
A.X 4
Collection
5 items
•
Updated
•
38
![]()
A.X 4.0 VL Light (pronounced “A dot X”) is a vision-language model (VLM) optimized for Korean vision and language understanding as well as enterprise deployment. Built upon A.X 4.0 Light, A.X 4.0 VL Light has been further trained on diverse multimodal datasets, with a particular focus on large-scale multimodal Korean datasets, to deliver exceptional performance in domestic business applications.
A brief comparison on representative benchmarks is as follows:
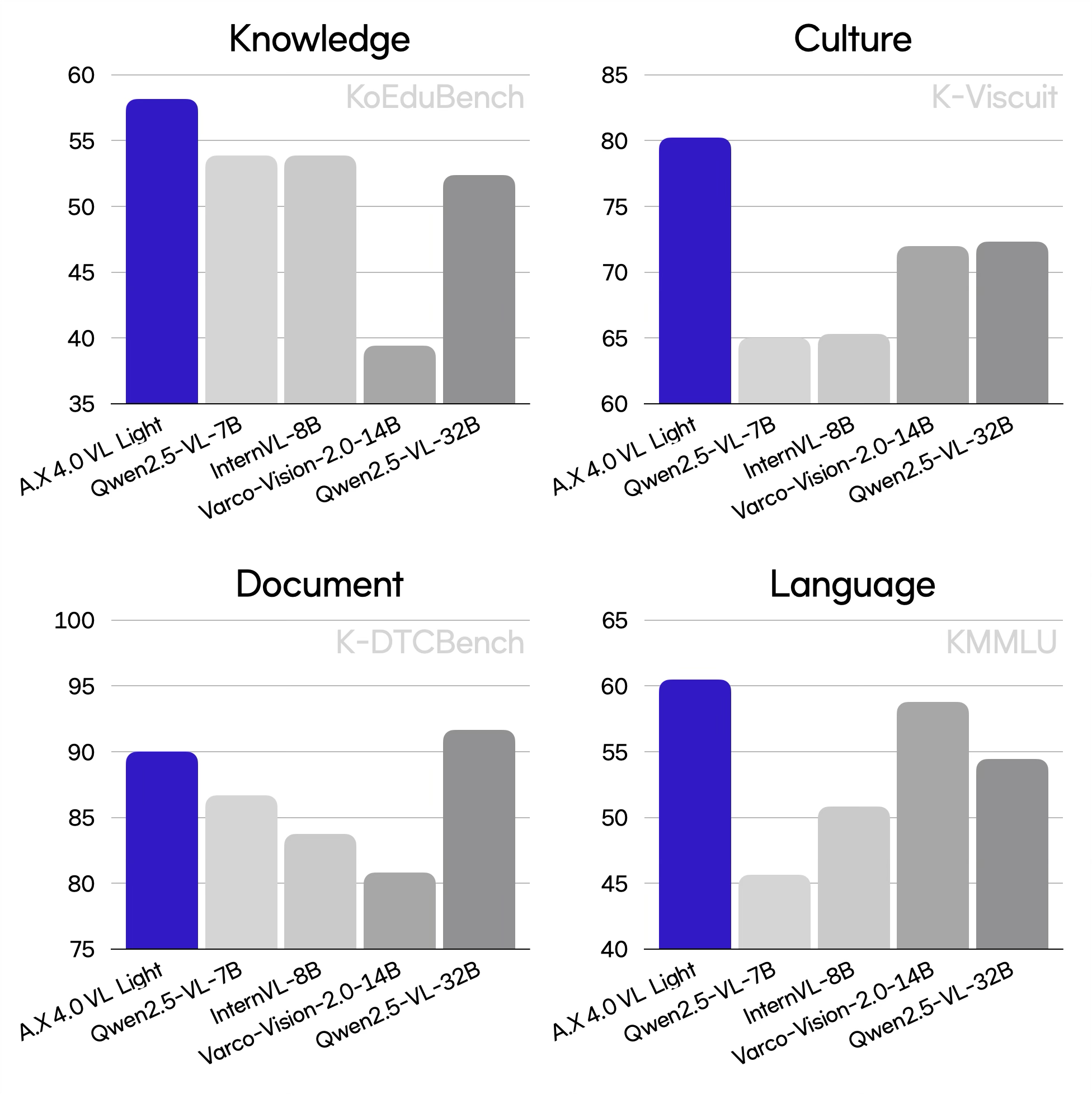
*Korean benchmarks, with K-Viscuit translated into Korean.
| Category | Benchmarks | A.X 4.0 VL Light | Qwen2.5-VL-7B | InternVL3-8B | VARCO-VISION-2.0-14B | Qwen2.5-VL-32B |
|---|---|---|---|---|---|---|
| Document | KoBizDoc* | 89.8 | 84.0 | 73.2 | 83.0 | 88.8 |
| K-DTCBench* | 90.0 | 86.7 | 83.8 | 80.8 | 91.7 | |
| ChartQA | 79.8 | 80.6 | 79.8 | 78.8 | 81.8 | |
| DocVQA | 94.4 | 95.3 | 92.4 | 91.9 | 94.5 | |
| InfoVQA | 78.5 | 82.7 | 76.2 | 80.0 | 82.7 | |
| SEEDBench2-Plus | 69.7 | 71.2 | 69.7 | 71.9 | 73.3 | |
| OCR | OutdoorKorean* | 97.3 | 91.9 | 72.7 | 79.7 | 86.9 |
| K-Handwriting* | 84.3 | 85.0 | 43.5 | 55.2 | 60.1 | |
| TextVQA | 82.0 | 85.4 | 82.1 | 80.3 | 79.8 | |
| Culture | K-Viscuit* | 80.2 | 65.0 | 65.3 | 72.0 | 72.3 |
| Knowledge | KoEduBench* | 58.1 | 53.9 | 53.9 | 39.4 | 52.4 |
| KoCertBench* | 54.9 | 50.1 | 39.4 | 51.4 | 47.5 | |
| MMMU | 54.1 | 56.3 | 59.4 | 58.3 | 63.6 | |
| ScienceQA | 95.3 | 87.2 | 97.8 | 92.2 | 92.4 | |
| General | K-LLaVA-W* | 83.2 | 73.0 | 67.0 | 80.0 | 84.3 |
| K-SEED* | 76.5 | 76.4 | 76.4 | 76.9 | 77.3 | |
| SEEDBench_IMG | 76.7 | 77.1 | 77.1 | 78.1 | 77.6 | |
| Hallucination | HallusionBench | 54.2 | 52.7 | 49.6 | 53.8 | 58.0 |
| IF | MM-IFEval | 53.5 | 51.4 | 51.9 | 50.8 | 59.3 |
The following in-house benchmarks have been established to rigorously assess model performance on Korean vision-language understanding and the comprehension of Korea-specific knowledge domains:
*Korean benchmarks.
| Category | Benchmarks | A.X 4.0 VL Light | Qwen2.5-VL-7B | InternVL3-8B | VARCO-VISION-2.0-14B |
|---|---|---|---|---|---|
| Knowledge | KMMLU* | 60.5 | 45.6 | 50.9 | 58.8 |
| MMLU | 72.6 | 71.9 | 77.5 | 80.7 | |
| Math | HRM8K* | 40.6 | 25.4 | 34.6 | 49.5 |
| MATH | 56.5 | 61.7 | 65.1 | 71.1 | |
| General | Ko-MT-bench* | 68.9 | 51.5 | 59.5 | 75.9 |
| MT-bench | 72.9 | 73.2 | 69.9 | 76.6 | |
| IF | Ko-IFEval* | 71.8 | 55.0 | 46.1 | 57.2 |
| IFEval | 81.9 | 66.6 | 67.5 | 75.3 |
transformers>=4.49.0 or the latest version is required to use skt/A.X-4.0-VL-Lightpip install transformers>=4.49.0
import torch
from transformers import AutoModelForCausalLM, AutoProcessor
from PIL import Image
import requests
from io import BytesIO
model_name = "skt/A.X-4.0-VL-Light"
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, torch_dtype=torch.bfloat16).to(device='cuda')
processor = AutoProcessor.from_pretrained(model_name, trust_remote_code=True)
url = "https://huggingface.co/skt/A.X-4.0-VL-Light/resolve/main/assets/image.png"
# 이미지 출처: 국가유산포털 (https://www.heritage.go.kr/unisearch/images/national_treasure/thumb/2021042017434700.JPG)
response = requests.get(url)
response.raise_for_status()
image = Image.open(BytesIO(response.content))
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "이미지에 대해서 설명해줘."},
],
}
]
inputs = processor(
images=[image],
conversations=[messages],
padding=True,
return_tensors="pt",
).to("cuda")
# Decoding parameters (top_p, temperature, top_k, repetition_penalty) should be tuned depending on the generation task.
generation_kwargs = {
"max_new_tokens": 256,
"top_p": 0.8,
"temperature": 0.5,
"top_k": 20,
"repetition_penalty": 1.05,
"do_sample": True,
}
generated_ids = model.generate(**inputs, **generation_kwargs)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
response = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(response[0])
"""
숭례문은 대한민국 서울에 위치한 국보 제1호로, 조선 시대에 건축된 목조 건축물이다. 이 문은 서울의 남쪽 대문으로, 전통적인 한국 건축 양식을 보여준다. 두 층으로 이루어진 이 문은 기와지붕을 얹고 있으며, 지붕의 곡선이 아름답게 표현되어 있다. 문 아래에는 아치형의 출입구가 있으며, 그 주위로는 견고한 석재로 쌓은 성벽이 이어져 있다. 배경에는 현대적인 고층 빌딩들이 자리잡고 있어, 전통과 현대가 공존하는 서울의 모습을 잘 나타낸다. 숭례문은 역사적, 문화적 가치가 높아 많은 관광객들이 찾는 명소이다.
"""
import torch
from transformers import AutoModelForCausalLM, AutoProcessor
from PIL import Image
import requests
from io import BytesIO
model_name = "skt/A.X-4.0-VL-Light"
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, torch_dtype=torch.bfloat16).to(device='cuda')
processor = AutoProcessor.from_pretrained(model_name, trust_remote_code=True)
url = "https://huggingface.co/skt/A.X-4.0-VL-Light/resolve/main/assets/document.png"
response = requests.get(url)
response.raise_for_status()
image = Image.open(BytesIO(response.content))
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "사진에 무엇이 적혀있나요? 다른 설명 없이 적혀있는 텍스트만 결과로 보여줘."},
],
}
]
inputs = processor(
images=[image],
conversations=[messages],
padding=True,
return_tensors="pt",
).to("cuda")
generation_kwargs = {
"max_new_tokens": 1024,
"top_p": 0.95,
"top_k": 1,
"temperature": 0.7,
"repetition_penalty": 1.05,
"do_sample": True,
}
generated_ids = model.generate(**inputs, **generation_kwargs)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
response = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(response[0])
"""
# A.X 4.0: 기업용 한국어 특화 대규모 언어 모델
View English README
SK텔레콤이 한국어 처리 능력과 기업 활용성을 높인 대규모 언어 모델(LLM) A.X 4.0 (에이닷엑스 4.0)을 2025년 4월 30일에 출시하였습니다. A.X 4.0은 오픈소스 모델인 Qwen2.5에 방대한 한국어 데이터를 추가로 학습시켜 국내 비즈니스 환경에 최적화된 성능을 발휘합니다.
## A.X 4.0, 무엇이 다른가요?
- 뛰어난 한국어 실력: 대표적인 한국어 능력 평가 벤치마크인 KMMLU에서 78.3점을 기록하여, GPT-40(72.5점)보다 우수한 성능을 보였습니다.
- 높은 한국 문화 이해도: 한국어 및 한국 문화 벤치마크인 CLiCk에서도 83.5점을 획득해, GPT-40(80.2점)보다 더 높은 이해도를 입증했습니다.
- 효율적인 토큰 처리: 동일한 한국어 텍스트를 입력해도 A.X 4.0보다 GPT-40가 약 1.5배 많은 토큰을 사용합니다.
- 방대한 정보 처리: 최대 131,072 토큰에 이르는 긴 문서나 대화도 한 번에 이해하고 처리할 수 있습니다.
- 도메인 지원: 코딩, 제조업 등 전문 지식이 필요한 분야에서도 활용할 수 있도록 기본 성능을 강화했습니다.
- 배포 옵션: 720억 개(72B) 매개변수를 갖춘 표준 모델과 70억 개(7B) 매개변수의 경량 모델로 제공되며, 기업 내부 서버에 직접 설치(온프레미스)할 수 있어 데이터 보안에 대한 걱정을 덜 수 있습니다.
## 핵심 기술은?
### 한국어 특화 토크나이저 적용
한국어의 고유한 특성을 잘 이해하도록 최적화된 토크나이저를 사용합니다. 이 토크나이저는 한국어의 다양한 표현과 문맥을 효과적으로 파악하도록 설계되었습니다. 내부 테스트 결과, 같은 한국어 문장을 입력했을 때 GPT-40보다 A.X 4.0이 33.3% 효율적으로 토큰을 사용합니다.
이는 실제 사용 환경에서 다음과 같은 장점이 있습니다.
- 같은 조건이라면 대략 1.5배 더 많은 한국어 정보를 처리할 수 있습니다.
- 토큰 수가 줄어들어 처리 비용을 34% 정도 절감할 수 있습니다.
- API를 호출할 때 토큰 사용량에 따라 비용이 책정되는 구조에서 유리합니다.
특히 문서 요약이나 검색 증강 생성(RAG) 등 긴 글을 다루는 기업 환경에서, 토큰 효율성은 운영 비용을 크게 절감하는 데 기여합니다.
### 한국어 이해와 생성 능력을 향상시키는 학습 데이터 구성
A.X 4.0에 사용된 학습 데이터는 다음과 같은 특징을 갖습니다.
- 고품질의 한국어 자료: 웹에서 추출한 고품질 데이터, 전문 서적, 합성 데이터를 포함한 대규모 고품질 데이터셋을 활용했습니다.
- 체계적인 데이터 분류: 다양한 분야에서 균형있게 높은 성능을 발휘하도록 주제별로 분류된 데이터셋을 구성했습니다.
- 균형 잡힌 언어 분포: 한국어 42%, 영어 51%, 기타 언어 및 코드 7%로 구성해 언어 간 균형을 유지했습니다.
이러한 데이터 구성은 모델이 한국어의 다양한 표현과 미묘한 문맥까지 깊이 이해하도록 돕습니다.
"""
The A.X 4.0 VL Light model is licensed under Apache License 2.0.
@article{SKTAdotX4VLLight,
title={A.X 4.0 VL Light},
author={SKT AI Model Lab},
year={2025},
url={https://huggingface.co/skt/A.X-4.0-VL-Light}
}
Base model
skt/A.X-4.0-Light