
Interesting comparisons!

Heya Ed! Thanks for posting this with some more comparisons and examples of your methodology. Qwen3-30B-A3B has so many quants available and a growing collections of benchmarks which makes it a good opportunity to test some of the evolving methods!
I haven't fully grok'd all the results in the tables, but at first glace a few things I notice:
- Your
IQ3_Mstands out as having pretty good scores for the size. I'd be curious if you did a ~2bpw e.g.IQ2_MorQ2_K_Las those benchmarked surprisingly well in some tests: https://www.reddit.com/r/LocalLLaMA/comments/1khwxal/the_great_quant_wars_of_2025/ - I was surprised that none of your quants ended up with "better" perplexity than the bf16 baseline. Most of ik's fork's
iq4_kswhich uses 32 block size were consistently scoring lower perplexity than bf16, almost like some kinda QAT was involved (though no mention of QAT for Qwen3 mentioned in the papers afaict). - If you had to pick a single one of your quants for benchmarking against some of the ones in the above reddit article, which would you choose e.g. maybe your
Q4_K_M? Not sure if @bartowski has time to throw one more quant into the backlog or not... hej hej hej...
Thanks, appreciate your contributions and "just try it then measure" engineering approach!
My pleasure @ubergarm
The IQ3_M is mostly a mix of 3.44 and 3.06 bpw:
--token-embedding-type iq3_s
--output-tensor-type iq3_s
--tensor-type "\.([0-9]|1[0-9]|2[0-3])\.attn_k=iq3_xxs"
--tensor-type "\.([0-9]|1[0-9]|2[0-3])\.attn_q=iq3_xxs"
--tensor-type "\.([0-9]|1[0-9]|2[0-3])\.attn_v=iq3_s"
--tensor-type attn_v=iq4_nl
--tensor-type "\.([0-9]|1[0124]|1[6-9]|2[0-4]|26)\.ffn_gate_exps=iq3_xxs"
--tensor-type "\.([0-9]|1[0124]|1[6-9]|2[0-4]|26)\.ffn_up_exps=iq3_xxs"
--tensor-type ffn_down_exps=iq4_nl
I saw the Qwen3 quantization experiments discussion but in my case, as you pointed out, all quants had a higher PPL than the baseline model. Not sure why this is. Maybe an unexpected benefit of the ik_llama enhancements? There's also the issue of my imatrix not activating all tensors. I'm sure there's some impact but I'd expect it to be < 0.2% PPL
As for benchmarking, I'd definitely choose Q4_K_M. The quant mixes I'm using aim to maximize compression for that type, plus both @bartowski and @danielhanchen offer versions of it: https://huggingface.co/bartowski/Qwen_Qwen3-30B-A3B-GGUF/blob/main/Qwen_Qwen3-30B-A3B-Q4_K_M.gguf & https://huggingface.co/unsloth/Qwen3-30B-A3B-GGUF/blob/main/Qwen3-30B-A3B-Q4_K_M.gguf
If not too much of a hassle, any chance you could also share the quant to baseline (BF16) PPL correlation coefficient?
Thanks, yes I've heard this model is challenging to activate all the tensors which can cause issues on smaller quants, though I didn't try anything smaller than ~4.5bpw myself.
If not too much of a hassle, any chance you could also share the quant to baseline (BF16) PPL correlation coefficient?
Is that this line under Perplexity statistics: Cor(ln(PPL(Q)), ln(PPL(base))): ? I copy pasted my rough log file that I parsed for the graphs and tables in the methodology and raw data portion of the qwen3moe benchmarking gist which has more stuff in it for the quants I tested:
👈 Raw Data Here
Qwen3-30B-A3B-GGUF Quant Comparison
All run on ik_llama.cpp@9ba36270 (before CUDA FA MMQ improvements)
Perplexity & KLD
Qwen/Qwen3-30B-A3B/Qwen3-30B-A3B-BF16-00001-of-00011.gguf (Baseline)
- 57GiB
- Final estimate: PPL = 9.0703 +/- 0.07223
wiki.test.raw - Final estimate: PPL = 15.1443 +/- 0.10239
ubergarm-kld-test-corpus.txt - No KLD data as this is the Baseline that generates the KLD base file. It doesn't diverge from itself.
ubergarm/Qwen3-30B-A3B-GGUF/Qwen3-30B-A3B-Q8_0
- 31GiB
- Final estimate: PPL = 9.0740 +/- 0.07228
wiki.test.raw ubergarm-kld-test-corpus.txt
====== Perplexity statistics ======
Mean PPL(Q) : 15.152095 ± 0.102398
Mean PPL(base) : 15.144396 ± 0.102391
Cor(ln(PPL(Q)), ln(PPL(base))): 99.96%
Mean ln(PPL(Q)/PPL(base)) : 0.000508 ± 0.000192
Mean PPL(Q)/PPL(base) : 1.000508 ± 0.000193
Mean PPL(Q)-PPL(base) : 0.007698 ± 0.002916
====== KL divergence statistics ======
Mean KLD: 0.002337 ± 0.000009
Maximum KLD: 0.359152
99.9% KLD: 0.039718
99.0% KLD: 0.013699
99.0% KLD: 0.013699
Median KLD: 0.001587
10.0% KLD: 0.000154
5.0% KLD: 0.000038
1.0% KLD: 0.000001
Minimum KLD: -0.000047
====== Token probability statistics ======
Mean Δp: -0.020 ± 0.003 %
Maximum Δp: 28.466%
99.9% Δp: 7.128%
99.0% Δp: 3.763%
95.0% Δp: 1.964%
90.0% Δp: 1.176%
75.0% Δp: 0.231%
Median Δp: -0.000%
25.0% Δp: -0.282%
10.0% Δp: -1.241%
5.0% Δp: -2.035%
1.0% Δp: -3.834%
0.1% Δp: -7.050%
Minimum Δp: -34.379%
RMS Δp : 1.279 ± 0.008 %
Same top p: 96.972 ± 0.039 %
ubergarm/Qwen3-30B-A3B-GGUF/Qwen3-30B-A3B-mix-IQ4_K
- 18 GiB
- Final estimate: PPL = 9.1184 +/- 0.07278
wiki.test.raw ubergarm-kld-test-corpus.txt
====== Perplexity statistics ======
Mean PPL(Q) : 15.218819 ± 0.103071
Mean PPL(base) : 15.144396 ± 0.102391
Cor(ln(PPL(Q)), ln(PPL(base))): 99.91%
Mean ln(PPL(Q)/PPL(base)) : 0.004902 ± 0.000286
Mean PPL(Q)/PPL(base) : 1.004914 ± 0.000287
Mean PPL(Q)-PPL(base) : 0.074423 ± 0.004389
====== KL divergence statistics ======
Mean KLD: 0.004821 ± 0.000024
Maximum KLD: 2.514502
99.9% KLD: 0.104454
99.0% KLD: 0.032109
99.0% KLD: 0.032109
Median KLD: 0.002970
10.0% KLD: 0.000298
5.0% KLD: 0.000080
1.0% KLD: 0.000004
Minimum KLD: -0.000048
====== Token probability statistics ======
Mean Δp: -0.025 ± 0.004 %
Maximum Δp: 39.508%
99.9% Δp: 10.626%
99.0% Δp: 5.373%
95.0% Δp: 2.682%
90.0% Δp: 1.592%
75.0% Δp: 0.326%
Median Δp: -0.000%
25.0% Δp: -0.376%
10.0% Δp: -1.645%
5.0% Δp: -2.742%
1.0% Δp: -5.522%
0.1% Δp: -11.731%
Minimum Δp: -44.213%
RMS Δp : 1.818 ± 0.011 %
Same top p: 95.945 ± 0.045 %
ubergarm/Qwen3-30B-A3B-GGUF/Qwen3-30B-A3B-IQ4_KS
- 16GiB
- Final estimate: PPL = 8.9862 +/- 0.07061
wiki.test.raw ubergarm-kld-test-corpus.txt
====== Perplexity statistics ======
Mean PPL(Q) : 15.182811 ± 0.102278
Mean PPL(base) : 15.144396 ± 0.102391
Cor(ln(PPL(Q)), ln(PPL(base))): 99.73%
Mean ln(PPL(Q)/PPL(base)) : 0.002533 ± 0.000496
Mean PPL(Q)/PPL(base) : 1.002537 ± 0.000497
Mean PPL(Q)-PPL(base) : 0.038415 ± 0.007513
====== KL divergence statistics ======
Mean KLD: 0.014617 ± 0.000068
Maximum KLD: 6.828948
99.9% KLD: 0.282245
99.0% KLD: 0.094074
99.0% KLD: 0.094074
Median KLD: 0.008934
10.0% KLD: 0.001003
5.0% KLD: 0.000292
1.0% KLD: 0.000018
Minimum KLD: -0.000031
====== Token probability statistics ======
Mean Δp: -0.209 ± 0.007 %
Maximum Δp: 89.561%
99.9% Δp: 16.987%
99.0% Δp: 8.691%
95.0% Δp: 4.167%
90.0% Δp: 2.398%
75.0% Δp: 0.442%
Median Δp: -0.003%
25.0% Δp: -0.796%
10.0% Δp: -3.073%
5.0% Δp: -5.017%
1.0% Δp: -10.000%
0.1% Δp: -20.721%
Minimum Δp: -75.475%
RMS Δp : 3.106 ± 0.019 %
Same top p: 93.625 ± 0.056 %
ubergarm/Qwen3-30B-A3B-GGUF/Qwen3-30B-A3B-smol-IQ4_KS
- 16GiB
- Final estimate: PPL = 8.9864 +/- 0.07061
wiki.test.raw ubergarm-kld-test-corpus.txt
====== Perplexity statistics ======
Mean PPL(Q) : 15.169532 ± 0.102138
Mean PPL(base) : 15.144396 ± 0.102391
Cor(ln(PPL(Q)), ln(PPL(base))): 99.72%
Mean ln(PPL(Q)/PPL(base)) : 0.001658 ± 0.000502
Mean PPL(Q)/PPL(base) : 1.001660 ± 0.000503
Mean PPL(Q)-PPL(base) : 0.025136 ± 0.007600
====== KL divergence statistics ======
Mean KLD: 0.014953 ± 0.000076
Maximum KLD: 9.010440
99.9% KLD: 0.285813
99.0% KLD: 0.096190
99.0% KLD: 0.096190
Median KLD: 0.009187
10.0% KLD: 0.001035
5.0% KLD: 0.000305
1.0% KLD: 0.000019
Minimum KLD: -0.000027
====== Token probability statistics ======
Mean Δp: -0.239 ± 0.007 %
Maximum Δp: 75.345%
99.9% Δp: 16.929%
99.0% Δp: 8.674%
95.0% Δp: 4.143%
90.0% Δp: 2.387%
75.0% Δp: 0.433%
Median Δp: -0.003%
25.0% Δp: -0.823%
10.0% Δp: -3.162%
5.0% Δp: -5.133%
1.0% Δp: -10.164%
0.1% Δp: -20.759%
Minimum Δp: -82.954%
RMS Δp : 3.134 ± 0.019 %
Same top p: 93.576 ± 0.056 %
unsloth/Qwen3-30B-A3B-GGUF/Qwen3-30B-A3B-UD-Q4_K_XL
- 17GiB
- Final estimate: PPL = 9.1688 +/- 0.07290
wiki.test.raw ubergarm-kld-test-corpus.txt
====== Perplexity statistics ======
Mean PPL(Q) : 15.281833 ± 0.103140
Mean PPL(base) : 15.144396 ± 0.102391
Cor(ln(PPL(Q)), ln(PPL(base))): 99.70%
Mean ln(PPL(Q)/PPL(base)) : 0.009034 ± 0.000524
Mean PPL(Q)/PPL(base) : 1.009075 ± 0.000529
Mean PPL(Q)-PPL(base) : 0.137437 ± 0.008012
====== KL divergence statistics ======
Mean KLD: 0.016495 ± 0.000071
Maximum KLD: 5.570370
99.9% KLD: 0.305740
99.0% KLD: 0.102021
99.0% KLD: 0.102021
Median KLD: 0.010432
10.0% KLD: 0.001152
5.0% KLD: 0.000315
1.0% KLD: 0.000015
Minimum KLD: -0.000016
====== Token probability statistics ======
Mean Δp: -0.320 ± 0.008 %
Maximum Δp: 67.990%
99.9% Δp: 17.384%
99.0% Δp: 8.910%
95.0% Δp: 4.261%
90.0% Δp: 2.460%
75.0% Δp: 0.421%
Median Δp: -0.005%
25.0% Δp: -0.938%
10.0% Δp: -3.508%
5.0% Δp: -5.582%
1.0% Δp: -11.111%
0.1% Δp: -21.984%
Minimum Δp: -85.356%
RMS Δp : 3.333 ± 0.020 %
Same top p: 93.169 ± 0.058 %
bartowski/Qwen_Qwen3-30B-A3B-GGUF/Qwen_Qwen3-30B-A3B-Q4_K_M
- 18GiB
- Final estimate: PPL = 9.2092 +/- 0.07381
wiki.test.raw ubergarm-kld-test-corpus.txt
====== Perplexity statistics ======
Mean PPL(Q) : 15.194468 ± 0.102605
Mean PPL(base) : 15.144396 ± 0.102391
Cor(ln(PPL(Q)), ln(PPL(base))): 99.81%
Mean ln(PPL(Q)/PPL(base)) : 0.003301 ± 0.000412
Mean PPL(Q)/PPL(base) : 1.003306 ± 0.000413
Mean PPL(Q)-PPL(base) : 0.050072 ± 0.006250
====== KL divergence statistics ======
Mean KLD: 0.010136 ± 0.000053
Maximum KLD: 5.985787
99.9% KLD: 0.195169
99.0% KLD: 0.063238
99.0% KLD: 0.063238
Median KLD: 0.006434
10.0% KLD: 0.000652
5.0% KLD: 0.000171
1.0% KLD: 0.000008
Minimum KLD: -0.000032
====== Token probability statistics ======
Mean Δp: -0.158 ± 0.006 %
Maximum Δp: 61.522%
99.9% Δp: 14.392%
99.0% Δp: 7.356%
95.0% Δp: 3.570%
90.0% Δp: 2.084%
75.0% Δp: 0.398%
Median Δp: -0.001%
25.0% Δp: -0.645%
10.0% Δp: -2.643%
5.0% Δp: -4.286%
1.0% Δp: -8.303%
0.1% Δp: -16.135%
Minimum Δp: -88.357%
RMS Δp : 2.619 ± 0.018 %
Same top p: 94.329 ± 0.053 %
bartowski/Qwen_Qwen3-30B-A3B-GGUF/Qwen_Qwen3-30B-A3B-Q4_K_S
- 17GiB
- Final estimate: PPL = 9.2232 +/- 0.07371
wiki.test.raw ubergarm-kld-test-corpus.txt
====== Perplexity statistics ======
Mean PPL(Q) : 15.202408 ± 0.102513
Mean PPL(base) : 15.144396 ± 0.102391
Cor(ln(PPL(Q)), ln(PPL(base))): 99.77%
Mean ln(PPL(Q)/PPL(base)) : 0.003823 ± 0.000463
Mean PPL(Q)/PPL(base) : 1.003831 ± 0.000465
Mean PPL(Q)-PPL(base) : 0.058012 ± 0.007021
====== KL divergence statistics ======
Mean KLD: 0.012915 ± 0.000065
Maximum KLD: 5.971601
99.9% KLD: 0.233980
99.0% KLD: 0.077885
99.0% KLD: 0.077885
Median KLD: 0.008261
10.0% KLD: 0.000862
5.0% KLD: 0.000235
1.0% KLD: 0.000013
Minimum KLD: -0.000038
====== Token probability statistics ======
Mean Δp: -0.227 ± 0.007 %
Maximum Δp: 66.795%
99.9% Δp: 15.420%
99.0% Δp: 7.972%
95.0% Δp: 3.866%
90.0% Δp: 2.215%
75.0% Δp: 0.402%
Median Δp: -0.002%
25.0% Δp: -0.780%
10.0% Δp: -3.006%
5.0% Δp: -4.787%
1.0% Δp: -9.230%
0.1% Δp: -18.122%
Minimum Δp: -87.019%
RMS Δp : 2.885 ± 0.019 %
Same top p: 93.804 ± 0.055 %
ikawrakow/Qwen3-30B-A3B-IQ4_KS-Bartowski
- 16GiB
- Final estimate: PPL = 9.0016 +/- 0.07078
wiki.test.raw ubergarm-kld-test-corpus.txt
====== Perplexity statistics ======
Mean PPL(Q) : 15.150462 ± 0.101931
Mean PPL(base) : 15.144396 ± 0.102391
Cor(ln(PPL(Q)), ln(PPL(base))): 99.71%
Mean ln(PPL(Q)/PPL(base)) : 0.000400 ± 0.000514
Mean PPL(Q)/PPL(base) : 1.000401 ± 0.000514
Mean PPL(Q)-PPL(base) : 0.006066 ± 0.007779
====== KL divergence statistics ======
Mean KLD: 0.015818 ± 0.000074
Maximum KLD: 6.971420
99.9% KLD: 0.290617
99.0% KLD: 0.099815
99.0% KLD: 0.099815
Median KLD: 0.009988
10.0% KLD: 0.001098
5.0% KLD: 0.000316
1.0% KLD: 0.000021
Minimum KLD: -0.000029
====== Token probability statistics ======
Mean Δp: -0.288 ± 0.007 %
Maximum Δp: 81.571%
99.9% Δp: 17.546%
99.0% Δp: 8.719%
95.0% Δp: 4.216%
90.0% Δp: 2.427%
75.0% Δp: 0.421%
Median Δp: -0.004%
25.0% Δp: -0.905%
10.0% Δp: -3.434%
5.0% Δp: -5.433%
1.0% Δp: -10.497%
0.1% Δp: -20.846%
Minimum Δp: -86.592%
RMS Δp : 3.244 ± 0.020 %
Same top p: 93.317 ± 0.057 %
ikawrakow/Qwen3-30B-A3B-IQ4_KS-IK
- 16GiB
- Final estimate: PPL = 9.0177 +/- 0.07094
wiki.test.raw ubergarm-kld-test-corpus.txt
====== Perplexity statistics ======
Mean PPL(Q) : 15.161535 ± 0.101972
Mean PPL(base) : 15.144396 ± 0.102391
Cor(ln(PPL(Q)), ln(PPL(base))): 99.70%
Mean ln(PPL(Q)/PPL(base)) : 0.001131 ± 0.000522
Mean PPL(Q)/PPL(base) : 1.001132 ± 0.000522
Mean PPL(Q)-PPL(base) : 0.017138 ± 0.007896
====== KL divergence statistics ======
Mean KLD: 0.016277 ± 0.000074
Maximum KLD: 7.146766
99.9% KLD: 0.301946
99.0% KLD: 0.102473
99.0% KLD: 0.102473
Median KLD: 0.010269
10.0% KLD: 0.001192
5.0% KLD: 0.000352
1.0% KLD: 0.000026
Minimum KLD: -0.000007
====== Token probability statistics ======
Mean Δp: -0.323 ± 0.007 %
Maximum Δp: 58.365%
99.9% Δp: 17.416%
99.0% Δp: 8.750%
95.0% Δp: 4.163%
90.0% Δp: 2.383%
75.0% Δp: 0.405%
Median Δp: -0.006%
25.0% Δp: -0.959%
10.0% Δp: -3.461%
5.0% Δp: -5.489%
1.0% Δp: -10.689%
0.1% Δp: -21.414%
Minimum Δp: -90.822%
RMS Δp : 3.265 ± 0.019 %
Same top p: 93.216 ± 0.057 %
ikawrakow/Qwen3-30B-A3B-IQ4_KS-Unslolth
- 16GiB
- Final estimate: PPL = 8.9171 +/- 0.06945
wiki.test.raw ubergarm-kld-test-corpus.txt
====== Perplexity statistics ======
Mean PPL(Q) : 15.109454 ± 0.101327
Mean PPL(base) : 15.144396 ± 0.102391
Cor(ln(PPL(Q)), ln(PPL(base))): 99.70%
Mean ln(PPL(Q)/PPL(base)) : -0.002310 ± 0.000528
Mean PPL(Q)/PPL(base) : 0.997693 ± 0.000527
Mean PPL(Q)-PPL(base) : -0.034942 ± 0.008017
====== KL divergence statistics ======
Mean KLD: 0.016845 ± 0.000077
Maximum KLD: 7.383745
99.9% KLD: 0.314624
99.0% KLD: 0.104796
99.0% KLD: 0.104796
Median KLD: 0.010667
10.0% KLD: 0.001218
5.0% KLD: 0.000351
1.0% KLD: 0.000023
Minimum KLD: -0.000012
====== Token probability statistics ======
Mean Δp: -0.366 ± 0.008 %
Maximum Δp: 78.742%
99.9% Δp: 18.042%
99.0% Δp: 8.799%
95.0% Δp: 4.173%
90.0% Δp: 2.355%
75.0% Δp: 0.396%
Median Δp: -0.006%
25.0% Δp: -1.015%
10.0% Δp: -3.610%
5.0% Δp: -5.698%
1.0% Δp: -11.082%
0.1% Δp: -21.919%
Minimum Δp: -86.065%
RMS Δp : 3.331 ± 0.020 %
Same top p: 93.217 ± 0.057 %
bartowski/Qwen3-30B-A3B-IQ2_M
- 9.8GiB
- Final estimate: PPL = 9.9788 +/- 0.08036
wiki.test.raw ubergarm-kld-test-corpus.txt
====== Perplexity statistics ======
Mean PPL(Q) : 15.436905 ± 0.102661
Mean PPL(base) : 15.144396 ± 0.102391
Cor(ln(PPL(Q)), ln(PPL(base))): 98.73%
Mean ln(PPL(Q)/PPL(base)) : 0.019130 ± 0.001075
Mean PPL(Q)/PPL(base) : 1.019315 ± 0.001096
Mean PPL(Q)-PPL(base) : 0.292509 ± 0.016351
====== KL divergence statistics ======
Mean KLD: 0.069100 ± 0.000258
Maximum KLD: 8.695639
99.9% KLD: 1.262156
99.0% KLD: 0.432021
99.0% KLD: 0.432021
Median KLD: 0.044448
10.0% KLD: 0.005231
5.0% KLD: 0.001459
1.0% KLD: 0.000068
Minimum KLD: -0.000004
====== Token probability statistics ======
Mean Δp: -1.300 ± 0.016 %
Maximum Δp: 80.027%
99.9% Δp: 31.659%
99.0% Δp: 16.466%
95.0% Δp: 7.477%
90.0% Δp: 4.031%
75.0% Δp: 0.538%
Median Δp: -0.039%
25.0% Δp: -2.590%
10.0% Δp: -8.541%
5.0% Δp: -13.210%
1.0% Δp: -24.583%
0.1% Δp: -48.093%
Minimum Δp: -96.452%
RMS Δp : 6.979 ± 0.033 %
Same top p: 86.303 ± 0.079 %
unsloth/Qwen3-30B-A3B-UD-IQ2_M
- 11GiB
- Final estimate: PPL = 10.3726 +/- 0.08541
wiki.test.raw ubergarm-kld-test-corpus.txt
====== Perplexity statistics ======
Mean PPL(Q) : 15.889509 ± 0.107834
Mean PPL(base) : 15.144396 ± 0.102391
Cor(ln(PPL(Q)), ln(PPL(base))): 98.76%
Mean ln(PPL(Q)/PPL(base)) : 0.048029 ± 0.001069
Mean PPL(Q)/PPL(base) : 1.049201 ± 0.001122
Mean PPL(Q)-PPL(base) : 0.745113 ± 0.017451
====== KL divergence statistics ======
Mean KLD: 0.066646 ± 0.000267
Maximum KLD: 8.153114
99.9% KLD: 1.370219
99.0% KLD: 0.457244
99.0% KLD: 0.457244
Median KLD: 0.039668
10.0% KLD: 0.004283
5.0% KLD: 0.001229
1.0% KLD: 0.000072
Minimum KLD: -0.000011
====== Token probability statistics ======
Mean Δp: -0.607 ± 0.015 %
Maximum Δp: 88.509%
99.9% Δp: 34.262%
99.0% Δp: 17.671%
95.0% Δp: 8.514%
90.0% Δp: 4.934%
75.0% Δp: 0.843%
Median Δp: -0.011%
25.0% Δp: -1.739%
10.0% Δp: -6.698%
5.0% Δp: -11.071%
1.0% Δp: -22.803%
0.1% Δp: -47.141%
Minimum Δp: -99.283%
RMS Δp : 6.627 ± 0.033 %
Same top p: 87.029 ± 0.077 %
Notes
These calculations made with ik_llama.cpp@9ba36270.
That's the one! thank you. I find the Pearson correlation coefficient to be an excellent measurement of the token probabilities deviation between the base (typically BF16) and the quantized version.
Taking ubergarm/Qwen3-30B-A3B-GGUF/Qwen3-30B-A3B-mix-IQ4_K as an example, the model is only 0.09% "off" from its base (𝜌PPL = 99.91%) and therefore it should behave just like the full BF16 version 99.91% of the times.
An advantage of the metric is that it allows for a like-for-like comparison between different quantizations so, based on the provided stats, one can conclude that your IQ4_K quant performs the closest to its BF16 counterpart than all of the other Q4 variants.
Wow that is interesting! To be fair the first layer (blk.0.attn_*) of my mix-IQ4_K is "juiced" to Q8_0 haha... I didn't do another version to see how much that actually helped, it was just more for fun as ik's layer-similarity score suggested it was most important. To be more fair, my quant is also the slowest inferencing of the Q4 variants psure as it is a bit heavier and the CUDA kernels on ik's fork are optimized more for other architectures currently I believe.
While I'm here, have you messed around with exllamav3 and the interesting "QTIP" inspired exl3 quants? The link goes to my very rough "guide" from my experience getting it going and cooking a few quants as well as setting up an API endpoint for inferencing. The references has some links to the original QTIP blog and paper as well as a fascinating github PR discussing various "magic numbers" for optimizing quantization performance and quality hahah...
So exllamav3 has an interesting tool called eval/compare_q.py which with a little work can be setup to automatically compare PPL and KLD across a number of quants and make a nice graph. However, I can't figure out how to run llama-perplexity directly and get apples-apples PPL scores as it uses llama-cpp-python bindings. All this to say I'm not sure how to compare ik's new quants with exl3 quants fairly... Just the things rumbling around in the back of my head this weekend lol...
Anyway, enjoy your weekend and glad you have some time to enjoy the hobby of extreme quantization too haha! Cheers!
Thanks for sharing @ubergarm and hope you had a nice weekend too! I was not aware of exllamav3, but will definitely add to the To-Do list.
I managed to properly take ik_llama for a spin. Very impressive! It would be amazing to integrate those capabilities into llama.cpp, but I suppose there's more than meets the eye on that regard.
I also managed to tweak my eaddario/imatrix-calibration files (you're welcome to them) and added weighted statistics per layer (as opposed to per tensor) into my llama-imatrix PR
Next weekend I'm hoping to requantize Qwen3-30B-A3B-GGUF with a proper imatrix, and complete the tests. Will update the repo and test results once done.
I managed to properly take ik_llama for a spin.
Oh nice! Yeah it is great for hybrid CPU+GPU inferencing with its repacked row interleaved _r4 quants which help on many CPU architectures. the iq6_k is great for attention tensors and iq4_ks is a good mix of speed and quality. Something for every taste haha...
I also managed to tweak my eaddario/imatrix-calibration files
Oh wow there is a lot of data in eaddario/imatrix-calibration. How do you use it for actual llama-imatrix calls? e.g. Can I convert some partial number of each parquet files to a single utf8 text file and use that with -f calibration.txt as using everything seems like it would take too long? I think the many calibration text files are just 1-3MiB or so depending?
Next weekend I'm hoping to requantize Qwen3-30B-A3B-GGUF with a proper imatrix, and complete the tests. Will update the repo and test results once done.
Qwen3-30B-A3B is a big enough model it can take a while to work with, but also it is an actually pretty good usable model as well as MoE which has its own challenges to activate all the routed experts. So glad to see you working with it too!
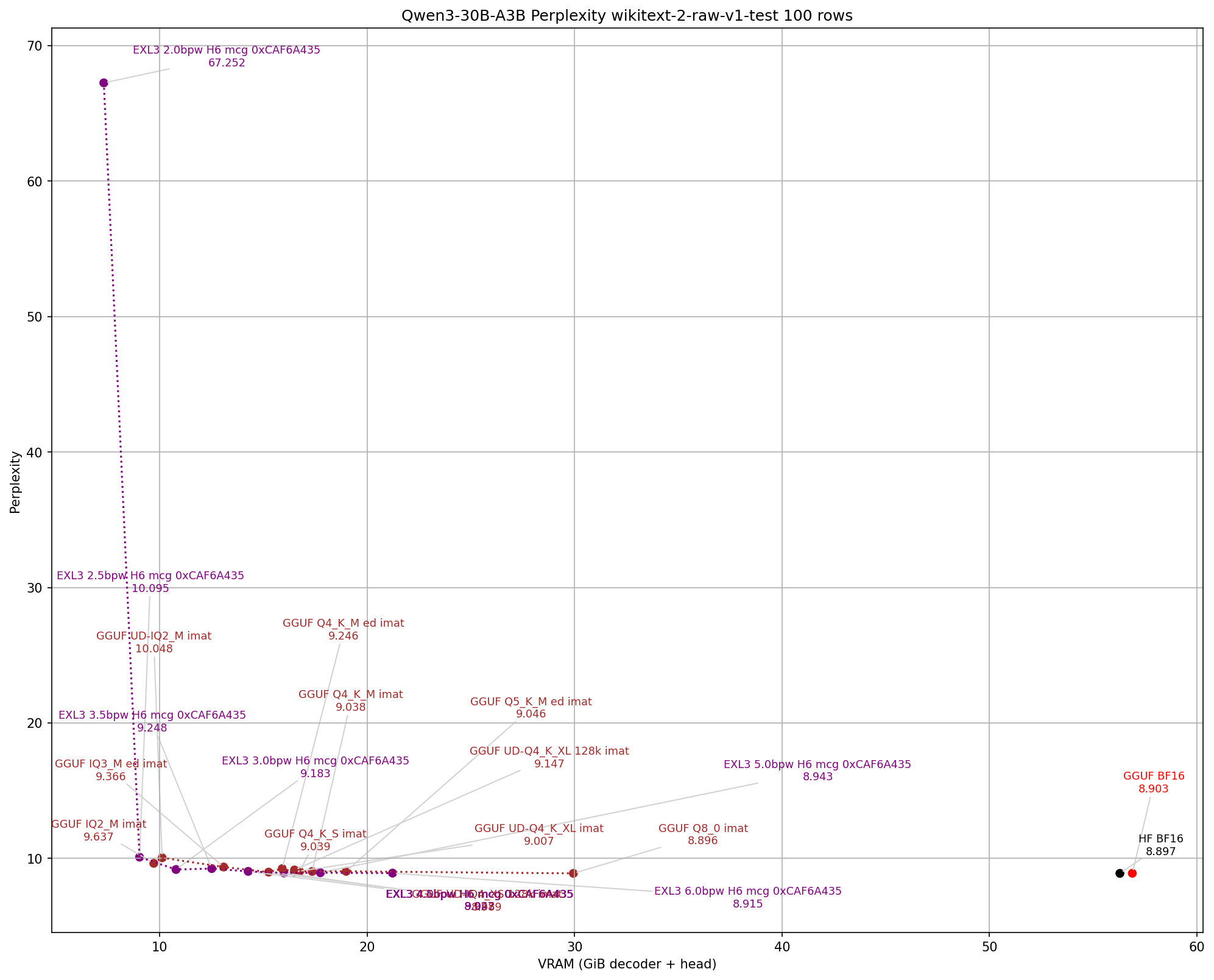
I just ran a bunch of PPL and KLD of some GGUFs including three of your current ones, some of bartowski's, and some unsloth, as well as my own exl3 for comparison. Unfortunately, I can't compare my ik quants using exllamav3/eval/compare_q.pyas it uses llama-cpp-python bindings.
The graphs are kind of crowded as this data just came out today, and I haven't had time to improve the scripts. Full json format data is provided if anyone wants the numbers for comparisons. fwiw you can't really compare with llama-imatrix for perplexity even if you run the same "100 rows" (~1.3MiB) of wiki.test.raw. Also interestingly the hugging face transformers bf16 safetensors has a slight KLD from the GGUF bf16 file. The KLD is using only "10 rows" of wiki.test.raw otherwise the logits file gets pretty big and it can OOM.
I'm curious to see how your next round goes with the improved imatrix corpus! Thanks!
👈Raw Data in JSON format
[
{
"label": "HF BF16",
"layer_bpw": 16.0,
"head_bpw": 16,
"vram_gb": 56.29052734375,
"ppl": 8.896963416807232,
"kld": 0.0
},
{
"label": "EXL3 2.0bpw H6 mcg 0xCAF6A435",
"layer_bpw": 2.0341227864035547,
"head_bpw": 6.007917910337247,
"vram_gb": 7.300313476473093,
"ppl": 67.25162091132263,
"kld": 2.2775095161326933
},
{
"label": "EXL3 2.5bpw H6 mcg 0xCAF6A435",
"layer_bpw": 2.5287238241261742,
"head_bpw": 6.007917910337247,
"vram_gb": 9.022481445223093,
"ppl": 10.095238979406716,
"kld": 0.1239086788918659
},
{
"label": "EXL3 3.0bpw H6 mcg 0xCAF6A435",
"layer_bpw": 3.0337020880442784,
"head_bpw": 6.007917910337247,
"vram_gb": 10.780782226473093,
"ppl": 9.182588255526754,
"kld": 0.0687279472209428
},
{
"label": "EXL3 3.5bpw H6 mcg 0xCAF6A435",
"layer_bpw": 3.528303125766898,
"head_bpw": 6.007917910337247,
"vram_gb": 12.502950195223093,
"ppl": 9.247539261362629,
"kld": 0.0343391250661969
},
{
"label": "EXL3 4.0bpw H6 mcg 0xCAF6A435",
"layer_bpw": 4.033281389685002,
"head_bpw": 6.007917910337247,
"vram_gb": 14.261250976473093,
"ppl": 9.042701868479641,
"kld": 0.024368329403625617
},
{
"label": "EXL3 4.5bpw H6 mcg 0xCAF6A435",
"layer_bpw": 4.527882427407621,
"head_bpw": 6.007917910337247,
"vram_gb": 15.983418945223093,
"ppl": 8.927166917597463,
"kld": 0.013147117029470714
},
{
"label": "EXL3 5.0bpw H6 mcg 0xCAF6A435",
"layer_bpw": 5.032860691325726,
"head_bpw": 6.007917910337247,
"vram_gb": 17.741719726473093,
"ppl": 8.942674618981622,
"kld": 0.009545976939601178
},
{
"label": "EXL3 6.0bpw H6 mcg 0xCAF6A435",
"layer_bpw": 6.03243999296645,
"head_bpw": 6.007917910337247,
"vram_gb": 21.222188476473093,
"ppl": 8.914982554441801,
"kld": 0.005315908464860837
},
{
"label": "GGUF BF16",
"layer_bpw": 16.00710575546037,
"head_bpw": 16.0,
"vram_gb": 29.64445686340332,
"ppl": 8.90307838931857,
"kld": 0.0018382440041680701
},
{
"label": "GGUF Q8_0 imat",
"layer_bpw": 8.510052079542378,
"head_bpw": 8.5,
"vram_gb": 29.939552307128906,
"ppl": 8.895864961372073,
"kld": 0.00376526105450302
},
{
"label": "GGUF UD-Q4_K_XL imat",
"layer_bpw": 4.620486385263758,
"head_bpw": 6.5625,
"vram_gb": 16.493436813354492,
"ppl": 9.006967324027388,
"kld": 0.02983071104526298
},
{
"label": "GGUF UD-IQ2_M imat",
"layer_bpw": 2.8071527555603777,
"head_bpw": 6.5625,
"vram_gb": 10.113798141479492,
"ppl": 10.04768989571527,
"kld": 0.1389737648072192
},
{
"label": "GGUF UD-Q4_K_XL 128k imat",
"layer_bpw": 4.620486385263758,
"head_bpw": 6.5625,
"vram_gb": 16.493436813354492,
"ppl": 9.147260263984773,
"kld": 0.06502522703666595
},
{
"label": "GGUF UD-IQ4_XS 128k imat",
"layer_bpw": 4.266403692463578,
"head_bpw": 6.5625,
"vram_gb": 15.247709274291992,
"ppl": 8.98860554080009,
"kld": 0.06928144145354515
},
{
"label": "GGUF Q4_K_S imat",
"layer_bpw": 4.691649893635455,
"head_bpw": 6.5625,
"vram_gb": 16.743803024291992,
"ppl": 9.039136994185384,
"kld": 0.024144081457776672
},
{
"label": "GGUF IQ2_M imat",
"layer_bpw": 2.702843329508759,
"head_bpw": 5.5,
"vram_gb": 9.708330154418945,
"ppl": 9.637042524624235,
"kld": 0.13621351244574528
},
{
"label": "GGUF Q4_K_M imat",
"layer_bpw": 4.863105026067801,
"head_bpw": 6.5625,
"vram_gb": 17.347013473510742,
"ppl": 9.038357988835012,
"kld": 0.01969047055205346
},
{
"label": "GGUF IQ3_M ed imat",
"layer_bpw": 3.681662516695381,
"head_bpw": 3.4375,
"vram_gb": 13.077281951904297,
"ppl": 9.36637604254197,
"kld": 0.08605257654904011
},
{
"label": "GGUF Q4_K_M ed imat",
"layer_bpw": 4.473586414830737,
"head_bpw": 4.5,
"vram_gb": 15.90190315246582,
"ppl": 9.246278950648936,
"kld": 0.037276722648089344
},
{
"label": "GGUF Q5_K_M ed imat",
"layer_bpw": 5.33928476917054,
"head_bpw": 5.5,
"vram_gb": 18.98381233215332,
"ppl": 9.045580650795506,
"kld": 0.01762934465542933
}
]


Wow thanks for linking that imatrix repo @ubergarm i hadn't noticed it, I see @eaddario is doing a ton more work than I realized (I had only ever seen your PR for adding stats to imatrix)
Ed, do you think you'd ever want to work together on this kind of stuff less asynchronously? If so, add me on Linkedin or discord (bartowski1182), would love to chat and collaborate 👀 (with any findings being completely public of course)
Also understand if you want to continue solo, in which case I appreciate you opening up so much information!
@ubergarm , thank you very much for the plots! Really helpful way to compare and contrast.
Regarding the calibration files, they are structured to make it easy to choose a single file based on what you're trying to optimise. For example, if you'd would like to test if a model has better text inference performance when prompts are in a particular language, say Chinese vs English, you'd create a couple of imatrices using text_cn_xxx and text_en_xxx where xxx is the size most appropriate to "light up" all the tensors.
All calibration files I used originally were heavy on text prompts and very light on coding/reasoning/math, hence the problem I had with my Qwen3-30B-A3B-GGUF imatrix. Now that I have updated the repo, and taking into consideration that Qwen3 supports 100+ languages, I'll try again using combined_all medium/large.
I didn't get a chance to find a good/curated source of function calling prompts, but I'll add them when I do. Let me know if you'd recommend any. Otherwise, I see lots of googling ahead!
@bartowski , I'd be delighted to help in any way I can, provided you're OK with weekend-only code warriors 😁. I tried to msg you on LinkedIn but not sure if this is you.
I haven't used Discord in a while and don't remember which email address I used, but as soon as I recover my account I'll ping you. In the meantime, feel free to msg me here