

pkupie/Llama-2-7b-ben
Updated
•
16
The viewer is disabled because this dataset repo requires arbitrary Python code execution. Please consider
removing the
loading script
and relying on
automated data support
(you can use
convert_to_parquet
from the datasets library). If this is not possible, please
open a discussion
for direct help.
Github | Paper
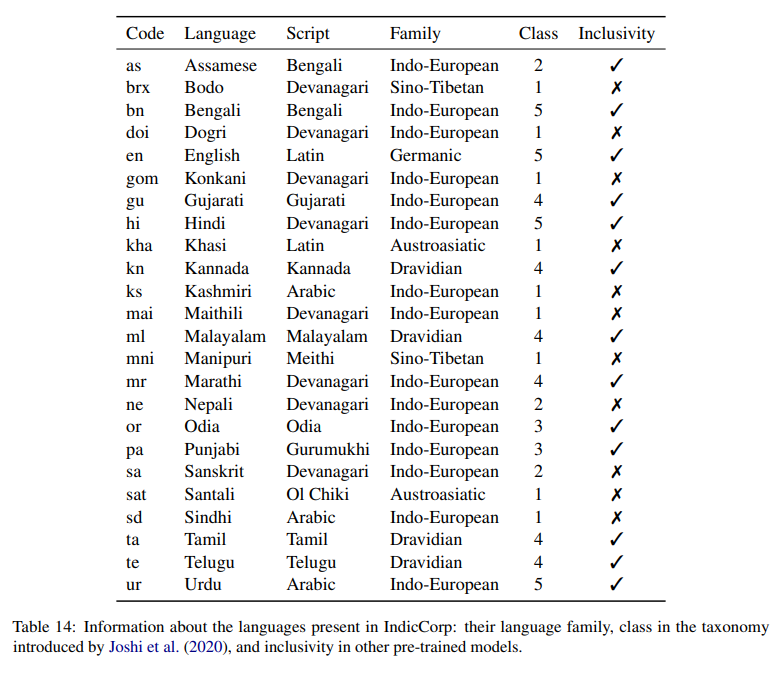
Languages: 24
The largest collection of texts for Indic languages consisting of 20.9 billion tokens of which 14.4B tokens correspond to 23 Indic languages and 6.5B tokens of Indian English content curated from Indian websites.
@article{Doddapaneni2022towards,
title={Towards Leaving No Indic Language Behind: Building Monolingual Corpora, Benchmark and Models for Indic Languages},
author={Sumanth Doddapaneni and Rahul Aralikatte and Gowtham Ramesh and Shreyansh Goyal and Mitesh M. Khapra and Anoop Kunchukuttan and Pratyush Kumar},
journal={ArXiv},
year={2022},
volume={abs/2212.05409}
}
