Datasets:

Tasks:
Text Generation
Formats:
parquet
Sub-tasks:
language-modeling
Languages:
Danish
Size:
1M - 10M
License:

Fixing minor things after reviews
Browse files- README.md +1 -1
- data/scrape_hovedstaden/descriptive_stats.json +1 -1
- data/scrape_hovedstaden/scrape_hovedstaden.md +13 -21
- descriptive_stats.json +1 -1
- images/domain_distribution.png +2 -2
- src/dynaword/typings.py +1 -0
- test_results.log +13 -14
README.md
CHANGED
|
@@ -336,7 +336,7 @@ Below follows a brief overview of the sources in the corpus along with their ind
|
|
| 336 |
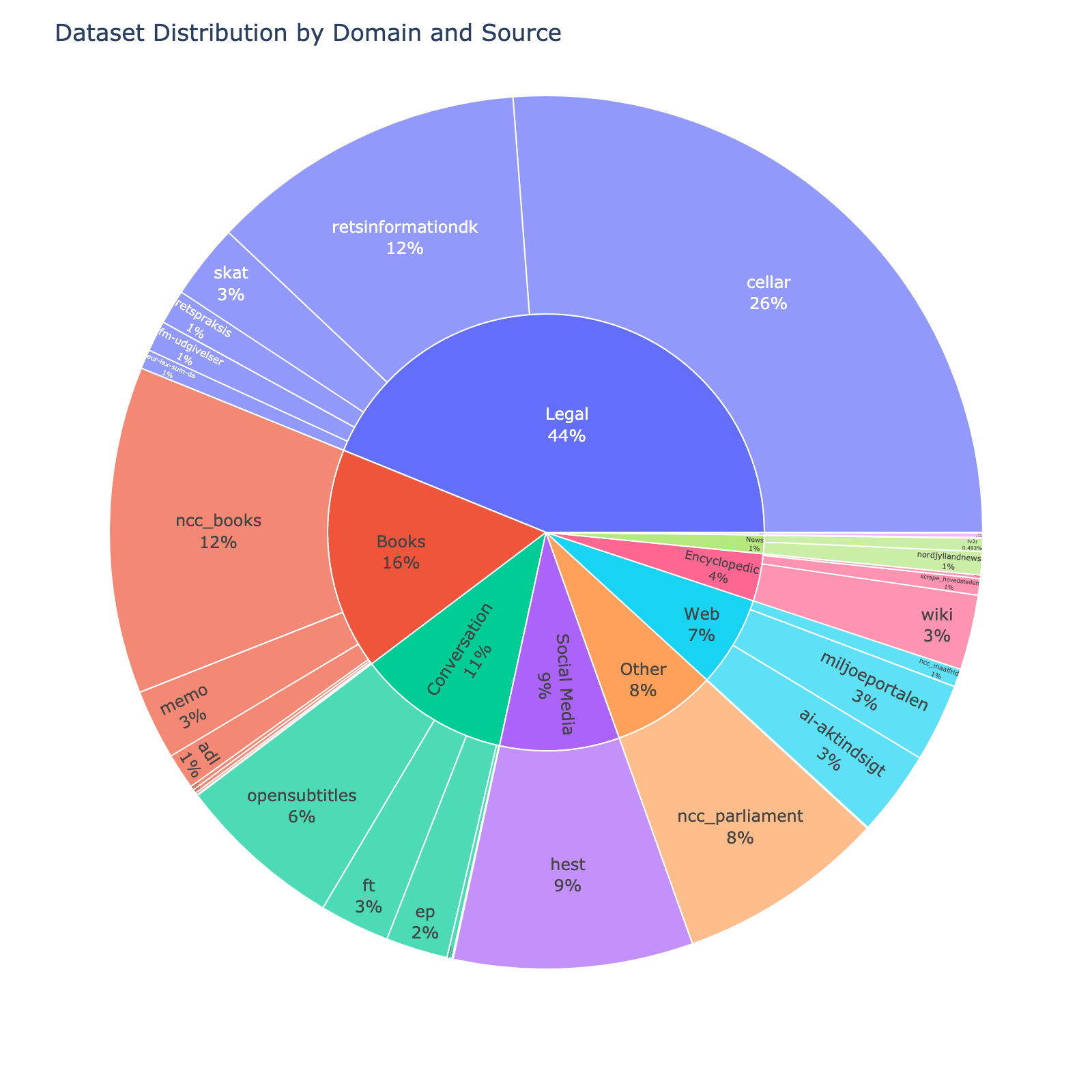
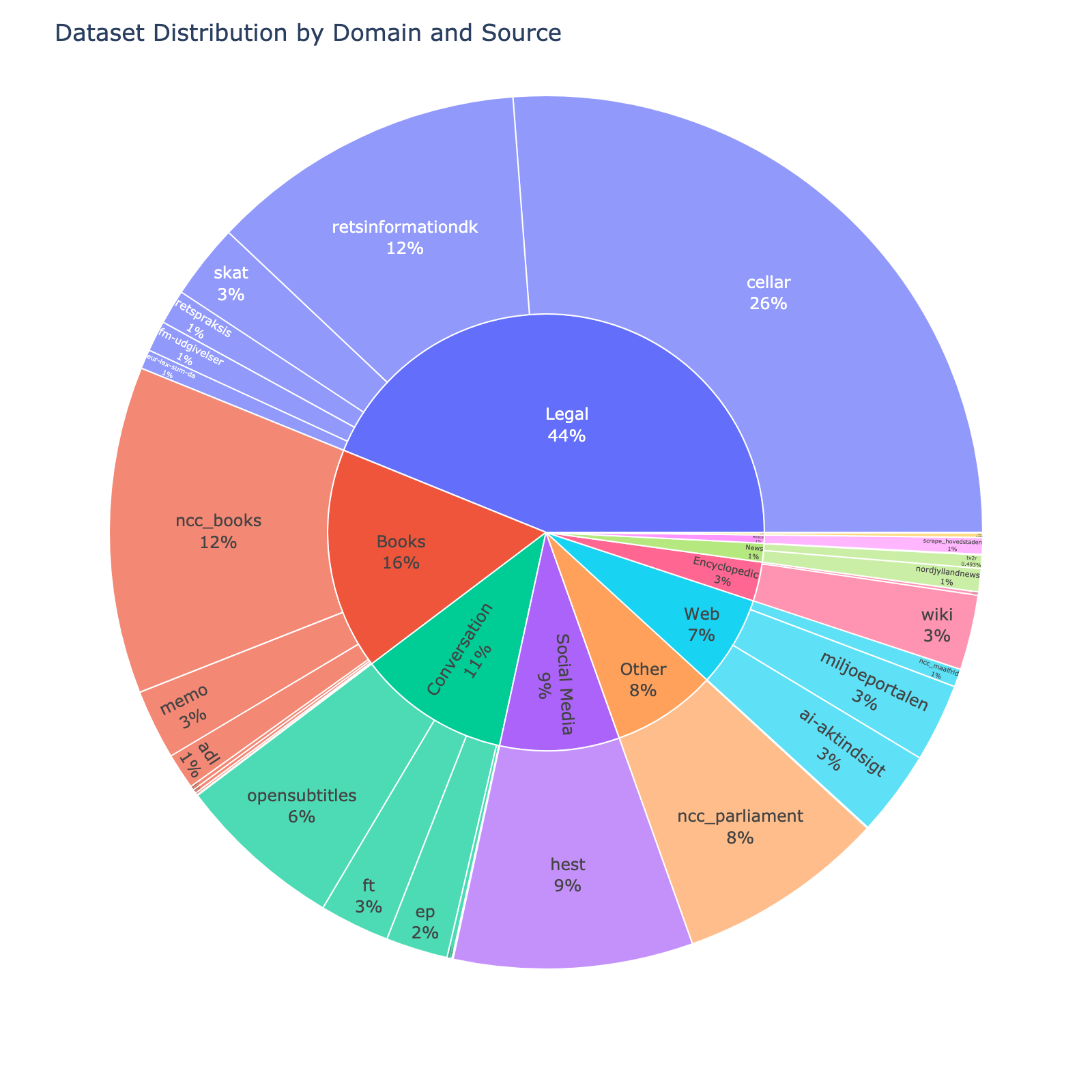
| [nordjyllandnews] | Articles from the Danish Newspaper [TV2 Nord](https://www.tv2nord.dk) | News | 37.90M | [CC-0] |
|
| 337 |
| [eur-lex-sum-da] | The Danish subsection of EUR-lex SUM consisting of EU legislation paired with professionally written summaries | Legal | 31.37M | [CC-BY-SA 4.0] |
|
| 338 |
| [ncc_maalfrid] | Danish content from Norwegian institutions websites | Web | 29.26M | [NLOD 2.0] |
|
| 339 |
-
| [scrape_hovedstaden] |
|
| 340 |
| [tv2r] | Contemporary Danish newswire articles published between 2010 and 2019 | News | 21.67M | [CC-BY-SA 4.0] |
|
| 341 |
| [danske-taler] | Danish Speeches from [dansketaler.dk](https://www.dansketaler.dk) | Conversation | 8.23M | [CC-0] |
|
| 342 |
| [nota] | The text only part of the [Nota lyd- og tekstdata](https://sprogteknologi.dk/dataset/nota-lyd-og-tekstdata) dataset | Readaloud | 7.30M | [CC-0] |
|
|
|
|
| 336 |
| [nordjyllandnews] | Articles from the Danish Newspaper [TV2 Nord](https://www.tv2nord.dk) | News | 37.90M | [CC-0] |
|
| 337 |
| [eur-lex-sum-da] | The Danish subsection of EUR-lex SUM consisting of EU legislation paired with professionally written summaries | Legal | 31.37M | [CC-BY-SA 4.0] |
|
| 338 |
| [ncc_maalfrid] | Danish content from Norwegian institutions websites | Web | 29.26M | [NLOD 2.0] |
|
| 339 |
+
| [scrape_hovedstaden] | Guidelines and informational documents for healthcare professionals from the Capital Region | Medical | 27.07M | [CC-0] |
|
| 340 |
| [tv2r] | Contemporary Danish newswire articles published between 2010 and 2019 | News | 21.67M | [CC-BY-SA 4.0] |
|
| 341 |
| [danske-taler] | Danish Speeches from [dansketaler.dk](https://www.dansketaler.dk) | Conversation | 8.23M | [CC-0] |
|
| 342 |
| [nota] | The text only part of the [Nota lyd- og tekstdata](https://sprogteknologi.dk/dataset/nota-lyd-og-tekstdata) dataset | Readaloud | 7.30M | [CC-0] |
|
data/scrape_hovedstaden/descriptive_stats.json
CHANGED
|
@@ -2,5 +2,5 @@
|
|
| 2 |
"number_of_samples": 23996,
|
| 3 |
"average_document_length": 3329.0515919319887,
|
| 4 |
"number_of_tokens": 27066716,
|
| 5 |
-
"revision": "
|
| 6 |
}
|
|
|
|
| 2 |
"number_of_samples": 23996,
|
| 3 |
"average_document_length": 3329.0515919319887,
|
| 4 |
"number_of_tokens": 27066716,
|
| 5 |
+
"revision": "78cc135f92c8c12ee8ba131d1a03befc5c78477d"
|
| 6 |
}
|
data/scrape_hovedstaden/scrape_hovedstaden.md
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
---
|
| 2 |
-
pretty_name: "
|
| 3 |
language:
|
| 4 |
- da
|
| 5 |
license: cc0-1.0
|
|
@@ -12,25 +12,22 @@ task_ids:
|
|
| 12 |
source_datasets:
|
| 13 |
- Den-Intelligente-Patientjournal/region_hovedstaden_text
|
| 14 |
domains:
|
|
|
|
| 15 |
- Encyclopedic
|
| 16 |
---
|
| 17 |
|
| 18 |
-
# Dataset Card for
|
| 19 |
|
| 20 |
<!-- START-SHORT DESCRIPTION -->
|
| 21 |
-
|
| 22 |
<!-- END-SHORT DESCRIPTION -->
|
| 23 |
|
| 24 |
The document collection consists of guidelines and informational documents for healthcare professionals in the Capital Region of Denmark. The documents therefore contain a number of specialized terms and concepts that are frequently used within the healthcare sector.
|
| 25 |
|
| 26 |
-
The corpus contains 9,941,236 tokens (word separation by spaces) extracted from 15,829 documents and 8,923 tables.
|
| 27 |
-
|
| 28 |
The corpus was created based on the texts in the document collection and has been post-processed so that the texts can be used for the development of language technology.
|
| 29 |
|
| 30 |
Martin Sundahl Laursen and Thiusius R. Savarimuthu from the University of Southern Denmark have assisted the Danish Agency for Digital Government with the post-processing of the data. Read their joint paper on "Automatic Annotation of Training Data for Deep Learning Based De-identification of Narrative Clinical Text."
|
| 31 |
|
| 32 |
-
Please note that the corpus has been developed for the purpose of language technology development and should not be used as a source of healthcare information. The documents were scraped at a specific time and will therefore not be updated with changes. In this regard, please refer to the Capital Region of Denmark's document collection.
|
| 33 |
-
|
| 34 |
|
| 35 |
|
| 36 |
|
|
@@ -38,7 +35,7 @@ Please note that the corpus has been developed for the purpose of language techn
|
|
| 38 |
|
| 39 |
<!-- START-DESC-STATS -->
|
| 40 |
- **Language**: dan, dansk, Danish
|
| 41 |
-
- **Domains**: Encyclopedic
|
| 42 |
- **Number of samples**: 24.00K
|
| 43 |
- **Number of tokens (Llama 3)**: 27.07M
|
| 44 |
- **Average document length (characters)**: 3329.05
|
|
@@ -76,6 +73,12 @@ An entry in the dataset consists of the following fields:
|
|
| 76 |
### Additional Processing
|
| 77 |
|
| 78 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 79 |
### Dataset Statistics
|
| 80 |
|
| 81 |
<!-- START-DATASET PLOTS -->
|
|
@@ -88,19 +91,8 @@ An entry in the dataset consists of the following fields:
|
|
| 88 |
# Additional Information
|
| 89 |
|
| 90 |
## License Information
|
| 91 |
-
|
| 92 |
|
| 93 |
### Citation Information
|
| 94 |
|
| 95 |
-
If you are using the data please reference the following paper
|
| 96 |
-
|
| 97 |
-
```
|
| 98 |
-
@inproceedings{laursen2023automatic,
|
| 99 |
-
title={Automatic Annotation of Training Data for Deep Learning Based De-identification of Narrative Clinical Text},
|
| 100 |
-
author={Laursen, Martin Sundahl and Pedersen, Jannik Skyttegaard and Vinholt, Pernille and Savarimuthu, Thiusius R},
|
| 101 |
-
booktitle={The First Workshop on Context-aware NLP in eHealth:(WNLPe-Health 2022)},
|
| 102 |
-
pages={30--44},
|
| 103 |
-
year={2023},
|
| 104 |
-
organization={CEUR Workshop Proceedings}
|
| 105 |
-
}
|
| 106 |
-
```
|
|
|
|
| 1 |
---
|
| 2 |
+
pretty_name: "Health Hovedstaden"
|
| 3 |
language:
|
| 4 |
- da
|
| 5 |
license: cc0-1.0
|
|
|
|
| 12 |
source_datasets:
|
| 13 |
- Den-Intelligente-Patientjournal/region_hovedstaden_text
|
| 14 |
domains:
|
| 15 |
+
- Medical
|
| 16 |
- Encyclopedic
|
| 17 |
---
|
| 18 |
|
| 19 |
+
# Dataset Card for Health Hovedstaden
|
| 20 |
|
| 21 |
<!-- START-SHORT DESCRIPTION -->
|
| 22 |
+
Guidelines and informational documents for healthcare professionals from the Capital Region
|
| 23 |
<!-- END-SHORT DESCRIPTION -->
|
| 24 |
|
| 25 |
The document collection consists of guidelines and informational documents for healthcare professionals in the Capital Region of Denmark. The documents therefore contain a number of specialized terms and concepts that are frequently used within the healthcare sector.
|
| 26 |
|
|
|
|
|
|
|
| 27 |
The corpus was created based on the texts in the document collection and has been post-processed so that the texts can be used for the development of language technology.
|
| 28 |
|
| 29 |
Martin Sundahl Laursen and Thiusius R. Savarimuthu from the University of Southern Denmark have assisted the Danish Agency for Digital Government with the post-processing of the data. Read their joint paper on "Automatic Annotation of Training Data for Deep Learning Based De-identification of Narrative Clinical Text."
|
| 30 |
|
|
|
|
|
|
|
| 31 |
|
| 32 |
|
| 33 |
|
|
|
|
| 35 |
|
| 36 |
<!-- START-DESC-STATS -->
|
| 37 |
- **Language**: dan, dansk, Danish
|
| 38 |
+
- **Domains**: Medical, Encyclopedic
|
| 39 |
- **Number of samples**: 24.00K
|
| 40 |
- **Number of tokens (Llama 3)**: 27.07M
|
| 41 |
- **Average document length (characters)**: 3329.05
|
|
|
|
| 73 |
### Additional Processing
|
| 74 |
|
| 75 |
|
| 76 |
+
|
| 77 |
+
### Unintended Uses
|
| 78 |
+
|
| 79 |
+
Please note that the corpus has been developed for the purpose of language technology development and should not be used as a source of healthcare information. The documents were scraped at a specific time and will therefore not be updated with changes. In this regard, please refer to the Capital Region of Denmark's document collection.
|
| 80 |
+
|
| 81 |
+
|
| 82 |
### Dataset Statistics
|
| 83 |
|
| 84 |
<!-- START-DATASET PLOTS -->
|
|
|
|
| 91 |
# Additional Information
|
| 92 |
|
| 93 |
## License Information
|
| 94 |
+
The dataset have been released under a CC-0 license.
|
| 95 |
|
| 96 |
### Citation Information
|
| 97 |
|
| 98 |
+
If you are using the data please reference the following paper [Automatic Annotation of Training Data for Deep Learning Based De-identification of Narrative Clinical Text](https://ceur-ws.org/Vol-3416/paper_5.pdf)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
descriptive_stats.json
CHANGED
|
@@ -2,5 +2,5 @@
|
|
| 2 |
"number_of_samples": 915090,
|
| 3 |
"average_document_length": 14778.0072255188,
|
| 4 |
"number_of_tokens": 4396075044,
|
| 5 |
-
"revision": "
|
| 6 |
}
|
|
|
|
| 2 |
"number_of_samples": 915090,
|
| 3 |
"average_document_length": 14778.0072255188,
|
| 4 |
"number_of_tokens": 4396075044,
|
| 5 |
+
"revision": "78cc135f92c8c12ee8ba131d1a03befc5c78477d"
|
| 6 |
}
|
images/domain_distribution.png
CHANGED
|
Git LFS Details
|
|
Git LFS Details
|
src/dynaword/typings.py
CHANGED
|
@@ -6,6 +6,7 @@ DOMAIN = Literal[
|
|
| 6 |
"Dialect",
|
| 7 |
"Encyclopedic",
|
| 8 |
"Legal",
|
|
|
|
| 9 |
"News",
|
| 10 |
"Other",
|
| 11 |
"Readaloud",
|
|
|
|
| 6 |
"Dialect",
|
| 7 |
"Encyclopedic",
|
| 8 |
"Legal",
|
| 9 |
+
"Medical",
|
| 10 |
"News",
|
| 11 |
"Other",
|
| 12 |
"Readaloud",
|
test_results.log
CHANGED
|
@@ -1,25 +1,24 @@
|
|
| 1 |
============================= test session starts ==============================
|
| 2 |
-
platform darwin -- Python 3.12.
|
| 3 |
-
rootdir: /Users/
|
| 4 |
configfile: pyproject.toml
|
| 5 |
-
|
| 6 |
-
collected 310 items
|
| 7 |
|
| 8 |
src/tests/test_dataset_schema.py ....................................... [ 12%]
|
| 9 |
-
|
| 10 |
src/tests/test_datasheets.py ........................................... [ 35%]
|
| 11 |
-
........................................................................ [
|
| 12 |
-
|
| 13 |
src/tests/test_load.py .. [ 77%]
|
| 14 |
-
src/tests/test_quality/test_duplicates.py .............................. [
|
| 15 |
-
|
| 16 |
-
src/tests/test_quality/test_short_texts.py ............................. [
|
| 17 |
-
|
| 18 |
src/tests/test_unique_ids.py . [100%]
|
| 19 |
|
| 20 |
=============================== warnings summary ===============================
|
| 21 |
-
src/tests/test_quality/test_short_texts.py:
|
| 22 |
-
/Users/
|
| 23 |
|
| 24 |
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
|
| 25 |
-
|
|
|
|
| 1 |
============================= test session starts ==============================
|
| 2 |
+
platform darwin -- Python 3.12.9, pytest-8.3.4, pluggy-1.5.0
|
| 3 |
+
rootdir: /Users/kristianjensen/Documents/danish-dynaword
|
| 4 |
configfile: pyproject.toml
|
| 5 |
+
collected 319 items
|
|
|
|
| 6 |
|
| 7 |
src/tests/test_dataset_schema.py ....................................... [ 12%]
|
| 8 |
+
............................... [ 21%]
|
| 9 |
src/tests/test_datasheets.py ........................................... [ 35%]
|
| 10 |
+
........................................................................ [ 57%]
|
| 11 |
+
............................................................ [ 76%]
|
| 12 |
src/tests/test_load.py .. [ 77%]
|
| 13 |
+
src/tests/test_quality/test_duplicates.py .............................. [ 86%]
|
| 14 |
+
.....s [ 88%]
|
| 15 |
+
src/tests/test_quality/test_short_texts.py ............................. [ 97%]
|
| 16 |
+
...... [ 99%]
|
| 17 |
src/tests/test_unique_ids.py . [100%]
|
| 18 |
|
| 19 |
=============================== warnings summary ===============================
|
| 20 |
+
src/tests/test_quality/test_short_texts.py: 35 warnings
|
| 21 |
+
/Users/kristianjensen/Documents/danish-dynaword/.venv/lib/python3.12/site-packages/datasets/utils/_dill.py:385: DeprecationWarning: co_lnotab is deprecated, use co_lines instead.
|
| 22 |
|
| 23 |
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
|
| 24 |
+
================= 318 passed, 1 skipped, 35 warnings in 28.20s =================
|