
MaPO
Collection
This collection includes the models and datasets as a part of the MaPO release.
•
9 items
•
Updated
•
5

We propose MaPO, a reference-free, sample-efficient, memory-friendly alignment technique for text-to-image diffusion models. For more details on the technique, please refer to our paper here.
This model was fine-tuned from Stable Diffusion XL on the yuvalkirstain/pickapic_v2 dataset.
Refer to our code repository here.

Below we report some quantitative metrics and use them to compare MaPO to existing models:
| Aesthetic | HPS v2.1 | Pickscore | |
|---|---|---|---|
| SDXL | 6.03 | 30.0 | 22.4 |
| SFTChosen | 5.95 | 29.6 | 22.0 |
| Diffusion-DPO | 6.03 | 31.1 | 22.7 |
| MaPO (Ours) | 6.17 | 31.2 | 22.5 |
We evaluated this checkpoint in the Imgsys public benchmark. MaPO was able to outperform or match 21 out of 25 state-of-the-art text-to-image diffusion models by ranking 7th on the leaderboard at the time of writing, compared to Diffusion-DPO’s 20th place, while also consuming 14.5% less wall-clock training time on adapting Pick-a-Pic v2. We appreciate the imgsys team for helping us get the human preference data.
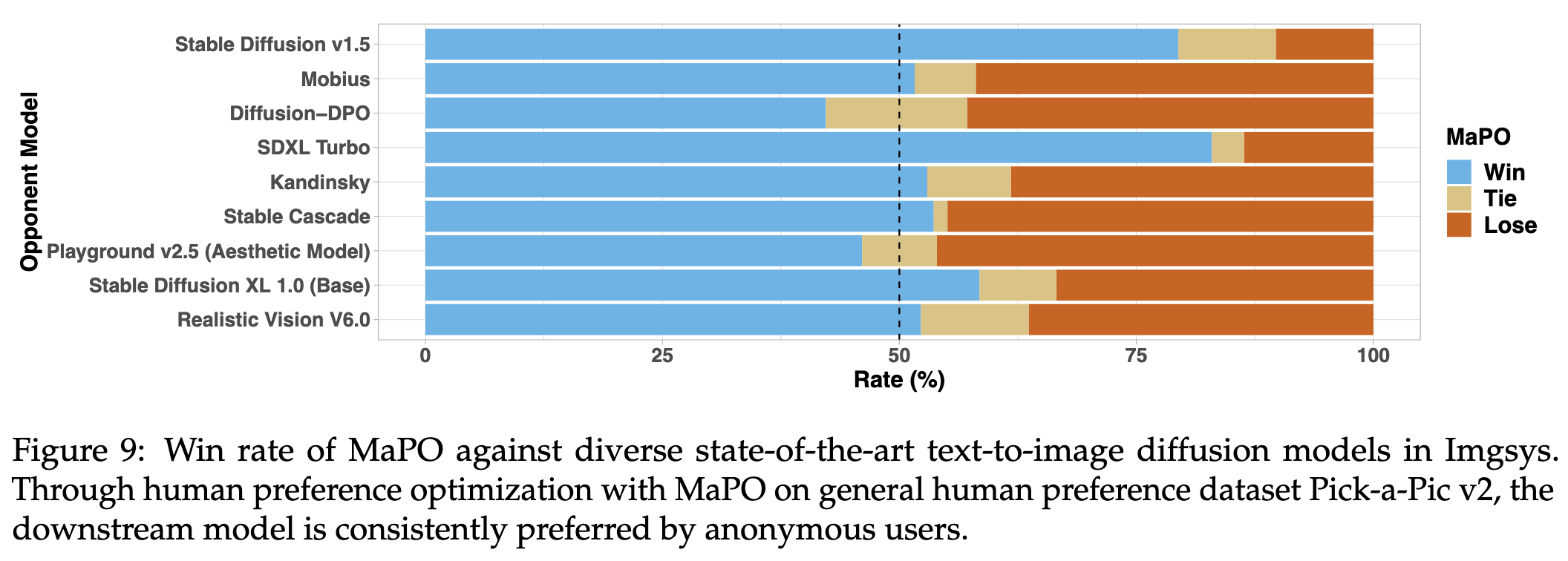
The table below reports memory efficiency of MaPO, making it a better alternative for alignment fine-tuning of diffusion models:
| Diffusion-DPO | MaPO (Ours) | |
|---|---|---|
| Time (↓) | 63.5 | 54.3 (-14.5%) |
| GPU Mem. (↓) | 55.9 | 46.1 (-17.5%) |
| Max Batch (↑) | 4 | 16 (×4) |
from diffusers import DiffusionPipeline, AutoencoderKL, UNet2DConditionModel
import torch
sdxl_id = "stabilityai/stable-diffusion-xl-base-1.0"
vae_id = "madebyollin/sdxl-vae-fp16-fix"
unet_id = "mapo-t2i/mapo-beta"
vae = AutoencoderKL.from_pretrained(vae_id, torch_dtype=torch.float16)
unet = UNet2DConditionModel.from_pretrained(unet_id, torch_dtype=torch.float16)
pipeline = DiffusionPipeline.from_pretrained(sdxl_id, vae=vae, unet=unet, torch_dtype=torch.float16).to("cuda")
prompt = "An abstract portrait consisting of bold, flowing brushstrokes against a neutral background."
image = pipeline(prompt=prompt, num_inference_steps=30).images[0]
For qualitative results, please visit our project website.
@misc{hong2024marginaware,
title={Margin-aware Preference Optimization for Aligning Diffusion Models without Reference},
author={Jiwoo Hong and Sayak Paul and Noah Lee and Kashif Rasul and James Thorne and Jongheon Jeong},
year={2024},
eprint={2406.06424},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Base model
stabilityai/stable-diffusion-xl-base-1.0