
Model Card for the TSpec-LLM Dataset
Demo:
Dataset Description
Abstract
This dataset contains processed documentation files from the 3GPP (3rd Generation Partnership Project) standards, converted to markdown and docx formats. It is intended for use in telecommunications research, natural language processing, and machine learning applications, particularly those focusing on telecommunications standards and technologies.
🚀 Dataset Update: Now Up-to-Date Until April 2025!
We are excited to announce that the TSpec-LLM dataset has been updated to include the latest 3GPP documentation up to April 2025.
How to Cite This Dataset
If you use this dataset, please cite our paper as follows:
@misc{nikbakht2024tspecllm, title={TSpec-LLM: An Open-source Dataset for LLM Understanding of 3GPP Specifications}, author={Rasoul Nikbakht, Mohamed Benzaghta, and Giovanni Geraci}, year={2024}, eprint={2406.01768}, archivePrefix={arXiv}, primaryClass={cs.NI} }
For more information, you can access the paper here:
Title: TSpec-LLM: An Open-source Dataset for LLM Understanding of 3GPP Specifications
Authors: Rasoul Nikbakht, Mohamed Benzaghta, Giovanni Geraci
Link: https://arxiv.org/abs/2406.01768
How to Download This Dataset
This dataset is public, but you need to accept the license.
First, log in with your Hugging Face account and accept the license for the dataset. Generate a token from your settings: Hugging Face Tokens.
Make sure you have git-lfs installed:
git lfs installClone the dataset repository:
git clone https://huggingface.co/datasets/rasoul-nikbakht/TSpec-LLMWhen prompted for the username and password, insert your Hugging Face username and the token you created as the password.
If it appears to be stuck, check your internet connection. If it shows download traffic, it is working fine.
Methodology
Data Collection
- Data Source: 3GPP official documentation.
- Collection Method: Automated download using
download_3gpp 0.7.0.
Data Processing
The dataset was processed through a comprehensive, custom-designed Python script, focusing on efficient handling and conversion of a large collection of 3GPP documents. The processing followed a two-step parallel approach to manage the high volume of files effectively.
Initial Preparation and Verification:
- The script operated within the
3GPP-allbase directory, targeting documents in its subdirectories. - Key functions included
file_existsfor verifying file existence andunzip_task_directoryfor automating the unzipping process. - Systematic traversal through nested directory structures was implemented to identify and prepare files for processing.
- The script operated within the
Parallel Processing for Efficiency:
- Utilized
ThreadPoolExecutorfor parallel processing, enhancing the efficiency of unzipping and document conversion tasks. - Employed multiple LibreOffice instances in parallel, addressing the challenge of converting a large number of documents simultaneously.
- This was achieved by using the
-env:UserInstallationcommand-line option to run multiple isolated LibreOffice instances, each with a unique user profile directory.
- Utilized
Document Conversion Methodology:
- The script converted documents to PDF, DOCX, and Markdown formats.
- For each document, a unique identifier was generated, and a corresponding LibreOffice user profile directory was created.
- The conversion process was headless, suitable for server-side operations and batch-processing scripts.
File Size Analysis and Management:
- A separate Python script was developed to analyze the file sizes of Markdown documents in the
3GPP-cleandirectory. - The script traversed through different releases and versions of the 3GPP documentation, calculating the total size of
.mdfiles. - The results were compiled into a comprehensive report, broken down by version and release, and saved as a JSON file.
- This analysis was crucial for managing and understanding the distribution of document sizes within the dataset.
- A separate Python script was developed to analyze the file sizes of Markdown documents in the
Script Execution and Output:
- The processing and analysis scripts were designed to be run in environments with access to the respective directories.
- The outputs included detailed logs, converted documents in multiple formats, and a summary report of file sizes.
This data processing approach ensured the creation of a well-structured and versatile dataset, suitable for various applications in telecommunications research and natural language processing.
Dataset Structure
Content
- File Types: Markdown (
.md), DOCX (.docx) - Directory Structure: Organized by 3GPP release versions (
Rel-*).
This section contains analysis data for the 3GPP documentation releases. The primary focus is on the file sizes of Markdown documents within each release.
File Size Analysis
The analysis involves calculating the total size of Markdown (.md) files in each release of the 3GPP documentation. The data provides insights into the volume of documentation across different releases.
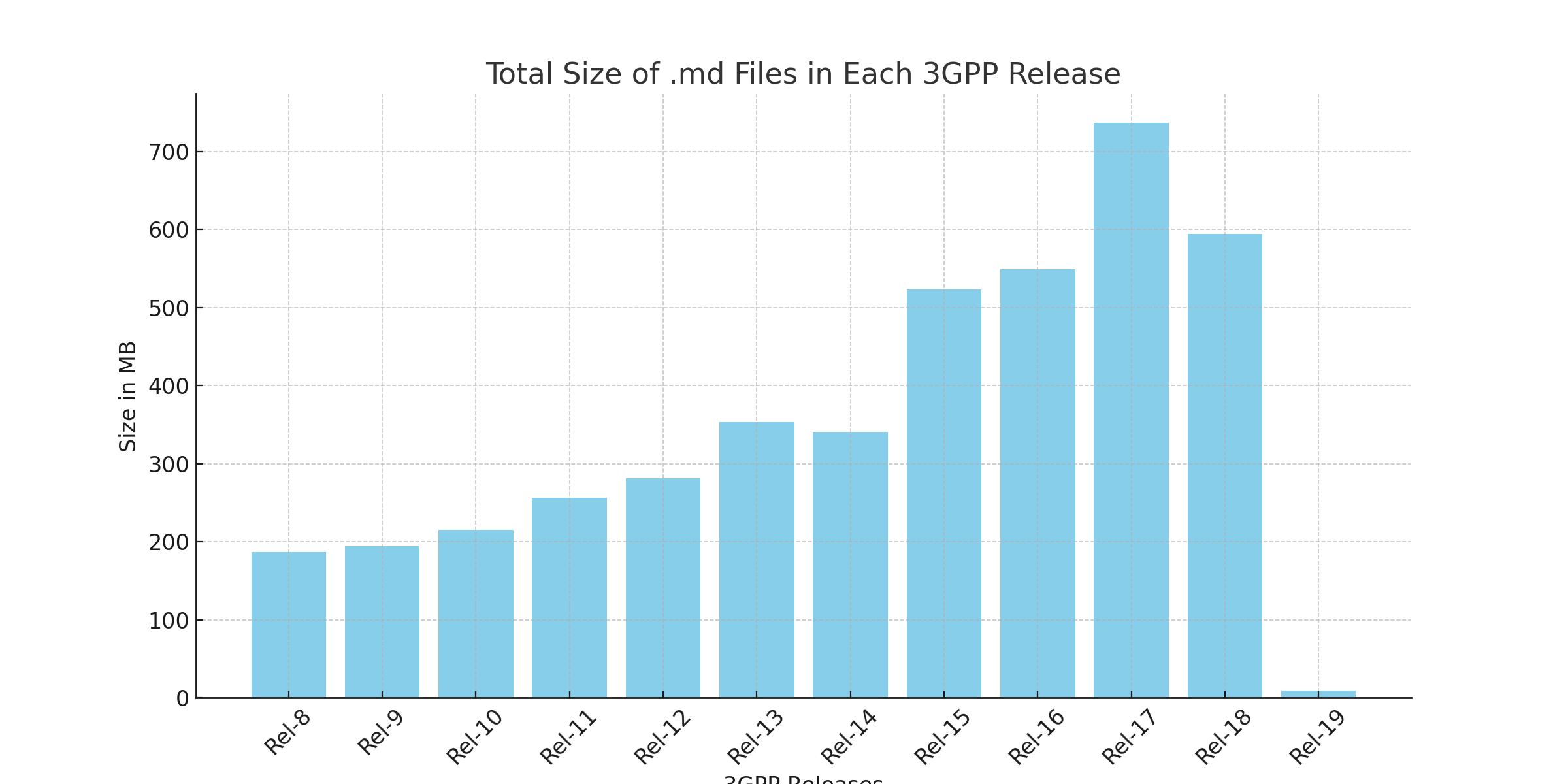
Graphical Representation
Below is a bar plot that shows the total size of .md files in each release, from Rel-8 to Rel-19. The sizes are represented in megabytes (MB).
Data Format
- Data is structured in Markdown and DOCX formats, suitable for text processing and analysis tasks.
Intended Use
Applications
- Natural Language Processing: Training and evaluation of models on telecommunications-specific content.
- Telecommunications Research: Analysis and review of 3GPP standards and documentation.
- Machine Learning: Feature extraction and data mining in telecommunications documents.
Limitations
- The dataset is specific to 3GPP standards and may not generalize to other domains.
- It is recommended for use by those with a background in telecommunications or related fields.
Maintenance
Updates
- Rel-19 is updated until April 2025
- Future updates will be provided based on new releases of 3GPP standards and improvements in processing scripts.
Dataset Version
- Dataset Version: 2.0
- Download Tool Version: download_3gpp 0.7.0
Contact Information
- For updates and inquiries, please contact Rasoul Nikbakht.
Acknowledgements
- This dataset was created using the
download_3gpp 0.7.0tool and processed through a custom Python script for parallel file handling and conversion.
- Downloads last month
- 475