
GLAP (Generalized Language Audio Pretraining)
Official PyTorch code for GLAP
Generalized Language Audio Pretraining

GLAP (Generalized Language Audio Pretraining)
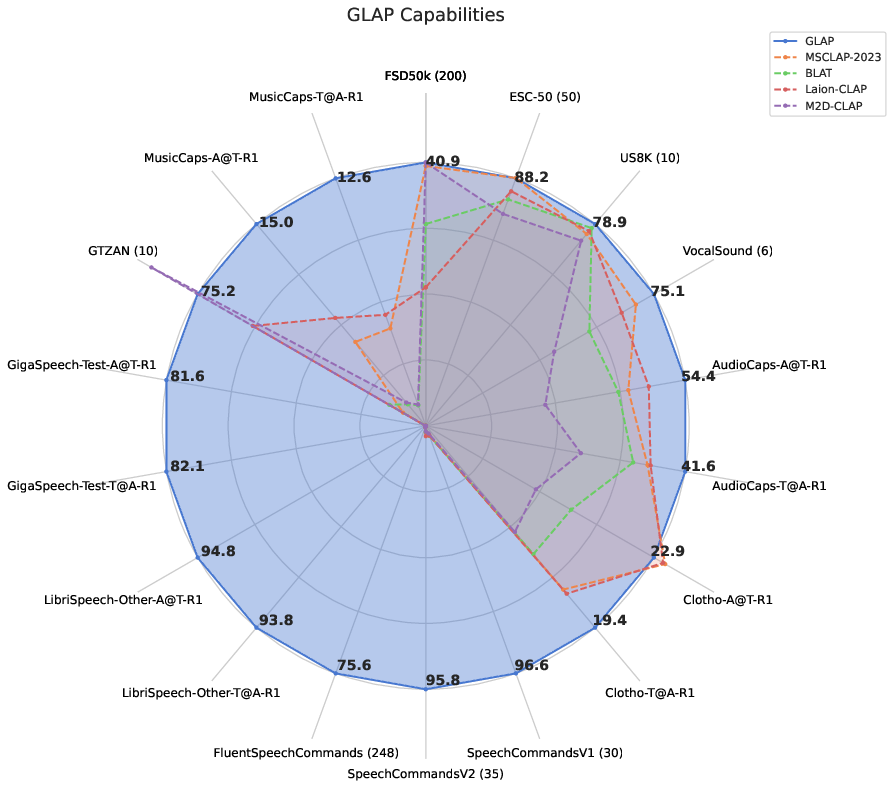
Features
- First all-in-one solution for general audio-text retrieval.
- Multilingual (8 + Languages) Speech, Music and Sound retrieval.
- Music and Sound retrieval performance in English matches previous baselines, while also supporting Languages like Japanese, German, Spanish, Chinese, Dutch and more.
Usage
pip install glap_model
Scoring audio-text pairs
We provide a simple commandline tool:
score_glap audio_input_file text1;text2;text3
Or in Python:
import torch
from glap_model import glap_inference
audio = torch.randn(1, 160000).tanh() # 10s of heavy noise
glap_model = glap_inference()
score = glap_model.score_forward(audio, text=["the sound of noise","a car is driving","a person is speaking"])
print(score)
Recommended Prompts
| Task | Prompt |
|---|---|
| Speech | {label} |
| Music | The music in the style of {label}. |
| Sound | The sound of {label} can be heard. |
Batched scoring
import torch
from glap_model import glap_inference
glap_model = glap_inference()
audio = torch.randn(1, 64000).tanh()
prefix = "The sound of"
labels = [ f"{prefix} {label}" for label in ("Cat","Dog","Water","Noise")]
text_embeds = glap_model.encode_text(labels)
audio_embeds = glap_model.encode_audio(audio)
scores = glap_model.score(audio_embeds, text_embeds)
for label_name, score in zip(labels, scores):
print(label_name,score)
Development
UV (Recommended)
git clone https://github.com/xiaomi-research/GLAP
cd GLAP
uv venv --python 3.10
source activate .venv/bin/activate
uv sync
#python3 -m pip install .
# Additionally, sndfile is needed
# conda install -c conda-forge libsndfile==1.0.31
Pip
git clone https://github.com/xiaomi-research/GLAP
cd GLAP
python3 -m pip install .
# Additionally, sndfile is needed
# conda install -c conda-forge libsndfile==1.0.31
# Or if you have root, use your package manager
Prepare data
Data needs to be in tar/tar.gz format:
# tar -tf a.tar
908-31957-0013.flac
908-31957-0013.json
2961-960-0013.flac
2961-960-0013.json
Each .json should have one of three fields caption, captions or text.
Data preparation can be done using the wavlist_to_tar script, which is provided in the dasheng dependency.
Further information how to process data can be seen here.
Training
For reference, we provide our original training config for GLAP configs/train/multilingual_dasheng_asr_sound2_sigmoidloss_balanced.yaml.
accelerate launch --mixed-precision='fp16' run.py train configs/train/multilingual_dasheng_asr_sound2_sigmoidloss_balanced.yaml
Zeroshot eval (one sample)
# There ; is a separator for different text keys
python3 run.py zeroshot pretrained_checkpoint/glap_checkpoint.pt PATH_TO_WAV_FLAC_MP3_SAMPLE.wav "The sound of a horse;Car;Mama;The sound of music;somebody is speaking;The sound of ein Pferd;一只马;Music is played;音乐的声音;Musik ist zu hoeren";Zero;One;Two;Three"
Retrieval scoring
# Should be run on a single GPU
accelerate launch --mixed-precision='fp16' run.py evaluate PATH_TO_CHECKPOINT
Notes on DDP
Using uneven training datasets without resample=True is not recommended
Translating data into a target language
For our experiments we used SONAR to translate audio captions into seven target languages. This can be reproduced using our code:
python3 run.py translate_sonar data/WavCaps/freesound/freesound_train_sample_0000* --output_path data/translations/WavCaps/freesound/
DDP is also supported:
accelerate launch run.py translate_sonar data/WavCaps/freesound/freesound_train_sample_0000* --output_path data/translations/WavCaps/freesound/
Citation
@misc{2506.11350,
Author = {Heinrich Dinkel and Zhiyong Yan and Tianzi Wang and Yongqing Wang and Xingwei Sun and Yadong Niu and Jizhong Liu and Gang Li and Junbo Zhang and Jian Luan},
Title = {GLAP: General contrastive audio-text pretraining across domains and languages},
Year = {2025},
Eprint = {arXiv:2506.11350},
}