Spaces:
Running

Running
Deepak Sahu
commited on
Commit
·
bd396f2
1
Parent(s):
0720e54
- .resources/eval7.png +3 -0
- .resources/preview.png +2 -2
- README.md +4 -4
- app.py +1 -1
.resources/eval7.png
ADDED
|
Git LFS Details
|
.resources/preview.png
CHANGED
|
Git LFS Details
|
|
Git LFS Details
|
README.md
CHANGED
|
@@ -236,14 +236,12 @@ The generation is handled by functions in script `z_hypothetical_summary.py`. Un
|
|
| 236 |
|
| 237 |

|
| 238 |
|
| 239 |
-
### Evaluation Metric
|
| 240 |
|
| 241 |
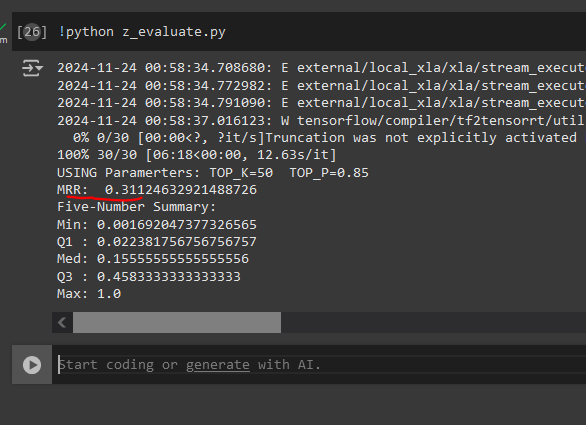
So for given input title we can get rank (by desc order cosine similarity) of the store title. To evaluate we the entire approach we are going to use a modified version **Mean Reciprocal Rank (MRR)**.
|
| 242 |
|
| 243 |

|
| 244 |
|
| 245 |
-
|
| 246 |
-
|
| 247 |
Test Plan:
|
| 248 |
- Take random 30 samples and compute the mean of their reciprocal ranks.
|
| 249 |
- If we want that our known book titles be in top 5 results then MRR >= 1/5 = 0.2
|
|
@@ -254,12 +252,14 @@ Test Plan:
|
|
| 254 |
python z_evaluate.py
|
| 255 |
```
|
| 256 |
|
| 257 |
-
 are sent as `CONST` in the `z_evaluate.py`; The current set of values are borrowed from the work: https://www.kaggle.com/code/tuckerarrants/text-generation-with-huggingface-gpt2#Top-K-and-Top-P-Sampling
|
| 260 |
|
| 261 |
MRR = 0.311 implies that there's a good change that the target book will be in rank (1/.311) ~ 3 (third rank) **i.e. within top 5 recommendations**
|
| 262 |
|
|
|
|
|
|
|
| 263 |
## Inference
|
| 264 |
|
| 265 |
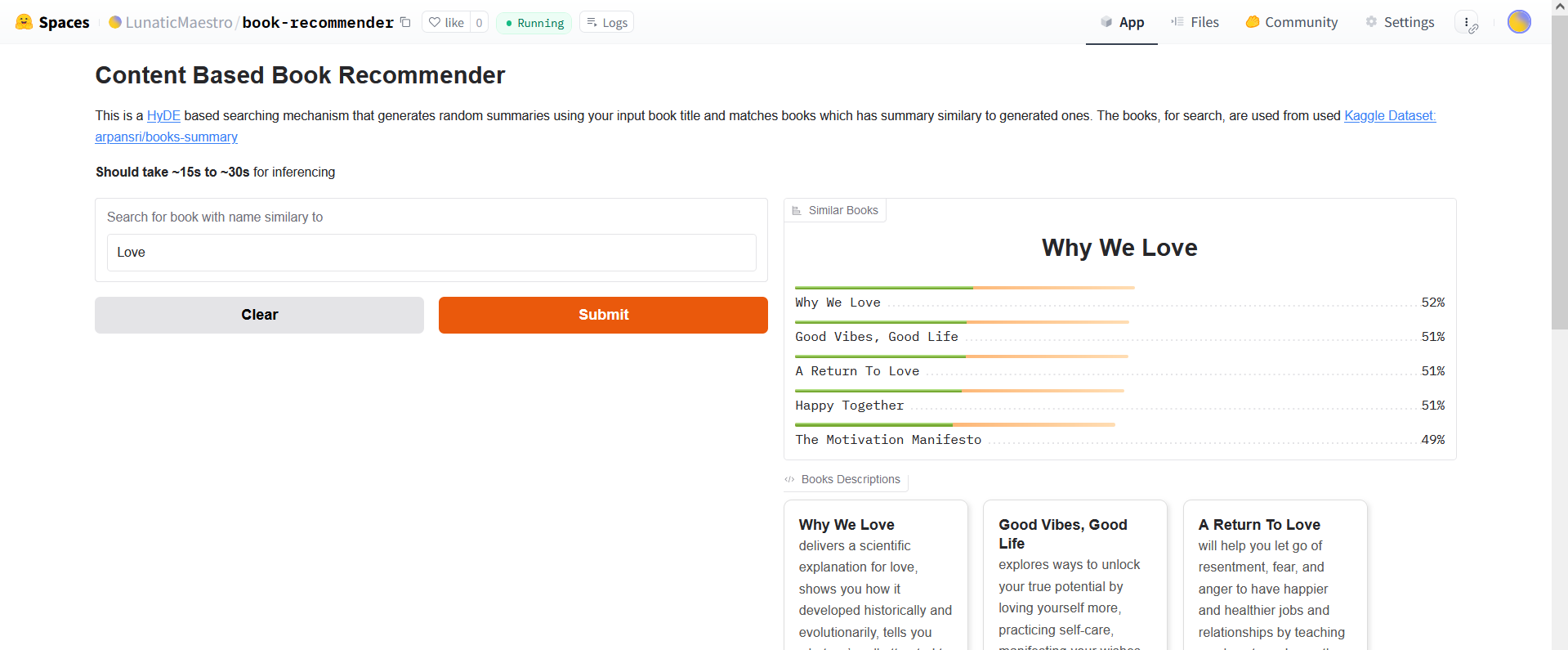
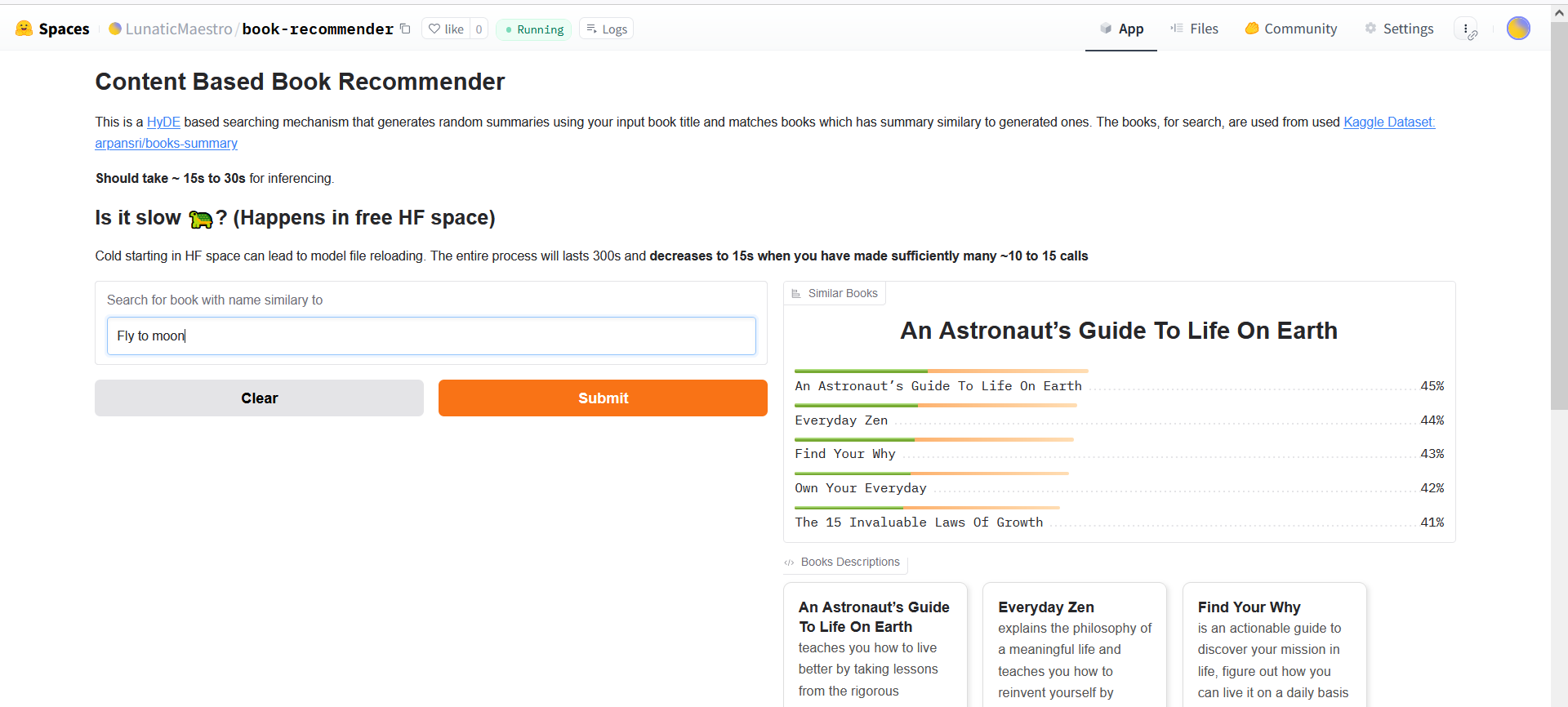
`app.py` is written so that it can best work with gradio interface in the HuggingFace, althought you can try it out locally as well :)
|
|
|
|
| 236 |
|
| 237 |

|
| 238 |
|
| 239 |
+
### Evaluation Metric & Result
|
| 240 |
|
| 241 |
So for given input title we can get rank (by desc order cosine similarity) of the store title. To evaluate we the entire approach we are going to use a modified version **Mean Reciprocal Rank (MRR)**.
|
| 242 |
|
| 243 |

|
| 244 |
|
|
|
|
|
|
|
| 245 |
Test Plan:
|
| 246 |
- Take random 30 samples and compute the mean of their reciprocal ranks.
|
| 247 |
- If we want that our known book titles be in top 5 results then MRR >= 1/5 = 0.2
|
|
|
|
| 252 |
python z_evaluate.py
|
| 253 |
```
|
| 254 |
|
| 255 |
+

|
| 256 |
|
| 257 |
The values of TOP_P and TOP_K (i.e. token sampling for our generator model) are sent as `CONST` in the `z_evaluate.py`; The current set of values are borrowed from the work: https://www.kaggle.com/code/tuckerarrants/text-generation-with-huggingface-gpt2#Top-K-and-Top-P-Sampling
|
| 258 |
|
| 259 |
MRR = 0.311 implies that there's a good change that the target book will be in rank (1/.311) ~ 3 (third rank) **i.e. within top 5 recommendations**
|
| 260 |
|
| 261 |
+
> TODO: A sampling study can be done to better make this conclusion.
|
| 262 |
+
|
| 263 |
## Inference
|
| 264 |
|
| 265 |
`app.py` is written so that it can best work with gradio interface in the HuggingFace, althought you can try it out locally as well :)
|
app.py
CHANGED
|
@@ -93,4 +93,4 @@ demo = gr.Interface(
|
|
| 93 |
description=GRADIO_DESCRIPTION
|
| 94 |
)
|
| 95 |
|
| 96 |
-
demo.launch()
|
|
|
|
| 93 |
description=GRADIO_DESCRIPTION
|
| 94 |
)
|
| 95 |
|
| 96 |
+
demo.launch(share=True)
|