
File size: 10,763 Bytes
e8ef193 425d325 e8ef193 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 |
---
tags:
- unsloth
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507-FP8/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-235B-A22B-Instruct-2507-FP8
---
> [!NOTE]
> Includes Unsloth **chat template fixes**! <br> For `llama.cpp`, use `--jinja`
>
<div>
<p style="margin-top: 0;margin-bottom: 0;">
<em><a href="https://docs.unsloth.ai/basics/unsloth-dynamic-v2.0-gguf">Unsloth Dynamic 2.0</a> achieves superior accuracy & outperforms other leading quants.</em>
</p>
<div style="display: flex; gap: 5px; align-items: center; ">
<a href="https://github.com/unslothai/unsloth/">
<img src="https://github.com/unslothai/unsloth/raw/main/images/unsloth%20new%20logo.png" width="133">
</a>
<a href="https://discord.gg/unsloth">
<img src="https://github.com/unslothai/unsloth/raw/main/images/Discord%20button.png" width="173">
</a>
<a href="https://docs.unsloth.ai/">
<img src="https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png" width="143">
</a>
</div>
</div>
# Qwen3-235B-A22B-Instruct-2507-FP8
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
We introduce the updated version of the **Qwen3-235B-A22B-FP8 non-thinking mode**, named **Qwen3-235B-A22B-Instruct-2507-FP8**, featuring the following key enhancements:
- **Significant improvements** in general capabilities, including **instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage**.
- **Substantial gains** in long-tail knowledge coverage across **multiple languages**.
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
- **Enhanced capabilities** in **256K long-context understanding**.
## Model Overview
This repo contains the FP8 version of **Qwen3-235B-A22B-Instruct-2507**, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 235B in total and 22B activated
- Number of Paramaters (Non-Embedding): 234B
- Number of Layers: 94
- Number of Attention Heads (GQA): 64 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
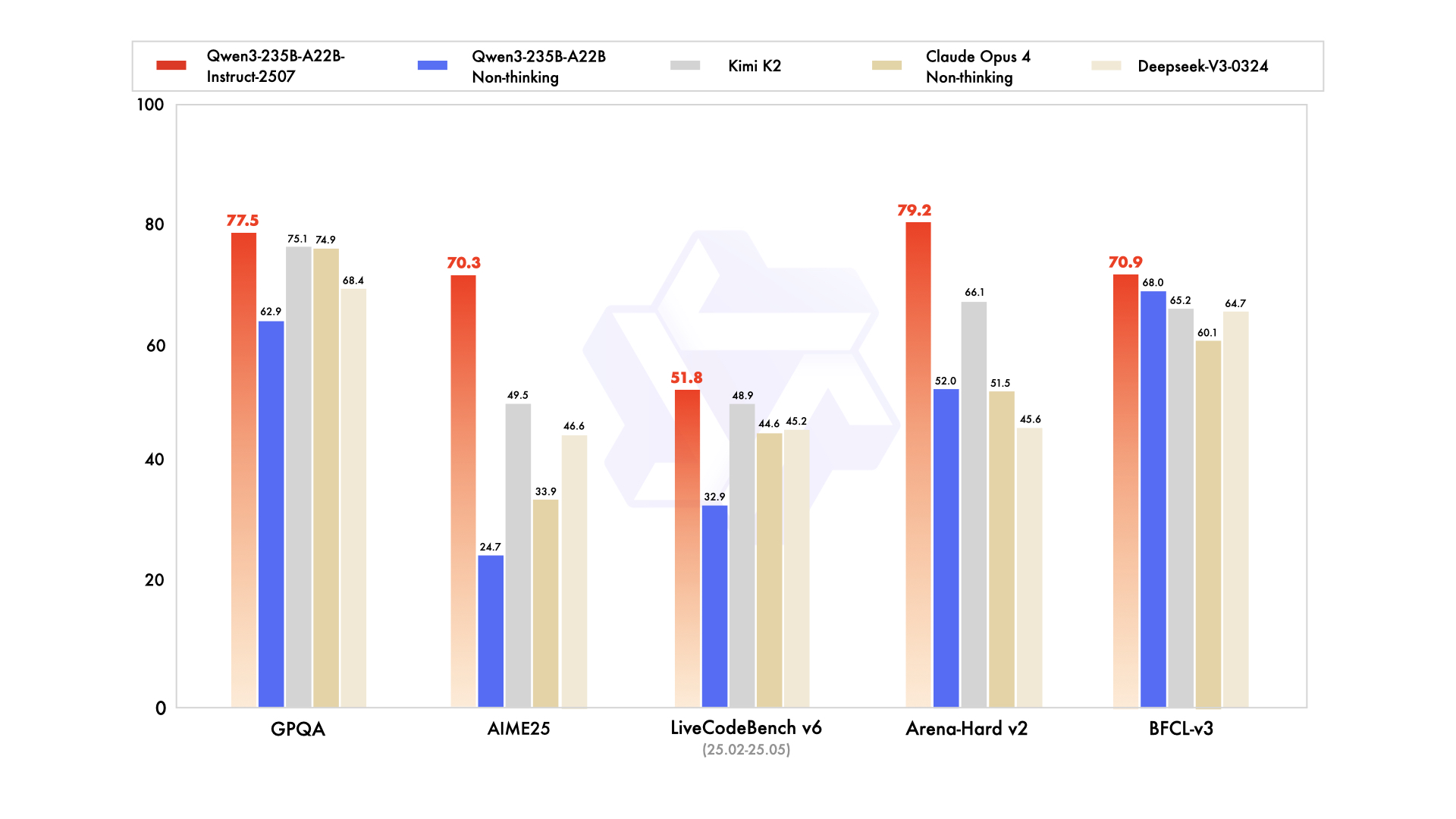
| | Deepseek-V3-0324 | GPT-4o-0327 | Claude Opus 4 Non-thinking | Kimi K2 | Qwen3-235B-A22B Non-thinking | Qwen3-235B-A22B-Instruct-2507 |
|--- | --- | --- | --- | --- | --- | ---|
| **Knowledge** | | | | | | |
| MMLU-Pro | 81.2 | 79.8 | **86.6** | 81.1 | 75.2 | 83.0 |
| MMLU-Redux | 90.4 | 91.3 | **94.2** | 92.7 | 89.2 | 93.1 |
| GPQA | 68.4 | 66.9 | 74.9 | 75.1 | 62.9 | **77.5** |
| SuperGPQA | 57.3 | 51.0 | 56.5 | 57.2 | 48.2 | **62.6** |
| SimpleQA | 27.2 | 40.3 | 22.8 | 31.0 | 12.2 | **54.3** |
| CSimpleQA | 71.1 | 60.2 | 68.0 | 74.5 | 60.8 | **84.3** |
| **Reasoning** | | | | | | |
| AIME25 | 46.6 | 26.7 | 33.9 | 49.5 | 24.7 | **70.3** |
| HMMT25 | 27.5 | 7.9 | 15.9 | 38.8 | 10.0 | **55.4** |
| ARC-AGI | 9.0 | 8.8 | 30.3 | 13.3 | 4.3 | **41.8** |
| ZebraLogic | 83.4 | 52.6 | - | 89.0 | 37.7 | **95.0** |
| LiveBench 20241125 | 66.9 | 63.7 | 74.6 | **76.4** | 62.5 | 75.4 |
| **Coding** | | | | | | |
| LiveCodeBench v6 (25.02-25.05) | 45.2 | 35.8 | 44.6 | 48.9 | 32.9 | **51.8** |
| MultiPL-E | 82.2 | 82.7 | **88.5** | 85.7 | 79.3 | 87.9 |
| Aider-Polyglot | 55.1 | 45.3 | **70.7** | 59.0 | 59.6 | 57.3 |
| **Alignment** | | | | | | |
| IFEval | 82.3 | 83.9 | 87.4 | **89.8** | 83.2 | 88.7 |
| Arena-Hard v2* | 45.6 | 61.9 | 51.5 | 66.1 | 52.0 | **79.2** |
| Creative Writing v3 | 81.6 | 84.9 | 83.8 | **88.1** | 80.4 | 87.5 |
| WritingBench | 74.5 | 75.5 | 79.2 | **86.2** | 77.0 | 85.2 |
| **Agent** | | | | | | |
| BFCL-v3 | 64.7 | 66.5 | 60.1 | 65.2 | 68.0 | **70.9** |
| TAU-Retail | 49.6 | 60.3# | **81.4** | 70.7 | 65.2 | 71.3 |
| TAU-Airline | 32.0 | 42.8# | **59.6** | 53.5 | 32.0 | 44.0 |
| **Multilingualism** | | | | | | |
| MultiIF | 66.5 | 70.4 | - | 76.2 | 70.2 | **77.5** |
| MMLU-ProX | 75.8 | 76.2 | - | 74.5 | 73.2 | **79.4** |
| INCLUDE | 80.1 | **82.1** | - | 76.9 | 75.6 | 79.5 |
| PolyMATH | 32.2 | 25.5 | 30.0 | 44.8 | 27.0 | **50.2** |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
\#: Results were generated using GPT-4o-20241120, as access to the native function calling API of GPT-4o-0327 was unavailable.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-235B-A22B-Instruct-2507-FP8"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B-Instruct-2507-FP8 --tp 4 --context-length 262144
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-235B-A22B-Instruct-2507-FP8 --tensor-parallel-size 4 --max-model-len 262144
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Note on FP8
For convenience and performance, we have provided `fp8`-quantized model checkpoint for Qwen3, whose name ends with `-FP8`. The quantization method is fine-grained `fp8` quantization with block size of 128. You can find more details in the `quantization_config` field in `config.json`.
You can use the Qwen3-235B-A22B-Instruct-2507-FP8 model with serveral inference frameworks, including `transformers`, `sglang`, and `vllm`, as the original bfloat16 model.
However, please pay attention to the following known issues:
- `transformers`:
- there are currently issues with the "fine-grained fp8" method in `transformers` for distributed inference. You may need to set the environment variable `CUDA_LAUNCH_BLOCKING=1` if multiple devices are used in inference.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-235B-A22B-Instruct-2507-FP8',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
``` |