
Step 1: Reproducing DeepSeek's Distilled Models
Collection
Code for training and evaluation: https://github.com/huggingface/open-r1 • 3 items • Updated • 3

OpenR1-Distill-7B is post-trained version of Qwen/Qwen2.5-Math-7B on Mixture-of-Thoughts: a curated dataset of 350k verified reasoning traces distilled from DeepSeek-R1. The dataset spans tasks in mathematics, coding, and science, and is designed to teach language models to reason step-by-step.
OpenR1-Distill-7B replicates the reasoning capabilities of deepseek-ai/DeepSeek-R1-Distill-Qwen-7B while remaining fully open and reproducible. It is ideal for research on inference-time compute and reinforcement learning with verifiable rewards (RLVR).
To chat with the model, first install 🤗 Transformers:
pip install transformers>0.52
Then run the chat CLI as follows:
transformers chat open-r1/OpenR1-Distill-7B \
max_new_tokens=2048 \
do_sample=True \
temperature=0.6 \
top_p=0.95
Alternatively, run the model using the pipeline() function:
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="open-r1/OpenR1-Distill-7B", torch_dtype=torch.bfloat16, device_map="auto")
messages = [
{"role": "user", "content": "Which number is larger, 9.9 or 9.11?"},
]
outputs = pipe(messages, max_new_tokens=2048, do_sample=True, temperature=0.6, top_p=0.95, return_full_text=False)
print(outputs[0]["generated_text"])
We use Lighteval to evaluate models on the following benchmarks:
| Model | AIME 2024 | MATH-500 | GPQA Diamond | LiveCodeBench v5 |
|---|---|---|---|---|
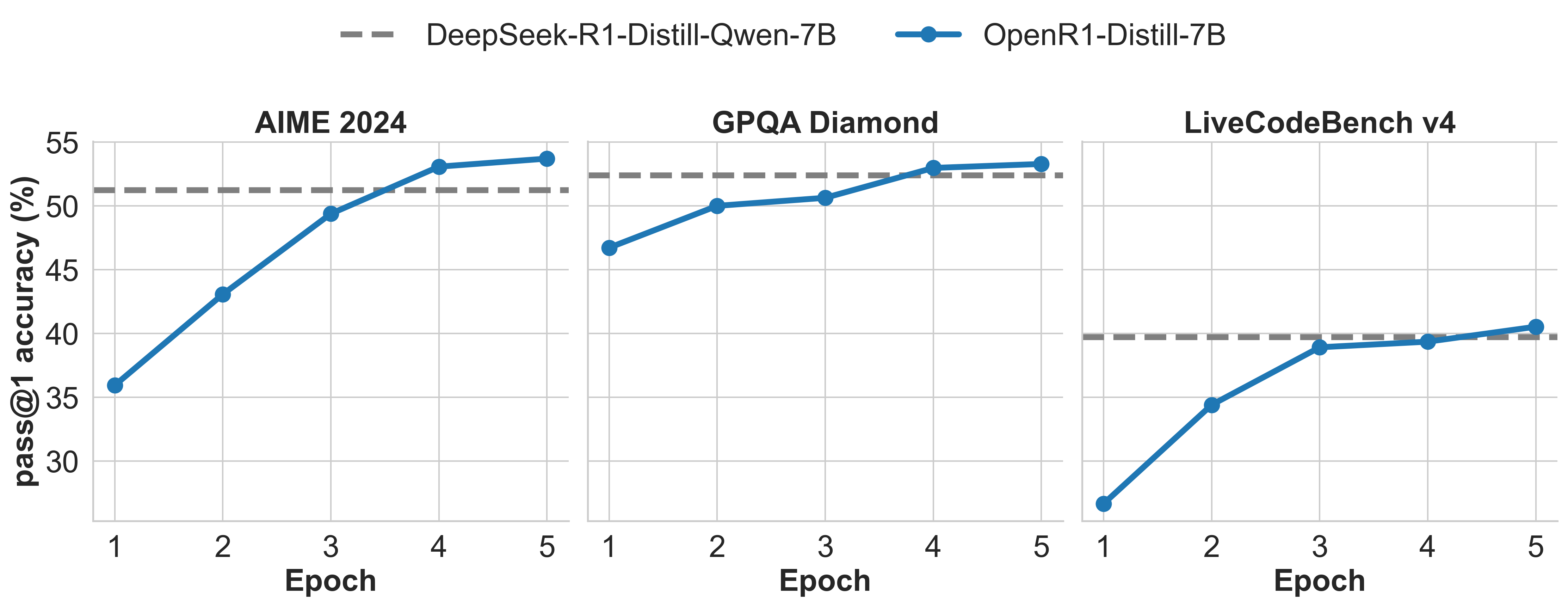
| OpenR1-Distill-7B | 52.7 | 89.0 | 52.8 | 39.4 |
| DeepSeek-R1-Distill-Qwen-7B | 51.3 | 93.5 | 52.4 | 37.4 |
All scores denote pass@1 accuracy and use sampling with temperature=0.6 and top_p=0.95. The DeepSeek-R1 tech report uses sampling with 4-64 responses per query to estimate pass@1, but does not specify the specific number of responses per benchmark. In the table above, we estimate pass@1 accuracy with the following number of responses per query:
| Benchmark | Number of responses per query |
|---|---|
| AIME 2024 | 64 |
| MATH-500 | 4 |
| GPQA Diamond | 8 |
| LiveCodeBench | 16 |
Note that for benchmarks like AIME 2024, it is important to sample many responses as there are only 30 problems and this introduces high variance across repeated runs. The choice of how many responses to sample per prompt likely explains the small differences between our evaluation results and those reported by DeepSeek. Check out the open-r1 repo for instructions on how to reproduce these results.
OpenR1-Distill-7B was trained using supervised fine-tuning (SFT) on the Mixture-of-Thoughts dataset, which contains 350k reasoning traces distilled from DeepSeek-R1. To optimise the data mixture, we followed the same methodology described in the Phi-4-reasoning tech report, namely that mixtures can be optimised independently per domain, and then combined into a single dataset. The figure below shows the evolution of our experiments on the math and code domains:
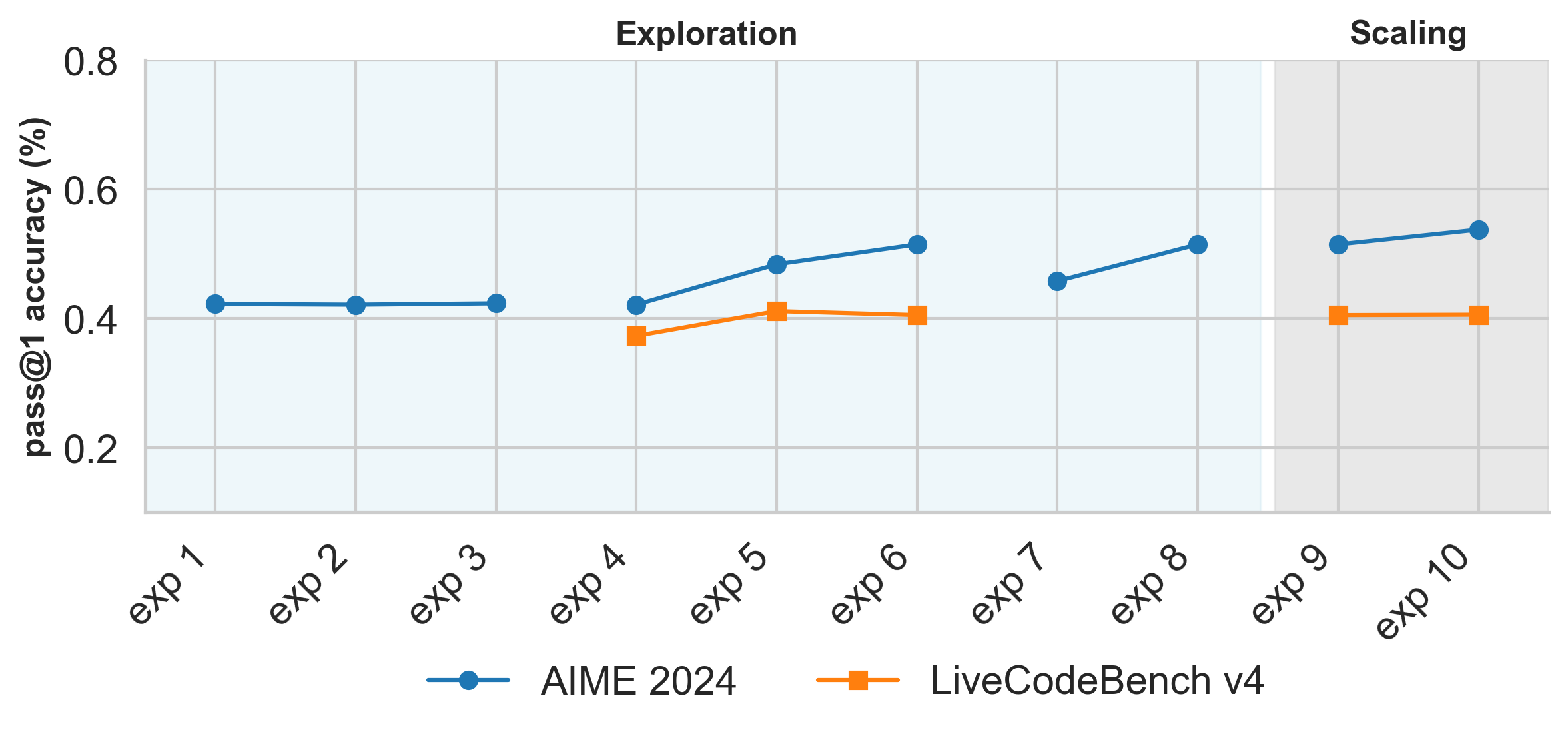
The individual experiments correspond to the following:
We use LiveCodeBench v4 to accelerate evaluation during our ablations as it contains around half the problems of v5, yet is still representative of the full benchmark.
The following hyperparameters were used during training:
During training, we monitor progress on AIME 2024, GPQA Diamond, and LiveCodeBench v4 every epoch. The following plot shows the training results:
If you find this model is useful in your own work, please consider citing it as follows:
@misc{openr1,
title = {Open R1: A fully open reproduction of DeepSeek-R1},
url = {https://github.com/huggingface/open-r1},
author = {Hugging Face},
month = {January},
year = {2025}
}
Base model
Qwen/Qwen2.5-7B