
Typhoon 2.1
Collection
Typhoon 2.1 Text ThaiLLM release by SCB 10X.
•
6 items
•
Updated
•
3
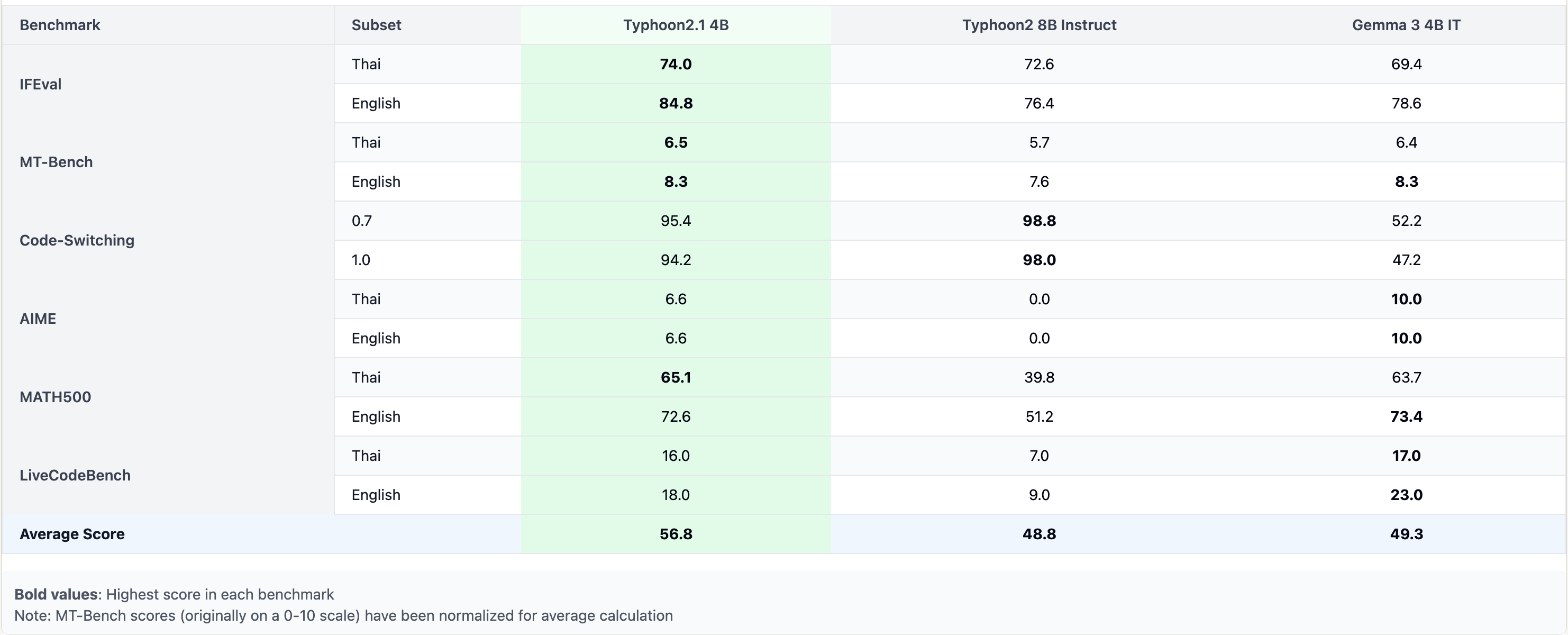
Typhoon2.1-Gemma3-4B: Thai Large Language Model (Instruct)
Typhoon2.1-Gemma3-4B is a instruct Thai 🇹🇭 large language model with 4 billion parameters, a 128K context length, and function-calling capabilities. It is based on Gemma3 4B.
This repo contains gguf q4_k_m quantization of the original Typhoon2.1 4B.
Remark: This is text only model.
Install llama.cpp through brew (works on Mac and Linux)
brew install llama.cpp
Invoke the llama.cpp server or the CLI.
llama-cli --hf-repo scb10x/typhoon2.1-gemma3-4b-gguf --hf-file typhoon2.1-gemma3-4b-q4_k_m.gguf -p "The meaning to life and the universe is"
llama-server --hf-repo scb10x/typhoon2.1-gemma3-4b-gguf --hf-file typhoon2.1-gemma3-4b-q4_k_m.gguf -c 2048
Note: You can also use this checkpoint directly through the usage steps listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
git clone https://github.com/ggerganov/llama.cpp
Step 2: Move into the llama.cpp folder and build it with LLAMA_CURL=1 flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
cd llama.cpp && LLAMA_CURL=1 make
Step 3: Run inference through the main binary.
./llama-cli --hf-repo scb10x/typhoon2.1-gemma3-4b-gguf --hf-file typhoon2.1-gemma3-4b-q4_k_m.gguf -p "The meaning to life and the universe is"
or
./llama-server --hf-repo scb10x/typhoon2.1-gemma3-4b-gguf --hf-file typhoon2.1-gemma3-4b-q4_k_m.gguf -c 2048
4-bit
Base model
scb10x/typhoon2.1-gemma3-4b