Datasets:

Tasks:
Text Generation
Formats:
parquet
Sub-tasks:
language-modeling
Languages:
Danish
Size:
1M - 10M
License:
Adding Scrape Hovedstaden
#70
by
kris927b
- opened
- CHANGELOG.md +13 -0
- README.md +47 -41
- data/danske-taler/create.py +112 -29
- data/danske-taler/danske-taler.log +110 -0
- data/danske-taler/danske-taler.md +10 -8
- data/danske-taler/danske-taler.parquet +2 -2
- data/danske-taler/descriptive_stats.json +4 -4
- data/danske-taler/images/dist_document_length.png +2 -2
- data/scrape_hovedstaden/create.py +76 -0
- data/scrape_hovedstaden/descriptive_stats.json +6 -0
- data/scrape_hovedstaden/images/dist_document_length.png +3 -0
- data/scrape_hovedstaden/scrape_hovedstaden.md +98 -0
- data/scrape_hovedstaden/scrape_hovedstaden.parquet +3 -0
- descriptive_stats.json +4 -4
- images/dist_document_length.png +2 -2
- images/domain_distribution.png +2 -2
- pyproject.toml +1 -1
- src/dynaword/typings.py +1 -0
- test_results.log +13 -14
- uv.lock +0 -0
CHANGELOG.md
CHANGED
|
@@ -5,6 +5,19 @@ All notable changes to this project will be documented in this file.
|
|
| 5 |
|
| 6 |
The format is based on [Keep a Changelog](http://keepachangelog.com/en/1.0.0/).
|
| 7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8 |
## [v1.2.0] - 2025-06-23
|
| 9 |
|
| 10 |
### Fixed
|
|
|
|
| 5 |
|
| 6 |
The format is based on [Keep a Changelog](http://keepachangelog.com/en/1.0.0/).
|
| 7 |
|
| 8 |
+
## [v1.2.2] - 2025-06-26
|
| 9 |
+
|
| 10 |
+
### Added
|
| 11 |
+
|
| 12 |
+
- Added the new `scrape_hovedstaden` dataset.
|
| 13 |
+
- Added a new domain type `Medical`.
|
| 14 |
+
|
| 15 |
+
## [v1.2.1] - 2025-06-24
|
| 16 |
+
|
| 17 |
+
### Fixed
|
| 18 |
+
|
| 19 |
+
- Updated the danske-taler dataset. This version fixes a problem where the texts from the API contains no newlines, and where there should have been newline there is now space between words and punctuation.
|
| 20 |
+
|
| 21 |
## [v1.2.0] - 2025-06-23
|
| 22 |
|
| 23 |
### Fixed
|
README.md
CHANGED
|
@@ -141,6 +141,10 @@ configs:
|
|
| 141 |
data_files:
|
| 142 |
- split: train
|
| 143 |
path: data/nota/*.parquet
|
|
|
|
|
|
|
|
|
|
|
|
|
| 144 |
annotations_creators:
|
| 145 |
- no-annotation
|
| 146 |
language_creators:
|
|
@@ -174,7 +178,7 @@ https://github.com/huggingface/datasets/blob/main/templates/README_guide.md
|
|
| 174 |
<!-- START README TABLE -->
|
| 175 |
| | |
|
| 176 |
| ------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
| 177 |
-
| **Version** | 1.2.
|
| 178 |
| **Language** | dan, dansk, Danish |
|
| 179 |
| **License** | Openly Licensed, See the respective dataset |
|
| 180 |
| **Models** | For model trained used this data see [danish-foundation-models](https://huggingface.co/danish-foundation-models) |
|
|
@@ -211,9 +215,9 @@ https://github.com/huggingface/datasets/blob/main/templates/README_guide.md
|
|
| 211 |
|
| 212 |
<!-- START-DESC-STATS -->
|
| 213 |
- **Language**: dan, dansk, Danish
|
| 214 |
-
- **Number of samples**:
|
| 215 |
-
- **Number of tokens (Llama 3)**: 4.
|
| 216 |
-
- **Average document length (characters)**:
|
| 217 |
<!-- END-DESC-STATS -->
|
| 218 |
|
| 219 |
|
|
@@ -311,43 +315,44 @@ This data generally contains no annotation besides the metadata attached to each
|
|
| 311 |
Below follows a brief overview of the sources in the corpus along with their individual license.
|
| 312 |
|
| 313 |
<!-- START-MAIN TABLE -->
|
| 314 |
-
| Source
|
| 315 |
-
|
| 316 |
-
| [cellar]
|
| 317 |
-
| [ncc_books]
|
| 318 |
-
| [retsinformationdk]
|
| 319 |
-
| [hest]
|
| 320 |
-
| [ncc_parliament]
|
| 321 |
-
| [opensubtitles]
|
| 322 |
-
| [ai-aktindsigt]
|
| 323 |
-
| [miljoeportalen]
|
| 324 |
-
| [skat]
|
| 325 |
-
| [wiki]
|
| 326 |
-
| [ft]
|
| 327 |
-
| [memo]
|
| 328 |
-
| [ep]
|
| 329 |
-
| [adl]
|
| 330 |
-
| [retspraksis]
|
| 331 |
-
| [fm-udgivelser]
|
| 332 |
-
| [nordjyllandnews]
|
| 333 |
-
| [eur-lex-sum-da]
|
| 334 |
-
| [ncc_maalfrid]
|
| 335 |
-
| [
|
| 336 |
-
| [
|
| 337 |
-
| [
|
| 338 |
-
| [
|
| 339 |
-
| [
|
| 340 |
-
| [
|
| 341 |
-
| [
|
| 342 |
-
| [
|
| 343 |
-
| [
|
| 344 |
-
| [
|
| 345 |
-
| [
|
| 346 |
-
| [
|
| 347 |
-
| [
|
| 348 |
-
| [
|
| 349 |
-
| [
|
| 350 |
-
|
|
|
|
|
| 351 |
|
| 352 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 353 |
[cellar]: data/cellar/cellar.md
|
|
@@ -383,6 +388,7 @@ Below follows a brief overview of the sources in the corpus along with their ind
|
|
| 383 |
[nordjyllandnews]: data/nordjyllandnews/nordjyllandnews.md
|
| 384 |
[relig]: data/relig/relig.md
|
| 385 |
[nota]: data/nota/nota.md
|
|
|
|
| 386 |
|
| 387 |
|
| 388 |
[CC-0]: https://creativecommons.org/publicdomain/zero/1.0/legalcode.en
|
|
|
|
| 141 |
data_files:
|
| 142 |
- split: train
|
| 143 |
path: data/nota/*.parquet
|
| 144 |
+
- config_name: scrape_hovedstaden
|
| 145 |
+
data_files:
|
| 146 |
+
- split: train
|
| 147 |
+
path: data/scrape_hovedstaden/*.parquet
|
| 148 |
annotations_creators:
|
| 149 |
- no-annotation
|
| 150 |
language_creators:
|
|
|
|
| 178 |
<!-- START README TABLE -->
|
| 179 |
| | |
|
| 180 |
| ------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
| 181 |
+
| **Version** | 1.2.2 ([Changelog](/CHANGELOG.md)) |
|
| 182 |
| **Language** | dan, dansk, Danish |
|
| 183 |
| **License** | Openly Licensed, See the respective dataset |
|
| 184 |
| **Models** | For model trained used this data see [danish-foundation-models](https://huggingface.co/danish-foundation-models) |
|
|
|
|
| 215 |
|
| 216 |
<!-- START-DESC-STATS -->
|
| 217 |
- **Language**: dan, dansk, Danish
|
| 218 |
+
- **Number of samples**: 915.09K
|
| 219 |
+
- **Number of tokens (Llama 3)**: 4.40B
|
| 220 |
+
- **Average document length (characters)**: 14778.01
|
| 221 |
<!-- END-DESC-STATS -->
|
| 222 |
|
| 223 |
|
|
|
|
| 315 |
Below follows a brief overview of the sources in the corpus along with their individual license.
|
| 316 |
|
| 317 |
<!-- START-MAIN TABLE -->
|
| 318 |
+
| Source | Description | Domain | N. Tokens | License |
|
| 319 |
+
|:---------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-------------|:------------|:-----------------------|
|
| 320 |
+
| [cellar] | The official digital repository for European Union legal documents and open data | Legal | 1.15B | [CC-BY-SA 4.0] |
|
| 321 |
+
| [ncc_books] | Danish books extracted from the [Norwegian Colossal Corpus](https://huggingface.co/datasets/NbAiLab/NCC) derived from OCR | Books | 531.97M | [CC-0] |
|
| 322 |
+
| [retsinformationdk] | [retsinformation.dk](https://www.retsinformation.dk) (legal-information.dk) the official legal information system of Denmark | Legal | 516.35M | [Danish Copyright Law] |
|
| 323 |
+
| [hest] | Samples from the Danish debate forum www.heste-nettet.dk | Social Media | 389.32M | [CC-0] |
|
| 324 |
+
| [ncc_parliament] | Collections from the Norwegian parliament in Danish. Extracted from the [Norwegian Colossal Corpus](https://huggingface.co/datasets/NbAiLab/NCC) derived from ocr | Other | 338.87M | [NLOD 2.0] |
|
| 325 |
+
| [opensubtitles] | Danish subsection of [OpenSubtitles](https://opus.nlpl.eu/OpenSubtitles/corpus/version/OpenSubtitles) | Conversation | 271.60M | [CC-0] |
|
| 326 |
+
| [ai-aktindsigt] | Multiple web scrapes from municipality websites collected as a part of the [AI-aktindsigt](https://ai-aktindsigt.dk) project | Web | 139.23M | [Apache 2.0] |
|
| 327 |
+
| [miljoeportalen] | Data from [Danmarks Miljøportalen](https://www.miljoeportal.dk/om-danmarks-miljoeportal/) (Denmark's Environment Portal) | Web | 127.38M | [CC-0] |
|
| 328 |
+
| [skat] | Skat is the Danish tax authority. This dataset contains content from its website skat.dk | Legal | 122.11M | [CC-0] |
|
| 329 |
+
| [wiki] | The Danish subsection of [wikipedia](https://en.wikipedia.org/wiki/Main_Page) | Encyclopedic | 122.00M | [CC-0] |
|
| 330 |
+
| [ft] | Records from all meetings of The Danish parliament (Folketinget) in the parliament hall | Conversation | 114.09M | [CC-0] |
|
| 331 |
+
| [memo] | The MeMo corpus comprising almost all Danish novels from the period 1870-1899, known as the Modern Breakthrough | Books | 113.74M | [CC-BY-SA 4.0] |
|
| 332 |
+
| [ep] | The Danish subsection of [Europarl](https://aclanthology.org/2005.mtsummit-papers.11/) | Conversation | 100.84M | [CC-0] |
|
| 333 |
+
| [adl] | Danish literature from 1700-2023 from the [Archive for Danish Literature](https://tekster.kb.dk/text?editorial=no&f%5Bsubcollection_ssi%5D%5B%5D=adl&match=one&search_field=Alt) (ADL) | Books | 58.49M | [CC-0] |
|
| 334 |
+
| [retspraksis] | Case law or judical practice in Denmark derived from [Retspraksis](https://da.wikipedia.org/wiki/Retspraksis) | Legal | 56.26M | [CC-0] |
|
| 335 |
+
| [fm-udgivelser] | The official publication series of the Danish Ministry of Finance containing economic analyses, budget proposals, and fiscal policy documents | Legal | 50.34M | [CC-BY-SA 4.0] |
|
| 336 |
+
| [nordjyllandnews] | Articles from the Danish Newspaper [TV2 Nord](https://www.tv2nord.dk) | News | 37.90M | [CC-0] |
|
| 337 |
+
| [eur-lex-sum-da] | The Danish subsection of EUR-lex SUM consisting of EU legislation paired with professionally written summaries | Legal | 31.37M | [CC-BY-SA 4.0] |
|
| 338 |
+
| [ncc_maalfrid] | Danish content from Norwegian institutions websites | Web | 29.26M | [NLOD 2.0] |
|
| 339 |
+
| [scrape_hovedstaden] | Guidelines and informational documents for healthcare professionals from the Capital Region | Medical | 27.07M | [CC-0] |
|
| 340 |
+
| [tv2r] | Contemporary Danish newswire articles published between 2010 and 2019 | News | 21.67M | [CC-BY-SA 4.0] |
|
| 341 |
+
| [danske-taler] | Danish Speeches from [dansketaler.dk](https://www.dansketaler.dk) | Conversation | 8.81M | [CC-0] |
|
| 342 |
+
| [nota] | The text only part of the [Nota lyd- og tekstdata](https://sprogteknologi.dk/dataset/nota-lyd-og-tekstdata) dataset | Readaloud | 7.30M | [CC-0] |
|
| 343 |
+
| [gutenberg] | The Danish subsection from Project [Gutenberg](https://www.gutenberg.org) | Books | 6.76M | [Gutenberg] |
|
| 344 |
+
| [wikibooks] | The Danish Subsection of [Wikibooks](https://www.wikibooks.org) | Books | 6.24M | [CC-0] |
|
| 345 |
+
| [wikisource] | The Danish subsection of [Wikisource](https://en.wikisource.org/wiki/Main_Page) | Encyclopedic | 5.34M | [CC-0] |
|
| 346 |
+
| [jvj] | The works of the Danish author and poet, [Johannes V. Jensen](https://da.wikipedia.org/wiki/Johannes_V._Jensen) | Books | 3.55M | [CC-BY-SA 4.0] |
|
| 347 |
+
| [spont] | Conversational samples collected as a part of research projects at Aarhus University | Conversation | 1.56M | [CC-0] |
|
| 348 |
+
| [dannet] | [DanNet](https://cst.ku.dk/projekter/dannet) is a Danish WordNet | Other | 1.48M | [DanNet 1.0] |
|
| 349 |
+
| [relig] | Danish religious text from the 1700-2022 | Books | 1.24M | [CC-0] |
|
| 350 |
+
| [ncc_newspaper] | OCR'd Newspapers derived from [NCC](https://huggingface.co/datasets/NbAiLab/NCC) | News | 1.05M | [CC-0] |
|
| 351 |
+
| [botxt] | The Bornholmsk Ordbog Dictionary Project | Dialect | 847.97K | [CC-0] |
|
| 352 |
+
| [naat] | Danish speeches from 1930-2022 | Conversation | 286.68K | [CC-0] |
|
| 353 |
+
| [depbank] | The Danish subsection of the [Universal Dependencies Treebank](https://github.com/UniversalDependencies/UD_Danish-DDT) | Other | 185.45K | [CC-BY-SA 4.0] |
|
| 354 |
+
| [synne] | Dataset collected from [synnejysk forening's website](https://www.synnejysk.dk), covering the Danish dialect sønderjysk | Other | 52.02K | [CC-0] |
|
| 355 |
+
| **Total** | | | 4.40B | |
|
| 356 |
|
| 357 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 358 |
[cellar]: data/cellar/cellar.md
|
|
|
|
| 388 |
[nordjyllandnews]: data/nordjyllandnews/nordjyllandnews.md
|
| 389 |
[relig]: data/relig/relig.md
|
| 390 |
[nota]: data/nota/nota.md
|
| 391 |
+
[scrape_hovedstaden]: data/scrape_hovedstaden/scrape_hovedstaden.md
|
| 392 |
|
| 393 |
|
| 394 |
[CC-0]: https://creativecommons.org/publicdomain/zero/1.0/legalcode.en
|
data/danske-taler/create.py
CHANGED
|
@@ -3,7 +3,11 @@
|
|
| 3 |
# dependencies = [
|
| 4 |
# "beautifulsoup4==4.13.3",
|
| 5 |
# "datasets>=3.0.0",
|
|
|
|
|
|
|
| 6 |
# ]
|
|
|
|
|
|
|
| 7 |
# ///
|
| 8 |
"""
|
| 9 |
Danske Taler API Downloader
|
|
@@ -26,6 +30,14 @@ It saves it into the following structure:
|
|
| 26 |
}
|
| 27 |
```
|
| 28 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 29 |
"""
|
| 30 |
|
| 31 |
import logging
|
|
@@ -34,21 +46,80 @@ from datetime import date
|
|
| 34 |
from pathlib import Path
|
| 35 |
from typing import Any
|
| 36 |
|
| 37 |
-
import
|
| 38 |
import pandas as pd
|
| 39 |
import requests
|
| 40 |
-
from bs4 import BeautifulSoup
|
| 41 |
from tqdm import tqdm
|
| 42 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 43 |
logger = logging.getLogger(__name__)
|
| 44 |
|
| 45 |
# Configuration
|
| 46 |
API_BASE_URL = "https://www.dansketaler.dk/api/v1"
|
| 47 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 48 |
|
| 49 |
def get_all_speeches() -> list[dict[str, Any]]:
|
| 50 |
# fetch first page, notably the total number of pages
|
| 51 |
-
url = f"{API_BASE_URL}/speeches"
|
| 52 |
response = requests.get(url)
|
| 53 |
response.raise_for_status()
|
| 54 |
speeches = response.json()
|
|
@@ -58,7 +129,7 @@ def get_all_speeches() -> list[dict[str, Any]]:
|
|
| 58 |
# fetch all pages
|
| 59 |
all_speeches = []
|
| 60 |
for page in range(1, total_pages + 1):
|
| 61 |
-
url = f"{API_BASE_URL}/speeches?page={page}"
|
| 62 |
response = requests.get(url)
|
| 63 |
response.raise_for_status()
|
| 64 |
speeches = response.json()
|
|
@@ -67,9 +138,9 @@ def get_all_speeches() -> list[dict[str, Any]]:
|
|
| 67 |
return all_speeches
|
| 68 |
|
| 69 |
|
| 70 |
-
def
|
| 71 |
url: str, max_retries: int = 3, backoff_factor: float = 0.5
|
| 72 |
-
) -> str | None:
|
| 73 |
"""
|
| 74 |
Fetches the license div from the page with retry logic.
|
| 75 |
|
|
@@ -90,8 +161,29 @@ def fetch_license_div(
|
|
| 90 |
|
| 91 |
soup = BeautifulSoup(response.text, "html.parser")
|
| 92 |
license_div = soup.find("div", class_="speech-copyright")
|
| 93 |
-
|
| 94 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 95 |
|
| 96 |
except (requests.RequestException, AttributeError) as e:
|
| 97 |
retries += 1
|
|
@@ -100,7 +192,7 @@ def fetch_license_div(
|
|
| 100 |
logger.info(
|
| 101 |
f"Failed to fetch license after {max_retries} attempts: {str(e)}"
|
| 102 |
)
|
| 103 |
-
return None
|
| 104 |
|
| 105 |
# Calculate backoff time using exponential backoff
|
| 106 |
wait_time = backoff_factor * (2 ** (retries - 1))
|
|
@@ -109,7 +201,7 @@ def fetch_license_div(
|
|
| 109 |
)
|
| 110 |
time.sleep(wait_time)
|
| 111 |
|
| 112 |
-
return None
|
| 113 |
|
| 114 |
|
| 115 |
def convert_to_license(license_information: str | None) -> str | None:
|
|
@@ -134,12 +226,12 @@ def convert_to_row(speech_meta: dict[str, Any]) -> dict[str, Any]:
|
|
| 134 |
date_of_speech_start = f"{date_of_speech}"
|
| 135 |
date_of_speech_end = f"{date_of_speech}"
|
| 136 |
|
| 137 |
-
license_information =
|
| 138 |
|
| 139 |
row = {
|
| 140 |
-
"text": speech_meta["transcription"],
|
| 141 |
-
"source": "danske-taler",
|
| 142 |
"id": f"danske-taler_{speech_id}",
|
|
|
|
|
|
|
| 143 |
# current date
|
| 144 |
"added": date.today().isoformat(),
|
| 145 |
"created": f"{date_of_speech_start}, {date_of_speech_end}",
|
|
@@ -192,28 +284,19 @@ def main():
|
|
| 192 |
df = df[df["license"] == "cc0"]
|
| 193 |
logger.info(f"Removed {len_df - len(df)} documents without a cc0 license")
|
| 194 |
|
| 195 |
-
|
| 196 |
-
len_df = len(df)
|
| 197 |
-
df = df.drop_duplicates(subset=["id"])
|
| 198 |
-
logger.info(f"Removed {len_df - len(df)} duplicate ids")
|
| 199 |
|
| 200 |
-
# remove rows with empty text
|
| 201 |
-
|
| 202 |
-
|
| 203 |
-
|
| 204 |
-
|
| 205 |
-
# remove rows with duplicate text
|
| 206 |
-
len_df = len(df)
|
| 207 |
-
df = df.drop_duplicates(subset=["text"])
|
| 208 |
-
logger.info(f"Removed {len_df - len(df)} rows with duplicate text")
|
| 209 |
|
| 210 |
-
dataset = datasets.Dataset.from_pandas(df)
|
| 211 |
assert len(set(dataset["id"])) == len(dataset), "IDs are not unique"
|
| 212 |
assert len(set(dataset["text"])) == len(dataset), "Texts are not unique"
|
| 213 |
-
assert len(set(
|
| 214 |
|
| 215 |
# check for html tags in text
|
| 216 |
-
assert not df["text"].
|
| 217 |
|
| 218 |
dataset.to_parquet(save_path)
|
| 219 |
|
|
|
|
| 3 |
# dependencies = [
|
| 4 |
# "beautifulsoup4==4.13.3",
|
| 5 |
# "datasets>=3.0.0",
|
| 6 |
+
# "transformers",
|
| 7 |
+
# "dynaword"
|
| 8 |
# ]
|
| 9 |
+
# [tool.uv.sources]
|
| 10 |
+
# dynaword = { git = "https://huggingface.co/datasets/danish-foundation-models/danish-dynaword", rev = "00e7f2aee7f7ad2da423419f77ecbb9c0536de0d" }
|
| 11 |
# ///
|
| 12 |
"""
|
| 13 |
Danske Taler API Downloader
|
|
|
|
| 30 |
}
|
| 31 |
```
|
| 32 |
|
| 33 |
+
Note: To run this script, you need to set `GIT_LFS_SKIP_SMUDGE=1` to be able to install dynaword:
|
| 34 |
+
|
| 35 |
+
```bash
|
| 36 |
+
GIT_LFS_SKIP_SMUDGE=1 uv run data/memo/create.py
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
This second version fixed previous issues with the download and processing of the Danish Memo repository:
|
| 40 |
+
https://huggingface.co/datasets/danish-foundation-models/danish-dynaword/discussions/67
|
| 41 |
"""
|
| 42 |
|
| 43 |
import logging
|
|
|
|
| 46 |
from pathlib import Path
|
| 47 |
from typing import Any
|
| 48 |
|
| 49 |
+
from datasets import Dataset
|
| 50 |
import pandas as pd
|
| 51 |
import requests
|
| 52 |
+
from bs4 import BeautifulSoup, NavigableString
|
| 53 |
from tqdm import tqdm
|
| 54 |
|
| 55 |
+
from dynaword.process_dataset import (
|
| 56 |
+
add_token_count,
|
| 57 |
+
ensure_column_order,
|
| 58 |
+
remove_duplicate_text,
|
| 59 |
+
remove_empty_texts,
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
logger = logging.getLogger(__name__)
|
| 63 |
|
| 64 |
# Configuration
|
| 65 |
API_BASE_URL = "https://www.dansketaler.dk/api/v1"
|
| 66 |
|
| 67 |
+
KNOWN_HTML_TAGS = {
|
| 68 |
+
"html",
|
| 69 |
+
"head",
|
| 70 |
+
"body",
|
| 71 |
+
"title",
|
| 72 |
+
"meta",
|
| 73 |
+
"link",
|
| 74 |
+
"script",
|
| 75 |
+
"style",
|
| 76 |
+
"div",
|
| 77 |
+
"span",
|
| 78 |
+
"p",
|
| 79 |
+
"a",
|
| 80 |
+
"ul",
|
| 81 |
+
"ol",
|
| 82 |
+
"li",
|
| 83 |
+
"table",
|
| 84 |
+
"tr",
|
| 85 |
+
"td",
|
| 86 |
+
"th",
|
| 87 |
+
"img",
|
| 88 |
+
"h1",
|
| 89 |
+
"h2",
|
| 90 |
+
"h3",
|
| 91 |
+
"h4",
|
| 92 |
+
"h5",
|
| 93 |
+
"h6",
|
| 94 |
+
"strong",
|
| 95 |
+
"em",
|
| 96 |
+
"br",
|
| 97 |
+
"hr",
|
| 98 |
+
"form",
|
| 99 |
+
"input",
|
| 100 |
+
"button",
|
| 101 |
+
"label",
|
| 102 |
+
"select",
|
| 103 |
+
"option",
|
| 104 |
+
"textarea",
|
| 105 |
+
"iframe",
|
| 106 |
+
"nav",
|
| 107 |
+
"footer",
|
| 108 |
+
"header",
|
| 109 |
+
"main",
|
| 110 |
+
"section",
|
| 111 |
+
"article",
|
| 112 |
+
}
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def contains_html_tags(text):
|
| 116 |
+
soup = BeautifulSoup(str(text), "html.parser")
|
| 117 |
+
return any(tag.name in KNOWN_HTML_TAGS for tag in soup.find_all())
|
| 118 |
+
|
| 119 |
|
| 120 |
def get_all_speeches() -> list[dict[str, Any]]:
|
| 121 |
# fetch first page, notably the total number of pages
|
| 122 |
+
url = f"{API_BASE_URL}/speeches?per_page=50"
|
| 123 |
response = requests.get(url)
|
| 124 |
response.raise_for_status()
|
| 125 |
speeches = response.json()
|
|
|
|
| 129 |
# fetch all pages
|
| 130 |
all_speeches = []
|
| 131 |
for page in range(1, total_pages + 1):
|
| 132 |
+
url = f"{API_BASE_URL}/speeches?per_page=50&page={page}"
|
| 133 |
response = requests.get(url)
|
| 134 |
response.raise_for_status()
|
| 135 |
speeches = response.json()
|
|
|
|
| 138 |
return all_speeches
|
| 139 |
|
| 140 |
|
| 141 |
+
def fetch_speech_content(
|
| 142 |
url: str, max_retries: int = 3, backoff_factor: float = 0.5
|
| 143 |
+
) -> tuple[str | None, str]:
|
| 144 |
"""
|
| 145 |
Fetches the license div from the page with retry logic.
|
| 146 |
|
|
|
|
| 161 |
|
| 162 |
soup = BeautifulSoup(response.text, "html.parser")
|
| 163 |
license_div = soup.find("div", class_="speech-copyright")
|
| 164 |
+
speech_div = soup.find("div", class_="speech-article-content")
|
| 165 |
+
speech = ""
|
| 166 |
+
if speech_div:
|
| 167 |
+
# Iterate over the children of the found div
|
| 168 |
+
for child_div in speech_div.children: # type: ignore
|
| 169 |
+
if child_div.name == "div": # type: ignore
|
| 170 |
+
current_paragraph = []
|
| 171 |
+
for content in child_div.contents: # type: ignore
|
| 172 |
+
if isinstance(content, NavigableString):
|
| 173 |
+
# Append text content
|
| 174 |
+
current_paragraph.append(str(content).strip())
|
| 175 |
+
elif content.name == "br":
|
| 176 |
+
# If a <br> is encountered, join and print the current paragraph, then reset
|
| 177 |
+
if current_paragraph:
|
| 178 |
+
speech += "".join(current_paragraph)
|
| 179 |
+
speech += "\n" # Add a newline for paragraph break
|
| 180 |
+
current_paragraph = []
|
| 181 |
+
# Print any remaining text in the current_paragraph list
|
| 182 |
+
if current_paragraph:
|
| 183 |
+
speech += "".join(current_paragraph)
|
| 184 |
+
speech += "\n" # Add a newline for paragraph break
|
| 185 |
+
|
| 186 |
+
return (license_div.text if license_div else None, speech)
|
| 187 |
|
| 188 |
except (requests.RequestException, AttributeError) as e:
|
| 189 |
retries += 1
|
|
|
|
| 192 |
logger.info(
|
| 193 |
f"Failed to fetch license after {max_retries} attempts: {str(e)}"
|
| 194 |
)
|
| 195 |
+
return (None, "")
|
| 196 |
|
| 197 |
# Calculate backoff time using exponential backoff
|
| 198 |
wait_time = backoff_factor * (2 ** (retries - 1))
|
|
|
|
| 201 |
)
|
| 202 |
time.sleep(wait_time)
|
| 203 |
|
| 204 |
+
return (None, "")
|
| 205 |
|
| 206 |
|
| 207 |
def convert_to_license(license_information: str | None) -> str | None:
|
|
|
|
| 226 |
date_of_speech_start = f"{date_of_speech}"
|
| 227 |
date_of_speech_end = f"{date_of_speech}"
|
| 228 |
|
| 229 |
+
(license_information, speech) = fetch_speech_content(speech_meta["url"])
|
| 230 |
|
| 231 |
row = {
|
|
|
|
|
|
|
| 232 |
"id": f"danske-taler_{speech_id}",
|
| 233 |
+
"text": speech,
|
| 234 |
+
"source": "danske-taler",
|
| 235 |
# current date
|
| 236 |
"added": date.today().isoformat(),
|
| 237 |
"created": f"{date_of_speech_start}, {date_of_speech_end}",
|
|
|
|
| 284 |
df = df[df["license"] == "cc0"]
|
| 285 |
logger.info(f"Removed {len_df - len(df)} documents without a cc0 license")
|
| 286 |
|
| 287 |
+
dataset = Dataset.from_pandas(df, preserve_index=False)
|
|
|
|
|
|
|
|
|
|
| 288 |
|
| 289 |
+
dataset = remove_empty_texts(dataset) # remove rows with empty text
|
| 290 |
+
dataset = remove_duplicate_text(dataset) # remove rows with duplicate text
|
| 291 |
+
dataset = add_token_count(dataset)
|
| 292 |
+
dataset = ensure_column_order(dataset)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 293 |
|
|
|
|
| 294 |
assert len(set(dataset["id"])) == len(dataset), "IDs are not unique"
|
| 295 |
assert len(set(dataset["text"])) == len(dataset), "Texts are not unique"
|
| 296 |
+
assert len(set(df["license"])) == 1, "Multiple licenses found"
|
| 297 |
|
| 298 |
# check for html tags in text
|
| 299 |
+
assert not df["text"].apply(contains_html_tags).any(), "HTML tags found in text"
|
| 300 |
|
| 301 |
dataset.to_parquet(save_path)
|
| 302 |
|
data/danske-taler/danske-taler.log
CHANGED
|
@@ -55,3 +55,113 @@ Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Erro
|
|
| 55 |
2025-03-29 14:28:03,549 - INFO - Removed 2 rows with empty text
|
| 56 |
2025-03-29 14:28:03,631 - INFO - Removed 2 rows with duplicate text
|
| 57 |
Creating parquet from Arrow format: 100%|██████████████████████████████████████████████████| 3/3 [00:00<00:00, 11.33ba/s]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 55 |
2025-03-29 14:28:03,549 - INFO - Removed 2 rows with empty text
|
| 56 |
2025-03-29 14:28:03,631 - INFO - Removed 2 rows with duplicate text
|
| 57 |
Creating parquet from Arrow format: 100%|██████████████████████████████████████████████████| 3/3 [00:00<00:00, 11.33ba/s]
|
| 58 |
+
2025-06-24 13:03:05,424 - INFO - Found 5103 speeches
|
| 59 |
+
2025-06-24 13:04:19,375 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 60 |
+
2025-06-24 13:04:29,734 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 61 |
+
2025-06-24 13:04:30,613 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 62 |
+
2025-06-24 13:04:31,856 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 63 |
+
2025-06-24 13:04:34,098 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/niels-hoejlund-pedersens-translokationstale-2020
|
| 64 |
+
2025-06-24 13:05:10,223 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 65 |
+
2025-06-24 13:05:11,113 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 66 |
+
2025-06-24 13:05:12,575 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 67 |
+
2025-06-24 13:05:14,814 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/katrine-lykke-pedersens-tale-til-unge-om-haab-i-en-coronatid
|
| 68 |
+
2025-06-24 13:05:15,208 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 69 |
+
2025-06-24 13:05:15,922 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 70 |
+
2025-06-24 13:05:17,117 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 71 |
+
2025-06-24 13:05:19,583 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/anastacia-halkens-tale-til-unge-om-haab-i-en-coronatid
|
| 72 |
+
2025-06-24 13:05:20,875 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 73 |
+
2025-06-24 13:05:21,619 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 74 |
+
2025-06-24 13:05:22,844 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 75 |
+
2025-06-24 13:05:25,074 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/thomas-vinterbergs-tale-ved-modtagelsen-af-oscar-prisen
|
| 76 |
+
2025-06-24 13:06:01,599 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 77 |
+
2025-06-24 13:06:02,313 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 78 |
+
2025-06-24 13:06:03,588 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 79 |
+
2025-06-24 13:06:05,817 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/pernille-vermunds-tale-ved-folketingets-aabningsdebat-2021
|
| 80 |
+
2025-06-24 13:06:08,990 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 81 |
+
2025-06-24 13:06:09,675 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 82 |
+
2025-06-24 13:06:10,912 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 83 |
+
2025-06-24 13:06:13,120 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/pernille-vermunds-tale-ved-nye-borgerliges-aarsmoede-2021
|
| 84 |
+
2025-06-24 13:06:13,512 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 85 |
+
2025-06-24 13:06:14,230 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 86 |
+
2025-06-24 13:06:15,462 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 87 |
+
2025-06-24 13:06:17,720 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/mette-thiesens-tale-ved-nye-borgerliges-aarsmoede-2021
|
| 88 |
+
2025-06-24 13:06:17,920 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 89 |
+
2025-06-24 13:06:18,656 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 90 |
+
2025-06-24 13:06:19,902 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 91 |
+
2025-06-24 13:06:22,132 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/peter-seier-christensens-tale-ved-nye-borgerliges-aarsmoede-2021
|
| 92 |
+
2025-06-24 13:07:56,628 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 93 |
+
2025-06-24 13:07:57,353 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 94 |
+
2025-06-24 13:07:58,586 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 95 |
+
2025-06-24 13:08:00,850 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/silke-ena-svares-tale-ved-demonstrationen-for-born-og-unge
|
| 96 |
+
2025-06-24 13:19:38,142 - INFO - Saving 5103 speeches to dataset
|
| 97 |
+
2025-06-24 13:19:38,322 - INFO - Unique licenses:
|
| 98 |
+
2025-06-24 13:19:38,322 - INFO - None
|
| 99 |
+
2025-06-24 13:19:38,322 - INFO - cc0
|
| 100 |
+
2025-06-24 13:19:38,322 - INFO - Manuskript taget fra ft.dk. med tilladelse fra udgiver.
|
| 101 |
+
2025-06-24 13:19:38,322 - INFO - Manuskript tilsendt af taler og udgivet af Danske Taler med tilladelse fra taler.
|
| 102 |
+
2025-06-24 13:19:38,322 - INFO - Materialet er beskyttet af ophavsret, da talen ikke er holdt i offentligheden.
|
| 103 |
+
2025-06-24 13:19:38,322 - INFO - Materialet er beskyttet af ophavsret
|
| 104 |
+
2025-06-24 13:19:38,322 - INFO - Materialet er beskyttet af ophavsret
|
| 105 |
+
2025-06-24 13:19:38,322 - INFO - Materialet et beskyttet af ophavsret
|
| 106 |
+
2025-06-24 13:19:38,322 - INFO - Manuskript taget fra ft.dk med tilladelse fra udgiver.
|
| 107 |
+
2025-06-24 13:19:38,322 - INFO - Materialet er beskyttet af ophavsret
|
| 108 |
+
2025-06-24 13:19:38,322 - INFO - Materialet er omfattet af ophavsret
|
| 109 |
+
2025-06-24 13:19:38,325 - INFO - Removed 2188 documents without a cc0 license
|
| 110 |
+
2025-06-24 13:19:38,326 - INFO - Removed 0 duplicate ids
|
| 111 |
+
2025-06-24 13:19:38,332 - INFO - Removed 1 rows with empty text
|
| 112 |
+
2025-06-24 13:19:38,345 - INFO - Removed 2 rows with duplicate text2025-06-24 14:44:36,089 - INFO - Downloading speeches and saving to /Users/kristianjensen/Documents/danish-dynaword/data/danske-taler/tmp/danske-taler-all.parquet
|
| 113 |
+
2025-06-24 14:44:36,089 - INFO - Fetching all speeches from Danske Taler API
|
| 114 |
+
2025-06-24 14:45:43,887 - INFO - Found 5107 speeches
|
| 115 |
+
2025-06-24 14:46:53,929 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 116 |
+
2025-06-24 14:46:54,627 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 117 |
+
2025-06-24 14:46:55,824 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 118 |
+
2025-06-24 14:46:58,015 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/niels-hoejlund-pedersens-translokationstale-2020
|
| 119 |
+
2025-06-24 14:47:34,505 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 120 |
+
2025-06-24 14:47:35,215 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 121 |
+
2025-06-24 14:47:36,514 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 122 |
+
2025-06-24 14:47:38,725 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/katrine-lykke-pedersens-tale-til-unge-om-haab-i-en-coronatid
|
| 123 |
+
2025-06-24 14:47:39,093 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 124 |
+
2025-06-24 14:47:39,798 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 125 |
+
2025-06-24 14:47:41,013 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 126 |
+
2025-06-24 14:47:43,253 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/anastacia-halkens-tale-til-unge-om-haab-i-en-coronatid
|
| 127 |
+
2025-06-24 14:47:44,528 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 128 |
+
2025-06-24 14:47:45,272 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 129 |
+
2025-06-24 14:47:46,492 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 130 |
+
2025-06-24 14:47:48,691 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/thomas-vinterbergs-tale-ved-modtagelsen-af-oscar-prisen
|
| 131 |
+
2025-06-24 14:48:26,340 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 132 |
+
2025-06-24 14:48:27,037 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 133 |
+
2025-06-24 14:48:28,248 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 134 |
+
2025-06-24 14:48:30,496 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/pernille-vermunds-tale-ved-folketingets-aabningsdebat-2021
|
| 135 |
+
2025-06-24 14:48:33,382 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 136 |
+
2025-06-24 14:48:34,125 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 137 |
+
2025-06-24 14:48:35,339 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 138 |
+
2025-06-24 14:48:37,570 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/pernille-vermunds-tale-ved-nye-borgerliges-aarsmoede-2021
|
| 139 |
+
2025-06-24 14:48:37,940 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 140 |
+
2025-06-24 14:48:38,663 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 141 |
+
2025-06-24 14:48:39,884 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 142 |
+
2025-06-24 14:48:42,101 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/mette-thiesens-tale-ved-nye-borgerliges-aarsmoede-2021
|
| 143 |
+
2025-06-24 14:48:42,357 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 144 |
+
2025-06-24 14:48:43,097 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 145 |
+
2025-06-24 14:48:44,340 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 146 |
+
2025-06-24 14:48:46,560 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/peter-seier-christensens-tale-ved-nye-borgerliges-aarsmoede-2021
|
| 147 |
+
2025-06-24 14:50:22,691 - INFO - Attempt 1 failed. Retrying in 0.50 seconds...
|
| 148 |
+
2025-06-24 14:50:23,446 - INFO - Attempt 2 failed. Retrying in 1.00 seconds...
|
| 149 |
+
2025-06-24 14:50:24,662 - INFO - Attempt 3 failed. Retrying in 2.00 seconds...
|
| 150 |
+
2025-06-24 14:50:26,911 - INFO - Failed to fetch license after 3 attempts: 500 Server Error: Internal Server Error for url: https://www.dansketaler.dk/tale/silke-ena-svares-tale-ved-demonstrationen-for-born-og-unge
|
| 151 |
+
2025-06-24 15:02:20,338 - INFO - Saving 5107 speeches to dataset
|
| 152 |
+
2025-06-24 15:02:20,503 - INFO - Unique licenses:
|
| 153 |
+
2025-06-24 15:02:20,503 - INFO - None
|
| 154 |
+
2025-06-24 15:02:20,503 - INFO - cc0
|
| 155 |
+
2025-06-24 15:02:20,503 - INFO - Materialet et beskyttet af ophavsret
|
| 156 |
+
2025-06-24 15:02:20,503 - INFO - Materialet er beskyttet af ophavsret
|
| 157 |
+
2025-06-24 15:02:20,503 - INFO - Materialet er omfattet af ophavsret
|
| 158 |
+
2025-06-24 15:02:20,503 - INFO - Manuskript taget fra ft.dk. med tilladelse fra udgiver.
|
| 159 |
+
2025-06-24 15:02:20,503 - INFO - Materialet er beskyttet af ophavsret
|
| 160 |
+
2025-06-24 15:02:20,503 - INFO - Manuskript taget fra ft.dk med tilladelse fra udgiver.
|
| 161 |
+
2025-06-24 15:02:20,503 - INFO - Materialet er beskyttet af ophavsret
|
| 162 |
+
2025-06-24 15:02:20,503 - INFO - Materialet er beskyttet af ophavsret, da talen ikke er holdt i offentligheden.
|
| 163 |
+
2025-06-24 15:02:20,503 - INFO - Manuskript tilsendt af taler og udgivet af Danske Taler med tilladelse fra taler.
|
| 164 |
+
2025-06-24 15:02:20,506 - INFO - Removed 2191 documents without a cc0 license
|
| 165 |
+
2025-06-24 15:02:20,508 - INFO - Removed 0 duplicate ids
|
| 166 |
+
2025-06-24 15:02:20,516 - INFO - Removed 2 rows with empty text
|
| 167 |
+
2025-06-24 15:02:20,529 - INFO - Removed 2 rows with duplicate text
|
data/danske-taler/danske-taler.md
CHANGED
|
@@ -31,15 +31,17 @@ The goal of the dataset is to collect historical and timely speeches and make th
|
|
| 31 |
|
| 32 |
Learn more about danske taler by reading their [about us](https://www.dansketaler.dk/om-os) page.
|
| 33 |
|
|
|
|
|
|
|
| 34 |
## Dataset Description
|
| 35 |
|
| 36 |
|
| 37 |
<!-- START-DESC-STATS -->
|
| 38 |
- **Language**: dan, dansk, Danish
|
| 39 |
- **Domains**: Conversation, Speeches, Spoken
|
| 40 |
-
- **Number of samples**: 2.
|
| 41 |
-
- **Number of tokens (Llama 3)**: 8.
|
| 42 |
-
- **Average document length (characters)**:
|
| 43 |
<!-- END-DESC-STATS -->
|
| 44 |
|
| 45 |
|
|
@@ -50,12 +52,12 @@ An example from the dataset looks as follows.
|
|
| 50 |
<!-- START-SAMPLE -->
|
| 51 |
```py
|
| 52 |
{
|
| 53 |
-
"id": "danske-
|
| 54 |
-
"text": "
|
| 55 |
"source": "danske-taler",
|
| 56 |
-
"added": "2025-
|
| 57 |
-
"created": "
|
| 58 |
-
"token_count":
|
| 59 |
}
|
| 60 |
```
|
| 61 |
|
|
|
|
| 31 |
|
| 32 |
Learn more about danske taler by reading their [about us](https://www.dansketaler.dk/om-os) page.
|
| 33 |
|
| 34 |
+
> NOTE: Danske-Taler is also collecting [sermons](https://www.dansketaler.dk/praedikener), but these are not included in this dataset.
|
| 35 |
+
|
| 36 |
## Dataset Description
|
| 37 |
|
| 38 |
|
| 39 |
<!-- START-DESC-STATS -->
|
| 40 |
- **Language**: dan, dansk, Danish
|
| 41 |
- **Domains**: Conversation, Speeches, Spoken
|
| 42 |
+
- **Number of samples**: 2.91K
|
| 43 |
+
- **Number of tokens (Llama 3)**: 8.81M
|
| 44 |
+
- **Average document length (characters)**: 9228.65
|
| 45 |
<!-- END-DESC-STATS -->
|
| 46 |
|
| 47 |
|
|
|
|
| 52 |
<!-- START-SAMPLE -->
|
| 53 |
```py
|
| 54 |
{
|
| 55 |
+
"id": "danske-taler_281",
|
| 56 |
+
"text": "Tyske landsmænd og -kvinder !\n\nSyv år er kort tid, en brøkdel af en enkel menneskelig normaltilværel[...]",
|
| 57 |
"source": "danske-taler",
|
| 58 |
+
"added": "2025-06-24",
|
| 59 |
+
"created": "1940-01-30, 1940-01-30",
|
| 60 |
+
"token_count": 3020
|
| 61 |
}
|
| 62 |
```
|
| 63 |
|
data/danske-taler/danske-taler.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d007e606854f868febcf61a513302f7299ff35222fe9de487d17b9baaaedf248
|
| 3 |
+
size 16089529
|
data/danske-taler/descriptive_stats.json
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
{
|
| 2 |
-
"number_of_samples":
|
| 3 |
-
"average_document_length":
|
| 4 |
-
"number_of_tokens":
|
| 5 |
-
"revision": "
|
| 6 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"number_of_samples": 2912,
|
| 3 |
+
"average_document_length": 9228.645260989011,
|
| 4 |
+
"number_of_tokens": 8809004,
|
| 5 |
+
"revision": "8d056aba9953ef0cf4c402ccb9deff745d8307af"
|
| 6 |
}
|
data/danske-taler/images/dist_document_length.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
data/scrape_hovedstaden/create.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# /// script
|
| 2 |
+
# requires-python = "==3.12"
|
| 3 |
+
# dependencies = [
|
| 4 |
+
# "datasets==3.2.0",
|
| 5 |
+
# "dynaword"
|
| 6 |
+
# ]
|
| 7 |
+
# [tool.uv.sources]
|
| 8 |
+
# dynaword = { git = "https://huggingface.co/datasets/danish-foundation-models/danish-dynaword", rev = "00e7f2aee7f7ad2da423419f77ecbb9c0536de0d" }
|
| 9 |
+
# ///
|
| 10 |
+
"""
|
| 11 |
+
Script for downloading and processing the Scrape Hovedstaden texts.
|
| 12 |
+
|
| 13 |
+
Note: To run this script, you need to set `GIT_LFS_SKIP_SMUDGE=1` to be able to install dynaword:
|
| 14 |
+
|
| 15 |
+
```bash
|
| 16 |
+
GIT_LFS_SKIP_SMUDGE=1 uv run data/scrape_hovedstaden/create.py
|
| 17 |
+
```
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
import logging
|
| 21 |
+
import subprocess
|
| 22 |
+
from datetime import datetime
|
| 23 |
+
from pathlib import Path
|
| 24 |
+
from typing import Any, cast
|
| 25 |
+
|
| 26 |
+
import pandas as pd
|
| 27 |
+
from datasets import Dataset, load_dataset
|
| 28 |
+
|
| 29 |
+
from dynaword.process_dataset import (
|
| 30 |
+
add_token_count,
|
| 31 |
+
ensure_column_order,
|
| 32 |
+
remove_duplicate_text,
|
| 33 |
+
remove_empty_texts,
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
logger = logging.getLogger(__name__)
|
| 37 |
+
|
| 38 |
+
download_path = Path(__file__).parent / "tmp"
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def main():
|
| 42 |
+
save_path = Path(__file__).parent / "scrape_hovedstaden.parquet"
|
| 43 |
+
# Download data from repo: Den-Intelligente-Patientjournal/region_hovedstaden_text
|
| 44 |
+
ds = load_dataset(
|
| 45 |
+
"Den-Intelligente-Patientjournal/region_hovedstaden_text", split="train"
|
| 46 |
+
)
|
| 47 |
+
dataset: Dataset = cast(Dataset, ds)
|
| 48 |
+
|
| 49 |
+
# Extract the cleaned column
|
| 50 |
+
dataset = dataset.rename_column("cleaned", "text")
|
| 51 |
+
|
| 52 |
+
# Add created column: 2015 and 2020
|
| 53 |
+
dataset = dataset.add_column("created", ["2015-01-01, 2020-12-31"] * len(dataset)) # type: ignore
|
| 54 |
+
# Add added column: today
|
| 55 |
+
dataset = dataset.add_column(
|
| 56 |
+
"added", [datetime.today().date().strftime("%Y-%m-%d")] * len(dataset)
|
| 57 |
+
) # type: ignore
|
| 58 |
+
# Add source column: scrape_hovedstaden
|
| 59 |
+
dataset = dataset.add_column("source", ["scrape_hovedstaden"] * len(dataset)) # type: ignore
|
| 60 |
+
# Add id column: scrape_hovedstade_{idx}
|
| 61 |
+
dataset = dataset.add_column(
|
| 62 |
+
"id", [f"scrape_hovedstaden_{i}" for i in range(len(dataset))]
|
| 63 |
+
) # type: ignore
|
| 64 |
+
|
| 65 |
+
# quality checks and processing
|
| 66 |
+
dataset = remove_empty_texts(dataset)
|
| 67 |
+
dataset = remove_duplicate_text(dataset)
|
| 68 |
+
dataset = add_token_count(dataset)
|
| 69 |
+
dataset = ensure_column_order(dataset)
|
| 70 |
+
|
| 71 |
+
# save to parquet
|
| 72 |
+
dataset.to_parquet(save_path)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
if __name__ == "__main__":
|
| 76 |
+
main()
|
data/scrape_hovedstaden/descriptive_stats.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"number_of_samples": 23996,
|
| 3 |
+
"average_document_length": 3329.0515919319887,
|
| 4 |
+
"number_of_tokens": 27066716,
|
| 5 |
+
"revision": "78cc135f92c8c12ee8ba131d1a03befc5c78477d"
|
| 6 |
+
}
|
data/scrape_hovedstaden/images/dist_document_length.png
ADDED
|
Git LFS Details
|
data/scrape_hovedstaden/scrape_hovedstaden.md
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
pretty_name: "Health Hovedstaden"
|
| 3 |
+
language:
|
| 4 |
+
- da
|
| 5 |
+
license: cc0-1.0
|
| 6 |
+
license_name: CC-0
|
| 7 |
+
task_categories:
|
| 8 |
+
- text-generation
|
| 9 |
+
- fill-mask
|
| 10 |
+
task_ids:
|
| 11 |
+
- language-modeling
|
| 12 |
+
source_datasets:
|
| 13 |
+
- Den-Intelligente-Patientjournal/region_hovedstaden_text
|
| 14 |
+
domains:
|
| 15 |
+
- Medical
|
| 16 |
+
- Encyclopedic
|
| 17 |
+
---
|
| 18 |
+
|
| 19 |
+
# Dataset Card for Health Hovedstaden
|
| 20 |
+
|
| 21 |
+
<!-- START-SHORT DESCRIPTION -->
|
| 22 |
+
Guidelines and informational documents for healthcare professionals from the Capital Region
|
| 23 |
+
<!-- END-SHORT DESCRIPTION -->
|
| 24 |
+
|
| 25 |
+
The document collection consists of guidelines and informational documents for healthcare professionals in the Capital Region of Denmark. The documents therefore contain a number of specialized terms and concepts that are frequently used within the healthcare sector.
|
| 26 |
+
|
| 27 |
+
The corpus was created based on the texts in the document collection and has been post-processed so that the texts can be used for the development of language technology.
|
| 28 |
+
|
| 29 |
+
Martin Sundahl Laursen and Thiusius R. Savarimuthu from the University of Southern Denmark have assisted the Danish Agency for Digital Government with the post-processing of the data. Read their joint paper on "Automatic Annotation of Training Data for Deep Learning Based De-identification of Narrative Clinical Text."
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
## Dataset Description
|
| 35 |
+
|
| 36 |
+
<!-- START-DESC-STATS -->
|
| 37 |
+
- **Language**: dan, dansk, Danish
|
| 38 |
+
- **Domains**: Medical, Encyclopedic
|
| 39 |
+
- **Number of samples**: 24.00K
|
| 40 |
+
- **Number of tokens (Llama 3)**: 27.07M
|
| 41 |
+
- **Average document length (characters)**: 3329.05
|
| 42 |
+
<!-- END-DESC-STATS -->
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
## Dataset Structure
|
| 46 |
+
An example from the dataset looks as follows.
|
| 47 |
+
|
| 48 |
+
<!-- START-SAMPLE -->
|
| 49 |
+
```py
|
| 50 |
+
{
|
| 51 |
+
"id": "scrape_hovedstaden_0",
|
| 52 |
+
"text": "Acetylsalicylsyre - Aspirin, Akutlægebil\n\nMålgrupper og anvendelsesområde\nDefinitioner\nFremgangsmåde[...]",
|
| 53 |
+
"source": "scrape_hovedstaden",
|
| 54 |
+
"added": "2025-06-25",
|
| 55 |
+
"created": "2015-01-01, 2020-12-31",
|
| 56 |
+
"token_count": 766
|
| 57 |
+
}
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
### Data Fields
|
| 61 |
+
|
| 62 |
+
An entry in the dataset consists of the following fields:
|
| 63 |
+
|
| 64 |
+
- `id` (`str`): An unique identifier for each document.
|
| 65 |
+
- `text`(`str`): The content of the document.
|
| 66 |
+
- `source` (`str`): The source of the document (see [Source Data](#source-data)).
|
| 67 |
+
- `added` (`str`): An date for when the document was added to this collection.
|
| 68 |
+
- `created` (`str`): An date range for when the document was originally created.
|
| 69 |
+
- `token_count` (`int`): The number of tokens in the sample computed using the Llama 8B tokenizer
|
| 70 |
+
<!-- END-SAMPLE -->
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
### Additional Processing
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
### Unintended Uses
|
| 78 |
+
|
| 79 |
+
Please note that the corpus has been developed for the purpose of language technology development and should not be used as a source of healthcare information. The documents were scraped at a specific time and will therefore not be updated with changes. In this regard, please refer to the Capital Region of Denmark's document collection.
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
### Dataset Statistics
|
| 83 |
+
|
| 84 |
+
<!-- START-DATASET PLOTS -->
|
| 85 |
+
<p align="center">
|
| 86 |
+
<img src="./images/dist_document_length.png" width="600" style="margin-right: 10px;" />
|
| 87 |
+
</p>
|
| 88 |
+
<!-- END-DATASET PLOTS -->
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
# Additional Information
|
| 92 |
+
|
| 93 |
+
## License Information
|
| 94 |
+
The dataset have been released under a CC-0 license.
|
| 95 |
+
|
| 96 |
+
### Citation Information
|
| 97 |
+
|
| 98 |
+
If you are using the data please reference the following paper [Automatic Annotation of Training Data for Deep Learning Based De-identification of Narrative Clinical Text](https://ceur-ws.org/Vol-3416/paper_5.pdf)
|
data/scrape_hovedstaden/scrape_hovedstaden.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:830fcdc9a16310bf1d165db79ba8b49bdee33cd7b3849ca0564b010d9f3df318
|
| 3 |
+
size 41434842
|
descriptive_stats.json
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
{
|
| 2 |
-
"number_of_samples":
|
| 3 |
-
"average_document_length":
|
| 4 |
-
"number_of_tokens":
|
| 5 |
-
"revision": "
|
| 6 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"number_of_samples": 915090,
|
| 3 |
+
"average_document_length": 14778.0072255188,
|
| 4 |
+
"number_of_tokens": 4396075044,
|
| 5 |
+
"revision": "8e2259b9aaa48bb3950b8b4111d10a92ba834459"
|
| 6 |
}
|
images/dist_document_length.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
images/domain_distribution.png
CHANGED

|
Git LFS Details
|
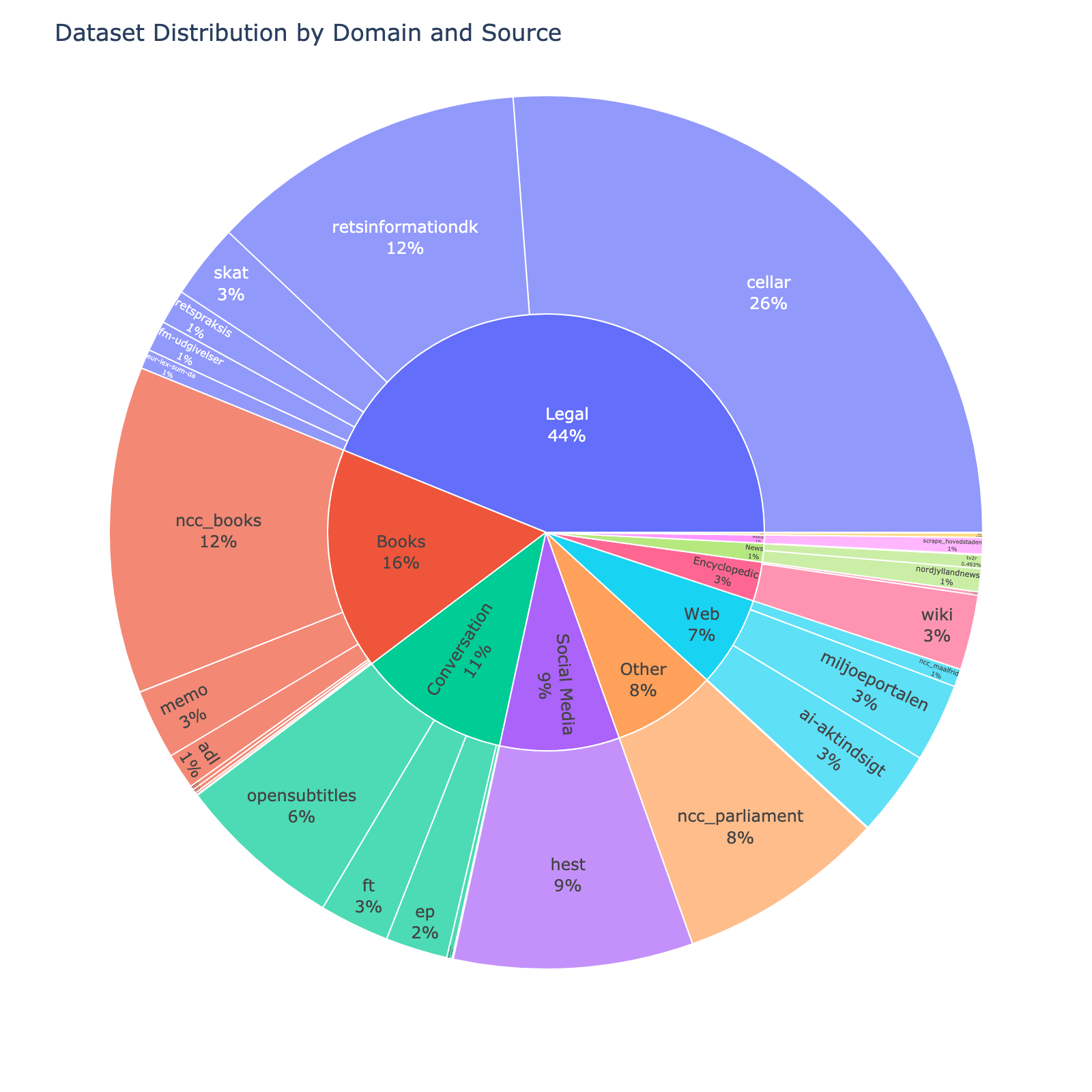
|
Git LFS Details
|
pyproject.toml
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
[project]
|
| 2 |
name = "dynaword"
|
| 3 |
-
version = "1.2.
|
| 4 |
description = "project code for the danish dynaword project"
|
| 5 |
readme = "README.md"
|
| 6 |
requires-python = ">=3.12,<3.13" # 3.13 have issues with spacy and pytorch
|
|
|
|
| 1 |
[project]
|
| 2 |
name = "dynaword"
|
| 3 |
+
version = "1.2.2"
|
| 4 |
description = "project code for the danish dynaword project"
|
| 5 |
readme = "README.md"
|
| 6 |
requires-python = ">=3.12,<3.13" # 3.13 have issues with spacy and pytorch
|
src/dynaword/typings.py
CHANGED
|
@@ -6,6 +6,7 @@ DOMAIN = Literal[
|
|
| 6 |
"Dialect",
|
| 7 |
"Encyclopedic",
|
| 8 |
"Legal",
|
|
|
|
| 9 |
"News",
|
| 10 |
"Other",
|
| 11 |
"Readaloud",
|
|
|
|
| 6 |
"Dialect",
|
| 7 |
"Encyclopedic",
|
| 8 |
"Legal",
|
| 9 |
+
"Medical",
|
| 10 |
"News",
|
| 11 |
"Other",
|
| 12 |
"Readaloud",
|
test_results.log
CHANGED
|
@@ -1,25 +1,24 @@
|
|
| 1 |
============================= test session starts ==============================
|
| 2 |
-
platform darwin -- Python 3.12.
|
| 3 |
-
rootdir: /Users/
|
| 4 |
configfile: pyproject.toml
|
| 5 |
-
|
| 6 |
-
collected 310 items
|
| 7 |
|
| 8 |
src/tests/test_dataset_schema.py ....................................... [ 12%]
|
| 9 |
-
|
| 10 |
src/tests/test_datasheets.py ........................................... [ 35%]
|
| 11 |
-
........................................................................ [
|
| 12 |
-
|
| 13 |
src/tests/test_load.py .. [ 77%]
|
| 14 |
-
src/tests/test_quality/test_duplicates.py .............................. [
|
| 15 |
-
|
| 16 |
-
src/tests/test_quality/test_short_texts.py ............................. [
|
| 17 |
-
|
| 18 |
src/tests/test_unique_ids.py . [100%]
|
| 19 |
|
| 20 |
=============================== warnings summary ===============================
|
| 21 |
-
src/tests/test_quality/test_short_texts.py:
|
| 22 |
-
/Users/
|
| 23 |
|
| 24 |
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
|
| 25 |
-
|
|
|
|
| 1 |
============================= test session starts ==============================
|
| 2 |
+
platform darwin -- Python 3.12.9, pytest-8.3.4, pluggy-1.5.0
|
| 3 |
+
rootdir: /Users/kristianjensen/Documents/danish-dynaword
|
| 4 |
configfile: pyproject.toml
|
| 5 |
+
collected 319 items
|
|
|
|
| 6 |
|
| 7 |
src/tests/test_dataset_schema.py ....................................... [ 12%]
|
| 8 |
+
............................... [ 21%]
|
| 9 |
src/tests/test_datasheets.py ........................................... [ 35%]
|
| 10 |
+
........................................................................ [ 57%]
|
| 11 |
+
............................................................ [ 76%]
|
| 12 |
src/tests/test_load.py .. [ 77%]
|
| 13 |
+
src/tests/test_quality/test_duplicates.py .............................. [ 86%]
|
| 14 |
+
.....s [ 88%]
|
| 15 |
+
src/tests/test_quality/test_short_texts.py ............................. [ 97%]
|
| 16 |
+
...... [ 99%]
|
| 17 |
src/tests/test_unique_ids.py . [100%]
|
| 18 |
|
| 19 |
=============================== warnings summary ===============================
|
| 20 |
+
src/tests/test_quality/test_short_texts.py: 35 warnings
|
| 21 |
+
/Users/kristianjensen/Documents/danish-dynaword/.venv/lib/python3.12/site-packages/datasets/utils/_dill.py:385: DeprecationWarning: co_lnotab is deprecated, use co_lines instead.
|
| 22 |
|
| 23 |
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
|
| 24 |
+
================= 318 passed, 1 skipped, 35 warnings in 27.88s =================
|
uv.lock
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|