
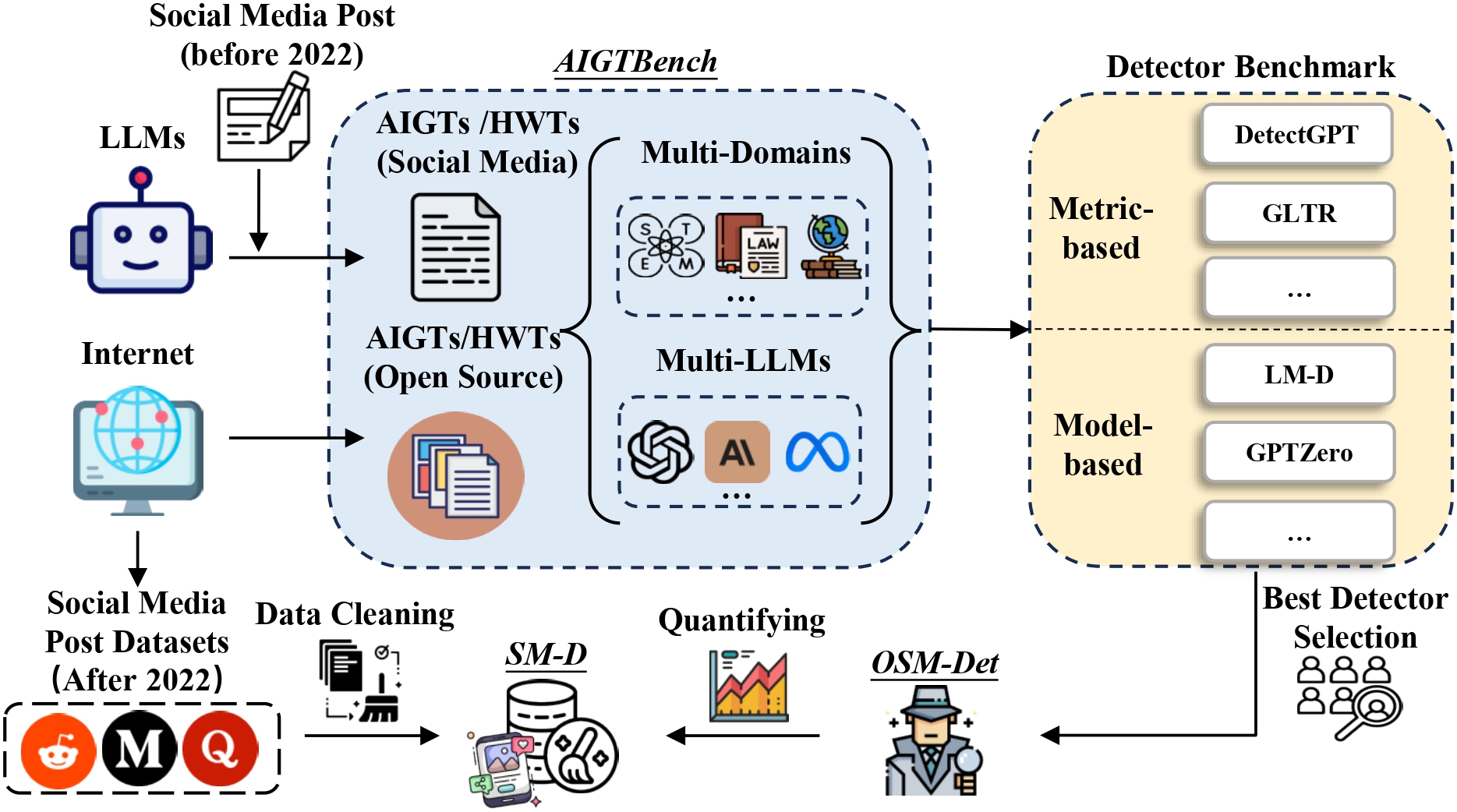
Are We in the AI-Generated Text World Already? Quantifying and Monitoring AIGT on Social Media
Paper
• 2412.18148 • Published
OSM-Det (Online Social Media Detector) is a AI-generated text detection model specifically designed for social media content. This model is introduced in the paper "Are We in the AI-Generated Text World Already? Quantifying and Monitoring AIGT on Social Media".
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
# Load model and tokenizer
model = AutoModelForSequenceClassification.from_pretrained("tarryzhang/OSM-Det")
tokenizer = AutoTokenizer.from_pretrained("tarryzhang/OSM-Det")
# Example text
text = "Your text to analyze here..."
# Tokenize and predict
inputs = tokenizer(text, return_tensors="pt", max_length=4096, truncation=True, padding=True)
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
predicted_class = torch.argmax(predictions, dim=1).item()
# Interpret results
labels = ["Human-written", "AI-generated"]
confidence = predictions[0][predicted_class].item()
print(f"Prediction: {labels[predicted_class]}")
print(f"Confidence: {confidence:.3f}")
def detect_ai_text_batch(texts, model, tokenizer, max_length=4096, batch_size=32):
results = []
for i in range(0, len(texts), batch_size):
batch_texts = texts[i:i+batch_size]
# Tokenize batch
inputs = tokenizer(
batch_texts,
return_tensors="pt",
max_length=max_length,
truncation=True,
padding=True
)
# Predict
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
predicted_classes = torch.argmax(predictions, dim=1)
# Store results
for j, text in enumerate(batch_texts):
pred_class = predicted_classes[j].item()
confidence = predictions[j][pred_class].item()
results.append({
'text': text,
'prediction': 'AI-generated' if pred_class == 1 else 'Human-written',
'confidence': confidence,
'ai_probability': predictions[j][1].item(),
'human_probability': predictions[j][0].item()
})
return results
OSM-Det was trained on AIGTBench, which includes:
@inproceedings{SZSZLBZH25,
title = {{Are We in the AI-Generated Text World Already? Quantifying and Monitoring AIGT on Social Media}},
author = {Zhen Sun and Zongmin Zhang and Xinyue Shen and Ziyi Zhang and Yule Liu and Michael Backes and Yang Zhang and Xinlei He},
booktitle = {{Annual Meeting of the Association for Computational Linguistics (ACL)}},
pages = {},
publisher ={ACL},
year = {2025}
}
Apache 2.0
Base model
allenai/longformer-base-4096