Spaces:
Runtime error

Runtime error
File size: 8,971 Bytes
8af039a dec70f4 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 |
---
title: Lesion-Cells DET
emoji: 🤗
colorFrom: indigo
colorTo: indigo
sdk: gradio
sdk_version: 4.2.0
app_file: app.py
pinned: false
license: mit
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference

</div>
### <div align="center"><h2>Description</h2></div>
**Lesion-Cells DET** stands for Multi-granularity **Lesion Cells Detection**.
The projects employs both CNN-based and Transformer-based neural networks for Object Detection.
The system excels at detecting 7 types of cells with varying granularity in images. Additionally, it provides statistical information on the relative sizes and lesion degree distribution ratios of the identified cells.
</div>
### <div align="center"><h2>Acknowledgements</h2></div>
***I would like to express my sincere gratitude to Professor Lio for his invaluable guidance in Office Hour and supports throughout the development of this project. Professor's expertise and insightful feedback played a crucial role in shaping the direction of the project.***

</div>
### <div align="center"><h2>Demonstration</h2></div>

</div>
### <div align="center"><h2>ToDo</h2></div>
- [x] ~~Change the large weights files with Google Drive sharing link~~
- [x] ~~Add Professor Lio's brief introduction~~
- [x] ~~Add a .gif demonstration instead of a static image~~
- [ ] deploy the demo on HuggingFace
- [ ] Train models that have better performance
- [ ] Upload part of the datasets, so that everyone can train their own customized models
</div>
### <div align="center"><h2>Quick Start</h2></div>
<details open>
<summary><h4>Installation</h4></summary>
*I strongly recommend you to use **conda**. Both Anaconda and miniconda is OK!*
1. create a virtual **conda** environment for the demo 😆
```bash
$ conda create -n demo python==3.8
$ conda activate demo
```
2. install essential **requirements** by run the following command in the CLI 😊
```bash
$ git clone https://github.com/Tsumugii24/lesion-cells-det
$ cd lesion-cells-det
$ pip install -r requirements.txt
```
3. download the **weights** files from Google Drive that have already been trained properly
here is the link, from where you can download your preferred model and then test its performance 🤗
```html
https://drive.google.com/drive/folders/1-H4nN8viLdH6nniuiGO-_wJDENDf-BkL?usp=sharing
```
4. remember to put the weights files under the root of the project 😉
</details>
<details open>
<summary><h4>Run</h4></summary>
```bash
$ python gradio_demo.py
```
Now, if everything is OK, your default browser will open automatically, and Gradio is running on local URL: http://127.0.0.1:7860
</details>
<details open>
<summary><h4>Datasets</h4></summary>
The original datasets origins from **Kaggle**, **iFLYTEK AI algorithm competition** and **other open source** sources.
Anyway, we annotated an object detection dataset of more than **2000** cells for a total of **7** categories.
| class number | class name |
| :----------- | :------------------ |
| 0 | normal_columnar |
| 1 | normal_intermediate |
| 2 | normal_superficiel |
| 3 | carcinoma_in_situ |
| 4 | light_dysplastic |
| 5 | moderate_dysplastic |
| 6 | severe_dysplastic |
We decided to share about 800 of them, which should be an adequate number for further test and study.
</details>
<details open>
<summary><h4>Train custom models</h4></summary>
You can train your own custom model as long as it can work properly.
</details>
</div>
### <div align="center"><h2>Training</h2></div>
<details open>
<summary><h4>example weights</h4></summary>
Example models of the project are trained with different methods, ranging from Convolutional Neutral Network to Vision Transformer.
| Model Name | Training Device | Open Source Repository for Reference | Average AP |
| ------------ | :--------------------------------: | :--------------------------------------------: | :--------: |
| yolov5_based | NVIDIA GeForce RTX 4090, 24563.5MB | https://github.com/ultralytics/yolov5.git | 0.721 |
| yolov8_based | NVIDIA GeForce RTX 4090, 24563.5MB | https://github.com/ultralytics/ultralytics.git | 0.810 |
| vit_based | NVIDIA GeForce RTX 4090, 24563.5MB | https://github.com/hustvl/YOLOS.git | 0.834 |
| detr_based | NVIDIA GeForce RTX 4090, 24563.5MB | https://github.com/lyuwenyu/RT-DETR.git | 0.859 |
</details>
<details open>
<summary><h4>architecture baselines</h4></summary>
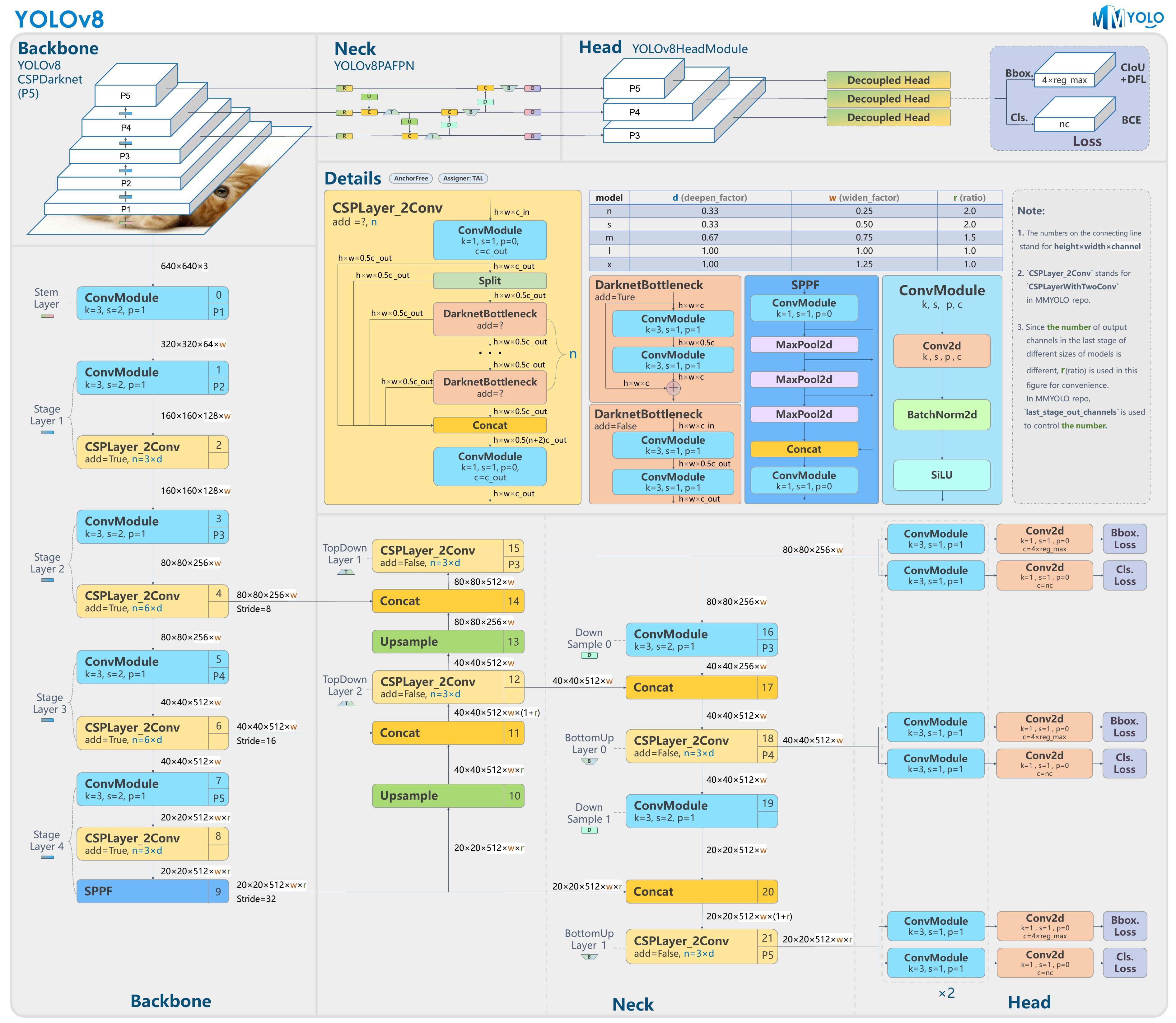
- #### **YOLO**
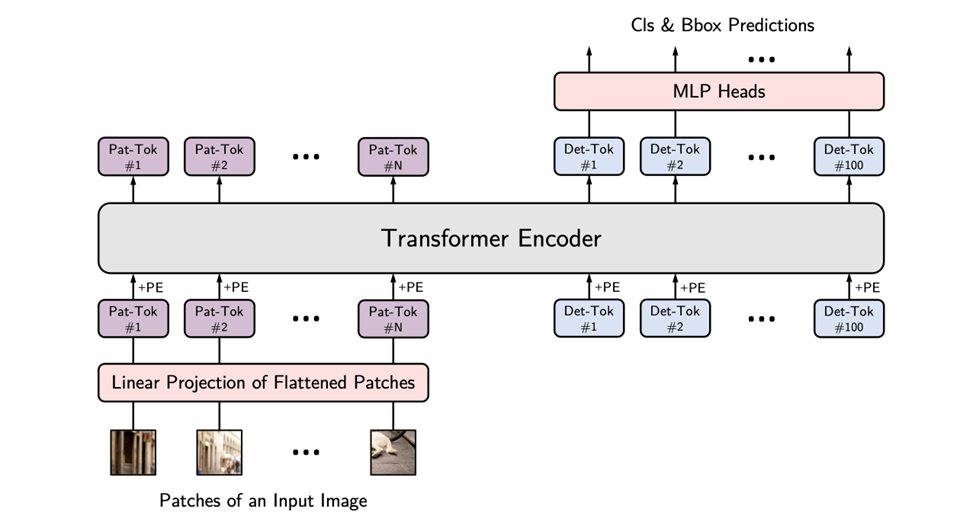
- #### **Vision Transformer**
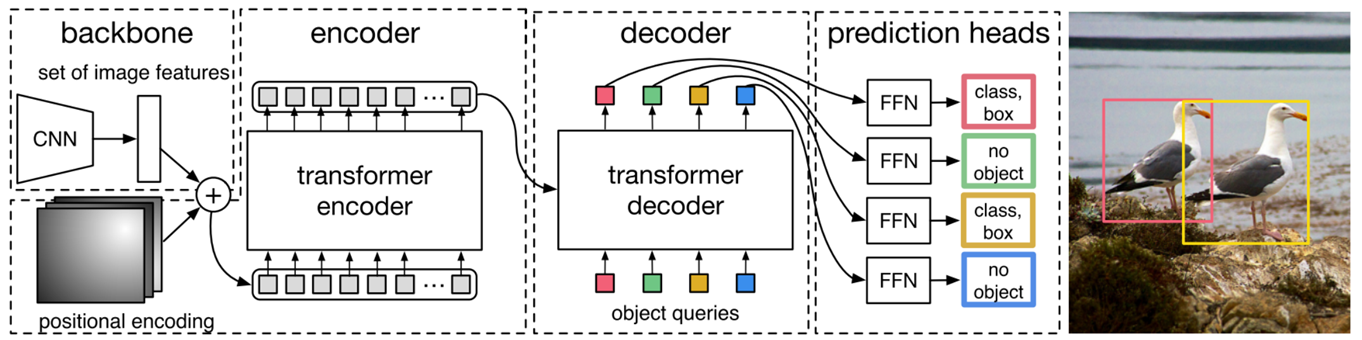
- #### **DEtection TRansformer**
</details>
</div>
### <div align="center"><h2>References</h2></div>
1. Jocher, G., Chaurasia, A., & Qiu, J. (2023). YOLO by Ultralytics (Version 8.0.0) [Computer software]. https://github.com/ultralytics/ultralytics
2. [Home - Ultralytics YOLOv8 Docs](https://docs.ultralytics.com/)
3. Jocher, G. (2020). YOLOv5 by Ultralytics (Version 7.0) [Computer software]. https://doi.org/10.5281/zenodo.3908559
4. [GitHub - hustvl/YOLOS: [NeurIPS 2021\] You Only Look at One Sequence](https://github.com/hustvl/YOLOS)
5. [GitHub - ViTAE-Transformer/ViTDet: Unofficial implementation for [ECCV'22\] "Exploring Plain Vision Transformer Backbones for Object Detection"](https://github.com/ViTAE-Transformer/ViTDet)
6. Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., & J'egou, H. (2020). Training data-efficient image transformers & distillation through attention. *International Conference on Machine Learning*.
7. Fang, Y., Liao, B., Wang, X., Fang, J., Qi, J., Wu, R., Niu, J., & Liu, W. (2021). You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection. *Neural Information Processing Systems*.
8. [YOLOS (huggingface.co)](https://huggingface.co/docs/transformers/main/en/model_doc/yolos)
9. Lv, W., Xu, S., Zhao, Y., Wang, G., Wei, J., Cui, C., Du, Y., Dang, Q., & Liu, Y. (2023). DETRs Beat YOLOs on Real-time Object Detection. *ArXiv, abs/2304.08069*.
10. [GitHub - facebookresearch/detr: End-to-End Object Detection with Transformers](https://github.com/facebookresearch/detr)
11. [PaddleDetection/configs/rtdetr at develop · PaddlePaddle/PaddleDetection · GitHub](https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/rtdetr)
12. [GitHub - lyuwenyu/RT-DETR: Official RT-DETR (RTDETR paddle pytorch), Real-Time DEtection TRansformer, DETRs Beat YOLOs on Real-time Object Detection. 🔥 🔥 🔥](https://github.com/lyuwenyu/RT-DETR)
13. J. Hu, L. Shen and G. Sun, "Squeeze-and-Excitation Networks," 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 2018, pp. 7132-7141, doi: 10.1109/CVPR.2018.00745.
14. Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020). End-to-End Object Detection with Transformers. ArXiv, abs/2005.12872.
15. Beal, J., Kim, E., Tzeng, E., Park, D., Zhai, A., & Kislyuk, D. (2020). Toward Transformer-Based Object Detection. ArXiv, abs/2012.09958.
16. Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., & Guo, B. (2021). Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 9992-10002.
17. Zong, Z., Song, G., & Liu, Y. (2022). DETRs with Collaborative Hybrid Assignments Training. ArXiv, abs/2211.12860.
</div>
### <div align="center"><h2>Contact</h2></div>
*Feel free to contact me through GitHub issues or directly send me a mail if you have any questions about the project.* 🐼
My Gmail Address 👉 [email protected]
|