gguf?

thanks

Yeah, we need GGUFs for 8-12gb vram, Q4KS-Q5KS-Q6K-Q8K variants.

Working on it, https://huggingface.co/lym00/Wan14BT2V_MoviiGen_AccVid_CausVid_MasterModel_GGUF
Redditor reported it works with VACE, https://www.reddit.com/r/StableDiffusion/comments/1l3o9ih/comment/mw3gk38/
Planning to test it with my VACE I2V Extend & Loop GGUF Workflow: https://civitai.com/models/1615710
Working on it, https://huggingface.co/lym00/Wan14BT2V_MoviiGen_AccVid_CausVid_MasterModel_GGUF
Redditor reported it works with VACE, https://www.reddit.com/r/StableDiffusion/comments/1l3o9ih/comment/mw3gk38/
Planning to test it with my VACE I2V Extend & Loop GGUF Workflow: https://civitai.com/models/1615710
Ty for GGUFs! Working like a charm!

Working on it, https://huggingface.co/lym00/Wan14BT2V_MoviiGen_AccVid_CausVid_MasterModel_GGUF
The page says "This repository contains a direct GGUF conversion of the vrgamedevgirl84/Wan14BT2V_MasterModel", so the source model is fp8, right?
Is it possible to create ggufs from fp16 or better yet fp32?
Working on it, https://huggingface.co/lym00/Wan14BT2V_MoviiGen_AccVid_CausVid_MasterModel_GGUF
The page says "This repository contains a direct GGUF conversion of the vrgamedevgirl84/Wan14BT2V_MasterModel", so the source model is fp8, right?
Is it possible to create ggufs from fp16 or better yet fp32?
Judging by its size, the source model is likely in FP8 format.
I used city96's conversion tool (https://github.com/city96/ComfyUI-GGUF/tree/main/tools) to convert the original model (in .safetensors format) to FP16 GGUF. After that, I quantized it and applied the 5D fix.
EDITED: I've also updated the GGUF page to include details about the source and conversion process.
If an FP16 or FP32 version of the source model are available, I’d be happy to redo the conversion.
It would be great if the owner could release fp16 or fp32 for proper gguf'ing :)
Sorry I do not get notifications so did not see messages. When it comes to the fp16 / 32 I can try doing that. I just am still learning all this :)
It would be great if the owner could release fp16 or fp32 for proper gguf'ing :)
the fp16 version is uploading now!!!
you guys are amazing, thank you very much!
We'll upload a separate set of GGUFs specifically for additional VACE compatibility, addressing the likeness issue when using the ComfyUI node (WanVaceToVideo):
https://huggingface.co/QuantStack/Wan-14B-T2V-FusionX-VACE-GGUF
Just updated the Hugging Face page with all the latest links and resources — including workflows, models, GGUFs, and example videos. Check out the new description! 🙂

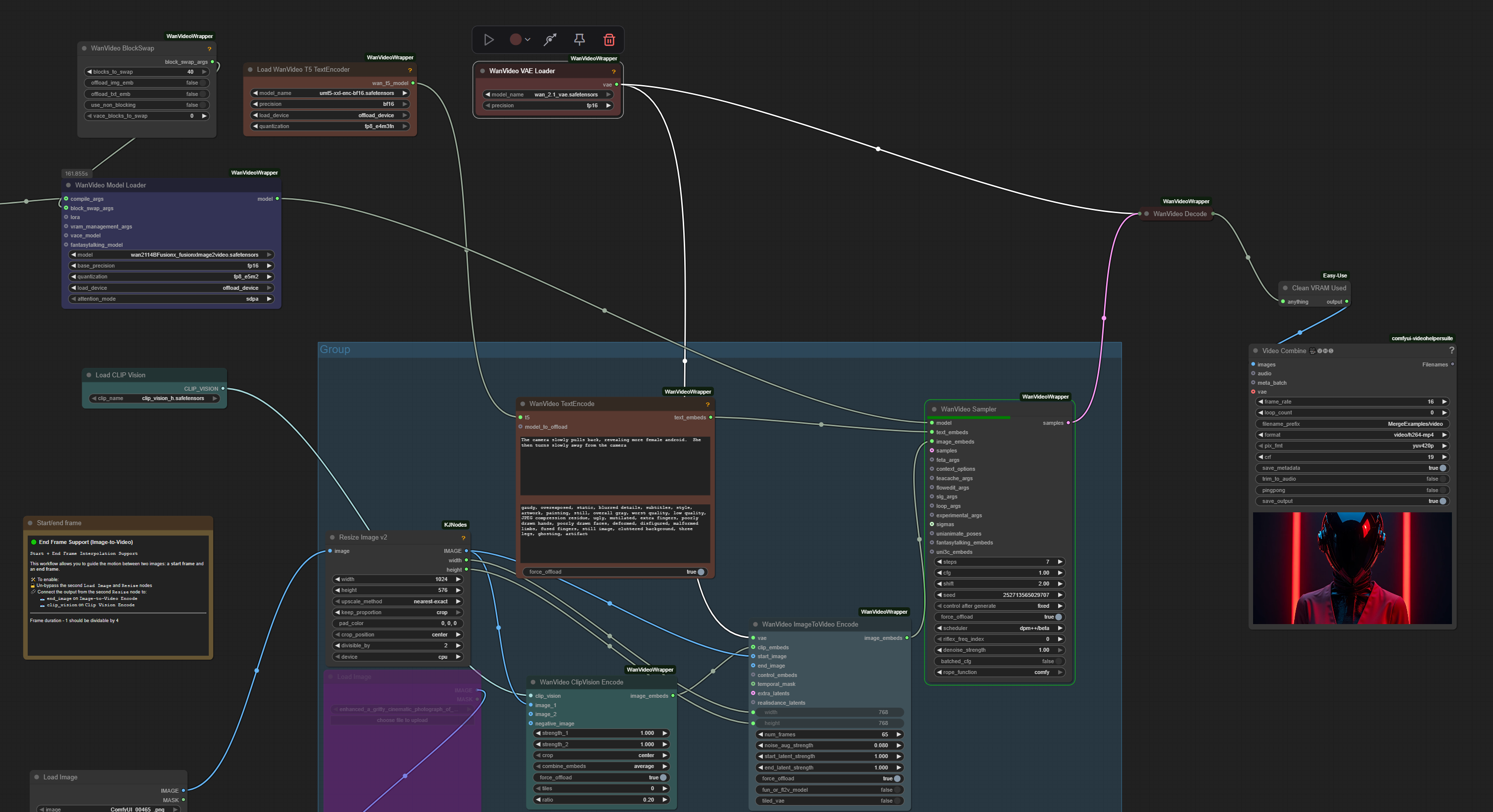
From my short novice experience, I recommend you stay away from the GGUF version and work with the full version in the WanVideoWrapper. If you run out of VRAM, you can increase the blocks to swap to the max (40). With these settings below (this is not a workflow png, just a screenshot of my settings) it renders 2X faster than GGUF with a native workflow on my RTX 2080 12GB vram