
Model Card for Omni DeepSeek
Model Training Details

Model Description
I've trained an interesting text-image-video CoT LLM through image-text space alignment, CoT-SFT warm-up, and GRPO training. I've observed that this model can provide more accurate answers through Chain-of-Thought reasoning, particularly excelling in complex instruction following and formatted output.
- Developed by: princepride
- Model type: text-image-video CoT LLM
Model Sources
- Demo :
- It can analysis the video with chain of thought to output a better result
- Input :

- Output :
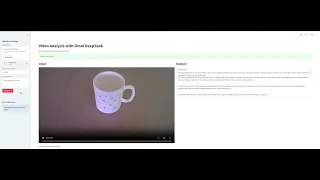
- Because chain of thought, it can better follow complex instructions and generate accurately formatted output:
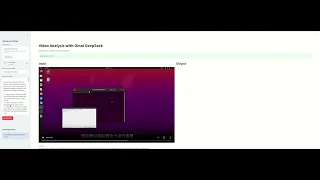
- Input :
- Output :
Uses(At least 24GB of VRAM is required)
pip install -r requirements.txt
streamlit run app.py
- Downloads last month
- 56
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support