tFINE-base-300m
An encoder-decoder (T5 architecture) pretrained with nanoT5:
- tokenizer: sentencepiece BPE w/ byte fallback, 48k vocab (from vocab scaling laws)
- data:
fineweb-edu-dedup split of HuggingFaceTB/smollm-corpus
- context length: 1024 ctx
details
Detailed info, including training logs, configs, and checkpoints can be found under checkpoints/ in this repo.
Expand hyperparameter overview
Model:
- Dropout rate: 0.0
- Activations:
silu, gated-silu
- torch compile: true
Data processing:
- Input length: 1024
- MLM probability: 0.15
Optimization:
- Optimizer: AdamW with scaling
- Base learning rate: 0.008
- Batch size: 120
- Total training steps: 80,000
- Warmup steps: 10,000
- Learning rate scheduler: Cosine
- Weight decay: 0.0001
- Gradient clipping: 1.0
- Gradient accumulation steps: 24
- Final cosine learning rate: 1e-5
Hardware:
- Device: RTX 4080
- Precision: bfloat16, tf32
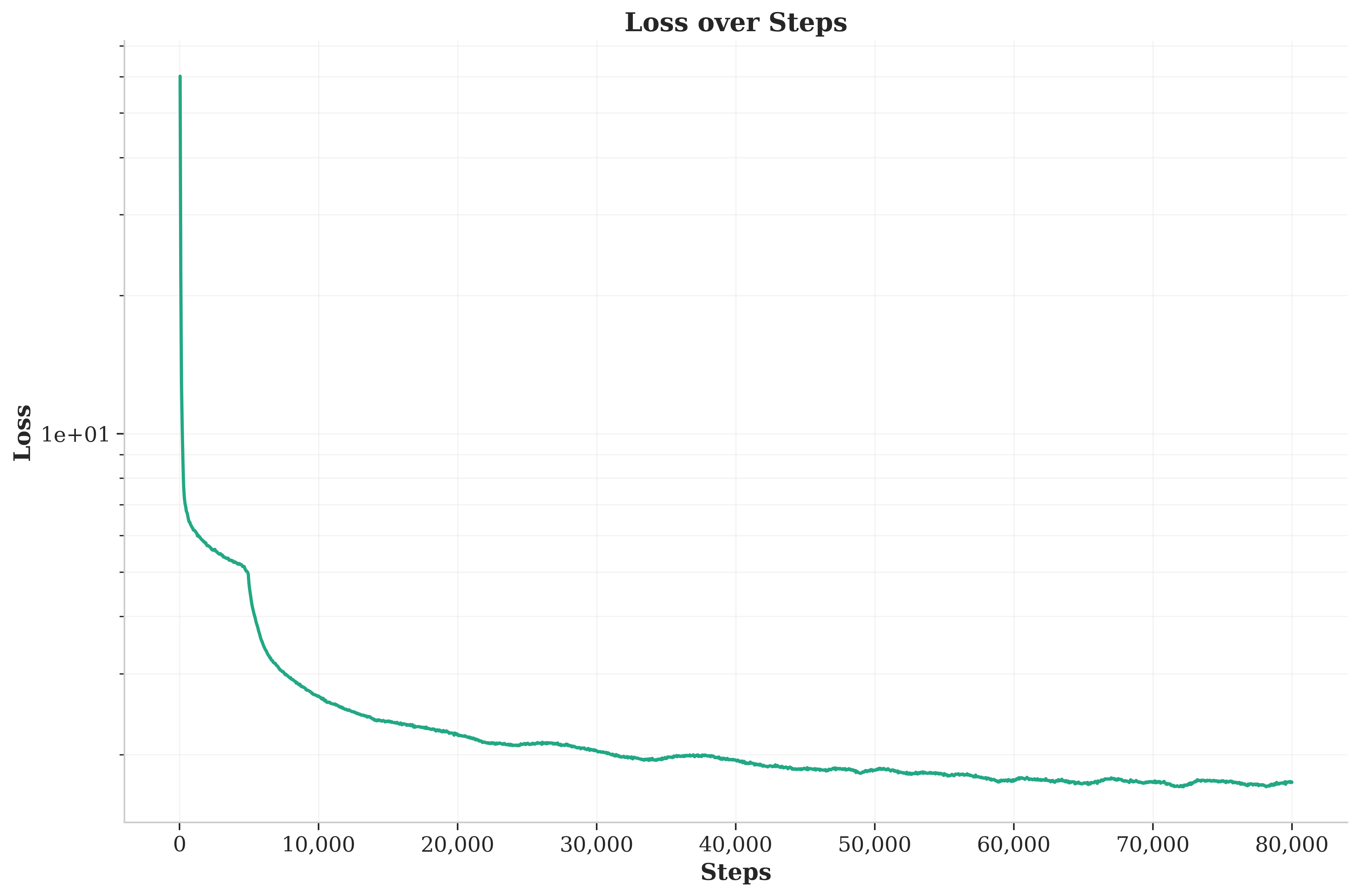
plots
training loss
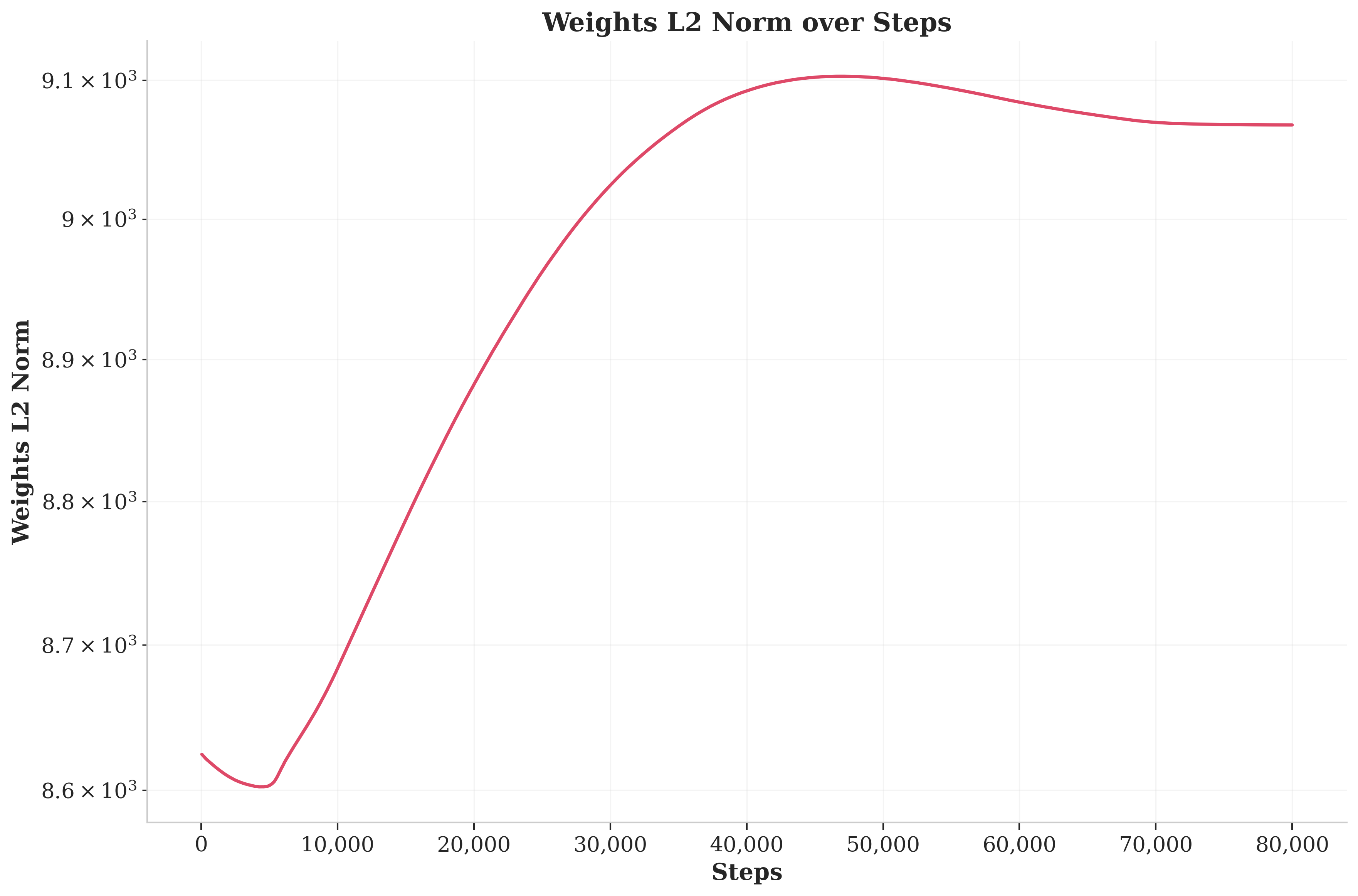
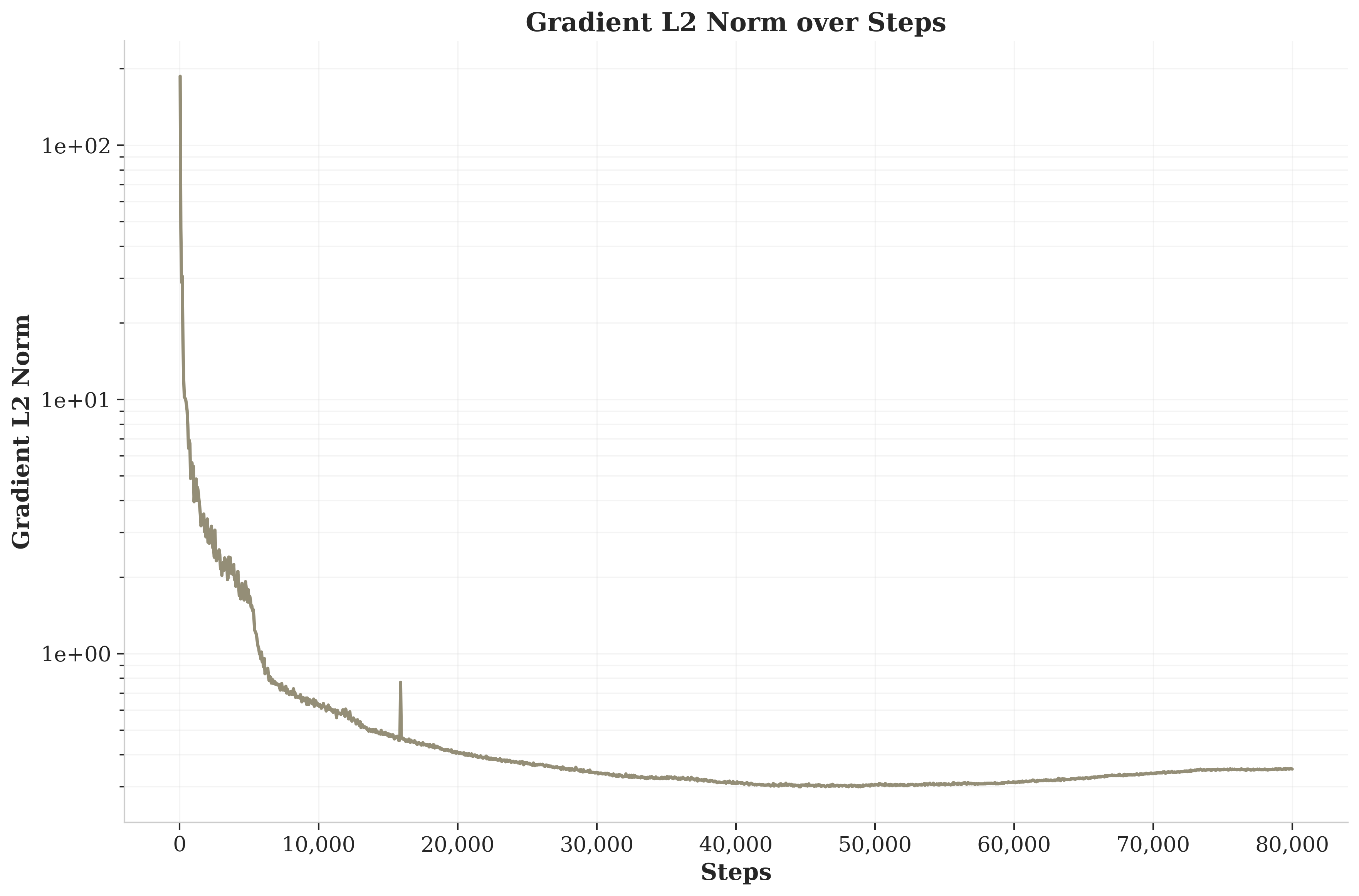
Expand grad and weights L2 norm plots
grad norm
weights norm