|
|
--- |
|
|
license: apache-2.0 |
|
|
base_model: |
|
|
- mistralai/Mistral-Small-24B-Instruct-2501 |
|
|
--- |
|
|
|
|
|
Following suggestions from section 6.2 in the [Llama-3 paper](https://arxiv.org/abs/2407.21783) and discussions elsewhere, here are experimental extra-large GGUF quantizations of vanilla [Mistral-Small-24B-Instruct-2501](https://huggingface.co/mistralai/Mistral-Small-24B-Instruct-2501), where: |
|
|
|
|
|
- `token_embd` and `output` are in BF16 precision; |
|
|
- All attention layers are in BF16 precision; |
|
|
- The entirety of the first and final transformer layers are in BF16 precision; |
|
|
- Intermediate feed-forward network (FFN) layers are in _uniformly **low**_ precision. |
|
|
|
|
|
For the same total model size, computed perplexity values _do not appear to be better_ than smaller standard GGUF quantizations, but supposedly this quantization scheme might help with real-world long-context performance and complex tasks while keeping size limited. Your mileage may vary. |
|
|
|
|
|
## KL divergence testing |
|
|
Computed using `llama-perplexity` on a custom text file over 4 chunks, n_ctx=2048, batch_size=2048, n_seq=1. Some results are strange but remained the same after repeating them several times. They might have been the result of using a short test file. |
|
|
|
|
|
[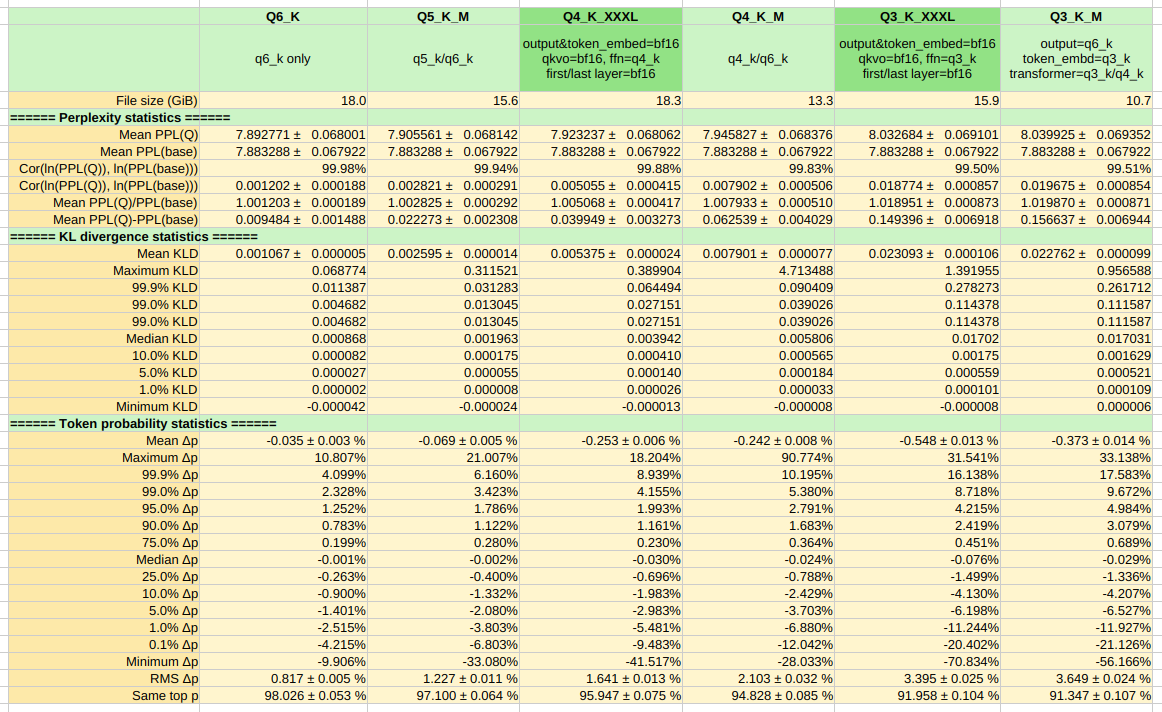](https://files.catbox.moe/wzrzlc.png) |
|
|
|
|
|
## Method |
|
|
These quantizations were made by naively modifying `llama-quant.cpp` in llama.cpp (specifically, the function `ggml_type llama_tensor_get_type()`), recompiling the project and invoking `llama-quantize` afterward. In summary, I forced the BF16 type for the attention layers and first and last transformer layers for Mistral-Small-24B, and forcing the Q4_K type for the FFN layers which would otherwise be in mixed Q4_K and Q6_K precision. `token_embed` and `output` could be set to BF16 precision with `llama-quantize` using the flags `--output-tensor-type BF16 --token-embedding-type BF16`. |
|
|
|
|
|
Some pseudocode with the modifications to `llama-quant.cpp` in the case of the Q4_K_XXXL quantization: |
|
|
|
|
|
```cpp |
|
|
static ggml_type llama_tensor_get_type(quantize_state_impl & qs, ggml_type new_type, const ggml_tensor * tensor, llama_ftype ftype) { |
|
|
... |
|
|
} else if (name.find("blk.0") != std::string::npos) { |
|
|
new_type = GGML_TYPE_BF16; |
|
|
} else if (name.find("blk.39") != std::string::npos) { |
|
|
new_type = GGML_TYPE_BF16; |
|
|
... |
|
|
} else if (name.find("attn_k.weight") != std::string::npos) { |
|
|
... |
|
|
else if (ftype == LLAMA_FTYPE_MOSTLY_Q4_K_M) { |
|
|
new_type = GGML_TYPE_BF16; |
|
|
} |
|
|
} else if (name.find("attn_q.weight") != std::string::npos) { |
|
|
... |
|
|
else if (ftype == LLAMA_FTYPE_MOSTLY_Q4_K_M) { |
|
|
new_type = GGML_TYPE_BF16; |
|
|
} |
|
|
} else if (name.find("ffn_down") != std::string::npos) { |
|
|
... |
|
|
else if (ftype == LLAMA_FTYPE_MOSTLY_Q4_K_M) { |
|
|
new_type = GGML_TYPE_Q4_K; |
|
|
} else if (name.find("attn_output.weight") != std::string::npos) { |
|
|
if (ftype == LLAMA_FTYPE_MOSTLY_Q4_K_M) { |
|
|
new_type = GGML_TYPE_BF16; |
|
|
} |
|
|
} else if (name.find("attn_qkv.weight") != std::string::npos) { |
|
|
... |
|
|
else if (ftype == LLAMA_FTYPE_MOSTLY_Q4_K_M) new_type = GGML_TYPE_BF16; |
|
|
``` |
