
Model Card for Model ID
Model Details
Model Description
This is an early fine-tuned version of Llama-3.1-8B-Instruct for structured information extraction (IE).
Particularly, the target task involve joint named entity recognition (NER) and relation extraction (RE) to identify & extract information about politicla elites, their educational and professional associations, events and timeframes, and family members. The extracted information is generated in a structured JSON output.
The fine-tuning process is adopted from Unsloth's procedure (unsloth/Llama-3.1-8B-Instruct).
Data for the fine-tuning comes from 2 sources: (1) mannual collection and (2) synthetic data generated by GPT-4.
- Developed by: Tu 'Eric' Ngo.
- Language(s) (NLP): English.
- Finetuned from: Unsloth's Llama-3.1-8B-Instruct.
Model Sources
- Repository: [To be added]
- Paper: [To be added]
Uses
The model is fine-tuned to structured information extraction from political elite biographies in a very specific way.
It follows a particular template that is very specific to the author's research project.
The actual JSON schema and prompt for this fine-tuned task will be published in the future.
Out-of-Scope Use
While the fine-tuned model may be able to perform similar structured IE tasks (especially for the simpler tasks with simpler JSON schema), the model is only trained with a specific task in mine.
However, in the future, the author intends to expand the range of structured IE tasks that the model can be used for.
Bias, Risks, and Limitations
[To be added]
Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
How to Get Started with the Model
[To be added]
Training Details
Training Data
Data for the fine-tuning comes from 2 sources: (1) mannual collection and (2) synthetic data generated by GPT-4.
The data is structured in an Alpaca format, with each training example consisting of Prompt (description of task, JSON schema, and one-shot example), Input (an elite's biographical text), and Output (JSON record).
Training Procedure
Training Hyperparameters
- Training regime: bf16 non-mixed precision
Speeds, Sizes, Times [optional]
- Num Epochs = 3 | Total steps = 99
- Batch size per device = 2 | Gradient accumulation steps = 4
- Data Parallel GPUs = 1 | Total batch size (2 x 4 x 1) = 8
- Trainable parameters = 83,886,080/8,000,000,000 (1.05% trained)
- 38.48 minutes used for training.
- Peak reserved memory = 10.107 GB.
- Peak reserved memory for training = 4.189 GB.

Evaluation
Testing
Metrics
F1, Precision, and Recall are used to evaluate the fine-tuned model.
Since the intended JSON schema is highly complex and include multiple levels of nested components, the evaluation metrics are calculated for each of the root-level (broad) fields.
Results


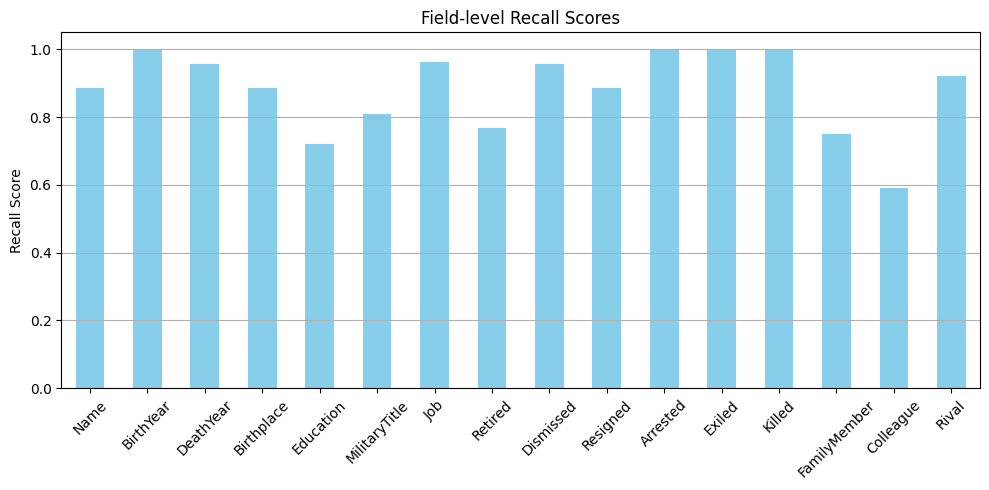
| Metric | Value |
|---|---|
| JSON Valid (%) | 70.270 |
| Exact Match (%) | 2.700 |
| Avg Jaccard Similarity | 0.535 |
| Avg Cosine Similarity | 0.672 |
Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type: [More Information Needed]
- Hours used: [More Information Needed]
- Cloud Provider: [More Information Needed]
- Compute Region: [More Information Needed]
- Carbon Emitted: [More Information Needed]
- Downloads last month
- 137
Model tree for tu-ericngo/llama-3.1-8B-StructuredIE
Base model
meta-llama/Llama-3.1-8B