Datasets:

license: gpl-3.0
language:
- en
tags:
- world-models
- arc
- abstraction-reasoning-corpus
- reasoning
- abstract-reasoning
- logical-reasoning
- causal-reasoning
- counterfactual-reasoning
- evaluation
- benchmark
- structural-causal-models
- causal-discovery
- test-time-training
- few-shot-learning
- in-context-learning
task_categories:
- question-answering
pretty_name: CausalARC – Abstract Reasoning with Causal World Models

Note: This page is currently under construction. See our official project page here: https://jmaasch.github.io/carc/
Overview
Reasoning requires adaptation to novel problem settings under limited data and distribution shift. This work introduces CausalARC: an experimental testbed for AI reasoning in low-data and out-of-distribution regimes, modeled after the Abstraction and Reasoning Corpus (ARC). Each CausalARC reasoning task is sampled from a fully specified causal world model, formally expressed as a structural causal model (SCM). Principled data augmentations provide observational, interventional, and counterfactual feedback about the world model in the form of few-shot, in-context learning demonstrations. As a proof-of-concept, we illustrate the use of CausalARC for four language model evaluation settings: (1) abstract reasoning with test-time training, (2) counterfactual reasoning with in-context learning, (3) program synthesis, and (4) causal discovery with logical reasoning.
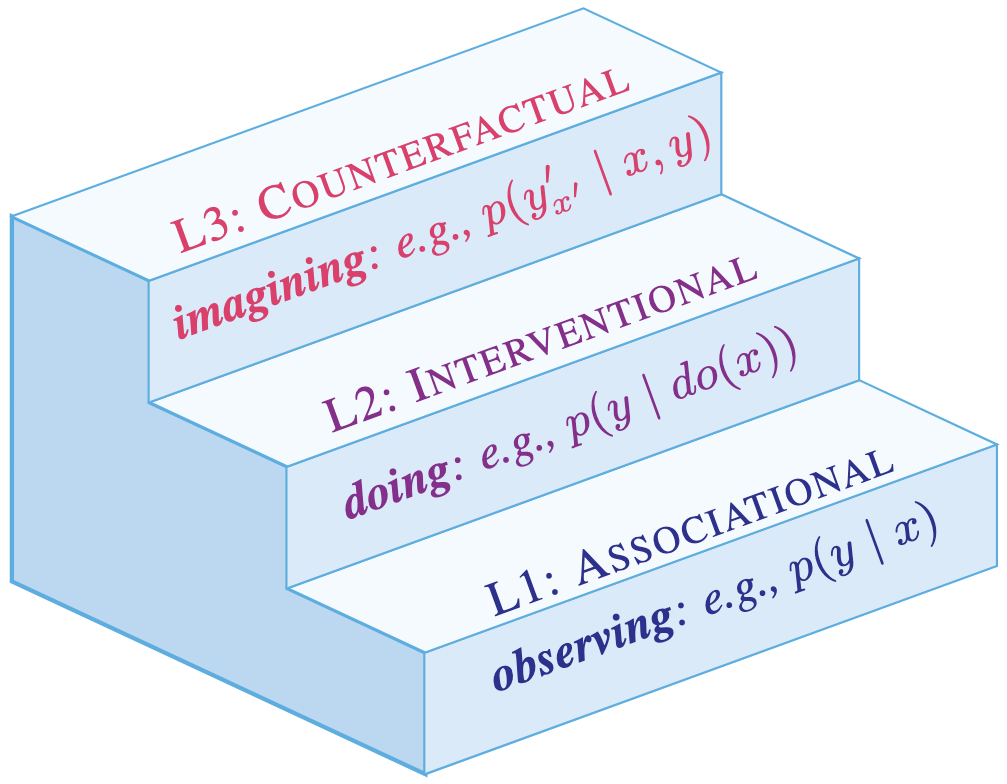 Pearl Causal Hierarchy: observing factual realities (L1), exerting actions to
induce interventional realities (L2), and imagining alternate counterfactual realities (L3)
[1]. Lower levels generally underdetermine higher levels.
Pearl Causal Hierarchy: observing factual realities (L1), exerting actions to
induce interventional realities (L2), and imagining alternate counterfactual realities (L3)
[1]. Lower levels generally underdetermine higher levels.
This work extends and reconceptualizes the ARC setup to support causal reasoning evaluation under limited data and distribution shift. Given a fully specified SCM, all three levels of the Pearl Causal Hierarchy (PCH) are well-defined: any observational (L1), interventional (L2), or counterfactual (L3) query can be answered about the environment under study [2]. This formulation makes CausalARC an open-ended playground for testing reasoning hypotheses at all three levels of the PCH, with an emphasis on abstract, logical, and counterfactual reasoning.
 The CausalARC testbed. (A) First, SCM M is manually transcribed in Python code. (B)
Input-output pairs are randomly sampled, providing observational (L1) learning signals about the
world model. (C) Sampling from interventional submodels M' of M yields interventional (L2)
samples (x', y'). Given pair (x, y), performing multiple interventions while holding the exogenous
context constant yields a set of counterfactual (L3) pairs. (D) Using L1 and L3 pairs as in-context
demonstrations, we can automatically generate natural language prompts for diverse reasoning tasks.
The CausalARC testbed. (A) First, SCM M is manually transcribed in Python code. (B)
Input-output pairs are randomly sampled, providing observational (L1) learning signals about the
world model. (C) Sampling from interventional submodels M' of M yields interventional (L2)
samples (x', y'). Given pair (x, y), performing multiple interventions while holding the exogenous
context constant yields a set of counterfactual (L3) pairs. (D) Using L1 and L3 pairs as in-context
demonstrations, we can automatically generate natural language prompts for diverse reasoning tasks.