
微调DeepSeek-R1-Distill-Llama-8B
一、什么是大模型微调(Fine-tuning)?
大模型微调是指在大规模预训练语言模型(如GPT、BERT、PaLM等)的基础上,针对特定任务或领域,用少量专用数据对模型参数进行进一步调整的过程。
预训练模型通过海量通用数据(如互联网文本)学习通用语言规律,而微调则是让模型在保留通用能力的同时,适应具体任务需求(如医疗问答、法律文书生成)或特定数据分布(如某企业的客服对话数据)。
二、为什么我们需要大模型微调?
微调可以使模型在特定任务中具有更好的性能,使其在现实应用中更有效、更通用。此过程对于将现有模型定制到特定任务或领域至关重要。
1. 任务适配性: 预训练模型学的是通用知识,但实际任务(如情感分析、代码生成)需要特定技能。微调通过少量任务数据调整模型,使其输出更贴合目标场景。
2. 领域专业化: 通用模型在垂直领域(如医学、金融)表现不足。例如,直接使用GPT回答医学问题可能不够准确,通过医学文献微调后,模型会更专业。
3. 数据分布对齐: 实际应用数据可能与预训练数据分布不同(如用户偏好、方言表达)。微调能缩小这种差异,提升模型在实际场景中的表现。
4. 降低资源成本: 从头训练大模型需要海量数据和算力,而微调只需少量领域数据,成本大幅降低。
5. 个性化需求: 企业或用户可能希望模型符合特定风格(如品牌话术、写作语气),微调可快速实现定制化。
6. 缓解幻觉问题: 针对特定任务微调(如事实性问答)可约束模型生成,减少胡编乱造(Hallucination)。
三、大模型微调的效果
硬件配置:
- GPU:Tesla T4
- 系统RAM:12GB
- GPU RAM:15.0GB
- 存储:200GB
微调数据:
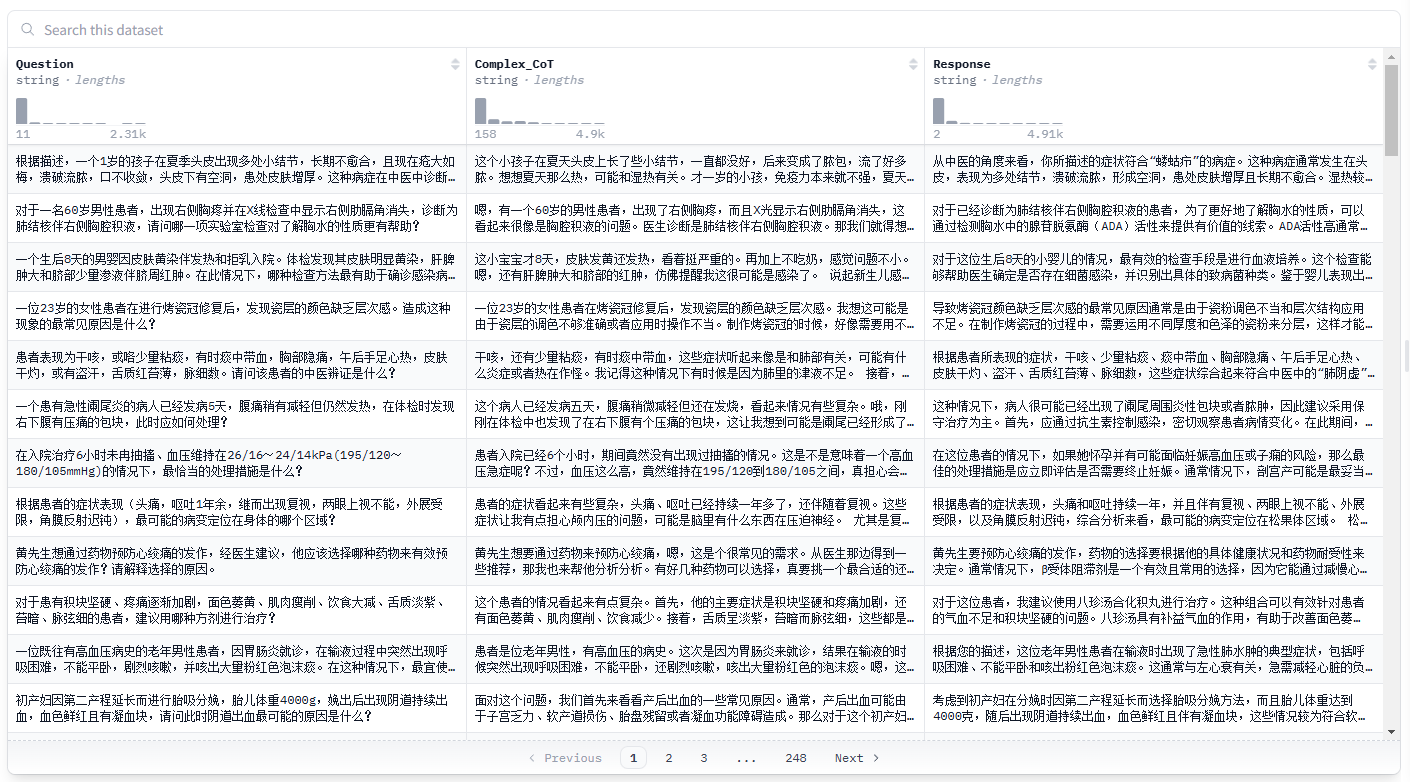
问题:
一个患有急性阑尾炎的病人已经发病5天,腹痛稍有减轻但仍然发热,在体检时发现右下腹有压痛的包块,此时应如何处理?
原始数据:

微调前:

微调后:

说明:
目前仅用一小部分测试数据,经过微调之后的结果,明显已经接近原始数据的解决思路,样式数据格式也达到的统一;相较未经过微调的回复,已经有了比较优质的提升,如果有更多的行业数据纳入训练,结果必然会有进一步的提升!
- Downloads last month
- 43
8-bit
Model tree for zeewin-ai/DeepSeek-R1-Medical-Distill-Llama-8B
Base model
deepseek-ai/DeepSeek-R1-Distill-Llama-8B