

license: apache-2.0
pipeline_tag: image-to-image
library_name: diffusers
In-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer

We present In-Context Edit, a novel approach that achieves state-of-the-art instruction-based editing using just 0.5% of the training data and 1% of the parameters required by prior SOTA methods. The first row illustrates a series of multi-turn edits, executed with high precision, while the second and third rows highlight diverse, visually impressive single-turn editing results from our method.
:open_book: For more visual results, go checkout our project page
This repository will contain the official implementation of ICEdit.
To Do List
- Inference Code
- Inference-time Scaling with VLM
- Pretrained Weights
- More Inference Demos
- Gradio demo
- Comfy UI demo
- Training Code
News
- [2025/4/30] 🔥 We release the inference code and pretrained weights on Huggingface 🤗!
- [2025/4/30] 🔥 We release the paper on arXiv!
- [2025/4/29] We release the project page and demo video! Codes will be made available in next week~ Happy Labor Day!
Installation
Conda environment setup
conda create -n icedit python=3.10
conda activate icedit
pip install -r requirements.txt
Download pretrained weights
If you can connect to Huggingface, you don't need to download the weights. Otherwise, you need to download the weights to local.
Inference in bash (w/o VLM Inference-time Scaling)
Now you can have a try!
Our model can only edit images with a width of 512 pixels (there is no restriction on the height). If you pass in an image with a width other than 512 pixels, the model will automatically resize it to 512 pixels.
If you found the model failed to generate the expected results, please try to change the
--seedparameter. Inference-time Scaling with VLM can help much to improve the results.
python scripts/inference.py --image assets/girl.png \
--instruction "Make her hair dark green and her clothes checked." \
--seed 42 \
Editing a 512×768 image requires 35 GB of GPU memory. If you need to run on a system with 24 GB of GPU memory (for example, an NVIDIA RTX3090), you can add the --enable-model-cpu-offload parameter.
python scripts/inference.py --image assets/girl.png \
--instruction "Make her hair dark green and her clothes checked." \
--enable-model-cpu-offload
If you have downloaded the pretrained weights locally, please pass the parameters during inference, as in:
python scripts/inference.py --image assets/girl.png \
--instruction "Make her hair dark green and her clothes checked." \
--flux-path /path/to/flux.1-fill-dev \
--lora-path /path/to/ICEdit-MoE-LoRA
Inference in Gradio Demo
We provide a gradio demo for you to edit images in a more user-friendly way. You can run the following command to start the demo.
python scripts/gradio_demo.py --port 7860
Like the inference script, if you want to run the demo on a system with 24 GB of GPU memory, you can add the --enable-model-cpu-offload parameter. And if you have downloaded the pretrained weights locally, please pass the parameters during inference, as in:
python scripts/gradio_demo.py --port 7860 \
--flux-path /path/to/flux.1-fill-dev (optional) \
--lora-path /path/to/ICEdit-MoE-LoRA (optional) \
--enable-model-cpu-offload (optional) \
Then you can open the link in your browser to edit images.
🎨 Enjoy your editing!
Comparison with Commercial Models
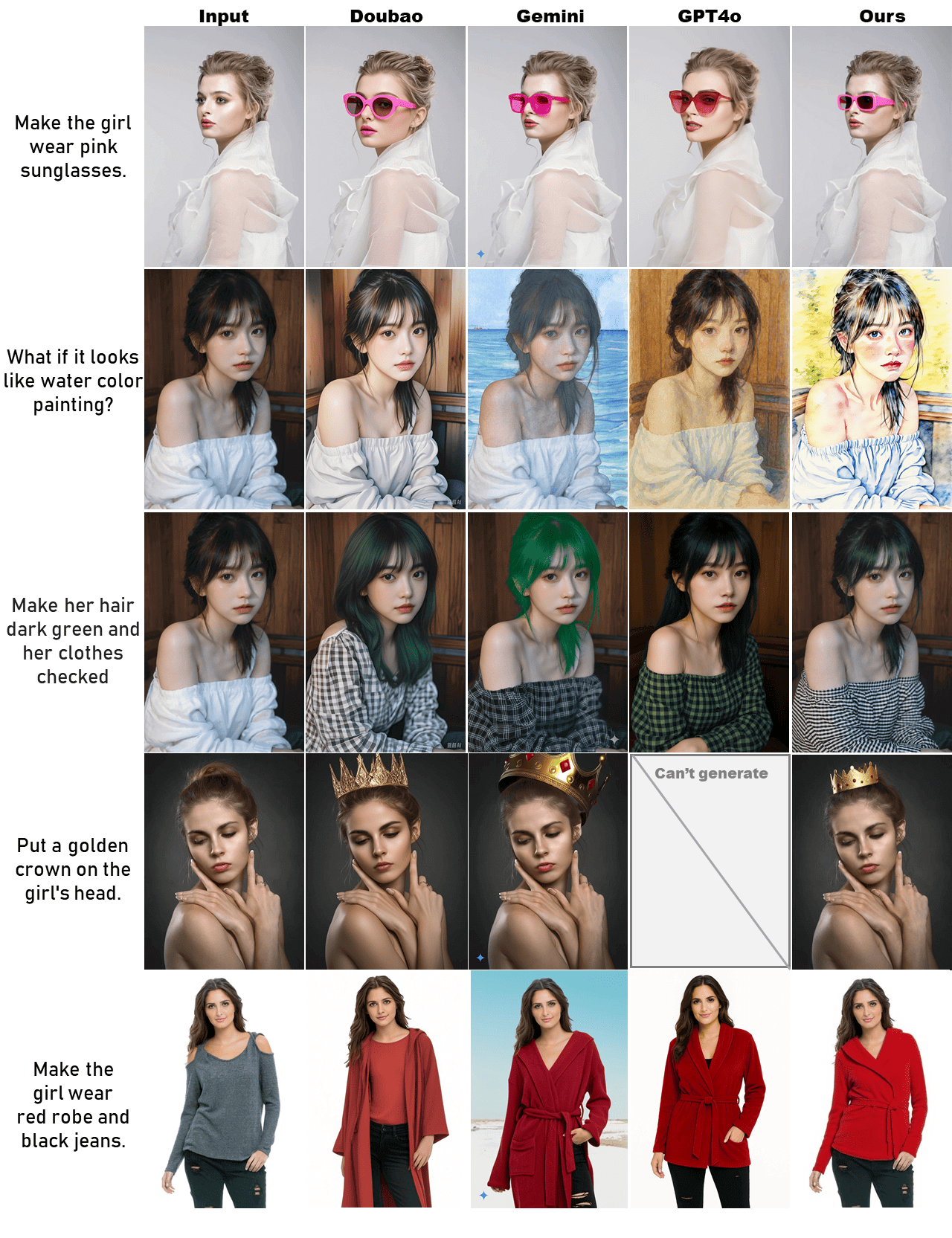
Compared with commercial models such as Gemini and GPT-4o, our methods are comparable to and even superior to these commercial models in terms of character ID preservation and instruction following. We are more open-source than them, with lower costs, faster speed (it takes about 9 seconds to process one image), and powerful performance.
Bibtex
If this work is helpful for your research, please consider citing the following BibTeX entry.
@misc{zhang2025ICEdit,
title={In-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer},
author={Zechuan Zhang and Ji Xie and Yu Lu and Zongxin Yang and Yi Yang},
year={2025},
eprint={2504.20690},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.20690},
}