Spaces:
Sleeping

Sleeping
Deepak Sahu
commited on
Commit
·
0720e54
1
Parent(s):
59b441e
section update
Browse files- .resources/eval2.png +3 -0
- .resources/eval3.png +3 -0
- .resources/eval4.png +3 -0
- .resources/eval5.png +3 -0
- .resources/eval6.png +3 -0
- README.md +23 -11
- app.py +4 -1
- z_evaluate.py +3 -1
.resources/eval2.png
ADDED
|
Git LFS Details
|
.resources/eval3.png
ADDED
|
Git LFS Details
|
.resources/eval4.png
ADDED
|
Git LFS Details
|
.resources/eval5.png
ADDED
|
Git LFS Details
|
.resources/eval6.png
ADDED
|
Git LFS Details
|
README.md
CHANGED
|
@@ -21,9 +21,11 @@ Try it out: https://huggingface.co/spaces/LunaticMaestro/book-recommender
|
|
| 21 |
|
| 22 |
- All images are my actual work please source powerpoint of them in `.resources` folder of this repo.
|
| 23 |
|
| 24 |
-
- Code is documentation is as per [Google's Python Style Guide](https://google.github.io/styleguide/pyguide.html)
|
| 25 |
|
| 26 |
-
- ALL files Paths are at set as CONST in beginning of each script, to make it easier while using the paths while inferencing & evaluation; hence not passing as CLI arguments
|
|
|
|
|
|
|
| 27 |
|
| 28 |
- prefix `z_` in filenames is just to avoid confusion (to human) of which is prebuilt module and which is custom during import.
|
| 29 |
|
|
@@ -220,31 +222,41 @@ The generation is handled by functions in script `z_hypothetical_summary.py`. Un
|
|
| 220 |
|
| 221 |

|
| 222 |
|
| 223 |
-
|
| 224 |
|
| 225 |
-
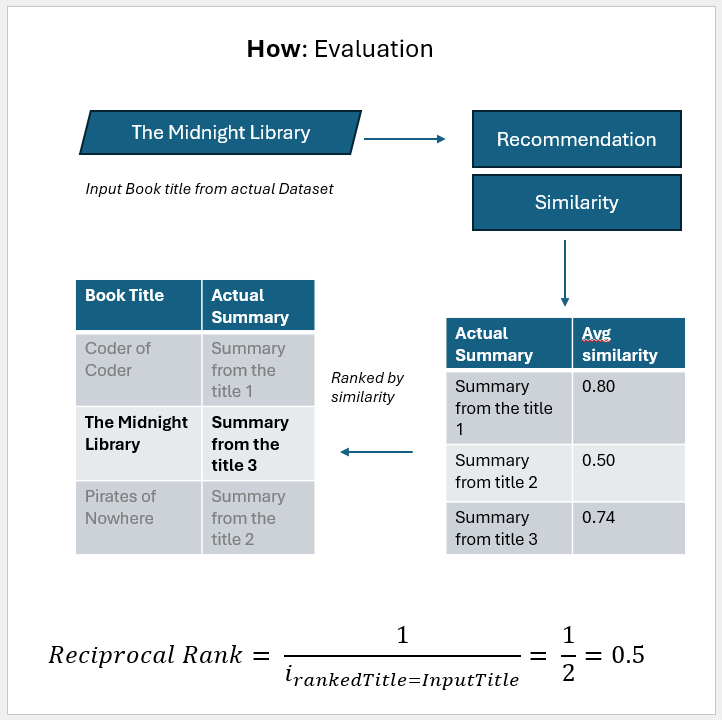
 of the store title. To evaluate we the entire approach we are going to use a modified version **Mean Reciprocal Rank (MRR)**.
|
| 240 |
|
| 241 |
-

|
| 246 |
|
| 247 |
-
The values of TOP_P and TOP_K (i.e. token sampling for our generator model) are sent as `CONST` in the `z_evaluate.py`; The current set of values
|
| 248 |
|
| 249 |
MRR = 0.311 implies that there's a good change that the target book will be in rank (1/.311) ~ 3 (third rank) **i.e. within top 5 recommendations**
|
| 250 |
|
|
|
|
| 21 |
|
| 22 |
- All images are my actual work please source powerpoint of them in `.resources` folder of this repo.
|
| 23 |
|
| 24 |
+
- Code is documentation is as per [Google's Python Style Guide](https://google.github.io/styleguide/pyguide.html).
|
| 25 |
|
| 26 |
+
- ALL files Paths are at set as CONST in beginning of each script, to make it easier while using the paths while inferencing & evaluation; hence not passing as CLI arguments.
|
| 27 |
+
|
| 28 |
+
- Seed value for code reproducability is set at as CONST as well.
|
| 29 |
|
| 30 |
- prefix `z_` in filenames is just to avoid confusion (to human) of which is prebuilt module and which is custom during import.
|
| 31 |
|
|
|
|
| 222 |
|
| 223 |

|
| 224 |
|
| 225 |
+
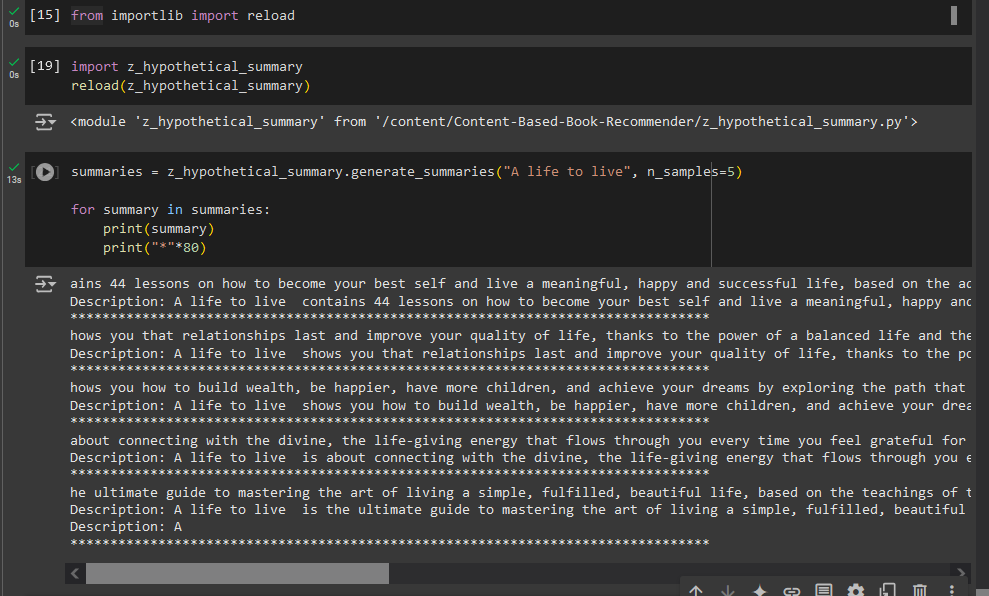
**Function Preview** I did the minimal post processing to chop of the `prompt` from the generated summaries before returning the result.
|
| 226 |
|
| 227 |
+

|
| 228 |
|
| 229 |
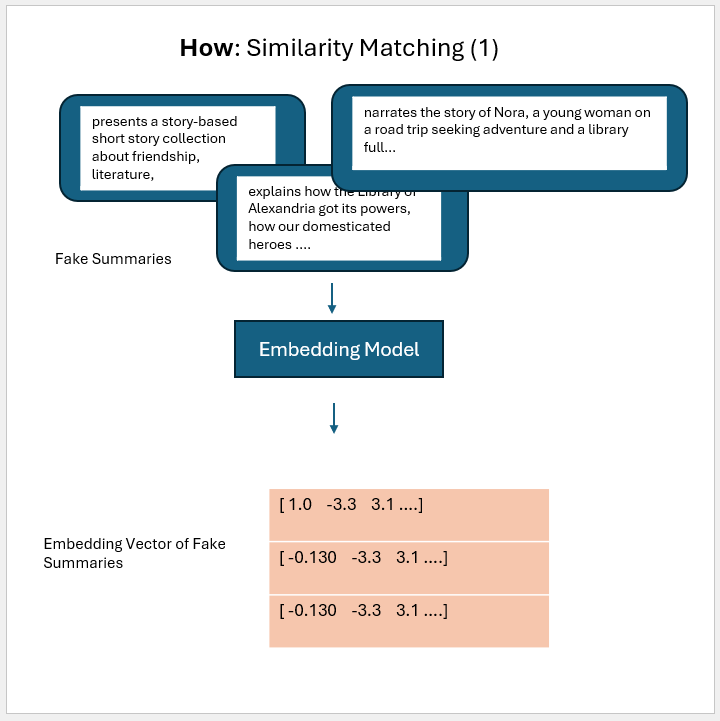
### Similarity Matching
|
| 230 |
|
| 231 |
+

|
| 232 |
|
| 233 |
+

|
| 234 |
|
| 235 |
+
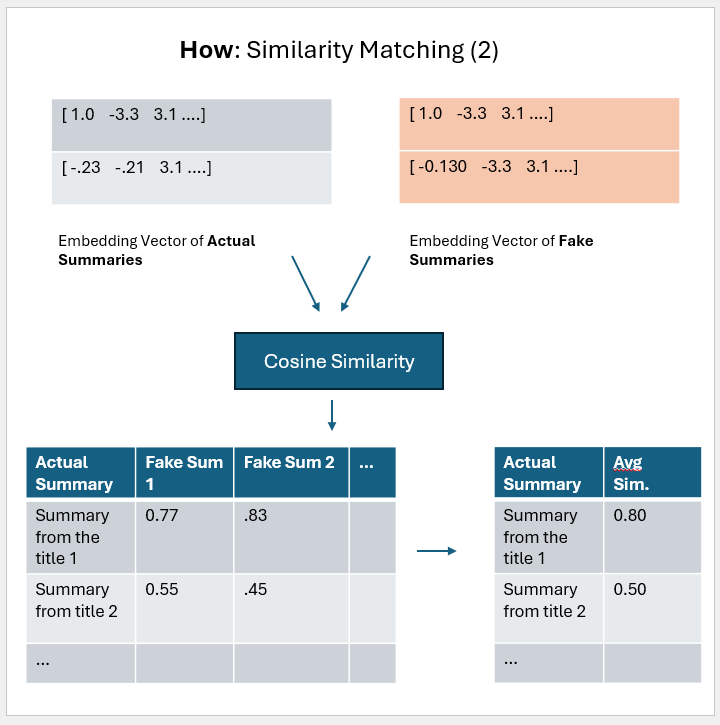
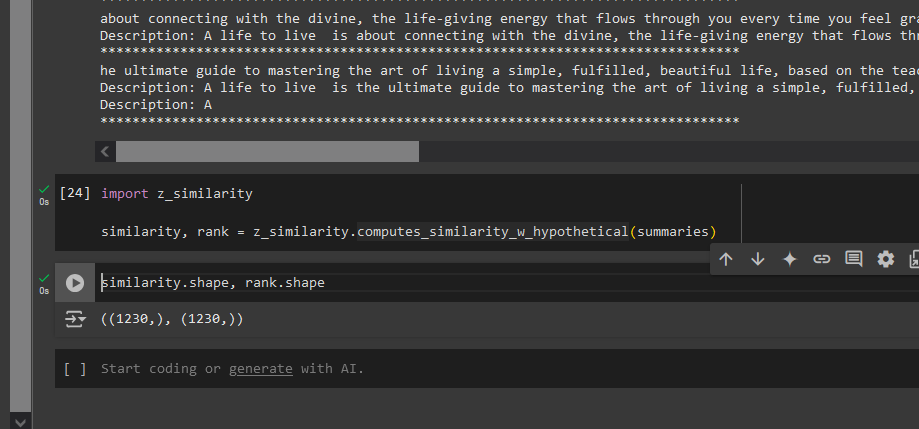
**Function Preview** Because there are 1230 unique titles so we get the averaged similarity vector of same size.
|
| 236 |
|
| 237 |
+

|
| 238 |
|
| 239 |
### Evaluation Metric
|
| 240 |
|
| 241 |
So for given input title we can get rank (by desc order cosine similarity) of the store title. To evaluate we the entire approach we are going to use a modified version **Mean Reciprocal Rank (MRR)**.
|
| 242 |
|
| 243 |
+

|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
Test Plan:
|
| 248 |
+
- Take random 30 samples and compute the mean of their reciprocal ranks.
|
| 249 |
+
- If we want that our known book titles be in top 5 results then MRR >= 1/5 = 0.2
|
| 250 |
|
| 251 |
+
**RUN**
|
| 252 |
+
|
| 253 |
+
```SH
|
| 254 |
+
python z_evaluate.py
|
| 255 |
+
```
|
| 256 |
|
| 257 |

|
| 258 |
|
| 259 |
+
The values of TOP_P and TOP_K (i.e. token sampling for our generator model) are sent as `CONST` in the `z_evaluate.py`; The current set of values are borrowed from the work: https://www.kaggle.com/code/tuckerarrants/text-generation-with-huggingface-gpt2#Top-K-and-Top-P-Sampling
|
| 260 |
|
| 261 |
MRR = 0.311 implies that there's a good change that the target book will be in rank (1/.311) ~ 3 (third rank) **i.e. within top 5 recommendations**
|
| 262 |
|
app.py
CHANGED
|
@@ -16,7 +16,10 @@ GRADIO_TITLE = "Content Based Book Recommender"
|
|
| 16 |
GRADIO_DESCRIPTION = '''
|
| 17 |
This is a [HyDE](https://arxiv.org/abs/2212.10496) based searching mechanism that generates random summaries using your input book title and matches books which has summary similary to generated ones. The books, for search, are used from used [Kaggle Dataset: arpansri/books-summary](https://www.kaggle.com/datasets/arpansri/books-summary)
|
| 18 |
|
| 19 |
-
**Should take ~ 15s to 30s** for inferencing.
|
|
|
|
|
|
|
|
|
|
| 20 |
'''
|
| 21 |
|
| 22 |
# Caching mechanism for gradio
|
|
|
|
| 16 |
GRADIO_DESCRIPTION = '''
|
| 17 |
This is a [HyDE](https://arxiv.org/abs/2212.10496) based searching mechanism that generates random summaries using your input book title and matches books which has summary similary to generated ones. The books, for search, are used from used [Kaggle Dataset: arpansri/books-summary](https://www.kaggle.com/datasets/arpansri/books-summary)
|
| 18 |
|
| 19 |
+
**Should take ~ 15s to 30s** for inferencing.
|
| 20 |
+
|
| 21 |
+
## Is it slow 🐢? (Happens in free HF space)
|
| 22 |
+
Cold starting in HF space can lead to model file reloading. The entire process will lasts 300s and **decreases to 15s when you have made sufficiently many ~10 to 15 calls**
|
| 23 |
'''
|
| 24 |
|
| 25 |
# Caching mechanism for gradio
|
z_evaluate.py
CHANGED
|
@@ -1,3 +1,5 @@
|
|
|
|
|
|
|
|
| 1 |
import random
|
| 2 |
from z_utils import get_dataframe
|
| 3 |
from z_similarity import computes_similarity_w_hypothetical
|
|
@@ -8,7 +10,7 @@ import numpy as np
|
|
| 8 |
# CONST
|
| 9 |
random.seed(53)
|
| 10 |
CLEAN_DF_UNIQUE_TITLES = "unique_titles_books_summary.csv"
|
| 11 |
-
N_SAMPLES_EVAL =
|
| 12 |
TOP_K = 50
|
| 13 |
TOP_P = 0.85
|
| 14 |
|
|
|
|
| 1 |
+
# This is one time script, hence no functions but sequential coding
|
| 2 |
+
|
| 3 |
import random
|
| 4 |
from z_utils import get_dataframe
|
| 5 |
from z_similarity import computes_similarity_w_hypothetical
|
|
|
|
| 10 |
# CONST
|
| 11 |
random.seed(53)
|
| 12 |
CLEAN_DF_UNIQUE_TITLES = "unique_titles_books_summary.csv"
|
| 13 |
+
N_SAMPLES_EVAL = 30
|
| 14 |
TOP_K = 50
|
| 15 |
TOP_P = 0.85
|
| 16 |
|