
See our collection for all versions of Qwen3 including GGUF, 4-bit & 16-bit formats.
Learn to run Qwen3-2507 correctly - Read our Guide.
Unsloth Dynamic 2.0 achieves superior accuracy & outperforms other leading quants.



✨ Read our Qwen3-2507 Guide here!
- Fine-tune Qwen3 (14B) for free using our Google Colab notebook here!
- Read our Blog about Qwen3 support: unsloth.ai/blog/qwen3
- View the rest of our notebooks in our docs here.
- Run & export your fine-tuned model to Ollama, llama.cpp or HF.
| Unsloth supports | Free Notebooks | Performance | Memory use |
|---|---|---|---|
| Qwen3 (14B) | ▶️ Start on Colab | 3x faster | 70% less |
| GRPO with Qwen3 (8B) | ▶️ Start on Colab | 3x faster | 80% less |
| Llama-3.2 (3B) | ▶️ Start on Colab | 2.4x faster | 58% less |
| Llama-3.2 (11B vision) | ▶️ Start on Colab | 2x faster | 60% less |
| Qwen2.5 (7B) | ▶️ Start on Colab | 2x faster | 60% less |
Qwen3-30B-A3B-Thinking-2507
Highlights
Over the past three months, we have continued to scale the thinking capability of Qwen3-30B-A3B, improving both the quality and depth of reasoning. We are pleased to introduce Qwen3-30B-A3B-Thinking-2507, featuring the following key enhancements:
- Significantly improved performance on reasoning tasks, including logical reasoning, mathematics, science, coding, and academic benchmarks that typically require human expertise.
- Markedly better general capabilities, such as instruction following, tool usage, text generation, and alignment with human preferences.
- Enhanced 256K long-context understanding capabilities.
NOTE: This version has an increased thinking length. We strongly recommend its use in highly complex reasoning tasks.
Model Overview
Qwen3-30B-A3B-Thinking-2507 has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Paramaters (Non-Embedding): 29.9B
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: 262,144 natively.
NOTE: This model supports only thinking mode. Meanwhile, specifying enable_thinking=True is no longer required.
Additionally, to enforce model thinking, the default chat template automatically includes <think>. Therefore, it is normal for the model's output to contain only </think> without an explicit opening <think> tag.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our blog, GitHub, and Documentation.
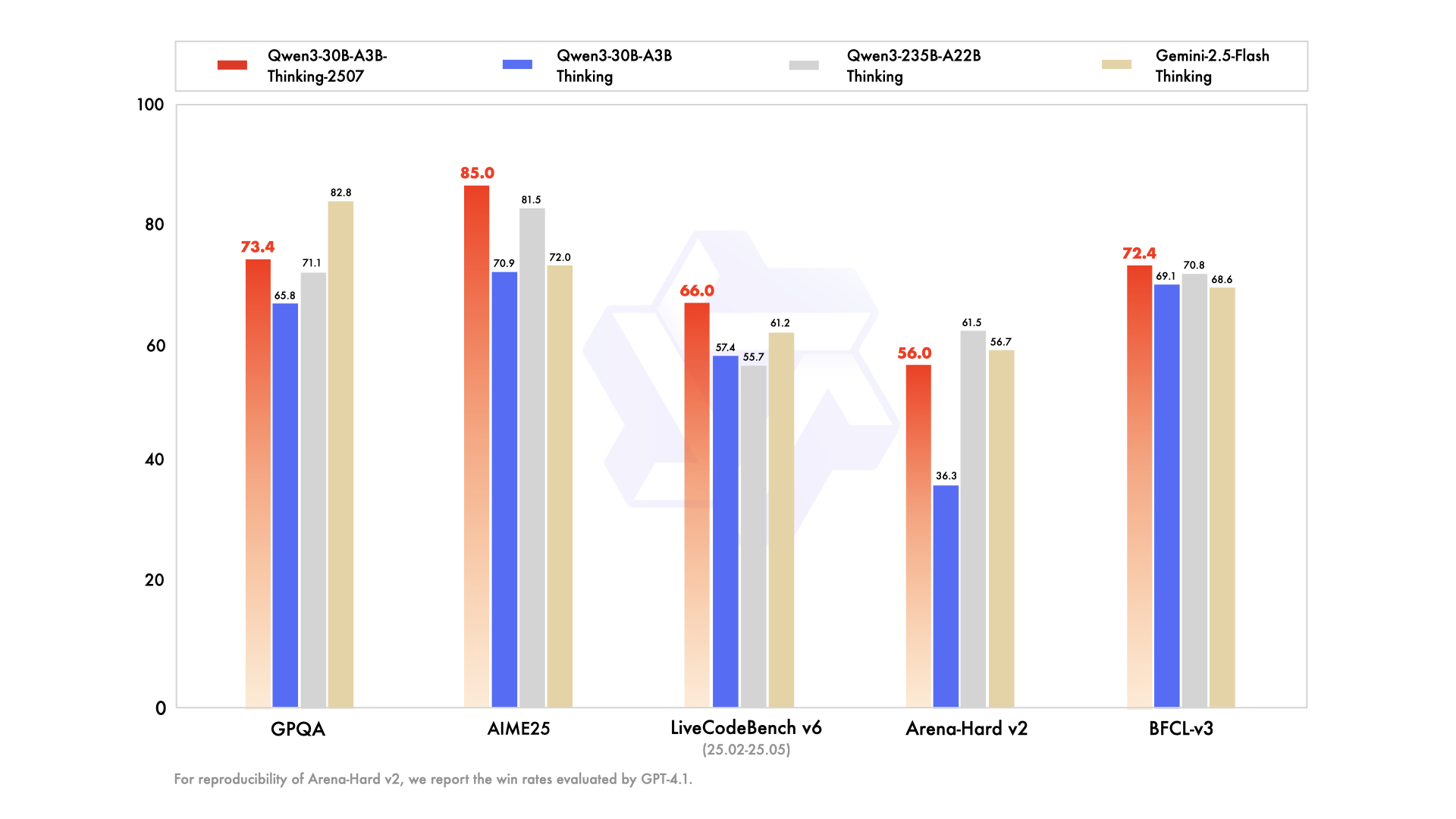
Performance
| Gemini2.5-Flash-Thinking | Qwen3-235B-A22B Thinking | Qwen3-30B-A3B Thinking | Qwen3-30B-A3B-Thinking-2507 | |
|---|---|---|---|---|
| Knowledge | ||||
| MMLU-Pro | 81.9 | 82.8 | 78.5 | 80.9 |
| MMLU-Redux | 92.1 | 92.7 | 89.5 | 91.4 |
| GPQA | 82.8 | 71.1 | 65.8 | 73.4 |
| SuperGPQA | 57.8 | 60.7 | 51.8 | 56.8 |
| Reasoning | ||||
| AIME25 | 72.0 | 81.5 | 70.9 | 85.0 |
| HMMT25 | 64.2 | 62.5 | 49.8 | 71.4 |
| LiveBench 20241125 | 74.3 | 77.1 | 74.3 | 76.8 |
| Coding | ||||
| LiveCodeBench v6 (25.02-25.05) | 61.2 | 55.7 | 57.4 | 66.0 |
| CFEval | 1995 | 2056 | 1940 | 2044 |
| OJBench | 23.5 | 25.6 | 20.7 | 25.1 |
| Alignment | ||||
| IFEval | 89.8 | 83.4 | 86.5 | 88.9 |
| Arena-Hard v2$ | 56.7 | 61.5 | 36.3 | 56.0 |
| Creative Writing v3 | 85.0 | 84.6 | 79.1 | 84.4 |
| WritingBench | 83.9 | 80.3 | 77.0 | 85.0 |
| Agent | ||||
| BFCL-v3 | 68.6 | 70.8 | 69.1 | 72.4 |
| TAU1-Retail | 65.2 | 54.8 | 61.7 | 67.8 |
| TAU1-Airline | 54.0 | 26.0 | 32.0 | 48.0 |
| TAU2-Retail | 66.7 | 40.4 | 34.2 | 58.8 |
| TAU2-Airline | 52.0 | 30.0 | 36.0 | 58.0 |
| TAU2-Telecom | 31.6 | 21.9 | 22.8 | 26.3 |
| Multilingualism | ||||
| MultiIF | 74.4 | 71.9 | 72.2 | 76.4 |
| MMLU-ProX | 80.2 | 80.0 | 73.1 | 76.4 |
| INCLUDE | 83.9 | 78.7 | 71.9 | 74.4 |
| PolyMATH | 49.8 | 54.7 | 46.1 | 52.6 |
$ For reproducibility, we report the win rates evaluated by GPT-4.1.
& For highly challenging tasks (including PolyMATH and all reasoning and coding tasks), we use an output length of 81,920 tokens. For all other tasks, we set the output length to 32,768.
Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face transformers and we advise you to use the latest version of transformers.
With transformers<4.51.0, you will encounter the following error:
KeyError: 'qwen3_moe'
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Thinking-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # no opening <think> tag
print("content:", content)
For deployment, you can use sglang>=0.4.6.post1 or vllm>=0.8.5 or to create an OpenAI-compatible API endpoint:
- SGLang:
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Thinking-2507 --context-length 262144 --reasoning-parser deepseek-r1 - vLLM:
vllm serve Qwen/Qwen3-30B-A3B-Thinking-2507 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1
Note: If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value. However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using Qwen-Agent to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
from qwen_agent.agents import Assistant
# Define LLM
# Using Alibaba Cloud Model Studio
llm_cfg = {
'model': 'qwen3-30b-a3b-thinking-2507',
'model_type': 'qwen_dashscope',
}
# Using OpenAI-compatible API endpoint. It is recommended to disable the reasoning and the tool call parsing
# functionality of the deployment frameworks and let Qwen-Agent automate the related operations. For example,
# `VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-30B-A3B-Thinking-2507 --served-model-name Qwen3-30B-A3B-Thinking-2507 --tensor-parallel-size 8 --max-model-len 262144`.
#
# llm_cfg = {
# 'model': 'Qwen3-30B-A3B-Thinking-2507',
#
# # Use a custom endpoint compatible with OpenAI API:
# 'model_server': 'http://localhost:8000/v1', # api_base without reasoning and tool call parsing
# 'api_key': 'EMPTY',
# 'generate_cfg': {
# 'thought_in_content': True,
# },
# }
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
Best Practices
To achieve optimal performance, we recommend the following settings:
Sampling Parameters:
- We suggest using
Temperature=0.6,TopP=0.95,TopK=20, andMinP=0. - For supported frameworks, you can adjust the
presence_penaltyparameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
- We suggest using
Adequate Output Length: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 81,920 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
Standardize Output Format: We recommend using prompts to standardize model outputs when benchmarking.
- Math Problems: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- Multiple-Choice Questions: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the
answerfield with only the choice letter, e.g.,"answer": "C"."
No Thinking Content in History: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
Citation
If you find our work helpful, feel free to give us a cite.
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
- Downloads last month
- 27
Model tree for unsloth/Qwen3-30B-A3B-Thinking-2507
Base model
Qwen/Qwen3-30B-A3B-Thinking-2507