Datasets:

task_categories:
- text-classification
language:
- en
- fr
tags:
- climate
pretty_name: CrisisTS
size_categories:
- 10K<n<100K
CrisisTS Dataset
CrisisTS Description
CrisisTS is a multimodal multilingual dataset containing textual data from social media and meteorological data for crisis managmement.
Dataset Summary
- Languages: 2 Languages (English and French)
- Total number of tweets: 22,291 (15,368 in French and 6,923 in English) (French textual data will be released soon)
- Total number of French meteorological data: 46,495 (3 hours frequency)
- Total number of English meteorological data: 1,460 (daily frequency)
- Type of crisis : Stroms, Hurricane, Flood, Wildfire, Explosion, Terrorist Attack, Collapse
- Domain: Crisis managment
Dataset utilisation
To use the dataset please use
git clone https://huggingface.co/datasets/Unknees/CrisisTS
Detailled English textual data information
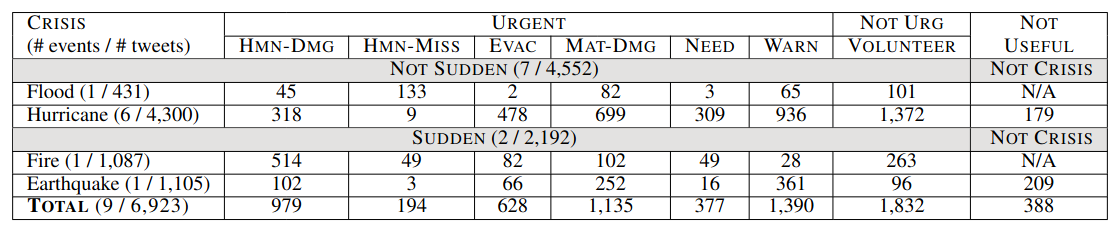
Detailled French textual data information
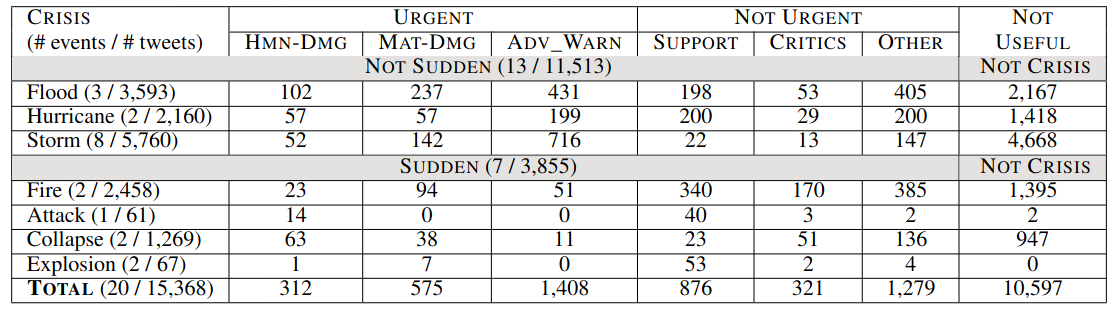
Data alignement
All the textual data have been spatially aligned with the meteorological data with the following strategy :
- If there is exactly one location mention in the text :
We use the keywords that we have in utils/Keywords in order to find in which state the location mention belongs.
- If there is no location mention :
We use crisis_knowledge_LANG.csv to find the location of the tweet by association with the location of the impact of the crisis the tweets refer to.
Raw Data and Adaptation
If you want to use only one modality, you can use the data contained in Textual_Data and Time_Series
The data inside Multi_modal_dataset are already merged with a fixed window for timeseries (48 hours window for French data and 5 day window for English data)
If you want to change the time series window you can use Linker_Fr.py and Linker_Eng.py. (WARNING : Linker_Fr can take some time)
To use the linker please use
python3 Linker_Eng.py --window_size 5 -output_file ./output_file.csv
or
python3 Linker_FR.py -w 16 -o ./output_file.csv
With : -w / --window_size : the size of your timeseries window (with 3hours frequency for French data and daily data for English data) -o / --output_file : path and name of your personnal dataset
Note that to launch the French linker, you will require the following librairies : pandas datetime numpy datetime pytz warnings argparse
Note that to launch the English linker, you will require the following librairies : pandas os json scikit-learn argparse
for more information on the dataset, please read readme.txt
Citation Information
If you use this dataset, please cite:
@inproceedings{
title={Crisis{TS}: Coupling Social Media Textual Data and Meteorological Time Series for Urgency Classification},
author= "Meunier, Romain and
Benamara, Farah and
Moriceau, Veronique and
Zhongzheng, Qiao and
Ramasamy, Savitha",
booktitle={The 63rd Annual Meeting of the Association for Computational Linguistics},
year={2025},
}