
Mitos y Leyendas de Iberoamérica 👹
Collection
5 items
•
Updated
•
1
Alineando modelos de lenguaje con la narrativa de mitos y leyendas de Iberoamérica.

Este modelo es una versión alineada del modelo por Unsloth, gemma-3-1b-it de Google, específicamente optimizado mediante técnicas de Aprendizaje por Refuerzo Generalizado a partir de Resultados Emparejados (GRPO) para tareas de generación de historias y personajes basadas en el patrimonio cultural de los mitos y leyendas de Iberoamérica. Fue entrenado utilizando el conjunto de datos ibero-tales-es, con un sistema de recompensas personalizado, para mejorar sus capacidades en la generación de narrativas y descripciones de personajes que se adhieren a formatos específicos y capturan la esencia cultural en español.
CausalLM) con optimización GRPO.Este modelo forma parte del proyecto Iberotales, cuyo objetivo es alinear modelos de lenguaje con la narrativa de mitos y leyendas de Iberoamérica para la preservación cultural y la generación de contenido.
Este modelo está específicamente diseñado y optimizado para:
El modelo no es adecuado para tareas que requieren:
El modelo, al ser alineado sobre datos específicos, hereda y presenta ciertos sesgos y limitaciones inherentes a los modelos de lenguaje y a los datos de entrenamiento:
<think>...</think><SOLUTION>...</SOLUTION>).Para mitigar sesgos y limitaciones y fomentar un uso responsable:
El modelo fue ajustado (fine-tuned) utilizando dos conjuntos de datos principales desarrollados como parte del proyecto Iberotales:
El dataset Ibero-Tales-ES fue construido seleccionando personajes del dataset Ibero-Characters-ES. Las tramas y temas se basaron parcialmente en temas literarios comunes para guiar la generación, creando múltiples tramas por tema seleccionado aleatoriamente, limitadas por personaje. Se generaron un total de 2283 registros de historias a partir de estas tramas y personajes. Para el entrenamiento GRPO, cada entrada del dataset se transformó en un par prompt (con system prompt y pregunta) y answer (la respuesta esperada en el formato estructurado).
Puedes revisar el notebook de entrenamiento, aquí. El modelo base unsloth/gemma-3-1b-it fue ajustado utilizando el algoritmo GRPO implementado en la biblioteca TRL (Transformer Reinforcement Learning) de Hugging Face, optimizado con Unsloth. GRPO entrena el modelo para generar respuestas que maximicen una recompensa definida por funciones, sin requerir un modelo de recompensa separado explícitamente entrenado en preferencias binarias como DPO.
El entrenamiento GRPO utilizó un system_prompt específico para guiar al modelo a generar una respuesta estructurada con un segmento de "pensamiento" (<think>...</think>) seguido de la "solución" (<SOLUTION>...</SOLUTION>).
Se definieron múltiples funciones de recompensa (reward_funcs) para guiar el aprendizaje:
match_format_exactly: Otorga una alta recompensa (3.0) si la respuesta generada se ajusta exactamente al formato estructurado esperado (<think>...</think><SOLUTION>...</SOLUTION>).match_format_approximately: Proporciona recompensas parciales (0.5) si las etiquetas de inicio y fin de pensamiento y solución aparecen exactamente una vez, penalizando (-0.5) si aparecen un número diferente de veces. Esto ayuda a guiar al modelo hacia el uso correcto de las etiquetas.check_text_similarity: Compara la "solución" extraída de la respuesta generada con la respuesta esperada del dataset utilizando una métrica de similitud simple basada en la intersección de palabras. Otorga hasta 3.0 puntos en función de la similitud.
https://github.com/mcdaqc/Iberotales/blob/main/src/train/unsloth_gemma3_finetuning.ipynb
Estas funciones de recompensa combinadas guían al modelo a aprender tanto el formato de salida deseado como a generar contenido relevante basado en la respuesta esperada.El entrenamiento se configuró utilizando TRL's GRPOConfig con los siguientes parámetros clave. Es importante notar que el entrenamiento se detuvo al alcanzar un máximo de 50 pasos (max_steps=50), lo cual prevaleció sobre la configuración de 3 épocas (num_train_epochs=3) ya que el límite de pasos se alcanzó primero.
learning_rate: 5e-6optim: "adamw_torch_fused" (optimizado)per_device_train_batch_size: 4gradient_accumulation_steps: 4num_generations: 4 (número de generaciones por prompt para evaluar con recompensas)max_prompt_length: 512max_completion_length: 1024num_train_epochs: 3 (Configurado, pero sobrescrito por max_steps=50)max_steps: 50 (El entrenamiento se detuvo al alcanzar este límite)save_steps: 50max_grad_norm: 0.1report_to: "wandb"El entrenamiento se realizó en el siguiente entorno:
La salida del entrenamiento final después de completar los 50 pasos reportó las siguientes métricas:
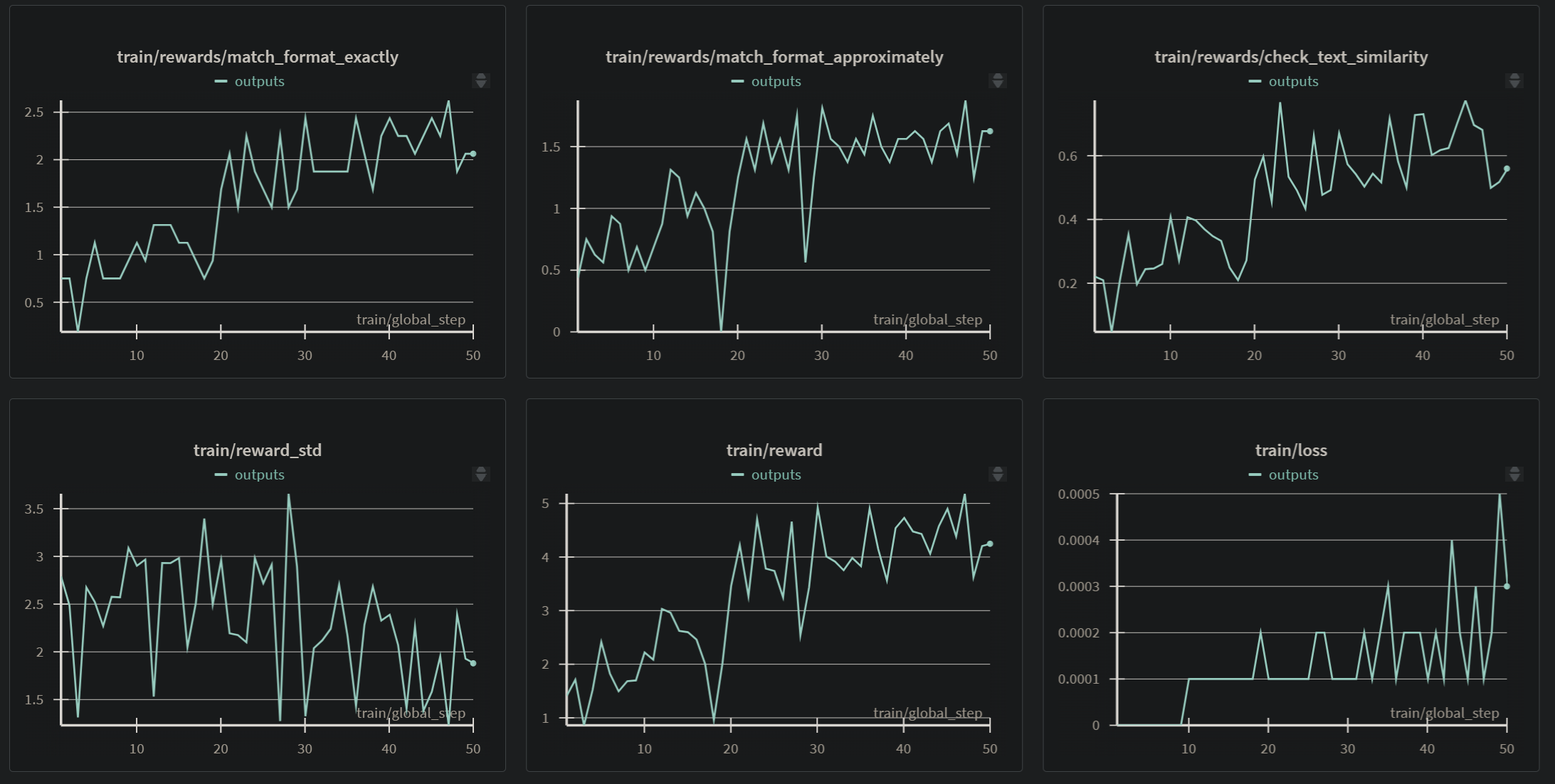
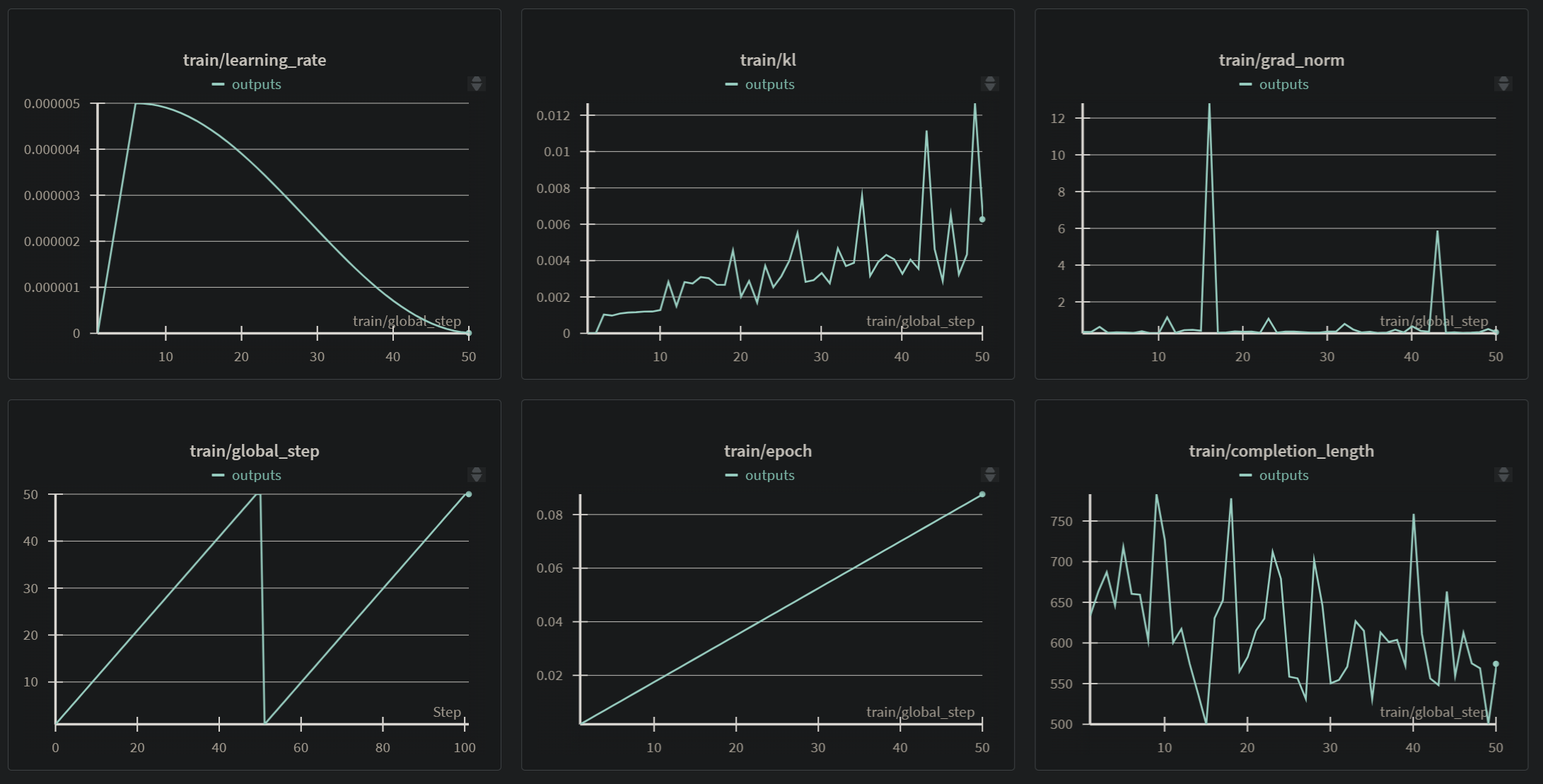
La evaluación del modelo se centró tanto en métricas intrínsecas (automatizadas) como en la calidad cualitativa del texto generado para asegurar su relevancia cultural, narrativa y adherencia al formato después del entrenamiento con GRPO.
<think>), la coherencia y relevancia de la solución (en <SOLUTION>), la fidelidad cultural, la fluidez del lenguaje y la calidad general de las narrativas generadas.El entrenamiento con GRPO resultó en un modelo ajustado con una notable mejora en la capacidad de generar narrativas fluidas y culturalmente relevantes en español. Lo más importante es que el modelo aprendió a seguir el formato estructurado de pensamiento/solución de manera más consistente, gracias a las funciones de recompensa diseñadas.
Conclusión de las Métricas de Entrenamiento:
La baja pérdida de entrenamiento final reportada (0.000136) después de 50 pasos globales es un indicador positivo de que el modelo ha optimizado la función objetivo de GRPO. Observando los gráficos de W&B:
train/learning_rate muestra el decaimiento del learning rate a lo largo de los pasos, siguiendo la configuración de "cosine", lo cual es un esquema de optimización estándar.train/rewards/match_format_exactly, train/rewards/match_format_approximately, train/rewards/check_text_similarity) muestran una clara tendencia ascendente a lo largo de los 50 pasos. Esto es la evidencia clave de que el modelo está aprendiendo exitosamente a generar respuestas que cumplen con el formato estructurado y se asemejan a las respuestas esperadas según las funciones de recompensa definidas. La recompensa promedio total (train/reward) también refleja esta mejora general.train/loss muestra una rápida disminución, alcanzando un valor muy bajo, lo que confirma la convergencia efectiva del proceso de optimización GRPO en los datos de entrenamiento.train/kl muestra un ligero aumento, lo cual es esperado en métodos RL/DPO/GRPO a medida que la política aprendida se aleja de la política inicial (el modelo base ajustado con SFT si aplicara, o simplemente el modelo al inicio del GRPO).train/grad_norm muestra algunos picos, pero la norma del gradiente se mantiene gestionada (probablemente debido a max_grad_norm=0.1), indicando un entrenamiento estable dentro de lo esperado para procesos RL.En conjunto, las métricas de entrenamiento sugieren que, dentro de los 50 pasos ejecutados, el modelo se adaptó efectivamente a las preferencias definidas por las funciones de recompensa GRPO, mejorando su capacidad para generar contenido relevante en el formato deseado. Sin embargo, la evaluación en datos de prueba y una evaluación cualitativa profunda son fundamentales para validar que este aprendizaje se generaliza bien y produce resultados de alta calidad más allá del conjunto de entrenamiento limitado.
El entrenamiento se ejecutó en una única GPU Nvidia L40S.
GRPOTrainer.accelerate, peft, bitsandbytes: Bibliotecas auxiliares necesarias para el entrenamiento y la carga optimizada.Puedes cargar y usar este modelo fácilmente con la biblioteca transformers de Hugging Face. Asegúrate de tener las bibliotecas necesarias instaladas. Se recomienda usar Unsloth para una inferencia más rápida.
pip install transformers torch unsloth accelerate peft trl bitsandbytes
Este método aprovecha las optimizaciones de Unsloth para una inferencia potencialmente más rápida. Es ideal si la velocidad o la memoria son una consideración clave.
from unsloth import FastLanguageModel
import torch
model_id = "daqc/iberotales-gemma-3-1b-it-es"
# La ventana de contexto real del modelo es 128K, ajusta max_seq_length según tu uso práctico
max_seq_length = 1024
# Cargar el modelo y tokenizador optimizados para inferencia
# Carga en 4-bit si load_in_4bit=True para ahorrar memoria
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = model_id,
max_seq_length = max_seq_length,
dtype = None, # Auto-detección (por ejemplo, bfloat16 si está disponible)
load_in_4bit = True,
)
# Habilitar inferencia rápida (opcional, pero recomendado)
FastLanguageModel.for_inference(model)
# Ejemplo de uso: Generar una historia en el formato estructurado
# El modelo fue entrenado con un system prompt y espera seguir el formato <think>...</think><SOLUTION>...</SOLUTION>
system_prompt = \
"""Resuelve el siguiente problema.
Primero, piensa en voz alta qué debes hacer, paso por paso y de forma resumida, entre <think> y </think>.
Luego, da la respuesta final entre <SOLUTION> y </SOLUTION>.
No escribas nada fuera de ese formato."""
user_question = "Escribe una historia corta sobre el Pombero, un personaje de la mitología guaraní, en el formato requerido:" # Ejemplo de pregunta
# Formatear el prompt usando el template de chat (recomendado ya que se usó en el entrenamiento)
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_question},
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) # Mover inputs al mismo dispositivo que el modelo
# Generar texto
# Ajusta los parámetros de generación para controlar la salida (creatividad, longitud, etc.)
outputs = model.generate(
**inputs,
max_new_tokens=512, # Máximo de tokens a generar en la respuesta (ajustar según la longitud esperada)
num_beams=1,
do_sample=True, # Habilitar muestreo para respuestas más creativas
top_k=50,
top_p=0.95,
temperature=0.7,
pad_token_id=tokenizer.eos_token_id, # Importante para evitar advertencias
eos_token_id=tokenizer.eos_token_id, # También útil para detener la generación
)
# Decodificar y imprimir la salida
# Se puede decodificar la secuencia completa y luego parsear el formato estructurado
generated_sequence = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_sequence)
# Opcional: Extraer solo la solución si el formato es correcto
# import re
# match_format = re.compile(r"^[\s]{0,}<think>.+?</think>.*?<SOLUTION>(.+?)</SOLUTION>[\s]{0,}$", flags = re.MULTILINE | re.DOTALL)
# match = match_format.search(generated_sequence)
# if match:
# extracted_solution = match.group(1).strip()
# print("\nSolución Extraída:")
# print(extracted_solution)
# else:
# print("\nFormato estructurado no detectado en la salida.")
Este método es más simple para comenzar si ya estás familiarizado con transformers y no necesitas las optimizaciones de Unsloth para la inferencia.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "daqc/iberotales-gemma-3-1b-it-es"
# Cargar el tokenizador y el modelo
# Puedes especificar dtype='auto' y device_map='auto' para que transformers maneje la carga
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Si no usas load_in_4bit, asegúrate de tener suficiente VRAM
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype='auto', device_map='auto')
# Ejemplo de uso: Generar una historia en el formato estructurado
# El modelo fue entrenado con un system prompt y espera seguir el formato <think>...</think><SOLUTION>...</SOLUTION>
system_prompt = \
"""Resuelve el siguiente problema.
Primero, piensa en voz alta qué debes hacer, paso por paso y de forma resumida, entre <think> y </think>.
Luego, da la respuesta final entre <SOLUTION> y </SOLUTION>.
No escribas nada fuera de ese formato."""
user_question = "Escribe una historia corta sobre el Pombero, un personaje de la mitología guaraní, en el formato requerido:" # Ejemplo de pregunta
# Formatear el prompt usando el template de chat (recomendado ya que se usó en el entrenamiento)
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_question},
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# Tokenizar el prompt
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) # Mover inputs al dispositivo correcto
# Generar texto
# Ajusta los parámetros de generación según tus necesidades
outputs = model.generate(
**inputs,
max_new_tokens=512, # Ajusta según la longitud esperada
num_beams=1,
do_sample=True,
top_k=50,
top_p=0.95,
temperature=0.7,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
# Decodificar y imprimir la salida
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
# Opcional: Extraer solo la solución si el formato es correcto
# import re
# match_format = re.compile(r"^[\s]{0,}<think>.+?</think>.*?<SOLUTION>(.+?)</SOLUTION>[\s]{0,}$", flags = re.MULTILINE | re.DOTALL)
# match = match_format.search(tokenizer.decode(outputs[0], skip_special_tokens=True))
# if match:
# extracted_solution = match.group(1).strip()
# print("\nSolución Extraída:")
# print(extracted_solution)
# else:
# print("\nFormato estructurado no detectado en la salida.")
BibTeX:
@misc{iberotales-gemma-3-1b-it-es,
title = {Iberotales Gemma-3-1b-it},
author = {David Quispe},
year = {2025},
month = {June},
url = {https://huggingface.co/somosnlp-hackathon-2025/iberotales-gemma-3-1b-it-es},
note = {Fine-tuned model for Ibero-American storytelling using GRPO}
}
APA: Quispe, D. (2025, junio). Iberotales Gemma-3-1b-it [Modelo ajustado en Hugging Face]. Recuperado de https://huggingface.co/daqc/iberotales-gemma-3-1b-it-es
Este proyecto fue parte de la hackathon de Somos NLP 2025.
