
Generative Frame Sampler for Long Video Understanding
Paper • 2503.09146 • Published • 1
🔗 Project Page · 📖 Paper · ⭐ GitHub · 📊 Dataset · 🤗 Checkpoints
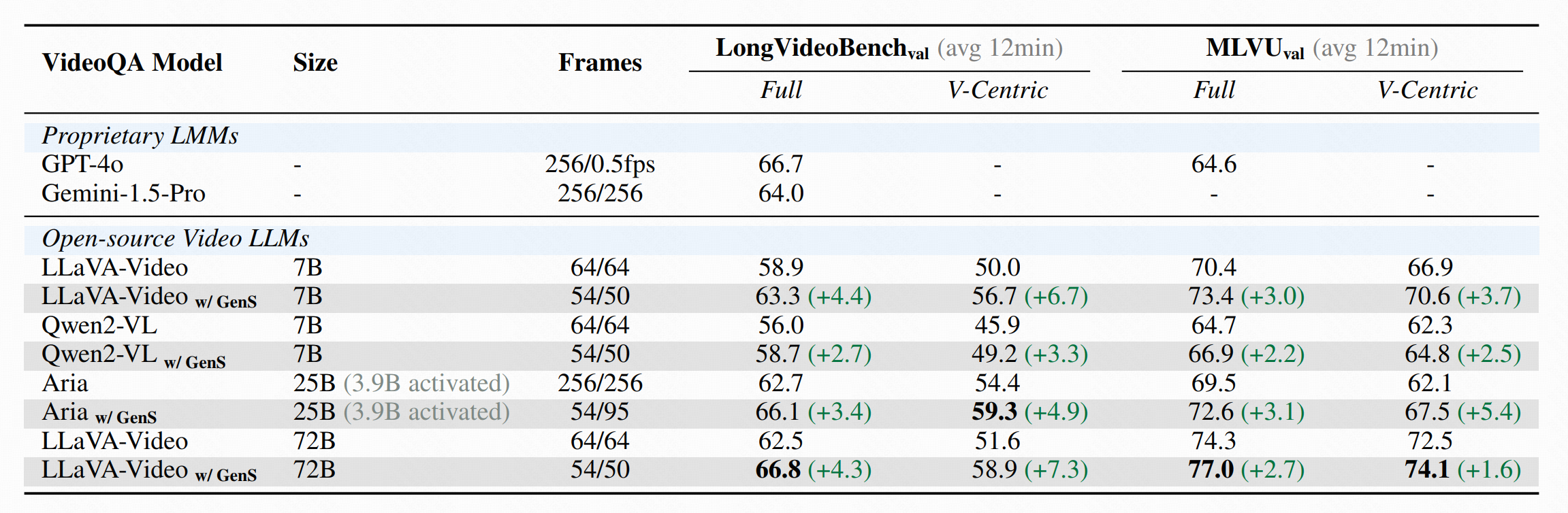
GenS (Generative Frame Sampler) is a novel approach that identifies question-relevant frames from long videos spanning minutes to hours. Given a long video and a user question, GenS effectively searches through the original massive collection of frames to produce a concise selection and enhances the performance of downstream VideoQA Assistants (such as Qwen2-VL, LLaVA-Video, VILA-v1.5, and Aria) by providing fewer but more informative frames.
GenS is built upon advanced long-context VideoLLMs (such as Aria and Qwen2.5VL), transforming key frame sampling into a generative task.
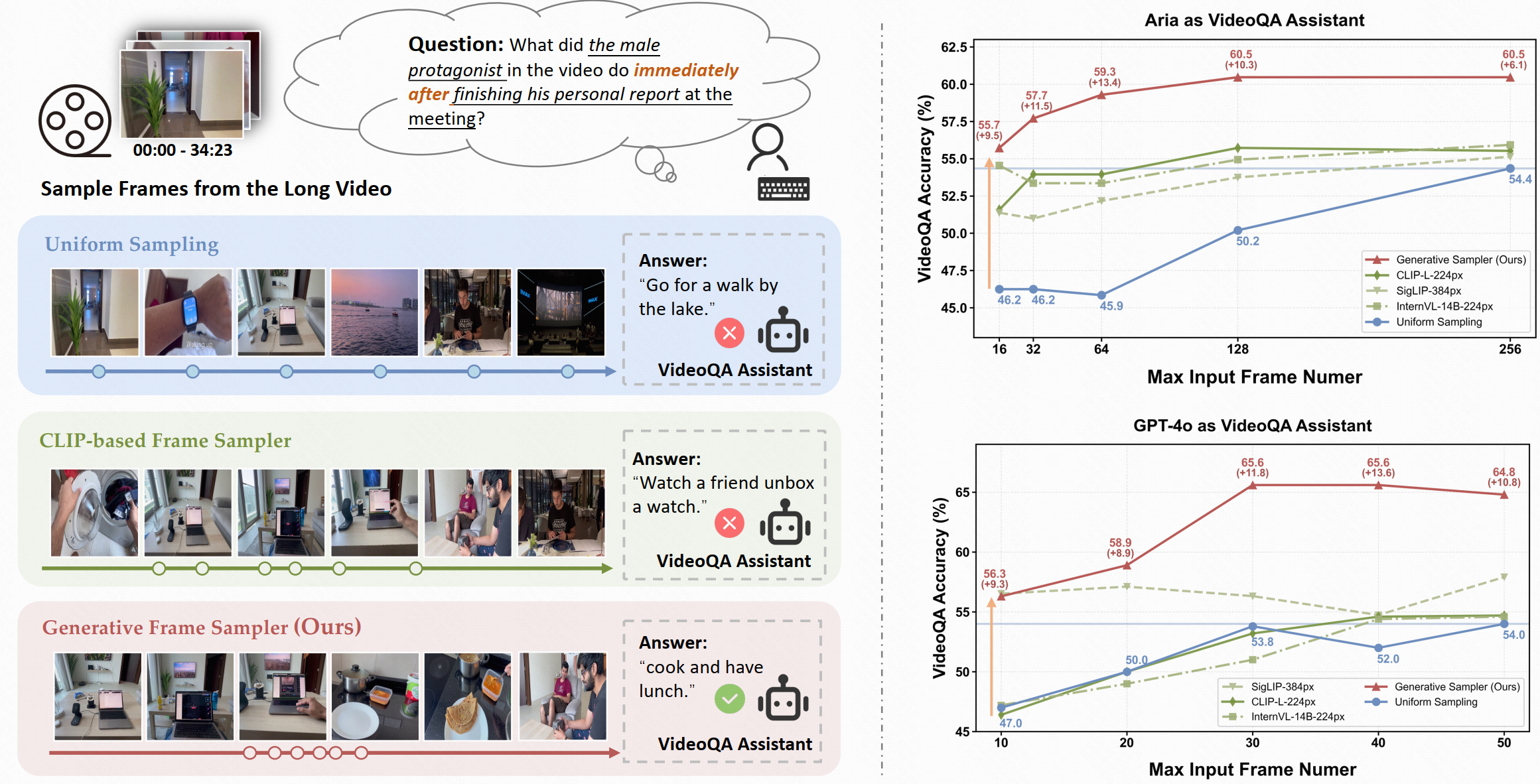
✨ Temporal Understanding: GenS effectively captures temporal relationships between successive frames, enabling complex reasoning about temporal sequences such as "immediately after" events in videos.
📝 Complex Instruction Understanding: Powered by built-in LLMs, GenS comprehends complex and flexible textual instructions, allowing it to interpret nuanced queries and identify the most relevant visual content.
⚡ Effective Video-Text Alignment: Its native multi-modal architecture enables sophisticated multi-hop reasoning by seamlessly aligning long-range temporal cues with language semantics, resulting in more accurate frame selection.
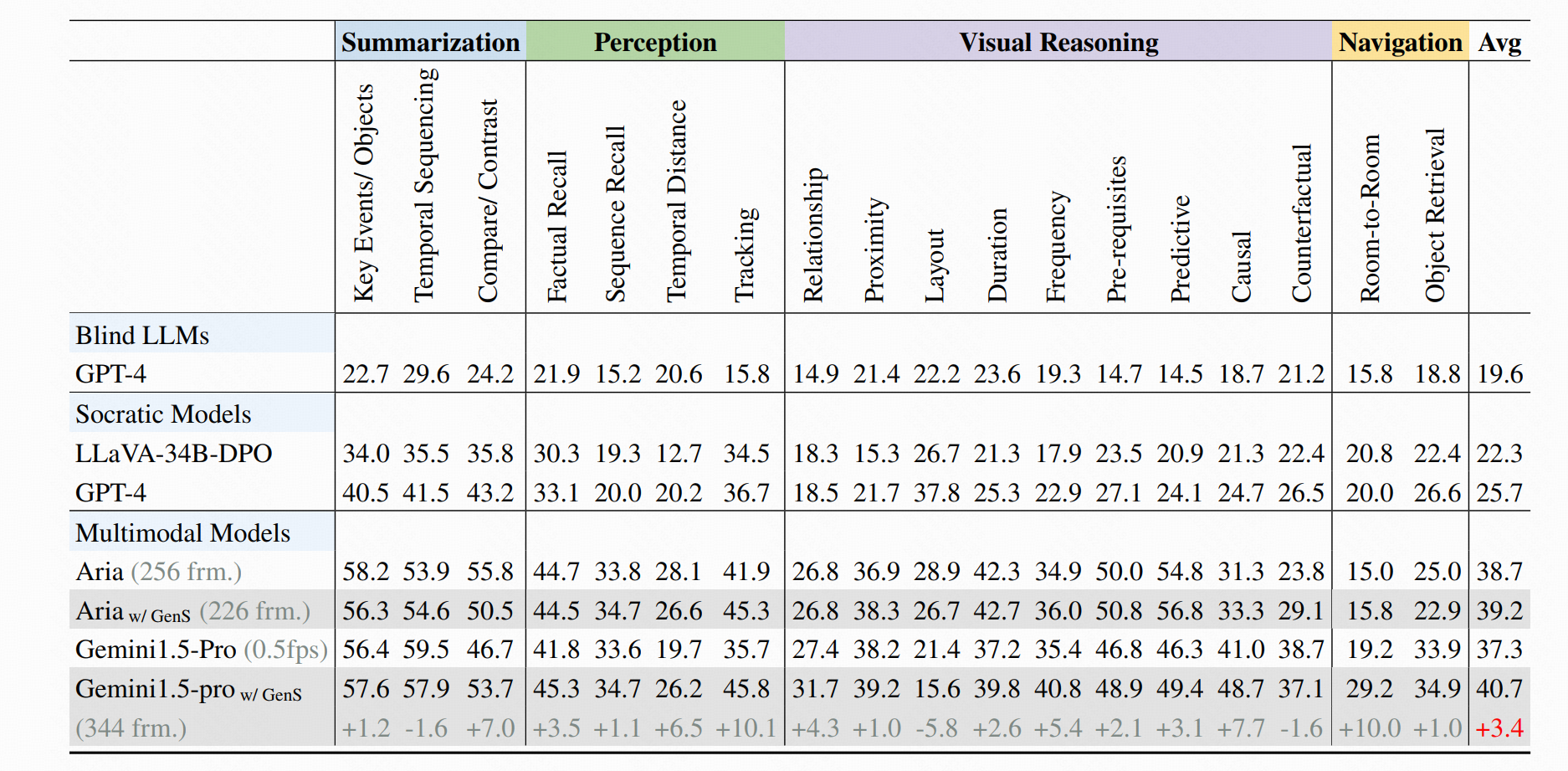
🎉 State-of-the-Art Performance: GenS significantly boosts the performance of various VideoQA models, achieving SOTA results on long-form video benchmarks when integrated with open-source models.
After creating your conda environment, install the required dependencies:
pip install transformers==4.45.0 accelerate==0.34.1 sentencepiece==0.2.0 torchvision requests torch Pillow
pip install flash-attn --no-build-isolation
import torch
from PIL import Image
import sys
import os
from typing import List
# Import required libraries
from transformers import AutoProcessor, AutoTokenizer, AutoConfig, AutoModel, AutoModelForCausalLM
from yivl.yivl_model_hf import YiVLForConditionalGeneration, YiVLConfig
from yivl.siglip_navit_490 import NaViTProcessor
from yivl.constants import (
DEFAULT_IMAGE_END_TOKEN,
DEFAULT_IMAGE_START_TOKEN,
DEFAULT_IMAGE_TOKEN,
IMAGE_TOKEN_INDEX,
)
from deepseekv1moe.modeling_deepseek import DeepseekConfig, DeepseekForCausalLM
def setup_model():
"""Set up and load the GenS model and its components."""
# Register custom models with the Auto classes
AutoConfig.register("yi_vl", YiVLConfig)
AutoModel.register(YiVLConfig, YiVLForConditionalGeneration)
AutoConfig.register("deepseek", DeepseekConfig)
AutoModelForCausalLM.register(DeepseekConfig, DeepseekForCausalLM)
# Load model from Hugging Face
model_id = "yaolily/GenS"
# Load configuration
config = AutoConfig.from_pretrained(model_id)
# Load model with optimizations
model = AutoModel.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
low_cpu_mem_usage=True,
torch_dtype=torch.bfloat16
).to(torch.device("cuda"))
# Load tokenizer with special token handling
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=False, trust_remote_code=True)
if not tokenizer.pad_token or tokenizer.pad_token_id < 0:
try:
tokenizer.add_special_tokens({"pad_token": "<unk>"})
if tokenizer.pad_token_id is None:
tokenizer.add_special_tokens({"pad_token": "<mask>"})
except ValueError:
tokenizer.add_special_tokens({"pad_token": "<|endoftext|>"})
# Initialize the custom image processor
processor = NaViTProcessor(image_max_size=490)
print("GenS Model loaded successfully!")
return model, tokenizer, processor
def gens_frame_sampler(question: str, frame_paths: List[str], model, tokenizer, processor):
"""
Use GenS model to identify and score relevant frames for a video question.
Args:
question: The question to answer about the video
frame_paths: List of paths to video frames
model: Pre-loaded GenS model
tokenizer: Pre-loaded tokenizer
processor: Pre-loaded image processor
Returns:
The model's response with relevance scores for frames
"""
# Load frames as PIL images
frames = []
for path in frame_paths:
try:
img = Image.open(path).convert("RGB")
# Optional: resize images to expected size
if img.width > 490 or img.height > 490:
ratio = min(490/img.width, 490/img.height)
new_size = (int(img.width * ratio), int(img.height * ratio))
img = img.resize(new_size)
frames.append(img)
except Exception as e:
print(f"Error loading image {path}: {e}")
if not frames:
return "Error: No valid frames could be loaded"
# Create prompt
prompt = """Please identify the video frames most relevant to the given question and provide
their timestamps in seconds along with a relevance score. The score should be on a
scale from 1 to 5, where higher scores indicate greater relevance. Return the output
strictly in the following JSON format: {"timestamp": score, ...}."""
# Format the input as expected by the model
frm_placeholders = ["<image1>" for _ in range(len(frames))]
content = "{}Question: {}
{}".format("".join(frm_placeholders), question, prompt)
question_data = [{"role": "user", "content": content}]
# Apply chat template
formatted_question = tokenizer.apply_chat_template(question_data, add_generation_prompt=True, tokenize=False)
# Process the images and text
inputs = processor(
text=[formatted_question],
images=frames,
padding=True,
return_tensors="pt"
)
inputs = {k: v.to(model.device) for k, v in inputs.items()}
# Generate the response
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=256,
do_sample=False,
temperature=0.0
)
# Decode and extract the relevant part of the response
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
result = response.split("assistant
")[-1].split("<|im_end|>")[0].strip()
return result
# Example usage
if __name__ == "__main__":
# Load model components
model, tokenizer, processor = setup_model()
# Example video frames (replace with your actual paths)
frame_paths = [
"/path/to/video/frames/00001.jpg",
"/path/to/video/frames/00002.jpg",
# Add more frames...
]
# Example question
question = "Which frames show a person opening the door?"
# Get frame relevance scores
result = gens_frame_sampler(question, frame_paths, model, tokenizer, processor)
print(f"Question: {question}")
print(f"Relevant frames with scores: {result}")
Output Format:
The model returns relevance scores for frames in JSON format
Example output: {"15": 5, "16": 4, "45-46": 3, ...} means frame indexing 15 has relevance score 5, frame indexing 16 has relevance score 4, frame indexing 45-46 has relevance score 3, ...
If you find our work helpful, please consider citing.
@article{yao2025generative,
title={Generative Frame Sampler for Long Video Understanding},
author={Yao, Linli and Wu, Haoning and Ouyang, Kun and Zhang, Yuanxing and Xiong, Caiming and Chen, Bei and Sun, Xu and Li, Junnan},
journal={arXiv preprint arXiv:2503.09146},
year={2025}
}