
VibeVoice
Collection
Frontier Text-to-Speech Models https://microsoft.github.io/VibeVoice/
•
3 items
•
Updated
•
12
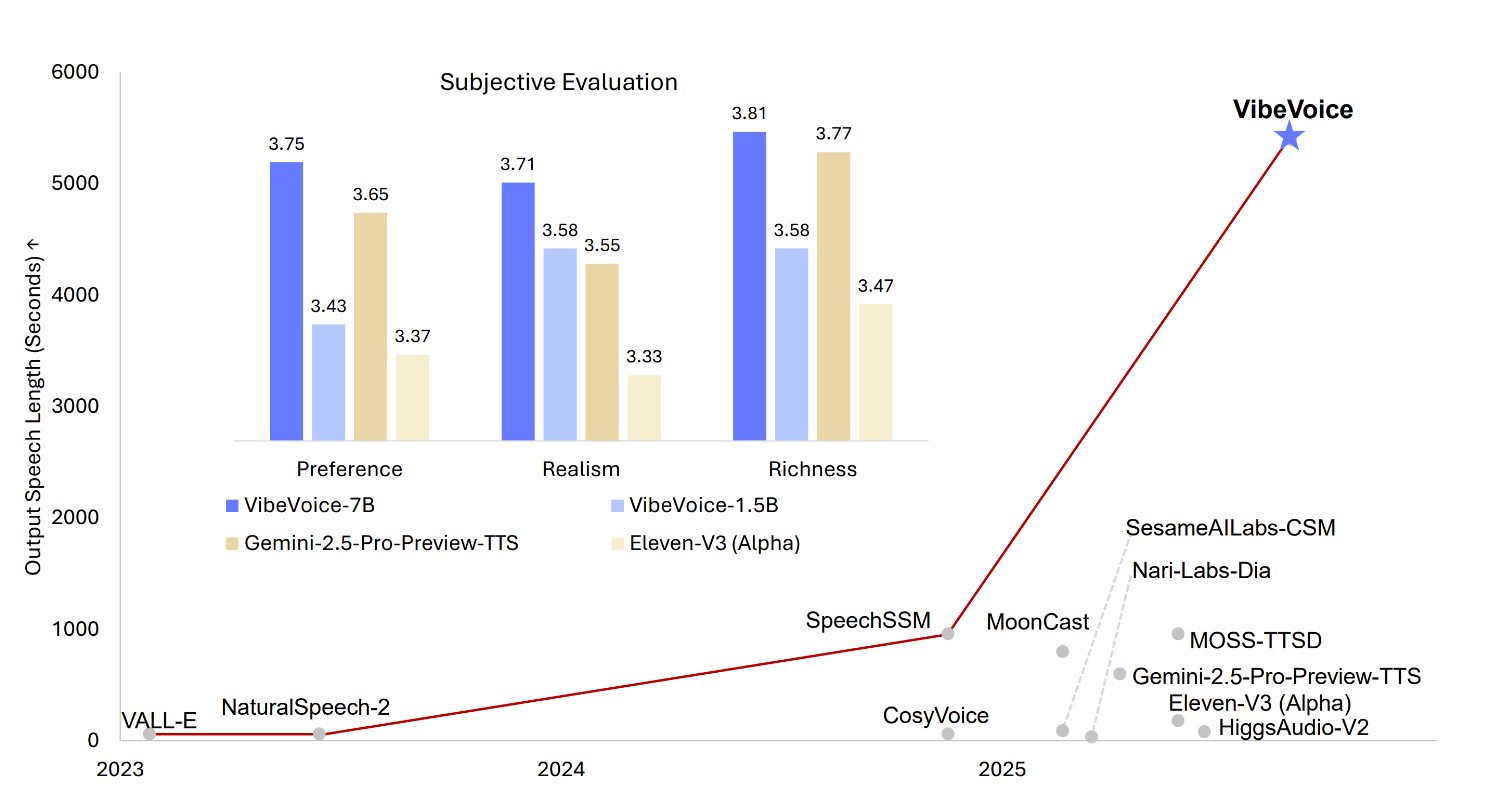
VibeVoice is a novel framework designed for generating expressive, long-form, multi-speaker conversational audio, such as podcasts, from text. It addresses significant challenges in traditional Text-to-Speech (TTS) systems, particularly in scalability, speaker consistency, and natural turn-taking.
A core innovation of VibeVoice is its use of continuous speech tokenizers (Acoustic and Semantic) operating at an ultra-low frame rate of 7.5 Hz. These tokenizers efficiently preserve audio fidelity while significantly boosting computational efficiency for processing long sequences. VibeVoice employs a next-token diffusion framework, leveraging a Large Language Model (LLM) to understand textual context and dialogue flow, and a diffusion head to generate high-fidelity acoustic details.
The model can synthesize speech up to 90 minutes long with up to 4 distinct speakers, surpassing the typical 1-2 speaker limits of many prior models.
➡️ Technical Report: VibeVoice Technical Report
➡️ Project Page: microsoft/VibeVoice
➡️ Code: microsoft/VibeVoice-Code
Transformer-based Large Language Model (LLM) integrated with specialized acoustic and semantic tokenizers and a diffusion-based decoding head.
The VibeVoice model is limited to research purpose use exploring highly realistic audio dialogue generation detailed in the paper published at [insert link].
Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by MIT License. Use to generate any text transcript. Furthermore, this release is not intended or licensed for any of the following scenarios:
While efforts have been made to optimize it through various techniques, it may still produce outputs that are unexpected, biased, or inaccurate. VibeVoice inherits any biases, errors, or omissions produced by its base model (specifically, Qwen2.5 1.5b in this release). Potential for Deepfakes and Disinformation: High-quality synthetic speech can be misused to create convincing fake audio content for impersonation, fraud, or spreading disinformation. Users must ensure transcripts are reliable, check content accuracy, and avoid using generated content in misleading ways. Users are expected to use the generated content and to deploy the models in a lawful manner, in full compliance with all applicable laws and regulations in the relevant jurisdictions. It is best practice to disclose the use of AI when sharing AI-generated content. English and Chinese only: Transcripts in language other than English or Chinese may result in unexpected audio outputs. Non-Speech Audio: The model focuses solely on speech synthesis and does not handle background noise, music, or other sound effects. Overlapping Speech: The current model does not explicitly model or generate overlapping speech segments in conversations.
We do not recommend using VibeVoice in commercial or real-world applications without further testing and development. This model is intended for research and development purposes only. Please use responsibly.
To mitigate the risks of misuse, we have: Embedded an audible disclaimer (e.g. “This segment was generated by AI”) automatically into every synthesized audio file. Added an imperceptible watermark to generated audio so third parties can verify VibeVoice provenance. Please see contact information at the end of this model card. Logged inference requests (hashed) for abuse pattern detection and publishing aggregated statistics quarterly. Users are responsible for sourcing their datasets legally and ethically. This may include securing appropriate rights and/or anonymizing data prior to use with VibeVoice. Users are reminded to be mindful of data privacy concerns.
This project was conducted by members of Microsoft Research. We welcome feedback and collaboration from our audience. If you have suggestions, questions, or observe unexpected/offensive behavior in our technology, please contact us at [email protected]. If the team receives reports of undesired behavior or identifies issues independently, we will update this repository with appropriate mitigations.