
Compatibility with Nexesenex/croco.cpp ???
Hey
@Nexesenex
I'm not able to open an issue on https://github.com/Nexesenex/croco.cpp but had a person on windows try your croco.cpp fork with this huggingface repo's pure-IQ4_KS. It was almost starting up but got an error that seems related to FUSED_RMS_NORM_FAILED.
They provided the logs and some screenshots as well, I'll put them here in case you want to look into it more. I'm not exactly sure which of my quants would be compatible on croco.cpp but am exicted to have a good option to suggest to koboldcpp folks especially those on windows who don't want to compile themselves.
Thanks!

👈debug logs
D:\ai\KoboldCPP>croco.cpp.exe --threads 36 --usecublas --highpriority --gpulayers 50 --tensor_split 16 17 17 --flashattention --contextsize 24576
***
Welcome to Croco.Cpp, fork of KoboldCpp - Version 1.94235, including Esobold RMv1.13.2m.
***
Based on LlamaCpp version b5757 and IK_Llama.cpp version IKLpr557
***
Release date: 2025/06/27
***
Cuda mode compiled, if any: Cu128_Ar86_SMC2_DmmvX32Y1
***
For command line arguments, please refer to --help
***
Loading Chat Completions Adapter: C:\Users\AIMO\AppData\Local\Temp\_MEI25002\kcpp_adapters\AutoGuess.json
Chat Completions Adapter Loaded
Setting process to Higher Priority - Use Caution
High Priority for Windows Set: Priority.NORMAL_PRIORITY_CLASS to Priority.HIGH_PRIORITY_CLASS
Detected Available GPU Memory: 24576 MB
Detected Available RAM: 123188 MB
Initializing dynamic library: koboldcpp_cublas.dll
==========
Namespace(model=[], model_param='E:/Qwen3-235B-A22B-Instruct-pure-IQ4_XS-00001-of-00003.gguf', port=5001, port_param=5001, host='', launch=False, config=None, threads=36, usecublas=[], usevulkan=None, useclblast=None, usecpu=False, contextsize=24576, gpulayers=50, tensor_split=[16.0, 17.0, 17.0], version=False, analyze='', maingpu=-1, ropeconfig=[0.0, 10000.0], blasbatchsize=128, blasubatchsize=0, blasthreads=36, lora=None, loramult=1.0, contextshift=False, nofastforward=False, useswa=False, usemmap=False, usemlock=False, noavx2=False, failsafe=False, debugmode=0, onready='', benchmark=None, prompt='', cli=False, promptlimit=100, multiuser=1, multiplayer=False, websearch=False, remotetunnel=False, highpriority=True, foreground=False, preloadstory='', savedatafile='', quiet=False, ssl=None, nocertify=False, mmproj='', mmprojcpu=False, visionmaxres=1024, draftmodel='', draftamount=8, draftgpulayers=999, draftgpusplit=None, password=None, ignoremissing=False, chatcompletionsadapter='AutoGuess', flashattention=True, quantkv=0, draft_quantkv=-1, forceversion=0, smartcontext=False, unpack='', exportconfig='', exporttemplate='', nomodel=False, moeexperts=-1, normrmseps=-1.0, poslayeroffset=0, neglayeroffset=0, defaultgenamt=512, nobostoken=False, enableguidance=False, maxrequestsize=32, overridekv='', overridetensors='', developerMode=False, showgui=False, skiplauncher=False, singleinstance=False, hordemodelname='', hordeworkername='', hordekey='', hordemaxctx=0, hordegenlen=0, sdmodel='', sdthreads=0, sdclamped=0, sdclampedsoft=0, sdt5xxl='', sdclipl='', sdclipg='', sdphotomaker='', sdvae='', sdvaeauto=False, sdquant=False, sdlora='', sdloramult=1.0, sdtiledvae=768, whispermodel='', ttsmodel='', ttswavtokenizer='', ttsgpu=False, ttsmaxlen=4096, ttsthreads=0, embeddingsmodel='', embeddingsmaxctx=0, embeddingsgpu=False, admin=False, adminpassword=None, admindir='', admintextmodelsdir='', admindatadir='', adminallowhf=False, hordeconfig=None, sdconfig=None, noblas=False, nommap=False, sdnotile=False)
==========
Loading Text Model: E:\Qwen3-235B-A22B-Instruct-pure-IQ4_XS-00001-of-00003.gguf
The reported GGUF Arch is: qwen3moe
Arch Category: 0
---
Identified as GGUF model.
Attempting to Load...
---
Trained max context length (value:2048).
Desired context length (value:24576).
RoPE Frequency Base value (value:10000.000).
RoPE base calculated via Gradient AI formula. (value:521981.0).
Using automatic RoPE scaling for GGUF. If the model has custom RoPE settings, they'll be used directly instead!
System Info: AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | AMX_INT8 = 0 | FMA = 1 | NEON = 0 | SVE = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | RISCV_VECT = 0 | WASM_SIMD = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 | LLAMAFILE = 1 |
CUDA MMQ: False
Not Using MMQ
Applying Tensor Split...
---
Initializing CUDA/HIP, please wait, the following step may take a few minutes (only for first launch)...
---
ggml_cuda_init: found 3 CUDA devices:
Device 0: NVIDIA GeForce RTX 3090, compute capability 8.6, VMM: yes
Device 1: NVIDIA GeForce RTX 3090, compute capability 8.6, VMM: yes
Device 2: NVIDIA GeForce RTX 3090, compute capability 8.6, VMM: yes
llama_model_load_from_file_impl: using device CUDA0 (NVIDIA GeForce RTX 3090) - 23305 MiB free
llama_model_load_from_file_impl: using device CUDA1 (NVIDIA GeForce RTX 3090) - 23306 MiB free
llama_model_load_from_file_impl: using device CUDA2 (NVIDIA GeForce RTX 3090) - 23306 MiB free
llama_model_loader: additional 2 GGUFs metadata loaded.
llama_model_loader: loaded meta data with 42 key-value pairs and 1131 tensors from E:\Qwen3-235B-A22B-Instruct-pure-IQ4_XS-00001-of-00003.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = qwen3moe
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = Qwen3 235B A22B Instruct 2507
llama_model_loader: - kv 3: general.version str = 2507
llama_model_loader: - kv 4: general.finetune str = Instruct
llama_model_loader: - kv 5: general.basename str = Qwen3
llama_model_loader: - kv 6: general.size_label str = 235B-A22B
llama_model_loader: - kv 7: general.license str = apache-2.0
llama_model_loader: - kv 8: general.license.link str = https://huggingface.co/Qwen/Qwen3-235...
llama_model_loader: - kv 9: general.tags arr[str,1] = ["text-generation"]
llama_model_loader: - kv 10: qwen3moe.block_count u32 = 94
llama_model_loader: - kv 11: qwen3moe.context_length u32 = 262144
llama_model_loader: - kv 12: qwen3moe.embedding_length u32 = 4096
llama_model_loader: - kv 13: qwen3moe.feed_forward_length u32 = 12288
llama_model_loader: - kv 14: qwen3moe.attention.head_count u32 = 64
llama_model_loader: - kv 15: qwen3moe.attention.head_count_kv u32 = 4
llama_model_loader: - kv 16: qwen3moe.rope.freq_base f32 = 5000000.000000
llama_model_loader: - kv 17: qwen3moe.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 18: qwen3moe.expert_used_count u32 = 8
llama_model_loader: - kv 19: qwen3moe.attention.key_length u32 = 128
llama_model_loader: - kv 20: qwen3moe.attention.value_length u32 = 128
llama_model_loader: - kv 21: general.file_type u32 = 145
llama_model_loader: - kv 22: qwen3moe.expert_count u32 = 128
llama_model_loader: - kv 23: qwen3moe.expert_feed_forward_length u32 = 1536
llama_model_loader: - kv 24: general.quantization_version u32 = 2
llama_model_loader: - kv 25: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 26: tokenizer.ggml.pre str = qwen2
llama_model_loader: - kv 27: tokenizer.ggml.tokens arr[str,151936] = ["!", "\"", "#", "$", "%", "&", "'", ...
llama_model_loader: - kv 28: tokenizer.ggml.token_type arr[i32,151936] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 29: tokenizer.ggml.merges arr[str,151387] = ["─á ─á", "─á─á ─á─á", "i n", "─á t",...
llama_model_loader: - kv 30: tokenizer.ggml.eos_token_id u32 = 151645
llama_model_loader: - kv 31: tokenizer.ggml.padding_token_id u32 = 151643
llama_model_loader: - kv 32: tokenizer.ggml.bos_token_id u32 = 151643
llama_model_loader: - kv 33: tokenizer.ggml.add_bos_token bool = false
llama_model_loader: - kv 34: tokenizer.chat_template str = {%- if tools %}\n {{- '<|im_start|>...
llama_model_loader: - kv 35: quantize.imatrix.file str = /mnt/raid/models/ubergarm/Qwen3-235B-...
llama_model_loader: - kv 36: quantize.imatrix.dataset str = ubergarm-imatrix-calibration-corpus-v...
llama_model_loader: - kv 37: quantize.imatrix.entries_count i32 = 753
llama_model_loader: - kv 38: quantize.imatrix.chunks_count i32 = 840
llama_model_loader: - kv 39: split.no u16 = 0
llama_model_loader: - kv 40: split.count u16 = 3
llama_model_loader: - kv 41: split.tensors.count i32 = 1131
llama_model_loader: - type f32: 471 tensors
llama_model_loader: - type iq4_k: 1 tensors
llama_model_loader: - type iq6_k: 1 tensors
llama_model_loader: - type iq4_ks: 658 tensors
print_info: file format = GGUF V3 (latest)
print_info: file type = IQ4_KS - 4.25 bpw
print_info: file size = 116.99 GiB (4.27 BPW)
init_tokenizer: initializing tokenizer for type 2
load: special tokens cache size = 26
load: token to piece cache size = 0.9311 MB
print_info: arch = qwen3moe
print_info: vocab_only = 0
print_info: n_ctx_train = 262144
print_info: n_embd = 4096
print_info: n_layer = 94
print_info: n_head = 64
print_info: n_head_kv = 4
print_info: n_rot = 128
print_info: n_swa = 0
print_info: is_swa_any = 0
print_info: n_embd_head_k = 128
print_info: n_embd_head_v = 128
print_info: n_gqa = 16
print_info: n_embd_k_gqa = 512
print_info: n_embd_v_gqa = 512
print_info: f_norm_eps = 0.0e+00
print_info: f_norm_rms_eps = 1.0e-06
print_info: f_clamp_kqv = 0.0e+00
print_info: f_max_alibi_bias = 0.0e+00
print_info: f_logit_scale = 0.0e+00
print_info: f_attn_scale = 0.0e+00
print_info: n_ff = 12288
print_info: n_expert = 128
print_info: n_expert_used = 8
print_info: causal attn = 1
print_info: pooling type = 0
print_info: rope type = 2
print_info: rope scaling = linear
print_info: freq_base_train = 5000000.0
print_info: freq_scale_train = 1
print_info: n_ctx_orig_yarn = 262144
print_info: rope_finetuned = unknown
print_info: ssm_d_conv = 0
print_info: ssm_d_inner = 0
print_info: ssm_d_state = 0
print_info: ssm_dt_rank = 0
print_info: ssm_dt_b_c_rms = 0
print_info: model type = 235B.A22B
print_info: model params = 235.09 B
print_info: general.name = Qwen3 235B A22B Instruct 2507
print_info: n_ff_exp = 1536
print_info: vocab type = BPE
print_info: n_vocab = 151936
print_info: n_merges = 151387
print_info: BOS token = 151643 '<|endoftext|>'
print_info: EOS token = 151645 '<|im_end|>'
print_info: EOT token = 151645 '<|im_end|>'
print_info: PAD token = 151643 '<|endoftext|>'
print_info: LF token = 198 '─è'
print_info: FIM PRE token = 151659 '<|fim_prefix|>'
print_info: FIM SUF token = 151661 '<|fim_suffix|>'
print_info: FIM MID token = 151660 '<|fim_middle|>'
print_info: FIM PAD token = 151662 '<|fim_pad|>'
print_info: FIM REP token = 151663 '<|repo_name|>'
print_info: FIM SEP token = 151664 '<|file_sep|>'
print_info: EOG token = 151643 '<|endoftext|>'
print_info: EOG token = 151645 '<|im_end|>'
print_info: EOG token = 151662 '<|fim_pad|>'
print_info: EOG token = 151663 '<|repo_name|>'
print_info: EOG token = 151664 '<|file_sep|>'
print_info: max token length = 256
load_tensors: loading model tensors, this can take a while... (mmap = false)
load_tensors: relocated tensors: 1 of 1131
ggml_cuda_host_malloc: failed to allocate 56182.66 MiB of pinned memory: out of memory
load_tensors: offloading 50 repeating layers to GPU
load_tensors: offloaded 50/95 layers to GPU
load_tensors: CPU model buffer size = 333.84 MiB
load_tensors: CPU model buffer size = 56182.66 MiB
load_tensors: CUDA0 model buffer size = 20251.33 MiB
load_tensors: CUDA1 model buffer size = 21517.04 MiB
load_tensors: CUDA2 model buffer size = 21517.04 MiB
load_all_data: no device found for buffer type CPU for async uploads
load_all_data: no device found for buffer type CPU for async uploads
..............................................load_all_data: using async uploads for device CUDA0, buffer type CUDA0, backend CUDA0
.................load_all_data: using async uploads for device CUDA1, buffer type CUDA1, backend CUDA1
..................load_all_data: using async uploads for device CUDA2, buffer type CUDA2, backend CUDA2
...................
Automatic RoPE Scaling: Using model internal value.
llama_context: constructing llama_context
llama_context: n_seq_max = 1
llama_context: n_ctx = 24576
llama_context: n_ctx_per_seq = 24576
llama_context: n_batch = 128
llama_context: n_ubatch = 128
llama_context: causal_attn = 1
llama_context: flash_attn = 1
llama_context: freq_base = 5000000.0
llama_context: freq_scale = 1
llama_context: n_ctx_per_seq (24576) < n_ctx_train (262144) -- the full capacity of the model will not be utilized
set_abort_callback: call
llama_context: CPU output buffer size = 0.58 MiB
create_memory: n_ctx = 24576 (padded)
llama_kv_cache_unified: CPU KV buffer size = 2112.00 MiB
llama_kv_cache_unified: CUDA0 KV buffer size = 768.00 MiB
llama_kv_cache_unified: CUDA1 KV buffer size = 816.00 MiB
llama_kv_cache_unified: CUDA2 KV buffer size = 816.00 MiB
llama_kv_cache_unified: size = 4512.00 MiB ( 24576 cells, 94 layers, 1 seqs), K (f16): 2256.00 MiB, V (f16): 2256.00 MiB
llama_context: enumerating backends
llama_context: backend_ptrs.size() = 4
llama_context: max_nodes = 65536
llama_context: worst-case: n_tokens = 128, n_seqs = 1, n_outputs = 0
llama_context: CUDA0 compute buffer size = 567.68 MiB
llama_context: CUDA1 compute buffer size = 36.00 MiB
llama_context: CUDA2 compute buffer size = 36.00 MiB
llama_context: CUDA_Host compute buffer size = 14.00 MiB
llama_context: graph nodes = 4236
llama_context: graph splits = 621 (with bs=128), 93 (with bs=1)
Threadpool set to 36 threads and 36 blasthreads...
attach_threadpool: call
This architecture has explicitly disabled the BOS token - if you need it, you must add it manually.
Starting model warm up, please wait a moment...
ggml_cuda_compute_forward: FUSED_RMS_NORM failed
CUDA error: the provided PTX was compiled with an unsupported toolchain.
current device: 0, in function ggml_cuda_compute_forward at Q:\GitHub\croco.cpp\ggml\src\ggml-cuda\ggml-cuda.cu:2692
err
Q:\GitHub\croco.cpp\ggml\src\ggml-cuda\ggml-cuda.cu:85: CUDA error

Hey
@ubergarm
.
The user's driver doesn't support CUD 12.9 I guess.
Also, Croco will likely fail on most MOEs atm.
But the support for IK_Quants is almost complete on my fork, besides Bitnet. (and that goes for IQ4_KS).
If that's not the driver, then it's the MOE part. Llama.cpp mainline had recently several commits which conflict with the fused ops of IK, and I need to sort this trough also.
Thanks for the explanation! Right good chance they were not on CUDA 12.9 yet. And I'll keep suggesting to folks to give croco a try with these new quants we're cooking!
So the user updated to CUDA 12.9 and indeed they could run this pure-IQ4_KS quant in this repo on their windows machine! Very cool!!!
So to answer my own original question "Yes! croco.cpp can run these quants!"
Thanks!

croco can also run "non ik_llamacpp specific" quants (i tested unsloth) of Qwen3 (tested today with Qwen3-235B-A22B-Instruct-2507)
i had a json format error with my tensor override, now, i am using "([3-9]+).ffn_.*_exps.=CPU" and it works like a charm, cannot wait to test IQ2_KL quant! (i only have 32 VRAM + 64 RAM, sadly)
cannot wait to test IQ2_KL quant! (i only have 32 VRAM + 64 RAM, sadly)
oookie dokie i'll upload before possibly moving on to https://huggingface.co/Qwen/Qwen3-Coder-480B-A35B-Instruct
lol it is a busy week :sweat-smile: lol
IQ2_KL is uploading! once its done i'll update the README and call it good for now!
Amazing! I'm so happy that Croco could be of use!
@ubergarm
: If you have the motivation, if it's worth trying with what you know, and in this case, when you have the time (it can wait ofc), could you cook a IQ2_KT custom quant of Qwen 235B A22B Inst 2507? I didn't experiment on this model, and even if, I also lack of compute power to quantize such a beast in a reasonable time. But I'd love to try it in close to full-offload. I have 64GB of VRAM and 32go of RAM.
Otherwise, and probably in any case, I'll try your IQ2_KL quant!
Yes I'll update my README and advertise for croco.cpp especially with pre-built windows binaries that will help a lot of folks I think!
I'm uploading a bigger IQ1_KT 108.702 GiB (1.945 BPW) now to https://huggingface.co/ubergarm/Qwen3-Coder-480B-A35B-Instruct-GGUF but that might be just out of reach!
I was having some hiccups with IQ3_KT quant last night, need to dig into that as was throwing some errors/segfaults when attempting to quantize but the IQ4/3/1_KT seem fine so not sure.
Hopefully no more models drop this week and I can dig out with a few more quants and testing by this weekend lol... Fun ride and appreciate all your positive vibes with the recent github debacle!
@ubergarm : Thanks! I do appreciate a lot all your contributions and your energy on IKL, as well as your quants.
Since the last Croco release I published, I made several merges (with sacrificed code) to improve what I use and I lost compatibility with MOEs. So I'm currently fixing that, in order to provide a more up to date MOE-able release which supports IQ1_KT and IQ4_KSS MMQ. I have already a working internal, but I need now to test more and roll-up to a recent LCPP mainline / KCPP master. I hope to publish a new release this week-end, or a couple of days later.
And yeah, the max I can hope to use is Qwen 235b or Nemotron 253b, which is already not bad. When I'll have the resources, I'll change my mobo and go to 128GB RAM at least, because for some reasons my current mobo has a lot of trouble with RAM compatibility beyond sticks of 8GB when using an APU, sadly.
In the meantime, keep up the great job with those quants, IQ_KT is not for the faint of heart, quantization compute wise!
could you cook a IQ2_KT custom quant of Qwen 235B A22B Inst 2507
I'd tried to cook up something smaller than my IQ2_KL 81.866 GiB (2.991 BPW) but given I'm still having issues with segfaulting with IQ3_KT I went with the new IQ4_KKS (which oddly is the same 4.0 BPW as the IQ3_KL [which I've never used lol])... So it ends up IQ2_KT 79.272 GiB (2.896 BPW) but the perplexity is quite a bit worse. My inkling is that maybe going below ~2.7BPW on ffn tensors for Qwen3-235B quality begins dropping off a bit steeper than say DeepSeek-671B models.
Here are a bunch of test quant measurements I made feeling around the 4BPW area mostly as well as the IQ2_KT on the left.
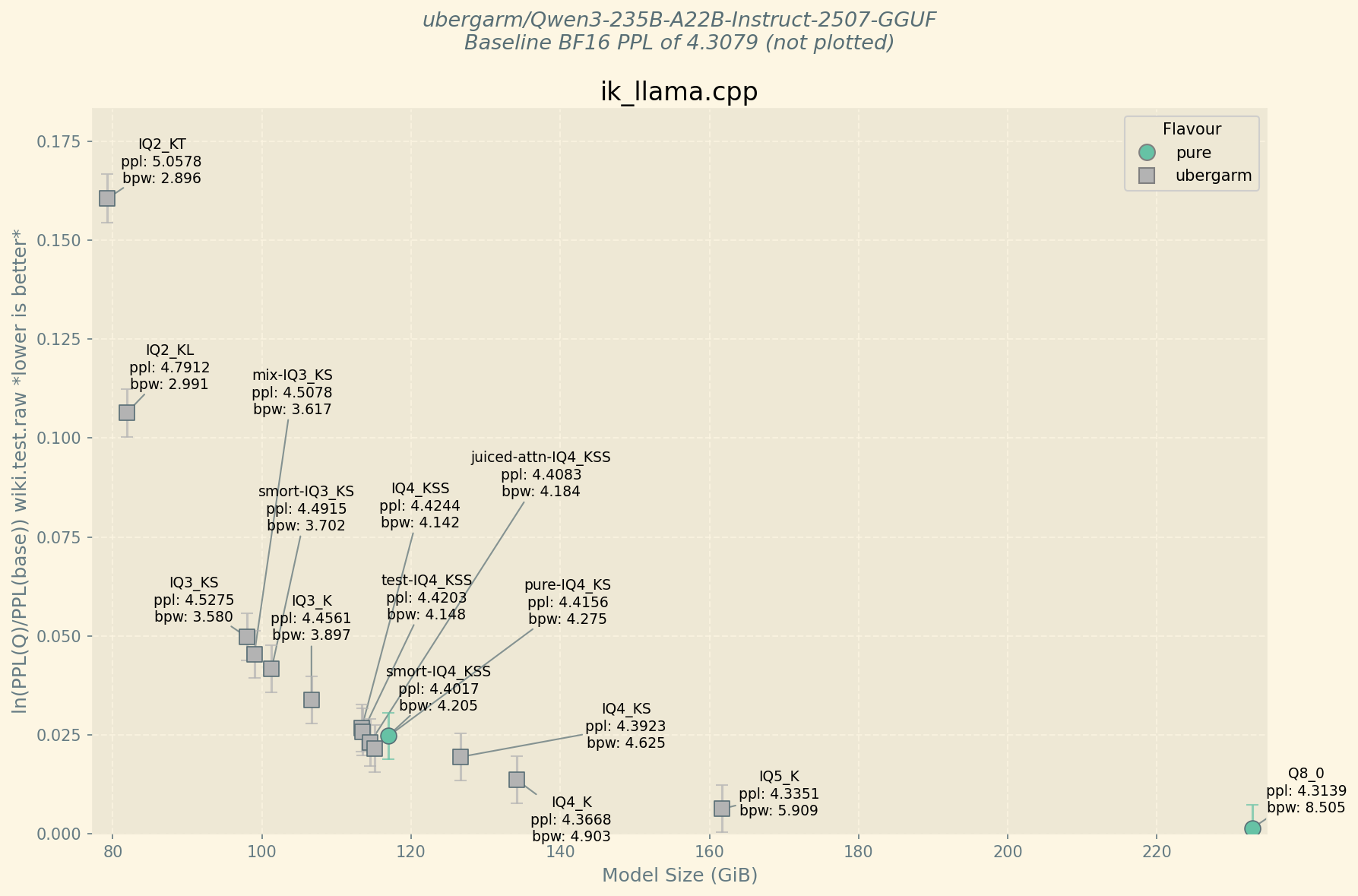
Still gotta open the ticket about the segfault or try to run it on a different CPU rig to see if it is hardware related as I've used IQ3_KT before.
Anyway, I'll keep searching for a good quant in the low side as the new thinking models seems fairly decent too and is the same size.
I'd tried to cook up something smaller than my
IQ2_KL81.866 GiB (2.991 BPW) but given I'm still having issues with segfaulting with IQ3_KT I went with the new IQ4_KKS (which oddly is the same 4.0 BPW as the IQ3_KL [which I've never used lol])... So it ends upIQ2_KT79.272 GiB (2.896 BPW) but the perplexity is quite a bit worse. My inkling is that maybe going below ~2.7BPW on ffn tensors for Qwen3-235B quality begins dropping off a bit steeper than say DeepSeek-671B models.Here are a bunch of test quant measurements I made feeling around the 4BPW area mostly as well as the IQ2_KT on the left.
Still gotta open the ticket about the segfault or try to run it on a different CPU rig to see if it is hardware related as I've used IQ3_KT before.
Anyway, I'll keep searching for a good quant in the low side as the new thinking models seems fairly decent too and is the same size.
Thanks for trying, @ubergarm . I'm surprised of the low bpw difference with the ffns in IQ2_KT (i would expect it around 65GB), but I don't know the arch. I will download and try your IQ2_KL soon anyway to have a taste of the model. And I urgently need at least 64GB of VRAM, because it seems Smart IQ3_KS is the real deal.
On my side, I have now an internal Croco working with IQ1_KT and IQ4_KSS MMQ, the MOEs like Wizard 8x22b working again, and even deepseek lite working also, with the last KoboldCPP and on the top of it Llama.cpp_b5995 included.
I have still some problems with the snowballing of glitches I made during months of merge (some KV cache combos are not working properly, GUI bugs, etc, etc) but nothing's out of reach I think, and I'll publish a release before attacking that part.
I'm surprised of the low bpw difference with the ffns in IQ2_KT (i would expect it around 65GB), but I don't know the arch.
Yeah normally I would use like IQ3_KT but as I'm having issues quantizing that currently i cheated and went all the way up to IQ4_KSS for the ffn_down which brought the total size up quite a bit. I would like to explore a smaller size but the slope really starts increasing perplexity. Maybe I just gotta throw some darts blindfolded and see if anything lands down there haha...
I guess I never released anything in the IQ3_KS range!? the smort basically had about the first 4 layers one size larger and juiced attn tensors. my thinking was people might just reach up for the IQ3_K if they're already in that ballpark. but happy to release it if you end up adding some more VRAM just lemme know!
I have now an internal Croco working with IQ1_KT and IQ4_KSS MMQ, the MOEs like Wizard 8x22b working again, and even deepseek lite working also, with the last KoboldCPP and on the top of it Llama.cpp_b5995 included.
Exciting! Glad you're able to share support for these sweet new quant types reaching a potentially wider audience!