
txt
stringlengths 93
37.3k
|
|---|
## dist_cpan-FRITH-Math-Libgsl-Multiset.md
[](https://travis-ci.org/frithnanth/raku-Math-Libgsl-Multiset)
# NAME
Math::Libgsl::Multiset - An interface to libgsl, the Gnu Scientific Library - Multisets.
# SYNOPSIS
```
use Math::Libgsl::Multiset;
```
# DESCRIPTION
Math::Libgsl::Multiset is an interface to the multiset functions of libgsl, the Gnu Scientific Library.
This package provides both the low-level interface to the C library (Raw) and a more comfortable interface layer for the Raku programmer.
### new(:$n!, :$k!)
### new($n!, $k!)
The constructor accepts two parameters: the total number of elements in the set and the number of elements chosen from the set; the parameters can be passed as Pair-s or as single values. The multiset object is already initialized in lexicographically first multiset, i.e. 0 repeated $k times.
### init(:$start? = TOP)
This method initialize the multiset object and returns **self**. The default is to initialize the object in lexicographically first multiset, but by specifying the optional parameter **$start** as **BOTTOM** the initialization is performed in the lexicographically last multiset, i.e. $n − 1 repeated $k times. TOP and BOTTOM are declared as values of the Starting-point enum.
### copy($src! where \* ~~ Math::Libgsl::Combination)
This method copies the multiset **$src** into the current multiset object and returns **self**.
### get(Int $elem! --> Int)
This method returns the multiset value at position **$elem**.
### all(--> Seq)
This method returns a Seq of all the elements of the current multiset.
### size(--> List)
This method returns the (n, k) parameters of the current multiset object.
### is-valid(--> Bool)
This method checks whether the current multiset is valid: the k elements should lie in the range 0 to $n − 1, with each value occurring once at most and in nondecreasing order.
### next()
### prev()
These functions advance or step backwards the multiset and return **self**, useful for method chaining.
### bnext(--> Bool)
### bprev(--> Bool)
These functions advance or step backwards the multiset and return a Bool: **True** if successful or **False** if there's no more multiset to produce.
### write(Str $filename! --> Int)
This method writes the multiset data to a file.
### read(Str $filename! --> Int)
This method reads the multiset data from a file. The multiset must be of the same size of the one to be read.
### fprintf(Str $filename!, Str $format! --> Int)
This method writes the multiset data to a file, using the format specifier.
### fscanf(Str $filename!)
This method reads the multiset data from a file. The multiset must be of the same size of the one to be read.
# C Library Documentation
For more details on libgsl see <https://www.gnu.org/software/gsl/>. The excellent C Library manual is available here <https://www.gnu.org/software/gsl/doc/html/index.html>, or here <https://www.gnu.org/software/gsl/doc/latex/gsl-ref.pdf> in PDF format.
# Prerequisites
This module requires the libgsl library to be installed. Please follow the instructions below based on your platform:
## Debian Linux
```
sudo apt install libgsl23 libgsl-dev libgslcblas0
```
That command will install libgslcblas0 as well, since it's used by the GSL.
## Ubuntu 18.04
libgsl23 and libgslcblas0 have a missing symbol on Ubuntu 18.04. I solved the issue installing the Debian Buster version of those three libraries:
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgslcblas0_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl23_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl-dev_2.5+dfsg-6_amd64.deb>
# Installation
To install it using zef (a module management tool):
```
$ zef install Math::Libgsl::Combination
```
# AUTHOR
Fernando Santagata [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2020 Fernando Santagata
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## after.md
after
Combined from primary sources listed below.
# [In StrDistance](#___top "go to top of document")[§](#(StrDistance)_method_after "direct link")
See primary documentation
[in context](/type/StrDistance#method_after)
for **method after**.
Also a class attribute, returns the string after the transformation:
```raku
say $str-dist.after; # OUTPUT: «fnew»
```
# [In Operators](#___top "go to top of document")[§](#(Operators)_infix_after "direct link")
See primary documentation
[in context](/language/operators#infix_after)
for **infix after**.
```raku
multi infix:<after>(Any, Any)
multi infix:<after>(Real:D, Real:D)
multi infix:<after>(Str:D, Str:D)
multi infix:<after>(Version:D, Version:D)
```
Generic ordering, uses the same semantics as [cmp](/routine/cmp). Returns `True` if the first argument is larger than the second.
# [In X::Parameter::WrongOrder](#___top "go to top of document")[§](#(X::Parameter::WrongOrder)_method_after "direct link")
See primary documentation
[in context](/type/X/Parameter/WrongOrder#method_after)
for **method after**.
Returns a string describing other parameters after which the current parameter was illegally placed (for example `"variadic"`, `"positional"` or `"optional"`).
|
## dist_zef-raku-community-modules-Grammar-Debugger.md
[](https://github.com/raku-community-modules/Grammar-Debugger/actions) [](https://github.com/raku-community-modules/Grammar-Debugger/actions) [](https://github.com/raku-community-modules/Grammar-Debugger/actions)
# NAME
Grammer::Debugger - Interactive debugger for Raku grammars
# SYNOPSIS
In the file that has your grammar definition, merely load the module in the same lexical scope:
```
use Grammar::Debugger;
grammar Some::Grammar { ... }
```
# DESCRIPTION
Grammar::Debugger is an interactive debugger for Raku grammars. It applies to all grammars in its lexical scope. When you run your program and start to parse a grammar, you should get an interactive prompt. Type `h` to get a list of commands:
```
$ raku my-grammar-program.raku
TOP
> h
r run (until breakpoint, if any)
<enter> single step
rf run until a match fails
r <name> run until rule <name> is reached
bp add <name> add a rule name breakpoint
bp list list all active rule name breakpoints
bp rm <name> remove a rule name breakpoint
bp rm removes all breakpoints
q quit
>
```
If you are debugging a grammar and want to set up breakpoints in code rather than entering them manually at the debug prompt, you can apply the breakpoint trait to any rule:
```
token name is breakpoint {
\w+ [\h+ \w+]*
}
```
If you want to conditionally break, you can also do something like:
```
token name will break { $_ eq 'Raku' } {
\w+ [\h+ \w+]*
}
```
Which will only break after the `name` token has matched "Raku".
# AUTHOR
Jonathan Worthington
# COPYRIGHT AND LICENSE
Copyright 2011 - 2017 Jonathan Worthington
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-TITSUKI-Algorithm-HierarchicalPAM.md
[](https://travis-ci.org/titsuki/p6-Algorithm-HierarchicalPAM)
# NAME
Algorithm::HierarchicalPAM - A Perl 6 Hierarchical PAM (model 2) implementation.
# SYNOPSIS
## EXAMPLE 1
```
use Algorithm::HierarchicalPAM;
use Algorithm::HierarchicalPAM::Formatter;
use Algorithm::HierarchicalPAM::HierarchicalPAMModel;
my @documents = (
"a b c",
"d e f",
);
my ($documents, $vocabs) = Algorithm::HierarchicalPAM::Formatter.from-plain(@documents);
my Algorithm::HierarchicalPAM $hpam .= new(:$documents, :$vocabs);
my Algorithm::HierarchicalPAMModel $model = $hpam.fit(:num-super-topics(3), :num-sub-topics(5), :num-iterations(500));
$model.topic-word-matrix.say; # show topic-word matrix
$model.document-topic-matrix; # show document-topic matrix
$model.log-likelihood.say; # show likelihood
$model.nbest-words-per-topic.say # show nbest words per topic
```
## EXAMPLE 2
```
use Algorithm::HierarchicalPAM;
use Algorithm::HierarchicalPAM::Formatter;
use Algorithm::HierarchicalPAM::HierarchicalPAMModel;
# Note: You can get AP corpus as follows:
# $ wget "https://github.com/Blei-Lab/lda-c/blob/master/example/ap.tgz?raw=true" -O ap.tgz
# $ tar xvzf ap.tgz
my @vocabs = "./ap/vocab.txt".IO.lines;
my @documents = "./ap/ap.dat".IO.lines;
my $documents = Algorithm::HierarchicalPAM::Formatter.from-libsvm(@documents);
my Algorithm::HierarchicalPAM $hpam .= new(:$documents, :@vocabs);
my Algorithm::HierarchicalPAM::HierarchicalPAMModel $model = $hpam.fit(:num-super-topics(10), :num-sub-topics(20), :num-iterations(500));
$model.topic-word-matrix.say; # show topic-word matrix
$model.document-topic-matrix; # show document-topic matrix
$model.log-likelihood.say; # show likelihood
$model.nbest-words-per-topic.say # show nbest words per topic
```
# DESCRIPTION
Algorithm::HierarchicalPAM - A Perl 6 Hierarchical PAM (model 2) implementation.
## CONSTRUCTOR
### new
Defined as:
```
submethod BUILD(:$!documents!, :$!vocabs! is raw) { }
```
Constructs a new Algorithm::HierarchicalPAM instance.
## METHODS
### fit
Defined as:
```
method fit(Int :$num-iterations = 500, Int :$num-super-topics!, Int :$num-sub-topics!, Num :$alpha = 0.1e0, Num :$beta = 0.1e0, Int :$seed --> Algorithm::HierarchicalPAM::HierarchicalPAMModel)
```
Returns an Algorithm::HierarchicalPAM::HierarchicalPAMModel instance.
* `:$num-iterations` is the number of iterations for gibbs sampler
* `:$num-super-topics!` is the number of super topics
* `:$num-sub-topics!` is the number of sub topics
* `alpha` is the prior for theta distribution (i.e., document-topic distribution)
* `beta` is the prior for phi distribution (i.e., topic-word distribution)
* `seed` is the seed for srand
# AUTHOR
titsuki [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2019 titsuki
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
The algorithm is from:
* Mimno, David, Wei Li, and Andrew McCallum. "Mixtures of hierarchical topics with pachinko allocation." Proceedings of the 24th international conference on Machine learning. ACM, 2007.
* Minka, Thomas. "Estimating a Dirichlet distribution." (2000): 4.
|
## bindoruse.md
class X::Proc::Async::BindOrUse
Error due to trying to bind a handle that is also used
```raku
class X::Proc::Async::BindOrUse does X::Proc::Async {}
```
In general, it occurs when there's some mistake in the direction the stream flows, for instance:
```raku
my $p = Proc::Async.new("ls", :w);
my $h = "ls.out".IO.open(:w);
$p.bind-stdin($h);
# Fails with OUTPUT: «Cannot both bind stdin to a handle and also use :w»
```
In this case, `stdin` is already bound and cannot be used again; one of them should flow `:out` and the other one `:w` to work correctly.
|
## dist_zef-antononcube-Math-SparseMatrix-Native.md
# Math::SparseMatrix::Native
[](https://github.com/antononcube/Raku-Math-SparseMatrix-Native/actions)
[](https://github.com/antononcube/Raku-Math-SparseMatrix-Native/actions)
[](https://opensource.org/licenses/Artistic-2.0)
Raku package with sparse matrix algebra functions implemented in C.
The package is a "standalone" implementation of sparse matrix functionalities using
Compressed Sparse Row (CSR) format. The intent, though, is to use the class `Math::SparseMatrix::Native::CSRStruct`
provided by this package in the general package
["Math::SparseMatrix"](https://github.com/antononcube/Raku-Math-SparseMatrix), [AAp1].
(See the section "Design" below.)
The core algorithms of the package follow the FORTRAN implementations given in the book
"Sparse Matrix Technology" by Pissanetzky, [SP1].
This package should be compared -- and likely replaced -- with Raku package(s) interfacing
sparse matrix algebra libraries, like,
["SuiteSparse"](https://github.com/DrTimothyAldenDavis/SuiteSparse).
(When/if such Raku packages are implemented.)
**Remark:** This package uses a C implementation based on standard C libraries ("math", "stdio", "stdlib", "string".)
Hence, it should be cross platform.
**Remark:** Currently, on macOS, Apple's Accelerate library is *not* used.
There are several reasons for this:
(i) lack of appropriate documentation to sparse linear algebra in C,
(i) using dense matrices for sparse matrix computations with its documented, older LAPACK interface libraries.
---
## Usage examples
Make two random -- relatively large -- sparse matrices:
```
use Math::SparseMatrix::Native;
use Math::SparseMatrix::Native::Utilities;
my $nrow = 1000;
my $ncol = 10_000;
my $density = 0.005;
my $nnz = ($nrow * $ncol * $density).Int;
my $seed = 3432;
my $matrix1 = Math::SparseMatrix::Native::CSRStruct.new.random(:$nrow, :$ncol, :$nnz, :$seed);
my $matrix2 = Math::SparseMatrix::Native::CSRStruct.new.random(nrow => $ncol, ncol => $nrow, :$nnz, :$seed);
say (:$matrix1);
say (:$matrix2);
```
```
# matrix1 => Math::SparseMatrix::Native::CSRStruct(:specified-elements(50000), :dimensions((1000, 10000)), :density(0.005))
# matrix2 => Math::SparseMatrix::Native::CSRStruct(:specified-elements(50000), :dimensions((10000, 1000)), :density(0.005))
```
**Remark:** Compare the dimensions, densities, and the number of "specified elements" in the gists.
Here are 100 dot-products of those matrices (with timings):
```
my $tstart=now;
my $n = 100;
for ^$n {
$matrix1.dot($matrix2)
}
my $tend=now;
say "Total time : {$tend - $tstart}";
say "Mean time : {($tend - $tstart)/$n}"
```
```
# Total time : 0.186986415
# Mean time : 0.00186986415
```
---
## Design
The primary motivation for implementing this package is the need to have *fast* sparse matrix computations.
* The pure-Raku implemented sparse matrix algorithms in
["Math::SparseMatrix"](https://raku.land/zef:antononcube/Math::SparseMatrix), [AAp1],
are too slow.
* Same algorithms implemented in C (in this package) are ≈100 times faster.
The `NativeCall` class `Math::SparseMatrix::Native::CSRStruct` has Compressed Sparse Row (CSR) format sparse matrix operations.
The [Adapter pattern](https://en.wikipedia.org/wiki/Adapter_pattern) is used to include `Math::SparseMatrix::Native::CSRStruct`
into the `Math::SparseMatrix` hierarchy:
```
classDiagram
class Abstract["Math::SparseMatrix::Abstract"] {
<<abstract>>
+value-at()
+row-at()
+column-at()
+row-slice()
+AT-POS()
+print()
+transpose()
+add()
+multiply()
+dot()
}
class CSRStruct {
<<C struct>>
}
class NativeCSR["Math::SparseMatrix::CSR::Native"] {
$row_ptr
$col_index
@values
nrow
ncol
implicit_value
}
class NativeAdapater["Math::SparseMatrix::NativeAdapter"] {
+row-ptr
+col-index
+values
+nrow
+ncol
+implicit-value
}
class SparseMatrix["Math::SparseMatrix"] {
Abstract core-matrix
+AT-POS()
+print()
+transpose()
+add()
+multiply()
+dot()
}
NativeAdapater --> Abstract : implements
SparseMatrix --> Abstract : Hides actual component class
SparseMatrix *--> Abstract
NativeAdapater *--> NativeCSR
NativeCSR -- CSRStruct : reprents
```
---
## TODO
* DONE Core functionalities
* DONE C-struct representation: data and methods
* DONE `transpose`
* DONE `dot-pattern`
* DONE `dot` matrix x dense vector
* DONE `dot` (and `dot-numeric`) matrix x matrix
* DONE `add` with a scalar
* DONE `add` with another matrix
* DONE `multiply` with a scalar
* DONE `multiply` with another matrix
* DONE Refactoring
* Consistent use of `unsigned int` or `int` for `row_ptr` and `col_index`.
* TODO Adaptation to "Math::SparseMatrix"
* This package was made in order to have faster computation with "Math::SparseMatrix".
* But it can be self-contained and independent from "Math::SparseMatrix".
* Hence, we make an adapter class in "Math::SparseMatrix".
* DONE Unit tests
* DONE Creation (and destruction)
* DONE Access
* DONE Element-wise operations
* DONE Dot product
---
## References
### Books
[SP1] Sergio Pissanetzky, Sparse Matrix Technology, Academic Pr (January 1, 1984), ISBN-10: 0125575807, ISBN-13: 978-0125575805.
### Packages
[AAp1] Anton Antonov,
[Math::SparseMatrix Raku package](https://github.com/antononcube/Raku-Math-SparseMatrix),
(2024),
[GitHub/antononcube](https://github.com/antononcube).
|
## dist_zef-knarkhov-Ethelia.md
# Raku Ethelia
**Ethelia** is Ethereum blockchain storage provider for different kinds of events. Visit our official site: <https://ethelia.pheix.org/>
Basically Ethelia uses [Pheix](https://pheix.org) as middle layer to access the data on Ethereum blockchain. Not as a service, but a framework. Technically Ethelia is a Pheix extension with business and service related logic in a set of independent modules. It uses Pheix features directly via object oriented model — methods and attributes.
Check out the list of [Ethelia related repositories](https://gitlab.com/groups/ethelia/-/shared?sort=name_asc) for more details.
## Testing with `Trove`
You can automate unit tests running with `Trove` [module](https://gitlab.com/pheix/raku-trove):
```
RAKULIB=.,$HOME/git/dcms-raku,$HOME/git/pheix-research/raku-dossier-prototype/ trove-cli -c --f=`pwd`/.trove.conf.yml --p=yq
```
## API
Please check full Ethelia [API documentation](https://docs.ethelia.pheix.org/api/auth/) and feel free to go through [Getting Started](https://docs.ethelia.pheix.org/rawhide/gettingstarted/) guide.
### Sample requests
#### Create
```
{
"credentials": {
"token": "0x99caaa44ecf6fd6e561a35a8892a92cc91a325c685db95e3c7b2a8b5097966f7"
},
"method": "GET",
"route": "/api/ethelia/event/store",
"payload": {
"code": "01982-1",
"topic": "blockchain_event_1",
"payload": {
"return": 1,
"score": 2022,
"result": "success",
"details": {
"items": [
1.87,
2.16,
3.52
],
"status": true
}
}
}
}
```
```
{
"credentials": {
"token": "0x99caaa44ecf6fd6e561a35a8892a92cc91a325c685db95e3c7b2a8b5097966f7"
},
"method": "GET",
"route": "/api/ethelia/event/store",
"payload": {
"code": "1004-1",
"topic": "pm2.5_event_1",
"payload": {
"sensorvalue": 24,
"sensordevice": "Xaomi Air Purifier 4 Lite"
}
}
}
```
#### Search
```
{
"credentials": {
"token": "0xd78776d2eec8eb2835e86d7c8bb070abf001543171ffd31f676e6997e6f54f33"
},
"method": "GET",
"route": "/api/ethelia/event/search",
"payload": {
"search": {
"target": "1",
"value": "*"
}
}
}
```
#### Decode input transaction data
1. `set`: <https://sepolia.etherscan.io/tx/0x75955f529abc5539b8ffeb11c9a08571e08c8054d82f794aea5bcd2379bc4afd>
2. `insert`: <https://sepolia.etherscan.io/tx/0x6ec5fafed26c3a7d7586f9d8c153e348ff14cd88f1b648434c9f6c03db37ed07>
```
{
"credentials": {
"token": "0xf97e55f06ff19dd7d4c2da52a289837641d029b92d336e65f9a0c88bb0d2e4ae"
},
"method": "GET",
"route": "/api/ethelia/transaction/decode",
"payload": {
"function": "set",
"inputdata": "0xf609bacf00000000000000000000000000000000000000000000000000000000000000a00000000000000000000000000000000000000000000000000000000065c8fc2e00000000000000000000000000000000000000000000000000000000000000e0000000000000000000000000000000000000000000000000000000000000000100000000000000000000000000000000000000000000000000000000000002a00000000000000000000000000000000000000000000000000000000000000010457874656e73696f6e457468656c696100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000019d425a6836314159265359ed2e145f00000d1f8040067ff23dffbff03ffffbf43001531b6b1153fd54c869808600832346269a32620da8c0d54fd4f4a3c29e2689b54dea9faa3406d324cd4c40068682535149e6a8f50f29a6d2681e53d4687a4da9ea7a987aa00d09a2f53767c332adf021cefcf5ce16d3ca926bf36cb6e67eae584449a530761ee33c2cb2b92a45027b28ecf27431af09c3a48c18431c004d74e27ac250747b43ae7dece391d0bbba90a509211a055725ba72037a996b781f42be8b2bb8a6331bdadcd6714c636ddca5293f00dac9ac1c84932679b6c84b3fbc187e296f4684c66dc244e5b566cf6f64dd27cf839ef50a0d3218b2971534984b91d18bd0d5b82d3a442919210a8001e678d21b6103da3b0320adf66d6c229f13bf8252fa7a90ea6d7e99631197217eb3eda933b94f76420ba02769a37551e3ab4fda37e6fe112212105e96ff94211edc089d44366c938433e3ae76e6287119cfe359ab51e95d4165bf41e24304eb17ea53c559c29c328f508c97688ebe62e0d0d6f7104ede16be5add2bb3e8ca8c29fd8d6188bb9229c284876970a2f8000000000000000000000000000000000000000000000000000000000000000000008430784443314543364436384337363732373243413834303344353332363532304235313036303545423539333032463833333232383542443634444242413233383843424133393736313133313435413145453745314441373633423231374534424444464332304534423438314233433446363630313237464444393332313437303100000000000000000000000000000000000000000000000000000000"
}
}
```
## Pre-launch Telegram channel
[](https://t.me/+0YOeSWFoceAyYjBi)
## License information
This is free and opensource software, so you can redistribute it and/or modify it under the terms of the [The Artistic License 2.0](https://opensource.org/licenses/Artistic-2.0).
## Author
Please contact me via [Matrix](https://matrix.to/#/@k.narkhov:matrix.org) or [LinkedIn](https://www.linkedin.com/in/knarkhov/). Your feedback is welcome at [narkhov.pro](https://narkhov.pro/contact-information.html).
|
## dist_zef-whity-Logger.md
# Logger
A simple logging class in raku.
[](https://github.com/whity/raku-log/actions/workflows/test.yml)
## Usage
```
use Logger;
sub MAIN() {
my $log = Logger.new;
# by default the log level is INFO and the output is $*OUT (can be any IO::Handle)
# Logger.new(level => Logger::DEBUG, output => $*ERR)
# log a message
$log.trace('trace message');
$log.debug('debug message');
$log.info('info message');
$log.warn('warn message');
$log.error('error message');
# ndc
$log.ndc.push('xxx'); # add a value to the stack
$log.ndc.pop(); # remove the last item from the stack
# mdc
$log.mdc.put('key', 'value');
# change the level
$log.level = Logger::DEBUG;
$log.debug('debug message');
# checking the current log level
say $log.is-error;
say $log.is-info;
# log pattern placeholders
# %m -> message
# %d -> current datetime
# %c -> message level
# %n -> new line feed '\n'
# %p -> process id
# %x -> NDC
# %X{key-name} -> MDC
$log.pattern = '%X{key} %x %m%n';
$log.info('test');
# register log object to use in other places
Logger.add('log-name', Logger.new);
#Log.add(Logger.new) # register the log object as 'main'
# get a registered log object
my $rlog = Logger.get('log-name');
#my $rlog = Logger.get; returns the log object 'main'
$rlog.info('from "log-name"');
# Set a formatter for the datetime
my $log = Logger.new(dt-formatter => -> $dt { sprintf "%sT%s", .dd-mm-yyyy, .hh-mm-ss given $dt)});
$log.info('test'); # prints: [20-11-2021T18:31:44][INFO] test
}
```
## Contributing
1. Fork it ( [https://github.com/[your-github-name]/raku-log/fork](https://github.com/%5Byour-github-name%5D/raku-log/fork) )
2. Create your feature branch (git checkout -b my-new-feature)
3. Commit your changes (git commit -am 'Add some feature')
4. Push to the branch (git push origin my-new-feature)
5. Create a new Pull Request
## Contributors
* whity(<https://github.com/whity>) André Brás - creator, maintainer
|
## exitcode.md
exitcode
Combined from primary sources listed below.
# [In Proc](#___top "go to top of document")[§](#(Proc)_method_exitcode "direct link")
See primary documentation
[in context](/type/Proc#method_exitcode)
for **method exitcode**.
```raku
method exitcode(Proc:D: --> Int:D)
```
Returns the exit code of the external process, or -1 if it has not exited yet.
|
## dist_zef-lizmat-String-Fields.md
[](https://github.com/lizmat/String-Fields/actions) [](https://github.com/lizmat/String-Fields/actions) [](https://github.com/lizmat/String-Fields/actions)
# NAME
String::Fields - class for setting fixed size fields in a Str
# SYNOPSIS
```
use String::Fields;
my $sf := String::Fields.new(2,3,4)
.say for $sf.set-string("abcdefghijklmnopqrstuvwxyz");
# ab
# cde
# fghi
my $sf := String::Fields.new(2 => 5, 8, 3);
my $s = "012345678901234567890";
$s.&apply-fields($sf); # or: apply-fields($s,$sf)
say $s; # 012345678901234567890
say $s[0]; # 23456
say $s[1]; # 78901234
say $s[2]; # 567
say $s.join(":"); # 23456:78901234:567
# one time application
$s.&apply-fields(2,3,4); # or: apply-fields($s,2,3,4)
# using a literal string
my @fields = "abcdefg".&apply-fields(2,3); # ["ab","cde"]
```
# DESCRIPTION
String::Fields allows one to specify fixed length fields that can be applied to a string, effectively turning it into a sequence of strings that can be individually accessed or iterated over.
When the object is loaded with a string, it can be used as a string in all the normal ways that a string would.
# METHODS
## new
```
my $sf := String::Fields.new(2,3,4)
```
The `new` method creates a new `String::Fields` object that contains the format information of the fields. It takes any number of arguments to indicate the position and width of the fields. If the argument consists of just a number, it means the width of a field from where the last field has ended (or from position 0 for the first argument). If the argument consists of a `Pair`, then the key is taken for the offset, and the value is taken to be the width.
Please note that this **just** sets the format information. This allows the same object to be used for different strings. Setting the string to be used, is either done with the `set-string` method, or by calling the `apply-fields` subroutine.
## join
```
$s.join(":");
```
Joins all fields together with the given separator.
## set-string
```
$sf.set-string($string)
```
The `set-string` method sets the string to which the format information should be applied.
# SUBROUTINES
## apply-fields
```
apply-fields($s,$sf); # or $s.&apply-fields($sf)
# one time application
$s.&apply-fields(2,3,4); # or: apply-fields($s,2,3,4)
# using a literal string
my @fields = "abcdefg".&apply-fields(2,3); # ["ab","cde"]
```
If the first argument to the `apply-fields` subroutine is a variable with a string in it, then it will become a `String::Fields` object (but will still act as the original string). If it is a string literal, then the created / applied `String::Fields` object will be returned. The other arguments indicate the fields that should be applie. This can be either be a `String::Fields` object, or it can any number of field specifications, as can be passed to the `new` method.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/String-Fields> . Comments and Pull Requests are welcome.
If you like this module, or what I'm doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2020, 2021, 2024 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-finanalyst-Collection-Raku-Documentation.md
# Collection-based Raku Documentation
> **Description** Distribution to set up Raku Documentation website.
> **Author** Richard Hainsworth, aka finanalyst
---
## Table of Contents
[Installation](#installation)
[Raku-Doc](#raku-doc)
[Raku-Doc as a wrapper for Collection::collect](#raku-doc-as-a-wrapper-for-collectioncollect)
[More contemporary web site.](#more-contemporary-web-site)
[In the future (not now)](#in-the-future-not-now)
[Enabling Cro App](#enabling-cro-app)
[Highlighting](#highlighting)
[Problems](#problems)
[Copyright and License](#copyright-and-license)
---
This Module creates a local website of the Raku documentation. It pulls together information held in several other distributions. The main content of this distribution is the `Raku-Doc` utility. It is intended to be as simple as possible. But the documentation system is large. The following contain other requirements.
* The documentation files are held in a github repository that is maintained and updated by the Raku community. `Raku-Doc` needs to have a local clone of the repository. It can be used to refresh the documents automatically.
* `Raku-Doc` uses Collection and Raku::Pod::Render to link all the Rakudoc (aka Pod6) files together. So `Collection` needs to be installed, which will install `Raku::Pod::Render`. By installing `Raku-Pod-Render` a user can then use `Pod::To::HTML2` to render individual `.rakudoc / .pod6` files into HTML, or `Pod::To::MarkDown2` to render them into `.md` files.
* `Collection` requires over a dozen plugins, which are automatically refreshed from a github repository by `Raku-Doc`.
* The Raku documentation system can currently be visualised in two ways:
* using the original web design started by Moritz Lenz (using the mode Website) - currently the default.
* using a new design by OgdenWebb (using the mode OgdenWebb).
* The website is intended to be served locally with a Cro app. Since making Cro a dependency can cause problems in a testing environment, the META6.json does not have Cro as a dependency. If Cro::HTTP is not installed, the completion plugin will exit with a note.
* A website contains templates and structure documents, which describe the website into which the Raku documentation fit. This content is also held in a separate repository. This is intended to keep the development of plugins separate from the structure documents and templates, and separate from the Raku documentation content.
# Installation
```
zef install Collection-Raku-Documentation
```
This installs the `Collection` (and other) dependencies and the `Raku-Doc` executable. These in turn install the the other main distributions and `Raku::Pod::Render`. By default `Raku::Pod::Render` does not install the highlighter automatically because `node.js` and `npm` are required.
See [Highlighting](Highlighting.md) for installation of highlighter.
# Raku-Doc
On a Linux based distributions, `Raku-Doc` depends on `git` and `unzip`, which typically are installed by default, to get and unpack other files.
Under Linux, in a terminal, the following will lead to the installation of a local copy of Raku docs and start a Cro app that will make the HTML documentation available in a browser at `localhost:30000`, and produce a progress status bar for the longer stages.
```
mkdir ~/raku-collection
cd raku-collection
Raku-Doc Init
```
This sets up a Collection directory by downloading the Website mode from github, then installs the Collection plugins.
By default the `Raku/doc` repository (containing all the Raku documentation files) will be created in the next step as **local\_raku\_docs**.
If a user wants to clone the Raku docs repository elsewhere or has an existing clone of the Raku repository, then the non-default path needs to be put into the config.raku file in the `sources-obtain` and `sources-refresh` keys. See the documentation for the `Collection` distribution for more information.
At the next invocation of **Raku-Doc**, the documentation source will be cloned, cached, and rendered.
For example, to render the full Raku Docs, the following would work, where `raku-local` is a local directory.
```
- raku-collection
- local_raku_docs # this is generated by the git clone command
- Website # this is generated by runnng 'Raku-Doc Init' in raku-collection
config.raku # as Website
```
After the `Init` stage, calling `Raku-Doc` without any other options implies the mode **Website** with default options.
The Raku Documentation source files are regularly updated. The **Website** mode is configured to pull the latest versions of the source files into the Collection whenever `Raku-Doc` is run, which then updates the cache for any sources that have changed, and then re-render all the html files that are affected. These stages are automatically called by running Raku-Doc with the config defaults given.
The Website mode files and plugins are being actively developed, so newer versions may be available. New versions of the plugins are automatically called on each invocation of Raku-Doc. To get new versions of the Website mode files (sources and additional plugins), use
```
Raku-Doc Update
```
`Raku-Doc` can be called with other options, which are described in the `Collection` documentation.
**Collection-Raku-Documentation** is set up with the default `mode` called **Website**.
The more contemporary web design by Ogden Webb is in a mode call **OgdenWebb**. It is generated thus:
```
Raku-Doc OgdenWebb
```
It can be made the default by changing the `mode` key in the top-level `config.raku` file.
# Raku-Doc as a wrapper for Collection::collect
With the exception of 'Init' and 'Update', `Raku-Doc` can be called with all the options listed for `Collection::collect`.
More information about these options is given in the Documentation for `Collection`.
## More contemporary web site.
A more contemporary web design by Ogden Webb is now included. It is generated by running
```
Raku-Doc OgdenWebb
```
## In the future (not now)
If `Raku-Doc` is called with a string other than 'Init' or 'Website', then the string is interpreted as another **Mode**, with its own sub-directory and [Configuration](Configuration.md) for the collection. For example,
```
Raku-Doc Book
```
would create the collection output defined by the configuration in the sub-directory `Book/config/`. This design is to allow for the creation of different Collection outputs to be defined for the same content files.
# Enabling Cro App
A Cro App is included that will run the website automatically by running `Raku-Doc`. The Cro App is called using a plugin that runs after the html files have been refreshed. The Cro App is called at completion (see Collection documentation). It contains a test to see if Cro::HTTP is installed.
Since installing Cro can cause testing problems, this distribution does not have Cro::HTTP as a dependency.
Cro in installed using zef as
```
zef install Cro::HTTP
```
Running `Raku-Doc` without options will now serve the documentation files locally on port 3000. So point your browser at `localhost:3000`
# Highlighting
The default highlighter at present is a Node based toolstack called **atom-perl-highlighter**. In order to install it automatically, `Raku::Pod::Render` requires an uptodate version of npm. The builder is known not to work with `node.js` > \*\*\*\*v13.0> and `npm` > **v14.15**.
For someone who has not installed `node` or `npm` before, or for whom they are only needed for the highlighter, the installation is ... confusing. It would seem at the time of writing that the easiest method is:
```
# Using Ubuntu
curl -sL https://deb.nodesource.com/setup_14.x | sudo -E bash -
sudo apt-get install -y nodejs
```
Then, **after the default installation of Raku::Pod::Render**, highlighting can be enabled by running the following in a terminal:
```
raku-render-install-highlighter
```
# Problems
Collection is still being actively developed.
* When running `Raku-Doc` with a `sources-refresh` key set to a git pull stanza, Raku-Doc teminates after a git pull. Workaround: run `Raku-Doc` again.
# Copyright and License
(c) Richard N Hainsworth, 2021-2022
**LICENSE** Artistic-2.0
---
Rendered from README at 2023-01-14T10:19:05Z
|
## dist_zef-Altai-man-deredere.md
# deredere
Simple scraper framework for Perl 6.
## Usage
Often we need to get some data from some web page over the Internet. Some sites provide an API, but many sites don't. This framework makes building of "data scraper" easier. You can just get the whole page, or parse it and do something with data. At this stage three basic cases are handled:
* Downloading of raw page by url.
* Downloading of raw page, data parsing and handling by default operator.
* Downloading of raw pages, where next link is extracted with outer function, data parsing and handling by custom operator.
`Parser` is just outer function, that converts an XML document to some data list.
`Operator` is just outer function, that takes data list and processes it.
`Default operator`, which is used when none passed, works like that: if parsed item is a URL, it will be downloaded, if parsed item is just some text, it will be appended to file with data.
## The real example itself
```
use deredere;
use XML;
sub src-extractor($node) {
($node.Str ~~ /src\=\"(.+?)\"/)[0].Str;
}
sub parser($doc) {
$doc.lookfor(:TAG<img>).race.map(&src-extractor);
}
# Just as pure example.
scrape("konachan.net/post", &parser);
```
See other examples for more info.
## Scrapers
```
sub scrape(Str $url);
sub scrape(Str $url, &parser, Str :$filename="scraped-data.txt");
# "Next" function has a default value of empty line function, in the case if we scrape the first page only.
sub scrape(Str $url, &parser, &operator, &next?, Int $gens=1, Int $delay=0);
```
## Installation
```
$ zef update
$ zef install deredere
```
Also, you can install `IO::Sockes::SSL` to work with "https" links. You also need `XML` to build effective data parsers.
## Testing
Tests are coming.
## To-do List
* Tests.
* More cases.
* More operators.
* Speed up.
|
## dist_github-ccworld1000-CCLog.md
## [CCLog](https://github.com/ccworld1000/CCLog)
```
Simple and lightweight cross-platform logs,
easy-to-use simple learning,
and support for multiple languages,
such as C, C++, Perl 6, shell, Objective-C
support ios, osx, watchos, tvos
support pod, cocoapods https://cocoapods.org/pods/CCLog
```
## Perl 6
```
There are 2 (CCLog & CCLogFull) ways of binding.
```
Call CCLog.pm6

Call CCLogFull.pm6

## Shell
```
Provide simple commands. fg:
ccnormal
ccwarning
ccerror
cctimer
ccloop
ccthread
ccprint
ccsay
ccdie
ccnetwork
These commands are automatically installed locally and can be called directly.
```
Call shell

## C && C++ && Objective-C
```
You can use C library or C source (CCLog.h CCLog.c) code directly.
```
Call C && C++ && Objective-C

## Objective-C
```
Objective-C can call C directly, Or follow other ways to import.
or use pod https://github.com/ccworld1000/CCLog
pod 'CCLog'
```
## Local installation and unloading
```
zef install .
zef uninstall CCLog
```
## Network install
```
zef update
zef install CCLog
```
## Check if the installation is successful
The installation may be as follows

Installation failure may be as follows, you can try again

## Color display control
Perl6 CCLog.pm6 call ccshowColor
Perl6 CCLogFull.pm6 call CCLog\_showColor
C && C++ && Objective-C call CCLog\_showColor
fg:

## Tips display control
fg:
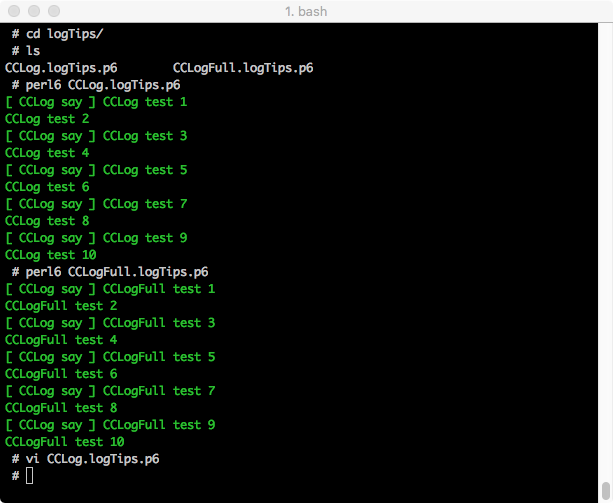
## Display log control
fg:

|
## dist_zef-dwarring-PDF-Lite.md
[[Raku PDF Project]](https://pdf-raku.github.io)
/ [PDF::Lite](https://pdf-raku.github.io/PDF-Lite-raku)
[](https://github.com/pdf-raku/PDF-Lite-raku/actions)
# PDF::Lite
`PDF::Lite` is a minimal class for creating or editing PDF documents, including:
* Basic Text
* Simple forms and images (GIF, JPEG & PNG)
* Graphics and Drawing
* Content reuse (Pages and form objects)
```
use v6;
use PDF::Lite;
my PDF::Lite $pdf .= new;
$pdf.media-box = 'Letter';
my PDF::Lite::Page $page = $pdf.add-page;
constant X-Margin = 10;
constant Padding = 10;
$page.graphics: {
enum <x0 y0 x1 y1>;
my $font = $pdf.core-font( :family<Helvetica>, :weight<bold>, :style<italic> );
my @position = [10, 10];
my @box = .say: "Hello World", :@position, :$font;
my PDF::Lite::XObject $img = .load-image: "t/images/lightbulb.gif";
.do: $img, :position[@box[x1] + Padding, 10];
}
given $pdf.Info //= {} {
.CreationDate = DateTime.now;
}
$pdf.save-as: "examples/hello-world.pdf";
```

#### Text
`.say` and `.print` are simple convenience methods for displaying simple blocks of text with encoding, optional line-wrapping, alignment and kerning.
These methods return a rectangle given the rendered text region;
```
use PDF::Lite;
enum <x0 y0 x1 y1>;
my PDF::Lite $pdf .= new;
$pdf.media-box = [0, 0, 500, 150];
my PDF::Lite::Page $page = $pdf.add-page;
my $font = $pdf.core-font( :family<Helvetica> );
my $header-font = $pdf.core-font( :family<Helvetica>, :weight<bold> );
$page.text: -> $txt {
$txt.font = $header-font, 16;
$txt.text-position = 250, 112;
$txt.say: 'Some Sample PDF::Lite Text', :align<center>, :valign<bottom>;
my $width := 200;
my $text = q:to"--END--";
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt
ut labore et dolore magna aliqua.
--END--
$txt.font = $font, 12;
# output text with left, top corner at (20, 100)
my @box = $txt.say: $text, :$width, :position[20, 100];
note "text height: {@box[y1] - @box[y0]}";
# output kerned paragraph, flow from right to left, right, top edge at (450, 100)
$txt.say( $text, :$width, :height(150), :align<right>, :kern, :position[450, 100] );
# add another line of text, flowing on to the next line
$txt.font = $pdf.core-font( :family<Helvetica>, :weight<bold> ), 12;
$txt.say( "But wait, there's more!!", :align<right>, :kern );
}
$pdf.save-as: "examples/sample-text.pdf";
```

#### Images (`.load-image` and `.do` methods):
The `.load-image` method can be used to open an image.
The `.do` method can them be used to render it.
```
use PDF::Lite;
my PDF::Lite $pdf .= new;
$pdf.media-box = [0, 0, 450, 250];
my PDF::Lite::Page $page = $pdf.add-page;
$page.graphics: -> $gfx {
my PDF::Lite::XObject $img = $gfx.load-image("t/images/snoopy-happy-dance.jpg");
$gfx.do($img, 50, 40, :width(150) );
# displays the image again, semi-transparently with translation, rotation and scaling
$gfx.transform( :translate[180, 100]);
$gfx.transform( :rotate(-.5), :scale(.75) );
$gfx.FillAlpha = 0.5;
$gfx.do($img, :width(150) );
}
$pdf.save-as: "examples/sample-image.pdf";
```

Note: at this stage, only the `JPEG`, `GIF` and `PNG` image formats are supported.
### Text effects
To display card suits symbols, using the ZapfDingbats core-font, with diamonds and hearts colored red:
```
use PDF::Lite;
use PDF::Content::Color :rgb;
my PDF::Lite $pdf .= new;
$pdf.media-box = [0, 0, 400, 120];
my PDF::Lite::Page $page = $pdf.add-page;
$page.graphics: {
$page.text: {
.text-position = [20, 70];
.font = [ $pdf.core-font('ZapfDingbats'), 24];
.WordSpacing = 16;
.print("♠ ♣\c[NO-BREAK SPACE]");
.FillColor = rgb(1, .3, .3); # reddish
.say("♦ ♥");
}
# Display outline, slanted text
my $header-font = $pdf.core-font( :family<Helvetica>, :weight<bold> );
$page.text: {
use PDF::Content::Ops :TextMode;
.font = ( $header-font, 18);
.TextRender = TextMode::FillOutlineText;
.LineWidth = .5;
.text-transform( :skew[0, -6], :translate[10, 30] );
.FillColor = rgb(.6, .7, .9);
.print('Outline Slanted Text @(10,30)');
}
}
$pdf.save-as: "examples/text-effects.pdf";
```

## Fonts
This module has built-in support for the PDF core fonts: Courier, Times, Helvetica, ZapfDingbats and Symbol.
The companion module [PDF::Font::Loader](https://pdf-raku.github.io/PDF-Font-Loader-raku) can be used to access a wider range of fonts:
```
use PDF::Lite;
use PDF::Font::Loader :load-font;
my PDF::Lite $pdf .= new;
$pdf.media-box = [0, 0, 400, 120];
my PDF::Lite::Page $page = $pdf.add-page;
my $noto = load-font: :file<t/fonts/NotoSans-Regular.ttf>;
# or find a system font by family and attributes (also requires FontConfig)
# $noto = load-font: :family<NotoSans>, :weight<book>;
$page.text: {
.text-position = [10,100];
.font = $noto;
.say: "Noto Sans Regular";
}
$pdf.save-as: "examples/fonts.pdf";
```

## Page sizes
The `media-box` method is used most commonly used to set page sizes. It can be set on the `PDF::Lite` object to set a default page size.
Individual pages can be given different page sizes.
```
use v6;
use PDF::Lite;
use PDF::Content::Page :PageSizes, :&to-landscape;
my PDF::Lite $pdf .= new;
$pdf.media-box = Letter; # Set a default page size
my $page1 = $pdf.add-page;
say $page1.media-box; # [0 0 612 792]
my $page2 = $pdf.add-page;
$page2.media-box = A4;
say $page2.media-box; # [0 0 595 842]
my $page3 = $pdf.add-page;
$page3.media-box = to-landscape(A4);
say $page3.media-box; # [0 0 842 595]
```
## Forms and Patterns
Forms are a reusable graphics component. They can be used wherever
images can be used.
A pattern can be used to fill an area with a repeating graphic.
```
use PDF::Lite;
use PDF::Content::Color :rgb;
my PDF::Lite $pdf .= new;
$pdf.media-box = [0, 0, 400, 120];
my PDF::Lite::Page $page = $pdf.add-page;
$page.graphics: {
my $font = $pdf.core-font( :family<Helvetica> );
my PDF::Lite::XObject $form = .xobject-form(:BBox[0, 0, 95, 25]);
$form.graphics: {
# Set a background color
.FillColor = rgb(.8, .9, .9);
.Rectangle: |$form<BBox>;
.paint: :fill;
.font = $font;
.FillColor = rgb(1, .3, .3); # reddish
.say("Simple Form", :position[2, 5]);
}
# display a simple form a couple of times
.do($form, 10, 10);
.transform: :translate(10,40), :rotate(.1), :scale(.75);
.do($form, 10, 10);
}
$page.graphics: {
my PDF::Lite::Tiling-Pattern $pattern = .tiling-pattern(:BBox[0, 0, 25, 25], );
$pattern.graphics: {
# Set a background color
.FillColor = rgb(.8, .8, .9);
.Rectangle: |$pattern<BBox>;
.paint: :fill;
# Display an image
my PDF::Lite::XObject $img = .load-image("t/images/lightbulb.gif");
.do($img, 6, 2 );
}
# fill a rectangle using this pattern
.FillColor = .use-pattern($pattern);
.Rectangle(125, 10, 200, 100);
.paint: :stroke, :fill;
}
$pdf.save-as: "examples/forms-and-patterns.pdf";
```

### Resources and Reuse
The `to-xobject` method can be used to convert a page to an XObject Form to lay-up one or more input pages on an output page.
```
use PDF::Lite;
my $pdf-with-images = PDF::Lite.open: "t/images.pdf";
my $pdf-with-text = PDF::Lite.open: "examples/sample-text.pdf";
my PDF::Lite $new-doc .= new;
$new-doc.media-box = [0, 0, 500, 400];
# add a page; layup imported pages and images
my PDF::Lite::Page $page = $new-doc.add-page;
my PDF::Lite::XObject $xobj-image = $pdf-with-images.page(1).images[6];
my PDF::Lite::XObject $xobj-with-text = $pdf-with-text.page(1).to-xobject;
my PDF::Lite::XObject $xobj-with-images = $pdf-with-images.page(1).to-xobject;
$page.graphics: {
# scale up an image; use it as a semi-transparent background
.FillAlpha = 0.5;
.do($xobj-image, 0, 0, :width(500), :height(400) );
};
$page.graphics: {
# overlay pages; scale these down
.do($xobj-with-text, 20, 100, :width(300) );
.do($xobj-with-images, 300, 100, :width(200) );
}
# copy whole pages from a document
for 1 .. $pdf-with-text.page-count -> $page-no {
$new-doc.add-page: $pdf-with-text.page($page-no);
}
$new-doc.save-as: "examples/reuse.pdf";
```


To list all images and forms for each page
```
use PDF::Lite;
my $pdf = PDF::Lite.open: "t/images.pdf";
for 1 ... $pdf.page-count -> $page-no {
say "page: $page-no";
my PDF::Lite::Page $page = $pdf.page: $page-no;
# get all X-Objects (images and forms) on the page
my PDF::Lite::XObject %object = $page.resources('XObject');
# also report on images embedded in the page content
my $k = "(inline-0)";
%object{++$k} = $_
for $page.gfx.inline-images;
for %object.keys -> $key {
my $xobject = %object{$key};
my $subtype = $xobject<Subtype>;
my $size = $xobject.encoded.codes;
say "\t$key: $subtype {$xobject.width}x{$xobject.height} $size bytes"
}
}
```
Resource types are: `ExtGState` (graphics state), `ColorSpace`, `Pattern`, `Shading`, `XObject` (forms and images) and `Properties`.
Resources of type `Pattern` and `XObject/Image` may have further associated resources.
Whole pages or individual resources may be copied from one PDF to another.
## Graphics Operations
A full range of general graphics is available for drawing and displaying text.
```
use PDF::Lite;
my PDF::Lite $pdf .= new;
my $page = $pdf.add-page;
# Draw a simple Bézier curve:
# ------------------------
# Alternative 1: Using operator functions (see PDF::Content)
sub draw-curve1($gfx) {
$gfx.Save;
$gfx.MoveTo(175, 720);
$gfx.LineTo(175, 700);
$gfx.CurveToInitial( 300, 800, 400, 720 );
$gfx.ClosePath;
$gfx.Stroke;
$gfx.Restore;
}
draw-curve1($page.gfx);
# ------------------------
# Alternative 2: draw from content instructions string:
sub draw-curve2($gfx) {
$gfx.ops: q:to"--END--"
q % save
175 720 m % move-to
175 700 l % line-to
300 800 400 720 v % curve-to
h % close
S % stroke
Q % restore
--END--
}
draw-curve2($pdf.add-page.gfx);
# ------------------------
# Alternative 3: draw from raw data
sub draw-curve3($gfx) {
$gfx.ops: [
'q', # save,
:m[175, 720], # move-to
:l[175, 700], # line-to
:v[300, 800,
400, 720], # curve-to
:h[], # close (or equivalently, 'h')
'S', # stroke (or equivalently, :S[])
'Q', # restore
];
}
draw-curve3($pdf.add-page.gfx);
```
Please see [PDF::API6 Appendix I - Graphics](https://pdf-raku.github.io/PDF-API6#appendix-i-graphics) for a description of available operators and graphics.
Graphics can also be read from an existing PDF file:
```
use PDF::Lite;
my $pdf = PDF::Lite.open: "examples/hello-world.pdf";
say $pdf.page(1).gfx.ops;
```
## Graphics and Rendering
A number of variables are maintained that describe the graphics state. In many cases these may be set directly:
```
use PDF::Lite;
my PDF::Lite $pdf .= new;
my PDF::Lite::Page $page = $pdf.add-page;
$page.graphics: {
.text: { # start a text block
.CharSpacing = 1.0; # show text with wide spacing
# Set the font to twelve point helvetica
my $face = $pdf.core-font( :family<Helvetica>, :weight<bold>, :style<italic> );
.font = [ $face, 10 ];
.TextLeading = 12; # new-line advances 12 points
.text-position = 10, 20;
.say("Sample Text", :position[10, 20]);
# '$gfx.say' has updated the text position to the next line
say .text-position;
} # restore previous text state
say .CharSpacing; # restored to 0
}
```
A renderer callback can be specified when reading content. This will be called for each graphics operation and has access to the graphics state, via
the `$*gfx` dynamic variable.
```
use PDF::Lite;
use PDF::Content::Ops :OpCode;
my PDF::Lite $pdf .= open: "examples/hello-world.pdf";
my &callback = -> $op, *@args {
given $op {
when SetTextMatrix {
say "text matrix set to: {$*gfx.TextMatrix}";
}
}
}
my $gfx = $pdf.page(1).render(:&callback);
# text matrix set to: 1 0 0 1 10 10
```
## See also
* [PDF::Font::Loader](https://pdf-raku.github.io/PDF-Font-Loader-raku) for using Postscript, TrueType and OpenType fonts.
* [HTML::Canvas::To::PDF](https://pdf-raku.github.io/HTML-Canvas-To-PDF-raku/) HTML Canvas renderer
* This module (PDF::Lite) is based on [PDF](https://pdf-raku.github.io/PDF-raku) and has all of it methods available. This includes:
* `open` to read an existing PDF or JSON file
* `save-as` to save to PDF or JSON
* `update` to perform an in-place incremental update of the PDF
* `Info` to access document meta-data
* [PDF::API6 Graphics Documentation](https://pdf-raku.github.io/PDF-API6#readme) for a fuller description of methods, operators and graphics variables, which are also applicable to this module. In particular:
* [Section II: Content Methods](https://pdf-raku.github.io/PDF-API6#section-ii-content-methods-inherited-from-pdfclass) for a description of available content methods.
* [Appendix I - Graphics](https://pdf-raku.github.io/PDF-API6#appendix-i-graphics) for a description of available operators and graphics.
|
## dist_zef-leont-Protocol-MQTT.md
[](https://github.com/Leont/raku-protocol-mqtt/actions)
# NAME
Protocol::MQTT - A (sans-io) MQTT client implementation
# SYNOPSIS
```
use Protocol::MQTT;
```
# DESCRIPTION
Protocol::MQTT contains a networking and timing independent implementation of the MQTT protocol. Currently only the client side is implemented, in the form of Protocol::MQTT::Client. Net::MQTT an actual client based on `Protocol::MQTT::Client`.
# AUTHOR
Leon Timmermans [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2021 Leon Timmermans
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-jnthn-DB-Migration-Declare.md
# DB::Migration::Declare
Database migrations are an ordered, append-only list of database change
operations that together bring the database up to a current schema. A table
in the database is used to track which migrations have been applied so far,
so that the database can be brought up to date by applying the latest
migrations.
This module allows one to specify database migrations using a Raku DSL. The
migrations are checked in various ways for correctness (for example, trying
to drop a table that never existed, or adding duplicate columns), and are
then translated into SQL and applied to the database.
If one is using a Raku ORM such as Red, it is probably worth looking into how
it might assist with migrations. This module is more aimed at those writing
their queries in SQL, perhaps using something like Badger to have those SQL
queries neatly wrapped up in Raku subs and thus avoid inline SQL.
**Warning**: The module should currently be considered as a BETA-quality
minimum viable product. Of note, only Postgres support is currently available,
migrations can only be applied in the "up" direction, and various kinds
of database change are not yet implemented.
## Setup
### Writing migrations
Migrations can be written in a single file or spread over multiple files in a
single directory, where the filenames will be used as the ordering. For now
we'll assume there is a single file `migrations.raku` where the migrations
will be written one after the other.
A migration file with a single migration looks like this:
```
use DB::Migration::Declare;
migration 'Setup', {
create-table 'skyscrapers', {
add-column 'id', integer(), :increments, :primary;
add-column 'name', text(), :!null, :unique;
add-column 'height', integer(), :!null;
}
}
```
Future changes to the database are specified by writing another migration
at the end of the file. For example, after adding another migration the
file overall could look as follows:
```
use DB::Migration::Declare;
migration 'Setup', {
create-table 'skyscrapers', {
add-column 'id', integer(), :increments, :primary;
add-column 'name', text(), :!null, :unique;
add-column 'height', integer(), :!null;
}
}
migration 'Add countries', {
create-table 'countries', {
add-column 'id', integer(), :increments, :primary;
add-column 'name', varchar(255), :!null, :unique;
}
alter-table 'skyscrapers',{
add-column 'country', integer();
foreign-key table => 'countries', from => 'country', to => 'id';
}
}
```
### Testing migrations
When a project has migrations, it is wise to write a test case to check that
the list of migrations are well-formed. This following can be placed in a
`t/migrations.rakutest`:
```
use DB::Migration::Declare::Database::Postgres;
use DB::Migration::Declare::Test;
use Test;
check-migrations
source => $*PROGRAM.parent.parent.add('migrations.raku'),
database => DB::Migration::Declare::Database::Postgres.new;
done-testing;
```
Which will produce the output:
```
ok 1 - Setup
ok 2 - Add countries
1..2
```
If we were to introduce an error into the migration:
```
alter-table 'skyskrapers',{
add-column 'country', integer();
foreign-key table => 'countries', from => 'country', to => 'id';
}
```
The test would fail:
```
ok 1 - Setup
not ok 2 - Add countries
# Failed test 'Add countries'
# Migration at migrations.raku:11 has problems:
# Cannot alter non-existent table 'skyskrapers'
1..2
# You failed 1 test of 2
```
With diagnostics indicating what is wrong. (If following this getting started
guide like a tutorial, undo the change introducing an error before continuing!)
### Applying migrations
To migrate a database to the latest version, assuming we are placing this in
a `service.raku` script, do this:
```
use DB::Migration::Declare::Applicator;
use DB::Migration::Declare::Database::Postgres;
use DB::Pg;
my $conn = $pg.new(:conninfo('...write your connection string here...'));
my $applicator = DB::Migration::Declare::Applicator.new:
schema-id => 'my-project',
source => $*PROGRAM.parent.add('migrations.raku'),
database => DB::Migration::Declare::Database::Postgres.new,
connection => $conn;
my $status = $applicator.to-latest;
note "Applied $status.migrations.elems() migration(s)";
```
Depending on your situation, you might have this as a distinct script, or
place it in the startup script for a Cro service to run the migrations upon
startup.
## Migration DSL
Top-level operations supported within a migration are:
* `create-table(Str $name, &steps)`
* `alter-table(Str $name, &steps)`
* `rename-table(Str $from, Str $to)` (or `rename-table(Str :$from!, Str :$to!)` or
`rename-table(Pair $renmaing)`)
* `drop-table(Str $name)`
* `execute(SQLLiteral :$up!, SQLLiteral :$down!)`
Within both `create-table` and `alter-table` one can use:
* `add-column(Str $name, $type, Bool :$increments, Bool :$null, Any :$default, Bool :$primary, Bool :$unique)`
* `primary-key(*@column-names)`
* `unique-key(*@column-names)`
* `foreign-key(Str :$from!, Str :$table!, Str :$to = $from, Bool :$restrict = False, Bool :$cascade = False)`
* `foreign-key(:@from!, Str :$table!, :@to = @from, Bool :$restrict = False, Bool :$cascade = False)`
Only within `alter-table` one can use:
* `rename-column(Str $from, Str $to)` (or `rename-column(Str :$from!, Str :$to!)` or
`rename-column(Pair $renmaing)`)
* `drop-column(Str $name)`
* `drop-unique-key(*@column-names)`
Column types are specified using any of the following functions:
* `char(Int $length)`
* `varchar(Int $length)`
* `text()`
* `boolean()`
* `integer(Int $bytes = 4)` (only 2, 4, and 8 are reliably supported)
* `date()`
* `timestamp(Bool :$timezone = False)` (a date/time)
* `arr($type, *@dimensions)` (dimensions are integers for fixed size of `*`
for variable size; specifying no dimensions results in a variable-length
single dimensional array)
* `type(Str $name, Bool :$checked = True)` (any other type, checked by the
database backend against a known type list by default, but trusted and
passed along regardless if `:!checked`)
SQL literals can be constructed either:
* Database agnostic: `sql(Str $sql)`
* Database specific: `sql(*%options)` (where the named argument names are database
IDs, such as `postgres`, and the argument value is the SQL)
* Polymorphic "now": `now()` (becomes the Right Thing depending on database and
column type when used as the default value of a date or timestamp column)
## Planned Features
* Migration DSL
* Indexes (currently only those implied by keys are available)
* Key and index dropping
* Column type and constraint alteration
* Column type declaration using Raku types
* Views
* Stored procedures
* Table-valued functions
* Tooling
* CLI: view migration history on a database against what is applied
* CLI: trigger up/down migrations
* CLI: use information schema to extract an initial migration and set
things up as if it was already applied, to ease getting started
* Comma: add migrations dependency, tests, etc.
* Comma: live annotation of migration problems
* Seed data insertion
* Schema export
* Down migrations
* Configurable data retention on lossy migrations in either direction
* Database support
* SQLite
* MySQL
|
## augment.md
augment
Combined from primary sources listed below.
# [In Variables](#___top "go to top of document")[§](#(Variables)_declarator_augment "direct link")
See primary documentation
[in context](/language/variables#The_augment_declarator)
for **The augment declarator**.
With `augment`, you can add methods, but not attributes, to existing classes and grammars, provided you activated the `MONKEY-TYPING` pragma first.
Since classes are usually `our` scoped, and thus global, this means modifying global state, which is strongly discouraged. For almost all situations, there are better solutions.
```raku
# don't do this
use MONKEY-TYPING;
augment class Int {
method is-answer { self == 42 }
}
say 42.is-answer; # OUTPUT: «True»
```
(In this case, the better solution would be to use a [function](/language/functions)).
For a better, and safer example, this is a practical way to create a class module to extend [`IO::Path`](/type/IO/Path) by adding a currently missing method to yield the part of the `basename` left after the `extension` is removed. (Note there is no clear developer consensus about what to call that part or even how it should be constructed.)
```raku
unit class IO::Barename is IO::Path;
method new(|c) {
return self.IO::Path::new(|c);
}
use MONKEY-TYPING;
augment class IO::Path {
method barename {
self.extension("").basename;
}
}
```
|
## dist_zef-lizmat-Cache-Async.md
[](https://github.com/lizmat/Cache-Async/actions) [](https://github.com/lizmat/Cache-Async/actions) [](https://github.com/lizmat/Cache-Async/actions)
# NAME
Cache::Async -- A Concurrent and Asynchronous Cache
# SYNOPSIS
```
my $cache = Cache::Async.new(max-size => 1000, producer => sub ($k) { ... });
say await $cache.get('key234');
```
# FEATURES
* Producer function that gets passed in on construction and that gets called by cache on misses
* Cache size and maximum entry age can be limited
* Cache allows refreshing of entries even before they have expired
* Calls producer async and returns promise to result, perfect for usage in an otherwise async or reactive system
* Transparent support for producers that return promises themselves
* Extra args can be passed through to producer easily
* Jitter for refresh and expiry to smooth out producer calls over time
* Locked internally so it can be used from multiple threads or a thread pool, but no lock help while calling the producer function.
* Propagates exceptions from producer transparently
* Get entry from cache only if present, without loading/refreshing.
* Configurably, Nil values can be passed through without caching them
* Monitoring of hit rate
## Upcoming Features
* Optimizations of the async producer case
* Object lifetimes can be restricted by producer function
# BLOG
I also have a short article that cache users might find interesting [The Surprising Sanity of Using a Cache but Not Updating It](https://github.com/Raku/CCR/blob/main/Remaster/Robert%20Lemmen/The%20Surprising%20Sanity%20of%20Using%20a%20Cache%20but%20Not%20Updating%20It.md).
# DESCRIPTION
This module tries to implement a cache that can be used easily in otherwise async or reactive system. As such it only returns Promises to results which can then be composed with other promises, or acted on directly.
It tries to be a 'transparent' cache in the sense that it will return a cached item, or a freshly produced or retrieved one without the caller being aware of the distinction. To do this, the cache is constructed over a producer sub that gets called on cache misses.
Sometimes other data that is required by the producer function can be captured at creation time, but in other cases they need to be provided at request time, e.g. credentials. Arguments like these can be passed through `Cache::Async` transparently as extra args.
All caches should have a fixed size limit, and so does Cache::Async of course. In addition a maximum global object lifetime can be specified to avoid overly old object entries. For cache eviction a LRU mechanism is used.
If caches are used in production systems, it is often desirable to monitor their hit rates. Cache::Async supports this through a method that reports hits and misses, but it does not do the monitoring itself or automatically.
# Constructor
```
new(:&producer, Int :$max-size, Duration :$max-age, Duration :$refresh-after,
Duration :$jitter, Bool :$cache-undefined = True)
```
Creates a new cache over the provided **&producer** sub, which must take a single string as the first argument, the key used to look up items in the cache with. It can take more arguments, see **get()** below.
The **$max-size** argument can be used to limit the number of items the cache will hold at any time, the default is 1024.
**$max-age** determines the maximum age an item can live in the cache before it is expired. By default items are not expired by age.
**$refresh-after** optionally sets a time after which an item will be refreshed by the cache in parallel with returning it. This can be used to reduce latency for frequently used entries. When set (to a value lower than **$max-age** of course), the cache will upon a hit on an entry that is older than this value immediately return the existing value, but also start an asyncronous re-fetch of the item as if it had experienced a cache miss. This can be used to make frequently used items always come from the cache, rather than incurring a cache hit with the corresponding fetch latency every now and then.
**$jitter** optionally sets a maximum jitter duration. When an item is refreshed and placed in the cache, the timestamp of the item is incremented by a random interval between 0 and this duration. This can be useful if your application loads many items after boot and wants to make sure that the refresh times spread out over time and do not stay clustered together. This value needs to be smaller than **$refresh-after** (and therefore **max-age**), the default is zero.
If **$cache-undefined** is set to False, then undefined return values from the producer function (as well as Promises that are undefined when kept of course) are not cached and will be retried the next time the coresponding key is queried.
The following example will create a simple cache with up to 100 items that live for up to 10 seconds. The values returned by the cache are promises that will hold the key specified when querying the cache enclosed in square brackets.
```
$cache = Cache::Async.new(producer => sub ($k) { return "[$k]"; },
max-size => 100,
max-age => Duration.new(10));
```
# Retrieval
In order to get items from, or better through, the cache, the **get()** method is used:
```
$cache.get($key, +@args)
```
The first argument is the **$key** used to look up items in the cache, and is passed through to the producer function the cache uses. Any other arguments are also passed to the producer functions. The call returns a `Promise` to the value produced or found in the cache.
With the cache constructed above, the call below would yield "[woot]". The first time this is called the producer is called, afterwards the cached value is used (until expiry or eviction).
```
await $cache.get('woot')
```
Multiple threads can of course safely call into the cache in parallel.
The producer function can of course return a `Promise` itself! In this case `Cache::Async` will *not* return a promise containing another promise, but it will detect the case and simply return the promise from the producer directly.
# Cache Content Management
The following methods can be used to manage the contents of the cache. This can for example be used to warm the cache on startup with some values, or clear it in error cases.
```
$cache.put($key, $value);
$cache.remove($key);
$cache.clear;
```
As a special case, you can also query for contents of the cache, but without calling the producer function on a miss, and without touching any cache statistics. This is useful to check for entry existence in cache maintenance tasks, but also and primarily when doing operations that violate the LRU criteria. For example imagine a cache with limited size over a very large backing resource, but with normal operations that show strong LRU characteristics. A perfect case for a cache, and you can expect good cache hit rates. Now every now and then a maintenance task kicks in that traverses all resources. This could also benefit from the cache, but if it updates the cache it would basically replace the whole cache with the tail end of it's iteration, destroying the LRU properties of the cache and causing increased cache misses for some time afterwards, a bit like a cache that is empty. This method allows utilising entries in the cache if present, but not touching the cache otherwise. Returns Nil if no entry is found.
```
$cache.get-if-present($key);
```
# Monitoring
The behavior of the cache can be monitored, the call will return total numbers since the last time this method was called (or the cache got constructed):
```
my ($hits, $misses) = $cache.hits-misses;
```
Note that the number of hits + misses is of course the number of calls to **get()**, but that the number of calls to the producer function is not necessarily the same as the number of misses returned from this method. The reason for this is that two calls to the cache with the same key in rapid succession could both be misses, but only the first one will call the producer. The second call will simply get chained to the first producer call.
# AUTHORS
Robert Lemmen
Elizabeth Mattijsen
Source can be located at: <https://github.com/lizmat/Cache-Async> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2018-2020 Robert Lemmen
Copyright 2021, 2024, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-jonathanstowe-EuclideanRhythm.md
# EuclideanRhythm
Implementation of the algorithm described in <http://cgm.cs.mcgill.ca/~godfried/publications/banff.pdf>

## Synopsis
```
use EuclideanRhythm;
my $r = EuclideanRhythm.new(slots => 16, fills => 7);
for $r.list {
# do something if the value is True
}
```
## Description
This provides an implementation of the algorithm described in
<http://cgm.cs.mcgill.ca/~godfried/publications/banff.pdf>
which is in turn derived from a Euclidean algorithm. Simply put it
provides a simple method to distribute a certain number of "fills"
(hits, beats, notes or whatever you want to call them,) as evenly as
possibly among a number of "slots". The linked paper describes how, using
this method, you can approximate any number of common rhythmic patterns
(as well as not so common ones.)
You could of course use it for something other than generating musical
rhythms: any requirement where a number of events need to be distributed
over a fixed number of slots may find this useful.
## Installation
Assuming you have a working installation of Rakudo then you should be able to install this with *zef*:
```
zef install EuclideanRhythm
```
or if you have a local copy of this repository:
```
zef install .
```
in the directory you found this file.
## Support
This is a fairly simple module such that the scope for any
egregious bugs is quite limited, however if you have any
suggestions, patches or comment the feel free to leave a post at
<https://github.com/jonathanstowe/EuclideanRhythm/issues>.
Because it is quite simple in both scope and implementation I would
anticipate that any higher level functionality (such as providing timing,)
would be implemented in another module.
## Licence and Copyright
This is free software. Please see the <LICENCE> file in the distribution.
© Jonathan Stowe 2016 - 2021
|
## notcomposed.md
class X::Inheritance::NotComposed
Error due to inheriting from a type that's not composed yet
```raku
class X::Inheritance::NotComposed is Exception {}
```
When you try to inherit from a class that hasn't been [composed](/language/mop#Composition_time_and_static_reasoning), an exception of type X::Inheritance::NotComposed is thrown.
Usually this happens because it's not yet fully parsed, or that is stubbed:
For example
```raku
class A { ... }; # literal ... for stubbing
class B is A { };
```
dies with
「text」 without highlighting
```
```
===SORRY!===
'B' cannot inherit from 'A' because 'A' isn't composed yet (maybe it is stubbed)
```
```
The second common way to trigger this error is by trying to inherit from a class from within the class body.
For example
```raku
class Outer {
class Inner is Outer {
}
}
```
dies with
「text」 without highlighting
```
```
===SORRY!===
'Outer::Inner' cannot inherit from 'Outer' because 'Outer' isn't composed yet (maybe it is stubbed)
```
```
# [Methods](#class_X::Inheritance::NotComposed "go to top of document")[§](#Methods "direct link")
## [method child-name](#class_X::Inheritance::NotComposed "go to top of document")[§](#method_child-name "direct link")
```raku
method child-name(X::Inheritance::NotComposed:D: --> Str:D)
```
Returns the name of the type that tries to inherit.
## [method parent-name](#class_X::Inheritance::NotComposed "go to top of document")[§](#method_parent-name "direct link")
```raku
method parent-name(X::Inheritance::NotComposed:D: --> Str:D)
```
Returns the name of the parent type that the type tries to inherit from
|
## dist_zef-jmaslak-IP-Random.md
[](https://travis-ci.org/jmaslak/Raku-IP-Random)
# NAME
IP::Random - Generate random IP Addresses
# SYNOPSIS
```
use IP::Random;
my $ipv4 = IP::Random::random_ipv4;
my @ips = IP::Random::random_ipv4( count => 100, allow-dupes => False );
```
# DESCRIPTION
This provides a random IP (IPv4 only currently) address, with some extensability to exclude undesired IPv4 addresses (I.E. don't return IP addresses that are in the multicast or RFC1918 ranges).
By default, the IP returned is a valid, publicly routable IP address, but this behavior can be adjusted.
# FUNCTIONS
## default\_ipv4\_exclude
Returns the default exclude list for IPv4, as a list of CIDR strings.
Additional CIDRs may be added to future versions, but in no case will standard Unicast publicly routable IPs be added. See <named_exclude> to determine what IP ranges will be included in this list.
## exclude\_ipv4\_list($type)
When passed a `$type`, such as `'rfc1918'`, will return a list of CIDRs that match that type. See <named_exclude> for the valid types.
## random\_ipv4( :@exclude, :$count )
```
say random_ipv4;
say random_ipv4( exclude => ('rfc1112', 'rfc1122') );
say random_ipv4( exclude => ('default', '24.0.0.0/8') );
say join( ',',
random_ipv4( exclude => ('rfc1112', 'rfc1122'), count => 2048 ) );
say join( ',',
random_ipv4( count => 2048, allow-dupes => False ) );
```
This returns a random IPv4 address. If called with no parameters, it will exclude any addresses in the default exclude list.
If called with the exclude optional parameter, which is passed as a list, it will use the exclude types (see <named_exclude> for the types) to exclude from generation. In addition, individual CIDRs may also be passed to exclude those CIDRs. If neither CIDRs or exclude types are passed, it will use the `default` tag to exclude the default excludes. Should you want to exclude nothing, pass an empty list. If you want to exclude something in addition to the default list, you must pass the `default` tag explictly.
The count optional parameter will cause c<random\_ipv4> to return a list of random IPv4 addresses (equal to the value of `count`). If `count` is greater than 128, this will be done across multiple CPU cores. Batching in this way will yield significantly higher performance than repeated calls to the `random_ipv4()` routine.
The `allow-dupes` parameter determines whether duplicate IP addresses are allowed to be returned within a batch. The default, `True`, allows duplicate addresses to be randomly picked. Obviously unless there is an extensive exclude list or a very large batch size, the chance of randomly selecting a duplicate is very small. But with extensive excludes and large batch sizes, it is possible to have duplicates selected. If the amount of non-excluded IPv4 space is less than the batch size (the `count` argument) and this parameter is set to `False`, then you will get a list of all possible IP addresses rather than `count` elements returned.
# CONSTANTS
## named\_exclude
```
%excludes = IP::RANDOM::named_exclude
```
A hash of all the named IP exludes that this `IP::Random` is aware of. The key is the excluded IP address. The value is a list of tags that this module is aware of. For instance, `192.168.0.0/16` would be a key with the values of `( 'rfc1918', 'default' )`.
This list contains:
* `0.0.0.0/8`
Tags: default, rfc1122
"This" Network (RFC1122, Section 3.2.1.3).
* `10.0.0.0/8`
Tags: default, rfc1918
Private-Use Networks (RFC1918).
* `100.64.0.0/10`
Shared Address Space (RFC6598)
* `127.0.0.0/8`
Tags: default, rfc1122
Loopback (RFC1122, Section 3.2.1.3)
* `169.254.0.0/16`
Link Local (RFC 3927)
* `172.16.0.0/12`
Tags: default, rfc1918
Private-Use Networks (RFC1918)
* `192.0.0.0/24`
IETF Protocol Assignments (RFC5736)
* `192.0.2.0/24`
TEST-NET-1 (RFC5737)
* `192.88.99.0/24`
6-to-4 Anycast (RFC3068)
* `192.168.0.0/16`
Tags: default, rfc1918
Private-Use Networks (RFC1918)
* `198.18.0.0/15`
Network Interconnect Device Benchmark Testing (RFC2544)
* `198.51.100.0/24`
TEST-NET-2 (RFC5737)
* `203.0.113.0/24`
TEST-NET-3 (RFC5737)
* `224.0.0.0/4`
Multicast (RFC3171)
* `240.0.0.0/4`
Reserved for Future Use (RFC 1112, Section 4)
# AUTHOR
Joelle Maslak [[email protected]](mailto:[email protected])
# CONTRIBUTORS
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
# EXPRESSING APPRECIATION
If this module makes your life easier, or helps make you (or your workplace) a ton of money, I always enjoy hearing about it! My response when I hear that someone uses my module is to go back to that module and spend a little time on it if I think there's something to improve - it's motivating when you hear someone appreciates your work!
I don't seek any money for this - I do this work because I enjoy it. That said, should you want to show appreciation financially, few things would make me smile more than knowing that you sent a donation to the Gender Identity Center of Colorado (See <http://giccolorado.org/>. This organization understands TIMTOWTDI in life and, in line with that understanding, provides life-saving support to the transgender community.
If you make any size donation to the Gender Identity Center, I'll add your name to "MODULE PATRONS" in this documentation!
# COPYRIGHT AND LICENSE
Copyright (C) 2018-2022 Joelle Maslak
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-Acme-Text-UpsideDown.md
[](https://github.com/lizmat/Acme-Text-UpsideDown/actions) [](https://github.com/lizmat/Acme-Text-UpsideDown/actions) [](https://github.com/lizmat/Acme-Text-UpsideDown/actions)
# NAME
Acme::Text::UpsideDown - provide logic to turn ASCII text upside-down
# SYNOPSIS
```
use Acme::Text::UpsideDown;
say upsidedown "The quick brown fox jumps over the lazy dog";
# ɓop ʎzɐꞁ ǝɥʇ ɹǝʌo sdɯnſ̣ xoɟ uʍoɹq ʞɔᴉnb ǝɥ⊥
say uʍopǝpᴉsdn "ɓop ʎzɐꞁ ǝɥʇ ɹǝʌo sdɯnſ̣ xoɟ uʍoɹq ʞɔᴉnb ǝɥ⊥";
# The quick brown fox jumps over the lazy Dog
```
# DESCRIPTION
Acme::Text::UpsideDown provides two subroutines that can be used to create strings from ASCII texts for upside-down reading. Inspired by the Perl version called Acme::Text::Viceversa.
# SUBROUTINES
## upsidedown
```
say upsidedown "The quick brown fox jumps over the lazy dog";
# ɓop ʎzɐꞁ ǝɥʇ ɹǝʌo sdɯnſ̣ xoɟ uʍoɹq ʞɔᴉnb ǝɥ⊥
say upsidedown "ɓop ʎzɐꞁ ǝɥʇ ɹǝʌo sdɯnſ̣ xoɟ uʍoɹq ʞɔᴉnb ǝɥ⊥";
# The quick brown fox jumps over the lazy dog
```
Return the string that allows reading of the given ASCII string upside-down, and vice-versa.
## uʍopǝpᴉsdn
```
say uʍopǝpᴉsdn "ɓop ʎzɐꞁ ǝɥʇ ɹǝʌo sdɯnſ̣ xoɟ uʍoɹq ʞɔᴉnb ǝɥ⊥";
# The quick brown fox jumps over the lazy dog
say uʍopǝpᴉsdn "The quick brown fox jumps over the lazy dog";
# ɓop ʎzɐꞁ ǝɥʇ ɹǝʌo sdɯnſ̣ xoɟ uʍoɹq ʞɔᴉnb ǝɥ⊥
```
Return the string that allows normal reading of a previously upside-downed string, and vice-versa. Basically a fun alias for `upsidedown`.
# COMMAND LINE INTERFACE
This module also installs a `ud` script for easy upsidedowning of text.
When called without any parameters, it will read from STDIN and print the upsidedowned text on STDOUT.
When called with a single parameter that indicates an existing file, then it will read that file and print the upsidedowned text on STDOUT.
In all other cases, the command line parameters will be joined together with a space, and then printed upsidedowned on STDOUT.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Acme-Text-UpsideDown> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Original Perl version of Acme::Text::Viceversa: Copyright 2019 吉田勇気, Raku re-imagining: Copyright 2019, 2021, 2024 Elizabeth Mattijsen
Some additional character mappings taken from <https://github.com/mcsnolte/Text-UpsideDown>.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-scovit-Scheduler-DRMAA.md
[](https://travis-ci.org/scovit/Scheduler-DRMAA)
# NAME
Scheduler::DRMAA - Bindings for the DRMAA cluster library
# SYNOPSIS
```
use DRMAA; # Loads the high-level bindings
use DRMAA::NativeCall; # Loads the C binings
```
The `libdrmaa.so` library needs to be installed in the loader path, or the directory added to `LD_LIBRARY_PATH` environment variable.
# DESCRIPTION
Scheduler::DRMAA are the Perl 6 bindings for the DRMAA library. You can use them in order to submit pipelines of work to a supercomputer. We provide two different interfaces:
* the DRMAA C library, it can be used through the `DRMAA::NativeCall` module, it uses `NativeCall` and `NativeHelpers::CBuffer` modules
* the object interface, provided by the `DRMAA` module. It requires `v6.d.PREVIEW` and supports all the C library functionalities but also an asynchronous event-based mechanism to keep track of job events and a pluggable job-dependency pipeline genearator, reminescent of the `Promise` API.
The library has been tested on a SLURM DRMAA implementation and does not provide any warrant or guarantee to work. First thing, in order to initialize and close the DRMAA session use the following commands:
```
DRMAA::Session.init;
# code goes here
DRMAA::Session.exit;
```
## OBJECTS
### DRMAA::Session
The DRMAA session is a singleton and represent the session level API. Upon initialization it also takes care of the event loop. It provides the following methods:
```
method init(Str :$contact, DRMAA::Native-specification :native-specification(:$ns));
```
initializes the session, optional arguments are the contact code, and the Native-specification plugin: if not provided explicitly it gets autodetected through a reasonable euristics.
```
method exit()
```
closes the session.
```
method native-specification(--> DRMAA::Native-specification)
```
returns the native-specification plugin.
```
method events(--> Supply)
```
returns a Supply to the DRMAA events, mostly Job terminations events or failures
Other methods:
```
method attribute-names(--> List)
method vector-attribute-names(--> List)
method contact(--> Str)
method DRM-system(--> Str)
method implementation(--> Str)
method version(--> Version)
```
### DRMAA::Job-template
Represents a Job template, must be constructed in order to launch one, or more jobs
```
submethod BUILD(*%all)
```
Construct the object, use it as `DRMAA::Job-template.new`, named parameters corresponds to attributes and/or methods, making it straightforward to create a submission, a simple example:
```
my $template = DRMAA::Job-template.new(
:remote-command<sleep> :argv<5>
);
```
creates a job template for something which will just sleep 5 seconds; an alternative way to do it uses heredocs:
```
my $template = DRMAA::Job-template.new(:script(q:to/⬅ 完/));
sleep 5;
say "Slept 5 seconds";
⬅ 完
```
will run the Perl 6 script, the library will exploit the following dynamic variables: `$*EXECUTABLE`, `@*ARGS` and `%*ENV`. For instance, to submit a shell script do the following:
```
my $*EXECUTABLE = "/bin/sh";
my @*ARGS = <5>;
my $template = DRMAA::Job-template.new(:script(q:to/⬅ 完/));
sleep $1
echo "Slept $1 seconds";
⬅ 完
```
Easy, isn't it?
To run a template, use one of the following methods:
```
method run(--> DRMAA::Submission)
multi method run-bulk(Int:D $start, Int:D $end, Int :$by --> List)
multi method run-bulk(Range:D $range, Int :$by --> List)
multi method run-bulk(Int:D $size --> List)
```
`run-bulk` methods are discouraged, seriously, just use `@list.map: DRMAA::Job-template.new`...
To resume, the most important attributes, which are also building parameters, are:
```
remote-command (scalar)
argv (list)
env (list)
```
The following are other available attributes, which are also building parameters
```
block-email (scalar)
email (list)
start-time (scalar)
deadline-time (scalar)
duration-hlimit (scalar)
duration-slimit (scalar)
wct-hlimit (scalar)
wct-slimit (scalar)
error-path (scalar)
input-path (scalar)
output-path (scalar)
job-category (scalar)
job-name (scalar)
join-files (scalar)
transfer-files (scalar)
js-state (scalar)
native-specification (scalar)
wd (scalar)
```
The following extra attributes are available if the Native-plugin implement the required functionality:
```
after (list)
afterend (list)
afterok (list)
afternotok (list)
```
Queue after the start/end/success/failure of the values: which shoud be a list of `DRMAA::Submission`. To create a `DRMAA::Submission` out of a job name, in case it doesn't come out of a `run` method just do like this: `DRMAA::Submission.new(:job-id("123456"))`.
### DRMAA::Submission
First of all: a submission is an Awaitable:
```
my $submission = $template.run;
my $result = await $submission;
```
It can be created either by the `run` method of a `DRMAA::Job-schedule` or from a job id:
```
DRMAA::Submission.new(job-id => "123456");
```
It provides the following methods
```
method suspend
method resume
method hold
method release
method terminate
method status
```
Retuns the one of the following status objects:
```
DRMAA::Submission::Status::Undetermined
DRMAA::Submission::Status::Queued-active
DRMAA::Submission::Status::System-on-hold
DRMAA::Submission::Status::User-on-hold
DRMAA::Submission::Status::User-system-on-hold
DRMAA::Submission::Status::Running
DRMAA::Submission::Status::System-suspended
DRMAA::Submission::Status::User-suspended
DRMAA::Submission::Status::User-system-suspended
DRMAA::Submission::Status::Done
DRMAA::Submission::Status::Failed
DRMAA::Submission::Status::Unimplemented
method events(--> Supply)
```
Returns a Supply with all events regarding the Submission
```
method done(--> Promise)
```
Returns a Promise which will be kept when the job is over. The result of the promise will contain one of the following:
```
class X::DRMAA::Submission::Status::Aborted is Exception {
has Str $.id;
has Bool $.exited;
has Int $.exit-code;
has Str $.signal;
has Str $.usage;
method message(--> Str:D) {
"Job $.id aborted";
}
}
class DRMAA::Submission::Status::Succeded {
has Str $.id;
has Bool $.exited;
has Int $.exit-code;
has Str $.signal;
has Str $.usage;
}
```
The result can also be accessed through:
```
method result
```
or
```
await
```
Another handy method:
```
method then(DRMAA::Job-template $what)
```
chain the jobs, same as specify the attribute `afterend` to `$what`, and then `run`; an example:
```
DRMAA::Job-template.new( :remote-command<sleep>, :argv<20> ).run.then(
DRMAA::Job-template.new( :remote-command<echo>, :argv<Hello world!> ));
```
the functionality should be implemented in the Native plugin, currently only works for SLURM.
# AUTHOR
Vittore F. Scolari [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2017 Institut Pasteur
This library is free software; you can redistribute it and/or modify it under the GPL License 3.0.
|
## dist_zef-lizmat-uniprop.md
[](https://github.com/lizmat/uniprop/actions)
# NAME
uniprop - Provide uniprop- subs
# SYNOPSIS
```
use uniprop; # provide uniprop-int, uniprop-bool, unitprop-str
```
# DESCRIPTION
The `uniprop` distribution provides 3 subroutines that used to live in the Rakudo core, but were in fact implementation detail / used for testing by core developers only. These have since then been removed from Rakudo.
This distribution has captured the code of these subroutines and will export them in any version of Rakudo that has them removed.
No further documentation is provided, as originally no additional documentation was provided and it was never the intention to expose this functionality this way.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/uniprop> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2022, 2024 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-tony-o-YAML-Parser-LibYAML.md
# YAML::Parser::LibYAML
Uses a wrapper and constructs a perl6 array/hash/whatever to represent the YAML. Use it for good (or bad, I don't care).
```
use YAML::Parser::LibYAML;
my $yaml = yaml-parse('path/to/yaml.yaml');
$yaml.perl.say;
```
Profit.
tony-o | thanks to ingy and tina for fuelling this creation with scotch and vegan pizza
If you must build this yourself, you can do
> zef build .
or
> src/build.sh
|
## dist_github-jsimonet-IRC-Client-Plugin-UserPoints.md
# NAME
IRC::Client::Plugin::UserPoints
# SYNOPSIS
```
use IRC::Client;
use IRC::Client::Plugin::UserPoints;
IRC::Client.new(
:nick<botte>
:host<irc.freenode.net>
:channels<#test>
:plugins( IRC::Client::Plugin::UserPoints.new )
).run;
```
```
<jsimonet> botte++
<botte> jsimonet, Adding one point to botte in « main » category
<jsimonet> botte2++ Perl6
<botte> jsimonet, Adding one point to botte2 in « Perl6 » category
<jsimonet> jsimonet++
<botte> jsimonet, Influencing points of himself is not possible.
<jsimonet> !scores
<botte> jsimonet, « botte » has some points : 1 for main
<botte> jsimonet, « botte2 » has some points : 1 in Perl6
<jsimonet> !sum
<botte> jsimonet, Total points : 2
```
# DESCRIPTION
This module is a plugin for `IRC::Client`, which aims to count points delivered to users.
A point can be categorized, for more precision :)
Points can be listed with the `scores` command, and passing one or more users
will list only theirs points.
A sum can be printed with `sum` command, and like `scores` command, a list of users
can be used.
# Attributes
```
IRC::Client::Plugin::UserPoints.new(
:db-file-name( 'path/to/file.txt' ),
:command-prefix( '!' ),
:list-scores-max-user(5),
:msg-confirm( '#channel1' => True )
)
```
## db-file-name
The file name of the points database.
## command-prefix
The command prefix is used to determine the char used to trigger the bot.
## list-scores-max-user
The maximum number of users the bot can print their points. Can be used to prevent spam.
Default value: +Inf (Infinite)
## msg-confirm
Confirm on IRC when a point have been handled.
Defaults to False.
# IRC COMMANDS
```
<nickName>++ # Add a point in "main" category
<nickName>-- # Remove a point in "main" category
<nickName>++ Perl6 # Add a point in "Perl6" category
!scores # Prints the attributed points
!scores <nickName> … # Prints the attributed points
!sum # Sum of all attributed points
!sum <nickName> … # Sum of attributed points for nickName
```
# BUGS
To report bugs or request features, please use
<https://github.com/jsimonet/IRC-Client-Plugin-UserPoints/issues>
# AUTHOR
Julien Simonet
|
## all.md
all
Combined from primary sources listed below.
# [In Any](#___top "go to top of document")[§](#(Any)_method_all "direct link")
See primary documentation
[in context](/type/Any#method_all)
for **method all**.
```raku
method all(--> Junction:D)
```
Interprets the invocant as a list and creates an [all](/routine/all)-[`Junction`](/type/Junction) from it.
```raku
say so 1 < <2 3 4>.all; # OUTPUT: «True»
say so 3 < <2 3 4>.all; # OUTPUT: «False»
```
|
## dist_cpan-CHSANCH-Lingua-Stem-Es.md
[](https://travis-ci.org/chsanch/perl6-Lingua-Stem-Es)
# NAME
Lingua::Stem::Es - Porter's steming algorithm for Spanish
# SYNOPSIS
```
use Lingua::Stem::Es
my $stem = stem( $word );
```
# DESCRIPTION
This module uses Porter's Stemming Algorithm to return a stemmed word.
The algorithm is implemented as described in: <http://snowball.tartarus.org/algorithms/spanish/stemmer.html>
# REPOSITORY
Fork this module on GitHub:
<https://github.com/chsanch/perl6-Lingua-Stem-Es>
# BUGS
To report bugs or request features, please use:
<https://github.com/chsanch/perl6-Lingua-Stem-Es/issues>
# AUTHOR
This module was inspired by Perl 5's module [Lingua::Stem::Es](https://metacpan.org/pod/Lingua::Stem::Es).
Christian Sánchez [[email protected]](mailto:[email protected]).
# LICENSE
You can use and distribute this module under the terms of the
The Artistic License 2.0. See the `LICENSE` file included in this
distribution for complete details.
The `META6.json` file of this distribution may be distributed and modified
without restrictions or attribution.
|
## dist_zef-rbt-DBIish-Pool.md
# DBIish::Pool - Database connection pooling for DBIish
## SYNOPSIS
```
my %connection-parameters = database => 'foo', user => 'bar', password => secret();
my $pool = DBIish.new(driver => 'Pg', initial-size => 1, max-connections => 10, min-spare-connections => 1,
max-idle-duration => Duration.new(60), |%connection-parameters);
my $dbh = $pool.get-connection()
$dbh.do({SELECT 1});
$dbh.dispose;
```
## DESCRIPTION
This module is useful for apps supporting multiple parallel users which arrive at an inconsistent rate, such as a
web application. In addition to connection reuse it allow configuring a maximum number of simultaneous connections to
ensure the database does not go over capacity.
Database connection reuse improves performance significantly for very simple transactions, or
long distance networks using SSL encrypted connections. 300% has been seen within the same network
for web requests, where each request was establishing a new connection.
To use, create a pool, then take a connection from that pool. The connection is returned to the pool when
dispose is called. Calling dispose is important as otherwise you may exhaust the pool due to garbage collection
being unpredictable.
See your database driver for a description of the connection parameters allowed. These are the same as the
C<DBIish.connect> call.
```
my $pool = DBIish::Pool.new(driver => 'Pg', max-connections => 20, max-idle-duration => Duration.new(60),
min-spare-connections => 3, initial-size => 5, |%dbiish-connection-parameters);
sub do-db-work() {
my $dbh = $pool.get-connection();
my $sth = $dbh.prepare(q{ SELECT session_state FROM sessions WHERE session_id = ? });
$sth.execute($session-id);
my $ret = $sth.allrows();
$dbh.dispose
return $ret;
}
```
### `new`
* `min-spare-connections`
The number of idle connections to keep around. These are ready for immediate use. Busy multi-threaded workloads
will want to raise this above 1 as there is a short time between when a connection is disposed and when it
will be ready for use again.
* `initial-size`
The number of connections to create when the pool is established. This may be kept equal to `min-spare-connections`
unless your app requires a very fast initial response time and is regularly restarted during peak periods.
* `max-idle-duration`
Connections which have not been used in this time period will be slowly closed, unless required to meet the
`min-spare-connections`.
* `max-connections`
Maximum number of database connections, including those currently being scrubbed of session state for reuse.
Overall performance is often better if the database has a consistent load and spikes are smoothed out.
* `|%dbiish-connection-parameters` are whatever `DBIish` allows. For a pool for a PostgreSQL driver might be established
like this:
```
my $pool = DBIish::Pool.new(driver => 'Pg', dbname => 'dbtest', user => 'postgres', port => 5432, max-connections => 20);
```
### `get-connection`
Returns a connection from the pool, establishing a new connection if necessary, when one becomes available. The
connection is checked for connectivity prior to returning it to the client.
Once `max-connections` is reached, this routine will not return a connection until one becomes available. Ensure you
call `dispose` after finished using the connection to shorten this timeframe as garbage collection is not predictable.
If preferred, you may obtain a connection asynchronously.
```
my $dbh = await $pool.get-connection(:async);
```
### Pool Statistics
A small Hash with pool connection statistics is available. This can be useful for automated monitoring purposes.
my %stats = $pool.stats();
Statistics fields include:
* inuse ➡ Number of connections currently in use.
* idle ➡ Number available for immediate use.
* starting ➡ Number starting up.
* scrub ➡ Numbers recently disposed, currently being scrubbed.
* total ➡ Total of the `inuse`, `idle`, `starting`, and `scrub` counters. Due to short race conditions, this may not add up at times.
* waiting ➡ Number of unfilled `connect` calls.
|
## radixoutofrange.md
class X::Syntax::Number::RadixOutOfRange
Compilation error due to an unallowed radix in a number literal
```raku
class X::Syntax::Number::RadixOutOfRange does X::Syntax { }
```
Syntax error that is thrown when the radix of a radix number is not allowed, like `:1<1>` or `:42<ouch>`.
# [Methods](#class_X::Syntax::Number::RadixOutOfRange "go to top of document")[§](#Methods "direct link")
## [method radix](#class_X::Syntax::Number::RadixOutOfRange "go to top of document")[§](#method_radix "direct link")
```raku
method radix(--> Int:D)
```
The offensive radix.
|
## dist_zef-raku-community-modules-HTTP-UserAgent.md
[](https://github.com/raku-community-modules/HTTP-UserAgent/actions) [](https://github.com/raku-community-modules/HTTP-UserAgent/actions)
# NAME
HTTP::UserAgent - Web user agent class
# SYNOPSIS
```
use HTTP::UserAgent;
my $ua = HTTP::UserAgent.new;
$ua.timeout = 10;
my $response = $ua.get("URL");
if $response.is-success {
say $response.content;
}
else {
die $response.status-line;
}
```
# DESCRIPTION
This module provides functionality to crawling the web witha handling cookies and correct User-Agent value.
It has TLS/SSL support.
# METHODS
## method new
```
method new(HTTP::UserAgent:U: :$!useragent, Bool :$!throw-exceptions, :$!max-redirects = 5, :$!debug)
```
Default constructor.
There are four optional named arguments:
* useragent
A string that specifies what will be provided in the `User-Agent` header in the request. A number of standard user agents are described in [HTTP::UserAgent::Common](http::UserAgent::Common), but a string that is not specified there will be used verbatim.
* throw-exceptions
By default the `request` method will not throw an exception if the response from the server indicates that the request was unsuccesful, in this case you should check `is-success` to determine the status of the [HTTP::Response](http::Response) returned. If this is specified then an exception will be thrown if the request was not a success, however you can still retrieve the response from the `response` attribute of the exception object.
* max-redirects
This is the maximum number of redirects allowed for a single request, if this is exceeded then an exception will be thrown (this is not covered by `no-exceptions` above and will always be throw,) the default value is 5.
* debug
It can etheir be a Bool like simply `:debug` or you can pass it a IO::Handle or a file name. Eg `:debug($*ERR)` will ouput on stderr `:debug("mylog.txt")` will ouput on the file.
## method auth
```
method auth(HTTP::UserAgent:, Str $login, Str $password)
```
Sets username and password needed to HTTP Auth.
## method get
```
multi method get(Str $url is copy, :bin?, *%headers)
multi method get(URI $uri, :bin?, *%headers)
```
Requests the $url site, returns HTTP::Response, except if throw-exceptions is set as described above whereby an exception will be thrown if the response indicates that the request wasn't successfull.
If the Content-Type of the response indicates that the content is text the `content` of the Response will be a decoded string, otherwise it will be left as a <Blob>.
If the ':bin' adverb is supplied this will force the response `content` to always be an undecoded <Blob>
Any additional named arguments will be applied as headers in the request.
## method post
```
multi method post(URI $uri, %form, *%header ) -> HTTP::Response
multi method post(Str $uri, %form, *%header ) -> HTTP::Response
```
Make a POST request to the specified uri, with the provided Hash of %form data in the body encoded as "application/x-www-form-urlencoded" content. Any additional named style arguments will be applied as headers in the request.
An [HTTP::Response](http::Response) will be returned, except if throw-exceptions has been set and the response indicates the request was not successfull.
If the Content-Type of the response indicates that the content is text the `content` of the Response will be a decoded string, otherwise it will be left as a <Blob>.
If the ':bin' adverb is supplied this will force the response `content` to always be an undecoded <Blob>
If greater control over the content of the request is required you should create an [HTTP::Request](http::Request) directly and populate it as needed,
## method request
```
method request(HTTP::Request $request, :bin?)
```
Performs the request described by the supplied [HTTP::Request](http::Request), returns a [HTTP::Response](http::Response), except if throw-exceptions is set as described above whereby an exception will be thrown if the response indicates that the request wasn't successful.
If the response has a 'Content-Encoding' header that indicates that the content was compressed, then it will attempt to inflate the data using Compress::Zlib, if the module is not installed then an exception will be thrown. If you do not have or do not want to install Compress::Zlib then you should be able to send an 'Accept-Encoding' header with a value of 'identity' which should cause a well behaved server to send the content verbatim if it is able to.
If the Content-Type of the response indicates that the content is text the `content` of the Response will be a decoded string, otherwise it will be left as a <Blob>. The content-types that are always considered to be binary (and thus left as a <Blob> ) are those with the major-types of 'image','audio' and 'video', certain 'application' types are considered to be 'text' (e.g. 'xml', 'javascript', 'json').
If the ':bin' adverb is supplied this will force the response `content` to always be an undecoded <Blob>
You can use the helper subroutines defined in [HTTP::Request::Common](http::Request::Common) to create the [HTTP::Request](http::Request) for you or create it yourself if you have more complex requirements.
## routine get :simple
```
sub get(Str $url) returns Str is export(:simple)
```
Like method get, but returns decoded content of the response.
## routine head :simple
```
sub head(Str $url) returns Parcel is export(:simple)
```
Returns values of following header fields:
* Content-Type
* Content-Length
* Last-Modified
* Expires
* Server
## routine getstore :simple
```
sub getstore(Str $url, Str $file) is export(:simple)
```
Like routine get but writes the content to a file.
## routine getprint :simple
```
sub getprint(Str $url) is export(:simple)
```
Like routine get but prints the content and returns the response code.
# SUPPORT MODULES
## HTTP::Cookie - HTTP cookie class
This module encapsulates single HTTP Cookie.
```
use HTTP::Cookie;
my $cookie = HTTP::Cookie.new(:name<test_name>, :value<test_value>);
say ~$cookie;
```
The following methods are provided:
### method new
```
my $c = HTTP::Cookie.new(:name<a_cookie>, :value<a_value>, :secure, fields => (a => b));
```
A constructor, it takes these named arguments:
| key | description |
| --- | --- |
| name | name of a cookie |
| value | value of a cookie |
| secure | Secure param |
| httponly | HttpOnly param |
| fields | list of field Pairs (field => value) |
### method Str
Returns a cookie as a string in readable (RFC2109) form.
## HTTP::Cookies - HTTP cookie jars
This module provides a bunch of methods to manage HTTP cookies.
```
use HTTP::Cookies;
my $cookies = HTTP::Cookies.new(
:file<./cookies>,
:autosave
);
$cookies.load;
```
### method new
```
my $cookies = HTTP::Cookies.new(
:file<./cookies.here>
:autosave,
);
Constructor, takes named arguments:
```
| key | description |
| --- | --- |
| file | where to write cookies |
| autosave | save automatically after every operation on cookies or not |
### method set-cookie
```
my $cookies = HTTP::Cookies.new;
$cookies.set-cookie('Set-Cookie: name1=value1; HttpOnly');
```
Adds a cookie (passed as an argument $str of type Str) to the list of cookies.
### method save
```
my $cookies = HTTP::Cookies.new;
$cookies.set-cookie('Set-Cookie: name1=value1; HttpOnly');
$cookies.save;
```
Saves cookies to the file ($.file).
### method load
```
my $cookies = HTTP::Cookies.new;
$cookies.load;
```
Loads cookies from file specified at instantiation ($.file).
### method extract-cookies
```
my $cookies = HTTP::Cookies.new;
my $response = HTTP::Response.new(Set-Cookie => "name1=value; Secure");
$cookies.extract-cookies($response);
```
Gets cookies ('Set-Cookie: ' lines) from the HTTP Response and adds it to the list of cookies.
### method add-cookie-header
```
my $cookies = HTTP::Cookies.new;
my $request = HTTP::Request.new;
$cookies.load;
$cookies.add-cookie-header($request);
```
Adds cookies fields ('Cookie: ' lines) to the HTTP Request.
### method clear-expired
```
my $cookies = HTTP::Cookies.new;
$cookies.set-cookie('Set-Cookie: name1=value1; Secure');
$cookies.set-cookie('Set-Cookie: name2=value2; Expires=Wed, 09 Jun 2021 10:18:14 GMT');
$cookies.clear-expired; # contains 'name1' cookie only
```
Removes expired cookies.
### method clear
```
my $cookies = HTTP::Cookies.new;
$cookies.load; # contains something
$cookies.clear; # will be empty after this action
```
Removes all cookies.
### method push-cookie
```
my $c = HTTP::Cookie.new(:name<a>, :value<b>, :httponly);
my $cookies = HTTP::Cookies.new;
$cookies.push-cookie: $c;
```
Pushes cookies (passed as an argument $c of type HTTP::Cookie) to the list of cookies.
### method Str
Returns all cookies in human (and server) readable form.
## HTTP::UserAgent::Common - the most commonly used User-Agents
This module provides a list of the most commonly used User-Agents.
```
use HTTP::UserAgent::Common;
say get-ua('chrome_linux');
```
### routine get-ua
```
say get-ua('chrome_linux');
```
Returns correct UserAgent or unchaged passed argument if UserAgent could not be found.
Available UserAgents:
```
chrome_w7_64 firefox_w7_64 ie_w7_64 chrome_w81_64 firefox_w81_64 mob_safari_osx
safari_osx chrome_osx firefox_linux chrome_linux
```
## HTTP::Header - class encapsulating HTTP message header
This module provides a class with a set of methods making us able to easily handle HTTP message headers.
```
use HTTP::Header;
my $h = HTTP::Header.new;
$h.field(Accept => 'text/plain');
say $h.field('Accept');
$h.remove-field('Accept');
```
### method new
```
my $head = HTTP::Header.new(:h1<v1>, :h2<v2>);
```
A constructor. Takes name => value pairs as arguments.
### method header
```
my $head = HTTP::Header.new(:h1<v1>, :h2<v2>);
say $head.header('h1');
my $head = HTTP::Header.new(:h1<v1>, :h2<v2>);
$head.header(:h3<v3>);
```
Gets/sets header field.
### method init-field
```
my $head = HTTP::Header.new;
$head.header(:h1<v1>);
$head.init-header(:h1<v2>, :h2<v2>); # it doesn't change the value of 'h1'
say ~$head;
```
Initializes a header field: adds a field only if it does not exist yet.
### method push-header
```
my $head = HTTP::Header.new;
$head.push-header( HTTP::Header::Field.new(:name<n1>, :value<v1>) );
say ~$head;
```
Pushes a new field. Does not check if exists.
### method remove-header
```
my $head = HTTP::Header.new;
$head.header(:h1<v1>);
$head.remove-header('h1');
```
Removes a field of name $field.
### method header-field-names
```
my $head = HTTP::Header.new(:h1<v1>, :h2<v2>);
my @names = $head.header-field-names;
say @names; # h1, h2
```
Returns a list of names of all fields.
### method clear
```
my $head = HTTP::Header.new(:h1<v1>, :h2<v2>);
$head.clear;
```
Removes all fields.
### method Str
Returns readable form of the whole header section.
### method parse
```
my $head = HTTP::Header.new.parse("h1: v1\r\nh2: v2\r\n");
say $head.raku;
```
Parses the whole header section.
## HTTP::Header::Field
This module provides a class encapsulating HTTP Message header field.
```
use HTTP::Header::Field;
my $header = HTTP::Header::Field.new(:name<Date>, values => (123, 456));
```
### method new
Constructor. Takes these named arguments:
| key | description |
| --- | --- |
| name | name of a header field |
| values | array of values of a header field |
### method Str
Stringifies an HTTP::Header::Field object. Returns a header field in a human (and server) readable form.
## HTTP::Request - class encapsulating HTTP request message
Module provides functionality to easily manage HTTP requests.
```
use HTTP::Request;
my $request = HTTP::Request.new(GET => 'http://www.example.com/');
```
### method new
A constructor, the first form takes parameters like:
* method => URL, where method can be POST, GET ... etc.
* field => values, header fields
```
my $req = HTTP::Request.new(:GET<example.com>, :h1<v1>);
```
The second form takes the key arguments as simple positional parameters and is designed for use in places where for example the request method may be calculated and the headers pre-populated.
### method set-method
```
my $req = HTTP::Request.new;
$req.set-method: 'POST';
```
Sets a method of the request.
### method uri
```
my $req = HTTP::Request.new;
$req.uri: 'example.com';
```
Sets URL to request.
### method add-cookies
```
method add-cookies(HTTP::Cookies $cookies)
```
This will cause the appropriate cookie headers to be added from the supplied HTTP::Cookies object.
### method add-form-data
```
multi method add-form-data(%data, :$multipart)
multi method add-form-data(:$multipart, *%data);
multi method add-form-data(Array $data, :$multipart)
```
Adds the form data, supplied either as a `Hash`, an `Array` of `Pair`s, or in a named parameter style, to the POST request (it doesn't make sense on most other request types).
The default is to use 'application/x-www-form-urlencoded' and 'multipart/form-data' can be used by providing the ':multipart' named argument. Alternatively a previously applied "content-type" header of either 'application/x-www-form-urlencoded' or 'multipart/form-data' will be respected and in the latter case any applied boundary marker will be retained.
As a special case for multipart data if the value for some key in the data is an `Array` of at least one item then it is taken to be a description of a file to be "uploaded" where the first item is the path to the file to be inserted, the second (optional) an alternative name to be used in the content disposition header and the third an optional `Array` of `Pair`s that will provide additional header lines for the part.
### method Str
Returns stringified object.
### method parse
```
method parse(Str $raw_request --> HTTP::Request:D)
```
Parses raw HTTP request. See `HTTP::Message`
## HTTP::Request::Common - Construct common HTTP::Request objects
```
use HTTP::Request::Common;
my $ua = HTTP::UserAgent.new;
my $response = $ua.request(GET 'http://google.com/');
```
This module provide functions that return newly created `HTTP::Request` objects. These functions are usually more convenient to use than the standard `HTTP::Request` constructor for the most common requests. The following functions are provided:
### GET $url, Header => Value...
The `GET` function returns an `HTTP::Request` object initialized with the "GET" method and the specified URL.
### HEAD $url, Header => Value,...
Like `GET` but the method in the request is "HEAD".
### DELETE $url, Header => Value,...
Like `GET` but the method in the request is "DELETE".
### `PUT $url, Header =` Value,..., content => $content>
Like `GET` but the method in the request is "PUT".
## HTTP::Response - class encapsulating HTTP response message
```
use HTTP::Response;
my $response = HTTP::Response.new(200);
say $response.is-success; # it is
```
Module provides functionality to easily manage HTTP responses.
Response object is returned by the .get() method of [HTTP::UserAgent](http::UserAgent).
### method new
```
my $response = HTTP::Response.new(200, :h1<v1>);
```
A constructor, takes named arguments:
| key | description |
| --- | --- |
| code | code of the response |
| fields | header fields (field\_name => values) |
### method is-success
```
my $response = HTTP::Response.new(200);
say 'YAY' if $response.is-success;
```
Returns True if response is successful (status == 2xx), False otherwise.
## method set-code
```
my $response = HTTP::Response.new;
$response.set-code: 200;
```
Sets code of the response.
### method Str
Returns stringified object.
### method parse
See `HTTP::Message`.
## HTTP::Message - class encapsulating HTTP message
```
use HTTP::Message;
my $raw_msg = "GET / HTTP/1.1\r\nHost: somehost\r\n\r\n";
my $mess = HTTP::Message.new.parse($raw_msg);
say $mess;
```
This module provides a bunch of methods to easily manage HTTP message.
### method new
```
my $msg = HTTP::Message.new('content', :field<value>);
```
A constructor, takes these named arguments:
| key | description |
| --- | --- |
| content | content of the message (optional) |
| fields | fields of the header section |
### method add-content
```
my $msg = HTTP::Message.new('content', :field<value>);
$msg.add-content: 's';
say $msg.content; # says 'contents'
```
Adds HTTP message content. It does not remove the existing value, it concats to the existing content.
### method decoded-content
```
my $msg = HTTP::Message.new();
say $msg.decoded-content;
```
Returns decoded content of the message (using <Encode> module to decode).
### method field
See `HTTP::Header`.
### method init-field
See `HTTP::Header`.
### method push-field
See `HTTP::Header`.
### method remove-field
See `HTTP::Header`.
### method clear
```
my $msg = HTTP::Message.new('content', :field<value>);
$msg.clear;
say ~$msg; # says nothing
```
Removes the whole message, both header and content section.
### method parse
```
my $msg = HTTP::Message.new.parse("GET / HTTP/1.1\r\nHost: example\r\ncontent\r\n");
say $msg.raku;
```
Parses the whole HTTP message.
It takes the HTTP message (with \r\n as a line separator) and obtains the header and content sections, creates a `HTTP::Header` object.
### method Str
Returns HTTP message in a readable form.
# AUTHOR
* Filip Sergot
Source can be located at: <https://github.com/raku-community-modules/HTTP-UserAgent> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2014 - 2022 Filip Sergot
Copyright 2023 - 2025 The Raku Community
This library is free software; you can redistribute it and/or modify it under the MIT License.
|
## test.md
module Test
Writing and running tests
This module provides a testing framework, and is used in the official suite that tests the specification. All its functions emit output conforming to the [Test Anything Protocol](https://testanything.org).
Also see [Writing and running tests in Raku](/language/testing).
# [Methods](#module_Test "go to top of document")[§](#Methods "direct link")
## [sub plan](#module_Test "go to top of document")[§](#sub_plan "direct link")
```raku
multi plan(Cool:D :skip-all($reason)!)
multi plan($number_of_tests)
```
Specify the count of tests -- usually written at the beginning of a test file.
```raku
plan 15; # expect to run 15 tests
```
In `subtest`s, `plan` is used to specify the count of tests within the subtest.
If a `plan` is used, it's not necessary to specify the end of testing with `done-testing`.
You can also provide a `:skip-all` named argument instead of a test count, to indicate that you want to skip all of the tests. Such a plan will call [`exit`](/routine/exit), unless used inside of a `subtest`.
```raku
plan :skip-all<These tests are only for Windows> unless $*DISTRO.is-win;
plan 1;
ok dir 'C:/'; # this won't get run on non-Windows
```
If used in a `subtest`, it will instead `return` from that `subtest`'s [`Callable`](/type/Callable). For that reason, to be able to use `:skip-all` inside a `subtest`, you must use a `sub` instead of a regular block:
```raku
plan 2;
subtest "Some Windows tests" => sub { # <-- note the `sub`; can't use bare block
plan :skip-all<We aren't on Windows> unless $*DISTRO.is-win;
plan 1;
ok dir 'C:/'; # this won't get run on non-Windows
}
ok 42; # this will run everywhere and isn't affected by skip-all inside subtest
```
Note that `plan` with `:skip-all` is to avoid performing any tests without marking the test run as failed (i.e. the plan is to not run anything and that's all good). Use [`skip-rest`](#sub_skip-rest) to skip all further tests, once the run has started (i.e. planned to run some tests, maybe even ran some, but now we're skipping all the rest of them). Use [`bail-out`](#sub_bail-out) to fail the test run without running any further tests (i.e. things are so bad, there's no point in running anything else; we've failed).
## [sub done-testing](#module_Test "go to top of document")[§](#sub_done-testing "direct link")
```raku
sub done-testing()
```
Specify that testing has finished. Use this function when you don't have a `plan` with the number of tests to run. A `plan` is not required when using `done-testing`.
It's recommended that the `done-testing` function be removed and replaced with a `plan` function when all tests are finalized. Use of `plan` can help detect test failures otherwise not reported because tests were accidentally skipped due to bugs in the tests or bugs in the compiler. For example:
```raku
sub do-stuff {@};
use Test;
ok .is-prime for do-stuff;
done-testing;
# output:
1..0
```
The above example is where a `done-testing` fails. `do-stuff()` returned nothing and tested nothing, even though it should've returned results to test. But the test suite doesn't know how many tests were meant to be run, so it passes.
Adding `plan` gives a true picture of the test:
```raku
sub do-stuff {@};
use Test;
plan 1;
ok .is-prime for do-stuff;
# output:
1..1
# Looks like you planned 1 test, but ran 0
```
Note that leaving the `done-testing` in place will have no effect on the new test results, but it should be removed for clarity.
The `done-testing` function returns `False` if any test has failed or less tests were run than planned, it returns `True` otherwise.
## [sub ok](#module_Test "go to top of document")[§](#sub_ok "direct link")
```raku
multi ok(Mu $cond, $desc = '')
```
The `ok` function marks a test as passed if the given `$cond` evaluates to `True`. It also accepts an optional description of the test as second argument.
```raku
my $response; my $query; ...;
ok $response.success, 'HTTP response was successful';
```
In principle, you could use `ok` for every kind of comparison test, by including the comparison in the expression passed to `$cond`:
```raku
sub factorial($x) { ... };
ok factorial(6) == 720, 'Factorial - small integer';
```
However, where possible it's better to use one of the specialized comparison test functions below, because they can print more helpful diagnostics output in case the comparison fails.
## [sub nok](#module_Test "go to top of document")[§](#sub_nok "direct link")
```raku
multi nok(Mu $cond, $desc = '')
```
The `nok` function marks a test as passed if the given `$cond` evaluates to `False`. It also accepts an optional description of the test as second argument.
```raku
my $response; my $query; ...;
nok $query.error, 'Query completed without error';
```
## [sub is](#module_Test "go to top of document")[§](#sub_is "direct link")
```raku
multi is(Mu $got, Mu:U $expected, $desc = '')
multi is(Mu $got, Mu:D $expected, $desc = '')
```
Marks a test as passed if `$got` and `$expected` compare positively with the [`eq` operator](/routine/eq), unless `$expected` is a type object, in which case [`===` operator](/routine/===) will be used instead; accepts an optional description of the test as the last argument.
**NOTE:** the `eq` operator stringifies its operands, which means `is()` is not a good function for testing more complex things, such as lists: `is (1, (2, (3,))), [1, 2, 3]` passes the test, even though the operands are vastly different. For those cases, use [`is-deeply` routine](#sub_is-deeply)
```raku
my $pdf-document; sub factorial($x) { ... }; ...;
is $pdf-document.author, "Joe", 'Retrieving the author field';
is factorial(6), 720, 'Factorial - small integer';
my Int $a;
is $a, Int, 'The variable $a is an unassigned Int';
```
**Note:** if *only* whitespace differs between the values, `is()` will output failure message differently, to show the whitespace in each values. For example, in the output below, the second test shows the literal `\t` in the `got:` line:
```raku
is "foo\tbar", "foo\tbaz"; # expected: 'foo baz'# got: 'foo bar'
is "foo\tbar", "foo bar"; # expected: "foo bar"# got: "foo\tbar"
```
## [sub isnt](#module_Test "go to top of document")[§](#sub_isnt "direct link")
```raku
multi isnt(Mu $got, Mu:U $expected, $desc = '')
multi isnt(Mu $got, Mu:D $expected, $desc = '')
```
Marks a test as passed if `$got` and `$expected` are **not** equal using the same rules as `is()`. The function accepts an optional description of the test.
```raku
isnt pi, 3, 'The constant π is not equal to 3';
my Int $a = 23;
$a = Nil;
isnt $a, Nil, 'Nil should not survive being put in a container';
```
## [sub is\_approx](#module_Test "go to top of document")[§](#sub_is_approx "direct link")
```raku
multi is_approx(Mu $got, Mu $expected, $desc = '')
```
**NOTE**: Removed with Rakudo release 2023.09, deprecated in older versions. Use `is-approx` instead.
## [sub is-approx](#module_Test "go to top of document")[§](#sub_is-approx "direct link")
```raku
multi is-approx(Numeric $got, Numeric $expected, $desc = '')
```
```raku
multi is-approx(Numeric $got, Numeric $expected, Numeric $abs-tol,
$desc = '')
```
```raku
multi is-approx(Numeric $got, Numeric $expected, $desc = '',
Numeric :$rel-tol is required)
```
```raku
multi is-approx(Numeric $got, Numeric $expected, $desc = '',
Numeric :$abs-tol is required)
```
```raku
multi is-approx(Numeric $got, Numeric $expected, $desc = '',
Numeric :$rel-tol is required,
Numeric :$abs-tol is required)
```
Marks a test as passed if the `$got` and `$expected` numerical values are approximately equal to each other. The subroutine can be called in numerous ways that let you test using relative tolerance (`$rel-tol`) or absolute tolerance (`$abs-tol`) of different values.
If no tolerance is set, the function will base the tolerance on the *absolute* value of `$expected`: if it's smaller than `1e-6`, use absolute tolerance of `1e-5`; if it's larger, use relative tolerance of `1e-6`.
```raku
my Numeric ($value, $expected, $abs-tol, $rel-tol) = ...
is-approx $value, $expected;
is-approx $value, $expected, 'test description';
is-approx $value, $expected, $abs-tol;
is-approx $value, $expected, $abs-tol, 'test description';
is-approx $value, $expected, :$rel-tol;
is-approx $value, $expected, :$rel-tol, 'test description';
is-approx $value, $expected, :$abs-tol;
is-approx $value, $expected, :$abs-tol, 'test description';
is-approx $value, $expected, :$abs-tol, :$rel-tol;
is-approx $value, $expected, :$abs-tol, :$rel-tol, 'test description';
```
### [Absolute tolerance](#module_Test "go to top of document")[§](#Absolute_tolerance "direct link")
When an absolute tolerance is set, it's used as the actual maximum value by which the first and the second parameters can differ. For example:
```raku
is-approx 3, 4, 2; # success
is-approx 3, 6, 2; # fail
is-approx 300, 302, 2; # success
is-approx 300, 400, 2; # fail
is-approx 300, 600, 2; # fail
```
Regardless of values given, the difference between them cannot be more than `2`.
### [Relative tolerance](#module_Test "go to top of document")[§](#Relative_tolerance "direct link")
When a relative tolerance is set, the test checks the relative difference between values. Given the same tolerance, the larger the numbers given, the larger the value they can differ by can be.
For example:
```raku
is-approx 10, 10.5, :rel-tol<0.1>; # success
is-approx 10, 11.5, :rel-tol<0.1>; # fail
is-approx 100, 105, :rel-tol<0.1>; # success
is-approx 100, 115, :rel-tol<0.1>; # fail
```
Both versions use `0.1` for relative tolerance, yet the first can differ by about `1` while the second can differ by about `10`. The function used to calculate the difference is:
「text」 without highlighting
```
```
|value - expected|
rel-diff = ────────────────────────
max(|value|, |expected|)
```
```
and the test will fail if `rel-diff` is higher than `$rel-tol`.
### [Both absolute and relative tolerance specified](#module_Test "go to top of document")[§](#Both_absolute_and_relative_tolerance_specified "direct link")
```raku
is-approx $value, $expected, :rel-tol<.5>, :abs-tol<10>;
```
When both absolute and relative tolerances are specified, each will be tested independently, and the `is-approx` test will succeed only if both pass.
## [sub is-approx-calculate](#module_Test "go to top of document")[§](#sub_is-approx-calculate "direct link")
```raku
sub is-approx-calculate($got, $expected, $abs-tol where { !.defined or $_ >= 0 },
$rel-tol where { !.defined or $_ >= 0 }, $desc)
```
This is the actual routine called by [`is-approx` when absolute and relative tolerance are specified](/type/Test#Both_absolute_and_relative_tolerance_specified). They are tested independently, and the test succeeds only if both pass.
## [sub is-deeply](#module_Test "go to top of document")[§](#sub_is-deeply "direct link")
```raku
multi is-deeply(Seq:D $got, Seq:D $expected, $reason = '')
multi is-deeply(Seq:D $got, Mu $expected, $reason = '')
multi is-deeply(Mu $got, Seq:D $expected, $reason = '')
multi is-deeply(Mu $got, Mu $expected, $reason = '')
```
Marks a test as passed if the first and second parameters are equivalent, using the same semantics as the [eqv operator](/routine/eqv). This is the best way to check for equality of (deep) data structures. The function accepts an optional description of the test as the last argument.
```raku
use Test;
plan 1;
sub string-info(Str() $_) {
Map.new: (
length => .chars,
char-counts => Bag.new-from-pairs: (
letters => +.comb(/<:letter>/),
digits => +.comb(/<:digit>/),
other => +.comb(/<.-:letter-:digit>/),
))
}
is-deeply string-info('42 Butterflies ♥ Raku'), Map.new((
:21length,
char-counts => Bag.new-from-pairs: ( :15letters, :2digits, :4other, )
)), 'string-info gives right info';
```
**Note:** for [historical reasons](https://github.com/rakudo/rakudo/commit/096bc17cd5), [`Seq`](/type/Seq)`:D` arguments to `is-deeply` get converted to [`List`](/type/List)s by calling [`.cache`](/routine/cache) on them. If you want to ensure strict [`Seq`](/type/Seq) comparisons, use [`cmp-ok $got, 'eqv', $expected, $desc`](/language/testing#By_arbitrary_comparison) instead.
## [sub cmp-ok](#module_Test "go to top of document")[§](#sub_cmp-ok "direct link")
```raku
multi cmp-ok(Mu $got is raw, $op, Mu $expected is raw, $desc = '')
```
Compares `$got` and `$expected` with the given `$op` comparator and passes the test if the comparison yields a `True` value. The description of the test is optional.
The `$op` comparator can be either a [`Callable`](/type/Callable) or a [`Str`](/type/Str) containing an infix operator, such as `'=='`, a `'~~'`, or a user-defined infix.
```raku
cmp-ok 'my spelling is apperling', '~~', /perl/, "bad speller";
```
Metaoperators cannot be given as a string; pass them as a [`Callable`](/type/Callable) instead:
```raku
cmp-ok <a b c>, &[!eqv], <b d e>, 'not equal';
```
A [`Callable`](/type/Callable) `$op` lets you use custom comparisons:
```raku
sub my-comp { $^a / $^b < rand };
cmp-ok 1, &my-comp, 2, 'the dice giveth and the dice taketh away'
cmp-ok 2, -> $a, $b { $a.is-prime and $b.is-prime and $a < $b }, 7,
'we got primes, one larger than the other!';
```
## [sub isa-ok](#module_Test "go to top of document")[§](#sub_isa-ok "direct link")
```raku
multi isa-ok(Mu $var, Mu $type, $desc = "The object is-a '$type.raku()'")
```
Marks a test as passed if the given object `$var` is, or inherits from, the given `$type`. For convenience, types may also be specified as a string. The function accepts an optional description of the test, which defaults to a string that describes the object.
```raku
class Womble {}
class GreatUncleBulgaria is Womble {}
my $womble = GreatUncleBulgaria.new;
isa-ok $womble, Womble, "Great Uncle Bulgaria is a womble";
isa-ok $womble, 'Womble'; # equivalent
```
Note that, unlike `isa`, `isa-ok` also matches `Roles`:
```raku
say 42.isa(Numeric); # OUTPUT: «False»
isa-ok 42, Numeric; # OUTPUT: «ok 1 - The object is-a 'Numeric'»
```
## [sub can-ok](#module_Test "go to top of document")[§](#sub_can-ok "direct link")
```raku
multi can-ok(Mu $var, Str $meth, $desc = "..." )
```
Marks a test as passed if the given `$var` can run the method named `$meth`. The function accepts an optional description. For instance:
```raku
class Womble {
method collect-rubbish { ... }
}
my $womble = Womble.new;
# with automatically generated test description
can-ok $womble, 'collect-rubbish';
# => An object of type 'Womble' can do the method 'collect-rubbish'
# with human-generated test description
can-ok $womble, 'collect-rubbish', "Wombles can collect rubbish";
# => Wombles can collect rubbish
```
## [sub does-ok](#module_Test "go to top of document")[§](#sub_does-ok "direct link")
```raku
multi does-ok(Mu $var, Mu $type, $desc = "...")
```
Marks a test as passed if the given `$var` can do the given role `$type`. The function accepts an optional description of the test.
```raku
# create a Womble who can invent
role Invent {
method brainstorm { say "Aha!" }
}
class Womble {}
class Tobermory is Womble does Invent {}
# ... and later in the tests
use Test;
my $tobermory = Tobermory.new;
# with automatically generated test description
does-ok $tobermory, Invent;
# => The object does role Type
does-ok $tobermory, Invent, "Tobermory can invent";
# => Tobermory can invent
```
## [sub like](#module_Test "go to top of document")[§](#sub_like "direct link")
```raku
sub like(Str() $got, Regex:D $expected, $desc = "text matches $expected.raku()")
```
Use it this way:
```raku
like 'foo', /fo/, 'foo looks like fo';
```
Marks a test as passed if the first parameter, when coerced to a string, matches the regular expression specified as the second parameter. The function accepts an optional description of the test with a default value printing the expected match.
## [sub unlike](#module_Test "go to top of document")[§](#sub_unlike "direct link")
```raku
multi unlike(Str() $got, Regex:D $expected, $desc = "text does not match $expected.raku()")
```
Used this way:
```raku
unlike 'foo', /bar/, 'foo does not look like bar';
```
Marks a test as passed if the first parameter, when coerced to a string, does **not** match the regular expression specified as the second parameter. The function accepts an optional description of the test, which defaults to printing the text that did not match.
## [sub use-ok](#module_Test "go to top of document")[§](#sub_use-ok "direct link")
```raku
multi use-ok(Str $code, $desc = "$code module can be use-d ok")
```
Marks a test as passed if the given `$module` loads correctly.
```raku
use-ok 'Full::Qualified::ModuleName';
```
Since `$code` is being turned into an `EVAL`, you can also pass arguments:
```raku
use-ok 'Full::Qualified::ModuleName :my-argument';
```
## [sub dies-ok](#module_Test "go to top of document")[§](#sub_dies-ok "direct link")
```raku
multi dies-ok(Callable $code, $reason = '')
```
Marks a test as passed if the given `$code` throws an [`Exception`](/type/Exception).
The function accepts an optional description of the test.
```raku
sub saruman(Bool :$ents-destroy-isengard) {
die "Killed by Wormtongue" if $ents-destroy-isengard;
}
dies-ok { saruman(ents-destroy-isengard => True) }, "Saruman dies";
```
## [sub lives-ok](#module_Test "go to top of document")[§](#sub_lives-ok "direct link")
```raku
multi lives-ok(Callable $code, $reason = '')
```
Marks a test as passed if the given `$code` **does not** throw an exception.
The function accepts an optional description of the test.
```raku
sub frodo(Bool :$destroys-ring) {
die "Oops, that wasn't supposed to happen" unless $destroys-ring;
}
lives-ok { frodo(destroys-ring => True) }, "Frodo survives";
```
## [sub eval-dies-ok](#module_Test "go to top of document")[§](#sub_eval-dies-ok "direct link")
```raku
multi eval-dies-ok(Str $code, $reason = '')
```
Marks a test as passed if the given `$string` throws an [`Exception`](/type/Exception) when `eval`ed as code.
The function accepts an optional description of the test.
```raku
eval-dies-ok q[my $joffrey = "nasty";
die "bye bye Ned" if $joffrey ~~ /nasty/],
"Ned Stark dies";
```
## [sub eval-lives-ok](#module_Test "go to top of document")[§](#sub_eval-lives-ok "direct link")
```raku
multi eval-lives-ok(Str $code, $reason = '')
```
Marks a test as passed if the given `$string` **does not** throw an exception when `eval`ed as code.
The function accepts an optional description of the test.
```raku
eval-lives-ok q[my $daenerys-burns = False;
die "Oops, Khaleesi now ashes" if $daenerys-burns],
"Dany is blood of the dragon";
```
## [sub throws-like](#module_Test "go to top of document")[§](#sub_throws-like "direct link")
```raku
sub throws-like($code, $ex_type, $reason?, *%matcher)
```
Marks a test as passed if the given `$code` throws the specific exception expected exception type `$ex_type`. The code `$code` may be specified as something [`Callable`](/type/Callable) or as a string to be `EVAL`ed. The exception is specified as a type object.
If an exception was thrown, it will also try to match the matcher hash, where the key is the name of the method to be called on the exception, and the value is the value it should have to pass. For example:
```raku
sub frodo(Bool :$destroys-ring) {
fail "Oops. Frodo dies" unless $destroys-ring
};
throws-like { frodo }, Exception, message => /dies/;
```
The function accepts an optional description of the test as the third positional argument.
The routine makes [`Failure`](/type/Failure)s fatal. If you wish to avoid that, use [`no fatal` pragma](/language/pragmas#fatal) and ensure the tested code does not sink the possible [`Failure`](/type/Failure)s. If you wish to test that the code returns a [`Failure`](/type/Failure) instead of throwing, use `fails-like` routine instead.
```raku
sub fails-not-throws { +"a" }
# test passes, even though it's just a Failure and would not always throw:
throws-like { fails-not-throws }, Exception;
# test detects nothing thrown, because our Failure wasn't sunk or made fatal:
throws-like { no fatal; my $ = fails-not-throws; Nil }, Exception;
```
Please note that you can only use the string form (for `EVAL`) if you are not referencing any symbols in the surrounding scope. If you are, you should encapsulate your string with a block and an EVAL instead. For instance:
```raku
throws-like { EVAL q[ fac("foo") ] }, X::TypeCheck::Argument;
```
## [sub fails-like](#module_Test "go to top of document")[§](#sub_fails-like "direct link")
```raku
sub fails-like ( \test where Callable:D|Str:D, $ex-type, $reason?, *%matcher)
```
Same interface as `throws-like`, except checks that the code returns a [`Failure`](/type/Failure) instead of throwing. If the code does throw or if the returned [`Failure`](/type/Failure) has already been [handled](/routine/handled), that will be considered as a failed test.
```raku
fails-like { +"a" }, X::Str::Numeric,
:message(/'Cannot convert string to number'/),
'converting non-numeric string to number fails';
```
## [sub subtest](#module_Test "go to top of document")[§](#sub_subtest "direct link")
```raku
multi subtest(Pair $what)
multi subtest($desc, &subtests)
multi subtest(&subtests, $desc = '')
```
The `subtest` function executes the given block, consisting of usually more than one test, possibly including a `plan` or `done-testing`, and counts as *one* test in `plan`, `todo`, or `skip` counts. It will pass the test only if **all** tests in the block pass. The function accepts an optional description of the subtest.
```raku
class Womble {}
class GreatUncleBulgaria is Womble {
has $.location = "Wimbledon Common";
has $.spectacles = True;
}
subtest {
my $womble = GreatUncleBulgaria.new;
isa-ok $womble, Womble, "Correct type";
is $womble.location, "Wimbledon Common", "Correct location";
ok $womble.spectacles, "Correct eyewear";
}, "Check Great Uncle Bulgaria";
```
You can also place the description as the first positional argument, or use a [`Pair`](/type/Pair) with description as the key and subtest's code as the value. This can be useful for subtests with large bodies.
```raku
subtest 'A bunch of tests', {
plan 42;
...
...
}
subtest 'Another bunch of tests' => {
plan 72;
...
...
}
```
## [sub todo](#module_Test "go to top of document")[§](#sub_todo "direct link")
```raku
multi todo($reason, $count = 1)
```
Sometimes tests just aren't ready to be run, for instance a feature might not yet be implemented, in which case tests can be marked as `todo`. Or it could be the case that a given feature only works on a particular platform - in which case one would `skip` the test on other platforms.
Mark `$count` tests as TODO, giving a `$reason` as to why. By default only one test will be marked TODO.
```raku
sub my-custom-pi { 3 };
todo 'not yet precise enough'; # Mark the test as TODO.
is my-custom-pi(), pi, 'my-custom-pi'; # Run the test, but don't report
# failure in test harness.
```
The result from the test code above will be something like:
「TAP」 without highlighting
```
```
not ok 1 - my-custom-pi # TODO not yet precise enough
# Failed test 'my-custom-pi'
# at test-todo.rakutest line 7
# expected: '3.14159265358979'
# got: '3'
```
```
Note that if you `todo` a `subtest`, all of the failing tests inside of it will be automatically marked TODO as well and will *not* count towards your original TODO count.
## [sub skip](#module_Test "go to top of document")[§](#sub_skip "direct link")
```raku
multi skip()
multi skip($reason, $count = 1)
```
Skip `$count` tests, giving a `$reason` as to why. By default only one test will be skipped. Use such functionality when a test (or tests) would die if run.
```raku
sub num-forward-slashes($arg) { ... } ;
if $*KERNEL ~~ 'linux' {
is num-forward-slashes("/a/b"), 2;
is num-forward-slashes("/a//b".IO.cleanup), 2;
}
else {
skip "Can't use forward slashes on Windows", 2;
}
```
Note that if you mark a test as skipped, you must also prevent that test from running.
## [sub skip-rest](#module_Test "go to top of document")[§](#sub_skip-rest "direct link")
```raku
sub skip-rest($reason = '<unknown>')
```
Skip the remaining tests. If the remainder of the tests in the test file would all fail due to some condition, use this function to skip them, providing an optional `$reason` as to why.
```raku
my $location; sub womble { ... }; ...;
unless $location ~~ "Wimbledon Common" {
skip-rest "We can't womble, the remaining tests will fail";
exit;
}
# tests requiring functional wombling
ok womble();
# ...
```
Note that `skip-rest` requires a `plan` to be set, otherwise the `skip-rest` call will throw an error. Note that `skip-rest` does not exit the test run. Do it manually, or use conditionals to avoid running any further tests.
See also [`plan :skip-all('...')`](#sub_plan) to avoid running any tests at all and [`bail-out`](#sub_bail-out) to abort the test run and mark it as failed.
## [sub bail-out](#module_Test "go to top of document")[§](#sub_bail-out "direct link")
```raku
sub bail-out ($desc?)
```
If you already know the tests will fail, you can bail out of the test run using `bail-out()`:
```raku
my $has-db-connection;
...
$has-db-connection or bail-out 'Must have database connection for testing';
```
The function aborts the current test run, signaling failure to the harness. Takes an optional reason for bailing out. The subroutine will call `exit()`, so if you need to do a clean-up, do it before calling `bail-out()`.
If you want to abort the test run, but without marking it as failed, see [`skip-rest`](#sub_skip-rest) or [`plan :skip-all('...')`](#sub_plan)
## [sub pass](#module_Test "go to top of document")[§](#sub_pass "direct link")
```raku
multi pass($desc = '')
```
The `pass` function marks a test as passed. `flunk` marks a test as **not** passed. Both functions accept an optional test description.
```raku
pass "Actually, this test has passed";
flunk "But this one hasn't passed";
```
Since these subroutines do not provide indication of what value was received and what was expected, they should be used sparingly, such as when evaluating a complex test condition.
## [sub flunk](#module_Test "go to top of document")[§](#sub_flunk "direct link")
```raku
multi flunk($reason = '')
```
The opposite of `pass`, makes a test fail with an optional message.
## [sub diag](#module_Test "go to top of document")[§](#sub_diag "direct link")
```raku
sub diag($message)
```
Display diagnostic information in a TAP-compatible manner on the standard error stream. This is usually used when a particular test has failed to provide information that the test itself did not provide. Or it can be used to provide visual markers on how the testing of a test-file is progressing (which can be important when doing stress testing).
```raku
diag "Yay! The tests got to here!";
```
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Test`
raku-type-graph
Test
Test
Any
Any
Test->Any
Mu
Mu
Any->Mu
[Expand chart above](/assets/typegraphs/Test.svg)
|
## dist_zef-raku-community-modules-SCGI.md
[](https://github.com/raku-community-modules/SCGI/actions)
# NAME
SCGI - A SCGI library for Raku
# DESCRIPTION
This is a simple SCGI library for Raku.
It's main influences are the Perl SCGI library, and the Raku HTTP::Daemon library.
It offers a bit of candy coating compared to the Perl version.
By default is uses a PSGI-compliant interface, but can also handle raw HTTP responses.
You don't need to create your own `IO::Socket::INET` object. Just pass an 'addr' and 'port' attribute to the new() declaration and it'll create the object for you.
# USAGE
The simplest (and recommended) form of usage is to use the handle() method with PSGI-compliant output. Here's an example:
```
use SCGI;
my $scgi = SCGI.new( :port(8118) );
sub handler(%env) {
my $name = %env<QUERY_STRING> || 'world';
my $status = '200';
my @headers = 'Content-Type' => 'text/plain';
my @body = "Hello $name\n";
@headers.push: 'Content-Length' => @body.join.encode.bytes;
[ $status, @headers, @body ]
}
$scgi.handle: &handler;
```
There are other ways of using SCGI, such as writing your own run loop, or using a raw HTTP output instead of PSGI. Here's an example doing both:
```
use SCGI;
my $scgi = SCGI.new( :port(8118), :!PSGI, :!P6SGI );
while my $connection = $scgi.accept() {
my $request = $connection.request;
if $request.success {
my $name = $request.env<QUERY_STRING> || 'world';
my $return = "Hello $name\n";
my $len = $return.encode.bytes;
my $headers = "Content-Type: text/plain\nContent-Length: $len\n";
$connection.send("$headers\n$return");
}
$connection.close;
}
```
Test script representing both examples can be found in the 'examples' folder.
If you are serious about using SCGI for web application development, see the [Web](https://github.com/raku-community-modules/Web/) library set, or one of the full blown frameworks built using it.
# CONFIGURATION
## nginx
Make sure you compiled nginx with the SCGI plugin (it is included by default.) Then, in one of your server blocks, add a location mount:
```
location /scgi/ {
scgi_pass 127.0.0.1:8118;
include scgi_params;
# Optionally rewrite document URI path
rewrite ^/scgi/(.*) /$1 break;
# Some applications may need rewritten URI in PATH_INFO
scgi_param PATH_INFO $uri;
}
```
## lighttpd
First, make sure the SCGI library is being loaded.
```
server.modules += ( "mod_scgi" )
```
Next, set up an SCGI handler:
```
scgi.server = (
"/scgi" =>
((
"host" => "127.0.0.1",
"port" => 8118,
"check-local" => "disable"
))
)
```
## Apache 2 with mod\_scgi:
Add the following line to your site config, changing the details to match your SCGI script configuration:
```
SCGIMount /scgi/ 127.0.0.1:8118
```
## Apache 2 with mod\_proxy\_scgi:
Add the following line to your site config, changes the details to match your SCGI script configuration:
```
<Proxy *>
Order deny,allow
Allow from all
</Proxy>
ProxyPass /scgi/ scgi://localhost:8118/
```
# AUTHOR
Timothy Totten
# COPYRIGHT AND LICENSE
Copyright 2013 - 2017 Timothy Totten
Copyright 2018 - 2022 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## trim.md
trim
Combined from primary sources listed below.
# [In Allomorph](#___top "go to top of document")[§](#(Allomorph)_method_trim "direct link")
See primary documentation
[in context](/type/Allomorph#method_trim)
for **method trim**.
```raku
method trim(Allomorph:D:)
```
Calls [`Str.trim`](/type/Str#method_trim) on the invocant's [`Str`](/type/Str) value.
# [In Str](#___top "go to top of document")[§](#(Str)_method_trim "direct link")
See primary documentation
[in context](/type/Str#method_trim)
for **method trim**.
```raku
method trim(Str:D: --> Str)
```
Remove leading and trailing whitespace. It can be used both as a method on strings and as a function. When used as a method it will return the trimmed string. In order to do in-place trimming, one needs to write `.=trim`
```raku
my $line = ' hello world ';
say '<' ~ $line.trim ~ '>'; # OUTPUT: «<hello world>»
say '<' ~ trim($line) ~ '>'; # OUTPUT: «<hello world>»
$line.trim;
say '<' ~ $line ~ '>'; # OUTPUT: «< hello world >»
$line.=trim;
say '<' ~ $line ~ '>'; # OUTPUT: «<hello world>»
```
See also [trim-trailing](/routine/trim-trailing) and [trim-leading](/routine/trim-leading).
# [In Cool](#___top "go to top of document")[§](#(Cool)_routine_trim "direct link")
See primary documentation
[in context](/type/Cool#routine_trim)
for **routine trim**.
```raku
sub trim(Str(Cool))
method trim()
```
Coerces the invocant (or in sub form, its argument) to [`Str`](/type/Str), and returns the string with both leading and trailing whitespace stripped.
```raku
my $stripped = ' abc '.trim;
say "<$stripped>"; # OUTPUT: «<abc>»
```
|
## dist_zef-lizmat-Array-Sorted-Map.md
[](https://github.com/lizmat/Array-Sorted-Map/actions) [](https://github.com/lizmat/Array-Sorted-Map/actions) [](https://github.com/lizmat/Array-Sorted-Map/actions)
# NAME
Array::Sorted::Map - Provide a Map interface for 2 sorted lists
# SYNOPSIS
```
use Array::Sorted::Util;
use Array::Sorted::Map;
my @keys;
my @values;
inserts(@keys, "a", @values, 42); # "inserts" from Array::Sorted::Util
inserts(@keys, "b", @values, 666);
my %map := Array::Sorted::Map.new(:$keys, :$values);
say %map<a>; # 42;
say %map<b>; # 666;
say %map<c>; # Nil
say %map.keys; # (a b)
say %map.values; # (42 666)
```
# DESCRIPTION
Array::Sorted::Map provides a class that can be used to provide a `Map` interface to two sorted lists: one for keys, and one for values, such as typically created / maintained by the subroutines offered by the `Array::Sorted::Util` distribution.
Optionally, a `:cmp` argument can be specified, indicating the logic that should be used for comparing elements from the keys. By default, the `infix:<cmp>` will be assumed.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Array-Sorted-Map> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2021, 2024, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-Text-Flags.md
[](https://github.com/lizmat/Text-Flags/actions) [](https://github.com/lizmat/Text-Flags/actions) [](https://github.com/lizmat/Text-Flags/actions)
# NAME
Text::Flags - easy interface to Unicode flags
# SYNOPSIS
```
use Text::Flags;
say "This is the flag of %regions<NL>: %flags<NL>"
```
# DESCRIPTION
Text::Flags provides an easy interface to the Unicode codepoints that render as flags, and their associated regions and names.
It also contains a command-line interface `tf` that either takes any number of flag identifiers (e.g. `tf chequered` will show 🏁). This also takes an optional `--list` argument to show all supported flags, and a `--verbose` argument to show additional information about the indicated flag(s).
# EXPORTED HASHES
## %flags
```
say %flags<chequered>; # 🏁
```
The `%flags` hash contains the mapping of country / region codes and some special flags, to their associated Unicode representations. Please note that some flags, or possibly all flags, may not render correctly on your platform, even if they are valid Unicode representations. Keys can be specified in either uppercase or lowercase.
You can use the `.keys` method to find out which flags are supported. Please note that only lowercase keys will be returned.
Note that flags of deprecated countries / regions **may** consist of a junction of possible renderings.
## %regions
```
say %regions<NL>; # The Netherlands
```
The `%regions` hash contains the mapping of country / region codes to their associated name. Keys can be specified in either uppercase or lowercase.
You can use the `.keys` method to find out which regions are supported. Please note that only lowercase keys will be returned.
## %deprecated
```
say %deprecated<BU>; # Burma
```
The `%deprecated` hash contains the mapping of deprecated country / region codes to their associated name. Keys can be specified in either uppercase or lowercase.
You can use the `.keys` method to find out which deprecations are known. Please note that only lowercase keys will be returned.
# EXPORTED SUBROUTINES
## ric
```
say ric("NL").uninames; # (REGIONAL INDICATOR SYMBOL LETTER N REGIONAL INDICATOR SYMBOL LETTER L)
```
The `ric` subroutine performs a Regional Indicator case conversion on a given string. Any letter (either lowercase or uppercase) is converted to its associated Regional Indicator version, e.g. "a" (also known as "LATIN SMALL LETTER A") is converted to "REGIONAL INDICATOR SYMBOL LETTER A".
This is primarily intended as a helper subroutine, but may have other uses outside of this module.
# SUPPORTED FLAGS
```
ac ad ae af ag ai al am ao aq ar as at au aw ax az
ba bb bd be bf bg bh bi bj bl bm bn bo bq br bs bt bv bw by bz
ca cc cd cf cg ch ci ck cl cm cn co cp cr cu cv cw cx cy cz
de dg dj dk dm do dz
ea ec ee eg eh er es et eu
fi fj fk fm fo fr
ga gb gd ge gf gg gh gi gl gm gn gp gq gr gs gt gu gw gy
hk hm hn hr ht hu
ic id ie il im in io iq ir is it
je jm jo jp
ke kg kh ki km kn kp kr kw ky kz
la lb lc li lk lr ls lt lu lv ly
ma mc md me mf mg mh mk ml mm mn mo mp mq mr ms mt mu mv mw mx my mz
na nc ne nf ng ni nl no np nr nu nz
om
pa pe pf pg ph pk pl pm pn pr ps pt pw py
qa
re ro rs ru rw
sa sb sc sd se sg sh si sj sk sl sm sn so sr ss st sv sx sy sz
ta tc td tf tg th tj tk tl tm tn to tr tt tv tw tz
ua ug um un us uy uz
va vc ve vg vi vn vu
wf ws xk
ye yt
za zm zw
an bu cs dd fx nt qu su tp yd yu zr
england scotland wales
california texas
black chequered crossed pirate rainbow transgender triangular white
```
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Text-Flags> . Comments and Pull Requests are welcome.
If you like this module, or what I'm doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2020, 2021, 2024 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-tbrowder-DateTime-Julian.md
[](https://github.com/tbrowder/DateTime-Julian/actions) [](https://github.com/tbrowder/DateTime-Julian/actions) [](https://github.com/tbrowder/DateTime-Julian/actions)
# DateTime::Julian
Provides a DateTime::Julian class (a subclass of Raku's class **DateTime**) that is instantiated by either a Julian Date (JD) or a Modified Julian Date (MJD) (or any of the DateTime instantiation methods).
It also provides addional time data not provided by the core class.
# SYNOPSIS
```
use DateTime::Julian :ALL; # export all constants
my $jd = nnnn.nnnn; # Julian Date for some event
my $mjd = nnnn.nnnn; # Modified Julian Date for some event
my $utc = DateTime::Julian.new: :julian-date($jd);
my $utc2 = DateTime::Julian.new: :modified-julian-date($mjd);
my $d = DateTime::Julian.now; # the default
```
# DESCRIPTION
Module **DateTime::Julian** defines a class (inherited from a Raku *DateTime* class) that is instantiated from a *Julian Date* or a *Modified Julian Date*.
Following are some pertinent definitions from Wikipedia topic [*Julian day*](https://en.m.wikipedia.org/wiki/Julian_day):
* The **Julian day** is the continuous count of the days since the beginning of the Julian period, and is used primarily by astronomers....
* The **Julian day number** (JDN) is the integer assigned to a whole solar day count starting from noon Universal time, with Julian day number 0 assigned to the day starting at noon on Monday, January 1, 4713 BC, proleptic [Note 1] Julian calendar (November 24, 4714 BC, in the proleptic Gregorian calendar), a date at which three multi-year cycles started (which are: indiction, Solar, and Lunar cycles) and which preceded any dates in recorded history. For example, the Julian day number for the day starting at 12:00 UT (noon) on January 1, 2000, was **2451545**.
* The **Julian date** (JD) of any instant is the Julian day number plus the fraction of a day since the preceding noon in Universal Time. Julian dates are expressed as a Julian day number with a decimal fraction added. For example, the Julian date for 00:30:00.0 UT (noon), January 1, 2013, is **2456293.520833**.
The following methods and routines were developed from the descriptions of code in [References 1 and 2](#References). The author of Ref. 3 has been very helpful with this author's questions about astronomy and the implementation of astronomical routines.
The main purpose of this module is to simplify time and handling for this author who still finds Julian dates to be somewhat mysterious, but absolutely necessary for dealing with astronomy and predicting object positions, especially the Sun and Moon, for local observation and producing astronomical almanacs.
This module plays a major supporting role in this author's Raku module **Astro::Almanac**. Much of this module's will likely be incorporated into that module..
## Class DateTime::Julian methods
### method new
```
new(:$julian-date, :$modified-julian-date) {...}
```
If both arguments are entered, the *Julian Date* is used. If neither is entered, the user is expected to use one of the normal **DateTime** creation methods. For example:
```
my $d = DateTime.now;
# the Julian Date returned is the current JD at the Prime
# Meridian (0 degrees longitude) based on the current local time
# (:timezone is ignored)
say $d.julian-date; # OUTPUT: «2460819.8055783305»
```
### method jdcent2000
```
jdcent2000(--> Real:D) {...}
# alternatively use aliases:
method cent2000(--> Real:D) {...}
method c2000(--> Real:D) {...}
method jdc2000(--> Real:D) {...}
method t2000(--> Real:D) {...}
method jc2000(--> Real:D) {...}
```
Returns time as the number of Julian centuries since epoch J2000.0 (time value used by Astro::Montenbruck for planet position calculations).
## Exported constants
Several commonly used astronautical constants are exported. See a complete list in [CONSTANTS](CONSTANTS.md) along with each constants' individual export tag. You may export them all with `use DateTime::Julian :ALL;`.
### MJD0
Returns the Julian Date value for the Modified Julian Date epoch of 1858-11-17T00:00:00Z.
```
use DateTime::Julian :ALL;
say MJD0; # OUTPUT: «2400000.5»
# alternatively use aliases:
say mjd0; # OUTPUT: «2400000.5»
```
### POSIX0
Returns the Julian Date value for the POSIX (Unix) epoch of 1970-01-01T00:00:00Z.
```
say POSIX0; # OUTPUT: «2440587.5»
# alternatively use alias:
say posix0; # OUTPUT: «2440587.5»
```
### JCE
The last day the Julian calendar was used. A DateTime object for 1582-10-04T00:00:00Z.
```
say JCE; # OUTPUT: «1582-10-04T00:00:00Z»
# alternatively use alias:
say jce; # OUTPUT: «1582-10-04T00:00:00Z»
```
### GC0
The official start date for the Gregorian calendar. A DateTime object for 1582-1014T00:00:00Z. The days of 5-14 were skipped (the 10 "lost days").
```
say GC0; # OUTPUT: «1582-10-15T00:00:00Z»
# alternatively use alias:
say gc0; # OUTPUT: «1582-10-15T00:00:00Z»
```
### J2000
Julian date for 2000-01-01T12:00:00Z (astronomical epoch 2000.0).
```
say J2000; # OUTPUT: «2451545»
# alternatively use alias:
say j2000; # OUTPUT: «2451545»
```
### J1900
Julian date for 1899-12-31T12:00:00Z (astronomical epoch 1900.0).
```
say J1900; # OUTPUT: «2415020»
# alternatively use alias:
say j1900; # OUTPUT: «2415020»
```
### sec-per-day
Seconds per 24-hour day.
```
say sec-per-day; # OUTPUT: «86400»
```
### sec-per-jcen
Seconds per Julian century.
```
say sec-per-jcen; # OUTPUT: «3155760000»
```
### days-per-jcen
Days per Julian century.
```
say days-per-jcen; # OUTPUT: «36525»
```
### solar2sidereal
Difference between Sidereal and Solar hour (the former is shorter).
```
say solar2sidereal; # OUTPUT: «1.002737909350795»
```
# To Do
* Add calculations (and tests) for Ephemeris Time and Universal Time. (See Ref. 1, section 3.4, p. 41.)
* Add calculations for local sidereal time
# Notes
1. A *proleptic calendar*, according to Wikipedia, "is a calendar that is applied to dates before its introduction."
# References
1. *Astronomy on the Personal Computer*, Oliver Montenbruck and Thomas Pfleger, Springer, 2000.
2. *Celestial Calculations: A Gentle Introduction to Computational Astronomy*, J. L. Lawrence, The MIT Press, 2019.
3. *Astro::Montenbruck*, Sergey Krushinsky, CPAN.
4. *Mapping Time: The Calendar and Its History*, E. G. Richards, Oxford University Press, 2000.
5. *Date Algorithms* (Version 5), Peter Baum, Aesir Research, 2020, <https://researchgate.net/publication/316558298>.
# See also
* Raku module Astro::Utils
# AUTHOR
Tom Browder ([[email protected]](mailto:[email protected]))
# COPYRIGHT AND LICENSE
© 2021-2022, 2025 Tom Browder
|
## role.md
role
Combined from primary sources listed below.
# [In Object orientation](#___top "go to top of document")[§](#(Object_orientation)_role_role "direct link")
See primary documentation
[in context](/language/objects#Roles)
for **Roles**.
Roles are a collection of attributes and methods; however, unlike classes, roles are meant for describing only parts of an object's behavior; this is why, in general, roles are intended to be *mixed in* classes and objects. In general, classes are meant for managing objects and roles are meant for managing behavior and code reuse within objects.
Roles use the keyword `role` preceding the name of the role that is declared. Roles are mixed in using the `does` keyword preceding the name of the role that is mixed in.
Roles can also be mixed into a class using `is`. However, the semantics of `is` with a role are quite different from those offered by `does`. With `is`, a class is punned from the role, and then inherited from. Thus, there is no flattening composition, and none of the safeties which `does` provides.
```raku
constant ⲧ = " " xx 4; #Just a ⲧab
role Notable {
has Str $.notes is rw;
multi method notes() { "$!notes\n" };
multi method notes( Str $note ) { $!notes ~= "$note\n" ~ ⲧ };
}
class Journey does Notable {
has $.origin;
has $.destination;
has @.travelers;
method Str { "⤷ $!origin\n" ~ ⲧ ~ self.notes() ~ "$!destination ⤶\n" };
}
my $trip = Journey.new( :origin<Here>, :destination<There>,
travelers => <þor Freya> );
$trip.notes("First steps");
notes $trip: "Almost there";
print $trip;
# OUTPUT:
#⤷ Here
# First steps
# Almost there
#
#There ⤶
```
Roles are immutable as soon as the compiler parses the closing curly brace of the role declaration.
# [In Glossary](#___top "go to top of document")[§](#(Glossary)_role_role "direct link")
See primary documentation
[in context](/language/glossary#Roles)
for **Roles**.
Roles, mix-ins or traits define interfaces and/or implementation of those interfaces as well as instance variables using them, and are mixed-in when declaring classes that follow that interface. [Abstract classes](#Abstract_class) are particular examples of Roles where the actual implementation is deferred to the class that uses that Role.
Roles are part of Raku's [object system](/language/objects), and are declared using the [role](/language/objects#index-entry-role_declaration-role) keyword and used in class declaration via [does](/routine/does).
|
## dist_zef-jonathanstowe-JSON-Class.md
# JSON::Class
A Role to allow Raku objects to be constructed and serialised from/to JSON.

## Synopsis
```
use JSON::Class;
class Something does JSON::Class {
has Str $.foo;
}
my Something $something = Something.from-json('{ "foo" : "stuff" }');
...
my Str $json = $something.to-json(); # -> '{ "foo" : "stuff" }'
```
or with 'opt-in' serialization:
```
use JSON::Class;
use JSON::OptIn;
class Something does JSON::Class[:opt-in] {
has Str $.foo is json;
has Str $.secret = 'secret';
}
my Something $something = Something.from-json('{ "foo" : "stuff" }');
...
my Str $json = $something.to-json(); # -> '{ "foo" : "stuff" }'
```
## Description
This is a simple role that provides methods to instantiate a class from a
JSON string that (hopefully,) represents it, and to serialise an object of
the class to a JSON string. The JSON created from an instance should
round trip to a new instance with the same values for the "public attributes".
"Private" attributes (that is ones without accessors,) will be ignored for
both serialisation and de-serialisation. The exact behaviour depends on that
of [JSON::Marshal](https://github.com/jonathanstowe/JSON-Marshal) and
[JSON::Unmarshal](https://github.com/tadzik/JSON-Unmarshal) respectively.
If the `:skip-null` adverb is provided to `to-json` all attributes
without a defined value will be ignored in serialisation. If you need
finer grained control then you should apply the `json-skip-null`
attribute trait (defined by `JSON::Marshal` ) to the attributes you
want to skip if they aren't defined (`:skip-null` will still have
the same effect though.)
If you don't need prettified, human readable JSON output then you can supply
the `:!pretty` adverb to `to-json`.
The [JSON::Marshal](https://github.com/jonathanstowe/JSON-Marshal) and
[JSON::Unmarshal](https://github.com/tadzik/JSON-Unmarshal) provide traits
for controlling the unmarshalling/marshalling of specific attributes which are
re-exported by the module.
If your application exposes the marshalled data via, for example, an API, then
you may choose to use the `:opt-in` parameter to the role, which will cause only
those attributes that are explicitly marked to be marshalled, avoiding the risk
of inadvertently exposing sensitive data. This is described in more detail in
[JSON::Marshal](https://github.com/jonathanstowe/JSON-Marshal).
## Installation
Assuming you have a working Rakudo installation you should be able to install this with *zef* :
```
# From the source directory
zef install .
# Remote installation
zef install JSON::Class
```
## Support
Suggestions/patches are welcomed via github at:
<https://github.com/jonathanstowe/JSON-Class>
## Licence
This is free software.
Please see the (LICENCE)[LICENCE] file in the distribution for the details.
© Jonathan Stowe 2015, 2016, 2017, 2019, 2020, 2021
|
## dist_cpan-RBT-Email-MIME.md
# Email::MIME
This is a port of perl 5's Email::MIME.
## Example Usage
```
use Email::MIME;
my $eml = Email::MIME.new($raw-mail-text);
say $eml.body-str;
my $new = Email::MIME.create(header-str => ['from' => '[email protected]',
'subject' => 'This is a»test.'],
attributes => {'content-type' => 'text/plain',
'charset' => 'utf-8',
'encoding' => 'quoted-printable'},
body-str => 'Hello«World');
say ~$new;
```
## Faster Base64 Encoding
To benefit from faster Base64 encoding and decoding install the `Base64::Native` module
which will be auto-detected and used automatically.
## Methods
* `new(Str $text)`
To work around the current limitation of new() requiring a well formed unicode Str, you will
need to set the correct decoding on Slurp.
```
my $msg = Email::MIME.new($file.IO.slurp: enc => 'utf8-c8');
```
* `create(:$header, :$header-str, :$attributes, :$parts, :$body, :$body-str)`
* `filename($force = False)`
* `invent-filename($ct?)`
* `filename-set($filename)`
* `boundary-set($string)`
* `content-type()`
* `content-type-set($ct)`
* `charset-set($charset)`
* `name-set($name)`
* `format-set($format)`
* `disposition-set($disposition)`
* `encoding-set($enc)`
* `parts()`
Returns the subparts of the current message. If there are no subparts, will
return the current message.
* `subparts()`
Returns the subparts of the current message. If there are no subparts, will
return an empty list.
* `walk-parts($callback)`
Visits each MIME part once, calling `$callback($part)` on each.
* `debug-structure()`
Prints out the part structure of the email.
* `parts-set(@parts)`
Sets the passed `Email::MIME` objects as the parts of the email.
* `parts-add(@parts)`
Adds the passed `Email::MIME` objects to the list of parts in the email.
* `body-str( --> Str)`
Returns the mail body, decoded according to the charset and transfer encoding
headers.
* `body-str-set(Str $body)`
Sets the mail body to $body, encoding it using the charset and transfer
encoding configured.
* `body( --> Buf)`
Returns the mail body as a binary blob, after decoding it from the
transfer encoding.
* `body-set(Blob $data)`
Sets the mail body to `$data`. Will encode $data using the configured
transfer encoding.
* `body-raw()`
Returns the raw body of the email (What will appear when .Str is called)
* `body-raw-set($body)`
Sets the raw body of the email (What will appear when .Str is called)
* `header-str-pairs()`
Returns the full header data for an email.
* `header-str($name, :$multi)`
Returns the email header with the name `$name`. If `:$multi` is not passed, then
this will return the first header found. If `:$multi` is set, then this will
return a list of all headers with the name `$name` (note the change from v1.0!)
* `header-str-set($name, *@lines)`
Sets the header `$name`. Adds one `$name` header for each additional argument
passed.
* `header-names()`
Returns a list of header names in the email.
* `headers()`
Alias of `header-names()`
* `header($name)`
Returns a list of email headers with the name `$name`. If used in string context,
will act like the first value of the list. (So you can call
`say $eml.header('Subject')` and it will work correctly). Note that this will
not decode any encoded headers.
* `header-set($name, *@lines)`
Sets the header `$name`. Adds one `$name` header for each additional argument
passed. This will not encode any headers, even if they have non-ascii
characters.
* `header-pairs()`
Returns the full header data for an email. Note that this will not decode any
encoded headers.
```
$eml.header-pairs(); # --> [['Subject', 'test'], ['From', '[email protected]']]
```
* `as-string()`, `Str()`
Returns the full raw email, suitable for piping into sendmail.
* `crlf()`
* `header-obj()`
* `header-obj-set($obj)`
## License
All files in this repository are licensed under the terms of the Creative Commons
CC0 License; for details, please see the LICENSE file
|
## dist_cpan-JMASLAK-App-Heater.md
[](https://travis-ci.org/jmaslak/Raku-App-Heater)
# POD
# NAME
`heater.raku` - Raku-based Foot Warmer
# SYNOPSIS
```
heater.raku
```
# DESCRIPTION
This program was written during a period of brutally cold weather, when the author was trying to figure out how to keep her feet warm. Since her computer is on the floor by her feet, and because she knows that the busier the CPU, the more heat generated, she wrote this module to load up the CPU.
# CAVEATS
Obviously your electrical usage footprint (no pun intended) will increase if you run this program. That said, I believe this program is only slightly less efficient to turn your computer into a space heater than an actual space heater of the same wattage would be (I.E. energy used for "useful work" on the computer like sending signals to your monitor or lighting the power LED would not be turned into heat, while an electric space heater has even less of these "housekeeping" functions). In practice, I believe the energy difference to be negligable.
Only use this if your feet are cold!
# USAGE
## ARGUMENTS
### `processes`
```
heater.raku --processes=3
```
Sets the number of "heater" threads to start. This defaults to the number of CPU cores in the machine, determined by `$*KERNEL.cpu-cores`.
# AUTHOR
Joelle Maslak `[email protected]`
# LEGAL
Licensed under the same terms as Raku.
Copyright © 2021 by Joelle Maslak
|
## gather-20take.md
gather take
Combined from primary sources listed below.
# [In Control flow](#___top "go to top of document")[§](#(Control_flow)_gather_take_gather_take "direct link")
See primary documentation
[in context](/language/control#gather/take)
for **gather/take**.
`gather` is a statement or block prefix that returns a [sequence](/type/Seq) of values. The values come from calls to [take](/type/Mu#routine_take) in the dynamic scope of the `gather` code. In the following example, we implement a subroutine to compute the factors of an integer with `gather` (note that the factors are not generated in order):
```raku
sub factors( Int:D \n ) {
my $k = 1;
gather {
while $k**2 < n {
if n %% $k {
take $k;
take n div $k;
}
$k++;
}
take $k if $k**2 == n;
}
}
say factors(36); # OUTPUT: «1, 36, 2, 18, 3, 12, 4, 9, 6»
```
The `gather/take` combination can generate values lazily, depending on context. Binding to a scalar or sigilless container will force laziness. If you want to force lazy evaluation use the [lazy](/type/Iterable#method_lazy) subroutine or method. For example:
```raku
my @vals = lazy gather {
take 1;
say "Produced a value";
take 2;
}
say @vals[0];
say 'between consumption of two values';
say @vals[1];
# OUTPUT:
# 1
# between consumption of two values
# Produced a value
# 2
```
`gather/take` is scoped dynamically, so you can call `take` from subs or methods that are called from within `gather`:
```raku
sub weird(@elems, :$direction = 'forward') {
my %direction = (
forward => sub { take $_ for @elems },
backward => sub { take $_ for @elems.reverse },
random => sub { take $_ for @elems.pick(*) },
);
return gather %direction{$direction}();
}
say weird(<a b c>, :direction<backward> ); # OUTPUT: «(c b a)»
```
If values need to be mutable on the caller side, use [take-rw](/type/Mu#routine_take-rw).
Note that the [`Seq`](/type/Seq) created by `gather/take` may be coerced to another type. An example with assignment to a hash:
```raku
my %h = gather { take "foo" => 1; take "bar" => 2};
say %h; # OUTPUT: «{bar => 2, foo => 1}»
```
**Note**: `gather/take` must not be used to collect results from `react/whenever`. The `whenever` block is not run from the thread that runs the `gather/react`, but the thread that runs the `emit`. On this thread, there is no handler for the control exception thrown by `take`, causing it to error out.
|
## dist_zef-lizmat-Text-Emoji.md
## Chunk 1 of 3
[](https://github.com/lizmat/Text-Emoji/actions) [](https://github.com/lizmat/Text-Emoji/actions) [](https://github.com/lizmat/Text-Emoji/actions)
# NAME
Text::Emoji - provide :text: to emoji translation
# SYNOPSIS
```
use Text::Emoji;
say to-emoji("I :heart: :beer:"); # I ❤️ 🍺
say to-text(":I: ❤️ 🍺"); # I :heart: :beer:
```
# DESCRIPTION
The `Text::Emoji` distribution contains information about transforming `:text:` to emoji transliteration. As such it exports a number of subroutines.
It also installs a convenience script `em` that will convert to emojis any arguments from the command line or from standard input.
# SUBROUTINES
## to-emoji
```
say to-emoji("I :heart: :beer:"); # I ❤️ 🍺
say to-emoji("I :love: :beer:", :love<❤️>); # I ❤️ 🍺
say to-emoji("I :love: :beer:", :love<heart>); # I ❤️ 🍺
say to-emoji("I :love: :beer:", %(love => "❤️")); # I ❤️ 🍺
say to-emoji("I :love: :beer:", %(love => "heart")); # I ❤️ 🍺
say to-emoji("baby: :baby-bottle::babybottle:"); # baby: 🍼🍼
```
The `to-emoji` subroutine in its simplest form takes a string as the first argument and attempt to transform any known emoji strings of the form `:word:` into the associated emoji. Note that the word *may* contain hyphens, but they are optional.
Additional mapping info may be specified as additional named arguments, or as a hash. The value for each additional mapping may be either the emoji directly, or the text equivalent of the emoji. Note that all text in these additional mappings, should be in **lowercase** only.
## to-text
```
say to-text("I ❤️ 🍺"); # I :heart: :beer:
say to-text("I ❤️ 🍺", :love<❤️>); # I :love: :beer:
say to-text("I ❤️ 🍺", :love<heart>); # I :love: :beer:
say to-text("I ❤️ 🍺", %(love => "❤️")); # I :love: :beer:
say to-text("I ❤️ 🍺", %(love => "heart")); # I :love: :beer:
```
The `to-text` subroutine in its simplest form takes a string as the first argument and attempt to transform any known emojis to the shortest possible `:word:` form known for that emoji.
The same type of additional map information as can be specified with `to-emoji`, can be specified with `to-text`.
## raw-emoji-data
```
say raw-emoji-data<❤️>.keys;
# (aliases category description emoji ios_version tags unicode_version)
```
The `raw-emoji-data` subroutine returns a `Map`, keyed to the supported emojis. The value associated with is a `Map` as well, which can be best described by its JSON representation:
```
{
"description": "red heart",
"category": "Smileys & Emotion",
"aliases": [
"heart"
],
"tags": [
"love"
],
"unicode_version": "",
"ios_version": "6.0"
}
```
# SCRIPTS
## em
```
$ em I :heart: :beer:
I ❤️ 🍺
$ echo I :heart: :beer: | em
I ❤️ 🍺
```
The `em` script converts any text given either on the command line, or from STDIN, to emojis where appropriate.
# MAPPINGS PROVIDED
## Activities
| name | emoji | name | emoji | name | emoji |
| --- | --- | --- | --- | --- | --- |
| 1st-place-medal | 🥇 | 2nd-place-medal | 🥈 | 3rd-place-medal | 🥉 |
| 8ball | 🎱 | art | 🎨 | badminton | 🏸 |
| balloon | 🎈 | bamboo | 🎍 | baseball | ⚾ |
| basketball | 🏀 | black-joker | 🃏 | bowling | 🎳 |
| boxing-glove | 🥊 | chess-pawn | ♟️ | christmas-tree | 🎄 |
| clubs | ♣️ | confetti-ball | 🎊 | cricket-game | 🏏 |
| crystal-ball | 🔮 | curling-stone | 🥌 | dart | 🎯 |
| diamonds | ♦️ | diving-mask | 🤿 | dolls | 🎎 |
| field-hockey | 🏑 | firecracker | 🧨 | fireworks | 🎆 |
| fishing-pole-and-fish | 🎣 | flags | 🎏 | flower-playing-cards | 🎴 |
| flying-disc | 🥏 | football | 🏈 | framed-picture | 🖼️ |
| game-die | 🎲 | gift | 🎁 | goal-net | 🥅 |
| golf | ⛳ | gun | 🔫 | hearts | ♥️ |
| ice-hockey | 🏒 | ice-skate | ⛸️ | jack-o-lantern | 🎃 |
| jigsaw | 🧩 | joystick | 🕹️ | kite | 🪁 |
| knot | 🪢 | lacrosse | 🥍 | magic-wand | 🪄 |
| mahjong | 🀄 | martial-arts-uniform | 🥋 | medal-military | 🎖️ |
| medal-sports | 🏅 | mirror-ball | 🪩 | nesting-dolls | 🪆 |
| performing-arts | 🎭 | pinata | 🪅 | ping-pong | 🏓 |
| red-envelope | 🧧 | reminder-ribbon | 🎗️ | ribbon | 🎀 |
| rice-scene | 🎑 | rugby-football | 🏉 | running-shirt-with-sash | 🎽 |
| sewing-needle | 🪡 | ski | 🎿 | sled | 🛷 |
| slot-machine | 🎰 | soccer | ⚽ | softball | 🥎 |
| spades | ♠️ | sparkler | 🎇 | sparkles | ✨ |
| tada | 🎉 | tanabata-tree | 🎋 | teddy-bear | 🧸 |
| tennis | 🎾 | thread | 🧵 | ticket | 🎫 |
| tickets | 🎟️ | trophy | 🏆 | video-game | 🎮 |
| volleyball | 🏐 | wind-chime | 🎐 | yarn | 🧶 |
| yo-yo | 🪀 | | | | |
## Animals & Nature
| name | emoji | name | emoji | name | emoji |
| --- | --- | --- | --- | --- | --- |
| ant | 🐜 | baby-chick | 🐤 | badger | 🦡 |
| bat | 🦇 | bear | 🐻 | beaver | 🦫 |
| bee | 🐝 | beetle | 🪲 | bird | 🐦 |
| bison | 🦬 | black-bird | 🐦⬛ | black-cat | 🐈⬛ |
| blossom | 🌼 | blowfish | 🐡 | boar | 🐗 |
| bouquet | 💐 | bug | 🐛 | butterfly | 🦋 |
| cactus | 🌵 | camel | 🐫 | cat | 🐱 |
| cat2 | 🐈 | cherry-blossom | 🌸 | chicken | 🐔 |
| chipmunk | 🐿️ | cockroach | 🪳 | coral | 🪸 |
| cow | 🐮 | cow2 | 🐄 | cricket | 🦗 |
| crocodile | 🐊 | deciduous-tree | 🌳 | deer | 🦌 |
| dodo | 🦤 | dog | 🐶 | dog2 | 🐕 |
| dolphin | 🐬 | donkey | 🫏 | dove | 🕊️ |
| dragon | 🐉 | dragon-face | 🐲 | dromedary-camel | 🐪 |
| duck | 🦆 | eagle | 🦅 | ear-of-rice | 🌾 |
| elephant | 🐘 | empty-nest | 🪹 | evergreen-tree | 🌲 |
| fallen-leaf | 🍂 | feather | 🪶 | feet | 🐾 |
| fish | 🐟 | flamingo | 🦩 | fly | 🪰 |
| four-leaf-clover | 🍀 | fox-face | 🦊 | frog | 🐸 |
| giraffe | 🦒 | goat | 🐐 | goose | 🪿 |
| gorilla | 🦍 | guide-dog | 🦮 | hamster | 🐹 |
| hatched-chick | 🐥 | hatching-chick | 🐣 | hedgehog | 🦔 |
| herb | 🌿 | hibiscus | 🌺 | hippopotamus | 🦛 |
| horse | 🐴 | hyacinth | 🪻 | jellyfish | 🪼 |
| kangaroo | 🦘 | koala | 🐨 | lady-beetle | 🐞 |
| leaves | 🍃 | leopard | 🐆 | lion | 🦁 |
| lizard | 🦎 | llama | 🦙 | lotus | 🪷 |
| mammoth | 🦣 | maple-leaf | 🍁 | microbe | 🦠 |
| monkey | 🐒 | monkey-face | 🐵 | moose | 🫎 |
| mosquito | 🦟 | mouse | 🐭 | mouse2 | 🐁 |
| mushroom | 🍄 | nest-with-eggs | 🪺 | octopus | 🐙 |
| orangutan | 🦧 | otter | 🦦 | owl | 🦉 |
| ox | 🐂 | palm-tree | 🌴 | panda-face | 🐼 |
| parrot | 🦜 | peacock | 🦚 | penguin | 🐧 |
| pig | 🐷 | pig-nose | 🐽 | pig2 | 🐖 |
| polar-bear | 🐻❄️ | poodle | 🐩 | potted-plant | 🪴 |
| rabbit | 🐰 | rabbit2 | 🐇 | raccoon | 🦝 |
| racehorse | 🐎 | ram | 🐏 | rat | 🐀 |
| rhinoceros | 🦏 | rooster | 🐓 | rose | 🌹 |
| rosette | 🏵️ | sauropod | 🦕 | scorpion | 🦂 |
| seal | 🦭 | seedling | 🌱 | service-dog | 🐕🦺 |
| shamrock | ☘️ | shark | 🦈 | sheep | 🐑 |
| shell | 🐚 | skunk | 🦨 | sloth | 🦥 |
| snail | 🐌 | snake | 🐍 | spider | 🕷️ |
| spider-web | 🕸️ | sunflower | 🌻 | swan | 🦢 |
| t-rex | 🦖 | tiger | 🐯 | tiger2 | 🐅 |
| tropical-fish | 🐠 | tulip | 🌷 | turkey | 🦃 |
| turtle | 🐢 | unicorn | 🦄 | water-buffalo | 🐃 |
| whale | 🐳 | whale2 | 🐋 | white-flower | 💮 |
| wilted-flower | 🥀 | wing | 🪽 | wolf | 🐺 |
| worm | 🪱 | zebra | 🦓 | | |
## Flags
| name | emoji | name | emoji | name | emoji |
| --- | --- | --- | --- | --- | --- |
| afghanistan | 🇦🇫 | aland-islands | 🇦🇽 | albania | 🇦🇱 |
| algeria | 🇩🇿 | american-samoa | 🇦🇸 | andorra | 🇦🇩 |
| angola | 🇦🇴 | anguilla | 🇦🇮 | antarctica | 🇦🇶 |
| antigua-barbuda | 🇦🇬 | argentina | 🇦🇷 | armenia | 🇦🇲 |
| aruba | 🇦🇼 | ascension-island | 🇦🇨 | australia | 🇦🇺 |
| austria | 🇦🇹 | azerbaijan | 🇦🇿 | bahamas | 🇧🇸 |
| bahrain | 🇧🇭 | bangladesh | 🇧🇩 | barbados | 🇧🇧 |
| belarus | 🇧🇾 | belgium | 🇧🇪 | belize | 🇧🇿 |
| benin | 🇧🇯 | bermuda | 🇧🇲 | bhutan | 🇧🇹 |
| black-flag | 🏴 | bolivia | 🇧🇴 | bosnia-herzegovina | 🇧🇦 |
| botswana | 🇧🇼 | bouvet-island | 🇧🇻 | brazil | 🇧🇷 |
| british-indian-ocean-territory | 🇮🇴 | british-virgin-islands | 🇻🇬 | brunei | 🇧🇳 |
| bulgaria | 🇧🇬 | burkina-faso | 🇧🇫 | burundi | 🇧🇮 |
| cambodia | 🇰🇭 | cameroon | 🇨🇲 | canada | 🇨🇦 |
| canary-islands | 🇮🇨 | cape-verde | 🇨🇻 | caribbean-netherlands | 🇧🇶 |
| cayman-islands | 🇰🇾 | central-african-republic | 🇨🇫 | ceuta-melilla | 🇪🇦 |
| chad | 🇹🇩 | checkered-flag | 🏁 | chile | 🇨🇱 |
| christmas-island | 🇨🇽 | clipperton-island | 🇨🇵 | cn | 🇨🇳 |
| cocos-islands | 🇨🇨 | colombia | 🇨🇴 | comoros | 🇰🇲 |
| congo-brazzaville | 🇨🇬 | congo-kinshasa | 🇨🇩 | cook-islands | 🇨🇰 |
| costa-rica | 🇨🇷 | cote-divoire | 🇨🇮 | croatia | 🇭🇷 |
| crossed-flags | 🎌 | cuba | 🇨🇺 | curacao | 🇨🇼 |
| cyprus | 🇨🇾 | czech-republic | 🇨🇿 | de | 🇩🇪 |
| denmark | 🇩🇰 | diego-garcia | 🇩🇬 | djibouti | 🇩🇯 |
| dominica | 🇩🇲 | dominican-republic | 🇩🇴 | ecuador | 🇪🇨 |
| egypt | 🇪🇬 | el-salvador | 🇸🇻 | england | 🏴 |
| equatorial-guinea | 🇬🇶 | eritrea | 🇪🇷 | es | 🇪🇸 |
| estonia | 🇪🇪 | ethiopia | 🇪🇹 | eu | 🇪🇺 |
| falkland-islands | 🇫🇰 | faroe-islands | 🇫🇴 | fiji | 🇫🇯 |
| finland | 🇫🇮 | fr | 🇫🇷 | french-guiana | 🇬🇫 |
| french-polynesia | 🇵🇫 | french-southern-territories | 🇹🇫 | gabon | 🇬🇦 |
| gambia | 🇬🇲 | gb | 🇬🇧 | georgia | 🇬🇪 |
| ghana | 🇬🇭 | gibraltar | 🇬🇮 | greece | 🇬🇷 |
| greenland | 🇬🇱 | grenada | 🇬🇩 | guadeloupe | 🇬🇵 |
| guam | 🇬🇺 | guatemala | 🇬🇹 | guernsey | 🇬🇬 |
| guinea | 🇬🇳 | guinea-bissau | 🇬🇼 | guyana | 🇬🇾 |
| haiti | 🇭🇹 | heard-mcdonald-islands | 🇭🇲 | honduras | 🇭🇳 |
| hong-kong | 🇭🇰 | hungary | 🇭🇺 | iceland | 🇮🇸 |
| india | 🇮🇳 | indonesia | 🇮🇩 | iran | 🇮🇷 |
| iraq | 🇮🇶 | ireland | 🇮🇪 | isle-of-man | 🇮🇲 |
| israel | 🇮🇱 | it | 🇮🇹 | jamaica | 🇯🇲 |
| jersey | 🇯🇪 | jordan | 🇯🇴 | jp | 🇯🇵 |
| kazakhstan | 🇰🇿 | kenya | 🇰🇪 | kiribati | 🇰🇮 |
| kosovo | 🇽🇰 | kr | 🇰🇷 | kuwait | 🇰🇼 |
| kyrgyzstan | 🇰🇬 | laos | 🇱🇦 | latvia | 🇱🇻 |
| lebanon | 🇱🇧 | lesotho | 🇱🇸 | liberia | 🇱🇷 |
| libya | 🇱🇾 | liechtenstein | 🇱🇮 | lithuania | 🇱🇹 |
| luxembourg | 🇱🇺 | macau | 🇲🇴 | macedonia | 🇲🇰 |
| madagascar | 🇲🇬 | malawi | 🇲🇼 | malaysia | 🇲🇾 |
| maldives | 🇲🇻 | mali | 🇲🇱 | malta | 🇲🇹 |
| marshall-islands | 🇲🇭 | martinique | 🇲🇶 | mauritania | 🇲🇷 |
| mauritius | 🇲🇺 | mayotte | 🇾🇹 | mexico | 🇲🇽 |
| micronesia | 🇫🇲 | moldova | 🇲🇩 | monaco | 🇲🇨 |
| mongolia | 🇲🇳 | montenegro | 🇲🇪 | montserrat | 🇲🇸 |
| morocco | 🇲🇦 | mozambique | 🇲🇿 | myanmar | 🇲🇲 |
| namibia | 🇳🇦 | nauru | 🇳🇷 | nepal | 🇳🇵 |
| netherlands | 🇳🇱 | new-caledonia | 🇳🇨 | new-zealand | 🇳🇿 |
| nicaragua | 🇳🇮 | niger | 🇳🇪 | nigeria | 🇳🇬 |
| niue | 🇳🇺 | norfolk-island | 🇳🇫 | north-korea | 🇰🇵 |
| northern-mariana-islands | 🇲🇵 | norway | 🇳🇴 | oman | 🇴🇲 |
| pakistan | 🇵🇰 | palau | 🇵🇼 | palestinian-territories | 🇵🇸 |
| panama | 🇵🇦 | papua-new-guinea | 🇵🇬 | paraguay | 🇵🇾 |
| peru | 🇵🇪 | philippines | 🇵🇭 | pirate-flag | 🏴☠️ |
| pitcairn-islands | 🇵🇳 | poland | 🇵🇱 | portugal | 🇵🇹 |
| puerto-rico | 🇵🇷 | qatar | 🇶🇦 | rainbow-flag | 🏳️🌈 |
| reunion | 🇷🇪 | romania | 🇷🇴 | ru | 🇷🇺 |
| rwanda | 🇷🇼 | samoa | 🇼🇸 | san-marino | 🇸🇲 |
| sao-tome-principe | 🇸🇹 | saudi-arabia | 🇸🇦 | scotland | 🏴 |
| senegal | 🇸🇳 | serbia | 🇷🇸 | seychelles | 🇸🇨 |
| sierra-leone | 🇸🇱 | singapore | 🇸🇬 | sint-maarten | 🇸🇽 |
| slovakia | 🇸🇰 | slovenia | 🇸🇮 | solomon-islands | 🇸🇧 |
| somalia | 🇸🇴 | south-africa | 🇿🇦 | south-georgia-south-sandwich-islands | 🇬🇸 |
| south-sudan | 🇸🇸 | sri-lanka | 🇱🇰 | st-barthelemy | 🇧🇱 |
| st-helena | 🇸🇭 | st-kitts-nevis | 🇰🇳 | st-lucia | 🇱🇨 |
| st-martin | 🇲🇫 | st-pierre-miquelon | 🇵🇲 | st-vincent-grenadines | 🇻🇨 |
| sudan | 🇸🇩 | suriname | 🇸🇷 | svalbard-jan-mayen | 🇸🇯 |
| swaziland | 🇸🇿 | sweden | 🇸🇪 | switzerland | 🇨🇭 |
| syria | 🇸🇾 | taiwan | 🇹🇼 | tajikistan | 🇹🇯 |
| tanzania | 🇹🇿 | thailand | 🇹🇭 | timor-leste | 🇹🇱 |
| togo | 🇹🇬 | tokelau | 🇹🇰 | tonga | 🇹🇴 |
| tr | 🇹🇷 | transgender-flag | 🏳️⚧️ | triangular-flag-on-post | 🚩 |
| trinidad-tobago | 🇹🇹 | tristan-da-cunha | 🇹🇦 | tunisia | 🇹🇳 |
| turkmenistan | 🇹🇲 | turks-caicos-islands | 🇹🇨 | tuvalu | 🇹🇻 |
| uganda | 🇺🇬 | ukraine | 🇺🇦 | united-arab-emirates | 🇦🇪 |
| united-nations | 🇺🇳 | uruguay | 🇺🇾 | us | 🇺🇸 |
| us-outlying-islands | 🇺🇲 | us-virgin-islands | 🇻🇮 | uzbekistan | 🇺🇿 |
| vanuatu | 🇻🇺 | vatican-city | 🇻🇦 | venezuela | 🇻🇪 |
| vietnam | 🇻🇳 | wales | 🏴 | wallis-futuna | 🇼🇫 |
| western-sahara | 🇪🇭 | white-flag | 🏳️ | yemen | 🇾🇪 |
| zambia | 🇿🇲 | zimbabwe | 🇿🇼 | | |
## Food & Drink
| name | emoji | name | emoji | name | emoji |
| --- | --- | --- | --- | --- | --- |
| amphora | 🏺 | apple | 🍎 | avocado | 🥑 |
| baby-bottle | 🍼 | bacon | 🥓 | bagel | 🥯 |
| baguette-bread | 🥖 | banana | 🍌 | beans | 🫘 |
| beer | 🍺 | beers | 🍻 | bell-pepper | 🫑 |
| bento | 🍱 | beverage-box | 🧃 | birthday | 🎂 |
| blueberries | 🫐 | bowl-with-spoon | 🥣 | bread | 🍞 |
| broccoli | 🥦 | bubble-tea | 🧋 | burrito | 🌯 |
| butter | 🧈 | cake | 🍰 | candy | 🍬 |
| canned-food | 🥫 | carrot | 🥕 | champagne | 🍾 |
| cheese | 🧀 | cherries | 🍒 | chestnut | 🌰 |
| chocolate-bar | 🍫 | chopsticks | 🥢 | clinking-glasses | 🥂 |
| cocktail | 🍸 | coconut | 🥥 | coffee | ☕ |
| cookie | 🍪 | corn | 🌽 | crab | 🦀 |
| croissant | 🥐 | cucumber | 🥒 | cup-with-straw | 🥤 |
| cupcake | 🧁 | curry | 🍛 | custard | 🍮 |
| cut-of-meat | 🥩 | dango | 🍡 | doughnut | 🍩 |
| dumpling | 🥟 | egg | 🥚 | eggplant | 🍆 |
| falafel | 🧆 | fish-cake | 🍥 | flatbread | 🫓 |
| fondue | 🫕 | fork-and-knife | 🍴 | fortune-cookie | 🥠 |
| fried-egg | 🍳 | fried-shrimp | 🍤 | fries | 🍟 |
| garlic | 🧄 | ginger-root | 🫚 | grapes | 🍇 |
| green-apple | 🍏 | green-salad | 🥗 | hamburger | 🍔 |
| hocho | 🔪 | honey-pot | 🍯 | hot-pepper | 🌶️ |
| hotdog | 🌭 | ice-cream | 🍨 | ice-cube | 🧊 |
| icecream | 🍦 | jar | 🫙 | kiwi-fruit | 🥝 |
| leafy-green | 🥬 | lemon | 🍋 | lobster | 🦞 |
| lollipop | 🍭 | mango | 🥭 | mate | 🧉 |
| meat-on-bone | 🍖 | melon | 🍈 | milk-glass | 🥛 |
| moon-cake | 🥮 | oden | 🍢 | olive | 🫒 |
| onion | 🧅 | oyster | 🦪 | pancakes | 🥞 |
| pea-pod | 🫛 | peach | 🍑 | peanuts | 🥜 |
| pear | 🍐 | pie | 🥧 | pineapple | 🍍 |
| pizza | 🍕 | plate-with-cutlery | 🍽️ | popcorn | 🍿 |
| potato | 🥔 | poultry-leg | 🍗 | pouring-liquid | 🫗 |
| pretzel | 🥨 | ramen | 🍜 | rice | 🍚 |
| rice-ball | 🍙 | rice-cracker | 🍘 | sake | 🍶 |
| salt | 🧂 | sandwich | 🥪 | shallow-pan-of-food | 🥘 |
| shaved-ice | 🍧 | shrimp | 🦐 | spaghetti | 🍝 |
| spoon | 🥄 | squid | 🦑 | stew | 🍲 |
| strawberry | 🍓 | stuffed-flatbread | 🥙 | sushi | 🍣 |
| sweet-potato | 🍠 | taco | 🌮 | takeout-box | 🥡 |
| tamale | 🫔 | tangerine | 🍊 | tea | 🍵 |
| teapot | 🫖 | tomato | 🍅 | tropical-drink | 🍹 |
| tumbler-glass | 🥃 | waffle | 🧇 | watermelon | 🍉 |
| wine-glass | 🍷 | | | | |
## Objects
| name | emoji | name | emoji | name | emoji |
| --- | --- | --- | --- | --- | --- |
| abacus | 🧮 | accordion | 🪗 | adhesive-bandage | 🩹 |
| alembic | ⚗️ | athletic-shoe | 👟 | axe | 🪓 |
| balance-scale | ⚖️ | ballet-shoes | 🩰 | ballot-box | 🗳️ |
| banjo | 🪕 | bar-chart | 📊 | basket | 🧺 |
| bathtub | 🛁 | battery | 🔋 | bed | 🛏️ |
| bell | 🔔 | bikini | 👙 | billed-cap | 🧢 |
| black-nib | ✒️ | blue-book | 📘 | bomb | 💣 |
| book | 📖 | bookmark | 🔖 | bookmark-tabs | 📑 |
| books | 📚 | boomerang | 🪃 | boot | 👢 |
| bow-and-arrow | 🏹 | briefcase | 💼 | broom | 🧹 |
| bubbles | 🫧 | bucket | 🪣 | bulb | 💡 |
| calendar | 📆 | calling | 📲 | camera | 📷 |
| camera-flash | 📸 | candle | 🕯️ | card-file-box | 🗃️ |
| card-index | 📇 | card-index-dividers | 🗂️ | carpentry-saw | 🪚 |
| cd | 💿 | chains | ⛓️ | chair | 🪑 |
| chart | 💹 | chart-with-downwards-trend | 📉 | chart-with-upwards-trend | 📈 |
| clamp | 🗜️ | clapper | 🎬 | clipboard | 📋 |
| closed-book | 📕 | closed-lock-with-key | 🔐 | coat | 🧥 |
| coffin | ⚰️ | coin | 🪙 | computer | 💻 |
| computer-mouse | 🖱️ | control-knobs | 🎛️ | couch-and-lamp | 🛋️ |
| crayon | 🖍️ | credit-card | 💳 | crossed-swords | ⚔️ |
| crown | 👑 | crutch | 🩼 | dagger | 🗡️ |
| dark-sunglasses | 🕶️ | date | 📅 | desktop-computer | 🖥️ |
| diya-lamp | 🪔 | dna | 🧬 | dollar | 💵 |
| door | 🚪 | dress | 👗 | drop-of-blood | 🩸 |
| drum | 🥁 | dvd | 📀 | electric-plug | 🔌 |
| elevator | 🛗 | email | 📧 | envelope | ✉️ |
| envelope-with-arrow | 📩 | euro | 💶 | eyeglasses | 👓 |
| fax | 📠 | file-cabinet | 🗄️ | file-folder | 📁 |
| film-projector | 📽️ | film-strip | 🎞️ | fire-extinguisher | 🧯 |
| flashlight | 🔦 | flat-shoe | 🥿 | floppy-disk | 💾 |
| flute | 🪈 | folding-hand-fan | 🪭 | fountain-pen | 🖋️ |
| funeral-urn | ⚱️ | gear | ⚙️ | gem | 💎 |
| gloves | 🧤 | goggles | 🥽 | green-book | 📗 |
| guitar | 🎸 | hair-pick | 🪮 | hammer | 🔨 |
| hammer-and-pick | ⚒️ | hammer-and-wrench | 🛠️ | hamsa | 🪬 |
| handbag | 👜 | headphones | 🎧 | headstone | 🪦 |
| high-heel | 👠 | hiking-boot | 🥾 | hook | 🪝 |
| identification-card | 🪪 | inbox-tray | 📥 | incoming-envelope | 📨 |
| iphone | 📱 | izakaya-lantern | 🏮 | jeans | 👖 |
| key | 🔑 | keyboard | ⌨️ | kimono | 👘 |
| lab-coat | 🥼 | label | 🏷️ | ladder | 🪜 |
| ledger | 📒 | level-slider | 🎚️ | link | 🔗 |
| lipstick | 💄 | lock | 🔒 | lock-with-ink-pen | 🔏 |
| long-drum | 🪘 | lotion-bottle | 🧴 | loud-sound | 🔊 |
| loudspeaker | 📢 | low-battery | 🪫 | mag | 🔍 |
| mag-right | 🔎 | magnet | 🧲 | mailbox | 📫 |
| mailbox-closed | 📪 | mailbox-with-mail | 📬 | mailbox-with-no-mail | 📭 |
| mans-shoe | 👞 | maracas | 🪇 | mega | 📣 |
| memo | 📝 | microphone | 🎤 | microscope | 🔬 |
| military-helmet | 🪖 | minidisc | 💽 | mirror | 🪞 |
| money-with-wings | 💸 | moneybag | 💰 | mortar-board | 🎓 |
| mouse-trap | 🪤 | movie-camera | 🎥 | moyai | 🗿 |
| musical-keyboard | 🎹 | musical-note | 🎵 | musical-score | 🎼 |
| mute | 🔇 | nazar-amulet | 🧿 | necktie | 👔 |
| newspaper | 📰 | newspaper-roll | 🗞️ | no-bell | 🔕 |
| notebook | 📓 | notebook-with-decorative-cover | 📔 | notes | 🎶 |
| nut-and-bolt | 🔩 | old-key | 🗝️ | one-piece-swimsuit | 🩱 |
| open-file-folder | 📂 | orange-book | 📙 | outbox-tray | 📤 |
| package | 📦 | page-facing-up | 📄 | page-with-curl | 📃 |
| pager | 📟 | paintbrush | 🖌️ | paperclip | 📎 |
| paperclips | 🖇️ | pen | 🖊️ | pencil2 | ✏️ |
| petri-dish | 🧫 | phone | ☎️ | pick | ⛏️ |
| pill | 💊 | placard | 🪧 | plunger | 🪠 |
| postal-horn | 📯 | postbox | 📮 | pouch | 👝 |
| pound | 💷 | prayer-beads | 📿 | printer | 🖨️ |
| probing-cane | 🦯 | purse | 👛 | pushpin | 📌 |
| radio | 📻 | razor | 🪒 | receipt | 🧾 |
| rescue-worker-helmet | ⛑️ | ring | 💍 | roll-of-paper | 🧻 |
| round-pushpin | 📍 | safety-pin | 🧷 | safety-vest | 🦺 |
| sandal | 👡 | sari | 🥻 | satellite | 📡 |
| saxophone | 🎷 | scarf | 🧣 | school-satchel | 🎒 |
| scissors | ✂️ | screwdriver | 🪛 | scroll | 📜 |
| shield | 🛡️ | shirt | 👕 | shopping | 🛍️ |
| shopping-cart | 🛒 | shorts | 🩳 | shower | 🚿 |
| smoking | 🚬 | soap | 🧼 | socks | 🧦 |
| sound | 🔉 | speaker | 🔈 | spiral-calendar | 🗓️ |
| spiral-notepad | 🗒️ | sponge | 🧽 | stethoscope | 🩺 |
| straight-ruler | 📏 | studio-microphone | 🎙️ | swim-brief | 🩲 |
| syringe | 💉 | telephone-receiver | 📞 | telescope | 🔭 |
| test-tube | 🧪 | thong-sandal | 🩴 | toilet | 🚽 |
| toolbox | 🧰 | toothbrush | � |
## dist_zef-lizmat-Text-Emoji.md
## Chunk 2 of 3
�� | tophat | 🎩 |
| trackball | 🖲️ | triangular-ruler | 📐 | trumpet | 🎺 |
| tv | 📺 | unlock | 🔓 | vhs | 📼 |
| video-camera | 📹 | violin | 🎻 | wastebasket | 🗑️ |
| window | 🪟 | womans-clothes | 👚 | womans-hat | 👒 |
| wrench | 🔧 | x-ray | 🩻 | yen | 💴 |
## People & Body
| name | emoji | name | emoji | name | emoji |
| --- | --- | --- | --- | --- | --- |
| +1 | 👍 | -1 | 👎 | adult | 🧑 |
| anatomical-heart | 🫀 | angel | 👼 | artist | 🧑🎨 |
| astronaut | 🧑🚀 | baby | 👶 | bald-man | 👨🦲 |
| bald-woman | 👩🦲 | bath | 🛀 | bearded-person | 🧔 |
| bicyclist | 🚴 | biking-man | 🚴♂️ | biking-woman | 🚴♀️ |
| biting-lip | 🫦 | blond-haired-man | 👱♂️ | blond-haired-person | 👱 |
| blond-haired-woman | 👱♀️ | bone | 🦴 | bouncing-ball-man | ⛹️♂️ |
| bouncing-ball-person | ⛹️ | bouncing-ball-woman | ⛹️♀️ | bow | 🙇 |
| bowing-man | 🙇♂️ | bowing-woman | 🙇♀️ | boy | 👦 |
| brain | 🧠 | breast-feeding | 🤱 | business-suit-levitating | 🕴️ |
| bust-in-silhouette | 👤 | busts-in-silhouette | 👥 | call-me-hand | 🤙 |
| cartwheeling | 🤸 | child | 🧒 | clap | 👏 |
| climbing | 🧗 | climbing-man | 🧗♂️ | climbing-woman | 🧗♀️ |
| construction-worker | 👷 | construction-worker-man | 👷♂️ | construction-worker-woman | 👷♀️ |
| cook | 🧑🍳 | couple | 👫 | couple-with-heart | 💑 |
| couple-with-heart-man-man | 👨❤️👨 | couple-with-heart-woman-man | 👩❤️👨 | couple-with-heart-woman-woman | 👩❤️👩 |
| couplekiss | 💏 | couplekiss-man-man | 👨❤️💋👨 | couplekiss-man-woman | 👩❤️💋👨 |
| couplekiss-woman-woman | 👩❤️💋👩 | crossed-fingers | 🤞 | curly-haired-man | 👨🦱 |
| curly-haired-woman | 👩🦱 | dancers | 👯 | dancing-men | 👯♂️ |
| dancing-women | 👯♀️ | deaf-man | 🧏♂️ | deaf-person | 🧏 |
| deaf-woman | 🧏♀️ | detective | 🕵️ | ear | 👂 |
| ear-with-hearing-aid | 🦻 | elf | 🧝 | elf-man | 🧝♂️ |
| elf-woman | 🧝♀️ | eye | 👁️ | eyes | 👀 |
| facepalm | 🤦 | factory-worker | 🧑🏭 | fairy | 🧚 |
| fairy-man | 🧚♂️ | fairy-woman | 🧚♀️ | family | 👪 |
| family-man-boy | 👨👦 | family-man-boy-boy | 👨👦👦 | family-man-girl | 👨👧 |
| family-man-girl-boy | 👨👧👦 | family-man-girl-girl | 👨👧👧 | family-man-man-boy | 👨👨👦 |
| family-man-man-boy-boy | 👨👨👦👦 | family-man-man-girl | 👨👨👧 | family-man-man-girl-boy | 👨👨👧👦 |
| family-man-man-girl-girl | 👨👨👧👧 | family-man-woman-boy | 👨👩👦 | family-man-woman-boy-boy | 👨👩👦👦 |
| family-man-woman-girl | 👨👩👧 | family-man-woman-girl-boy | 👨👩👧👦 | family-man-woman-girl-girl | 👨👩👧👧 |
| family-woman-boy | 👩👦 | family-woman-boy-boy | 👩👦👦 | family-woman-girl | 👩👧 |
| family-woman-girl-boy | 👩👧👦 | family-woman-girl-girl | 👩👧👧 | family-woman-woman-boy | 👩👩👦 |
| family-woman-woman-boy-boy | 👩👩👦👦 | family-woman-woman-girl | 👩👩👧 | family-woman-woman-girl-boy | 👩👩👧👦 |
| family-woman-woman-girl-girl | 👩👩👧👧 | farmer | 🧑🌾 | female-detective | 🕵️♀️ |
| firefighter | 🧑🚒 | fist-left | 🤛 | fist-oncoming | 👊 |
| fist-raised | ✊ | fist-right | 🤜 | foot | 🦶 |
| footprints | 👣 | frowning-man | 🙍♂️ | frowning-person | 🙍 |
| frowning-woman | 🙍♀️ | genie | 🧞 | genie-man | 🧞♂️ |
| genie-woman | 🧞♀️ | girl | 👧 | golfing | 🏌️ |
| golfing-man | 🏌️♂️ | golfing-woman | 🏌️♀️ | guard | 💂 |
| guardsman | 💂♂️ | guardswoman | 💂♀️ | haircut | 💇 |
| haircut-man | 💇♂️ | haircut-woman | 💇♀️ | hand | ✋ |
| hand-with-index-finger-and-thumb-crossed | 🫰 | handball-person | 🤾 | handshake | 🤝 |
| health-worker | 🧑⚕️ | heart-hands | 🫶 | horse-racing | 🏇 |
| index-pointing-at-the-viewer | 🫵 | judge | 🧑⚖️ | juggling-person | 🤹 |
| kneeling-man | 🧎♂️ | kneeling-person | 🧎 | kneeling-woman | 🧎♀️ |
| leftwards-hand | 🫲 | leftwards-pushing-hand | 🫷 | leg | 🦵 |
| lips | 👄 | lotus-position | 🧘 | lotus-position-man | 🧘♂️ |
| lotus-position-woman | 🧘♀️ | love-you-gesture | 🤟 | lungs | 🫁 |
| mage | 🧙 | mage-man | 🧙♂️ | mage-woman | 🧙♀️ |
| male-detective | 🕵️♂️ | man | 👨 | man-artist | 👨🎨 |
| man-astronaut | 👨🚀 | man-beard | 🧔♂️ | man-cartwheeling | 🤸♂️ |
| man-cook | 👨🍳 | man-dancing | 🕺 | man-facepalming | 🤦♂️ |
| man-factory-worker | 👨🏭 | man-farmer | 👨🌾 | man-feeding-baby | 👨🍼 |
| man-firefighter | 👨🚒 | man-health-worker | 👨⚕️ | man-in-manual-wheelchair | 👨🦽 |
| man-in-motorized-wheelchair | 👨🦼 | man-in-tuxedo | 🤵♂️ | man-judge | 👨⚖️ |
| man-juggling | 🤹♂️ | man-mechanic | 👨🔧 | man-office-worker | 👨💼 |
| man-pilot | 👨✈️ | man-playing-handball | 🤾♂️ | man-playing-water-polo | 🤽♂️ |
| man-scientist | 👨🔬 | man-shrugging | 🤷♂️ | man-singer | 👨🎤 |
| man-student | 👨🎓 | man-teacher | 👨🏫 | man-technologist | 👨💻 |
| man-with-gua-pi-mao | 👲 | man-with-probing-cane | 👨🦯 | man-with-turban | 👳♂️ |
| man-with-veil | 👰♂️ | massage | 💆 | massage-man | 💆♂️ |
| massage-woman | 💆♀️ | mechanic | 🧑🔧 | mechanical-arm | 🦾 |
| mechanical-leg | 🦿 | men-wrestling | 🤼♂️ | mermaid | 🧜♀️ |
| merman | 🧜♂️ | merperson | 🧜 | metal | 🤘 |
| middle-finger | 🖕 | mountain-bicyclist | 🚵 | mountain-biking-man | 🚵♂️ |
| mountain-biking-woman | 🚵♀️ | mrs-claus | 🤶 | muscle | 💪 |
| mx-claus | 🧑🎄 | nail-care | 💅 | ninja | 🥷 |
| no-good | 🙅 | no-good-man | 🙅♂️ | no-good-woman | 🙅♀️ |
| nose | 👃 | office-worker | 🧑💼 | ok-hand | 👌 |
| ok-man | 🙆♂️ | ok-person | 🙆 | ok-woman | 🙆♀️ |
| older-adult | 🧓 | older-man | 👴 | older-woman | 👵 |
| open-hands | 👐 | palm-down-hand | 🫳 | palm-up-hand | 🫴 |
| palms-up-together | 🤲 | people-holding-hands | 🧑🤝🧑 | people-hugging | 🫂 |
| person-bald | 🧑🦲 | person-curly-hair | 🧑🦱 | person-feeding-baby | 🧑🍼 |
| person-fencing | 🤺 | person-in-manual-wheelchair | 🧑🦽 | person-in-motorized-wheelchair | 🧑🦼 |
| person-in-tuxedo | 🤵 | person-red-hair | 🧑🦰 | person-white-hair | 🧑🦳 |
| person-with-crown | 🫅 | person-with-probing-cane | 🧑🦯 | person-with-turban | 👳 |
| person-with-veil | 👰 | pilot | 🧑✈️ | pinched-fingers | 🤌 |
| pinching-hand | 🤏 | point-down | 👇 | point-left | 👈 |
| point-right | 👉 | point-up | ☝️ | point-up-2 | 👆 |
| police-officer | 👮 | policeman | 👮♂️ | policewoman | 👮♀️ |
| pouting-face | 🙎 | pouting-man | 🙎♂️ | pouting-woman | 🙎♀️ |
| pray | 🙏 | pregnant-man | 🫃 | pregnant-person | 🫄 |
| pregnant-woman | 🤰 | prince | 🤴 | princess | 👸 |
| raised-back-of-hand | 🤚 | raised-hand-with-fingers-splayed | 🖐️ | raised-hands | 🙌 |
| raising-hand | 🙋 | raising-hand-man | 🙋♂️ | raising-hand-woman | 🙋♀️ |
| red-haired-man | 👨🦰 | red-haired-woman | 👩🦰 | rightwards-hand | 🫱 |
| rightwards-pushing-hand | 🫸 | rowboat | 🚣 | rowing-man | 🚣♂️ |
| rowing-woman | 🚣♀️ | runner | 🏃 | running-man | 🏃♂️ |
| running-woman | 🏃♀️ | santa | 🎅 | sauna-man | 🧖♂️ |
| sauna-person | 🧖 | sauna-woman | 🧖♀️ | scientist | 🧑🔬 |
| selfie | 🤳 | shrug | 🤷 | singer | 🧑🎤 |
| skier | ⛷️ | sleeping-bed | 🛌 | snowboarder | 🏂 |
| speaking-head | 🗣️ | standing-man | 🧍♂️ | standing-person | 🧍 |
| standing-woman | 🧍♀️ | student | 🧑🎓 | superhero | 🦸 |
| superhero-man | 🦸♂️ | superhero-woman | 🦸♀️ | supervillain | 🦹 |
| supervillain-man | 🦹♂️ | supervillain-woman | 🦹♀️ | surfer | 🏄 |
| surfing-man | 🏄♂️ | surfing-woman | 🏄♀️ | swimmer | 🏊 |
| swimming-man | 🏊♂️ | swimming-woman | 🏊♀️ | teacher | 🧑🏫 |
| technologist | 🧑💻 | tipping-hand-man | 💁♂️ | tipping-hand-person | 💁 |
| tipping-hand-woman | 💁♀️ | tongue | 👅 | tooth | 🦷 |
| troll | 🧌 | two-men-holding-hands | 👬 | two-women-holding-hands | 👭 |
| v | ✌️ | vampire | 🧛 | vampire-man | 🧛♂️ |
| vampire-woman | 🧛♀️ | vulcan-salute | 🖖 | walking | 🚶 |
| walking-man | 🚶♂️ | walking-woman | 🚶♀️ | water-polo | 🤽 |
| wave | 👋 | weight-lifting | 🏋️ | weight-lifting-man | 🏋️♂️ |
| weight-lifting-woman | 🏋️♀️ | white-haired-man | 👨🦳 | white-haired-woman | 👩🦳 |
| woman | 👩 | woman-artist | 👩🎨 | woman-astronaut | 👩🚀 |
| woman-beard | 🧔♀️ | woman-cartwheeling | 🤸♀️ | woman-cook | 👩🍳 |
| woman-dancing | 💃 | woman-facepalming | 🤦♀️ | woman-factory-worker | 👩🏭 |
| woman-farmer | 👩🌾 | woman-feeding-baby | 👩🍼 | woman-firefighter | 👩🚒 |
| woman-health-worker | 👩⚕️ | woman-in-manual-wheelchair | 👩🦽 | woman-in-motorized-wheelchair | 👩🦼 |
| woman-in-tuxedo | 🤵♀️ | woman-judge | 👩⚖️ | woman-juggling | 🤹♀️ |
| woman-mechanic | 👩🔧 | woman-office-worker | 👩💼 | woman-pilot | 👩✈️ |
| woman-playing-handball | 🤾♀️ | woman-playing-water-polo | 🤽♀️ | woman-scientist | 👩🔬 |
| woman-shrugging | 🤷♀️ | woman-singer | 👩🎤 | woman-student | 👩🎓 |
| woman-teacher | 👩🏫 | woman-technologist | 👩💻 | woman-with-headscarf | 🧕 |
| woman-with-probing-cane | 👩🦯 | woman-with-turban | 👳♀️ | woman-with-veil | 👰♀️ |
| women-wrestling | 🤼♀️ | wrestling | 🤼 | writing-hand | ✍️ |
| zombie | 🧟 | zombie-man | 🧟♂️ | zombie-woman | 🧟♀️ |
## Smileys & Emotion
| name | emoji | name | emoji | name | emoji |
| --- | --- | --- | --- | --- | --- |
| 100 | 💯 | alien | 👽 | anger | 💢 |
| angry | 😠 | anguished | 😧 | astonished | 😲 |
| black-heart | 🖤 | blue-heart | 💙 | blush | 😊 |
| boom | 💥 | broken-heart | 💔 | brown-heart | 🤎 |
| clown-face | 🤡 | cold-face | 🥶 | cold-sweat | 😰 |
| confounded | 😖 | confused | 😕 | cowboy-hat-face | 🤠 |
| cry | 😢 | crying-cat-face | 😿 | cupid | 💘 |
| cursing-face | 🤬 | dash | 💨 | disappointed | 😞 |
| disappointed-relieved | 😥 | disguised-face | 🥸 | dizzy | 💫 |
| dizzy-face | 😵 | dotted-line-face | 🫥 | drooling-face | 🤤 |
| exploding-head | 🤯 | expressionless | 😑 | eye-speech-bubble | 👁️🗨️ |
| face-exhaling | 😮💨 | face-holding-back-tears | 🥹 | face-in-clouds | 😶🌫️ |
| face-with-diagonal-mouth | 🫤 | face-with-head-bandage | 🤕 | face-with-open-eyes-and-hand-over-mouth | 🫢 |
| face-with-peeking-eye | 🫣 | face-with-spiral-eyes | 😵💫 | face-with-thermometer | 🤒 |
| fearful | 😨 | flushed | 😳 | frowning | 😦 |
| frowning-face | ☹️ | ghost | 👻 | gift-heart | 💝 |
| green-heart | 💚 | grey-heart | 🩶 | grimacing | 😬 |
| grin | 😁 | grinning | 😀 | hand-over-mouth | 🤭 |
| hankey | 💩 | hear-no-evil | 🙉 | heart | ❤️ |
| heart-decoration | 💟 | heart-eyes | 😍 | heart-eyes-cat | 😻 |
| heart-on-fire | ❤️🔥 | heartbeat | 💓 | heartpulse | 💗 |
| heavy-heart-exclamation | ❣️ | hole | 🕳️ | hot-face | 🥵 |
| hugs | 🤗 | hushed | 😯 | imp | 👿 |
| innocent | 😇 | japanese-goblin | 👺 | japanese-ogre | 👹 |
| joy | 😂 | joy-cat | 😹 | kiss | 💋 |
| kissing | 😗 | kissing-cat | 😽 | kissing-closed-eyes | 😚 |
| kissing-heart | 😘 | kissing-smiling-eyes | 😙 | laughing | 😆 |
| left-speech-bubble | 🗨️ | light-blue-heart | 🩵 | love-letter | 💌 |
| lying-face | 🤥 | mask | 😷 | melting-face | 🫠 |
| mending-heart | ❤️🩹 | money-mouth-face | 🤑 | monocle-face | 🧐 |
| nauseated-face | 🤢 | nerd-face | 🤓 | neutral-face | 😐 |
| no-mouth | 😶 | open-mouth | 😮 | orange-heart | 🧡 |
| partying-face | 🥳 | pensive | 😔 | persevere | 😣 |
| pink-heart | 🩷 | pleading-face | 🥺 | pouting-cat | 😾 |
| purple-heart | 💜 | rage | 😡 | raised-eyebrow | 🤨 |
| relaxed | ☺️ | relieved | 😌 | revolving-hearts | 💞 |
| right-anger-bubble | 🗯️ | robot | 🤖 | rofl | 🤣 |
| roll-eyes | 🙄 | saluting-face | 🫡 | scream | 😱 |
| scream-cat | 🙀 | see-no-evil | 🙈 | shaking-face | 🫨 |
| shushing-face | 🤫 | skull | 💀 | skull-and-crossbones | ☠️ |
| sleeping | 😴 | sleepy | 😪 | slightly-frowning-face | 🙁 |
| slightly-smiling-face | 🙂 | smile | 😄 | smile-cat | 😸 |
| smiley | 😃 | smiley-cat | 😺 | smiling-face-with-tear | 🥲 |
| smiling-face-with-three-hearts | 🥰 | smiling-imp | 😈 | smirk | 😏 |
| smirk-cat | 😼 | sneezing-face | 🤧 | sob | 😭 |
| space-invader | 👾 | sparkling-heart | 💖 | speak-no-evil | 🙊 |
| speech-balloon | 💬 | star-struck | 🤩 | stuck-out-tongue | 😛 |
| stuck-out-tongue-closed-eyes | 😝 | stuck-out-tongue-winking-eye | 😜 | sunglasses | 😎 |
| sweat | 😓 | sweat-drops | 💦 | sweat-smile | 😅 |
| thinking | 🤔 | thought-balloon | 💭 | tired-face | 😫 |
| triumph | 😤 | two-hearts | 💕 | unamused | 😒 |
| upside-down-face | 🙃 | vomiting-face | 🤮 | weary | 😩 |
| white-heart | 🤍 | wink | 😉 | woozy-face | 🥴 |
| worried | 😟 | yawning-face | 🥱 | yellow-heart | 💛 |
| yum | 😋 | zany-face | 🤪 | zipper-mouth-face | 🤐 |
| zzz | 💤 | | | | |
## Symbols
| name | emoji | name | emoji | name | emoji |
| --- | --- | --- | --- | --- | --- |
| 1234 | 🔢 | a | 🅰️ | ab | 🆎 |
| abc | 🔤 | abcd | 🔡 | accept | 🉑 |
| aquarius | ♒ | aries | ♈ | arrow-backward | ◀️ |
| arrow-double-down | ⏬ | arrow-double-up | ⏫ | arrow-down | ⬇️ |
| arrow-down-small | 🔽 | arrow-forward | ▶️ | arrow-heading-down | ⤵️ |
| arrow-heading-up | ⤴️ | arrow-left | ⬅️ | arrow-lower-left | ↙️ |
| arrow-lower-right | ↘️ | arrow-right | ➡️ | arrow-right-hook | ↪️ |
| arrow-up | ⬆️ | arrow-up-down | ↕️ | arrow-up-small | 🔼 |
| arrow-upper-left | ↖️ | arrow-upper-right | ↗️ | arrows-clockwise | 🔃 |
| arrows-counterclockwise | 🔄 | asterisk | \*️⃣ | atm | 🏧 |
| atom-symbol | ⚛️ | b | 🅱️ | baby-symbol | 🚼 |
| back | 🔙 | baggage-claim | 🛄 | ballot-box-with-check | ☑️ |
| bangbang | ‼️ | beginner | 🔰 | biohazard | ☣️ |
| black-circle | ⚫ | black-large-square | ⬛ | black-medium-small-square | ◾ |
| black-medium-square | ◼️ | black-small-square | ▪️ | black-square-button | 🔲 |
| blue-square | 🟦 | brown-circle | 🟤 | brown-square | 🟫 |
| cancer | ♋ | capital-abcd | 🔠 | capricorn | ♑ |
| children-crossing | 🚸 | cinema | 🎦 | cl | 🆑 |
| congratulations | ㊗️ | cool | 🆒 | copyright | ©️ |
| curly-loop | ➰ | currency-exchange | 💱 | customs | 🛃 |
| diamond-shape-with-a-dot-inside | 💠 | do-not-litter | 🚯 | eight | 8️⃣ |
| eight-pointed-black-star | ✴️ | eight-spoked-asterisk | ✳️ | eject-button | ⏏️ |
| end | 🔚 | exclamation | ❗ | fast-forward | ⏩ |
| female-sign | ♀️ | five | 5️⃣ | fleur-de-lis | ⚜️ |
| four | 4️⃣ | free | 🆓 | gemini | ♊ |
| green-circle | 🟢 | green-square | 🟩 | grey-exclamation | ❕ |
| grey-question | ❔ | hash | #️⃣ | heavy-check-mark | ✔️ |
| heavy-division-sign | ➗ | heavy-dollar-sign | 💲 | heavy-equals-sign | 🟰 |
| heavy-minus-sign | ➖ | heavy-multiplication-x | ✖️ | heavy-plus-sign | ➕ |
| high-brightness | 🔆 | id | 🆔 | ideograph-advantage | 🉐 |
| infinity | ♾️ | information-source | ℹ️ | interrobang | ⁉️ |
| keycap-ten | 🔟 | khanda | 🪯 | koko | 🈁 |
| large-blue-circle | 🔵 | large-blue-diamond | 🔷 | large-orange-diamond | 🔶 |
| latin-cross | ✝️ | left-luggage | 🛅 | left-right-arrow | ↔️ |
| leftwards-arrow-with-hook | ↩️ | leo | ♌ | libra | ♎ |
| loop | ➿ | low-brightness | 🔅 | m | Ⓜ️ |
| male-sign | ♂️ | medical-symbol | ⚕️ | menorah | 🕎 |
| mens | 🚹 | mobile-phone-off | 📴 | name-badge | 📛 |
| negative-squared-cross-mark | ❎ | new | 🆕 | next-track-button | ⏭️ |
| ng | 🆖 | nine | 9️⃣ | no-bicycles | 🚳 |
| no-entry | ⛔ | no-entry-sign | 🚫 | no-mobile-phones | 📵 |
| no-pedestrians | 🚷 | no-smoking | 🚭 | non-potable-water | 🚱 |
| o | ⭕ | o2 | 🅾️ | ok | 🆗 |
| om | 🕉️ | on | 🔛 | one | 1️⃣ |
| ophiuchus | ⛎ | orange-circle | 🟠 | orange-square | 🟧 |
| orthodox-cross | ☦️ | parking | 🅿️ | part-alternation-mark | 〽️ |
| passport-control | 🛂 | pause-button | ⏸️ | peace-symbol | ☮️ |
| pisces | ♓ | place-of-worship | 🛐 | play-or-pause-button | ⏯️ |
| potable-water | 🚰 | previous-track-button | ⏮️ | purple-circle | 🟣 |
| purple-square | 🟪 | put-litter-in-its-place | 🚮 | question | ❓ |
| radio-button | 🔘 | radioactive | ☢️ | record-button | ⏺️ |
| recycle | ♻️ | red-circle | 🔴 | red-square | 🟥 |
| registered | ®️ | repeat | 🔁 | repeat-one | 🔂 |
| restroom | 🚻 | rewind | ⏪ | sa | 🈂️ |
| sagittarius | ♐ | scorpius | ♏ | secret | ㊙️ |
| seven | 7️⃣ | signal-strength | 📶 | six | 6️⃣ |
| six-pointed-star | 🔯 | small-blue-diamond | 🔹 | small-orange-diamond | 🔸 |
| small-red-triangle | 🔺 | small-red-triangle-down | 🔻 | soon | 🔜 |
| sos | 🆘 | sparkle | ❇️ | star-and-crescent | ☪️ |
| star-of-david | ✡️ | stop-button | ⏹️ | symbols | 🔣 |
| taurus | ♉ | three | 3️⃣ | tm | ™️ |
| top | 🔝 | transgender-symbol | ⚧️ | trident | 🔱 |
| twisted-rightwards-arrows | 🔀 | two | 2️⃣ | u5272 | 🈹 |
| u5408 | 🈴 | u55b6 | 🈺 | u6307 | 🈯 |
| u6708 | 🈷️ | u6709 | 🈶 | u6e80 | 🈵 |
| u7121 | 🈚 | u7533 | 🈸 | u7981 | 🈲 |
| u7a7a | 🈳 | underage | 🔞 | up | 🆙 |
| vibration-mode | 📳 | virgo | ♍ | vs | 🆚 |
| warning | ⚠️ | wavy-dash | 〰️ | wc | 🚾 |
| wheel-of-dharma | ☸️ | wheelchair | ♿ | white-check-mark | ✅ |
| white-circle | ⚪ | white-large-square | ⬜ | white-medium-small-square | ◽ |
| white-medium-square | ◻️ | white-small-square | ▫️ | white-square-button | 🔳 |
| wireless | 🛜 | womens | 🚺 | x | ❌ |
| yellow-circle | 🟡 | yellow-square | 🟨 | yin-yang | ☯️ |
| zero | 0️⃣ | | | | |
## Travel & Places
| name | emoji | name | emoji | name | emoji |
| --- | --- | --- | --- | --- | --- |
| aerial-tramway | 🚡 | airplane | ✈️ | alarm-clock | ⏰ |
| ambulance | 🚑 | anchor | ⚓ | articulated-lorry | 🚛 |
| artificial-satellite | 🛰️ | auto-rickshaw | 🛺 | bank | 🏦 |
| barber | 💈 | beach-umbrella | 🏖️ | bellhop-bell | 🛎️ |
| bike | 🚲 | blue-car | 🚙 | boat | ⛵ |
| bricks | 🧱 | bridge-at-night | 🌉 | building-construction | 🏗️ |
| bullettrain-front | 🚅 | bullettrain-side | 🚄 | bus | 🚌 |
| busstop | 🚏 | camping | 🏕️ | canoe | 🛶 |
| car | 🚗 | carousel-horse | 🎠 | church | ⛪ |
| circus-tent | 🎪 | city-sunrise | 🌇 | city-sunset | 🌆 |
| cityscape | 🏙️ | classical-building | 🏛️ | clock1 | 🕐 |
| clock10 | 🕙 | clock1030 | 🕥 | clock11 | 🕚 |
| clock1130 | 🕦 | clock12 | 🕛 | clock1230 | 🕧 |
| clock130 | 🕜 | clock2 | 🕑 | clock230 | 🕝 |
| clock3 | 🕒 | clock330 | 🕞 | clock4 | 🕓 |
| clock430 | 🕟 | clock5 | 🕔 | clock530 | 🕠 |
| clock6 | 🕕 | clock630 | 🕡 | clock7 | 🕖 |
| clock730 | 🕢 | clock8 | 🕗 | clock830 | 🕣 |
| clock9 | 🕘 | clock930 | 🕤 | closed-umbrella | 🌂 |
| cloud | ☁️ | cloud-with-lightning | 🌩️ | cloud-with-lightning-and-rain | ⛈️ |
| cloud-with-rain | 🌧️ | cloud-with-snow | 🌨️ | comet | ☄️ |
| compass | 🧭 | construction | 🚧 | convenience-store | 🏪 |
| crescent-moon | 🌙 | cyclone | 🌀 | department-store | 🏬 |
| derelict-house | 🏚️ | desert | 🏜️ | desert-island | 🏝️ |
| droplet | 💧 | earth-africa | 🌍 | earth-americas | 🌎 |
| earth-asia | 🌏 | european-castle | 🏰 | european-post-office | 🏤 |
| factory | 🏭 | ferris-wheel | 🎡 | ferry | ⛴️ |
| fire | 🔥 | fire-engine | 🚒 | first-quarter-moon | 🌓 |
| first-quarter-moon-with-face | 🌛 | flight-arrival | 🛬 | flight-departure | 🛫 |
| flying-saucer | 🛸 | fog | 🌫️ | foggy | 🌁 |
| fountain | ⛲ | fuelpump | ⛽ | full-moon | 🌕 |
| full-moon-with-face | 🌝 | globe-with-meridians | 🌐 | helicopter | 🚁 |
| hindu-temple | 🛕 | hospital | 🏥 | hotel | 🏨 |
| hotsprings | ♨️ | hourglass | ⌛ | hourglass-flowing-sand | ⏳ |
| house | 🏠 | house-with-garden | 🏡 | houses | 🏘️ |
| hut | 🛖 | japan | 🗾 | japanese-castle | 🏯 |
| kaaba | 🕋 | kick-scooter | 🛴 | last-quarter-moon | 🌗 |
| last-quarter-moon-with-face | 🌜 | light-rail | 🚈 | love-hotel | 🏩 |
| luggage | 🧳 | mantelpiece-clock | 🕰️ | manual-wheelchair | 🦽 |
| metro | 🚇 | milky-way | 🌌 | minibus | 🚐 |
| monorail | 🚝 | moon | 🌔 | mosque | 🕌 |
| motor-boat | 🛥️ | motor-scooter | 🛵 | motorcycle | 🏍️ |
| motorized-wheelchair | 🦼 | motorway | 🛣️ | mount-fuji | 🗻 |
| mountain | ⛰️ | mountain-cableway | 🚠 | mountain-railway | 🚞 |
| mountain-snow | 🏔️ | national-park | 🏞️ | new-moon | 🌑 |
| new-moon-with-face | 🌚 | night-with-stars | 🌃 | ocean | 🌊 |
|
## dist_zef-lizmat-Text-Emoji.md
## Chunk 3 of 3
| office | 🏢 | oil-drum | 🛢️ | oncoming-automobile | 🚘 |
| oncoming-bus | 🚍 | oncoming-police-car | 🚔 | oncoming-taxi | 🚖 |
| open-umbrella | ☂️ | parachute | 🪂 | parasol-on-ground | ⛱️ |
| partly-sunny | ⛅ | passenger-ship | 🛳️ | pickup-truck | 🛻 |
| playground-slide | 🛝 | police-car | 🚓 | post-office | 🏣 |
| racing-car | 🏎️ | railway-car | 🚃 | railway-track | 🛤️ |
| rainbow | 🌈 | ring-buoy | 🛟 | ringed-planet | 🪐 |
| rock | 🪨 | rocket | 🚀 | roller-coaster | 🎢 |
| roller-skate | 🛼 | rotating-light | 🚨 | school | 🏫 |
| seat | 💺 | shinto-shrine | ⛩️ | ship | 🚢 |
| skateboard | 🛹 | small-airplane | 🛩️ | snowflake | ❄️ |
| snowman | ⛄ | snowman-with-snow | ☃️ | speedboat | 🚤 |
| stadium | 🏟️ | star | ⭐ | star2 | 🌟 |
| stars | 🌠 | station | 🚉 | statue-of-liberty | 🗽 |
| steam-locomotive | 🚂 | stop-sign | 🛑 | stopwatch | ⏱️ |
| sun-behind-large-cloud | 🌥️ | sun-behind-rain-cloud | 🌦️ | sun-behind-small-cloud | 🌤️ |
| sun-with-face | 🌞 | sunny | ☀️ | sunrise | 🌅 |
| sunrise-over-mountains | 🌄 | suspension-railway | 🚟 | synagogue | 🕍 |
| taxi | 🚕 | tent | ⛺ | thermometer | 🌡️ |
| timer-clock | ⏲️ | tokyo-tower | 🗼 | tornado | 🌪️ |
| tractor | 🚜 | traffic-light | 🚥 | train | 🚋 |
| train2 | 🚆 | tram | 🚊 | trolleybus | 🚎 |
| truck | 🚚 | umbrella | ☔ | vertical-traffic-light | 🚦 |
| volcano | 🌋 | waning-crescent-moon | 🌘 | waning-gibbous-moon | 🌖 |
| watch | ⌚ | waxing-crescent-moon | 🌒 | wedding | 💒 |
| wheel | 🛞 | wind-face | 🌬️ | wood | 🪵 |
| world-map | 🗺️ | zap | ⚡ | | |
# INSPIRATION
Inspired by Simon Harms' [`Avolution::Emoji`](https://github.com/ukn-ubi/Avolution-Emoji) module, but completely re-imagined from scratch using the table provided by the [`gemoji`](https://github.com/github/gemoji) library.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Text-Emoji> . Comments and Pull Requests are welcome.
If you like this module, or what I'm doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2024 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-finanalyst-Collection.md
## Chunk 1 of 2
```
# Raku Collection Module
```
> **DESCRIPTION** # DESCRIPTION
> Software to collect content files written in Rakudoc (aka POD6) and render them in a chosen format. Extensive use is made of plugins to customise the rendering. A distinction is made between the Rakudoc files for the main content (sources) and the Rakudoc files that describe the whole collection of sources (mode-sources), eg. the landing page (*index.html*) of a website, or the Contents page of the same sources in book form. The collection process is in stages at the start of which plugin callables (Raku programs) can be added that transform intermediate data or add templates, or add new Pod::Blocks for the rendering.
> **AUTHOR** # AUTHOR
> Richard Hainsworth aka finanalyst
---
## Table of Contents
[Installation](#installation)
[Usage](#usage)
[Life cycle of processing](#life-cycle-of-processing)
[Modes](#modes)
[Milestones](#milestones)
[Stopping or dumping information at milestones](#stopping-or-dumping-information-at-milestones)
[Source Milestone](#source-milestone)
[Mode Milestone](#mode-milestone)
[Setup Milestone](#setup-milestone)
[Render Milestone](#render-milestone)
[Compilation Milestone](#compilation-milestone)
[Transfer Milestone](#transfer-milestone)
[Report Milestone](#report-milestone)
[Completion Milestone](#completion-milestone)
[Collection Structure](#collection-structure)
[Collection Content](#collection-content)
[Extra assets (images, videos, etc)](#extra-assets-images-videos-etc)
[Cache](#cache)
[Mode](#mode)
[Templates](#templates)
[Configuration](#configuration)
[Top level configuration](#top-level-configuration)
[Mode-level configuration](#mode-level-configuration)
[Plugin level configuration](#plugin-level-configuration)
[Control flags](#control-flags)
[Plugin management](#plugin-management)
[Disabling a plugin](#disabling-a-plugin)
[Plugin types](#plugin-types)
[Setup](#setup)
[Render](#render)
[Compilation](#compilation)
[Transfer](#transfer)
[Report](#report)
[Completion](#completion)
[Plugin development](#plugin-development)
[Collection plugin specification](#collection-plugin-specification)
[Collection plugin tests](#collection-plugin-tests)
[Plugin updating](#plugin-updating)
[Mapping released plugins to mode directories](#mapping-released-plugins-to-mode-directories)
[Released plugins directory](#released-plugins-directory)
[Refresh process](#refresh-process)
[CLI Plugin Management System](#cli-plugin-management-system)
[Problems and TODO items](#problems-and-todo-items)
[Archiving and Minor Changes](#archiving-and-minor-changes)
[Dump file formatting](#dump-file-formatting)
[Post-cache methods](#post-cache-methods)
[multi method add(Str $fn, Array $p --> Pod::From::Cache )](#multi-method-addstr-fn-array-p----podfromcache-)
[multi method mask(Str $fn --> Pod::From::Cache)](#multi-method-maskstr-fn----podfromcache)
[multi method add-alias(Str $fn, Str :alias! --> Pod::From::Cache)](#multi-method-add-aliasstr-fn-str-alias----podfromcache)
[method behind-alias(Str $fn --> Str )](#method-behind-aliasstr-fn----str-)
[method pod(Str $fn)](#method-podstr-fn)
[multi method last-version( @version-data )](#multi-method-last-version-version-data-)
[Head](#head)
[Asset-cache methods](#asset-cache-methods)
[Copyright and License](#copyright-and-license)
---
This module is used by the module **Collection-Raku-Documentation**, but is intended to be more general, such as building a personal site.
# Installation
To install the distribution, a refresh utility (see [Plugin refreshing](Plugin refreshing.md)), and the default plugin directory (see [Released plugin directory](Released plugin directory.md)), use
```
zef install Collection
```
For those who really want to have a non-default plugin directory, it is possible. But **warning**: extra user input will be needed for other utilities, so read the whole of this file), eg, to have a hidden directory `.Collection` in the home directory (under \*nix), use
```
PluginPath=~/.Collection zef install Collection
```
# Usage
The Collection module expects there to be a `config.raku` file in the root of the collection, which provides information about how to obtain the content (Pod6/rakudoc> sources, a default Mode to render and output the collection. All the configuration, template, and plugin files described below are **Raku** programs that evaluate to a Hash. They are described in the documentation for the `RakuConfig` module.
A concrete example of `Collection` is the [Collection-Raku-Documentation (CRD)](https://github.com/finanalyst/collection-raku-documentation.git) module. *CRD* contains a large number of plugins (see below). Some plugin examples are constructed for the extended tests. Since the test examples files are deleted by the final test, try:
```
NoDelete=1 prove6 -I. xt
```
and then look at eg., `xt/test-dir`.
The main subroutine is `collect`. It requires a file `config.raku` to be in the `$CWD` (current working directory). In *CRD* the executable `Raku-Doc` initiates the collection by setting up sources and installing a `config.raku` file. It is then simply a command line interface to `collect`.
# Life cycle of processing
The content files are processed in several stages separated by milestones. At each milestone, intermediary data can be processed using plugin callables, the data after the plugin callables can be dumped, or the processed halted.
`collect` can be called with option flags, which have the same effect as configuration options. The run-time values of the [Control flags](Control flags.md) take precedence over the configuration options.
`collect` should be called with a [Mode](Mode.md). A **Mode** is the name of a set of configuration files, templates, and plugins that control the way the source files are processed and rendered. The main configuration file must contain a key called `mode`, which defines the default mode that `collect` uses if called with no explicit mode, so if `collect` is called without a **Mode**, the default will be used.
# Modes
A Mode:
* is the name of the process by which a *Collection* is rendered and presented. At present, only `Website` is implemented, but it is planned to have Modes for `epub` and `pdf` formats. The presentation may be serving HTML files locally, or the creation of a single epub file for publishing.
* is the name of a sub-directory under the Collection directory.
* may not be named with any '\_' in it. This allows for sub-directories in a Collection folder that are not modes, eg., a Raku documentation repository
* A Mode sub-directory must contain:
* a sub-directory `configs`, and/or a `config.raku` file.
# Milestones
The `collect` sub can be called once the collection directory contains a `config.raku`, which in turn contains the location of a directory of rakudoc source files, which must contain recursively at least one source.
Processing occurs during a stage named by the milestone which starts it. Each stage is affected by a set of [Control flags](Control flags.md). Certain flags will be passed to the underlying objects, eg. `RakuConfig` and `ProcessedPod` (see `Raku::Pod::Render`).
Plugin callables may be called at each milestone (except 'Source' and 'Mode', where they are not defined). Plugins are described in more detail in [Plugin management](Plugin management.md). plugin callables are milestone specific, with the call parameters and return values depending on the milestone.
The milestones are:
* Source
* Mode
* Setup
* Render
* Compilation
* Transfer
* Report
* Completion
## Stopping or dumping information at milestones
Intermediate data can be dumped at the milestone **without stopping** the processing, eg.,
```
collect(:dump-at<source render>);
```
Alternatively, the processing can be **stopped** and intermediate data inspected, EITHER after the stage has run, but before the plugin callables for the next stage have been triggered, eg.,
```
my $rv = collect(:after<setup>);
```
OR after the previous stage has run and after the plugin callables for the milestone have been triggered, eg.,
```
my $rv = collect(:before<render>);
```
The return value `$rv` is an array of the objects provided to plugin callables at that milestone, and an array of the plugin callables triggered (note the plugin callables used will be a difference between the `:before` and `:after` stop points). The plugins-used array is not provided to all plugin callables, except at the Report milestone.
The return value `$rv` at `:after` will contain the object provided by the milestone after the named milestone. For example, milestone milestone 'Setup' is followed by milestone 'Render'. The return object for `:after<setup>` will be the return object for milestone 'Render'. See Milestones for more information.
The object returned by `:before<render>` may be affected by the plugin callables that are triggered before the named stage.
The `:before`, `:after` and `:dump-at` option values are the (case-insensitive) name(s) of the inspection point for the milestone. `:before` and `:after` only take one name, but `:dump-at` may take one or all of them in a space-delimited unordered list.
The `dump-at` option calls `.raku` [TODO pretty-dump, when it handles BagHash and classes] on the same objects as above and then outputs them to a file(s) called `dump-at-<milestone name>.txt`.
## Source Milestone
(Skipped if the `:without-processing` flag is True)
Since this is the start of the processing, no plugins are defined as there are no objects for them to operate on.
The `config.raku` file must exist and must contain a minimum set of keys. It may optionally contain keys for the control flags that control the stage, see below. The intent is to keep the options for the root configuration file as small as possible and only refer to the source files. Most other options are configured by the Mode.
During the subsequent **Source** stage, the source files in the collection are brought in, if the collection has not been fully initiated, using the `source-obtain` configaturation list. Alternatively, any updates are brought in using the `source-refresh` list. Commonly, sources will be in a *git* repository, which has separate commands for `clone` and `pull`. If the `source-obtain` and `source-refresh` options are not given (for example during a test), no changes will be made to the source directory.
Any changes to the source files are cached by default.
The control flags for this stage are:
* **no-refresh** (default False)
Prevents source file updates from being brought in.
* **recompile**
Forces all the source files to be recompiled into the cache.
## Mode Milestone
(Skipped if the `:without-processing` flag is True)
Collection makes a distinction between Rakudoc source files that are the main content, and the source files needed to integrate the main content into a whole. The integration sources will differ according to the final output. For example, a book may have a Foreward, a Contents, a Glossary, etc, whilst a website will have a landing page (eg., *index.html*), and perhaps other index pages for subsections. A book may also organise content into sections that depend on metadata in the source files. A book will have a defined order of sections, but a website has no order. A website will require CSS files and perhaps jQuery scripts to be associated with Blocks. A book will have different formating requirements for pages.
These differences are contained in the **mode** configuration, and the plugins and templates for the mode.
At this milestone, the source files have been cached. The **mode** sub-directory has not been tested, and the configuration for the mode has not been used. Since plugin management is dependent on the mode configuration, no plugin callables can be called.
The **return value** of `collect` with `:after<source>` is a single `Pod::From::Cache` object that does a `Post-Cache` role (see below for `Post-Cache` methods).
A `Pod::From::Cache` object provides a list of updated files, and a full set of source files. It will provide a list of Pod::Blocks contained in each content files, using the filename as the key.
During the stage the source files for the Mode are obtained, compiled and cached. The process is controlled by the same options as the *Source* stage. For example, the **Mode** for `Collection-Raku-Documentation` is *Website*.
If a sub-directory with the same name as *mode* does not exist, or there are no config files in the `<mode>/config` directory, `collect` will throw an `X::Collection::NoMode` exception at the start of the stage.
Mode source files are stored under the mode sub-directory and cached there. If the mode source files are stored remotely and updated independently of the collection, then the `mode-obtain` and `mode-refresh` keys are used.
## Setup Milestone
(Skipped if the `:without-processing` flag is True)
If **setup** plugin callables are defined and in the mode's plugins-required list, then the cache objects for the sources and the mode's sources (and the **full-render** value) are passed to the program defined by the plugin's **setup** key.
The purpose of this milestone is to allow for content files to be pre-processed, perhaps to creates several sub-files from one big file, or to combine files in some way, or to gather information for a search algorithm.
During the setup stage,
* the `ProcessedPod` object is prepared,
* templates specified in the `templates` directory are added
* the key **mode-name** is added to the `ProcessedPod` object's plugin-data area and given the value of the mode.
The Setup stage depends on the following options:
* **full-render**
By default, only files that are changed are re-rendered, which includes an assumption that if any source file is changed, then all the **mode** sources must be re-rendered as well. (See the Problems section below for a caveat.)
When **full-render** is True, the output directory is emptied of content, forcing all files to be rendered.
**full-render** may be combined with **no-refresh**, for example when templates or plugins are changed and the aim is to see what effect they have on exactly the same sources. In such a case, the cache will not be changed, but the cache object will not contain any files generated by **setup** plugin callables.
## Render Milestone
(Skipped if the `:without-processing` flag is True)
At this milestone `render` plugins are supplied to the `ProcessedPod` object. New Pod::Blocks can be defined, and the templates associated with them can be created.
The source files (by default only those that have been changed) are rendered.
The stage is controlled by the same options as *Setup* and
* with-only - affects which Documents are rendered, see Configuration for more
* ignore - prevents docs from being Cached, see Configuration for more
## Compilation Milestone
(Skipped if the `:without-processing` flag is True)
During the stage after this milestone, the structure documents are rendered. They can have Pod-blocks which use data included by templates and plugins during the render stage. They can also add to data, which means that the order in which a plugin is called may be important.
At this milestone plugin callables are provided to add compiled data to the `ProcessedPod` object, so that the sources in the mode's directory can function.
During the **Render** stage, the `%processed` hash is constructed whose keys are the filenames of the output files, and whose values are a hash of the page components of each page.
The `compilation` plugin callables could, eg, collect page component data (eg., Table of Contents, Glossaries, Footnotes), and write them into the `ProcessedPod` object separately so there is a TOC, Glossary, etc structure whose keys are filenames.
The return value of `collect` at the inspection point is a list of `ProcessedPod`, `%process`, with the `ProcessedPod` already changed by the `compilation` plugin callables.
The stage is controlled by the same options as *Setup* and
* with-only - same as include but for structure documents
* ignore-mode - as for ignore above
## Transfer Milestone
(Skipped if the `:without-processing` flag is True)
Plugins may generate assets that are not transfered by them, or it is important to ensure that a plugin runs after all other plugins.
In addition, render plugins may create files that are transfered at the render stage, but should be removed after all plugins have run. So a transfer milestone plugin can be created to clean up the plugin's local directory.
## Report Milestone
(Skipped if the `:without-processing` flag is True)
Once a collection has been rendered, all the links between files, and to outside targets can be subjected to tests. It is also possible to subject all the rendered files to tests. This is accomplished using `report` plugin callables.
In addition, all the plugin callables that have been used at each stage (except for the Report stage itself) are listed. The aim is to provide information for debugging.
The report stage is intended for testing the outputs and producing reports on the tests.
## Completion Milestone
Once the collection has been tested, it can be activated. For example, a collection could be processed into a book, or a `Cro` App run that makes the rendered files available on a browser. This is done using `completion` plugin callables.
The **without-completion** option allows for the completion phase to be skipped.
Setting **without-processing** to True and **without-completion** to True should have no effect unless
* there are no caches, which will be the case the first time `collect` is run
* the destination directory is missing, which will be the case the first time `collect` is run
# Collection Structure
A distribution contains content files, which may be updated on a regular basis, a cache, templates, extra assets referenced in a content file (such as images), and one or more modes.
## Collection Content
The content of the distribution is contained in **rakudoc** files. In addition to the source files, there are Collection content files which express things like the Table of Contents for the whole collection.
Collection content are held separately to the source content, so that each mode may have different pages.
This allows for active search pages for a Website, not needed for an epub, or publisher data for an output formation that will be printed.
## Extra assets (images, videos, etc)
Assets such as images, which are directly referenced in content file, but exist in different formats, eg, png, are held apart from content Pod6 files, but are processed with content files.
The reasoning for this design is that Pod6 files are compiled and cached in a manner that does not suit image files. But when an image file is processed for inclusion in a content file, the image may need to be processed by the template (eg., image effects specified in a Pod Block config).
The assets are all held in the same directory, specified by the configuration key `asset-basenamme`, but each asset may exist in subdirectories for each type of asset, specified by the `asset-paths` key.
(Asset files relating to the rendering of a content file, such as css, javascript, etc, are managed by plugins, see below for more on plugins.)
A class to manage asset files is added to the `ProcessedPod` object with a role, so the assets can be manipulated by plugins and templates. Assets that are in fact used by a Pod content file are marked as used. The aim of this functionality is to allow for report-stage plugin callables to detect whether all images have been used.
Plugins can also transform the assets, and create new files in the ProcessedPod object for inclusion in the output.
At the end of the compilation stage, all the assets that have been used are written to a directory specified in the Mode configuration file. It is the task of the template rendering block to ensure that the path where the asset is stored is the same as the path the final output (eg. the browser rendering html files) processor requests.
In keeping with the principle that collection level meta data is kept in the top-level config file, and output data is associated with the specific mode, there are two asset-path definitions.
* Collection level assets. The source of assets is kept in the top-level `config.raku` file. In order to have each asset in its own directory, the following is possible:
```
...
:asset-basename<assets>,
asset-paths => %(
image => %(
:directory<images>,
:extensions<png jpeg jpeg svg>,
),
video-clips => %(
:directory<videos>,
:extensions<mp4 webm>,
),
),
...
```
Notice that the `type`, eg. *image* and *video-clips* above, are arbitrary and not dependent on the actual format.
* Output configuration. The output destination is kept in the mode configuration, eg., `Website/configs/03-images.raku` contains
```
%(
:asset-out-path<html/assets>
),
)
```
For more see [Asset-cache methods](Asset-cache methods.md)
## Cache
The **cache** is a Precomp structure into which the content files are pre-preprocessed.
## Mode
The **Mode** is the collection of templates and configuration for some output. A collection may contain multiple Modes, each in their own subdirectory.
The default Mode for **Collection-Raku-Documentation** is **Website**, for example.
The string defining `mode` must refer to an immediate directory of the root of the collection, so it is compared to `/ ^ \W+ (\w+) '/'? .* $ /` and only the inner `\w` chars are used.
The templates, configuration, output files, and other assets used by a Mode are associated with the Mode, and should reside beneath the Mode sub-directory.
## Templates
The **templates**, which may be any format (currently RakuClosure or Mustache) accepted by `ProcessedPod`, define how the following are expressed in the output:
* the elements of the content files, eg. paragraphs, headers
* the files as entities, eg, whether as single files, or chapters of a book
* the collective components of content files, viz, Table of Contents, footnotes, Glossary, Meta data
* All the templates may be in one file, or distributed between files.
* If there are no templates in the directory, the default files in `ProcessedPod` are used.
* If there are multiple files in the directory, they will all be evaluated in alphanumeric order. Note that existing keys will be over-written if they exist in later templates. This is **not** the same behaviour as for Configuration files.
# Configuration
There are three levels of configuration:
* The top-level configuration resides in `config.raku` in the root directory of the Collection. The `collect` sub will fail without this file.
* The Mode configuration typically resides in the `configs` directory, in several files (the names are not important).
* Each plugin has its own config, in the `config.raku` file of its directory.
## Top level configuration
In the descriptions below, simple illustrative names are given to files with configuration, templates, callables. These files are generally **Raku** programs, which are compiled and run. They will almost certainly contain errors during development and the **Rakudo** compiler will provide information based on the filename. So it is good practice to name the files that make them easier to locate, such as prefixing them with the plugin name.
`config.raku` **must** contain the following keys:
* the **cache** directory, relative to the root directory of the collection
* `Collection-Raku-Documentation` default: 'doc-cache',
* the **sources** directory, relative to the root of the collection and must contain at least one content file
* `Collection-Raku-Documentation` default: 'raku-docs'
* **mode** is the default mode for the collection, and must be a sub-directory, which must exist and contain a `configs` sub-directory (note the plural ending). See Mode level configuration below.
* `Collection-Raku-Documentation` default: 'Website'
* **without-processing** as described in Milestones
* default: False
* **no-refresh** as described in Milestones
* default: False
* **recompile** as described in Milestones
* default: False
The following are optional keys, together with the defaults
* the allowed **extensions** for content files. These are provided to the `Pod::From::Cache` object.
* default: < rakudoc pod pod6 p6 pm pm6 >
* no-status This option controls whether a progress bar is provided in the terminal
* default: False
* **source-obtain** is the array of strings sent to the OS by `run` to obtain sources, eg git clone and assumes CWD is set to the directory of collection. Without this key, there must already be files in `sources`.
* default: ()
* **source-refresh** is the array of strings run to refresh the sources, assumes CWD set to the directory of sources. No key assumes the sources never change.
* default: ()
* **ignore** is a list of files in the **sources** directory that are not cached. This is a Collection level configuration. The option **include-only** is Mode level configuration, see below.
* default: ()
* **no-status** as described in Milestones
* default: False
* **without-report** as described in Milestones
* default: False
* **full-render** as described in Milestones
* default: False
* **asset-basename** as described in [Asset-cache methods](Asset-cache methods.md)
* `Collection-Raku-Documentation` default: 'asset\_base'
## Mode-level configuration
The mode-level configuration resides in one or more **files** that are under the **configs/** sub-directory of the `mode` directory. This arrangement is used to allow for configuration to be separated into different named files for ease of management.
The following rules apply:
* If the **configs** directory for a mode does not exist or is empty, **Raku-Doc** (`collect` sub) will fail.
* The Configuration consists of one or more `Raku` files that each evaluate to a hash.
* Each Config file in the **Configs** directory will be evaluated in alphabetical order.
* Configuration keys may not be over-written. An `X::RakuConfig::OverwriteKey` exception will be thrown if an attempt is made to redefine a key.
All the following keys are mandatory. Where a key refers to a directory (path), it should normally be relative to the `mode` sub-directory.
* **mode-sources** location of the source files for the Collection pages, eg., TOC.
* **mode-cache** location of the cache files
* the **templates** subdirectory, which must contain raku files as described in `ProcessedPod`. These are all passed at the **Render** milestone directly to the `ProcessedPod` object.
* **destination** directory where the output files are rendered
* **report-path** is the path to which `report` plugins should output their reports.
* **plugin-format** defines the format the plugins relate to. Each Mode is specified to produce output in a specific format, and the plugins, which include templates, are related to the format. Published plugins are stored for a particular format.
* **plugins-required** points to a hash whose keys are milestone names where plugin callables can be applied
* **setup** a list of plugin names, see [Plugin management](Plugin management.md), for pre-processing cache contents
* **render** plugins used to render Pod::Blocks
* **compilation** plugins prepare the `ProcessedPod` object for collection pages.
* **assets** plugins that mark assets created in previous milestones
* **report** plugins to test and report on the rendering process
* **completion** plugins that define what happens after rendering
* **cleanup** plugins if cleanup is needed.
* **landing-place** is the name of the file that comes first during the completion stage. For example, in a Website, the landing file is usually called `index.html`
* **output-ext** is the extension for the output files
* **plugin-options** is mandatory, see [Plugin level configuration](Plugin level configuration.md) for more information
All optional control flags are False by default. For the Mode configuration they are:
* no-status
* full-render
* without-completion
* without-report
* no-preserved-state
* debug-when
* verbose-when
* no-code-escape
## Plugin level configuration
Each plugin has its own configuration (more information in the sections on Plugins). In addition to the mandatory keys, a plugin may have its own configuration data. The configuration data in the plugin directory will be over-written each time a plugin is updated.
In order to provide for preservation of configuration data at the Mode level, the key `plugin-options` (typically kept in a separate config file) is used. The value of `plugin-options` is a Hash whose keys are the names of plugins. Each plugin-name key has a value that is a Hash of the keys required by the plugin.
For example, the `Collection-Raku-Documentation` plugin `cro-app` has the configuration options `:port` and `:host`. The default `Collection-Raku-Documentation` configuration contains the snippet:
```
plugin-options => %(
cro-app => %(
:port<30000>,
:host<localhost>,
),
),
```
in a file under the Mode's `configs/` directory. These values will over-ride the plugin's default config values.
The plugin should therefore take configuration data from the ProcessedPod instance and not from the config file it is distributed with. This means that if a new plugin is intended to be used in place of an pre-existing one (see [Refresh process](Refresh process.md)), then the developer needs to check the configuration information from the namespace of the replaced name.
The Setup and Completion plugins are passed `plugin-options` directly because the ProcessedPod instance is out of scope.
`plugin-options` is a mandatory option in the Mode configuration. It may be set to Empty, viz.,
```
plugin-options()
```
in which case, all plugins will use their default options.
The ProcessPod instance is only modified by `Render` plugins, so if there is plugin configuration data that is needed by another Milestone callable, the plugin should call a blank callable, with empty block and templates.
# Control flags
The control flags are also covered in [Milestones](Milestones.md). Control flags by default are False.
* **no-status**
No progress status is output at any time.
* **without-processing**
Setting **without-processing** to True will skip all the stages except **Completion**, so long as the destination directories exist.
* **no-preserved-state**
In order to allow for changes in some source files, or in only mode files, after all the sources have been processed once, the processing state must be archived. This may not be needed in testing or if the archiving takes too long.
Setting no-preserved-state = True prevents storage of state, but also forces **without-processing** to False, and **recompile** to True.
* **recompile**
Controls the updating and caching of the content files. If true, then all files will be recompiled and cached.
A True value is over-ridden by **without-processing**
Normally False, which allows for only changed files to be processed.
* **no-refresh**
Prevents the updating of content files, so no changes will be made.
* **full-render**
Forces all files to be rendered. Even if there are no changes to source files, plugins or templates may be added/changed, thus changing the output, so all files need to be re-rendered.
This flag is set to False if **without-processing** is True.
* **without-report**
Normally, report plugin callables report on the final state of the output files. This flag prevents report plugin callables from being loaded or run.
If **without-processing** is set, then the **Report** stage is skipped. If, however, the caches do not exist (deleted or first run), then the value of **without-processing** is ignored and the value of **without-report** is observed.
* **debug-when & verbose-when**
ProcessedPod uses `debug` and `verbose`, which provide information about which blocks are processed (debug), and the result after the application of the template (verbose). This is a lot of information and generally, it is only a few files that are of interest.
These two flags take a string, eg., `:debug-when<Introduction.pod6>` or `:debug-when<101 about>` , and when the string matches the filename, then the debug/verbose flag is set for that file only.
Note `verbose` is **only** effective when `debug` is True.
* **collection-info**
Causes collect to produce information about milestones and valid and invalid plugins
* **with-only** filename
Collect is run only with that filename, which must be in the sources or mode-sources, and is specified like `debug-when`.
The option takes a string containing the filename. An empty string means all filenames in sources and mode-sources.
* **no-code-escape**
`ProcessedPod` has a special flag for turning off escaping in code sections when a highlighter is used to pre-process code. In some cases, the highlighter also does HTML escaping, so RPR has to avoid it.
This has to be done at the Mode level and not left to `render` plugin callables.
# Plugin management
Plugin callables are **Raku** programs that are executed at specific milestones in the rendering process. The milestone names are given in [Milestones](Milestones.md) above.
The **plugins-required** key in the Mode's configuration contains a hash with keys whose names are the milestone names. Each key points to a list of plugin names, which are called in the order given.
All plugins must reside within the mode **plugins**.
All plugin names **must** be the name of a sub-directory under the **plugins** subdirectory. Within each plugin sub-directory, there must be a `config.raku` file containing information for the plugin, and for `Collection`. If *no* `config.raku` files exists, the plugin is not valid and will be skipped.
With the exception of 'render' plugin callables, the config file must contain a key for the milestone type, which points to the program to be called, and when the file is evaluated, it yields a subroutine that takes the parameters needed for the plugin of that milestone. If no key exists with the name of the milestone, then the plugin is not valid.
Plugin's may need other configurable data, which should be kept in the config file for the plugin.
All plugin callables are expected to adhere to `no-status` and `collection-info`, which are interpretted as
* `no-status` if true means 'no output at all', equivalent to a **quiet** flag
* `collection-info` if true means 'output extra information' (if need be), equivalent to a **verbose** flag.
## Disabling a plugin
When it's necessary to disable a plugin, this can be done by:
* Removing the plugin name from the `plugins-required` key of the Mode's config file;
* Renaming / removing the `config.raku` file name inside the plugin directory
* Renaming / removing the milestone key inside the plugin's `config.raku` file.
## Plugin types
The plugin types are as follows.
### Setup
Config hash must contain **setup** which is the name of a Raku program (a callable) that evaluates to a sub that takes a list of five items, eg.,
```
sub ( $source-cache, $mode-cache, Bool $full-render, $source-root, $mode-root, %plugin-options, %options ) { ... }
```
* **$source-cache**
A `Pod::From::Cache+PostCache` object containing the pod of the sources files New files can be added to the cache object inside the sub using the `.add` method, see [Sources](Sources.md).
* **$mode-cache**
Like the above for the mode content files
* **$full-render**
If True, then the sub should process the cache objects with the .sources method on the cache objects, otherwise with the .list-files method on the cache objects (the .list-files method only provides the files that have changed).
* **$source-root**
This path must be prepended to any sources added (see below) to the cache, otherwise they will not be added to the destination file.
* **$mode-root**
Likewise for the mode sources.
* **%plugin-options**
Has the values of plugin options that over-ride a plugin's own defaults. See [Plugin level configuration](Plugin level configuration.md) for more information.
* **%options**
Has the values of 'collection-info' and 'no-status' flags.
### Render
The Collection plugin-manager calls the `ProcessedPod.add-plugin` method with the config keys and the path modified to the plugin's subdirectory. The ProcessPod instance is only modified by `Render` plugins, so if there is plugin configuration data that is needed |
## dist_zef-finanalyst-Collection.md
## Chunk 2 of 2
by another Milestone callable, the plugin should call a blank callable, with empty block and templates.
If the `render` key is True, no callable is provided, and the plugin name will be added via the **.add-plugin** method of the `ProcessedPod` object. See `ProcessedPod` documentation.
If the `render` key is a Str, then it is the filename of a Raku callable of the form
```
sub ( $pr, %options --> Array ) {...}
```
where
* **$pr** is a object,
* **%options** is the same as for Setup, and
* the callable **returns** a list of triples, with the form (to, from-plug, file)
* **to** is the destination under the `%config<destination>` directory where the asset will be looked for, eg., an image file to be served.
* **from-plug** is the name of the plugin in whose directory the asset is contained, where the value `myself` means the path of the plugin calling the render callable. Actually, 'myself' is the value of Collection::MYSELF.
* **file** is the filename local to the source plugin's subdirectory that is to be copied to the destination. This may contain a path relative to the plugin's subdirectory.
* For example for an HTML file, this would be the relative URL for the `src` field. Eg., `to = 'asset/image'`, `file = 'new-image.png'`, `from-plug = 'myself'` and the html would be `<img src="asset/image/new-image.png" />` .
Since a render plugin is to be added using the `ProcessedPod` interface, it must have the `custom-raku` and `template-raku` keys defined, even if they evaluate to blank (eg. `:custom-raku()` ).
So the config file must have:
* render (True | name of callable)
* custom-raku => a Raku program that evaluates to an array of custom blocks (must be set to `()` if no Raku program )
* template-raku => a Raku program that evaluates to a hash of RakuClosure templates (must be set to `()` if no Raku program)
It is possible to specify `path` but it must be relative to the plugin's sub-directory.
### Compilation
Note that the structure files are rendered after the `compilation` stage, BUT the information for rendering the structure files, that is the custom blocks and the templates must accompany a `render` plugin. Compilation plugin callables are to process the data accumulated during the rendering of the content files, and to make it available for the custom blocks / templates that will be invoked when the structure documents are rendered.
The `compilation` key must point to a Raku program that delivers a sub object
```
sub ( $pr, %processed, %options ) { ... }
```
> **$pr**
> is the ProcessedPod object rendering the content files.
> **%processed**
> is a hash whose keys are source file names with a hash values containing TOC, Glossary, Links, Metadata, Footnotes, Templates-used structures produced by B.
> **%options**
> as for setup
If the return value of the callable is an Array of triplets (as for a Render callable), then assets are transferred from the plugin directory. Any other type of return value is ignored.
### Transfer
The `transfer` key points to a Raku file that evaluates to a
```
sub ($pr, %processed, %options --> Array ) {...}
```
> **%processed**
> as in Compilation
> **$pr**
> as in Compilation
> **%options**
> as for Setup
> **return object**
> as for the compilation plugin
## Report
The `report` key points to a Raku file that evaluates to a
```
sub (%processed, @plugins-used, $pr, %options --> Array ) {...}
```
> **%processed**
> as in Compilation
> **@plugins-used**
> is an array of Pairs whose key is the milestone and value is a hash of the plugins used and their config parameters.
> **$pr**
> as in Compilation
> **%options**
> as for Setup
The plugin should return an Array of Pair, where for each Pair .key = (path/)name of the report file with extension, and .value is the text of the report in the appropriate format
The `collect` sub will write the file to the correct directory.
### Completion
The `completion` key points to a Raku file that evaluates to a
```
sub ($destination, $landing-place, $output-ext, %plugin-options, %options) {...}
```
* **$destination**
is the name of the output path from the mode directory (defined in the mode configuration)
* **$landing-place**
is the first file to be processed since, eg., for a website, order is not sufficient. name is relative to the destination directory.
* **$output-ext**
is the output extension.
* **%plugin-options**
As for Setup
* **%options**
As for Setup
There is no return value specified for this plugin type.
# Plugin development
There is a separate development distribution `raku-collection-plugin-development`, which contains several tools for adding and testing plugins. However, a single plugin can be tested using the module `Collection::TestPlugin`, which is included in this distribution.
## Collection plugin specification
All Collection plugins must conform to the following rules
* The plugin name must:
* start with a letter
* followed by at least one \w or -
* not contain \_ or .
* thus a name matches / <[\w] + [-] - [\_]>+ /
* The plugin directory contains
* `config.raku`, which is a file that evaluates to a Raku hash.
* README.rakudoc
* t/01-basic.rakutest
* The `config.raku` file must contain the following keys
* `name`. This is the released name of the plugin. It will be possible for a new plugin to have the same functionality as another, while extending or changing the output. For more detail, see [Collection plugin management system](Collection plugin management system.md). Typically, the name of the plugin will match the name of the sub-directory it is in.
* `version`. This point to a Str in the format \d+.\d+.\d+ which matches the semantic version conventions.
* `auth`. This points to a Str that is consistent with the Raku 'auth' conventions.
* `license`. Points to a SPDX license type.
* `authors`. This points to a sequence of names of people who are the authors of the plugin.
* one or more of `render setup report compilation completion`
* If render then
* the render key may be a boolean
* or the render key is a Str which must
* be a filename in the directory
* be a raku program that evaluated to a callable
* the callable has a signature defined for render callables
* the key `custom-raku`
* must exist
* must either be empty, viz. `custom-raku()`
* or must have a Str value
* if it has a Str value and the key `:information` does contain `custom-raku` then it is treated as if `custom-raku` is empty
* if it has a Str value and the key `:information` does NOT contain `custom-raku` then the Str value should
* point to a file name in the current directory
* and the filename should contain a Raku program that evaluates to an Array.
* the key `template-raku`
* must exist
* must either be empty, viz. `template-raku()`
* or must have a Str value
* if it has a Str value and the key `:information` does contain `template-raku` then it is treated as if `template-raku` is empty
* if it has a Str value and the key `:information` does NOT contain `template-raku` then the Str value should
* point to a file name in the current directory
* and the filename should contain a Raku program that evaluates to a Hash.
* If not render, then the value must point to a Raku program and evaluate to a callable.
* *Other key names*. If other keys are present, they must point to filenames in the current directory.
* `information`. This key does not need to exist.
* If it exists, then it must contain the names of other keys.
* If a key named in the `:information` list contains a Str, the filename will NOT exist in the plugin directory, but will be generated by the plugin itself, or is used as information by the plugin.
* This config key is intended only for plugin testing purposes.
## Collection plugin tests
This distribution contains the module `Collection::TestPlugin` with a single exported subroutine `plugin-ok`. This subroutine verifies that the plugin rules are kept for the plugin.
Additional plugin specific tests should be included.
# Plugin updating
The local computer may contain
* More than one collection, eg. a personal website and a Raku documentation collection
* Each Collection may have more than one Mode, eg., a HTML website, an epub producer.
* A collection/mode combination may rely on a previous API of a plugin, which may be broken by a later API.
* A new plugin may have been written as a drop-in replacement for an older version, and the new plugin may have a different name, or auth, or version.
In order to implement this flexibility, the following are specified:
* There is a released plugins directory (see [Released plugins directory](Released plugins directory.md)) to contain all Collection plugins.
* The semantic versioning scheme is mandated for Collection plugins. A version is `v<major>.<minor>,<patch>`. Changes at the `<patch>` level do not affect the plugin's functionality. Changes at the `<minor>` level introduce new functionality, but are backward compatible. Changes at the `<major>` level break backward compatibility.
* Each distributed plugin is contained in the release directory in a subdirectory named by the plugin name, the auth field, and the major version number (minor and patch numbers are not included because they should not by definition affect the API).
* Each Mode configuration only contains the name of the plugin (without the auth, or version names).
* The developer may define which name/version/auth of a released plugin is to be mapped to the plugin required in the Mode configuration. Thus
* changes in API can be frozen to earlier versions of the plugin for some concrete Mode.
* different plugin versions can be used for different collection/modes
* a differently named plugin can be mapped to a plugin required by a specific collection/mode.
* **Note** an alternate plugin, as given by `name` may also have a non-default `auth`, so `auth` may need to be added to `plugins.rakuon` as well.
* Consequently, all released plugins are defined for
* a **format** (eg. html)
* a **major** version
* an **auth** name
* The mapping information from a released plugin to a Mode is contained in a file in the root of a Collection.
* When the plugins are updated
* all the latest versions for each Format/Name/Version/Auth are downloaded.
* a symlink is generated (or if the OS does not allow symlink, the whole directory is copied) from the released version to the directory where each mode expects its plugins to be located.
* Each Collection root directory (the directory containing the topmost `config.raku` file) will contain the file `plugins.rakuon`.
* The plugin management tool (PMT)
* checks if a `plugins.rakuon` exists. If not, it generates a minimal one.
* runs through the plugins-required of each **Mode** in the collection.
* for each distinct plugin verifies whether
* the plugin has an entry in `plugins.rakuon`, in which case
* the PMT maps (or remaps if the constraint is new) the released plugin name/auth/ver to the plugin-required name using the rules of `plugins.rakuon` as given in [Mapping released plugins to mode directories](Mapping released plugins to mode directories.md)
* the plugin does not have an entry, which means it has not yet been mapped, and there are no constraints on the plugin, so the default name/auth/version are used.
## Mapping released plugins to mode directories
The file `plugins.rakuon` contains a hash with the following keys:
* `_metadata_`. Contains a hash with data for the `refresh` functionality.
* `collection-plugin-root` This contains the name of a directory reachable from the Collection root directory with the released plugins are downloaded.
* `update-behaviour` Defines what happens when a new released plugin has an increased Major number. Possible values are:
* *auto* All relevant plugin names are updated to the new version, a message is issued
* *conserve* Plugins are not updated to the new version, a warning is issued, updating is then plugin by plugin with a `-force` flag set.
* **Note** The update behaviour is not initially implemented.
* Every other toplevel key that meets the plugin naming convenstion is interpreted as a Mode. This means a mode cannot be named `_metadata_`.
* The Mode key will point to a hash with the keys:
* `_mode_format` Each mode may only contain plugins from one Format, eg., *html*.
* By the plugin naming rules, a *plugin* may not be named `_mode_format`.
* Every other key in a mode hash must be a plugin name contained in the Mode's plugins-required configuration.
* There may be zero plugin keys
* If a plugin in the plugins-required configuration list does not have an entry at this level, then it has not been mapped to a sub-directory of the `released-directory`.
* A plugin key that exists must point to a Hash, which must at least contain:
* mapped => the name of the released plugin
* The plugin hash may also point to one or more of:
* name => the name of the alternate released plugin
* the default name (if the key is absent) is the plugin-required's name
* if a different name is given, a released plugin is mapped to the required directory in the mode sub-directory
* major => the major number preceeded by 'v'
* the default value (if the key is absent) is the greatest released major value
* A major value is the maximum major value of the full version permitted, thus freezing at that version
* auth => the auth value
* the default value (if the key is absent) is 'collection'
* If there is no distributed plugin for a specified `auth | major | name` , then an error is thrown.
Some examples:
* The Raku-Collection-Raku-Documentation, Website mode, requires the plugin `Camelia`. The plugin exists as a HTML format. It has version 1.0.0, and an auth 'collection'. It is distributed as `html/camelia_v1_auth_collection`. Suppose a version with a new API is created. Then two versions of the plugin will be distributed, including the new one `html/camelia_v2_auth_collection`.
If the key for camelia in the hash for mode Website only contains an empty `version` key, then the defaults will be implied and a link (or copy) will be made between the released directory `html/camelia_v2_auth_collection` and `Website/plugins/camelia`
* If plugins.rakuon contains the following: `Website =` %( :FORMA"> {{{ contents }}}
, :camelia( %( :major(1), ) ) > then the link will be between `html/camelia_v1_auth_collection` and `Website/plugins/camelia`
* Suppose there is another valid `auth` string **raku-dev** and there is a distributed plugin *html/camelia\_v2\_auth\_raku-dev*, and suppose `plugins.rakuon` contains the following: `Website =` %( :FORMA"> {{{ contents }}}
, :camelia( %( :auth, ) ) > then the link will be made between `html/camelia_v2_auth_raku-dev` and `Website/plugins/camelia`
* Suppose a different icon is developed called `new-camelia` by `auth` **raku-dev**, then `plugins.rakuon` may contain the following: `Website =` %( :FORMA"> {{{ contents }}}
, camelia( %( :name, :auth, ) ) > then a link (copy) is made between `html/new-camelia_v2_auth_raku-dev` and `Website/plugins/camelia`
```
* Note how the auth must be given for a renaming if there is not a `collection` version of the plugin
```
## Released plugins directory
When Collection is installed, a directory called (by default) `$*HOME/.local/share/Collection` is created (on a Linux system this will be the same as `~/.local/share/Collection`).
If the Environment variable `PluginPath` is set to a valid path name upon installation, then that will be used instead. But when `refresh-collection-plugins` is first used, then the non-default name must be supplied.
The directory is initialised to point at the `https://github.com/finanalyst/collection-plugins` repo and the `manifest.rakuon` file is downloaded.
If another release directory location is desired, then
* it can be specified when `refresh-collection-plugins` is first run for each collection, in which case the file `plugin.rakuon` is given the value for the `:collection-plugin-root`.
* a custom Raku program for refreshing Collection files can be written, eg., the github repo is to be located in `~/.my_own_collection`
```
use v6.d;
use Collection::RefreshPlugins;
sub MAIN(|c) {
$Collection::RefreshPlugins::release-dir = "$*HOME/.my_own_collection";
refresh( |c );
}
```
## Refresh process
The intent is for the released plugins to be held in a single directory (called the *released plugins* directory), and for the references in a Collection-Mode `plugins` directory to be links (OS dependent) to the *released plugins* directory.
The *released plugins* directory is a Github repository, so doing a `git pull` will pull in the most recent versions of the plugins. Consequently, each Collection-Mode plugin reference will automatically be updated.
A `git pull` is therefore one form of a refresh. (TODO if an OS does not have directory links, then this form of refresh will need to be enhanced with a copy operation).
Refresh needs to deal with other situations
* A new plugin name is added to the Collection-Mode's `plugins-required` list.
* A link needs to be added to the Collections-Mode's `plugins` directory.
* A new entry exists for the plugin name in the `plugins.rakuon`
* An entry changes the release name associated with the Collection-Mode plugin.
* If the desired released plugin does not exist, then an Exception is thrown. Default behaviour might lead to an infinite loop.
* A released plugin major version has increased since the last refresh.
* The default is for a Collection-Mode plugin initially to be linked to the most recent version of the plugin
* Several behaviours are possible:
* The default *update-behaviour* is given in the `_metadata_` hash of `plugins.rakuon`
* *force* Leave the existing links in place, issue a warning, update to latest only when forced. Include suggestion to change plugins.rakuon file to suppress warnings.
* *auto* (default) Automatically update to the latest version, issuing a message
## CLI Plugin Management System
Collection contains the utility `collection-refresh-plugins` as a (PMS). It is called as follows:
```
collection-refresh-plugins [-collection=<path>] [-collections='path1 path2 path3']
```
`-collection` is the path to a Collection directory. By default it is the Current Working Directory.
`-collections` is a space delimited list of paths to Collections
When a Collection directory contains a file `plugins.rakuon`, then the utility will inspect the release directory, updates it, and maps (copy) the most recent plugins according this file. See below for more detail about the specification of `plugins.rakuon`.
When a Collection does not contain a file <plugins.rakuon>, it generates one from the `plugin-required` key of each of the `config.raku` files in each Mode. During this process, the user is prompted for the directory name (relative to the current working directory) of released plugin directory.
# Problems and TODO items
## Archiving and Minor Changes
In principle, if a small change is made in a source file of a Collection, only the rendered version of that file should be changed, and the Collection pages (eg., the index and the glossaries) updated. The archiving method chosen here is based on `Archive::Libarchive` and a `.7z` format. It works in tests where a small quantity of data is stored.
**However**, when there are many source files (eg., the Raku documentation), the process of restoring state information is **significantly** longer than re-rendering all the cached files. Consequently, the option `no-preserve-state` prevents the archiving of processed state. (TODO understanding and optimising the de-archiving process.)
## Dump file formatting
The aim is to use `PrettyDump` instead of <.raku> to transform information into text. However, does not handle `Bags` properly.
# Post-cache methods
Post-cache is a role added to a `Pod::From::Load` object so that Setup plugin callables can act on Cache'd content by adding pod files to the Cache (perhaps pre-processing primary source files) that will be rendered, masking primary pod files so that they are not rendered, or aliasing primary pod files.
If a secondary source file in the Cache is given a name that is the same as a primary source file, then if the underlying cache object should remain visible, another name (alias) should be given to the file in the Post-cache database.
The Post-cache methods `sources`, `list-files`, and `pod` have the same function and semantics as `Pod::From::Cache` except that the post-cache database is searched first, and if contents are found there, the contents are returned (which is why post-cache file names hide primary file names). If there is no name in the Post-cache database, then it is passed on to the underlying cache.
## multi method add(Str $fn, Array $p --> Pod::From::Cache )
Adds the filename $fn to the cache. $p is expected to be an array of Pod::Blocks, but no check is made. This is intentional to allow the developer flexibility, but then a call to `pod( $fn )` will yield an array that is not POD6, which might not be expected.
The invocant is returned, thus allowing add to be chained with mask and alias.
## multi method mask(Str $fn --> Pod::From::Cache)
This will add only a filename to the database, and thus mask any existing filename in the underlying cache.
Can be chained.
## multi method add-alias(Str $fn, Str :alias! --> Pod::From::Cache)
This will add a filename to the database, with the value of a key in the underlying cache. Chain with mask to prevent the original spelling of the filename in the underlying cache being visible.
Can be chained.
If the alias is already taken, an exception is thrown. This will even occur if the same alias is used for the same cached content file.
## method behind-alias(Str $fn --> Str )
Returns the original name of the cached content file, if an alias has been created, otherwise returns the same filename.
## method pod(Str $fn)
Will return
* an array of Pod::Block (or other content - beware of adding other content) if the underlying Cache or database have content,
* the array of Pod::Block in an underlying filename, spelt differently
* `Nil` if there is no content (masking an underlying file in Cache)
* throw a NoPodInCache Exception if there is no pod associated with either the database or the underlying cache. If the original filename is used after an alias have been generated, the Exception will also be thrown.
## multi method last-version( @version-data )
The `@version-data` contains an array of strings to be given to a `run` sub. Typically it is a call to `git revparse`. The return value is the result of the command to the Operating System.
# head
multi method last-version( @per-file-version, $fn, $doc-source, :debug)
The `@per-file-version` array of strings is appended by the value of $fn, changed to the underlying source if it is an alias.
Typically, the string is a git command. However, the git command in particular runs on a directory, but the source file may be in a sub-directory, which needs to be stripped, so `$doc-source` is provided to enable the correct filename.
`:debug` generates information about the `run` command, if true.
# Asset-cache methods
Asset-cache handles content that is not in Pod6 form. The instance of the Asset-cache class is passed via the plugin-data interface of `ProcessedPod`, so it is available to all plugin callables after the setup milestone, for example in the plugin callable:
```
sub render-plugin( $pp ) {
my $image-manager = $pp.get-data('image-manager');
...
$pp.add-data('custom-block', $image-manager);
}
```
By creating a name-space in the plugin data section and assigning it the value of the image-manager, the plugin callable can make the image-manager available to templates that get that data, which is a property in parameters called by the name-space.
`ProcessedPod` provides data from the name-space of a Block, if it exists, as a parameter to the template called for the Block. Note that the default name-space for a block is all lower-case, unless a `name-space` config option is provided with the Pod Block in the content file.
If a plugin provides an asset (eg., image, jquery script), it needs to provide a `render` callable that returns the triple so that Collect moves the asset from the plugin directory to the output directory where it can be served. This needs to be done separately if a CSS contains a url for local image.
The basename for the assets is set in the Top level configuration in the option `asset-basename`
`$image-manager` is of type Asset-cache, which has the following methods:
```
#| the directory base, not included in filenames
has Str $.basename is rw;
#| the name of the file being rendered
Str $.current-file
#| asset-sources provides a list of all the items in the cache
method asset-sources
#| asset-used-list provides a list of all the items that referenced by Content files
method asset-used-list
#| asset-add adds an item to the data-base, for example, a transformed image
method asset-add( $name, $object, :$by = (), :$type = 'image' )
#| returns name / type / by information in database (not the object blob)
method asset-db
#| remove the named asset, and return its metadata
method asset-delete( $name --> Hash )
#| returns the type of the asset
method asset-type( $name --> Str )
#| if an asset with name and type exists in the database, then it is marked as used by the current file
#| returns true with success, and false if not.
method asset-is-used( $asset, $type --> Bool )
#| brings all assets in directory with given extensions and with type
#| these are set in the configuration
multi method asset-slurp( $directory, @extensions, $type )
#| this just takes the value of the config key in the top-level configuration
multi method asset-slurp( %asset-paths )
#| with type 'all', all the assets are sent to the same output directory
multi method asset-spurt( $directory, $type = 'all' )
#| the value of the config key in the mode configuration
multi method asset-spurt( %asset-paths )
```
# Copyright and License
(c) Copyright, 2021-2022 Richard Hainsworth
**LICENSE** Artistic-2.0
---
Rendered from README at 2024-04-22T12:38:14Z
|
## dist_github-antifessional-Net-Jupyter.md
# Net::Jupyter
## SYNOPSIS
Net::Jupyter is a Perl6 Jupyter kernel
## Introduction
This is a perl6 kernel for jupyter
the minumum required messages are implemented: kernel\_info\_request and execute\_request
also implemented: shutdown\_request
#### Version 0.1.3
#### Status
In development.
Todo:
1. Implement Magic statements (see section below)
2. Implement additional messages
#### Alternatives
1. <https://github.com/timo/iperl6kernel>
2. <https://github.com/bduggan/p6-jupyter-kernel>
#### Portability
relies on [Net::ZMQ](https://github.com/gabrielash/perl6-zmq)
## Documentation
see also <http://jupyter.org/>
### Installation
First, install the module:
```
git clone https://github.com/gabrielash/p6-net-jupyter
cd p6-net-jupyter
zef install .
```
then, install the kernel:
```
bin/kernel-install.sh [ dir ]?
```
Assuming jupyter is already installed on your system, and LOCAL\_HOME is defined,
it will try to install in the correct .local subdir that Anaconda recognizes
for jupyter kernels. You can also specify a custom dirctory as an argument.
### Docker Installation
```
docker run -d --name jupyter-als \
-p 8888:8888 \
-v $CONFIG:/home/jovyan/.jupyter \
-v $NOTEBOOKS:/home/jovyan/work \
gabrielash/all-spark-notebook
```
1. set CONFIG to the directory (Full Path) for overriding jupyter settings. For example
to substitute a fixed authentification token. There is a demo
jupyter\_notebook\_config.py in the docker dir that you can copy into it and edit.
2. set NOTEBOOKS to the directory that will hold all notebooks created. It will be the top directory
for the Jupyter server.
see also [Jupyter's all-spark-notebook docker image](https://github.com/jupyter/docker-stacks/tree/master/all-spark-notebook)
An alternative minimal image based on jupyter base-notebook is also provided.
see the docker directory.
### Magic declarations
magic declrations are lines beginning and ending with %%.
All magic declarations apply to the whole cell, must come at the top, and cannot be interleaved
with Perl6 code.
#### Implemented:
```
%% timeout 5 %%
# sets a timeout on execution
%% class Classname %%
does Positional {
...
}
# defines a class. Note that the magic declaration replaces the beginning
# of the class declaration, but any qualification must follow outside it
```
|
## dist_github-dankogai-Num-HexFloat.md
[](https://github.com/dankogai/p6-num-hexfloat/actions/workflows/test.yml)
# NAME
Num::HexFloat - Rudimentary C99 Hexadecimal Floating Point Support in Perl6
## SYNOPSIS
```
use v6;
use Num::HexFloat;
say to-hexfloat(pi);
# '0x1.921fb54442d18p+1'
say from-hexfloat('0x1.921fb54442d18p+1') == pi;
# True
my $src = "e=0x1.5bf0a8b145769p+1, pi=0x1.921fb54442d18p+1";
say $src.subst($RE_HEXFLOAT, &from-hexfloat, :g);
# e=2.71828182845905, pi=3.14159265358979
```
## DESCRIPTION
`Num::HexFloat` exports the following:
### `$RE_HEXFLOAT`
A regex that matches hexadecimal floating point notation.
### `from-hexfloat($arg) returns Num`
Parses `$arg` as a C99 hexadecimal floating point notation and returns
`Num`, or `NaN` if it fails.
`$arg` can be either `Str` or `Match` so you can go like:
```
$src.subst($RE_HEXFLOAT, &from-hexfloat, :g);
```
### `to-hexfloat(Numeric $num) returns Str`
Stringifies `$num` in C99 hexadecimal floating point notation.
|
## mustbestarted.md
class X::Proc::Async::MustBeStarted
Error due to interacting with a Proc::Async stream before spawning its process
```raku
class X::Proc::Async::MustBeStarted is Exception {}
```
Several methods from [`Proc::Async`](/type/Proc/Async) expect that the external program has been spawned (by calling `.start` on it), including `say`, `write`, `print` and `close-stdin`. If one of those methods is called before `.start` was called, they throw an exception of type `X::Proc::Async::MustBeStarted`.
```raku
Proc::Async.new('echo', :w).say(42);
CATCH { default { put .^name, ': ', .Str } };
# OUTPUT: «X::Proc::Async::MustBeStarted: Process must be started first before calling 'say'»
```
# [Methods](#class_X::Proc::Async::MustBeStarted "go to top of document")[§](#Methods "direct link")
## [method method](#class_X::Proc::Async::MustBeStarted "go to top of document")[§](#method_method "direct link")
```raku
method method(X::Proc::Async::MustBeStarted:D --> Str:D)
```
Returns the name of the method that was illegally called before starting the external program.
|
## about.md
About the docs
How to contribute to Raku and to the documents, how to generate the docs locally
This document collection represents the on-going effort to document the Raku programming language with the goals of being comprehensive, easy to use, easy to navigate, and useful to both newcomers and experienced Raku programmers.
An [HTML version of the documentation](https://docs.raku.org) is available.
The official source for this documentation is located at [Raku/doc on GitHub](https://github.com/Raku/doc).
# [Structure](#About_the_docs "go to top of document")[§](#Structure "direct link")
All of the documentation is written in Raku Pod and kept in the `doc/` directory. These files are processed are rendered to HTML, and also processed into some generated pages, using the `.rakudoc` files as sources.
# [Generating HTML from Pod](#About_the_docs "go to top of document")[§](#Generating_HTML_from_Pod "direct link")
The build process is managed through a separate repository, [Raku/doc-website on GitHub](https://github.com/Raku/doc-website).
# [Contributing](#About_the_docs "go to top of document")[§](#Contributing "direct link")
For a quick introduction to Raku Pod, see [Raku Pod](/language/pod).
For historic details about the Raku Pod specification, see [Synopsis 26, Documentation](https://github.com/Raku/old-design-docs/blob/master/S26-documentation.pod).
For information on how to contribute to the documentation, please read [CONTRIBUTING.md](https://github.com/Raku/doc/blob/main/CONTRIBUTING.md).
|
## dist_cpan-ARNE-Transit-Network.md
# NAME
Transit::Network - Plan and set up public transportation routes or networks
# SYNOPSIS
```
use Transit::Network;
```
# DESCRIPTION
Transit::Network (and the bundled programs) enables you to plan and set up public transportation
routes or complete networks.
See <https://raku-musings.com/transit-network/> for a description of this module.
The module comes with some sample networks. Use the «--help» command line option, or the «help»
command, to get the location of the zip file.
```
$ networkplanner --help
$ networkplanner
networkplanner: Enter «exit» to exit
> help
```
# AUTHOR
Arne Sommer [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2021-2022 Arne Sommer
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-guifa-Intl-Token-Number.md
# Intl::Token::Number
A regex token for detecting localized numbers
To use, simply include the token `<local-number>` in anything interpreted as regex.
```
use Intl::Token::Number;
# (assuming English)
if '15,859,333.41' ~~ /<local-number>/ {
say ~$<local-number>; # 15,859,333.41 <-- stringified
say +$<local-number>; # 15859333.41 <-- numerical
}
```
The `<local-number>` token defaults to using the language provided by `user-language`.
This makes it quite useful for parsing CLI. Sometimes, though, you'll want / need to specify the language directly.
Just include it after a colon:
```
# Korean uses commas to separate thousands
'1,234' ~~ /<local-number: 'ko'>/;
say +$<local-number>; # 1234
# Spanish uses commas to separate integers from fractionals
'1,234' ~~ /<local-number: 'es'>/;
say +$<local-number>; # 1.234
```
Formats including percents, permilles, and exponential notation are supported:
```
# Assuming English
'90%' ~~ /<local-number>/;
say +$<local-number>; # 0.9
'1.23E3' ~~ /<local-number>/;
say +$<local-number>; # 123
```
For those interested in details about the match, the match object is introspectable:
* `base-number`: the number matched, ignoring percent/exponential modifiers
* `exponent`: the exponent used (defaults to 1 for non-exponential numbers)
* `number-type`: any of `standard`, `percent`, `permille`, `exponential`
## To do
* Add support for native/traditional/financial-style numbers
* Add support for lenient parsing (e.g. accept any of `<,٫⹁︐﹐,>` for `,`).
* This will be very important for languages like Finnish, which uses a non-breaking space, but is probably entered as a plain space by most people.
* Enforce grouping digits? Present, *1,2,3,4* will parse as *1234*.
* Additional formats like approximately, at least, etc.
## Version history
* **v0.6**
* Optimized grammar
* Now uses RakuAST for generation.
* Match role provides more introspection
* Now prefer `User::Language` to `Intl::UserLanguage`
* **v.0.5.0**
* First published version as an independent module
* Adapted to work with newest version of `Intl::CLDR`
* Housekeeping
* Cleaned up code, added documentation, improved tests
* **v.0.4.2**
* Renamed to **Intl::CLDR::Numbers**
* **v.0.4.1**
* Published as a part of `Intl::CLDR` (as `Intl::CLDR::Numbers::NumberFinder`)
* Support for basic number parsing using default numeric systems
|
## win32.md
class IO::Spec::Win32
Platform specific operations on file and directory paths for Windows
```raku
class IO::Spec::Win32 is IO::Spec::Unix { }
```
An object of this type is available via the variable `$*SPEC` if the Raku interpreter is running on a Windows-like platform.
About this class and its related classes also see [`IO::Spec`](/type/IO/Spec).
# [Methods](#class_IO::Spec::Win32 "go to top of document")[§](#Methods "direct link")
## [method basename](#class_IO::Spec::Win32 "go to top of document")[§](#method_basename "direct link")
```raku
method basename(Str:D $path --> Str:D)
```
Takes a path as a string and returns a possibly-empty portion after the last slash or backslash:
```raku
IO::Spec::Win32.basename("foo/bar/") .raku.say; # OUTPUT: «""»
IO::Spec::Win32.basename("foo/bar\\").raku.say; # OUTPUT: «""»
IO::Spec::Win32.basename("foo/bar/.").raku.say; # OUTPUT: «"."»
IO::Spec::Win32.basename("foo/bar") .raku.say; # OUTPUT: «"bar"»
```
## [method canonpath](#class_IO::Spec::Win32 "go to top of document")[§](#method_canonpath "direct link")
```raku
method canonpath(Str() $path, :$parent --> Str:D)
```
Returns a string that is a canonical representation of `$path`. If `:$parent` is set to true, will also clean up references to parent directories. **NOTE:** the routine does not access the filesystem.
```raku
IO::Spec::Win32.canonpath("C:/foo//../bar/../ber").say;
# OUTPUT: «C:\foo\..\bar\..\ber»
IO::Spec::Win32.canonpath("C:/foo///./../bar/../ber").say;
# OUTPUT: «C:\foo\..\bar\..\ber»
IO::Spec::Win32.canonpath("C:/foo///./../bar/../ber", :parent).say;
# OUTPUT: «C:\ber»
```
## [method catdir](#class_IO::Spec::Win32 "go to top of document")[§](#method_catdir "direct link")
```raku
method catdir (*@parts --> Str:D)
```
Concatenates multiple path fragments and returns the canonical representation of the resultant path as a string. The `@parts` are [`Str`](/type/Str) objects and are allowed to contain path separators.
```raku
IO::Spec::Win32.catdir(<foo/bar ber raku>).say;
# OUTPUT: «foo\bar\ber\raku»
```
## [method catfile](#class_IO::Spec::Win32 "go to top of document")[§](#method_catfile "direct link")
Alias for [`catdir`](/routine/catdir).
## [method catpath](#class_IO::Spec::Win32 "go to top of document")[§](#method_catpath "direct link")
```raku
method catpath (Str:D $volume, Str:D $dir, Str:D $file --> Str:D)
```
Concatenates a path from given volume, a chain of directories, and file. An empty string can be given for any of the three arguments. No attempt to make the path canonical is made. Use [`canonpath`](/routine/canonpath) for that purpose.
```raku
IO::Spec::Win32.catpath('C:', '/some/dir', 'foo.txt').say;
# OUTPUT: «C:/some/dir\foo.txt»
IO::Spec::Win32.catpath('C:', '/some/dir', '').say;
# OUTPUT: «C:/some/dir»
IO::Spec::Win32.catpath('', '/some/dir', 'foo.txt').say;
# OUTPUT: «/some/dir\foo.txt»
IO::Spec::Win32.catpath('E:', '', 'foo.txt').say;
# OUTPUT: «E:foo.txt»
```
## [method devnull](#class_IO::Spec::Win32 "go to top of document")[§](#method_devnull "direct link")
```raku
method devnull(--> Str:D)
```
Returns the string `"nul"` representing the ["Null device"](https://en.wikipedia.org/wiki/Null_device):
```raku
$*SPEC.devnull.IO.spurt: "foo bar baz";
```
## [method dir-sep](#class_IO::Spec::Win32 "go to top of document")[§](#method_dir-sep "direct link")
```raku
method dir-sep(--> Str:D)
```
Returns the string `「\」` representing canonical directory separator character.
```raku
IO::Spec::Win32.dir-sep.say; # OUTPUT: «\»
```
## [method is-absolute](#class_IO::Spec::Win32 "go to top of document")[§](#method_is-absolute "direct link")
```raku
method is-absolute(Str:D $path --> Bool:D)
```
Returns `True` if the `$path` starts with a slash (`"/"`) or backslash (`"\"`), even if they have combining character on them, optionally preceded by a volume:
```raku
say IO::Spec::Win32.is-absolute: "/foo"; # OUTPUT: «True»
say IO::Spec::Win32.is-absolute: "/\x[308]foo"; # OUTPUT: «True»
say IO::Spec::Win32.is-absolute: 「C:\foo」; # OUTPUT: «True»
say IO::Spec::Win32.is-absolute: "bar"; # OUTPUT: «False»
```
## [method join](#class_IO::Spec::Win32 "go to top of document")[§](#method_join "direct link")
```raku
method join (Str:D $volume, Str:D $dir, Str:D $file --> Str:D)
```
Similar to [`catpath`](/routine/catpath), takes two path fragments and concatenates them, adding or removing a path separator, if necessary, except it will return just `$file` if both `$dir` and `$file` are string `'/'` or if `$dir` is the string `'.'`. The first argument is ignored (it exists to maintain consistent interface with other [`IO::Spec`](/type/IO/Spec) types for systems that have volumes).
```raku
IO::Spec::Win32.join('C:', '/some/dir', 'foo.txt').say;
# OUTPUT: «C:/some/dir\and/more»
IO::Spec::Win32.join('C:', '.', 'foo.txt').say;
# OUTPUT: «C:foo.txt»
IO::Spec::Win32.join('C:', 「\」, '/').say;
# OUTPUT: «C:\»
IO::Spec::Win32.join('//server/share', 「\」, '/').say;
# OUTPUT: «//server/share»
IO::Spec::Win32.join('E:', '', 'foo.txt').say;
# OUTPUT: «E:foo.txt»
```
## [method path](#class_IO::Spec::Win32 "go to top of document")[§](#method_path "direct link")
```raku
method path(--> Seq:D)
```
Splits the value of `%*ENV<PATH>` (or `%*ENV<Path>` if the former is not set) on semicolons (`";"`) and returns a [`Seq`](/type/Seq) with each of the resultant parts, always adding element `"."` to the head. Removes all double quotes (`"`) it finds.
```raku
%*ENV<PATH> = 'foo;"bar"/"ber"';
IO::Spec::Win32.path.raku.say; # OUTPUT: «(".", "foo", "bar/ber").Seq»
```
## [method rel2abs](#class_IO::Spec::Win32 "go to top of document")[§](#method_rel2abs "direct link")
```raku
method rel2abs(Str() $path, $base = $*CWD --> Str:D)
```
Returns a string representing `$path` converted to absolute path, based at `$base`, which defaults to `$*CWD`. If `$base` is not an absolute path, it will be made absolute relative to `$*CWD`, unless `$*CWD` and `$base` are the same.
```raku
say $*CWD; # OUTPUT: «"C:\Users\camelia".IO»
say IO::Spec::Win32.rel2abs: 'foo'; # OUTPUT: «C:\Users\camelia\foo»
say IO::Spec::Win32.rel2abs: './'; # OUTPUT: «C:\Users\camelia»
say IO::Spec::Win32.rel2abs: 'foo/../../'; # OUTPUT: «C:\Users\camelia\foo\..\..»
say IO::Spec::Win32.rel2abs: '/foo/'; # OUTPUT: «C:\foo»
say IO::Spec::Win32.rel2abs: 'foo', 'bar'; # OUTPUT: «C:\Users\camelia\bar\foo»
say IO::Spec::Win32.rel2abs: './', '/bar'; # OUTPUT: «\bar»
say IO::Spec::Win32.rel2abs: '/foo/', 'bar'; # OUTPUT: «C:\foo»
say IO::Spec::Win32.rel2abs: 'foo/../../', 'bar';
# OUTPUT: «C:\Users\camelia\bar\foo\..\..»
```
## [method rootdir](#class_IO::Spec::Win32 "go to top of document")[§](#method_rootdir "direct link")
```raku
method rootdir(--> Str:D)
```
Returns string `「\」`, representing root directory.
## [method split](#class_IO::Spec::Win32 "go to top of document")[§](#method_split "direct link")
```raku
method split(IO::Spec::Win32: Cool:D $path)
```
Creates an [`IO::Path::Parts`](/type/IO/Path/Parts) for `$path`.
```raku
IO::Spec::Win32.split('C:/foo/bar.txt').raku.say;
# OUTPUT: «IO::Path::Parts.new("C:","/foo","bar.txt")»
IO::Spec::Win32.split('/foo/').raku.say;
# OUTPUT: «IO::Path::Parts.new("","/","foo")»
IO::Spec::Win32.split('///').raku.say;
# OUTPUT: «IO::Path::Parts.new("","/","\\")»
IO::Spec::Win32.split('./').raku.say;
# OUTPUT: «IO::Path::Parts.new("",".",".")»
IO::Spec::Win32.split('.').raku.say;
# OUTPUT: «IO::Path::Parts.new("",".",".")»
IO::Spec::Win32.split('').raku.say;
# OUTPUT: «IO::Path::Parts.new("","","")»
```
**Note**: Before Rakudo version 2020.06 this method split the given `$path` into "volume", "dirname", and "basename" and returned the result as a [`List`](/type/List) of three [`Pair`](/type/Pair)s, in that order.
## [method splitdir](#class_IO::Spec::Win32 "go to top of document")[§](#method_splitdir "direct link")
```raku
method splitdir(Cool:D $path --> List:D)
```
Splits the given `$path` on slashes and backslashes.
```raku
IO::Spec::Win32.splitdir('C:\foo/bar.txt').raku.say;
# OUTPUT: «("C:", "foo", "bar.txt")»
IO::Spec::Win32.splitdir('/foo/').raku.say;
# OUTPUT: «("", "foo", "")»
IO::Spec::Win32.splitdir('///').raku.say;
# OUTPUT: «("", "", "", "")»
IO::Spec::Win32.splitdir('./').raku.say;
# OUTPUT: «(".", "")»
IO::Spec::Win32.splitdir('.').raku.say;
# OUTPUT: «(".",)»
IO::Spec::Win32.splitdir('').raku.say;
# OUTPUT: «("",)»
```
## [method splitpath](#class_IO::Spec::Win32 "go to top of document")[§](#method_splitpath "direct link")
```raku
method splitpath(Cool:D $path, :$nofile --> List:D)
```
Splits the given `$path` into a list of 3 strings: volume, dirname, and file. The volume is always an empty string, returned for API compatibility with other [`IO::Spec`](/type/IO/Spec) types. If `:$nofile` named argument is set to `True`, the content of the file string is undefined and should be ignored; this is a means to get a performance boost, as implementations may use faster code path when file is not needed.
```raku
IO::Spec::Win32.splitpath('C:\foo/bar.txt').raku.say;
# OUTPUT: «("C:", "\\foo/", "bar.txt")»
IO::Spec::Win32.splitpath('C:\foo/bar.txt', :nofile).raku.say;
# OUTPUT: «("C:", "\\foo/bar.txt", "")»
IO::Spec::Win32.splitpath('/foo/').raku.say;
# OUTPUT: «("", "/foo/", "")»
IO::Spec::Win32.splitpath('/foo/', :nofile).raku.say;
# OUTPUT: «("", "/foo/", "")»
IO::Spec::Win32.splitpath('///').raku.say;
# OUTPUT: «("", "///", "")»
IO::Spec::Win32.splitpath('./').raku.say;
# OUTPUT: «("", "./", "")»
IO::Spec::Win32.splitpath('.').raku.say;
# OUTPUT: «("", "", ".")»
IO::Spec::Win32.splitpath('').raku.say;
# OUTPUT: «("", "", "")»
```
## [method tmpdir](#class_IO::Spec::Win32 "go to top of document")[§](#method_tmpdir "direct link")
```raku
method tmpdir(--> IO::Path:D)
```
Attempts to locate a system's temporary directory by checking several typical directories and environment variables. Uses current directory if no suitable directories are found.
|
## dist_zef-raku-community-modules-Lingua-EN-Stem-Porter.md
[](https://github.com/raku-community-modules/Lingua-EN-Stem-Porter/actions)
# NAME
Lingua::EN::Stem::Porter - Implementation of the Porter stemming algorithm
# SYNOPSIS
```
use Lingua::EN::Stem::Porter;
say porter("establishment"); # establish
```
# DESCRIPTION
Lingua::EN::Stem::Porter implements the Porter stemming algorithm by exporting a single subroutine `porter` which takes an English word and returns the stem given by the Porter algorithm.
# AUTHOR
John Spurr
# COPYRIGHT AND LICENSE
Copyright 2016 John Spurr
Copyright 2017 - 2022 Raku Community
This library is free software; you can redistribute it and/or modify it under the MIT License 2.0.
|
## dist_github-Raku-Noise-Gang-Music-Helpers.md
# NAME
Music::Helpers - Abstractions for handling musical content
# SYNOPSIS
```
use Music::Helpers;
my $mode = Mode.new(:root(C), :mode('major'))
# prints 'C4 E4 G4 ==> C maj (inversion: 0)'
say $mode.tonic.Str;
# prints 'F4 A4 C5 ==> F maj (inversion: 0)'
say $mode.next-chord($mode.tonic, intervals => [P4]).Str;
```
# DESCRIPTION
This module provides a few OO abstraction for handling musical content. Explicitly these are the classes `Mode`, `Chord` and `Note` as well as Enums `NoteName` and `Interval`. As anyone with even passing musical knowledge knows, `Mode`s and `Chord`s consists of `Note`s with one of those being the root and the others having a specific half-step distance from this root. As the main purpose for this module is utilizing these classes over MIDI (via [Audio::PortMIDI](https://github.com/jonathanstowe/Audio-PortMIDI/)), non-standard tunings will have to be handled by the instruments that play these notes. For convenience two enums, `NoteName` and `Interval` are exported as well. Note that the former uses only sharp notes, and uses a lower case 's' as the symbol for that, e.g:
```
say Cs; # works
say C#, Db, C♯, D♭; # don't work
```
`Interval` only exports from unison to octave:
```
# prints (P1 => 0 m2 => 1 M2 => 2 m3 => 3 M3 => 4 P4 => 5 TT => 6 P5 => 7 m6 => 8 M6 => 9 m7 => 10 M7 => 11 P8 => 12)
say Interval.enums.sort(*.value);
```
The arithmetic operators `&infix:<+>` and `&infix:<->` are overloaded and exported for any combination between `Note`s and `Interval`s, and return new `Note`s or `Interval`s, depending on invocation:
```
my $c = Note.new(:48midi);
# $g contains 'Note.new(:43midi)'
my $g = ($c - P4);
# prints 'P4'
say $c - $g;
```
A `Mode` knows, which natural triads it contains, and memoizes the `Note`s and `Chord`s on each step of the scale for probably more octaves than necessary. (That is, 10 octaves, from C-1 to C9, MIDI values 0 to 120.) Further, a `Chord` knows via a set of Roles applied at construction time, which kind of alterations on it are feasible. E.g:
```
my $mode = Mode.new(:root(F), :mode<major>);
my $fmaj = $mode.tonic;
my $fdom7 = $fmaj.dom7;
# prints 'F4 G4 C5 => F4 sus2 (inversion: 0)'
say $fsus2.Str;
my $mode = Mode.new(:root(F), :mode<minor>);
my $fmin = $mode.tonic;
# dies, "Method 'dom7' not found for invocant of class 'Music::Helpers::Chord+{Music::Helpers::min}'
my $fdom7 = $fmin.dom7;
```
Although I do readily admit that not all possible alterations and augmentations are currently implemented. A `Chord` tells you, which variants it support via the methods `.variant-methods` and `.variant-roles`:
```
my @notes = do [ Note.new(midi => $_ + 4 * P8) for C, E, G];
my $chord = Chord.new(:@notes, :0inversion);
# prints '[(sus2) (sus4) (maj6) (maj7) (dom7)]'
say $chord.variant-roles;
# prints '[sus2 sus4 maj6 maj7 dom7]'
say $chord.variant-methods;
# prints 'C4 E4 G4 B4 ==> C4 maj7 (inversion: 0)'
say $chord.variant-methods[3]($chord);
```
Note that `.variant-methods` is usually what you want to use when trying to create a variant of a given `Chord`.
Further, positive and negative inversions are supported via the method `.invert`:
```
# prints 'C5 F5 A5 ==> F5 maj (inversion: 2)'
say $fmaj.invert(2).Str;
# prints 'C4 F4 A4 ==> F4 maj (inversion: 2)'
say $fmaj.invert(-1).Str;
```
Finally, a `Note` knows how to build a `Audio::PortMIDI::Event` that can be sent via a `Audio::PortMIDI::Stream`, and a `Chord` knows to ask the `Note`s it consists of for these Events:
```
# prints a whole lot, not replicated for brevity
say $fmaj.OnEvents;
```
Note that this documentation is a work in progress. The file bin/example.pl6 in this repository might be of interest.
|
## routine.md
class Routine
Code object with its own lexical scope and `return` handling
```raku
class Routine is Block { }
```
A `Routine` is a code object meant for units of code larger than [`Block`](/type/Block). Routine is the common superclass for [`Sub`](/type/Sub) (and therefore operators) and [`Method`](/type/Method), the two primary code objects for code reuse, as well as [`Macro`](/type/Macro) and [`Submethod`](/type/Submethod).
Routines serve as a scope limiter for `return` (i.e. a `return` returns from the innermost outer Routine).
The routine level is also the one at which [multiness](/language/glossary#Multi-dispatch) (multi subs and multi methods) are handled. Subroutines can also be declared `anon`. See the [documentation on the `anon` declarator](/language/variables#The_anon_declarator) for more information.
Routines are the lowest objects in the [`Code`](/type/Code) hierarchy that can introspect through the [`&?ROUTINE` variable](/language/variables#%26%3FROUTINE), which is defined automatically, and contains the corresponding `Routine` object.
```raku
class Foo {
submethod bar { &?ROUTINE.^name }
};
say Foo.bar; # OUTPUT: «Submethod»
```
# [Methods](#class_Routine "go to top of document")[§](#Methods "direct link")
## [method name](#class_Routine "go to top of document")[§](#method_name "direct link")
```raku
method name(Routine:D: --> Str:D)
```
Returns the name of the sub or method.
## [method package](#class_Routine "go to top of document")[§](#method_package "direct link")
```raku
method package(Routine:D:)
```
Returns the package in which the routine is defined.
## [method multi](#class_Routine "go to top of document")[§](#method_multi "direct link")
```raku
method multi(Routine:D: --> Bool:D)
```
Returns `True` if the routine is a multi sub or method. Note that the name of a multi sub refers to its [`proto`](/syntax/proto) and this method would return false if called on it. It needs to be called on the candidates themselves:
```raku
multi foo ($, $) {};
say &foo.multi; # OUTPUT: «False»
say &foo.candidates».multi; # OUTPUT: «(True)»
```
## [method candidates](#class_Routine "go to top of document")[§](#method_candidates "direct link")
```raku
method candidates(Routine:D: --> Positional:D)
```
Returns a list of multi candidates, or a one-element list with itself if it's not a multi
## [method cando](#class_Routine "go to top of document")[§](#method_cando "direct link")
```raku
method cando(Capture $c)
```
Returns a possibly-empty list of candidates that can be called with the given [`Capture`](/type/Capture), ordered by narrowest candidate first. For methods, the first element of the Capture needs to be the invocant:
```raku
.signature.say for "foo".^can("comb")[0].cando: \(Cool, "o");
# OUTPUT: «(Cool $: Str $matcher, $limit = Inf, *%_)»
```
## [method wrap](#class_Routine "go to top of document")[§](#method_wrap "direct link")
```raku
method wrap(Routine:D: &wrapper)
```
Wraps (i.e. in-place modifies) the routine. That means a call to this routine first calls `&wrapper`, which then can (but doesn't have to) call the original routine with the `callsame`, `callwith`, `nextsame` and `nextwith` dispatchers. The return value from the routine is also the return value from the wrapper.
`wrap` returns an instance of a private class called [`Routine::WrapHandle`](/type/Routine/WrapHandle), which you can pass to [unwrap](/routine/unwrap) to restore the original routine.
## [method unwrap](#class_Routine "go to top of document")[§](#method_unwrap "direct link")
```raku
method unwrap($wraphandle)
```
Restores the original routine after it has been wrapped with [wrap](/routine/wrap). While the signature allows any type to be passed, only the [`Routine::WrapHandle`](/type/Routine/WrapHandle) type returned from `wrap` can usefully be.
## [method is-wrapped](#class_Routine "go to top of document")[§](#method_is-wrapped "direct link")
```raku
method is-wrapped()
```
Returns `True` or `False`, depending on the whether or not the `Routine` is wrapped.
## [method yada](#class_Routine "go to top of document")[§](#method_yada "direct link")
```raku
method yada(Routine:D: --> Bool:D)
```
Returns `True` if the routine is a stub
```raku
say (sub f() { ... }).yada; # OUTPUT: «True»
say (sub g() { 1; }).yada; # OUTPUT: «False»
```
## [trait is cached](#class_Routine "go to top of document")[§](#trait_is_cached "direct link")
```raku
multi trait_mod:<is>(Routine $r, :$cached!)
```
Causes the return value of a routine to be stored, so that when subsequent calls with the same list of arguments are made, the stored value can be returned immediately instead of re-running the routine.[[1]](#fn1)
Useful when storing and returning the computed value is much faster than re-computing it every time, and when the time saved trumps the cost of the use of more memory.
Even if the arguments passed to the routine are "reference types" (such as objects or arrays), then for the purpose of caching they will only be compared based on their contents. Thus the second invocation will hit the cache in this case:
```raku
say foo( [1, 2, 3] ); # runs foo
say foo( [1, 2, 3] ); # doesn't run foo, uses cached value
```
Since it's still at the experimental stage, you will have to insert the `use experimental :cached;` statement in any module or script that uses it.
```raku
use experimental :cached;
sub nth-prime(Int:D $x where * > 0) is cached {
say "Calculating {$x}th prime";
return (2..*).grep(*.is-prime)[$x - 1];
}
say nth-prime(43);
say nth-prime(43);
say nth-prime(43);
```
produces this output:
「text」 without highlighting
```
```
Calculating 43th prime
191
191
191
```
```
**Note**: This feature is not thread-safe.
## [trait is pure](#class_Routine "go to top of document")[§](#trait_is_pure "direct link")
```raku
multi trait_mod:<is>(Routine $r, :$pure!)
```
Marks a subroutine as *pure*, that is, it asserts that for the same input, it will always produce the same output without any additional side effects.
The `is pure` trait is a promise by the programmer to the compiler that it can constant-fold calls to such functions when the arguments are known at compile time.
```raku
sub syllables() is pure {
say "Generating syllables";
my @vowels = <a e i o u>;
return @vowels.append: <k m n sh d r t y> X~ @vowels;
}
```
You can mark function as pure even if they throw exceptions in edge cases or if they modify temporary objects; hence the `is pure` trait can cover cases that the compiler cannot deduce on its own. On the other hand, you might not want to constant-fold functions that produce a large return value (such as the string or list repetition operators, infix `x` and `xx`) even if they are pure, to avoid large precompilation files.
To see it an action with a particular compiler you can try this example:
```raku
BEGIN { say ‘Begin’ }
say ‘Start’;
say (^100).map: { syllables().pick(4).join("") };
# Example output:
# Begin
# Generating syllables
# Start
# (matiroi yeterani shoriyuru...
```
Essentially this allows the compiler to perform some operations at compile time. The benefits of constant-folding *may* include better performance, especially in cases when the folded code is precompiled.
In addition, using a pure function or operator in sink context (that is, where the result is discarded) may lead to a warning. The code
```raku
sub double($x) is pure { 2 * $x };
double(21);
say "anything";
# WARNING: «Useless use of "double(21)" in expression "double(21)" in sink context (line 2)»
```
If you want to apply this trait to a `multi`, you need to apply it to the `proto`; it will not work otherwise, at least in versions 2018.08 and below.
## [trait is rw](#class_Routine "go to top of document")[§](#trait_is_rw "direct link")
```raku
multi trait_mod:<is>(Routine $r, :$rw!)
```
When a routine is modified with this trait, its return value will be writable. This is useful when returning variables or writable elements of hashes or arrays, for example:
```raku
sub walk(\thing, *@keys) is rw {
my $current := thing;
for @keys -> $k {
if $k ~~ Int {
$current := $current[$k];
}
else {
$current := $current{$k};
}
}
$current;
}
my %hash;
walk(%hash, 'some', 'key', 1, 2) = 'autovivified';
say %hash.raku;
```
produces
```raku
("some" => {"key" => [Any, [Any, Any, "autovivified"]]}).hash
```
Note that `return` marks return values as read only; if you need an early exit from an `is rw` routine, you have to use `return-rw` instead.
## [trait is export](#class_Routine "go to top of document")[§](#trait_is_export "direct link")
```raku
multi trait_mod:<is>(Routine $r, :$export!)
```
Marks a routine as exported to the rest of the world
```raku
module Foo {
sub double($x) is export {
2 * $x
}
}
import Foo; # makes sub double available
say double 21; # 42
```
From inside another file you'd say `use Foo;` to load a module and import the exported functions.
See [Exporting and Selective Importing Modules](/language/modules#Exporting_and_selective_importing) for more details.
## [trait is DEPRECATED](#class_Routine "go to top of document")[§](#trait_is_DEPRECATED "direct link")
```raku
multi trait_mod:<is>(Routine:D $r, :$DEPRECATED!)
```
Marks a `Routine` as deprecated; that is, it should no longer be used going forward, and will eventually be removed. An optional message specifying the replacement functionality can be specified
By having both the original (deprecated) and new `Routine` available simultaneously, you can avoid a breaking change in a single release, by allowing users time and instructions on how to update their code. Remove the deprecated version only after at least one release that includes both the warning and the new `Routine`.
This code
```raku
sub f() is DEPRECATED('the literal 42') { 42 }
say f();
```
produces this output:
「text」 without highlighting
```
```
42
Saw 1 occurrence of deprecated code.
================================================================================
Sub f (from GLOBAL) seen at:
deprecated.raku, line 2
Please use the literal 42 instead.
--------------------------------------------------------------------------------
Please contact the author to have these occurrences of deprecated code
adapted, so that this message will disappear!
```
```
## [trait is hidden-from-backtrace](#class_Routine "go to top of document")[§](#trait_is_hidden-from-backtrace "direct link")
```raku
multi trait_mod:<is>(Routine:D, :$hidden-from-backtrace!)
```
Hides a routine from showing up in a default backtrace. For example
```raku
sub inner { die "OH NOEZ" };
sub outer { inner() };
outer();
```
produces the error message and backtrace
「text」 without highlighting
```
```
OH NOEZ
in sub inner at bt.raku:1
in sub outer at bt.raku:2
in block <unit> at bt.raku:3
```
```
but if `inner` is marked with `hidden-from-backtrace`
```raku
sub inner is hidden-from-backtrace { die "OH NOEZ" };
sub outer { inner() };
outer();
```
the error backtrace does not show it:
「text」 without highlighting
```
```
OH NOEZ
in sub outer at bt.raku:2
in block <unit> at bt.raku:3
```
```
## [trait is default](#class_Routine "go to top of document")[§](#trait_is_default "direct link")
```raku
multi trait_mod:<is>(Routine:D $r, :$default!)
```
There is a special trait for `Routine`s called `is default`. This trait is designed as a way to disambiguate `multi` calls that would normally throw an error because the compiler would not know which one to use. This means that given the following two `Routine`s, the one with the `is default` trait will be called.
```raku
multi f() is default { say "Hello there" }
multi f() { say "Hello friend" }
f(); # OUTPUT: «"Hello there"»
```
The `is default` trait can become very useful for debugging and other uses but keep in mind that it will only resolve an ambiguous dispatch between two `Routine`s of the same precedence. If one of the `Routine`s is narrower than another, then that one will be called. For example:
```raku
multi f() is default { say "Hello there" }
multi f(:$greet) { say "Hello " ~ $greet }
f(); # "Use of uninitialized value $greet..."
```
In this example, the `multi` without `is default` was called because it was actually narrower than the [`Sub`](/type/Sub) with it.
## [trait is raw](#class_Routine "go to top of document")[§](#trait_is_raw "direct link")
```raku
multi trait_mod:<is>(Routine:D $r, :$raw!)
```
Gives total access to the data structure returned by the routine.
```raku
my @zipi = <zape zapatilla>;
sub þor() is raw {
return @zipi
};
þor()[1] = 'pantuflo';
say @zipi; # OUTPUT: «[zape pantuflo]»
```
## [trait is test-assertion](#class_Routine "go to top of document")[§](#trait_is_test-assertion "direct link")
```raku
multi trait_mod:<is>(Routine:D, :$test-assertion!)
```
Declares that a routine generates test output (aka TAP). When failures are reported, the calling routine's location is used instead of this routine. For example:
```raku
use Test;
sub foo-test($value) is test-assertion {
is $value, 42, "is the value 42?";
}
foo-test(666); # <-- error is reported on this line
```
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Routine`
raku-type-graph
Routine
Routine
Block
Block
Routine->Block
Mu
Mu
Any
Any
Any->Mu
Callable
Callable
Code
Code
Code->Any
Code->Callable
Block->Code
Sub
Sub
Sub->Routine
Method
Method
Method->Routine
Macro
Macro
Macro->Routine
Submethod
Submethod
Submethod->Routine
Regex
Regex
Regex->Method
[Expand chart above](/assets/typegraphs/Routine.svg)
1 [[↑]](#fnret1) This is still in experimental stage. Please check [the corresponding section in the experimental features document](/language/experimental#cached)
|
## dist_zef-raku-community-modules-System-Passwd.md
[](https://github.com/raku-community-modules/System-Passwd/actions)
# NAME
System::Passwd - easily search for system users on Unix based systems
## DESCRIPTION
System::Passwd is a Raku distribution for searching the `/etc/passwd` file. It provides subroutines to search for a `System::Passwd::User` user by uid, username or full name. `System::Passwd` should work on Linux, Unix, FreeBSD, NetBSD, OpenBSD and MacOS (although not all MacOS users are stored in `/etc/passwd`).
## SYNOPSIS
```
use System::Passwd;
my $root-user = get-user-by-uid(0);
say $root-user.username;
say $root-user.uid;
say $root-user.gid;
say $root-user.fullname;
say $root-user.login-shell;
say $root-user.home-directory;
say $root-user.password; # This won't be a useful value on most systems
# can search for users other methods
my $user = get-user-by-username('sillymoose');
# or:
my $user = get-user-by-fullname('David Farrell');
```
## AUTHOR
David Farrell
# COPYRIGHT AND LICENSE
Copyright 2014 David Farrell
Copyright 2015 - 2022 Raku Community
This library is free software; you can redistribute it and/or modify it under the FreeBSD license.
|
## warn.md
warn
Combined from primary sources listed below.
# [In Exception](#___top "go to top of document")[§](#(Exception)_sub_warn "direct link")
See primary documentation
[in context](/type/Exception#sub_warn)
for **sub warn**.
```raku
multi warn(*@message)
```
Throws a resumable warning exception, which is considered a control exception, and hence is invisible to most normal exception handlers. The outermost control handler will print the warning to `$*ERR`. After printing the warning, the exception is resumed where it was thrown. To override this behavior, catch the exception in a `CONTROL` block. A `quietly {...}` block is the opposite of a `try {...}` block in that it will suppress any warnings but pass fatal exceptions through.
To simply print to `$*ERR`, please use `note` instead. `warn` should be reserved for use in threatening situations when you don't quite want to throw an exception.
```raku
warn "Warning message";
```
|
## dist_zef-lizmat-Fasta.md
[](https://github.com/lizmat/Fasta/actions) [](https://github.com/lizmat/Fasta/actions) [](https://github.com/lizmat/Fasta/actions)
# NAME
Fasta - Library of FASTA related functionality
# SYNOPSIS
```
use Fasta;
my %counts = Fasta.count-bases($file);
say %counts{"Carsonella ruddii"}; # bag with frequencies
my %sequences = Fasta.sequences($file);
say %sequences{"Carsonella ruddii"}; # sequence as string
```
# DESCRIPTION
A library for Fasta processing related logic.
## count-bases
```
my %labels = Fasta.count-bases($file);
say %label{"Carsonella ruddii"}; # bag with frequencies
```
Takes the name of a Fasta file, and creates a hash with labels encountered as keys, and a Bag with the nucleotide letters and their frequencies.
## sequences
```
my %sequences = Fasta.sequences($file);
say %sequences{"Carsonella ruddii"}; # sequence as string
```
Takes the name of a Fasta file, and creates a hash with labels encountered as keys, and a string with the actual sequence.
# INSPIRATION
Inspired by the Suman Khanal's:
```
https://sumankhanal.netlify.app/post/raku/count_dna/
```
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Fasta> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2020, 2021, 2024, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-kimryan-Lingua-EN-Fathom.md
# NAME
Lingua::EN::Fathom - Measure readability of English text
# SYNOPSIS
```
use Lingua::EN::Fathom;
my $sample =
q{Determine the readability of the given text file or block. Words
need to contain letters, and optionally numbers (such as Gr8). There
is no understanding of context.
Numbers like 1.234 are valid, but strings like #### are ignored.};
my $f = Fathom.new();
$f.analyse_block($sample,0);
say $f.report;
#`[Output is:
Number of characters : 227
Number of words : 37
Percent of complex words : 13.51
Average syllables per word : 1.5676
Number of sentences : 4
Average words per sentence : 9.2500
Number of text lines : 4
Number of blank lines : 1
Number of paragraphs : 2
READABILITY INDICES
Fog : 9.1054s
Flesch : 64.8300
Flesch-Kincaid : 6.5148
]
# Access individual statistics
say $f.percent_complex_words; # 13.51
# Analyse file contents, accumulating statistics over successive calls
my $accumulate = 1;
$f.analyse_file('sample1.txt',$accumulate);
$f.analyse_file('sample2.txt',$accumulate);
say $f.report;
```
# DESCRIPTION
This module analyses English text in either a string or file. Totals are
then calculated for the number of characters, words, sentences, blank
and non blank (text) lines and paragraphs.
Three common readability statistics are also derived, the Fog, Flesch and
Kincaid indices.
All of these properties can be accessed through method attributes, or by
generating a text report. The attributes are:
```
num_sents
num_text_lines
num_blank_lines
num_paragraphs
num_chars
num_syllables
num_complex_words
words_per_sentence
syllables_per_word
percent_complex_words
fog
flesch
kincaid;
```
See /doc/Fathom.rakudoc for a full description.
# LIMITATIONS
The syllable count provided in Lingua::EN::Syllable is about 90% accurate
The fog index should exclude proper names
# AUTHOR
Lingua::EN::Fathom was written by Kim Ryan .
This is a port from the Perl version in CPAN.
# COPYRIGHT AND LICENSE
Copyright (c) 2023 Kim Ryan. All rights reserved.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-antononcube-WWW-MistralAI.md
# WWW::MistralAI
## In brief
This Raku package provides access to the machine learning service [MistralAI](https://mistral.ai), [MAI1].
For more details of the MistralAI's API usage see [the documentation](https://docs.mistral.ai), [MAI2].
**Remark:** To use the MistralAI API one has to register and obtain authorization key.
**Remark:** This Raku package is much "less ambitious" than the official Python package, [MAIp1], developed by MistralAI's team.
Gradually, over time, I expect to add features to the Raku package that correspond to features of [MAIp1].
This package is very similar to the packages
["WWW::OpenAI"](https://github.com/antononcube/Raku-WWW-OpenAI), [AAp1], and
["WWW::PaLM"](https://github.com/antononcube/Raku-WWW-PaLM), [AAp2].
"WWW::MistralAI" can be used with (is integrated with)
["LLM::Functions"](https://github.com/antononcube/Raku-LLM-Functions), [AAp3], and
["Jupyter::Chatbook"](https://github.com/antononcube/Raku-Jupyter-Chatbook), [AAp5].
Also, of course, prompts from
["LLM::Prompts"](https://github.com/antononcube/Raku-LLM-Prompts), [AAp4],
can be used with MistralAI's functions.
---
## Installation
Package installations from both sources use [zef installer](https://github.com/ugexe/zef)
(which should be bundled with the "standard" Rakudo installation file.)
To install the package from [Zef ecosystem](https://raku.land/) use the shell command:
```
zef install WWW::MistralAI
```
To install the package from the GitHub repository use the shell command:
```
zef install https://github.com/antononcube/Raku-WWW-MistralAI.git
```
---
## Usage examples
**Remark:** When the authorization key, `auth-key`, is specified to be `Whatever`
then the functions `mistralai-*` attempt to use the env variable `MISTRAL_API_KEY`.
### Universal "front-end"
The package has an universal "front-end" function `mistral-playground` for the
[different functionalities provided by MistralAI](https://docs.mistral.ai).
Here is a simple call for a "chat completion":
```
use WWW::MistralAI;
mistralai-playground('Where is Roger Rabbit?');
```
```
# [{finish_reason => length, index => 0, message => {content => Roger Rabbit is a fictional character from animation. He first appeared in the, role => assistant}}]
```
Another one using Bulgarian:
```
mistralai-playground('Колко групи могат да се намерят в този облак от точки.', max-tokens => 300, random-seed => 234232, format => 'values');
```
```
# To determine the number of groups in this cluster of points, I would need more information. Traditionally, groups in a set of data points are identified using clustering algorithms. The number of groups identified depends on the specific clustering algorithm used and the parameters set for that algorithm.
#
# For example, if we use K-Means clustering, we need to specify the number of clusters (K) beforehand. The algorithm will then group the points into K clusters based on their proximity to the centroids. If we don't know how many clusters exist in the data, we can try different values of K and evaluate the results using measures like the Silhouette score.
#
# Without applying a clustering algorithm to the given set of points or having some prior knowledge about the number of groups, it is not possible to give an answer to this question.
```
**Remark:** The functions `mistralai-chat-completion` or `mistralai-completion` can be used instead in the examples above.
(The latter is synonym of the former.)
### Models
The current MistralAI models can be found with the function `mistralai-models`:
```
*<id>.say for |mistralai-models;
```
```
# mistral-medium
# mistral-small
# mistral-tiny
# mistral-embed
```
### Code generation
There are two types of completions : text and chat. Let us illustrate the differences
of their usage by Raku code generation. Here is a text completion:
```
mistralai-completion(
'generate Raku code for making a loop over a list',
max-tokens => 120,
format => 'values');
```
```
# Here's an example of how to make a loop over a list in Raku:
#
# ```raku
# my @numbers = (1, 2, 3, 4, 5); # create a list of numbers
#
# for ^@numbers -> $number { # use a for loop to iterate over the list
# say "$number squared is: ", $number ** 2; # perform an operation on each number
# }
# ```
#
# In the example above, we use a `for` loop with the `^@
```
Here is a chat completion:
```
mistralai-completion(
'generate Raku code for making a loop over a list',
max-tokens => 120,
format => 'values');
```
```
# In Raku, you can use the `for` keyword to loop over a list. Here is an example of how to use it:
#
# ```raku
# my @numbers = (1, 2, 3, 4, 5);
#
# for ^@numbers -> $number {
# say "Current number: $number";
# }
# ```
#
# In this example, we define a list `@numbers` with the elements 1, 2, 3, 4, and 5. The `for` loop
```
### Embeddings
Embeddings can be obtained with the function `mistralai-embeddings`. Here is an example of finding the embedding vectors
for each of the elements of an array of strings:
```
my @queries = [
'make a classifier with the method RandomForeset over the data dfTitanic',
'show precision and accuracy',
'plot True Positive Rate vs Positive Predictive Value',
'what is a good meat and potatoes recipe'
];
my $embs = mistralai-embeddings(@queries, format => 'values', method => 'tiny');
$embs.elems;
```
```
# 4
```
Here we show:
* That the result is an array of four vectors each with length 1536
* The distributions of the values of each vector
```
use Data::Reshapers;
use Data::Summarizers;
say "\$embs.elems : { $embs.elems }";
say "\$embs>>.elems : { $embs>>.elems }";
records-summary($embs.kv.Hash.&transpose);
```
```
# $embs.elems : 4
# $embs>>.elems : 1024 1024 1024 1024
# +----------------------------------+-----------------------------------+----------------------------------+-----------------------------------+
# | 3 | 0 | 1 | 2 |
# +----------------------------------+-----------------------------------+----------------------------------+-----------------------------------+
# | Min => -0.088867 | Min => -0.140381 | Min => -0.091675 | Min => -0.126343 |
# | 1st-Qu => -0.022064 | 1st-Qu => -0.019684 | 1st-Qu => -0.021881 | 1st-Qu => -0.021805 |
# | Mean => -0.0014019259251654148 | Mean => 0.0001275218091905117 | Mean => -0.0014658444561064243 | Mean => -0.00016893696738407016 |
# | Median => -0.0015511512756347656 | Median => -0.00012609362602233888 | Median => -0.0017815 | Median => 0.0005223751068115234 |
# | 3rd-Qu => 0.019516 | 3rd-Qu => 0.021347 | 3rd-Qu => 0.019943 | 3rd-Qu => 0.021469 |
# | Max => 0.10968 | Max => 0.088867 | Max => 0.111755 | Max => 0.097534 |
# +----------------------------------+-----------------------------------+----------------------------------+-----------------------------------+
```
Here we find the corresponding dot products and (cross-)tabulate them:
```
use Data::Reshapers;
use Data::Summarizers;
my @ct = (^$embs.elems X ^$embs.elems).map({ %( i => $_[0], j => $_[1], dot => sum($embs[$_[0]] >>*<< $embs[$_[1]])) }).Array;
say to-pretty-table(cross-tabulate(@ct, 'i', 'j', 'dot'), field-names => (^$embs.elems)>>.Str);
```
```
# +---+----------+----------+----------+----------+
# | | 0 | 1 | 2 | 3 |
# +---+----------+----------+----------+----------+
# | 0 | 1.000405 | 0.580262 | 0.736048 | 0.546892 |
# | 1 | 0.580262 | 1.000174 | 0.663682 | 0.534618 |
# | 2 | 0.736048 | 0.663682 | 1.000578 | 0.545032 |
# | 3 | 0.546892 | 0.534618 | 0.545032 | 0.999975 |
# +---+----------+----------+----------+----------+
```
**Remark:** Note that the fourth element (the cooking recipe request) is an outlier.
(Judging by the table with dot products.)
### Chat completions with engineered prompts
Here is a prompt for "emojification" (see the
[Wolfram Prompt Repository](https://resources.wolframcloud.com/PromptRepository/)
entry
["Emojify"](https://resources.wolframcloud.com/PromptRepository/resources/Emojify/)):
```
my $preEmojify = q:to/END/;
Rewrite the following text and convert some of it into emojis.
The emojis are all related to whatever is in the text.
Keep a lot of the text, but convert key words into emojis.
Do not modify the text except to add emoji.
Respond only with the modified text, do not include any summary or explanation.
Do not respond with only emoji, most of the text should remain as normal words.
END
```
```
# Rewrite the following text and convert some of it into emojis.
# The emojis are all related to whatever is in the text.
# Keep a lot of the text, but convert key words into emojis.
# Do not modify the text except to add emoji.
# Respond only with the modified text, do not include any summary or explanation.
# Do not respond with only emoji, most of the text should remain as normal words.
```
Here is an example of chat completion with emojification:
```
mistralai-chat-completion([ system => $preEmojify, user => 'Python sucks, Raku rocks, and Perl is annoying'], max-tokens => 200, format => 'values')
```
```
# 😠 Python sucks, 🌈 Raku rocks, 😓 Perl is annoying
```
---
## Command Line Interface
### Playground access
The package provides a Command Line Interface (CLI) script:
```
mistralai-playground --help
```
```
# Usage:
# mistralai-playground [<words> ...] [--path=<Str>] [--mt|--max-tokens[=UInt]] [-m|--model=<Str>] [-r|--role=<Str>] [-t|--temperature[=Real]] [--response-format=<Str>] [-a|--auth-key=<Str>] [--timeout[=UInt]] [-f|--format=<Str>] [--method=<Str>] -- Command given as a sequence of words.
#
# --path=<Str> Path, one of 'chat/completions', 'images/generations', 'images/edits', 'images/variations', 'moderations', 'audio/transcriptions', 'audio/translations', 'embeddings', or 'models'. [default: 'chat/completions']
# --mt|--max-tokens[=UInt] The maximum number of tokens to generate in the completion. [default: 100]
# -m|--model=<Str> Model. [default: 'Whatever']
# -r|--role=<Str> Role. [default: 'user']
# -t|--temperature[=Real] Temperature. [default: 0.7]
# --response-format=<Str> The format in which the response is returned. [default: 'url']
# -a|--auth-key=<Str> Authorization key (to use MistralAI API.) [default: 'Whatever']
# --timeout[=UInt] Timeout. [default: 10]
# -f|--format=<Str> Format of the result; one of "json", "hash", "values", or "Whatever". [default: 'Whatever']
# --method=<Str> Method for the HTTP POST query; one of "tiny" or "curl". [default: 'tiny']
```
**Remark:** When the authorization key argument "auth-key" is specified set to "Whatever"
then `mistralai-playground` attempts to use the env variable `MISTRAL_API_KEY`.
---
## Mermaid diagram
The following flowchart corresponds to the steps in the package function `mistralai-playground`:
```
graph TD
UI[/Some natural language text/]
TO[/"MistralAI<br/>Processed output"/]
WR[[Web request]]
MistralAI{{https://console.mistral.ai}}
PJ[Parse JSON]
Q{Return<br>hash?}
MSTC[Compose query]
MURL[[Make URL]]
TTC[Process]
QAK{Auth key<br>supplied?}
EAK[["Try to find<br>MISTRAL_API_KEY<br>in %*ENV"]]
QEAF{Auth key<br>found?}
NAK[/Cannot find auth key/]
UI --> QAK
QAK --> |yes|MSTC
QAK --> |no|EAK
EAK --> QEAF
MSTC --> TTC
QEAF --> |no|NAK
QEAF --> |yes|TTC
TTC -.-> MURL -.-> WR -.-> TTC
WR -.-> |URL|MistralAI
MistralAI -.-> |JSON|WR
TTC --> Q
Q --> |yes|PJ
Q --> |no|TO
PJ --> TO
```
---
## References
### Packages
[AAp1] Anton Antonov,
[WWW::OpenAI Raku package](https://github.com/antononcube/Raku-WWW-OpenAI),
(2023),
[GitHub/antononcube](https://github.com/antononcube).
[AAp2] Anton Antonov,
[WWW::PaLM Raku package](https://github.com/antononcube/Raku-WWW-PaLM),
(2023),
[GitHub/antononcube](https://github.com/antononcube).
[AAp3] Anton Antonov,
[LLM::Functions Raku package](https://github.com/antononcube/Raku-LLM-Functions),
(2023),
[GitHub/antononcube](https://github.com/antononcube).
[AAp4] Anton Antonov,
[LLM::Prompts Raku package](https://github.com/antononcube/Raku-LLM-Prompts),
(2023),
[GitHub/antononcube](https://github.com/antononcube).
[AAp5] Anton Antonov,
[Jupyter::Chatbook Raku package](https://github.com/antononcube/Raku-Jupyter-Chatbook),
(2023),
[GitHub/antononcube](https://github.com/antononcube).
[MAI1] MistralAI, [MistralAI platform](https://mistral.ai).
[MAI2] MistralAI Platform documentation, [MistralAI documentation](https://docs.mistral.ai).
[MAIp1] MistralAI,
[https://github.com/mistralai/client-python),
(2023),
[GitHub/mistralai](https://github.com/mistralai).
|
## dist_zef-FRITH-Math-Libgsl-Permutation.md
[](https://github.com/frithnanth/raku-Math-Libgsl-Permutation/actions)
# NAME
Math::Libgsl::Permutation - An interface to libgsl, the Gnu Scientific Library - Permutations.
# SYNOPSIS
```
use Math::Libgsl::Raw::Permutation :ALL;
use Math::Libgsl::Permutation;
```
# DESCRIPTION
Math::Libgsl::Permutation provides an interface to the permutation functions of libgsl, the GNU Scientific Library.
This package provides both the low-level interface to the C library (Raw) and a more comfortable interface layer for the Raku programmer.
### new(:$elems!)
### new($elems!)
The constructor accepts one parameter: the number of elements in the permutation; it can be passed as a Pair or as a single value. The permutation object is already initialized to the identity (0, 1, 2 … $elems - 1).
All the following methods *throw* on error if they return **self**, otherwise they *fail* on error.
### init()
This method initialize the permutation object to the identity and returns **self**.
### copy($src! where \* ~~ Math::Libgsl::Permutation)
This method copies the permutation **$src** into the current permutation object and returns **self**.
### get(Int $elem! --> Int)
This method returns the permutation value at position **$elem**.
### all(--> Seq)
This method returns a Seq of all the elements of the current permutation.
### swap(Int $elem1!, Int $elem2!)
This method swamps two elements of the current permutation object and returns **self**.
### size(--> Int)
This method returns the size of the current permutation object.
### is-valid(--> Bool)
This method checks whether the current permutation is valid: the n elements should contain each of the numbers 0 to n - 1 once and only once.
### reverse()
This method reverses the order of the elements of the current permutation object.
### inverse($dst! where \* ~~ Math::Libgsl::Permutation)
This method computes the inverse of the current permutation and stores the result into **$dst**.
### next()
### prev()
These functions advance or step backwards the permutation and return **self**, useful for method chaining.
### bnext(--> Bool)
### bprev(--> Bool)
These functions advance or step backwards the permutation and return a Bool: **True** if successful or **False** if there's no more permutation to produce.
### permute(@data!, Int $stride! --> List)
This method applies the current permutation to the **@data** array with stride **$stride**.
### permute-inverse(@data!, Int $stride! --> List)
This method applies the inverse of the current permutation to the **@data** array with stride **$stride**.
### permute-complex64(Complex @data!, Int $stride! --> List)
This method applies the current permutation to the **@data** array array of Complex with stride **$stride**.
### permute-complex64-inverse(Complex @data!, Int $stride! --> List)
This method applies the inverse of the current permutation to the **@data** array of Complex with stride **$stride**.
### permute-complex32(Complex @data!, Int $stride! --> List)
This method applies the current permutation to the **@data** array array of Complex with stride **$stride**, trating the numbers as single precision floats.
### permute-complex32-inverse(Complex @data!, Int $stride! --> List)
This method applies the inverse of the current permutation to the **@data** array of Complex with stride **$stride**, trating the numbers as single precision floats.
### permute-vector(Math::Libgsl::Vector $v)
This method applies the permutation to a Vector object and returns the Vector object itself. As in the case of the Vector object, this method is available for all the supported data type, so we have
* permute-vector-num32
* permute-vector-int32
* permute-vector-uint32
…and so on.
### permute-vector-inv(Math::Libgsl::Vector $v)
This method applies the inverse permutation to a Vector object and returns the Vector object itself. As in the case of the Vector object, this method is available for all the supported data type, so we have
* permute-vector-inv-num32
* permute-vector-inv-int32
* permute-vector-inv-uint32
…and so on.
### permute-matrix(Math::Libgsl::Matrix $m) This method applies the permutation to a Matrix object and returns the Matrix object itself. As in the case of the Matrix object, this method is available for all the supported data type, so we have
* permute-matrix-num32
* permute-matrix-int32
* permute-matrix-uint32
…and so on.
### write(Str $filename! --> Int)
This method writes the permutation data to a file.
### read(Str $filename! --> Int)
This method reads the permutation data from a file. The permutation must be of the same size of the one to be read.
### fprintf(Str $filename!, Str $format! --> Int)
This method writes the permutation data to a file, using the format specifier.
### fscanf(Str $filename!)
This method reads the permutation data from a file. The permutation must be of the same size of the one to be read.
### multiply($dst! where \* ~~ Math::Libgsl::Permutation, $p2! where \* ~~ Math::Libgsl::Permutation)
This method combines the current permutation with the permutation **$p2**, stores the result into **$dst** and returns **self**.
### to-canonical($dst! where \* ~~ Math::Libgsl::Permutation)
This method computes the canonical form of the current permutation, stores the result into **$dst** and returns **self**.
### to-linear($dst! where \* ~~ Math::Libgsl::Permutation)
This method computes the linear form of the current permutation, stores the result into **$dst** and returns **self**.
### inversions(--> Int)
This method counts the number of inversions in the current permutation.
### linear-cycles(--> Int)
This method counts the number of cycles in the current permutation given in linear form.
### canonical-cycles(--> Int)
This method counts the number of cycles in the current permutation given in canonical form.
# C Library Documentation
For more details on libgsl see <https://www.gnu.org/software/gsl/>. The excellent C Library manual is available here <https://www.gnu.org/software/gsl/doc/html/index.html>, or here <https://www.gnu.org/software/gsl/doc/latex/gsl-ref.pdf> in PDF format.
# Prerequisites
This module requires the libgsl library to be installed. Please follow the instructions below based on your platform:
## Debian Linux and Ubuntu 20.04+
```
sudo apt install libgsl23 libgsl-dev libgslcblas0
```
That command will install libgslcblas0 as well, since it's used by the GSL.
## Ubuntu 18.04
libgsl23 and libgslcblas0 have a missing symbol on Ubuntu 18.04. I solved the issue installing the Debian Buster version of those three libraries:
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgslcblas0_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl23_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl-dev_2.5+dfsg-6_amd64.deb>
# Installation
To install it using zef (a module management tool):
```
$ zef install Math::Libgsl::Permutation
```
# AUTHOR
Fernando Santagata [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2020 Fernando Santagata
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-FRITH-Desktop-Notify.md
## Desktop::Notify
Desktop::Notify A simple interface to libnotify
## Build Status
| Operating System | Build Status | CI Provider |
| --- | --- | --- |
| Linux | [Build Status](https://travis-ci.org/frithnanth/perl6-Desktop-Notify) | Travis CI |
## Example
```
use Desktop::Notify::Simple;
my $n = Desktop::Notify::Simple.new(
:app-name('testone'),
:summary('Attention!'),
:body('What just happened?'),
:icon('stop')
).show;
sleep 2;
$n.update(:summary('Oh well!'), :body('Not quite a disaster!'), :icon('stop')).show;
```
```
use v6;
use Desktop::Notify :constants;
my $notify = Desktop::Notify.new(app-name => 'myapp');
my $n = $notify.new-notification('Attention!', 'What just happened?', 'stop');
$notify.set-timeout($n, NOTIFY_EXPIRES_NEVER);
$notify.show($n);
sleep 2;
$notify.update($n, 'Oh well!', 'Not quite a disaster!', 'stop');
$notify.show($n);
```
If you run the second program, note that the notification doesn't fade by itself, but you need to click on it
in order to close it.
For more examples see the `example` directory.
## Documentation
There are three interfaces available: the `Raw` interface which maps the library's C functions, an OO interface
which exposes most of the low level functionality, and a `Simple` interface.
To use the low-level interface:
```
use Desktop::Notify::Raw;
```
to use the intermediate-level interface:
```
use Desktop::Notify;
```
to use the simple interface:
```
use Desktop::Notify::Simple;
```
### The Raw interface
Please refer to the original C library documentation [here](https://developer.gnome.org/libnotify/0.7/).
### The intermediate-level interface
#### new(Str $appname)
Constructs a new `Desktop::Notify` object. It takes one **mandatory** argument:
`app-name`, the name of the app that will be registered with the notify dæmon.
#### is-initted(--> Bool)
Returns True if the object has been successfully initialized.
#### app-name(--> Str)
#### app-name(Str $appname)
Queries or sets the app name.
#### new-notification(Str $summary!, Str $body!, Str $icon! --> NotifyNotification)
#### new-notification(Str :$summary!, Str :$body!, Str :$icon!, Int :$timeout?, Str :$category?, NotifyUrgency :$urgency? --> NotifyNotification)
Creates a new notification.
The first form takes three positional arguments: the summary string, the notification string and
the icon to display (See the libnotify documentation for the available icons).
The second form takes a number of named argument. `summary`, `body`, and `icon` are **mandatory**,
the others are optional. If `timeout`, `category`, and `urgency` are defined, this method will call
the corresponding "set" methods documented below.
#### show(NotifyNotification $notification!, GError $err? --> Bool)
Shows the notification on screen. It takes one mandatory argument, the
NotifyNotification object, and one optional argument, the GError object.
(The default Desktop::Notify error handling is not thread safe. See `Threading safety`
for more info)
#### close(NotifyNotification $notification!, GError $err? --> Bool)
Closes the notification. It takes one mandatory argument, the NotifyNotification
object, and one optional argument, the GError object. (The default
Desktop::Notify error handling is not thread safe. See `Threading safety` for
more info)
Note that usually there's no need to explicitly `close` a notification, since
the default is to automatically expire after a while.
#### why-closed(NotifyNotification $notification! --> Int)
Returns the the closed reason code for the notification. It takes one argument,
the NotifyNotification object. (See the libnotify documentation for the meaning of
this code)
#### get-type(--> Int)
Returns the notification type.
#### update(NotifyNotification $notification!, Str $summary, Str $body, Str $icon --> Bool)
Modifies the messages of a notification which is already on screen.
#### set-timeout(NotifyNotification $notification!, Int $timeout!)
Sets the notification timeout. There are two available constants,
`NOTIFY_EXPIRES_DEFAULT` and `NOTIFY_EXPIRES_NEVER`, when explicitly imported
with `use Desktop::Notify :constants;`.
#### set-category(NotifyNotification $notification, Str $category!)
Sets the notification category (See the libnotify documentation).
#### set-urgency(NotifyNotification $notification, NotifyUrgency $urgency!)
Sets the notification urgency. An `enum NotifyUrgency <NotifyUrgencyLow NotifyUrgencyNormal NotifyUrgencyCritical>`
is available when explicitly imported with `use Desktop::Notify :constants;`.
#### server-caps(--> Seq)
Collects the server capabilities and returns a sequence.
#### server-info(--> Hash)
Reads the server info and returns an hash. The return value of the C function call is
returned as the value of the `return` key of the hash.
### The simple interface
#### new(Str :$app-name!, Str :$summary!, Str :$body!, Str :$icon!, Int :$timeout?, Str :$category?, NotifyUrgency :$urgency?)
Constructs a new `Desktop::Notify::Simple` object. It takes four mandatory arguments:
* $app-name the name of the app that will be registered with the notify dæmon.
* $summary appears in bold on the top side of the notification
* $body notification body
* $icon icon name
and three optional arguments:
* $timeout expressed in seconds (while Desktop::Notify uses milliseconds)
* $category can be used by the notification server to filter or display the data in a certain way
* $urgency urgency level of this notification
An `enum NotifyUrgency <NotifyUrgencyLow NotifyUrgencyNormal NotifyUrgencyCritical>` is available.
#### show(GError $err?)
Shows the notification on screen. It takes one optional argument, the GError object.
(The default Desktop::Notify error handling is not thread safe. See `Threading safety` for more info)
#### update(Str :$summary, Str :$body, Str :$icon)
Modifies the messages of a notification which is already on screen.
#### close(GError $err?)
Closes the notification. It takes one optional argument, the GError object. (The default Desktop::Notify error
handling is not thread safe. See `Threading safety` for more info)
Note that usually there's no need to explicitly 'close' a notification, since the default is to automatically
expire after a while.
## Threading safety
Desktop::Notify offers a simple interface which provides an `error` class member,
which is automatically used by the functions that need it.
Since `error` is a shared class member, if a program makes use of threading, its value
might be written by another thread before it's been read.
In this case one can declare their own GError variables:
```
my $err = Desktop::Notify::GError.new;
```
and pass it as an optional argument to the .show() and .close() methods; it will be
used instead of the object-wide one.
## Prerequisites
This module requires the libnotify library to be installed. Please follow the
instructions below based on your platform:
### Debian Linux
```
sudo apt-get install libnotify4
```
## Installation
```
$ zef install Desktop::Notify
```
## Testing
To run the tests:
```
$ prove -e "perl6 -Ilib"
```
## Author
Fernando Santagata
## License
The Artistic License 2.0
|
## spurt.md
spurt
Combined from primary sources listed below.
# [In IO::Handle](#___top "go to top of document")[§](#(IO::Handle)_method_spurt "direct link")
See primary documentation
[in context](/type/IO/Handle#method_spurt)
for **method spurt**.
```raku
multi method spurt(IO::Handle:D: Blob $data, :$close = False)
multi method spurt(IO::Handle:D: Cool $data, :$close = False)
```
Writes all of the `$data` into the filehandle, closing it when finished, if `$close` is `True`. For [`Cool`](/type/Cool) `$data`, will use the encoding the handle is set to use ([`IO::Handle.open`](/routine/open) or [`IO::Handle.encoding`](/routine/encoding)).
Behavior for spurting a [`Cool`](/type/Cool) when the handle is in binary mode or spurting a [`Blob`](/type/Blob) when the handle is NOT in binary mode is undefined.
# [In IO::Path](#___top "go to top of document")[§](#(IO::Path)_method_spurt "direct link")
See primary documentation
[in context](/type/IO/Path#method_spurt)
for **method spurt**.
```raku
method spurt(IO::Path:D: $data, :$enc, :$append, :$createonly)
```
Opens the path for writing, and writes all of the `$data` into it. File will be closed afterwards. Will [`fail`](/routine/fail) if it cannot succeed for any reason. The `$data` can be any [`Cool`](/type/Cool) type or any [`Blob`](/type/Blob) type. Arguments are as follows:
* `:$enc` — character encoding of the data. Takes same values as `:$enc` in [`IO::Handle.open`](/routine/open). Defaults to `utf8`. Ignored if `$data` is a [`Blob`](/type/Blob).
* `:$append` — open the file in `append` mode, preserving existing contents, and appending data to the end of the file.
* `:$createonly` — [`fail`](/routine/fail) if the file already exists.
```raku
method spurt(IO::Path:D:)
```
As of the 2020.12 release of the Rakudo compiler, it is also possible to call the `spurt` method without any data. This will either create an empty file, or will truncate any existing file at the given path.
# [In Independent routines](#___top "go to top of document")[§](#(Independent_routines)_sub_spurt "direct link")
See primary documentation
[in context](/type/independent-routines#sub_spurt)
for **sub spurt**.
```raku
multi spurt(IO() $path, |c)
```
The `$path` can be any object with an IO method that returns an [`IO::Path`](/type/IO/Path) object. Calls [`IO::Path.spurt`](/routine/spurt) on the `$path`, forwarding any of the remaining arguments.
|
## dist_github-ugexe-App-ecogen.md
## App::ecogen
Generate an index from cpan and the p6c ecosystem
See: <https://github.com/ugexe/Perl6-ecosystems>
## Installation
```
$ zef install App::ecogen
```
## Usage
```
# Create, save, and push cpan package index
ecogen update cpan
# Create, save, and push p6c ecosystem package index
ecogen update p6c
# Create, save, and push both cpan and p6c ecosystem package indexes
ecogen update cpan p6c
```
|
## dist_zef-tbrowder-IO-Stem.md
[](https://github.com/tbrowder/IO-Stem/actions)
# NAME
**IO::Stem** - Provides the part of an IO.basename left with the IO.extension removed
# SYNOPSIS
```
use IO::Stem;
say "finance.data".IO.stem; # OUTPUT: «finance»
# aliases for method 'stem':
say "finance.data".IO.barename; # OUTPUT: «finance»
say "finance.data".IO.name; # OUTPUT: «finance»
say "finance.data".IO.filename; # OUTPUT: «finance»
```
# DESCRIPTION
**Class IO::Stem** is an extension of core class `IO::Path` which currently has no method to provide that part of a basename remaining after its extension is removed. Its methods are intended to be candidates for inclusion in the next major release of Raku. Each method name has been found to be used for the same purpose in several well-known domains including `make`, `LaTeX`, and `shell`.
For heavier work on paths it is easier to get a new **IO::Stem** object and save some keystrokes. The same results shown in the code block above can be expressed as follows:
```
use IO::Stem;
my $o = IO::Stem.new: "finance.data";
say $o.stem; # OUTPUT: «finance»
# aliases for method 'stem':
say $o.barename; # OUTPUT: «finance»
say $o.name; # OUTPUT: «finance»
say $o.filename; # OUTPUT: «finance»
```
# AUTHOR
Tom Browder [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2022 Tom Browder
This library is free software; you may redistribute it or modify it under the Artistic License 2.0.
|
## dist_cpan-ANTONOV-Data-ExampleDatasets.md
# Data::ExampleDatasets Raku package
Raku package for (obtaining) example datasets.
Currently, this repository contains only [datasets metadata](./resources/dfRdatasets.csv).
The datasets are downloaded from the repository
[Rdatasets](https://github.com/vincentarelbundock/Rdatasets/),
[VAB1].
---
## Usage examples
### Setup
Here we load the Raku modules
[`Data::Generators`](https://modules.raku.org/dist/Data::Generators:cpan:ANTONOV),
[`Data::Summarizers`](https://github.com/antononcube/Raku-Data-Summarizers),
and this module,
[`Data::ExampleDatasets`](https://github.com/antononcube/Raku-Data-ExampleDatasets):
```
use Data::Reshapers;
use Data::Summarizers;
use Data::ExampleDatasets;
```
```
# (Any)
```
### Get a dataset by using an identifier
Here we get a dataset by using an identifier and display part of the obtained dataset:
```
my @tbl = example-dataset('Baumann', :headers);
say to-pretty-table(@tbl[^6]);
```
```
#ERROR: If the first argument is an array then it is expected that it can be coerced into a array-of-hashes, array-of-positionals, or hash-of-hashes, which in turn can be coerced into a full two dimensional array.
# Nil
```
Here we summarize the dataset obtained above:
```
records-summary(@tbl)
```
```
#ERROR: No such method 'value' for invocant of type 'Array'. Did you mean
#ERROR: 'values'?
# Nil
```
**Remark**: The values for the first argument of `example-dataset` correspond to the values
of the columns “Item” and “Package”, respectively, in the
[metadata dataset](https://vincentarelbundock.github.io/Rdatasets/articles/data.html)
from the GitHub repository “Rdatasets”, [VAB1].
See the datasets metadata sub-section below.
The first argument of `example-dataset` can take as values:
* Strings that correspond to the column "Items" of the metadata dataset
* E.g. `example-dataset("mtcars")`
* Strings that correspond to the columns "Package" and "Items" of the metadata dataset
* E.g. `example-dataset("COUNT::titanic")`
* Regexes
* E.g. `example-dataset(/ .* mann $ /)`
* `Whatever` or `WhateverCode`
### Get a dataset by using an URL
Here we get a dataset by using an URL and display a summary of the obtained dataset:
```
my $url = 'https://raw.githubusercontent.com/antononcube/Raku-Data-Reshapers/main/resources/dfTitanic.csv';
my @tbl2 = example-dataset($url, :headers);
records-summary(@tbl2);
```
```
# +-----------------+----------------+---------------------+-------------------+---------------+
# | id | passengerClass | passengerAge | passengerSurvival | passengerSex |
# +-----------------+----------------+---------------------+-------------------+---------------+
# | Min => 1 | 3rd => 709 | Min => -1 | died => 809 | male => 843 |
# | 1st-Qu => 327.5 | 1st => 323 | 1st-Qu => 10 | survived => 500 | female => 466 |
# | Mean => 655 | 2nd => 277 | Mean => 23.550038 | | |
# | Median => 655 | | Median => 20 | | |
# | 3rd-Qu => 982.5 | | 3rd-Qu => 40 | | |
# | Max => 1309 | | Max => 80 | | |
# +-----------------+----------------+---------------------+-------------------+---------------+
```
### Datasets metadata
Here we:
1. Get the dataset of the datasets metadata
2. Filter it to have only datasets with 13 rows
3. Keep only the columns "Item", "Title", "Rows", and "Cols"
4. Display it in "pretty table" format
```
my @tblMeta = get-datasets-metadata();
@tblMeta = @tblMeta.grep({ $_<Rows> == 13}).map({ $_.grep({ $_.key (elem) <Item Title Rows Cols>}).Hash });
say to-pretty-table(@tblMeta)
```
```
# +------+------------+------+--------------------------------------------------------------------+
# | Cols | Item | Rows | Title |
# +------+------------+------+--------------------------------------------------------------------+
# | 4 | Snow.pumps | 13 | John Snow's Map and Data on the 1854 London Cholera Outbreak |
# | 7 | BCG | 13 | BCG Vaccine Data |
# | 5 | cement | 13 | Heat Evolved by Setting Cements |
# | 2 | kootenay | 13 | Waterflow Measurements of Kootenay River in Libby and Newgate |
# | 5 | Newhouse77 | 13 | Medical-Care Expenditure: A Cross-National Survey (Newhouse, 1977) |
# | 2 | Saxony | 13 | Families in Saxony |
# +------+------------+------+--------------------------------------------------------------------+
```
### Keeping downloaded data
By default the data is obtained over the web from
[Rdatasets](https://github.com/vincentarelbundock/Rdatasets/),
but `example-dataset` has an option to keep the data "locally."
(The data is saved in `XDG_DATA_HOME`, see
[[JS1](https://modules.raku.org/dist/XDG::BaseDirectory:cpan:JSTOWE)].)
This can be demonstrated with the following timings of a dataset with ~1300 rows:
```
my $startTime = now;
my $data = example-dataset( / 'COUNT::titanic' $ / ):keep;
my $endTime = now;
say "Geting the data first time took { $endTime - $startTime } seconds";
```
```
# Geting the data first time took 2.90335873 seconds
```
```
$startTime = now;
$data = example-dataset( / 'COUNT::titanic' $/ ):keep;
$endTime = now;
say "Geting the data second time took { $endTime - $startTime } seconds";
```
```
# Geting the data second time took 1.559416817 seconds
```
---
## References
### Functions, packages, repositories
[AAf1] Anton Antonov,
[`ExampleDataset`](https://resources.wolframcloud.com/FunctionRepository/resources/ExampleDataset),
(2020),
[Wolfram Function Repository](https://resources.wolframcloud.com/FunctionRepository).
[VAB1] Vincent Arel-Bundock,
[Rdatasets](https://github.com/vincentarelbundock/Rdatasets/),
(2020),
[GitHub/vincentarelbundock](https://github.com/vincentarelbundock).
[JS1] Jonathan Stowe,
[`XDG::BaseDirectory`](https://modules.raku.org/dist/XDG::BaseDirectory:cpan:JSTOWE),
(last updated on 2021-03-31),
[Raku Modules](https://modules.raku.org/).
### Interactive interfaces
[AAi1] Anton Antonov,
[Example datasets recommender interface](https://antononcube.shinyapps.io/ExampleDatasetsRecommenderInterface/),
(2021),
[Shinyapps.io](https://antononcube.shinyapps.io/).
|
## dist_cpan-JKRAMER-Proc-Editor.md
[](https://travis-ci.org/jkramer/p6-proc-editor)
# NAME
Proc::Editor - Start a text editor
# SYNOPSIS
```
use Proc::Editor;
my $text = edit('original text');
say "Edited text: {$text.trim}";
```
# DESCRIPTION
Proc::Editor runs a text editor and returns the edited text.
# ROUTINES
## `edit(...)`
This is merely a shortcut for convenience, all arguments are passed on to `Proc::Editor.new.edit(...)`.
# METHODS
## `new(:editors(...))`
Create a new instance of `Proc::Editor`. `:editors` may be used to override the default list of editors to try. By default, the environment variables $VISUAL and $EDITOR are checked, then it tries /usr/bin/vi, /bin/vi and /bin/ed (in that order).
## `edit(Str $text?, IO::Path :$file, Bool :$keep)`
Writes `$text` to a temporary file runs an editor with that file as argument. On success, the contents of the file are returned. If `$file` is defined, it is used instead of creating a temporary file. The file used (temporary or not) are deleted afterwards unless `:keep` is provided.
## `edit-file(IO::Path $path)`
Starts an editor with the given `$path` as argument. Returns the editors exit-code on success (which should always be 0) or dies on error.
# AUTHOR
Jonas Kramer [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2018 Jonas Kramer
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-ASTJ-SQL-NamedPlaceholder.md
[](https://travis-ci.org/astj/p6-SQL-NamedPlaceholder)
# NAME
SQL::NamedPlaceholder - extension of placeholder
# SYNOPSIS
```
use SQL::NamedPlaceholder;
my ($sql, $bind) = bind-named(q[
SELECT *
FROM entry
WHERE
user_id = :user_id
], {
user_id => $user_id
});
$dbh.prepare($sql).execute(|$bind);
```
# DESCRIPTION
SQL::NamedPlaceholder is extension of placeholder. This enable more readable and robust code.
# FUNCTION
* [$sql, $bind] = bind-named($sql, $hash);
The $sql parameter is SQL string which contains named placeholders. The $hash parameter is map of bind parameters.
The returned $sql is new SQL string which contains normal placeholders ('?'), and $bind is List of bind parameters.
# SYNTAX
* :foobar
Replace as placeholder which uses value from $hash{foobar}.
* foobar = ?, foobar > ?, foobar < ?, foobar <> ?, etc.
This is same as 'foobar (op.) :foobar'.
# AUTHOR
astj [[email protected]](mailto:[email protected])
# ORIGINAL AUTHOR
This module is port of [SQL::NamedPlaceholder in Perl5](https://github.com/cho45/SQL-NamedPlaceholder).
Author of original SQL::NamedPlaceholder in Perl5 is cho45 [[email protected]](mailto:[email protected]).
# SEE ALSO
[SQL::NamedPlaceholder in Perl5](https://github.com/cho45/SQL-NamedPlaceholder)
# LICENSE
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
Original Perl5's SQL::NamedPlaceholder is licensed under following terms:
This library is free software; you can redistribute it and/or modify it under the same terms as Perl itself.
|
## dist_zef-raku-community-modules-Automata-Cellular.md
[](https://github.com/raku-community-modules/Automata-Cellular/actions) [](https://github.com/raku-community-modules/Automata-Cellular/actions) [](https://github.com/raku-community-modules/Automata-Cellular/actions)
# NAME
Automata::Cellular - Cellular Automata in Raku
# SYNOPSIS
```
use Automata::Cellular;
```
# DESCRIPTION
Wolfram elementary cellular automata in Raku.
See <https://mathworld.wolfram.com/ElementaryCellularAutomaton.html>.
This started out as an obfuscated Raku tweet some years ago. It provides text output of Wolfram automata.
# SCRIPTS
## wolfram-rule
```
$ wolfram-rule --rule=30
..................................................X..................................................
.................................................XXX.................................................
................................................XX..X................................................
...............................................XX.XXXX...............................................
..............................................XX..X...X..............................................
.............................................XX.XXXX.XXX.............................................
............................................XX..X....X..X............................................
...........................................XX.XXXX..XXXXXX...........................................
..........................................XX..X...XXX.....X..........................................
.........................................XX.XXXX.XX..X...XXX.........................................
........................................XX..X....X.XXXX.XX..X........................................
.......................................XX.XXXX..XX.X....X.XXXX.......................................
......................................XX..X...XXX..XX..XX.X...X......................................
.....................................XX.XXXX.XX..XXX.XXX..XX.XXX.....................................
....................................XX..X....X.XXX...X..XXX..X..X....................................
...................................XX.XXXX..XX.X..X.XXXXX..XXXXXXX...................................
..................................XX..X...XXX..XXXX.X....XXX......X..................................
.................................XX.XXXX.XX..XXX....XX..XX..X....XXX.................................
................................XX..X....X.XXX..X..XX.XXX.XXXX..XX..X................................
...............................XX.XXXX..XX.X..XXXXXX..X...X...XXX.XXXX...............................
..............................XX..X...XXX..XXXX.....XXXX.XXX.XX...X...X..............................
.............................XX.XXXX.XX..XXX...X...XX....X...X.X.XXX.XXX.............................
............................XX..X....X.XXX..X.XXX.XX.X..XXX.XX.X.X...X..X............................
...........................XX.XXXX..XX.X..XXX.X...X..XXXX...X..X.XX.XXXXXX...........................
..........................XX..X...XXX..XXXX...XX.XXXXX...X.XXXXX.X..X.....X..........................
.........................XX.XXXX.XX..XXX...X.XX..X....X.XX.X.....XXXXX...XXX.........................
........................XX..X....X.XXX..X.XX.X.XXXX..XX.X..XX...XX....X.XX..X........................
.......................XX.XXXX..XX.X..XXX.X..X.X...XXX..XXXX.X.XX.X..XX.X.XXXX.......................
......................XX..X...XXX..XXXX...XXXX.XX.XX..XXX....X.X..XXXX..X.X...X......................
.....................XX.XXXX.XX..XXX...X.XX....X..X.XXX..X..XX.XXXX...XXX.XX.XXX.....................
....................XX..X....X.XXX..X.XX.X.X..XXXXX.X..XXXXXX..X...X.XX...X..X..X....................
...................XX.XXXX..XX.X..XXX.X..X.XXXX.....XXXX.....XXXX.XX.X.X.XXXXXXXXX...................
..................XX..X...XXX..XXXX...XXXX.X...X...XX...X...XX....X..X.X.X........X..................
.................XX.XXXX.XX..XXX...X.XX....XX.XXX.XX.X.XXX.XX.X..XXXXX.X.XX......XXX.................
................XX..X....X.XXX..X.XX.X.X..XX..X...X..X.X...X..XXXX.....X.X.X....XX..X................
...............XX.XXXX..XX.X..XXX.X..X.XXXX.XXXX.XXXXX.XX.XXXXX...X...XX.X.XX..XX.XXXX...............
..............XX..X...XXX..XXXX...XXXX.X....X....X.....X..X....X.XXX.XX..X.X.XXX..X...X..............
.............XX.XXXX.XX..XXX...X.XX....XX..XXX..XXX...XXXXXX..XX.X...X.XXX.X.X..XXXX.XXX.............
............XX..X....X.XXX..X.XX.X.X..XX.XXX..XXX..X.XX.....XXX..XX.XX.X...X.XXXX....X..X............
...........XX.XXXX..XX.X..XXX.X..X.XXXX..X..XXX..XXX.X.X...XX..XXX..X..XX.XX.X...X..XXXXXX...........
..........XX..X...XXX..XXXX...XXXX.X...XXXXXX..XXX...X.XX.XX.XXX..XXXXXX..X..XX.XXXXX.....X..........
.........XX.XXXX.XX..XXX...X.XX....XX.XX.....XXX..X.XX.X..X..X..XXX.....XXXXXX..X....X...XXX.........
........XX..X....X.XXX..X.XX.X.X..XX..X.X...XX..XXX.X..XXXXXXXXXX..X...XX.....XXXX..XXX.XX..X........
.......XX.XXXX..XX.X..XXX.X..X.XXXX.XXX.XX.XX.XXX...XXXX.........XXXX.XX.X...XX...XXX...X.XXXX.......
......XX..X...XXX..XXXX...XXXX.X....X...X..X..X..X.XX...X.......XX....X..XX.XX.X.XX..X.XX.X...X......
.....XX.XXXX.XX..XXX...X.XX....XX..XXX.XXXXXXXXXXX.X.X.XXX.....XX.X..XXXXX..X..X.X.XXX.X..XX.XXX.....
....XX..X....X.XXX..X.XX.X.X..XX.XXX...X...........X.X.X..X...XX..XXXX....XXXXXX.X.X...XXXX..X..X....
...XX.XXXX..XX.X..XXX.X..X.XXXX..X..X.XXX.........XX.X.XXXXX.XX.XXX...X..XX......X.XX.XX...XXXXXXX...
..XX..X...XXX..XXXX...XXXX.X...XXXXXX.X..X.......XX..X.X.....X..X..X.XXXXX.X....XX.X..X.X.XX......X..
.XX.XXXX.XX..XXX...X.XX....XX.XX......XXXXX.....XX.XXX.XX...XXXXXXXX.X.....XX..XX..XXXX.X.X.X....XXX.
```
# AUTHORS
* David Brunton
* Tommy Brunton
# COPYRIGHT AND LICENSE
Copyright 2006 - 2016 David Brunton, Tommy Brunton
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-Files-Containing.md
[](https://github.com/lizmat/Files-Containing/actions) [](https://github.com/lizmat/Files-Containing/actions) [](https://github.com/lizmat/Files-Containing/actions)
# NAME
Files-Containing - Search for strings in files
# SYNOPSIS
```
use Files-Containing;
.say for files-containing("foo", :files-only)
for files-containing("foo") {
say .key.relative;
for .value {
say .key ~ ': ' ~ .value; # linenr: line
}
}
for files-containing("foo", :count-only) {
say .key.relative ~ ': ' ~ .value;
}
```
# DESCRIPTION
Files-Containing exports a single subroutine `files-containing` which produces a list of files and/or locations in those files given a certain path specification and needle.
# EXPORTED SUBROUTINES
## files-containing
The `files-containing` subroutine returns either a list of filenames (when the `:files-only` named argument is specified) or a list of pairs, of which the key is the filename, and the value is a list of pairs, in which the key is the linenumber and the value is the line in which the needle was found.
### Positional Arguments
#### needle
The first positional argument is the needle to search for. This can either be a `Str`, a `Regex` or a `Callable`. See the documentation of the [Lines::Containing](https://raku.land/zef:lizmat/Lines::Containing) module for the exact semantics of each possible needle.
If the needle is a `Callable`, then the dynamic variable `$*IO` will contain the `IO::Path` object of the file being processed.
#### files or directory
The second positional argument is optional. If not specified, or specified with an undefined value, then it will assume to search from the current directory.
It can be specified with a list of files to be searched. Or it can be a scalar value indicating the directory that should be searched for recursively. If it is a scalar value and it is an existing file, then only that file will be searched.
### Named Arguments
#### :batch
The `:batch` named argument to be passed to the hypering logic for parallel searching. It determines the number of files that will be processed per thread at a time. Defaults to whatever the default of `hyper` is.
#### :count-only
The `count-only` named argument to be passed to the `lines-containing|https://raku.land/zef:lizmat/lines-containing` subroutine, which will only return a count of matched lines if specified with a `True` value. `False` by default.
#### :degree
The `:degree` named argument to be passed to the hypering logic for parallel searching. It determines the maximum number of threads that will be used to do the processing. Defaults to whatever the default of `hyper` is.
#### :dir
The `:dir` named argument to be passed to the [paths](https://raku.land/zef:lizmat/paths) subroutine. By default will look in all directories, except the ones that start with a period.
Ignored if a list of files was specified as the second positional argument.
#### :extensions
The `:extensions` named argument indicates the extensions of the files that should be searched.
Ignored if a `:file` named argument was specified. Defaults to all extensions.
#### :file
The `:file` named argument to be passed to the [paths](https://raku.land/zef:lizmat/paths) subroutine. Ignored if a list of files was specified as the second positional argument.
#### :files-only
The `:files-only` named argument determines whether only the filename should be returned, rather than a list of pairs, in which the key is the filename, and the value is a list of filenumber / line pairs.
#### :follow-symlinks
The `:follow-symlinks` named argument to be passed to the [paths](https://raku.land/zef:lizmat/paths) subroutine. Ignored if a list of files was specified as the second positional argument.
#### :i or :ignorecase
The `:i` (or `:ignorecase`) named argument indicates whether searches should be done without regard to case. Ignored if the needle is **not** a `Str`.
#### :include-dot-files
The `:include-dot-files` named argument is a boolean indicating whether filenames that start with a period should be included.
Ignored if a `:file` named argument was specified. Defaults to `False`, indicating to **not** include filenames that start with a period.
#### :invert-match
The `:invert-match` named argument is a boolean indicating whether to produce files / lines that did **NOT** match (if a true value is specified). Default is `False`, so that only matching files / lines will be produced.
#### :m or :ignoremark
The `:m` (or `:ignoremark`) named argument indicates whether searches should be done by only looking at the base characters, without regard to any additional accents. Ignored if the needle is **not** a `Str`.
#### :max-count=N
The `:max-count` named argument indicates the maximum number of lines that should be reported per file. Defaults to `Any`, indicating that all possible lines will be produced. Ignored if `:files-only` is specified with a true value.
#### :offset=N
The `:offset` named argument indicates the value of the first line number in a file. It defaults to **0**. Ignored if the `:files-only` named argument has been specified with a true value.
#### :sort
The `:sort` named argument indicates whether the list of files obtained from the [paths](https://raku.land/zef:lizmat/paths) subroutine should be sorted. Ignored if a list of files was specified as the second positional argument. Can either be a `Bool`, or a `Callable` to be used by the sort routine to sort.
#### :type=words|starts-with|ends-with|contains
Only makes sense if the needle is a `Cool` object. With `words` specified, will look for needle as a word in a line, with `starts-with` will look for the needle at the beginning of a line, with `ends-with` will look for the needle at the end of a line, with `contains` will look for the needle at any position in a line. Which is the default.
## has-word
The `has-word` subroutine, as provided by the version of [has-word](https://raku.land/zef:lizmat/has-word) that is used.
## paths
The `paths` subroutine, as provided by the version of [paths](https://raku.land/zef:lizmat/paths) that is used.
## lines-containing
The `lines-containing` subroutine, as provided by the version of [lines-containing](https://raku.land/zef:lizmat/Lines::Containing) that is used.
# RE-EXPORTED SUBROUTINES
## hyperize
As provided by the `hyperize` module that is used by this module.
## lines-containing
As provided by the `Lines::Containing` module that is used by this module.
## paths
As provided by the `paths` module that is used by this module.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Files-Containing> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2022, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-librasteve-Physics-Error.md
# raku-Physics-Error
some code to handle physical measurement errors (nothing to do with programming errors!)
[](https://app.travis-ci.com/librasteve/raku-Physics-Error)
# Instructions
Installs automatically with`zef --verbose install Physics-Measure`
uninstall with, `zef uninstall Physics::Measure` and `zef uninstall Physics::Error`
# Context
In wikipedia, the general topic is <https://en.wikipedia.org/wiki/Propagation_of_uncertainty>
* this gets fairly heavy fairly quickly ... real world physical errors can be non-linear and accelerate rapidly
* this module is definitively LINEAR ONLY ;-)
#### this module is not intended for use in mission critical applications
# Synopsis
Take a look at your keyboard... there's probably a '±' key?
Physics::Error works with the [Physics::Measure](https://github.com/librasteve/raku-Physics-Measure) and [Physics::Unit](https://github.com/librasteve/raku-Physics-Unit) modules to do this:
```
use Physics::Measure :ALL;
my $x1 = 12.5nm ± 1; #SI units as raku postfix operators
my $x2 = Length.new(value => 12.5, units => 'nm', error => '4.3%'); #standard raku .new syntax
my $x3 = ♎️ '12.5 ft ±0.5'; #libra prefix shorthand
# Error values are included in Measures when output
say ~$x1; #12.5nm ±4% or 12.5nm ±1
# They can be accessed directly via the .error object
say $x1.error.absolute; #1
say $x1.error.relative; #0.08
say $x1.error.relative.^name; #Rat
say $x1.error.percent; #8%
```
All of the main Measure capabilities work as expected...
```
# Unit conversions and normalization
my $y = Length.new(value => 12.5e2, units => 'nm', error => '4.3%');
say ~$y; #1250nm ±53.75
say ~$y.in('mm'); #0.00125mm ±0.0000538
say ~$y.norm; #1.25μm ±0.05375
my $t = Time.new(value => 10, units => 'ms', error => 0.2);
say ~( 17 / $t ); #1700Hz ±34
# Measure math adjusts units and error automagically
say ~( $y / $t ); #0.000125m/s ±0.000007875e0
# works with add, subtract, multiply, divide, power and root
# add & subtract add absolute error
# multiply & divide add relative error
# power and root multiply relative error by power
my Length $w = Length.new(value => 10, units => 'm', error => '2%');
my $z = $w ** 3; say ~$z; #1000m^3 ±60
$z = $z ** <1/3>; say ~$z; #10m ±2.00e-01
# As do Measure cmp operators (to within error limits)
say $w cmp $y; #More
```
Controls for Error output format and rounding of percentage errors (here with default values). These only act on the .Str output rendering and leave the .error.absolute "truth" untouched.
```
$Physics::Error::default = 'absolute'; #default error output [absolute|percent]
$Physics::Error::round-per = 0.001; #control rounding of percent
```
Two ways for Measure output precision control. These only act on the .Str output rendering and leave the Measure .value and .error.absolute "truth" untouched.
#### Automagic
This option uses .error.denorm to right shift the error value and align to the mantissa precision of the measure value. The number of significant digits in the error is then used to round the measure value.
```
# Here's the mass of the electron Em in action...
my \Em = 9.109_383_701_5e-31kg ±0.000_000_002_8e-31;
say ~Em; #9.1093837015e-31kg ±0.0000000028e-31
say Em.error.absolute; #2.8e-40
say Em.error.relative; #3.0737534961217373e-10
say Em.error.relative.^name; #Num
say Em.error.percent; #0%
```
#### Manual
Manual precision can be set - this overrides the automagic behaviour.
```
$Physics::Measure::round-val = 0.01;
my $c = ♎️ '299792458 m/s';
my $ℎ = ♎️ '6.626070015e-34 J.s';
my \λ = 2.5nm;
is ~λ, '2.5nm', '~λ';
my \ν = $c / λ;
is ~ν.norm, '119.92PHz', '~ν.norm';
my \Ep = $ℎ * ν;
is ~Ep.norm, '79.46aJ', '~Ep.norm';
```
Physics::Error supports the three use cases for making Measure objects with value, units & error as outlined in the Physics::Measure [README.md](https://github.com/librasteve/raku-Physics-Measure/blob/master/README.md). The formats are dissected below:
#### Option 1: Postfix Operator Syntax (SI Units)
```
my Length $x = 12.5nm ± 10%;
------ -- - ------ - ---
| | | | | | |
| | | | | | > Rat percent error [or '±4.2%' Rat relative error]
| | | | | |
| | | | | > ± symbol as custom raku infix operator
| | | | |
| | | | > 'nm' Unit constructor as custom raku postfix operator (no ws)
| | | |
| | | > Real number
| | |
| | > assignment of new Object from postfix rhs
| |
| > a scalar variable
|
> Type (Length is Measure) ... can be omitted
```
#### Option 2: Object Constructor Syntax
```
my Length $x = Length.new(value => 12.5, units => 'nm', error => [0.5|'4.3%']);
say ~$x; #42 ±4.2nanometre
```
#### Option 3: Libra Shorthand Syntax
```
my Length $x = ♎️ '12.5 nm ±0.05';
------ -- -- ---- -- -----
| | | | | | |
| | | | | | |
| | | | | | > Real absolute error [or '±4.2%' Rat relative error]
| | | | | |
| | | | | > '±' symbol as custom raku prefix operator
| | | | |
| | | | > Str units (of Type Length is Measure)
| | | |
| | | > Real number
| | |
| | > parse rhs string, construct object and assign to lhs (♎️ <-- custom <libra> operator)
| |
| > a scalar variable
|
> Type (Length is Measure) ... can be omitted
```
#### Help Wanted
Over time I imagine an eco-system of equation parsing / pde plugins and machine calibration matrices - feel free to continue the journey in this direction with a pull request!
|
## dist_cpan-MARTIMM-Semaphore-ReadersWriters.md
# Semaphore Readers Writers Pattern or Light switch
[](https://travis-ci.org/MARTIMM/semaphore-readerswriters) [](http://www.perlfoundation.org/artistic_license_2_0)
## Synopsis
```
use Semaphore::ReadersWriters;
my Semaphore::ReadersWriters $rw .= new;
$rw.add-mutex-names('shv');
my $shared-var = 10;
# After creating threads ...
# Some writer thread
$rw.writer( 'shv', {$shared-var += 2});
# Some reader thread
say 'Shared var is ', $rw.reader( 'shv', {$shared-var;});
```
# Documentation
The Markdown files in this package uses the atom plugin **Markdown Preview Enhanced**. E.g. the synopsis can be run by placing the cursor in the code and type `shift-enter' or, if not possible, look for the readme pdf in doc)
* [README pdf](https://github.com/MARTIMM/semaphore-readerswriters/blob/master/doc/README.pdf)
* [ReadersWriters pdf](https://github.com/MARTIMM/semaphore-readerswriters/blob/master/doc/ReadersWriters.pdf)
## TODO
* Implement other variants of this pattern.
* Readers priority variant.
* No writer starvation variant.
* Document return value restrictions. Only items, no List.
## CHANGELOG
See [semantic versioning](http://semver.org/). Please note point 4. on that page: *Major version zero (0.y.z) is for initial development. Anything may change at any time. The public API should not be considered stable.*
* 0.2.6
* Methods `reader` and `writer` returned a failure object when things are wrong. This poses a problem in some situations. Now it will throw an exception.
* 0.2.5
* Changed last method into check-mutex-names() to test for more than one name.
* 0.2.4
* Added convenience method check-mutex-name().
* 0.2.3
* add-mutex-names throws an exception when keys are reused
* 0.2.2
* Added $.debug to show messages about the actions. This will be deprecated later when I am confident enough that everything works well enough.
* 0.2.1
* Removed debugging texts to publish class
* 0.2.0
* Documentation
* Bugfixes, hangups caused by overuse of same semaphores. Added more semaphores per critical section.
* Preparations for other variations of this pattern
* 0.1.0 First tests
* 0.0.1 Setup
# Other info
## Perl6 version
Tested on the latest version of perl6 on moarvm
## Install
Install package using zef
```
zef install Semaphore::ReadersWriters
```
## Author
Marcel Timmerman
## Contact
MARTIMM on github
|
## dist_zef-raku-community-modules-File-Ignore.md
[](https://github.com/raku-community-modules/File-Ignore/actions) [](https://github.com/raku-community-modules/File-Ignore/actions) [](https://github.com/raku-community-modules/File-Ignore/actions)
# NAME
File::Ignore - Parsing and application of .gitignore-style ignore files
# SYNOPSIS
```
use File::Ignore;
my $ignores = File::Ignore.parse: q:to/IGNORE/
# Output
*.[ao]
build/**
# Editor files
*.swp
IGNORE
for $ignores.walk($some-dir) {
say "Did not ignore file $_";
}
say $ignores.ignore-file('src/foo.c'); # False
say $ignores.ignore-file('src/foo.o'); # True
say $ignores.ignore-directory('src'); # False
say $ignores.ignore-directory('build'); # True
```
# DESCRIPTION
Parses ignore rules, of the style found in `.gitignore` files, and allows files and directories to be tested against the rules. Can also walk a directory and return all files that are not ignored.
# USAGE
## Pattern syntax
The following pattern syntax is supported for matching within a path segment (that is, between slashes):
| | |
| --- | --- |
| ? | Matches any character in a path segment |
| \* | Matches zero or more characters in a path segment |
| [abc] | Character class; matches a, b, or c |
| [!0] | Negated character class; matches anything but 0 |
| [a-z] | Character ranges inside of character classes |
Additionally, `**` is supported to match zero or more path segments. Thus, the rule `a/**/b` will match `a/b`, `a/x/b`, `a/x/y/b`, etc.
## Construction
The `parse` method can be used in order to parse rules read in from an ignore file. It breaks the input up in to lines, and ignores lines that start with a `#`, along with lines that are entirely whitespace.
```
my $ignores = File::Ignore.parse(slurp('.my-ignore'));
say $ignores.WHAT; # File::Ignore
```
Alternatively, `File::Ignore` can be constructed using the `new` method and passing in an array of rules:
```
my $ignores = File::Ignore.new(rules => <*.swp *.[ao]>);
```
This form treats everything it is given as a rule, not applying any comment or empty line syntax rules.
## Walking files with ignores applied
The `walk` method takes a path as a `Str` and returns a `Seq` of paths in that directory that are not ignored. Both `.` and `..` are excluded, as is usual with the Raku `dir` function.
## Use with your own walk logic
The `ignore-file` and `ignore-directory` methods are used by `walk` in order to determine if a file or directory should be ignored. Any rule that ends in a `/` is considered as only applying to a directory name, and so will not be considered by `ignore-file`. These methods are useful if you need to write your own walking logic.
There is an implicit assumption that this module will be used when walking over directories to find files. The key implication is that it expects a directory will be tested with `ignore-directory`, and that programs will not traverse the files within that directory if the result is `True`. Thus:
```
my $ignores = File::Ignore.new(rules => ['bin/']);
say $ignores.ignore-directory('bin');
```
Will, unsurprisingly, produce `True`. However:
```
my $ignores = File::Ignore.new(rules => ['bin/']);
say $ignores.ignore-file('bin/x');
```
Will produce `False`, since no ignore rule explicitly ignores that file. Note, however, that a rule such as `bin/**` would count as explicitly ignoring the file (but would not ignore the `bin` directory itself).
## Using File::Ignore in non-walk scenarios
Sometimes it is desirable to apply the ignore rules against an existing list of paths. For example, a `find` command run on a remote server produces a set of paths. Calling `ignore-file` on each of these will not work reliably, thanks to the assumption that it will never be asked about files in a directory that would be ignored by `ignore-directory`.
The `ignore-path` method not only checks that a file should be ignored, but also checks if any of the directories making up the path should be ignored. This means it is safe to apply it to a simple list of paths, in a non-walk scenario.
```
my $ignores = File::Ignore.new(rules => ['bin/']);
say $ignores.ignore-file('bin/x'); # False
say $ignores.ignore-path('bin/x'); # True
```
## Negation
A rule can be negated by placing a `!` before it. Negative rules are ignored until a file or directory matches a positive rule. Then, only negative rules are considered, to see if it is then un-ignored. If a matching negative rule is found, positive rules continue to be searched.
Therefore, these two rules:
```
foo/bar/*
!foo/bar/ok
```
Would ignore everything in `foo/bar/` except `ok`. However:
```
!foo/bar/ok
foo/bar/*
```
Would not work because the negation comes before the ignore. Further, negated file ignores cannot override directory ignores, so:
```
foo/bar/
!foo/bar/ok
```
Would also not work; the trailing `*` is required.
## Thread safety
Once constructed, a `File::Ignore` object is immutable, and thus it is safe to use an instance of it concurrently (for example, to call `walk` on the same instance in two threads). Construction, either through `new` or `parse`, is also thread safe.
# AUTHOR
Jonathan Worthington
# COPYRIGHT AND LICENSE
Copyright 2016 - 2017 Jonathan Worthington
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-Math-Sequences.md
[](https://github.com/raku-community-modules/Math-Sequences/actions) [](https://github.com/raku-community-modules/Math-Sequences/actions) [](https://github.com/raku-community-modules/Math-Sequences/actions)
# NAME
Math::Sequences - Various mathematical sequences of moderate use
# SYNOPSIS
```
use Math::Sequences::Integer; # You have to include one ...
use Math::Sequences::Real; # ... or the other
say factorial(33); # from Math::Sequences::Integer;
say sigma( 8 );
say FatPi;
say ℝ.gist(); # from Math::Sequences::Real;
say ℝ.from(pi)[0]
```
# DESCRIPTION
`Math::Sequences` is a module with integer and floating point sequences and some helper modules.
# INCLUDED COMPONENTS
## Math::Sequences::Integer
Integer sequences
### class Integers
Generic Integer sequences class
### class Naturals
More specific finite-starting-point class
### ℤ
The integers as a range
### 𝕀
The naturals (from 0) as a range
### ℕ
The naturals (from 1) as a range
### @AXXXXXX
All of the core OEIS sequences from <https://oeis.org/wiki/Index_to_OEIS:_Section_Cor>
### %oeis-core
A mapping of English names to sequences (e.g. `%oeis-core<primes>`.
### OEIS
A function that returns the sequence for a given name, but can also search for sequences (`.search` flag) whose names start with the given string, in which case a hash of name/sequence pairs is returned. Names can be the `%oeis-core` aliases or the OEIS key such as `A000001`.
## Math::Sequences::Real
Real sequences
### class Reals
Generic Real number sequences class
### ℝ
The reals as a range
## Math::Sequences::Numberphile
OEIS sequences featured on the [Numberphile YouTube channel](https://youtube.com/numberphile).
### @AXXXXXX
As with `Math::Sequences::Integer`. these are exported by default and contain the sequence of values for that OEIS entry. They include:
```
A001220 A002210 A002904 A006567 A006933 A010727 A023811
A058883 A087019 A087409 A125523 A125524 A131645 A181391
A232448 A249572 A316667
```
### topologically-ordered-numbers(:@ordering=[<1 4 8>], :$radix=10)
A generator for "holey" numbers.
### digit-grouped-multiples(:$of, :$group=2)
A generator for sequences of numbers that are generated by taking the multiplication table for the given `:$of` value and grouping the resulting digits in groups of `:$group` which results in a new sequence.
### contains-letters($number, $letters)
A test that returns true if the words for `$number` (e.g. "one thousand four hundred five") contain the given `$letters`.
### spiral-board(Int $size, Bool :$flip, Int :$rotate=0)
Returns a list of lists containing a spiral numbering sequence starting from the geometric middle of the square and spiraling out to fill it. This is used by `@A316667`. The optional flip and rotate parameters can be used to modify the orientation of the resulting board.
# SUPPORT ROUTINES
These routines and operators are defined to support the definition of the sequences. Because they're not the primary focus of this library, they may be moved out into some extrnal library in the future...
## Integer support routines
To gain access to these, use:
```
use Math::Sequences::Integer :support;
```
### $a choose $b
(binomial) The choose and ichoose (for integer-only results) infix operators return the binomial coefficient on the inputs.
### binpart($n)
The binary partitions of n.
### Entringer($n, $k)
Alternating permutation (or zigzag permutation) of the set 1 through n, taken k at a time, where each is an arrangement that is alternately greater or less than the preceding.
### Eulers-number($terms)
Returns digits of e to terms places after the decimal as a FatRat.
### factorial($n)
The factorial of n.
### factors($n, :%map)
The prime factors (non-unique) of n. Takes an optional map of inputs to results, mostly used to deal with the ambiguous factors of 0 and 1.
### divisors($n)
The unique list of whole divisors of n. e.g. `divisors(6)` gives `(1, 2, 3, 6)`.
### moebius($n)
The Möbius number of n.
### sigma($n, $exponent=1)
The sum of positive divisors function σ. The optional exponent is the power to which each divisor is raised before summing.
### Sterling1($n, $k)
Count permutations according to their number of cycles.
### Sterling2($n, $k)
The number of ways to partition a set of n objects into k non-empty subsets.
### totient($n)
The numbers from zero to n that are co-prime to n.
### planar-partitions($n)
The planar partitions of n. See: <https://mathworld.wolfram.com/PlanePartition.html>.
### strict-partitions($n)
The strict partitions of *n* are the ways that *n* can be generated by summing unique positive, non-zero integers. See: <https://math.stackexchange.com/questions/867760/what-is-the-count-of-the-strict-partitions-of-n-in-k-parts-not-exceeding-m>
### Pi-digits
A generator of digits for pi. Relatively fast and very memory-efficient.
### FatPi($digits=100)
This function is certainly going to be moved out of this library at some point, as it is not used here and doesn't return an integer, but it's a simple wrapper around Pi-digits which returns a `FatRat` rational for pi to the given number of digits. e.g. `FatPi(17).nude` gives: `(7853981633974483 2500000000000000)`.
# ABOUT UNICODE
This library uses a few non-ASCII Unicode characters that are widely used within the mathematical community. They are entirely optional, however, and if you wish to use their ASCII equivalents this table will help you out:
(the following assume `use Math::Sequences::Integer; use Math::Sequences::Real;`.
* ℤ - Integers.new
* 𝕀 - Naturals.new.from(0) or simply Naturals.new
* ℕ - Naturals.new.from(1)
* ℝ - Reals.new
The following, respectively, are defined 'ASCII equivalent' constants for each of the above:
* Z
* I
* N
* R
## Entering symbols
To enter each of these Unicode symbols, here are common shortcuts in vim and emacs:
### ℤ - DOUBLE-STRUCK CAPITAL Z - U+2124
* vim - Ctrl-v u 2 1 2 4
* emacs - Ctrl-x 8 `enter` 2 1 2 4 `enter`
### 𝕀 - MATHEMATICAL DOUBLE-STRUCK CAPITAL I - U+1D540
* vim - Ctrl-v U 0 0 0 1 d 5 4 0
* emacs - Ctrl-x 8 `enter` 1 d 5 4 0 `enter`
### ℕ - DOUBLE-STRUCK CAPITAL N - U+2115
* vim - Ctrl-v u 2 1 1 5
* emacs - Ctrl-x 8 `enter` 2 1 1 5 `enter`
### ℝ - DOUBLE-STRUCK CAPITAL R - U+211D
* vim - Ctrl-v u 2 1 1 d
* emacs - Ctrl-x 8 `enter` 2 1 1 d `enter`
# EXAMPLES
See the [examples](./examples) directory for usage.
# AUTHORS
* Aaron Sherman
* JJ Merelo
# COPYRIGHT AND LICENSE
Copyright 2016 - 2019 Aaron Sherman
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-TITSUKI-Geo-Hash.md
[](https://travis-ci.org/titsuki/raku-Geo-Hash)
# NAME
Geo::Hash - A Raku bindings for libgeohash
# SYNOPSIS
```
use Geo::Hash;
my $hash = geo-encode(42.60498046875e0, -5.60302734375e0, 5);
say $hash; # OUTPUT: «ezs42»
my Geo::Hash::Coord $coord = geo-decode($hash);
say $coord.latitude; # OUTPUT: «42.60498046875e0»
say geo-neighbors($hash); # OUTPUT: «[ezs48 ezs49 ezs43 ezs41 ezs40 ezefp ezefr ezefx]»
```
# DESCRIPTION
Geo::Hash is a Raku bindings for libgeohash.
## SUBS
### geo-encode
Defined as:
```
sub geo-encode(Num $lat, Num $lng, Int $precision --> Str) is export(:MANDATORY)
```
Encodes given `$lat` and `$lng` pair with precision of `$precision` and creates a hash value.
### geo-decode
Defined as:
```
sub geo-decode(Str $hash --> Geo::Hash::Coord) is export(:MANDATORY)
```
Decodes given `$hash` and creates a `Geo::Hash::Coord` object.
### geo-neighbors
Defined as:
```
sub geo-neighbors(Str $hash --> List) is export(:MANDATORY)
```
Returns the 8-neighboring positions, where each position is represented as hash code.
# AUTHOR
titsuki [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2017 titsuki
libgeohash ( <https://github.com/simplegeo/libgeohash> ) by Derek Smith is licensed under the BSD-3-Clause License.
This library is free software; you can redistribute it and/or modify it under the BSD-3-Clause License.
|
## dist_zef-sdondley-Karabiner-CompModGenerator.md
[](https://github.com/sdondley/Karabiner-CompModGenerator/actions)
# NAME
Karabiner::CompModGenerator - Generate complex modifcations for the [Karabiner-Elements](https://karabiner-elements.pqrs.org) app on macOS
# SYNOPSIS
From the command line:
```
kcmg ActivateApps.cfg
```
# DESCRIPTION
This module generates json files containing "complex modification" rules for use with the the [Karabiner-Elements](https://karabiner-elements.pqrs.org) app on macOS. The goal of the module is to make it easier to create and regenerate complex modification files and avoid the headache of editing json files directly.
The files containing the complex modifications are generated from templates, so the rules you can create are limited by the templates provided by the module, which currently include:
* **ActivateApps** – opens/activiates applications by pressing a modifier key while double or triple tapping another key
* **SafariTabs** – activate Safari and a specific tab by pressing a modifier key and a double tap (best used in conjunction with Safari's "pinned" tab feature)
More templates will be added in the future. Feel welcome to contribute your own template modules to extend `Karabiner::CompModGenerator`'s capabilities.
Follow the [USAGE](#USAGE) instructions below for more details.
# INSTALLATION
Assuming Raku and zef is already installed, install the module with:
`zef install Karabiner::CompModGenerator`
Once you get the module installed follow the [USAGE](#USAGE) instructions to learn how to generate new rules for use with Karabiner-Elements.
If you don't have Raku with zef installed yet, it's easiest to install them both with homebrew if you already have brew installed:
`brew install rakudo-star`
If you don't have brew installed, install it with:
`/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"`
Note, however, that the homebrew install may be months out of date.
To ensure you get the absolute latest version of Raku, [see this page](https://course.raku.org/essentials/how-to-install-rakudo/) for other installation options. Whatever method you choose to install Raku, just be sure the `zef` command gets installed and is working on your machine as well.
# USAGE
The four steps to generating and using the complex modification files are:
1. creating a configuration file; see [Configuration File](#Configuration File) for details
2. running the `kcmg` command, followed by the path to your configuration file, to create the json file containing the complex modification rules
3. copy the json file into Karabiner-Elements configuration directory on your drive
4. open Karabiner-Elements and load the new rules
The json file created in step 2 above gets saved to the same directory you ran the command from. It has the same base file name as your configuration file but with a `.json` file extension. Place this file into your Karbiner-Elements configuration directory. By default, this directory is at `~/.config/Karabiner/assets/complex_modifications`.
Now, with the new json file in place, open Karabiner-Elements and do the following:
1. click the "Complex Modifications" tab
2. click the "Add rule" button
3. click "Enable" for all the rules or individual rules you wish to use
## Configuration File
A configuration file is a text file that contains the comma separated values that get inserted into a template file. Each line in the file outputs a new rule that ends up in json file that's output by the `kcmg` command. An associated template module, as determined by the name of the configuration file, contains the logic for processing the configuration file.
You can use any text editor to create the configuration files.
### Naming Your Configuration File
A configuration file can have any file extention. However, the first part of your file name (aka the base name), **must exactly match the name of an installed template module.** For example, if you want your configuration file to use the `Karabiner::Template::ActivateApps` template, name your file something like `ActivateApps.cfg` or `ActivateApps.txt`.
### Writing Your Configuration File
Here is a sample configuration file for use with the `ActivateApps` template:
```
# Filename: ActivateApps.cfg
# lines beginning with the '#' character get ignored
# LINE FORMAT:
# 1st app name, 2nd app name*, key, modifier*
# The '*' indicates an optional field
Adobe Photoshop 2021, Preview, p, command
zoom.us, z, option
```
Blank lines and lines beginning with the '#' sign are are comments and are ignored.
The uncommented lines contain the data that the template inserts into a pre-defined json template file. Each piece of data is delimited with a comma. Spaces before and after a comma are ignored.
The sample configuration file above creates the following three shortcuts:
* assigns ⌘-p-p (hold down command key and double tap "p") to open Adobe Photoshop
* assigns ⌘-p-p-p (hold down command key and triple tap "p")to open Preview
* assigns ⌘-z-z (hold down command key and double tap "z") to open Zoom
Notice the second app name is optional. If only one app name is provided, only one shortcut (a double tap) will be generated. If two app names are provided, the first app is assigned to the double tap shortcut and the second app is assigned to the triple tap shortcut.
The "modifier" argument is also optional. If not provided, it defaults to the "command" key when using the `ActivateApps` template. You may use "option," "control," "shift," or "command" for the modifier key.
**PRO TIP for ActiveApps template:** The app name in the configuration file must exactly match the name of the offical app name as installed on your Mac. The official name can differ substantially than the app's common name. For example, the app name for "Zoom" is "zoom.us". To ensure you app name correct, use the Mac::Application::List module installed with this module to list out the apps installed on your machine. Alternatively, use the Karabiner-EventViewer application. The module will warn you if it does not recognize the name of an app in your configuration file.
# AUTHOR
Steve Dondley [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2022 Steve Dondley
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-Acme-Meow.md
[](https://github.com/raku-community-modules/Acme-Meow/actions) [](https://github.com/raku-community-modules/Acme-Meow/actions) [](https://github.com/raku-community-modules/Acme-Meow/actions)
# NAME
Acme::Meow - The kitty you always wanted, now in Raku
# SYNOPSIS
```
use Acme::Meow;
my $kitty = Acme::Meow.new;
$kitty.pet;
$kitty.feed("milk");
```
# DESCRIPTION
This is a Raku port of Perl's [Acme::Meow](https://metacpan.org/pod/Acme::Meow).
It's not a verbatim port. Some things have changed, and there is more to come. Stay tuned for more fun :)
## class Acme::Meow
Our cute, artificial cat (perfect for allergics!)
### method pet
```
method pet() returns Mu
```
pet our kitty
### method feed
```
method feed(
$food?
) returns Mu
```
feed our kitty
### method is-sleeping
```
method is-sleeping() returns Mu
```
is our kitty sleeping?
### method nip
```
method nip() returns Mu
```
handy method to feed your cat with a nip
### method milk
```
method milk() returns Mu
```
another one to give some milk to our kitty
# AUTHOR
Tadeusz Sośnierz
# COPYRIGHT AND LICENSE
Copyright 2010 - 2017 Tadeusz Sośnierz
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-antononcube-Lingua-Translation-DeepL.md
# Lingua::Translation::DeepL
## In brief
This Raku package provides access to the language translation service [DeepL](https://www.deepl.com), [DL1].
For more details of the DeepL's API usage see [the documentation](https://www.deepl.com/docs-api), [DL2].
**Remark:** To use the DeepL API one has to register and obtain authorization key.
**Remark:** This Raku package is much "less ambitious" than the official Python package, [DLp1], developed by DeepL's team.
Gradually, over time, I expect to add features to the Raku package that correspond to features of [DLp1].
---
## Installation
Package installations from both sources use [zef installer](https://github.com/ugexe/zef)
(which should be bundled with the "standard" Rakudo installation file.)
To install the package from [Zef ecosystem](https://raku.land/) use the shell command:
```
zef install Lingua::Translation::DeepL
```
To install the package from the GitHub repository use the shell command:
```
zef install https://github.com/antononcube/Raku-Lingua-Translation-DeepL.git
```
---
## Usage examples
**Remark:** When the authorization key, `auth-key`, is specified to be `Whatever`
then `deepl-translation` attempts to use the env variable `DEEPL_AUTH_KEY`.
### Basic translation
Here is a simple call (automatic language detection by DeepL and translation to English):
```
use Lingua::Translation::DeepL;
say deepl-translation('Колко групи могат да се намерят в този облак от точки.');
```
```
# [{detected_source_language => BG, text => How many groups can be found in this point cloud.}]
```
### Multiple texts
Here we translate from Bulgarian, Russian, and Portuguese to English:
```
my @texts = ['Препоръчай двеста неща от рекомендационната система smrGoods.',
'Сделать классификатор с логистической регрессии',
'Fazer um classificador florestal aleatório com 200 árvores'];
my @res = |deepl-translation(@texts,
from-lang => Whatever,
to-lang => 'English',
auth-key => Whatever);
.say for @res;
```
```
# {detected_source_language => BG, text => Recommend two hundred things from the smrGoods recommendation system.}
# {detected_source_language => RU, text => Making a classifier from logistic regression}
# {detected_source_language => PT, text => Make a random forest classifier with 200 trees}
```
**Remark:** DeepL allows up to 50 texts to be translated in one API call.
Hence, if the first argument is an array with more than 50 elements, then it is partitioned
into up-to-50-elements chunks and those are given to `deepl-translation`.
### Formality of the translations
The argument "formality" controls whether translations should lean toward informal or formal language.
This option is only available for some target languages; see [DLp1] for details.
```
say deepl-translation('How are you?', to-lang => 'German', auth-key => Whatever, formality => 'more');
say deepl-translation('How are you?', to-lang => 'German', auth-key => Whatever, formality => 'less');
```
```
# [{detected_source_language => EN, text => Wie geht es Ihnen?}]
# [{detected_source_language => EN, text => Wie geht es dir?}]
```
```
say deepl-translation('How are you?', to-lang => 'Russian', auth-key => Whatever, formality => 'more');
say deepl-translation('How are you?', to-lang => 'Russian', auth-key => Whatever, formality => 'less');
```
```
# [{detected_source_language => EN, text => Как дела?}]
# [{detected_source_language => EN, text => Как ты?}]
```
### Languages
The function `deepl-translation` verifies that the argument languages given to it are
valid DeepL from- and to-languages.
See the section ["Request Translation"](https://www.deepl.com/docs-api/translate-text/translate-text/).
Here we get the mappings of abbreviations to source language names:
```
deepl-source-languages()
```
```
# {bulgarian => BG, chinese => ZH, czech => CS, danish => DA, dutch => NL, english => EN, estonian => ET, finnish => FI, french => FR, german => DE, greek => EL, hungarian => HU, indonesian => ID, italian => IT, japanese => JA, latvian => LV, lithuanian => LT, polish => PL, portuguese => PT, romanian => RO, russian => RU, slovak => SK, slovenian => SL, spanish => ES, swedish => SV, turkish => TR, ukrainian => UK}
```
Here we get the mappings of abbreviations to target language names:
```
deepl-target-languages()
```
```
# {bulgarian => BG, chinese simplified => ZH, czech => CS, danish => DA, dutch => NL, english => EN, english american => EN-US, english british => EN-GB, estonian => ET, finnish => FI, french => FR, german => DE, greek => EL, hungarian => HU, indonesian => ID, italian => IT, japanese => JA, latvian => LV, lithuanian => LT, polish => PL, portuguese => PT, portuguese brazilian => PT-BR, portuguese non-brazilian => PT-PT, romanian => RO, russian => RU, slovak => SK, slovenian => SL, spanish => ES, swedish => SV, turkish => TR, ukrainian => UK}
```
---
## Command Line Interface
The package provides a Command Line Interface (CLI) script:
```
deepl-translation --help
```
```
# Usage:
# deepl-translation [<text>] [-f|--from-lang=<Str>] [-t|--to-lang=<Str>] [-a|--auth-key=<Str>] [--formality=<Str>] [--tag-handling=<Str>] [--timeout[=UInt]] [--format=<Str>] -- Text translation using the DeepL API.
# deepl-translation [<words> ...] [-f|--from-lang=<Str>] [-t|--to-lang=<Str>] [-a|--auth-key=<Str>] [--formality=<Str>] [--tag-handling=<Str>] [--timeout[=UInt]] [--format=<Str>] -- Command given as a sequence of words.
#
# [<text>] Text to be translated. If a file name, its content is used.
# -f|--from-lang=<Str> Source language. [default: 'Whatever']
# -t|--to-lang=<Str> Target language. [default: 'English']
# -a|--auth-key=<Str> Authorization key (to use DeepL API.) [default: 'Whatever']
# --formality=<Str> Language formality in the translated text; one of ('more', 'less', 'prefer_more', 'prefer_less', 'default', or 'Whatever'.) [default: 'Whatever']
# --tag-handling=<Str> Tag handling spec; one of ('xml', 'html', 'default', or 'Whatever'.) [default: 'Whatever']
# --timeout[=UInt] Timeout. [default: 10]
# --format=<Str> Format of the result; one of "json", "hash", or "text". [default: 'text']
```
**Remark:** When the authorization key argument "auth-key" is specified set to "Whatever"
then `deepl-translation` attempts to use the env variable `DEEPL_AUTH_KEY`.
---
## Mermaid diagram
The following flowchart corresponds to the steps in the package function `deepl-translation`:
```
graph TD
UI[/Some natural language text/]
TO[/Translation output/]
WR[[Web request]]
DeepL{{deepl.com}}
PJ[Parse JSON]
Q{Return<br>hash?}
QT50{Are texts<br>> 50?}
MMTC[Compose multiple queries]
MSTC[Compose one query]
MURL[[Make URL]]
TTC[Translate]
QAK{Auth key<br>supplied?}
EAK[["Try to find<br>DEEPL_AUTH _KEY<br>in %*ENV"]]
QEAF{Auth key<br>found?}
NAK[/Cannot find auth key/]
UI --> QAK
QAK --> |yes|QT50
QAK --> |no|EAK
EAK --> QEAF
QT50 --> |no|MSTC
MSTC --> TTC
QT50 --> |yes|MMTC
MMTC --> TTC
QEAF --> |no|NAK
QEAF --> |yes|QT50
TTC -.-> MURL -.-> WR -.-> TTC
WR -.-> |URL|DeepL
DeepL -.-> |JSON|WR
TTC --> Q
Q --> |yes|PJ
Q --> |no|TO
PJ --> TO
```
---
## Potential problems
On some platforms (say, macOS with M1 processor) execution of `deepl-translation` might give the message:
> WARNING rakudo is loading libcrypto in an unsafe way
See ["Problem with libcrypto on MacOS 11 (Big Sur) #81"](https://github.com/sergot/openssl/issues/81)
for potential solutions.
---
## TODO
* TODO Implementation
* TODO Implement accepting `to-lang` value of multiple languages to translate to
* TODO CLI implement the multi-lang argument in the CLI script
* TODO Testing
* Add xt unit tests
* TODO Documentation
* DONE Basic usage documentation
* TODO Describe utilization and comparisons with LLMs
* How using translation LLM prompts compare with DeepL?
---
## References
[DL1] DeepL, [DeepL Translator](https://www.deepl.com/translator).
[DL2] DeepL, [DeepL API](https://www.deepl.com/docs-api/).
[DLp1] DeepL,
[DeepL Python Library](https://github.com/DeepLcom/deepl-python),
(2021),
[GitHub/DeepLcom](https://github.com/DeepLcom/).
|
## dist_cpan-UFOBAT-Temp-Path.md
# NAME
Temp::Path - Make a temporary path, file, or directory
# SYNOPSIS
```
use Temp::Path;
with make-temp-path {
.spurt: 'meows';
say .slurp: :bin; # OUTPUT: «Buf[uint8]:0x<6d 65 6f 77 73>»
say .absolute; # OUTPUT: «/tmp/1E508EE56B7C069B7ABB7C71F2DE0A3CE40C20A1398B45535AF3694E39199E9A»
}
with make-temp-path :content<meows> :chmod<423> :suffix<.txt> {
.slurp.say; # OUTPUT: «meows»
.mode .say; # OUTPUT: «0647»
say .absolute; # OUTPUT «/tmp/8E548EE56B7C119B7ABB7C71F2DE0A3CE40C20A1398B45535AF3694E39199EAE.txt»
}
with make-temp-dir {
.add('meows').spurt: 'I ♥ Perl 6!';
.dir.say; # OUTPUT: «("/tmp/B42F3C9D8B6A0C5C911EE24DD93DD213F1CE1DD0239263AC3A7D29A2073621A5/meows".IO)»
}
{
temp $*TMPDIR = make-temp-dir :chmod<0o700>;
$*TMPDIR.say;
# OUTPUT:
# "/tmp/F5AA112627DA7B59C038900A3C8C7CB05477DCCCEADF2DC447EC304017A1009E".IO
say make-temp-path;
# OUTPUT:
# "/tmp/F5AA112627DA7B59C038900A3C8C7CB05477DCCCEADF2DC447EC304017A1009E/…
# …C41E7114DD24C65C6722981F8C5693E762EBC5958238E23F7B324A1BDD37A541".IO
}
```
# EXPORTED TERMS
This module exports terms (not subroutines), so you don't need to use parentheses to avoid block gobbling errors. Just use these same way as you'd use constant `π`
If you have to use parens for some reason, make them go around the whole them, not just the args:
```
make-temp-path(:content<foo> :chmod<423>) # WRONG
(make-temp-path :content<foo> :chmod<423>) # RIGHT
```
## `make-temp-path`
Defined as:
```
sub term:<make-temp-path> (
:$content where Any|Blob:D|Cool:D,
Int :$chmod,
Str() :$prefix = '',
Str() :$suffix = ''
--> IO::Path:D
)
```
Creates an [IO::Path](https://docs.perl6.org/type/IO::Path) object pointing to a path inside [$\*TMPDIR](https://docs.perl6.org/language/variables#index-entry-%24%2ATMPDIR) that will be deleted (see [DETAILS OF DELETION](#details-of-deletion) section below).
Unless `:$chmod` or `:$content` are given, no files will be created. If `:$chmod` is given a file containing `:$content` (or empty, if no `:$content` is given) will be created with `$chmod` [permissions](https://docs.perl6.org/type/IO::Path#method_chmod). If `:$content` is given without `:$chmod`, the mode will be the default resulting from files created with [IO::Handle.open](https://docs.perl6.org/type/IO::Handle#method_open).
The [basename](https://docs.perl6.org/type/IO::Path#method_basename) of the path is currently a SHA256 hash, but your program should not make assumptions about the format of the basename.
**Security Note:** at the moment, `:chmod` is set *after* the file is created and its content is written. This will be fixed once a way to create a file with a specific mode is available in Rakudo. While it will work at the moment, it might not be the best idea to assume `:$content` will be successfully written if you set `:$chmod` that does not let the current process write to the file.
## `make-temp-dir`
Defined as:
```
sub term:<make-temp-dir> (Int :$chmod, Str() :$prefix = '', Str() :$suffix = '' --> IO::Path:D)
```
Creates a directory inside [$\*TMPDIR](https://docs.perl6.org/language/variables#index-entry-%24%2ATMPDIR) that will be deleted (see [DETAILS OF DELETION](#details-of-deletion) section below) and returns the [IO::Path](https://docs.perl6.org/type/IO::Path) object pointing to it.
If `:$chmod` is provided, the directory will be created with that mode. Otherwise, the default `.mkdir` [mode](https://docs.perl6.org/type/IO::Path#routine_mkdir) will be used.
Note that currently `.mkdir` pays attention to [umask](https://en.wikipedia.org/wiki/Umask) and `make-temp-dir` will first the `:$chmod` to `.mkdir`, to create `umask` masked directory, and then it will [.chmod](https://docs.perl6.org/type/IO::Path#method_chmod) it, to remove the effects of the `umask`.
# DETAILS OF DELETION
The deletion of files created by this module will happen either when the returned `IO::Path` objects are garbage collected or when the `END` phaser gets run. Note that this means temporary files/directories may be left behind if your program crashes or gets aborted.
The temporary `IO::Path` objects created by `make-temp-path` and `make-temp-dir` terms have a role `Temp::Path::AutoDel` mixed in that will [rmtree](https://github.com/labster/p6-file-directory-tree#rmtree) or [.unlink](https://docs.perl6.org/type/IO::Path#routine_unlink) the filesystem object the path points to.
Note that deletion will happen only if the path was created by this module. For example doing `make-temp-dir.sibling: 'foo'` will still give you an `IO::Path` with `Temp::Path::AutoDel` mixed in due to how `IO::Path` methods create new objects. But new objects created by `.sibling`, `.add`, `.child`, `.parent`, etc won't be deleted, when the object gets garbage collected, because *you* created it and not the module. Of course, when a parent directory, that was created by this module gets deleted, all its contents that you created with `.child` gets removed from the disk. Siblings need to be removed manually.
# REPOSITORY
Fork this module on GitHub: <https://github.com/ufobat/perl6-Temp-Path>
# BUGS
To report bugs or request features, please use <https://github.com/ufobat/perl6-Temp-Path/issues>
# AUTHOR
* Zoffix Znet (<http://perl6.party/>)
* Martin Barth (ufobat)
# LICENSE
You can use and distribute this module under the terms of the The Artistic License 2.0. See the LICENSE file included in this distribution for complete details.
The META6.json file of this distribution may be distributed and modified without restrictions or attribution.
|
## handled.md
handled
Combined from primary sources listed below.
# [In Failure](#___top "go to top of document")[§](#(Failure)_method_handled "direct link")
See primary documentation
[in context](/type/Failure#method_handled)
for **method handled**.
```raku
method handled(Failure:D: --> Bool:D) is rw
```
Returns `True` for handled failures, `False` otherwise.
```raku
sub f() { fail }; my $v = f; say $v.handled; # OUTPUT: «False»
```
The `handled` method is an [lvalue](/language/glossary#lvalue), see [routine trait `is rw`](/type/Routine#trait_is_rw), which means you can also use it to set the handled state:
```raku
sub f() { fail }
my $v = f;
$v.handled = True;
say $v.handled; # OUTPUT: «True»
```
|
## dist_zef-finanalyst-Rakuast-RakuDoc-Render.md
# RakuDoc renderer
```
Renders RakuDoc sources into an output format dependent on templates
```
---
## Table of Contents
[SYNOPSIS](#SYNOPSIS)
[Overview](#Overview)
[Command line invocation](#Command_line_invocation)
[RenderDocs utility](#RenderDocs_utility)
[Docker image](#Docker_image)
[Documentation](#Documentation)
[RenderTextify utility](#RenderTextify_utility)
[Wrapping](#Wrapping)
[Troubleshooting](#Troubleshooting)
[Credits](#Credits)
## SYNOPSIS
• Clone the repository
▹ `git clone https://github.com/finanalyst/rakuast-rakudoc-render.git`
▹ `cd rakuast-rakudoc-render`
• Install using zef as follows (flag is important)
▹ `zef install . -/precompile-install`
Note that `zef` runs the tests in `t/`, and those cause compilation of the modules in the distribution.
To eliminate the possibility of RakuDoc errors, use
```
verify-rakudoc filename
```
where ****filename**** is a RakuDoc source. If necessary, *.rakudoc* will be appended.
Also a docker container is available as described in Docker image
## Overview
This distribution is intended to provide several renderers from RakuDoc v2 into commonly used output formats. For those reading this file on *finanalyst.github.io*, the distribution can be found at [Github repo](https://github.com/finanalyst/rakuast-rakudoc-render).
The basic render engine is `RakuDoc::Render`, which renders a RakuDoc source into text for display on a terminal.
The Renderer class is designed to be extended to other output formats by subclassing.
It is easier to use [RenderDocs](RenderDocs utility), which handles output to different formats and saves to a file.
This software uses bleeding edge Rakudo, so look [at troubleshooting below](Troubleshooting).
## Command line invocation
The RakuDoc documentation describes a command line invocation, which is described here, but [RenderDocs](RenderDocs utility) is recommended.
The **canonical method** for generating rendered text is possible using the *Generic* renderer and sends the output to STDOUT, so its best to pipe to a file, namely
```
RAKUDO_RAKUAST=1 raku --rakudoc=Generic rakudociem-ipsum.rakudoc > store-output
```
Some [naive wrapping and width modification](Wrapping) is possible using environment variables.
The file [rakudociem-ipsum.rakudoc](https://github.com/Raku/RakuDoc-GAMMA/blob/main/compliance-document/rakudociem-ipsum.rakudoc) is the file for testing RakuDoc v2 compliance. An up-to-date copy can be obtained with:
```
bin/get-compliance-document
```
A copy of `rakudociem-ipsum.rakudoc` is also contained in `resources/compliance-rendering`, together with renderings of the file using the output renderers in this distribution.
In order to avoid environment variables, eg for Windows, a RakuDoc file can be rendered to Text using the [RenderTextify](RenderTextify utility). It avoids some installation problems, stores the output and offers some other output options, eg.
```
bin/RenderTextify rakudociem-ipsum
```
(the .rakudoc extension may be omitted if desired)
## RenderDocs utility
*RenderDoc* has several advantages over a `raku` invocation:
• Output to different formats is managed using the `--format` command line option:
▹ *no --format* or `--format=md`: generates a file in Markdown with an ***.md*** extension
▹ `--format=HTML --single`: generates a file in HTML, ending ***\_singlefile.html***, which can be opened directly in a browser without internet connection.
▹ `--format=HTML`: generates a file in HTML, ending ***.html***, the HTML is intended for use with an internet connection and has a number of custom blocks.
• Simpler file specification
▹ By default, **all** the *rakudoc* sources from `docs/` are rendered
▹ By default, all the output files are stored at the *Current working directory*
▹ The first word after the options (eg ****documents****) is taken to be the file **docs/documents.rakudoc**
▹ The source location can be given with `--src=...` and the output with `--to=...`
Given these defaults, the following will render all the \**.rakudocs* in *docs/* to <./\*.md> in Markdown.
```
bin/RenderDocs
```
In order to get the command line options try
```
bin/RenderDocs -h
```
An example of rendering a single file, put the basename without *.rakudoc* as a string parameter, eg.
```
bin/RenderDocs README
```
In order to override the source and output defaults use `--src` and `--to` options, eg.
```
bin/RenderDocs --src='sources/' --to='rendered/' some-file
```
In order to get single file HTML, rather than markdown, and output it into *rendered/*
```
bin/Render --to='rendered' --html --single README
```
In order to get the possibilities offered by RakuDoc::To::HTML-Extra, including maps, graphs, themes and the Bulma CSS framework, use `--format=html`, eg.
```
bin/Render --format=html src=docs/plugins Graphviz
```
Two debug options `--debug` and `--verbose` are available and are described in [Render](Render.md).
## Docker image
The distribution contains a `Dockerfile`, which shows the installation steps needed. An image of a recent distribution can be found at `docker.io/finanalyst/rakuast-rakudoc-render:latest`
The docker image was designed for use as a *github CI action*. For example, place the following content in the file `.workflows/GenerateDocs.yml` in the root of a *github* repository:
```
name: RakuDoc to MD
on:
# Runs on pushes targeting the main branch
push:
branches: ["main"]
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
jobs:
container-job:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@master
with:
persist-credentials: false
fetch-depth: 0
- name: Render docs/sources
uses: addnab/docker-run-action@v3
with:
image: finanalyst/rakuast-rakudoc-render:latest
registry: docker.io
options: -v ${{github.workspace}}/docs:/docs -v ${{github.workspace}}:/to
run: RenderDocs --src=/docs --to=/to --force
- name: Commit and Push changes
uses: Andro999b/[email protected]
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
branch: 'main'
```
Then whenever commits are pushed to the repository, all new or modified documents in **docs/** are rendered into Markdown and copied to the root of the repository (remember to `git pull` locally).
## Documentation
If you are reading this from the repo, an HTML version of the documentation can be found at [finanalyst.github.io](https://finanalyst.github.io).
The two main documentation sources are:
• [An overview of the generic renderer](https://finanalyst.github.io/Render)
• [The templating system](https://finanalyst.github.io/Templates)
## RenderTextify utility
The utility `bin/RenderTexify` can be called with a RakuDoc source and it saves the result directly to a file, rather than to STDOUT.
For example,
```
bin/RenderTextify rakudociem-ipsum
```
will produce the file
```
rakudociem-ipsum.rakudoc.text
```
The executable `bin/RenderTexify` can also be called with the flags `test` and `pretty` and the name of a file to render. The use case of these options is to see what templates receive from the rendering engine when developing new templates.
The file is output to text files with the flag and `.text` appended to the name. The file format `.rakudoc` is assumed, and added if missing.
For example,
```
bin/RenderTextify --pretty rakudociem-ipsum
```
will produce the file
```
rakudociem-ipsum.rakudoc.pretty.text
```
## Wrapping
The text output will be naively wrapped (the algorithm is still being developed), either by setting the environment variable POSTPROCESSING=1 or using RenderTextify. For example,
```
POSTPROCESSING=1 RAKUDO_RAKUAST=1 raku --rakudoc=Generic doc.rakudoc > store-output
```
or
```
bin/RenderTextify --post-processing doc
```
If the environment variable WIDTH (--width) is also set, the text output will be wrapped to the value. WIDTH by default is set at 80 chars. To set at 70, use:
```
POSTPROCESSING=1 WIDTH=70 RAKUDO_RAKUAST=1 raku --rakudoc=Generic doc.rakudoc > store-output
```
or
```
bin/RenderTextify --post-processing --width=70 doc
```
The utility can also be used for debugging new templates. For more information, see the Render and Templates documents. To get all the debugging information, and information on the template for `C-markup` try
```
bin/RenderTextify --debug='All' --verbose='C-markup' doc
```
## Troubleshooting
In order to get the RakuDoc render test file (rakudociem-ipsum) to work, a recent version of the Rakudoc compiler is needed, after v2024.07.
If the cannonical command `raku` invocation fails, perhaps with a message such as
```
===SORRY!===
This element has not been resolved. Type: RakuAST::Type::Simple
```
or
```
Out-of-sync package detected in LANG1 at r => Str=「{ $!front-matter }」
(value in braid: RakuAST::Class, value in $*PACKAGE: RakuAST::Class)
===SORRY!===
No such method 'IMPL-REGEX-QAST' for invocant of type 'RakuAST::Regex'
```
then try
```
bin/force-compile
```
This deletes the `.precomp` files in the current directory, and runs `prove6 -I.`, which causes a recompilation of all the modules.
## Credits
Richard Hainsworth aka finanalyst
## VERSION
v0.20.0
---
---
Rendered from docs/README.rakudoc/README at 17:16 UTC on 2025-01-05
Source last modified at 17:15 UTC on 2025-01-05
|
## types.md
Documented Types
Built-in types
This is a list of the built-in types that are documented, sorted by class/enum/module/role and by categories.
Basic classes
[Subset UInt](type/UInt)
Unsigned integer (arbitrary-precision)
[class AST](type/AST)
Abstract representation of a piece of source code
[class Allomorph](type/Allomorph)
Dual value number and string
[class Any](type/Any)
Thing/object
[class Block](type/Block)
Code object with its own lexical scope
[class CallFrame](type/CallFrame)
Captures the current frame state
[class Code](type/Code)
Code object
[class Collation](type/Collation)
Encapsulates instructions about how strings should be sorted
[class Compiler](type/Compiler)
Information related to the compiler that is being used
[class Complex](type/Complex)
Complex number
[class ComplexStr](type/ComplexStr)
Dual value complex number and string
[class Cool](type/Cool)
Object that can be treated as both a string and number
[class CurrentThreadScheduler](type/CurrentThreadScheduler)
Scheduler that synchronously executes code on the current thread
[class Date](type/Date)
Calendar date
[class DateTime](type/DateTime)
Calendar date with time
[class Distribution::Hash](type/Distribution/Hash)
Distribution::Hash
[class Distribution::Locally](type/Distribution/Locally)
Distribution::Locally
[class Distribution::Path](type/Distribution/Path)
Distribution::Path
[class Distribution::Resource](type/Distribution/Resource)
Every one of the resources installed with a distribution
[class Duration](type/Duration)
Length of time
[class Encoding::Registry](type/Encoding/Registry)
Management of available encodings
[class FatRat](type/FatRat)
Rational number (arbitrary-precision)
[class ForeignCode](type/ForeignCode)
Rakudo-specific class that wraps around code in other languages (generally NQP)
[class Format](type/Format)
Convert values to a string given a format specification
[class Formatter](type/Formatter)
Produce Callable for given format specification
[class HyperSeq](type/HyperSeq)
An object for performing batches of work in parallel with ordered output
[class HyperWhatever](type/HyperWhatever)
Placeholder for multiple unspecified values/arguments
[class Instant](type/Instant)
Specific moment in time
[class Int](type/Int)
Integer (arbitrary-precision)
[class IntStr](type/IntStr)
Dual value integer and string
[class Junction](type/Junction)
Logical superposition of values
[class Label](type/Label)
Tagged location in the source code
[class Lock::Async](type/Lock/Async)
A non-blocking, non-re-entrant, mutual exclusion lock
[class Macro](type/Macro)
Compile-time routine
[class Method](type/Method)
Member function
[class Mu](type/Mu)
The root of the Raku type hierarchy.
[class Nil](type/Nil)
Absence of a value or a benign failure
[class Num](type/Num)
Floating-point number
[class NumStr](type/NumStr)
Dual value floating-point number and string
[class ObjAt](type/ObjAt)
Unique identification for an object
[class Parameter](type/Parameter)
Element of a Signature
[class Perl](type/Perl)
Perl related information
[class Proxy](type/Proxy)
Item container with custom storage and retrieval
[class RaceSeq](type/RaceSeq)
Performs batches of work in parallel without respecting original order.
[class Raku](type/Raku)
Raku related information
[class RakuAST::Doc::Block](type/RakuAST/Doc/Block)
Contains the information of a RakuDoc block
[class RakuAST::Doc::Declarator](type/RakuAST/Doc/Declarator)
Contains the declarator docs of a RakuAST object
[class RakuAST::Doc::Markup](type/RakuAST/Doc/Markup)
Contains the information about RakuDoc markup
[class RakuAST::Doc::Paragraph](type/RakuAST/Doc/Paragraph)
Contains the information about a RakuDoc paragraph
[class Rat](type/Rat)
Rational number (limited-precision)
[class RatStr](type/RatStr)
Dual value rational number and string
[class Routine](type/Routine)
Code object with its own lexical scope and `return` handling
[class Routine::WrapHandle](type/Routine/WrapHandle)
Holds all information needed to unwrap a wrapped routine.
[class Scalar](type/Scalar)
A mostly transparent container used for indirections
[class Signature](type/Signature)
Parameter list pattern
[class Str](type/Str)
String of characters
[class StrDistance](type/StrDistance)
Contains the result of a string transformation.
[class Sub](type/Sub)
Subroutine
[class Submethod](type/Submethod)
Member function that is not inherited by subclasses
[class Telemetry](type/Telemetry)
Collect performance state for analysis
[class Telemetry::Instrument::Thread](type/Telemetry/Instrument/Thread)
Instrument for collecting Thread data
[class Telemetry::Instrument::ThreadPool](type/Telemetry/Instrument/ThreadPool)
Instrument for collecting ThreadPoolScheduler data
[class Telemetry::Instrument::Usage](type/Telemetry/Instrument/Usage)
Instrument for collecting getrusage data
[class Telemetry::Period](type/Telemetry/Period)
Performance data over a period
[class Telemetry::Sampler](type/Telemetry/Sampler)
Telemetry instrument pod
[class ValueObjAt](type/ValueObjAt)
Unique identification for value types
[class Variable](type/Variable)
Object representation of a variable for use in traits
[class Version](type/Version)
Module version descriptor
[class Whatever](type/Whatever)
Placeholder for the value of an unspecified argument
[class WhateverCode](type/WhateverCode)
Code object constructed by Whatever-priming
[class atomicint](type/atomicint)
Integer (native storage at the platform's atomic operation size)
[class int](native/int)
Native integer
[package RakuAST](type/RakuAST)
Namespace for holding RakuAST related classes
[role Numeric](type/Numeric)
Number or object that can act as a number
Composite classes
[class Array](type/Array)
Sequence of itemized values
[class Bag](type/Bag)
Immutable collection of distinct objects with integer weights
[class BagHash](type/BagHash)
Mutable collection of distinct objects with integer weights
[class Capture](type/Capture)
Argument list suitable for passing to a Signature
[class Hash](type/Hash)
Mapping from strings to itemized values
[class IterationBuffer](type/IterationBuffer)
Low level storage of positional values
[class List](type/List)
Sequence of values
[class Map](type/Map)
Immutable mapping from strings to values
[class Mix](type/Mix)
Immutable collection of distinct objects with Real weights
[class MixHash](type/MixHash)
Mutable collection of distinct objects with Real weights
[class NFC](type/NFC)
Codepoint string in Normal Form C (composed)
[class NFD](type/NFD)
Codepoint string in Normal Form D (decomposed)
[class NFKC](type/NFKC)
Codepoint string in Normal Form KC (compatibility composed)
[class NFKD](type/NFKD)
Codepoint string in Normal Form KD (compatibility decomposed)
[class Pair](type/Pair)
Key/value pair
[class PseudoStash](type/PseudoStash)
Stash type for pseudo-packages
[class Range](type/Range)
Interval of ordered values
[class Seq](type/Seq)
An iterable, potentially lazy sequence of values
[class Set](type/Set)
Immutable collection of distinct objects
[class SetHash](type/SetHash)
Mutable collection of distinct objects
[class Slip](type/Slip)
A kind of List that automatically flattens into an outer container
[class Stash](type/Stash)
Table for "our"-scoped symbols
[class Uni](type/Uni)
A string of Unicode codepoints
[class utf8](type/utf8)
Mutable uint8 buffer for utf8 binary data
Domain-specific classes
[class Attribute](type/Attribute)
Member variable
[class Cancellation](type/Cancellation)
Removal of a task from a Scheduler before normal completion
[class Channel](type/Channel)
Thread-safe queue for sending values from producers to consumers
[class CompUnit](type/CompUnit)
CompUnit
[class CompUnit::Repository::FileSystem](type/CompUnit/Repository/FileSystem)
CompUnit::Repository::FileSystem
[class CompUnit::Repository::Installation](type/CompUnit/Repository/Installation)
CompUnit::Repository::Installation
[class Distro](type/Distro)
Distribution related information
[class Grammar](type/Grammar)
Formal grammar made up of named regexes
[class IO::ArgFiles](type/IO/ArgFiles)
Iterate over contents of files specified on command line
[class IO::CatHandle](type/IO/CatHandle)
Use multiple IO handles as if they were one
[class IO::Handle](type/IO/Handle)
Opened file or stream
[class IO::Notification](type/IO/Notification)
Asynchronous notification for file and directory changes
[class IO::Notification::Change](type/IO/Notification/Change)
Changes in a file, produced by watch-file
[class IO::Path](type/IO/Path)
File or directory path
[class IO::Path::Cygwin](type/IO/Path/Cygwin)
IO::Path pre-loaded with IO::Spec::Cygwin
[class IO::Path::Parts](type/IO/Path/Parts)
IO::Path parts encapsulation
[class IO::Path::QNX](type/IO/Path/QNX)
IO::Path pre-loaded with IO::Spec::QNX
[class IO::Path::Unix](type/IO/Path/Unix)
IO::Path pre-loaded with IO::Spec::Unix
[class IO::Path::Win32](type/IO/Path/Win32)
IO::Path pre-loaded with IO::Spec::Win32
[class IO::Pipe](type/IO/Pipe)
Buffered inter-process string or binary stream
[class IO::Socket::Async](type/IO/Socket/Async)
Asynchronous socket in TCP or UDP
[class IO::Socket::Async::ListenSocket](type/IO/Socket/Async/ListenSocket)
A tap for listening TCP sockets
[class IO::Socket::INET](type/IO/Socket/INET)
TCP Socket
[class IO::Spec](type/IO/Spec)
Platform specific operations on file and directory paths
[class IO::Spec::Cygwin](type/IO/Spec/Cygwin)
Platform specific operations on file and directory paths for Cygwin
[class IO::Spec::QNX](type/IO/Spec/QNX)
Platform specific operations on file and directory paths QNX
[class IO::Spec::Unix](type/IO/Spec/Unix)
Platform specific operations on file and directory paths for POSIX
[class IO::Spec::Win32](type/IO/Spec/Win32)
Platform specific operations on file and directory paths for Windows
[class IO::Special](type/IO/Special)
Path to special I/O device
[class Kernel](type/Kernel)
Kernel related information
[class Lock](type/Lock)
A low-level, re-entrant, mutual exclusion lock
[class Lock::ConditionVariable](type/Lock/ConditionVariable)
Condition variables used in locks
[class Match](type/Match)
Result of a successful regex match
[class Pod::Block](type/Pod/Block)
Block in a Pod document
[class Pod::Block::Code](type/Pod/Block/Code)
Verbatim code block in a Pod document
[class Pod::Block::Comment](type/Pod/Block/Comment)
Comment in a Pod document
[class Pod::Block::Declarator](type/Pod/Block/Declarator)
Declarator block in a Pod document
[class Pod::Block::Named](type/Pod/Block/Named)
Named block in a Pod document
[class Pod::Block::Para](type/Pod/Block/Para)
Paragraph in a Pod document
[class Pod::Block::Table](type/Pod/Block/Table)
Table in a Pod document
[class Pod::Defn](type/Pod/Defn)
Pod definition list
[class Pod::FormattingCode](type/Pod/FormattingCode)
Pod formatting code
[class Pod::Heading](type/Pod/Heading)
Heading in a Pod document
[class Pod::Item](type/Pod/Item)
Item in a Pod enumeration list
[class Proc](type/Proc)
Running process (filehandle-based interface)
[class Proc::Async](type/Proc/Async)
Running process (asynchronous interface)
[class Promise](type/Promise)
Status/result of an asynchronous computation
[class Regex](type/Regex)
String pattern
[class Semaphore](type/Semaphore)
Control access to shared resources by multiple threads
[class Supplier](type/Supplier)
Live Supply factory
[class Supplier::Preserving](type/Supplier/Preserving)
Cached live Supply factory
[class Supply](type/Supply)
Asynchronous data stream with multiple subscribers
[class Tap](type/Tap)
Subscription to a Supply
[class Thread](type/Thread)
Concurrent execution of code (low-level)
[class ThreadPoolScheduler](type/ThreadPoolScheduler)
Scheduler that distributes work among a pool of threads
[class Unicode](type/Unicode)
Unicode related information
[class VM](type/VM)
Raku Virtual Machine related information
Exception classes
[class Backtrace](type/Backtrace)
Snapshot of the dynamic call stack
[class Backtrace::Frame](type/Backtrace/Frame)
Single frame of a Backtrace
[class CX::Done](type/CX/Done)
Done control exception
[class Exception](type/Exception)
Anomalous event capable of interrupting normal control-flow
[class Failure](type/Failure)
Delayed exception
[class X::AdHoc](type/X/AdHoc)
Error with a custom message
[class X::Anon::Augment](type/X/Anon/Augment)
Compilation error due to augmenting an anonymous package
[class X::Anon::Multi](type/X/Anon/Multi)
Compilation error due to declaring an anonymous multi
[class X::Assignment::RO](type/X/Assignment/RO)
Exception thrown when trying to assign to something read-only
[class X::Attribute::NoPackage](type/X/Attribute/NoPackage)
Compilation error due to declaring an attribute outside of a package
[class X::Attribute::Package](type/X/Attribute/Package)
Compilation error due to declaring an attribute in an ineligible package
[class X::Attribute::Required](type/X/Attribute/Required)
Compilation error due to not declaring an attribute with the `is required` trait
[class X::Attribute::Undeclared](type/X/Attribute/Undeclared)
Compilation error due to an undeclared attribute
[class X::Augment::NoSuchType](type/X/Augment/NoSuchType)
Compilation error due to augmenting a non-existing type
[class X::Bind](type/X/Bind)
Error due to binding to something that is not a variable or container
[class X::Bind::NativeType](type/X/Bind/NativeType)
Compilation error due to binding to a natively typed variable
[class X::Bind::Slice](type/X/Bind/Slice)
Error due to binding to a slice
[class X::Caller::NotDynamic](type/X/Caller/NotDynamic)
Error while trying to access a non dynamic variable through CALLER
[class X::Cannot::Empty](type/X/Cannot/Empty)
Error due to inappropriate usage of an empty collection
[class X::Cannot::Lazy](type/X/Cannot/Lazy)
Error due to inappropriate usage of a lazy list
[class X::Channel::ReceiveOnClosed](type/X/Channel/ReceiveOnClosed)
Error due to calling receive on a closed channel
[class X::Channel::SendOnClosed](type/X/Channel/SendOnClosed)
Error due to calling send on a closed channel
[class X::Composition::NotComposable](type/X/Composition/NotComposable)
Compilation error due to composing an ineligible type
[class X::Constructor::Positional](type/X/Constructor/Positional)
Error due to passing positional arguments to a default constructor
[class X::ControlFlow](type/X/ControlFlow)
Error due to calling a loop control command in an ineligible scope
[class X::ControlFlow::Return](type/X/ControlFlow/Return)
Error due to calling return outside a routine
[class X::DateTime::TimezoneClash](type/X/DateTime/TimezoneClash)
Error due to using both time zone offset and :timezone
[class X::Declaration::Scope](type/X/Declaration/Scope)
Compilation error due to a declaration with an ineligible scope
[class X::Declaration::Scope::Multi](type/X/Declaration/Scope/Multi)
Compilation error due to declaring a multi with an ineligible scope
[class X::Does::TypeObject](type/X/Does/TypeObject)
Error due to mixing into a type object
[class X::Dynamic::NotFound](type/X/Dynamic/NotFound)
Runtime error thrown when a dynamic variable does not exist
[class X::Eval::NoSuchLang](type/X/Eval/NoSuchLang)
Error due to specifying an unknown language for EVAL
[class X::Export::NameClash](type/X/Export/NameClash)
Compilation error due to exporting the same symbol twice
[class X::IO::BinaryMode](type/X/IO/BinaryMode)
Error while invoking methods on a handle in binary mode.
[class X::IO::Chdir](type/X/IO/Chdir)
Error while trying to change the working directory
[class X::IO::Chmod](type/X/IO/Chmod)
Error while trying to change file permissions
[class X::IO::Chown](type/X/IO/Chown)
Error while trying to change file ownership
[class X::IO::Copy](type/X/IO/Copy)
Error while trying to copy a file
[class X::IO::Cwd](type/X/IO/Cwd)
Error while trying to determine the current working directory
[class X::IO::Dir](type/X/IO/Dir)
Error while trying to get a directory's contents
[class X::IO::DoesNotExist](type/X/IO/DoesNotExist)
Error while doing file tests on a non existing path
[class X::IO::Link](type/X/IO/Link)
Error while trying to create a link
[class X::IO::Mkdir](type/X/IO/Mkdir)
Error while trying to create a directory
[class X::IO::Move](type/X/IO/Move)
Error while trying to move a file
[class X::IO::Rename](type/X/IO/Rename)
Error while trying to rename a file or directory
[class X::IO::Rmdir](type/X/IO/Rmdir)
Error while trying to remove a directory
[class X::IO::Symlink](type/X/IO/Symlink)
Error while trying to create a symbolic link
[class X::IO::Unlink](type/X/IO/Unlink)
Error while trying to remove a file
[class X::Inheritance::NotComposed](type/X/Inheritance/NotComposed)
Error due to inheriting from a type that's not composed yet
[class X::Inheritance::Unsupported](type/X/Inheritance/Unsupported)
Compilation error due to inheriting from an ineligible type
[class X::Method::InvalidQualifier](type/X/Method/InvalidQualifier)
Error due to calling a qualified method from an ineligible class
[class X::Method::NotFound](type/X/Method/NotFound)
Error due to calling a method that isn't there
[class X::Method::Private::Permission](type/X/Method/Private/Permission)
Compilation error due to calling a private method without permission
[class X::Method::Private::Unqualified](type/X/Method/Private/Unqualified)
Compilation error due to an unqualified private method call
[class X::Mixin::NotComposable](type/X/Mixin/NotComposable)
Error due to using an ineligible type as a mixin
[class X::NYI](type/X/NYI)
Error due to use of an unimplemented feature
[class X::NoDispatcher](type/X/NoDispatcher)
Error due to calling a dispatch command in an ineligible scope
[class X::Numeric::CannotConvert](type/X/Numeric/CannotConvert)
Error while trying to coerce a number to another type
[class X::Numeric::DivideByZero](type/X/Numeric/DivideByZero)
Error while trying to divide by zero
[class X::Numeric::Real](type/X/Numeric/Real)
Error while trying to coerce a number to a Real type
[class X::Obsolete](type/X/Obsolete)
Compilation error due to use of obsolete syntax
[class X::OutOfRange](type/X/OutOfRange)
Error due to indexing outside of an allowed range
[class X::Package::Stubbed](type/X/Package/Stubbed)
Compilation error due to a stubbed package that is never defined
[class X::Parameter::Default](type/X/Parameter/Default)
Compilation error due to an unallowed default value in a signature
[class X::Parameter::MultipleTypeConstraints](type/X/Parameter/MultipleTypeConstraints)
Compilation error due to a parameter with multiple type constraints
[class X::Parameter::Placeholder](type/X/Parameter/Placeholder)
Compilation error due to an unallowed placeholder in a signature
[class X::Parameter::Twigil](type/X/Parameter/Twigil)
Compilation error due to an unallowed twigil in a signature
[class X::Parameter::WrongOrder](type/X/Parameter/WrongOrder)
Compilation error due to passing parameters in the wrong order
[class X::Phaser::Multiple](type/X/Phaser/Multiple)
Compilation error due to multiple phasers of the same type
[class X::Phaser::PrePost](type/X/Phaser/PrePost)
Error due to a false return value of a PRE/POST phaser
[class X::Placeholder::Block](type/X/Placeholder/Block)
Compilation error due to a placeholder in an ineligible block
[class X::Placeholder::Mainline](type/X/Placeholder/Mainline)
Compilation error due to a placeholder in the mainline
[class X::Proc::Async::AlreadyStarted](type/X/Proc/Async/AlreadyStarted)
Error due to calling start on an already started Proc::Async object
[class X::Proc::Async::BindOrUse](type/X/Proc/Async/BindOrUse)
Error due to trying to bind a handle that is also used
[class X::Proc::Async::CharsOrBytes](type/X/Proc/Async/CharsOrBytes)
Error due to tapping the same Proc::Async stream for both text and binary reading
[class X::Proc::Async::MustBeStarted](type/X/Proc/Async/MustBeStarted)
Error due to interacting with a Proc::Async stream before spawning its process
[class X::Proc::Async::OpenForWriting](type/X/Proc/Async/OpenForWriting)
Error due to writing to a read-only Proc::Async object
[class X::Proc::Async::TapBeforeSpawn](type/X/Proc/Async/TapBeforeSpawn)
Error due to tapping a Proc::Async stream after spawning its process
[class X::Proc::Unsuccessful](type/X/Proc/Unsuccessful)
Exception thrown if a Proc object is sunk after the process it ran exited unsuccessfully
[class X::Promise::CauseOnlyValidOnBroken](type/X/Promise/CauseOnlyValidOnBroken)
Error due to asking why an unbroken promise has been broken.
[class X::Promise::Vowed](type/X/Promise/Vowed)
Error due to directly trying to keep/break a vowed promise.
[class X::Redeclaration](type/X/Redeclaration)
Compilation error due to declaring an already declared symbol
[class X::Role::Initialization](type/X/Role/Initialization)
Error due to passing an initialization value to an ineligible role
[class X::Scheduler::CueInNaNSeconds](type/X/Scheduler/CueInNaNSeconds)
Error caused by passing NaN to Scheduler.cue as :at, :in, or :every
[class X::Seq::Consumed](type/X/Seq/Consumed)
Error due to trying to reuse a consumed sequence
[class X::Sequence::Deduction](type/X/Sequence/Deduction)
Error due to constructing a sequence from ineligible input
[class X::Signature::NameClash](type/X/Signature/NameClash)
Compilation error due to two named parameters with the same name
[class X::Signature::Placeholder](type/X/Signature/Placeholder)
Compilation error due to placeholders in a block with a signature
[class X::Str::Match::x](type/X/Str/Match/x)
Invalid argument type for :x argument to Str matching methods
[class X::Str::Numeric](type/X/Str/Numeric)
Error while trying to coerce a string to a number
[class X::StubCode](type/X/StubCode)
Runtime error due to execution of stub code
[class X::Syntax::Augment::WithoutMonkeyTyping](type/X/Syntax/Augment/WithoutMonkeyTyping)
Compilation error due to augmenting a type without the `MONKEY-TYPING` pragma
[class X::Syntax::Comment::Embedded](type/X/Syntax/Comment/Embedded)
Compilation error due to a malformed inline comment
[class X::Syntax::Confused](type/X/Syntax/Confused)
Compilation error due to unrecognized syntax
[class X::Syntax::InfixInTermPosition](type/X/Syntax/InfixInTermPosition)
Compilation error due to an infix in term position
[class X::Syntax::Malformed](type/X/Syntax/Malformed)
Compilation error due to a malformed construct (usually a declarator)
[class X::Syntax::Missing](type/X/Syntax/Missing)
Compilation error due to a missing piece of syntax
[class X::Syntax::NegatedPair](type/X/Syntax/NegatedPair)
Compilation error due to passing an argument to a negated colonpair
[class X::Syntax::NoSelf](type/X/Syntax/NoSelf)
Compilation error due to implicitly using a `self` that is not there
[class X::Syntax::Number::RadixOutOfRange](type/X/Syntax/Number/RadixOutOfRange)
Compilation error due to an unallowed radix in a number literal
[class X::Syntax::P5](type/X/Syntax/P5)
Compilation error due to use of Perl-only syntax
[class X::Syntax::Perl5Var](type/X/Syntax/Perl5Var)
Compilation error due to use of Perl-only default variables
[class X::Syntax::Regex::Adverb](type/X/Syntax/Regex/Adverb)
Compilation error due to an unrecognized regex adverb
[class X::Syntax::Regex::SolitaryQuantifier](type/X/Syntax/Regex/SolitaryQuantifier)
Compilation error due to a regex quantifier without preceding atom
[class X::Syntax::Reserved](type/X/Syntax/Reserved)
Compilation error due to use of syntax reserved for future use
[class X::Syntax::Self::WithoutObject](type/X/Syntax/Self/WithoutObject)
Compilation error due to invoking `self` in an ineligible scope
[class X::Syntax::Signature::InvocantMarker](type/X/Syntax/Signature/InvocantMarker)
Compilation error due to a misplaced invocant marker in a signature
[class X::Syntax::Term::MissingInitializer](type/X/Syntax/Term/MissingInitializer)
Compilation error due to declaring a term without initialization
[class X::Syntax::UnlessElse](type/X/Syntax/UnlessElse)
Compilation error due to an `unless` clause followed by `else`
[class X::Syntax::Variable::Match](type/X/Syntax/Variable/Match)
Compilation error due to declaring a match variable
[class X::Syntax::Variable::Numeric](type/X/Syntax/Variable/Numeric)
Compilation error due to declaring a numeric symbol
[class X::Syntax::Variable::Twigil](type/X/Syntax/Variable/Twigil)
Compilation error due to an unallowed twigil in a declaration
[class X::Temporal::InvalidFormat](type/X/Temporal/InvalidFormat)
Error due to using an invalid format when creating a DateTime or Date
[class X::TypeCheck](type/X/TypeCheck)
Error due to a failed type check
[class X::TypeCheck::Assignment](type/X/TypeCheck/Assignment)
Error due to a failed type check during assignment
[class X::TypeCheck::Binding](type/X/TypeCheck/Binding)
Error due to a failed type check during binding
[class X::TypeCheck::Return](type/X/TypeCheck/Return)
Error due to a failed typecheck during `return`
[class X::TypeCheck::Splice](type/X/TypeCheck/Splice)
Compilation error due to a macro trying to splice a non-AST value
[class X::Undeclared](type/X/Undeclared)
Compilation error due to an undeclared symbol
[role CX::Emit](type/CX/Emit)
Emit control exception
[role CX::Last](type/CX/Last)
Last control exception
[role CX::Next](type/CX/Next)
Next control exception
[role CX::Proceed](type/CX/Proceed)
Proceed control exception
[role CX::Redo](type/CX/Redo)
Redo control exception
[role CX::Return](type/CX/Return)
Return control exception
[role CX::Succeed](type/CX/Succeed)
Succeed control exception
[role CX::Take](type/CX/Take)
Take control exception
[role CX::Warn](type/CX/Warn)
Control exception warning
[role X::Control](type/X/Control)
Role for control exceptions
Metamodel classes
[class Metamodel::ClassHOW](type/Metamodel/ClassHOW)
Metaobject representing a Raku class.
[class Metamodel::DefiniteHOW](type/Metamodel/DefiniteHOW)
Metaobject for type definiteness
[class Metamodel::EnumHOW](type/Metamodel/EnumHOW)
Metaobject representing a Raku enum.
[class Metamodel::PackageHOW](type/Metamodel/PackageHOW)
Metaobject representing a Raku package.
[class Metamodel::Primitives](type/Metamodel/Primitives)
Metaobject that supports low-level type operations
[role Metamodel::ConcreteRoleHOW](type/Metamodel/ConcreteRoleHOW)
Provides an implementation of a concrete instance of a role
[role Metamodel::CurriedRoleHOW](type/Metamodel/CurriedRoleHOW)
Support for parameterized roles that have not been instantiated
Basic enums
[enum Bool](type/Bool)
Logical Boolean
[enum Endian](type/Endian)
Indicate endianness (6.d, 2018.12 and later)
Domain-specific enums
[enum Order](type/Order)
Human readable form for comparison operators.
Module modules
[module Test](type/Test)
Writing and running tests
Basic roles
[class RakuAST::Doc::DeclaratorTarget](type/RakuAST/Doc/DeclaratorTarget)
Provide leading/trailing doc functionality
[role Callable](type/Callable)
Invocable code object
[role Dateish](type/Dateish)
Object that can be treated as a date
[role Distribution](type/Distribution)
Distribution
[role Encoding](type/Encoding)
Support for character encodings.
[role PredictiveIterator](type/PredictiveIterator)
Iterators that can predict number of values
[role Rational](type/Rational)
Number stored as numerator and denominator
[role Real](type/Real)
Non-complex number
[role Stringy](type/Stringy)
String or object that can act as a string
Composite roles
[role Associative](type/Associative)
Object that supports looking up values by key
[role Baggy](type/Baggy)
Collection of distinct weighted objects
[role Blob](type/Blob)
Immutable buffer for binary data ('Binary Large OBject')
[role Buf](type/Buf)
Mutable buffer for binary data
[role Enumeration](type/Enumeration)
Working with the role behind the enum type
[role Iterable](type/Iterable)
Interface for container objects that can be iterated over
[role Iterator](type/Iterator)
Generic API for producing a sequence of values
[role Mixy](type/Mixy)
Collection of distinct objects with Real weights
[role Positional](type/Positional)
Object that supports looking up values by index
[role PositionalBindFailover](type/PositionalBindFailover)
Failover for binding to a Positional
[role QuantHash](type/QuantHash)
Object hashes with a limitation on the type of values
[role Sequence](type/Sequence)
Common methods of sequences
[role Setty](type/Setty)
Collection of distinct objects
Domain-specific roles
[role CompUnit::PrecompilationRepository](type/CompUnit/PrecompilationRepository)
CompUnit::PrecompilationRepository
[role CompUnit::Repository](type/CompUnit/Repository)
CompUnit::Repository
[role IO](type/IO)
Input/output related routines
[role IO::Socket](type/IO/Socket)
Network socket
[role Scheduler](type/Scheduler)
Scheme for automatically assigning tasks to threads
[role Systemic](type/Systemic)
Information related to the build system
Exception roles
[role X::Comp](type/X/Comp)
Common role for compile-time errors
[role X::IO](type/X/IO)
IO related error
[role X::OS](type/X/OS)
Error reported by the operating system
[role X::Pod](type/X/Pod)
Pod related error
[role X::Proc::Async](type/X/Proc/Async)
Exception thrown by Proc::Async
[role X::Syntax](type/X/Syntax)
Syntax error thrown by the compiler
[role X::Temporal](type/X/Temporal)
Error related to DateTime or Date
Metamodel roles
[role Metamodel::AttributeContainer](type/Metamodel/AttributeContainer)
Metaobject that can hold attributes
[role Metamodel::C3MRO](type/Metamodel/C3MRO)
Metaobject that supports the C3 method resolution order
[role Metamodel::Documenting](type/Metamodel/Documenting)
Metarole for documenting types.
[role Metamodel::Finalization](type/Metamodel/Finalization)
Metaobject supporting object finalization
[role Metamodel::MROBasedMethodDispatch](type/Metamodel/MROBasedMethodDispatch)
Metaobject that supports resolving inherited methods
[role Metamodel::MethodContainer](type/Metamodel/MethodContainer)
Metaobject that supports storing and introspecting methods
[role Metamodel::Mixins](type/Metamodel/Mixins)
Metaobject for generating mixins
[role Metamodel::MultipleInheritance](type/Metamodel/MultipleInheritance)
Metaobject that supports multiple inheritance
[role Metamodel::Naming](type/Metamodel/Naming)
Metaobject that supports named types
[role Metamodel::ParametricRoleGroupHOW](type/Metamodel/ParametricRoleGroupHOW)
Represents a group of roles with different parameterizations
[role Metamodel::ParametricRoleHOW](type/Metamodel/ParametricRoleHOW)
Represents a non-instantiated, parameterized, role.
[role Metamodel::PrivateMethodContainer](type/Metamodel/PrivateMethodContainer)
Metaobject that supports private methods
[role Metamodel::RoleContainer](type/Metamodel/RoleContainer)
Metaobject that supports holding/containing roles
[role Metamodel::RolePunning](type/Metamodel/RolePunning)
Metaobject that supports *punning* of roles.
[role Metamodel::Stashing](type/Metamodel/Stashing)
Metarole for type stashes
[role Metamodel::Trusting](type/Metamodel/Trusting)
Metaobject that supports trust relations between types
[role Metamodel::Versioning](type/Metamodel/Versioning)
Metaobjects that support versioning
|
## dist_github-azawawi-File-Which.md
# File::Which
[](https://github.com/azawawi/raku-file-which/actions)
This is a Raku Object-oriented port of [File::Which (CPAN)](https://metacpan.org/pod/File::Which).
File::Which finds the full or relative paths to an executable program on the
system. This is normally the function of which utility which is typically
implemented as either a program or a built in shell command. On some unfortunate
platforms, such as Microsoft Windows it is not provided as part of the core
operating system.
This module provides a consistent API to this functionality regardless of the
underlying platform.
```
use File::Which :whence;
# All raku executables in PATH
say which('raku', :all);
# First executable in PATH
say which('raku');
# Same as which('raku')
say whence('raku');
```
## Installation
To install it using zef (a module management tool bundled with Rakudo Star):
```
$ zef install File::Which
```
## Testing
* To run tests:
```
$ prove --ext .rakutest -ve "raku -I."
```
* To run all tests including author tests (Please make sure
[Test::Meta](https://github.com/jonathanstowe/Test-META) is installed):
```
$ zef install Test::META
$ AUTHOR_TESTING=1 prove --ext .rakutest -ve "raku -I."
```
## Author
Raku port:
* Ahmad M. Zawawi, azawawi on #raku, <https://github.com/azawawi/>
* Nick Logan, ugexe on #raku, <https://github.com/ugexe>
* Steve Dondley, sdondley on #raku, <https://github.com/sdondley>
A bit of tests:
* Altai-man, sena\_kun on libera, <https://github.com/Altai-man/>
Perl 5 version:
* Author: Per Einar Ellefsen [[email protected]](mailto:[email protected])
* Maintainers:
* Adam Kennedy [[email protected]](mailto:[email protected])
* Graham Ollis [[email protected]](mailto:[email protected])
## License
MIT License
|
## dist_zef-tbrowder-DateTime-US.md
[](https://github.com/tbrowder/DateTime-US/actions) [](https://github.com/tbrowder/DateTime-US/actions) [](https://github.com/tbrowder/DateTime-US/actions)
# NAME
**DateTime::US** - Provides time zone (TZ) and Daylight Saving Time (DST) information for US states and territories
# SYNOPSIS
```
use DateTime::US;
```
...work with US timezone calculations
```
use DateTime::US::Subs :ALL;
```
This module is part of the 'DateTime::US' distribution, but it's not required for the use of the base module.
# DESCRIPTION
Module **DateTime::US** provides a class with methods used to help Raku programs needing US time zone and DST information. The user creates a `DateTime::US` object by providing a US time zone abbreviation (note the TZ input abbreviation may be in either format for standard or daylight saving time, e.g., 'CST' or 'CDT'). The list of known data may be listed without an object:
```
$ raku
> use DateTime::US;
> show-us-data;
```
The main use case that motivated the module is to convert time in UTC to local time for creating calendars and almanacs. For example, local Sunrise is given in UTC and will normally be shown on a calendar in local time:
```
my $tz = DateTime::US.new: :timezone<CST>;
my $sunriseZ = DateTime.new: "2024-02-21T12:23:00Z";
say $sunriseZ; # OUTPUT: «2024-02-21T12:23:00Z»
my $localtime = $tz.to-localtime :utc($sunriseZ);
say $localtime; # OUTPUT: «2024-02-21T06:23:00 CST»
```
## Class methods
* **to-localtime**(DateTime :$utc! --> DateTime) {...}
Given a time in UTC, convert to local time and adjust for DST.
* **to-utc**(DateTime :$localtime! --> DateTime) {...}
Given a local time, convert to UTC with adjustment for DST.
## Module 'DateTime::US::Subs'
It is useful to have a "perpetual" calculation of the begin/end dates for DST for all years covered by the current governing federal law for the US. Assisted by the `Date::Utils` module, the following routines do that, and they require an `export` tag for use to avoid possible conflict from other modules.
The `:$year` argument defaults to the current year if it is not provided.
* begin-dst(:$year --> Date) is export(:begin-dst) {...}
* dst-begin(:$year --> Date) is export(:dst-begin) {...} # alias for begin-dst
* end-dst(:$year --> Date) is export(:end-dst) {...}
* dst-end(:$year --> Date) is export(:dst-end) {...} # alias for end-dst
The final routine is for use by module `Date::Event`. The `:$set-id` argument is used to provide a globally unique ID (GUID) to allow multiple `Date::Event` objects for a `Date` in a `Hash` keyed by `Date`s.
* get-dst-dates(:$year!, :$set-id! --> Hash) is export(:get-dst-date) {...}
# SEE ALSO
* Module **DateTime::Timezones:auth<zef:guifa>**
In contrast to Matthew Stuckwisch's module, `DateTime::US` does not use any of the IANA timezone database. It relies only on the power of the Raku `Date` and `DateTime` types, the short list of time zone UTC offsets for standard US time zones, the standard dates and time of Daylight Saving Time begin/end times enshrined in US Public Law, and the "perpetual" `Date` routines provided by module `Date::Utils`.
# Todo
Provide handling for the exceptions to the use of DST where indicated.
# Note
The author is happy to create or collaborate on a similar module for other regions. If interested, simply file an issue or discuss it on IRC #raku (author's handle is 'tbrowder').
# AUTHOR
Tom Browder [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
© 2021-2025 Tom Browder
This library is free software; you may redistribute or modify it under the Artistic License 2.0.
|
## dist_gitlab-pheix-LZW-Revolunet.md
# Lempel–Ziv–Welch (LZW) algorithm implementation in Raku
## Synopsis
```
my int $r = 0;
my str $d = 'Тексты - это не энциклопедические и не лингвистические системы.' x 255;
# create LWZ object with default dictionary size (97000)
my $lzw = LZW::Revolunet.new;
# OR create LWZ object with user defined dictionary size (be careful)
my $lzw = LZW::Revolunet.new(:dictsize(200000));
# compress
my $cmp = $lzw.compress(:s($lzw.encode_utf8(:s($d))));
# get compression ratio
$r = $lzw.get_ratio;
# decompress
my $dcmp = $lzw.decode_utf8(:s($lzw.decompress(:s($cmp))));
# validate
if !($dcmp eq $d) {
die 'decompressed data is corrupted';
}
# compress/decompress statistics
('compression ratio ' ~ $r ~ '%').say;
```
## Description
**LZW::Revolunet** — [Raku](https://raku.org) implementation of universal lossless data compression [algorithm](https://en.wikipedia.org/wiki/Lzw) created by Abraham Lempel, Jacob Ziv, and Terry Welch. This module is based on JavaScript implementation ([lzw\_encoder.js](https://gist.github.com/revolunet/843889)) by [Julien Bouquillon](https://github.com/revolunet)
## License
**LZW::Revolunet** is free and opensource software, so you can redistribute it and/or modify it under the terms of the [The Artistic License 2.0](https://opensource.org/licenses/Artistic-2.0).
## Author
Please contact me via [LinkedIn](https://www.linkedin.com/in/knarkhov/) or [Twitter](https://twitter.com/CondemnedCell). Your feedback is welcome at [narkhov.pro](https://narkhov.pro/contact-information.html).
## See also
[LZW Data Compression](https://www2.cs.duke.edu/csed/curious/compression/lzw.html)
|
## dist_cpan-TOBS-OEIS.md
# NAME
OEIS - Look up sequences on the On-Line Encyclopedia of Integer Sequences®
# SYNOPSIS
```
use OEIS;
say OEIS::lookup 1, 1, * + * ... *;
#= OEIS A000045 «Fibonacci numbers: F(n) = F(n-1) + F(n-2) with F(0) = 0 and F(1) = 1.»
say OEIS::lookup(1, 2, 4 ... ∞).mathematica.head;
#= Table[2^n, {n, 0, 50}]
# Notice that only some terms of the Seq are evaluated!
with OEIS::lookup-all(1, 1, * + * ... *).grep(* !~~ OEIS::easy).head {
say .gist; #= OEIS A290689 «Number of transitive rooted trees with n nodes.»
say .sequence; #= [1 1 1 2 3 5 8 13 21 34 55 88 143 229 370 592 955 1527 2457 3929]
}
```
# DESCRIPTION
This module provides an interface to the [On-Line Encyclopedia of Integer Sequences® (OEIS®)](https://oeis.org), a web database of integer sequences. Stick an array or Seq into the `OEIS::lookup` routine and get back the most relevant result that OEIS finds, as an instance of OEIS::Entry. With the `:all` adverb or as the `OEIS::lookup-all` method, it returns a lazy Seq of all results. Sequences can also be looked up by their IDs. See below for details.
## sub fetch
```
multi fetch (Int $ID, :$type = 'A')
multi fetch (Str $ID where { … })
multi fetch (Seq $seq)
multi fetch (*@partial-seq)
```
Searches for a sequence identified by
* its `Int $ID` under the `$type` namespace, e.g. the Fibonacci numbers are sequence 45 in type `A`, 692 in type `M` and 256 in type `N`,
* its `Str $ID` already containing the `$type`, again the Fibonacci numbers are "A000045", "M0692" or "N0256",
* a Seq generating the sequence,
* an array containing sequence elements
and returns all result pages in OEIS's internal text format as a lazy Seq.
This is a very low-level method. See OEIS::lookup for a more convenient interface.
## sub chop-records
```
multi chop-records (Seq \pages)
multi chop-records (Str $page)
```
Takes a single page in OEIS' internal format, or a Seq of them (the return value of OEIS::fetch), and returns a Seq of all OEIS records contained in them, as multiline strings.
You will only need this sub if you get pages from a source that isn't OEIS::fetch, e.g. from a cache on disk, or if you want the textual records instead of OEIS::Entry objects.
For a more convenient interface, see OEIS::lookup.
## sub lookup
```
sub lookup (:$all = False, |c)
```
This high-level sub calls OEIS::fetch with the captured arguments `|c`, followed by OEIS::chop-records and then creates for each record an OEIS::Entry object. Naturally, all search features of OEIS::fetch are supported.
By default only the first record is returned. This is the one that OEIS deems most relevant to the search. If the named argument `$all` is True, all records are returned as a lazy Seq.
If no result was found, the Seq is empty. Note that a too general query leads to "too many results, please narrow search" error from the OEIS. For other possible errors, see X::OEIS.
## sub lookup-all
```
sub lookup-all (|c)
```
This sub is equivalent to `lookup(:all, |c)`. It exists because when you write a Seq directly into the `lookup` call, the `:all` adverb is swallowed into the Seq by the comma operator, unless the Seq is parenthesized, which you may want to avoid having to do.
# SEE ALSO
* [OEIS Internal Format documentation](https://oeis.org/eishelp1.html)
# AUTHOR
Tobias Boege [[email protected]](mailto:[email protected])
# COPYRIGHT AND LICENSE
Copyright 2018/9 Tobias Boege
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-alabamenhu-Token-Foreign.md
# TokenForeign
A Raku module that provides a token allowing easy access to external grammars
This module was developed as a response to Mike Clark's article [“Multiple Co-operating Grammars in Raku”](http://clarkema.org/lab/2022/2022-02-09-raku-multiple-grammars/).
In it, he discusses his approach to calling one grammar from another. While the approaches make sense to those familiar with grammars (and feels downright obvious when you see how it works), the process is admittedly less intuitive at first.
Nonetheless, people do [want to mix grammars](https://www.reddit.com/r/rakulang/comments/sex4qa/comment/humrie1/?utm_source=share&utm_medium=web2x&context=3), and this could be a powerful feature for Raku.
This module originally expanded on Mike's approach, but that had a limitation: the match tree wasn't preserved (only the AST via `make`/`made`).
After reviewing [Daniel Sockwell's thoughts](https://www.codesections.com/blog/grammatical-actions/) and trying to see if I could mimic his technique without multiple levels of inheritance/composition, I stumbled across a better technique.
The result? An absolutely dirt simple way to integrate multiple grammars.
To use:
```
use Token::Foreign;
# OPTION A: token added via mixin
grammar Foo does Foreign {
token foo { ... <foreign: BarGrammar, BarActions> ... }
token foo2 { ... <bar=foreign: BarGrammar, BarActions> ... }
}
# OPTION B: imperative addition via sub call
grammar Foo {
add-foreign: 'bar', BarGrammar, BarActions;
add-foreign: 'baz', BazGrammar, BazActions;
token foo { ... <bar> <baz: OtherBazActions> ... }
}
# OPTION C: trait with autonaming
grammar Foo
is extended(BarGrammar, BarActions)
is extended(BazGrammar, BazActions)
{
token foo { ... <bar> <baz: OtherBazActions> ... }
}
# With OPTION C: specifying actions at parse time
Foo.parse:
:actions(FooActions),
:ext-actions{
baz => DifferentBazActions,
bar => DifferentBarActions
}
```
Each method has its advantages and disadvantages:
* Option A is extremely versatile, but a bit clunkier.
* Option B is a bit less clunky since it provides an explicitly named token, so your grammars are cleaner.
* Option C is designed to be very DWIM. It will automatically generate the token name by removing the word "Grammar" from the grammar class name as well as any trailing hyphen/underscore (`Perl6Grammar` would become `perl6`, `HTML-Grammar` would become `html`).
Both Options B and C allow you to specify an actions class to use by default.
If you want to override that one, just pass an actions class as an argument to the token (e.g. `<foo: ActionClass>`).
Note that both Options B and C require *compile time* knowledge of the external grammars (actions may be unknown until runtime) -- that's probably not an issue in most cases.
With Option A, you could integrate grammars that are not known until runtime.
With Option C, the precedence of actions are inline (`<foo: Actions>`), parse arguments (`.parse: ext-actions{foo => Actions)`), and lastly the trait actions (`is extended(Foo, Actions)`)
If you are curious how the module works, I have tried to fully documented the code.
###Version history
* **v0.3.1**
* Trait access improved with actions specifiable at `.parse`
* **v0.3.0**
* Access via subs and traits (requires compile time knowledge)
* **v0.2.0**
* Full match tree is provided
* Requires mixing in a role
* **v0.1.0**
* First release
### License and Copyright
Copyright © 2022 Matthew Stephen Stuckwisch. Licensed under the Artistic License 2.0.
That said, just integrate the code/technique directly if it better suites your project and you wish to avoid dependencies.
|
## finalization.md
role Metamodel::Finalization
Metaobject supporting object finalization
```raku
role Metamodel::Finalization { ... }
```
*Warning*: this role is part of the Rakudo implementation, and is not a part of the language specification.
This role takes care that `DESTROY` submethods are called (if they exist) when an object is garbage-collected.
# [Methods](#role_Metamodel::Finalization "go to top of document")[§](#Methods "direct link")
## [method setup\_finalization](#role_Metamodel::Finalization "go to top of document")[§](#method_setup_finalization "direct link")
```raku
method setup_finalization($obj)
```
Collects the `DESTROY` submethods from this class and all its superclasses, and marks the class as needing action on garbage collection.
A metamodel for a kind that implements finalization semantics must call this method at type composition time.
## [method destroyers](#role_Metamodel::Finalization "go to top of document")[§](#method_destroyers "direct link")
```raku
method destroyers($obj --> List:D)
```
Returns a list of all finalization methods.
|
## dist_zef-tbrowder-Storable-Lite.md
[](https://github.com/tbrowder/Storable-Lite/actions)
# NAME
Storable::Lite - Provides persistent storage of Raku classes and other types in the local user's file system
# SYNOPSIS
```
use Storable::Lite;
```
# DESCRIPTION
**Storable::Lite** is a copy of the current Raku module **PerlStore** with a name change and other changes to reflect the new Raku name of the original Perl 6. It is also now under management of **App::Mi6** and published to the **Zef** Raku module repository.
# ORIGINAL DESCRIPTION (rakuized)
.raku serialization class and module
This module will work only for only simple situations. All data that is not visible after calling [.raku](http://doc.raku.org/routine/perl) method will be lost. This may be considered a limitation or feature.
```
$foo.to-file('tt1.raku');
my $tested = Foo.from-file('tt1.raku');
```
# AUTHOR
Tom Browder [[email protected]](mailto:[email protected])
Kamil Kułaga [github:teodozjan (original author)]
# COPYRIGHT AND LICENSE
Copyright 2021 Tom Browder
This library is free software; you may redistribute it or modify it under the Artistic License 2.0.
|
## dist_github-cygx-Unicode-GCB.md
# Unicode::GCB [Build Status](https://travis-ci.org/cygx/p6-unicode-gcb)
Unicode grapheme cluster boundary detection
# Synopsis
```
use Unicode::GCB;
say GCB.always(0x600, 0x30);
say GCB.maybe(
"\c[REGIONAL INDICATOR SYMBOL LETTER G]".ord,
"\c[REGIONAL INDICATOR SYMBOL LETTER B]".ord);
say GCB.clusters("äöü".NFD);
```
# Description
Implements the [Unicode 9.0 grapheme cluster boundary rules](http://www.unicode.org/reports/tr29/tr29-29.html#Grapheme_Cluster_Boundary_Rules) or [Unicode 11.0 grapheme cluster boundary rules](http://www.unicode.org/reports/tr29/tr29-33.html#Grapheme_Cluster_Boundary_Rules) depending on the Rakudo version in use.
In contrast to earlier versions of the standard, it is no longer possible
to unambiguously decide if there's a cluster break between two Unicode
characters by looking at just these two characters.
In particular, there's a break between a pair of regional indicator symbols
only if the first symbol has already been paired up with another indicator
and there's no break between extension characters and emoji modifiers if the
current cluster forms an emoji sequence. *[FIXME: Unicode 11.0 rules]*
Therefore, the module provides two different methods `GCB.always()` and
`GCB.maybe()` which both expect two Unicode codepoints as arguments.
The method `GCB.clusters()` expects a `Uni` object as argument and returns
a sequence of such objects split along cluster boundaries.
# Bugs and Development
Development happens at [GitHub](https://github.com/cygx/p6-unicode-gcb). If you found a bug or have a feature
request, use the [issue tracker](https://github.com/cygx/p6-unicode-gcb/issues) over there.
# Copyright and License
Copyright (C) 2016 by [[email protected]](mailto:[email protected])
Distributed under the [Boost Software License, Version 1.0](http://www.boost.org/LICENSE_1_0.txt)
|
## dist_cpan-TIMOTIMO-SDL2-Raw.md
# SDL2::Raw
[](https://travis-ci.org/timo/SDL2_raw-p6) [](https://ci.appveyor.com/project/timo/SDL2_raw-p6/branch/master)
A low-sugar binding to SDL2.
## Synopsis
```
use SDL2::Raw;
die "couldn't initialize SDL2: { SDL_GetError }"
if SDL_Init(VIDEO) != 0;
my $window = SDL_CreateWindow(
"Hello, world!",
SDL_WINDOWPOS_CENTERED_MASK, SDL_WINDOWPOS_CENTERED_MASK,
800, 600,
OPENGL
);
my $render = SDL_CreateRenderer($window, -1, ACCELERATED +| PRESENTVSYNC);
my $event = SDL_Event.new;
main: loop {
SDL_SetRenderDrawColor($render, 0, 0, 0, 0);
SDL_RenderClear($render);
while SDL_PollEvent($event) {
if $event.type == QUIT {
last main;
}
}
SDL_SetRenderDrawColor($render, 255, 255, 255, 255);
SDL_RenderFillRect($render,
SDL_Rect.new(
2 * min(now * 300 % 800, -now * 300 % 800),
2 * min(now * 470 % 600, -now * 470 % 600),
sin(3 * now) * 50 + 80, cos(4 * now) * 50 + 60));
SDL_RenderPresent($render);
}
SDL_Quit;
```
## Status
There's a bunch of functions and structs already covered, but there's also a whole bunch of things I haven't touched at all. If you need any specific part of the API covered, feel free to open a ticket on github or even a pull request!
## Installation
| Platform | Installation |
| --- | --- |
| Ubuntu 14.04 and above | `sudo apt install libsdl2-dev` |
| Fedora 25 and above | `yum install SDL2-devel` |
| Arch Linux | `pacman -S sdl2` |
| Gentoo | `emerge -av libsdl2` |
| macOS | `brew install sdl2 pkg-config` |
| Windows | <https://libsdl.org/download-2.0.php> |
## Examples
### Snake

A simple Snake game. Control it with the arrow keys, guide your snake to eat the red circles, and avoid running into your tail.
This code uses `Cairo` to create the images for the snake's body and tail.
### Particles

A very simple particle system that spews white pixels from a central point that get pulled down by gravity and bounce on the floor.
### Shooter

A more complicated game. Control it with the arrow keys and hold the spacebar to fire.
The code also uses `Cairo` to render the player's spaceship and the enemy spaceships. In generating the starfields it shows how to render to a texture with `SDL2`.
### White Noise
Just draws random white and black pixels to a texture and displays it.

|
## installation.md
class CompUnit::Repository::Installation
CompUnit::Repository::Installation
```raku
class CompUnit::Repository::Installation
does CompUnit::Repository::Locally
does CompUnit::Repository::Installable
{ }
```
A [`CompUnit::Repository`](/type/CompUnit/Repository) implementation backed by the filesystem, but uses an internal storage format to:
* Handle case sensitivity issues on filesystems that may conflict as a [`CompUnit::Repository::FileSystem`](/type/CompUnit/Repository/FileSystem).
* Handle allowable filename issues (e.g. unicode) on filesystems that don't support them.
* Allow multiple distributions with the same name, but with different `ver` and/or `auth` and/or `api` values, to be installed and separately accessible in a single repository.
* Enable faster module loading by providing module precompilation.
Because of the internal storage format the usual way to add a distribution is not by copying files but by calling [CompUnit::Repository::Installation#method\_install](/type/CompUnit/Repository/Installation#method_install).
# [Methods](#class_CompUnit::Repository::Installation "go to top of document")[§](#Methods "direct link")
## [method install](#class_CompUnit::Repository::Installation "go to top of document")[§](#method_install "direct link")
```raku
method install(Distribution $distribution, Bool :$force)
```
Copies modules into a special location so that they can be loaded afterwards.
`:$force` will allow installing over an existing distribution that has the same `name`, `auth`, `api`, and `ver`. Otherwise such a situation will result in [`Failure`](/type/Failure).
```raku
my $inst-repo = CompUnit::RepositoryRegistry.repository-for-name("site");
my $dist = Distribution::Path.new(...);
$inst-repo.install($dist);
```
## [method uninstall](#class_CompUnit::Repository::Installation "go to top of document")[§](#method_uninstall "direct link")
```raku
method uninstall(Distribution $distribution)
```
Removes the `$distribution` from the repository. `$distribution` should be obtained from the repository it is being removed from:
```raku
my $inst-repo = CompUnit::RepositoryRegistry.repository-for-name("site");
my $dist = $inst-repo.candidates("Acme::Unused").head;
$inst-repo.uninstall($dist);
```
## [method candidates](#class_CompUnit::Repository::Installation "go to top of document")[§](#method_candidates "direct link")
```raku
multi method candidates(Str:D $name, :$auth, :$ver, :$api)
multi method candidates(CompUnit::DependencySpecification $spec)
```
Return all distributions that contain a module matching the specified `$name`, `auth`, `ver`, and `api`.
```raku
my $inst-repo-path = CompUnit::RepositoryRegistry.repository-for-name("perl").prefix;
my $inst-repo = CompUnit::Repository::Installation.new(prefix => $inst-repo-path);
my $dist = $inst-repo.candidates("Test").head;
say "Test version: " ~ $dist.meta<ver>; # OUTPUT: «6.d»
```
## [method files](#class_CompUnit::Repository::Installation "go to top of document")[§](#method_files "direct link")
```raku
multi method files(Str:D $name, :$auth, :$ver, :$api)
multi method files(CompUnit::DependencySpecification $spec)
```
Return all distributions that match the specified `auth` `ver` and `api`, and contains a non-module file matching the specified `$name`.
```raku
# assuming Zef is installed to the default location...
my $repo = CompUnit::RepositoryRegistry.repository-for-name("site");
say $repo.files('bin/zef', :ver<419.0+>).head.<name> // "Nada"; # OUTPUT: «Nada»
say $repo.files('resources/config.txt', :ver<419.0+>).head.<name> // "Nada"; # OUTPUT: «Nada»
say $repo.files('bin/zef', :ver<0.4.0+>).head.<name>; # OUTPUT: «zef»
say $repo.files('resources/config.txt', :ver<0.4.0+>).head.<name>; # OUTPUT: «zef»
```
## [method resolve](#class_CompUnit::Repository::Installation "go to top of document")[§](#method_resolve "direct link")
```raku
method resolve(CompUnit::DependencySpecification $spec --> CompUnit:D)
```
Returns a [`CompUnit`](/type/CompUnit) mapped to the highest version distribution matching `$spec` from the first repository in the repository chain that contains any version of a distribution matching `$spec`.
## [method need](#class_CompUnit::Repository::Installation "go to top of document")[§](#method_need "direct link")
```raku
method need(
CompUnit::DependencySpecification $spec,
CompUnit::PrecompilationRepository $precomp = self.precomp-repository(),
CompUnit::PrecompilationStore :@precomp-stores = self!precomp-stores(),
--> CompUnit:D)
```
Loads and returns a [`CompUnit`](/type/CompUnit) which is mapped to the highest version distribution matching `$spec` from the first repository in the repository chain that contains any version of a distribution matching `$spec`.
## [method load](#class_CompUnit::Repository::Installation "go to top of document")[§](#method_load "direct link")
```raku
method load(IO::Path:D $file --> CompUnit:D)
```
Load the `$file` and return a [`CompUnit`](/type/CompUnit) object representing it.
## [method loaded](#class_CompUnit::Repository::Installation "go to top of document")[§](#method_loaded "direct link")
```raku
method loaded(--> Iterable:D)
```
Returns all [`CompUnit`](/type/CompUnit)s this repository has loaded.
## [method short-id](#class_CompUnit::Repository::Installation "go to top of document")[§](#method_short-id "direct link")
```raku
method short-id()
```
Returns the repo short-id, which for this repository is `inst`.
|
## threadpool.md
class Telemetry::Instrument::ThreadPool
Instrument for collecting ThreadPoolScheduler data
```raku
class Telemetry::Instrument::ThreadPool { }
```
**Note:** This class is a Rakudo-specific feature and not standard Raku.
Objects of this class are generally not created directly, but rather through making a [snap](/type/Telemetry)shot. They provide the following attributes (in alphabetical order):
* atc
The number of tasks completed by affinity thread workers (**a**ffinity-**t**asks-**c**ompleted).
* atq
The number of tasks queued for execution for affinity thread workers (**a**ffinity-**t**asks-**q**ueued).
* aw
The number of affinity thread workers (**a**ffinity-**w**orkers).
* gtc
The number of tasks completed by general workers (**g**eneral-**t**asks-**c**ompleted).
* gtq
The number of tasks queued for execution by general worker (**g**eneral-**t**asks-**q**ueued).
* gw
The number of general workers (**g**eneral-**w**orkers).
* s
The number of supervisor threads running, usually `0` or `1` (**s**upervisor).
* ttc
The number of tasks completed by timer workers (**t**imer-**t**asks-**c**ompleted).
* ttq
The number of tasks queued for execution by timer workers (**t**imer-**t**asks-**q**ueued).
* tw
The number of timer workers (**t**imer-**w**orkers).
|
## bool.md
Bool
Combined from primary sources listed below.
# [In Match](#___top "go to top of document")[§](#(Match)_method_Bool "direct link")
See primary documentation
[in context](/type/Match#method_Bool)
for **method Bool**.
```raku
method Bool(Capture:D: --> Bool:D)
```
Returns `True` on successful and `False` on unsuccessful matches. Please note that any zero-width match can also be successful.
```raku
say 'abc' ~~ /^/; # OUTPUT: «「」»
say $/.from, ' ', $/.to, ' ', ?$/; # OUTPUT: «0 0 True»
```
# [In role Baggy](#___top "go to top of document")[§](#(role_Baggy)_method_Bool "direct link")
See primary documentation
[in context](/type/Baggy#method_Bool)
for **method Bool**.
```raku
method Bool(Baggy:D: --> Bool:D)
```
Returns `True` if the invocant contains at least one element.
```raku
my $breakfast = ('eggs' => 1).BagHash;
say $breakfast.Bool; # OUTPUT: «True»
# (since we have one element)
$breakfast<eggs> = 0; # weight == 0 will lead to element removal
say $breakfast.Bool; # OUTPUT: «False»
```
# [In StrDistance](#___top "go to top of document")[§](#(StrDistance)_method_Bool "direct link")
See primary documentation
[in context](/type/StrDistance#method_Bool)
for **method Bool**.
Returns `True` if `before` is different from `after`.
# [In role Numeric](#___top "go to top of document")[§](#(role_Numeric)_method_Bool "direct link")
See primary documentation
[in context](/type/Numeric#method_Bool)
for **method Bool**.
```raku
multi method Bool(Numeric:D:)
```
Returns `False` if the number is equivalent to zero, and `True` otherwise.
# [In Mu](#___top "go to top of document")[§](#(Mu)_routine_Bool "direct link")
See primary documentation
[in context](/type/Mu#routine_Bool)
for **routine Bool**.
```raku
multi Bool(Mu --> Bool:D)
multi method Bool( --> Bool:D)
```
Returns `False` on the type object, and `True` otherwise.
Many built-in types override this to be `False` for empty collections, the empty [string](/type/Str) or numerical zeros
```raku
say Mu.Bool; # OUTPUT: «False»
say Mu.new.Bool; # OUTPUT: «True»
say [1, 2, 3].Bool; # OUTPUT: «True»
say [].Bool; # OUTPUT: «False»
say %( hash => 'full' ).Bool; # OUTPUT: «True»
say {}.Bool; # OUTPUT: «False»
say "".Bool; # OUTPUT: «False»
say 0.Bool; # OUTPUT: «False»
say 1.Bool; # OUTPUT: «True»
say "0".Bool; # OUTPUT: «True»
```
# [In role Blob](#___top "go to top of document")[§](#(role_Blob)_method_Bool "direct link")
See primary documentation
[in context](/type/Blob#method_Bool)
for **method Bool**.
```raku
multi method Bool(Blob:D:)
```
Returns `False` if and only if the buffer is empty.
```raku
my $blob = Blob.new();
say $blob.Bool; # OUTPUT: «False»
$blob = Blob.new([1, 2, 3]);
say $blob.Bool; # OUTPUT: «True»
```
# [In role Rational](#___top "go to top of document")[§](#(role_Rational)_method_Bool "direct link")
See primary documentation
[in context](/type/Rational#method_Bool)
for **method Bool**.
```raku
multi method Bool(Rational:D: --> Bool:D)
```
Returns `False` if [numerator](/routine/numerator) is `0`, otherwise returns `True`. This applies for `<0/0>` zero-denominator <`Rational` as well, despite `?<0/0>.Num` being `True`.
# [In List](#___top "go to top of document")[§](#(List)_method_Bool "direct link")
See primary documentation
[in context](/type/List#method_Bool)
for **method Bool**.
```raku
method Bool(List:D: --> Bool:D)
```
Returns `True` if the list has at least one element, and `False` for the empty list.
```raku
say ().Bool; # OUTPUT: «False»
say (1).Bool; # OUTPUT: «True»
```
# [In Junction](#___top "go to top of document")[§](#(Junction)_method_Bool "direct link")
See primary documentation
[in context](/type/Junction#method_Bool)
for **method Bool**.
```raku
multi method Bool(Junction:D:)
```
Collapses the `Junction` and returns a single Boolean value according to the type and the values it holds. Every element is transformed to [`Bool`](/type/Bool).
```raku
my $n = Junction.new( "one", 1..6 );
say $n.Bool; # OUTPUT: «False»
```
All elements in this case are converted to `True`, so it's false to assert that only one of them is.
```raku
my $n = Junction.new( "one", <0 1> );
say $n.Bool; # OUTPUT: «True»
```
Just one of them is truish in this case, `1`, so the coercion to [`Bool`](/type/Bool) returns `True`.
# [In Capture](#___top "go to top of document")[§](#(Capture)_method_Bool "direct link")
See primary documentation
[in context](/type/Capture#method_Bool)
for **method Bool**.
```raku
method Bool(Capture:D: --> Bool:D)
```
Returns `True` if the `Capture` contains at least one named or one positional argument.
```raku
say \(1,2,3, apples => 2).Bool; # OUTPUT: «True»
say \().Bool; # OUTPUT: «False»
```
# [In Allomorph](#___top "go to top of document")[§](#(Allomorph)_method_Bool "direct link")
See primary documentation
[in context](/type/Allomorph#method_Bool)
for **method Bool**.
```raku
multi method Bool(::?CLASS:D:)
```
Returns `False` if the invocant is numerically `0`, otherwise returns `True`. The [`Str`](/type/Str) value of the invocant is not considered.
**Note**: For the `Allomorph` subclass [`RatStr`](/type/RatStr) also see [`Rational.Bool`](/type/Rational#method_Bool).
# [In Str](#___top "go to top of document")[§](#(Str)_method_Bool "direct link")
See primary documentation
[in context](/type/Str#method_Bool)
for **method Bool**.
```raku
method Bool(Str:D: --> Bool:D)
```
Returns `False` if the string is empty, `True` otherwise.
# [In role Setty](#___top "go to top of document")[§](#(role_Setty)_method_Bool "direct link")
See primary documentation
[in context](/type/Setty#method_Bool)
for **method Bool**.
```raku
multi method Bool(Setty:D: --> Bool:D)
```
Returns `True` if the invocant contains at least one element.
```raku
my $s1 = Set.new(1, 2, 3);
say $s1.Bool; # OUTPUT: «True»
my $s2 = $s1 ∩ Set.new(4, 5); # set intersection operator
say $s2.Bool; # OUTPUT: «False»
```
# [In Promise](#___top "go to top of document")[§](#(Promise)_method_Bool "direct link")
See primary documentation
[in context](/type/Promise#method_Bool)
for **method Bool**.
```raku
multi method Bool(Promise:D:)
```
Returns `True` for a kept or broken promise, and `False` for one in state `Planned`.
# [In Proc](#___top "go to top of document")[§](#(Proc)_method_Bool "direct link")
See primary documentation
[in context](/type/Proc#method_Bool)
for **method Bool**.
```raku
multi method Bool(Proc:D:)
```
Awaits for the process to finish and returns `True` if both exit code and signal of the process were 0, indicating a successful process termination. Returns `False` otherwise.
# [In Failure](#___top "go to top of document")[§](#(Failure)_method_Bool "direct link")
See primary documentation
[in context](/type/Failure#method_Bool)
for **method Bool**.
```raku
multi method Bool(Failure:D: --> Bool:D)
```
Returns `False`, and marks the failure as handled.
```raku
sub f() { fail };
my $v = f;
say $v.handled; # OUTPUT: «False»
say $v.Bool; # OUTPUT: «False»
say $v.handled; # OUTPUT: «True»
```
# [In Regex](#___top "go to top of document")[§](#(Regex)_method_Bool "direct link")
See primary documentation
[in context](/type/Regex#method_Bool)
for **method Bool**.
```raku
multi method Bool(Regex:D: --> Bool:D)
```
Matches against the caller's [$\_](/syntax/$_) variable, and returns `True` for a match or `False` for no match.
# [In Map](#___top "go to top of document")[§](#(Map)_method_Bool "direct link")
See primary documentation
[in context](/type/Map#method_Bool)
for **method Bool**.
```raku
method Bool(Map:D: --> Bool:D)
```
Returns `True` if the invocant contains at least one key/value pair.
```raku
my $m = Map.new('a' => 2, 'b' => 17);
say $m.Bool; # OUTPUT: «True»
```
|
## dist_cpan-CTILMES-JSON-simd.md
# JSON::simd - Raku bindings for simdjson
## Introduction
A [Raku](https://raku.org/) interface to
[simdjson](https://simdjson.org/), a library for parsing JSON.
While the `simdjson` library itself is blazing fast at parsing JSON,
transferring all the data it has parsed into Raku data structures
isn't actually much faster than parsing with other Raku libraries such
as [JSON::Fast](https://github.com/timo/json_fast).
In some situations, especially if you don't need all the data,
`JSON::simd` can offer some advantages.
## Subroutines
Drop in replacement for `JSON::Fast`:
```
use JSON::simd :subs;
$x = from-json '{ "a" : "b" }'; # Parse a string
$x = from-json-file 'file.json'; # Read from a file
```
As an added bonus, this also imports `to-json` from `JSON::Fast`,
which works exactly as usual.
## Object oriented use
`JSON::simd` also supports object usage. This allocates the parser
and its memory buffers only once, reusing for each document parsed.
```
use JSON::simd;
my $json = JSON::simd.new;
my $x = $json.parse: '{ "a" : "b" }'; # Parse a string
my $x = $json.load: 'file.json'; # Read from a file
```
These methods act identically to the above subs.
## Delayed object access
The `:delay` option performs the entire parse (extremely fast), but
doesn't actually pull all the data out of the parser object into Raku.
Instead it seamlessly replaces Objects and Arrays with placeholder
objects. The placeholder objects act (almost) identically to the
traditional ones, and pull in data as it is accessed. This can slow
things down if you walk the entire data structure, causing everything
to be pulled in, but if you access only portions of the data, it can
be dramatically faster.
```
my $x = $json.parse: '...json stuff...', :delay;
say $x<somekey>[17]<another>;
```
If you always want objects delayed, you can use the `:delay` option on
the inital object creation:
```
my json = JSON::simd.new(:delay); # Set default parse to delay
$x = $json.parse(...); # This one will get delayed
$x = $json.parse(..., :!delay); # This one will not delay
```
`simdjson` also supports [JSON Pointer](https://tools.ietf.org/html/rfc6901)
access through both the Object and Array placeholder objects.
Instead of calling `$x<somekey>[17]<another>`, the same result will be
returned with `$x<somekey/17/another>` without actually retrieving the
intermediate objects/arrays in full.
**IMPORTANT -- CAVEAT EMPTOR**
One drawback of delayed access is that the actual data remains in the
parser, precluding its further use until all data access is complete.
If another JSON document is parsed by the same parser followed by
access to the previous placeholder objects, things are likely to
crash.
## Multiple
The simdjson library also supports multithreaded JSON streaming
through a large file containing many smaller JSON documents in either
[ndjson](http://ndjson.org/) or [JSON lines](http://jsonlines.org/)
format. If your JSON documents all contain arrays or objects, they can
be concatenated without whitespace. The concatenated file has no size
restrictions (including larger than 4GB), though each individual
document must be less than 4GB.
These are implemented by returning a `Channel`. As long as JSON
objects are successfully parsed, they are sent through the Channel.
If parsing encounters an error, a `Failure` is sent through the
channel which will be thrown as an `Exception`.
```
for $json.parse-many('[1,2,3][4,5,6]').list -> $record {
...Do something with each $record...
}
```
There is also a `.load-many` method, and subs for `from-json-many` and
`from-json-file-many`.
There is no delay option for the 'many' parsing. All objects are
completely received and separate from the parser object.
## Maximum depth of parsing
By default the maximum depth of JSON data structures is 1024. This
can be set manually with the `:max-depth` option on intial object
creation, or with the `.allocate` method.
```
my $json = JSON::simd.new(max-depth => 16);
$json.allocate(max-depth => 32);
```
## Manual capacity allocation
The simdjson library automatically expands its memory capacity when
larger documents are parsed, so that you don't unexpectedly fail. In a
short process that reads a bunch of files and then exits, this works
pretty flawlessly.
You can query the current capacity like this:
```
say $json.capacity;
```
For better control of memory in long running processes, the simdjson
library lets you adjust your allocation strategy to prevent your
server from growing without bound.
```
my $json = JSON::simd.new(max-capacity => 1_000_0000);
```
You can also manually set the allocation (setting max-capacity to 0
prevents it from ever auto-expanding):
```
my $json = JSON::simd.new(max-capacity => 0, size => 1_000_000);
$json.allocate(size => 2_000_000); # Manually reset capacity;
```
More information is available at [Server Loops: Long-Running Processes and Memory Capacity](https://github.com/simdjson/simdjson/blob/master/doc/performance.md#server-loops-long-running-processes-and-memory-capacity).
## Implementation
`simdjson` has highly tuned implementations for various processor
capabilities. When first run, they test the processor and choose the
best implementation. If you are curious, you can see which
implementation is active:
```
say JSON::simd.implmentation-name, JSON::simd.implementation-description;
```
# Installation
This library is very dependent on 64-bit architectures and should only
be installed on a 64-bit OS.
Building the C++ library requires a C++ compiler. The commands below
may or may not help you install one.
For Windows and MacOS, pre-built libraries are also available as fallbacks
if the build doesn't find a compiler.
If you have trouble installing, please file an issue with as many
details about your setup as possible.
* Debian/Ubuntu
```
apt update
apt install -y g++
zef install JSON::simd
```
If you get g++ compiling errors, it may be due to an older compiler.
You can try this and then the commands above:
```
echo deb http://ftp.us.debian.org/debian testing main contrib non-free >> /etc/apt/sources.list
```
* Alpine Linux
```
apt add --update --no-cache g++
zef install JSON::simd
```
* CentOS
```
yum install -y gcc-c++
zef install JSON::simd
```
# License
The original `simdjson` code is available under Apache License 2.0.
The additional interface code and Raku bindings are Copyright © 2020
United States Government as represented by the Administrator, National
Aeronautics and Space Administration. No Copyright is claimed in the
United States under Title 17, U.S. Code. All Other Rights Reserved.
|
## dist_zef-lizmat-Array-Sparse.md
[](https://github.com/lizmat/Array-Sparse/actions) [](https://github.com/lizmat/Array-Sparse/actions) [](https://github.com/lizmat/Array-Sparse/actions)
# NAME
Array::Sparse - role for sparsely populated Arrays
# SYNOPSIS
```
use Array::Sparse;
my @a is Array::Sparse;
```
# DESCRIPTION
Exports an `Array::Sparse` role that can be used to indicate the implementation of an array (aka Positional) that will not allocate anything for indexes that are not used. It also allows indexes to be used that exceed the native integer size.
Unless memory is of the most importance, if you populate more than 5% of the indexes, you will be better of just using a normal array.
Since `Array::Sparse` is a role, you can also use it as a base for creating your own custom implementations of arrays.
# Iterating Methods
Methods that iterate over the sparse array, will only report elements that actually exist. This affects methods such as `.keys`, `.values`, `.pairs`, `.kv`, `.iterator`, `.head`, `.tail`, etc.
# AUTHOR
Elizabeth Mattijsen [[email protected]](mailto:[email protected])
Source can be located at: <https://github.com/lizmat/Array-Sparse> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2018, 2020, 2021, 2023, 2024 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-JNTHN-Cro-WebApp.md
# Cro::WebApp Build Status
This is a library to make it easier to build server-side web applications using
Cro. See the [Cro website](http://cro.services/) for further information and
documentation.
|
## dist_zef-tony-o-HTTP-Server-Async-Plugins-Router-Simple.md
# HTTP::Server::Async::Plugins::Router::Simple
Provides a simple routing mechanism for the common RESTful HTTP methods. Please check out the test for more examples.
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.