
ImageBind: One Embedding Space To Bind Them All
To appear at CVPR 2023 (Highlighted paper)
[Paper] [Blog] [Demo] [Supplementary Video] [BibTex]
PyTorch implementation and pretrained models for ImageBind. For details, see the paper: ImageBind: One Embedding Space To Bind Them All.
ImageBind learns a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data. It enables novel emergent applications ‘out-of-the-box’ including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection and generation.
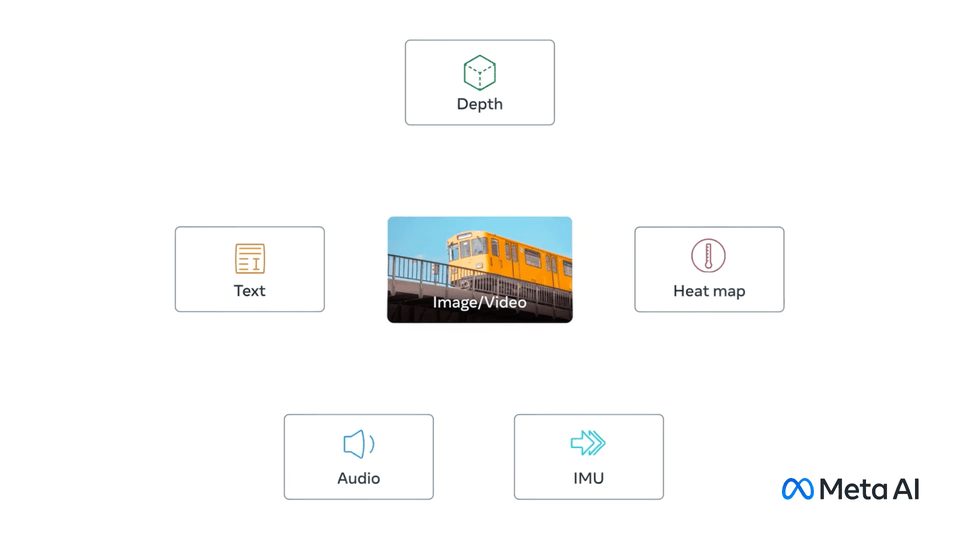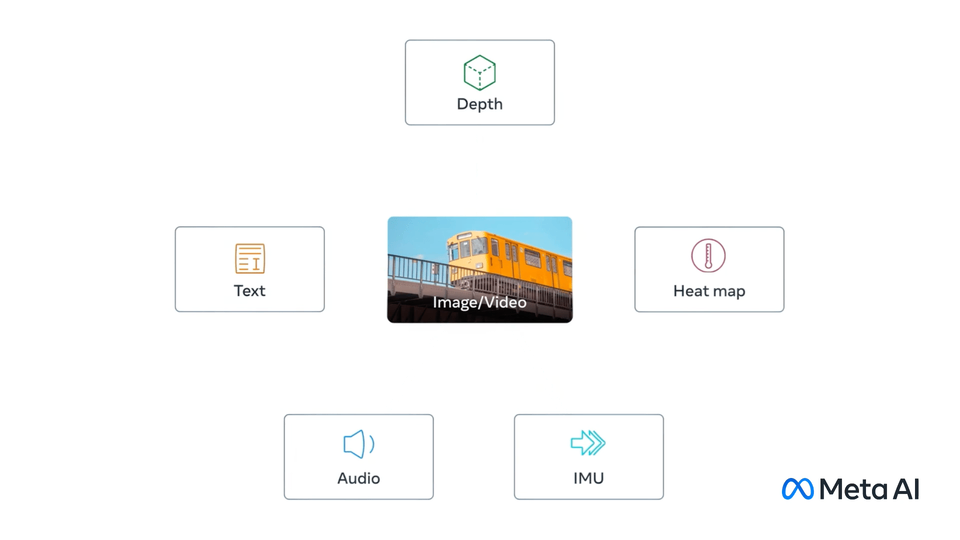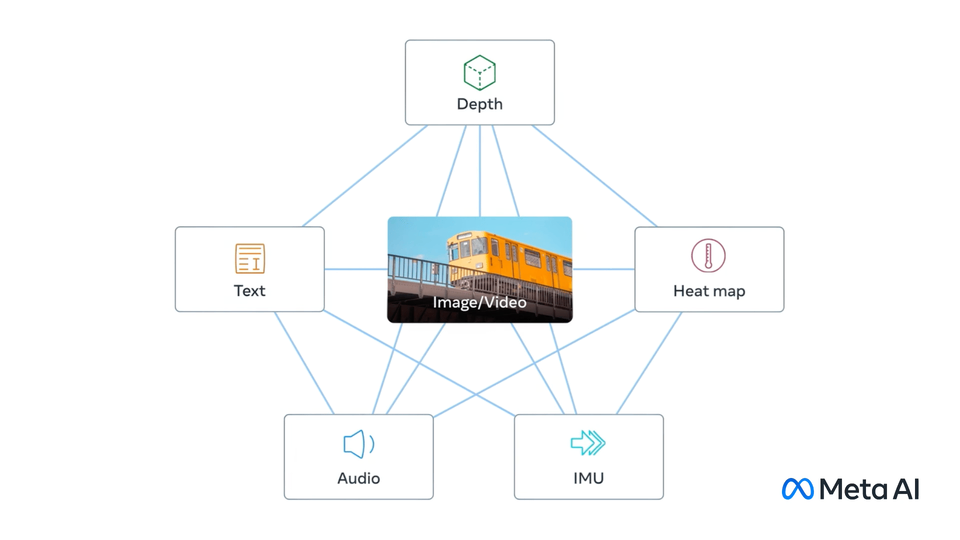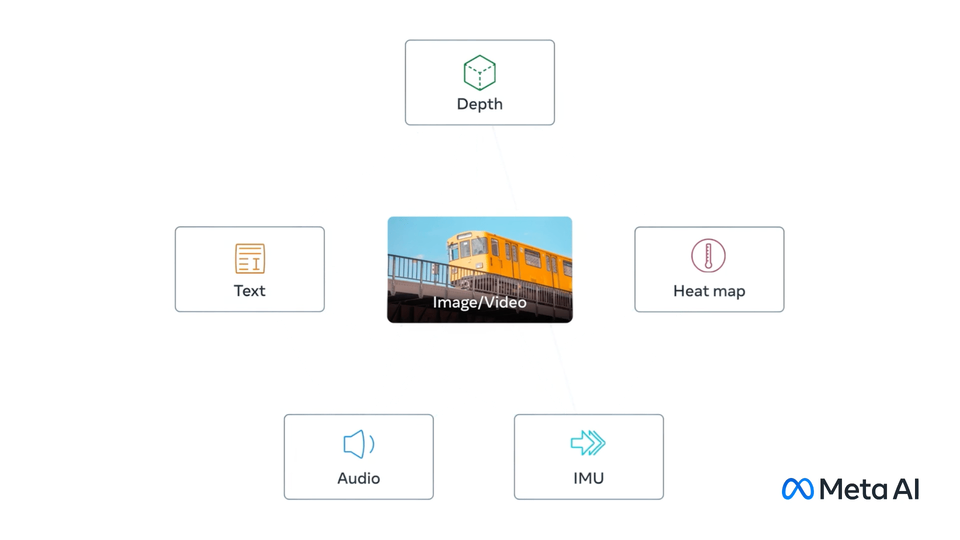
ImageBind model
Emergent zero-shot classification performance.
| Model | IN1k | K400 | NYU-D | ESC | LLVIP | Ego4D |
|---|---|---|---|---|---|---|
| imagebind_huge | 77.7 | 50.0 | 54.0 | 66.9 | 63.4 | 25.0 |
Usage
First git clone the repository:
git clone -b feature/add_hf https://github.com/nielsrogge/ImageBind.git
cd ImageBind
Next, install pytorch 1.13+ and other 3rd party dependencies.
conda create --name imagebind python=3.8 -y
conda activate imagebind
pip install .
For windows users, you might need to install soundfile for reading/writing audio files. (Thanks @congyue1977)
pip install soundfile
Extract and compare features across modalities (e.g. Image, Text and Audio).
from imagebind import data
import torch
from imagebind.models import imagebind_model
from imagebind.models.imagebind_model import ModalityType
from imagebind.models.imagebind_model import ImageBindModel
text_list=["A dog.", "A car", "A bird"]
image_paths=[".assets/dog_image.jpg", ".assets/car_image.jpg", ".assets/bird_image.jpg"]
audio_paths=[".assets/dog_audio.wav", ".assets/car_audio.wav", ".assets/bird_audio.wav"]
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = ImageBindModel.from_pretrained("nielsr/imagebind-huge")
model.eval()
model.to(device)
# Load data
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text_list, device),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),
ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, device),
}
with torch.no_grad():
embeddings = model(inputs)
print(
"Vision x Text: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Audio x Text: ",
torch.softmax(embeddings[ModalityType.AUDIO] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Vision x Audio: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.AUDIO].T, dim=-1),
)
# Expected output:
#
# Vision x Text:
# tensor([[9.9761e-01, 2.3694e-03, 1.8612e-05],
# [3.3836e-05, 9.9994e-01, 2.4118e-05],
# [4.7997e-05, 1.3496e-02, 9.8646e-01]])
#
# Audio x Text:
# tensor([[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]])
#
# Vision x Audio:
# tensor([[0.8070, 0.1088, 0.0842],
# [0.1036, 0.7884, 0.1079],
# [0.0018, 0.0022, 0.9960]])
License
ImageBind code and model weights are released under the CC-BY-NC 4.0 license. See LICENSE for additional details.
Citation
@inproceedings{girdhar2023imagebind,
title={ImageBind: One Embedding Space To Bind Them All},
author={Girdhar, Rohit and El-Nouby, Alaaeldin and Liu, Zhuang
and Singh, Mannat and Alwala, Kalyan Vasudev and Joulin, Armand and Misra, Ishan},
booktitle={CVPR},
year={2023}
}
- Downloads last month
- 218