Datasets:

language:
- en
license: apache-2.0
size_categories:
- 1K<n<10K
task_categories:
- video-text-to-text
pretty_name: lsdbench
configs:
- config_name: default
data_files:
- split: test
path: mc_qa_annotations_1300.json
tags:
- video
- text
- reasoning
- long-video
- temporal
- grounding
- sampling-strategy
- action
- fine-grained
Dataset Card for LSDBench: Long-video Sampling Dilemma Benchmark
A benchmark that focuses on the sampling dilemma in long-video tasks. Through well-designed tasks, it evaluates the sampling efficiency of long-video VLMs.
Arxiv Paper: 📖 Does Your Vision-Language Model Get Lost in the Long Video Sampling Dilemma?
Github : https://github.com/dvlab-research/LSDBench
 (Left) In Q1, identifying a camera wearer's visited locations requires analyzing the entire video. However, key frames are sparse, so sampling one frame per minute often provides enough information. In contrast, Q2 examines the packing order during checkout, requiring high-resolution sampling to capture rapid actions. (Right) Sampling Dilemma emerges in tasks like Q2: a low sampling density fails to provide sufficient visual cues for accurate answers, while a high sampling density results in redundant frames, significantly slowing inference speed. This challenge underscores the need for adaptive sampling strategies, especially for tasks with high necessary sampling density.
(Left) In Q1, identifying a camera wearer's visited locations requires analyzing the entire video. However, key frames are sparse, so sampling one frame per minute often provides enough information. In contrast, Q2 examines the packing order during checkout, requiring high-resolution sampling to capture rapid actions. (Right) Sampling Dilemma emerges in tasks like Q2: a low sampling density fails to provide sufficient visual cues for accurate answers, while a high sampling density results in redundant frames, significantly slowing inference speed. This challenge underscores the need for adaptive sampling strategies, especially for tasks with high necessary sampling density.
LSDBench
The LSDBench dataset is designed to evaluate the sampling efficiency of long-video VLMs. It consists of multiple-choice question-answer pairs based on hour-long videos, focusing on short-duration actions with high Necessary Sampling Density (NSD).
- Number of QA Pairs: 1304
- Number of Videos: 400
- Average Video Length: 45.39 minutes (ranging from 20.32 to 115.32 minutes)
- Average Target Segment Duration: 3 minutes
Evaluation on LSDBench
Please see our github repo for detailed evaluation guide.
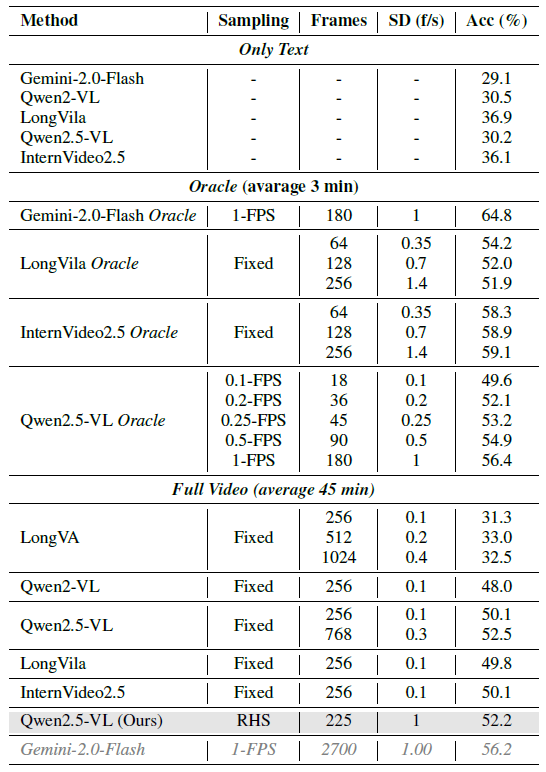
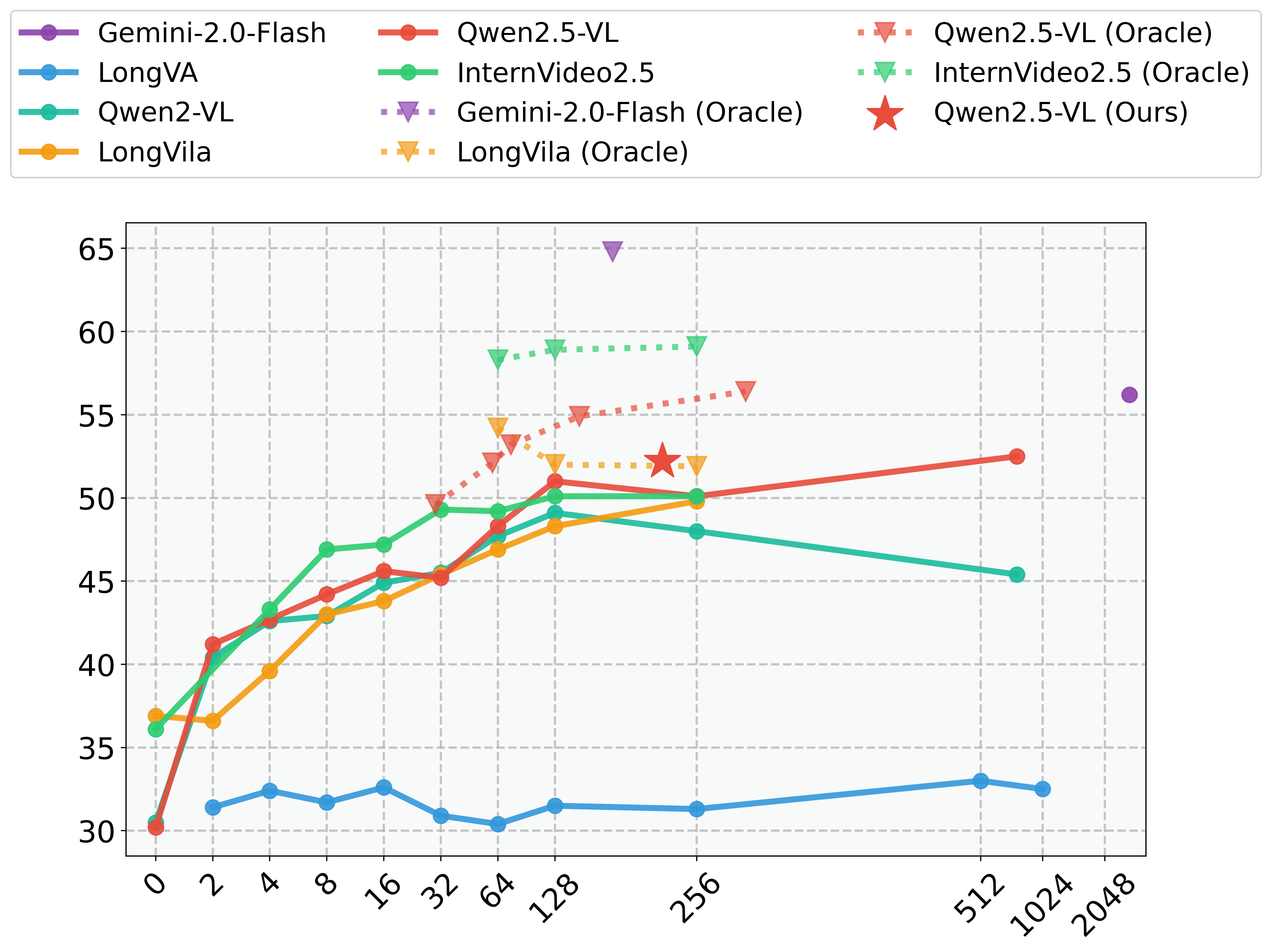
Performance comparison of different models and sampling strategies. We present three testing settings in total: Only Text, Oracle, and Full Video. In the Only Text setting, the model is provided with no visual information whatsoever. The Oracle setting involves using the annotated target segment as the video input, while the Full Video setting provides the complete long video as input. The ”Sampling” column lists the sampling strategies used: FPS represents sampling at fixed time intervals, fixed denotes uniform sampling with a fixed number of frames, and 2stage refers to the method we propose. Under each sampling strategy, the average number of sampled frames during evaluation on the LSDBench dataset is reported in the ”Frames” column, along with the corresponding sampling density (SD).