
Neuropath Vision
Collection
Models related to neuropathology projects.
•
1 item
•
Updated
This model is a Vision Transformer adapted for neuropathology tasks, developed using data from the University of Kentucky. It leverages principles from self-supervised learning models like DINOv2.
This model serves as an initial test while a proper training and evaluation dataset is generated
This model is intended for research purposes in the field of neuropathology.
facebook/dinov2-giant loaded from Hugging Face Hub.Task(s): Classification, KNN, Clustering, Robustness
Metrics: Accuracy, Precision, Recall, F1
Dataset(s): Neuro Path dataset
Results: The model achieved strong performance across multiple evaluation methods using the Neuro Path dataset.
Linear Probe Performance:
K-Nearest Neighbors Classification:
Clustering Quality:
Robustness Score: 0.574
Overall Performance Score: 0.646
| Model | Accuracy | F1 | Precision | Recall |
|---|---|---|---|---|
| NP-TEST-0 | 0.802 | 0.779 | 0.792 | 0.796 |
| dinov2-giant | 0.667 | 0.648 | 0.669 | 0.667 |
| dinov2-giant_distilled_prov | 0.769 | 0.756 | 0.755 | 0.769 |
| dinov2-large_distilled_prov | 0.772 | 0.758 | 0.758 | 0.772 |
| distilled_prov_finetuned | 0.779 | 0.762 | 0.770 | 0.779 |
| prov-gigapath | 0.776 | 0.762 | 0.764 | 0.776 |
| UNI | 0.741 | 0.731 | 0.734 | 0.741 |
| UNI2-h | 0.768 | 0.750 | 0.753 | 0.768 |
While the evaluation dataset was distinct from the training set, they were from the same institution, using the same staining, and obtained from the same scanner. It is not unexpected that a model fine-tuned on such a closely associated dataset would perform better. An evaluation dataset with broader representation is needed for a proper evaluation of generalized performance.
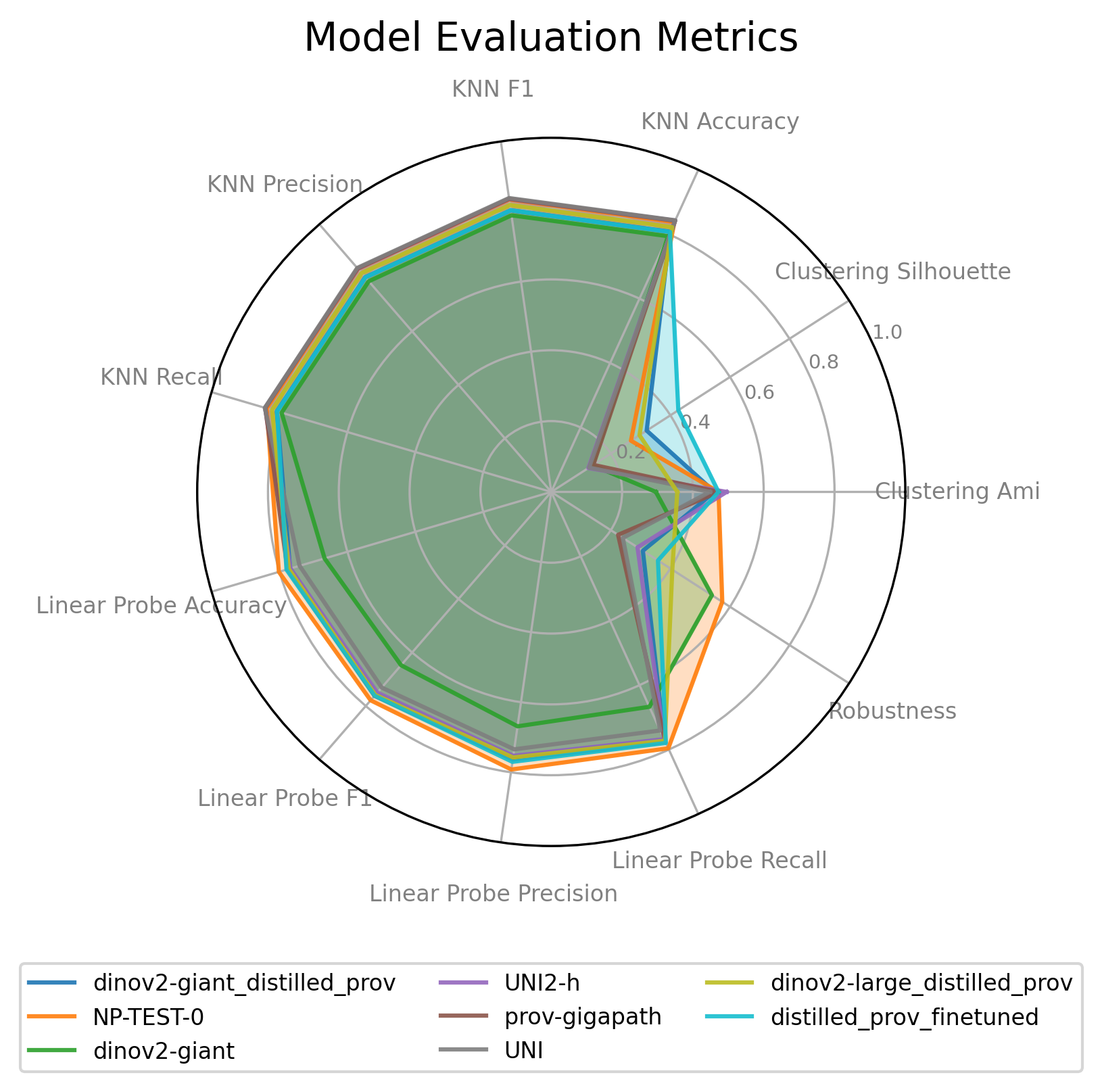
The radar chart provides a visual comparison of multiple models across several performance metrics. Each axis extending from the center represents a different metric. The farther a model's line is from the center along a particular axis, the better its score for that specific metric (assuming higher is better for the metric).
How to Interpret:
Tests
Three example methods using Hugging Face transformers (adjust based on your actual model and task):
import torch
from PIL import Image
from transformers import AutoModel, AutoImageProcessor
from torchvision import transforms
def get_embeddings_with_processor(image_path, model_path):
"""
Extract embeddings using a HuggingFace image processor.
This approach handles normalization and resizing automatically.
Args:
image_path: Path to the image file
model_path: Path to the model directory
processor_path: Path to the processor config directory
Returns:
Image embeddings from the model
"""
# Load model
model = AutoModel.from_pretrained(model_path)
model.eval()
# Load processor from config
image_processor = AutoImageProcessor.from_pretrained(model_path)
# Process the image
with torch.no_grad():
image = Image.open(image_path).convert('RGB')
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
embeddings = outputs.last_hidden_state[:, 0, :]
return embeddings
def get_embeddings_direct(image_path, model_path, mean=[0.83800817, 0.6516568, 0.78056043], std=[0.08324149, 0.09973671, 0.07153901]):
"""
Extract embeddings directly without an image processor.
This approach works with various image resolutions since transformers handle
different input sizes by design.
Args:
image_path: Path to the image file
model_path: Path to the model directory
mean: Normalization mean values
std: Normalization standard deviation values
Returns:
Image embeddings from the model
"""
# Load model
model = AutoModel.from_pretrained(model_path)
model.eval()
# Define transformation - just converting to tensor and normalizing
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)
])
# Process the image
with torch.no_grad():
# Open image and convert to RGB
image = Image.open(image_path).convert('RGB')
# Convert image to tensor
image_tensor = transform(image).unsqueeze(0) # Add batch dimension
# Feed to model
outputs = model(pixel_values=image_tensor)
# Get embeddings
embeddings = outputs.last_hidden_state[:, 0, :]
return embeddings
def get_embeddings_resized(image_path, model_path, size=(224, 224), mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):
"""
Extract embeddings with explicit resizing to 224x224.
This approach ensures consistent input size regardless of original image dimensions.
Args:
image_path: Path to the image file
model_path: Path to the model directory
size: Target size for resizing (default: 224x224)
mean: Normalization mean values
std: Normalization standard deviation values
Returns:
Image embeddings from the model
"""
# Load model
model = AutoModel.from_pretrained(model_path)
model.eval()
# Define transformation with explicit resize
transform = transforms.Compose([
transforms.Resize(size, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)
])
# Process the image
with torch.no_grad():
image = Image.open(image_path).convert('RGB')
image_tensor = transform(image).unsqueeze(0) # Add batch dimension
outputs = model(pixel_values=image_tensor)
embeddings = outputs.last_hidden_state[:, 0, :]
return embeddings
# Example usage
if __name__ == "__main__":
image_path = "test.jpg"
model_path = "IBI-CAAI/NP-TEST-0"
# Method 1: Using image processor (recommended for consistency)
embeddings1 = get_embeddings_with_processor(image_path, model_path)
print('Embedding shape (with processor):', embeddings1.shape)
# Method 2: Direct approach without resizing (works with various resolutions)
embeddings2 = get_embeddings_direct(image_path, model_path)
print('Embedding shape (direct):', embeddings2.shape)
# Method 3: With explicit resize to 224x224
embeddings3 = get_embeddings_resized(image_path, model_path)
print('Embedding shape (resized):', embeddings3.shape)
Acknowledgements:
This initial work was supported by the broader Brain Digital Slide Archive (BDSA) Team.
This research was supported by the National Institute of Neurological Disorders and Stroke (NINDS) of the National Institutes of Health (NIH) under award numbers:
For any additional questions or comments, contact CAAI ([email protected]),
Mahmut Gokmen ([email protected])
Cody Bumgardner ([email protected]).
In process
Base model
facebook/dinov2-giant