
HEST-1k: A Dataset for Spatial Transcriptomics and Histology Image Analysis
Paper • 2406.16192 • Published • 1
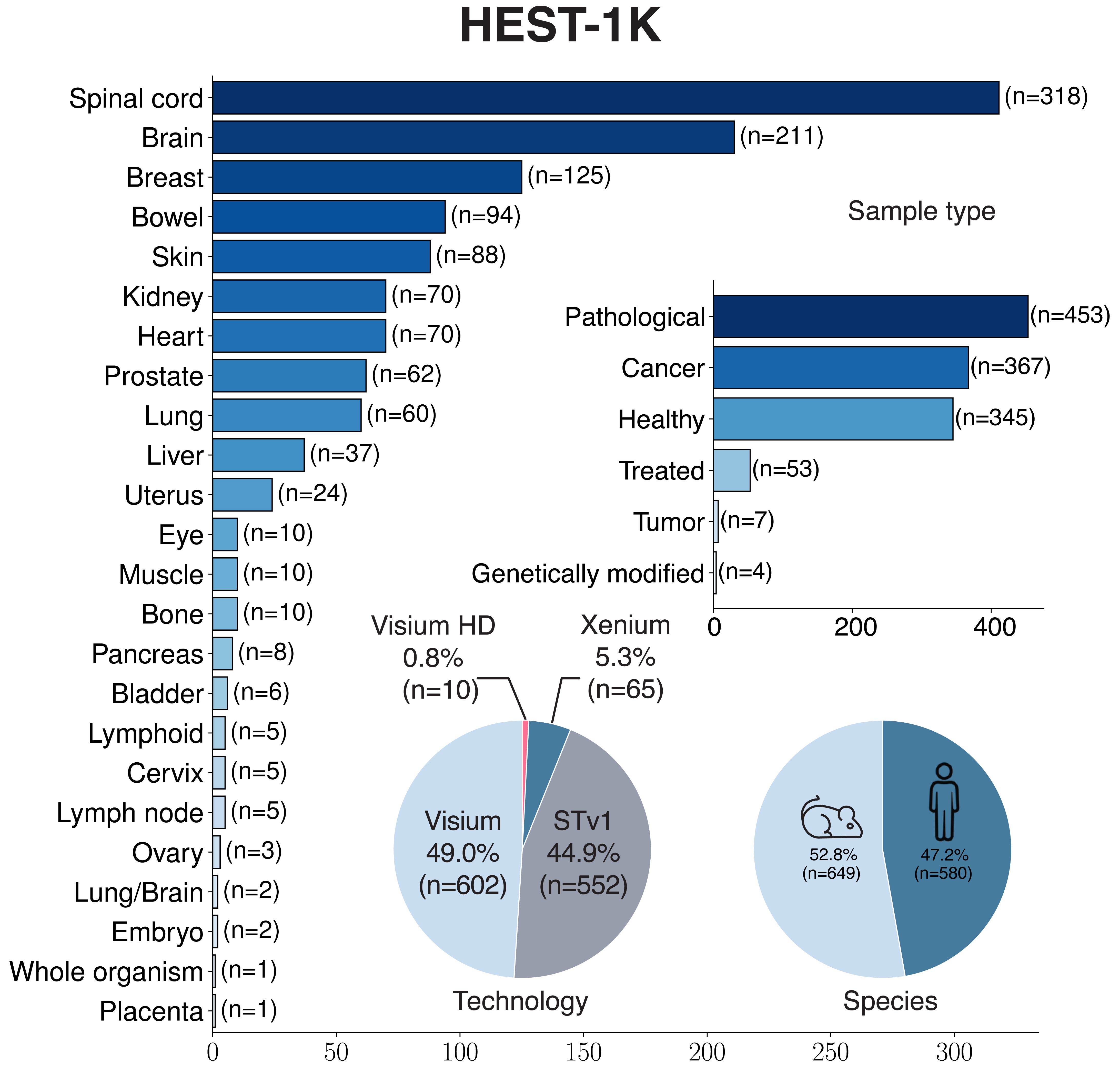
HEST-1k processing enabled the identification of >1.5 million expression/morphology pairs and >76 million nuclei
8.02.26: 18 new Xenium (including Xenium 5k) samples added to HEST (v1.3.0)!
6.01.26: 27 new high-quality Visium HD samples added to HEST (v1.2.0)!
21.10.24: HEST has been accepted to NeurIPS 2024 as a Spotlight! We will be in Vancouver from Dec 10th to 15th. Send us a message if you wanna learn more about HEST (gjaume@bwh.harvard.edu).
23.09.24: 121 new samples released, including 27 Xenium and 7 Visium HD! We also make the aligned Xenium transcripts + the aligned DAPI segmented cells/nuclei public.
30.08.24: HEST-Benchmark results updated. Includes H-Optimus-0, Virchow 2, Virchow, and GigaPath. New COAD task based on 4 Xenium samples. HuggingFace bench data have been updated.
28.08.24: New set of helpers for batch effect visualization and correction. Tutorial here.
Follow the instructions provided on the HuggingFace sign-up page.
Files and versionGo to Settings: Navigate to your profile settings by clicking on your profile picture in the top right corner and selecting Settings from the dropdown menu.
Access Tokens: In the settings menu, find and click on Access tokens.
Create New Token:
New token.hest).Write.Create.Copy Token: After the token is created, copy it to your clipboard. You will need this token for authentication.
pip install huggingface-hub
from huggingface_hub import login
login(token="YOUR HUGGINGFACE TOKEN")
import os
import zipfile
from huggingface_hub import snapshot_download
from tqdm import tqdm
def download_hest(patterns, local_dir):
repo_id = 'MahmoodLab/hest'
snapshot_download(repo_id=repo_id, allow_patterns=patterns, repo_type="dataset", local_dir=local_dir)
seg_dir = os.path.join(local_dir, 'cellvit_seg')
if os.path.exists(seg_dir):
print('Unzipping cell vit segmentation...')
for filename in tqdm([s for s in os.listdir(seg_dir) if s.endswith('.zip')]):
path_zip = os.path.join(seg_dir, filename)
with zipfile.ZipFile(path_zip, 'r') as zip_ref:
zip_ref.extractall(seg_dir)
local_dir='hest_data' # hest will be dowloaded to this folder
# Note that the full dataset is around 1TB of data
download_hest('*', local_dir)
import datasets
local_dir='hest_data' # hest will be dowloaded to this folder
ids_to_query = ['TENX96', 'TENX99'] # list of ids to query
list_patterns = [f"*{id}[_.]**" for id in ids_to_query]
download_hest(list_patterns, local_dir) # see method definition above
import datasets
import pandas as pd
local_dir='hest_data' # hest will be dowloaded to this folder
meta_df = pd.read_csv("hf://datasets/MahmoodLab/hest/HEST_v1_3_0.csv")
# Filter the dataframe by organ, oncotree code...
meta_df = meta_df[meta_df['oncotree_code'] == 'IDC']
meta_df = meta_df[meta_df['organ'] == 'Breast']
ids_to_query = meta_df['id'].values
list_patterns = [f"*{id}[_.]**" for id in ids_to_query]
download_hest(list_patterns, local_dir) # see method definition above
hest
Once downloaded, you can then easily iterate through the dataset:
from hest import iter_hest
for st in iter_hest('../hest_data', id_list=['TENX95']):
print(st)
Please visit the github repo and the documentation for more information about the hest library API.
For each sample:
wsis/: H&E stained Whole Slide Images in pyramidal Generic TIFF (or pyramidal Generic BigTIFF if >4.1GB)st/: spatial transcriptomics expressions in a scanpy .h5ad objectmetadata/: metadataspatial_plots/: overlay of the WSI with the st spotsthumbnails/: downscaled version of the WSItissue_seg/: tissue segmentation masks:pixel_size_vis/: visualization of the pixel sizepatches/: 224x224px H&E patches (0.5µm/px) extracted around ST spots in a .h5 object optimized for deep-learning. Each patch is matched to the corresponding ST profile (see st/) with a barcode.patches_vis/: visualization of the mask and patches on a downscaled WSI.cellvit_seg/: cellvit nuclei segmentationFor each xenium sample:
transcripts/: individual transcripts aligned to H&E for xenium samples; read with pandas.read_parquet; aligned coordinates in pixel are in columns ['he_x', 'he_y']xenium_seg/: xenium segmentation on DAPI and aligned to H&E@article{jaume2024hest,
author = {Jaume, Guillaume and Doucet, Paul and Song, Andrew H. and Lu, Ming Y. and Almagro-Perez, Cristina and Wagner, Sophia J. and Vaidya, Anurag J. and Chen, Richard J. and Williamson, Drew F. K. and Kim, Ahrong and Mahmood, Faisal},
title = {{HEST-1k: A Dataset for Spatial Transcriptomics and Histology Image Analysis}},
journal = {arXiv},
year = {2024},
month = jun,
eprint = {2406.16192},
url = {https://arxiv.org/abs/2406.16192v1}
}
gjaume@bwh.harvard.edu)pdoucet@bwh.harvard.edu)The dataset is distributed under the Attribution-NonCommercial-ShareAlike 4.0 International license (CC BY-NC-SA 4.0 Deed)