

VLM2Vec/VLM2Vec-V2.0
Image-Text-to-Text • Updated • 15.9k • 29
Website |Github | 🏆Leaderboard | 📖MMEB-V2/VLM2Vec-V2 Paper | | 📖MMEB-V1/VLM2Vec-V1 Paper |
Building upon on our original MMEB, MMEB-V2 expands the evaluation scope to include five new tasks: four video-based tasks — Video Retrieval, Moment Retrieval, Video Classification, and Video Question Answering — and one task focused on visual documents, Visual Document Retrieval. This comprehensive suite enables robust evaluation of multimodal embedding models across static, temporal, and structured visual data settings.
This Hugging Face repository contains the image and video frames used in MMEB-V2, which need to be downloaded in advance.
Please review this section carefully for all MMEB-V2–related data.
We present an overview of the MMEB-V2 dataset below:
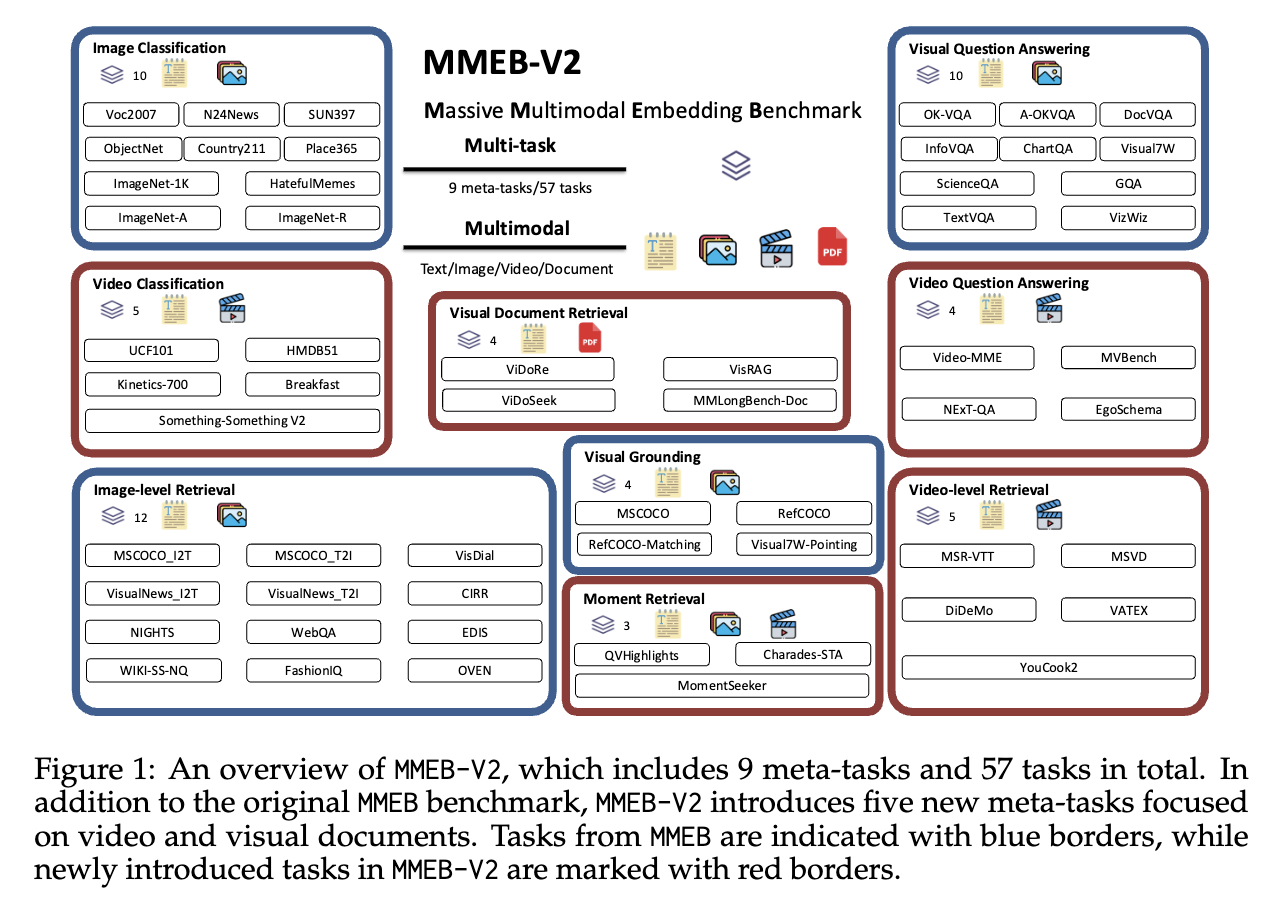
The directory structure of this Hugging Face repository is shown below.
For video tasks, we provide sampled frames in this repo. For image tasks, we provide the raw images.
Files from each meta-task are zipped together, resulting in six files. For example, video_cls.tar.gz contains the sampled frames for the video classification task.
→ video-tasks/
├── frames/
│ ├── video_cls.tar.gz
│ ├── video_qa.tar.gz
│ ├── video_ret.tar.gz
│ └── video_mret.tar.gz
→ image-tasks/
├── mmeb_v1.tar.gz
└── visdoc.tar.gz
After downloading and unzipping these files locally, you can organize them as shown below. (You may choose to use Git LFS or wget for downloading.)
Then, simply specify the correct file path in the configuration file used by your code.
→ MMEB
├── video-tasks/
│ └── frames/
│ ├── video_cls/
│ │ ├── UCF101/
│ │ │ └── video_1/ # video ID
│ │ │ ├── frame1.png # frame from video_1
│ │ │ ├── frame2.png
│ │ │ └── ...
│ │ ├── HMDB51/
│ │ ├── Breakfast/
│ │ └── ... # other datasets from video classification category
│ ├── video_qa/
│ │ └── ... # video QA datasets
│ ├── video_ret/
│ │ └── ... # video retrieval datasets
│ └── video_mret/
│ └── ... # moment retrieval datasets
├── image-tasks/
│ ├── mmeb_v1/
│ │ ├── OK-VQA/
│ │ │ ├── image1.png
│ │ │ ├── image2.png
│ │ │ └── ...
│ │ ├── ImageNet-1K/
│ │ └── ... # other datasets from MMEB-V1 category
│ └── visdoc/
│ └── ... # visual document retrieval datasets