Datasets:

id
int64 | label
int64 | ct
string |
|---|---|---|
1,210,352,657,010,843,600 | 0 | CT_1 |
1,212,723,988,356,587,500 | 0 | CT_1 |
1,212,763,173,767,368,700 | 0 | CT_1 |
1,212,902,979,059,232,800 | 0 | CT_1 |
1,213,048,269,321,851,000 | 0 | CT_1 |
1,213,178,213,649,793,000 | 0 | CT_1 |
1,213,204,380,716,916,700 | 0 | CT_1 |
1,213,284,871,864,377,300 | 0 | CT_1 |
1,213,444,173,271,093,200 | 0 | CT_1 |
1,213,505,471,849,648,000 | 0 | CT_1 |
1,213,670,780,736,684,000 | 0 | CT_1 |
1,214,191,387,786,305,500 | 0 | CT_1 |
1,214,228,966,052,991,000 | 0 | CT_1 |
1,214,260,248,837,607,400 | 0 | CT_1 |
1,214,293,082,935,636,000 | 0 | CT_1 |
1,214,348,156,202,344,400 | 0 | CT_1 |
1,214,459,570,581,426,200 | 0 | CT_1 |
1,214,492,448,921,141,200 | 0 | CT_1 |
1,214,522,240,722,591,700 | 0 | CT_1 |
1,214,536,965,032,272,000 | 0 | CT_1 |
1,214,547,549,375,385,600 | 0 | CT_1 |
1,214,605,969,818,357,800 | 0 | CT_1 |
1,214,889,434,346,348,500 | 0 | CT_1 |
1,214,917,192,132,833,300 | 0 | CT_1 |
1,215,104,723,008,786,400 | 0 | CT_1 |
1,215,143,093,332,103,200 | 0 | CT_1 |
1,215,209,541,316,567,000 | 0 | CT_1 |
1,215,355,754,699,358,200 | 0 | CT_1 |
1,215,468,769,155,408,000 | 0 | CT_1 |
1,215,653,162,071,158,800 | 0 | CT_1 |
1,215,663,393,971,024,000 | 0 | CT_1 |
1,216,038,982,963,753,000 | 0 | CT_1 |
1,216,050,924,164,198,400 | 0 | CT_1 |
1,216,183,551,600,652,300 | 0 | CT_1 |
1,216,307,632,962,564,000 | 0 | CT_1 |
1,216,407,527,426,023,400 | 0 | CT_1 |
1,216,491,142,105,247,700 | 0 | CT_1 |
1,216,736,944,799,076,400 | 0 | CT_1 |
1,216,781,772,249,354,200 | 0 | CT_1 |
1,216,832,861,162,000,400 | 0 | CT_1 |
1,216,891,891,826,004,000 | 0 | CT_1 |
1,216,938,607,392,411,600 | 0 | CT_1 |
1,217,044,576,260,644,900 | 0 | CT_1 |
1,217,102,278,026,461,200 | 0 | CT_1 |
1,217,129,720,137,109,500 | 0 | CT_1 |
1,217,222,399,587,954,700 | 0 | CT_1 |
1,217,286,707,529,363,500 | 0 | CT_1 |
1,217,304,551,348,457,500 | 0 | CT_1 |
1,217,462,190,627,795,000 | 0 | CT_1 |
1,217,514,273,016,033,300 | 0 | CT_1 |
1,217,672,792,612,708,400 | 1 | CT_1 |
1,217,849,969,887,056,000 | 0 | CT_1 |
1,217,859,056,708,333,600 | 0 | CT_1 |
1,217,860,697,251,623,000 | 0 | CT_1 |
1,218,170,866,590,154,800 | 0 | CT_1 |
1,218,219,696,597,565,400 | 0 | CT_1 |
1,218,249,673,653,260,300 | 0 | CT_1 |
1,218,274,477,659,656,200 | 0 | CT_1 |
1,218,330,189,106,761,700 | 0 | CT_1 |
1,218,420,562,789,163,000 | 0 | CT_1 |
1,218,651,043,871,043,600 | 0 | CT_1 |
1,218,916,088,408,395,800 | 0 | CT_1 |
1,218,974,912,896,958,500 | 0 | CT_1 |
1,219,054,004,388,466,700 | 0 | CT_1 |
1,219,237,686,009,122,800 | 0 | CT_1 |
1,219,245,440,849,391,600 | 0 | CT_1 |
1,219,253,725,262,491,600 | 0 | CT_1 |
1,219,383,350,454,112,300 | 1 | CT_1 |
1,219,415,863,423,651,800 | 0 | CT_1 |
1,219,425,665,335,738,400 | 0 | CT_1 |
1,219,698,037,200,695,300 | 0 | CT_1 |
1,219,699,650,585,821,200 | 0 | CT_1 |
1,219,706,726,032,793,600 | 0 | CT_1 |
1,219,735,174,054,846,500 | 0 | CT_1 |
1,219,743,404,004,905,000 | 0 | CT_1 |
1,219,751,110,044,528,600 | 1 | CT_1 |
1,219,762,280,226,623,500 | 0 | CT_1 |
1,219,769,920,306,798,600 | 0 | CT_1 |
1,219,787,086,678,630,400 | 0 | CT_1 |
1,219,796,780,038,013,000 | 0 | CT_1 |
1,219,804,818,430,185,500 | 0 | CT_1 |
1,219,833,538,213,830,700 | 0 | CT_1 |
1,219,851,805,590,352,000 | 1 | CT_1 |
1,219,857,693,998,862,300 | 0 | CT_1 |
1,219,985,530,684,833,800 | 0 | CT_1 |
1,220,020,289,712,611,300 | 0 | CT_1 |
1,220,025,741,053,759,500 | 0 | CT_1 |
1,220,032,217,738,547,200 | 1 | CT_1 |
1,220,093,798,216,355,800 | 0 | CT_1 |
1,220,099,993,710,878,700 | 0 | CT_1 |
1,220,134,079,506,546,700 | 1 | CT_1 |
1,220,135,019,991,027,700 | 1 | CT_1 |
1,220,275,326,883,967,000 | 1 | CT_1 |
1,220,291,531,220,930,600 | 0 | CT_1 |
1,220,349,432,379,641,900 | 0 | CT_1 |
1,220,352,342,278,770,700 | 1 | CT_1 |
1,220,366,866,759,192,600 | 0 | CT_1 |
1,220,366,947,055,022,000 | 0 | CT_1 |
1,220,368,160,169,365,500 | 0 | CT_1 |
1,220,420,957,879,316,500 | 0 | CT_1 |
Dataset Card for Dataset Name
The dataset includes approximately 54,000 tweet IDs collected through the Twitter API between November 2019 and December 2021, along with annotations indicating whether a tweet supports a particular conspiracy theory.
Dataset Details
- Curated by: Izabela Krysinska
- Funded by [optional]: EEA Financial Mechanism 2014–2021. Project registration number: 2019/35/J/HS6/03498
- Shared by [optional]: Izabela Krysinska
- Language(s) (NLP): English
- License: cc-by-4.0
Uses
This dataset is explicitly designed for the purpose of classifying and understanding tweets related to COVID-19 conspiracy theories, particularly to determine whether a tweet supports a specific conspiracy theory or not.
Out-of-Scope Use
The dataset is not intended for, and should not be used to facilitate generation or propagation of tweets that endorse or support any conspiracy theory. Any use of the dataset for such purposes is considered unethical and goes against the intended use case. The datasets's primary purpose is to help identify tweets related to COVID-19 conspiracy theories, and it is not intended to stifle legitimate public discourse or eliminate discussions that merely resemble conspiracy theories.
Dataset Structure
{
'id': '1210352657010843649',
'ct': 'CT_1',
'label': 0
}
id: a tweet idct: a conspiracy theory identifierlabel: label; 0 - the tweet does not express support for the CT, 1 - the tweet expresses support for the CT
Conspiracy theories mapping:
CT_1: Deliberate strategy to create economic instability or benefit large corporations. The coronavirus or the government's response to it is a deliberate strategy to create economic instability or to benefit large corporations over small businesses.
CT_2: Public was intentionally misled about the true nature of the virus and prevention. The public is being intentionally misled about the true nature of the Coronavirus, its risks, or the efficacy of certain treatments or prevention methods.
CT_3: Human made and bioweapon. The Coronavirus was created intentionally, made by humans, or as a bioweapon.
CT_4: Governments and politicians spread misinformation. Politicians or government agencies are intentionally spreading false information, or they have some other motive for the way they are responding to the coronavirus.
CT_5: The Chinese intentionally spread the virus. The Chinese government intentionally created or spread the coronavirus to harm other countries.
CT_6: Vaccines are unsafe. The coronavirus vaccine is either unsafe or part of a larger plot to control people or reduce the population.
Dataset Creation
Curation Rationale
The dataset was curated to facilitate classification of tweets related to COVID-19 conspiracy theories.
Source Data
All the tweets were collected from November 2019 to December 2021 via Twitter API, and only those containing phrases related to the COVID-19 pandemic were selected.
Data Collection and Processing
We started with a dataset of 40 million tweets and selected tweets that were similar to the CTs. To calculate similarity, we used a cosine similarity method between a tweet embedding and CT embedding, both of which were generated with the Sentence Transformer model all-MiniLM-L6-v2. After careful selection, we ended up with a dataset of 60,000 tweets, with 10,000 tweets for each CT. Of these tweets, 25% had similarity scores between 0.25 and 0.45, 25% had scores between 0.45 and 0.65, and 50% had scores above 0.65. We then removed non-English tweets and those containing only mentions, links, or emojis. Finally, we were left with 53734 tweets in our dataset.
Who are the source data producers?
The source data producers are English speaking Twitter users.
Annotations
For annotation process we used three different platforms:
- (Prolific)[https://app.prolific.com/] to recruit annotators.
- lab.js to create a study.
- open-lab to run the study and collect responses.
The study stimuli designed in lab.js:

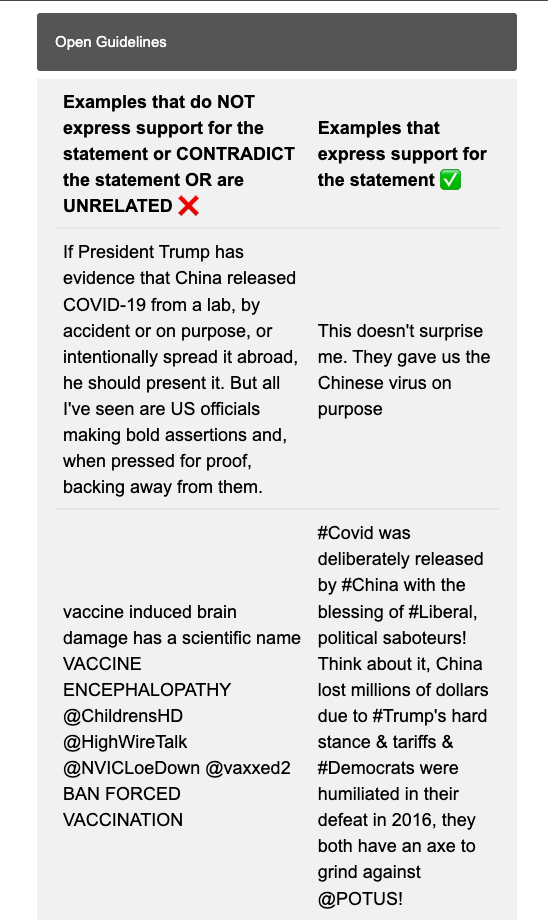
Guidelines
All the annotators were given with the following guidelines (instruction, CT definition, and examples of tweets with labels):

Annotation process
Every annotator annotated approximately 100 tweets. Every tweet was annotated by 3 different annotators. The annotators were paid equivalent to 9 GBP per hour.
Who are the annotators?
We gathered annotations from 1151 unique US citizen annotators who are native English speakers.
| Highest education level completed | |
|---|---|
| Doctorate degree (PhD/other) | 37 |
| Graduate degree (MA/MSc/MPhil/other) | 283 |
| Undergraduate degree (BA/BSc/other) | 831 |
| Political affiliation | |
| Democrat | 430 |
| Independent | 442 |
| Republican | 279 |
| Ethnicity | |
| Asian | 80 |
| Black | 148 |
| Mixed | 75 |
| Other | 32 |
| White | 813 |
| Age | |
| 19-30 | 233 |
| 30-40 | 327 |
| 40-50 | 193 |
| 50-60 | 163 |
| >60 | 119 |
| Student Status | |
| No | 919 |
| Yes | 146 |
| Employment status | |
| Due to start a new job within the next month | 8 |
| Full-Time | 656 |
| Not in paid work (e.g. homemaker', 'retired or disabled) | 114 |
| Other | 40 |
| Part-Time | 147 |
| Unemployed (and job seeking) | 74 |
Agreement
| Conspiracy Theory | PABAK | Krippendorf's alpha |
|---|---|---|
| Deliberate strategy to create economic instability or benefit large corporations. | 0.432 | 0.296 |
| Public was intentionally misled about the true nature of the virus and prevention. | 0.283 | 0.268 |
| Human made and bioweapon. | 0.527 | 0.412 |
| Governments and politicians spread misinformation. | 0.240 | 0.238 |
| The Chinese intentionally spread the virus. | 0.523 | 0.430 |
| Vaccines are unsafe. | 0.437 | 0.356 |
Bias, Risks, and Limitations
Users should be aware of the risks, biases and limitations of the dataset, especially low agreement between annotators and imbalanced data.
Dataset Card Contact
The research leading to these results has received funding from the EEA Financial Mechanism 2014–2021. Project registration number: 2019/35/J/HS6/03498
- Downloads last month
- 18