
Glyph: Scaling Context Windows via Visual-Text Compression
Paper
•
2510.17800
•
Published
•
67
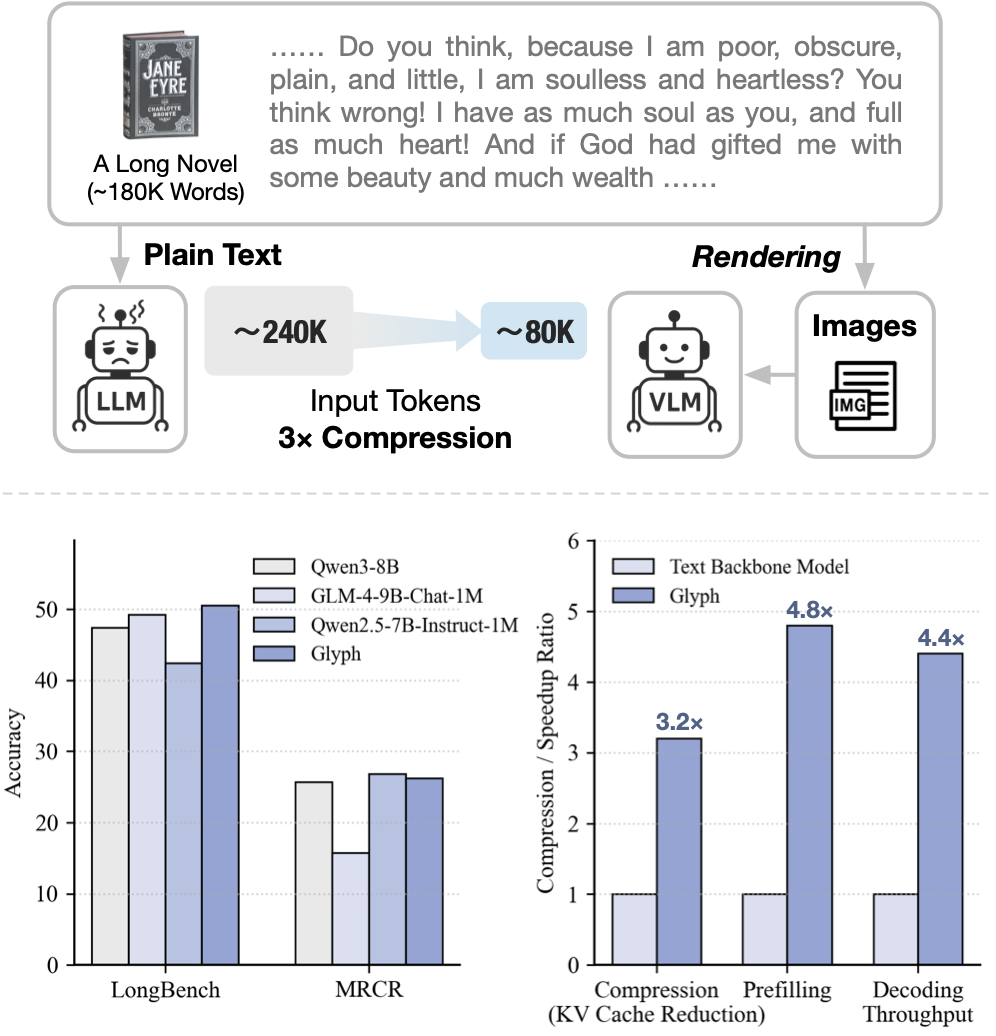
Glyph is a framework for scaling the context length through visual-text compression. Instead of extending token-based context windows, Glyph renders long textual sequences into images and processes them using vision–language models (VLMs). This design transforms the challenge of long-context modeling into a multimodal problem, substantially reducing computational and memory costs while preserving semantic information.
Our model is built on GLM-4.1V-9B-Base.
This is a simple example of running single-image inference using the transformers library.
First, install the transformers library:
pip install transformers>=4.57.1
Then, run the following code:
from transformers import AutoProcessor, AutoModelForImageTextToText
import torch
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://raw.githubusercontent.com/thu-coai/Glyph/main/assets/Little_Red_Riding_Hood.png"
},
{
"type": "text",
"text": "Who pretended to be Little Red Riding Hood's grandmother"
}
],
}
]
processor = AutoProcessor.from_pretrained("zai-org/Glyph")
model = AutoModelForImageTextToText.from_pretrained(
pretrained_model_name_or_path="zai-org/Glyph",
torch_dtype=torch.bfloat16,
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
See our Github Repo for more detailed usage.
If you find our model useful in your work, please cite it with:
@article{cheng2025glyphscalingcontextwindows,
title={Glyph: Scaling Context Windows via Visual-Text Compression},
author={Jiale Cheng and Yusen Liu and Xinyu Zhang and Yulin Fei and Wenyi Hong and Ruiliang Lyu and Weihan Wang and Zhe Su and Xiaotao Gu and Xiao Liu and Yushi Bai and Jie Tang and Hongning Wang and Minlie Huang},
journal={arXiv preprint arXiv:2510.17800},
year={2025}
}