TRL documentation
Aligning Text-to-Image Diffusion Models with Reward Backpropagation
Aligning Text-to-Image Diffusion Models with Reward Backpropagation
The why
If your reward function is differentiable, directly backpropagating gradients from the reward models to the diffusion model is significantly more sample and compute efficient (25x) than doing policy gradient algorithm like DDPO. AlignProp does full backpropagation through time, which allows updating the earlier steps of denoising via reward backpropagation.
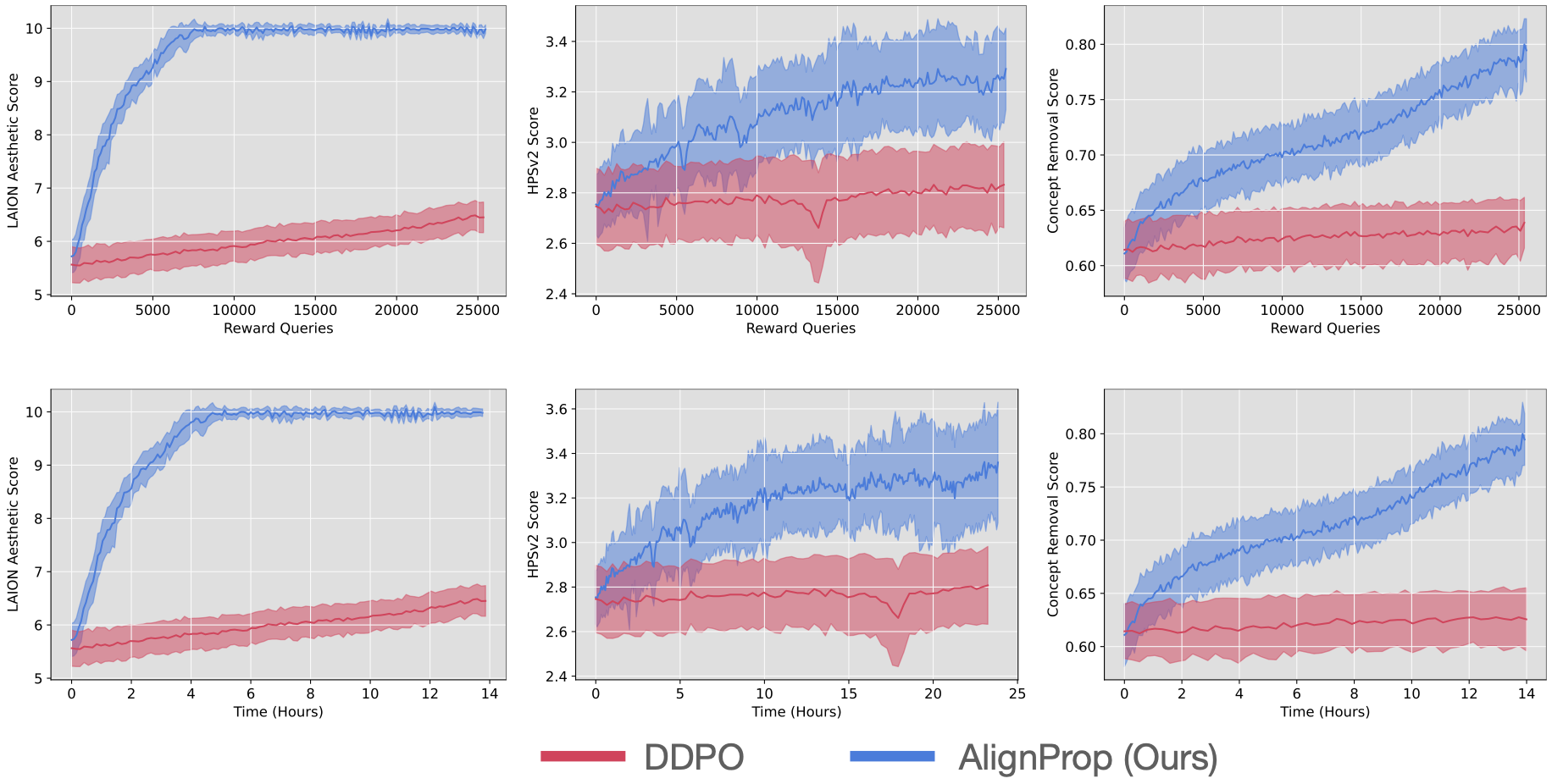
Getting started with examples/scripts/alignprop.py
The alignprop.py script is a working example of using the AlignProp trainer to finetune a Stable Diffusion model. This example explicitly configures a small subset of the overall parameters associated with the config object (AlignPropConfig).
Note: one A100 GPU is recommended to get this running. For lower memory setting, consider setting truncated_backprop_rand to False. With default settings this will do truncated backpropagation with K=1.
Almost every configuration parameter has a default. There is only one commandline flag argument that is required of the user to get things up and running. The user is expected to have a huggingface user access token that will be used to upload the model post finetuning to HuggingFace hub. The following bash command is to be entered to get things running
python alignprop.py --hf_user_access_token <token>To obtain the documentation of stable_diffusion_tuning.py, please run python stable_diffusion_tuning.py --help
The following are things to keep in mind (The code checks this for you as well) in general while configuring the trainer (beyond the use case of using the example script)
- The configurable randomized truncation range (
--alignprop_config.truncated_rand_backprop_minmax=(0,50)) the first number should be equal and greater to 0, while the second number should equal or less to the number of diffusion timesteps (sample_num_steps) - The configurable truncation backprop absolute step (
--alignprop_config.truncated_backprop_timestep=49) the number should be less than the number of diffusion timesteps (sample_num_steps), it only matters when truncated_backprop_rand is set to False
Setting up the image logging hook function
Expect the function to be given a dictionary with keys
['image', 'prompt', 'prompt_metadata', 'rewards']
and image, prompt, prompt_metadata, rewardsare batched.
You are free to log however you want the use of wandb or tensorboard is recommended.
Key terms
rewards: The rewards/score is a numerical associated with the generated image and is key to steering the RL processprompt: The prompt is the text that is used to generate the imageprompt_metadata: The prompt metadata is the metadata associated with the prompt. A situation where this will not be empty is when the reward model comprises of aFLAVAsetup where questions and ground answers (linked to the generated image) are expected with the generated image (See here: https://github.com/kvablack/ddpo-pytorch/blob/main/ddpo_pytorch/rewards.py#L45)image: The image generated by the Stable Diffusion model
Example code for logging sampled images with wandb is given below.
# for logging these images to wandb
def image_outputs_hook(image_data, global_step, accelerate_logger):
# For the sake of this example, we only care about the last batch
# hence we extract the last element of the list
result = {}
images, prompts, rewards = [image_data['images'],image_data['prompts'],image_data['rewards']]
for i, image in enumerate(images):
pil = Image.fromarray(
(image.cpu().numpy().transpose(1, 2, 0) * 255).astype(np.uint8)
)
pil = pil.resize((256, 256))
result[f"{prompts[i]:.25} | {rewards[i]:.2f}"] = [pil]
accelerate_logger.log_images(
result,
step=global_step,
)
Using the finetuned model
Assuming you’ve done with all the epochs and have pushed up your model to the hub, you can use the finetuned model as follows
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
pipeline.to("cuda")
pipeline.load_lora_weights('mihirpd/alignprop-trl-aesthetics')
prompts = ["squirrel", "crab", "starfish", "whale","sponge", "plankton"]
results = pipeline(prompts)
for prompt, image in zip(prompts,results.images):
image.save(f"dump/{prompt}.png")Credits
This work is heavily influenced by the repo here and the associated paper Aligning Text-to-Image Diffusion Models with Reward Backpropagation by Mihir Prabhudesai, Anirudh Goyal, Deepak Pathak, Katerina Fragkiadaki.
< > Update on GitHub