
Metis-RISE
Collection
2 items
•
Updated
![]()
![]()
![]()
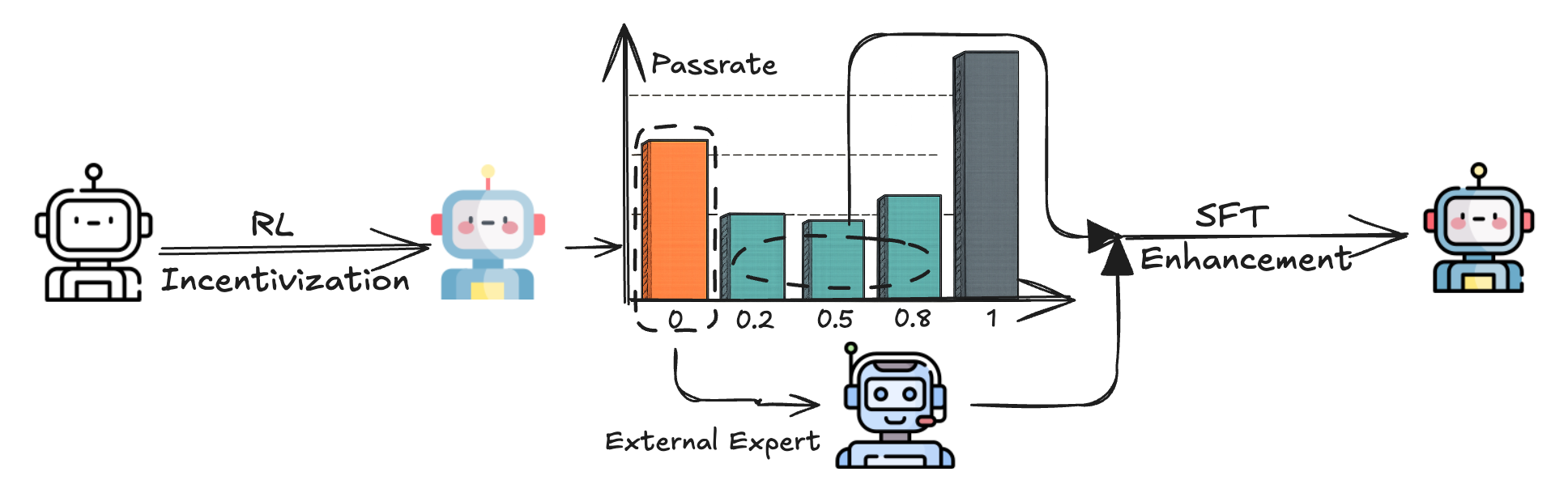
We introduces Metis-RISE (RL Incentivizes and SFT Enhances), a hybrid training paradigm that strategically sequences RL and SFT to significantly advance multimodal reasoning in MLLMs. By prioritizing RL-driven exploration, Metis-RISE incentivizes the model to unlock latent reasoning skills and avoids premature convergence often seen in SFT-first approaches. Subsequently, targeted SFT stages enhance these capabilities by efficiently addressing inconsistent reasoning through self-distilled trajectories and rectifying fundamental capability absence via expert knowledge injection. Metis-RISE-72B scores an average of 56.6 on the OpenCompass Multimodal Reasoning Leaderboard, ranking tied for fourth on the overall leaderboard (as of June 26, 2025).
We evaluate both Metis-RISE-7B and Metis-RISE-72B on the comprehensive OpenCompass Multimodal Reasoning Leaderboard. Both of them achieve state-of-the-art performance among similar-sized models, with the 72B version ranking fourth overall on the full leaderboard (as of June 26, 2025), validating the effectiveness and scalability of the Metis-RISE framework for enhancing multimodal reasoning.
| Model | Avg. | MathVista | MathVision | MathVerse | DynaMath | WeMath | LogicVista |
|---|---|---|---|---|---|---|---|
| Proprietary Models | |||||||
| Seed1.5-VL | 73.3 | 86.8 | 67.3 | 79.3 | 56.1 | 77.5 | 72.7 |
| Gemini-2.5-Pro | 72.5 | 80.9 | 69.1 | 76.9 | 56.3 | 78.0 | 73.8 |
| Doubao-1.5-Pro | 61.6 | 78.6 | 51.5 | 64.7 | 44.9 | 65.7 | 64.2 |
| Gemini-2.0-Pro | 56.6 | 71.3 | 48.1 | 67.3 | 43.3 | 56.5 | 53.2 |
| ChatGPT-4o-202504 | 54.8 | 71.6 | 43.8 | 49.9 | 48.5 | 50.6 | 64.4 |
| Gemini-2.0-Flash | 50.6 | 70.4 | 43.6 | 47.8 | 42.1 | 47.4 | 52.3 |
| Claude 3.7 Sonnet | 50.4 | 66.8 | 41.9 | 46.7 | 39.7 | 49.3 | 58.2 |
| GLM-4v-Plus-202501 | 49.2 | 73.5 | 51.1 | 40.7 | 27.5 | 47.7 | 54.4 |
| Open-source ≤10B Models | |||||||
| Kimi-VL-A3B-Instruct | 35.8 | 66.0 | 21.8 | 34.1 | 18.0 | 32.3 | 42.7 |
| Qwen2.5-VL-7B | 40.1 | 68.1 | 25.4 | 41.1 | 21.8 | 36.2 | 47.9 |
| InternVL3-8B | 41.4 | 70.5 | 30.0 | 38.5 | 25.7 | 39.5 | 44.5 |
| VLAA-Thinker-7B | 42.5 | 68.0 | 26.4 | 48.2 | 22.4 | 41.5 | 48.5 |
| Metis-RISE-7B | 46.4 | 75.8 | 28.7 | 51.0 | 27.7 | 45.2 | 49.7 |
| Open-source >10B Models | |||||||
| InternVL3-14B | 46.0 | 74.4 | 34.0 | 43.7 | 30.3 | 41.3 | 52.1 |
| Ovis2-34B | 47.9 | 76.1 | 31.9 | 50.1 | 27.5 | 51.9 | 49.9 |
| QVQ-72B-Preview | 46.9 | 70.3 | 34.9 | 48.2 | 30.7 | 39.0 | 58.2 |
| LLaVA-OneVision-72B | 34.7 | 67.1 | 25.3 | 27.2 | 15.6 | 32 | 40.9 |
| Qwen2.5-VL-72B | 50.3 | 74.2 | 39.3 | 47.3 | 35.9 | 49.1 | 55.7 |
| InternVL3-78B | 51.0 | 79.0 | 38.8 | 51.0 | 35.1 | 46.1 | 55.9 |
| Metis-RISE-72B | 56.6 | 80.4 | 42.7 | 59.8 | 42.5 | 55.1 | 58.8 |
Below is a simple example of how to use Metis-RISE series models for multimodal reasoning tasks:
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
# Load model (choose between 7B or 72B version)
model_path = 'mmthinking/Metis-RISE-7B' # or mmthinking/Metis-RISE-72B
# Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_path, torch_dtype="auto", device_map="auto"
)
# Best practices to use the following system_prompt and pixel range by default
system_prompt = """Solve the question. The user asks a question, and you solves it. You first thinks about the reasoning process in the mind and then provides the user with the answer. The answer is in latex format and wrapped in $...$. The final answer must be wrapped using the \\boxed{} command. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> Since $1+1=2$, so the answer is $2$. </think><answer> The answer is $\\boxed{2}$ </answer>, which means assistant's output should start with <think> and end with </answer>."""
processor = AutoProcessor.from_pretrained(model_path, min_pixels=128*28*28, max_pixels=16384*28*28)
# Prepare input with image and text
messages = [
{
"role": "system",
"content": system_prompt
},
{
"role": "user",
"content": [
{
"type": "image",
"image": "assets/example_case.jpg",
},
{"type": "text", "text": "If the pattern continues, what would be the Y value when X=11?"},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to(model.device)
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=8192)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text[0])
| Model | Huggingface |
|---|---|
| Metis-RISE-7B | mmthinking/Metis-RISE-7B |
| Metis-RISE-72B | mmthinking/Metis-RISE-72B |
We sincerely appreciate LLaMA-Factory and MM-EUREKA for providing reference training framework.
@article{qiu2025metis,
title={Metis-RISE: RL Incentivizes and SFT Enhances Multimodal Reasoning Model Learning},
author={Qiu, Haibo and Lan, Xiaohan and Liu, Fanfan and Sun, Xiaohu and Ruan, Delian and Shi, Peng and Ma, Lin},
journal={arXiv preprint arXiv:2506.13056},
year={2025}
}