
},
},
qw<...>,
];
```
|
## dist_zef-lizmat-Git-Files.md
[](https://github.com/lizmat/Git-Files/actions) [](https://github.com/lizmat/Git-Files/actions) [](https://github.com/lizmat/Git-Files/actions)
# NAME
Git::Files - List known files of a git repository
# SYNOPSIS
```
use Git::Files;
.say for git-files; # current directory
.say for git-files <lib t>; # "lib" and "t" dirs from current dir
.say for git-files :non-existing-also; # also non-existing files
.say for git-files "/path/to/git/repo"; # all files in git repo
.say for git-files "/path/to/git/repo/dir"; # files in dir in git repo
```
# DESCRIPTION
The `Git::Files` distribution exports a single subroutine `git-files` which takes zero or more paths, and returns a `Slip` of paths (as strings) of all the files that are known to Git in the specified paths.
If no paths are specified, will assume the current directory.
Since it is possible that Git still knows about files that have been deleted, but not yet committed, returned paths may not actually exist. These will not be returned, unless the `:non-existing-also` named argument is specified with a true value.
# SCRIPTS
The `Git::Files` distribution also installs a `git-ls` script for convenience, to allow access to the same functionality from the command line.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Git-Files> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2022, 2024, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-sylvarant-Compress-Brotli.md
# Perl6 Brotli Compression
[](https://travis-ci.org/sylvarant/Compress-Brotli) [](https://opensource.org/licenses/Artistic-2.0)
Provides acces to [Brotli compression](https://github.com/google/brotli) by means of the perl6 NativeCall API.
## Usage
A simple compression/decompression round trip can be written as follows.
```
use Compress::Brotli;
my Buf $blob = compress("a simple string");
my Buf $buffer = decompress($blob);
say $buffer.decode('UTF-8');
```
To control the [parameters](https://github.com/google/brotli/blob/master/enc/encode.h) of the brotli compression
an object of class `Compress::Brotli::Config` can be passed as an argument to the `compress` subroutine.
```
use Compress::Brotli;
# a low quality text compression
my Config $conf = Config.new(:mode(1),:quality(1),:lgwin(10),:lgblock(0));
my Buf $blob = compress("a simple string",$conf);
```
## Platforms
Linux, FreeBSD and Mac OSX are tested and supported.
## Dependencies
To build brotli the [libbrotli](https://github.com/bagder/libbrotli/) project is used.
To succesfully compile libbrotli and the added wrapper library you need:
`libtool`, `autoconf`, `gmake` and `automake`.
## License
[Artistic License 2.0](http://www.perlfoundation.org/artistic_license_2_0)
|
## dist_zef-patrickb-EcosystemMakerFaker.md
# NAME
The Ecosystem Maker / Faker
Creates static, ad-hoc and local ecosystems
# Synopsis
```
$ # Pass a flat list of dist folders
$ ecosystem-maker-faker --create some-dir-with-dists/*
Successfully added EMF-1
$ # List previously created ecos
$ ecosystem-maker-faker --list
I see the following maker faker ecosystems:
- EMF-1: /home/fooman/EMF-1.json
$ # Remove a previously created eco
$ ecosystem-maker-faker --rm EMF-1
Successfully removed EMF-1
```
# Description
Creates a static, ad-hoc and local ecosystem. Is basically just mushes the
`META6.json` files in the given folders into a single JSON file and then
adds that file to the local zef config as a new repo.
# What a ---- module name is that?
It seems the module is bordering the lower end of usefulness of a module. So I
didn't want to squat on an actually reasonable name. Also -ofun forever!
# AUTHOR
Patrick Böker [[email protected]](mailto:[email protected])
# License
This module is distributed under the terms of the Artistic License 2.0.
|
## qnx.md
class IO::Spec::QNX
Platform specific operations on file and directory paths QNX
```raku
class IO::Spec::QNX is IO::Spec::Unix { }
```
An object of this type is available via the variable `$*SPEC` if the Raku interpreter is running on a `QNX` platform.
About this class and its related classes also see [`IO::Spec`](/type/IO/Spec).
# [Methods](#class_IO::Spec::QNX "go to top of document")[§](#Methods "direct link")
## [method canonpath](#class_IO::Spec::QNX "go to top of document")[§](#method_canonpath "direct link")
```raku
method canonpath(Str() $path, :$parent --> Str:D)
```
Returns a string that is a canonical representation of `$path`. If `:$parent` is set to true, will also clean up references to parent directories. **NOTE:** the routine does not access the filesystem, so no symlinks are followed.
```raku
IO::Spec::QNX.canonpath("foo//../bar/../ber").say;
# OUTPUT: «foo/../bar/../ber»
IO::Spec::QNX.canonpath("foo///./../bar/../ber").say;
# OUTPUT: «foo/../bar/../ber»
IO::Spec::QNX.canonpath("foo///./../bar/../ber", :parent).say;
# OUTPUT: «ber»
```
|
## endian.md
enum Endian
Indicate endianness (6.d, 2018.12 and later)
```raku
enum Endian <NativeEndian LittleEndian BigEndian>;
```
An enum for indicating endianness, specifically with methods on `blob8` and `buf8`. Consists of `NativeEndian`, `LittleEndian` and `BigEndian`.
# [Methods](#enum_Endian "go to top of document")[§](#Methods "direct link")
## [routine Numeric](#enum_Endian "go to top of document")[§](#routine_Numeric "direct link")
```raku
multi method Numeric(Endian:D --> Int:D)
```
Returns the value part of the `enum` pair.
```raku
say NativeEndian.Numeric; # OUTPUT: «0»
say LittleEndian.Numeric; # OUTPUT: «1»
say BigEndian.Numeric; # OUTPUT: «2»
```
Note that the actual numeric values are subject to change. So please use the named values instead.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Endian`
raku-type-graph
Endian
Endian
Int
Int
Endian->Int
Mu
Mu
Any
Any
Any->Mu
Cool
Cool
Cool->Any
Numeric
Numeric
Real
Real
Real->Numeric
Int->Cool
Int->Real
[Expand chart above](/assets/typegraphs/Endian.svg)
|
## dist_zef-raku-community-modules-HTML-Strip.md
[](https://github.com/raku-community-modules/HTML-Strip/actions) [](https://github.com/raku-community-modules/HTML-Strip/actions) [](https://github.com/raku-community-modules/HTML-Strip/actions)
# NAME
HTML::Strip - Strip HTML markup from text.
# SYNOPSIS
```
use HTML::Strip;
my $html = q{<body>my <a href="http://">raku module</a></body>};
my $clean = html_strip($html);
# $clean: my raku module
```
# DESCRIPTION
HTML::Strip removes HTML tags and comments from given text.
This module is inspired by the Perl module HTML::Strip and provides the same functionality. However, both its interface and implementation differs. This module is implemented using Raku grammars.
Note that this module does no XML/HTML validation. Garbage in might give you garbage out.
## `strip_html(Str)`
Removes HTML tags and comments from given text.
This module will also decode HTML encoded text. For example < will become < .
### `:emit_space`
By default all tags are replaced by space. Set this optional parameter to False if you want them to be replaced by nothing.
### `:decode_entities`
By default HTML entities will be decoded. For example < becomes <
Set this to false if you do not want this.
# AUTHORS
* Dagur Valberg Johannsson
* Raku Community
# COPYRIGHT AND LICENSE
Copyright 2013 - 2017 Dagur Valberg Johannsson.
Copyright 2024 - 2025 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-Git-Add.md
[](https://github.com/lizmat/Git-Add/actions) [](https://github.com/lizmat/Git-Add/actions) [](https://github.com/lizmat/Git-Add/actions)
# NAME
Git::Add - add paths to a git repository
# SYNOPSIS
```
use Git::Add;
my $status := Git::Add.new(
:$directory,
:@add,
);
if $status.added -> @added {
say "Added:";
.say for @added;
}
```
# DESCRIPTION
Git::Add provides a simple way to add paths to a git repository.
# PARAMETERS
## directory
The directory of the git repository. Can be specified as either an `IO::Path` object, or as a string. Defaults to `$*CWD`. It should be readable.
## add
One or more paths to be added to the repository. Can be specified as strings or as `IO::Path` objects.
# METHODS
## added
The paths of files that have been added.
## gist
A text representation of the object, empty string if there were no added paths.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Git-Add> . Comments and Pull Requests are welcome.
If you like this module, or what I'm doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2021, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-manchicken-Fcntl.md
# perl6-Fcntl
Fcntl implementation (mimicking Perl 5)
# Build Status
[](https://travis-ci.org/manchicken/perl6-Fcntl)
# Approach
For this module, I'm trying to give you a module which has the native
definitions for constants for a given OS, generated from `C` headers but
available in a pure Perl 6 module. In order to do this, I've written a very
small `C` program which appends Perl 6 code to a template, and then that's
what you use. I've also written a small test program that allows me to verify
the values are what C thinks they should be when I send them back in.
For more details, read the POD.
|
## perl.md
class Perl
Perl related information
```raku
class Perl is Raku { }
```
A class that provides the same internal language information as the [Raku](/type/Raku) class. Only maintained for historical reasons.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Perl`
raku-type-graph
Perl
Perl
Raku
Raku
Perl->Raku
Mu
Mu
Any
Any
Any->Mu
Systemic
Systemic
Raku->Any
Raku->Systemic
[Expand chart above](/assets/typegraphs/Perl.svg)
|
## dist_zef-thundergnat-Gray-Code-RBC.md
[](https://github.com/thundergnat/Gray-Code-RBC/actions)
# NAME Gray::Code::RBC
A simple implementation of reflected binary Gray code
# SYNOPSIS
```
use Gray::Code::RBC;
say gray-encode(73);
# 93
say gray-encode(73).fmt: '%b';
# 1101101
say gray-decode(93);
# 73
say gray-encode("١٢٣");
# 70
```
# DESCRIPTION
Gray code is an integer encoding such that adjacent values differ by at most one bit.
```
binary decimal de- round-
number binary encoded encoded coded trip
0: 0000 => 0000 0 => 0000 0
1: 0001 => 0001 1 => 0001 1
2: 0010 => 0011 3 => 0010 2
3: 0011 => 0010 2 => 0011 3
4: 0100 => 0110 6 => 0100 4
5: 0101 => 0111 7 => 0101 5
6: 0110 => 0101 5 => 0110 6
7: 0111 => 0100 4 => 0111 7
8: 1000 => 1100 12 => 1000 8
9: 1001 => 1101 13 => 1001 9
10: 1010 => 1111 15 => 1010 10
11: 1011 => 1110 14 => 1011 11
12: 1100 => 1010 10 => 1100 12
13: 1101 => 1011 11 => 1101 13
14: 1110 => 1001 9 => 1110 14
15: 1111 => 1000 8 => 1111 15
```
Gray::Code::RBC is a simple implementation of the most common: reflected binary code Gray code. (Note that the spelling is always *Gray* as it is named after [Bell Labs scientist: Frank Gray](https://en.wikipedia.org/wiki/Frank_Gray_(researcher)) who originally popularized and patented it.)
(There are other types of Gray code but this module doesn't provide them.)
Exports two routines:
`gray-encode()` - Convert a decimal Integer to Gray code (Takes an Integer, returns an Integer).
and
`gray-decode()` - Convert a Gray code value to a decimal Integer (Takes an Integer, returns an Integer).
Both routines only accept and return Integers (or a String that can be coerced to an Integer). Any conversion to or from binary falls to other code.
Not limited by integer size. It is not unusual that Gray codes in practice are limited to some small (12, 16, 32) power of two. These routines are not thus limited and will handle arbitrarily large Integers.
# AUTHOR
Steve Schulze (thundergnat)
# COPYRIGHT AND LICENSE
Copyright 2020 thundergnat
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## codes.md
codes
Combined from primary sources listed below.
# [In Uni](#___top "go to top of document")[§](#(Uni)_method_codes "direct link")
See primary documentation
[in context](/type/Uni#method_codes)
for **method codes**.
```raku
method codes(Uni:D: --> Int:D)
```
Returns the number of codepoints in the invocant.
# [In Cool](#___top "go to top of document")[§](#(Cool)_routine_codes "direct link")
See primary documentation
[in context](/type/Cool#routine_codes)
for **routine codes**.
```raku
sub codes(Str(Cool))
method codes()
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns the number of [Unicode code points](https://en.wikipedia.org/wiki/Code_point).
```raku
say 'møp'.codes; # OUTPUT: «3»
```
The same result will be obtained with
```raku
say +'møp'.ords; # OUTPUT: «3»
```
[ords](/routine/ords) first obtains the actual codepoints, so there might be a difference in speed.
|
## dist_zef-tbrowder-Math-Trig.md
[](https://github.com/tbrowder/Math-Trig/actions)
# Math::Trig
Provides subroutines for coverting between degrees, radians, and gradians; converting between different coordinate systems (cartesian, spherical, cylindrical); and great circle formulas.
Also provides versions of the common trigonemetric functions that take or return their arguments in degrees:
```
sind
cosd
tand
asind
acosd
atand
atan2d
```
There are also some useful constants defined:
```
pi2 = pi/2;
pi4 = pi/4;
_2pi = pi*2;
_4pi = pi*4;
```
## SYNOPSIS
```
use Math::Trig; # no trigonometric functions exported
use Math::Trig :ALL; # includes the trig functions
```
## INSTALLATION
```
zef install Math::Trig
```
## BUGS
* This is a work in progress. Caveat emptor.
## AUTHORS
* Tom Browder ([[email protected]](mailto:[email protected])) [from 2020-02-14]
* Original author: the late Jonathan Scott Duff <@perlpilot>, RIP
## LICENSE
Artistic 2.0. See that license [here](./LICENSE).
## COPYRIGHT
Copyright © 2019-2022 by Tom Browder.
Copyright © 2015 by Jonathan Scott Duff.
## ACKNOWLEDGEMENTS
Jonathan Duff's words: "This module is shamelessly based on the [Perl 5 module](https://metacpan.org/pod/Math::Trig) of the same name. Without the authors and maintainers of *that* module, this module wouldn't exist in this form."
|
## dist_cpan-HANENKAMP-Auth-SASL.md
# NAME
Auth::SASL - Simple Authentication Security Layer
# SYNOPSIS
```
use Auth::SASL;
use Base64;
# naïve ESMTP handler...
my $smtp = IO::Socket::INET.new(:host<localhost>, :port(25));
$smtp.print("EHLO localhost\n");
my ($more, %properties);
repeat {
if $smtp.get ~~ /^ (\d\d\d)(<[-\ ]>)(.*) $/ {
my ($code, $more, $props) = ("$0", $1 eq "-", "$2");
if $props ~~ /(<[-\w]>+) >> <[=\ \t]>* (<-[\n]>*)/ {
%properties{ "$0" } = "$1";
}
}
else {
die "error occurred while initiating SMTP connection";
}
} while $more;
my $mechanisms = %properties<AUTH>;
my $sasl = Auth::SASL.new;
$sasl.begin-session(
data => %(
user => 'zostay',
pass => 'secret',
authname => 'zostay',
),
);
my ($response-code, $challenge);
MECHANISM: for $sasl.attempt-mechanisms($mechanisms, :service<smtp>, :host<localhost>) {
$smtp.print("AUTH $_.mechanism\n");
($response-code, $challenge) = $smtp.get.split(' ', 2);
next MECHANISM unless $response-code eq '334';
$challenge = '';
repeat {
$smtp.print(encode-base64(.step($challenge), :str) ~ "\n");
($response-code, $challenge) = $smtp.get.split(' ', 2);
next MECHANISM unless $response-code ~~ /^ 2 | 3 /;
} until .is-complete;
last MECHANISM if $response-code eq '235';
CATCH {
when X::Auth::SASL {
$smtp.print("*\n");
}
}
}
die "unable to authenticate" unless $response-code eq '235';
# Send email...
...
```
# DESCRIPTION
SASL stands for Simple Authentication and Security Layer. It is really just a means of exchanging authentication strings with a service. This library implements the client-side interaction for SASL. SASL itself is complicated only in the fact that it provides a means of exchanging authentication strings, but without specifying the protocol-specific details. Therefore, to use this module for a given protocol, any encoding, error handling, or other details must be implemented by the application developer.
This API is designed to work in a very modular way. This class, `Auth::SASL`, is designed to operate as the front-end. As long as you are just making use of this module distribution to implement a SASL protocol for a client service, such as SMTP, IMAP, or LDAP, this class will provide most of what you need.
The factory objects are used to find and build mechanism objects. Mechanism objects provide handling to implement each kind of SASL authentication mechanism. The session objects provide the information about the identity that is being authenticated.
# METHODS
## method new
```
method new(Auth::SASL:U:
Auth::SASL::Session :$session,
Auth::SASL::Factory :$factory = Auth::SASL::Raku.new,
--> Auth::SASL:D
)
```
Constructs an `Auth::SASL` front-end. Both arguments are optional. The `$factory` defaults to Auth::SASL::Raku, which provides a pure Raku implementation of some SASL mechanisms. Without setting `$session`, you will be required to call [.begin-session](#method begin-session) to initiate a session.
## method begin-session
```
multi method begin-session(Auth::SASL:D: Auth::SASL::Session $session)
multi method begin-session(Auth::SASL:D: :%data, :&callback)
```
Starts a new session. The session provides information about the identity being authenticated.
For simple cases, you can provide `%data` directly. These will be simple key/value pairs that provide the authentication details. The keys required will vary by the mechanisms involved.
For more complex cases you can provide a `&callback`, this will be a <Callable> routine that will be called each time a mechanism object requires a property. The callback must provide a signature compatible with:
```
sub (Str:D $property-name, Str:D :$service, Str:D :$host --> Str)
```
It should always return defined string. If it does not and the authentication method depends on that value, authentication mechansim will fail with an X::Auth::SASL::Property exception.
Finally, you can provide an object implementing Auth::SASL::Session.
## method end-session
```
method end-session(Auth::SASL:D:)
```
Clears the session. The front-end will not work until a new session is started by calling [.begin-session](#method begin-session).
## method supports-client-mechanisms
```
multi method supports-client-mechanisms(Auth::SASL:D: Str:D $mechanisms --> Bool:D)
multi method supports-client-mechanisms(Auth::SASL:D: Mixy:D $mechanisms --> Bool:D)
```
Returns a `True` value if at least one of the mechanisms listed in `$mechanisms` is supported by the current, `False` otherwise.
## method attempt-mechanisms
```
multi method attempt-mechanisms(Auth::SASL:D: Str:D $mechanisms, Str:D :$service = '', Str:D :$host = '' --> Seq:D)
multi method attempt-mechanisms(Auth::SASL:D: Mixy:D $mechanisms, Str:D :$service = '', Str:D :$host = '' --> Seq:D)
```
Once a session has been established, this method may be called to itereate over potential authentication mechanisms. The `$mechanisms` should be set to the list of mechanisms the server has reported as supporting. The factory will then use this and the list of mechanisms it supports to select the mechanisms to attempt. The <Seq> returned will allow you to iterate through 1 or more Auth::SASL::Mechanism::WorkingClient objects to use for authentication. If no compatible mechanism is found, the [X::Auth::SASL::NotFound](X::Auth::SASL#class X::Auth::SASL::NotFound) exception will be thrown.
If `$mechanisms` is passed as a string, it may either be a single mechanism name, e.g., `PLAIN`, or it it can be a space separated list of mechanism names, e.g., `PLAIN ANONYMOUS`. The factory object will determine which mechanisms are most preferable in this case.
If `$mechanisms` is passed as a <Mixy> object, such as a <Mix> or <MixHash>, the factory can use the score assigned to each key in the <Mixy> object to reorder the mechanisms and go in a different order.
The `$service` and `$host` parameters are optional and are used to allow a single session to connect to multiple services safely and even concurrently, so long as only a particular mechanism is permitted to make its attempt on a given `$service` and `$host` concurrently. The `$service` and `$host` parameters can also be used to allow a session to have multiple configurations for a given identity for different service/host combinations.
|
## dist_cpan-MELEZHIK-Sparky-Plugin-Notify-Email.md
# SYNOPSIS
Sparky plugin to send email notifications upon completed builds.
# INSTALL
```
$ zef install Sparky::Plugin::Notify::Email
```
# USAGE
```
$ cat sparky.yaml
# send me a notifications on failed builds
plugins:
- Sparky::Plugin::Notify::Email:
run_skope: fail
parameters:
to: [email protected]
```
# Author
Alexey Melezhik
|
## containers.md
Containers
A low-level explanation of Raku containers
This section explains how raw data, variables and containers relate to each other in Raku. The different types of containers used in Raku are explained and the actions applicable to them like assigning, binding and flattening. More advanced topics like self-referential data, type constraints and custom containers are discussed at the end.
For a deeper discussion of the various kinds of *ordered* containers in Raku, see the overview of [lists, sequences, and arrays](/language/list); for *unordered* containers, see [sets, bags, and mixes](/language/setbagmix).
# [What is a variable?](#Containers "go to top of document")[§](#What_is_a_variable? "direct link")
Some people like to say "everything is an object", but in fact a variable is not a user-exposed object in Raku.
When the compiler encounters a variable scope declaration like `my $x`, it registers it in some internal symbol table. This internal symbol table is used to detect undeclared variables and to tie the code generation for the variable to the correct scope.
At runtime, a variable appears as an entry in a *lexical pad*, or *lexpad* for short. This is a per-scope data structure that stores a pointer for each variable.
In the case of `my $x`, the lexpad entry for the variable `$x` is a pointer to an object of type [`Scalar`](/type/Scalar), usually just called *the container*.
# [Scalar containers](#Containers "go to top of document")[§](#Scalar_containers "direct link")
Although objects of type [`Scalar`](/type/Scalar) are everywhere in Raku, you rarely see them directly as objects, because most operations *decontainerize*, which means they act on the [`Scalar`](/type/Scalar) container's contents instead of the container itself.
In code like
```raku
my $x = 42;
say $x;
```
the assignment `$x = 42` stores a pointer to the [`Int`](/type/Int) object 42 in the scalar container to which the lexpad entry for `$x` points.
The assignment operator asks the container on the left to store the value on its right. What exactly that means is up to the container type. For [`Scalar`](/type/Scalar) it means "replace the previously stored value with the new one".
Note that subroutine signatures allow passing containers around:
```raku
sub f($a is rw) {
$a = 23;
}
my $x = 42;
f($x);
say $x; # OUTPUT: «23»
```
Inside the subroutine, the lexpad entry for `$a` points to the same container that `$x` points to outside the subroutine. Which is why assignment to `$a` also modifies the contents of `$x`.
Likewise, a routine can return a container if it is marked as `is rw`:
```raku
my $x = 23;
sub f() is rw { $x };
f() = 42;
say $x; # OUTPUT: «42»
```
For explicit returns, `return-rw` instead of `return` must be used.
Returning a container is how `is rw` attribute accessors work. So
```raku
class A {
has $.attr is rw;
}
```
is equivalent to
```raku
class A {
has $!attr;
method attr() is rw { $!attr }
}
```
Scalar containers are transparent to type checks and most kinds of read-only accesses. A `.VAR` makes them visible:
```raku
my $x = 42;
say $x.^name; # OUTPUT: «Int»
say $x.VAR.^name; # OUTPUT: «Scalar»
```
And `is rw` on a parameter requires the presence of a writable Scalar container:
```raku
sub f($x is rw) { say $x };
f 42;
CATCH { default { say .^name, ': ', .Str } };
# OUTPUT: «X::Parameter::RW: Parameter '$x' expected a writable container, but got Int value»
```
# [Callable containers](#Containers "go to top of document")[§](#Callable_containers "direct link")
Callable containers provide a bridge between the syntax of a [`Routine`](/type/Routine) call and the actual call of the method [CALL-ME](/type/Callable#method_CALL-ME) of the object that is stored in the container. The sigil `&` is required when declaring the container and has to be omitted when executing the [`Callable`](/type/Callable). The default type constraint is [`Callable`](/type/Callable).
```raku
my &callable = -> $ν { say "$ν is ", $ν ~~ Int ?? "whole" !! "not whole" }
callable(⅓); # OUTPUT: «0.333333 is not whole»
callable(3); # OUTPUT: «3 is whole»
```
The sigil has to be provided when referring to the value stored in the container. This in turn allows [`Routine`](/type/Routine)s to be used as [arguments](/language/signatures#Constraining_signatures_of_Callables) to calls.
```raku
sub f() {}
my &g = sub {}
sub caller(&c1, &c2){ c1, c2 }
caller(&f, &g);
```
# [Binding](#Containers "go to top of document")[§](#Binding "direct link")
Next to assignment, Raku also supports *binding* with the `:=` operator. When binding a value or a container to a variable, the lexpad entry of the variable is modified (and not just the container it points to). If you write
```raku
my $x := 42;
```
then the lexpad entry for `$x` directly points to the [`Int`](/type/Int) 42. Which means that you cannot assign to it anymore:
```raku
my $x := 42;
$x = 23;
CATCH { default { say .^name, ': ', .Str } };
# OUTPUT: «X::AdHoc: Cannot assign to an immutable value»
```
You can also bind variables to other variables:
```raku
my $a = 0;
my $b = 0;
$a := $b;
$b = 42;
say $a; # OUTPUT: «42»
```
Here, after the initial binding, the lexpad entries for `$a` and `$b` both point to the same scalar container, so assigning to one variable also changes the contents of the other.
You've seen this situation before: it is exactly what happened with the signature parameter marked as `is rw`.
Sigilless variables and parameters with the trait `is raw` always bind (whether `=` or `:=` is used):
```raku
my $a = 42;
my \b = $a;
b++;
say $a; # OUTPUT: «43»
sub f($c is raw) { $c++ }
f($a);
say $a; # OUTPUT: «44»
```
# [Scalar containers and listy things](#Containers "go to top of document")[§](#Scalar_containers_and_listy_things "direct link")
There are a number of positional container types with slightly different semantics in Raku. The most basic one is [`List`](/type/List), which is created by the comma operator.
```raku
say (1, 2, 3).^name; # OUTPUT: «List»
```
A list is immutable, which means you cannot change the number of elements in a list. But if one of the elements happens to be a scalar container, you can still assign to it:
```raku
my $x = 42;
($x, 1, 2)[0] = 23;
say $x; # OUTPUT: «23»
($x, 1, 2)[1] = 23; # Cannot modify an immutable value
CATCH { default { say .^name, ': ', .Str } };
# OUTPUT: «X::Assignment::RO: Cannot modify an immutable Int»
```
So the list doesn't care about whether its elements are values or containers, they just store and retrieve whatever was given to them.
Lists can also be lazy; in that case, elements at the end are generated on demand from an iterator.
An [`Array`](/type/Array) is just like a list, except that it forces all its elements to be containers, which means that you can always assign to elements:
```raku
my @a = 1, 2, 3;
@a[0] = 42;
say @a; # OUTPUT: «[42 2 3]»
```
`@a` actually stores three scalar containers. `@a[0]` returns one of them, and the assignment operator replaces the integer value stored in that container with the new one, `42`.
# [Assigning and binding to array variables](#Containers "go to top of document")[§](#Assigning_and_binding_to_array_variables "direct link")
Assignment to a scalar variable and to an array variable both do the same thing: discard the old value(s), and enter some new value(s).
Nevertheless, it's easy to observe how different they are:
```raku
my $x = 42; say $x.^name; # OUTPUT: «Int»
my @a = 42; say @a.^name; # OUTPUT: «Array»
```
This is because the [`Scalar`](/type/Scalar) container type hides itself well, but [`Array`](/type/Array) makes no such effort. Also assignment to an array variable is coercive, so you can assign a non-array value to an array variable.
To place a non-[`Array`](/type/Array) into an array variable, binding works:
```raku
my @a := (1, 2, 3);
say @a.^name; # OUTPUT: «List»
```
# [Binding to array elements](#Containers "go to top of document")[§](#Binding_to_array_elements "direct link")
As a curious side note, Raku supports binding to array elements:
```raku
my @a = (1, 2, 3);
@a[0] := my $x;
$x = 42;
say @a; # OUTPUT: «[42 2 3]»
```
If you've read and understood the previous explanations, it is now time to wonder how this can possibly work. After all, binding to a variable requires a lexpad entry for that variable, and while there is one for an array, there aren't lexpad entries for each array element, because you cannot expand the lexpad at runtime.
The answer is that binding to array elements is recognized at the syntax level and instead of emitting code for a normal binding operation, a special method (called [`BIND-POS`](/routine/BIND-POS)) is called on the array. This method handles binding to array elements. There is also an equivalent method for binding to hash elements as well (called [`BIND-KEY`](/routine/BIND-KEY))
Note that, while supported, one should generally avoid directly binding uncontainerized things into array elements. Doing so may produce counter-intuitive results when the array is used later.
```raku
my @a = (1, 2, 3);
@a[0] := 42; # This is not recommended, use assignment instead.
my $b := 42;
@a[1] := $b; # Nor is this.
@a[2] = $b; # ...but this is fine.
@a[1, 2] := 1, 2; # runtime error: X::Bind::Slice
CATCH { default { say .^name, ': ', .Str } };
# OUTPUT: «X::Bind::Slice: Cannot bind to Array slice»
```
Operations that mix Lists and Arrays generally protect against such a thing happening accidentally.
# [Flattening, items and containers](#Containers "go to top of document")[§](#Flattening,_items_and_containers "direct link")
The `%` and `@` sigils in Raku generally indicate multiple values to an iteration construct, whereas the `$` sigil indicates only one value.
```raku
my @a = 1, 2, 3;
for @a { }; # 3 iterations
my $a = (1, 2, 3);
for $a { }; # 1 iteration
```
`@`-sigiled variables do not flatten in list context:
```raku
my @a = 1, 2, 3;
my @b = @a, 4, 5;
say @b.elems; # OUTPUT: «3»
```
There are operations that flatten out sublists that are not inside a scalar container: slurpy parameters (`*@a`) and explicit calls to `flat`:
```raku
my @a = 1, 2, 3;
say (flat @a, 4, 5).elems; # OUTPUT: «5»
sub f(*@x) { @x.elems };
say f @a, 4, 5; # OUTPUT: «5»
```
You can also use `|` to create a [`Slip`](/type/Slip), introducing a list into the other.
```raku
my @l := 1, 2, (3, 4, (5, 6)), [7, 8, (9, 10)];
say (|@l, 11, 12); # OUTPUT: «(1 2 (3 4 (5 6)) [7 8 (9 10)] 11 12)»
say (flat @l, 11, 12) # OUTPUT: «(1 2 3 4 5 6 7 8 (9 10) 11 12)»
```
In the first case, every element of `@l` is *slipped* as the corresponding elements of the resulting list. `flat`, in the other hand, *flattens* all elements including the elements of the included array, except for `(9 10)`.
As hinted above, scalar containers prevent that flattening:
```raku
sub f(*@x) { @x.elems };
my @a = 1, 2, 3;
say f $@a, 4, 5; # OUTPUT: «3»
```
The `@` character can also be used as a prefix to coerce the argument to a list, thus removing a scalar container:
```raku
my $x = (1, 2, 3);
.say for @$x; # 3 iterations
```
However, the *decont* operator `<>` is more appropriate to decontainerize items that aren't lists:
```raku
my $x = ^Inf .grep: *.is-prime;
say "$_ is prime" for @$x; # WRONG! List keeps values, thus leaking memory
say "$_ is prime" for $x<>; # RIGHT. Simply decontainerize the Seq
my $y := ^Inf .grep: *.is-prime; # Even better; no Scalars involved at all
```
Methods generally don't care whether their invocant is in a scalar, so
```raku
my $x = (1, 2, 3);
$x.map(*.say); # 3 iterations
```
maps over a list of three elements, not of one.
# [Self-referential data](#Containers "go to top of document")[§](#Self-referential_data "direct link")
Container types, including [`Array`](/type/Array) and [`Hash`](/type/Hash), allow you to create self-referential structures.
```raku
my @a;
@a[0] = @a;
put @a.raku;
# OUTPUT: «((my @Array_75093712) = [@Array_75093712,])»
```
Although Raku does not prevent you from creating and using self-referential data, by doing so you may end up in a loop trying to dump the data. As a last resort, you can use Promises to [handle](/type/Promise#method_in) timeouts.
# [Type constraints](#Containers "go to top of document")[§](#Type_constraints "direct link")
Any container can have a type constraint in the form of a [type object](/language/typesystem#Type_objects) or a [subset](/language/typesystem#subset). Both can be placed between a declarator and the variable name or after the trait [of](/type/Variable#trait_of). The constraint is a property of the variable, not the container.
```raku
subset Three-letter of Str where .chars == 3;
my Three-letter $acronym = "ÞFL";
```
In this case, the type constraint is the (compile-type defined) subset `Three-letter`.
The default type constraint of a [`Scalar`](/type/Scalar) container is [`Mu`](/type/Mu). Introspection of type constraints on containers is provided by `.VAR.of` method, which for `@` and `%` sigiled variables gives the constraint for values:
```raku
my Str $x;
say $x.VAR.of; # OUTPUT: «(Str)»
my Num @a;
say @a.VAR.of; # OUTPUT: «(Num)»
my Int %h;
say %h.VAR.of; # OUTPUT: «(Int)»
```
## [Definedness constraints](#Containers "go to top of document")[§](#Definedness_constraints "direct link")
A container can also enforce a variable to be defined. Put a smiley in the declaration:
```raku
my Int:D $def = 3;
say $def; # OUTPUT: «3»
$def = Int; # Typecheck failure
```
You'll also need to initialize the variable in the declaration, it can't be left undefined after all.
It's also possible to have this constraint enforced in all variables declared in a scope with the [default defined variables pragma](/language/variables#Default_defined_variables_pragma). People coming from other languages where variables are always defined will want to have a look.
# [Custom containers](#Containers "go to top of document")[§](#Custom_containers "direct link")
To provide custom containers Raku employs the class [`Proxy`](/type/Proxy). Its constructor takes two arguments, `FETCH` AND `STORE`, that point to methods that are called when values are fetched or stored from the container. Type checks are not done by the container itself and other restrictions like readonlyness can be broken. The returned value must therefore be of the same type as the type of the variable it is bound to. We can use [type captures](/language/signatures#Type_captures) to work with types in Raku.
```raku
sub lucky(::T $type) {
my T $c-value; # closure variable
return-rw Proxy.new(
FETCH => method () { $c-value },
STORE => method (T $new-value) {
X::OutOfRange.new(what => 'number', got => '13', range => '-∞..12, 14..∞').throw
if $new-value == 13;
$c-value = $new-value;
}
);
}
my Int $a := lucky(Int);
say $a = 12; # OUTPUT: «12»
say $a = 'FOO'; # X::TypeCheck::Binding
say $a = 13; # X::OutOfRange
CATCH { default { say .^name, ': ', .Str } };
```
|
## num.md
Num
Combined from primary sources listed below.
# [In role Rational](#___top "go to top of document")[§](#(role_Rational)_method_Num "direct link")
See primary documentation
[in context](/type/Rational#method_Num)
for **method Num**.
```raku
method Num(Rational:D: --> Num:D)
```
Coerces the invocant to [`Num`](/type/Num) by dividing [numerator](/routine/numerator) by [denominator](/routine/denominator). If [denominator](/routine/denominator) is `0`, returns `Inf`, `-Inf`, or `NaN`, based on whether [numerator](/routine/numerator) is a positive number, negative number, or `0`, respectively.
# [In Num](#___top "go to top of document")[§](#(Num)_method_Num "direct link")
See primary documentation
[in context](/type/Num#method_Num)
for **method Num**.
```raku
method Num()
```
Returns the invocant.
# [In Str](#___top "go to top of document")[§](#(Str)_method_Num "direct link")
See primary documentation
[in context](/type/Str#method_Num)
for **method Num**.
```raku
method Num(Str:D: --> Num:D)
```
Coerces the string to [`Num`](/type/Num), using the same rules as [`Str.Numeric`](/type/Str#method_Numeric) and handling negative zero, `-0e0`, and positive zero, `0e0`.
```raku
my Str $s = "-0/5";
say (.self, .^name) given $s.Numeric; # OUTPUT: «(0 Rat)»
say (.self, .^name) given $s.Num; # OUTPUT: «(-0 Num)»
```
# [In NumStr](#___top "go to top of document")[§](#(NumStr)_method_Num "direct link")
See primary documentation
[in context](/type/NumStr#method_Num)
for **method Num**.
```raku
method Num
```
Returns the [`Num`](/type/Num) value of the `NumStr`.
# [In Cool](#___top "go to top of document")[§](#(Cool)_method_Num "direct link")
See primary documentation
[in context](/type/Cool#method_Num)
for **method Num**.
```raku
multi method Num()
```
Coerces the invocant to a [`Numeric`](/type/Numeric) and calls its [`.Num`](/routine/Num) method. [Fails](/routine/fail) if the coercion to a [`Numeric`](/type/Numeric) cannot be done.
```raku
say 1+0i.Num; # OUTPUT: «1»
say 2e1.Num; # OUTPUT: «20»
say (16/9)².Num; # OUTPUT: «3.1604938271604937»
say (-4/3).Num; # OUTPUT: «-1.3333333333333333»
say "foo".Num.^name; # OUTPUT: «Failure»
```
# [In role Real](#___top "go to top of document")[§](#(role_Real)_method_Num "direct link")
See primary documentation
[in context](/type/Real#method_Num)
for **method Num**.
```raku
method Num(Real:D:)
```
Calls the [`Bridge` method](/routine/Bridge) on the invocant and then the [`Num` method](/routine/Num) on its return value.
|
## dist_zef-andinus-antlia.md
```
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
ANTLIA
Antlia is a text based Rock paper scissors game
Andinus
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Table of Contents
─────────────────
Demo
Installation
Documentation
News
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Website
Source
GitHub (mirror)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Demo
════
This was recorded with `asciinema'.
[https://asciinema.org/a/410736.png]
⁃ Antlia v0.1.0:
[https://asciinema.org/a/410736.png]
Installation
════════════
Antlia is released to CPAN, you can get it from there or install it
from source. In any case, `zef' is required to install the
distribution.
You can run Antlia without `zef'. Just run `raku -Ilib bin/antlia'
from within the source directory.
Release
───────
1. Run `zef install antlia'.
Antlia should be installed, try running `antlia --version' to confirm.
From Source
───────────
You can either download the release archive generated by cgit/GitHub
or clone the project if you have `git' installed.
Without `git'
╌╌╌╌╌╌╌╌╌╌╌╌╌
1. Download the release:
•
•
2. Extract the file.
3. Run `zef install .' in source directory.
With `git'
╌╌╌╌╌╌╌╌╌╌
All commits will be signed by my [PGP Key].
┌────
│ # Clone the project.
│ git clone https://git.tilde.institute/andinus/antlia
│ cd antlia
│
│ # Install octans.
│ zef install .
└────
[PGP Key]
Documentation
═════════════
Implementation
──────────────
Just enter the player names & it'll print each throw along with
scores. Press enter to play another round.
Options
───────
players
╌╌╌╌╌╌╌
Number of players. Default is 2, should be an integer equal to or
greater than 2.
News
════
v0.1.2 - 2021-05-25
───────────────────
⁃ Update dependencies in `META6.json'.
v0.1.1 - 2021-05-01
───────────────────
⁃ Added support for more than 2 players.
⁃ Prints a scorecard after the last round.
v0.1.0 - 2021-04-29
───────────────────
Initial Implementation
```
|
## dist_zef-antononcube-Lingua-Stem-Russian.md
# Lingua::Stem::Russian Raku package
## Introduction
This Raku package is for stemming Russian words.
It implements the Snowball algorithm presented in
[[SNa1](http://snowball.tartarus.org/algorithms/russian/stemmer.html)].
---
## Usage examples
The `RussianStem` function is used to find stems:
```
use Lingua::Stem::Russian;
say RussianStem('всходы')
```
```
# всход
```
`RussianStem` also works with lists of words:
```
say RussianStem('Всходы урожая ожидаются с терпением, питьем и беконом.'.words)
```
```
# (Всход урож ожида с терпением, пит и беконом.)
```
The function `russian-word-stem` can be used as a synonym of `RussianStem`.
---
## Command Line Interface (CLI)
The package provides the CLI function `RussianStem`. Here is its usage message:
```
RussianStem --help
```
```
# Usage:
# RussianStem <text> [--splitter=<Str>] [--format=<Str>] -- Finds stems of Russian words in text.
# RussianStem [<words> ...] [--format=<Str>] -- Finds stems of Russian words.
# RussianStem [--format=<Str>] -- Finds stems of Russian words in (pipeline) input.
#
# <text> Text to spilt and its words stemmed.
# --splitter=<Str> String to make a split regex with. [default: '\W+']
# --format=<Str> Output format one of 'text', 'lines', or 'raku'. [default: 'text']
# [<words> ...] Words to be stemmed.
```
Here are example shell commands of using the CLI function `RussianStem`:
```
RussianStem Какие
```
```
# Как
```
```
RussianStem --format=raku "Модуль Raku, предоставляющий процедуру для русского языка."
```
```
# ["Модул", "Raku", "предоставля", "процедур", "для", "русск", "язык", ""]
```
```
RussianStem Проверить корректность подбора по словарям и правилам
```
```
# Провер корректност подбор по словар и правил
```
Here is a pipeline example using the CLI function `get-tokens` of the package
["Grammar::TokenProcessing"](https://github.com/antononcube/Raku-Grammar-TokenProcessing),
[AAp1]:
```
get-tokens ./DataQueryPhrases-template | RussianStem --format=raku
# ("ассоциац", "ассоциирован", "ассоциирова", "безопасн", "восходя", "выбер", "заказа", "комбайн", "крестообразн",
# "поверхност", "мутирова", "обзор", "обобщ", "переименова", "пол", "просмотрет", "разгруппирова", "разделител",
# "распла", "расстав", "символ", "слит", "слиян", "сплит", "табулирова", "тольк", "убыва", "уверен", "форм",
# "формат", "формирова", "формул", "широк")
```
**Remark:** These kind of tokens (literals) transformations are used in the packages
["DSL::Bulgarian"](https://github.com/antononcube/Raku-DSL-Bulgarian), [AAp2],
and
["DSL::Russian"](https://github.com/antononcube/Raku-DSL-Russian), [AAp3],
---
## Implementation notes
* Reprogrammed to Raku from : <https://github.com/neilb/Lingua-Stem-Ru/blob/master/lib/Lingua/Stem/Ru.pm> .
---
## TODO
* DONE Respect the word case in the returned result.
* `RussianStem('ТАБЛА')` should return `'ТАБЛ'`.
* (Not `'табл'` as it currently does.)
* DONE CLI that can be inserted in UNIX pipelines.
* TODO Performance statistics.
* TODO More detailed documentation.
---
## References
### Articles
[SNa1] Snowball Team,
[Russian stemming algorithm](http://snowball.tartarus.org/algorithms/russian/stemmer.html),
(2002),
[snowball.tartarus.org](http://snowball.tartarus.org).
### Packages
[AAp1] Anton Antonov,
[Grammar::TokenProcessing Raku package](https://github.com/antononcube/Raku-Grammar-TokenProcessing),
(2022),
[GitHub/antononcube](https://github.com/antononcube).
[AAp2] Anton Antonov,
[DSL::Bulgarian Raku package](https://github.com/antononcube/Raku-DSL-Bulgarian),
(2022),
[GitHub/antononcube](https://github.com/antononcube).
[AAp3] Anton Antonov,
[DSL::Russian Raku package](https://github.com/antononcube/Raku-DSL-Russian),
(2023),
[GitHub/antononcube](https://github.com/antononcube).
|
## dist_zef-jonathanstowe-WebService-Soundcloud.md
# WebService::Soundcloud
Provide a Raku interface to the Soundcloud REST API.

## Synopsis
You can use the Full OAuth flow:
```
use WebService::Soundcloud;
my $scloud = WebService::Soundcloud.new(:$client-id, :$client-secret, redirect-uri => 'http://mydomain.com/callback' );
# Now get authorization url
my $authorization_url = $scloud.get-authorization-url();
# Now your appplication should redirect the user to the authorization uri
# When the User has authenticated and approved the connection they will
# in turn be redirected back to your redirect URI with either the grant code
# (as code) or an error (as error) as query parameters
# Get Access Token with the code provided as query parameter to the redirect
my $access_token = $scloud.get-access-token($code);
# Save access_token and refresh_token, expires_in, scope for future use
my $oauth_token = $access_token<access_token>;
# a GET request '/me' - gets users details
my $user = $scloud->get('/me');
# a PUT request '/me' - updated users details
my $user = $scloud->put('/me', to-json( { user => { description => 'Have fun with the Raku wrapper to Soundcloud API' } } ) );
# Comment on a Track PoSt request usage
my $comment = $scloud->post('/tracks/<track_id>/comments',
{ body => 'I love this hip-hop track' } );
# Delete a track
my $track = $scloud->delete('/tracks/{id}');
```
or you can use direct credential based authorisation that can skip the redirections:
```
use WebService::Soundcloud;
my $sc = WebService::Soundcloud.new(:$client-id,:$client-secret,:$username,:$password);
# Because the credentials were provided the access-token can be requested directly
# without the need for a grant code
my $token = $sc.get-access-token();
my $me = $sc.get-object('/me');
my $tracks = $sc.get-list('/me/tracks');
```
## Description
This provides an interface to the [Soundcloud
API](https://developers.soundcloud.com/docs/api/reference), managing
the authorisation, connection and marshalling of the data.
You can build client side applications that authenticate with user
credentials or server applications that use the full OAuth authorization.
In order to use this module you will need to register your application
with Soundcloud at <http://soundcloud.com/you/apps> : your application will
be given a client ID and a client secret which you will need to use to
connect. The client ID used in the tests will not work correctly for your
own application as the callback URI is set to 'localhost'.
## Installation
If you have a working Rakudo installation can install directly with "zef":
```
# From the source directory
zef install .
# Remote installation
zef install WebService::Soundcloud
```
## Support
Suggestions/patches are welcomed via github at:
<https://github.com/jonathanstowe/WebService-Soundcloud/issues>
## Licence
This is free software.
Please see the <LICENCE> file in the distribution
© Jonathan Stowe 2015 - 2021
|
## dist_cpan-ANTONOV-Data-Generators.md
# Raku Data::Generators
[](https://opensource.org/licenses/Artistic-2.0)
This Raku package has functions for generating random strings, words, pet names, vectors, and
(tabular) datasets.
### Motivation
The primary motivation for this package is to have simple, intuitively named functions
for generating random vectors (lists) and datasets of different objects.
Although, Raku has a fairly good support of random vector generation, it is assumed that commands
like the following are easier to use:
```
say random-string(6, chars => 4, ranges => [ <y n Y N>, "0".."9" ] ).raku;
```
---
## Random strings
The function `random-string` generates random strings.
Here we generate a vector of random strings with length 4 and characters that belong to specified ranges:
```
use Data::Generators;
say random-string(6, chars => 4, ranges => [ <y n Y N>, "0".."9" ] ).raku;
```
```
# ("115y", "y9Yn", "n7N9", "16YN", "1083", "58Y0")
```
---
## Random words
The function `random-word` generates random words.
Here we generate a list with 12 random words:
```
random-word(12)
```
```
# (service smooth-bodied Oniscidae scurf corkage commensally Lozal witchery convection chickweed hueless anthropometrical)
```
Here we generate a table of random words of different types:
```
use Data::Reshapers;
my @dfWords = do for <Any Common Known Stop> -> $wt { $wt => random-word(6, type => $wt) };
say to-pretty-table(@dfWords);
```
```
# +--------+------------+--------------+-----------+---------------+------------+---------------+
# | | 2 | 3 | 0 | 5 | 4 | 1 |
# +--------+------------+--------------+-----------+---------------+------------+---------------+
# | Any | Wykehamist | euthanasia | Estronol | supplementary | a.m. | tacit |
# | Common | stutter | studiousness | loggia | rhinitis | roundabout | circumstances |
# | Known | Goldwyn | commotion | Tocharian | stolid | doctorfish | fulfil |
# | Stop | how's | between | i | he'll | whole | hasn't |
# +--------+------------+--------------+-----------+---------------+------------+---------------+
```
**Remark:** `Whatever` can be used instead of `'Any'`.
**Remark:** The function `to-pretty-table` is from the package
[Data::Reshapers](https://modules.raku.org/dist/Data::Reshapers:cpan:ANTONOV).
---
## Random pet names
The function `random-pet-name` generates random pet names.
The pet names are taken from publicly available data of pet license registrations in
the years 2015–2020 in Seattle, WA, USA. See [DG1].
The following command generates a list of six random pet names:
```
srand(32);
random-pet-name(6).raku
```
```
# ("Margot", "Millie", "Roberta", "Tati", "Chewie", "Tati")
```
The named argument `species` can be used to specify specie of the random pet names.
(According to the specie-name relationships in [DG1].)
Here we generate a table of random pet names of different species:
```
my @dfPetNames = do for <Any Cat Dog Goat Pig> -> $wt { $wt => random-pet-name(6, species => $wt) };
say to-pretty-table(@dfPetNames);
```
```
# +------+----------+------------------+-----------------------+----------+-----------+-----------+
# | | 4 | 5 | 2 | 0 | 3 | 1 |
# +------+----------+------------------+-----------------------+----------+-----------+-----------+
# | Any | Guinness | Sister Bertrille | Roswell | Tanner | Guinness | Atticus |
# | Cat | Nibbles | male | The Little Muffin Man | Ink | Schmeeber | Safi-Sana |
# | Dog | Yummy | Abita | Sonoma | Peeve | Hook | Merfy |
# | Goat | Frosty | Arya | Pepina | Tacoma | Darcy | Piper |
# | Pig | Guinness | Atticus | Guinness | Guinness | Atticus | Millie |
# +------+----------+------------------+-----------------------+----------+-----------+-----------+
```
**Remark:** `Whatever` can be used instead of `'Any'`.
The named argument (adverb) `weighted` can be used to specify random pet name choice
based on known real-life number of occurrences:
```
srand(32);
say random-pet-name(6, :weighted).raku
```
```
# ("Tati", "Miss Scarlett", "Millie", "Professor Nibblesworth", "Atticus", "Atticus")
```
The weights used correspond to the counts from [DG1].
**Remark:** The implementation of `random-pet-name` is based on the Mathematica implementation
[`RandomPetName`](https://resources.wolframcloud.com/FunctionRepository/resources/RandomPetName),
[AAf1].
---
## Random pretentious job titles
The function `random-pretentious-job-title` generates random pretentious job titles.
The following command generates a list of six random pretentious job titles:
```
random-pretentious-job-title(6).raku
```
```
# ("International Paradigm Manager", "National Security Planner", "Forward Response Associate", "Global Marketing Executive", "Interactive Tactics Strategist", "Dynamic Marketing Representative")
```
The named argument `number-of-words` can be used to control the number of words in the generated job titles.
The named argument `language` can be used to control in which language the generated job titles are in.
At this point, only Bulgarian and English are supported.
Here we generate pretentious job titles using different languages and number of words per title:
```
my $res = random-pretentious-job-title(12, number-of-words => Whatever, language => Whatever);
say to-pretty-table($res.rotor(3));
```
```
# +-------------------------------+-----------------------------------+---------------------------+
# | 0 | 1 | 2 |
# +-------------------------------+-----------------------------------+---------------------------+
# | Областен Асистент на Интранет | Вътрешен Консултант на Показатели | Lead Group Designer |
# | Data Coordinator | Техник | Старши Проектант по Екипи |
# | Lead Security Coordinator | Synergist | Стратег по Комуникации |
# | Проектант | Национален Инженер по Фактори | Дизайнер |
# +-------------------------------+-----------------------------------+---------------------------+
```
**Remark:** `Whatever` can be used as values for the named arguments `number-of-words` and `language`.
**Remark:** The implementation uses the job title phrases in <https://www.bullshitjob.com> .
It is, more-or-less, based on the Mathematica implementation
[`RandomPretentiousJobTitle`](https://resources.wolframcloud.com/FunctionRepository/resources/RandomPretentiousJobTitle),
[AAf2].
---
## Random reals
This module provides the function `random-variate` that can be used to generate lists of real numbers
using distribution specifications.
Here are examples:
```
say random-variate(NormalDistribution.new(:mean(10), :sd(20)), 5);
```
```
# (-18.615180334983382 -14.777307898313193 11.744540271606233 32.83415351542184 23.05439201645865)
```
```
say random-variate(NormalDistribution.new( µ => 10, σ => 20), 5);
```
```
# (35.82804554696579 -12.643547444336193 16.320377789979375 27.16893715675326 14.117125819449708)
```
```
say random-variate(UniformDistribution.new(:min(2), :max(60)), 5);
```
```
# (27.66534628863628 15.022852723841478 41.15611113824118 54.085283581723125 57.46240753137406)
```
**Remark:** Only Normal distribution and Uniform distribution are implemented at this point.
**Remark:** The signature design follows Mathematica's function
[`RandomVariate`](https://reference.wolfram.com/language/ref/RandomVariate.html).
Here is an example of 2D array generation:
```
say random-variate(NormalDistribution.new, [3,4]);
```
```
# [[-0.4479067963939533 0.28167926816285005 -1.075347558796815 1.3360794891272738]
# [1.4424534618996863 -1.0817181852485276 1.1124463316112607 0.8958722847013001]
# [0.9971898647548 0.5300761587505801 -0.19123738083454592 -0.04397620670389424]]
```
---
## Random tabular datasets
The function `random-tabular-dataset` can be used generate tabular *datasets*.
**Remark:** In this module a *dataset* is (usually) an array of arrays of pairs.
The dataset data structure resembles closely Mathematica's data structure
[`Dataset`]https://reference.wolfram.com/language/ref/Dataset.html), [WRI2].
**Remark:** The programming languages R and S have a data structure called "data frame" that
corresponds to dataset. (In the Python world the package `pandas` provides data frames.)
Data frames, though, are column-centric, not row-centric as datasets.
For example, data frames do not allow a column to have elements of heterogeneous types.
Here are basic calls:
```
random-tabular-dataset();
random-tabular-dataset(Whatever):row-names;
random-tabular-dataset(Whatever, Whatever);
random-tabular-dataset(12, 4);
random-tabular-dataset(Whatever, 4);
random-tabular-dataset(Whatever, <Col1 Col2 Col3>):!row-names;
```
Here is example of a generated tabular dataset that column names that are cat pet names:
```
my @dfRand = random-tabular-dataset(5, 3, column-names-generator => { random-pet-name($_, species => 'Cat') });
say to-pretty-table(@dfRand);
```
```
# +----------+--------------------+----------------+
# | Winton | Liliquoi | Cheddar |
# +----------+--------------------+----------------+
# | Praia | 19.859813619203255 | musingly |
# | schlock | 21.238698325857193 | prudery |
# | Dacca | 21.52325074237404 | oleaginousness |
# | drably | 22.069553581961273 | underside |
# | complain | 12.188987647044241 | latticework |
# +----------+--------------------+----------------+
```
The display function `to-pretty-table` is from
[`Data::Reshapers`](https://modules.raku.org/dist/Data::Reshapers:cpan:ANTONOV).
**Remark:** At this point only
[*wide format*](https://en.wikipedia.org/wiki/Wide_and_narrow_data)
datasets are generated. (The long format implementation is high in my TOOD list.)
**Remark:** The signature design and implementation are based on the Mathematica implementation
[`RandomTabularDataset`](https://resources.wolframcloud.com/FunctionRepository/resources/RandomTabularDataset),
[AAf3].
---
## TODO
1. Random tabular datasets generation
* Row spec
* Column spec that takes columns count and column names
* Column names generator
* Wide form implementation only
* Generators of column values
* Column-generator hash
* List of generators
* Single generator
* Turn "generators" that are lists into sampling pure functions
* Long form implementation
* Max number of values
* Min number of values
* Form (long or wide)
* Row names (automatic)
2. Random reals vectors generation
3. Figuring out how to handle and indicate missing values
4. Random reals vectors generation according to distribution specs
* Uniform distribution
* Normal distribution
* Poisson distribution
* Skew-normal distribution
* Triangular distribution
5. Selection between `roll` and `pick` for:
* `RandomWord`
* `RandomPetName`
---
## References
### Articles
[AA1] Anton Antonov,
["Pets licensing data analysis"](https://mathematicaforprediction.wordpress.com/2020/01/20/pets-licensing-data-analysis/),
(2020),
[MathematicaForPrediction at WordPress](https://mathematicaforprediction.wordpress.com).
### Functions, packages
[AAf1] Anton Antonov,
[RandomPetName](https://resources.wolframcloud.com/FunctionRepository/resources/RandomPetName),
(2021),
[Wolfram Function Repository](https://resources.wolframcloud.com/FunctionRepository).
[AAf2] Anton Antonov,
[RandomPretentiousJobTitle](https://resources.wolframcloud.com/FunctionRepository/resources/RandomPretentiousJobTitle),
(2021),
[Wolfram Function Repository](https://resources.wolframcloud.com/FunctionRepository).
[AAf3] Anton Antonov,
[RandomTabularDataset](https://resources.wolframcloud.com/FunctionRepository/resources/RandomTabularDataset),
(2021),
[Wolfram Function Repository](https://resources.wolframcloud.com/FunctionRepository).
[SHf1] Sander Huisman,
[RandomString](https://resources.wolframcloud.com/FunctionRepository/resources/RandomString),
(2021),
[Wolfram Function Repository](https://resources.wolframcloud.com/FunctionRepository).
[WRI1] Wolfram Research (2010),
[RandomVariate](https://reference.wolfram.com/language/ref/RandomVariate.html),
Wolfram Language function.
[WRI2] Wolfram Research (2014),
[Dataset](https://reference.wolfram.com/language/ref/Dataset.html),
Wolfram Language function.
### Data repositories
[DG1] Data.Gov,
[Seattle Pet Licenses](https://catalog.data.gov/dataset/seattle-pet-licenses),
[catalog.data.gov](https://catalog.data.gov).
|
## dist_github-ramiroencinas-System-Stats-DISKUsage.md
# System::Stats::DISKUsage
[](https://travis-ci.com/github/ramiroencinas/System-Stats-DISKUsage)
Raku module - Provides Disk Usage Stats.
## OS Supported:
* GNU/Linux (Kernel 2.6+) by /proc/diskstats
## Installing the module
```
zef update
zef install System::Stats::DISKUsage
```
## Example Usage:
```
use v6;
use System::Stats::DISKUsage;
my %diskUsage = DISK_Usage();
say "\nDisk Usage per second:\n";
say "Drive BytesRead BytesWritten\n";
for %diskUsage.sort(*.key)>>.kv -> ($drive, $usage) {
printf "%-5s %-9d %-d\n", $drive, $usage<bytesreadpersec>, $usage<byteswrittenpersec>;
}
```
## TODO:
* Win32 version.
|
## dist_cpan-SAMGWISE-Structable.md
[](https://travis-ci.org/samgwise/p6-structable)
# NAME
Structable - Runtime validation of associative datastructures
# SYNOPSIS
```
use Structable;
# Define the structure of a record
my $struct = struct-def
(struct-int 'id_weight'),
(struct-str 'name_subject'),
(struct-rat 'weight_subject'),
(struct-date 'date_measure');
# Conform an acceptable Map to the given structure
say conform($struct,
{ id_weight => 1
, name_subject => 'Foo'
, weight_subject => 3.21
, date_measure => '2019-01-25'
}
).ok("Err conforming to struct.").perl;
# output ${:date_measure(Date.new(2019,1,25)), :id_weight(1), :name_subject("Foo"), :weight_subject(3.21)}
# A bad Map of values, something is missing...
{
my $result = conform($struct,
{ not_the_id => 2
, name_subject => 'Bar'
, weight_subject => 1.23
, date_measure => '2019-01-25'
}
);
given $result {
when .is-err {
.error.say
}
}
}
# output: Unable to find value for 'id_weight', keys provided were: 'not_the_id', 'date_measure', 'name_subject', 'weight_subject'
# A good map after some coercion
say conform($struct,
{ id_weight => "3" #Now it's an Str, just like you commonly find being returned from a parsed JSON document
, name_subject => 'Baz'
, weight_subject => "7.65"
, date_measure => '2019-01-25'
, Something_extra => False
}
).ok("Err conforming to struct").perl;
# output: ${:date_measure(Date.new(2019,1,25)), :id_weight(3), :name_subject("Baz"), :weight_subject(7.65)}
# The conformed values have been coerced into their specified types
# Converting complex types back to a simple structure
say simplify($struct,
{ id_weight => 3
, name_subject => 'Baz'
, weight_subject => 7.65
, date_measure => Date.new('2019-01-25')
}
).ok("Err performing simplification with struct").perl;
# output: ${:date_measure("2019-01-25"), :id_weight(3), :name_subject("Baz"), :weight_subject(7.65)}
# The conformed values have been coerced into their specified types
```
# DESCRIPTION
The Structable module provides a mechanism for defining an ordered and typed data definition.
Validating input like JSON is often a tedious task, however with Structable you can create concise definitions which you can apply at runtime. If the input is valid (perhaps with a bit of coercion) then the conformed data will be returned in a Result::Ok object and if there was something wrong, a Result::Err will be returned with a helpful error message. This means that you can use conform operations in a stream of values instead of resorting to try/catch constructs to handle your validation errors.
The struct definition also defines an order, so by grabbing a list of keys you can easily iterate over values in a conformed Map in a uniformly specified order.
## Custom types
If you need more types than those bundled in this module you can add your own! All members of a Strucatable::Struct are Structable::Type[T], a parametric role. Simply pass your type as the role's type parameter and away you go.
## Caveats
Although this module helps provide assurances about the data you are injesting it has not yet been audited and tested to provide any assurances regarding security. Data from an unstrusted source may still be untrustworthy after passing through a conform step provided by this module. Particular caution should be given to the size of payload you are conforming, there are no inbuilt mechanisims to prevent this style of abuse in this module.
# AUTHOR
Sam Gillespie [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENCE
Copyright 2018 Sam Gillespie
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
## class Mu $
Generic role defining the Structable::Type interface. This role is punnable for scalar container types and specilisable for collection types.
### sub struct-def
```
sub struct-def(
+@members
) returns Structable::Struct
```
A factory for defining a new C defenition. Each argument must be a CStructable::Type and is checked on execution of this function.
### sub conform
```
sub conform(
Structable::Struct:D $s,
Map:D $m
) returns Result::Any
```
This subroutine attempts to conform a Map (such as a Hash) to a given struct. The outcome is returned as a C object. A CResult::Ok holds a filtered version of a hash which adhears to the given struct. A CResult::Err represents an error and holds an error message describing why the given Map is not conformant to the given Struct.
### sub str-to-int
```
sub str-to-int(
$val
) returns Result::Any
```
A simple coercer for mapping a Str of Int to Int If you can call Int on it, it'll be acceptable as an Int. This routine is package scoped and not exported when used.
### sub str-to-rat
```
sub str-to-rat(
$val
) returns Result::Any
```
A simple coercer for mapping a Str of Rat to Rat If you can call Int on it, it'll be acceptable as an Int. This routine is package scoped and not exported when used.
### sub struct-int
```
sub struct-int(
Str:D $name,
Bool :$optional,
Bool :$maybe,
:$default
) returns Structable::Type
```
A factory for creating a struct element of type Int. By default this Type element will try and coerce Str values to Int.
### sub buf-to-str
```
sub buf-to-str(
$val
) returns Result::Any
```
A simple coercer for mapping a Buf of Str to Str If you can call decode on it, it'll be acceptable as an Str. This routine is package scoped and not exported when used.
### sub struct-str
```
sub struct-str(
Str:D $name,
Bool :$optional,
Bool :$maybe,
:$default
) returns Structable::Type
```
A factory for creating a struct element of type Str No coercion behaviours are defined for this Type
### sub struct-rat
```
sub struct-rat(
Str:D $name,
Bool :$optional,
Bool :$maybe,
:$default
) returns Structable::Type
```
A factory for creating a struct element of type Rat. By default this Type element will try and coerce Str values to Rat.
### sub str-to-date
```
sub str-to-date(
$val
) returns Result::Any
```
A simple coercer for mapping a Str containing a date string to a Date object This routine is package scoped and not exported when used.
### sub struct-date
```
sub struct-date(
Str:D $name,
Bool :$optional,
Bool :$maybe,
:$default
) returns Structable::Type
```
A factory for creating a struct element of type Date. Coerces date strings to Dat objects according to inbuild Date object behaviour.
### sub str-to-datetime
```
sub str-to-datetime(
$val
) returns Result::Any
```
A simple coercer for mapping a Str containing an ISO time stamp string to a DateTime object This routine is package scoped and not exported when used.
### sub struct-datetime
```
sub struct-datetime(
Str:D $name,
Bool :$optional,
Bool :$maybe,
:$default
) returns Structable::Type
```
A factory for creating a struct element of type DateTime. Coerces date strings to Dat objects according to inbuild Date object behaviour.
### sub any-to-bool
```
sub any-to-bool(
$val
) returns Result::Any
```
A Bool coercer, searching for truethy values. Since a simple coercer could just return a .so result, this function is a little more aggressive. .so logic is applied but strings are also checked for empty string and the string '0'.
### sub struct-bool
```
sub struct-bool(
Str:D $name,
Bool :$optional,
Bool :$maybe,
Bool :$default
) returns Structable::Type
```
A factory for creating a struct element of type Bool. A struct def for Bool types, this is built with the any-to-bool coercion function.
### sub struct-nested
```
sub struct-nested(
Str:D $name,
Structable::Struct $struct,
:$optional = Bool::False,
:$default,
:&coercion,
:&to-simple
) returns Mu
```
A factory for creating a struct element of another Structable::Struct. The provided struct will be used for simplifying and conforming the nested values. Conform and simplify actions cascade into the defenition.
### sub struct-list
```
sub struct-list(
Str:D $name,
Structable::Type $list-type,
:$optional = Bool::False,
:$default,
:&coercion,
:&to-simple
) returns Mu
```
A factory for creating a struct element list defenition. The List must be of a uniform type as specified by the Structable type provided. Conform and simplify actions cascade into the defenition.
### sub any-to-str
```
sub any-to-str(
$val
) returns Result::Any
```
A basic simplifier which calls the .Str method to perform simplification This routine is package scoped and not exported when the module is used.
### sub simplify
```
sub simplify(
Structable::Struct:D $s,
Map:D $m
) returns Result::Any
```
Pack a given map according to a given struct. This function is the complement of conform and facilitates packing a map down to a simple map, ready for serialisation to a format such as JSON.
|
## race.md
race
Combined from primary sources listed below.
# [In role Iterable](#___top "go to top of document")[§](#(role_Iterable)_method_race "direct link")
See primary documentation
[in context](/type/Iterable#method_race)
for **method race**.
```raku
method race(Int(Cool) :$batch = 64, Int(Cool) :$degree = 4 --> Iterable)
```
Returns another Iterable that is potentially iterated in parallel, with a given batch size and degree of parallelism (number of parallel workers).
Unlike [`hyper`](/routine/hyper), `race` does not preserve the order of elements (mnemonic: in a race, you never know who will arrive first).
```raku
say ([1..100].race.map({ $_ +1 }).list);
```
Use race in situations where it is OK to do the processing of items in parallel, and the output order does not matter. See [`hyper`](/routine/hyper) for situations where you want items processed in parallel and the output order should be kept relative to the input order.
**[Blog post on the semantics of hyper and race](https://6guts.wordpress.com/2017/03/16/considering-hyperrace-semantics/)**
See [`hyper`](/routine/hyper) for an explanation of `:$batch` and `:$degree`.
# [In HyperSeq](#___top "go to top of document")[§](#(HyperSeq)_method_race "direct link")
See primary documentation
[in context](/type/HyperSeq#method_race)
for **method race**.
```raku
method race(HyperSeq:D:)
```
Creates a [`RaceSeq`](/type/RaceSeq) object out of the current one.
# [In RaceSeq](#___top "go to top of document")[§](#(RaceSeq)_method_race "direct link")
See primary documentation
[in context](/type/RaceSeq#method_race)
for **method race**.
```raku
method race(RaceSeq:D:)
```
Returns the object.
|
## dist_github-avuserow-Binary-Structured.md
# NAME
Binary::Structured - read and write binary formats defined by classes
# SYNOPSIS
```
use Binary::Structured;
# Binary format definition
class PascalString is Binary::Structured {
has uint8 $!length is written(method {$!string.bytes});
has Buf $.string is read(method {self.pull($!length)}) is rw;
}
# Reading
my $parser = PascalString.new;
$parser.parse(Buf.new("\x05hello world".ords));
say $parser.string.decode("ascii"); # "hello"
# Writing
$parser.string = Buf.new("some new data".ords);
say $parser.build; # Buf:0x<0d 73 6f 6d 65 20 6e 65 77 20 64 61 74 61>
```
# DESCRIPTION
Binary::Structured provides a way to define classes which know how to parse and emit binary data based on the class attributes. The goal of this module is to provide building blocks to describe an entire file (or well-defined section of a file), which can easily be parsed, edited, and rebuilt.
This module was inspired by the Python library `construct`, with the class-based representation inspired by Perl 6's `NativeCall`.
Types of the attributes are used whenever possible to drive behavior, with custom traits provided to add more smarts when needed to parse more formats.
These attributes are parsed in order of declaration, regardless of if they are public or private, but only attributes declared in that class directly. The readonly or rw traits are ignored for attributes. Methods are also ignored.
WARNING: As this is a pre-1.0 module, the API is subject to change between versions without deprecation.
# TYPES
Perl 6 provides a wealth of native sized types. The following native types may be used on attributes for parsing and building without the help of any traits:
* int8
* int16
* int32
* uint8
* uint16
* uint32
These types consume 1, 2, or 4 bytes as appropriate for the type. These values are interpreted as little endian by default. Big endian representations may be indicated by using the `is big-endian` trait, see the traits section below.
* Buf
Buf is another type that lends itself to representing this data. It has no obvious length and requires the `read` trait to consume it (see the traits section below).
Note that you can provide both `is read` and `is written` to compute the value when parsing and building, allowing you to put in arbitrary bytes at this position. See `StreamPosition` below if you just want to keep track of the current position.
* StaticData
A variant of Buf, `StaticData`, is provided to represent bytes that are known in advance. It requires a default value of a Buf, which is used to determine the number of bytes to consume, and these bytes are checked with the default value. An exception is raised if these bytes do not match. An appropriate use of this would be the magic bytes at the beginning of many file formats, or the null terminator at the end of a CString, for example:
```
# Magic for PNG files
class PNGFile is Binary::Structured {
has StaticData $.magic = Buf.new(0x89, 0x50, 0x4e, 0x47, 0x0d, 0x0a, 0x1a, 0x0a);
}
```
* StreamPosition
This exported class consumes no bytes, and writes no bytes. It just records the current stream position into this attribute when reading or writing so other variables can reference it later. Reader and writer traits are ignored on this attribute.
* StreamEvent
This exported class consumes no bytes, and writes no bytes. It executes the `is read` and `is written` attributes, allowing you to put arbitrary code in the parse or build process at this point. This is a good place to put a call to `rewrite-attribute`, allowing you to update a previous value once you know what it should be.
* Binary::Structured subclass
These structures may be nested. Provide an attribute that subclasses `Binary::Structured` to include another structure at this position. This inner structure takes over control until it is done parsing or building, and then the outer structure resumes parsing or building.
```
class Inner is Binary::Structured {
has int8 $.value;
}
class Outer is Binary::Structured {
has int8 $.before;
has Inner $.inner;
has int8 $.after;
}
# This would be able to parse Buf.new(1, 2, 3)
# $outer.before would be 1, $outer.inner.value would be 2,
# and $outer.after would be 3.
```
* Array[Binary::Structured]
Multiple structures can be handled by using an `Array` of subclasses. Use the `read` trait to control when it stops trying to adding values into the array. See the traits section below for examples on controlling iteration.
# METHODS
## class X::Binary::Structured::StaticMismatch
Exception raised when data in a C does not match the bytes consumed.
## class Binary::Structured
Superclass of formats. Some methods are meant for implementing various trait helpers (see below).
### has Int $.pos
Current position of parsing of the Buf.
### has Blob $.data
Data being parsed.
### method peek
```
method peek(
Int $count
) returns Mu
```
Returns a Buf of the next C<$count> bytes but without advancing the position, used for lookahead in the C trait.
### method peek-one
```
method peek-one() returns Mu
```
Returns the next byte as an Int without advancing the position. More efficient than regular C, used for lookahead in the C trait.
### method pull
```
method pull(
Int $count
) returns Mu
```
Method used to consume C<$count> bytes from the data, returning it as a Buf. Advances the position by the specified count.
### method pull-elements
```
method pull-elements(
Int $count
) returns ElementCount
```
Helper method for reader methods to indicate a certain number of elements/iterations rather than a certain number of bytes.
### method rewrite-attribute
```
method rewrite-attribute(
Str $attribute
) returns Mu
```
Helper method to rewrite a previous attribute that is marked C. Only works on seekable buffers and may not change the length of the buffer. Specify the attribute via string using the C<$!foo> syntax (regardless of if it is public or private).
### method parse
```
method parse(
Blob $data,
Int :$pos = 0
) returns Mu
```
Takes a Buf of data to parse, with an optional position to start parsing at.
### method build
```
method build() returns Blob
```
Construct a C from the current state of this object.
# TRAITS
Traits are provided to add additional parsing control. Most of them take methods as arguments, which operate in the context of the parsed (or partially parsed) object, so you can refer to previous attributes.
## `is read`
The `is read` trait controls reading of `Buf`s and `Array`s. For `Buf`, return a `Buf` built using `self.pull($count)` (to ensure the position is advanced properly). `$count` here could be a reference to a previously parsed value, could be a constant value, or you can use a loop along with `peek-one`/`peek` to concatenate to a Buf.
For `Array`, return a count of bytes as an `Int`, or return a number of elements to read using `self.pull-elements($count)`. Note that `pull-elements` does not advance the position immediately so `peek` is less useful here.
## `is written`
The `is written` trait controls how a given attribute is constructed when `build` is called. It provides a way to update values based on other attributes. It's best used on things that would be private attributes, like lengths and some checksums. Since `build` is only called when all attributes are filled, you can refer to attributes that have not been written (unlike `is read`).
## `is big-endian`
Applies to native integers (int16, int32, uint16, uint32), and indicates that this value should be read and written as a big endian value (with the most significant byte first) rather than the default of little endian.
## `is little-endian`
Little endian is the default for numeric values, but the trait is provided for completeness.
# REQUIREMENTS
* Rakudo Perl v6.c or above (tested on 2016.08.1)
# TODO
See <TODO>.
|
## notification.md
class IO::Notification
Asynchronous notification for file and directory changes
```raku
enum FileChangeEvent (:FileChanged(1), :FileRenamed(2));
```
```raku
class IO::Notification {}
```
Essentially, this class exists as a placeholder for the `IO::Notification.watch-path($path)` method, that produces a [`Supply`](/type/Supply) of [`IO::Notification::Change`](/type/IO/Notification/Change) events for a file or directory.
# [Methods](#class_IO::Notification "go to top of document")[§](#Methods "direct link")
## [method watch-path](#class_IO::Notification "go to top of document")[§](#method_watch-path "direct link")
```raku
method watch-path(IO::Notification: Str() $path, :$scheduler = $*SCHEDULER)
```
Returns a [`Supply`](/type/Supply) that emits [`IO::Notification::Change`](/type/IO/Notification/Change) objects.
If `$path` is a file, only modifications of that file are reported. If `$path` is a directory, both modifications to the directory itself (for example permission changes) and to files in the directory (including new files in the directory) are reported.
The `:$scheduler` named argument allows you to specify which thread scheduler is going to be responsible for the notification stream; it can be omitted if the default scheduler is used.
```raku
my $supply = IO::Notification.watch-path( "/var/log/syslog" );
$supply.tap( -> $v { say "Got ", $v });
sleep 60;
```
This snippet of code sets a watch on the system log file, emitting the kind of event that has occurred or capturing an error otherwise; the created [`Supply`](/type/Supply) is tapped, and the event printed. It does so for 60 minutes, emitting something like this:
「text」 without highlighting
```
```
Got /var/log/syslog: FileChanged
Got /var/log/syslog: FileChanged
Got /var/log/syslog: FileChanged
Got /var/log/syslog: FileChanged
Got /var/log/syslog: FileChanged
Got /var/log/syslog: FileChanged
Got /var/log/syslog: FileChanged
Got /var/log/syslog: FileChanged
```
```
The only kind of information this method provides is the bare fact that something has change or been renamed. You will need to actually open and read the file or directory to check the actual changes.
|
## numerator.md
numerator
Combined from primary sources listed below.
# [In X::Numeric::DivideByZero](#___top "go to top of document")[§](#(X::Numeric::DivideByZero)_method_numerator "direct link")
See primary documentation
[in context](/type/X/Numeric/DivideByZero#method_numerator)
for **method numerator**.
```raku
method numerator()
```
If present, returns the numerator of the operation.
# [In role Rational](#___top "go to top of document")[§](#(role_Rational)_method_numerator "direct link")
See primary documentation
[in context](/type/Rational#method_numerator)
for **method numerator**.
```raku
method numerator(Rational:D: --> NuT:D)
```
Returns the numerator.
|
## chr.md
chr
Combined from primary sources listed below.
# [In Int](#___top "go to top of document")[§](#(Int)_routine_chr "direct link")
See primary documentation
[in context](/type/Int#routine_chr)
for **routine chr**.
```raku
multi chr(Int:D --> Str:D)
multi method chr(Int:D: --> Str:D)
```
Returns a one-character string, by interpreting the integer as a Unicode codepoint number and converting it to the corresponding character.
Example:
```raku
65.chr; # returns "A"
196.chr; # returns "Ä"
```
# [In Cool](#___top "go to top of document")[§](#(Cool)_routine_chr "direct link")
See primary documentation
[in context](/type/Cool#routine_chr)
for **routine chr**.
```raku
sub chr(Int(Cool))
method chr()
```
Coerces the invocant (or in sub form, its argument) to [`Int`](/type/Int), interprets it as a [Unicode code points](https://en.wikipedia.org/wiki/Code_point), and returns a [`Str`](/type/Str) made of that code point.
```raku
say '65'.chr; # OUTPUT: «A»
```
The inverse operation is [ord](/routine/ord).
Mnemonic: turns an integer into a *char*acter.
|
## unlesselse.md
class X::Syntax::UnlessElse
Compilation error due to an `unless` clause followed by `else`
```raku
class X::Syntax::UnlessElse does X::Syntax { }
```
Syntax error thrown when an `unless` clause is followed by an `else` clause.
For example
```raku
unless 1 { } else { };
```
dies with
「text」 without highlighting
```
```
===SORRY!===
"unless" does not take "else", please rewrite using "if"
```
```
|
## classify.md
classify
Combined from primary sources listed below.
# [In Any](#___top "go to top of document")[§](#(Any)_routine_classify "direct link")
See primary documentation
[in context](/type/Any#routine_classify)
for **routine classify**.
```raku
multi method classify()
multi method classify(Whatever)
multi method classify($test, :$into!, :&as)
multi method classify($test, :&as)
multi classify($test, +items, :$into!, *%named )
multi classify($test, +items, *%named )
```
The first form will always fail. The second form classifies on the identity of the given object, which usually only makes sense in combination with the `:&as` argument.
The rest include a `$test` argument, which is a function that will return a scalar for every input; these will be used as keys of a hash whose values will be arrays with the elements that output that key for the test function.
```raku
my @years = (2003..2008).map( { Date.new( $_~"-01-01" ) } );
@years.classify( *.is-leap-year , into => my %leap-years );
say %leap-years;
# OUTPUT: «{False => [2003-01-01 2005-01-01 2006-01-01 2007-01-01],
# True => [2004-01-01 2008-01-01]}»
```
Similarly to [`.categorize`](/type/Any#routine_categorize), elements can be normalized by the [`Callable`](/type/Callable) passed with the `:as` argument, and it can use the `:into` named argument to pass a [`Hash`](/type/Hash) the results will be classified into; in the example above, it's defined on the fly.
From version 6.d, `.classify` will also work with [`Junction`](/type/Junction)s.
Support for using [`Whatever`](/type/Whatever) as the test was added in Rakudo compiler version 2023.02.
# [In List](#___top "go to top of document")[§](#(List)_routine_classify "direct link")
See primary documentation
[in context](/type/List#routine_classify)
for **routine classify**.
```raku
multi method classify($test, :$into!, :&as)
multi method classify($test, :&as)
multi classify($test, +items, :$into!, *%named )
multi classify($test, +items, *%named )
```
Transforms a list of values into a hash representing the classification of those values; each hash key represents the classification for one or more of the incoming list values, and the corresponding hash value contains an array of those list values classified into the category of the associated key. `$test` will be an expression that will produce the hash keys according to which the elements are going to be classified.
Example:
```raku
say classify { $_ %% 2 ?? 'even' !! 'odd' }, (1, 7, 6, 3, 2);
# OUTPUT: «{even => [6 2], odd => [1 7 3]}»
say ('hello', 1, 22/7, 42, 'world').classify: { .Str.chars };
# OUTPUT: «{1 => [1], 2 => [42], 5 => [hello world], 8 => [3.142857]}»
```
It can also take `:as` as a named parameter, transforming the value before classifying it:
```raku
say <Innie Minnie Moe>.classify( { $_.chars }, :as{ lc $_ });
# OUTPUT: «{3 => [moe], 5 => [innie], 6 => [minnie]}»
```
This code is classifying by number of characters, which is the expression that has been passed as `$test` parameter, but the `:as` block lowercases it before doing the transformation. The named parameter `:into` can also be used to classify *into* a newly defined variable:
```raku
<Innie Minnie Moe>.classify( { $_.chars }, :as{ lc $_ }, :into( my %words{Int} ) );
say %words; # OUTPUT: «{3 => [moe], 5 => [innie], 6 => [minnie]}»
```
We are declaring the scope of `%words{Int}` on the fly, with keys that are actually integers; it gets created with the result of the classification.
|
## dist_github-retupmoca-Compress-Zlib-Raw.md
# Compress::Zlib::Raw
[](https://travis-ci.org/retupmoca/P6-Compress-Zlib-Raw) [](https://ci.appveyor.com/project/retupmoca/P6-Compress-Zlib-Raw/branch/master)
Low-level interface to zlib.
Note: This will probably only work on 64bit \*nix, due to hardcoded library name
and `sizeof` numbers.
##Example
```
use v6;
use Compress::Zlib::Raw;
use NativeCall;
my $to-compress = "test".encode;
my $return-buf-len = CArray[long].new;
$return-buf-len[0] = 128;
my $return-buf = buf8.new;
$return-buf[127] = 0;
my $result = compress($return-buf, $return-buf-len, $to-compress, 4);
die if $result != Compress::Zlib::Raw::Z_OK;
my $orig-buf = buf8.new;
$orig-buf[127] = 1;
my $orig-size = CArray[long].new;
$orig-size[0] = 128;
$result = uncompress($orig-buf, $orig-size, $return-buf, $return-buf-len[0]);
die if $result != Compress::Zlib::Raw::Z_OK;
```
## Author
Andrew Egeler, retupmoca on #perl6, <https://github.com/retupmoca/>
## License
MIT License
|
## dist_cpan-PMQS-Raku-GitHub-Workflows.md
# Raku GitHub Workflows





This distribution contains a number of GitHub workflows that can be used for testing [Raku](https://www.raku.org/) (Perl6) modules. The Raku code under `lib` and `t` is just dummy code that acts as a test harness for the workflows. Look in `.github/workflows` for the real deliverables from this dstribution.
## Summary of Workflows Available
The workflows vary in the amount of control they have over the version of Raku used and the OS they run on. The table below summarised the feature set available in each.
| Workflow File | OS Supported | Raku Origin | Uses [Rakudo Star](https://rakudo.org/star) | Control Raku Version Used | Option To Run Latest Raku | GitHub Cache Support |
| --- | --- | --- | --- | --- | --- | --- |
| wf-caching.yml | Linux, MacOS & Windows | [Rakudo Downloads](https://rakudo.org/downloads/rakudo) | No | Yes | Yes | Yes |
| wf-linux-docker.yml | Linux | [Docker](https://hub.docker.com/r/jjmerelo/alpine-raku) | No | Yes | Yes | No |
| wf-linux-star-docker.yml | Linux | [Rakudo Star Official Docker](https://hub.docker.com/_/rakudo-star/) | Yes | Yes | Yes | No |
| wf-macos-star.yml | MacOS | [Homebrew](https://github.com/Homebrew/homebrew-core/blob/master/Formula/rakudo-star.rb) | Yes | No | No | No |
| wf-windows-star.yml | Windows | [Chocolatey](https://chocolatey.org/packages/rakudostar) | Yes | No | No | No |
## Which one should you use?
For casual testing, one of the workflows that use [Rakudo Star](https://rakudo.org/star) is a good starting point. They usually have a relatively recent build of Raku, plus they come with a set of commonly used modules. Less chance of needing any prerequisite modules to be installed.
## Why you may need a Caching Workflow
All the workflows use the [zef](https://github.com/ugexe/zef) Module Manager to automatically install Raku depencencies. If you are using a workflow that uses [Rakudo Star](https://rakudo.org/star) there may be no need to install any. [Rakudo Star](https://rakudo.org/star) may already include them.
If you have a use-case where your module dependencies are not present in a [Rakudo Star](https://rakudo.org/star) distribution, and you are not using workflow caching, those dependencies will get resolved by [zef](https://github.com/ugexe/zef) every time the workflow runs.
At the time of writing, installing Raku module dependencies can take a *long* time to run -- 5 minutes is typical. This is where a caching workflow can help. The `wf-caching.yml` workflow has been setup to use a GitHub cache to store all the modules that [zef](https://github.com/ugexe/zef) installs.
This means that the first time you run the workflow you will take the 5 minute hit, but the subsequent runs should be completed in seconds.
## Limitations of Caching
GitHub will only retain the cache for about a week if it isn't accessed.
## Support
Suggestions/patches/comments are welcomed at [Raku-GitHub-WorkFlows](https://github.com/pmqs/Raku-GitHub-Workflows)
|
## utf8.md
class utf8
Mutable uint8 buffer for utf8 binary data
```raku
class utf8 does Blob[uint8] is repr('VMArray') {}
```
A `utf8` is a subtype of Blob which is specifically uint8 data for holding UTF-8 encoded text.
```raku
my utf8 $b = "hello".encode;
say $b[1].fmt("0x%X"); # OUTPUT: «0x65»
```
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `utf8`
raku-type-graph
utf8
utf8
Any
Any
utf8->Any
Blob
Blob
utf8->Blob
Mu
Mu
Any->Mu
Positional
Positional
Stringy
Stringy
Blob->Positional
Blob->Stringy
[Expand chart above](/assets/typegraphs/utf8.svg)
|
## dist_zef-sdondley-Distribution-Extension-Updater.md
[](https://github.com/sdondley/Distribution-Extension-Updater/actions)
# NAME
Distribution::Extension::Updater - Update legacy file extensions in a Raku distribution.
# SYNOPSIS
```
# On the command line...
# upgrade all legacy extensions in a distribution directory, defaults to '.'
rdeu [ '/path/to/distro' ]
# do a dry run, don't change anything
rdeu -d
rdeu --/tests # don't upgrade test extensions
rdeu --/mods # don't update module extensions
rdeu --/tests --/docs # don't update tests or docs
# don't display messages to stdout
rdeu -q
# In a module...
use Distribution::Extension::Updater;
my $distro = Distribution::Extension::Updater.new('/path/to/dir');
my $bool = $distro.has-legacy-extensions;
$distro.report;
perform the upgrade on files with the extensions passed
$distro.update-extensions( <t p6 pm pm6 pod pod6> );
```
# DESCRIPTION
Distribution::Extension::Updater searches a distribution on a local machine for legacy Perl 6 file extensions and updates them to the newer Raku extensions. The following file types and extensions can be updated:
* modules with `.pm`, `.p6`, and `.pm6` extensions
* documentation with `.pod` and `.pod6` extensions
* tests with the `.t` extension
This module also updates the META6.json file as unobtrusively as possible without reorganizing it by swapping out the `provides` section of the file with an updated version containing the new file extensions.
If the module determines that the git command is available and the distribution has a .git directory, it will `git mv` the files. Otherwise, it will move the files with Raku's `move` command.
After the module updates the extensions, the changes can be added and committed to the local git repo and then uploaded to the appropriate ecosystem manually. This module does not attempt to modify the `Changes` file.
The module does not update files located in the `resources` directory or the `.precomp` directory.
The module is designed to be run from the command line with the `rdeu` command but also provides an API for running it from a script or other module.
# COMMAND LINE OPERATION
## rdeu [ path/to/distro ]
Updates the test, documentation, and module files found in the distribution with the following extensions: `.t, .pm, .p6, .pm6, .pod, .pod6`. If no path is given, the command is run in the current directory.
### Options
#### -d|--dry-run
Performs a dry-run to give a user a chance to preview what will be changed.
#### -q|--quiet
Suppresses messages to standard output. Warnings will still be printed.
#### -h
Provides help for the `rdeu` command.
#### --/mods|modules --/documentation|docs --/tests
These three options can be used alone or in combination, can be used to prevent the updating of certain types of legacy extensions.
##### `--mods` turns off the updating of files with extension of `.p6, .pm, .pm6`.
##### `--tests` turns off the updating of files with extension of `.t`.
##### `--docs` turns off the updating of files with extension of `.pod6, .pod`.
# OBJECT CONSTRUCTION AND METHODS
As mentioned, the module can also be used from within Raku code using the following methods.
## Construction
### new(Str $d = '', :d(:$dir) = $d || '.', Bool :$quiet = False, Bool :$dry-run = False, \*%\_ ())
Creates a new D::E::U object. If no directory is provided either with a positional argument or a named argument, defaults to the current directly, '.'. Boolean arguments, `:quiet` and `:dry-run` determine whether output messages are printed and whether changes to the distribution are actually made.
## Methods
### has-legacy-extensions (\*@exts where @exts ⊆ @valid-ext)
Returns a boolean value `True` if any legacy extensions passed via @exts are found, `False` otherwise. With no arguments, will search for all known legacy extensions.
### update-extensions( @exts );
Perform the upgrade on files with the extensions passed in `@exts`. Only `.p6`, `.pm`, `.pm6`, `.t`, `.pod` and `.pod6` extensions are permitted.
### report
Get a simple report that counts the number of files found for each legacy extensions.
### get-meta
Returns the `Path::IO` object to the meta json file if found, `False` otherwise.
### has-git
Return `True` if it determines git is installed, `False` otherwisek.
### find( Str:D $ext )
Creates a key in the `%.ext` object attribute that points to a list of files with the extension supplied by `$ext`.
# AUTHOR
Steve Dondley [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2023 Steve Dondley
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-FRITH-Math-Libgsl-Function.md
## Chunk 1 of 3
[](https://travis-ci.org/frithnanth/raku-Math-Libgsl-Function)
# NAME
Math::Libgsl::Function - An interface to libgsl, the Gnu Scientific Library - Special functions.
# SYNOPSIS
```
use Math::Libgsl::Raw::Function :ALL;
use Math::Libgsl::Function :ALL;
```
# DESCRIPTION
Math::Libgsl::Function provides an interface to special function evaluation in libgsl, the GNU Scientific Library.
Math::Libgsl::Function makes these tags available:
* :airy
* :bessel
* :coulomb
* :coupling
* :dawson
* :debye
* :dilog
* :mult
* :ellint
* :ellfun
* :err
* :exp
* :fermidirac
* :gammabeta
* :gegen
* :hermite
* :hyperg
* :laguerre
* :lambert
* :legendre
* :log
* :mathieu
* :pow
* :psi
* :sync
* :transport
* :trig
* :zeta
Throughout this module the subs whose name ends with "-e" return a List of two values: the result and its associated error.
### sub Ai(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Ai-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the Airy function Ai(x) with an accuracy specified by mode.
### sub Bi(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Bi-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the Airy function Bi(x) with an accuracy specified by mode.
### sub Ai-scaled(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Ai-scaled-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the scaled value of the Airy function Ai(x) with an accuracy specified by mode.
### sub Bi-scaled(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Bi-scaled-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the scaled value of the Airy function Bi(x) with an accuracy specified by mode.
### sub Ai-deriv(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Ai-deriv-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the scaled value of the Airy function derivative A'i(x) with an accuracy specified by mode.
### sub Bi-deriv(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Bi-deriv-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the scaled value of the Airy function derivative B'i(x) with an accuracy specified by mode.
### sub Ai-deriv-scaled(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Ai-deriv-scaled-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the scaled value of the Airy function derivative A'i(x) with an accuracy specified by mode.
### sub Bi-deriv-scaled(Num(Cool) $x, UInt $mode --> Num) is export(:airy)
### sub Bi-deriv-scaled-e(Num(Cool) $x, UInt $mode --> List) is export(:airy)
These routines compute the scaled value of the Airy function derivative B'i(x) with an accuracy specified by mode.
### sub Ai-zero(UInt $s --> Num) is export(:airy)
### sub Ai-zero-e(UInt $s --> List) is export(:airy)
These routines compute the location of the s-th zero of the Airy function Ai(x).
### sub Bi-zero(UInt $s --> Num) is export(:airy)
### sub Bi-zero-e(UInt $s --> List) is export(:airy)
These routines compute the location of the s-th zero of the Airy function Bi(x).
### sub Ai-deriv-zero(UInt $s --> Num) is export(:airy)
### sub Ai-deriv-zero-e(UInt $s --> List) is export(:airy)
These routines compute the location of the s-th zero of the Airy function derivative A'i(x).
### sub Bi-deriv-zero(UInt $s --> Num) is export(:airy)
### sub Bi-deriv-zero-e(UInt $s --> List) is export(:airy)
These routines compute the location of the s-th zero of the Airy function derivative B'i(x).
### sub J0(Num(Cool) $x --> Num) is export(:bessel)
### sub J0-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular cylindrical Bessel function of zeroth order, J₀(x).
### sub J1(Num(Cool) $x --> Num) is export(:bessel)
### sub J1-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular cylindrical Bessel function of first order, J₁(x).
### sub Jn(Int $n, Num(Cool) $x --> Num) is export(:bessel)
### sub Jn-e(Int $n, Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular cylindrical Bessel function of order n, Jₙ(x).
### sub Jn-array(Int $nmin, Int $nmax where $nmin < $nmax, Num(Cool) $x --> List) is export(:bessel)
This routine computes the values of the regular cylindrical Bessel functions Jₙ(x) for n from nmin to nmax inclusive.
### sub Y0(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Y0-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the irregular cylindrical Bessel function of zeroth order, Y₀(x).
### sub Y1(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Y1-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the irregular cylindrical Bessel function of first order, Y₁(x).
### sub Yn(Int $n, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Yn-e(Int $n, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the irregular cylindrical Bessel function of order n, Yₙ(x).
### sub Yn-array(Int $nmin, Int $nmax where $nmin < $nmax, Num(Cool) $x --> List) is export(:bessel)
This routine computes the values of the irregular cylindrical Bessel functions Yₙ(x) for n from nmin to nmax inclusive.
### sub I0(Num(Cool) $x --> Num) is export(:bessel)
### sub I0-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular modified cylindrical Bessel function of zeroth order, I₀(x).
### sub I1(Num(Cool) $x --> Num) is export(:bessel)
### sub I1-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular modified cylindrical Bessel function of first order, I₁(x).
### sub In(Int $n, Num(Cool) $x --> Num) is export(:bessel)
### sub In-e(Int $n, Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular modified cylindrical Bessel function of order n, Iₙ(x).
### sub In-array(UInt $nmin, UInt $nmax where $nmin < $nmax, Num(Cool) $x --> List) is export(:bessel)
This routine computes the values of the regular modified cylindrical Bessel functions Iₙ(x) for n from nmin to nmax inclusive.
### sub I0-scaled(Num(Cool) $x --> Num) is export(:bessel)
### sub I0-scaled-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the scaled regular modified cylindrical Bessel function of zeroth order exp(−|x|)I₀(x).
### sub I1-scaled(Num(Cool) $x --> Num) is export(:bessel)
### sub I1-scaled-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the scaled regular modified cylindrical Bessel function of first order exp(−|x|)I₁(x).
### sub In-scaled(Int $n, Num(Cool) $x --> Num) is export(:bessel)
### sub In-scaled-e(Int $n, Num(Cool) $x --> List) is export(:bessel)
These routines compute the scaled regular modified cylindrical Bessel function of order n exp(−|x|)Iₙ(x).
### sub In-scaled-array(UInt $nmin, UInt $nmax where $nmin < $nmax, Num(Cool) $x --> List) is export(:bessel)
This routine computes the values of the scaled regular cylindrical Bessel functions exp(−|x|)Iₙ(x) for n from nmin to nmax inclusive.
### sub K0(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub K0-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the irregular modified cylindrical Bessel function of zeroth order, K₀(x).
### sub K1(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub K1-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the irregular modified cylindrical Bessel function of first order, K₁(x).
### sub Kn(Int $n, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Kn-e(Int $n, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the irregular modified cylindrical Bessel function of order n, Kₙ(x).
### sub Kn-array(UInt $nmin, UInt $nmax where $nmin < $nmax, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
This routine computes the values of the irregular modified cylindrical Bessel functions K n (x) for n from nmin to nmax inclusive.
### sub K0-scaled(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub K0-scaled-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified cylindrical Bessel function of zeroth order exp(x)K₀(x).
### sub K1-scaled(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub K1-scaled-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified cylindrical Bessel function of first order exp(x)K₁(x).
### sub Kn-scaled(Int $n, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Kn-scaled-e(Int $n, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified cylindrical Bessel function of order n exp(x)Kₙ(x).
### sub Kn-scaled-array(UInt $nmin, UInt $nmax where $nmin < $nmax, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
This routine computes the values of the scaled irregular cylindrical Bessel functions exp(x)Kₙ(x) for n from nmin to nmax inclusive.
### sub j0(Num(Cool) $x --> Num) is export(:bessel)
### sub j0-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular spherical Bessel function of zeroth order, j₀(x).
### sub j1(Num(Cool) $x --> Num) is export(:bessel)
### sub j1-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular spherical Bessel function of first order, j₁(x).
### sub j2(Num(Cool) $x --> Num) is export(:bessel)
### sub j2-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular spherical Bessel function of second order, j₂(x).
### sub jl(UInt $l, Num(Cool) $x where \* ≥ 0 --> Num) is export(:bessel)
### sub jl-e(UInt $l, Num(Cool) $x where \* ≥ 0 --> List) is export(:bessel)
These routines compute the regular spherical Bessel function of order l, jₗ(x).
### sub jl-array(UInt $lmax, Num(Cool) $x where \* ≥ 0 --> List) is export(:bessel)
This routine computes the values of the regular spherical Bessel functions jₗ(x) for l from 0 to lmax inclusive.
### sub jl-steed-array(UInt $lmax, Num(Cool) $x where \* ≥ 0 --> List) is export(:bessel)
This routine uses Steed’s method to compute the values of the regular spherical Bessel functions jₗ(x) for l from 0 to lmax inclusive.
### sub y0(Num(Cool) $x --> Num) is export(:bessel)
### sub y0-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the irregular spherical Bessel function of zeroth order, y₀(x).
### sub y1(Num(Cool) $x --> Num) is export(:bessel)
### sub y1-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the irregular spherical Bessel function of first order, y₁(x).
### sub y2(Num(Cool) $x --> Num) is export(:bessel)
### sub y2-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the irregular spherical Bessel function of second order, y₂(x).
### sub yl(UInt $l, Num(Cool) $x --> Num) is export(:bessel)
### sub yl-e(UInt $l, Num(Cool) $x --> List) is export(:bessel)
These routines compute the irregular spherical Bessel function of order l, yₗ(x).
### sub yl-array(UInt $lmax, Num(Cool) $x --> List) is export(:bessel)
This routine computes the values of the irregular spherical Bessel functions yₗ(x) for l from 0 to lmax inclusive.
### sub i0-scaled(Num(Cool) $x --> Num) is export(:bessel)
### sub i0-scaled-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the scaled regular modified spherical Bessel function of zeroth order.
### sub i1-scaled(Num(Cool) $x --> Num) is export(:bessel)
### sub i1-scaled-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the scaled regular modified spherical Bessel function of first order.
### sub i2-scaled(Num(Cool) $x --> Num) is export(:bessel)
### sub i2-scaled-e(Num(Cool) $x --> List) is export(:bessel)
These routines compute the scaled regular modified spherical Bessel function of second order.
### sub il-scaled(UInt $l, Num(Cool) $x --> Num) is export(:bessel)
### sub il-scaled-e(UInt $l, Num(Cool) $x --> List) is export(:bessel)
These routines compute the scaled regular modified spherical Bessel function of order l.
### sub il-scaled-array(UInt $lmax, Num(Cool) $x --> List) is export(:bessel)
This routine computes the values of the scaled regular modified spherical Bessel functions for l from 0 to lmax inclusive.
### sub k0-scaled(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub k0-scaled-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified spherical Bessel function of zeroth order.
### sub k1-scaled(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub k1-scaled-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified spherical Bessel function of first order.
### sub k2-scaled(Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub k2-scaled-e(Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified spherical Bessel function of second order.
### sub kl-scaled(UInt $l, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub kl-scaled-e(UInt $l, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified spherical Bessel function of order l.
### sub kl-scaled-array(UInt $lmax, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
This routine computes the values of the scaled irregular modified spherical Bessel functions for l from 0 to lmax inclusive.
### sub Jnu(Num(Cool) $ν, Num(Cool) $x --> Num) is export(:bessel)
### sub Jnu-e(Num(Cool) $ν, Num(Cool) $x --> List) is export(:bessel)
These routines compute the regular cylindrical Bessel function of fractional order ν, Jν(x).
### sub Jnu-sequence(Num(Cool) $ν, UInt $mode, Positional $x --> List) is export(:bessel)
This function computes the regular cylindrical Bessel function of fractional order ν, Jν(x), with an accuracy specified by $mode, evaluated at a series of x values.
### sub Ynu(Num(Cool) $ν, Num(Cool) $x --> Num) is export(:bessel)
### sub Ynu-e(Num(Cool) $ν, Num(Cool) $x --> List) is export(:bessel)
These routines compute the irregular cylindrical Bessel function of fractional order ν, Yν(x).
### sub Inu(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0--> Num) is export(:bessel)
### sub Inu-e(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the regular modified Bessel function of fractional order ν, Iν(x).
### sub Inu-scaled(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Inu-scaled-e(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled regular modified Bessel function of fractional order ν.
### sub Knu(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Knu-e(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the irregular modified Bessel function of fractional order ν, Kν(x).
### sub lnKnu(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub lnKnu-e(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the logarithm of the irregular modified Bessel function of fractional order ν, ln(Kν(x)).
### sub Knu-scaled(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> Num) is export(:bessel)
### sub Knu-scaled-e(Num(Cool) $ν where \* > 0, Num(Cool) $x where \* > 0 --> List) is export(:bessel)
These routines compute the scaled irregular modified Bessel function of fractional order ν.
### sub J0-zero(UInt $s --> Num) is export(:bessel)
### sub J0-zero-e(UInt $s --> List) is export(:bessel)
These routines compute the location of the s-th positive zero of the Bessel function J₀(x).
### sub J1-zero(UInt $s --> Num) is export(:bessel)
### sub J1-zero-e(UInt $s --> List) is export(:bessel)
These routines compute the location of the s-th positive zero of the Bessel function J₁(x).
### sub Jnu-zero(Num(Cool) $ν where \* ≥ 0, UInt $s --> Num) is export(:bessel)
### sub Jnu-zero-e(Num(Cool) $ν where \* ≥ 0, UInt $s --> List) is export(:bessel)
These routines compute the location of the s-th positive zero of the Bessel function Jν(x).
### sub clausen(Num(Cool) $x --> Num) is export(:clausen)
### sub clausen-e(Num(Cool) $x --> List) is export(:clausen)
These routines compute the Clausen integral Cl₂(x).
### sub hydrogenic-R1(Num(Cool) $Z, Num(Cool) $r --> Num) is export(:coulomb)
### sub hydrogenic-R1-e(Num(Cool) $Z, Num(Cool) $r --> List) is export(:coulomb)
These √ routines compute the lowest-order normalized hydrogenic bound state radial wavefunction R₁.
### sub hydrogenic-R(Int $n, Int $l, Num(Cool) $Z, Num(Cool) $r --> Num) is export(:coulomb)
### sub hydrogenic-R-e(Int $n, Int $l, Num(Cool) $Z, Num(Cool) $r --> List) is export(:coulomb)
These routines compute the n-th normalized hydrogenic bound state radial wavefunction Rₙ.
### sub coulomb-wave-FG-e(Num(Cool) $eta, Num(Cool) $x where \* > 0, Num(Cool) $LF where \* > -½, Int $k --> List) is export(:coulomb)
This function computes the Coulomb wave functions Fₗ(η, x), Gₗ₋ₖ(η, x) and their derivatives Fₗ’(η, x), Gₗ₋ₖ’(η, x) with respect to x. It returns a List of Pairs (that can be read as a Hash):
* :Fval the Fₗ(η, x) value
* :Ferr the Fₗ(η, x) error
* :Fpval the Fₗ’(η, x) value
* :Fperr the Fₗ’(η, x) error
* :Gval the Gₗ₋ₖ(η, x) value
* :Gerr the Gₗ₋ₖ(η, x) error
* :Gpval the Gₗ₋ₖ’(η, x) value
* :Gperr the Gₗ₋ₖ’(η, x) error
* :overflow Bool: if an overflow occurred, this is True, otherwise False
* :expF if an overflow occurred, this is the scaling exponent for Fₗ(η, x)
* :expG if an overflow occurred, this is the scaling exponent for Gₗ₋ₖ(η, x)
my %res = coulomb-wave-FG-e(1, 5, 0, 0);
say %res;
say %res;
say %res;
say %res;
### sub coulomb-wave-F-array(Num(Cool) $lmin, UInt $kmax, Num(Cool) $eta, Num(Cool) $x where \* > 0 --> List) is export(:coulomb)
This function computes the Coulomb wave function Fₗ(η, x) for l = lmin … lmin + kmax. It returns a List of Pairs (that can be read as a Hash):
* :outF array of Fₗ(η, x) values
* :overflow Bool: if an overflow occurred, this is True, otherwise False
* :expF if an overflow occurred, this is the scaling exponent for Fₗ(η, x)
### sub coulomb-wave-FG-array(Num(Cool) $lmin, UInt $kmax, Num(Cool) $eta, Num(Cool) $x where \* > 0 --> List) is export(:coulomb)
This function computes the functions Fₗ(η, x), Gₗ(η, x) for l = lmin … lmin + kmax. It returns a List of Pairs (that can be read as a Hash):
* :outF array of Fₗ(η, x) values
* :outG array of Gₗ(η, x) values
* :overflow Bool: if an overflow occurred, this is True, otherwise False
* :expF if an overflow occurred, this is the scaling exponent for Fₗ(η, x)
* :expG if an overflow occurred, this is the scaling exponent for Gₗ₋ₖ(η, x)
### sub coulomb-wave-FGp-array(Num(Cool) $lmin, UInt $kmax, Num(Cool) $eta, Num(Cool) $x where \* > 0 --> List) is export(:coulomb)
This function computes the functions Fₗ(η, x), Gₗ(η, x) and their derivatives F’ₗ(η, x), G’ₗ(η, x) for l = lmin … lmin + kmax It returns a List of Pairs (that can be read as a Hash):
* :outF array of Fₗ(η, x) values
* :outG array of Gₗ(η, x) values
* :outFp array of Fₗ’(η, x) values
* :outGp array of Gₗ’(η, x) values
* :overflow Bool: if an overflow occurred, this is True, otherwise False
* :expF if an overflow occurred, this is the scaling exponent for Fₗ(η, x)
* :expG if an overflow occurred, this is the scaling exponent for Gₗ₋ₖ(η, x)
### sub coulomb-wave-sphF-array(Num(Cool) $lmin, UInt $kmax, Num(Cool) $eta, Num(Cool) $x where \* > 0 --> List) is export(:coulomb)
This function computes the Coulomb wave function divided by the argument Fₗ(η, x)/x for l = lmin… lmin + kmax It returns a List of Pairs (that can be read as a Hash):
* :outF array of Fₗ(η, x) values
* :overflow Bool: if an overflow occurred, this is True, otherwise False
* :expF if an overflow occurred, this is the scaling exponent for Fₗ(η, x)
### sub coulomb-CL-e(Num(Cool) $L where \* > -1, Num(Cool) $eta --> List) is export(:coulomb)
This function computes the Coulomb wave function normalization constant Cₗ(η).
### sub coulomb-CL-array(Num(Cool) $lmin where \* > -1, UInt $kmax, Num(Cool) $eta --> List) is export(:coulomb)
This function computes the Coulomb wave function normalization constant C L (η) for l = lmin … lmin + kmax.
### sub coupling3j(Int $two-ja, Int $two-jb, Int $two-jc, Int $two-ma, Int $two-mb, Int $two-mc --> Num) is export(:coupling)
### sub coupling3j-e(Int $two-ja, Int $two-jb, Int $two-jc, Int $two-ma, Int $two-mb, Int $two-mc --> List) is export(:coupling)
These routines compute the Wigner 3-j coefficient. The arguments are given in half-integer units: two\_ja/2, two\_ma/2, etc.
### sub coupling6j(Int $two-ja, Int $two-jb, Int $two-jc, Int $two-jd, Int $two-je, Int $two-jf --> Num) is export(:coupling)
### sub coupling6j-e(Int $two-ja, Int $two-jb, Int $two-jc, Int $two-jd, Int $two-je, Int $two-jf --> List) is export(:coupling)
These routines compute the Wigner 6-j coefficient. The arguments are given in half-integer units: two\_ja/2, two\_ma/2, etc.
### sub coupling9j(Int $two-ja, Int $two-jb, Int $two-jc, Int $two-jd, Int $two-je, Int $two-jf, Int $two-jg, Int $two-jh, Int $two-ji --> Num) is export(:coupling)
### sub coupling9j-e(Int $two-ja, Int $two-jb, Int $two-jc, Int $two-jd, Int $two-je, Int $two-jf, Int $two-jg, Int $two-jh, Int $two-ji --> List) is export(:coupling)
These routines compute the Wigner 9-j coefficient. The arguments are given in half-integer units: two\_ja/2, two\_ma/2, etc.
### sub dawson(Num(Cool) $x --> Num) is export(:dawson)
### sub dawson-e(Num(Cool) $x --> List) is export(:dawson)
These routines compute the value of Dawson’s integral for x.
### sub debye1(Num(Cool) $x --> Num) is export(:debye)
### sub debye1-e(Num(Cool) $x --> List) is export(:debye)
These routines compute the first-order Debye function D₁(x).
### sub debye2(Num(Cool) $x --> Num) is export(:debye)
### sub debye2-e(Num(Cool) $x --> List) is export(:debye)
These routines compute the first-order Debye function D₂(x).
### sub debye3(Num(Cool) $x --> Num) is export(:debye)
### sub debye3-e(Num(Cool) $x --> List) is export(:debye)
These routines compute the first-order Debye function D₃(x).
### sub debye4(Num(Cool) $x --> Num) is export(:debye)
### sub debye4-e(Num(Cool) $x --> List) is export(:debye)
These routines compute the first-order Debye function D₄(x).
### sub debye5(Num(Cool) $x --> Num) is export(:debye)
### sub debye5-e(Num(Cool) $x --> List) is export(:debye)
These routines compute the first-order Debye function D₅(x).
### sub debye6(Num(Cool) $x --> Num) is export(:debye)
### sub debye6-e(Num(Cool) $x --> List) is export(:debye)
These routines compute the first-order Debye function D₆(x).
### sub dilog(Num(Cool) $x --> Num) is export(:dilog)
### sub dilog-e(Num(Cool) $x --> List) is export(:dilog)
These routines compute the dilogarithm for a real argument.
### sub complex-dilog-xy-e(Num(Cool) $x, Num(Cool) $y --> List) is export(:dilog)
### sub complex-dilog-e(Num(Cool) $r, Num(Cool) $θ --> List) is export(:dilog)
This function computes the full complex-valued dilogarithm for the complex argument z = r exp(iθ).
### sub complex-spence-xy-e(Num(Cool) $x, Num(Cool) $y --> List) is export(:dilog)
This function computes the full complex-valued Spence integral. It returns a List: the first element is the value as a Raku’s Complex datatype, the following are the errors on the real and imaginary part.
### sub multiply(Num(Cool) $x, Num(Cool) $y --> Num) is export(:mult)
### sub multiply-e(Num(Cool) $x, Num(Cool) $y --> List) is export(:mult)
These functions multiply x and y, allowing for the propagation of errors.
### sub multiply-err-e(Num(Cool) $x, Num(Cool) $dx, Num(Cool) $y, Num(Cool) $dy --> List) is export(:mult)
This function multiplies x and y with associated absolute errors dx and dy.
### sub Kcomp(Num(Cool) $k, UInt $mode --> Num) is export(:ellint)
### sub Kcomp-e(Num(Cool) $k, UInt $mode --> List) is export(:ellint)
These routines compute the complete elliptic integral K(k) to the accuracy specified by the mode variable mode.
### sub Ecomp(Num(Cool) $k, UInt $mode --> Num) is export(:ellint)
### sub Ecomp-e(Num(Cool) $k, UInt $mode --> List) is export(:ellint)
These routines compute the complete elliptic integral E(k) to the accuracy specified by the mode variable mode.
### sub Pcomp(Num(Cool) $k, Num(Cool) $n, UInt $mode --> Num) is export(:ellint)
### sub Pcomp-e(Num(Cool) $k, Num(Cool) $n, UInt $mode --> List) is export(:ellint)
These routines compute the complete elliptic integral Π(k,n) to the accuracy specified by the mode variable mode.
### sub Dcomp(Num(Cool) $k, UInt $mode --> Num) is export(:ellint)
### sub Dcomp-e(Num(Cool) $k, UInt $mode --> List) is export(:ellint)
These routines compute the complete elliptic integral D(k) to the accuracy specified by the mode variable mode.
### sub F(Num(Cool) $Φ, Num(Cool) $k, UInt $mode --> Num) is export(:ellint)
### sub F-e(Num(Cool) $Φ, Num(Cool) $k, UInt $mode --> List) is export(:ellint)
These routines compute the incomplete elliptic integral F(φ, k) to the accuracy specified by the mode variable mode.
### sub E(Num(Cool) $Φ, Num(Cool) $k, UInt $mode --> Num) is export(:ellint)
### sub E-e(Num(Cool) $Φ, Num(Cool) $k, UInt $mode --> List) is export(:ellint)
These routines compute the incomplete elliptic integral E(φ, k) to the accuracy specified by the mode variable mode.
### sub P(Num(Cool) $Φ, Num(Cool) $k, Num(Cool) $n, UInt $mode --> Num) is export(:ellint)
### sub P-e(Num(Cool) $Φ, Num(Cool) $k, Num(Cool) $n, UInt $mode --> List) is export(:ellint)
|
## dist_cpan-FRITH-Math-Libgsl-Function.md
## Chunk 2 of 3
These routines compute the incomplete elliptic integral P(φ, k) to the accuracy specified by the mode variable mode.
### sub D(Num(Cool) $Φ, Num(Cool) $k, UInt $mode --> Num) is export(:ellint)
### sub D-e(Num(Cool) $Φ, Num(Cool) $k, UInt $mode --> List) is export(:ellint)
These routines compute the incomplete elliptic integral D(φ, k) to the accuracy specified by the mode variable mode.
### sub RC(Num(Cool) $x, Num(Cool) $y, UInt $mode --> Num) is export(:ellint)
### sub RC-e(Num(Cool) $x, Num(Cool) $y, UInt $mode --> List) is export(:ellint)
These routines compute the incomplete elliptic integral RC(x, y) to the accuracy specified by the mode variable mode.
### sub RD(Num(Cool) $x, Num(Cool) $y, Num(Cool) $z, UInt $mode --> Num) is export(:ellint)
### sub RD-e(Num(Cool) $x, Num(Cool) $y, Num(Cool) $z, UInt $mode --> List) is export(:ellint)
These routines compute the incomplete elliptic integral RD(x, y, z) to the accuracy specified by the mode variable mode.
### sub RF(Num(Cool) $x, Num(Cool) $y, Num(Cool) $z, UInt $mode --> Num) is export(:ellint)
### sub RF-e(Num(Cool) $x, Num(Cool) $y, Num(Cool) $z, UInt $mode --> List) is export(:ellint)
These routines compute the incomplete elliptic integral RF(x, y, z) to the accuracy specified by the mode variable mode.
### sub RJ(Num(Cool) $x, Num(Cool) $y, Num(Cool) $z, Num(Cool) $p, UInt $mode --> Num) is export(:ellint)
### sub RJ-e(Num(Cool) $x, Num(Cool) $y, Num(Cool) $z, Num(Cool) $p, UInt $mode --> List) is export(:ellint)
These routines compute the incomplete elliptic integral RJ(x, y, z, p) to the accuracy specified by the mode variable mode.
### sub elljac-e(Num(Cool) $u, Num(Cool) $m --> List) is export(:ellfun)
This function computes the Jacobian elliptic functions sn(u|m), cn(u|m), dn(u|m) by descending Landen transformations.
### sub erf(Num(Cool) $x --> Num) is export(:err)
### sub erf-e(Num(Cool) $x --> List) is export(:err)
These routines compute the error function erf(x).
### sub erfc(Num(Cool) $x --> Num) is export(:err)
### sub erfc-e(Num(Cool) $x --> List) is export(:err)
These routines compute the complementary error function erfc(x) = 1 − erf(x).
### sub log-erfc(Num(Cool) $x --> Num) is export(:err)
### sub log-erfc-e(Num(Cool) $x --> List) is export(:err)
These routines compute the logarithm of the complementary error function log(erfc(x)).
### sub erf-Z(Num(Cool) $x --> Num) is export(:err)
### sub erf-Z-e(Num(Cool) $x --> List) is export(:err)
These routines compute the Gaussian probability density function Z(x).
### sub erf-Q(Num(Cool) $x --> Num) is export(:err)
### sub erf-Q-e(Num(Cool) $x --> List) is export(:err)
These routines compute the upper tail of the Gaussian probability function Q(x).
### sub hazard(Num(Cool) $x --> Num) is export(:err)
### sub hazard-e(Num(Cool) $x --> List) is export(:err)
These routines compute the hazard function for the normal distribution.
### sub gexp(Num(Cool) $x --> Num) is export(:exp)
### sub gexp-e(Num(Cool) $x --> List) is export(:exp)
These routines provide an exponential function exp(x) using GSL semantics and error checking.
### sub gexp-e10(Num(Cool) $x --> List) is export(:exp)
This function computes the exponential exp(x) and returns a result with extended range. This function may be useful if the value of exp(x) would overflow the numeric range of double. It returns a list of three numbers: the value, the error, and the scaling exponent.
### sub gexp-mult(Num(Cool) $x, Num(Cool) $y --> Num) is export(:exp)
### sub gexp-mult-e(Num(Cool) $x, Num(Cool) $y --> List) is export(:exp)
These routines exponentiate x and multiply by the factor y to return the product y exp(x).
### sub gexp-mult-e10(Num(Cool) $x, Num(Cool) $y --> List) is export(:exp)
This function computes the product y exp(x) and returns a result with extended range. This function may be useful if the value of exp(x) would overflow the numeric range of double. It returns a list of three numbers: the value, the error, and the scaling exponent.
### sub gexpm1(Num(Cool) $x --> Num) is export(:exp)
### sub gexpm1-e(Num(Cool) $x --> List) is export(:exp)
These routines compute the quantity exp(x) − 1 using an algorithm that is accurate for small x.
### sub gexprel(Num(Cool) $x --> Num) is export(:exp)
### sub gexprel-e(Num(Cool) $x --> List) is export(:exp)
These routines compute the quantity (exp(x) − 1)/x using an algorithm that is accurate for small x.
### sub gexprel2(Num(Cool) $x --> Num) is export(:exp)
### sub gexprel2-e(Num(Cool) $x --> List) is export(:exp)
These routines compute the quantity 2(exp(x) − 1 − x)/x 2 using an algorithm that is accurate for small x.
### sub gexprel-n(Int $n, Num(Cool) $x --> Num) is export(:exp)
### sub gexprel-n-e(Int $n, Num(Cool) $x --> List) is export(:exp)
These routines compute the N -relative exponential, which is the n-th generalization of the functions gexprel, gexprel2, gexprel-e, and gexprel2-e.
### sub gexp-err-e(Num(Cool) $x, Num(Cool) $dx --> List) is export(:exp)
This function exponentiates x with an associated absolute error dx.
### sub gexp-err-e10(Num(Cool) $x, Num(Cool) $dx --> List) is export(:exp)
This function exponentiates a quantity x with an associated absolute error dx and returns a result with extended range. This function may be useful if the value of exp(x) would overflow the numeric range of double. It returns a list of three numbers: the value, the error, and the scaling exponent.
### sub gexp-mult-err-e(Num(Cool) $x, Num(Cool) $dx, Num(Cool) $y, Num(Cool) $dy --> List) is export(:exp)
This routine computes the product y exp(x) for the quantities x, y with associated absolute errors dx, dy.
### sub gexp-mult-err-e10(Num(Cool) $x, Num(Cool) $dx, Num(Cool) $y, Num(Cool) $dy --> List) is export(:exp)
This routine computes the product y exp(x) for the quantities x, y with associated absolute errors dx, dy and returns a result with extended range. This function may be useful if the value of exp(x) would overflow the numeric range of double. It returns a list of three numbers: the value, the error, and the scaling exponent.
### sub E1(Num(Cool) $x --> Num) is export(:expint)
### sub E1-e(Num(Cool) $x --> List) is export(:expint)
These routines compute the exponential integral E₁(x).
### sub E2(Num(Cool) $x --> Num) is export(:expint)
### sub E2-e(Num(Cool) $x --> List) is export(:expint)
These routines compute the exponential integral E₂(x).
### sub En(Int $n, Num(Cool) $x --> Num) is export(:expint)
### sub En-e(Int $n, Num(Cool) $x --> List) is export(:expint)
These routines compute the exponential integral Eₙ(x) of order n.
### sub Ei(Num(Cool) $x --> Num) is export(:expint)
### sub Ei-e(Num(Cool) $x --> List) is export(:expint)
These routines compute the exponential integral Ei(x).
### sub Shi(Num(Cool) $x --> Num) is export(:expint)
### sub Shi-e(Num(Cool) $x --> List) is export(:expint)
These routines compute the hyperbolic integral Shi(x).
### sub Chi(Num(Cool) $x --> Num) is export(:expint)
### sub Chi-e(Num(Cool) $x --> List) is export(:expint)
These routines compute the hyperbolic integral Chi(x).
### sub expint3(Num(Cool) $x where \* ≥ 0 --> Num) is export(:expint)
### sub expint3-e(Num(Cool) $x where \* ≥ 0 --> List) is export(:expint)
These routines compute the third-order exponential integral Ei₃(x).
### sub Si(Num(Cool) $x --> Num) is export(:expint)
### sub Si-e(Num(Cool) $x --> List) is export(:expint)
These routines compute the Sine integral Si(x).
### sub Ci(Num(Cool) $x where \* > 0 --> Num) is export(:expint)
### sub Ci-e(Num(Cool) $x where \* > 0 --> List) is export(:expint)
These routines compute the Cosine integral Ci(x).
### sub atanint(Num(Cool) $x --> Num) is export(:expint)
### sub atanint-e(Num(Cool) $x --> List) is export(:expint)
These routines compute the Arctangent integral.
### sub fd-m1(Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd-m1-e(Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral with an index of −1.
### sub fd0(Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd0-e(Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral with an index of 0.
### sub fd1(Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd1-e(Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral with an index of 1.
### sub fd2(Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd2-e(Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral with an index of 2.
### sub fd-int(Int $j, Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd-int-e(Int $j, Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral with an integer index j.
### sub fd-mhalf(Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd-mhalf-e(Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral F₋₁/₂(x).
### sub fd-half(Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd-half-e(Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral F₁/₂(x).
### sub fd-half3(Num(Cool) $x --> Num) is export(:fermidirac)
### sub fd-half3-e(Num(Cool) $x --> List) is export(:fermidirac)
These routines compute the complete Fermi-Dirac integral F₃/₂(x).
### sub fd-inc0(Num(Cool) $x, Num(Cool) $b --> Num) is export(:fermidirac)
### sub fd-inc0-e(Num(Cool) $x, Num(Cool) $b --> List) is export(:fermidirac)
These routines compute the incomplete Fermi-Dirac integral with an index of zero, F₀(x, b).
### sub gamma(Num(Cool) $x where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> Num) is export(:gammabeta)
### sub gamma-e(Num(Cool) $x where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> List) is export(:gammabeta)
These routines compute the Gamma function Γ(x).
### sub lngamma(Num(Cool) $x where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> Num) is export(:gammabeta)
### sub lngamma-e(Num(Cool) $x where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> List) is export(:gammabeta)
These routines compute the logarithm of the Gamma function, log(Γ(x)).
### sub lngamma-sgn-e(Num(Cool) $x where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> List) is export(:gammabeta)
This routine computes the sign of the gamma function and the logarithm of its magnitude. It returns three numbers: the value, its associated error, and the sign.
### sub gammastar(Num(Cool) $x where \* > 0 --> Num) is export(:gammabeta)
### sub gammastar-e(Num(Cool) $x where \* > 0 --> List) is export(:gammabeta)
These routines compute the regulated Gamma Function Γ\*(x).
### sub gammainv(Num(Cool) $x where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> Num) is export(:gammabeta)
### sub gammainv-e(Num(Cool) $x where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> List) is export(:gammabeta)
These routines compute the reciprocal of the gamma function, 1/Γ(x) using the real Lanczos method.
### sub lngamma-complex-e(Num(Cool) $zr where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) }, Num(Cool) $zi where { $\_ > 0 || ($\_ < 0 && $\_ ≠ $\_.Int) } --> List) is export(:gammabeta)
This routine computes log(Γ(z)) for complex z = zᵣ + izᵢ. The returned parameters are lnr = log |Γ(z)|, its error, arg = arg(Γ(z)) in (−π, π], and its error.
### sub fact(UInt $n where \* ≤ GSL\_SF\_FACT\_NMAX --> Num) is export(:gammabeta)
### sub fact-e(UInt $n where \* ≤ GSL\_SF\_FACT\_NMAX --> List) is export(:gammabeta)
These routines compute the factorial n!.
### sub doublefact(UInt $n where \* ≤ GSL\_SF\_DOUBLEFACT\_NMAX --> Num) is export(:gammabeta)
### sub doublefact-e(UInt $n where \* ≤ GSL\_SF\_DOUBLEFACT\_NMAX --> List) is export(:gammabeta)
These routines compute the double factorial n!! = n(n − 2)(n − 4)…
### sub lnfact(UInt $n --> Num) is export(:gammabeta)
### sub lnfact-e(UInt $n --> List) is export(:gammabeta)
These routines compute the logarithm of the factorial of n, log(n!).
### sub lndoublefact(UInt $n --> Num) is export(:gammabeta)
### sub lndoublefact-e(UInt $n --> List) is export(:gammabeta)
These routines compute the logarithm of the double factorial of n, log(n!!).
### sub choose(UInt $n, UInt $m --> Num) is export(:gammabeta)
### sub choose-e(UInt $n, UInt $m --> List) is export(:gammabeta)o
These routines compute the combinatorial factor n choose m = n!/(m!(n − m)!).
### sub lnchoose(UInt $n, UInt $m --> Num) is export(:gammabeta)
### sub lnchoose-e(UInt $n, UInt $m --> List) is export(:gammabeta)
These routines compute the logarithm of n choose m.
### sub taylorcoeff(UInt $n, Num(Cool) $x where \* ≥ 0 --> Num) is export(:gammabeta)
### sub taylorcoeff-e(UInt $n, Num(Cool) $x where \* ≥ 0 --> List) is export(:gammabeta)
These routines compute the Taylor coefficient xⁿ/n!.
### sub poch(Num(Cool) $a, Num(Cool) $x --> Num) is export(:gammabeta)
### sub poch-e(Num(Cool) $a, Num(Cool) $x --> List) is export(:gammabeta)
These routines compute the Pochhammer symbol (a)ₓ = Γ(a + x)/Γ(a).
### sub lnpoch(Num(Cool) $a, Num(Cool) $x --> Num) is export(:gammabeta)
### sub lnpoch-e(Num(Cool) $a, Num(Cool) $x --> List) is export(:gammabeta)
These routines compute the Pochhammer symbol log((a)ₓ) = log(Γ(a + x)/Γ(a)).
### sub lnpoch-sgn-e(Num(Cool) $a, Num(Cool) $x --> List) is export(:gammabeta)
These routines compute the sign of the Pochhammer symbol and the logarithm of its magnitude. It returns three numbers: the value, its associated error, and the sign.
### sub pochrel(Num(Cool) $a, Num(Cool) $x --> Num) is export(:gammabeta)
### sub pochrel-e(Num(Cool) $a, Num(Cool) $x --> List) is export(:gammabeta)
These routines compute the relative Pochhammer symbol ((a)ₓ − 1)/x
### sub gamma-inc(Num(Cool) $a where \* > 0, Num(Cool) $x where \* ≥ 0 --> Num) is export(:gammabeta)
### sub gamma-inc-e(Num(Cool) $a, Num(Cool) $x where \* ≥ 0 --> List) is export(:gammabeta)
These functions compute the unnormalized incomplete Gamma Function Γ(a, x).
### sub gamma-inc-Q(Num(Cool) $a where \* > 0, Num(Cool) $x where \* ≥ 0 --> Num) is export(:gammabeta)
### sub gamma-inc-Q-e(Num(Cool) $a where \* > 0, Num(Cool) $x where \* ≥ 0 --> List) is export(:gammabeta)
These routines compute the normalized incomplete Gamma Function Q(a, x) = 1/Γ(a).
### sub gamma-inc-P(Num(Cool) $a where \* > 0, Num(Cool) $x where \* ≥ 0 --> Num) is export(:gammabeta)
### sub gamma-inc-P-e(Num(Cool) $a where \* > 0, Num(Cool) $x where \* ≥ 0 --> List) is export(:gammabeta)
These routines compute the complementary normalized incomplete Gamma Function P (a, x).
### sub beta(Num(Cool) $a where \* > 0, Num(Cool) $b where \* > 0 --> Num) is export(:gammabeta)
### sub beta-e(Num(Cool) $a where \* > 0, Num(Cool) $b where \* > 0 --> List) is export(:gammabeta)
These routines compute the Beta Function, B(a, b).
### sub lnbeta(Num(Cool) $a where \* > 0, Num(Cool) $b where \* > 0 --> Num) is export(:gammabeta)
### sub lnbeta-e(Num(Cool) $a where \* > 0, Num(Cool) $b where \* > 0 --> List) is export(:gammabeta)
These routines compute the logarithm of the Beta Function, log(B(a, b)).
### sub beta-inc(Num(Cool) $a where \* > 0, Num(Cool) $b where \* > 0, Num(Cool) $x where 0 ≤ \* ≤ 1 --> Num) is export(:gammabeta)
### sub beta-inc-e(Num(Cool) $a where \* > 0, Num(Cool) $b where \* > 0, Num(Cool) $x where 0 ≤ \* ≤ 1 --> List) is export(:gammabeta)
These routines compute the normalized incomplete Beta function I x (a, b).
### sub gegenpoly1(Num(Cool) $lambda, Num(Cool) $x --> Num) is export(:gegen)
### sub gegenpoly1-e(Num(Cool) $lambda, Num(Cool) $x --> List) is export(:gegen)
### sub gegenpoly2(Num(Cool) $lambda, Num(Cool) $x --> Num) is export(:gegen)
### sub gegenpoly2-e(Num(Cool) $lambda, Num(Cool) $x --> List) is export(:gegen)
### sub gegenpoly3(Num(Cool) $lambda, Num(Cool) $x --> Num) is export(:gegen)
### sub gegenpoly3-e(Num(Cool) $lambda, Num(Cool) $x --> List) is export(:gegen)
These functions evaluate the Gegenbauer polynomials Cₙλ(x) using explicit representations for n = 1, 2, 3.
### sub gegenpolyn(UInt $n, Num(Cool) $lambda where \* > -½, Num(Cool) $x --> Num) is export(:gegen)
### sub gegenpolyn-e(UInt $n, Num(Cool) $lambda where \* > -½, Num(Cool) $x --> List) is export(:gegen)
These functions evaluate the Gegenbauer polynomials Cₙλ(x) for a specific value of n, λ, x.
### sub gegenpoly-array(UInt $nmax, Num(Cool) $lambda where \* > -½, Num(Cool) $x --> List) is export(:gegen)
This function computes an array of Gegenbauer polynomials Cₙλ(x) for n = 0, 1, 2 … $nmax.
### sub hermite(Int $n, Num(Cool) $x --> Num) is export(:hermite)
### sub hermite-e(Int $n, Num(Cool) $x --> List) is export(:hermite)
These routines evaluate the physicist Hermite polynomial H n (x) of order n at position x.
### sub hermite-array(Int $nmax, Num(Cool) $x --> List) is export(:hermite)
This routine evaluates all physicist Hermite polynomials H n up to order nmax at position x.
### sub hermite-series(Int $n, Num(Cool) $x, \*@a --> Num) is export(:hermite)
### sub hermite-series-e(Int $n, Num(Cool) $x, \*@a --> List) is export(:hermite)
These routines evaluate the series Σ aⱼHⱼ(x) for j = 0 … n.
### sub hermite-prob(Int $n, Num(Cool) $x --> Num) is export(:hermite)
### sub hermite-prob-e(Int $n, Num(Cool) $x --> List) is export(:hermite)
These routines evaluate the probabilist Hermite polynomial He n (x) of order n at position x.
### sub hermite-prob-array(Int $nmax, Num(Cool) $x --> List) is export(:hermite)
This routine evaluates all probabilist Hermite polynomials Heₙ(x) up to order nmax at position x.
### sub hermite-prob-series(Int $n, Num(Cool) $x, \*@a --> Num) is export(:hermite)
### sub hermite-prob-series-e(Int $n, Num(Cool) $x, \*@a --> List) is export(:hermite)
These routines evaluate the series Σ aⱼHeⱼ(x) for j = 0 … n.
### sub hermite-der(Int $n, Int $m, Num(Cool) $x --> Num) is export(:hermite)
### sub hermite-der-e(Int $n, Int $m, Num(Cool) $x --> List) is export(:hermite)
These routines evaluate the m-th derivative of the physicist Hermite polynomial Hₙ(x) of order n at position x.
### sub hermite-array-der(Int $m, Int $nmax, Num(Cool) $x --> List) is export(:hermite)
This routine evaluates the m-th derivative of all physicist Hermite polynomials Hₙ(x) from orders 0 … nmax at position x.
### sub hermite-der-array(Int $mmax, Int $n, Num(Cool) $x --> List) is export(:hermite)
This routine evaluates all derivative orders from 0 … mmax of the physicist Hermite polynomial of order n, Hₙ, at position x.
### sub hermite-prob-der(Int $m, Int $n, Num(Cool) $x --> Num) is export(:hermite)
### sub hermite-prob-der-e(Int $m, Int $n, Num(Cool) $x --> List) is export(:hermite)
These routines evaluate the m-th derivative of the probabilist Hermite polynomial Heₙ(x) of order n at position x.
### sub hermite-prob-array-der(Int $m, Int $nmax, Num(Cool) $x --> List) is export(:hermite)
This routine evaluates the m-th derivative of all probabilist Hermite polynomials Heₙ(x) from orders 0 … nmax at position x.
### sub hermite-prob-der-array(Int $mmax, Int $n, Num(Cool) $x --> List) is export(:hermite)
This routine evaluates all derivative orders from 0 … mmax of the probabilist Hermite polynomial of order n, Heₙ, at position x.
### sub hermite-func(Int $n, Num(Cool) $x --> Num) is export(:hermite)
### sub hermite-func-e(Int $n, Num(Cool) $x --> List) is export(:hermite)
These routines evaluate the Hermite function ψₙ(x) of order n at position x.
### sub hermite-func-array(Int $nmax, Num(Cool) $x --> List) is export(:hermite)
This routine evaluates all Hermite functions ψₙ(x) for orders n = 0 … nmax at position x.
### sub hermite-func-series(Int $n, Num(Cool) $x, \*@a --> Num) is export(:hermite)
### sub hermite-func-series-e(Int $n, Num(Cool) $x, \*@a --> List) is export(:hermite)
These routines evaluate the series Σ aⱼψⱼ(x) for j = 0 … n.
### sub hermite-func-der(Int $m, Int $n, Num(Cool) $x --> Num) is export(:hermite)
### sub hermite-func-der-e(Int $m, Int $n, Num(Cool) $x --> List) is export(:hermite)
These routines evaluate the m-th derivative of the Hermite function ψₙ(x) of order n at position x.
### sub hermite-zero(Int $n, Int $s --> Num) is export(:hermite)
### sub hermite-zero-e(Int $n, Int $s --> List) is export(:hermite)
These routines evaluate the s-th zero of the physicist Hermite polynomial Hₙ(x) of order n.
### sub hermite-prob-zero(Int $n, Int $s --> Num) is export(:hermite)
### sub hermite-prob-zero-e(Int $n, Int $s --> List) is export(:hermite)
These routines evaluate the s-th zero of the probabilist Hermite polynomial Heₙ(x) of order n.
### sub hermite-func-zero(Int $n, Int $s --> Num) is export(:hermite)
### sub hermite-func-zero-e(Int $n, Int $s --> List) is export(:hermite)
These routines evaluate the s-th zero of the Hermite function ψₙ(x) of order n.
### sub F01(Num(Cool) $c, Num(Cool) $x --> Num) is export(:hyperg)
### sub F01-e(Num(Cool) $c, Num(Cool) $x --> List) is export(:hyperg)
These routines compute the hypergeometric function ₀F₁(c, x).
### sub F11(Num(Cool) $a, Num(Cool) $b, Num(Cool) $x --> Num) is export(:hyperg)
### sub F11-e(Num(Cool) $a, Num(Cool) $b, Num(Cool) $x --> List) is export(:hyperg)
These routines compute the confluent hypergeometric function ₁F₁(a, b, x).
### sub F11-int(Int $m, Int $n, Num(Cool) $x --> Num) is export(:hyperg)
### sub F11-int-e(Int $m, Int $n, Num(Cool) $x --> List) is export(:hyperg)
These routines compute the confluent hypergeometric function ₁F₁(m, n, x) for integer parameters m, n.
### sub U(Num(Cool) $a, Num(Cool) $b, Num(Cool) $x --> Num) is export(:hyperg)
### sub U-e(Num(Cool) $a, Num(Cool) $b, Num(Cool) $x --> List) is export(:hyperg)
These routines compute the confluent hypergeometric function U(a, b, x).
### sub U-e10(Num(Cool) $a, Num(Cool) $b, Num(Cool) $x --> List) is export(:hyperg)
This routine computes the confluent hypergeometric function U(a, b, x) and returns a result with extended range. It returns a list of three numbers: the value, the error, and the scaling exponent.
### sub U-int(Int $m, Int $n, Num(Cool) $x --> Num) is export(:hyperg)
### sub U-int-e(Int $m, Int $n, Num(Cool) $x --> List) is export(:hyperg)
These routines compute the confluent hypergeometric function U(m, n, x) for integer parameters m, n.
### sub U-int-e10(Int $m, Int $n, Num(Cool) $x --> List) is export(:hyperg)
This routine computes the confluent hypergeometric function U(m, n, x) for integer parameters m, n and returns a result with extended range. It returns a list of three numbers: the value, the error, and the scaling exponent.
### sub F21(Num(Cool) $a, Num(Cool) $b, Num(Cool) $c, Num(Cool) $x --> Num) is export(:hyperg)
### sub F21-e(Num(Cool) $a, Num(Cool) $b, Num(Cool) $c, Num(Cool) $x --> List) is export(:hyperg)
These routines compute the Gauss hypergeometric function ₂F₁(a, b, c, x).
### sub F21-conj(Num(Cool) $aR, Num(Cool) $aI, Num(Cool) $c, Num(Cool) $x where -1 < \* < 1 --> Num) is export(:hyperg)
### sub F21-conj-e(Num(Cool) $aR, Num(Cool) $aI, Num(Cool) $c, Num(Cool) $x where -1 < \* < 1 --> List) is export(:hyperg)
These routines compute the Gauss hypergeometric function ₂F₁(aᵣ + iaᵢ, aᵣ − iaᵢ, c, x).
### sub F21-renorm(Num(Cool) $a, Num(Cool) $b, Num(Cool) $c, Num(Cool) $x where -1 < \* < 1 --> Num) is export(:hyperg)
### sub F21-renorm-e(Num(Cool) $a, Num(Cool) $b, Num(Cool) $c, Num(Cool) $x where -1 < \* < 1 --> List) is export(:hyperg)
These routines compute the renormalized Gauss hypergeometric function ₂F₁(a, b, c, x)/Γ(c).
### sub F21-conj-renorm(Num(Cool) $aR, Num(Cool) $aI, Num(Cool) $c, Num(Cool) $x where -1 < \* < 1 --> Num) is export(:hyperg)
### sub F21-conj-renorm-e(Num(Cool) $aR, Num(Cool) $aI, Num(Cool) $c, Num(Cool) $x where -1 < \* < 1 --> List) is export(:hyperg)
These routines compute the renormalized Gauss hypergeometric function ₂F₁(aᵣ + iaᵢ, aᵣ − iaᵢ, c, x)/Γ(c).
### sub F20(Num(Cool) $a, Num(Cool) $b, Num(Cool) $x --> Num) is export(:hyperg)
### sub F20-e(Num(Cool) $a, Num(Cool) $b, Num(Cool) $x --> List) is export(:hyperg)
These routines compute the hypergeometric function ₂F₀(a, b, x).
### sub laguerre1(Num(Cool) $a, Num(Cool) $x --> Num) is export(:laguerre)
### sub laguerre1-e(Num(Cool) $a, Num(Cool) $x --> List) is export(:laguerre)
### sub laguerre2(Num(Cool) $a, Num(Cool) $x --> Num) is export(:laguerre)
### sub laguerre2-e(Num(Cool) $a, Num(Cool) $x --> List) is export(:laguerre)
### sub laguerre3(Num(Cool) $a, Num(Cool) $x --> Num) is export(:laguerre)
### sub laguerre3-e(Num(Cool) $a, Num(Cool) $x --> List) is export(:laguerre)
These routines evaluate the generalized Laguerre polynomials L₁a(x), L₂a(x), L₃a(x) using explicit representations.
### sub laguerre-n(UInt $n, Num(Cool) $a where \* > -1, Num(Cool) $x --> Num) is export(:laguerre)
### sub laguerre-n-e(UInt $n, Num(Cool) $a where \* > -1, Num(Cool) $x --> List) is export(:laguerre)
These routines evaluate the generalized Laguerre polynomials Lₙa(x).
### sub lambert-W0(Num(Cool) $x --> Num) is export(:lambert)
### sub lambert-W0-e(Num(Cool) $x --> List) is export(:lambert |
## dist_cpan-FRITH-Math-Libgsl-Function.md
## Chunk 3 of 3
)
These compute the principal branch of the Lambert W function, W₀(x).
### sub lambert-Wm1(Num(Cool) $x --> Num) is export(:lambert)
### sub lambert-Wm1-e(Num(Cool) $x --> List) is export(:lambert)
These compute the principal branch of the Lambert W function, W₋₁(x).
### sub legendre-P1(Num(Cool) $x --> Num) is export(:legendre)
### sub legendre-P1-e(Num(Cool) $x --> List) is export(:legendre)
### sub legendre-P2(Num(Cool) $x --> Num) is export(:legendre)
### sub legendre-P2-e(Num(Cool) $x --> List) is export(:legendre)
### sub legendre-P3(Num(Cool) $x --> Num) is export(:legendre)
### sub legendre-P3-e(Num(Cool) $x --> List) is export(:legendre)
These functions evaluate the Legendre polynomials Pₗ(x) using explicit representations for l = 1, 2, 3.
### sub legendre-Pl(UInt $l, Num(Cool) $x where -1 ≤ \* ≤ 1 --> Num) is export(:legendre)
### sub legendre-Pl-e(UInt $l, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
These functions evaluate the Legendre polynomial Pₗ(x) for a specific value of l, x.
### sub legendre-Pl-array(UInt $lmax, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
### sub legendre-Pl-deriv-array(UInt $lmax, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
These functions compute arrays of Legendre polynomials Pₗ(x) and derivatives dPₗ(x)/dx for l = 0 … lmax.
### sub legendre-Q0(Num(Cool) $x where
### sub legendre-Q0-e(Num(Cool) $x where
These routines compute the Legendre function Q₀(x).
### sub legendre-Q1(Num(Cool) $x where
### sub legendre-Q1-e(Num(Cool) $x where
These routines compute the Legendre function Q₁(x).
### sub legendre-Ql(UInt $l, Num(Cool) $x where { $\_ > -1 && $\_ ≠ 1 } --> Num) is export(:legendre)
### sub legendre-Ql-e(UInt $l, Num(Cool) $x where { $\_ > -1 && $\_ ≠ 1 } --> List) is export(:legendre)
These routines compute the Legendre function Qₗ(x).
### sub legendre-array-index(UInt $l, UInt $n --> UInt) is export(:legendre)
This function returns the index into the result array, corresponding to Pⁿₗ(x), P’ⁿₗ, or P”ⁿₗ(x).
### sub legendre-array(Int $norm, size\_t $lmax where \* ≤ 150, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
### sub legendre-array-e(Int $norm, UInt $lmax, Num(Cool) $x where -1 ≤ \* ≤ 1, Num(Cool) $csphase where \* == 1|-1 --> List) is export(:legendre)
These functions calculate all normalized associated Legendre polynomials. The parameter norm specifies the normalization to be used.
### sub legendre-deriv-array(Int $norm, size\_t $lmax where \* ≤ 150, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
### sub legendre-deriv-array-e(Int $norm, UInt $lmax, Num(Cool) $x where -1 ≤ \* ≤ 1, Num(Cool) $csphase where \* == 1|-1 --> List) is export(:legendre)
These functions calculate all normalized associated Legendre functions and their first derivatives up to degree lmax. The parameter norm specifies the normalization to be used. They return a List of Pairs (that can be read as a Hash):
* :out array of Pⁿₗ(x) values
* :derout array of dPⁿₗ(x)/dx values
### sub legendre-deriv-alt-array(Int $norm, size\_t $lmax where \* ≤ 150, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
### sub legendre-deriv-alt-array-e(Int $norm, UInt $lmax, Num(Cool) $x where -1 ≤ \* ≤ 1, Num(Cool) $csphase where \* == 1|-1 --> List) is export(:legendre)
These functions calculate all normalized associated Legendre functions and their (alternate) first derivatives up to degree lmax. The parameter norm specifies the normalization to be used. To include or exclude the Condon-Shortley phase factor of (−1)ⁿ, set the parameter csphase to either −1 or 1 respectively. They return a List of Pairs (that can be read as a Hash):
* :out array of Pⁿₗ(x) values
* :derout array of dPⁿₗ(x)/dx values
### sub legendre-deriv2-array(Int $norm, size\_t $lmax where \* ≤ 150, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
### sub legendre-deriv2-array-e(Int $norm, UInt $lmax, Num(Cool) $x where -1 ≤ \* ≤ 1, Num(Cool) $csphase where \* == 1|-1 --> List) is export(:legendre)
These functions calculate all normalized associated Legendre functions and their first and second derivatives up to degree lmax. The parameter norm specifies the normalization to be used. They return a List of Pairs (that can be read as a Hash):
* :out array of Pⁿₗ(x) values
* :derout array of dPⁿₗ(x)/dx values
* :derout2 array of d²Pⁿₗ(x)/d²x values
### sub legendre-deriv2-alt-array(Int $norm, size\_t $lmax where \* ≤ 150, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
### sub legendre-deriv2-alt-array-e(Int $norm, UInt $lmax, Num(Cool) $x where -1 ≤ \* ≤ 1, Num(Cool) $csphase where \* == 1|-1 --> List) is export(:legendre)
These functions calculate all normalized associated Legendre functions and their (alternate) first and second derivatives up to degree lmax. The parameter norm specifies the normalization to be used. To include or exclude the Condon-Shortley phase factor of (−1)ⁿ, set the parameter csphase to either −1 or 1 respectively. They return a List of Pairs (that can be read as a Hash):
* :out array of normalized Pⁿₗ(x) values
* :derout array of dPⁿₗ(cos(θ))/dθ values
* :derout2 array of d²Pⁿₗ(cos(θ))/d²θ values
### sub legendre-Plm(UInt $l, UInt $n, Num(Cool) $x where -1 ≤ \* ≤ 1 --> Num) is export(:legendre)
### sub legendre-Plm-e(UInt $l, UInt $n, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
These routines compute the associated Legendre polynomial Pⁿₗ(x).
### sub legendre-sphPlm(UInt $l, UInt $m, Num(Cool) $x where -1 ≤ \* ≤ 1 --> Num) is export(:legendre)
### sub legendre-sphPlm-e(UInt $l, UInt $m, Num(Cool) $x where -1 ≤ \* ≤ 1 --> List) is export(:legendre)
These routines compute the normalized associated Legendre polynomial.
### sub conicalP-half(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> Num) is export(:legendre)
### sub conicalP-half-e(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> List) is export(:legendre)
These routines compute the irregular Spherical Conical Function.
### sub conicalP-mhalf(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> Num) is export(:legendre)
### sub conicalP-mhalf-e(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> List) is export(:legendre)
These routines compute the regular Spherical Conical Function.
### sub conicalP0(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> Num) is export(:legendre)
### sub conicalP0-e(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> List) is export(:legendre)
These routines compute the conical function P⁰.
### sub conicalP1(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> Num) is export(:legendre)
### sub conicalP1-e(Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> List) is export(:legendre)
These routines compute the conical function P¹.
### sub conicalP-sph-reg(Int $l where \* ≥ -1, Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> Num) is export(:legendre)
### sub conicalP-sph-reg-e(Int $l where \* ≥ -1, Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> List) is export(:legendre)
These routines compute the Regular Spherical Conical Function.
### sub conicalP-cyl-reg(Int $m where \* ≥ -1, Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> Num) is export(:legendre)
### sub conicalP-cyl-reg-e(Int $m where \* ≥ -1, Num(Cool) $lambda, Num(Cool) $x where \* > -1 --> List) is export(:legendre)
These routines compute the Regular Cylindrical Conical Function.
### sub legendre-H3d0(Num(Cool) $lambda, Num(Cool) $eta where \* ≥ 0 --> Num) is export(:legendre)
### sub legendre-H3d0-e(Num(Cool) $lambda, Num(Cool) $eta where \* ≥ 0 --> List) is export(:legendre)
These routines compute the zeroth radial eigenfunction of the Laplacian on the 3-dimensional hyperbolic space.
### sub legendre-H3d1(Num(Cool) $lambda, Num(Cool) $eta where \* ≥ 0 --> Num) is export(:legendre)
### sub legendre-H3d1-e(Num(Cool) $lambda, Num(Cool) $eta where \* ≥ 0 --> List) is export(:legendre)
These routines compute the first radial eigenfunction of the Laplacian on the 3-dimensional hyperbolic space.
### sub legendre-H3d(UInt $l, Num(Cool) $lambda, Num(Cool) $eta where \* ≥ 0 --> Num) is export(:legendre)
### sub legendre-H3d-e(UInt $l, Num(Cool) $lambda, Num(Cool) $eta where \* ≥ 0 --> List) is export(:legendre)
These routines compute the l-th radial eigenfunction of the Laplacian on the 3-dimensional hyperbolic space.
### sub legendre-H3d-array(UInt $lmax, Num(Cool) $lambda, Num(Cool) $eta where \* ≥ 0 --> List) is export(:legendre)
This function computes an array of radial eigenfunctions.
### sub gsl-log(Num(Cool) $x where \* > 0 --> Num) is export(:log)
### sub gsl-log-e(Num(Cool) $x where \* > 0 --> List) is export(:log)
These routines compute the logarithm of x.
### sub gsl-log-abs(Num(Cool) $x where \* ≠ 0 --> Num) is export(:log)
### sub gsl-log-abs-e(Num(Cool) $x where \* ≠ 0 --> List) is export(:log)
These routines compute the logarithm of the magnitude of x.
### sub gsl-log-complex-e(Num(Cool) $zr, Num(Cool) $zi --> List) is export(:log)
This routine computes the complex logarithm of z = zᵣ + izᵢ. The returned parameters are the radial part, its error, θ in the range [−π, π], and its error.
### sub gsl-log1plusx(Num(Cool) $x where \* > -1 --> Num) is export(:log)
### sub gsl-log1plusx-e(Num(Cool) $x where \* > -1 --> List) is export(:log)
These routines compute log(1 + x).
### sub gsl-log1plusx-mx(Num(Cool) $x where \* > -1 --> Num) is export(:log)
### sub gsl-log1plusx-mx-e(Num(Cool) $x where \* > -1 --> List) is export(:log)
These routines compute log(1 + x) − x.
### sub mathieu-a(Int $n, Num(Cool) $q --> Num) is export(:mathieu)
### sub mathieu-a-e(Int $n, Num(Cool) $q --> List) is export(:mathieu)
### sub mathieu-b(Int $n, Num(Cool) $q --> Num) is export(:mathieu)
### sub mathieu-b-e(Int $n, Num(Cool) $q --> List) is export(:mathieu)
These routines compute the characteristic values aₙ(q), bₙ(q) of the Mathieu functions ceₙ(q, x) and seₙ(q, x), respectively.
### sub mathieu-a-array(Int $order-min, Int $order-max, Num(Cool) $q --> List) is export(:mathieu)
### sub mathieu-b-array(Int $order-min, Int $order-max, Num(Cool) $q --> List) is export(:mathieu)
These routines compute a series of Mathieu characteristic values aₙ(q), bₙ(q) for n from order\_min to order\_max inclusive.
### sub mathieu-ce(Int $n, Num(Cool) $q, Num(Cool) $x --> Num) is export(:mathieu)
### sub mathieu-ce-e(Int $n, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
### sub mathieu-se(Int $n, Num(Cool) $q, Num(Cool) $x --> Num) is export(:mathieu)
### sub mathieu-se-e(Int $n, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
These routines compute the angular Mathieu functions ceₙ(q, x) and seₙ(q, x), respectively.
### sub mathieu-ce-array(Int $order-min, Int $order-max, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
### sub mathieu-se-array(Int $order-min, Int $order-max, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
These routines compute a series of the angular Mathieu functions ceₙ(q, x) and seₙ(q, x) of order n from nmin to nmax inclusive.
### sub mathieu-Mc(Int $j where \* == 1|2, Int $n, Num(Cool) $q, Num(Cool) $x --> Num) is export(:mathieu)
### sub mathieu-Mc-e(Int $j where \* == 1|2, Int $n, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
### sub mathieu-Ms(Int $j where \* == 1|2, Int $n, Num(Cool) $q, Num(Cool) $x --> Num) is export(:mathieu)
### sub mathieu-Ms-e(Int $j where \* == 1|2, Int $n, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
These routines compute the radial j-th kind Mathieu functions Mcₙ(q, x) and Msₙ(q, x) of order n.
### sub mathieu-Mc-array(Int $j where \* == 1|2, Int $nmin, Int $nmax, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
### sub mathieu-Ms-array(Int $j where \* == 1|2, Int $nmin, Int $nmax, Num(Cool) $q, Num(Cool) $x --> List) is export(:mathieu)
These routines compute a series of the radial Mathieu functions of kind j, with order from nmin to nmax inclusive.
### sub pow-int(Num(Cool) $x, Int $n --> Num) is export(:pow)
### sub pow-int-e(Num(Cool) $x, Int $n --> List) is export(:pow)
These routines compute the power xⁿ for integer n.
### sub psi-int(UInt $n where \* > 0 --> Num) is export(:psi)
### sub psi-int-e(UInt $n where \* > 0 --> List) is export(:psi)
These routines compute the Digamma function ψ(n) for positive integer n.
### sub psi(Num(Cool) $x where \* ≠ 0 --> Num) is export(:psi)
### sub psi-e(Num(Cool) $x where \* ≠ 0 --> List) is export(:psi)
These routines compute the Digamma function ψ(x) for general x.
### sub psi1piy(Num(Cool) $y --> Num) is export(:psi)
### sub psi1piy-e(Num(Cool) $y --> List) is export(:psi)
These routines compute the real part of the Digamma function on the line 1 + iy.
### sub psi1-int(UInt $n where \* > 0 --> Num) is export(:psi)
### sub psi1-int-e(UInt $n where \* > 0 --> List) is export(:psi)
These routines compute the Trigamma function ψ’(n) for positive integer n.
### sub psi1(Num(Cool) $x --> Num) is export(:psi)
### sub psi1-e(Num(Cool) $x --> List) is export(:psi)
These routines compute the Trigamma function ψ’(x) for general x.
### sub psin(UInt $n, Num(Cool) $x where \* > 0 --> Num) is export(:psi)
### sub psin-e(UInt $n, Num(Cool) $x where \* > 0 --> List) is export(:psi)
These routines compute the polygamma function ψ⁽ⁿ⁾(x).
### sub synchrotron1(Num(Cool) $x where \* ≥ 0 --> Num) is export(:sync)
### sub synchrotron1-e(Num(Cool) $x where \* ≥ 0 --> List) is export(:sync)
These routines compute the first synchrotron function.
### sub synchrotron2(Num(Cool) $x where \* ≥ 0 --> Num) is export(:sync)
### sub synchrotron2-e(Num(Cool) $x where \* ≥ 0 --> List) is export(:sync)
These routines compute the second synchrotron function.
### sub transport2(Num(Cool) $x where \* ≥ 0 --> Num) is export(:transport)
### sub transport2-e(Num(Cool) $x where \* ≥ 0 --> List) is export(:transport)
These routines compute the transport function J(2, x).
### sub transport3(Num(Cool) $x where \* ≥ 0 --> Num) is export(:transport)
### sub transport3-e(Num(Cool) $x where \* ≥ 0 --> List) is export(:transport)
These routines compute the transport function J(3, x).
### sub transport4(Num(Cool) $x where \* ≥ 0 --> Num) is export(:transport)
### sub transport4-e(Num(Cool) $x where \* ≥ 0 --> List) is export(:transport)
These routines compute the transport function J(4, x).
### sub transport5(Num(Cool) $x where \* ≥ 0 --> Num) is export(:transport)
### sub transport5-e(Num(Cool) $x where \* ≥ 0 --> List) is export(:transport)
These routines compute the transport function J(5, x).
### sub gsl-sin(Num(Cool) $x --> Num) is export(:trig)
### sub gsl-sin-e(Num(Cool) $x --> List) is export(:trig)
These routines compute the sine function sin(x).
### sub gsl-cos(Num(Cool) $x --> Num) is export(:trig)
### sub gsl-cos-e(Num(Cool) $x --> List) is export(:trig)
These routines compute the cosine function cos(x).
### sub gsl-hypot(Num(Cool) $x, Num(Cool) $y --> Num) is export(:trig)
### sub gsl-hypot-e(Num(Cool) $x, Num(Cool) $y --> List) is export(:trig)
These routines compute the hypotenuse function.
### sub gsl-sinc(Num(Cool) $x --> Num) is export(:trig)
### sub gsl-sinc-e(Num(Cool) $x --> List) is export(:trig)
These routines compute sinc(x) = sin(πx)/(πx).
### sub gsl-complex-sin-e(Num(Cool) $zr, Num(Cool) $zi --> List) is export(:trig)
This function computes the complex sine.
### sub gsl-complex-cos-e(Num(Cool) $zr, Num(Cool) $zi --> List) is export(:trig)
This function computes the complex cosine.
### sub gsl-complex-logsin-e(Num(Cool) $zr, Num(Cool) $zi --> List) is export(:trig)
This function computes the logarithm of the complex sine.
### sub gsl-lnsinh(Num(Cool) $x where \* > 0 --> Num) is export(:trig)
### sub gsl-lnsinh-e(Num(Cool) $x where \* > 0 --> List) is export(:trig)
These routines compute log(sinh(x)).
### sub gsl-lncosh(Num(Cool) $x --> Num) is export(:trig)
### sub gsl-lncosh-e(Num(Cool) $x --> List) is export(:trig)
These routines compute log(cosinh(x)).
### sub polar-to-rect(Num(Cool) $r, Num(Cool) $θ where -π ≤ \* ≤ π --> List) is export(:trig)
This function converts the polar coordinates (r, θ) to rectilinear coordinates (x, y).
### sub rect-to-polar(Num(Cool) $x, Num(Cool) $y --> List) is export(:trig)
This function converts the rectilinear coordinates (x, y) to polar coordinates (r, θ).
### sub angle-restrict-symm(Num(Cool) $θ --> Num) is export(:trig)
### sub angle-restrict-symm-e(Num(Cool) $θ --> Num) is export(:trig)
These routines force the angle θ to lie in the range (−π, π].
### sub angle-restrict-pos(Num(Cool) $θ --> Num) is export(:trig)
### sub angle-restrict-pos-e(Num(Cool) $θ --> Num) is export(:trig)
These routines force the angle θ to lie in the range [0, 2π).
### sub gsl-sin-err-e(Num(Cool) $x, Num(Cool) $dx --> List) is export(:trig)
This routine computes the sine of an angle x with an associated absolute error dx, sin(x ± dx).
### sub gsl-cos-err-e(Num(Cool) $x, Num(Cool) $dx --> List) is export(:trig)
This routine computes the cosine of an angle x with an associated absolute error dx, cosin(x ± dx).
### sub zeta-int(Int $n where \* ≠ 1 --> Num) is export(:zeta)
### sub zeta-int-e(Int $n where \* ≠ 1 --> List) is export(:zeta)
These routines compute the Riemann zeta function ζ(n).
### sub zeta(Num(Cool) $s where \* ≠ 1 --> Num) is export(:zeta)
### sub zeta-e(Num(Cool) $s where \* ≠ 1 --> List) is export(:zeta)
These routines compute the Riemann zeta function ζ(s) for arbitrary s.
### sub zetam1-int(Int $n where \* ≠ 1 --> Num) is export(:zeta)
### sub zetam1-int-e(Int $n where \* ≠ 1 --> List) is export(:zeta)
These routines compute ζ(n) − 1 for integer n.
### sub zetam1(Num(Cool) $s where \* ≠ 1 --> Num) is export(:zeta)
### sub zetam1-e(Num(Cool) $s where \* ≠ 1 --> List) is export(:zeta)
These routines compute ζ(s) − 1 for arbitrary s.
### sub hzeta(Num(Cool) $t where \* > 1, Num(Cool) $q where \* > 0 --> Num) is export(:zeta)
### sub hzeta-e(Num(Cool) $t where \* > 1, Num(Cool) $q where \* > 0 --> List) is export(:zeta)
These routines compute the Hurwitz zeta function ζ(t, q).
### sub eta-int(Int $n --> Num) is export(:zeta)
### sub eta-int-e(Int $n --> List) is export(:zeta)
These routines compute the eta function η(n) for integer n.
### sub eta(Num(Cool) $s --> Num) is export(:zeta)
### sub eta-e(Num(Cool) $s --> List) is export(:zeta)
These routines compute the eta function η(s) for arbitrary s.
# C Library Documentation
For more details on libgsl see <https://www.gnu.org/software/gsl/>. The excellent C Library manual is available here <https://www.gnu.org/software/gsl/doc/html/index.html>, or here <https://www.gnu.org/software/gsl/doc/latex/gsl-ref.pdf> in PDF format.
# Prerequisites
This module requires the libgsl library to be installed. Please follow the instructions below based on your platform:
## Debian Linux
```
sudo apt install libgsl23 libgsl-dev libgslcblas0
```
That command will install libgslcblas0 as well, since it's used by the GSL.
## Ubuntu 18.04
libgsl23 and libgslcblas0 have a missing symbol on Ubuntu 18.04. I solved the issue installing the Debian Buster version of those three libraries:
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgslcblas0_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl23_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl-dev_2.5+dfsg-6_amd64.deb>
# Installation
To install it using zef (a module management tool):
```
$ zef install Math::Libgsl::Function
```
# AUTHOR
Fernando Santagata [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2020 Fernando Santagata
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-librasteve-Dan.md
[](https://opensource.org/licenses/Artistic-2.0)
[](https://github.com/librasteve/raku-Dan/actions/workflows/dan-weekly.yaml)
*THIS MODULE IS EXPERIMENTAL AND SUBJECT TO CHANGE WITHOUT NOITCE*
# raku Dan
Top level raku **D**ata **AN**alysis Module that provides **a base set of raku-style** datatype roles, accessors & methods, primarily:
* Series
* DataFrames
A common basis for bindings such as ... [Dan::Pandas](https://github.com/librasteve/raku-Dan-Pandas) (via Inline::Python), [Dan::Polars](https://github.com/librasteve/raku-Dan-Polars) (via NativeCall / Rust FFI), etc.
It's rather a zen concept since raku contains many Data Analysis constructs & concepts natively anyway (see note 7 below)
Contributions via PR are very welcome - please see the backlog Issue, or just email [[email protected]](mailto:[email protected]) to share ideas!
# INSTALLATION
```
zef install Dan;
```
# SYNOPSIS
more examples in [bin/synopsis.raku](https://github.com/librasteve/raku-Dan/blob/main/bin/synopsis-dan.raku)
```
use Dan :ALL;
### Series ###
my \s = Series.new( [b=>1, a=>0, c=>2] ); #from Array of Pairs
# -or- Series.new( [rand xx 5], index => <a b c d e>);
# -or- Series.new( data => [1, 3, 5, NaN, 6, 8], index => <a b c d e f>, name => 'john' );
say ~s;
# Accessors
say s[1]; #2 (positional)
say s<b c>; #2 1 (associative with slice)
# Map/Reduce
say s.map(*+2); #(3 2 4)
say [+] s; #3
# Hyper
say s >>+>> 2; #(3 2 4)
say s >>+<< s; #(2 0 4)
# Update
s.data[1] = 1; # set value
s.splice(1,2,(j=>3)); # update index & value
# Combine
my \t = Series.new( [f=>1, e=>0, d=>2] );
s.concat: t; # concatenate
say "=============================================";
### DataFrames ###
my \dates = (Date.new("2022-01-01"), *+1 ... *)[^6];
my \df = DataFrame.new( [[rand xx 4] xx 6], index => dates, columns => <A B C D> );
# -or- DataFrame.new( [rand xx 5], columns => <A B C D>);
# -or- DataFrame.new( [rand xx 5] );
say ~df;
say "---------------------------------------------";
# Data Accessors [row;col]
say df[0;0];
df[0;0] = 3; # set value
# Cascading Accessors (ok to mix Positional and Associative)
say df[0][0];
say df[0]<A>;
say df{"2022-01-03"}[1];
# Object Accessors & Slices (see note 1)
say ~df[0]; # 1d Row 0 (DataSlice)
say ~df[*]<A>; # 1d Col A (Series)
say ~df[0..*-2][1..*-1]; # 2d DataFrame
say ~df{dates[0..1]}^; # the ^ postfix converts an Array of DataSlices into a new DataFrame
say "---------------------------------------------";
### DataFrame Operations ###
# 2d Map/Reduce
say df.map(*.map(*+2).eager);
say [+] df[*;1];
say [+] df[*;*];
# Hyper
say df >>+>> 2;
say df >>+<< df;
# Transpose
say ~df.T;
# Describe
say ~df[0..^3]^; # head
say ~df[(*-3..*-1)]^; # tail
say ~df.shape;
say ~df.describe;
# Sort
say ~df.sort: { .[1] }; # sort by 2nd col (ascending)
say ~df.sort: { -.[1] }; # sort by 2nd col (descending)
say ~df.sort: { df[$++]<C> }; # sort by col C
say ~df.sort: { df.ix[$++] }; # sort by index
# Grep (binary filter)
say ~df.grep( { .[1] < 0.5 } ); # by 2nd column
say ~df.grep( { df.ix[$++] eq <2022-01-02 2022-01-06>.any } ); # by index (multiple)
say "---------------------------------------------";
my \df2 = DataFrame.new([
A => 1.0,
B => Date.new("2022-01-01"),
C => Series.new(1, index => [0..^4], dtype => Num),
D => [3 xx 4],
E => Categorical.new(<test train test train>),
F => "foo",
]);
say ~df2;
say df2.data;
say df2.dtypes;
say df2.index; #Hash (name => row number) -or- df.ix; #Array
say df2.columns; #Hash (label => col number) -or- df.cx; #Array
say "---------------------------------------------";
### DataFrame Splicing ### (see notes 2 & 3)
# row-wise splice:
my $ds = df2[1]; # get a DataSlice
$ds.splice($ds.index<d>,1,7); # tweak it a bit
df2.splice( 1, 2, [j => $ds] ); # default
# column-wise splice:
my $se = df2.series: <a>; # get a Series
$se.splice(2,1,7); # tweak it a bit
df2.splice( :ax, 1, 2, [K => $se] ); # axis => 1
say "---------------------------------------------";
### DataFrame Concatenation ### (see notes 4 & 5)
my \dfa = DataFrame.new(
[['a', 1], ['b', 2]],
columns => <letter number>,
);
#`[
letter number
0 a 1
1 b 2
#]
my \dfc = DataFrame.new(
[['c', 3, 'cat'], ['d', 4, 'dog']],
columns => <animal letter number>,
);
#`[
letter number animal
0 c 3 cat
1 d 4 dog
#]
dfa.concat: dfc; # row-wise / outer join is default
#`[
letter number animal
0 a 1 NaN
1 b 2 NaN
0⋅1 c 3 cat
1⋅1 d 4 dog
#]
dfa.concat: dfc, join => 'inner';
#`[
letter number
0 a 1
1 b 2
0⋅1 c 3
1⋅1 d 4
#]
my \dfd = DataFrame.new( [['bird', 'polly'], ['monkey', 'george']],
columns=> <animal name>, );
dfa.concat: dfd, axis => 1; #column-wise
#`[
letter number animal name
0 a 1 bird polly
1 b 2 monkey george
#]
say "=============================================";
```
Notes:
[1] raku accessors may use any function that makes a List, e.g.
Positional slices: `[1,3,4], [0..3], [0..*-2], [*]`
Associative slices: `<A C D>, {'A'..'C'}`
viz. <https://docs.raku.org/language/subscripts>
[2] splice is the core update method
for all add, drop, move, delete, update & insert operations
viz. <https://docs.raku.org/routine/splice>
[3] named parameter 'axis' indicates if row(0) or col(1)
if omitted, default=0 (row) / 'ax' is an alias
use a Pair literal like `:!axis, :axis(1) or :ax`
[4] concat is the core combine method
for all join, merge & combine operations
duplicate labels are extended with `$mark ~ $i++`
`# $mark = '⋅'; # unicode Dot Operator U+22C5`
use `:ii (:ignore-index)` to reset the index (row or col)
[5] concat supports `join => outer|inner|right|left`
unknown values are set to NaN
default is outer, :jn is alias, and you can go :jn on first letter
set axis param (see splice above) for col-wise concatenation
[6] relies on hypers instead of overriding dyadic operators [+-\*/]
```
say ~my \quants = Series.new([100, 15, 50, 15, 25]);
say ~my \prices = Series.new([1.1, 4.3, 2.2, 7.41, 2.89]);
say ~my \costs = Series.new( quants >>*<< prices );
```
[7] what are we getting from raku core that others do in libraries?
* pipes & maps
* multi-dimensional arrays
* slicing & indexing
* references & views
* map, reduce, hyper operators
* operator overloading
* concurrency
* types (incl. NaN)
copyright(c) 2022-2023 Henley Cloud Consulting Ltd.
|
## dist_cpan-FRITH-Image-Libexif.md
## Image::Libexif
Image::Libexif - An interface to libexif.
## Build Status
| Operating System | Build Status | CI Provider |
| --- | --- | --- |
| Linux | [Build Status](https://travis-ci.org/frithnanth/perl6-Image-Libexif) | Travis CI |
## Example
High-level interface:
```
use v6;
use Image::Libexif :tagnames;
use Image::Libexif::Constants;
#| Prints all the EXIF tags
sub MAIN($file! where { .IO.f // die "file $file not found" })
{
my Image::Libexif $e .= new: :$file;
my @tags := $e.alltags: :tagdesc;
say @tags».keys.flat.elems ~ ' tags found';
for ^EXIF_IFD_COUNT -> $group {
say "Group $group: " ~ «'Image info' 'Camera info' 'Shoot info' 'GPS info' 'Interoperability info'»[$group];
for %(@tags[$group]).kv -> $k, @v {
say "%tagnames{$k.Int}: @v[1] => @v[0]";
}
}
}
```
```
use v6;
use Concurrent::File::Find;
use Image::Libexif;
use Image::Libexif::Constants;
#| This program displays the EXIF date and time for every file in a directory tree
sub MAIN($dir where {.IO.d // die "$dir not found"})
{
my @files := find $dir, :extension('jpg'), :exclude-dir('thumbnails') :file, :!directory;
@files.race.map: -> $file {
my Image::Libexif $e .= new: :file($file);
try say "$file " ~ $e.lookup(EXIF_TAG_DATE_TIME_ORIGINAL); # don't die if no EXIF is present
$e.close;
}
}
```
Raw interface:
```
use v6;
use Image::Libexif::Raw;
use Image::Libexif::Constants;
use NativeHelpers::Blob;
#| This program extracts an EXIF thumbnail from an image and saves it into a new file (in the same directory as the original).
sub MAIN($file! where { .IO.f // die "file '$file' not found" })
{
my $l = exif_loader_new() // die ’Can't create an exif loader‘;
# Load the EXIF data from the image file
exif_loader_write_file($l, $file);
# Get the EXIF data
my $ed = exif_loader_get_data($l) // die ’Can't get the exif data‘;
# The loader is no longer needed--free it
exif_loader_unref($l);
$l = Nil;
if $ed.data && $ed.size {
my $thumb-name = $file;
$thumb-name ~~ s/\.jpg/_thumb.jpg/;
my $data = blob-from-pointer($ed.data, :elems($ed.size), :type(Blob));
spurt $thumb-name, $data, :bin;
} else {
say "No EXIF thumbnail in file $file";
}
# Free the EXIF data
exif_data_unref($ed);
}
```
For more examples see the `example` directory.
## Description
Image::Libexif provides an interface to libexif and allows you to access the EXIF records of an image.
For more details on libexif see L<https://github.com/libexif> and L<https://libexif.github.io/docs.html>.
## Documentation
#### use Image::Libexif;
#### use Image::Libexif :tagnames;
If asked to import the additional symbol `tagnames`, Image::Libexif will make available the Hash %tagnames, which
has tag numbers as keys and a short description as values.
#### new()
Creates an Image::Libexif object.
If the optional argument `$file` is provided, then it will be opened and read; if not provided
during the initialization, the program may call the `open` method later.
If the optional argument `data` is provided, then the object will be initialized from the provided data; if not
provided during the initialization, the program may call the `load` method later.
#### open(Str $file!)
Opens a file and reads it into an initialiazed object (when no file or data has been provided during initialization).
#### load(Buf $data!)
Reads the data into an initialiazed object (when no file or data has been provided during initialization).
#### close
Closes the internal libexif object, frees the memory and cleans up.
#### info(--> Hash)
Gathers some info:
* `ordercode`: the byte order as a code
* `orderstr`: the byte order as a string
* `datatype`: the data type
* `tagcount`: the number of tags
#### lookup(Int $tag!, Int $group! --> Str)
#### lookup(Int $tag! --> Str)
Looks up a tag in a specific group or in all groups. A tag may be present in more than one group.
Group names are available as constants:
* `IMAGE_INFO`
* `CAMERA_INFO`
* `SHOOT_INFO`
* `GPS_INFO`
* `INTEROPERABILITY_INFO`
#### tags(Int $group! where 0 <= \* < 5, :$tagdesc? --> Hash)
Delivers all the tags in a specific group into a hash; the keys are the tag numbers.
If the tag description is requested, the hash values are presented as an array [value, tag description].
#### alltags(:$tagdesc? --> Array)
Delivers an array of hashes, one for each group.
If the tag description is requested, the hash values are presented as an array [value, tag description].
#### notes(--> Array)
Reads the Maker Note data as an array of strings.
Each string is a concatenation of the note description, name, title, and value.
#### method thumbnail($file where { .IO.f // fail X::Libexif.new: errno => 1, error => "File $\_ not found" } --> Blob)
#### sub thumbnail($file where { .IO.f // fail X::Libexif.new: errno => 1, error => "File $\_ not found" } --> Blob) is export(:thumbnail)
Returns the thumbnail found in the original file, if any, as a Blob.
This functionality is available as a method and a sub, since the library doesn't really need a fully initialized
exif object.
To use the sub import it explicitly: `use Image::Libexif :thumbnail;`.
#### Errors
There one case when an error may be returned: trying to open a non-existent file.
This can happen while initializing an object with .new() and calling the .open() method.
In both cases the method will return a Failure object, which can
be trapped and the exception can be analyzed and acted upon.
## Prerequisites
This module requires the libexif library to be installed. Please follow the instructions below based on your platform:
### Debian Linux
```
sudo apt-get install libexif12
```
The module looks for a library called libexif.so.
## Installation
To install it using zef (a module management tool):
```
$ zef update
$ zef install Image::Libexif
```
## Testing
To run the tests:
```
$ prove -e "perl6 -Ilib"
```
## Note
Image::Libexif relies on a C library which might not be present in one's
installation, so it's not a substitute for a pure Perl6 module.
## Author
Fernando Santagata
## Copyright and license
The Artistic License 2.0
|
## val.md
val
Combined from primary sources listed below.
# [In Str](#___top "go to top of document")[§](#(Str)_routine_val "direct link")
See primary documentation
[in context](/type/Str#routine_val)
for **routine val**.
```raku
multi val(*@maybevals)
multi val(Slip:D \maybevals)
multi val(List:D \maybevals)
multi val(Pair:D \ww-thing)
multi val(\one-thing)
multi val(Str:D $MAYBEVAL, :$val-or-fail)
```
Given a `Str` that may be parsable as a numeric value, it will attempt to construct the appropriate [allomorph](/language/glossary#Allomorph), returning one of [`IntStr`](/type/IntStr), [`NumStr`](/type/NumStr), [`RatStr`](/type/RatStr) or [`ComplexStr`](/type/ComplexStr) or a plain `Str` if a numeric value cannot be parsed.
```raku
say val("42").^name; # OUTPUT: «IntStr»
say val("42e0").^name; # OUTPUT: «NumStr»
say val("42.0").^name; # OUTPUT: «RatStr»
say val("42+0i").^name; # OUTPUT: «ComplexStr»
```
You can use the plus and minus sign, as well as the Unicode "Minus Sign" as part of the String
```raku
say val("−42"); # OUTPUT: «−42»
```
While characters belonging to the Unicode categories `Nl` (number letters) and `No` (other numbers) can be used as numeric literals in the language, they will not be converted to a number by `val`, by design, and using `val` on them will produce a failure. The same will happen with synthetic numerics (such as 7̈ ). See [unival](/routine/unival) if you need to convert such characters to [`Numeric`](/type/Numeric).
|
## proxy.md
class Proxy
Item container with custom storage and retrieval
```raku
class Proxy {}
```
A Proxy is an object that allows you to set a hook that executes whenever a value is retrieved from a container (`FETCH`) or when it is set (`STORE`). Please note that `Proxy` can introduce mutability at places where it would break behavior, e.g. in [`Hash`](/type/Hash) keys.
To create a container that returns twice what was stored in it, you do something like this:
```raku
sub double() is rw {
my $storage = 0;
Proxy.new(
FETCH => method () { $storage * 2 },
STORE => method ($new) { $storage = $new },
)
}
my $doubled := double();
$doubled = 4;
say $doubled; # OUTPUT: «8»
```
# [Methods](#class_Proxy "go to top of document")[§](#Methods "direct link")
## [method new](#class_Proxy "go to top of document")[§](#method_new "direct link")
```raku
method new(:&FETCH!, :&STORE! --> Proxy:D)
```
Creates a new `Proxy` object. `&FETCH` is called with one argument (the proxy object) when the value is accessed, and must return the value that the fetch produces. `&STORE` is called with two arguments (the proxy object, and the new value) when a new value is stored in the container.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Proxy`
raku-type-graph
Proxy
Proxy
Any
Any
Proxy->Any
Mu
Mu
Any->Mu
[Expand chart above](/assets/typegraphs/Proxy.svg)
|
## dist_github-salortiz-JsonC.md
# JsonC
Using NativeCall this module binds to the popular json-c library, offering a different
approach to JSON handling in Perl6.
In adition to the traditional `to-json` and `from-json` routines this module provides
a `JSON` class.
## Usage
```
use JsonC;
# The traditional API use the same semantincs of other JSON modules.
my %h = from-json('{ "foo": "mamá", "arr": [ 1, 4, 10 ] }');
my $str = to-json(%h, :pretty);
```
So JsonC can be used as a drop-in replacement, see "pros" and "cons" ahead.
If you need finer grained control over the process, or the JSON data is big,
you can use the full power of this module:
```
use JsonC;
my $json = JSON.new-from-file('foo.json');
given $json {
when Associative {
# You got an object.
say $_<foo>;
say so $_<bar>:exists;
for %$_.pairs {
# Do someting
}
}
when Positional {
# You got an array
my @a := $_; # You can bind to one
say @a[10..20];
say @a.elems; # How many
my $foo = @a.shift;
# But beware:
say so @a ~~ Array; # False, not a Perl6's Array
say so @a ~~ JSON-P; # True but a JSON Positional
# Need a real Array?
my @foo = @a; # Do a copy to an Array;
my @bar := Array(@a); # Or cast to one, better
}
when Int { ... }
when Bool { ... }
when Str { ... }
when Any { ... } # null
}
```
|
## dist_zef-raku-community-modules-IO-Socket-Async-SSL.md
[](https://github.com/raku-community-modules/IO-Socket-Async-SSL/actions) [](https://github.com/raku-community-modules/IO-Socket-Async-SSL/actions) [](https://github.com/raku-community-modules/IO-Socket-Async-SSL/actions)
# NAME
IO::Socket::Async::SSL - Provides an API like IO::Socket::Async, but with TLS support
# SYNOPSIS
Client:
```
use IO::Socket::Async::SSL;
my $conn = await IO::Socket::Async::SSL.connect('raku.org', 443);
$conn.print: "GET / HTTP/1.0\r\nHost: raku.org\r\n\r\n";
react {
whenever $conn {
.print
}
}
$conn.close;
```
Server (assumes certificate and key files `server-crt.pem` and `server-key.pem`):
```
use IO::Socket::Async::SSL;
react {
my %ssl-config =
certificate-file => 'server-crt.pem',
private-key-file => 'server-key.pem';
whenever IO::Socket::Async::SSL.listen(
'localhost', 4433, |%ssl-config
) -> $conn {
my $req = '';
whenever $conn {
$req ~= $_;
if $req.contains("\r\n\r\n") {
say $req.lines[0];
await $conn.print(
"HTTP/1.0 200 OK\r\nContent-type: text/html\r\n\r\n"
~ "<strong>Hello from a Raku HTTP server</strong>\n");
$conn.close;
}
}
}
}
```
# DESCRIPTION
This module provides a secure sockets implementation with an API very much like that of the Raku built-in `IO::Socket::Async` class. For the client case, provided the standard certificate and host verification are sufficient, it is drop-in replacement. The server case only needs two extra arguments to `listen`, specifying the server key and certificate.
As with `IO::Socket::Async`, it is safe to have concurrent connections and to share them across threads.
## Client
The `connect` method on `IO::Socket::Async::SSL` is used to establish a SSL connection to a server. It requires two positional arguments, which specify the `host` and `port` to connect to. It returns a `Promise`, which will be kept with an `IO::Socket::Async::SSL` instance when the connection is established and the SSL handshake completed.
```
my $conn = await IO::Socket::Async::SSL.connect($host, $port);
```
By default, the SSL certificate will be verified, using the default set of accepted Certificate Authorities. The `Promise` returned by `connect` will be broken if verification fails.
Sometimes it is convenient to create a Certificate Authority (CA) and use it to sign certificates for internal use, for example to secure communications between a set of services on an internal network. In this case, the `ca-file` named argument can be passed to specify the certificate authority certificate file:
```
my $ca-file = '/config/ca-crt.pem';
my $conn = await IO::Socket::Async::SSL.connect(
'user-service', 443, :$ca-file
);
```
Alternatively, a `ca-path` argument can be specified, indicating a directory where one or more certificates may be found.
It is possible to disable certificate verification by passing the `insecure` named argument a true value. As the name suggests, **this is not a secure configuration**, since there is no way for the client to be sure that it is communicating with the intended server. Therefore, it is vulnerable to man-in-the-middle attacks.
For control over the ciphers that may be used, pass the `ciphers` argument to `connect`. It should be a string in [OpenSSL cipher list format](https://www.openssl.org/docs/man1.0.2/apps/ciphers.html).
If wishing to view encrypted traffic with a tool such as Wireshark for debugging purposes, pass a filename to the `ssl-key-log-file` name argument. Session keys will be written to this log file, and Wireshark can then be configured to introspect the encrypted traffic (Preferences -> Protocols -> TLS -> (Pre-)-Master-Secret log filename). Note that this key exposure compromises the security of the session!
## Server
The `listen` method returns a `Supply` that, when tapped, will start an SSL server. The server can be shut down by closing the tap.
Whenever a connection is made to the server, the `Supply` will emit an `IO::Socket::Async::SSL` instance. The `listen` method requires two positional arguments, specifying the `host` and `port` to listen on. Two named arguments are also required, providing the `certificate-file` and `private-key-file`.
```
my %ssl-config =
certificate-file => 'server-crt.pem',
private-key-file => 'server-key.pem';
my $connections = IO::Socket::Async::SSL.listen(
'localhost', 4433, |%ssl-config
);
react {
my $listener = do whenever $connections -> $conn {
say "Got a connection!";
$conn.close;
}
whenever signal(SIGINT) {
say "Shutting down...";
$listener.close;
exit;
}
}
```
For control over the ciphers that may be used, pass the `ciphers` named argument to `connect`. It should be a string in [OpenSSL cipher list format](https://www.openssl.org/docs/man1.0.2/apps/ciphers.html).
The following boolean options are also accepted:
* `prefer-server-ciphers` - indicates that the order of the ciphers list as configured on the server should be preferred over that of the one presented by the client
* `no-compression` - disables compression
* `no-session-resumption-on-renegotiation`
## Common client and server functionality
Both the `connect` and `listen` methods take the following optional named arguments:
* `enc`, which specifies the encoding to use when the socket is used in character mode. Defaults to `utf-8`.
* `scheduler`, which specifies the scheduler to use for processing events from the underlying `IO::Socket::Async` instance. The default is `$*SCHEDULER`. There is rarely a need to change this.
The `Supply`, `print`, `write`, and `close` methods have the same semantics as in [IO::Socket::Async](https://docs.raku.org/type/IO/Socket/Async).
## Upgrading connections
Some protocols use [opportunistic TLS](https://en.wikipedia.org/wiki/Opportunistic_TLS), where the decision to use transport layer security is first negotiated using a non-encrypted protocol - provided negotiation is successful - a TLS handshake is then performed.
This functionality is provided by the `upgrade-server` and `upgrade-client` methods. Note that the socket to upgrade must be an instance of `IO::Socket::Async`. Further, it is important to **stop reading from the socket before initiating the upgrade**, which will typically entail working with the `Tap` directly, something not normally needed in `react`/`whenever` blocks.
Here is an example of using `upgrade-server`:
```
my $server = IO::Socket::Async.listen('localhost', TEST_PORT);
react whenever $server -> $plain-conn {
my $plain-tap = do whenever $plain-conn.Supply -> $start {
if $start eq "Psst, let's talk securely!\n" {
# Must stop reading...
$plain-tap.close;
# ...so the module can take over the socket.
my $enc-conn-handshake = IO::Socket::Async::SSL.upgrade-server(
$plain-conn,
private-key-file => 't/certs-and-keys/server.key',
certificate-file => 't/certs-and-keys/server-bundle.crt'
);
whenever $enc-conn-handshake -> $enc-conn {
uc-service($enc-conn);
}
$plain-conn.print("OK, let's talk securely!\n");
}
else {
$plain-conn.print("OK, let's talk insecurely\n");
uc-service($plain-conn);
}
}
sub uc-service($conn) {
whenever $conn -> $crypt-text {
whenever $conn.print($crypt-text.uc) {
$conn.close;
}
}
}
}
```
Here's an example using `upgrade-client`; again, take note of the careful handling of the `Tap`:
```
my $plain-conn = await IO::Socket::Async.connect('localhost', TEST_PORT);
await $plain-conn.print("Psst, let's talk securely!\n");
react {
my $plain-tap = do whenever $plain-conn -> $msg {
$plain-tap.close;
my $enc-conn-handshake = IO::Socket::Async::SSL.upgrade-client(
$plain-conn,
host => 'localhost',
ca-file => 't/certs-and-keys/ca.crt'
);
whenever $enc-conn-handshake -> $enc-conn {
await $enc-conn.print("hello!\n");
whenever $enc-conn.head -> $got {
print $got; # HELLO!
done;
}
}
}
}
```
## Method reference
## class IO::Socket::Async::SSL
An asynchronous socket with Transport Layer Security. Has an API very similar to the builtin IO::Socket::Async.
### method connect
```
method connect(
Str(Any) $host,
Int(Any) $port,
:$enc = "utf8",
:$scheduler = Code.new,
Numeric :$version where { ... } = Code.new,
:$ca-file,
:$ca-path,
:$insecure,
:$alpn,
Str :$ciphers,
:$ssl-key-log-file
) returns Promise
```
Establish a TLS connection. Returns a Promise that will be kept with an IO::Socket::Async::SSL instance if the connection is successful, or broken if the connection fails.
### method upgrade-client
```
method upgrade-client(
IO::Socket::Async:D $conn,
:$enc = "utf8",
Numeric :$version where { ... } = Code.new,
:$ca-file,
:$ca-path,
:$insecure,
:$alpn,
Str :$ciphers,
Str :$host,
:$ssl-key-log-file
) returns Promise
```
Upgrade an existing client socket to TLS. This is useful when implementing StartTLS. It is important that the plaintext tap of the asynchronous socket's Supply is closed, so that it can be re-tapped by this module. Returns a Promise that will be kept with an IO::Socket::Async::SSL instance provided the upgrade succeeds, or broken if it fails.
### method listen
```
method listen(
Str(Any) $host,
Int(Any) $port,
Int(Any) $backlog = 128,
:$enc = "utf8",
:$scheduler = Code.new,
Numeric :$version where { ... } = Code.new,
:$certificate-file,
:$private-key-file,
:$alpn,
Str :$ciphers,
:$prefer-server-ciphers,
:$no-compression,
:$no-session-resumption-on-renegotiation
) returns Supply
```
Open a socket on the specified host and port, and start listening for incoming TLS connections. Returns a Supply, upon which successfully established incoming TLS connections will be emitted.
### method upgrade-server
```
method upgrade-server(
IO::Socket::Async:D $socket,
:$enc = "utf8",
Numeric :$version where { ... } = Code.new,
:$certificate-file,
:$private-key-file,
:$alpn,
Str :$ciphers,
:$prefer-server-ciphers,
:$no-compression,
:$no-session-resumption-on-renegotiation
) returns Supply
```
Upgrade an existing server socket to TLS. This is useful when implementing StartTLS. It is important that the plaintext tap of the asynchronous socket's Supply is closed, so that it can be re-tapped by this module. Returns a Supply that will emit IO::Socket::Async::SSL instance provided the upgrade succeeds, or quit if it fails.
### method Supply
```
method Supply(
:$bin,
:$enc = Code.new,
:$scheduler = Code.new
) returns Supply
```
Get a Supply of incoming data, either as a byte buffer if the :bin option is passed, or as strings otherwise. Note that strings will, in applicable encodings, be produced in NFG.
### method print
```
method print(
Str(Any) $str,
:$scheduler = Code.new
) returns Promise
```
Encode a string and send its bytes over the TLS connection. Returns a Promise that will be kept if the data is sent, and broken in the case of an error.
### method write
```
method write(
Blob $b,
:$scheduler = Code.new
) returns Mu
```
Send the bytes in the passed blob over the TLS connection. Returns a Promise that will be kept if the data is sent, and broken in the case of an error.
### method peer-host
```
method peer-host() returns Mu
```
Get the peer (remote) host
### method peer-port
```
method peer-port() returns Mu
```
Get the peer (remote) port
### method socket-host
```
method socket-host() returns Mu
```
Get the socket (local) host
### method socket-port
```
method socket-port() returns Mu
```
Get the socket (local) port
### method native-descriptor
```
method native-descriptor() returns Mu
```
Get the socket native descriptor
### method close
```
method close() returns Nil
```
Closes the connection. This will await the completion of any outstanding writes before closing.
### method supports-alpn
```
method supports-alpn() returns Bool
```
Check if ALPN support is available
## Bugs, feature requests, and contributions
Please use GitHub Issues to file bug reports and feature requests. If you wish to contribute to this module, please open a GitHub Pull Request.
Please send an email to the Raku Security Team ([[email protected]](mailto:[email protected])) to report security vulnerabilities.
# AUTHOR
Jonathan Worthington
# COPYRIGHT AND LICENSE
Copyright 2017 - 2024 Jonathan Worthington
Copyright 2024 - 2025 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-FRITH-Archive-Libarchive.md
## Archive::Libarchive
Archive::Libarchive - OO interface to libarchive.
## Build Status
[](https://github.com/frithnanth/perl6-Archive-Libarchive/actions)
## Example
```
use v6;
use Archive::Libarchive;
use Archive::Libarchive::Constants;
sub MAIN(:$file! where { .IO.f // die "file '$file' not found" })
{
my Archive::Libarchive $a .= new:
operation => LibarchiveExtract,
file => $file,
flags => ARCHIVE_EXTRACT_TIME +| ARCHIVE_EXTRACT_PERM +| ARCHIVE_EXTRACT_ACL +| ARCHIVE_EXTRACT_FFLAGS;
try {
$a.extract: sub (Archive::Libarchive::Entry $e --> Bool) { $e.pathname eq 'test2' };
CATCH {
say "Can't extract files: $_";
}
}
$a.close;
}
```
For more examples see the `example` directory.
## Description
Archive::Libarchive provides an OO interface to libarchive using Archive::Libarchive::Raw.
As the Libarchive site (<http://www.libarchive.org/>) states, its implementation is able to:
* Read a variety of formats, including tar, pax, cpio, zip, xar, lha, ar, cab, mtree, rar, and ISO images.
* Write tar, pax, cpio, zip, xar, ar, ISO, mtree, and shar archives.
* Handle automatically archives compressed with gzip, bzip2, lzip, xz, lzma, or compress.
## Documentation
#### new(LibarchiveOp :$operation!, Any :$file?, Int :$flags?, Str :$format?, :@filters?)
Creates an Archive::Libarchive object. It takes one **mandatory** argument:
`operation`, what kind of operation will be performed.
The list of possible operations is provided by the `LibarchiveOp` enum:
* `LibarchiveRead`: open the archive to list its content.
* `LibarchiveWrite`: create a new archive. The file must not be already present.
* `LibarchiveOverwrite`: create a new archive. The file will be overwritten if present.
* `LibarchiveExtract`: extract the archive content.
When extracting one can specify some options to be applied to the newly created files. The default options are:
`ARCHIVE_EXTRACT_TIME +| ARCHIVE_EXTRACT_PERM +| ARCHIVE_EXTRACT_ACL +| ARCHIVE_EXTRACT_FFLAGS`
Those constants are defined in Archive::Libarchive::Constants, part of the Archive::Libarchive::Raw
distribution.
More details about those operation modes can be found on the libarchive site: <http://www.libarchive.org/>
If the optional argument `$file` is provided, then it will be opened; if not provided
during the initialization, the program must call the `open` method later.
If the optional `$format` argument is provided, then the object will select that specific format
while dealing with the archive.
List of possible read formats:
* 7zip
* ar
* cab
* cpio
* gnutar
* iso9660
* lha
* mtree
* rar
* raw
* tar
* warc
* xar
* zip
List of possible write formats:
* 7zip
* ar
* cpio
* gnutar
* iso9660
* mtree
* pax
* raw
* shar
* ustar
* v7tar
* warc
* xar
* zip
If the optional `@filters` parameter is provided, then the object will add those filter to the archive.
Multiple filters can be specified, so a program can manage a file.tar.gz.uu for example.
The order of the filters is significant, in order to correctly deal with such files as file.tar.uu.gz and
file.tar.gz.uu .
List of possible read filters:
* bzip2
* compress
* gzip
* grzip
* lrzip
* lz4
* lzip
* lzma
* lzop
* none
* rpm
* uu
* xz
List of possible write filters:
* b64encode
* bzip2
* compress
* grzip
* gzip
* lrzip
* lz4
* lzip
* lzma
* lzop
* none
* uuencode
* xz
##### Note
Recent versions of libarchive implement an automatic way to determine the best mix of format and filters.
If one is using a pretty recent libarchive, both $format and @filters may be omitted: the `new` method will
determine automatically the right combination of parameters.
Older versions though don't have that capability and the programmer has to define explicitly both parameters.
#### open(Str $filename!, Int :$size?, :$format?, :@filters?)
#### open(Buf $data!)
Opens an archive; the first form is used on files, while the second one is used to open an archive that
resides in memory.
The first argument is always mandatory, while the other ones might been omitted.
`$size` is the size of the internal buffer and defaults to 10240 bytes.
`Note:` this module does't apply `$*CWD` to the file name under the hood, so this will create a file in the
original directory.
```
use Archive::Libarchive;
my Archive::Libarchive $a .= new: operation => LibarchiveWrite;
chdir 'subdir';
$a.open: 'file.tar.gz', format => 'gnutar', filters => ['gzip'];
…
```
#### close
Closes the internal archive object, frees the memory and cleans up.
#### extract-opts(Int $flags?)
Sets the options for the files created when extracting files from an archive.
The default options are:
`ARCHIVE_EXTRACT_TIME +| ARCHIVE_EXTRACT_PERM +| ARCHIVE_EXTRACT_ACL +| ARCHIVE_EXTRACT_FFLAGS`
#### next-header(Archive::Libarchive::Entry:D $e! --> Bool)
When reading an archive this method fills the Entry object and returns True till it reaches the end of the archive.
The Entry object is pubblicly defined inside the Archive::Libarchive module. It's initialized this way:
`my Archive::Libarchive::Entry $e .= new;`
So a complete archive lister can be implemented in few lines:
```
use v6;
use Archive::Libarchive;
sub MAIN(Str :$file! where { .IO.f // die "file '$file' not found" })
{
my Archive::Libarchive $a .= new: operation => LibarchiveRead, file => $file;
my Archive::Libarchive::Entry $e .= new;
while $a.next-header($e) {
$e.pathname.say;
$a.data-skip;
}
$a.close;
}
```
#### data-skip(--> Int)
When reading an archive this method skips file data to jump to the next header.
It returns `ARCHIVE_OK` or `ARCHIVE_EOF` (defined in Archive::Libarchive::Constants)
#### read-file-content(Archive::Libarchive::Entry $e! --> Buf)
This method reads the content of a file represented by its Entry object and returns it.
#### write-header(Str $file, Str :$pathname?, Int :$size?, Int :$filetype?, Int :$perm?, Int :$atime?, Int :$mtime?, Int :$ctime?, Int :$birthtime?, Int :$uid?, Int :$gid?, Str :$uname?, Str :$gname? --> Bool)
When creating an archive this method writes the header entry for the file being inserted into the archive.
The only mandatory argument is the file name, every other argument has a reasonable default.
If the being inserted into the archive is a symbolic link, the target will be composed as a pathname relative to the
base directory of the file, not as a full pathname.
More details can be found on the libarchive site.
Each optional argument is available as a method of the Archive::Libarchive::Entry object and it can be set when needed.
Note: `write-header` has a lot of optional arguments whose values are collected from the file one is adding to the
archive. When using the second form of `write-data` one has to provide at least these arguments:
* $size
* $atime
* $mtime
* $ctime
For example:
```
$a.write-header($filename,
:size($buffer.bytes),
:atime(now.Int),
:mtime(now.Int),
:ctime(now.Int));
```
#### write-data(Str $path --> Bool)
#### write-data(Buf $data --> Bool)
When creating an archive this method writes the data for the file being inserted into the archive.
`$path` is the pathname of the file to be archived, while `$data` is a data buffer.
#### extract(Str $destpath? --> Bool)
#### extract(&callback:(Archive::Libarchive::Entry $e --> Bool)!, Str $destpath? --> Bool)
When extracting files from an archive this method does all the dirty work.
If used in the first form it extracts all the files.
The second form takes a callback function, which receives a Archive::Libarchive::Entry object.
The callback function receives a Archive::Libarchive::Entry object.
For example, this will extract only the file whose name is `test2`:
`$a.extract: sub (Archive::Libarchive::Entry $e --> Bool) { $e.pathname eq 'test2' };`
In both cases one can specify the directory into which the files will be extracted.
#### lib-version
Returns a hash with the version number of libarchive and of each library used internally.
### Errors
When the underlying library returns an error condition, the methods will return a Failure object, which can
be trapped and the exception can be analyzed and acted upon.
The exception object has two fields: $errno and $error, and return a message stating the error number and
the associated message as delivered by libarchive.
## Prerequisites
This module requires Archive::Libarchive::Raw Raku module and the libarchive library
to be installed. Please follow the instructions below based on your platform:
### Debian Linux
```
sudo apt-get install libarchive13
```
The module looks for a library called libarchive.so, or whatever it finds in
the environment variable `PERL6_LIBARCHIVE_LIB` (provided that the library one
chooses uses the same API).
## Installation
To install it using zef (a module management tool):
```
$ zef update
$ zef install Archive::Libarchive
```
## Note
Archive::Libarchive::Raw and in turn this module rely on a C library which might not be present in one's
installation, so it's not a substitute for a pure Raku module.
This is a OO interface to the functions provided by the C library, accessible through the Archive::Libarchive::Raw
module.
## Author
Fernando Santagata
## Contributions
Many thanks to Haythem Elganiny for implementing some multi methods in the `Entry` class.
## Copyright and license
The Artistic License 2.0
|
## dist_cpan-KAIEPI-Failable.md
[](https://travis-ci.org/Kaiepi/p6-Failable)
# NAME
Failable - Failure sum type
# SYNOPSIS
```
use Failable;
sub cat(*@params --> Str:D) {
my Proc:D $proc = run "cat", |@params, :out, :err;
my Str:D $out = $proc.out.slurp(:close);
my Str:D $err = $proc.err.slurp(:close);
fail $err if $err;
$out
}
my Failable[Str:D] $output = cat "/etc/hosts";
say $output.WHAT; # OUTPUT: (Str)
my Failable[Str:D] $error = cat '.';
say $error.WHAT; # OUTPUT: (Failure)
```
# DESCRIPTION
Failable is a class for creating Failure sum types. Parameterizing Failable creates a new subset of Failure and the parameter passed. This allows you to type variables that are declared using the return values of routines that can fail.
# AUTHOR
Ben Davies (Kaiepi)
# COPYRIGHT AND LICENSE
Copyright 2019 Ben Davies
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-jjmerelo-Native-FindVersion.md
# Native::FindVersion [Test-install distro](https://github.com/JJ/raku-native-findversion/actions/workflows/test.yaml)
Tries to find all available versions of the shared libraries used in `native` modules.
## Installing
Just the usual `zef install Native::FindVersion`.
## Running
It exports a single function, `latest-version`. An example (from the test)
```
use Native::FindVersion;
constant $lib-name = "gcc_s";
my $version;
BEGIN {
$version = latest-version($lib-name);
}
sub __addvdi3( int32 $a, int32 $b) returns int32 is native($lib-name, $version )
{*};
say __addvdi3( 3, 3 )
```
Since the version needs to be known at compile time, it needs to be assigned
during the `BEGIN` phase. You can use either the short form (`foo`) or the
long form (`libfoo`).
In this case we're using a shared library and function that can be found in
most Linux systems, `libgcc`.
For ease of use, there's a function that returns directly the `native` argument:
```
constant @native-arg = latest-version-arg("gcc_s");
sub gcc-mod( int32 $a, int32 $b)
returns int32
is native(@native-arg)
is symbol("__modti3")
{*};
```
## See also
[`NativeLibs`](https://raku.land/github:salortiz/NativeLibs) includes
`NativeLib::Searcher` that will help you find a library using the symbols
found in it and a range of possible versions.
## Caveats
Untested in Windows and MacOS. If they don't append the version number to the
extension, it will not work.
## License
(c) JJ Merelo, [[email protected]](mailto:[email protected]) 2022
This module will be licensed, by default, under the Artistic 2.0 License (the same as Raku itself).
|
## dist_zef-kimryan-Lingua-EN-Sentence.md
NAME
Lingua::EN::Sentence - Module for splitting text into sentences.
SYNOPSIS
```
use Lingua::EN::Sentence;
add_acronyms(' Lt Gen'); ## adding support for 'Lt. Gen.'
$text = Q[First sentence with some abbreviations, Mr. J. Smith, 2 Jones St. SomeTown Ariz. U.S.A. is an address.
Sentence 2: Sequences like ellipsis ... are handled. Sentence 3, numbered sections such as point 1. are ok.];
my @sentences = $text.sentences;
for @sentences -> $sent {
say $sent;
}
Output is:
First sentence with some abbreviations, Mr. J. Smith, 2 Jones St. SomeTown Ariz. U.S.A. is an address.
Sentence 2: Sequences like ellipsis ... are handled.
Sentence 3, numbered sections such as point 1. are ok.
```
DESCRIPTION
The Lingua::EN::Sentence module contains the method sentences, which splits
text into its constituent sentences, based on regular expressions, a list
of abbreviations (built in and given) and other rules.
Certain well know exceptions, such as abbreviations like Mr., Calif. and
Ave. will cause incorrect segmentations. But many of these are already
integrated into this code and are being taken care of. Note that
abbreviations are case sensitive.
The add\_acronyms method allows you to add custom abbreviations.
ALGORITHM
Before any regex processing, quotations are hidden away and inserted after
the sentences are split. That entails that no sentence splitting will be
attempted between pairs of double quotes. Common cases of full stops that
do not denote an end of sentence are also hidden. These include the dot
after abbreviations mentioned above, acronymns and ellipsis.
Basically, I use a 'brute' regular expression to split the text into
sentences. (Well, nothing is yet split - I just mark the end-of-sentence).
Then I look into a set of rules which decide when an end-of-sentence is
justified and when it's a mistake. In case of a mistake, the
end-of-sentence mark is removed.
What are such mistakes? Cases of abbreviations, for example. I have a list
of such abbreviations (Please see `Acronym/Abbreviations list' section),
and more general rules (for example, the abbreviations 'i.e.' and 'e.g.'
need not to be in the list as a special rule takes care of all single
letter abbreviations).
FUNCTIONS
$text.sentences
A very convenient extension to the Perl6 Str string type, the .sentences
method allows us to natively request the sentences in a string, similarly
to the Str "words" method.
The sentences method takes a Str variable containing the text as an
argument and returns an array of sentences that the text has been split
into.
Returned sentences will be trimmed (beginning and end of sentence) of
white-spaces.
Strings with no alpha-numeric characters in them, won't be returned as
sentences.
add\_acronyms( @acronyms )
This function is used for adding acronyms not supported by this code.
Please see `Acronym/Abbreviations list' section for the abbreviations
already supported by this module.
get\_acronyms()
This function will return the defined list of acronyms.
set\_acronyms( @my\_acronyms )
This function replaces the predefined acroynm list with the given list.
get\_EOS()
This function returns the value of the string used to mark the end of
sentence. You might want to see what it is, and to make sure your text
doesn't contain it. You can use set\_EOS() to alter the end-of-sentence
string to whatever you desire.
set\_EOS( $new\_EOS\_string )
This function alters the end-of-sentence string used to mark the end of
sentences.
Acronym/Abbreviations list
You can use the get\_acronyms() function to get acronyms. It has become too
long to specify in the documentation.
If I come across a good general-purpose list - I'll incorporate it into
this module. Feel free to suggest such lists.
Limitations
There are some valid cases cannot be detected, such as: This belongs to
John A. Smith, which will break after A. This cannot be distinguished from
a valid sequence like so said I. Next sentence. A sentence ending in an
acronym does not cause a split such as St.
AUTHOR
Deyan Ginev, 2013. Kim Ryan, 2023
Perl5 CPAN author: Shlomo Yona ([[email protected]](mailto:[email protected]))
Released under the same terms as Perl 6; see the LICENSE file for details.
|
## dist_cpan-PMQS-IO-Compress-Lzf.md
```
IO-Compress-Lzf
Version 2.094
13 July 2020
Copyright (c) 2005-2020 Paul Marquess. All rights reserved.
This program is free software; you can redistribute it
and/or modify it under the same terms as Perl itself.
DESCRIPTION
-----------
This module provides a Perl interface to allow reading and writing of
lzf files/buffers.
PREREQUISITES
-------------
Before you can build IO-Compress-Lzf you need to have the following
installed on your system:
* Perl 5.006 or better.
* Compress::LZF
* IO::Compress::Base
BUILDING THE MODULE
-------------------
Assuming you have met all the prerequisites, the module can now be built
using this sequence of commands:
perl Makefile.PL
make
make test
INSTALLATION
------------
To install IO-Compress-Lzf, run the command below:
make install
TROUBLESHOOTING
---------------
SUPPORT
-------
General feedback/questions/bug reports should be sent to
https://github.com/pmqs/IO-Compress-Lzf/issues (preferred) or
https://rt.cpan.org/Public/Dist/Display.html?Name=IO-Compress-Lzf.
FEEDBACK
--------
How to report a problem with IO-Compress-Lzf.
To help me help you, I need all of the following information:
1. The Versions of everything relevant.
This includes:
a. The *complete* output from running this
perl -V
Do not edit the output in any way.
Note, I want you to run "perl -V" and NOT "perl -v".
If your perl does not understand the "-V" option it is too
old. This module needs Perl version 5.004 or better.
b. The version of IO-Compress-Lzf you have.
If you have successfully installed IO-Compress-Lzf, this one-liner
will tell you:
perl -MIO::Compress::Lzf -e 'print qq[ver $IO::Compress::Lzf::VERSION\n]'
If you are running windows use this
perl -MIO::Compress::Lzf -e "print qq[ver $IO::Compress::Lzf::VERSION\n]"
If you haven't installed IO-Compress-Lzf then search IO::Compress::Lzf.pm
for a line like this:
$VERSION = "2.094" ;
2. If you are having problems building IO-Compress-Lzf, send me a
complete log of what happened. Start by unpacking the IO-Compress-Lzf
module into a fresh directory and keep a log of all the steps
[edit config.in, if necessary]
perl Makefile.PL
make
make test TEST_VERBOSE=1
Paul Marquess
```
|
## dist_zef-raku-community-modules-Shell-Command.md
[](https://github.com/raku-community-modules/Shell-Command/actions)
# NAME
Shell::Command - provide cross-platform routines emulating common \*NIX shell commands
# SYNOPSIS
```
use Shell::Command;
# Recursive folder copy
cp 't/dir1', 't/dir2', :r;
# Remove a file
rm_f 'to_delete';
# Remove directory
rmdir 't/dupa/foo/bar';
# Make path
mkpath 't/dir2';
# Remove path
rm_rf 't/dir2';
# Find Raku in executable path
my $raku-path = which('raku');
# Concatenate the contents of a file or list of files and print to STDOUT
cat "file1.txt", "file2.txt";
# A cross platfrom syncronous run()
my $command = $*DISTRO.is-win ?? 'binary.exe' !! 'binary';
run-command($binary, 'some', 'parameter');
```
# AUTHOR
Tadeusz “tadzik” Sośnierz"
# COPYRIGHT AND LICENSE
Copyright 2010-2017 Tadeusz Sośnierz Copyright 2023 Raku Community
This library is free software; you can redistribute it and/or modify it under the MIT license.
Please see the LICENCE file in the distribution
# CONTRIBUTORS
* Dagur Valberg Johansson
* Elizabeth Mattijsen
* Filip Sergot
* Geoffrey Broadwell
* GlitchMr
* Heather
* Kamil Kułaga
* Moritz Lenz
* Steve Mynott
* timo
* Tobias Leich
* Tim Smith
* Ahmad M. Zawawi (azawawi @ #raku)
* Martin Barth
|
## dist_github-jaffa4-Ini-Storage.md
# Ini::Storage
Read/write ini files and manipulate them in memory.
Groups in function names refer to sections.
Key refers to "group/key" format.
## Usage
```
use Ini::Storage;
my $o = Ini::Storage.new("my.cfg",True); # True -> read from disk immediately if it exists.
$o.Write("g/id",7); # write section g with key id = 7
my $v = $o.Read("g/id",0); # read section g with key id... if it is not found return 0
$o.FLush; # write to disk
$o.SetDisk(False); # will not write anything to disk, even when object destructs
```
##functions
method new($filename,$isdisk)
```
method GetFilename
method SetFilename($newfn)
method Read($key,$default)
method Exchange($key,$key2)
method GetEntryName($group,$no is copy)
method Write($key,$value)
method Copy($obj)
method CountEntries($group)
method CopyGroup($obj,$group,$newgroupname?)
method DeleteEntry($key)
method RenameEntry($key,$keynew)
method DeleteEntryFromArray($key)
method GetLastArrayIndex($key)
method DeleteGroup($group)
method GroupExists($group)
method Exists($key)
method GetGroups
method GetEntriesInGroup($group)
method FindIndexInArrayByValue($group,$arrayname,$value)
method FindAValueInRecordByKey($group,$arrayname,$value,$arrayname2)
method GetArrayInGroupK($key)
method GetArrayInGroupGE($group,$name)
method SetArrayInGroup ($group,$name,@arr)
method ReadFile()
method WriteFile
method PrintGroup($group)
method SetDisk($disk)
method Flush
```
|
## dist_zef-tbrowder-FontConverter.md
[](https://github.com/tbrowder/FontConverter/actions) [](https://github.com/tbrowder/FontConverter/actions) [](https://github.com/tbrowder/FontConverter/actions)
# NAME
**FontConverter** - Enables conversion between TrueType, OpenType, and PostScript Type 1 fonts
# SYNOPSIS
```
use FontConverter;
fc-convert-font Times-Roman.pfb # OUTPUT: «Times-Roman.ttf»
```
# DESCRIPTION
**FontConverter** provides tools to convert PostScript Type 1 binary font files to TrueType as well as conversion from TrueType or OpenType to PostScript Type 1. It requires the following system programs to be installed:
* fontforge (and its Python3 components, if any)
To convert PostScript Type 1 to TrueType (X.pfb to X.ttf).
Note the conversion from PostScript to TrueType requires a Python3 script because `fontforge`'s own scripting language is broken (see its issue #5261 at <https://github.com/fontforge/fontforge>). We are fortunate to have found and been able to incorporate such a ready-made program at <https://antlarr-suse>, and we are indebted to its author, Antonio Larrosa (who also happens to be a contributor to the **SUSE** Linux distribution).
Note it looks like there is a conversion path from '.pfb' to '.otf', but that will require some more research and Python3 expertise.
* ttf2ufm
To convert TrueType or OpenType to PostScript Type 1 (X.ttf or X.otf to X.pfb, X.pfa [same as X.t1a], X.t1a, and X.afm).
Other font-related system programs:
* pdffonts - information on fonts in a PDF document
* printafm - shows metrics from a PostScript font
* showttf - provides details of a TrueType or OpenType font
# Cautions and limitations
Font file names may not always be named exactly after the actual font being described internally and, consequently, the resulting filename may not bear any semblance to the input filename. If there is any doubt, use one of the system tools (`showttf` or `printafm`) to investigate further.
Eventually this module will be able to notify you of any font or file naming difficulties, but, until then, it should not let you convert files **into** the users's current directory; instead, you must always enter the `to-dir=D` option to name the output directory (which must exist and cannot be the same as the input directory).
It is also recommended that the output directory be empty before starting font conversions.
# Motivation
## Convert PostScript Type 1 to TrueType
The author has been creating Raku modules to convert his old (but cool) PostScript-generating programs to direct PDF-generation using David Warring's Raku PDF modules. In the process, he wanted to convert old PostScript Type 1 fonts he bought for special projects to TrueType. Hence this module, which brings together the necessary tools into an easy-to-use, double-duty module and encourages use of Unicode in multi-language printed products.
## Convert TrueType or OpenType to PostScript Type 1
For completeness, the module also provides the opposite conversion for the rare case of wanting a PostScript version of a modern font for direct inclusion into a PostScript product.
# AUTHOR
Tom Browder [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
© 2023 Tom Browder
This library is free software; you may redistribute it or modify it under the Artistic License 2.0.
# ADDITIONAL LICENSE
The included Python3 program, `ttf-converter`, has its own license which is embedded in its contents at the top of the file. The first few lines are repeated here:
```
# Copyright (C) 20202 [sic] <Antonio Larrosa <[email protected]>
# This file is part of ttf-converter
# <https://github.com/antlarr-suse/ttf-converter>.
#
# ttf-converter is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License.
```
|
## dist_zef-raku-community-modules-JSON-JWT.md
[](https://github.com/raku-community-modules/JSON-JWT/actions) [](https://github.com/raku-community-modules/JSON-JWT/actions)
# NAME
JSON::JWT - JSON Web Token (JWT) implementation for Raku
# SYNOPSIS
```
use JSON::JWT;
my $jwt = JSON::JWT.encode($data, :alg<none>); # no encryption
my $jwt = JSON::JWT.encode($data, :alg<HS256>, :$secret); # HS256 encryption
my $jwt = JSON::JWT.encode($data, :alg<RS256>, :$pem); # RS256 encryption
my $data = JSON::JWT.decode($jwt, :alg<none>); # no encryption
my $data = JSON::JWT.decode($jwt, :alg<HS256>, :$secret); # HS256 encryption
my $data = JSON::JWT.decode($jwt, :alg<RS256>, :$pem); # RS256 encryption
```
# DESCRIPTION
JSON::JWT provides a class with an implementation of the JSON Web Token (JWT) standard, with support for `HS256` and `RS256` encryption, or no encryption.
# AUTHOR
Andrew Egeler
Source can be located at: <https://github.com/raku-community-modules/JSON-JWT> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2017 - 2018 Andrew Egeler
Copyright 2019 - 2024 Raku Community
All files in this repository are licensed under the terms of Create Commons License; for details please see the LICENSE file
|
## dist_github-vendethiel-Sprockets.md
# Sprockets
Raku version of Sprockets
### Usage
### Syntax
```
# application.js
/*
*= require a
*= require "b"
*/
```
|
## dist_cpan-JNTHN-JSON-Pointer.md
# JSON::Pointer
A JSON Pointer implementation in Perl 6.
## Synopsis
```
use JSON::Pointer;
# An example document to resolve pointers in
my $sample-json = {
foo => [
{
bar => 42
},
{
'weird~odd/name' => 101
}
]
}
# Simple usage
my $p = JSON::Pointer.parse('/foo/0/bar');
say $p.tokens; # [foo 0 bar]
say $p.resolve($sample-json); # 42
# ~ and / are escaped as ~0 and ~1
my $p2 = JSON::Pointer.parse('/foo/1/weird~0odd~1name');
say $p2.tokens; # [foo 1 weird~odd/name]
say $p2.resolve($sample-json); # 101
# A Failure is returned upon resolution failure
my $p3 = JSON::Pointer.parse('/foo/2/missing');
without $p3.resolve($sample-json) {
say "Could not resolve";
}
# Construct a JSON pointer
my $p4 = JSON::Poiner.new('foo', 0, 'weird~odd/name');
say ~$p4; # /foo/0/weird~0odd~1name
```
## Description
JSON::Pointer is a Perl 6 module that implements JSON Pointer conception.
## Author
Alexander Kiryuhin [[email protected]](mailto:[email protected])
## Copyright and License
Copyright 2018 Edument Central Europe sro.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-GARLANDG-Libui.md
# Libui
## Perl6 binding to [andlabs/libui](https://github.com/andlabs/libui)
andlabs/libui is currently alpha software. This binding works with the current release, 0.4.1. It does not have full functionality, and is subject to change as andlabs/libui changes underneath it. The raw bindings accessible in Libui::Raw should be feature-complete, but only some widgets have an object-oriented implementation.
### Cross-platform: Windows, Mac, Linux
This library provides an object-oriented interface to libui. Shared libraries ui.dll, libui.dylib, and libui.so are provided in resources.
#### Windows Windows requires a 64-bit Visual C++ Redistributable to properly function.
#### Linux
Linux requires GTK3.
Debian: `apt install libgtk-3-0`
### Basic Use:
```
use Libui;
Libui::Init;
my Libui::App $app .= new("test");
#This allows the window to be closed
#when the titlebar's close button is clicked
$app.window.closing.tap({$app.exit});
$app.run();
```
### Widgets Provided:
| Widget | Description |
| --- | --- |
| Button | A button with a label |
| Checkbox | A checkbox with a label |
| Combobox | A simple combobox |
| ColorButton | A button for selecting a color |
| EditableCombobox | A combobox that can be edited |
| Entry | Text input, can be disabled |
| FontButton | A button for selecting a font (Incomplete: Cannot set programmatically) |
| Form | A container that takes labels for its contents |
| Grid | A container that aligns widgets for window design |
| Group | A container that provides a title for a set of items |
| Label | Displays a single line of text |
| Menu | Creates a single column of an application menu |
| MultilineEntry | An entry that allows multiple lines |
| Time and Date Pickers | Allows choosing of a date and/or time |
| ProgressBar | Displays a progress bar |
| RadioButton | A set of radio buttons |
| Separator | A simple vertical or horizontal separator |
| Slider | A draggable slider for choosing a value in a range |
| Spinbox | A numerical input with a minimum and maximum range |
| Tab | A set named tabs for placing items in |
| Window | Contains any other widget, cannot be embedded in a container |
| VBox, HBox | A vertical or horizontal box for grouping items |
#### Install from CPAN with:
`zef install Libui`
#### Documentation
View on the web: <https://github.com/Garland-g/perl6-libui/wiki>
Use p6doc: e.g. `p6doc Libui::Button`
## Examples:
### Controlgallery Tab: Basic Controls
#### Linux
<./examples/controlgallery-linux.png>
#### Windows
<./examples/controlgallery-windows.png>
#### Macos
<./examples/controlgallery-macos.png>
### License
[Artistic License 2.0](./LICENSE)
### Author
Travis Gibson
|
## dist_zef-dwarring-HarfBuzz.md
[[Raku HarfBuzz Project]](https://harfbuzz-raku.github.io)
/ [[HarfBuzz Module]](https://harfbuzz-raku.github.io/HarfBuzz-raku)
# HarfBuzz-raku
Bindings to the HarfBuzz text shaping library.
Minimum supported HarfBuzz version is v2.6.4 - See [Installation](#installation)
Note: If the HarfBuzz::Subset module is being installed, then the minimum HarfBuzz
library version is v3.0.0+.
## Name
HarfBuzz - Use HarfBuzz for text shaping and font manipulation.
## Synopsis
```
use HarfBuzz::Font;
use HarfBuzz::Buffer;
use HarfBuzz::Shaper;
use HarfBuzz::Feature;
use HarfBuzz::Glyph;
my HarfBuzz::Feature() @features = <smcp -kern -liga>; # enable small-caps, disable kerning and ligatures
my $file = 't/fonts/NimbusRoman-Regular.otf';
my HarfBuzz::Font $font .= new: :$file, :size(36), :@features;
my HarfBuzz::Buffer $buf .= new: :text<Hello!>;
my HarfBuzz::Shaper $shaper .= new: :$font :$buf;
for $shaper.shape -> HarfBuzz::Glyph $glyph { ... }
my Hash @info = $shaper.ast;
```
## Description
HarfBuzz is a Raku module that provides access to a small subset of the native HarfBuzz library.
The subset is suitable for typesetting programs, whether they need to do basic glyph selection and layout, or deal with complex languages like Devanagari, Hebrew or Arabic.
Following the above example, the returned info is an array of hashes, one element for each glyph to be typeset. The hash contains the following items:
```
ax: horizontal advance
ay: vertical advance
dx: horizontal offset
dy: vertical offset
c: input character position
g: glyph index in font (CId)
name: glyph name
```
Note that the number of glyphs does not necessarily match the number of input characters!
## Classes/Modules in this distribution
* [HarfBuzz::Buffer](https://harfbuzz-raku.github.io/HarfBuzz-raku/HarfBuzz/Buffer) - Shaping text and context
* [HarfBuzz::Font](https://harfbuzz-raku.github.io/HarfBuzz-raku/HarfBuzz/Font) - Shaping font
* [HarfBuzz::Feature](https://harfbuzz-raku.github.io/HarfBuzz-raku/HarfBuzz/Feature) - Font Features
* [HarfBuzz::Glyph](https://harfbuzz-raku.github.io/HarfBuzz-raku/HarfBuzz/Glyph) - Shaped Glyphs
* [HarfBuzz::Shaper](https://harfbuzz-raku.github.io/HarfBuzz-raku/HarfBuzz/Shaper) - Shape a buffer using a given font and features
* [HarfBuzz::Raw](https://harfbuzz-raku.github.io/HarfBuzz-raku/HarfBuzz/Raw) - Native bindings
* [HarfBuzz::Raw::Defs](https://harfbuzz-raku.github.io/HarfBuzz-raku/HarfBuzz/Raw/Defs) - Enumerations and other constants
## Installation
This module requires HarfBuzz 2.6.4+.
`$ sudo apt-get install libharfbuzz-dev # Debian 12+`
If you are installing this as a [HarfBuzz::Subset](https://harfbuzz-raku.github.io/HarfBuzz-Subset-raku/) dependency, HarfBuzz 3.0.0+ is required, which may
(as of February 2022) require building from source [its repo](https://github.com/harfbuzz/harfbuzz/releases/).
## Additional Modules
* [HarfBuzz::Font::FreeType](https://harfbuzz-raku.github.io/HarfBuzz-Font-FreeType-raku/) - HarfBuzz / FreeType integration
* [HarfBuzz::Shaper::Cairo](https://harfbuzz-raku.github.io/HarfBuzz-Shaper-Cairo-raku/) - HarfBuzz / Cairo shaping integration
* [HarfBuzz::Subset](https://harfbuzz-raku.github.io/HarfBuzz-Subset-raku/) - Raku bindings to harfbuzz-subset font subsetting library
## See Also
* [HarfBuzz::Shaper](https://metacpan.org/pod/HarfBuzz::Shaper) - Perl CPAN module.
|
## private-methods.md
private\_methods
Combined from primary sources listed below.
# [In role Metamodel::PrivateMethodContainer](#___top "go to top of document")[§](#(role_Metamodel::PrivateMethodContainer)_method_private_methods "direct link")
See primary documentation
[in context](/type/Metamodel/PrivateMethodContainer#method_private_methods)
for **method private methods**.
```raku
method private_methods($obj)
```
Returns a list of private method names.
|
## openforwriting.md
class X::Proc::Async::OpenForWriting
Error due to writing to a read-only Proc::Async object
```raku
class X::Proc::Async::OpenForWriting is Exception {}
```
When a [`Proc::Async`](/type/Proc/Async) object is opened only for reading from the external program (no `:w` passed to open), and a write operation such as `write`, `print` and `say` is performed, an exception of type `X::Proc::Async::OpenForWriting` is thrown:
```raku
my $proc = Proc::Async.new("echo");
$proc.start;
$proc.say(42);
CATCH { default { put .^name, ': ', .Str } };
# OUTPUT: «X::Proc::Async::OpenForWriting: Process must be opened for writing with :w to call 'say'»
```
To fix that you can use writable commands with :w flag:
```raku
my $prog = Proc::Async.new(:w, 'cat');
$prog.stdout.tap( -> $str {
print $str;
});
my $promise = $prog.start;
await $prog.say('foo');
$prog.close-stdin;
await $promise;
```
# [Methods](#class_X::Proc::Async::OpenForWriting "go to top of document")[§](#Methods "direct link")
## [method method](#class_X::Proc::Async::OpenForWriting "go to top of document")[§](#method_method "direct link")
```raku
method method(X::Proc::Async::OpenForWriting:D:)
```
Returns the method name that was called and which caused the exception.
|
## dist_cpan-ASTJ-HandleSupplier.md
[](https://travis-ci.org/astj/p6-HandleSupplier)
# NAME
HandleSupplier - generate Supplier for an IO::Handle object
# SYNOPSIS
```
use HandleSupplier;
my $supplier = supplier-for-handle($*ERR);
# "hello\n" will be written to STDERR
$supplier.emit("hello");
```
# DESCRIPTION
HandleSupplier is a utility which provides a Supplier to emit messages to corresponding IO::Handle object.
# AUTHOR
Asato Wakisaka [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2017 Asato Wakisaka
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-grizzlysmit-Usage-Utils.md
# Usage::Utils
## Table of Contents
* [NAME](#name)
* [AUTHOR](#author)
* [VERSION](#version)
* [TITLE](#title)
* [SUBTITLE](#subtitle)
* [COPYRIGHT](#copyright)
* [Introduction](#introduction)
* [grammar UsageStr & action class UsageStrActions](#grammar-usagestr--action-class-usagestractions)
* [say-coloured(…)](#say-coloured)
* [You need to implement these or similar in your code](#you-need-to-implement-these-or-similar-in-your-code)
# NAME
Usage::Utils
# AUTHOR
Francis Grizzly Smit ([[email protected]](mailto:[email protected]))
# VERSION
v0.1.1
# TITLE
Usage::Utils
# SUBTITLE
A Raku module to provide syntax highlighting for the **`$*USAGE`** string.
# COPYRIGHT
LGPL V3.0+ [LICENSE](https://github.com/grizzlysmit/Usage-Utils/blob/main/LICENSE)
[Top of Document](#table-of-contents)
# Introduction
This is a Raku Module for those who like to colour their Usage messages.
### grammar UsageStr & action class UsageStrActions
```
grammar UsageStr is BasePaths is export {
token TOP { ^ 'Usage:' \h* [ \v+ <usage-line> ]+ \v* $ }
token usage-line { ^^ \h* <prog> <fixed-args-spec> <pos-spec> <optionals-spec> <slurpy-array-spec> <options-spec> <slurpy-hash-spec> \h* $$ }
token fixed-args-spec { [ \h* <fixed-args> ]? }
token pos-spec { [ \h* <positional-args> ]? }
regex optionals-spec { [ \h* <optionals> ]? }
regex slurpy-array-spec { [ \h* <slurpy-array> ]? }
token options-spec { [ \h* <options> ]? }
token slurpy-hash-spec { [ \h* <slurpy-hash> ]? }
token prog { [ <prog-name> <!before [ '/' || '~/' || '~' ] > || <base-path> <prog-name> ] }
token prog-name { \w+ [ [ '-' || '+' || ':' || '@' || '=' || ',' || '%' || '.' ]+ \w+ ]* }
token fixed-args { [ <fixed-arg> [ \h+ <fixed-arg> ]* ]? }
token fixed-arg { \w+ [ [ '-' || '+' || ':' || '.' ]+ \w+ ]* }
regex positional-args { [ <positional-arg> [ \h+ <positional-arg> ]* ]? }
regex positional-arg { '<' \w+ [ '-' \w+ ]* '>' }
regex optionals { [ <optional> [ \h+ <optional> ]* ] }
regex optional { '[<' [ \w+ [ '-' \w+ ]* ] '>]' }
regex slurpy-array { [ '[<' [ \w+ [ '-' \w+ ]* ] '>' \h '...' ']' ] }
regex options { [ <option> [ \h+ <option> ]* ] }
regex option { [ <int-opt> || <other-opt> || <bool-opt> ] }
regex int-opt { [ '[' <opts> '[=Int]]' ] }
regex other-opt { [ '[' <opts> '=<' <type> '>]' ] }
regex bool-opt { [ '[' <opts> ']' ] }
token opts { <opt> [ '|' <opt> ]* }
regex opt { [ <long-opt> || <short-opt> ] }
regex short-opt { [ '-' \w ] }
regex long-opt { [ '--' \w ** {2 .. Inf} [ '-' \w+ ]* ] }
regex type { [ 'Str' || 'Num' || 'Rat' || 'Complex' || [ \w+ [ [ '-' || '::' ] \w+ ]* ] ] }
regex slurpy-hash { [ '[--<' [ \w+ [ '-' \w+ ]* ] '>=...]' ] }
}
class UsageStrActions does BasePathsActions is export {
method prog($/) {
my $prog;
if $/<base-path> {
$prog = $/<base-path>.made ~ $/<prog-name>.made;
} else {
$prog = $/<prog-name>.made;
}
make $prog;
}
method prog-name($/) {
my $prog-name = ~$/;
make $prog-name;
}
...
...
...
...
method slurpy-hash($/) {
my $slurpy-hash = ~$/;
make $slurpy-hash;
}
method usage-line($/) {
my %line = prog => $/<prog>.made, fixed-args => $/<fixed-args-spec>.made,
positional-args => $/<pos-spec>.made, optionals => $/<optionals-spec>.made,
slurpy-array => $/<slurpy-array-spec>.made, options => $/<options-spec>.made,
slurpy-hash => $/<slurpy-hash-spec>.made;
my %usage-line = kind => 'usage-line', value => %line;
make %usage-line;
}
method TOP($made) {
my %u = kind => 'usage', value => 'Usage:';
my @top = %u, |($made<usage-line>».made);
$made.make: @top;
}
} # class UsageStrActions does PathsActions is export #
```
### say-coloured(…)
A function to call from within a GENERATE-USAGE(&main, |capture --> Int)
```
sub say-coloured(Str:D $USAGE, Bool:D $nocoloured, *%named-args, *@args --> True) is export
```
[Top of Document](#table-of-contents)
### You need to implement these or similar in your code
```
multi sub MAIN('help', Bool:D :n(:nocolor(:$nocolour)) = False, *%named-args, *@args) returns Int {
my @_args is Array[Str] = |@args[1 .. *];
#say @_args.shift;
say-coloured($*USAGE, $nocolour, |%named-args, |@_args);
exit 0;
}
sub USAGE(Bool:D :n(:nocolor(:$nocolour)) = False, *%named-args, *@args --> Int) {
say-coloured($*USAGE, False, %named-args, @args);
exit 0;
}
multi sub GENERATE-USAGE(&main, |capture --> Int) {
my @capture = |(capture.list);
my @_capture;
if @capture && @capture[0] eq 'help' {
@_capture = |@capture[1 .. *];
} else {
@_capture = |@capture;
}
my %capture = |(capture.hash);
if %capture«nocolour» || %capture«nocolor» || %capture«n» {
say-coloured($*USAGE, True, |%capture, |@_capture);
} else {
#dd @capture;
say-coloured($*USAGE, False, |%capture, |@_capture);
#&*GENERATE-USAGE(&main, |capture)
}
exit 0;
}
```
[Top of Document](#table-of-contents)
|
## pairs.md
pairs
Combined from primary sources listed below.
# [In List](#___top "go to top of document")[§](#(List)_routine_pairs "direct link")
See primary documentation
[in context](/type/List#routine_pairs)
for **routine pairs**.
```raku
sub pairs($list --> Seq:D)
method pairs(List:D: --> Seq:D)
```
Returns a sequence of pairs, with the indexes as keys and the list values as values.
```raku
say <a b c>.pairs; # OUTPUT: «(0 => a 1 => b 2 => c)»
```
# [In role Baggy](#___top "go to top of document")[§](#(role_Baggy)_method_pairs "direct link")
See primary documentation
[in context](/type/Baggy#method_pairs)
for **method pairs**.
```raku
method pairs(Baggy:D: --> Seq:D)
```
Returns all elements and their respective weights as a [`Seq`](/type/Seq) of [`Pair`](/type/Pair)s where the key is the element itself and the value is the weight of that element.
```raku
my $breakfast = bag <bacon eggs bacon>;
my $seq = $breakfast.pairs;
say $seq.sort; # OUTPUT: «(bacon => 2 eggs => 1)»
```
# [In Capture](#___top "go to top of document")[§](#(Capture)_method_pairs "direct link")
See primary documentation
[in context](/type/Capture#method_pairs)
for **method pairs**.
```raku
multi method pairs(Capture:D: --> Seq:D)
```
Returns all arguments, the positional followed by the named, as a [`Seq`](/type/Seq) of [`Pair`](/type/Pair)s. Positional arguments have their respective ordinal value, starting at zero, as key while the named arguments have their names as key.
```raku
my Capture $c = \(2, 3, apples => (red => 2));
say $c.pairs; # OUTPUT: «(0 => 2 1 => 3 apples => red => 2)»
```
# [In Map](#___top "go to top of document")[§](#(Map)_method_pairs "direct link")
See primary documentation
[in context](/type/Map#method_pairs)
for **method pairs**.
```raku
method pairs(Map:D: --> Seq:D)
```
Returns a [`Seq`](/type/Seq) of all pairs in the Map.
```raku
my $m = Map.new('a' => (2, 3), 'b' => 17);
say $m.pairs; # OUTPUT: «(a => (2 3) b => 17)»
```
# [In Pair](#___top "go to top of document")[§](#(Pair)_method_pairs "direct link")
See primary documentation
[in context](/type/Pair#method_pairs)
for **method pairs**.
```raku
multi method pairs(Pair:D:)
```
Returns a list of one `Pair`, namely this one.
```raku
my $p = (Raku => "d");
say $p.pairs.^name; # OUTPUT: «List»
say $p.pairs[0]; # OUTPUT: «Raku => d»
```
# [In Any](#___top "go to top of document")[§](#(Any)_method_pairs "direct link")
See primary documentation
[in context](/type/Any#method_pairs)
for **method pairs**.
```raku
multi method pairs(Any:U:)
multi method pairs(Any:D:)
```
Returns an empty [`List`](/type/List) if the invocant is a type object:
```raku
say Num.pairs; # OUTPUT: «()»
```
For a value object, it converts the invocant to a [`List`](/type/List) via the `list` method and returns the result of [List.pairs](/type/List#routine_pairs) on it.
```raku
<1 2 2 3 3 3>.Bag.pairs.say;# OUTPUT: «(1 => 1 3 => 3 2 => 2)»
```
In this case, every element (with weight) in a bag is converted to a pair.
|
## dist_cpan-FRITH-Hash-Timeout_1.md
[](https://travis-ci.org/frithnanth/perl6-Hash-Timeout)
# NAME
Hash::Timeout - Role for hashes whose elements timeout and disappear
# SYNOPSIS
```
use Hash::Timeout;
my %cookies does Hash::Timeout[0.5];
%cookies<user001> = 'id';
sleep 1;
say %cookies.elems; # prints 0
```
# DESCRIPTION
Hash::Timeout provides a `role` that can be mixed with a `Hash`.
There's just one optional parameter, the timeout, which accepts fractional seconds and defaults to 1 hour.
# AUTHOR
Fernando Santagata [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2018 Fernando Santagata
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## ords.md
ords
Combined from primary sources listed below.
# [In Str](#___top "go to top of document")[§](#(Str)_method_ords "direct link")
See primary documentation
[in context](/type/Str#method_ords)
for **method ords**.
```raku
multi method ords(Str:D: --> Seq)
```
Returns a list of Unicode codepoint numbers that describe the codepoints making up the string.
Example:
```raku
"aå«".ords; # (97 229 171)
```
Strings are represented as graphemes. If a character in the string is represented by multiple codepoints, then all of those codepoints will appear in the result of `ords`. Therefore, the number of elements in the result may not always be equal to [chars](/routine/chars), but will be equal to [codes](/routine/codes); [codes](/routine/codes) computes the codepoints in a different way, so the result might be faster.
The codepoints returned will represent the string in [`NFC`](/type/NFC). See the [`NFD`](/type/NFD), [`NFKC`](/type/NFKC), and [`NFKD`](/type/NFKD) methods if other forms are required.
# [In Cool](#___top "go to top of document")[§](#(Cool)_routine_ords "direct link")
See primary documentation
[in context](/type/Cool#routine_ords)
for **routine ords**.
```raku
sub ords(Str(Cool) $str)
method ords()
```
Coerces the invocant (or in the sub form, the first argument) to [`Str`](/type/Str), and returns a list of Unicode codepoints for each character.
```raku
say "Camelia".ords; # OUTPUT: «67 97 109 101 108 105 97»
say ords 10; # OUTPUT: «49 48»
```
This is the list-returning version of [ord](/routine/ord). The inverse operation in [chrs](/routine/chrs). If you are only interested in the number of codepoints, [codes](/routine/codes) is a possibly faster option.
# [In Nil](#___top "go to top of document")[§](#(Nil)_method_ords "direct link")
See primary documentation
[in context](/type/Nil#method_ords)
for **method ords**.
Returns an empty [`Seq`](/type/Seq), but will also issue a warning depending on the context it's used (for instance, a warning about using it in string context if used with `say`).
|
## dist_cpan-HOLLI-Scalar-History.md
# NAME
Scalar::History - A personal history for any scalar
# DESCRIPTION
This module implements the history variable pattern, that is variables which store not only their current value, but also the values they have contained in the past.
You can make a history variable by calling the `create` function and bind (not assign) it to a scalar. All assignments to the variable will be stored in a history and can be fetched at any point in your program.
# SYNOPSIS
```
use Scalar::History;
# This adds a history to $abc
my $abc := Scalar::History.create("a");
# We can now assign new values
$abc = "b";
$abc = "d";
# At any point we can ask for past values, here: ("a", "b")
$abc.VAR.get-history.say;
# Oh my, we forgot "c", we must rewind
$abc.VAR.rewind-history( 1 );
# So the current value is now "b" again
$abc.say;
# rewinding only moves a pointer and you can
# call `forward-history($steps)` to move into the
# other (future) direction, no values get deleted.
# But when we ask for the history we only get
# historic values up to the current value, here ("a")
$abc.VAR.get-history().say;
# You can specify the :all adverb to get all historic
# values, regardless. Here ("a", "b")
say $abc.VAR.get-history( :all );
# Notice there is no "d" in the history, it is here:
say $abc.VAR.latest-value;
# When assigning in a rewound state however,
# everything after the rewind point gets forgotten
$abc = "c";
$abc = "d";
$abc = "e";
$abc.say; # "e"
$abc.VAR.get-history.say; # ("a", "b", "c", "d")
# You can enforce a type by passing it into `create`
my Int $int := Scalar::History.create(1, Int);
# The history variables behave just like normal ones
$int++;
# You can pass it to functions, but you need to use the `is raw`
# in order to not lose the magic
sub count-to-ten (Int $n is raw)
{
$n++;
return-rw $n if $n == 10;
return-rw count-to-ten( $n );
}
# Also, don't forget to bind the return value
my $new := count-to-ten($int);
$new.say; # 10
$new.VAR.get-history.say; # (1,2,3,4,5,6,7,8,9)
```
# INSTALLATION
```
$ zef install Scalar::History
```
# HINT
If you want to make sure, you forward to the last known value, or rewind to the very first, you can call the respective methods using `Inf` as argument.
```
$history.VAR.rewind-history( Inf );
```
|
## dist_cpan-YNOTO-DB-Xoos_1.md
# Xoos
Xoos is an ORM designed for convenience and ease of use, it is modeled after DBIx::\* if you're into that kind of thing already (note: some concepts and names have deviated).
(This module was originally named Koos until my friends in Israel let me know that that's a vulgar word in Arabic)
[](https://circleci.com/gh/tony-o/perl6-xoo)
## what works
* relationships
* row object inflation (calling .first on a query returns a Xoos::Row)
* row objects inherit from the model::@columns
* model level convenience methods
* row level convenience methods
* basic handling compounded primary keys
* column validation hooks
* YAML models (auto composed)
* decouple SQL generation from Xoos::Searchable (this includes decoupling the SQL generation from the DB layer) - DB::Pg is intended to be used but epoll is not ported to OSX
## todo
* soft validation of model/table/relationships when model loads
* prefetch relationships option (currently everything is prefetched)
# Usage
Below is a minimum viable model setup for your app. Xoos does *not* create the table for you, that is up to you.
### lib/app.pm6
```
use DB::Xoos::SQLite;
my DB::Xoos::SQLite $d .=new;
$d.connect('sqlite://xyz.sqlite3');
my $customer-model = $d.model('Customer');
my $new-customer = $customer-model.new-row;
$new-customer.name('xyz co');
$new-customer.rate(150);
$new-customer.update; # runs an insert because this is a new row
my $xyz = $customer-model.search({ name => { 'like' => '%xyz%' } }).first;
$xyz.rate( $xyz.rate * 2 ); #twice the rate!
$xyz.update; # UPDATEs the database
my $xyz-orders = $xyz.orders.count;
```
### lib/Model/Customer.pm6
```
use DB::Xoos::Model;
unit class Model::Customer does DB::Xoos::Model['customer'];
has @.columns = [
id => {
type => 'integer',
nullable => False,
is-primary-key => True,
auto-increment => 1,
},
name => {
type => 'text',
},
rate => {
type => 'integer',
},
];
has @.relations = [
orders => { :has-many, :model<Order>, :relate(id => 'customer_id') },
];
```
# role DB::Xoos::Model
What is a model? A model is essentially a table in your database. Your ::Model::X is pretty barebones, in this module you'll defined `@.columns` and `@.relations` (if there are any relations).
## Example
```
use DB::Xoos::Model;
# the second argument below is optional and also accepts a type.
# if the arg is omitted then it attempts to auto load ::Row::Customer
# if it fails to auto load then it uses an anonymous Row and adds convenience methods to that
unit class X::Model::Customer does DB::Xoos::Model['customer', 'X::Row::Customer'];
has @.columns = [
id => {
type => 'integer',
nullable => False,
is-primary-key => True,
auto-increment => 1,
},
name => {
type => 'text',
},
contact => {
type => 'text',
},
country => {
type => 'text',
},
];
has @.relations = [
orders => { :has-many, :model<Order>, :relate(id => 'customer_id') },
open_orders => { :has-many, :model<Order>, :relate(id => 'customer_id', '+status' => 'open') },
completed_orders => { :has-many, :model<Order>, :relate(id => 'customer_id', '+status' => 'closed') },
];
# down here you can have convenience methods
method delete-all { #never do this in real life
die '.delete-all disabled in prod or if %*ENV{in-prod} not defined'
if !defined %*ENV{in-prod} || so %*ENV{in-prod};
my $s = self.search({ id => { '>' => -1 } });
$s.delete;
!so $s.count;
}
```
In this example we're creating a customer model with columns `id, name, contact, country` and relations with specific filter criteria. You may notice the `+status => 'open'` on the open\_orders relationship, the `+` here indicates it's a filter on the original table.
### Breakdown
`class :: does DB::Xoos::Model['table-name', 'Optional String or Type'];`
Here you can see the role accepts one or two parameters, the first is the DB table name, the latter is a String or Type of the row you'd like to use for this model. If no row is found then Xoos will create a generic row and add helper methods for you using the model's column data.
`@.columns`
A list of columns in the table. It is highly recommended you have *one* `is-primary-key` or `.update` will have unexpected results.
`@.relations`
This accepts a list of key values, the key defining the accessor name, the later a hash describing the relationship. `:has-one` and `:has-many` are both used to dictate whether a Xoos model returns an inflated object (:has-one) or a filterable object (:has-many).
## Methods
### `search(%filter?, %options?)`
Creates a new filterable model and returns that. Every subsequent call to `.search` will *add* to the existing filters and options the best it can.
Example:
```
my $customer = $dbo.model('Customer').search({
name => { like => '%bozo%' },
}, {
order-by => [ created_date => 'DESC', 'customer_name' ],
});
# later on ...
my $geo-filtered-customers = $customer.search({ country => 'usa' });
# $geo-filtered-customers effective filter is:
# {
# name => { like => '%bozo%' },
# country => 'usa',
# }
```
### `.all(%filter?)`
Returns all rows from query (an array of inflated `::Row::XYZ`). Providing `%filter` is the same as doing `.search(%filter).all` and is provided only for convenience.
### `.first(%filter?, :$next = False)`
Returns the first row (again, inflated `::Row::XYZ`) and caches the prepared statement (this is destroyed and ignored if $next is falsey)
### `.next(%filter?)`
Same as calling `.first(%filter, :next)`
### `.count(%filter?)`
Returns the result of a `select count` for the current filter selection. Providing `%filter` results in `.search(%filter).count`
### `.delete(%filter?)`
Deletes all rows matching criteria. Providing `%filter` results in `.search(%filter).delete`
### `.new-row(%field-data?)`
Creates a new row with %field-data.
## Convenience methods
Xoos::Model inheritance allows you to have convenience methods, these methods can act on whatever the current set of filters is.
Consider the following:
Convenience model definition:
```
class X::Model::Customer does Xoos::Model['customer'];
# columns and relations
method remove-closed-orders {
self.closed_orders.delete;
}
```
Later in your code:
```
my $customers = $dbo.model('Customer');
my $all-customers = $customers.search({ id => { '>' => -1 } });
my $single-customers = $customers.search({ id => 5 });
$all-customers.remove-closed-orders;
# this removes all orders for customers with an id > -1
$single-customer.remove-closed-orders;
# this removes all orders for customers with id = 5
```
# role Xoos::Row
A role to apply to your `::Row::Customer`. If there is no `::Row::Customer` a generic row is created using the column and relationship data specified in the corresponding `Model` and this file is only really necessary if you want to add convenience methods.
When a `class :: does Xoos::Row`, it receives the info from the model and adds the methods for setting/getting field data.
With the model definition above:
```
my $invoice-model = $dbo.model('invoice');
my $invoice = $invoice-model.new-row({
customer_id => $customer.id,
amount => 400,
}); # this $invoice is NOT in the database until .update
my $old-amount = $invoice.amount; # = 400
$invoice.amount($invoice.amount * 2);
my $new-amount = $invoice.amount; # = 800
$invoice.update;
```
If there is a collision in the naming conventions between your model and the row then you'll need to use `[set|get]-column`
## Methods
### `.duplicate`
Duplicates the row omitting the `is-primary-key` field so the subsequent `.save` results in a new row rather than updating
### `.as-hash`
Returns the current field data for the row as a hash. If there has been unsaved updates to fields then it returns *those* values instead of what is in the database. You can determine whether the row has field-changes with `is-dirty`
### `.set-column(Str $key, $value)`
Updates the field data for the column (not stored in database until `.update` is called). If you want to `.wrap` a field setter for a certain key, wrap this and filter for the key
### `.get-column(Str $key)`
Retrieves the value for `$key` with any field changes having priority over data in database, use `.is-dirty`
### `.get-relation(Str $column, :%spec?)`
It is recommended any Model with a relationship name that conflicts and causes no convenience method to be generated be renamed, but use this if you must. `$customer.orders` is calling essentially `$customer.get-relation('orders')`. Do not provide `%spec` unless you know what you're doing.
### `.update`
Saves the row in the database. If the field with a positive `is-primary-key` is *set* then it runs and `UPDATE ...` statement, otherwise it `INSERT ...`s and updates the Row's `is-primary-key` field. Ensure you set one field with `is-primary-key`
## Field validation
It's just this easy:
```
has @.columns = [
qw<...>,
phone => {
type => 'text',
validate => sub ($new-value) {
# return Falsey value here for validation to fail
# Truthy value will cause validation to succeed
},
},
qw<...>,
];
```
|
## dist_github-leejo-Geo-IP2Location-Lite.md
# NAME
Geo::IP2Location::Lite - Lightweight lookup of IPv4 address details using BIN files from <http://www.ip2location.com>
[](https://travis-ci.org/leejo/geo-ip2location-lite-p6?branch=master)
[](https://coveralls.io/r/leejo/geo-ip2location-lite-p6?branch=master)
# SYNOPSIS
```
#!perl6
use Geo::IP2Location::Lite;
my $obj = Geo::IP2Location::Lite.new(
# required path to IP2Location BIN file
file => "/path/to/IP-COUNTRY.BIN"
);
# IPv4 formatted address
my $ip = "20.11.187.239";
my $countryshort = $obj.get_country_short( $ip );
my $countrylong = $obj.get_country_long( $ip );
my $region = $obj.get_region( $ip );
my $city = $obj.get_city( $ip );
my $isp = $obj.get_isp( $ip );
my $zipcode = $obj.get_zipcode( $ip );
my $domain = $obj.get_domain( $ip );
my $timezone = $obj.get_timezone( $ip );
my $netspeed = $obj.get_netspeed( $ip );
my $iddcode = $obj.get_iddcode( $ip );
my $areacode = $obj.get_areacode( $ip );
my $ws_code = $obj.get_weatherstationcode( $ip );
my $ws_name = $obj.get_weatherstationname( $ip );
my $carrier_code = $obj.get_mcc( $ip );
my $network_code = $obj.get_mnc( $ip );
my $mobile_brand = $obj.get_mobilebrand( $ip );
my $elevation = $obj.get_elevation( $ip );
my $usage_type = $obj.get_usagetype( $ip );
my $latitude = $obj.get_latitude( $ip );
my $longitude = $obj.get_longitude( $ip );
my ( $country_short,$country_long,$region,$city,... )
= $obj.get_all("20.11.187.239");
```
# DESCRIPTION
This module allows you to lookup IPv4 details using the BIN files as sourced
from <http://www.ip2location.com>. Full usage is described in the SYNOPSIS
above.
Note the module expects an IPv4 formatted address to be passed to all lookup
methods. Anything else will throw a type constraint error.
When constructing the object the file parameter is mandatory.
# SEE ALSO
<http://www.ip2location.com>
# VERSION
0.10
# AUTHOR
Lee Johnson `[email protected]`. If you would like to contribute documentation,
features, bug fixes, or anything else then please raise an issue / pull request:
```
https://github.com/leejo/geo-ip2location-lite-v6
```
# LICENSE
The Artistic License 2.0 (See LICENSE in github repo)
|
## dist_zef-guifa-Intl-CLDR.md

> *¿Cómo se diz na vuestra, na nuestra llingua, la palabra futuru?*
> — Lecciones de gramática (Berta Piñán)
# Intl::CLDR
An attempt to bring in the data from CLDR into Raku.
As of **v0.5.0**, performance was vastly improved but some slight API changes were needed.
Always ensure to use a version statement. (at least until v.1.0)
To install, be aware that due to the number of files, you may need to increase the maximum number of open files (on most systems, the default is several thousand, but on macOS, it's a paltry 256).
```
> ulimit -n 4096
> zef install Intl::CLDR
```
## CLDR objects
Each `CLDR::*` object is `Associative`, and attributes can generally be accessed both from
hashy accessors (`{'foo'}`) or method/attribute accessors (`.foo`).
True attributes are defined with kebab-case, but camel-case alternates are available as well (this is because CLDR began with camel case, and now tends to prefer kebab-case, and it's hard to remember when to use which).
## Other thoughts
Because CLDR is designed to be stable, they have had to make some odd design choices for legacy compatibility.
An obvious example of this is the `<codePatterns>` vs `<localeDisplayPattern>` that really logically should go together.
This also happens with the `dateFormats`, `timeFormats`, and `dateTimeFormats`.
The latter three are currently organized exactly as in CLDR, but I may rearrange these simply to provide a more convenient/logical method of accessing things (e.g. `calendar.formats<time date datetime interval>`).
# Version History
* 0.7.5
* Added method `standard-raw`, `punctuation-raw`, etc, to `CLDR::ExemplarCharacters`. When calling the former names like `standard`, the raw forms will be processed into a cached `Seq` so current code need not be changed.
* 0.7.4
* Update `CLDR::PercentFormats` and `CLDR::ScientificFormats` to be fully aliased (needed to do, e.g., `$percent-formats<latn>`)
* 0.7.3
* Removed embarrassing hold over of `Immutability.pm6`
* 0.7.2
* Readded numbering system aliases for `CLDR::Symbols`
* 0.7.1
* Fixed data generation bug (users of 0.7.0 should update and recompile modules dependent on `Intl::CLDR` for correct data handling)
* 0.7.0
* CLDR update to v42.0
* Completely refactored module files
* Better long term maintenance
* Lower run-time overhead
* Module reorganized
* Various tools moved out of `/resources` into `/tools`
* Language loading no longer relies on hacky `%?RESOURCES` existence check, instead uses foreknowledge of processed language files.
* New feature
* Initial timezone data added
* `CLDR::WindowsTimezone` (from `<windowsZones>`) to convert Windows' timezone IDs to Olson IDs
* Forthcoming: `CLDR::Metazone` (from `<metaZone>`) converts Olson IDs to notional zones
* 0.6.0
* CLDR update to v39.0
* New features
* Added language-agnostic `CLDR::Supplement`. Accessed via `CLDR.supplement.subdivisions`
* Support for `<subdivisions>` tag (provides data to be fed into main language data classes)
* Support for supplemental-ish `<grammaticalDerivations>` added (`<grammaticalFeatures>` NYI).
* Version attributes
* Use `CLDR.module-version` to get the current module version (currently `v0.6.0`)
* Use `CLDR.cldr-version` to get the version of the CLDR database used (currently `v38.1`)
* Minor changes
* Removed redundant measurement type prefix from units (e.g. **meter** instead of **length-meter**).
* Hash-y access for `CompoundUnitSet::Selector`
* Bug fixes
* Long/narrow display-name/per-unit patterns for simple units were swapped.
* Fixed encoding for exemplar characters that incorrect `.ellipses` and `.more-info` values to appear in `CLDR::Characters`
* Locale display patterns `<localePattern>` (`.main`), `<localeSeparator>` (`.separator`), and `<localeKeyTypePattern>` (`.extension`) are now properly encoded
* Code improvements
* Transition from using the `CLDR-ItemNew` in `Immutability.pm6` (a holdover from pre-v0.5) to using `CLDR::Item` in `Core.pm6`
* Use `CLDR::Type` instead of `CLDR-Type`
* Use `is aliased-by` instead of `detour`
* Use `is built` and similar instead of `!bind_init`
* Cleaner handling of cases in `Units.pm6` (to be mirrored in other similar files in subsequent updates)
* 0.5.1
* Updated `DecimalFormatSystem`, `CurrencyFormatSystem` and `ScientificFormatSystem` to support Hash-y access.
* Pulled out `Intl::Format::Numbers` into its own module (as `Intl::Format::Number`)
* Fixed an issue with `ExemplarCharacters` pre-processing, which caused a space to be added to every set
* Pulled out `Intl::CLDR::Plural` into its own module (as `Intl::Number::Plural`)
* Support for supplemental `<plurals>`. (Found in new top level unit `Grammar`)
* Fixed a bug in `SimpleUnitSet` and `CompoundUnitSet` that caused the wrong pattern to be returned
* 0.5.0
* Redesigned data structure, and it's all about speed
* See docs for full details.
* Pulled out `Intl::Format::DateTime` into its own module
* Pulled out `Intl::Format::List` into its own module
* **Not** backwards compatible with v.0.4.3, make sure to specify version in `use` statement
* 0.4.3
* Fixed install issues
* Significant work towards fast attribute access (works on Calendar items)
* 0.4.2
* Added some new tokens , etc.
* Initial support for format-date and others.
* 0.4.1
* Greatly improved support for a token.
* Added support for Genders (only people, as that's what CLDR data has).
* 0.4.0
* Initial support for importing all CLDR data into a single repository in `Intl::CLDR`
* DateTime formatting currently uses it.
* Number / list formatting will be updated in the near future to use it (they still maintain their own separate database ATM)
* Not all languages are fully supported because I'm too lazy to manually add them all to the META6 file (I'll eventually automate it)
* 0.3.0
* Added support for formatting numbers of all types in the CLDR except for currency.
* Added preliminary support for finding localized numbers in grammars.
* 0.2.1
* Added preliminary support for Ge'ez numerals.
* Added preliminary support for Roman numerals.
* 0.2.0
* Added support for cardinal plural count.
* Ordinal *should* be working but there's a bug somewhere
* 0.1.0
* First working version. Support for list formatting.
# License
The resources directory "cldr-common" comes directly from the Unicode CLDR data.
These files are copyrighted by Unicode, Inc., and are available and distributed
in accordance with [their terms](http://www.unicode.org/copyright.html), which are
also distributed in that directory.
Everything else (that is, all the Raku code), is licensed under the Artistic License 2.0 (see license file).
|
## dist_zef-jonathanstowe-XML-Fast.md
# XML-Fast
A Raku module to turn XML into a Hash structure, to satisfy the AI that Cursor uses
[](https://github.com/jonathanstowe/XML-Fast/actions/workflows/main.yml)
## Synopsis
```
use JSON::Fast;
use XML::Fast;

my $xml = q:to/END_XML/;
<root>
<person>
<name>John</name>
<age>30</age>
</person>
<person>
<name>Jane</name>
<age>25</age>
</person>
</root>
END_XML

my $json = to-json(from-xml($xml));
say $json;
```
## Description
This provides a simple and probably very dumb means to turn XML text into a Raku Hash.
I wrote this because I was playing around with [Cursor](https://www.cursor.so/) - a new IDE that uses some AI engine to generate and edit code. I thought I'd start out with something relatively simple which people probably do all the time in various languages:
> Create a Raku program to transform XML to JSON
Easy right? It gave me the exact code in the Synopsis.
It looks plausible: it got the Raku heredoc syntax right and knows about JSON::Fast. One problem though: the module `XML::Fast` *doesn't exist*. I'm guessing it extrapolated from `JSON::Fast` (possibly with a nod to the [Perl module of the same name](https://metacpan.org/pod/XML::Fast)), made up a plausible kebab-cased function name and just suggested code that used this made up module. When I told it that the module `XML::Fast` didn't exist it told me to install it with `zef`!
I eventually got the AI to implement something using [LibXML](https://libxml-raku.github.io/LibXML-raku/), but it couldn't get it completely right after a lot of prompting: it probably needs to spend more time with the Raku docs.
Anyway, being a relatively easy thing to do, I decided that I would implement the `XML::Fast` that the AI had hallucinated so if anyone else were to ask it the same thing they wouldn't get disappointed and try another language or spend several frustrating hours trying to work out why the code doesn't work however many suggestions are made.
This is probably not the module you are looking for if you have any more than the simplest requirement: it flattens attributes into the Hash representing an element and doesn't deal with namespaces at all. It doesn't purport to have the same interface or functionality as the Perl module of the same name.
The only surprising thing may be the way it deals with what a schema definition might call "Complex Type with simple content", that is an element with an attribute which only has a text child:
```
<person id="1">
Rod
</person>
```
Which will get rendered as the Raku structure:
```
{
person => {
id => "1",
text => "Rod",
}
```
Because the other choices might be either lose the attribute (undesirable,) or introduce a new type ( in which case one might as well use e.g. [XML::Class](https://github.com/jonathanstowe/XML-Class).)
There is no `to-xml` as this would imply the ability to round-trip the data accurately, too much information is lost about the structure of the original XML to make this meaningful. Again consider using something like `XML::Class` which allows you to preserve the structure of the expected XML as you see fit.
## Installation
Assuming you have a working rakudo installation you should be able to install with *zef*:
```
zef install XML::Fast
```
Because it uses `LibXML` under the hood you may need to install `libxml2` on your system first.
## Support
Because this module exists purely to make the AI suggested code in the Synopsis work it's unlikely to gain any additional features, if you want something a bit like this but more flexible then feel free to copy the code and extend it, I might even do that myself.
If you do however find a real bug (like it makes garbage output with some XML data,) please [raise an issue on Github](https://github.com/jonathanstowe/XML-Fast/issues). Test cases with the offending XML are appreciated.
## Copyright & Licence
This library is free software. Please see the <LICENCE> in the distribution for details.
© Jonathan Stowe 2023
|
## dist_zef-thundergnat-FixedInt.md
[](https://github.com/thundergnat/FixedInt/actions)
# NAME
FixedInt - Unsigned fixed sized Integers
# SYNOPSIS
```
use FixedInt;
my \fixedint = FixedInt.new(:8bit);
say fixedint; # 0
say fixedint -= 12; # 244
say fixedint.signed; # -12
say fixedint.bin; # 0b11110100
say fixedint.hex; # 0xF4
say fixedint += 2500; # 184
say fixedint.signed; # -72
say fixedint.bin; # 0b10111000
say fixedint.hex; # 0xB8
```
# DESCRIPTION
FixedInt provides an easy way to work with fixed-sized unsigned integers in Raku. Rakus Integers by default are unfixed, arbitrary size. Doing unsigned fixed-size bitwise operations requires a bunch of extra bookkeeping. This module hides that bookkeeping behind an interface.
One major caveat to be aware of when using this module. The class instance **may not** be instantiated in a $ sigiled variable.
Raku $ sigiled scalar variables do not implement a STORE method, but instead do direct assignment; and there doesn't seem to be any easy way to override that behaviour.
An implication of that is that classes that **do** implement a STORE method can not be held in a $ sigiled variable. (Well, they **can**, they just won't work correctly. The first time you try to store a new value, the entire class instance will be overwritten and disappear.)
There are two work-arounds. One is to use an unsigiled variable. Unsigiled variables have no preconception of what may or may not be allowed, so don't override a STORE method. They work well, but if you really want a $ sigiled container, your only real option is to fake it using a constant term (rather than a variable.)
```
my \int32 = FixedInt.new; # unsigiled constant
# or
constant term:<$int32> = FixedInt.new; # "sigiled" constant term
# looks like a variable but is really a constant term
```
The FixedInt module allows creating and working with **any** sized fixed size Integer. Not only the "standard" sizes: 8, 16, 32, 64, etc., but also: 11, 25, 103, whatever. Once instantiated, it can be treated like any other variable. You can add to it, subtract from it, multiply, divide, whatever; the value stored in the variable will always stay the specified bit size. Any excesses will "roll over" the value. Works correctly for any standard bitwise or arithmatic operator, though you must remember to assign to the variable to get the fixed sized properties.
Provides some bit-wise operators that don't make sense for non-fixed size integers. Provides a few "format" operators that return a formatted IntStr; useful for display but also directly usable as an integer value.
## Methods
Note that most of the method examples below show binary representations of the value. That's just for demonstration purposes. Returns decimal numbers by default. All of the method examples below assume an 8 bit fixedint.
### .new()
Specify the number of bits. May be any positive integer. Defaults to 32 bit. Accepts :bit or :bits. Defaults to value of 0; will not accept a Nil value.
```
my \fixedint = FixedInt.new(:8bit);
# or
my \fixedint = FixedInt.new(:bits(8));
# or
my \fixedint = FixedInt.new(bits => 8);
```
### .ror (Int $bits)
Rotate right by the given number of bits (default 1)
```
# before 00000011 (3)
fixedint.=ror(1);
# after 10000001 (129)
```
### .rol (Int $bits)
Rotate left by the given number of bits (default 1)
```
# before 10000001 (129)
fixedint.=rol(3);
# after 00001100 (12)
```
### .C1
Ones complement. Every bit is negated.
```
# before 00001100 (12)
fixedint.=C1;
# after 11110011 (243)
```
### .C2
Twos complement. A "negated" integer.
```
# before 00001100 (12)
fixedint.=C2;
# after 11110100 (244)
```
### .signed
Treats the fixed size unsigned integer as a signed integer, returns negative numbers for FixedInts with a set most significant bit.
```
say fixedint # 244
say fixedint.signed # -12
```
### .bin
Returns a binary formatted IntStr;
```
say fixedint # 244
say fixedint.bin # 0b11110100
```
### .oct
Returns a octal formatted IntStr;
```
say fixedint # 244
say fixedint.oct # 0o364
```
### .hex
Returns a hex formatted IntStr;
```
say fixedint # 244
say fixedint.hex # 0xF4
```
# AUTHOR
Steve Schulze (thundergnat)
# COPYRIGHT AND LICENSE
Copyright 2020 Steve Schulze
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## subparse.md
subparse
Combined from primary sources listed below.
# [In Grammar](#___top "go to top of document")[§](#(Grammar)_method_subparse "direct link")
See primary documentation
[in context](/type/Grammar#method_subparse)
for **method subparse**.
```raku
method subparse($target, :$rule = 'TOP', Capture() :$args = \(), Mu :$actions = Mu, *%opt)
```
Does exactly the same as [method parse](/routine/parse), except that cursor doesn't have to reach the end of the string to succeed. That is, it doesn't have to match the whole string.
Note that unlike [method parse](/routine/parse), `subparse` *always* returns a [`Match`](/type/Match), which will be a failed match (and thus falsy), if the grammar failed to match.
```raku
grammar RepeatChar {
token start($character) { $character+ }
}
say RepeatChar.subparse('bbbabb', :rule('start'), :args(\('b')));
say RepeatChar.parse( 'bbbabb', :rule('start'), :args(\('b')));
say RepeatChar.subparse('bbbabb', :rule('start'), :args(\('a')));
say RepeatChar.subparse('bbbabb', :rule('start'), :args(\('a')), :pos(3));
# OUTPUT:
# 「bbb」
# Nil
# #<failed match>
# 「a」
```
|
## dist_zef-lizmat-P5seek.md
[](https://github.com/lizmat/P5seek/actions)
# NAME
Raku port of Perl's seek() built-in
# SYNOPSIS
```
use P5seek;
seek($filehandle, 42, 0);
seek($filehandle, 42, SEEK_SET); # same, SEEK_CUR / SEEK_END also available
```
# DESCRIPTION
This module tries to mimic the behaviour of Perl's `seek` built-in as closely as possible in the Raku Programming Language.
# ORIGINAL PERL DOCUMENTATION
```
seek FILEHANDLE,POSITION,WHENCE
Sets FILEHANDLE's position, just like the "fseek" call of "stdio".
FILEHANDLE may be an expression whose value gives the name of the
filehandle. The values for WHENCE are 0 to set the new position in
bytes to POSITION; 1 to set it to the current position plus
POSITION; and 2 to set it to EOF plus POSITION, typically
negative. For WHENCE you may use the constants "SEEK_SET",
"SEEK_CUR", and "SEEK_END" (start of the file, current position,
end of the file) from the Fcntl module. Returns 1 on success,
false otherwise.
Note the in bytes: even if the filehandle has been set to operate
on characters (for example by using the ":encoding(utf8)" open
layer), tell() will return byte offsets, not character offsets
(because implementing that would render seek() and tell() rather
slow).
If you want to position the file for "sysread" or "syswrite",
don't use "seek", because buffering makes its effect on the file's
read-write position unpredictable and non-portable. Use "sysseek"
instead.
Due to the rules and rigors of ANSI C, on some systems you have to
do a seek whenever you switch between reading and writing. Amongst
other things, this may have the effect of calling stdio's
clearerr(3). A WHENCE of 1 ("SEEK_CUR") is useful for not moving
the file position:
seek(TEST,0,1);
This is also useful for applications emulating "tail -f". Once you
hit EOF on your read and then sleep for a while, you (probably)
have to stick in a dummy seek() to reset things. The "seek"
doesn't change the position, but it does clear the end-of-file
condition on the handle, so that the next "<FILE>" makes Perl try
again to read something. (We hope.)
If that doesn't work (some I/O implementations are particularly
cantankerous), you might need something like this:
for (;;) {
for ($curpos = tell(FILE); $_ = <FILE>;
$curpos = tell(FILE)) {
# search for some stuff and put it into files
}
sleep($for_a_while);
seek(FILE, $curpos, 0);
}
```
# PORTING CAVEATS
For convenience, the terms `SEEK_SET`, `SEEK_CUR` and `SEEK_END` are also exported.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/P5seek> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2018, 2019, 2020, 2021 Elizabeth Mattijsen
Re-imagined from Perl as part of the CPAN Butterfly Plan.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-avuserow-DateTime-Format-LikeGo.md
# NAME
DateTime::Format::LikeGo - format dates using Go's reference format
# SYNOPSIS
```
use DateTime::Format::LikeGo;
# Format a date
say go-date-format("2006-01-02", DateTime.now);
# convert to strftime format:
say DateTime::Format::LikeGo::go-to-strftime("2006-01-02"); # %Y-%m-%d
```
# DESCRIPTION
A simple module that converts from Golang's "reference time" format to
strftime. The intention is for you to specify how a certain datetime would be
formatted, and it then can format any date in that style.
The reference date is 2006-01-02T15:04:05-0700, which is written as a series of
ascending digits, if rearranged, and 3pm is used instead of 15.
Inspired by complaints about the Go time format.
# FUNCTIONS
## go-date-format(Str $format, DateTime $date) is export returns Str
Format the given time according to the provided format string.
## go-to-strftime(Str $format) returns Str
Return the strftime version of the go format.
# EXCEPTIONS
A string exception is thrown if the converted strftime format has any digits
left over, which typically indicate a bad input format.
# CAVEATS
* Timezone support is missing in DateTime::Format, so strings using timezones
will fail until it is added.
* Not well tested overall.
# REQUIREMENTS
* Rakudo Perl 6 2014.11 or above. Tested primarily on MoarVM.
* DateTime::Format
# SEE ALSO
[f\*\*\*inggodateformat.com](http://fuckinggodateformat.com/) - inspiration for this module
[Documentation for Go's time package](http://golang.org/pkg/time/)
|
## dist_cpan-SKAJI-Acme-Test-Module.md
[](https://travis-ci.org/skaji/perl6-Acme-Test-Module)
# NAME
Acme::Test::Module - a test module
# SYNOPSIS
```
use Acme::Test::Module;
```
# DESCRIPTION
Acme::Test::Module is a test module.
# AUTHOR
Shoichi Kaji [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2017 Shoichi Kaji
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-Sys-Hostname.md
[](https://github.com/lizmat/Sys-Hostname/actions)
# NAME
Raku port of Perl's Sys::Hostname module
# SYNOPSIS
```
use Sys::Hostname;
$host = hostname;
```
# DESCRIPTION
This module tries to mimic the behaviour of Perl's `Sys::Hostname` module as closely as possible in the Raku Programming Language.
Obtain the system hostname as Raku sees it.
All NULs, returns, and newlines are removed from the result.
# PORTING CAVEATS
At present, the behaviour of the built-in `gethostname` sub is used. Any bugs in its behaviour should be fixed there.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Sys-Hostname> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2018, 2019, 2020, 2021 Elizabeth Mattijsen
Originally developed by David Sundstrom and Greg Bacon. Re-imagined from Perl as part of the CPAN Butterfly Plan.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-coke-App-SudokuHelper.md
# NAME
sudoku - command-line sudoku utility
# DESCRIPTION
```
$ sudoku combo 6
6
1 5
2 4
1 2 3
```
Display all combinations of sudoku digits that add to the given sum. Solutions
displayed in order from shortest to longest, then in numerical order.
```
$ sudoku combo 30 4
6 7 8 9
```
Display combinations that add to the given sum using the specified number of digits.
```
$ sudoku combo -s 6
6
2 4
$ sudoku combo --sandwich 9
2 7
3 6
4 5
2 3 4
```
Display combinations that add to the given sum that are valid for sandwich suduko.
That is, that exclude the digits 1 and 9.
```
$ sudoku combo -x 10
2 8
3 1 6
3 2 5
4 1 2 3
```
Display combinations where the number of digits in the combination is one of the
digits. `-x` for x-sums variant, where the number outside the puzzle shows the
total of the first `x` digits, where `x` is the first digit. The first digit of
each row is the `x`.
```
$ sudoku combo --sequence 13
6 7
```
Display only combinations where the digits form a sequence.
|
## dist_zef-Tux-Text-CSV.md
## Module [Test raku](https://github.com/Tux/CSV/actions/workflows/test.yaml)
Text::CSV - Handle CSV data in Raku
## Description
Text::CSV provides facilities for the composition and decomposition
of comma-separated values. An instance of the Text::CSV class can
combine fields into a CSV string and parse a CSV string into fields.
This module provides both an OO API and a functional API to parse
and produce CSV data.
```
use Text::CSV;
my $csv = Text::CSV.new;
my $io = open "file.csv", :r, chomp => False;
my @dta = $csv.getline_all($io);
my @dta = csv(in => "file.csv");
```
Additional (still incomplete) documentation in [the `doc` directory](/doc), including [a markdown version](/doc/Text-CSV.md). Check out also the [examples](/examples).
Debugging information can be obtained by setting the `RAKU_VERBOSE`
environment variable with values ranging to 2 to 9, less to annoyingly verbose.
## Installation
Recent changes can be (re)viewed in the public GIT repository at
<https://github.com/Tux/CSV>
Feel free to clone your own copy:
```
$ git clone https://github.com/Tux/CSV Text-CSV
```
## Prerequisites
* raku 6.c
* File::Temp - as long as in-memory IO is not native
* Slang::Tuxic - to support my style
## Build/Installation
```
$ zef install Text::CSV
```
Or just
```
$ zef install .
```
for the already downloaded repo
## License
Copyright (c) 2015-2023 H.Merijn Brand. All rights reserved.
This program is free software; you can redistribute it and/or
modify it under the same terms as Raku itself, which is
GNU General Public License or Artistic License 2.
## Author
H.Merijn Brand [[email protected]](mailto:[email protected])
|
## dist_zef-jjmerelo-Doc-TypeGraph.md
[](https://github.com/JJ/Raku-Doc-TypeGraph/actions/workflows/test.yaml)
# NAME
Doc::TypeGraph - Parse a description of the types for documentation.
# SYNOPSIS
```
use Doc::TypeGraph;
# create and initialize it
my $tg = Doc::TypeGraph.new-from-file("./resources/type-graph.txt");
# and use it!
say $tg.sorted;
```
# DESCRIPTION
Doc::TypeGraph creates a graph of all types in a file that describes
them. It gives you info about what classes a type inherits from and the roles it does. In addition, it also computes the inversion of this relations, which let you know what types inherit a given type and the types implementing a specific role.
All types are represented using a `Doc::Type` object. Categories are just
descriptive and are not really used in the generation of graphs. They will
probably be eliminated in later iterations of this library.
# Installation
You will need to have `graphviz` installed to generate the graphs; it uses
`dot`
# FILE SYNTAX
```
[ Category ]
# only one-line comments are supported
packagetype typename[role-signature]
packagetype typename[role-signature] is typename[role-signature] # inheritance
packagetype typename[role-signature] does typename[role-signature] # roles
[ Another cateogory ]
```
* Supported categories: `Metamodel`, `Domain-specific`, `Basic`, `Composite`, `Exceptions` and `Core`.
* Supported packagetypes: `class`, `module`, `role` and `enum`.
* Supported typenames: whatever string following the syntax
`class1::class2::class3 ...`; `class` follows the usual identifier
format that might include apostrophes and dashes.
* `[role-signature]` is not processed, but you can add it anyway.
* If your type inherits from more than one type or implements several roles, you can add more `is` and `does` statements (separated by spaces).
Example:
```
[Metamodel]
# Metamodel
class Metamodel::Archetypes
role Metamodel::AttributeContainer
class Metamodel::GenericHOW does Metamodel::Naming
class Metamodel::MethodDispatcher is Metamodel::BaseDispatcher is Another::Something
enum Bool is Int
module Test
```
(whitespace is only included for appearance, it does not have any
meaning)
### has Associative %.types
Format: $name => Doc::Type.
### has Positional @.sorted
Sorted array of type names.
### method new-from-file
```
method new-from-file(
$fn
) returns Mu
```
Initialize %.types from a file.
### method parse-from-file
```
method parse-from-file(
$fn
) returns Mu
```
Parse the file (using the Decl grammar) and initialize %.types and @.sorted
### method topo-sort
```
method topo-sort() returns Mu
```
This method takes all Doc::Type objects in `%.types` and sort them
by its name. After that, recursively, add all roles and supers in the
object to `@!sorted`
# AUTHOR
Moritz Lenz <@moritz> Antonio Gámiz <@antoniogamiz>
# COPYRIGHT AND LICENSE
This module is a spin-off from the Official Doc repo, if you want to see the
past changes go to the [official doc](https://github.com/Raku/doc).
Copyright 2019 Moritz and Antonio This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-tony-o-Text-CSV-LibCSV.md
# Text::CSV::LibCSV
Uses a wrapper that can stream data/records from a csv file using libcsv.
# Options
## Delimiter (`.new(:delimiter<>)`)
LibCSV allows a char to be specified for the delimiter, if you provide a multicharacter string only the first ordinal will be used.
## Quote (`.new(:quote<>)`)
LibCSV allows a char to be specified for the quoting char, if you provide a multicharacter string only the first ordinal will be used.
## Preserve Whitespace (`.new(:preserve-ws)`)
You can choose to not auto-trim tabs and spaces from data by passing this option along
## Parser Options (`.new(:parser-options(int32))`)
See your local libcsv documentation for what is acceptable here, out of the box is provided the structure:
```
CSV-STRICT => 1
CSV-REPALL-NL => 2
CSV-STRICT-FINI => 4
CSV-APPEND-NULL => 8
CSV-EMPTY-IS-NULL => 16
```
You can build your own options with the enum (example: `CSV-STRICT +| CSV-EMPTY-IS-NULL`) or the convenience method: `Text::CSV::LibCSV.build-options(:CSV-STRICT, :CSV-EMPTY-IS-NULL)`
## Has Headers (`.new(:has-headers) | .read-file(:has-headers)`)
When provided to `.new` this option will set the default parsing mode to assuming there are headers in the CSV file. This option can be overridden by passing this option to `.read-file`. This option will also cause a hash containing `header => <value>` pairs rather than array to be returned from parsing
## Auto Decode (`.new(:auto-decode)`)
This will auto-decode the data records that are emitted from libcsv. If this option is left empty then the user will receive `Buf` types back
# Usage
## OO interface
```
use Text::CSV::LibCSV;
my $parser-options = CSV-STRICT +| CSV-EMPTY-IS-NULL;
my Text::CSV::LibCSV $parser .=new(:$parser-options, :auto-decode('utf8'), :has-headers);
my @lines = $parser.read-file('path-to-file');
# @lines = [ { ... }, { ... }, ... ];
```
## Procedural
```
use Text::CSV::LibCSV :csv-read-file;
my @lines = csv-read-file('path-to-file', :$parser-options, :auto-decode('utf8'), :has-headers);
# @lines = [ { ... }, { ... }, ... ];
```
# Streaming
Sometimes your CSV files are large or simply want to act as the record/data is available. This is possible with the following pattern:
```
use Text::CSV::LibCSV;
my Supplier $on-data .=new;
my Supplier $on-record .=new;
$on-data.Supply.tap( -> $data {
# depending on your options $data contains a Buf or Buf.decode()
});
$on-record.Supply.tap( -> $record {
# depending on your options $record contains a hash or array
});
my $parser-options = CSV-STRICT +| CSV-EMPTY-IS-NULL;
my Text::CSV::LibCSV $parser .=new(:$parser-options, :auto-decode('utf8'), :has-headers);
$parser.read-file('path-to-file', :$on-data, :$on-record, :!return-all);
```
|
## dist_zef-skaji-App-Mi6.md
[](https://github.com/skaji/mi6/actions)
# NAME
App::Mi6 - minimal authoring tool for Raku
# SYNOPSIS
```
$ mi6 new Foo::Bar # create Foo-Bar distribution for Zef ecosystem
$ mi6 build # build the distribution and re-generate README.md/META6.json
$ mi6 test # run tests
$ mi6 release # release your distribution to Zef ecosystem
```
# INSTALLATION
First make sure you have rakudo v2020.11 or later. If not, install rakudo from <https://rakudo.org/downloads>.
Then:
```
$ zef install App::Mi6
```
# DESCRIPTION
App::Mi6 is a minimal authoring tool for Raku. Features are:
* Create minimal distribution skeleton for Raku
* Generate README.md from lib/Main/Module.rakumod's pod
* Run tests by `mi6 test`
* Release your distribution to [Zef ecosystem](https://deathbyperl6.com/faq-zef-ecosystem/) or [CPAN ecosystem](https://www.cpan.org/authors/id/)
# FAQ
## Can I customize mi6 behavior?
Yes. Use `dist.ini`:
```
; dist.ini
name = Your::Module::Name
; mi6 automatically guesses source-url by `git remote -v`.
; if it doesn't work for some reasons, you can specify source-url:
source-url = https://github.com/you/Your-Module-Name.git
[ReadmeFromPod]
; if you want to disable generating README.md from main module's pod, then:
; enabled = false
;
; if you want to change a file that generates README.md, then:
; filename = lib/Your/Tutorial.pod
[UploadToZef] ; Upload your distribution to Zef ecosystem
; [UploadToCPAN] ; You can also use UploadToCPAN instead, to upload your distribution to CPAN ecosystem
[PruneFiles]
; if you want to prune files when packaging, then
; filename = utils/tool.pl
;
; you can use Raku regular expressions
; match = ^ 'xt/'
[MetaNoIndex]
; if you do not want to list some files in META6.json as "provides", then
; filename = lib/Should/Not/List/Provides.rakumod
[AutoScanPackages]
; if you do not want mi6 to scan packages at all,
; but you want to manage "provides" in META6.json by yourself, then:
; enabled = false
[Badges]
; if you want to add badges to README.md, then
; provider = travis-ci.org
; provider = travis-ci.com
; provider = appveyor
; provider = github-actions/name.yml
; execute some commands before `mi6 build`
[RunBeforeBuild]
; %x will be replaced by $*EXECUTABLE
; cmd = %x -e 'say "hello"'
; cmd = %x -e 'say "world"'
; execute some commands after `mi6 build`
[RunAfterBuild]
; cmd = some shell command here
```
## How can I manage depends, build-depends, test-depends?
Write them to META6.json directly :).
## Where is the spec of META6.json?
<https://design.raku.org/S22.html>
See also [The Meta spec, Distribution, and CompUnit::Repository explained-ish](https://perl6advent.wordpress.com/2016/12/16/day-16-the-meta-spec-distribution-and-compunitrepository-explained-ish/) by ugexe.
## What is the format of the .pause file?
Mi6 uses the .pause file in your home directory to determine the username. This is a flat text file, designed to be compatible with the .pause file used by the Perl5 `cpan-upload` module (<https://metacpan.org/pod/cpan-upload>). Note that this file only needs to contain the "user" and "password" directives. Unknown directives are ignored.
An example file could consist of only two lines:
```
user your_pause_username
password your_pause_password
```
Replace `your_pause_username` with your PAUSE username, and replace `your_pause_password` with your PAUSE password.
This file can also be encrypted with GPG if you do not want to leave your PAUSE credentials in plain text.
## What existing files are modified by `mi6`?
After the initial `mi6` creation step, the following files are changed by `mi6` during each build or release operation:
* `README.md`
* `Changes`
* `META6.json`
* modules in the lib directory
## How is the version number specified?
When you are ready to release a module and enter at the CLI mi6 release, you will get a response presenting a proposed version number which you can either accept or enter a new one (which must be greater than the one offered by default).
During the release, `mi6` updates the files mentioned above with the selected version number.
## What is the required format of the `Changes` file before a release?
Ensure your `Changes` file looks like something like this **before** you start a release operation
```
{{$NEXT}}
- Change entry line 1
- Change entry line 2
- Change entry line 3
```
Notes:
* `mi6 release` will replace the `{{$NEXT}}` line with the new version number and its timestamp
* You **must** have at least one change entry line
* The first change entry line **must** start with a space or tab
## What is the source of the author's email address?
The email is taken from the author's `.gitconfig` file. In general, that same email address should match any email address existing in a module's `META6.json` file.
## How does one change an existing distribution created with `mi6` to use Zef ecosystem instead of CPAN ecosystem?
First, the author must have an active account with [fez](https://github.com/tony-o/raku-fez) which will create a `.fez-config.json` file in the author's home directory.
Then, starting with an existing module created with `mi6`, do the following:
* Add the following line to your `dist.ini` file:
`[UploadToZef]`
* Change all instances of the `auth<cpan:CPAN-USERNAME>` to `auth<zef:zef-username>`. Check files `META6.json` and the module's leading or main module file in directory `./lib`.
* Optional, but recommended: Add an entry in the module's `Changes` file mentioning the change.
* Run `mi6 build; mi6 test`.
* Commit all changes.
* Run `mi6 release` and accept (or increase) the version number offered by `mi6`.
# TODO
documentation
# SEE ALSO
<https://github.com/tokuhirom/Minilla>
<https://github.com/rjbs/Dist-Zilla>
# AUTHOR
Shoichi Kaji [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2015 Shoichi Kaji
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## ff-circumflex-accent.md
ff^
Combined from primary sources listed below.
# [In Operators](#___top "go to top of document")[§](#(Operators)_infix_ff^ "direct link")
See primary documentation
[in context](/language/operators#infix_ff^)
for **infix ff^**.
```raku
sub infix:<ff^>(Mu $a, Mu $b)
```
Works like [ff](/routine/ff), except it does not return `True` for items matching the stop condition (including items that first matched the start condition).
```raku
my @list = <X A B C Y>;
say $_ if /A/ ff /C/ for @list; # OUTPUT: «ABC»
say $_ if /A/ ff^ /C/ for @list; # OUTPUT: «AB»
```
The sed-like version can be found in [fff^](/routine/fff$CIRCUMFLEX_ACCENT).
This operator cannot be overloaded, as it's handled specially by the compiler.
|
## dist_cpan-JGOFF-Grammar-Common.md
# Grammar-Common [Build Status](http://travis-ci.org/drforr/perl6-Grammar-Common)
# Grammar-Common
Common bits for grammars, such as math expressions.
All files here will be roles, rather than standalone grammars and actions.
Yes, simple actions are included that return simple hashes containing the parse
tree. You can override these as well, or simply include your own actions.
The test suite shows you how to return more complex objects - I elected not
to do this even though it does make quite a bit more sense because I didn't
want to arbitrary clutter the grammar namespace.
Read the individual Grammar::Common files for more documentation, but these
are generally meant to be dropped in with
'also does Grammar::Common::Expression::Infix;' and using the resulting
rule as you like.
In most cases default values will be provided, although I'm probably going to
go with C-style variables and values, just because adding a full Perl-style
expression encourages people to think it's reparsing Perl 6, but that's another
module.
# Installation
* Using zef (a module management tool bundled with Rakudo Star):
```
zef update && zef install Grammar::Common
```
## Testing
To run tests:
```
prove -e perl6
```
## Author
Jeffrey Goff, DrForr on #perl6, <https://github.com/drforr/>
## License
Artistic License 2.0
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.