Datasets:

Tasks:
Text Generation
Formats:
parquet
Sub-tasks:
language-modeling
Languages:
Danish
Size:
10M - 100M
ArXiv:
DOI:
License:

Adding the scrape_hovedstaden data
Browse files- README.md +46 -40
- data/scrape_hovedstaden/create.py +76 -0
- data/scrape_hovedstaden/descriptive_stats.json +6 -0
- data/scrape_hovedstaden/images/dist_document_length.png +3 -0
- data/scrape_hovedstaden/scrape_hovedstaden.md +106 -0
- data/scrape_hovedstaden/scrape_hovedstaden.parquet +3 -0
- descriptive_stats.json +4 -4
- images/dist_document_length.png +2 -2
- images/domain_distribution.png +2 -2
- uv.lock +0 -0
README.md
CHANGED
|
@@ -141,6 +141,10 @@ configs:
|
|
| 141 |
data_files:
|
| 142 |
- split: train
|
| 143 |
path: data/nota/*.parquet
|
|
|
|
|
|
|
|
|
|
|
|
|
| 144 |
annotations_creators:
|
| 145 |
- no-annotation
|
| 146 |
language_creators:
|
|
@@ -211,9 +215,9 @@ https://github.com/huggingface/datasets/blob/main/templates/README_guide.md
|
|
| 211 |
|
| 212 |
<!-- START-DESC-STATS -->
|
| 213 |
- **Language**: dan, dansk, Danish
|
| 214 |
-
- **Number of samples**:
|
| 215 |
-
- **Number of tokens (Llama 3)**: 4.
|
| 216 |
-
- **Average document length (characters)**:
|
| 217 |
<!-- END-DESC-STATS -->
|
| 218 |
|
| 219 |
|
|
@@ -311,43 +315,44 @@ This data generally contains no annotation besides the metadata attached to each
|
|
| 311 |
Below follows a brief overview of the sources in the corpus along with their individual license.
|
| 312 |
|
| 313 |
<!-- START-MAIN TABLE -->
|
| 314 |
-
| Source
|
| 315 |
-
|
| 316 |
-
| [cellar]
|
| 317 |
-
| [ncc_books]
|
| 318 |
-
| [retsinformationdk]
|
| 319 |
-
| [hest]
|
| 320 |
-
| [ncc_parliament]
|
| 321 |
-
| [opensubtitles]
|
| 322 |
-
| [ai-aktindsigt]
|
| 323 |
-
| [miljoeportalen]
|
| 324 |
-
| [skat]
|
| 325 |
-
| [wiki]
|
| 326 |
-
| [ft]
|
| 327 |
-
| [memo]
|
| 328 |
-
| [ep]
|
| 329 |
-
| [adl]
|
| 330 |
-
| [retspraksis]
|
| 331 |
-
| [fm-udgivelser]
|
| 332 |
-
| [nordjyllandnews]
|
| 333 |
-
| [eur-lex-sum-da]
|
| 334 |
-
| [ncc_maalfrid]
|
| 335 |
-
| [
|
| 336 |
-
| [
|
| 337 |
-
| [
|
| 338 |
-
| [
|
| 339 |
-
| [
|
| 340 |
-
| [
|
| 341 |
-
| [
|
| 342 |
-
| [
|
| 343 |
-
| [
|
| 344 |
-
| [
|
| 345 |
-
| [
|
| 346 |
-
| [
|
| 347 |
-
| [
|
| 348 |
-
| [
|
| 349 |
-
| [
|
| 350 |
-
|
|
|
|
|
| 351 |
|
| 352 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 353 |
[cellar]: data/cellar/cellar.md
|
|
@@ -383,6 +388,7 @@ Below follows a brief overview of the sources in the corpus along with their ind
|
|
| 383 |
[nordjyllandnews]: data/nordjyllandnews/nordjyllandnews.md
|
| 384 |
[relig]: data/relig/relig.md
|
| 385 |
[nota]: data/nota/nota.md
|
|
|
|
| 386 |
|
| 387 |
|
| 388 |
[CC-0]: https://creativecommons.org/publicdomain/zero/1.0/legalcode.en
|
|
|
|
| 141 |
data_files:
|
| 142 |
- split: train
|
| 143 |
path: data/nota/*.parquet
|
| 144 |
+
- config_name: scrape_hovedstaden
|
| 145 |
+
data_files:
|
| 146 |
+
- split: train
|
| 147 |
+
path: data/scrape_hovedstaden/*.parquet
|
| 148 |
annotations_creators:
|
| 149 |
- no-annotation
|
| 150 |
language_creators:
|
|
|
|
| 215 |
|
| 216 |
<!-- START-DESC-STATS -->
|
| 217 |
- **Language**: dan, dansk, Danish
|
| 218 |
+
- **Number of samples**: 915.09K
|
| 219 |
+
- **Number of tokens (Llama 3)**: 4.40B
|
| 220 |
+
- **Average document length (characters)**: 14778.01
|
| 221 |
<!-- END-DESC-STATS -->
|
| 222 |
|
| 223 |
|
|
|
|
| 315 |
Below follows a brief overview of the sources in the corpus along with their individual license.
|
| 316 |
|
| 317 |
<!-- START-MAIN TABLE -->
|
| 318 |
+
| Source | Description | Domain | N. Tokens | License |
|
| 319 |
+
|:---------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-------------|:------------|:-----------------------|
|
| 320 |
+
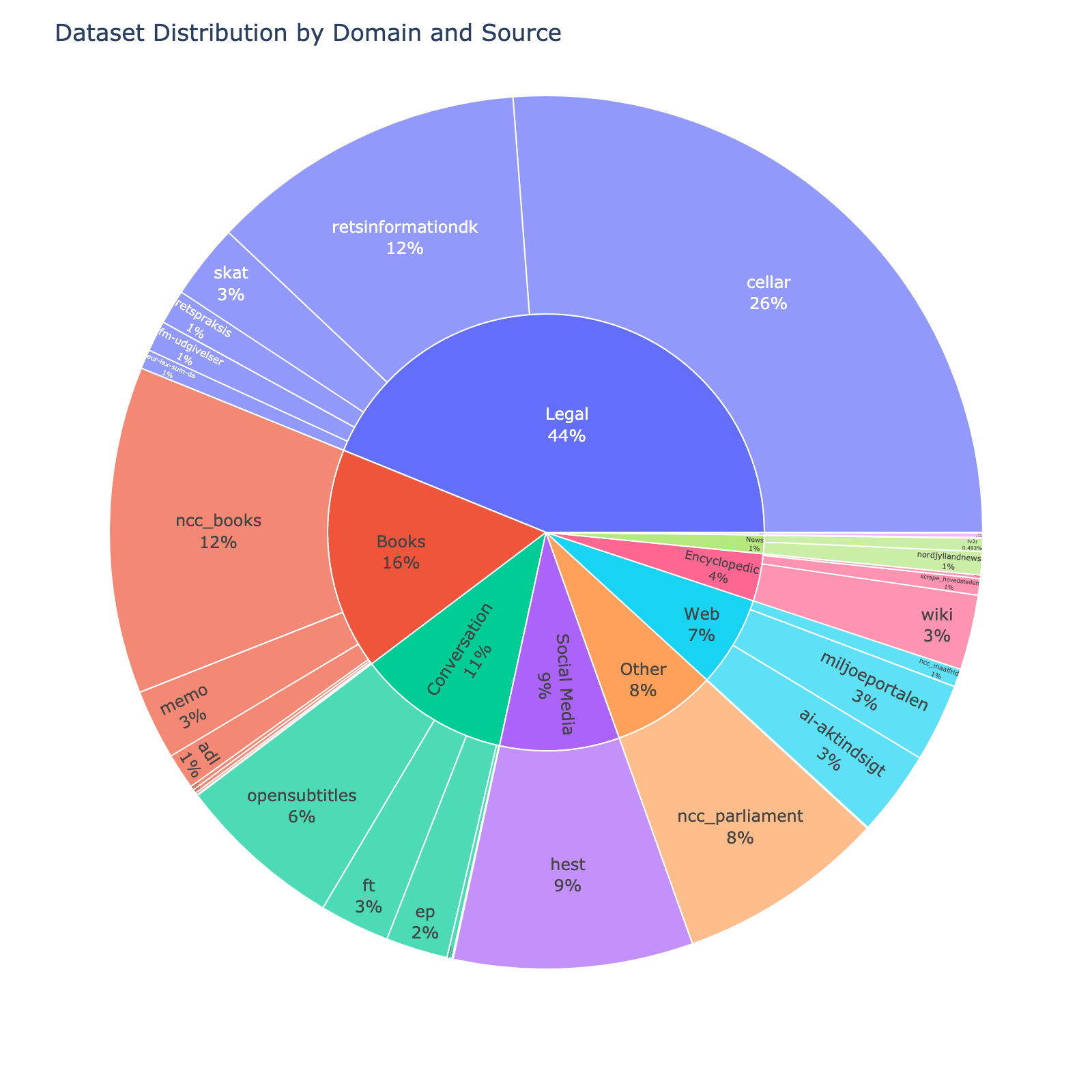
| [cellar] | The official digital repository for European Union legal documents and open data | Legal | 1.15B | [CC-BY-SA 4.0] |
|
| 321 |
+
| [ncc_books] | Danish books extracted from the [Norwegian Colossal Corpus](https://huggingface.co/datasets/NbAiLab/NCC) derived from OCR | Books | 531.97M | [CC-0] |
|
| 322 |
+
| [retsinformationdk] | [retsinformation.dk](https://www.retsinformation.dk) (legal-information.dk) the official legal information system of Denmark | Legal | 516.35M | [Danish Copyright Law] |
|
| 323 |
+
| [hest] | Samples from the Danish debate forum www.heste-nettet.dk | Social Media | 389.32M | [CC-0] |
|
| 324 |
+
| [ncc_parliament] | Collections from the Norwegian parliament in Danish. Extracted from the [Norwegian Colossal Corpus](https://huggingface.co/datasets/NbAiLab/NCC) derived from ocr | Other | 338.87M | [NLOD 2.0] |
|
| 325 |
+
| [opensubtitles] | Danish subsection of [OpenSubtitles](https://opus.nlpl.eu/OpenSubtitles/corpus/version/OpenSubtitles) | Conversation | 271.60M | [CC-0] |
|
| 326 |
+
| [ai-aktindsigt] | Multiple web scrapes from municipality websites collected as a part of the [AI-aktindsigt](https://ai-aktindsigt.dk) project | Web | 139.23M | [Apache 2.0] |
|
| 327 |
+
| [miljoeportalen] | Data from [Danmarks Miljøportalen](https://www.miljoeportal.dk/om-danmarks-miljoeportal/) (Denmark's Environment Portal) | Web | 127.38M | [CC-0] |
|
| 328 |
+
| [skat] | Skat is the Danish tax authority. This dataset contains content from its website skat.dk | Legal | 122.11M | [CC-0] |
|
| 329 |
+
| [wiki] | The Danish subsection of [wikipedia](https://en.wikipedia.org/wiki/Main_Page) | Encyclopedic | 122.00M | [CC-0] |
|
| 330 |
+
| [ft] | Records from all meetings of The Danish parliament (Folketinget) in the parliament hall | Conversation | 114.09M | [CC-0] |
|
| 331 |
+
| [memo] | The MeMo corpus comprising almost all Danish novels from the period 1870-1899, known as the Modern Breakthrough | Books | 113.74M | [CC-BY-SA 4.0] |
|
| 332 |
+
| [ep] | The Danish subsection of [Europarl](https://aclanthology.org/2005.mtsummit-papers.11/) | Conversation | 100.84M | [CC-0] |
|
| 333 |
+
| [adl] | Danish literature from 1700-2023 from the [Archive for Danish Literature](https://tekster.kb.dk/text?editorial=no&f%5Bsubcollection_ssi%5D%5B%5D=adl&match=one&search_field=Alt) (ADL) | Books | 58.49M | [CC-0] |
|
| 334 |
+
| [retspraksis] | Case law or judical practice in Denmark derived from [Retspraksis](https://da.wikipedia.org/wiki/Retspraksis) | Legal | 56.26M | [CC-0] |
|
| 335 |
+
| [fm-udgivelser] | The official publication series of the Danish Ministry of Finance containing economic analyses, budget proposals, and fiscal policy documents | Legal | 50.34M | [CC-BY-SA 4.0] |
|
| 336 |
+
| [nordjyllandnews] | Articles from the Danish Newspaper [TV2 Nord](https://www.tv2nord.dk) | News | 37.90M | [CC-0] |
|
| 337 |
+
| [eur-lex-sum-da] | The Danish subsection of EUR-lex SUM consisting of EU legislation paired with professionally written summaries | Legal | 31.37M | [CC-BY-SA 4.0] |
|
| 338 |
+
| [ncc_maalfrid] | Danish content from Norwegian institutions websites | Web | 29.26M | [NLOD 2.0] |
|
| 339 |
+
| [scrape_hovedstaden] | A document collection containing guidelines and informational documents for healthcare professionals | Encyclopedic | 27.07M | [CC-0] |
|
| 340 |
+
| [tv2r] | Contemporary Danish newswire articles published between 2010 and 2019 | News | 21.67M | [CC-BY-SA 4.0] |
|
| 341 |
+
| [danske-taler] | Danish Speeches from [dansketaler.dk](https://www.dansketaler.dk) | Conversation | 8.23M | [CC-0] |
|
| 342 |
+
| [nota] | The text only part of the [Nota lyd- og tekstdata](https://sprogteknologi.dk/dataset/nota-lyd-og-tekstdata) dataset | Readaloud | 7.30M | [CC-0] |
|
| 343 |
+
| [gutenberg] | The Danish subsection from Project [Gutenberg](https://www.gutenberg.org) | Books | 6.76M | [Gutenberg] |
|
| 344 |
+
| [wikibooks] | The Danish Subsection of [Wikibooks](https://www.wikibooks.org) | Books | 6.24M | [CC-0] |
|
| 345 |
+
| [wikisource] | The Danish subsection of [Wikisource](https://en.wikisource.org/wiki/Main_Page) | Encyclopedic | 5.34M | [CC-0] |
|
| 346 |
+
| [jvj] | The works of the Danish author and poet, [Johannes V. Jensen](https://da.wikipedia.org/wiki/Johannes_V._Jensen) | Books | 3.55M | [CC-BY-SA 4.0] |
|
| 347 |
+
| [spont] | Conversational samples collected as a part of research projects at Aarhus University | Conversation | 1.56M | [CC-0] |
|
| 348 |
+
| [dannet] | [DanNet](https://cst.ku.dk/projekter/dannet) is a Danish WordNet | Other | 1.48M | [DanNet 1.0] |
|
| 349 |
+
| [relig] | Danish religious text from the 1700-2022 | Books | 1.24M | [CC-0] |
|
| 350 |
+
| [ncc_newspaper] | OCR'd Newspapers derived from [NCC](https://huggingface.co/datasets/NbAiLab/NCC) | News | 1.05M | [CC-0] |
|
| 351 |
+
| [botxt] | The Bornholmsk Ordbog Dictionary Project | Dialect | 847.97K | [CC-0] |
|
| 352 |
+
| [naat] | Danish speeches from 1930-2022 | Conversation | 286.68K | [CC-0] |
|
| 353 |
+
| [depbank] | The Danish subsection of the [Universal Dependencies Treebank](https://github.com/UniversalDependencies/UD_Danish-DDT) | Other | 185.45K | [CC-BY-SA 4.0] |
|
| 354 |
+
| [synne] | Dataset collected from [synnejysk forening's website](https://www.synnejysk.dk), covering the Danish dialect sønderjysk | Other | 52.02K | [CC-0] |
|
| 355 |
+
| **Total** | | | 4.40B | |
|
| 356 |
|
| 357 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 358 |
[cellar]: data/cellar/cellar.md
|
|
|
|
| 388 |
[nordjyllandnews]: data/nordjyllandnews/nordjyllandnews.md
|
| 389 |
[relig]: data/relig/relig.md
|
| 390 |
[nota]: data/nota/nota.md
|
| 391 |
+
[scrape_hovedstaden]: data/scrape_hovedstaden/scrape_hovedstaden.md
|
| 392 |
|
| 393 |
|
| 394 |
[CC-0]: https://creativecommons.org/publicdomain/zero/1.0/legalcode.en
|
data/scrape_hovedstaden/create.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# /// script
|
| 2 |
+
# requires-python = "==3.12"
|
| 3 |
+
# dependencies = [
|
| 4 |
+
# "datasets==3.2.0",
|
| 5 |
+
# "dynaword"
|
| 6 |
+
# ]
|
| 7 |
+
# [tool.uv.sources]
|
| 8 |
+
# dynaword = { git = "https://huggingface.co/datasets/danish-foundation-models/danish-dynaword", rev = "00e7f2aee7f7ad2da423419f77ecbb9c0536de0d" }
|
| 9 |
+
# ///
|
| 10 |
+
"""
|
| 11 |
+
Script for downloading and processing the Scrape Hovedstaden texts.
|
| 12 |
+
|
| 13 |
+
Note: To run this script, you need to set `GIT_LFS_SKIP_SMUDGE=1` to be able to install dynaword:
|
| 14 |
+
|
| 15 |
+
```bash
|
| 16 |
+
GIT_LFS_SKIP_SMUDGE=1 uv run data/scrape_hovedstaden/create.py
|
| 17 |
+
```
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
import logging
|
| 21 |
+
import subprocess
|
| 22 |
+
from datetime import datetime
|
| 23 |
+
from pathlib import Path
|
| 24 |
+
from typing import Any, cast
|
| 25 |
+
|
| 26 |
+
import pandas as pd
|
| 27 |
+
from datasets import Dataset, load_dataset
|
| 28 |
+
|
| 29 |
+
from dynaword.process_dataset import (
|
| 30 |
+
add_token_count,
|
| 31 |
+
ensure_column_order,
|
| 32 |
+
remove_duplicate_text,
|
| 33 |
+
remove_empty_texts,
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
logger = logging.getLogger(__name__)
|
| 37 |
+
|
| 38 |
+
download_path = Path(__file__).parent / "tmp"
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def main():
|
| 42 |
+
save_path = Path(__file__).parent / "scrape_hovedstaden.parquet"
|
| 43 |
+
# Download data from repo: Den-Intelligente-Patientjournal/region_hovedstaden_text
|
| 44 |
+
ds = load_dataset(
|
| 45 |
+
"Den-Intelligente-Patientjournal/region_hovedstaden_text", split="train"
|
| 46 |
+
)
|
| 47 |
+
dataset: Dataset = cast(Dataset, ds)
|
| 48 |
+
|
| 49 |
+
# Extract the cleaned column
|
| 50 |
+
dataset = dataset.rename_column("cleaned", "text")
|
| 51 |
+
|
| 52 |
+
# Add created column: 2015 and 2020
|
| 53 |
+
dataset = dataset.add_column("created", ["2015-01-01, 2020-12-31"] * len(dataset)) # type: ignore
|
| 54 |
+
# Add added column: today
|
| 55 |
+
dataset = dataset.add_column(
|
| 56 |
+
"added", [datetime.today().date().strftime("%Y-%m-%d")] * len(dataset)
|
| 57 |
+
) # type: ignore
|
| 58 |
+
# Add source column: scrape_hovedstaden
|
| 59 |
+
dataset = dataset.add_column("source", ["scrape_hovedstaden"] * len(dataset)) # type: ignore
|
| 60 |
+
# Add id column: scrape_hovedstade_{idx}
|
| 61 |
+
dataset = dataset.add_column(
|
| 62 |
+
"id", [f"scrape_hovedstaden_{i}" for i in range(len(dataset))]
|
| 63 |
+
) # type: ignore
|
| 64 |
+
|
| 65 |
+
# quality checks and processing
|
| 66 |
+
dataset = remove_empty_texts(dataset)
|
| 67 |
+
dataset = remove_duplicate_text(dataset)
|
| 68 |
+
dataset = add_token_count(dataset)
|
| 69 |
+
dataset = ensure_column_order(dataset)
|
| 70 |
+
|
| 71 |
+
# save to parquet
|
| 72 |
+
dataset.to_parquet(save_path)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
if __name__ == "__main__":
|
| 76 |
+
main()
|
data/scrape_hovedstaden/descriptive_stats.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"number_of_samples": 23996,
|
| 3 |
+
"average_document_length": 3329.0515919319887,
|
| 4 |
+
"number_of_tokens": 27066716,
|
| 5 |
+
"revision": "16931a4cca4569bf00335846bc85c549ea59a82a"
|
| 6 |
+
}
|
data/scrape_hovedstaden/images/dist_document_length.png
ADDED
|
Git LFS Details
|
data/scrape_hovedstaden/scrape_hovedstaden.md
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
pretty_name: "Scrape fra dokumentsamling p\xE5 Vip Region Hovedstaden"
|
| 3 |
+
language:
|
| 4 |
+
- da
|
| 5 |
+
license: cc0-1.0
|
| 6 |
+
license_name: CC-0
|
| 7 |
+
task_categories:
|
| 8 |
+
- text-generation
|
| 9 |
+
- fill-mask
|
| 10 |
+
task_ids:
|
| 11 |
+
- language-modeling
|
| 12 |
+
source_datasets:
|
| 13 |
+
- Den-Intelligente-Patientjournal/region_hovedstaden_text
|
| 14 |
+
domains:
|
| 15 |
+
- Encyclopedic
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
# Dataset Card for Scrape fra dokumentsamling på Vip Region Hovedstaden
|
| 19 |
+
|
| 20 |
+
<!-- START-SHORT DESCRIPTION -->
|
| 21 |
+
A document collection containing guidelines and informational documents for healthcare professionals.
|
| 22 |
+
<!-- END-SHORT DESCRIPTION -->
|
| 23 |
+
|
| 24 |
+
The document collection consists of guidelines and informational documents for healthcare professionals in the Capital Region of Denmark. The documents therefore contain a number of specialized terms and concepts that are frequently used within the healthcare sector.
|
| 25 |
+
|
| 26 |
+
The corpus contains 9,941,236 tokens (word separation by spaces) extracted from 15,829 documents and 8,923 tables.
|
| 27 |
+
|
| 28 |
+
The corpus was created based on the texts in the document collection and has been post-processed so that the texts can be used for the development of language technology.
|
| 29 |
+
|
| 30 |
+
Martin Sundahl Laursen and Thiusius R. Savarimuthu from the University of Southern Denmark have assisted the Danish Agency for Digital Government with the post-processing of the data. Read their joint paper on "Automatic Annotation of Training Data for Deep Learning Based De-identification of Narrative Clinical Text."
|
| 31 |
+
|
| 32 |
+
Please note that the corpus has been developed for the purpose of language technology development and should not be used as a source of healthcare information. The documents were scraped at a specific time and will therefore not be updated with changes. In this regard, please refer to the Capital Region of Denmark's document collection.
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
## Dataset Description
|
| 38 |
+
|
| 39 |
+
<!-- START-DESC-STATS -->
|
| 40 |
+
- **Language**: dan, dansk, Danish
|
| 41 |
+
- **Domains**: Encyclopedic
|
| 42 |
+
- **Number of samples**: 24.00K
|
| 43 |
+
- **Number of tokens (Llama 3)**: 27.07M
|
| 44 |
+
- **Average document length (characters)**: 3329.05
|
| 45 |
+
<!-- END-DESC-STATS -->
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
## Dataset Structure
|
| 49 |
+
An example from the dataset looks as follows.
|
| 50 |
+
|
| 51 |
+
<!-- START-SAMPLE -->
|
| 52 |
+
```py
|
| 53 |
+
{
|
| 54 |
+
"id": "scrape_hovedstaden_0",
|
| 55 |
+
"text": "Acetylsalicylsyre - Aspirin, Akutlægebil\n\nMålgrupper og anvendelsesområde\nDefinitioner\nFremgangsmåde[...]",
|
| 56 |
+
"source": "scrape_hovedstaden",
|
| 57 |
+
"added": "2025-06-25",
|
| 58 |
+
"created": "2015-01-01, 2020-12-31",
|
| 59 |
+
"token_count": 766
|
| 60 |
+
}
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
### Data Fields
|
| 64 |
+
|
| 65 |
+
An entry in the dataset consists of the following fields:
|
| 66 |
+
|
| 67 |
+
- `id` (`str`): An unique identifier for each document.
|
| 68 |
+
- `text`(`str`): The content of the document.
|
| 69 |
+
- `source` (`str`): The source of the document (see [Source Data](#source-data)).
|
| 70 |
+
- `added` (`str`): An date for when the document was added to this collection.
|
| 71 |
+
- `created` (`str`): An date range for when the document was originally created.
|
| 72 |
+
- `token_count` (`int`): The number of tokens in the sample computed using the Llama 8B tokenizer
|
| 73 |
+
<!-- END-SAMPLE -->
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
### Additional Processing
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
### Dataset Statistics
|
| 80 |
+
|
| 81 |
+
<!-- START-DATASET PLOTS -->
|
| 82 |
+
<p align="center">
|
| 83 |
+
<img src="./images/dist_document_length.png" width="600" style="margin-right: 10px;" />
|
| 84 |
+
</p>
|
| 85 |
+
<!-- END-DATASET PLOTS -->
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
# Additional Information
|
| 89 |
+
|
| 90 |
+
## License Information
|
| 91 |
+
Udgivet under en CC-0 licens.
|
| 92 |
+
|
| 93 |
+
### Citation Information
|
| 94 |
+
|
| 95 |
+
If you are using the data please reference the following paper:
|
| 96 |
+
|
| 97 |
+
```
|
| 98 |
+
@inproceedings{laursen2023automatic,
|
| 99 |
+
title={Automatic Annotation of Training Data for Deep Learning Based De-identification of Narrative Clinical Text},
|
| 100 |
+
author={Laursen, Martin Sundahl and Pedersen, Jannik Skyttegaard and Vinholt, Pernille and Savarimuthu, Thiusius R},
|
| 101 |
+
booktitle={The First Workshop on Context-aware NLP in eHealth:(WNLPe-Health 2022)},
|
| 102 |
+
pages={30--44},
|
| 103 |
+
year={2023},
|
| 104 |
+
organization={CEUR Workshop Proceedings}
|
| 105 |
+
}
|
| 106 |
+
```
|
data/scrape_hovedstaden/scrape_hovedstaden.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:830fcdc9a16310bf1d165db79ba8b49bdee33cd7b3849ca0564b010d9f3df318
|
| 3 |
+
size 41434842
|
descriptive_stats.json
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
{
|
| 2 |
-
"number_of_samples":
|
| 3 |
-
"average_document_length":
|
| 4 |
-
"number_of_tokens":
|
| 5 |
-
"revision": "
|
| 6 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"number_of_samples": 915090,
|
| 3 |
+
"average_document_length": 14778.0072255188,
|
| 4 |
+
"number_of_tokens": 4396075044,
|
| 5 |
+
"revision": "16931a4cca4569bf00335846bc85c549ea59a82a"
|
| 6 |
}
|
images/dist_document_length.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
images/domain_distribution.png
CHANGED

|
Git LFS Details
|
|
Git LFS Details
|
uv.lock
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|