
arxiv_id
stringlengths 11
13
| markdown
stringlengths 2.09k
423k
| paper_doi
stringlengths 13
47
⌀ | paper_authors
sequencelengths 1
1.37k
| paper_published_date
stringdate 2014-06-03 15:22:49
2024-08-02 17:59:51
| paper_updated_date
stringdate 2014-06-03 15:22:49
2025-04-29 20:34:17
| categories
sequencelengths 1
7
| title
stringlengths 15
236
| summary
stringlengths 57
2.54k
|
|---|---|---|---|---|---|---|---|---|
1408.0001v1 | ## The Bones of the Milky Way
Alyssa A. Goodman
Harvard-Smithsonian Center for Astrophysics, Cambridge, MA 02138
Jo˜ ao Alves
University of Vienna, 1180 Vienna, Austria
Christopher N. Beaumont Harvard-Smithsonian Center for Astrophysics, Cambridge, MA 02138
Robert A. Benjamin University of Wisconsin-Whitewater, Whitewater, WI 53190
Michelle A. Borkin Harvard University, Cambridge, MA 02138
Andreas Burkert University of Munich, Munich, Germany
Thomas M. Dame
Smithsonian Astrophysical Observatory, Cambridge, MA 02138
James Jackson Boston University, Boston, MA 02215
Jens Kauffmann California Institute of Technology, Pasadena, CA 91125
Thomas Robitaille Max Planck Institute for Astronomy, Heidelberg, Germany
Institut f¨r Theoretische Astrophysik, Zentrum f¨r Astronomie der Universi¨t Heidelberg,
Rowan J. Smith u u a Heidelberg, Germany
Received
;
accepted
To appear in The Astrophysical Journal (ApJ)
## ABSTRACT
The very long and thin infrared dark cloud 'Nessie' is even longer than had been previously claimed, and an analysis of its Galactic location suggests that it lies directly in the Milky Way's mid-plane, tracing out a highly elongated bonelike feature within the prominent Scutum-Centaurus spiral arm. Re-analysis of mid-infrared imagery from the Spitzer Space Telescope shows that this IRDC is at least 2, and possibly as many as 5 times longer than had originally been claimed by Nessie's discoverers, Jackson et al. (2010); its aspect ratio is therefore at least 300:1, and possibly as large as 800:1. A careful accounting for both the Sun's offset from the Galactic plane ( ∼ 25 pc) and the Galactic center's offset from the ( l II , b II ) = (0 0) position shows that the latitude of the true Galactic , mid-plane at the 3.1 kpc distance to the Scutum-Centaurus Arm is not b = 0, but instead closer to b = -0 4, which is the latitude of Nessie to within a few pc. . An analysis of the radial velocities of low-density (CO) and high-density (NH ) 3 gas associated with the Nessie dust feature suggests that Nessie runs along the Scutum-Centaurus Arm in position-position-velocity space, which means it likely forms a dense 'spine' of the arm in real space as well. The Scutum-Centaurus arm is the closest major spiral arm to the Sun toward the inner Galaxy, and, at the longitude of Nessie, it is almost perpendicular to our line of sight, making Nessie the easiest feature to see as a shadow elongated along the Galactic Plane from our location. Future high-resolution dust mapping and molecular line observations of the harder-to-find Galactic 'bones' should allow us to exploit the Sun's position above the plane to gain a (very foreshortened) view 'from above' of the Milky Way's structure.
## 1. Introduction
Determining the structure of the Milky Way, from our vantage point within it, is a perpetual challenge for astronomers. We know the Galaxy has spiral arms, but it remains unclear exactly how many (cf. Vall´e 2008). e Recent observations of maser proper motions give unprecedented accuracy in determining the three-dimensional position of the Galaxy's center and rotation speed (Reid et al. 2009; Brunthaler et al. 2011). But, to date, we still do not have a definitive picture of the Milky Way's three dimensional structure.
The analysis offered in this paper suggests that some Infrared Dark Clouds -in 1 particular very long, very dark, clouds-appear to delineate major features of our Galaxy as would be seen from outside of it. In particular, we study a > 3 -long cloud associated ◦ with the IRDC called 'Nessie' (Jackson et al. 2010), and we show that it appears to lie parallel to, and no more than just a few pc from, the true Galactic Plane.
Our analysis uses diverse data sets, but it hinges on combining those data sets with a modern understanding of the meaning of Galactic coordinates. When, in 1959, the IAU established the current system of Galactic ( l, b ) coordinates (Blaauw et al. 1959), the positions of the Sun with respect to the 'true' Galactic disk, and of the Galactic Center, were not as well determined as they are now. As a result, the Galactic Plane is typically not at b = 0, as projected onto the sky. The exact offset from b = 0 depends on distance, as we explain in § 3.1. Taking these offsets into account, one can profitably re-examine data relevant to the Milky Way's 3D structure. The Sun's vantage point slightly 'above' the plane of the Milky Way offers useful perspective.
'IRDCs' are loosely defined as clouds with column densities high enough to be obvious
1 The term 'Infrared Dark Cloud' or 'IRDC' typically refers to any cloud which is opaque in the mid-infrared.
as patches of significant extinction against the diffuse galactic background at mid-infrared wavelengths. Peretto & Fuller (2009) set the boundaries of IRDCs at an optical depth of 0.35 at 8 µ m wavelength, equivalent to an H 2 column density ≈ 10 22 cm -2 . In the Peretto & Fuller (2010) sample, clouds have average column densities of a few 10 22 cm -2 . Some IRDCs actively form high-mass stars (e.g., Pillai et al. 2006 and Rathborne et al. 2007). Kauffmann & Pillai (2010) explain that while some 'starless' IRDCs are potential sites of future high-mass star formation, and the few hundred densest and the most massive, IRDCs may very well contain a large fraction of the star-forming gas in the Milky Way, it is still true that most IRDCs are not massive and dense enough to form high-mass stars. Thus, a small number of very dense and massive IRDCs may be responsible for a large fraction of the galactic star formation rate, and an extragalactic observer of the Milky Way might 'see' IRDCs not unlike Nessie hosting young massive stars as the predominant mode of star formation here.
The traditional ISM-based probes of the Milky Way's structure have been HI and CO. Emission in these tracers gives line intensity as a function of velocity, so the positionposition-velocity data resulting from HI and CO observations can give three dimensional views of the Galaxy, if a rotation curve is used to translate line-of-sight velocity into a distance. Unfortunately, though, the Galaxy is filled with HI and CO, so it is very hard to disentangle features when they overlap in velocity along the line of sight. Nonetheless, much of the basic understanding of the Milky Way's spiral structure we have now comes from HI and CO observations of the Galaxy, much of it from the compilation of CO data presented by Dame et al. (2001).
Recently, several groups have targeted high-mass star-forming regions in the plane of the Milky Way for high-resolution observation. In their BeSSeL Survey, Reid et al. are using hundreds of hours of VLBA time to observe hundreds of regions for maser emission,
which can give both distance and kinematic information for very high-density ( n > 10 8 cm -3 ) gas (Reid et al. 2009; Brunthaler et al. 2011). In the HOPS Survey, hundreds of positions associated with the dense peaks of infrared dark clouds have now been surveyed for NH emission (Purcell et al. 2012), yielding high-spectral resolution velocity measurements 3 towards gas whose density typically exceeds 10 4 cm -3 . In follow-up spectral-line surveys to the ATLASGAL (Beuther et al. 2012) dust-based survey of the Galactic Plane, Wienen et al. (2012) have measured NH 3 emission in nearly 1000 locations. The ThrUMMs Survey aims to map the entire fourth quadrant of the Milky Way in CO and higher-density tracers (Barnes et al. 2010), and it should yield additional high-resolution velocity measurements.
Targets in high-resolution (e.g. BeSSeL) studies are usually identified based on continuum surveys, which show the locations of the highest column-density regions, either as extinction features ('dark clouds' in the optical, 'IRDCs' in the infrared), as dust emission features (in surveys of the thermal infrared), or as gas emission features (e.g. HII regions).
Great power lies in the careful combination of continuum and spectral-line data when one wants to understand the structure of the ISM in three-dimensions. Thus, there have already been several efforts to combine dust maps with spectral-line data, whose goal is often the assignment of more accurate distances to particular clouds or regions (e.g. Foster et al. 2012). These improved distances allow for more reliable conversion of measured quantities (e.g. fluxes) to physical ones (e.g. mass).
In this study, our aim is to combine morphological information from large-scale mid-infrared continuum 'dust' maps of the Galactic Plane with spectral-line data, so as to understand the nature of very long infrared dark clouds that appear parallel to the Galactic Plane. We focus in particular on the IRDC named 'Nessie' in the study presented by Jackson et al. (2010). In that 2010 paper, Nessie is shown to be a highly elongated
filamentary cloud (see Figure 1) exhibiting the after-effects of a sausage instability that led to several massive-star-forming peaks spaced at regular intervals. We extend the work of Jackson et al. by first by literally 'extending' the cloud, to a length of at least 3 degrees ( § 2). In § 3, we show that a careful accounting for the modern measures of the Sun's height off of the Galactic mid-plane and of the true position of the Galactic Center imply that Nessie lies not just parallel to the Galactic Plane, but in the Galactic Plane. We consider what velocity-resolved measures of the material associated with Nessie tell us about its three-dimensional position in the Galaxy, and we conclude, in § 4.1 that Nessie likely marks the 'spine' of the Scutum-Centaurus arm of the Milky Way in which it lies. In § 4.2, we consider the likelihood of finding more 'Nessie-like' structures in the future, and of using them, in conjunction with the Sun's vantage point just above the mid-plane of the Milky Way, to map out the skeleton of our Galaxy.
## 2. Nessie is Longer than We Thought
Nessie was discovered and named using Spitzer Space Telescope images that show the cloud as a very clear absorption feature at mid-infrared wavelengths Jackson et al. (2010). Using observations of the dense-gas tracer HNC, Jackson et al. (2010) further show that the section of the cloud from l =337.85 to 339.1 (labelled 'Nessie Classic' in Figure 1) exhibits very similar line-of-sight velocities, ranging over -40 < v LSR < -36 km s -1 . The similarities of these line-of-sight velocities (cf. Figure 7) is taken to mean that the cloud is a coherent, long structure, and not a chance plane-of-the-sky projection of disconnected features. Thus, 'Nessie Classic' is shown to be a dense, long ( ∼ 1 ), narrow ( ◦ ∼ 0 01 ), . ◦ filament, and Jackson et al. (2010) ultimately conclude that it is undergoing a sausage instability leading to density peaks hosting active sites of massive star formation.
Our purpose in looking at Nessie again here is not to further analyze the star-forming
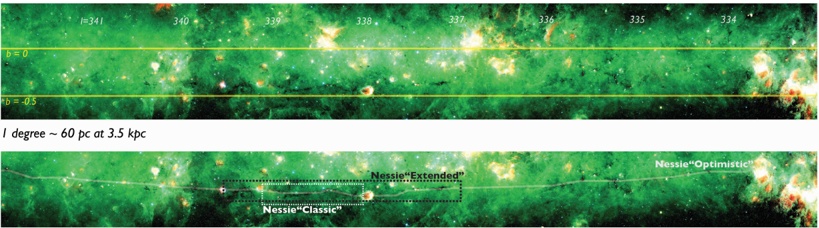
Fig. 1.Nessie 'Classic,' 'Extended,' and 'Optimistic.' It is recommended that this high resolution figure be viewed electronically, as zooming and panning are necessary to reveal the structures discussed. Background imagery is a three-color image constructed from Spitzer where red shows MIPS 24 µ m, green IRAC 8.0 µ m, and blue IRAC 5.8 µ m. Image (brightness/contrast) adjustment used emphasizes Nessie and also makes the image look a bit greener than is 'natural.' Yellow horizontal lines show b = 0 ◦ and b = -0 5 . . ◦ Small white numbers show galactic longitude ( ) in degrees. l Full size version of this figure is available at this link (submit to Journal). A non-annotated high-dynamic-range view of this Spitzer image is available as a supplement to this paper at http://hdl.handle.net/1902.1/22050. (Note that related figures below show less exaggerated contrast, and zoom in on the central portions of Nessie.)
nature of this cloud. Instead, our focus is on how long the full Nessie feature might be, and on what that length combined with Nessie's special position in the Galaxy imply about how similar structures can be used to chart the structure of the Galaxy. Casual inspection of Spitzer imagery given in Figure 1 suggests that Nessie is at least two or three times longer than 'Nessie Classic,' measuring at least 3 ◦ long ('Nessie-Extended'). Very careful inspection (pan and zoom Figure 1) of the Spitzer images suggests that Nessie could be even longer. If one optimistically connects what appear to be all the relevant pieces then 'Nessie Optimistic' could be as much as 8 ◦ long (light white chalk line in Figure 1). The optimism
involved in seeing the longest extent for Nessie could be warranted if bright star-forming regions have broken up the continuous extinction feature, and/or if the background emission fluctuates enough to make the extinction hard to detect.
Determining the physical, three-dimensional, nature of extensions to the Nessie cloud requires a detailed analysis of the velocity of the gas associated with the dust responsible for mid-IR extinction. We offer such an analysis below ( § 3), but here we note that if Nessie (as is nearly certain given its velocity range) lies in or near the Scutum-Centaurus Arm of the Milky Way, then its distance is roughly 3.1 kpc (cf. Jackson et al. 2010). At that distance, Nessie Classic is roughly 80 pc long, Nessie Extended is 160 pc long, and Nessie Optimistic is 430 pc long. For any of these lengths, the dark filament's width is of order 0.01 degrees (0.5 pc), according to Jackson et al.'s (2010) analysis of the Spitzer imagery. Thus, clouds's axial ratio is about 150 for Nessie Classic, 300 for Nessie Extended, and nearly three times more, 800, for Nessie Optimistic. (These calculations are based on Table 1 a publicly-available interactive spreadsheet, at this link, a snapshot of which is shown as Figure 2.)
## 3. The Three-Dimensional Position of Nessie within the Milky Way
## 3.1. Looking 'Down' on the Galaxy
Astronomers would love to leave the Milky Way, so that we could observe its spiral pattern face-on, as we do for other galaxies. But our Sun is so entrenched in the Milky Way's plane that an 'overhead view' of the Milky Way's structure is impossible. Or is it? What if the Sun were just far enough above the Galactic Plane that we could use its height to give ourselves a tiny bit of perspective on the Galactic Plane that would spatially separate long skinny in-plane features located at different distances to be at different
7DEOHglyph<c=3,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=29,font=/NEXZBU+Georgia>glyph<c=3,font=/NEXZBU+Georgia>(VWLPDWHVglyph<c=3,font=/NEXZBU+Georgia>RIglyph<c=3,font=/NEXZBU+Georgia>1HVVLHglyph<c=10,font=/NEXZBU+Georgia>Vglyph<c=3,font=/NEXZBU+Georgia>'HQVLW\glyph<c=3,font=/NEXZBU+Georgia>DQGglyph<c=3,font=/NEXZBU+Georgia>0DVV
| $VVXPSWLRQVglyph<c=29,font=/NEXZBU+Georgia> | %DU\RQLFglyph<c=3,font=/NEXZBU+Georgia>PDVVglyph<c=3,font=/NEXZBU+Georgia>RIglyph<c=3,font=/NEXZBU+Georgia>0LON\glyph<c=3,font=/NEXZBU+Georgia>:D\glyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>0VXQVglyph<c=12,font=/NEXZBU+Georgia> 'LVWDQFHglyph<c=3,font=/NEXZBU+Georgia>WRglyph<c=3,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>SFglyph<c=12,font=/NEXZBU+Georgia> | %DU\RQLFglyph<c=3,font=/NEXZBU+Georgia>PDVVglyph<c=3,font=/NEXZBU+Georgia>RIglyph<c=3,font=/NEXZBU+Georgia>0LON\glyph<c=3,font=/NEXZBU+Georgia>:D\glyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>0VXQVglyph<c=12,font=/NEXZBU+Georgia> 'LVWDQFHglyph<c=3,font=/NEXZBU+Georgia>WRglyph<c=3,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>SFglyph<c=12,font=/NEXZBU+Georgia> | %DU\RQLFglyph<c=3,font=/NEXZBU+Georgia>PDVVglyph<c=3,font=/NEXZBU+Georgia>RIglyph<c=3,font=/NEXZBU+Georgia>0LON\glyph<c=3,font=/NEXZBU+Georgia>:D\glyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>0VXQVglyph<c=12,font=/NEXZBU+Georgia> 'LVWDQFHglyph<c=3,font=/NEXZBU+Georgia>WRglyph<c=3,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>SFglyph<c=12,font=/NEXZBU+Georgia> | %DU\RQLFglyph<c=3,font=/NEXZBU+Georgia>PDVVglyph<c=3,font=/NEXZBU+Georgia>RIglyph<c=3,font=/NEXZBU+Georgia>0LON\glyph<c=3,font=/NEXZBU+Georgia>:D\glyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>0VXQVglyph<c=12,font=/NEXZBU+Georgia> 'LVWDQFHglyph<c=3,font=/NEXZBU+Georgia>WRglyph<c=3,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>SFglyph<c=12,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> glyph<c=22,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> glyph<c=22,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> glyph<c=22,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> glyph<c=22,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> glyph<c=22,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> glyph<c=22,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> glyph<c=22,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> |
|---------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1LFNQDPH | /HQJWK GHJ | 5DGLXV GHJ | /HQJWK SF | 5DGLXV SF | $YHUDJH GHQVLW\ FPAglyph<c=16,font=/NEXZBU+Georgia>glyph<c=22,font=/NEXZBU+Georgia> | +glyph<c=21,font=/NEXZBU+Georgia>glyph<c=3,font=/NEXZBU+Georgia>FROXPQ GHQVLW\ FPAglyph<c=16,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | (TXLYglyph<c=17,font=/NEXZBU+Georgia> $Y PDJ | 0DVV 0VXQV | 0DVVglyph<c=3,font=/NEXZBU+Georgia>SHU XQLW OHQJWK 0VXQVglyph<c=18,font=/NEXZBU+Georgia>SF | glyph<c=6,font=/NEXZBU+Georgia>glyph<c=3,font=/NEXZBU+Georgia>WRglyph<c=3,font=/NEXZBU+Georgia>HTXDO PDVVglyph<c=3,font=/NEXZBU+Georgia>RI 0LON\glyph<c=3,font=/NEXZBU+Georgia>:D\ | DVSHFW UDWLR |
| glyph<c=5,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>&ODVVLFglyph<c=5,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=22,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=27,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=25,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> |
| glyph<c=5,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>([WHQGHGglyph<c=5,font=/NEXZBU+Georgia> | glyph<c=22,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=25,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=22,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=21,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=27,font=/NEXZBU+Georgia> | glyph<c=25,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=22,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> |
| glyph<c=5,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>2SWLPLVWLFglyph<c=5,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia>glyph<c=22,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=22,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=27,font=/NEXZBU+Georgia> | glyph<c=21,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> |
| glyph<c=5,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>&ODVVLFglyph<c=5,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=21,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=26,font=/NEXZBU+Georgia> | glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia> | glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=23,font=/NEXZBU+Georgia> | glyph<c=25,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=23,font=/NEXZBU+Georgia> | glyph<c=22,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=25,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> |
| glyph<c=5,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>([WHQGHGglyph<c=5,font=/NEXZBU+Georgia> | glyph<c=22,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=25,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=21,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=26,font=/NEXZBU+Georgia> | glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=25,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=23,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=25,font=/NEXZBU+Georgia> | glyph<c=22,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> |
| glyph<c=5,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>2SWLPLVWLFglyph<c=5,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia>glyph<c=22,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=21,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=26,font=/NEXZBU+Georgia> | glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia> | glyph<c=22,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=25,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=23,font=/NEXZBU+Georgia> | glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> |
Fig. 2.- Estimates for the density and mass of Nessie, under various assumptions about its length. The top set of values shows estimates for a cylinder with radius, length, and average density appropriate to the Spitzer 'shadow' shown in Figure 1. The average density is set to 10 5 cm -3 so as to achieve a visual extinction of ∼ 100 magnitudes, consistent with the typical extinction on tenths of pc scales in an IRDC. The lower set of values is different only in that a density of 500 cm -3 is used, as an estimate of the typical density of the region seen to emit in HNC by Jackson et al. 2010. Readers can test alternative assumptions for the calculations shown here in the interactive version of this table at http://tinyurl.com/nessietable.
projected latitudes? Turns out we are lucky in this way-the Sun is apparently located a bit above the Plane (see below), and we can use that vantage point to out advantage.
To understand why most modern astronomers do not typically think about the possibility or value of an overhead view, we need to consider the origin of our current Galactic coordinate system, and our current understanding of the Sun's and the Galactic Center's 3D positions. Writing in 1959 on behalf of the International Astronomical Union's (IAU's) sub-commission 33b, Blaauw et al. wrote:
The equatorial plane of the new co-ordinate system must of necessity pass through the sun. It is a fortunate circumstance that, within the observational uncertainty, both the sun and Sagittarius A lie in the mean plane of the Galaxy as determined from hydrogen observations. If the sun had not been so placed, points in the mean plane would not lie on the galactic equator.
In a further explanation of the IAU system in 1960, Blaauw et al. explain that stellar observations did, at that time, indicate the Sun to be at z Sun = 22 ± 2 (22 pc above the plane), but the authors then discount those observations as too dangerously affected by hard-to-correct-for extinction in and near the Galactic Plane (Blaauw et al. 1960). Instead, the 1959 IAU system relies on the 1950s measurements of HI, which showed the Sun to be at z Sun = 4 ± 12 pc off the Plane, consistent with the Sun being directly in the Plane ( z Sun = 0). Interestingly, since the 1950s, the Milky Way's HI layer has been shown to have corrugations on the scale of 10's of pc (Malhotra 1995), and there may be similar fluctuations in the mid-plane of the H 2 (Malhotra 1994), so it is still tricky to use gas measurements to determine the Sun's height off the plane. Although the Sun's ( ∼ 25 pc) offset from the Galactic plane is not large in comparison with the half-thickness of the plane as traced by Population I objects such as GMCs and HII regions ( ∼ 200 pc; Rix & Bovy (2013)), it is much larger than the thickness of an extremely thin gas layer that may, as we argue in § 4.1, be traced out by Nessie-like 'bones' of the Milky Way.
Astronomers today are still using the ( l II , b II ) Galactic coordinate system defined by Blaauw et al. (1959), but it is not still the case, within observational uncertainty, that the Sun is in the mean plane of the Galaxy, and the true position of the Galactic Center is no longer at ( l II = 0 , b II = 0). Instead, a variety of lines of evidence (Chen et al. 2001; Ma´ ız-Apell´niz 2001; Juri´ et al. 2008) show that the Sun is approximately 25 pc above the a c stellar Galactic mid-plane, and VLBA proper motion observations of masers show that the
Galactic Center is about 7 pc below where the ( l II , b II ) system would put it, at b = -0 046 . ◦ (Reid & Brunthaler 2004). After analysis of the spatial distribution of dense gas revealed in the ATLASGAL survey showed a mean at negative latitude, Beuther et al. (2012) noted that their observations are indicative of a real global offset of the Galactic mid-plane from its conventional position where the axis between the Sun and the Galactic center is located at b = 0 deg.
The offsets of the Sun and the Galactic Center from their IAU ' b = 0' positions, as anticipated by Blaauw et al., imply that 'points in the mean plane [do] not lie on the galactic equator.'
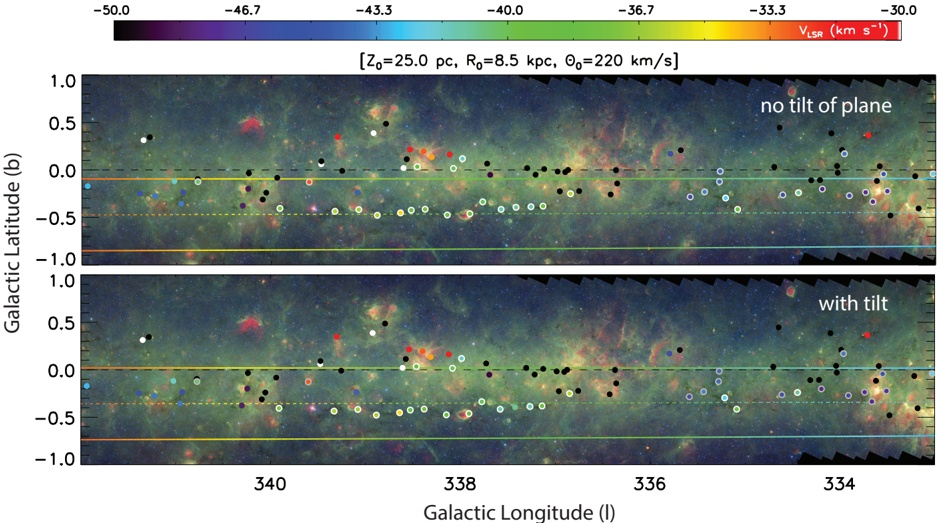
Figure 3 shows a schematic (not-to-scale) diagram of the effect of the Sun's and the Galactic Center's offsets from the mid-plane defined by the IAU in 1959 (and still in use as ( l II , b II ) today). The tilt of the the true, physical, Galactic mid-plane to the presently IAU-defined plane means that, within about 12 kpc of Sun 2 any feature that is truly 'in' the Galactic mid-plane will appear on the Sky at negative b II . Figure 5 shows an example of this effect, where the rainbow-colored dashed line indicates the sky position of the physical Galactic mid-plane at a Nessie-like distance of 3.1 kpc (assuming the the Sun is 25 pc off the plane, a distance to Sgr A** of 8.5 kpc, a rotation speed for the Milky Way of 220 km s -1 , and (U,V,W) motion for the Sun of 11.1, 12.4, and 7.2 km s -1 , respectively).
2 12 kpc is the approximate distance where the physical and IAU planes cross, on a line toward the Galactic Center. Along other directions toward the Inner Galaxy, as shown in the lower panel of Figure 4, it will be further to the crossing point, and toward the Outer Galaxy, for a 'flat' disk, the mid-plane will always appear at negative latitudes.
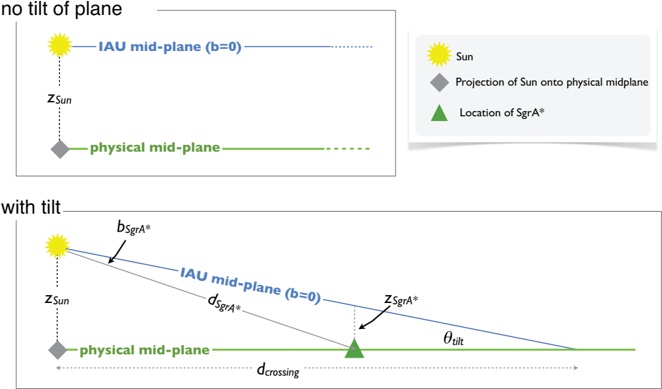
Fig. 3.- . Schematic side-views of the of the physical mid-plane of the Galaxy with respect to the IAU-defined mid-plane. The drawings are not to scale . In both panels, z Sun represents the height of the Sun above the Galactic mid-plane. In the upper panel , and in figures labeled 'no tilt of plane' below, we consider only the Sun's offset from the plane in calculating the observed coordinates of the true 'physical' mid-plane. In the lower panel , and in figures labeled 'with tilt' below, we also take the offset, z SgrA ∗ , of the Galactic Center (Sgr A*) into account. For reference, if the distance to SgrA*, d SgrA ∗ , is 8.5 kpc and z Sun =25 pc and z SgrA ∗ = 7 pc (based on b = -0 046 . ◦ for SgrA*) then the angle by which the IAU mid-plane is tilted with respect to the physical plane is θ tilt = 0 12 . ◦ and the distance from the Sun to where the two planes cross is d crossing = 12 kpc.
## 3.2. Using Rotation Curves and Velocity Measurements to Place Nessie in 3D
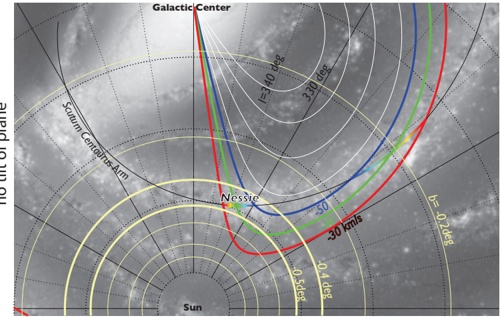
Ever since velocity-resolved observations of stars and gas have been possible, astronomers have been modeling the rotation pattern of the Milky Way. Using a measured rotation curve for the Milky Way's gas (e.g. McClureGriffiths & Dickey 2007), one can translate observed LSR velocities to a unique distance in the Outer Galaxy, and to one of two possible ('Near' or 'Far') distances toward the Inner Galaxy. Figure 4 shows isov LSR contours toward the Inner Galaxy, around the longitude range of Nessie, superimposed on the data-driven cartoon of our current understanding of the Milky Way's structure. Notice that velocities associated with the near-side of the Scutum-Centaurus Arm in Nessie's longitude range should be near 40 km s -1 .
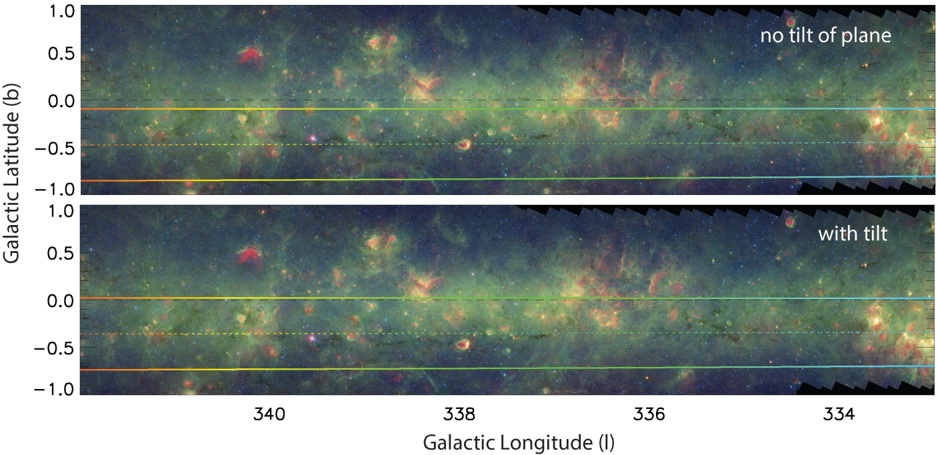
Combining a modern estimate for the Sun's height above the plane ( z Sun ∼ 25 pc), with the IAU Galactic coordinate definitions, we can determine where the physical mid-Plane of the Galaxy should appear in the ( l II , b II ) system at any particular distance from the Sun. Figure 5 shows where the Scutum-Centaurus Arm would appear on the Sky (for a distance to Sgr A** of 8.5 kpc, a rotation speed for the Milky Way of 220 km s -1 , and (U,V,W) motion for the Sun of 11.1, 12.4, and 7.2 km s -1 , respectively). As its caption explains in detail, Figure 5's colored lines are associated with the near part of the Scutum-Centaurus Arm. Two versions of this plane-of-the-Sky view are shown, one only accounting for the offset of the Sun, and the other also accounting for the tilt of the coordinate system caused by the Galactic Center also not lying in the IAU plane (see Figure 3).
The dashed colored lines in Figure 5, indicating the predicted position of the Galactic Plane on the Sky at the distance to the near side of the Scutum-Centaurus Arm, pass almost directly through Nessie, regardless of whether or not one considers the 'tilt' of the coordinate system caused by SgrA*'s offset. Solid colored lines show 20 pc above and below the Plane at the distance to the Scutum-Centaurus Arm, so Figure 5 makes it is very clear
that Nessie lies within just a few pc of the Plane, along its entire length. This is either an extremely fortuitous coincidence, or an indication that Nessie is tracing a significant feature that effectively marks the mean location of the Galactic Plane. Given the waviness of the plane on 10 pc scales (see above, (Malhotra 1994)), the location at even less than 10 pc from the mean plane may be fortuitous-but the location so close to the mean is not.
## 3.2.1. CO Velocities
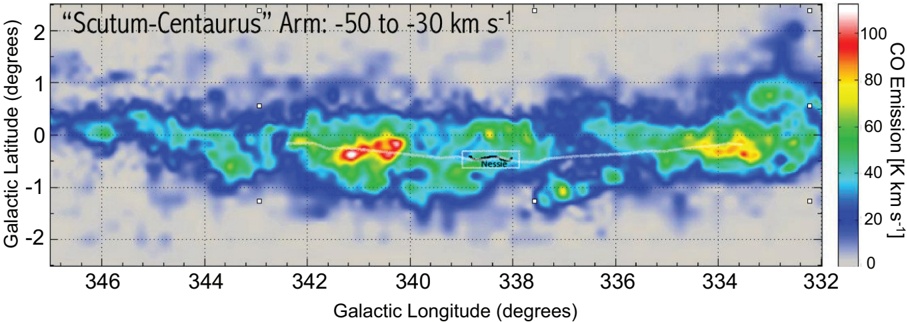
CO observations trace gas with mean density around 100 cm -3 . CO emission associated with the Scutum-Centaurus Arm of the Milky Way (Dame et al. 2001; Dame & Thaddeus 2011) is shown in Figure 6, which presents a plane-of-the-sky map integrated over -50 < v LSR < -30 km s -1 . The velocity range is centered on -40 km s -1 , the average velocity of the Scutum-Centaurus Arm in Nessie's longitude range (see Figures 4 and 5). The white chalk line superimposed on Figure 6 is the same tracing of 'Nessie Optimistic' shown in Figure 1. The black feature labeled 'Nessie' refers to 'Nessie Classic.'
Judging by-eye, the vertical (latitude) centroid of the CO emission in Figure 6 appears to follow Nessie remarkably well, even out to the full 8 ◦ (430 pc) extent of Nessie Optimistic. We have also calculated a curve representing the locus of latitude centroids for CO in this velocity range, and even at this coarse resolution, a curve following Nessie's shape is clearly a better fit than a straight line passing through the CO centroids.
Table 1 estimates that the Nessie IRDC has a typical H 2 column density of ∼ 10 23 cm -2 and a typical volume density of ∼ 10 5 cm -3 . Thus, the plane-of-the-sky coincidence of the line-of-sight-velocity-selected 'Scutum-Centaurus' CO emission and the mid-IR extinction suggests that the Nessie IRDC may be a kind of dense 'spine' or 'bone' of this section of the Scutum-Centaurus Arm, as traced by much-less-dense ( ∼ 100 cm -3 ) CO-traced gas.
no tilt of plane
Galactic Center
Scutum Centaurus Arm l=340 deg
330 deg
-50
-40
-30 km/s
-0.4 deg
-0.3 deg
Sun
Fig. 4.For the fourth quadrant of the Milky Way, contours of constant LSR velocity of -30,-40,and-50 km s -1 (using a rotation curve from McClureGriffiths & Dickey 2007, ) are superimposed on a cartoon model of the Milky Way. CO and dense gas observations (see below) give LSR velocities associated with Nessie (shown here as rainbow curve) near -40 km -1 , placing Nessie in the Scutum-Centaurus arm (highlighted in black), about 3.1 kpc from the Sun. Yellow-highlighted curves show positions in the Galaxy that would have the labeled value of Galactic Latitude ( b ) when viewed from the Sun. In the top panel , only the height of the Sun off the plane (taken to be 25 pc in this example) is considered in drawing the iso-b curves, and in the bottom panel , a 7 pc offset of the Galactic Center (see text), which causes an overall tilt of 0 12 . ◦ is also taken into account.
with tilt
Nessie b=-0.1 deg
Fig. 5.- . Predicted Sky Position and Radial Velocities for the Scutum-Centaurus Arm of the Milky Way. In both panels, the colored lines are color-coded by velocity, given in the color bar at the top. The colored dashed line shows the predicted position for the Galactic Plane for the near side of the Scutum-Centaurus Arm (roughly 3.1 kpc from the Sun). The solid colored lines show ± 20 pc from the mid-Plane at the same ( ∼ 3 1 kpc) distance. . These lines and colors are calculated using a model of a (flat) Milky Way described by the parameters shown below the color bar. Background imagery is from Spitzer, as in Figure 1. A black dashed line emphasizes the position of b = 0. As in Figure 4: in the top panel , only a 25 pc offset of the Sun above is taken into account; and in the bottom panel , a 7 pc offset for the Galactic Center is also used in the calculation.
But, the spatial resolution of the CO map is too low (8 ), and the 20 km s ′ -1 velocity range associated with the Arm in CO is too broad to decide based on this evidence alone whether Nessie is a well-centered 'spine' or just a long skinny feature associated with, but
potentially significantly inclined to, the Scutum-Centaurus Arm.
Fig. 6.CO emission, integrated between -50 and -30 km s -1 , as projected on the sky, based on data from (Dame et al. 2001), with trace of Nessie Optimistic (light white line) from Figure 1 superimposed. The dark black squiggle labeled 'Nessie' (surrounded by a light white box) marks the position of Nessie Classic.
## 3.2.2. NH 3 Velocities
To estimate the 3D orientation of Nessie more precisely, we need to employ a gas tracer whose emission is sparser than CO's, and more associated with high-density gas, in position-position-velocity space. Many recent studies have shown that IRDCs typically host over-dense blobs of gas (often called 'clumps' or 'cores') that provide the gaseous reservoirs for the formation of massive stars. Thus, several studies have been undertaken to survey IRDCs and their ilk for emission in molecular lines that trace high-density ( glyph[greatermuch] 10 3 cm -3 ), potentially star-forming, gas.
The H O Southern Galactic Plane (HOPS) Survey (Purcell et al. 2012) has surveyed 2
hundreds of sites of massive star formation visible from the Southern Hemisphere for NH 3 emission, which traces gas at densities n glyph[greaterorsimilar] 10 4 cm -3 . The HOPS targets were selected based on H O maser emission, thermal molecular emission, and radio recombination lines, 2 so as to include nearly all known regions of massive star formation within the surveyed area. These 'massive-star-forming region' selection criteria mean that the HOPS database includes NH 3 spectra for dozens of positions within the longitude range covered by Nessie.
Figure 7 adds an overlay of HOPS sources' NH -determined LSR velocities to the 3 information presented in Figure 5, which illustrates how well Nessie fits the prediction of where the Scutum-Centaurus' arm's center would be in position-position-velocity space. The (color-coded) velocities of the HOPS sources, for both Nessie Classic, and Nessie Extended (see Figure 1), agree remarkably well with what is predicted for the Scutum-Centaurus Arm (color-coded lines). Note that agreement of the NH 3 and predicted velocity to better than 5 km s -1 is indicated by grey circles around the HOPS symbol. White circles, indicating agreement to within 2.5 km s -1 , surround all of the Nessie Extended sources, which are also shown in Figure 8, below. Most of the HOPS sources coincident with Nessie Optimistic, especially at the lower longitudes, also appear likely to be associated with the Scutum-Centaurus arm, based on their agreement with arm velocities to within 5 km s -1 , as indicated by grey circles. The velocities of sources at latitudes much different from Nessie's within this longitude range largely do not agree, and those sources are unlikely to be associated with the near-side of the Scutum-Centaurus Arm. For reference, the typical velocity dispersion within molecular gas (with density ∼ 50 cm -3 ) is about 5 km s -1 (Larson 1981), so any white or grey outlined point in Figure 7 is plausibly associated with a structure whose systemic velocity is typical of the near side of the Scutum-Centaurus Arm.
For Nessie Classic, Jackson et al. (2010) had already noted a very narrow velocity range for dense gas associated with the IRDC, based on HNC observations. What is new here
is the three-dimensional (latitude, longitude, and velocity) association of a longer Nessie's dense gas with predictions for where the centroid of the Milky Way's Scutum-Centaurus Arm's 'middle' would lie.
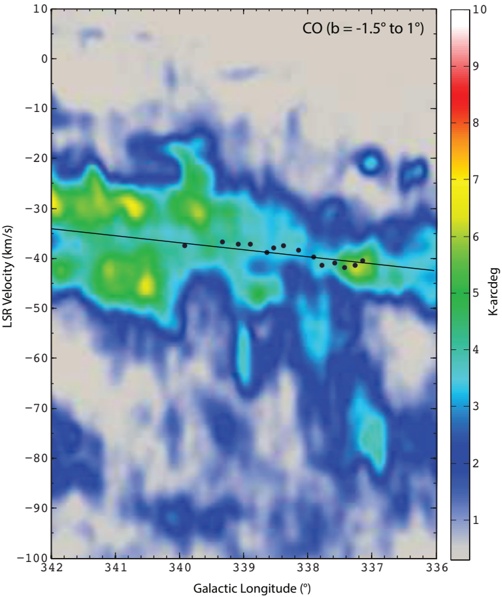
Figure 8, which offers a position-velocity diagram of CO (color) and NH 3 emission (black dots) together, shows the association of the Nessie-HOPS sources with the Scutum Centaurus Arm most clearly. What is most remarkable about Figure 8 is that the black line sloping through the figure is not a fit to the black dots representing the HOPS sources. Instead, that line indicates the position-velocity trace of the Scutum-Centaurus Arm based on (Dame & Thaddeus 2011) data for the full Galaxy, not just this small longitude range. Figure 8 implies that Nessie goes right down the 'spine' of the Scutum-Centaurus Arm, as best we can measure its position in CO position-velocity space.
## 4. What is the Significance of Nessie-like structures within a Spiral Galaxy?
## 4.1. A Bone of the Galaxy
All the evidence presented in this paper, taken together, strongly suggests that Nessie forms a bone-like feature that closely follows the center of the Scutum-Centaurus Arm of the Milky Way. How did it get there? Is it the crest of a classic spiral density wave (Lin & Shu 1964), or does it have some other cause? One would na¨ ıevely expect that any feature this long and skinny that is not controlled by Galactic-scale forces will be subject to a variety of instabilities, and would not last long.
Until very recently, no numerical simulation of gas in a Milky Way-like galaxy had sufficient resolution to reveal features as thin as Nessie. As of 2013, state-of-the-art simulations by Dobbs & Pringle (2013) showed many elongated features along and between
Fig. 7.Superposition of HOPS Sources, color-coded by NH -determined LSR velocity. 3 Colored lines have the same meaning (predicted LSR velocity) as in Figure 5, so the colorful dashed lines at b ∼ -0 5 , . ◦ in both panels, represent the physical Galactic mid-plane, and the solid colorful lines indicate 20 pc above and below the plane. Agreement of the NH 3 and predicted LSR velocity (color) to within 2.5 km s -1 is indicated by a white circle around the HOPS symbol, and grey circles indicate agreement to within 5 km s -1 . As in Figures 4 and 5: in the top panel , only a 25 pc offset of the Sun above is taken into account; and in the bottom panel , a 7 pc offset for the Galactic Center is also used in the calculations.
arms, 3 but the thickness of the features was ∼ 10 pc, an order of magnitude too coarse.
Figures 9 and 10 offer top-down and edge-on snapshots of a brand-new numerical simulation of the gas in a Milky Way-like spiral galaxy from Smith et al. (2014), and this
3 Simulation video online at http://empslocal.ex.ac.uk/people/staff/cld214/movies.htm.
Global Sct-Cen fi
t (Dame & Thaddeus 2011)
HOPS sources ('Nessie Extended')
Fig. 8.- Position-velocity diagram of CO and NH . Colored background shows CO emission 3 integrated over -1 5 . < b < 1 . ◦ Black dots show HOPS sources coincident with Nessie Extended, also shown in Figure 7 as white-circle-highlighted colored points. The dots are plotted at the longitudes given in Figure 7, and the LSR velocities given by the centroid of the NH 3 emission for each HOPS source. The black line shown is not a fit to the HOPS or the CO data shown: it is a segment of a global log-spiral fit to CO data for the entire Scutum-Centaurus Arm, extending almost 360 ◦ around the Galaxy (taken from Fig. 4 of Dame & Thaddeus (2011).
simulation is the first to offer resolution high enough to see potentially Nessie-like features. The AREPO moving mesh code used in these new simulations provides resolution ∼ 0 3 . pc resolution in regions where the gas density n > 10 3 cm -3 , and slightly better in the highest-density cells. The high-resolution views of the simulation in the inset in Figure 9 and in Figure 10 exhibit many spatial features that are as long and thin as Nessie. The overlain lines in Figure 10 additionally show that the Nessie-like high-contrast filamentary structures like centered in the 'Galactic Plane' of the simulation, and that they have vertical extent not unlike Nessie (cf. Figure 5). So as not to over-emphasize the apparently remarkable agreement of the Smith et al. (2014) simulations and Nessie-like structure, we should point out that the simulations do not include the results of feedback from stars and HII Regions, nor do they include magnetic fields. Including these effects in future simulations will likely cause disruption of some filaments, and changes in topology and/or filament orientation where magnetic energy is significant. For reference, the half-thickness of the Milky Way's plane as traced by Population I objects such as GMCs and HII regions is estimated to be ∼ 200 pc (Rix & Bovy 2013), which is the starting thickness of the evolving torus in the Smith et al. (2014) simulation. For now, we offer these simulations as the first evidence that gas in a spiral galaxy is very likely to contain very high-contrast, extraordinarily long and thin, filamentary structure marking out what we call the galaxy's 'skeleton.'
Many of the features that appear to be trailing off from the major spiral arms apparent in Figure 9 are similar to the 'spurs' and 'feathers' that have been previously simulated and observed by E. Ostriker and colleagues (Shetty & Ostriker 2006; La Vigne et al. 2008; Corder et al. 2008) and seen in the simulations of Dobbs & Pringle (2013). Figure 11 shows a recent infrared (WISE) image of the galaxy IC342 (Jarrett et al. 2013), and it is clear from that image that some 'spiral' galaxies also exhibit inter-arm filaments that are even more pronounced than the simulated spurs and feathers. Thus, both simulations and
observations show long, filamentary, structures within, and between arms.
The highest-resolution simulations (Smith et al. 2014) suggest that the highest-contrast filaments tend to largely be found in the plane of a spiral galaxy (Figure 10) associated with arms, rather than inter-arm regions (Figure 9). But, high-density contrast alone does not imply that a filament lies along a spiral arm rather than between arms. The existence of many dense cores within Nessie (see § 3.2.2) implies an over-density of at least 10 3 (comparing NH 3 gas and CO-emitting gas) at many positions along the filament. Similar over-densities, and strings of dense cores, are seen in many IRDCs. Battersby & Bally (2014) identified G32.02+0.06 as a sinuous, long, thin, 80-pc long 'Massive Molecular Filament' near (but not quite in) the Galactic plane, and in very recent work, Ragan et al. (2014) added seven more 'Giant Molecular Filaments' almost as long and thin as Nessie to the list of very long-thin ∼ 10 5 M glyph[circledot] filamentary IRDCs known in the Milky Way.
In using observations to judge whether a specific highly-elongated filamentary cloud lies along (within) an arm, or is highly inclined to an arm, the velocity of the associated gas offers the most relevant evidence. In the case of Nessie, the analysis of the HOPS NH 3 data presented in § 3.2.2, showing agreement with spiral arm line-of-sight velocities, and its location at what is predicted to be the vertical center of the Scutum-Centaurus arm, argues very strongly that Nessie is, three-dimensionally, a spine-like 'bone' of the Scutum-Centaurus Arm.
Estimates for the mass of Nessie under various assumptions are given in Table 1. Jackson et al. 2010 model Nessie as a(n unmagnetized) self-gravitating fluid cylinder supported against collapse by a 'turbulent' analog of thermal pressure, undergoing the sausage instability discussed in Chandrasekhar & Fermi (1953). For the observed line width of HNC, the theoretical critical mass per unit length, m l , is 525 M glyph[circledot] pc -1 for Nessie. But, if, as Jackson et al. explain, one estimates m l using HNC emission itself and (uncertain)
abundance values for HNC, then 110 < m < l 5 × 10 4 M glyph[circledot] pc -1 . Given that the low end of this range (110 M glyph[circledot] pc -1 , favored by Jackson et al.) gives a very low value for extinction toward Nessie ( A V ∼ 4 mag), we favor higher values of m l , needed to be consistent with the observed IR extinction. Recent LABOCA observations of dust continuum emission from pieces of Nessie (Kauffmann, private communication), suggest that m l glyph[greaterorsimilar] 10 3 in the mid-IR-opaque portions of Nessie. So, at present, it would appear that there is at least an order-of-magnitude uncertainty in m l . Some of this uncertainty is caused by the definition of Nessie's shape, which makes it unclear which 'mass' to measure in calculating m l , but more is due to the vagaries of converting molecular line emission and/or dust continuum to true masses.
What most interests us here is not Nessie's exact mass, mass per unit length, or density profile, but instead its total mass as a fraction of the Galaxy's mass, so that we can use that estimate in assessing how many Nessie-like structures may be findable in the Milky Way. To begin that assessment, we only need estimate Nessie's total mass. Toward that end, Table 1 offers very simple estimates of the mass of cylinders, whose (constant) average density is set so that the typical extinctions associated with Nessie's IR-dark ( A v ∼ 100 mag) and HNC bright ( A V glyph[greaterorsimilar] a few mag) radii are sensible. Using HNC emission directly to calculate mass is dangerous, because, as mentioned above (Jackson et al. 2010), the fractional abundance of HNC is uncertain by as much as three orders of magnitude. Calculating masses using a filament diameter of 0 01 pc and a characteristic column density . A V = 80 mag (corresponding a a volume density of 10 5 cm -3 ), Nessie Classic is 1 × 10 5 M , glyph[circledot] Nessie Extended is 2 × 10 5 M glyph[circledot] and Nessie Optimistic is 5 × 10 5 M . If one assumes that glyph[circledot] the envelope traced by the HNC observations of Jackson et al. (2010) for Nessie Classic continues along Nessie's length, then the mass of an n ∼ 500 cm -3 cylinder with diameter 0.1 pc (see Table 1) associated with Nessie would be 5 × 10 4 M glyph[circledot] for Classic and 3 × 10 5 M glyph[circledot] for Optimistic. For the Optimistic case, this mass amounts to 2 millionths of the total gas
mass (assuming ∼ 10 11 M glyph[circledot] total) of the Milky Way.
Most of the mass in molecular clouds, which typically follows a log-normal distribution (cf. Goodman et al. 2009, and references therein), is at densities substantially lower than the 500 cm -3 we have used for Nessie's outer HNC-emitting regions. For example, Battisti & Heyer (2014) find that the Dense Gas Mass Fraction (DGMF) in molecular clouds is of order 10 percent, using the mass in sub-mm-emitting dense dusty cores (from the BGPS Survey, Rosolowsky et al. 2010) as the numerator and the full mass of 13 CO-emitting clouds (from the GRS Survey, Jackson et al. 2006) as the denominator. Emission from 13 CO typically traces of order 10 percent of the total molecular mass (cf. Pineda et al. 2008, and references therein). So, correcting for a a 10% DGMF and 13 CO tracing at most 10% of the total H , in the limiting case that 2 all dense gas were in Nessie-like structures, the total number of 'Nessie Optimistics' that one could find in the Milky Way is at least 100 times less than the 500,000 listed in Table 1 under 'number to equal mass of Milky Way.' By-eye inspection of Figures 9 and 10 gives the impression that roughly 20% of the very high column density ( A V ∼ 100 mag) gas will be in easy-to-identify long, straight structures. So, a coarse estimate of 'how many Nessies' are detectable in the Milky Way can be based on the ratio ( ∼ 500 000) of the Milky Way's gas mass divided by Nessie's mass traced by , HNC, reduced by × ∼ 0 1 to account for the dense gas mass fraction, another . × ∼ 0 1 to . account for the ratio of total molecular to 13 CO-emitting gas, and another at best × ∼ 0 2 . to account for the topology in evidence in the Smith et al. simulations. That leaves us with an estimate that of order many hundreds to thousands of additional Nessie-like features that should be discoverable in the Milky Way. And, of course, features nearer to us, and oriented more perpendicular to our line of sight, as Nessie is, will be the easiest to find.
To make more robust estimates of how discoverable our Galaxy's bones will be, future work should use simulated observations of galaxy simulations like those presented in
Smith et al. (2014), and/or high-resolution extragalactic observations of spiral galaxies, to statistically model what structures could be observable. For reference, the 40 pc resolution of the interferometric state-of-the-art PAWS Survey of CO in the nearby spiral M51 (Schinnerer et al. 2013) is not high enough to find Nessie-like structures. Future ALMA observations with resolution of several pc may be able to find evidence for bones by finding their 'envelopes,' as traced, for example, by the HNC observations in Jackson et al. (2010).
## 4.2. Can We Map the Full Skeleton of the Milky Way?
We have long thought that generating an outside-in view of the Milky Way is impossible, almost as inhabitants of Edwin A. Abbott's Flatland (Abbott 1884) residents cannot envision a 3D view of their 2D world. But, we can escape flatland by realizing that the tiny offset of the Sun above the Milky Way's midplane can give us a tiny, but useful, bit of perspective on the 3D structure of the Milky Way . This view is only useful for mapping structure using very high-contrast, very narrow, features like Nessie, because puffier features will overlap too much to be identifiable in such a foreshortened view. The identification of Nessie as a bone-like feature implies that modern observations are good enough, and features are sharp enough, to identify at least some of our Galaxy's skeleton.
It turns out that Nessie is located in a place where seeing a very long IRDC projected parallel to the Galactic Plane should be easiest. Look again at Figure 4, and consider Nessie's placement there. According to the current (data-based cartoon) view of the Milky Way shown in Figure 4, Nessie is in the closest major spiral arm (Scutum-Centaurus) to us, along a direction toward, but not exactly toward, the (confusing) Galactic Center. Nessie's placement there means that it will have a bright background illumination as seen from further out in the Galaxy (e.g. from the Sun), and that it will have a long extent on the Sky as compared with more distant or less perpendicular-to-our-line-of-sight objects. It is
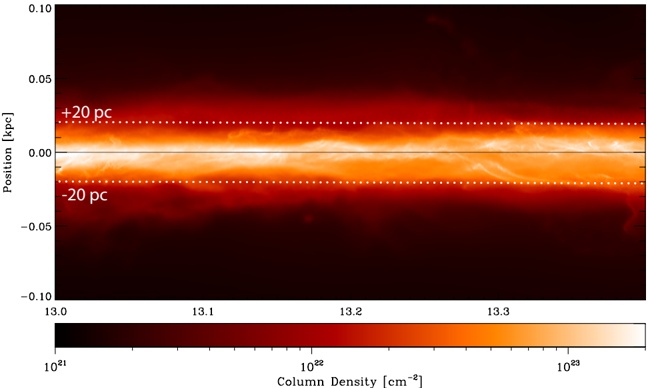
Fig. 9.Top-down view of the total column density in a simulation of structures forming within a spiral galaxy based on Smith et al. (2014). The main bright curving features show spiral arm structures. Note the 100 pc scale bar within the zoom box, which shows that the simulation's resolution is very close to high enough to compare directly with structures with 'Nessie,' whose width is just under 1 pc.
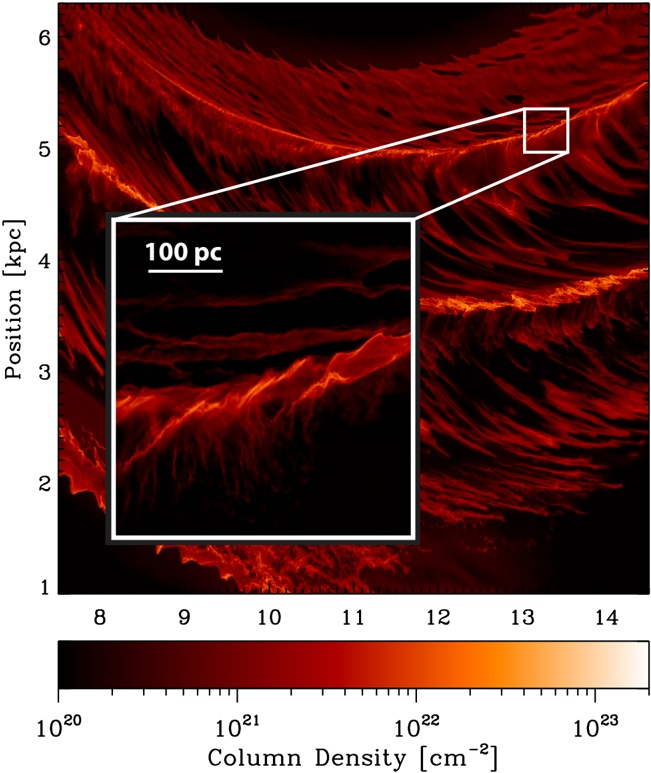
Fig. 10.Edge-on view of the total column density in a simulation of structures forming within a spiral galaxy based on Smith et al. (2014). Note the white dotted lines drawn at 20 pc above and below the Galactic Plane (black line), and, by comparing with Figure 5, notice how the scale of the highly-elongated whitest high-density features in this simulation is approximately comparable to Nessie.
always good when one finds what should be the easiest-to-see example of a new phenomenon first, so we are reassured that Nessie was the first 'Bone' of the Milky Way found. Now, though, we need to think about how to find Bones not as prominent as Nessie. There are essentially two approaches.
In one approach, one can conduct a strategic search for long thin clouds, or broken pieces of such, in places on the Sky where they 'should' occur according to our current understanding of the Milky Way's spatial and velocity structure. Specifically, using current estimates for the Milky Way's arm's 3D locations, one can draw more velocity-encoded traces like the ones shown in Figure 5 on the 2D Sky, showing where arms should appear.
With such predictions in hand, one can design algorithms to look for dust clouds elongated
(roughly) along those lines, and then examine the velocity structure of the elongated features, as we do in § 3, above. Of course, one need be flexible about which features one accepts as possible 'bones,' remembering that the model used to draw the expected features on the Sky is the same one being refined! It is likely that an iterative approach, using the extant Milky Way model as a prior, will succeed in this way.
Taking a less targeted survey approach, one can search the Sky for long, thin, dense clouds, and assess their relationship to Galactic structure after the fact. This blind search approach has recently been taken by Ragan et al. (2014) in the first quadrant of the Milky Way, using near and mid-infrared images. Of the seven new clouds (dubbed 'Giant Molecular Filaments') identified by Ragan et al. (2014) none appears to be tracing spiral arm structures like Nessie. One cloud, GMF 20.0-17.9, appears to be a spur off of the Scutum-Centaurus Arm. Ragan et al. (2014) confirm our claim that Nessie lies in the middle of the Scutum-Centaurus Arm, and they speculate that perhaps identifying bone-like features in the first quadrant is more difficult than in the fourth, where Nessie lies. Examining Figure 4, it is clear that Nessie and other clouds in the Scutum-Centaurus arm would be much more perpendicular to our line of sight, and thus easier-to-detect, in the fourth quadrant than in the first, so we agree with Ragan et al.'s speculation.
In a related approach, a 'connect the dots,' strategy for finding long features is also possible. Using the output of exhaustive (automated) searches for high-density peaks, once can look for non-random, long, straightish, patterns in the distribution of those peaks. For example, in plotting out the Peretto & Fuller (2009) catalog of the positions of 11,000 roundish high-density peaks on the Sky, long thin IRDCs appear to the eye as strings of easy-to-connect sources. Nessie itself is comprised of ∼ 100 Peretto & Fuller sources superimposed on a slightly-lower-density connecting structure. It may be possible to use automated structure-finding algorithms, such as Minimum Spanning Trees, to
connect-the-peaks in efforts to identify additional bones of the Milky Way.
Prior to our work on assessing the role of (a lengthened) Nessie in Galactic structure, and Ragan et al.'s 2014 survey, at least two other exceptionally long molecular clouds near the Galactic plane were presented in the literature. The so-called 'Massive Molecular Filament' G32.02+0.06, studied by Battersby & Bally (2014), does not appear to be tracing an arm structure. And the 500-pc long molecular 'wisp' discussed by Li et al. (2013) also does not presently appear directly related to Galactic structure, although it is interesting to think about its past. As we discuss in § 4.1, it will likely prove important to model the effects of feedback on the evolution of bone-like star-forming molecular clouds. None of the other long, thin, dense clouds discovered to date are as elongated and straight as Nessie. Intuitively, one can guess that over very long time scales, the star formation going on with clouds like Nessie will re-shape them and break them into pieces very hard to recognize as ever having been bone-like.
As extinction, dust emission, and molecular spectral-line maps cover more and more of the sky at ever-improving resolution and sensitivity, it should be possible to map more and more of the Milky Way's skeleton. New wide-field extinction-based efforts based at first on Pan-Starrs (e.g. Green et al. 2014), and ultimately on Gaia, will be tremendously helpful in these efforts in the coming decade. Once enough features are identified on the Sky and in 3D space using dust maps, and in position-position-velocity space (using information from spectral-line observations), it should be possible to fit features together into a skeletal pattern of arms, spurs, and more, in much the same way one solves a jigsaw puzzle by finding the most obvious connections first. Ultimately, we may have enough examples of 'bones' to apply a machine-learning algorithm that would search for additional pieces of the Milky Way's skeleton based on known examples, in much the same way that Beaumont et al. (2011) used the output of the Milky Way Project's citizen science effort as
input to a Support Vector Machine algorithm that quantifies estimates of the density and characteristics of bubble-like features in the interstellar medium.
While many long, thin, IRDCs will likely be identified in the coming years as 'bones' of the Milky Way, it is important to point out that not every long-thin IRDC should be expected to trace a spiral arm. The image of IC342 in Figure 11 and the simulation in Figure 9 illustrate that spiral galaxies' structure can include much more than arm-like high-contrast structures, and we can predict that shear and feedback disrupt long features over time. This complexity will make piecing together the Milky Way's skeleton from its bones very challenging, but it should be an achievable goal.
## 5. Contributions and Facilities
## 5.1. Contributions
This paper was a truly a group effort, and the author list includes only some of the many people who have contributed to it. The entire project was inspired by a question: 'Is Nessie parallel to the Galactic Plane?,' asked by Andi Burkert at the 2012 Early Phases of Star Formation (EPoS) meeting at the Max Planck Society's Ringberg Castle in Bavaria. Three EPoS attendees beyond the author list contributed significant ideas and data to this work, most notably Steven Longmore, Eli Bressert, and Henrik Beuther. We are grateful to Cormac Purcell for giving us advance online access to the HOPS data, and to Mark Reid for generously sharing his expertise on Galactic structure. The text here was largely written by Alyssa Goodman; the theoretical ideas come primarily from Andi Burkert and Rowan Smith; and much of the geometrical analysis was carried out by Christopher Beaumont, Bob Benjamin, and Tom Robitaille. Tom Dame and Bob Benjamin provided expertise on Galactic structure, and they created several of the figures shown here. Jens Kauffmann
Fig. 11.- . IC342 as seen by WISE, reproduced from Jarrett et al. 2013. The colors correspond to WISE bands: 3.4 µ m (blue), 4.6 µ m (cyan/green), 12.0 µ m (orange), 22 µ m (red).

provided expertise on IRDCs, and also was first to point out the potential relevance of the Sun's non-zero height above the Galactic Plane. Joao Alves provided expertise on the
potential for using extinction maps to find more Nessie-like features, and Michelle Borkin was instrumental in early visualization work that led to our present proposals for using the Sun's 'high' vantage point to map out the Milky Way. Jim Jackson contributed critical expertise on the Nessie IRDC, based both on the 2010 study he led and on unpublished work since. During revisions to this manuscript, Rowan Smith provided the new simulations referenced here as Smith et al. (2014).
The article you are reading now was the first to be prepared using a collaborative authoring system called Authorea. The early drafts of the paper, as well as the (preprint) submitted version, were, and will remain, open to the public, at this link. We thank Authorea's founders Alberto Pepe and Nathan Jenkins, and advisors Eli Bressert and Matteo Cantiello, for assistance as the work proceeded.
The final version of this paper benefitted significantly from responses to the comments of an usually thorough referee, to whom we are grateful.
A.B. acknowledges support from the Cluster of Excellence 'Origin and Structure of the Universe.' A.G. and C.B. thank Microsoft Research, the National Science Foundation (AST-0908159) and NASA (ADAP NNX12AE11G) for their support. M.B. was supported by the Department of Defense through the National Defense Science & Engineering Graduate Fellowship (NDSEG) Program. R.B. acknowledges NASA grant NNX10AI70G.
## 5.2. Facilities
Data in this paper were taken with the following telescopes. The CO Survey of the Milky Way data Dame & Thaddeus (2011) are from the 1.2-Meter Millimeter-Wave Telescope in Cambridge, Massachusetts, USA. NH 3 observations of cores Purcell et al. (2012) in and near Nessie are from the Mopra 22-meter telescope near Coonabarabran,
Australia. The mid-infrared images of the Galactic Plane used to define Nessie are from NASA's Spitzer Space Telescope, and they were made as part of the GLIMPSE (Benjamin et al. 2003; Churchwell et al. 2009) and MIPSGAL (Carey et al. 2009) Surveys of the Galactic Plane.
## REFERENCES
Abbott, E. A. 1884, Flatland: A Romance of Many Dimensions (London: Seely), 103
Barnes, P., Lo, N., Muller, E., et al. 2010, ATNF proposal M566
Battersby, C., & Bally, J. 2014, in Astrophysics and Space Science Proceedings, ed. D. Stamatellos, S. Goodwin, & D. Ward-Thompson, Vol. 36, 417
Battisti, A. J., & Heyer, M. H. 2014, ApJ, 780, 173
Beaumont, C. N., Williams, J. P., & Goodman, A. A. 2011, 741, 14
Benjamin, R. A., Churchwell, E., Babler, B. L., et al. 2003, PASP, 115, 953
Beuther, H., Tackenberg, J., Linz, H., et al. 2012, ApJ, 747, 43
Blaauw, A., Gum, C. S., Pawsey, J. L., & Westerhout, G. 1959, ApJ, 130, 702
Blaauw, A., Gum, C. S., Pawsey, J. L., & Westerhout, G. 1960, MNRAS, 121, 123
Brunthaler, A., Reid, M., Menten, K., et al. 2011, Astronomische Nachrichten, 332, 461
Carey, S. J., Noriega-Crespo, A., Mizuno, D. R., et al. 2009, PASP, 121, 76
Chandrasekhar, S., & Fermi, E. 1953, ApJ, 118, 116
Chen, B., Stoughton, C., Smith, J. A., et al. 2001, ApJ, 553, 184
Churchwell, E., Babler, B. L., Meade, M. R., et al. 2009, PASP, 121, 213
Corder, S., Sheth, K., Scoville, N. Z., et al. 2008, ApJ, 689, 148
Dame, T. M., Hartmann, D., & Thaddeus, P. 2001, ApJ, 547, 792
Dame, T. M., & Thaddeus, P. 2011, ApJ, 734, L24
Dobbs, C. L., & Pringle, J. E. 2013, MNRAS, 432, 653
Foster, J. B., Stead, J. J., Benjamin, R. A., Hoare, M. G., & Jackson, J. M. 2012, ApJ, 751, 157
Goodman, A. A., Pineda, J. E., & Schnee, S. L. 2009, The Astrophysical Journal, 692, 91
Green, G. M., Schlafly, E. F., Finkbeiner, D. P., et al. 2014, The Astrophysical Journal, 783, 114
Jackson, J. M., Finn, S. C., Chambers, E. T., Rathborne, J. M., & Simon, R. 2010, ApJ, 719, L185
Jackson, J. M., Rathborne, J. M., Shah, R. Y., et al. 2006, The Astrophysical Journal Supplement Series, 163, 145
Jarrett, T. H., Masci, F., Tsai, C. W., et al. 2013, AJ, 145, 6
Juri´, M., Ivezi´, v., Brooks, A., et al. 2008, ApJ, 673, 864 c c
Kauffmann, J., & Pillai, T. 2010, ApJ, 723, L7
La Vigne, M., Vogel, S., & Ostriker, E. 2008, ApJ, 818
Larson, R. B. 1981, MNRAS, 194, 809
Li, G.-X., Wyrowski, F., Menten, K., & Belloche, A. 2013, A&A, 559, A34
Lin, C. C., & Shu, F. H. 1964, ApJ, 140, 646
Ma´ ız-Apell´niz, J. 2001, AJ, 121, 2737 a
Malhotra, S. 1994, ApJ, 433, 687
Malhotra, S. 1995, ApJ, 448, 138
McClureGriffiths, N. M., & Dickey, J. M. 2007, ApJ, 671, 427
Peretto, N., & Fuller, G. A. 2009, A&A, 505, 405 Peretto, N., & Fuller, G. A. 2010, ApJ, 723, 555 Pillai, T., Wyrowski, F., Menten, K. M., & Krugel, E. 2006, A&A, 447, 929 Pineda, J. E., Caselli, P., & Goodman, A. A. 2008, The Astrophysical Journal, 679, 481 Purcell, C. R., Longmore, S. N., Walsh, A. J., et al. 2012, MNRAS, 426, 1972 Ragan, S. E., Henning, T., Tackenberg, J., et al. 2014, ArXiv e-prints, arXiv:1403.1450 Rathborne, J. M., Simon, R., & Jackson, J. M. 2007, ApJ, 662, 1082 Reid, M. J., & Brunthaler, A. 2004, ApJ, 616, 872 Reid, M. J., Menten, K. M., Zheng, X. W., et al. 2009, ApJ, 700, 137 Rix, H.-W., & Bovy, J. 2013, A&A Rev., 21, 61 Rosolowsky, E., Dunham, M. K., Ginsburg, A., et al. 2010, The Astrophysical Journal Supplement Series, 188, 123 Schinnerer, E., Meidt, S. E., Pety, J., et al. 2013, The Astrophysical Journal, 779, 42 Shetty, R., & Ostriker, E. C. 2006, ApJ, 647, 997 Smith, R. J., Glover, S. C. O., Clark, P. C., Klessen, R. S., & Springel, V. 2014, MNRAS, 441, 1628 Vall´e, J. P. 2008, AJ, 135, 1301 e
Wienen, M., Wyrowski, F., Schuller, F., et al. 2012, A&A, 544, A146
This manuscript was prepared with the AAS LT E X macros v5.2. A | 10.1088/0004-637X/797/1/53 | [
"Alyssa A. Goodman",
"Joao Alves",
"Christopher N. Beaumont",
"Robert A. Benjamin",
"Michelle A. Borkin",
"Andreas Burkert",
"Thomas M. Dame",
"James Jackson",
"Jens Kauffmann",
"Thomas Robitaille",
"Rowan J. Smith"
] | 2014-07-31T15:03:52+00:00 | 2014-07-31T15:03:52+00:00 | [
"astro-ph.GA"
] | The Bones of the Milky Way | The very long and thin infrared dark cloud "Nessie" is even longer than had
been previously claimed, and an analysis of its Galactic location suggests that
it lies directly in the Milky Way's mid-plane, tracing out a highly elongated
bone-like feature within the prominent Scutum-Centaurus spiral arm. Re-analysis
of mid-infrared imagery from the Spitzer Space Telescope shows that this IRDC
is at least 2, and possibly as many as 5 times longer than had originally been
claimed by Nessie's discoverers (Jackson et al. 2010); its aspect ratio is
therefore at least 300:1, and possibly as large as 800:1. A careful accounting
for both the Sun's offset from the Galactic plane ($\sim 25$ pc) and the
Galactic center's offset from the $(l^{II},b^{II})=(0,0)$ position shows that
the latitude of the true Galactic mid-plane at the 3.1 kpc distance to the
Scutum-Centaurus Arm is not $b=0$, but instead closer to $b=-0.4$, which is the
latitude of Nessie to within a few pc. An analysis of the radial velocities of
low-density (CO) and high-density (${\rm NH}_3$) gas associated with the Nessie
dust feature suggests that Nessie runs along the Scutum-Centaurus Arm in
position-position-velocity space, which means it likely forms a dense `spine'
of the arm in real space as well. The Scutum-Centaurus arm is the closest major
spiral arm to the Sun toward the inner Galaxy, and, at the longitude of Nessie,
it is almost perpendicular to our line of sight, making Nessie the easiest
feature to see as a shadow elongated along the Galactic Plane from our
location. Future high-resolution dust mapping and molecular line observations
of the harder-to-find Galactic "bones" should allow us to exploit the Sun's
position above the plane to gain a (very foreshortened) view "from above" of
the Milky Way's structure. |
1408.0002v2 | "## DWARF GALAXY ANNIHILATION AND DECAY EMISSION PROFILES FOR DARK MATTER EXPERIMENTS\n\nALEX GERING(...TRUNCATED) | 10.1088/0004-637X/801/2/74 | [
"Alex Geringer-Sameth",
"Savvas M. Koushiappas",
"Matthew Walker"
] | 2014-07-31T20:00:00+00:00 | 2015-03-11T18:52:54+00:00 | [
"astro-ph.CO",
"astro-ph.GA",
"astro-ph.HE"
] | Dwarf galaxy annihilation and decay emission profiles for dark matter experiments | "Gamma-ray searches for dark matter annihilation and decay in dwarf galaxies\nrely on an understandi(...TRUNCATED) |
1408.0003v1 | "## New physics in resonant production of Higgs boson pairs\n\nVernon Barger , Lisa L. Everett a a ,(...TRUNCATED) | 10.1103/PhysRevLett.114.011801 | [
"Vernon Barger",
"Lisa L. Everett",
"C. B. Jackson",
"Andrea Peterson",
"Gabe Shaughnessy"
] | 2014-07-31T20:00:00+00:00 | 2014-07-31T20:00:00+00:00 | [
"hep-ph",
"hep-ex"
] | New physics in resonant production of Higgs boson pairs | "We advocate a search for an extended scalar sector at the LHC via $hh$\nproduction, where $h$ is th(...TRUNCATED) |
1408.0004v1 | "## Biharmonic Split Ring Resonator Metamaterial: Artificially dispersive effective density in thin (...TRUNCATED) | 10.1209/0295-5075/107/44002 | [
"M. Farhat",
"S. Enoch",
"S. Guenneau"
] | 2014-07-28T15:53:22+00:00 | 2014-07-28T15:53:22+00:00 | [
"cond-mat.mtrl-sci"
] | "Biharmonic Split Ring Resonator Metamaterial: Artificially dispersive effective density in thin per(...TRUNCATED) | "We present in this paper a theoretical and numerical analysis of bending\nwaves localized on the bo(...TRUNCATED) |
1408.0005v1 | "## Star Formation in the vicinity of Nuclear Black Holes: Young Stellar Objects close to Sgr A*\n\n(...TRUNCATED) | 10.1093/mnras/stu1483 | ["B. Jalali","F. I. Pelupessy","A. Eckart","S. Portegies Zwart","N. Sabha","A. Borkar","J. Moultaka"(...TRUNCATED) | 2014-07-31T20:00:08+00:00 | 2014-07-31T20:00:08+00:00 | [
"astro-ph.GA"
] | Star Formation in the vicinity of Nuclear Black Holes: Young Stellar Objects close to Sgr A* | "It is often assumed that the strong gravitational field of a super-massive\nblack hole disrupts an (...TRUNCATED) |
1408.0006v2 | "## More on the Matter of 6D SCFTs\n\nJonathan J. Heckman ∗ 1, 2\n\n1 Department of Physics, Unive(...TRUNCATED) | null | [
"Jonathan J. Heckman"
] | 2014-07-31T20:00:09+00:00 | 2020-07-14T18:09:07+00:00 | [
"hep-th"
] | More on the Matter of 6D SCFTs | "M5-branes probing an ADE singularity lead to 6D SCFTs with (1,0)\nsupersymmetry. On the tensor bran(...TRUNCATED) |
1408.0007v1 | "## On the equilibrium of rotating filaments\n\n## S. Recchi 1 /star , A. Hacar 1 † and A. Palesti(...TRUNCATED) | 10.1093/mnras/stu1566 | [
"S. Recchi",
"A. Hacar",
"A. Palestini"
] | 2014-07-31T20:00:13+00:00 | 2014-07-31T20:00:13+00:00 | [
"astro-ph.GA"
] | On the equilibrium of rotating filaments | "The physical properties of the so-called Ostriker isothermal, non-rotating\nfilament have been clas(...TRUNCATED) |
1408.0008v1 | "## Optical investigation of thermoelectric topological crystalline insulator Pb 0 77 . Sn 0 23 . Se(...TRUNCATED) | 10.1103/PhysRevB.90.235144 | ["Anjan A. Reijnders","Jason Hamilton","Vivian Britto","Jean-Blaise Brubach","Pascale Roy","Quinn D.(...TRUNCATED) | 2014-07-31T20:00:20+00:00 | 2014-07-31T20:00:20+00:00 | [
"cond-mat.mtrl-sci"
] | Optical investigation of thermoelectric topological crystalline insulator Pb$_{0.77}$Sn$_{0.23}$Se | "Pb$_{0.77}$Sn$_{0.23}$Se is a novel alloy of two promising thermoelectric\nmaterials PbSe and SnSe (...TRUNCATED) |
1408.0009v1 | "## The low mass star and sub-stellar populations of the 25 Orionis group\n\nJuan Jos´ e Downes 1 2(...TRUNCATED) | 10.1093/mnras/stu1553 | ["Juan José Downes","César Briceño","Cecilia Mateu","Jesús Hernández","Anna Katherina Vivas","N(...TRUNCATED) | 2014-07-31T20:00:21+00:00 | 2014-07-31T20:00:21+00:00 | [
"astro-ph.SR"
] | The low mass star and sub-stellar populations of the 25 Orionis group | "We present the results of a survey of the low mass star and brown dwarf\npopulation of the 25 Orion(...TRUNCATED) |
1408.0010v2 | "IPHT-T14/088 CRM-3338 RIKEN-MP-90\n\n## Towards U( N M | ) knot invariant from ABJM theory\n\nBertr(...TRUNCATED) | 10.1007/s11005-017-0936-0 | [
"Bertrand Eynard",
"Taro Kimura"
] | 2014-07-31T20:00:22+00:00 | 2016-12-05T05:12:41+00:00 | [
"hep-th",
"math-ph",
"math.GT",
"math.MP",
"81T60, 81T45, 57M27, 14H81"
] | Towards U(N|M) knot invariant from ABJM theory | "We study U(N|M) character expectation value with the supermatrix Chern-Simons\ntheory, known as the(...TRUNCATED) |
Dataset card for arxiv-markdown
[25/04/2025] Images are now hosted on Cloudflare R2 and referenced in the markdowns as external URLs rather than embedded base64. This significantly reduces storage requirements while maintaining full image access. Images are referenced in the dataset as . Community mirrors are welcome!
This dataset contains open-access papers retrieved from arXiv and converted to markdown format using docling; specifically, we use the following docling pipeline:
pipeline_options = PdfPipelineOptions()
pipeline_options.images_scale = IMAGE_RESOLUTION_SCALE # 2.0
pipeline_options.generate_page_images = True # Necessary for the extraction of figures (as far as I understand)
pipeline_options.generate_picture_images = True # For the extraction of figures
pipeline_options.do_code_enrichment = True # For obtaining code blocks
pipeline_options.do_formula_enrichment = True # For converting formulas to LaTeX
converter = DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options)
}
)
Currently the dataset constains entries extracted from August 2014, August 2019 and August 2024; we are currently dedicating an RTX 3090 full-time for the extraction of this data and will continue to upload new entries as they get processed.
You can find the code we are using for the data generation on GitHub (optimizations and general suggestions are very welcome!).
Processed Papers
The distribution of the data currently is like this:
2014-08: 1097 papers (and growing)2019-08: 994 papers2024-08: 1178 papers
More papers will be added for already present months and more!
Dataset Scope
This dataset is being built as the first step to expanding the academic-chains dataset, but other creative uses of this dataset by the community are welcome and encouraged! You can check our license below in this same file.
Limitations and Biases
- Extraction Fidelity: While docling is amazing, it is not perfect, and extraction glitches (especially in tables) may still be present
- Slow Data Generation: Document extraction while doing formula and code enrichment and picture extraction is SLOW on our 3090; we didn't use these options while extracting MDs for the academic-chains dataset because it was not strictly necessary, but we would like to do things right this time, even though it will slow us down (relatively)
Note: We see there is work going on on supporting batched inference for docling, and updates on using VLMs too, so we will try to keep our pipeline up to date and efficient!
Acknowledgements
A big-big-BIG thank you to arXiv and to all the authors of the open-access papers present in our dataset (and to all the others too!). And thank you to whoever supported my original academic-chains dataset too, you are the reason why I started working on this so soon and with a smile on my face!
Licensing Information
This dataset is licensed under the CC-BY-4.0 License.
Citation Information
@misc{marcodsn_2025_arxivmarkdown,
title = {arxiv-arkdown},
author = {Marco De Santis},
month = {April},
year = {2025},
url = {https://huggingface.co/datasets/marcodsn/arxiv-markdown}
}
- Downloads last month
- 93