
File size: 5,548 Bytes
8f27baa |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 |
---
license: mit
language:
- en
- zh
base_model:
- THUDM/GLM-4.1V-9B-Thinking
pipeline_tag: image-text-to-text
library_name: transformers
tags:
- reasoning
- unsloth
---
> [!NOTE]
> Includes Unsloth **chat template fixes**! <br> For `llama.cpp`, use `--jinja`
>
<div>
<p style="margin-top: 0;margin-bottom: 0;">
<em><a href="https://docs.unsloth.ai/basics/unsloth-dynamic-v2.0-gguf">Unsloth Dynamic 2.0</a> achieves superior accuracy & outperforms other leading quants.</em>
</p>
<div style="display: flex; gap: 5px; align-items: center; ">
<a href="https://github.com/unslothai/unsloth/">
<img src="https://github.com/unslothai/unsloth/raw/main/images/unsloth%20new%20logo.png" width="133">
</a>
<a href="https://discord.gg/unsloth">
<img src="https://github.com/unslothai/unsloth/raw/main/images/Discord%20button.png" width="173">
</a>
<a href="https://docs.unsloth.ai/">
<img src="https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png" width="143">
</a>
</div>
</div>
# GLM-4.1V-9B-Thinking
<div align="center">
<img src=https://raw.githubusercontent.com/THUDM/GLM-4.1V-Thinking/99c5eb6563236f0ff43605d91d107544da9863b2/resources/logo.svg width="40%"/>
</div>
<p align="center">
📖 View the GLM-4.1V-9B-Thinking <a href="https://arxiv.org/abs/2507.01006" target="_blank">paper</a>.
<br>
💡 Try the <a href="https://huggingface.co/spaces/THUDM/GLM-4.1V-9B-Thinking-Demo" target="_blank">Hugging Face</a> or <a href="https://modelscope.cn/studios/ZhipuAI/GLM-4.1V-9B-Thinking-Demo" target="_blank">ModelScope</a> online demo for GLM-4.1V-9B-Thinking.
<br>
📍 Using GLM-4.1V-9B-Thinking API at <a href="https://www.bigmodel.cn/dev/api/visual-reasoning-model/GLM-4.1V-Thinking">Zhipu Foundation Model Open Platform</a>
</p>
## Model Introduction
Vision-Language Models (VLMs) have become foundational components of intelligent systems. As real-world AI tasks grow
increasingly complex, VLMs must evolve beyond basic multimodal perception to enhance their reasoning capabilities in
complex tasks. This involves improving accuracy, comprehensiveness, and intelligence, enabling applications such as
complex problem solving, long-context understanding, and multimodal agents.
Based on the [GLM-4-9B-0414](https://github.com/THUDM/GLM-4) foundation model, we present the new open-source VLM model
**GLM-4.1V-9B-Thinking**, designed to explore the upper limits of reasoning in vision-language models. By introducing
a "thinking paradigm" and leveraging reinforcement learning, the model significantly enhances its capabilities. It
achieves state-of-the-art performance among 10B-parameter VLMs, matching or even surpassing the 72B-parameter
Qwen-2.5-VL-72B on 18 benchmark tasks. We are also open-sourcing the base model GLM-4.1V-9B-Base to
support further research into the boundaries of VLM capabilities.
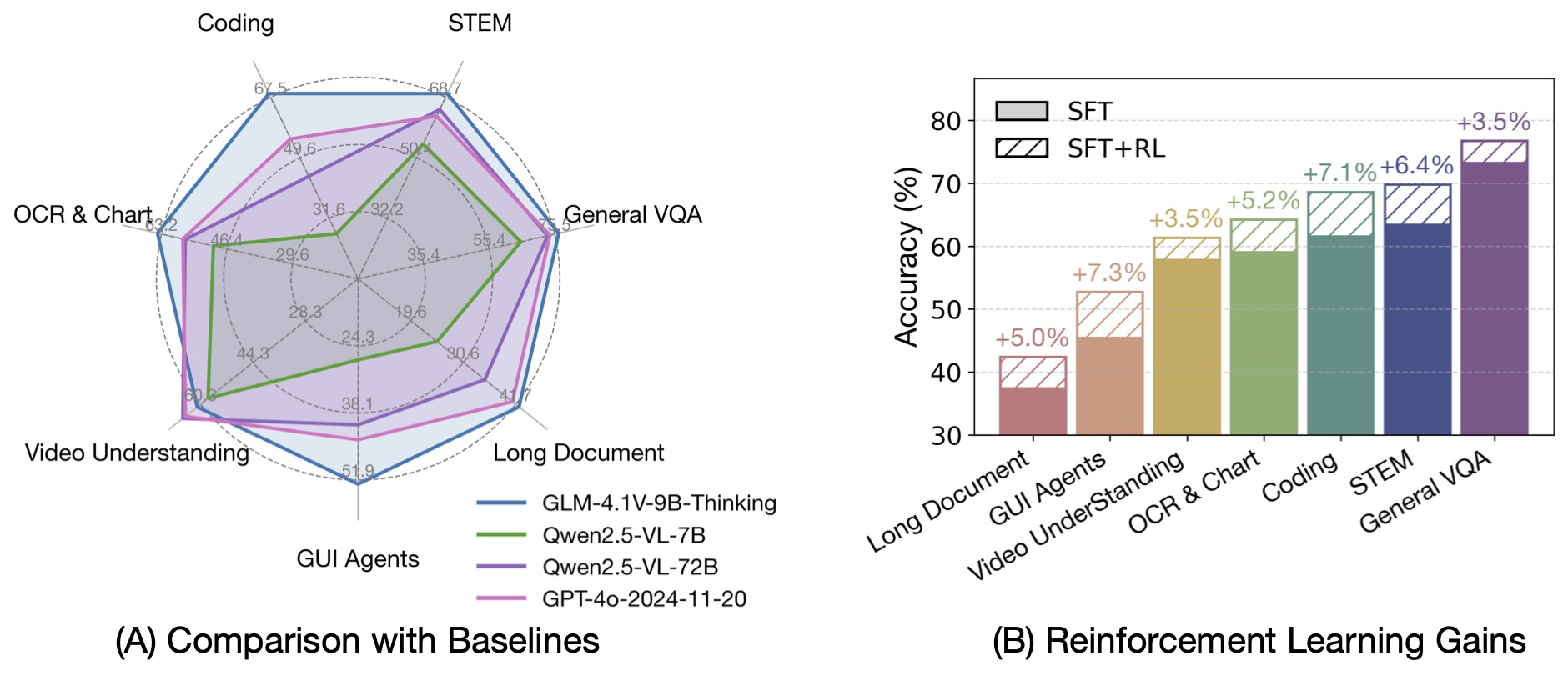
Compared to the previous generation models CogVLM2 and the GLM-4V series, **GLM-4.1V-Thinking** offers the
following improvements:
1. The first reasoning-focused model in the series, achieving world-leading performance not only in mathematics but also
across various sub-domains.
2. Supports **64k** context length.
3. Handles **arbitrary aspect ratios** and up to **4K** image resolution.
4. Provides an open-source version supporting both **Chinese and English bilingual** usage.
## Benchmark Performance
By incorporating the Chain-of-Thought reasoning paradigm, GLM-4.1V-9B-Thinking significantly improves answer accuracy,
richness, and interpretability. It comprehensively surpasses traditional non-reasoning visual models.
Out of 28 benchmark tasks, it achieved the best performance among 10B-level models on 23 tasks,
and even outperformed the 72B-parameter Qwen-2.5-VL-72B on 18 tasks.

## Quick Inference
This is a simple example of running single-image inference using the `transformers` library.
First, install the `transformers` library from source:
```
pip install git+https://github.com/huggingface/transformers.git
```
Then, run the following code:
```python
from transformers import AutoProcessor, Glm4vForConditionalGeneration
import torch
MODEL_PATH = "THUDM/GLM-4.1V-9B-Thinking"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://upload.wikimedia.org/wikipedia/commons/f/fa/Grayscale_8bits_palette_sample_image.png"
},
{
"type": "text",
"text": "describe this image"
}
],
}
]
processor = AutoProcessor.from_pretrained(MODEL_PATH, use_fast=True)
model = Glm4vForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
```
For video reasoning, web demo deployment, and more code, please check
our [GitHub](https://github.com/THUDM/GLM-4.1V-Thinking). |