
AceReason
Collection
Math and Code reasoning model trained through reinforcement learning (RL)
•
7 items
•
Updated
•
14
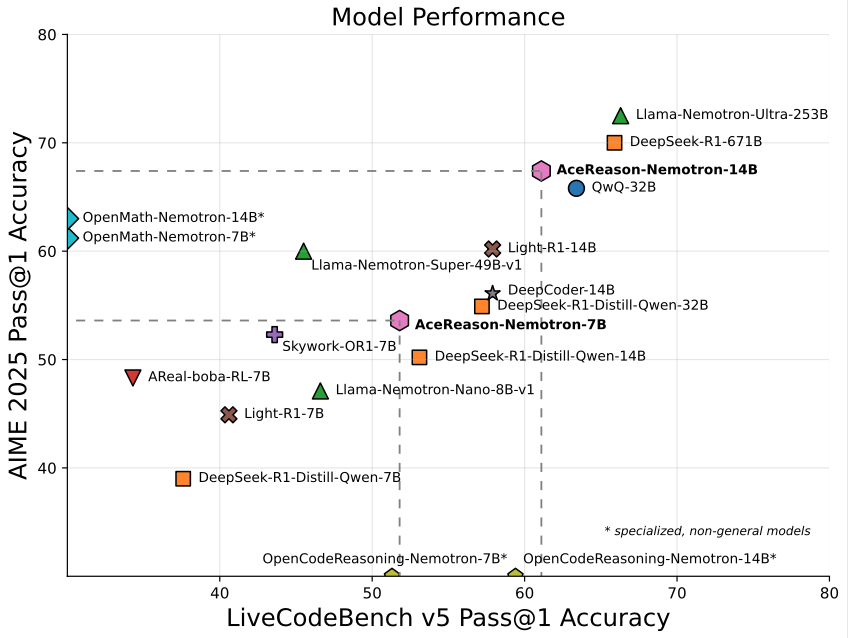
We're thrilled to introduce AceReason-Nemotron-14B, a math and code reasoning model trained entirely through reinforcement learning (RL), starting from the DeepSeek-R1-Distilled-Qwen-14B. It delivers impressive results, achieving 78.6% on AIME 2024 (+8.9%), 67.4% on AIME 2025 (+17.4%), 61.1% on LiveCodeBench v5 (+8%), 54.9% on LiveCodeBench v6 (+7%), and 2024 on Codeforces (+543). We systematically study the RL training process through extensive ablations and propose a simple yet effective approach: first RL training on math-only prompts, then RL training on code-only prompts. Notably, we find that math-only RL not only significantly enhances the performance of strong distilled models on math benchmarks, but also code reasoning tasks. In addition, extended code-only RL further improves code benchmark performance while causing minimal degradation in math results. We find that RL not only elicits the foundational reasoning capabilities acquired during pre-training and supervised fine-tuning (e.g., distillation), but also pushes the limits of the model's reasoning ability, enabling it to solve problems that were previously unsolvable.
We share our training recipe, training logs in our technical report.
We evaluate our model against competitive reasoning models of comparable size within Qwen2.5 and Llama3.1 model family on AIME 2024, AIME 2025, LiveCodeBench v5 (2024/08/01 - 2025/02/01), and LiveCodeBench v6 (2025/02/01-2025/05/01). More evaluation results can be found in our technical report.
| Model | AIME 2024 (avg@64) |
AIME 2025 (avg@64) |
LCB v5 (avg@8) |
LCB v6 (avg@8) |
|---|---|---|---|---|
| QwQ-32B | 79.5 | 65.8 | 63.4 | - |
| DeepSeek-R1-671B | 79.8 | 70.0 | 65.9 | - |
| Llama-Nemotron-Ultra-253B | 80.8 | 72.5 | 66.3 | - |
| o3-mini (medium) | 79.6 | 76.7 | 67.4 | - |
| Light-R1-14B | 74 | 60.2 | 57.9 | 51.5 |
| DeepCoder-14B (32K Inference) | 71 | 56.1 | 57.9 | 50.4 |
| OpenMath-Nemotron-14B | 76.3 | 63.0 | - | - |
| OpenCodeReasoning-Nemotron-14B | - | - | 59.4 | 54.1 |
| Llama-Nemotron-Super-49B-v1 | 67.5 | 60.0 | 45.5 | - |
| DeepSeek-R1-Distilled-Qwen-14B | 69.7 | 50.2 | 53.1 | 47.9 |
| DeepSeek-R1-Distilled-Qwen-32B | 72.6 | 54.9 | 57.2 | - |
| AceReason-Nemotron-7B 🤗 | 69.0 | 53.6 | 51.8 | 44.1 |
| AceReason-Nemotron-14B 🤗 | 78.6 | 67.4 | 61.1 | 54.9 |
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = 'nvidia/AceReason-Nemotron-14B'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Jen enters a lottery by picking $4$ distinct numbers from $S=\\{1,2,3,\\cdots,9,10\\}.$ $4$ numbers are randomly chosen from $S.$ She wins a prize if at least two of her numbers were $2$ of the randomly chosen numbers, and wins the grand prize if all four of her numbers were the randomly chosen numbers. The probability of her winning the grand prize given that she won a prize is $\\tfrac{m}{n}$ where $m$ and $n$ are relatively prime positive integers. Find $m+n$."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to("cuda")
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768,
temperature=0.6,
top_p=0.95
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
question = "" # code question
starter_code = "" # starter code function header
code_instruction_nostartercode = """Write Python code to solve the problem. Please place the solution code in the following format:\n```python\n# Your solution code here\n```"""
code_instruction_hasstartercode = """Please place the solution code in the following format:\n```python\n# Your solution code here\n```"""
if starter_code != "":
question += "\n\n" + "Solve the problem starting with the provided function header.\n\nFunction header:\n" + "```\n" + starter_code + "\n```"
question += "\n\n" + code_instruction_hasstartercode
else:
question += "\n\n" + code_instruction_nostartercode
final_prompt = "<|User|>" + question + "<|Assistant|><think>\n"
Please check evaluation code, scripts, cached prediction files in https://huggingface.co/nvidia/AceReason-Nemotron-14B/blob/main/README_EVALUATION.md
Yang Chen ([email protected]), Zhuolin Yang ([email protected]), Zihan Liu ([email protected]), Chankyu Lee ([email protected]), Wei Ping ([email protected])
Your use of this model is governed by the NVIDIA Open Model License.
@article{chen2025acereason,
title={AceReason-Nemotron: Advancing Math and Code Reasoning through Reinforcement Learning},
author={Chen, Yang and Yang, Zhuolin and Liu, Zihan and Lee, Chankyu and Xu, Peng and Shoeybi, Mohammad and Catanzaro, Bryan and Ping, Wei},
journal={arXiv preprint arXiv:2505.16400},
year={2025}
}