
Quantifying the Carbon Emissions of Machine Learning
Paper • 1910.09700 • Published • 45
The model was fine-tuned to build a chat agent in our Honours project in 2025W.
The model was fine-tuned using Deep-R1-Distill-Qwen-7B, a distilled version of deepseek r1. Deepseek r1 was a general large language model(LLM) developed by DeepSeek in 2024, a Chinese company specialized in AGI R&D.
The dataset used for fine-tuning is medical-o1-reasoning-SFT, which contains 20k+ of verifiable medical questions from various medical exams, along with a complete chain-of-thought(CoT) that leads to a ground truth answer. It was very effective in fine-tuning the base model, enabling it to infer the patient's symptoms efficiently and effectively in the medical scenario.
The model will serve as an NLP agent in our honours project - AI-Driven Health Monitoring and Prediction Application, which aims to develop a modern web application that focuses on personal health management and virtual healthcare services. Our project is part of the CSI4900: Honours Project course in Winter 2025 Semester at the University of Ottawa.
The model is intended to handle text-generation and question-answering tasks in a medical scenario. Potential users include companies and researchers that are interested in AI + healthcare applications.
The model might not work well in real-world applications as it was based on a distilled model with a limited number of parameters, which can lead to inaccurate or misleading answers. Our model was mainly used for educational purposes only. For serious applications, consider using models with more parameters.
The output of the model is subjected to false and inaccurate information. For medical purposes such as symptom diagnosis and treatment please consult with professional personnel at your local hospital/clinics.
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
Use the code below to get started with the model.
Using Conda with FastAPI, we can set up a local environment that can run the model in a local server, that can be accessed by other applications via API.
from fastapi import FastAPI
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
app = FastAPI()
# Model path
model_path = "Insert path to your model here"
# Load Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
my_quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype="float16"
)
# Load model and move to GPU/CPU
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
quantization_config=my_quantization_config
)
@app.get("/generate")
async def generate_text(prompt: str) -> dict:
inputs = tokenizer(prompt, return_tensors="pt").to(device)
outputs = model.generate(inputs["input_ids"],attention_mask=inputs["attention_mask"], max_length=1024, repetition_penalty=1.2)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
clean_response = generated_text[len(prompt):].strip()
# generated_text = "This is the response"
return {"generated_text": clean_response}
For cloud deployment, consider using Huggingface Inference Endpoints or Amazon Sagemaker
Please check out the training datasets above.
We trained our model using the LoRA (Low-Rank Adaptation) algorithm for a total of 30 epochs. The total training time is around 20-30 hours.
Since we are short on budget (and GPU computational power), we only used a batch size of 2 (as using more will lead to CUDA out of memory problem), which leads to long training time.
We have reserved 20% of the data for validation.
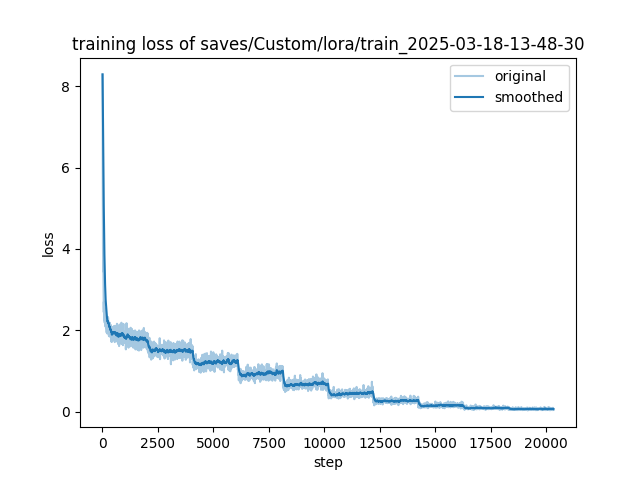
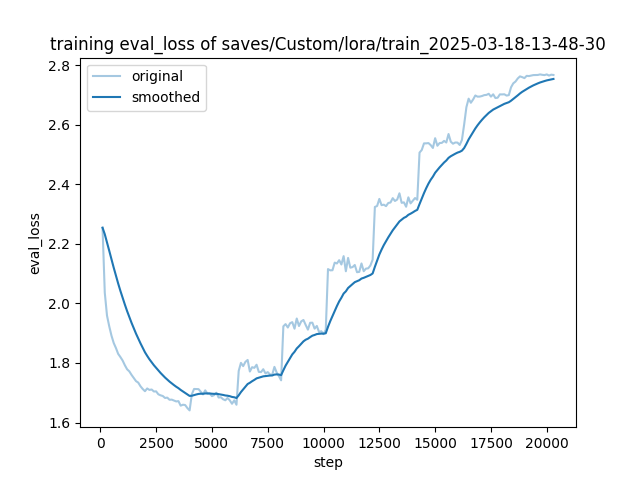
Training loss and evaluation loss
Training loss:
Evaluation loss:
Evaluation, manually using medical questions:
CoT before training:

CoT after training:

Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
For any inquiries, please send them to this email address: jwang751@uOttawa.ca. Thank you!